News - Steinbuch Centre for Computing (SCC)
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
news
STEINBUCH CENTRE FOR COMPUTING AUSGABE 2 | 2020
Kompetenz in der KI-Forschung – Das Helmholtz AI Local Energy Consultant Team
Competence in AI research – The Helmholtz AI Local Energy Consultant Team
Auf zu neuen Herausforderungen: Let’s go Quantum
Towards new challenges: Let’s go Quantum
Anwendungs- und Systemüberwachung für SAP-Systeme
Application and System Monitoring for SAP Systems
KIT – Die Forschungsuniversität in der Helmholtz-Gemeinschaft www.kit.edu
Editorial Liebe Leserinnen und Leser, effiziente und nachhaltige Lösungen für unsere Energiesysteme und -versor- gung zu entwickeln, ist eine der großen Herausforderungen der Zukunft. Sie basieren zunehmend auf KI-Anwendungen und ermöglichen unter anderem neue Modelle der Energieverteilung, die den stark veränderten Voraussetzun- gen und Anforderungen gerecht werden. Praktische KI-Methoden müssen für diesen Anwendungsbereich entwickelt und angepasst werden. Hier kommt das seit Oktober am SCC aktive Helmholtz AI Consultant-Team ins Spiel (Titelbild), das Forschende in der Helmholtz-Gemeinschaft mit Fachwissen über KI-Me- thoden, Werkzeuge und Software-Engineering bei Energieforschungsprojekten unterstützt. Wir stellen Ihnen das Consultant-Team und dessen Mission ab Seite 20 vor. ‚Auf zu neuen Herausforderungen‘ heißt es, wenn es um ein anderes vielver- sprechendes Forschungsfeld geht: um das Quantencomputing. Es verheißt mit potentiell exponentiellen Rechenbeschleunigungen ein hohes Innovations- potenzial. Sollen Maschinen effizient Strukturen in Daten erkennen, können Quantencomputer anderen Rechnern weit überlegen sein. Ein Team des SCC beschäftigt sich daher mit dem Ziel, Algorithmen für Quantencomputer zu erforschen und in Machine Learning-Anwendungen zu übersetzen. Ab Seite 22 berichten wir darüber, wie junge Wissenschaftlerinnen und Wissenschaftler des SCC die Herausforderung „Let’s go Quantum“ motiviert annehmen. Als „Herz“ der Geschäftsprozesse, z.B. für das Personal- und Finanzmanagement, den Einkauf und die finanzielle Projektumsetzung sowie für diverse Self-Services, „schlägt“ das SAP-System im KIT. Erst durch das Zusammenspiel einer Vielzahl von Server-, Speicher-, und Applikationssystemen versorgt das SAP-System zahlreiche Dienstleistungseinheiten und Institute zuverlässig mit Diensten und Anwendun- gen. Besonders herausfordernd ist es, dieses Herz „gesund“ zu erhalten und frühzeitig zu erkennen, ob sich Unregelmäßigkeiten oder Probleme anbahnen. Das SAP-Betriebsteam hat hierfür ein Überwachungs- und Diagnosesystem der Meisterklasse aufgebaut (Seite 6). Viel Freude beim Lesen Martin Frank, Bernhard Neumair, Martin Nußbaumer, Achim Streit Dear reader, developing efficient and sustainable software for our energy supply systems is one of the grand challenges of the future. Increasingly based on artificial intelligence (AI) the new software among other things, enables energy distribution models that meet the changed prerequisites and requirements. For this, practical AI methods must be developed or adapted, which is where the Helmholtz AI consul- tant team, active since October, comes into play (cover picture). The team supports scientists doing energy research in the Helmholtz Association with specialists knowledge of AI methods, tools and software engineering. We introduce you the consultant team and their mission from page 20 onwards. ‘Off to new challenges’ is said of the another very promising field of research: quantum computing. With theoretically exponential computing acceleration it promises a high potential for innovation. If machines are to efficiently recognize structures in data, quantum computers can be far superior to todays computers. Therefore a team at SCC is researching algorithms for quantum computers and translating them into machine learning applications. Starting on page 22, we report on how young SCC scientists are motivated to take on the ‘Let's go Quantum’ challenge. At the ‘heart’ of the business processes at KIT, e.g. for personnel and financial management, purchasing and financial project im- plementation as well as for various self-services, ‘beats’ the SAP system. Only through the interaction of a large number of servers, storage and application systems does it dependably supply services and applications to numerous organisational units and institutes. It is particularly challenging to keep this heart ‘healthy’ and to recognize early on whether irregularities or problems are looming. For this purpose the SAP operations team has set up a first class monitoring and diagnosis system (page 6). Enjoy reading Martin Frank, Bernhard Neumair, Martin Nußbaumer, Achim Streit 02 | SCCnews

Inhaltsverzeichnis
DIENSTE UND INNOVATION
04 RADAR4KIT – ein generisches Forschungsdatenrepositorium
für das KIT
06 Anwendungs- und Systemüberwachung für SAP-Systeme am KIT
09 Das neue NETVS
12 Der GridKa-Rechencluster – Wissenschaft Non-Stop
14 Jupyter@SCC
FORSCHUNG UND PROJEKTE
16 Lohnt sich das Upgrade auf die neue NVIDIA A100 GPU?
18 EU-Projekt DEEP-Hybrid-Datacloud bringt Werkzeuge
für Benutzer und Entwickler von KI Anwendungen
20 Kompetenz in der KI-Forschung – Das Helmholtz AI Local
Energy Consultant Team stellt sich vor
22 Auf zu neuen Herausforderungen: Let’s go Quantum
25 NFDI – Nationale Forschungsdateninfrastruktur am SCC
28 Landesprojekt bwCard: Digitale Identitätskarte
STUDIUM UND WISSENSVERMITTLUNG
32 MathSEE Modeling Week – Studierende präsentieren Ergebnisse
VERSCHIEDENES
34 SCC wird Zentrum für Nationales Hochleistungsrechnen
35 Impressum & Kontakt
SCCnews | 03
DI E N STE UND I NN OVATION
RADAR4KIT – ein generisches Forschungs-
datenrepositorium für das KIT
Das KIT stellt Wissenschaftlerinnen und Wissenschaftlern ein
neues disziplinübergreifendes Repositorium für die Archivie-
rung und Publikation ihrer Forschungsdaten zur Verfügung.
Die Speicherung der Daten findet ausschließlich auf der IT-Infra-
struktur des KIT am SCC statt. Felix Bach
RADAR4KIT - Research Data Repository Metadaten soll es Forschenden erleichtert als „Datengeber”, welche ihre Daten
for KIT - ist ein disziplinübergreifen- werden, die Daten bei einer späteren archivieren oder publizieren wollen.
des Forschungsdatenrepositorium für Nachnutzung interpretieren zu können. Daten können für Dritte („Datennutzer“)
die Archivierung und Publikation von Das Ziel ist es, Forschungsdaten „FAIR2 zu zugänglich gemacht oder im Internet
Forschungsdaten - z.B. aus wissenschaft- machen“ – das heißt findable, accessible, publiziert werden. RADAR4KIT steht als
lichen Studien und Projekten des KIT. interoperable und reusable. Online-Dienst über ein Web-Portal4 bereit,
Unter Forschungsdaten werden digitale Forschende des KIT können sich mit
Daten verstanden, die im Forschungs- RADAR4KIT wird vom Karlsruher Institut ihrem KIT-Konto direkt anmelden - eine
prozess entstehen1. Im Repositorium für Technologie als Dienstleistung für die Registrierung ist zur Dienstnutzung nicht
RADAR4KIT werden Forschungsdaten Wissenschaft angeboten und setzt auf erforderlich. Lediglich spezielle Berech-
in Form von Datensätzen, die aus einer den von FIZ Karlsruhe betriebenen Dienst tigungen für Datengeber müssen in Ab-
oder mehreren Dateien bestehen können, RADAR3 auf. Die Speicherung der Daten sprache mit dem Serviceteam RDM@KIT5
gespeichert. Diese Datenpakete enthalten findet ausschließlich auf IT-Infrastruktur zugeteilt werden. Es können auch Konten
die eigentlichen Forschungsdaten sowie des KIT am SCC statt. Der Dienst richtet für KIT-Externe angelegt werden, die z.B.
beschreibende Metadaten. Durch die sich primär an Forschende des KIT an Projekten des KIT beteiligt sind.
Abbildung 1: Ablauf der Erstellung von Datenpaketen und deren Archivierung und Publikation.
04 | SCCnews
D IE N S T E U N D IN N OVAT I O N
Für verschiedene Nutzergruppen (z.B. chier- und zugreifbar. Für die Daten kann Publikation in den Status „in Begutach-
Forschungsgruppen, Projekte, Institute) der Datengeber optional einen Embargo- tung“ versetzt werden. In diesem Zustand
können voneinander getrennte Arbeits- zeitraum bestimmen, innerhalb dessen ist das Datenpaket nicht mehr editierbar.
bereiche in Absprache mit dem Service- nur die Metadaten öffentlich recherchier- Über einen eindeutigen Link, den der Da-
team RDM@KIT eingerichtet werden. Bei und verfügbar sind. Nach Ablauf der Em- tengeber an den zuständigen Verlag bzw.
RADAR4KIT registrierte Nutzerinnen und bargofrist werden auch die zugehörigen die Gutachter weitergeben kann, wird
Nutzer können darin unterschiedliche Daten automatisch öffentlich zugreifbar. ein temporärer Zugriff auf das noch nicht
Rechte erhalten - etwa als Datengeber RADAR4KIT vergibt für jedes publizierte veröffentlichte Datenpaket ermöglicht.
mit Publikationsrechten für einen oder Datenpaket einen Persistenten Identifier Für die inhaltliche Qualitätssicherung
mehrere Arbeitsbereiche (auch „Kurator“ (hier: Digital Object Identifier, kurz DOI) der eingestellten Forschungsdaten sind
genannt). Kuratoren können in die für sie und registriert diesen bei DataCite. Über die Datengeber ansonsten grundsätzlich
bestimmten Arbeitsbereiche Forschungs- diesen DOI ist das publizierte Datenpaket selbst verantwortlich.
daten hochladen, diese bearbeiten, ar- nachhaltig identifizierbar, zitierfähig und
chivieren und gegebenenfalls publizieren. kann mit einer herkömmlichen wissen-
Sie können außerdem weitere registrierte schaftlichen Publikation z.B. im Reposito-
Personen als sog. Subkuratoren für ihren rium KITopen der KIT-Bibliothek verknüpft
Arbeitsbereich berechtigen. Subkurato- werden. Publizierte Datensätze werden
ren sind ebenfalls Datengeber, haben im Langzeitarchivdienst bwDataArchive6
jedoch nicht die Möglichkeit, Datenpa- für mindestens 10 Jahre archiviert.
kete eigenständig zu archivieren bzw. zu
publizieren oder andere als Subkuratoren Datensätze können auch lediglich ar-
zu bestimmen. Durch diese Rollen und chiviert werden. Diese können ebenfalls
Rechte sind unterschiedliche Arbeits- durch Metadaten beschrieben werden,
prozesse umsetzbar (Abbildung 1), die erhalten jedoch keinen DOI und sind nur
gemeinsam mit den Wissenschaftlerinnen für einen ausgewählten, vom Datengeber
und Wissenschaftlern aus den diversen berechtigten Personenkreis, zugreifbar.
Disziplinen vom Serviceteam RDM@KIT
nach und nach ausgestaltet werden. RADAR4KIT bietet außerdem weitrei- RADAR4KIT – a generic research
chende Möglichkeiten zur Integration data repository for the KIT
Datenpakete, die noch nicht archiviert in die IT-Infrastruktur am KIT. Z.B. kann KIT provides scientists with a new
oder publiziert wurden, sich also im zusätzlich zur webbasierten Benutzungs- interdisciplinary repository for archiving
Bearbeitungszustand befinden, sind nur oberfläche über eine REST-basierte Pro- and publishing their research data. The
für berechtigte Datengeber sowie die Ad- grammierschnittstelle (API) auf den Dienst data is stored exclusively on the KIT IT
ministratoren einsehbar. Ein Kurator kann zugegriffen werden. Weiterhin werden infrastructure at the SCC. Research data
im eigenen Arbeitsbereich jederzeit an die deskriptiven Metadaten sowohl im is digital data that is created during
weitere bei RADAR4KIT Registrierte das RADAR-eigenen als auch im standardi- the research process. The RADAR4KIT
Recht vergeben, als Datengeber (Kurator sierten DublinCore-Format über einen repository stores research data in the
oder Subkurator) zu agieren. OAI-Provider öffentlich zum Harvesting form of data sets, which may consist of
angeboten, so dass Nachweissysteme one or more files. These data packages
Für die Publikation eines Datenpakets und Suchportale diese Daten indizieren, contain the actual research data as well
sind dessen valide Beschreibung in Form aufbereiten und nachnutzen können. as descriptive metadata. The metadata
deskriptiver Metadaten sowie die Verga- is intended to make it easier for resear-
be einer Lizenz durch den Datengeber RADAR4KIT unterstützt einen Peer chers to interpret the data in the event
erforderlich. Nach der Publikation sind die Review-Prozess vor einer Datenpublika- of subsequent use.
Metadaten und Daten öffentlich recher- tion. Dazu kann ein Datenpaket vor der
1
www.rdm.kit.edu/fodaten.php
² www.force11.org/group/fairgroup/fairprinciples
³ www.radar-service.eu
4
radar.kit.edu
5
www.rdm.kit.edu
6
bwDataArchive Homepage: www.rda.kit.edu
SCCnews | 05
DI E N STE UND I NN OVATION
Anwendungs- und Systemüberwachung für SAP-Systeme
am KIT
Das SAP Enterprise Resource Planning (ERP)-System unterstützt mit diversen Anwendungen die Geschäftspro-
zesse am KIT. Es wurde das Ziel gesetzt, eine Überwachungs- und Störungsmanagement-Infrastruktur für aktu-
elle und zukünftige SAP-Systeme aufzubauen. Das Konzept zur Realisierung dieses Ziels besteht aus zwei Teilen:
Erstens aus der Systemüberwachung der gesamten SAP-Systemumgebung und zweitens einer Geschäftspro-
zessüberwachung. Der erste Teil des Ziels konnte vom SAP-Systemteam im Juli umgesetzt werden und wird hier
erläutert. Die Prozessüberwachung befindet sich in der Konzeption. Dimitri Nilsen, Oleg Dulov, Gerald Helck
Systemüberwachung Betriebssysteme ein. Sie besteht aus Metriken werden anschließend an die
vielen verschieden Komponenten, wie InfluxDB Zeitreihen-Datenbank verschickt.
In der Vergangenheit wurde die System- Applikations-Server, Datenbanken, Außerdem wird InfluxDB für das Sammeln
überwachung des SAP-Systems des KIT Nutzer-Frontends und diverse Server für von sowohl SAP-spezifischen Daten als
auf der Basis der bestehenden SAP- Dokumentenablagen. Außerdem ist ein auch für Daten von diversen Hilfssyste-
Anwendung innerhalb von SAP ohne Umstieg auf die modernere SAP HANA- men der SAP-Systemlandschaft benutzt.
zusätzliche Überwachungswerkzeuge im- Technologie (Datenbank und die neuen Die Visualisierung und die Benachrichti-
plementiert. Somit bestand keine zentrale SAP-Anwendungen) bereits im Gange. gung (Alerting) erfolgt mittels Grafana-
Anlaufstelle für die Problemerkennung. Dashboards.
Dies entspricht nicht mehr den modernen Für die Metriken des Betriebssystems (z.B.
Anforderungen im Betrieb einer solch CPU-Load, Disk Usage, Netzwerk-Traffic) Ein weiteres Open-Source-Tool, Ansible,
umfangreichen SAP-Umgebung und wird ein Open-Source-Stack mit folgen- wird für die automatisierte Konfiguration
bietet zudem keine Integration zwischen den drei Komponenten eingesetzt: Tele- auf Betriebssystemebene verwendet. Die
den einzelnen SAP-Instanzen. graf, InfluxDB und Grafana (Abbildung 1). Ansible-Skripte werden im GitLab-Repo-
Telegraf ist ein Dienst, welcher auf den zu sitorium des KIT gespeichert und mittels
Die aktuelle SAP-Systemlandschaft überwachenden Systemen läuft und die Continuous Deployment und Rolling
setzt sowohl Windows- als auch Linux- relevanten Metriken sammelt. Diese Upgrades auf die Zielmaschinen ausge-
Abbildung 1: Nutzung des produktiven SAP-Systems dargestellt in Grafana
06 | SCCnews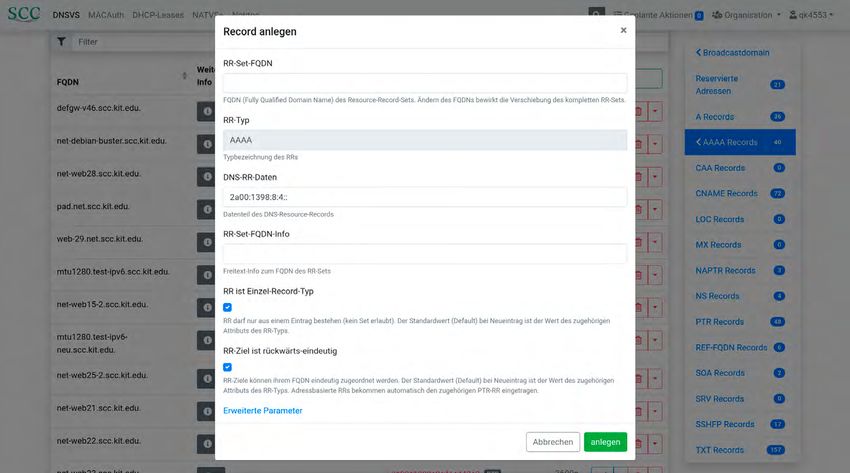
D IE N S T E U N D IN N OVAT I O N
Abbildung 2: Wotan Monitoring Dashboard
rollt. Der für die Systemüberwachung Wotan Monitoring im SAP-System, einige davon sind unten
in SAP verwendete Monitoring Stack aufgeführt:
orientiert sich an Verfahren, die bereits im Für die Überwachung der weiteren SAP-
Zusammenhang mit dem Grid Computing spezifischen Metriken hat das SCC eine Laufzeitanalyse von abgebrochenen
Centre Karlsruhe (GridKa) sowie den Lan- auf der Open-Source-Lösung Nagios/ oder fehlerhaften SAP-Jobs
desdiensten bwCloud und bwSync&Share Icinga basierende Software Wotan Laufzeitanalyse der SAP BTC/DIA/UPD-
verwendet wurden. Allerdings wird er um Monitoring gekauft und eingesetzt. Die Prozesse, Status von UPD (Background
SAP-spezifische Werkzeuge erweitert, um Wotan Monitoring-Software ermöglicht Updates)
alle hier benötigten Daten sammeln zu eine schnelle Problemerkennung und ein Datenbank-Metriken und Analysen der
können. zuverlässiges Eskalationsmanagement DB-Transaktionen
bei Zwischenfällen und umfasst Überwa- SAP-System- und Kundeneinstellungen
Die so implementierte Systemüberwa- chung, Alarmierung, Berichterstattung Überprüfung von externen Anbindun-
chung bietet folgende Funktionen an: und Dokumentation. Die Konfiguration gen, REST- und RFC-Schnittstellen
basiert auf einem Vorlagenkonzept. Betriebssystemüberwachung
Statusübersicht technischer Systeme
einschließlich einzelner Instanzen, Vordefinierte Konfigurationsvorlagen kön- SAP Solution Manager
Datenbanken und Hosts nen als Ausgangspunkt für die Ableitung
Visualisierung von Metriken und Ereig- eigener kundenspezifischer Vorlagen für Der SAP Solution Manager (SolMan) ist
nissen mit ihrer aktuellen Bewertung SAP- und Nicht-SAP-Metriken verwendet ein Produkt von SAP und dient als zentra-
und den zuletzt gemeldeten Werten werden (Abbildung 2). le Instanz für die Überwachung des Kon-
Drill-Down-Funktionen von Statusin- figurations- und Installationsstatus aller
formationen über technische Systeme Die Wotan-Agenten sind sowohl auf dem SAP-Systeme sowie für das Change Ma-
bis hin zu einzelnen Metriken Betriebssystem als auch im SAP-System nagement. Der integrierte Maintenance
Visualisierung von Metriken und Ereig- als SAP-spezifische Anwendungen ins- Optimizer (MOPZ) beschleunigt und
nissen einschließlich Schwellenwerten talliert. Außerdem bietet Wotan Moni- verbessert die Vorbereitung und Durch-
Jump-in-Fähigkeit in den metrischen toring ein Plug-in zur Visualisierung der führung von Updates und Upgrades. Das
Monitor zur Anzeige historischer met- Daten in Grafana. Wotan verfügt über Einspielen von Support Packages kann
rischer Werte einschließlich interaktiver zahlreiche Prüfungen zur Überwachung mit dem Maintenance Optimizer und
Auswahl des anzuzeigenden Zeitraums von SAP-Prozessen und -Aufträgen direkt den von SAP bereitgestellten Upgrade-
SCCnews | 07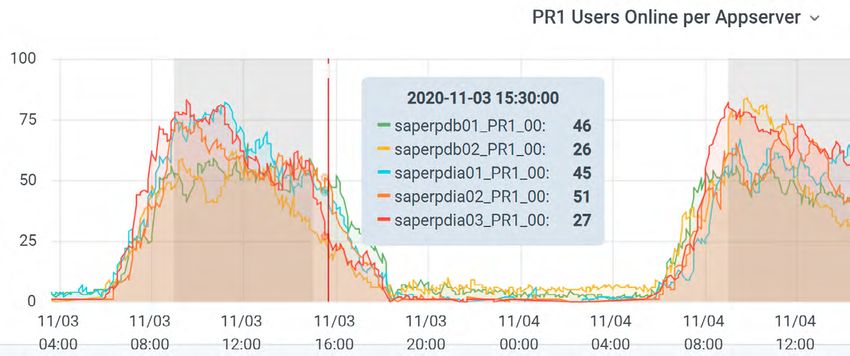
DI E N STE UND I NN OVATION
Abbildung 3: Die in der SAP-Systemlandschaft eingesetzte Benachrichtigungsinfrastruktur macht einen effizienten
Incident Management-Prozess möglich.
Inhalten sicherer durchgeführt werden. Servicemanagement-Tool Jira werden frastruktur sowohl für IT-System- als auch
Das SAP-Betriebsteam setzt den SolMan die erkannten Probleme aus Wotan in für SAP-spezifische Metriken geschaffen.
vor allem zur Überwachung von Schnitt- Jira-Tickets umgewandelt und stehen zur Die nächsten Schritte sind unter anderem
stellen und Geschäftsprozessen ein. weiteren Bearbeitung zur Verfügung. Dies die kontinuierliche Verbesserung der
stellt einen transparenten Fehlerbehe- Alarmierung und die Einrichtung der ver-
Alerting und IT-Incident Management bungsprozess für die SAP-Administrato- schiedenen Überwachungsfunktionen des
ren und -Administratorinnen dar. SAP Solution Managers für das IT-Service-
Um die schnelle und zuverlässige Reak- Management sowie für die Geschäfts-
tion auf die vom Monitoring erkannten Ausblick prozesse. Für die Zukunft ist eine stärkere
Probleme zu gewährleisten, wird eine Integration von Jira geplant.
Reihe von Benachrichtigungsmedien Durch den Einsatz von Top-Level-Mo-
eingesetzt (Abbildung 3). Standardmäßig nitoring-Lösungen wurde eine zentrale
wird eine Benachrichtigung per E-Mail Überwachungs- und Benachrichtigungsin-
versendet. Weitere Benachrichtigungska-
näle sind MS Teams Chats und SMS (bei
Wotan Monitoring).
Application and System Monitoring for SAP Systems at KIT
Wotan bietet die Möglichkeit, verschie- The SAP Enterprise Resource Planning (ERP) system supports business processes at KIT
dene Arten von Wartungszeiträumen with various applications. The objective was to establish a monitoring and incident
(Downtimes) zu definieren, z.B. periodi- management infrastructure for current and future SAP systems. The concept to reach
sche Downtimes, bei denen Zeiträume this goal consists of two parts: Firstly, system monitoring of the entire SAP system
für sich wiederholende Wartungen environment and secondly, business process monitoring. The first part of the objective
eingeplant werden können. Durch die was implemented by the SAP system team in July and is explained here. The process
Verbindung der Wotan-Software mit dem monitoring is currently in the conception phase.
08 | SCCnews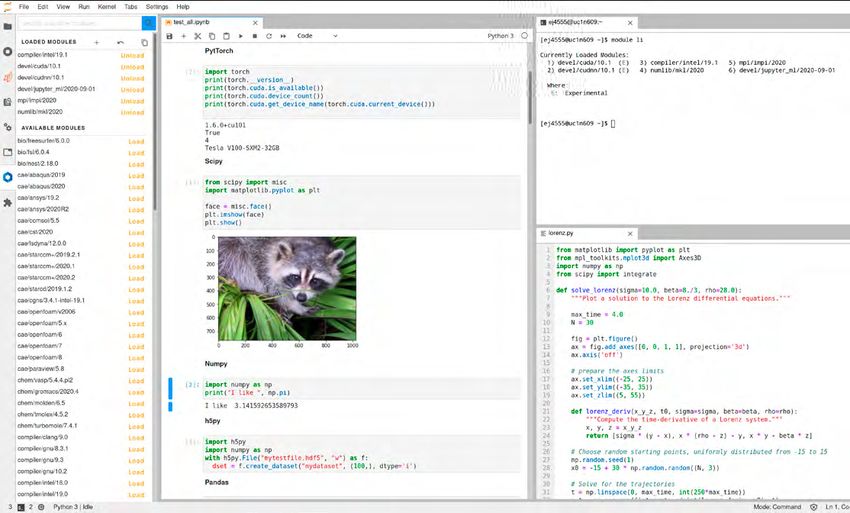
D IE N S T E U N D IN N OVAT I O N
Das neue NETVS
Das SCC stellt bereits seit vielen Jahren eine mandantenfähige Oberfläche für die Verwaltung von Netzdiensten
wie beispielsweise DNS für die IT-Beauftragten und Verantwortlichen in der IT-Administration am KIT zur Verfü-
gung. Nun geht das Netzdiensteverwaltungsystem (NETVS) in die nächste Runde – mit neuer Oberfläche, Archi-
tektur und Features. Dieser Artikel soll einen Einblick in die Architektur und Neuerungen des NETVS schaffen.
Janis Streib
Der Netzbetrieb steht regelmäßig vor bestimmten großen Ausgaben zu einer Die Anmeldung im NETVS geschieht auch
neuen Anforderungen und Herausforde- sehr hohen Serverlast und gegebenenfalls nicht mehr über eine eigene Anmelde-
rungen. Um diesen gerecht zu werden, sogar zum Abbruch der Anfrage geführt. maske, sondern über OpenID Connect2.
wird das hauseigene NETVS1 mitsamt Die Anmeldung erfolgt somit zentral über
zugehöriger Datenbankstruktur und An- 2. Wartbarkeit den Shibboleth Identity Provider des KIT,
wendungslogik stetig weiter entwickelt. Die Serveranwendung hinter dem der auch eine Zwei-Faktor-Authentifizie-
Seit dem Wochenende des 7./8.11.2020 Webinterface kommunizierte direkt mit rung erlaubt (Abbildung 1).
ist nun das neue Webinterface mit neuer der Datenbank. So musste das gesamte
Entwicklungsschnittstelle und Datenbank Datenmodell nochmals erneut (parallel API 3.0
in Betrieb. Kernfunktionen sind derzeit zum API-Server) vorgehalten werden.
die Verwaltung von DNS-Einträgen sowie Das führte dazu, dass alle Änderungen Die Entwicklerschnittstelle wurde
von MAC-Adressen-basierter Authen- am Datenmodell an mehreren Stellen ebenfalls grundsätzlich überarbeitet
tifikation. Dabei können Änderungen gepflegt werden mussten. und löst API 2.x ab, die nun nur noch
transaktional – also durch Ausführung eingeschränkt zur Verfügung steht. Damit
mehrerer Aktionen in einem Durchlauf, 3. Konsistenz wurde erreicht, dass die Struktur über alle
ohne die gegenseitige Beeinflussung Die Datenein- und -ausgabe verhielten Ebenen hinweg konsistent ist und sich
paralleler Ausführungen – geplant und sich zwischen API und Webinterface nicht die Semantik und Dokumentation aus der
durchgeführt werden. konsistent. So waren manche Ausgaben API ableiten lässt – die API dokumentiert
in der API nicht möglich, die das Web- sich somit selbst. Durch diese Eigen-
Anwendungsarchitektur interface jedoch darstellen konnte und schaften ist es erstmals möglich, einfach
umgekehrt. Genauso waren Feldbeschrei- zu wartende, erweiterte Ressourcen für
Das NETVS besteht im Kern aus drei bungen und die Semantik von Parame- Entwickler bereitzustellen. So gibt es nun
Komponenten: Der Datenbank samt tern nicht immer gleich. einen API-Browser3 sowie eine Python-
integrierter Anwendungslogik (NETDB), Bibliothek4, die automatisch aus der API
dem API-Server zur Bereitstellung der Um diese Probleme anzugehen, wurde erzeugt werden.
Programmierschnittstelle (API) sowie ein vollständiges Redesign der Architektur
dem Webinterface. In der bisherigen vorgenommen. Das Webinterface besteht Ein weiteres neues Werkzeug in der API
Architektur bestand das Webinterface nun aus zwei Komponenten: Der Middle- ist die Join-Funktion im Transaktions-
aus genau einer Serverkomponente, die ware, die serverseitig ausgeführt wird, so- kontext. Diese erlaubt die Formulierung
mittels des Templatesystems “Jinja2” und wie einem JavaScript-Frontend, was beim komplexerer API-Abfragen, vergleichbar
einer direkten Verbindung zur NETDB das Nutzer im Browser läuft. Die Middleware zu Joins in relationalen Datenbanken. Bei-
Webinterface mitsamt den gewünschten dient jetzt nur noch zur Bereitstellung von spielsweise kann man nun in genau einer
Daten serverseitig erzeugt. Allerdings API-Diensten, die nicht durch die NETDB Abfrage zu allen Domain-Namen, die ei-
zeigten sich schnell einige Nachteile bereitgestellt werden können (beispiels- nem bestimmten Muster entsprechen, die
dieses Entwurfs: weise MacFinder), und zur Erstellung von zugehörigen DNS-Einträge transaktional
Session-Tokens. Alle anderen NETDB- abfragen, ohne dafür separate Anfragen
1. Performance bezogenen Anfragen werden vom Client tätigen zu müssen.
Da bei jedem Seitenaufruf die Seite nun direkt an den API-Server gerichtet.
serverseitig neu und individuell erzeugt Die Darstellung erfolgt dann komplett im
werden musste, hatte man mit einer Client.
bestimmten Mindestladezeit zu rechnen. 1 netvs.scc.kit.edu
Außerdem skalierte die Ausgabe gro- ² www.scc.kit.edu/dienste/openid-connect.php
ßer Datenmengen nicht. Das hatte bei ³ git.scc.kit.edu/scc-net/netvs/netdb-client-lib
4
netvs.scc.kit.edu/swagger
SCCnews | 09
DI E N STE UND I NN OVATION
NETVS NETVS
NETDB (PostgreSQL) Account-Daten
Account-Daten
NETDB (PostgreSQL)
Daten
Gruppenmitgliedschaften LDAP (IDM)
Daten
PlPython Anwendungslogik
PlPython Anwendungslogik
Session-Token
NETVS Middleware
NETVS Middleware
API-Server Flask, Jinja2, Bootstrap Authentifikation LDAP (IDM)
API-Server Flask Nutzerdaten OpenID Connect Provider
CherryPy Tools
(z.B. MacFinder) CherryPy Tools
(z.B. MacFinder)
API-Anwendung Nutzer Session-Metadata
z.B. curl Webbrowser Anwendungsdaten NETVS Frontend
wget Vue.js, Bootstrap
...
API-Anwendung Nutzer Session-Initiierung
z.B. netdb client-lib Webbrowser
curl
wget
...
Abbildung 1: Übersicht über die bisherige (links) und die neue Architektur (rechts) des NETVS
Abbildung 2: Die Eingabefunktionen werden nun einheitlich und größtenteils konsistent mit der API dargestellt.
Dieses “traditionelle” Vorgehen hat einen Hier werden die nötigen Parameter, Feld- Rechteverwaltung
größeren lokalen Verarbeitungsaufwand namen und Feldbeschreibungen vollstän-
zur Folge und kann – je nach Anwen- dig zur Laufzeit aus der API generiert. Bei Große Änderungen ergeben sich auch bei
dung – keine Konsistenz zwischen den Anpassungen der API sind keine Anpas- der Rechteverwaltung. IT-Beauftrage und
Anfragen garantieren. sungen im Client mehr nötig. Verantwortliche in der IT-Administration
Die Selbstdokumentation sowie die Mit der API 3.0 ändert sich auch die haben jetzt feinere Kontrolle über die
Join-Funktion bilden die Grundpfeiler des Authentifikation: Anstatt wie bisher mit Berechtigungen auf die ihnen zugeteilten
JavaScript-Clients. Ein Beispiel hierfür ist Client-Zertifikaten erfolgt die Authenti- Ressourcen.
die Generalisierung der Eingabefunktionen fikation nun über Tokens, die über das
(Anlegen und Bearbeiten) (Abbildung 2). NETVS erstellt werden können.
10 | SCCnewsD IE N S T E U N D IN N OVAT I O N
Hierzu wurden mehrere neue Konzepte 3. Organisationseinheiten und
eingeführt: Unter-Organisationseinheiten
Organisationseinheiten (OEs) sind nun
1. Unterkonten expliziter in die Rechteverwaltung ein-
Unterkonten dienen zur Einschränkung gebunden. IT-Beauftragte (ITBs) nehmen
der API-Tokens. So kann man jetzt ein hierbei die Rolle der OE-Betreuer ein und
Unterkonto seines eigenen Kontos können alle Gruppen und Broadcast-
anlegen, welches beispielsweise keine Domains, die ihrer OE zugeteilt sind,
datenmodifizierenden Funktionen erlaubt. administrieren. Auch können durch OE-
Reguläre Tokens zur Verwendung in eige- Betreuer weitere OE-Betreuer hinzugefügt
nen Anwendungen können ausschließlich werden. Des Weiteren verfügen OEs
für Unterkonten angelegt werden. über eine Domainliste, die als möglicher
Namensraum für die Gruppen zugeteilt
2. Gruppen und Untergruppen werden können.
Gruppen bestimmen im neuen NETVS
nun, welche Konten Rechte auf Broad- OEs können beliebig viele Unter-OEs
cast-Domains (also den Adressraum, besitzen. Die Rechte der OE-Betreuer
kurz BCDs) und Domains (Namensraum) vererben sich entsprechend durch die
haben. Mitglieder einer Gruppe können Hierarchie.
dann Operationen auf den durch die
Gruppe vorgegebenen Namens- und Die bisherigen Adressbereiche im DNS-
Adressraum ausführen (z.B. DNS-Records Verwaltungssystem (DNSVS), die zuvor
anlegen). Gruppen können optional mit Einstiegspunkt und Rechteanker waren,
den gleichnamigen Gruppen aus dem existieren nun nicht mehr. Stattdessen
zentralen Identity Management (IDM) ergeben sich die Adressbereiche aus Fazit
synchronisiert werden (Abbildung 3). den BCDs, denen der jeweils vorherige
DNSVS-Adressbereich zugeordnet war. Das neue NETVS bringt viele
Hierdurch sind auch Dualstack-Bereiche technische und strukturelle Neu-
Gruppe (also Bereiche mit einem IPv4- und IPv6- erungen mit sich. Neben weitrei-
Subnetz) in einer Ansicht einsehbar und chenden Umstrukturierungen –
Mitglieder verwaltbar. Zuvor waren hierfür zwei begonnen bei den Änderungen der
ab1234 separate DNSVS-Bereiche nötig. Architektur bis hin zu der neuen
xy6789 Gruppenstruktur – sind auch neue,
mächtige Werkzeuge hinzugekom-
men.
BCDs
oe-netz1
Die Umstellung lief im Großen und
oe-netz2
Ganzen erfolgreich, und kleinere
Probleme konnten schnell behoben
FQDNs werden. Sollten dennoch Probleme
oe.kit.edu auftreten, hilft das NETVS-Team
gerne. E-Mail: netvs@scc.kit.edu
Abbildung 3: Betreuer-, Broadcastdo-
main- und Domainzuordungen werden
nun über Gruppen abgebildet.
The new NETVS
For many years, the SCC has provided a multi-client capable interface for the
Untergruppen bilden hier das Gegenstück
administration of network services such as DNS for the IT appointees and
zu den Unterkonten und erlauben die
administrators at KIT. Now the network services management system (NETVS)
Einschränkung des Namens- und Adress-
is entering the next round – with a new interface, architecture and features.
raums der Unterkonten. Untergruppen
This article is intended to provide an insight into the architecture and innova-
können von den Gruppenmitgliedern
tions of NETVS.
selbst angelegt und administriert werden.
SCCnews | 11DI E N STE UND I NN OVATION
Der GridKa-Rechencluster – Wissenschaft Non-Stop
Seit fast zwei Jahrzehnten bietet das Grid Computing Centre Karlsruhe (GridKa) Ressourcen und Services für da-
ten- und rechenintensive Experimente der Teilchen- und Astroteilchenphysik. Neben Tape- und Platten-Speicher
betreibt das GridKa einen der größten Rechencluster des weltweiten LHC Computing Grids. Für eine hohe
Verfügbarkeit ist das GridKa praktisch durchgehend in Betrieb und durchläuft daher bereits seit Jahren eine
andauernde Evolution. Max Fischer
Als eines von 13 Tier-1-Zentren des Welt- für die Auswertung aufbereiten, bis hin
weiten LHC Computing Grids (WLCG) zu Physikanalysen, die unentwegt Daten
ist das Grid Computing Centre Karlsruhe durchsuchen, ist alles dabei. Natürlich
(GridKa) speziell auf die Bedürfnisse der hat dabei jede Forschungskollaboration
großen Kollaborationen aus Teilchen- und unterschiedliche Schwerpunkte, die sich
Astroteilchenphysik ausgelegt. Eines der auch über die Zeit ändern. Wer diese Wo-
Alleinstellungsmerkmale eines Tier-1-Zen- che noch CPUs mit Simulationen an ihre
trums im WLCG ist die Verfügbarkeit Grenzen bringt, liest vielleicht nächste
eines Tape-Speichers: Dieser ermöglicht Woche schon Daten aus aller Welt über
die sichere und langfristige Speicherung das Netzwerk.
von Rohdaten aus den Detektoren der
einzigartigen Experimente. Zusätzlich bie- Apropos Kollaborationen: Einzelne Nutze-
tet der Platten-Speicher1 sowohl Volumen rinnen oder Nutzer sucht man im GridKa-
als auch Bandbreite, um Daten kurz- und Rechencluster fast vergeblich. Stattdessen
mittelfristig zu speichern und diese auf schickt praktisch jede Nutzergruppe soge-
der ganzen Welt verfügbar zu machen. nannte Pilot Jobs, welche als Platzhalter
Für die effiziente Vorverarbeitung und agieren und sich nur für Ressourcen in
Analyse dieser Daten dient der GridKa- der Warteschlange des Rechenclusters
Rechencluster. anstellen. Erst wenn eine Maschine des
Clusters den Pilot Job ausführt, ruft dieser
Bunter Mix an Arbeit die aktuellsten Rechenaufträge der Nut-
zergruppe ab und führt sie aus. Nur auf
Der Rechencluster am GridKa ist diese Art können die fast 200 Rechen-
ausschließlich ausgelegt auf High- cluster im WLCG durch tausende Nutzer
Throughput Computing (HTC), also einen von dutzenden Institutionen verwendet
möglichst hohen Gesamtdurchsatz an werden, ohne im Verwaltungschaos zu
Berechnungen und Daten. Jeder einzelne enden – sowohl für Administrierende als
Rechenauftrag (Job) ist „klein“, mit einer auch Nutzende.
Nutzung von 1 oder 8 CPU-Kernen, 2 bis
4 GB RAM pro Kern und typischen Lauf- Keine Zeit für Pausen
zeiten bis zu einem Tag, maximal einer
Woche. Den Ausgleich macht die Masse: Eine solche Menge und Vielfalt an Jobs
Ungefähr 30.000 Jobs laufen gleichzeitig abzuarbeiten, bringt seine ganz eigenen
auf den fast 50.000 CPU-Kernen des Herausforderungen mit sich. Während
Clusters. So werden weit mehr als zwei HPC-Rechencluster wie HoreKa oder
Millionen Jobs im Monat abgearbeitet. ForHLR im wahrsten Sinne des Wortes
einen Scheduler – also einen Terminplaner
Blick in den Rechnerraum
Dabei könnten die Rechenaufgaben für die Ausführung von Jobs – betrei-
des Grid Computing Centre
nicht unterschiedlicher sein. Von Simu- ben, ist dies in einem HTC-Rechencluster
Karlsruhe (GridKa) am
Campus Nord des KIT. (© KIT) lationen, die hauptsächlich physikalische wie dem von GridKa heutzutage nicht
Modelle berechnen, über Datenrekons- realistisch: Die Vielzahl kleiner Jobs ohne
truktionen, welche Detektor-Rohdaten vorab bekannte Laufzeit bedeutet, dass
12 | SCCnewsD IE N S T E U N D IN N OVAT I O N
Mit CPUs gegen COVID-19
Das Zusammenspiel des GridKa-Clusters und der Pilot Jobs der Nutzerkollaborationen ist technisch angelehnt am Volunteer-
Computing, dem Verfügbarmachen von Rechenressourcen als Beitrag zu einem größeren Rechenvorhaben aus kleinen Einzel-
aufgaben. Dies macht es möglich, schnell und zuverlässig Ressourcen für wichtige Rechenaufgaben zur Verfügung zu stellen:
Seit April spendet das GridKa dauerhaft zwischen 5.000 und 10.000 CPU-Kerne an die Volunteer-Computing-Projekte
Folding@Home und Rosetta@home sowie die Kollaboration WeNMR, um damit die Forschung über die Viruskrankheit
COVID-19 zu unterstützen und zu beschleunigen.3,4 (doi.org/10.1051/epjconf/201921403053)
andauernd irgendwo im Cluster Ressour- Die Tore zur Welt
cen freiwerden. Um eine möglichst hohe
Auslastung zu erreichen, müssen diese Obwohl der GridKa-HTCondor-Rechen-
Ressourcen sowohl schnell, als auch für cluster immer noch seine ursprünglichen
alle Nutzergruppen fair neu vergeben Kernkomponenten nutzt, ist er bis heute
werden. bereits auf mehr als die doppelte Größe
angewachsen. Über 1.000 Rechner wer-
Da die Hardware des GridKa-Clusters den von dem System verwaltet und ihre
regelmäßig erweitert wird, muss auch Ressourcen stetig neu aufgeteilt, um den
seine Steuersoftware – das Batch System aktuellen Anforderungen der unterstütz-
– fortlaufend angepasst und verbessert ten Kollaborationen zu entsprechen.
werden. Um dadurch nicht die angestreb- Doch tatsächlich ist etwas scheinbar
te Auslastung von 95% bis 98% zunichte Simples wie “Ressourcen aufzuteilen” bei
zu machen, muss dies im laufenden dieser Größe alles andere als trivial. Wäh-
Betrieb geschehen. Bereits Anfang 2018, rend die kleinsten Rechner des GridKa-
als der GridKa-Cluster nur etwa 20.000 Clusters nur 16 CPU-Kerne bieten, wartet
CPU-Kerne umfasste, war die damalige die neueste Generation mit 256 CPU-Ker-
Batch System Software jedoch bis an die nen auf. Diese gleichmäßig, schnell und
Grenze ihrer Möglichkeiten ausgereizt. fair an die anstehenden Jobs aufzuteilen,
Ein kompletter Austausch gegen eine ist auch weiterhin eine Herausforderung.
weitaus besser skalierende Software war
unumgänglich. Doch nicht nur der GridKa-Cluster selbst
entwickelt sich weiter, auch das Grid geht
Zu Gute kam in dieser Situation die hohe mit der Zeit. Die Verbindung zwischen
Flexibilität der neu gewählten Batch Rechencluster und Grid sind die Compute
System Software HTCondor2. Ausgelegt Elements (CE): im Prinzip Submittierungs-
auf hochgradig verteilte, unabhängige knoten für den Rechencluster, zugänglich
The GridKa Compute Cluster –
Komponenten, skaliert diese fast automa- über die Authentifizierungsverfahren des
non-stop scientific computing!
tisch mit der Größe eines Rechenclusters Grid. Nachdem das GridKa jahrelang die
For almost two decades, the Grid
und nicht mit der Rechenleistung einer Grid Computing Middleware Nordugrid
Computing Centre Karlsruhe (GridKa) is
einzigen zentralen Maschine. Über einen ARC CE betrieben hat, ist dieses Jahr
providing resources and services for data-
Zeitraum von mehreren Wochen konnten auch hier ein Generationenwechsel voll-
and computation-intensive experiments
somit schrittweise einzelne Rechenknoten zogen worden: seit August wird bei Grid-
in particle and astroparticle physics. In
aus der Kontrolle des alten Batch-Systems Ka nun das HTCondor CE verwendet und
addition to tape and online storage, Grid-
in das neue überführt werden. bietet somit eine einheitliche Technologie
Ka operates one of the largest computing
sowohl lokal als auch für die Anbindung
clusters of the worldwide LHC Compu-
an die Welt.
ting Grid. To ensure high availability, Grid-
Ka is in operation literally continuously
1
SCC News 2/2018 and has therefore been undergoing a
2
research.cs.wisc.edu/htcondor continuous evolution for years.
3
www.erum-data-idt.de/post/cobald_tardis_covid-19/
4
www.scc.kit.edu/ueberuns/13531.php
SCCnews | 13DI E N STE UND I NN OVATION
Jupyter@SCC
Einsteiger und Studierende sehen sich bei der Nutzung der HPC-Systeme des SCC häufig mit einer steilen Lern-
kurve konfrontiert. Seit Oktober 2020 steht daher nun zusätzlich auch Jupyter als alternativer, graphischer und
web-basierter Zugangsweg zu den HPC-Systemen zur Verfügung.
Jennifer Buchmüller, Samuel Braun und Simon Raffeiner
Der Zugriff auf HPC-Systeme erfolgt Schritte, hier am Beispiel einer Python- des Codes nötigen Schritte (z.B. Aufruf
traditionell über textbasierte Komman- Anwendung dargestellt: eines Compilers) manuell durchgeführt
dozeilenschnittstellen, die mit Hilfe von werden.
verschlüsselten Netzwerkprotokollen, z.B. Aufbau einer SSH-Verbindung
Secure Shell (SSH), über Netzwerke wie Editieren der Python-Dateien in einem Jupyter auf den HPC-Systemen
das Internet genutzt werden. Wird diese Texteditor
Verbindung durch Protokolle wie X11 Einstellen eines Jobs in die Warte- Das Einrichten eines JupyterLab auf einem
oder VNC erweitert, ist auch eine graphi- schlange Laptop oder PC nimmt weniger als 20
sche Ausgabe möglich. Das klingt nicht Analyse der Ergebnisse Minuten in Anspruch. Die Einführung von
nur kompliziert, insbesondere für Erstnut- JupyterLab in der komplexen Infrastruktur
zerinnen und -nutzer ist es das auch. Ein JupyterLab kombiniert diese Schritte in eines HPC-Systems mit Hunderten von Re-
einer einzigen, interaktiven Web-Ansicht. chenknoten, einem Queuing-System, ei-
Was ist Jupyter? Die Verbindung zum HPC-System wird ner Benutzerverwaltung mit einer Vielzahl
automatisch hergestellt. von Projekten, komplexen Zugriffsregeln
Das vor einigen Jahren gegründete Die Bearbeitung des Codes wird durch und strikten Sicherheitsregeln erfordert
Jupyter-Projekt1 stellt eine einfache, web- sogenannte „Code-Konsolen“ direkt im hingegen deutlich mehr Aufwand. Die
basierte Entwicklungsumgebung zur Ver- Browser realisiert. Diese bieten Syntax- verschiedenen Bestandteile eines Jupy-
fügung. Die darin verwendeten Program- Highlighting, integrierte Code-Prüfung terLabs müssen voneinander entkoppelt,
miersprachen Julia, Python und R (daher und andere Komfortfunktionen ähnlich auf verschiedene Hardwarekomponenten
der Name „Jupyter“) sind in einigen Diszi- einer traditionellen Integrierten Entwick- aufgeteilt und mit einigen zusätzlichen
plinen wie dem der Künstlichen Intelligenz lungsumgebung (IDE) (Abbildung 1). Die Komponenten versehen werden.
und dem Machine Learning (KI/ML) stark meisten Jupyter-Code-Konsolen unter-
verbreitet und besonders geeignet für den stützen Dateiformate wie Bilder, CSV- und Dazu wird auf einem speziellen Server, der
Einstieg ins [technisch-wissenschaftliche] JSON-Dateien, Markdown, PDFs, Vega- sich in der Nähe des HPC-Systems befin-
Programmieren. Die Nutzenden können und Vega-Lite-Visualisierungen. det, die Software „JupyterHub“ installiert.
in einem Web-Frontend Dateien öffnen, Auf den HPC-Systemen werden die zu
diese in einem sogenannten „JupyterLab“ Die eigentlichen Laufzeitumgebungen, unterstützenden Jupyter-Kernel installiert,
interaktiv bearbeiten und dort auch direkt die für die Ausführung des Codes benutzt da die Berechnungen dort und nicht auf
ausführen. Die Ausgaben des Programm- werden, liegen als sogenannte „Kernel“ dem Web-Frontend laufen werden.
codes sind direkt im Dokument sichtbar. vor. Über das Kernel-Backend können
die Nutzerinnen und Nutzer die in der Das JupyterHub-Web-Frontend über-
Seit Ende Oktober bietet das SCC Jupyter Code-Konsole bearbeiteten Codes sofort nimmt zunächst im Zusammenspiel mit
als Service an. Neben dem klassischen Zu- interaktiv ausführen. Einer der bekann- dem föderierten Identitätsmanagement-
gang via SSH, ist nun auch der interaktive testen Kernel im Jupyter-Projekt ist der system bwIDM die Zwei-Faktor-Authen-
Zugriff auf alle HPC-Systeme des SCC via ipython-Kernel. Dieser ermöglicht die tifizierung mittels OpenID Connect.
Webbrowser möglich. interaktive Ausführung von Python-Code. Nach erfolgter Authentifizierung wählen
Das Jupyter-Projekt bietet eine ständig die Anwenderinnen und Anwender die
Programmieren leicht gemacht wachsende Liste von Kerneln für Laufzeit- gewünschten Ressourcen aus einer Liste
umgebungen wie z.B. Julia, R, Octave, vorgefertigter Optionen z.B. eine GPU für
Jupyter ermöglicht damit eine neue Art Haskell, C/C++ an. Sollte Jupyter eine eine Dauer von einer Stunde. Aus dieser
des interaktiven Supercomputings. Der Laufzeitumgebung noch nicht unterstüt- Auswahl wird automatisch eine Anforde-
klassische Prozess der Programmierung zen, können der Code im Web-Frontend rung für das Queueing-System generiert.
einer Anwendung, die auf dem Super- editiert und dann in der interaktiven Dieses prüft die Anforderung und allokiert
computer läuft, umfasst mindestens vier Kommando-Konsole die zur Ausführung die Ressourcen auf den Compute-
14 | jupyter.org
1
SCCnewsD IE N S T E U N D IN N OVAT I O N
Effektive Nutzerunter-
stützung
Das SCC vertritt schon
lange die Philosophie, dass
auf den HPC-Systemen
sogenannte „Modulsyste-
me“ angeboten werden,
die einen einfachen Zugriff
auf gängige Softwarekom-
ponenten wie wissenschaft-
liche Bibliotheken oder
Compiler ermöglichen. Un-
ter diesen Modulsystemen
befinden sich auch solche,
die verschiedene Python-
Module, Bibliotheken und
andere Softwarekompo-
nenten für bestimmte
Einsatzzwecke bündeln. Die
Abbildung 1: Beispiel einer Programmieraufgabe in der JupyterLab-Entwicklungsumgebung.
KI/ML-Community findet
beispielsweise im Modul
Knoten des HPC-Systems. Innerhalb wenn verschiedenen wissenschaftlichen „jupyter_ml“ mehr als 30 gängige Py-
dieser Ressourcen wird ein sogenannter Gemeinschaften genau die Softwareum- thon-Module und kann diese mit Jupyter
„JupyterSpawner“ gestartet, der die gebung zur Verfügung steht, die am bes- sofort für Berechnungen auf den neuen
Verbindung zwischen Web-Frontend und ten zu ihnen passt. Die Komplexität dieser GPUs nutzen. Die eingangs erwähnte stei-
HPC-System realisiert. Gleichzeitig wird Aufgabe lässt sich bereits an einem ein- le Lernkurve, die bei einem textbasierten
in der Web-Anwendung eine JupyterLab- fachen Beispiel, nämlich der Berechnung SSH-Zugang nötig wäre, entfällt. Jupyter
Instanz gestartet und im Hintergrund eine einer Sinusreihe, zeigen. Sogar in Python, ist sowohl auf dem deutschlandweit
Verbindung von dieser JupyterLab-Instanz der derzeit meistverbreiteten Skriptspra- verfügbaren Tier-2-System ForHLR II als
zum zugehörigen JupyterRunner auf dem che, gibt es dafür mindestens drei verbrei- auch auf dem für das KIT und das Land
HPC-System geschaltet. Damit ist die Ein- tete Lösungen. In Python muss man zuerst betriebenen bwUniCluster 2.0 verfügbar.
richtung komplett und alle im Web-Brow- ein Modul wählen, das die Sinusfunktion Weitere Informationen zu Jupyter@SCC
ser ausgelösten Aktionen und Programme implementiert und die Auswertung der finden sich unter www.scc.kit.edu/diens-
laufen nun auf den HPC-Ressourcen. Die Programmzeile print(sin(x)) for te/JupyterHPC.
Ausgaben der Berechnungen werden x in list(xi) ermöglicht. Sowohl
wieder zurück an den Web-Browser über- das integrierte math-Modul als auch
Jupyter@SCC
tragen und können dort sofort visualisiert die bei Wissenschaftlern weit verbrei-
Since October 2020 the SCC now also offers
werden. Die Ausführung des Codes findet teten Module NumPy und SciPy bieten
Jupyter as an alternative access path to the
komplett auf dem HPC-System statt, die entsprechende Funktionen. NumPy und
HPC systems. Jupyter is a new way of “inter-
Anwenderinnen und Anwender können SciPy wiederum können auf verschiedene
active supercomputing”, enabling interactive
also auch auf Software oder Hardware numerische Hilfsbibliotheken (z.B. Intel
work with runtime environments like Python
zugreifen, die lokal nicht installiert oder MKL oder OpenBLAS) zurückgreifen. Am
and data visualizations. Users only need a
nicht vorhanden ist. Ende hängt die Performance des Python-
web browser on their local system to use
Codes auf einem bestimmten System von
Jupyter and have access to all resources on
Herausforderung Jupyter-Software- der richtigen Kombination aller genann-
the HPC systems, including GPUs. Preconfi-
Ökosystem ten Komponenten ab. Dies ist ein sehr
gured software environments, e.g. for GPU-
einfaches Beispiel, bei Anwendungen
accelerated Machine Learning using Python,
Auf den ersten Blick sieht dieses Konzept der Künstlichen Intelligenz (KI) und des
are available. Jupyter is
bereits wie eine sehr gute Lösung aus, Maschinellen Lernens (ML) wird es noch
available both on ForHLR II and bwUniCluster
allerdings wird es nun erst richtig kom- viel komplizierter.
2.0. More information can be found
pliziert. Höchste Leistung und effizientes
at www.scc.kit.edu/dienste/JupyterHPC.
Arbeiten werden erst dann ermöglicht,
SCCnews | 15F O R SCHUNG UN D PR OJEKTE
Lohnt sich das Upgrade auf die neue NVIDIA A100 GPU?
Immer mehr Supercomputer der Spitzenklasse nutzen die Rechenpower von Hardware-Beschleunigern. Zum
ersten Mal wird auch ein System mit den neuen NVIDIA A100 GPUs unter den Top500 gelistet. Die Hardware-
Architektur der Beschleuniger ist dabei speziell für KI-Algorithmen entwickelt worden. Doch lohnt sich ein Um-
stieg auf diese neuen Systeme? Die Berechnungen für diese Studie wurden auf den im Juli am SCC in Betrieb
genommenen Hochleistungsservern vom Typ DGX A100 durchgeführt. Hartwig Anzt, Tobias Ribizel
In den letzten zehn Jahren haben Gra- In Abbildung 1 sind die Beschleunigun- Sparse-Linear-Algebra- und wissenschaft-
fikkarten (GPUs) immer mehr Einzug gen dargestellt, die sich ergeben, wenn liche Rechenanwendungen – hängen
in HPC-Plattformen (High Performance man eine NVIDIA V100-GPU durch eine die Leistungsverbesserungen vom
Computing) gehalten, und in der Top500- NVIDIA A100-GPU ohne Code-Modifi- individuellen Datenformat, der Kernel-
Liste vom November 2020 wurden sechs kationen ersetzt. Während die Haupt- Implementierung und den spezifischen
der zehn schnellsten Systeme mit GPU- speicherbandbreite auf dem Papier von Problemeigenschaften ab. Die in Abbil-
Beschleunigern ausgestattet. Die gängigs- 900 GB/s (V100) auf 1.555 GB/s (A100) dung 1 dargestellten Beschleunigungs-
te Form von Beschleunigern sind GPUs. gestiegen ist, liegen die Beschleunigungs- werte für die SpMV-Kernel aus NVIDIAs
Die Juni 2020-Ausgabe der Top500 listet faktoren für die STREAM-Benchmark- cuSPARSE-Bibliothek und der Open-
zum ersten Mal ein System mit NVIDIAs Routinen2 bei großen Datensätzen zwi- Source-Bibliothek Ginkgo (s. SCC-News
neuen A100-GPUs auf – eine GPU mit der schen 1,6 und 1,72. Gleichzeitig konnte 01/2019) sind alle über die mehr als
HPC-zentrierten Ampere-Architektur, die beobachtet werden, dass beim Zugriff auf 2.800 in der Suite Sparse Matrix Collec-
für KI-Anwendungen entwickelt wurde. kleine Datensätze die Speicherbandbreite tion verfügbaren Testmatrizen gemittelt.
Drei DGX A100-Systeme mit jeweils acht der A100-Architektur tatsächlich geringer Da viele dieser Matrizen klein sind, sind
NVIDIA A100 GPUs sind seit Juli am SCC ist als die Bandbreite der V100. die Kernel nicht in der Lage, die volle
im Einsatz1. Jetzt, wo dieser neue Flagg- Speicherbandbreite zu erreichen. Folglich
schiff-Chip von NVIDIA auf dem Markt ist, Für das Sparse Matrix-Vektor-Produkt sind die Beschleunigungswerte für die
fragen sich Anwendungswissenschaftler, (SpMV) – ein Schlüsselalgorithmus für SpMV-Kernel im Allgemeinen niedriger
die sich auf GPU-beschleunigte wissen-
schaftliche Simulationscodes verlassen,
ob es nicht an der Zeit ist, ihre Hardware
aufzurüsten.
Um diese Frage zu beantworten, wer-
fen wir einen Blick auf die Performanz,
die iterative Löser und Batch-Routinen
mit der NVIDIA A100-GPU erzielen,
und quantifizieren die Beschleunigung
gegenüber ihrem Vorgänger, der NVIDIA
V100-GPU. Die Motivation, sich auf diese
Routinen zu konzentrieren, liegt darin,
dass viele wissenschaftliche Anwen-
dungen entweder (1) auf Batch- und
Sparse-Linear-Algebra-Bibliotheksroutinen
basieren oder (2) aus Operationen mit
sehr ähnlichen Eigenschaften bestehen.
Folglich können Leistungsgewinne für
diese Benchmarks ein guter Indizwert für
die Beschleunigung sein, die man für wis-
senschaftliche Anwendungen erwarten
kann, ohne zusätzliche Code-Modifikatio-
nen vornehmen zu müssen.
Abbildung 1: Die A100- versus V100-Architektur - ein detaillierter Beschleunigungsvergleich.
16 | www.scc.kit.edu/ueberuns/13772
1
SCCnews 2
2018. Evaluating attainable memory bandwidth of parallel programming models via BabelStream.
Int. J. Comput. Sci. Eng. 17, 3 (January 2018), 247–262. dl.acm.org/doi/10.5555/3292750.3292751FOR S C H U N G U N D P RO J E K T E
als die für die STREAM-Benchmarks. Bei zum 1,6-fachen, die "umsonst" kom- ger nutzen kann, beträgt die theoretische
der Leistungsanalyse für die iterativen men. Erwähnenswert ist zudem, dass der Spitzenleistung 19,5 Teraflops (das wäre
linearen Löser von Ginkgo konzentrieren A100-GPU-Tensorecore-Beschleuniger um den Faktor 2,6 besser).
wir uns auf große Testprobleme, um Berechnungen in IEEE754 double precis-
sicherzustellen, dass die Bandbreite in ion durchführen kann. Dies ist eine neue Angesichts dieser insgesamt konsisten-
den Vektoroperationen voll ausgeschöpft Hardware-Fähigkeit, die bei den A100- ten Ergebnisse können wir erwarten,
wird. Je nach individuellem Algorithmus Vorgängern nicht vorhanden war. Solche dass auch komplexe wissenschaftliche
laufen die iterativen Löser von Ginkgo auf drastischen Architekturverbesserungen Rechenanwendungen 1,3 bis 1,7-mal
der A100-GPU im Vergleich zur V100- stellen eine Herausforderung für Open- schneller ausgeführt werden können,
GPU zwischen 1,5 und 1,8-mal schneller. Source-Bibliotheken wie MAGMA dar, die ohne architekturspezifische Änderungen
darauf abzielen, hochgradig abgestimm- vorzunehmen. Zwar kann die Frage, ob
Schließlich gilt es auch die Beschleuni- te numerische Software für eine breite dies die Investition in neue Hardware
gung von Batch-Routinen zu untersu- Palette von Hardware-Architekturen rechtfertigt, hier nicht eindeutig beant-
chen, die ebenfalls in wissenschaftlichen bereitzustellen. Beispielsweise nutzen die worten werden, aber es wird klar, dass
Rechenanwendungen üblich sind. Es ist vorhandenen, rechenintensiven Codes die neue Architektur von NVIDIA mit
wichtig zu erwähnen, dass MAGMAs in MAGMA derzeit nicht die Vorteile der Schwerpunkt auf KI-Algorithmen eine
Batch-Routinen zwar besonders für A100-Tensorcores für IEEE754 double erhebliche Leistungssteigerung gegen-
die V100-Architektur entwickelt wur- precision. Dies bedeutet, dass diese über dem Vorgängermodell bietet. Das
den, durch Feintuning auf die A100- Codes bestenfalls durch eine theoretische SCC freut sich, einige der weltweit ersten
Architektur aber möglicherweise noch Spitzenleistung von 9,7 Teraflops (das ist A100 GPUs zu betreiben, die bereits von
höhere Beschleunigungen möglich sind. etwa 1,3-mal besser als der V100) be- Anwendungswissenschaftlern eingesetzt
Nichtsdestotrotz ergeben sich aus den schränkt sind. Wenn MAGMA jedoch die werden.
Tests attraktive Leistungssteigerungen bis Vorteile der neuen Tensorcore-Beschleuni-
Is the NVIDIA A100 GPU Performance Worth a Hardware Upgrade?
Over the last decade, GPU accelerators have seen an increasing rate of adoption in high-performance computing (HPC) platforms, and in
the June 2020 Top500 list, eight of the ten fastest systems featured GPUs. The June 2020 edition of the Top500 is the first edition listing a
system equipped with NVIDIA’s new A100 GPU – the HPC-centric Ampere GPU designed with AI applications in mind. With this new flag-
ship NVIDIA chip now on the market, domain scientists relying on GPU-accelerated scientific simulation codes wonder whether it is time to
upgrade their hardware.
To help answer this question, we take a look at the performance we achieve on the NVIDIA A100 for sparse and batched computations and
quantify the acceleration over its predecessor, the NVIDIA V100 GPU. The motivation for focusing on these routines is that many scientific
applications are either (1) based on batched and sparse linear algebra library routines or (2) composed of operations with very similar cha-
racteristics. Consequently, the performance gains for these benchmarks may be indicative of the acceleration we may see when porting a
scientific computing application from a V100 platform to the A100 architecture, without applying additional code modifications.
In Figure 1, we are visualizing the speedups we get when replacing an NVIDIA V100 GPU with an NVIDIA A100 GPU without code modifi-
cation. While the main memory bandwidth has increased on paper from 900 GB/s (V100) to 1,555 GB/s (A100), the speedup factors for the
STREAM benchmark routines range between 1.6× and 1.72× for large data sets.
For the sparse matrix-vector product (SpMV) the performance improvements depend on the individual sparse data format, the kernel imple-
mentation and the specific problem characteristics, and are generally much lower than those for the STREAM benchmarks.
In the performance analysis for Ginkgo’s iterative linear solvers, we focus on large test problems to ensure the bandwidth is saturated in the
vector operations. Depending on the individual algorithm, Ginkgo’s iterative solvers run between 1.5× and 1.8× faster on the A100 GPU
over the V100 GPU.
For batched routines, we observe performance gains up to 1.6× that come “for free” by just switching to newer hardware architecture. It is
worth mentioning that the A100 GPU provides tensor core acceleration for FP64 arithmetic. This is a new hardware capability that did not
exist on the A100 predecessors, and is hence not yet reflected in the algorithm implementations available in open source libraries such as
MAGMA.
While we cannot answer the question of whether these performance improvements justify the investment, it is clear that the NVIDIA team
succeeded in delivering an architecture with a new focus that delivers considerable performance improvement over its predecessor – not just
incremental acceleration. At the SCC, we are happy to host some of the first A100 worldwide, ready to be used by application scientists.
SCCnews | 17Sie können auch lesen

















































