Einheitliche Repr asentation heterogener Datenquellen mit Topic Maps
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Fachbereich Informatik
Fachgebiet Sicherheit in der Informationstechnik
Fraunhofer-Institut für Sichere Informationstechnologie SIT
Prof. Dr. Claudia Eckert
Technische Universität Darmstadt
Diplomarbeit
Einheitliche Repräsentation
heterogener Datenquellen mit
Topic Maps
Johannes Bergmann
Januar 2006
Betreuer:
Prof. Dr. Claudia Eckert
Dipl. Inform. Jens HeiderInhaltsverzeichnis
Inhaltsverzeichnis
1. Einleitung 1
1.1. Sichere mobile Informationsverteilung . . . . . . . . . . . . . . . . . . 1
1.1.1. E-Mail . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1.2. Das MIDMAY Konzept . . . . . . . . . . . . . . . . . . . . . 2
1.2. Bearbeiteter Teilaspekt . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2. Problemanalyse 4
2.1. Benutzung der Repräsentation . . . . . . . . . . . . . . . . . . . . . . 5
2.1.1. Finden von Informationsobjekten . . . . . . . . . . . . . . . . 5
2.1.2. Verwalten der Informationsobjekte und ihrer Repräsentation . 6
2.2. Anforderungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2.1. Funktionale Anforderungen . . . . . . . . . . . . . . . . . . . 7
2.2.2. Nicht-Funktionale Anforderungen . . . . . . . . . . . . . . . . 9
2.3. Aktuelle Ansätze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.3.1. Suchmaschinen . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.3.2. Verwaltungs-Systeme (Content Management) . . . . . . . . . 12
2.3.3. Knowledge Management Systeme . . . . . . . . . . . . . . . . 13
3. Formate zur Repräsentation von Wissen 13
3.1. Topic Maps . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.1.1. Topics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.1.2. Occurrences . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.1.3. Associations . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.1.4. Scope . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.1.5. Subject Identity . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.2. RDF . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.2.1. RDF Konzepte . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.2.2. RDF-Schema . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.2.3. Web Ontology Language (OWL) . . . . . . . . . . . . . . . . 20
3.3. Vergleich . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.3.1. Ziele der Technologien . . . . . . . . . . . . . . . . . . . . . . 21
3.3.2. Einordnung der Standards von Topic Maps und RDF . . . . . 22
3.3.3. Identität . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.3.4. Aussagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.3.5. Constraint Languages . . . . . . . . . . . . . . . . . . . . . . . 26
3.3.6. Interoperabilität von Repräsentationen . . . . . . . . . . . . . 28
3.3.7. Syntax . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
3.3.8. Fazit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4. Lösungsansatz 31
4.1. Architektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
IInhaltsverzeichnis
4.1.1. Komponenten . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.1.2. Schnittstellen . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.2. Sicherheit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.2.1. Authentifizierung und sichere Datenübertragung . . . . . . . . 38
4.2.2. Schutz der Zugangs- und Repräsentationsdaten . . . . . . . . 38
4.2.3. Mehrbenutzer-Aspekte . . . . . . . . . . . . . . . . . . . . . . 38
4.3. Darstellung und Navigation . . . . . . . . . . . . . . . . . . . . . . . 39
4.3.1. Visualisierung von Topic Maps als Graph . . . . . . . . . . . . 40
4.3.2. Visualisierung von Hierarchien . . . . . . . . . . . . . . . . . . 42
4.3.3. Klassifizierung von Informationen durch Facets . . . . . . . . 42
4.3.4. Darstellung einzelner Topics . . . . . . . . . . . . . . . . . . . 43
4.4. Modellierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.4.1. Published Subjects . . . . . . . . . . . . . . . . . . . . . . . . 44
4.4.2. Topic Map Templates . . . . . . . . . . . . . . . . . . . . . . . 45
4.4.3. Patterns für Topic Maps . . . . . . . . . . . . . . . . . . . . . 46
4.4.4. Topic Map Modell zur Indizierung von Datenquellen . . . . . 48
4.4.5. Dateisysteme . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4.4.6. E-Mail . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
4.4.7. Eigenschafts-Hierarchien . . . . . . . . . . . . . . . . . . . . . 54
4.4.8. Modellierung weiterer Datenquellen . . . . . . . . . . . . . . . 56
5. Implementierung 58
5.1. Topic Map APIs für Java . . . . . . . . . . . . . . . . . . . . . . . . . 59
5.1.1. TMAPI . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
5.1.2. TinyTIM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
5.1.3. TM4J . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
5.1.4. Verwendete API . . . . . . . . . . . . . . . . . . . . . . . . . . 60
5.2. API für Topic Map Patterns . . . . . . . . . . . . . . . . . . . . . . . 60
5.3. Data Retrieval Modul . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
5.3.1. Zugriff auf die Datenquelle . . . . . . . . . . . . . . . . . . . . 62
5.3.2. Extraktion von Metadaten . . . . . . . . . . . . . . . . . . . . 63
5.3.3. Information Mapping . . . . . . . . . . . . . . . . . . . . . . . 64
5.3.4. Information Object Retrieval . . . . . . . . . . . . . . . . . . 65
5.4. Unified Representation Modul . . . . . . . . . . . . . . . . . . . . . . 65
5.4.1. Konfiguration der Extraktoren . . . . . . . . . . . . . . . . . . 65
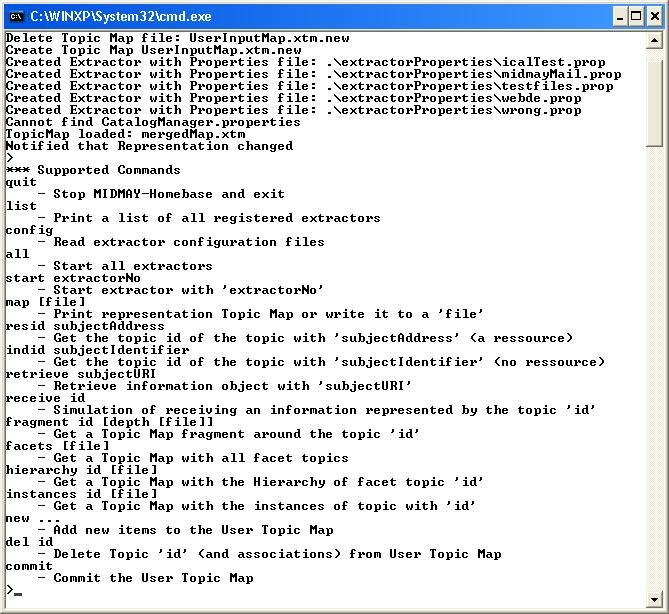
5.4.2. Extraktoren und InputMaps . . . . . . . . . . . . . . . . . . . 67
5.4.3. Vereinigen der Topic Maps . . . . . . . . . . . . . . . . . . . . 67
5.4.4. Zugriff auf die Repräsentation und die Informationsobjekte . . 70
6. Fazit 72
6.1. Ergebnisse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
6.2. Bewertung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
6.2.1. Konzepte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
IIInhaltsverzeichnis
6.2.2. Software Architektur und Schnittstellen . . . . . . . . . . . . . 73
6.2.3. Implementierung . . . . . . . . . . . . . . . . . . . . . . . . . 73
6.2.4. Bewertung gegenüber den Anforderungen . . . . . . . . . . . . 74
6.3. Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77
A. Abkürzungen und Definitionen 78
B. Verwendete Published Subject Identifiers 79
B.1. Generische Topics . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 79
B.2. Eigenschaften von Informationsobjekten . . . . . . . . . . . . . . . . 80
B.3. Dateisystem . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81
B.4. E-Mail . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82
IIIInhaltsverzeichnis
Eidesstattliche Erklärung
Hiermit versichere ich, dass ich die vorliegende Diplomarbeit ohne Hilfe Dritter
und nur mit den angegebenen Quellen und Hilfsmitteln angefertigt habe. Diese
Arbeit hat in gleicher oder ähnlicher Form noch keiner Prüfungsbehörde vorgelegen.
IV1 EINLEITUNG
1. Einleitung
1.1. Sichere mobile Informationsverteilung
Digitale Informationen werden in der heutigen Zeit Dank einer guten Kommuni-
kations-Infrastruktur in großen Mengen schnell und zuverlässig übertragen. Dabei
kommen viele unterschiedliche Protokolle für die Übertragung und Datenformate für
die Speicherung der Informationen zum Einsatz. Wenn ein Benutzer Informationen
an einen bestimmten Empfänger übermitteln möchte, ist er daran interessiert, die
Informationen schnell aufzufinden und ohne großen Aufwand versenden zu können.
Sind seine Informationen jedoch über unterschiedliche Datenquellen verteilt, muss
er je nach Übertragungsprotokoll unterschiedliche Programme verwenden um die zu
versendenden Informationen zusammenzustellen, wie es z. B. bei der Informations-
verteilung per E-Mail der Fall ist.
1.1.1. E-Mail
Der Informationsaustausch über E-Mail bietet die Möglichkeit Informationen in un-
terschiedlichen Datenformaten zusammen mit der E-Mail-Nachricht zu versenden
und ist durch komfortable E-Mail Clients sehr benutzerfreundlich. Das E-Mail Kon-
zept hat jedoch einige Nachteile, insbesondere wenn ein sicherer Datenaustausch
gewünscht wird oder mobile Endgeräte zum Versenden der Informationen genutzt
werden sollen.
Um Informationen vertraulich übertragen zu können, ist eine Kryptographie-Infra-
struktur notwendig. Deren Nutzung bedeutet jedoch einen höheren Aufwand in der
Konfiguration und Benutzung des E-Mail Clients durch den Anwender, weil Zer-
tifikate von Authentifizierungsstellen oder Kommunikationspartnern vom Benutzer
verwaltet werden müssen.
Weiterhin ist es nur möglich Informationen vertraulich zu senden, wenn sie auf dem
benutzten Rechner lokal vorhanden sind, da sie vom E-Mail Client mit dem öffentli-
chen Schlüssel des Empfängers verschlüsselt werden. Insbesondere bei der Nutzung
eines E-Mail Clients auf einem mobilen Endgerät mit beschränkter Bandbreite und
hohen Übertragungskosten ist es unvorteilhaft, dass die Daten vorher vollständig
zum Client übertragen werden müssen. Dieses Problem kann gelöst werden, indem
die Entschlüsselung von E-Mails auf einem speziellen Server durchgeführt wird. Da
der Server den mobilen Client über neue E-Mails sofort benachrichtigt, wird die-
ser Service als Push“-Service bezeichnet. Die E-Mail gelangt so direkt vom Sender
”
zum Empfänger, der nun entscheiden kann, welche Anhänge der E-Mail auch auf
sein mobiles Gerät übertragen werden sollen.
11 EINLEITUNG
Um seine Informationen verwalten zu können, muss der Benutzer auf unterschiedli-
che verteilte Datenquellen wie Dateiserver, Datenbanken und E-Mails zugreifen und
dafür verschiedene Protokolle und Programme verwenden. Dabei erhält er Sichten
auf seine Informationen, die vom Zugriffsprotokoll und Datenformat und nicht vom
Inhalt der Information abhängen. Die Verwaltung wird auch dadurch erschwert,
dass die Eigenschaften der verteilt gespeicherten Informationen nicht direkt mitein-
ander vergleichbar sind. Außerdem fehlen Funktionen, mit denen die Informationen
miteinander in Beziehung gesetzt werden können.
1.1.2. Das MIDMAY Konzept
Um den Anforderungen einer sicheren Verwaltung und Verteilung von Information
über mobile Endgeräte gerecht zu werden, wird ein neues Konzept der Informations-
verteilung benötigt. Das MIDMAY Konzept (Mobile Information Distribution and
Access for You!) [10] soll dem Benutzer eine einheitliche Sicht auf verteilt gespei-
cherte Informationen bieten und den vertraulichen Informationsaustausch zwischen
zwei sich zuvor unbekannten Personen ermöglichen. Es basiert auf einem mobilen
Client zur Präsentation und Auswahl der verteilt gespeicherten Informationen des
Benutzers, und einer Homebase, welche auf die verteilten Datenquellen zugreifen
kann.
In Abbildung 1 wird gezeigt, wie die Kommunikation zwischen zwei MIDMAY
Benutzern abläuft, die zum ersten Mal Informationen austauschen wollen. Zuerst
werden die MIDMAY-Identitäten zwischen den mobilen Geräte ausgetauscht (1).
Die Identitäten enthalten den öffentlichen Schlüssel und die Homebase-Adresse des
Kommunikationspartners. Über den Client wird die zu versendende Information aus-
gewählt (2) und die Homebase angewiesen diese Informationen von den verteilten
Datenquellen auf die Homebase zu laden (3+4), um sie von dort verschlüsselt an
die Homebase des Kommunikationspartners zu senden (5). Ist das Endgerät des
Empfängers erreichbar, kann dieser benachrichtigt werden (6) und entscheiden, an
welches Ausgabegerät die Informationen weitergeleitet oder wo sie abgelegt werden
sollen (7+8). Alternativ kann die Homebase auch selbstständig über die Ablage der
Informationen entscheiden, z. B. wenn das Endgerät nicht erreichbar ist.
1.2. Bearbeiteter Teilaspekt
Ein großer Vorteil von MIDMAY ist, dass der Benutzer Informationen vor dem Ver-
senden nicht erst selbst mit Hilfe von verschiedenen Anwendungen und Protokollen
auf sein mobiles Gerät übertragen muss, sondern von seinem MIDMAY-Client ei-
ne einheitliche Sicht auf seine Informationen erhält. Die einheitliche Sicht wird von
der MIDMAY-Homebase als Repräsentation aller verteilt gespeicherten Informatio-
nen des Benutzers erstellt. Mit Hilfe der Repräsentation bietet MIDMAY Positions-
21 EINLEITUNG
2. 3. 4.
Informationsauswahl Instruktion der Homebase Abfrage der Informationen
Homebase (Sender)
Sender
1.
Drahtloser MIDMAY Informationen 5.
Austausch Identität und Metadaten Übertragung
Empfänger Homebase (Empfänger)
6. 7. 8.
Benachrichtigung Ablageinstruktionen Ablage/Weiterleitung
Abbildung 1: MIDMAY Szenario
und Zugriffstransparenz [8]. Der Benutzer kann auf seinem MIDMAY-Client ein In-
formationsobjekt auswählen, ohne dass er den physischen Speicherort des Objekts
kennt (Positionstransparenz). Für die Suche nach Informationsobjekten stehen dem
Benutzer dabei unabhängig von der Art der Datenquelle, ob E-Mail-Postfach oder
Dateisystem, die gleichen Operationen zur Verfügung (Zugriffstransparenz).
Ziel dieser Arbeit ist es, ein Konzept zur Erstellung der einheitlichen Repräsentation
aus den Informationen der verteilten Datenquellen zu entwickeln und prototypisch zu
implementieren. Dazu muss untersucht werden, wie die Datenquellen modelliert und
ihre Informationen abgebildet werden, welche Datenstruktur sich für die Repräsen-
tation eignet und welche Anforderungen an das Software-Modul zur Erstellung der
Repräsentation bestehen.
Im MIDMAY Konzept sind zwei Software-Module vorgegeben, die zusammen für die
Repräsentation der Datenquellen verantwortlich sind. Das Data Retrieval Module
(DRM) ist für den Zugriff auf die verschiedenen verteilten Datenquellen zuständig.
Es indiziert die auf den Datenquellen vorhandenen Informationen und bildet sie
in die Datenstruktur der Repräsentation ab. Das Unified Representation Module
(URM) ist für die Verwaltung dieser Datenstruktur zuständig. Es bietet dem DRM
32 PROBLEMANALYSE
und dem Client Schnittstellen für den Zugriff auf die Repräsentation. Das DRM
muss zur Erstellung und Aktualisierung der Repräsentation mit dem URM kom-
munizieren. Der Client muss auf die Repräsentation zugreifen können, damit der
Benutzer in der Repräsentation seiner Informationen navigieren, suchen und diese
strukturieren kann. Abbildung 2 zeigt alle Module der MIDMAY Homebase und
veranschaulicht, welche Funktionen die Module DRM und URM erfüllen müssen.
Die Anforderungen an Data Retrieval Module“ und Unified Representation Mo-
” ”
dule“ sollen in dieser Diplomarbeit ermittelt und in einem demonstrationsfähigen
Prototyp in der Programmiersprache Java umgesetzt werden.
Client
Informationen suchen
und auswählen
Unified Representation ID Management Context Awareness
Homebase
Module Module Module
(URM) (IDM) (CAM)
Data Retrieval Security Assertion Data Transfer
Module Module Module
(DRM) (SAM) (DTM)
Indizierung von Austausch von
Informationen Informationen
Homebase
Verteilte Datenquellen
Abbildung 2: MIDMAY Module
2. Problemanalyse
Innerhalb MIDMAY ist die Hauptaufgabe der einheitlichen Repräsentation, den
Benutzer beim Auffinden und Verwalten seiner verteilt gespeicherter Informations-
objekte zu unterstützen. Es wird im folgenden beschrieben, wie die Benutzung der
Repräsentation aussehen soll, um daraus Anforderungen an ein System zur Erstel-
lung, Verarbeitung und Bereitstellung der Repräsentation herzuleiten. Abschließend
42 PROBLEMANALYSE
werden bereits bestehende Ansätze für den einheitlichen Zugriff auf heterogene Da-
tenquellen betrachtet und bezüglich der aufgestellten Anforderungen bewertet.
2.1. Benutzung der Repräsentation
Zur Verwaltung- und Verteilung der gespeicherten Informationen sollen im
MIDMAY-Konzept mobile Geräte wie Smartphones, PDAs oder Notebooks zum
Einsatz kommen. Diese Geräte verwenden kabellose Kommunikationsverbindungen,
um auf die Repräsentation der Informationen zuzugreifen. Um eine größtmögliche
Verfügbarkeit der Repräsentation für den Benutzer zu ermöglichen, ist die Zu-
griffsmöglichkeit über stationäre öffentliche Internet-PCs ebenfalls sinnvoll. Sobald
sich der Benutzer bei seiner Homebase angemeldet und authentifiziert hat, kann
er mit der Repräsentation seiner verteilt gespeicherten Informationen arbeiten. Er
kann nun Funktionen zum Auffinden und zur Verwaltung seiner Informationsobjekte
nutzen.
2.1.1. Finden von Informationsobjekten
Für die Suche nach Informationen auf einer entfernten Datenquelle ist der Benutzer
auf die Funktionen angewiesen, die ihm das jeweilige Protokoll oder das Client-
Programm anbietet. Die Repräsentation der Informationsobjekte seiner verteilten
Datenquellen ermöglicht dagegen eine Suche, die unabhängig von Datenquelle, Pro-
tokoll und Client ist.
Angenommen der Benutzer möchte ein Dokument X versenden, das die Projekt-
planung des Projekts P enthält. Falls er den Speicherort von X (z. B. einen
FTP-Fileserver) kennt, kann er diese Datenquelle auswählen und wie in einem
Dateisystem-Browser zu dem entsprechenden Verzeichnis navigieren. Ist der Spei-
cherort von X unbekannt aber der Name (oder ein Teil des Namens) bekannt, kann
er eine Volltextsuche innerhalb der Repräsentation ausführen und so das Doku-
ment über alle repräsentierten Datenquellen hinweg suchen. Weiß der Benutzer den
Namen nicht, kann ihm die Angabe verschiedener Metainformationen oder Eigen-
schaften des Informationsobjekts helfen. Der Benutzer könnte z. B. wissen, dass das
gesuchte Dokument im PDF Format vorliegt und dass es in einem bestimmten Zeit-
raum gespeichert wurde (nämlich in dem Zeitraum, in dem Projekt P geplant wurde)
und sich alle passenden Informationsobjekte anzeigen lassen. Es könnte auch sein,
dass das Projekt P selbst in der Repräsentation repräsentiert ist. Dann kann der
Benutzer das Projekt P auswählen, um zu allen Dokumenten zu gelangen die mit
Projekt P in Zusammenhang stehen. Dafür muss zuvor das Projekt P selbst in die
Repräsentation aufgenommen, und eine Verbindung zwischen P und den zugehöri-
gen Informationsobjekten hergestellt worden sein. Damit solche Erweiterungen in
52 PROBLEMANALYSE
der Repräsentation vorgenommen werden können, sollten Verwaltungsfunktionen
zur Verfügung gestellt werden.
2.1.2. Verwalten der Informationsobjekte und ihrer Repräsentation
Das Verwalten von Informationen erfolgt auf zwei unterschiedlichen Ebenen: Zum
einen werden empfangene Informationsobjekte an einem passenden Ort abgelegt.
Zum anderen kann die Repräsentation dieser Informationsobjekte erweitert und
strukturiert werden. Die Verwaltung auf diesen beiden Ebenen kann wiederum
durch zwei unterschiedliche Akteure erfolgen, durch den Benutzer und durch weitere
Software-Module.
Der Benutzer hat das Ziel seine Informationsobjekte logisch so abzulegen, dass er
sie möglichst leicht wiederfindet. Dabei muss er sich jedoch für einen Ablageort ent-
scheiden, wenn er die Information nicht redundant abspeichern will. Er kann so nur
eine eindimensional Einordnung der Information vornehmen. In der Repräsentation
der Informationsobjekte kann dagegen ein einzelnes Informationsobjekt zugleich in
verschiedene logische Strukturen eingeordnet werden, je nach dem aus welcher Sicht
es betrachtet wird. In obigem Beispiel könnte Dokument X einmal als Dokument
”
des Projekts P“ eingeordnet werden, aber ebenso als Dokument in Bearbeitung“
”
und als Dokument von Autor A“. Der Benutzer benötigt die Möglichkeit, die Re-
”
präsentation um eigene Konzepte zu erweitern und ihr eine Struktur zu geben, die
ihm das Auffinden seiner Informationen erleichtert.
Die Aufgabe Informationsobjekte einzuordnen sollte soweit möglich durch Software-
Module unterstützt werden. Dass ein Dokument von Autor A bearbeitet wird, könnte
z. B. innerhalb des Dokuments als Metainformation gespeichert sein, so dass dieses
Dokument automatisch als Dokument von Autor A“ klassifiziert werden kann. In
”
anderen Fällen, in denen eine vollautomatische Einordnung zu unzuverlässig wäre,
könnten zumindest Vorschläge für den Benutzer generiert werden. Das MIDMAY-
Konzept sieht auch ein Kontext-Modul vor, das Kontextinformationen bereitstellt,
die zusammen mit den Informationsobjekten versendet werden. Die Kontextinfor-
mationen können dann beim Empfänger dazu benutzt werden, automatisch zu be-
stimmen, an welchem Ort das Informationsobjekt abgespeichert und wie es in die
Repräsentation eingeordnet werden soll.
2.2. Anforderungen
In Abschnitt 1.2 wurden Umfang und Aufgaben der MIDMAY-Module URM und
DRM bereits kurz dargestellt. Im vorhergehenden Abschnitt wurde näher auf die
Benutzung der Repräsentation eingegangen. In diesem Abschnitt werden die bereits
62 PROBLEMANALYSE
beschriebenen Funktionen und Eigenschaften in konkrete Anforderungen an ein Sys-
tem zur Erstellung, Verarbeitung und Bereitstellung der Repräsentation gefasst.
2.2.1. Funktionale Anforderungen
1. Erstellung
a) Indizierung
Die Informationen unterschiedlicher verteilter Datenquellen sollen indi-
ziert werden
Informationen darüber, welche Informationsobjekte mit welchen Eigen-
schaften auf einer Datenquelle vorliegen, sollen in die Repräsentation
übertragen werden. Falls die Informationsobjekte als Container für wei-
tere Informationsobjekte dienen, wie es z. B. bei einer E-Mail mit Datei-
anhängen der Fall ist, sollen auch diese untergeordneten Informationsob-
jekte mit in die Repräsentation aufgenommen werden.
Das System zur Erstellung der Repräsentation soll um beliebige Arten von
persönlichen Datenquellen erweiterbar sein. Mit persönlichen Datenquel-
len sind solche gemeint, auf denen persönliche Dokumente, Nachrichten
und Informationen gespeichert sind und die nur für einen beschränkten
Nutzerkreis zugänglich sind.
b) Repräsentation von Metainformationen
Zu den Informationsobjekten sollen Metainformationen in der Repräsen-
tation gespeichert werden
Bei der Abbildung eines Informationsobjekts in die Repräsentation sol-
len verschiedene Eigenschaften des Informationsobjekts extrahiert und
repräsentiert werden. Solche Eigenschaften können z. B. der Typ, der Au-
tor oder das Erstellungsdatum eines Informationsobjekts sein. Andere In-
formationen, die in irgendeiner Weise in Bezug zum Informationsobjekt
stehen, sollen ebenfalls als Metainformation repräsentiert werden können.
Darunter fallen z. B. Informationen über den Kontext, in dem ein Infor-
mationsobjekt versendet wurde oder Informationen, welche Dokumente
projektbezogen zusammengehören (siehe 2.1.2)). Solche zu repräsentie-
renden Metainformationen können sowohl vom Benutzer erstellt als auch
von Software-Modulen generiert werden.
c) Einheitliche Repräsentation
Bei der Repräsentation von Informationsobjekten und Metainformatio-
nen sollen, soweit möglich, gemeinsame einheitliche Typen verwendet
werden
Bestimmte Eigenschaftstypen, wie Autor oder Erstellungsdatum, können
zur Beschreibung von Informationsobjekten unterschiedlicher Datenquel-
72 PROBLEMANALYSE
len dienen. Innerhalb der Repräsentation sollten daher solche Typen zur
Angabe von Metainformationen einheitlich definiert und genutzt werden.
So können die Informationsobjekte unabhängig von ihrer Datenquelle an-
hand ihrer Metainformationen betrachtet werden.
2. Zugriff
a) Geräteunabhängiger Zugriff
Die Anzeige und Bearbeitung der Repräsentation soll auf Geräten mit
unterschiedlichen Eingabe- und Darstellungsmöglichkeiten möglich sein
Der Zugriff auf die Repräsentation soll unabhängig von den Möglich-
keiten des verwendeten Gerät erfolgen können. Nicht nur PCs sollen
für die Informationssuche, Auswahl und Verwaltung verwendet werden
können, sondern auch Geräte mit kleinen Displays oder beschränkten Ein-
gabemöglichkeiten wie Handys oder PDAs. Die Client-Schnittstelle muss
also den Abruf von Information und die Navigation in der Repräsentation
für verschiedene Geräte ermöglichen. Client-Implementierungen müssen
dabei nicht immer alle Funktionen der Client-Schnittstelle nutzen. Be-
stimmte Grundfunktionen zum Auffinden von Objekten sollten mit je-
dem Gerät ausführbar sein. Weitere Funktionen, wie z. B. das in Anfor-
derung 3c beschriebene Strukturieren der Repräsentation, können je nach
Möglichkeiten des jeweiligen Endgeräts angeboten werden.
b) Mobiler Zugriff
Der Zugriff auf die Repräsentation soll ortsunabhängig und mit mobilen
Geräten möglich sein
Das in Abschnitt 1.1.2 beschriebenen Szenario geht davon aus, dass ein
Zugriff gerade dann möglich ist, wenn der Benutzer sich in einer frem-
den Umgebung befindet und Informationen mit einer zuvor unbekannten
Person austauschen möchte. Der Benutzer sollte also unabhängig vom
Standort möglichst jederzeit in der Lage sein auf die Repräsentation zu-
zugreifen. Um dieser Anforderung gerecht zu werden, müssen die Daten
vom mobilen Endgerät mit einer kabelloser Kommunikationsverbindung
übertragen werden können. Da bei mobilen kabellosen Kommunikations-
verbindungen meistens geringere Übertragungsgeschwindigkeiten möglich
sind als bei stationär vernetzten PCs, ergibt sich hieraus auch die An-
forderung, die übertragenen Daten möglichst gering zu halten oder zu
komprimieren.
3. Benutzung
a) Datenquellen übergreifende Suche
Die Suche nach einem Informationsobjekt soll ohne Angabe seiner Da-
tenquelle möglich sein
Wenn der Benutzer eine bestimmte Information, z. B. eine Datei sucht,
82 PROBLEMANALYSE
wird von ihm nicht verlangt die Datenquelle zu kennen, auf der die Infor-
mation vorhanden ist. Stattdessen kann er in der Repräsentation über al-
le Datenquellen hinweg z. B. nach dem Namen eines Informationsobjekts
suchen. Weitere von den Datenquellen unabhängige Suchmöglichkeiten
werden in Anforderung 3b beschrieben.
b) Suche über Metainformationen
Ein Informationsobjekt soll durch die Angabe von Metainformationen auf-
gefunden werden können
Nach Anforderung 1b sind in der Repräsentation die Eigenschaften ei-
nes Informationsobjekts als Metainformationen gespeichert. Der Benut-
zer soll die Möglichkeit haben ein Informationsobjekt zu finden, indem
er eine oder mehrere Eigenschaften des gesuchten Objekts angibt, so wie
es in Abschnitt 2.1.1 beschrieben ist. Ihm werden dann als Ergebnis alle
Informationsobjekte präsentiert, die diese Eigenschaften besitzen.
c) Strukturierung der Repräsentation
Der Benutzer soll der Repräsentation Informationen hinzufügen und sie
strukturieren können
Das Hinzufügen von Informationen ermöglicht dem Benutzer, seine eige-
nen gedachten Konzepte in die Repräsentation zu integrieren (siehe Ab-
schnitt 2.1.2) und Metainformationen zu den Informationsobjekten an-
zugeben (vergleiche Anforderung 1b). In der Repräsentation kann er Ver-
bindungen zwischen den Informationsobjekten und seinen hinzugefügten
Konzepten erstellen, die ihm ein späteres Auffinden der so eingeordneten
Informationsobjekte erleichtern.
2.2.2. Nicht-Funktionale Anforderungen
4. Benutztbarkeit
a) Aktualität
Es soll ein möglichst aktueller Stand der Datenquellen repräsentiert wer-
den
Der Benutzer soll auch erst kürzlich empfangene oder erstellte Informatio-
nen in der Repräsentation auswählen können. Dazu muss die Repräsen-
tation zum Zeitpunkt des Zugriffs den aktuellen Stand der Datenquellen
repräsentieren. Eine Repräsentation, die zu jedem Zeitpunkt den vorhan-
denen Informationen entspricht, ist jedoch nicht möglich, da für das Er-
kennen von Veränderungen auf den Datenquellen und für die Abbildung
der Informationen in die Repräsentation Zeit benötigt wird. Es kann also
nicht garantiert werden, dass immer alle Informationen der Datenquellen
in der Repräsentation vorhanden sind.
92 PROBLEMANALYSE
b) Kurze Antwortzeit
Operationen auf der Repräsentation sollen in angemessener Zeit ein Er-
gebnis liefern
Damit der MIDMAY-Client auf Aktionen des Benutzers reagieren kann,
benötigt er möglichst schnell bestimmte Daten der Repräsentation. Die
Antwortzeit von der Anfrage bis zum Ergebnis hängt dabei nicht nur
von der Geschwindigkeit ab, mit der das Repräsentations-Modul die ge-
suchten Daten findet. Insbesondere bei mobilen Clients spielt die Men-
ge der übertragenen Daten auch eine Rolle. Die Schnittstelle des Re-
präsentations-Moduls zum Client sollte daher so gestaltet werden, dass
der Client gezielt auf bestimmte Ausschnitte der Repräsentation zugreifen
kann. Der Client hat dann die Möglichkeit, Daten nur dann anzufordern,
wenn sie vom Benutzer jetzt oder wahrscheinlich in Zukunft benötigt
werden.
5. Sicherheit
a) Sichere Kommunikation
Der Datenaustausch zwischen Client und dem URM der MIDMAY-
Homebase sowie zwischen Datenquellen und dem DRM soll über einen
sicheren Kommunikationskanal ablaufen
Die Daten, welche der Benutzer über seinen Client anfordert, sollen nicht
von Dritten eingesehen oder verändert werden können. Damit sie nicht
eingesehen werden können, ist ein verschlüsselter Kommunikationskanal
nötig. Um die Verfälschung der Daten durch einen Dritten zu verhindern,
müssen sich Client und MIDMAY-Homebase gegenseitig authentifizieren.
b) Schutz der Repräsentations-Daten
Die Daten der Repräsentation sollen vor unberechtigtem Zugriff und vor
Manipulation geschützt sein
Die Repräsentations-Daten müssen so abgespeichert werden, dass sie
nur über die Schnittstellen des URM zugänglich sind. Das URM besitzt
Schnittstellen in zwei Richtungen: Einmal zum Client hin, für den Zugriff
durch den Benutzer, und zum anderen für weitere MIDMAY Software-
Module, die Informationen der Repräsentation erstellen oder nutzen. Wei-
terhin muss durch Authentifizierung- und Autorisierungsmechanismen si-
chergestellt werden, dass über diese Schnittstellen keine unberechtigten
Benutzer bzw. Software-Module auf die Repräsentation zugreifen.
c) Schutz der Zugangsdaten
Schutz der Zugangsdaten des Benutzers vor unberechtigtem Zugriff
Um die Informationen der verteilten Datenquellen abzurufen und sie in
die Repräsentation abzubilden zu können, werden die Zugangsdaten der
Datenquellen benötigt. Die Repräsentation muss regelmäßig und automa-
tisch aktualisiert werden um immer den aktuellen Stand zu repräsentieren
102 PROBLEMANALYSE
(Anforderung 4a). Deshalb müssen die Zugangsdaten der Datenquellen
auf der MIDMAY-Homebase hinterlegt sein. Weil diese Daten den Zu-
griff auf beliebige Informationen des Benutzers ermöglichen, müssen sie
vor unberechtigtem Zugriff geschützt werden. Nur MIDMAY Software-
Module sollen auf die Zugangsdaten zugreifen dürfen, und die Zugangs-
daten dürfen die MIDMAY-Homebase ausschließlich zum Zweck der An-
meldung bei einer Datenquelle verlassen.
2.3. Aktuelle Ansätze
Um eine mobile Informationsverteilung und -verwaltung zu realisieren, benötigt
MIDMAY Funktionen, die teilweise auch von anderen Software-Produkten ange-
boten werden. Insbesondere die Funktionen über verschiedene Datenquellen hinweg
Informationen zu indizieren und einheitlich zu repräsentieren (Anforderungen 1a,
1b und 1c), werden in vielen Informationssystemen benötigt. In diesem Abschnitt
werden drei verschiedene Ansätze zur Erfassung und Bereitstellung von Informa-
tionen vorgestellt. Zu den betrachteten Ansätzen gehören Suchmaschinen, Systeme
zur Verwaltung von Informationen (Content Management Systeme) und System zur
Verwaltung von Wissen“ (Knowledge Management Systeme). Suchmaschinen sind
”
darauf spezialisiert Informationen innerhalb großer Datenmengen zu finden. Content
Management Systeme verwalten Informationen, indem sie Funktionen zur Erfas-
sung, Überarbeitung und Veröffentlichung der Informationen bieten. In Knowledge
Management Systemen wird das Wissen eines Unternehmens erfasst und verwal-
tet. Im Folgenden wird untersucht, welche Funktionen und Vorgehensweisen dieser
drei Ansätze sich auch in MIDMAY wiederfinden und wo sich MIDMAY von den
existierenden Software-Produkten unterscheidet.
2.3.1. Suchmaschinen
Suchmaschinen werden zur Suche nach Informationen in großen Datenmengen ver-
wendet. Suchmaschinen müssen dazu die vorliegenden Informationen indexieren. Sie
bauen eine Datenstruktur auf, die dabei hilft den Ort einer Ressource anhand der
Eigenschaften einer Information zu bestimmen. Bei den Informationen kann es sich
um strukturierte Informationen handeln, beispielsweise um Produktinformationen
in einer Datenbank oder in einem XML-Format, oder um unstrukturierte, meist
verteilt gespeicherte Informationen, wie z. B. Webseiten und Dateien im Internet.
Auch in MIDMAY soll für die Suche in unstrukturierten verteilten Informationen
die MIDMAY-Repräsentation als Index erstellt werden. Mit Hilfe der Repräsenta-
tion soll jedoch auch visualisiert werden können, welche Informationen vorhanden
sind und wie diese durch ihre Eigenschaften zusammenhängen. Eine Suchmaschine
112 PROBLEMANALYSE
liefert auf eine Suchanfrage nur eine Liste mit passenden, nach Relevanz geordne-
ten Informationen zurück, so dass keine Visualisierung von Zusammenhängen und
Navigation in den Informationen möglich ist.
So genannte Desktop-Suchmaschinen“ kommen dem MIDMAY Ziel den Benutzer
”
beim Auffinden persönlicher Informationen zu unterstützen am nächsten. Bei diesen
Suchmaschinen werden die Dateien eines PC indiziert, so dass sich der PC auf glei-
che Weise durchsuchen lässt wie das Internet mit einer Internet-Suchmaschine. Die
Google Desktop Search Software1 indiziert beispielsweise die gängigsten Dateiforma-
te und auch E-Mails. Allerdings findet die Suche nur lokal auf dem Dateisystem
statt. Andere Datenquellen könnten aber durch Plugins integriert werden. Es exis-
tiert bereits ein Plugin2 für die Integration entfernter Dateisysteme und eines, das
den entfernten Zugriff auf die lokale Desktop-Suchmaschine ermöglicht.
2.3.2. Verwaltungs-Systeme (Content Management)
Systeme zur Verwaltung von Informationen werden auch als Content Management
Systeme (CMS) bezeichnet. Unter dem Begriff Content werden inhaltlichen Infor-
mationen jeglicher Art, z. B. strukturierte Datensätze, Textdokumente oder Bilder
verstanden. Content setzt sich aus dem Inhalt und zugehörigen Meta-Informationen
zusammen. Die Meta-Informationen sind nicht unbedingt für den Nutzer sichtbar,
sondern können auch nur zur Verwaltung und Kontrolle des eigentlichen Inhalts
dienen. Die Funktionen eines Content Management Systems sind nicht einheitlich
definiert, sie sind vom Einsatzbereich des Systems abhängig. Im Internet können
z. B. Web Content Management Systeme (WCMS) eingesetzt werden, um die Inhal-
te von Webseiten zu erstellen und zu verwalten. Zur Speicherung der Inhalte kommt
meistens eine Datenbank zum Einsatz.
Im Unterschied zu MIDMAY wird durch ein Content Management System keine
Repräsentation verteilter Informationen erstellt, sondern Informationen werden in
das CMS übertragen und dort gespeichert. Das CMS hat so die Kontrolle über
die Informationen und kann Funktionen wie Versionierung, Suche, Verteilung und
Aufbereitung der Inhalte anbieten. Der Nachteil ist, dass Informationen zur Be-
arbeitung aus dem CMS geholt und nach der Bearbeitung wieder in das System
übertragen werden müssen. In MIDMAY ist es nicht nötig Informationen von ihrer
eigentlichen Datenquelle auf einen Server zu übertragen, um sie für eine Suche oder
Verteilung verfügbar zu machen. Statt der eigentlichen Inhalte werden nur die Meta-
Informationen erfasst, auf die MIDMAY Homebase übertragen und dort verwaltet.
1
Google Desktop Search: http://desktop.google.de/
2
Google Desktop Search Plugins: http://desktop.google.de/plugins.html
123 FORMATE ZUR REPRÄSENTATION VON WISSEN
2.3.3. Knowledge Management Systeme
Mit einem Knowledge Management System (KMS) soll das gesamte in einer Organi-
sation verankerte Wissen erfasst, verwaltet und verfügbar gemacht werden. Know-
ledge Management Systeme und MIDMAY haben als gemeinsames Ziel, verteilte
Informationen verfügbar zu machen. Dafür ist die Integration verschiedener exis-
tierender Datenquellen in das System notwendig. Es ist aber auch möglich, dass
externe globale Ressourcen (das Internet) oder menschliche Ressourcen (Kollegen,
Berater) über ein KMS befragt werden können, wie es in [25] beschrieben wird. Wis-
sensmanagement mit einem KMS geht jedoch über die Versorgung der Benutzer mit
Informationen hinaus. Ein KMS muss den Benutzern auch die Möglichkeit geben,
ihre Informationen und ihr Wissen in das System einzugeben oder bestehende Infor-
mationen zu bearbeiten. Daten, Informationen, Prozesse und Fähigkeiten innerhalb
einer Organisation sollen so explizit gemacht und im KMS gespeichert werden. Der
Fokus in MIDMAY liegt auf der Strukturierung von Informationen, die außerhalb
von MIDMAY erstellt und bearbeitet werden. Das Wissen darüber, wo Informatio-
nen abgelegt sind und wie sie in Beziehung zueinander stehen, soll explizit gemacht
werden.
3. Formate zur Repräsentation von Wissen
Eine Wissensrepräsentation ist ein Platzhalter für reale Objekte, Eigenschaften oder
Ereignisse. Sie bildet die Grundlage zur intelligenten Herleitung von weiterem Wis-
sen und dient als Medium zur Kommunikation über Wissen [3]. In der natürlichen
Sprache wird Wissen informal repräsentiert, für die maschinelle Verarbeitung ist da-
gegen eine formale Darstellung notwendig. In diesem Abschnitt soll untersucht wer-
den, welches Format sich zur Repräsentation des Wissens über Inhalte und Struk-
turen von Datenquellen eignet. Ein solches Format muss einzelne Dateneinheiten
der Datenquellen und ihre Eigenschaften und Beziehungen untereinander darstellen
können. Die Dateneinheiten können unterschiedliche Informationsobjekte wie z. B.
Dateien und Ordner eines Dateisystems, aber auch Termine einer Terminverwaltung
sein.
Die meisten Menschen werden ein gemeinsames Verständnis davon haben was ein
Termin“ ist und vielleicht auch unter dem Begriff Datei“ dasselbe verstehen. Ein
” ”
Format zur formalen Wissensrepräsentation muss sich jedoch auf Ontologien stützen,
damit eine Eindeutigkeit der verwendeten Symbole und Begriffe und so eine Wie-
derverwendung und Interoperabilität des repräsentierten Wissens möglich ist. Eine
Ontologie ist die explizite Spezifikation einer vereinfachten Sicht auf einen Ausschnitt
der Welt (Konzeptualisierung) [9]. Mit ihr wird formal festgelegt, welche abstrakten
und konkreten Objekte, Konzepte und Relationen im repräsentierten Weltausschnitt
133 FORMATE ZUR REPRÄSENTATION VON WISSEN
existieren. Einzelne Objekte einer Wissensrepräsentation können dann mit dem fest-
gelegten Vokabular der Ontologie beschreiben werden.
Ein Format zur Wissensrepräsentation sollte sich jedoch nicht nur prinzipiell zur
Erfassung und Verarbeitung des beabsichtigten Wissensbereichs eignen, sondern es
sollten auch Werkzeuge für das Format verfügbar sein. Aus diesem Grund werden
hier die beiden standardisierten Formate Topic Maps und RDF betrachtet, für die
bereits verschiedene Verarbeitung-Werkzeuge existieren. Die Grundlagen dieser For-
mate werden erläutert, sowie Ziele und Einsatzgebiete untersucht.
3.1. Topic Maps
Topic Maps ermöglichen die Beschreibung von Wissensstrukturen und die Ver-
knüpfung dieser Wissensstrukturen mit existierenden Informationsressourcen [21].
Eine Topic Map bildet eine strukturierte Informationsschicht über diesen Informati-
onsressourcen, die dadurch mit weiteren Informationen angereichert werden können.
Topic Maps als Format zur Beschreibung und zum Austausch von Wissensstruktu-
ren wurden im ISO Standard 13250 [11] auf Basis von SGML standardisiert. Später
wurde die XML Topic Map Syntax XTM [27] in den ISO Standard mit aufgenom-
men. Zwischen dem Austauschformat der ursprünglichen ISO Spezifikation und der
XTM Syntax von Topic Maps gibt es leichte Unterschiede, so dass noch nicht geklärt
ist, wie sich die beiden Formate aufeinander abbilden lassen [12]. Zur Zeit wird an
einem formalen Topic Map Daten-Modell gearbeitet, welches als Referenz-Modell
zur Einbindung verschiedener Syntax-Definitionen dienen soll [13].
Gegenwärtig ist die XTM Spezifikation [27] der aktuellste gültige Standard und
durch die Verwendung von XML als Austauschformat auch einfacher anzuwenden.
Deshalb bezieht sich die folgende Beschreibung der Topic-Map-Konzepte, soweit
nicht anders angegeben, auf diese Spezifikation.
In den nächsten Abschnitten werden die wesentlichen Bestandteile einer Topic Map
beschrieben: Topics (Themen), Occurrences (Vorkommensangaben) und Associa-
tions (Assoziationen). Als weitere wichtige Konzepte werden Subject Identity und
Scope vorgestellt. Um Topic Map Bestandteile und Strukturen zu veranschaulichen,
wird auf eine in [1] beschriebene UML basierte Notation für Topic Maps zurückge-
griffen.
3.1.1. Topics
In einer Topic Map wird jedes Ding, ob Objekt, Begriff oder Idee, als Topic repräsen-
tiert. Im Topic-Map-Standard werden die Dinge der realen Welt, für die ein Topic
steht, Subjects genannt. Topics (als Repräsentanten) und Subjects (als repräsentierte
143 FORMATE ZUR REPRÄSENTATION VON WISSEN
Objekte) sollten möglichst in einer Eins-zu-Eins Beziehung stehen, um Redundanzen
und Widersprüche in der Repräsentation zu vermeiden.
Ein Topic wird durch drei Eigenschaften charakterisiert: Namen, Occurrences (Vor-
kommensangaben) und Rollen in den Assoziationen. Als Namen kann ein Topic
verschiedene Basenames und Variantnames besitzen (siehe Abbildung 3). Ein Ba-
sename ist ein Name in Form einer Zeichenkette, während ein Variantname eine
Ressource referenziert und deshalb eine beliebige andere Form haben kann. Ein Va-
riantname gibt eine alternative Form des Basename an, und legt mit einem oder
mehreren Topics als Parameter den Verarbeitungskontext fest, in dem der Variant-
name verwendet werden soll. Als Parameter für das Anzeigen bzw. Sortieren eines
Topics sind bereits die Topics Display und Sort definiert.
«Topic» «Base Name»
1 *
Base Name String
1
1 «Variant» «Parameter»
* 1 *
* Variant Name
«Occurence»
Abbildung 3: Zusammenhang zwischen Topic, Basename, Variantname und Occur-
rence
Die beiden Topic-Eigenschaften Ocurrences und Rollen werden in den nächsten zwei
Abschnitten erläutert.
3.1.2. Occurrences
Durch Vorkommensangaben werden Topics mit Ressourcen verbunden, die relevante
Informationen zu diesem Topic enthalten. Dies sind z. B. nähere Beschreibungen,
Dokumente oder Bilder, die etwas über das Subject aussagen, welches das Topic
repräsentiert. Die Ressourcen müssen nicht in der Topic-Map selbst vorhanden sein,
sondern es können unterschiedliche externe Quellen referenziert werden. In XTM
wird eine Vorkommensangabe durch einen URI referenziert. Die Topic-Map bildet
durch diese Möglichkeit der Referenzierung eine strukturierte Informationsschicht
über den unzusammenhängenden referenzierten Ressourcen.
3.1.3. Associations
Eine Beziehung zwischen zwei oder mehreren Topics wird durch eine Assoziation
beschrieben. Eine Assoziation ist eine ungerichtete Relation auf den Topics. In der
153 FORMATE ZUR REPRÄSENTATION VON WISSEN
Assoziation werden die teilnehmenden Topics definiert und die jeweilige Rolle, die
sie in der Assoziation spielen. Im Standard bereits definiert sind die superclass-
subclass und die class-instance Assoziation mit zugehörigen Rollen. Die superclass-
subclass Assoziation kann verwendet werden um Klassenhierarchien zu definieren.
Abbildung 4 zeigt auf der linken Seite ein Beispiel einer solchen Assoziation und
auf der rechten Seite die Darstellung des gleichen Sachverhalts in UML. Das Topic
Adresse“ nimmt hier in der Rolle superclass in der Beziehung teil, das Topic E-
” ”
Mail Adresse“ in der Rolle subclass. Durch die Assoziation wird beschrieben, dass
Adresse“ eine Generalisierung des Topics E-Mail Adresse“ ist, bzw. dass E-Mail
” ” ”
Adresse“ eine Spezialisierung des Topics Adresse“ ist.
”
Adresse
supeclass-subclass
Adresse superclass E-Mail Adresse E-Mail Adresse
subclass
Abbildung 4: Eine superclass-subclass Assoziation (links) und die entsprechende
UML Beschreibung (rechts)
Die class-instance Assoziation wird verwendet um Topics als Instanzen anderer To-
pics zu deklarieren. Abbildung 5 zeigt eine class-instance Assoziation die beschreibt,
dass alice@xyz.com“ eine Instanz des Topics E-Mail Adresse“ ist.
” ”
E-Mail Adresse
class-instance «instanceOf»
E-Mail Adresse alice@xyz.com alice@xyz.com
class instance
Abbildung 5: Eine class-instance Assoziation (links) und die Beschreibung in UML
(rechts)
Rollen wie class, instance, superclass und subclass sind selbst Topics der Topic Map.
Jedes Topic kann als Rolle für Topics in Assoziationen oder als Typ für andere
Topics oder Assoziationen verwendet werden. Durch dieses Konzept können Topic-
und Assoziationstypen und deren Bedeutung frei definiert werden.
Die Topic-Map-Spezifikation lässt allerdings offen, wie Assoziations-Eigenschaften
oder Bedingungen für Assoziationen definiert werden. Die Eigenschaften einer As-
soziationen wie Transitivität, Reflexivität oder Symmetrie ermöglichen zusammen
163 FORMATE ZUR REPRÄSENTATION VON WISSEN
mit Inferenzregeln das automatische Herleiten von weiterem impliziten Wissen aus
einer Topic Map oder auch eine Konsistenzprüfung der repräsentierten Aussagen.
Bedingungen für Assoziationen, z. B. wieviele Topics in welchen Rollen teilnehmen
dürfen, ermöglichen die Validation einer Topic Map gegen die festgelegten Bedin-
gungen. Auch wenn die notwendigen Konzepte für Inferenz, Konsistenzprüfung oder
Validation der Inhalte einer Topic Map nicht von vornherein im Standard spezifiziert
sind, bieten Topic Maps die Möglichkeit diese Konzepte selbst als Topics innerhalb
einer Topic Map zu definieren und für die entsprechenden Zwecke anzuwenden [24].
3.1.4. Scope
Aussagen über ein Topic werden durch die bereits beschriebenen Topic-Eigenschaf-
ten (Namen, Vorkommensangaben und Rollen in Assoziationen) gemacht. Diese Aus-
sagen müssen jedoch nicht universell gültig sein, sondern können mit der Angabe
eines Scope auf einen bestimmten Gültigkeitsbereich beschränkt werden. So kann
z. B. angegeben werden, dass ein Topic-Name nur im Kontext einer bestimmten
Sprache gültig ist oder eine Assoziation nur eine einzelne Meinung repräsentiert, die
nicht von allen geteilt wird. Der Scope (Gültigkeitsbereich) einer Topic-Eigenschaft
kann durch die Angabe einer Menge von Scoping-Topics festgelegt werden. Die Ver-
einigung dieser Topics bestimmt den Kontext, in dem die Topic-Eigenschaften gültig
ist. Ohne diese Angabe liegt eine Topic-Eigenschaft im Unconstrained Scope und ist
damit immer gültig. Es gibt jedoch keine weiteren Vorgaben, wie die Scope-Angabe
bei der Verarbeitung einer Topic Map verwendet werden soll. Insbesondere für die
Herleitung der Gültigkeit einer Topic-Eigenschaft bei gegebenem Kontext gibt es
verschiedene Möglichkeiten, die in [23] betrachtet werden.
Bei Topic-Basenames legt ein angegebener Scope nicht nur den Gültigkeitsbereich
des Namens fest, sondern definiert auch einen Namensraum. Es gilt das so genann-
te Topic Naming Constraint: Es darf keine zwei Topics in einer Topic Map geben,
die den selben Basename im selben Scope besitzen. Falls das doch der Fall ist,
repräsentieren die beiden Topics das selbe Subject und müssen zu einem Topic ver-
einigt werden. Das resultierende Topic besitzt die Eigenschaften beider Topics, also
alle Namen, Vorkommensangaben und Rollen in Assoziationen, welche die beiden
Topics charakterisieren.
Unter Topic Map Experten ist jedoch umstritten, ob das Topic Naming Constraint
sinnvoll ist [5], da es in jedem Fall Scope-Angaben für Topics erzwingt, um Na-
men eindeutig zu halten. In der realen Welt sind eindeutige Namen jedoch eher
die Ausnahme3 . Im neusten Topic Map Draft des ISO Komitees [13] wird deswegen
3
Um z. B. ein Telefonbuch zu repräsentieren, könnten die eingetragenen Personen durch eine As-
soziation mit ihrer Telefonnummer verknüpft werden. Die Namen in einem Telefonbuch sind
aber nicht eindeutig und die Telefonnummer müsste deshalb im Scope für den Namen einer Per-
173 FORMATE ZUR REPRÄSENTATION VON WISSEN
die Eindeutigkeit der Namen nicht mehr vorgeschrieben. Stattdessen werden Name-
Typen eingeführt, mit denen unter anderem auch die Eindeutigkeit eines Basename
auf Wunsch definiert werden kann.
3.1.5. Subject Identity
Topics sind Stellvertreter für Dinge innerhalb und außerhalb der Topic Map. Deshalb
können in unterschiedlichen Topic Maps verschiedene Topics das gleiche Subject der
realen Welt repräsentieren. Wenn das Wissen zweier Topic-Maps vereinigt werden
soll, ist es sinnvoll für jedes Topic wieder eine Eins-zu-Eins Beziehung zwischen Topic
und Subject herzustellen, um einen einzigen Zugriffspunkt auf das Wissen über ein
Subject zu haben.
Das Konzept der Subject Identity ermöglicht es festzustellen, ob zwei Topics das selbe
Subject repräsentieren. Wenn das der Fall ist, können die Eigenschaften der beiden
Topics vereinigt werden. Die Identität eines Subjects kann auf zwei verschiedene Ar-
ten definiert werden. Wenn eine elektronische Ressource repräsentiert werden soll,
kann einfach deren URL als Subject Address verwendet werden. Topics, welche die
gleiche Subject Address besitzen, repräsentieren das selbe Subject. Für andere Ob-
jekte oder gedachte Begriffe ist es jedoch notwendig eine URI-Adresse zur indirekten
Identifikation des Subjects zu definieren. Eine solche Adresse wird als Subject Identi-
fier bezeichnet, die Informationsressource auf die sie zeigt als Subject Indicator. Die
Subject Identifier Adresse wird vom Computer fast auf die gleiche Weise verwen-
det wie die Subject Address eines direkt adressierbaren Subjects. Haben zwei Topics
einen Subject Identifier gemeinsam, repräsentieren sie das selbe Subject. Der Subject
Indicator wird nicht vom Computer verwendet, sondern vom Menschen. Die Infor-
mationsressource weist Menschen darauf hin (engl.: to indicate) um welches Subject
es sich handelt. Werden Subject Identifiers und Subject Indicators explizit für die
Identifikation von Subjects definiert und erstellt, wird von Published Subject Iden-
tifiers (PSIDs) und Published Subject Indicators (PSIs) gesprochen. Die Definition
von PSIDs und PSIs geschieht nicht zentral, sondern als offener verteilter Prozess.
Jeder kann PSIs verwenden oder eigene definieren, wobei er sich an Empfehlungen
des OASIS Published Subjects Komitees zur Erstellung von PSIs [19] orientieren
kann.
3.2. RDF
Das Ressource Description Framework (RDF) wurde entwickelt, um der Vision des
Semantic Web [2] näher zu kommen, indem es die Strukturierung und Beschrei-
son benutzt werden. Dann enthält die Topic Map aber redundante Information, die konsistent
gehalten werden muss.
183 FORMATE ZUR REPRÄSENTATION VON WISSEN
bung von Ressourcen im World Wide Web ermöglicht. Es können verschiedene Vo-
kabularien für die Beschreibung von Ressourcen bestimmter Anwendungsdomänen
definiert werden. Mit RDF und darauf aufbauenden Ontologiesprachen wie OWL
kann der Kontext von Ressourcen explizit beschrieben werden, so dass sie durch
den Computer besser interpretiert werden können. Zur RDF-Spezifikation gehört
ein Datenmodell mit einer XML-Syntax [30] sowie eine Syntax zur Definition von
Vokabularien (RDFS [29]).
3.2.1. RDF Konzepte
Das RDF Datenmodell besteht aus den Kernkonzepten Ressource, Property und
Statement. Jedes Ding, das beschrieben werden kann, wird in der RDF-Spezifikation
als Ressource bezeichnet. Im Topic-Map-Standard wird statt Ressource“ der Begriff
”
Subject“ verwendet. Die beschriebenen Dinge werden in RDF, durch einen RDF-
”
Knoten (Node) repräsentiert und durch einen URI identifiziert. Um die Eigenschaft
einer Ressource zu beschreiben, werden so genannte RDF-Properties als Prädikate
auf der Ressource benutzt. Mit einer RDF-Property kann eine gerichtete Eigen-
schaftsbeziehung zwischen zwei Ressourcen, dem Subjekt und dem Objekt herge-
stellt werden. Das Tripel aus Subjekt, Prädikat und Objekt wird als RDF-Statement
(Aussage) bezeichnet. Abbildung 6 zeigt ein RDF-Statement in Graphensyntax-
Notation.
Subject Objekt
Prädikat
authoredBy
http://articles/xyz.html http://alice.net
Abbildung 6: Beispiel für ein RDF-Statement
Ebenso wie in Topic Maps ist es möglich Aussagen über Aussagen zu machen. Dazu
wird ein RDF-Statement wieder als Ressource betrachtet werden und kann so in
einem weiteren RDF-Statement verwendet werden.
3.2.2. RDF-Schema
Ein RDF-Schema (RDFS) enthält Aussagen, um die Konzepte einer bestimmten An-
wendungsdomäne zu definieren. Dazu werden unter anderem RDF-Klassen verwen-
det. Als RDF-Klassen werden die Ressourcen innerhalb eines Schemas bezeichnet,
193 FORMATE ZUR REPRÄSENTATION VON WISSEN
von denen in einer RDF-Beschreibung Instanzen gebildet werden können. Sie die-
nen also der Typisierung von RDF-Ressourcen. Außerdem kann für eine RDF-Klasse
festgelegt werden, welche Arten von Eigenschaften die Instanz dieser Klasse besitzen
kann. Weiterhin können Klassen- und Eigenschaftshierarchien definiert werden, um
Spezialisierungsbeziehungen zu modellieren.
RDF-Schemata können erweitert und miteinander kombiniert werden. Durch die
Verwendung bereits vorhandener RDF-Schemata soll die Interoperabilität von RDF-
Ressourcenbeschreibungen im Web verbessert werden. Eine RDF-Beschreibung kann
unterschiedliche RDF-Schemata nebeneinander verwenden. Wenn ein RDF-Schema
verwendet werden soll, wird es durch eine URI referenziert. Die XML-Syntax von
RDF erlaubt es, den Namen einer RDF-Klasse im XML-Tag zu verwenden, um eine
Instanz dieser Klasse zu erzeugen (Abbildung 7 zeigt das Statement aus Abbildung 6
in XML-Syntax). Dadurch ist die Menge der XML-Tags für die XML-Syntax von
RDF nicht festgelegt, wie es bei der XML-Syntax von Topic Maps der Fall ist.
Abbildung 7: RDF Statement in XML Syntax
3.2.3. Web Ontology Language (OWL)
Die Web Ontology Language (OWL) ist eine formale Beschreibungssprache für On-
tologien, die auf RDF-Konzepten aufbaut. Zusätzlich definierte Sprachkonstrukte
erlauben es, Ausdrücke ähnlich der Prädikatenlogik zu formulieren. OWL soll als
Nachfolger der Ontologiesprache DAML+OIL für die Verwirklichung des Seman-
”
tic Web“ eingesetzt werden, und wird gegenwärtig vom W3C standardisiert [28]. In
OWL wird zwischen Klassen und Individuen als Instanzen der Klassen unterschie-
den. Individuen werden durch Eigenschaften beschrieben, wobei entweder XML-
Schema-Datentypen oder andere Individuen als Eigenschaftswerte verwendet wer-
den können. Für Klassen können verschiedene Eigenschaftsbeschränkungen festge-
legt werden, die ihre Instanzen erfüllen müssen.
OWL existiert in drei unterschiedlichen Varianten, OWL Lite, OWL DL und OWL
Full, die sich durch ihre Ausdrucksmächtigkeit unterscheiden. OWL Lite ist die
einfachste Variante, mit der die Hauptkomponenten einer Ontologie, Hierarchien zur
203 FORMATE ZUR REPRÄSENTATION VON WISSEN
Klassifizierung von Individuen, beschrieben werden können. OWL DL4 soll möglichst
umfangreiche Beschreibungsmöglichkeiten bieten, wobei die Entscheidbarkeit jeder
Aussage jedoch garantiert bleiben soll. In OWL DL gibt es als Ergänzung zu den
hierarchischen Beziehungen zwischen Klassen weitere Typen von Beziehungen, mit
denen z. B. ausgedrückt werden kann, dass zwei Klassen disjunkt oder äquivalent
sind. OWL Full bietet die größte Ausdrucksstärke und kann mit den Möglichkeiten,
die RDF und RDFS bieten, um eigene Konzepte zur Beschreibung von Ontologien
erweitert werden.
3.3. Vergleich
RDF und Topic Maps haben viele Gemeinsamkeiten. Beides sind Technologien, die
eine formale Beschreibung verschiedener Dinge, Ressourcen, Konzepte oder Aussa-
gen ermöglichen. Die Entwicklung der beiden Technologien wurde jedoch von un-
terschiedlichen Zielen geleitet, so dass beide verschiedene Schwerpunkte für ihren
Einsatz haben. In diesem Abschnitt werden die Unterschiede der Technologien be-
trachtet, um abschließend bewerten zu können, zu welchen Vor- und Nachteilen ein
Einsatz von Topic Maps in MIDMAY führt.
3.3.1. Ziele der Technologien
Dass die beiden ähnlichen Technologien RDF und Topic Maps nebeneinander exis-
tieren, ist vor allem historisch bedingt. Zwei verschiedene Arbeitsgruppen haben
unabhängig, ohne voneinander zu wissen, begonnen ihre“ Technologie für einen be-
”
stimmten Zweck zu entwickeln [7]. Topic Maps sind als Format für die Indizierung
von Informationsressourcen entwickelt, und von der ISO standardisiert worden. Das
Hauptziel bestand darin, ein Austauschformat für Indizes zu schaffen, dessen Daten-
modell eine Navigation“ durch die Informationen ermöglicht und die Vereinigung
”
verschiedener Indizes unterstützt [5]. RDF wurde vom W3C zur Unterstützung des
Semantic Web“ entwickelt. Das Semantic Web“ ist eine Erweiterung des herkömm-
” ”
lichen Webs, in der Informationen mit eindeutigen Bedeutungen versehen werden, so
dass Computer und Menschen besser zusammenarbeiten können. [2]. Ziel von RDF
ist es, ein Datenmodell für die Beschreibung von Ressourcen im World Wide Web
(WWW) anzubieten. Mit diesem Datenmodell können Ressourcen durch strukturier-
te Metadaten beschrieben werden, die als Grundlage für Interferenz-Mechanismen
dienen. Suchmaschinen oder Software-Agenten haben durch die eindeutige Beschrei-
bung bessere Möglichkeiten, für den Menschen relevante Informationen zu finden.
4
DL steht für Description Logics
21Sie können auch lesen