EDITOR FÜR EINE DSL ANHAND DER SPRING VALIDIERUNGSSPRACHE - PRAKTIKUM MDSD SS008 UNI AUGSBURG HADIDENIZ WISSAMODEH WEIZHAO 15.05.2008
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Editor für eine DSL anhand der Spring Validierungssprache Praktikum MDSD SS008 Uni Augsburg Hadi Deniz Wissam Odeh Wei Zhao 15.05.2008
Gliederung
Einleitung …………………………………………………………………………… 1
1. Spring Validation …………………………………………………………………...1
1.1. Validation………………………………………………………………………..1
1.1.1 Einführung…………………………………………………………………1
1.1.2 Validator allgemein……………………………………….………………..1
1.1.3 Valang Validator………………………………………….………………..2
1.2. Valang ……...………………………………………………….………………...3
1.2.1. Valang Syntax………………………………………….…………………3
1.2.1.1. Regelkonfiguration………………………………….………………..3
1.2.1.2. Aussagen……………………………………………….…………….4
1.2.1.3. Operatoren…………………………………………………………...4
2. OAW und XText …………………………………………………………………...6
2.1. MDSD …………...……………………………………………………………...6
2.1.1. Modell …………………………………………………………………....6
2.1.2. Metamodell ………………………………………………………………6
2.1.3. MDSD Definition ………………………………………………………..6
2.2. OpenArchitectureWare………………………………………………………….7
2.2.1. OpenArchitectureWare Definition ………………………………………7
2.2.2. OpenArchitectureWare Komponente ……………………………………7
2.2.3. Vor- und Nachteile ………………………………………………………7
2.3. XText Framework ………………………………………………………………8
2.3.1. XText Architektur ……………………………………………………….8
2.3.2. Language Projekt in Details …………………………………………......9
2.3.3. Editor Projekt in Details ………………………………………………...10
2.3.4. Generator Projekt ………………………………………………………..10
2.3.5. xText Grammatik ………………………………………………………..11
2.4. XPand Framework ……………………………………………………………...13
2.4.1. Struktur ………………………………………………………………….13
2.4.2. Wichtige Befehle in Überblick ………………………………………….13
3. Die Eclipce Rich Client Plattform......…………………………………………......15
3.1. Plattform für Rich-Clients ..………...………………………………………......15
3.2. Die Eclipse RCP für das Projekt ……………………………………………….16
3.2.1. Oberfläche für Editor …………………….……………………………...17
3.2.2. Integration von Plug-in ……………………………………………….....17
3.2.3. Erstellung einer Aplikation ……………………………………………...17
4. Implementierung …………………………………….…………………………......18
4.1. OpenArchitectureWare- (Implemnierung) …..………………………………… 18
4.1.1. DSL für Valang ………..……………………...........................................19
4.1.2. Constraints……………………………………………………............…...22
4.1.3. Extentions………………...............................................................……….25
4.1.4. Outline…………………………………………………………………..…30
4.1.5. Auto-Complete (Syntaxvervollständigung) ……………………………… 32
4.1.6. xPand-Templates…………………………………………………………..34
4.2 Die Eclipse Rich Client Plattform – (Implementierung) ………….……………..40
4.2.1 Eclipse Plattform für Rich-Clients………………………………………….40
4.2.2 Die Eclipse RCP für das Projekt…...……………………………………….41
4.2.3 RCP-Implementierung……………………………………………………....42
4.2.4.Architekturen von Editor…………………………………………………....44
4.3 Zusammenfassung und Ausblick ……………………………………………..….46
1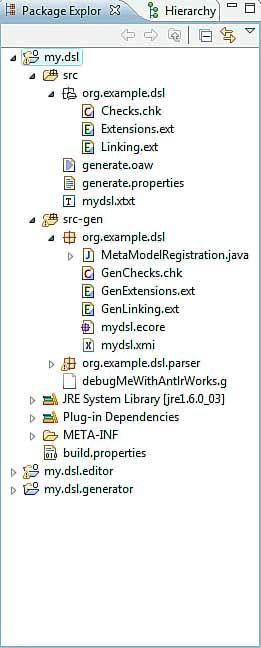
Einleitung
Software Projekte sind immer von Umfang her großer und komplexer geworden. Um diese
Komplexität zu vermeiden, bietet MDSD die Möglichkeit ein Teil dieser Software
automatisch zu generieren und Subsysteme wieder zu verwenden. In unserem Projekt werden
wir mit Hilfe von OpenArchitekturWare(OAW) Framework ein Editor für eine DSLs anhand
der Spring-Validierungssprache realisieren.
In dieser Dokumentation stellen wir in erstem Kapitel Validierung und Validator von
Spring vor. Im nächsten Kapitel kennen wir xText und xPand von OAW lernen und in
drittem Kapitel behandeln wir die Architektur und Konzept von Eclipse RCP. Im letzten
Kapitel wird die konkrete Implementierung durchgeführt.
1. Spring Validation
1.1 Einführung
Validierung(Validation) ist die dokumentierte Beweisführung, dass ein System die
Anforderungen in der Praxis erfüllt. In der Softwaretechnik bezeichnet Validierung (auch
Plausibilisierung, als Test auf Plausibilität, oder engl. Sanity Check genannt) die Kontrolle
eines konkreten Wertes darauf, ob er zu einem bestimmten Datentyp gehört oder in einem
vorgegebenen Wertebereich oder einer vorgegebenen Wertemenge liegt. Sie ist ein wichtiger
Aspekt der Qualitätssicherung, der sicherstellen soll, dass ein implementiertes Programm den
vorher aufgestellten Anforderungen genügt. Die meisten Programmfehler und
Sicherheitsprobleme sind letztlich auf fehlende Plausibilisierung von Eingabewerten
zurückzuführen1.
Die Validierung ist ein wichtiges Instrument, um die Qualität von Arbeitsergebnissen
sicherzustellen, in der pharmazeutischen Technologie, Biotechnologie, analytischen Chemie,
klinischen Medizin oder Computertechnologie. Zu diesem Zweck wird ein dokumentierter
Nachweis erbracht, der stets vor der Entwicklung oder Einführung eines Computersystems
geführt wird.
Validierung und Verifizierung werden manchmal verwechselt. Verifikation ist die
Überprüfung, ob ein System die formale Spezifikation erfüllt. Umgangssprachlich ist die
Validierung Antwort auf die Frage : baue ich das richtige Haus? Und Verifizierung ist die
Antwort auf die Frage: baue ich das Haus richtig?
1.1.1 Validator
Validators sind die Werkzeuge die uns ermöglichen die Gültigkeit von unserem Kode
festzustellen. Validator die wir hier benutzen sind die implementierungen von
Springframework. Springframework hat zwei Arten von Validators; Einer ist
programmatischer Validator,in dem Validierungsregeln schon kodiert sind und der andere ist
1
http://de.wikipedia.org/wiki/Validierung_%28Informatik%29
2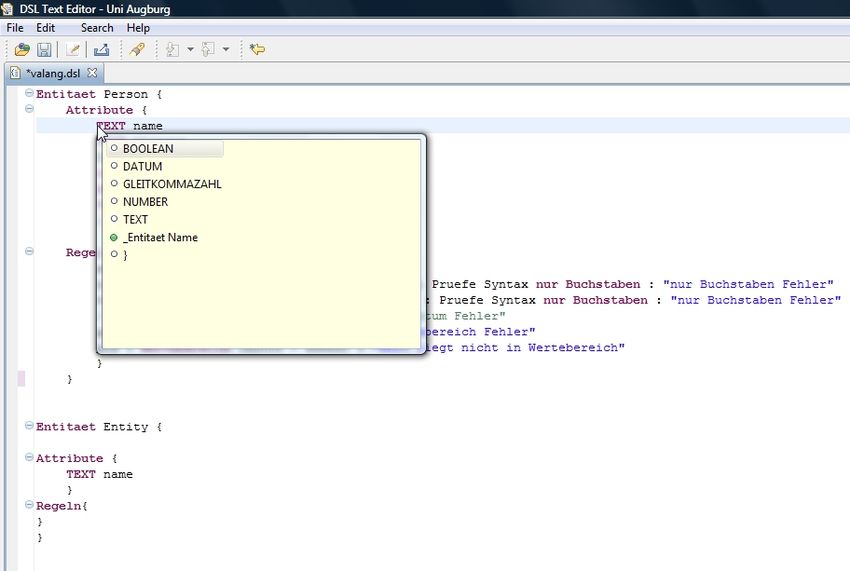
deklarativer Validator, was Validierungsregeln und Beschränkungen auf Konstruktionen
beruhen2. In unserem Fall werden wir die zweite Validator behandeln.
Für die declarativer Validator hat Spring drei Validierungswerkzeuge
• Commons Validator
• Valang Validator
• Bean Validation Framework
Der Commons Validator verwendet eine XML-Konfigurationsdatei um die Beschränkung
declerativ zu spezifizieren. Allerdings, ist die Konfiguration nicht intuitiv, und seine
Konfiguration-Format ist sehr verbose.
Das Bean Validation Framework ist das neueste und wurde entwickelt, um die Lücken in den
anderen verfügbaren Validierung Werkzeuge, nämlich commons Validator und Valang
Validator zu füllen.
Die wichtigsten Ziele dieses Framework sind:
• Ermöglichen klare Trennung von Interessen, wenn es zur Validierung kommt.
• Extrahieren Sie die besten Eigenschaften von den anderen Ansätze(Werkzeuge) und
vereinigen sie in einem Rahmen
• Die neueste Technologie und und Methoden verwenden
• Macht die die Validierungsregeln so intuitiv und einfach wie möglich für die
Definition in der Anwendungen.
Bean validation Framework-Validator ist das Beste unter diesen Tools, weil es flexibler ,
leistungsfähiger ist. Ausserdem unterstützt es auch XML Deklaration.
(hier wird noch erweitert )
Da unsere Arbeit auf Valang basiert werden wir uns hier hauptsächlich auf Valang-Validator
konzentrieren.
1.1.2 Valang Validator
Valang, das für Validierungssprache steht, ist eine Sprache, die spezifisch für die Validierung
der Zielobjekte bestimmt ist. Seine Darstellung ist kurz und spezifisch auf das Erhalten von
valiedierende Daten ausgerichtet. Das ist ein Opensource Projekt und in Spring Modulen zu
erhalten. Wie man eigenes Validator schreibt werden wir mit dem Beispile in Syntaxteil
verdeutlichen.
Die zwei wichtigste Klasse von Spring-Validation sind die Klassen
org.springframework.validation.Validator und org.springframework.validation.Errors.
Die Klasse Errors bedient wie eine Registry für die Errors, die mit dem ziel Objekt kombiniert
sind. Validator interface bietet einen Vorgang um ziel Objekt zu validieren und kombinierte
Errors zu registrieren. Unsere Kode werden hier überprüft und im Fall eines Fehlers wird ein
gebundenen Fehler vom Errors geholt und angezeigt.
1.2 Valang
Valang(Validation Language), bietet einen einfachen und intuitiven Weg zum Erstellen von
Spring Validator. Valang hat drei wichtige Ziele
2
Expert Spring MVC and Web Flow
3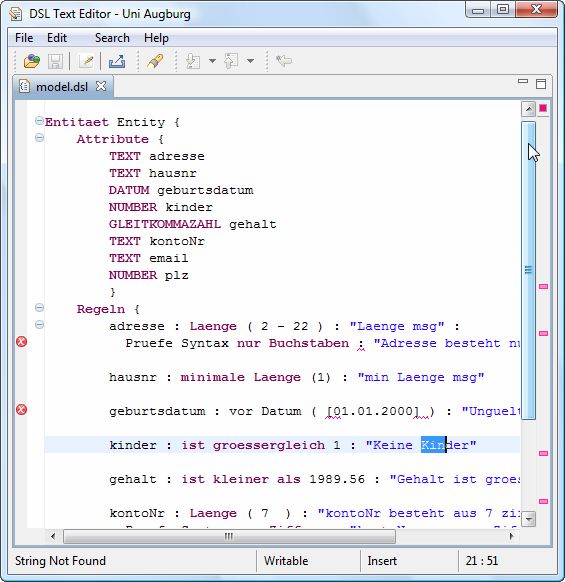
• Validierungsregeln Schnell und ohne Java Klassen zu schreiben
• Vereinfacht die Verwendung von Spring Validation Werkzeuge
• Erstellt die Validationsregeln kompakt, lesbar und einfach bedienbar
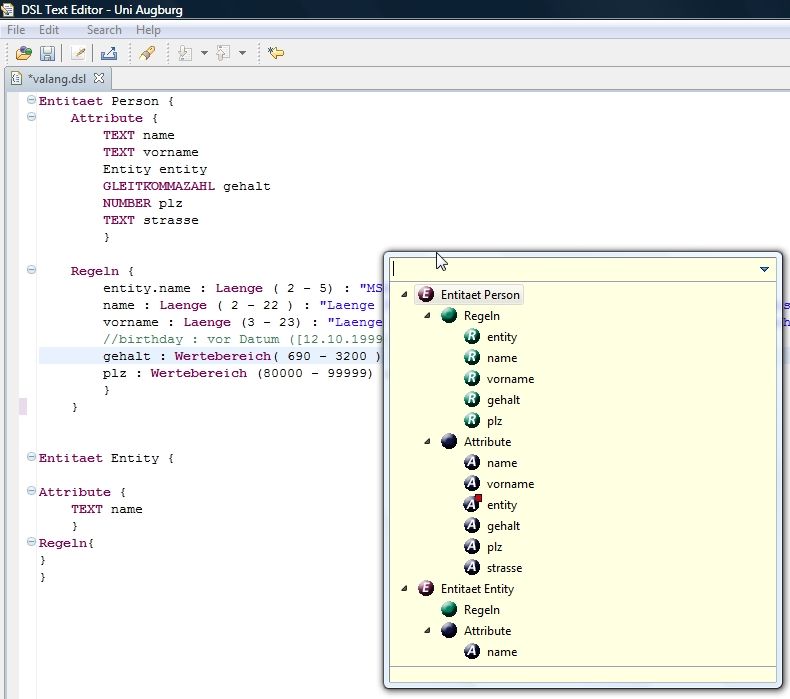
Hier unten werden wir ein Beispiel überprüfen
Hier wie wir sehen erstens keine neue klasse wurde erstellt aber man verwendet hier eine
vordefinierte Klasse . Zweitens PersonValidator ist kein Teil von Java Kode aber könnte eine
java Klasse(ValangValidator) instanzieren. Als drittes die Validationsregeln wurden mit
Valang expression Language geschrieben, welche sehr einfach und schnell zu schreiben sind.
Um diese regeln zu schreiben hat Valang einen umfangreichen Syntax.
1.2.1 Valang Syntax
Valang Syntax basiert auf Valang Expression language und valang validation rule
configration. Ein Teil von diesen Regeln und funktionen sins vordefiniert ein Teil können wir
selber definieren.
1.2.1.1 Regelkonfiguration:
Alle Regeln werden in geschweifte Klammer geschrieben und die Felder werden mit :
trennen. Es gibt obligatorische Felder und optionale Felder mit folgendem Beispiel lernen wir
Grundstruktur kennen.
Bsp;
{ firstName : length(?) < 30 : 'First name too long' : 'first_name_length' : 30}
Grundstruktur
{ : : [: [: ]] }
=firstName- das ist der Schlüßelname mit dem ein Error verbunden ist. Das ist
validierende Zielobjekt.
: =length(?)-das ist eine Valangaussage was das prädikat definiert.
Das ist die Beschränkung die gesucht ist. ? ist für firstName damit wird Redundant
vermieden
4=‘first name too long’ das ist Error Nachricht kann leer gelassen werden. In dem Fall wird ein default Nachricht ausgegeben Die oberen drei Felder sind obligatorisch den Rest ist optional die sind die Nachrichten die man über Error Kode mehr details geben kann. 1.2.1.2 Aussagen: Die Prädikate(Aussagen ), die wir bei den Regeln verwenden, werden mit Expression Language wie folgend definiert. ::= ( ( "AND" | "OR" ) )+ | besteht aus operatoren, literalen, bean properties, Funktionen, und mathematische Ausdrücken. 1..2.1.3 Operatoren Binary Operators: diese haben Leftseite und Linkeseite String, Boolean, Date and Number Operatoren: = | == | IS | EQUALS != | | >< | IS NOT | NOT EQUALS Number und Date Operatoren: > | GREATER THAN | IS GREATER THAN < | LESS THAN | IS LESS THAN >= | => | GREATER THAN OR EQUALS | IS GREATER THAN OR EQUALS
BETWEEN / NOT BETWEEN
IN / NOT IN
NOT
Bsp:
width between 10 and 90
length(name) between minLength and maxLength
Funktionen :
Funktion Syntax ist wie folgend;
function ::= "(" ( | |
) ( "," ( | | ) )* ")"
Es gibt auch vordefinierte Funktionen :
Length, size, count : die ergeben die Länge ein Objekt
Match, matchs : vergleicht zwei Objekte
Upper,lower : konvertiert die Strings nach groß bzw. Klein Buchstaben
Unterstütze Mathematische Operatoren:
• +
• -
• *
• / | div
• % | mod3
2 OpenArchitectureWare, xText und xPand
3
https://springmodules.dev.java.net/docs/reference/0.8/html/validation.html alle beispiele sind aus der Seite
6Einleitung
Nachdem wir im letzten Kapitel den Valang Validator von Spring dargestellt haben und die
Valang Syntax im letzten Abschnitt vorgestellt haben, führen wir in diesem Kapitel ein ganz
anderes Thema ein, und zwar das Tool, dass wir nutzen werden, um ein Text-Editor für die
Valang-Sprache zu erstellen.
In Diesem Kapitel werden wir mit einer groben Definition des „MDSD“ Begriffs anfangen,
gefolgt von der Vorstellung des „OpenArchitectureWare“ Projekts und seine
Hauptkomponente, danach werden wir die xText und xPand Frameworks und ihre
Grammatiken und Strukturen detaillierter besprechen.
2.1 Model Driven Software Development (MDSD)
2.1.1 Modell
„Ein Modell ist allgemein eine auf bestimmte Zwecke ausgerichtete vereinfachende
Beschreibung der Wirklichkeit. In der wissenschaftlichen Theoriebildung ist ein Modell das
Ergebnis einer abstrahierenden und Relationen hervorhebenden Darstellung des behandelten
Phänomens. Ein Modell entsteht, wenn Elemente aus dem Phänomen abstrahiert und
zueinander in Beziehung gesetzt werden. Die Funktion des Modells besteht darin, aus den
dargestellten Zusammenhängen Bedingungen und Prognosen bezüglich des Phänomens (oder
Problems) ableiten zu können.“ (Wikipedia)
2.1.2 Metamodell
Das Metamodell ist ein auf höhere Abstraktionsschicht liegende Modell. Dieses beschreibt
die Struktur der Domäne formal und hilft bei der Festlegung welche Elemente im Modell
vorkommen dürfen und wie sie zueinander in Beziehung stehen. Diese formale Beschreibung
ermöglicht erst die spätere Automatisierung der Outputgenerierung.
2.1.3 MDSD-Definition
„Modellgetriebene Softwareentwicklung (Model Driven Software Development, MDSD) ist
ein Oberbegriff für Techniken, die aus formalen Modellen automatisiert lauffähige Software
erzeugen.“(Stahl/Völter 2007, S.11)
Formale Modelle: Sind die Modelle, die klare eindeutige Aussagen über einen Aspekt der zu
entwickelnden Software ermitteln.
Lauffähige Software erzeugen: Ziel eines MDSD ist eine lauffähige Software zu erzeugen.
Wenn die formale Modelle nur die Dokumentation dienen, heißt das nicht, dass wir uns mit
einem MDSD Project beschäftigen, da in diesem Fall keine Erzeugung stattfindet. Zwei
Methoden zur Erzeugung lauffähige Software aus Modelle sind bekannt, Generatoren und
Interpreter, wobei Generator aus einem Modell Quelltext einer andere Programmiersprache
erzeugt und wird als Bestandteil des Build-Prozesses betrachtet, ein Interpreter, auf der
anderen Seite, ist dazu verantwortlich, ein Modell zur Laufzeit einliest und abhängig von
seinem Inhalt verschiedene Aktionen ausführt.
Automatisch: Das bedeutet, dass es mindestens ein Teil der Software Automatisch durch
Eingabe des Modells erzeugt wird. Hier wird noch mal betönt, dass das Modell nicht nur zur
Dokumentation zur Verfügung steht, sondern ist ein wichtiger Teil bei der Erzeugung der
Software. Das bedeutet, dass die Modelle als Quelletexte betrachtet werden, auf denen
Änderungen vorgenommen werden, diese Änderungen werden später bei der Generierung
reflektiert.
72.2 OpenArchitectureWare
2.2.1 OpenArchitectureWare (OAW)
openArchitectureWare ist ein Generator Framework für die Modell getriebene
Softwareentwicklung (MDSD) bzw. Modell getriebene Architecture (MDA), OAW Baut auf
Eclipse-Plugins des "Eclipse Modeling Project" auf, z.B. EMF, GMF, UML2. es ist ein
Opensource Projekt und seit der Version 4 ist ein Subprojekt bei Eclipse geworden.
OAW unterstützt den Entwicklungsprozess eines MDSD Projekt von Erstellung und
Überprüfung des Eingabemodells, Erstellung des Metamodells bis zur Codegenerierung in
verschiedene Formen (Java, XML ..).
2.2.2 OpenArchitectureWare Komponente
OAW besteht aus einer Vielzahl von Einzelkomponenten:
• Workflow: Workflow ermöglicht ein flexibel konfigurierbares Genratorprozess.
• Check-Framework: Modellvalidierung mit OCL-basierten Templates.
• xPand Framework: zur Erzeugung beliebiger Ausgabedateien, Modell zu Text
Transformation (M2T).
• Extend Framework: Modell zu Modell (M2M) Transformation.
• xText Framework: Modellerstellung durch Parsen von Text-Dateien.
• Expression-Framework: Es besteht aus einem Typsystem (engl. Type System) und
einer Expression-Sprache.
Dieses Framework kommt sowohl innerhalb von xPand als auch in Check-Language
zum Einsatz. Es bietet die Möglichkeit auf unterschiedliche Metamodelle immer mit
der gleichen Syntax zuzugreifen.
2.2.3 Vor- und Nachteile
OAW stellet ein umfangreiches flexibles Framework für MDSD Entwicklung und hat viele
Vorteile, von denen:
• Sehr gut in Eclipse Integriert und können Java Erweiterung zugefügt werden.
• Es lassen sich beliebige Metamodelle verwendet, hat keine Einschränkung auf UML
Modelle
• Auch in der Ausgabe hat sich erwiesen, dass OAW flexible ist. Es können beliebige
Textdateien generiert werden
• Das xText-Framework stellt für den Projektstart ein gutes Werkzeug zur Erzeugung
von Metamodell und Modelleditor mit zahlreichen Erweiterungsoptionen wie
Codevervollständigung und Syntaxhighlighting.
Neben den Vorteilen gibt es einige Aspekte, die als Nachteile betrachtet werden können.
• Der Installationsvorgang ist ziemlich komplex, es werden nicht nur OAW Plugins
installiert sondern auch zusätzliche Plugins wie EMF, GMF, UML etc.
• Das Verstehen von den verschiedenen Komponenten und ihrer Beziehung zueinander
am Anfang ist nötig
• Die Dokumentation von OAW ist teilweise veraltet oder nicht vollständig
2.3 xText-Framework
Für die Erstellung eines eigenen Metamodells bringt OAW das xText-Framework mit. Mit
xText kann man eigene textuelle DSLs erstellen. Daraus erzeugt xText ein Metamodell, einen
Parser für das Modell und ein Editor-Plugin mit Codevervollständigung und
Syntaxhighlighting für Eclipse. Die Grammatik der Metasprache und des Modells wird mit
einer an die erweiterte Backus-Naur-Form (EBNF) angelehnten Sprache beschrieben.
82.3.1 Architecture
Bei Erstellung eines xText-Projekt werden drei Subprojekte automatisch erstellt (doch nicht
die vollständige Inhalte) Language-Projekt, Editor-Projekt und Generator-Projekt.
Wie wird der ganze Ablauf aussehen? zuerst kommt das DSL (.xtxt Datei) ins Spiel, nachdem
die Grammatik in der xtxt Datei definiert wird und der Generator Eigenschafen eingestellt
sind, kann der Generator ausgeführt werden. Wenn diese Ausführung Fehlerfrei erfolgt,
werden das Metamodell, den Parser und den Editor-Projekt-Inhalt erstellt, dann können die
optionale Bereiche manuell ergänzt werden(siehe Abbildung 2.1, 2.2,2.3).
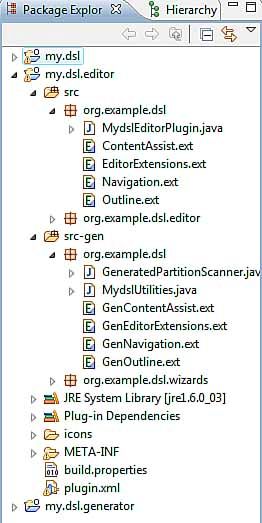
Abbildung 2.1
2.3.2 Language Projekt in Details
Hier ist ein Überblick auf die wichtigen Dateien im Language Projekt
9Language Project
Checkdatei, hier können
Semantik-Constrains zur Sprache
zugefügt werden.
Enthält die Metamodell -
Extensions.
Workflow Datei für den xText
Generator.
Generator-Properties
Die Grammatik, die das DSL
beschreibt.
Generierte Basis Dateien
Von der Grammatik Generiertes
Metamodell
Generierte xText Regeln Datei
Generierte Antlr Parserartefakt
(Abbildung 2.2)
2.3.3 Editor Projekt in Details
10Editor Projekt
Vervollständigung anpassen
Outline-Ansicht anpassen.
“find Reference” und “go to”
Definition anpassen.
Outline Labels und Icons
anpassen
Enthält die wichtige DSL-
spezifische Informationen,
Änderungen sind durchführbar in
Unterklassen, in diesem Fall soll
die MydslEditorPlugin.java Datei
entsprechend angepasst werden.
Generierte Basis Dateien
Outline Icons
(Abbildung 2.3)
2.3.4 Generator Projekt
wie früher erwähnt, OAW unterstützt die MDSD-Projekt bis zur Erzeugung von
Ausgabedateien in verschiedenen Formaten wie XML, Java etc. dies erfolgt mit Hilfe der
xPand-Templates (und Plattform-Spezifische Extend Dateien). Diese Dateien befinden sich
im Generator Projekt. die xPand-Templates werden wir im Letzten Abschnitt dieses Kaptitels
näher besprechen.
2.3.5 xText Grammatik
11xText Grammatik basiert sich auf das extended Backus–Naur form (EBNF) und besteht
aus einer Sammlung von Regeln, eine Regel muss einen Name haben, gefolgt von „:“ und
endet mit „;“ dazwischen befindet sich die Beschreibung der Regel.
Die Regeln können in 4 Kategorien eingeteilt werden:
• String Regel: um selbstdefinierte Zeichensequenz zu definiert.
String JavaIdentifier :
ID ("." ID)*;
• Enum Regel: geeignet für Aufzählungstypen, die in einem endlichen Wertebereich
liegen.
Enum Farbe:
green=“GRÜN“|blue=“BLAU“|red=“ROT“ ;
• Native Regel: um lexerregeln zu definieren, die nicht mit den normalen xText-Syntax
ausdrückbar sind. Z.B. um Float Ausdruck zu definieren, kann die Folgende Regel
hilfreich sein.
Native FLOAT:
„(‚-‚)?(‚0’..’9’)+’.’(‚0’..’9’)+“;
• Type Regel: ist im DSL Grammatik am meisten zu sehen, sie beginnt mit einem
Name, dieser Name wird im Metamodell als „EClass“ abgebildet, gefolgt von „:“ dann
kommt die Relgelbeschreibung, die Beschreibung ist eine Sammlung von Token, die
Token sind Keywords (String) ,Properties, andere selbstdefinierte Typen oder
Instanzen von den sogenannten „Built-in Lexer“.
ein Beispiel wird dies anschaulicher machen aber vorher stellen wir die Build-in Lexer vor:
• ID: Identifier, erlaubt den folgenden Sequenz
(‚a-zA-Z_’ (‚a-zA-Z_0-9’)*)
• STRING: erlaubt einen Zeichenkettenausdruck.
• INT: erlaubt einen Integerausdruck (kein Float).
• LINE: Manchmal will man keinen Text innerhalb von Terminals einschließen,
sondern will alles zwischen eine Charakterreihenfolge und das Ende der Zeile
bekommen.
z.B. ein Kommentar der mit # beginnt und endet mit dem Zeilenende wird in der
folgenden Regel beschrieben.
Attribute :
(comment=LINE("#"))?
type=DataType name=ID;
Mit dieser Regel können wir die folgende Syntax ausdrücken
entity Customer {
string name;
#should include the street number, too.
string street;
int age;
bool isPremiumCustomer;
}
12Einfaches Beispiel:
Entity :
„entity“ name=ID „{„
(features+=Feature)*
„}“ ;
Unsere Typregel hat den Name „Entity“, dieser Name wird auch so im Metamodell als
„EClass“ abgebildet. die Beschreibung besteht aus einem „name“ als ID, den Keywords
„entity“ und die geschtreifte Klammern und einem Ausdruck „(features+=Feature)*“ mit dem
Property „+=“ und dem „*“. Dieser Ausdruck besagt, dass ein Entity Type kann beliebig
viele Instanzen von dem Typ Feature enthalten und wird im Metamodell als „EAttribute“
Abgebildet.
Ein Feature Beschreibung kann so aussehen:
Feature :
type=ID name=ID „;“;
Was kann man mit dieser Grammatik ausdrücken?
entity Customer {
String name;
String street;
Integer age;
Boolean isPremiumCustomer;
}
Es sind drei Mögliche Properties mit vier möglichen Kardinalitäten:
„=“ : Gleichheitszuweisung
„+=“ : Additionszuweisung
„?=“ : Boolean-Zuweisung
„*“ : Beliebig viele (0..n)
„+“ : Mindestens Eins (1..n)
„?“ : Optional (0 oder 1)
Nichts: Eins zu Eins Abbildung (1..1)
132.4 xPand Framework
xPand ist eine Sprache des OAW und wird in die Templates genutzt, um die generierte
Ausgabe zu kontrollieren, mit Hilfe der xPand-Templates können verschiedene Modell-zu-
Text Transformationen durchgeführt werden, z.B. Java, XML oder selbstdefinierte
Textausgaben. Das Haupttemplate befindet sich in dem Generator Projekt unter den Name
„main.xpt“. Wir werden in den folgenden Abschnitt die Struktur und kurz die vorliegende
Befehle vorstellen.
2.4.1 Struktur
Ein xPand Template besteht aus den Befehlen der xPand-Sprache und normalem Text,
xPand Befehle werden zwischen einem öffnenden und schließenden Guillemot geschrieben
«XPand/Befehl». Mit Hilfe der xPand-Befehle können die verschiedene Elemente und
ihre Eigenschaften aufgerufen werden.
Generelle Template-Struktur:
«IMPORT meta::model»
«EXTENSION my::ExtensionFile»
«DEFINE javaClass FOR Entity»
«FILE fileName()»
package «javaPackage()»;
public class «name» {
// implementation
}
«ENDFILE»
«ENDDEFINE»
Ein Template-Datei enthält beliebig viele Importbefehle, beliebig viele Extenstionsbefehle gefolgt von
einem oder mehreren Definitonsblöcken.
2.4.2 Wichtige Befehle in Überblick
• IMPORT: IMPORT Befehl ermöglicht es, ein namespace einzubinden, ähnlich wie
die Import Befehl in java, «IMPORT meta::model» = import meta.model.*; ,
Unterscheidet sich nur daran, dass in xPand nur komplette Pakete importiert werden
können.
• EXTENSION: Bindet die Extend-Datei ein, die die nötigen Extensions enthält.
«EXTENSION my::ExtensionFile»
• DEFINE: Das DEFINE-Block ist das eigentliche Template, enthält einen Name als
Referenz, der von der Workflow-Datei oder andere Templates genutzt werden kann,
gefolgt von „FOR“ gefolgt von der Elementtyp des Metamodells, für das das Template
definiert ist. Der DEFINE-Block endet mit einem «ENDDEFINE» Befehl.
• FILE: Enthält einen Name, einen Outletname und beliebig viele Befehle, diese
Befehle werden ausgewertet und in der generierten Zieldatei reflektiert.
«FILE expression [outletName]»
a sequence of statements
«ENDFILE»
14• EXPAND: Um ein anderes Define-Block innerhalb ein eXpand-Template
hinzufügen.
«EXPAND definitionName [(parameterList)]
[FOR expression | FOREACH expression [SEPARATOR expression] ]»
• FOR: bezeichnet den Elementtyp, zu dem das/der Define-Block/Expand-Befehl
ausgeführt wird.
• FOREACH: Um Befehle auf eine Menge von Elemente durchzuführen.
«FOREACH expression AS variableName [ITERATOR iterName] [SEPARATOR
expression]»
a sequence of statements using variableName to access the
current element of the iteration
«ENDFOREACH»
• IF: Unterstützt bedingte Anfragen, endet mit ENDIF Befehl
«IF expression»
a sequence of statements
[ «ELSEIF expression» ]
a sequence of statements ]
[ «ELSE»
a sequence of statements ]
«ENDIF»
• LET: um lokale Variablen zu spezifizieren
«LET expression AS variableName»
a sequence of statements
«ENDLET»
• ERROR: bricht die Auswertung des Templates mit einer xPand-Exception ab.
«ERROR expression»
• Comments: Kommentare können mit Hilfe des REM Befehls eingefügt werden
«REM»
text comment
«ENDREM»
153 Die Eclipse Rich Client Plattform
Auf serverbasierten Systemen und mobilen Endgeräten ist die Java-Technologie weit
verbreitet und erfolgreich im Einsatz. Bei vielen Unternehmen hat sich die Java EE als
Standard für die Entwicklung von Geschäftsanwendungen etabliert. Die Benutzerschnittstelle
– sofern innerhalb der Java-Anwendung überhaupt vorhanden – wird vorrangig auf Basis von
Web-Technologie entwickelt, der clientseitige Zugriff für den Anwender erfolgt demnach mit
einem Web-Browser als Thin-Client.
Thin-Client (z.B. Web-Anwendungen) werden zentral betrieben und bieten deshalb Vorteile
bei Roll-Out, Verwaltung und Pflege. Clientseitig müssen nur Grundvoraussetzungen erfüllt
werden, beispielsweise das Vorhandensein eines Browsers. Anforderungen wie z.B. die
Nutzung des lokalen Dateisystems bzw. anderer lokaler Ressourcen oder etwa Offline-
Funktionalität mit anschließender Datensynchronisierung ließen sich mit Web-Clients, wenn
überhaupt, nur unter größten Schwierigkeiten umsetzen.
Auf dem Desktop hingegen war die Akzeptanz von Java bis zuletzt sehr gering. Erst seit
kurzer Zeit kann Java auch in diesem Bereich ein stetiges Wachstum an Popularität
verzeichnen. Dieser Trend ist eng mit dem Begriff des Rich-Clients verbunden. Ein
Framework zur Entwicklung von Rich-Clients bietet allerdings nicht nur ein vorgefertigtes,
umfangreiches Set an Oberflächenkomponenten, sondern bringt üblicherweise eine modulare
Grundstruktur und ein einheitliches Modell zur Entwicklung von eigenen Komponenten mit.
3.1 Eclipse Plattform für Rich-Clients
Das Anforderungsprofil für Rich-Clients ist umfangreich und der Einsatz eines umfassenden
Applikation Frameworks für die verschiedensten Problemstellungen ist damit ein kritischer
Erfolgsfaktor für Realisierungsprojekte. In diesem Umfeld hat sich die "Rich Client
Plattform" von Eclipse (Eclipse RCP) etabliert und zeigt momentan eindrucksvoll wie
erfolgreich Java-basierte Anwendungen auf dem Desktop entwickelt werden können.
Die Eclipse RCP selbst ist im Wesentlichen in zwei Bereiche gegliedert: Einerseits Equinox,
die Laufzeitumgebung für Komponenten, den so genannten Plug-In, und andererseits die
"Workbench" als eine Art Baukastensystem für Benutzeroberflächen.
Equinox basiert auf der Spezifikation der Open Services Gateway initiative (OSGi), und
ermöglicht die Steuerung des Lebenszyklus der Plug-In. So können beispielsweise Plug-In
während der Laufzeit installiert, ausgeschaltet oder ausgetauscht werden. Equinox verwaltet
dabei die Abhängigkeiten zwischen den einzelnen Plug-In und bildet das Fundament der
Eclipse RCP.
16Abbildung 3.1 Architektur von Eclipse RCP
Die Workbench bietet eine erweiterbare Infrastruktur für die Darstellung von
Oberflächenkomponenten wie Dialoge, Menüs oder Toolbars und koordiniert ihr
Zusammenspiel in den verschiedenen Fenstern einer Anwendung. Wichtige Kernbestandteile
der Workbench sind das bereits erwähnte SWT und das darauf aufbauende JFace-Toolkit.
JFace standardisiert einige Anforderungen mit denen Entwickler häufig konfrontiert werden:
Damit sind beispielsweise die Entwicklung von Wizards, die Verwaltung von Ressourcen für
die Benutzeroberfläche oder die saubere Trennung zwischen den Komponenten und den
dahinter liegenden Aktionen gemeint.
Auf dieser Basis hält Eclipse RCP noch viele weitere, optionale Komponenten, wie ein
Hilfesystem, einen Update-Manager, Reporting-Tools und Frameworks für Text- oder
graphische Editoren bereit. Auch das individuelle "Branding" des Richt-Clients an einen
gewünschten Styleguide ist möglich.
Die Eclipse RCP ermöglicht es dem Entwickler sich größtenteils auf die Entwicklung der
eigentlichen Anwendungskomponenten und deren Integration in die Plattform zu
konzentrieren.
Der Ansatz der Rich-Clients, insbesondere in der Ausprägung der Eclipse RCP, hat sich in der
Praxis als sehr geeignete Plattform erwiesen, um auch in Java performante und den üblichen
Standards und Gewohnheiten entsprechende Desktop-Applikationen im Enterprise-Umfeld zu
entwickeln.
3.2 Die Eclipse RCP für das Projekt
3.2.1 Oberfläche für Editor
Views sind bei Eclipse kleine Fenster, welche Aufgabenbereiche unter verschiedenen
Sichtweisen anzeigen. Diese Fenster können durch Drag und Drop beliebig angeordnet
werden, in Form von Tabs, die durch Klick auf den Reiter aktiviert werden, in Form von
dauerhaft sichtbaren Fenstern oder in Form von fast Views, die als Symbole in einer
weitgehend frei positionierbaren Leiste angeordnet sind und die nur bei Klick auf das Symbol
17eingeblendet werden. Beispiele für Views sind der Klassenexplorer, der baumartig strukturiert
Symbole für die Klassen, Funktionen und Eigenschaften eines geöffneten Quelltextes anzeigt
oder das Suchfenster, das die Ergebnisse einer Suche auflistet.
Editoren sind die Sichtfenster, die meist den Quelltext mit Syntaxhervorhebung anzeigen,
wobei es meist für jede unterstützte Programmiersprache einen eigenen Editor gibt (zum
Beispiel für DSL). Genauso gibt es aber auch visuelle Editoren oder die Baumstrukturen
anzeigen. Mehrere geöffnete Quelltexte werden als Reiter geöffnet, die über Tabs am oberen
Rand in den Vordergrund gebracht werden können, weiterhin können Tabs fixiert werden, so
dass der zugehörige Quelltext nicht versehentlich geschlossen wird. Auch Editoren können
weitgehend frei per Drag und Drop angeordnet werden. Eine Datei kann in mehreren Editoren
gleichzeitig geöffnet werden.
Menü und Tools-bar sind Schnellzugriff auf bestimmte, häufig verwendete Funktion
ermöglicht, z.B. ‘‘Öffnen‘‘, ‘‘Speichern‘‘ .
3.2.2 Integration von Plug-In
DSL-Module wird als ein Plug-In in Editor integriert, so dass Quelltexte von DSL unterstützt
werden.
3.2.3 Erstellung einer Applikation
Nach der Integration von DSL-Module werden die Programme als eine Standalone -
Applikation exportiert.
184. Implementierung
4.1 OpenArchitectureWare (Implementierung)
Aufgabenstellung:
Erstellung eines Editors für eine textuelle DSL zur Definition von Validierungsregeln mit
entsprechender Generierung von Regeln in XML/VALANG.
Gefordert ist ein Editor, der einen Modellierer bei der Formulierung der Regeln unterstützt
(z.B. mit Syntaxhighlighting, Syntax-Prüfung und –Vervollständigung).
4.1.1 Domain Spezifische Sprache (DSL) für Valang
xText bietet die Möglichkeit, Eigene DSLs anhand der erweiterten Backus-Naur-Form
(EBNF) zu erstellen. xText hat vier Buuild-in Lexer (ID, INT, STRING, LINE), weiterhin
gibt es vier mögliche Regeln (Typregel, String-Regel, Enum-Regel, Nativ-Regel) um die
Grammatik zu definieren.
Unsere Grammatik soll die häufig verwendeten Funktionen und Attributtypen, die bei
Formular-Validierung verkommen, unterstützen.
Die behandelten Attributtypen:
• Integer = NUMBER
• Float = GLEITKOMMAZAHL
• String = TEXT
• Boolaen = BOOLEAN
• Date = DATUM
• Und Objekte, die Kombinationen von den genannten Attributtypen bilden
Die verfügbaren Funktionen
• Länge Funktionen
o Laenge
o Minimale Laenge
o Maximale Laenge
o Wertebereich (für Integer)
• Match Funktionen
o Match
o Match mit case
o Match ohne case
• Numerische Funktionen
o ist grosser als
o ist kleiner als
o ist grosser gleich
o ist kleiner gleich
o ist gleich
o ist nicht gleich
• Boolean Funktionen
o ist True
o ist False
• Datum Funktionen
o vor
o nach
o ist den
19o zwischen
• Pruefe Syntax Funktionen
o Nur Ziffern
o Nur Buchstaben
o Nur Kleinbuchstaben
o Nur Grossbuchstaben
o E-Mail
o Beginnt mit
o Endet mit
Da Datum Syntax und Float nicht von den Build-in Lexer, haben wir die in Nativregeln
definiert.
DSL Definition in xText:
Modell: (entitaet+=Entitaet)*;
Entitaet: "Entitaet" entitaetName=EntitaetName "{" attBlock=AttributeBlock
regelnBlock=RegelnBlock "}" ;
EntitaetName: entName=ID;
AttributeBlock: "Attribute" "{" (attribute+=Attribute)* "}" ;
//selbstdefinierterAttrTyp: gedacht für Instanzen der definierten
Entitaeten
Attribute: (vordefinierterAttrTyp=VordefinierterAttrTyp
|selbstdefinierterAttrTyp=SelbstdefinierterAttrTyp) name=ID;
SelbstdefinierterAttrTyp: sdAttrTyp=ID;
Enum VordefinierterAttrTyp: text="TEXT"|number="NUMBER"|datum="DATUM"|
boolean="BOOLEAN"|gleitkommazahl="GLEITKOMMAZAHL";//...
RegelnBlock: "Regeln" "{" (regel+=Regel)* "}" ;
Regel: attrName=ID (verketteteAttribute+=VerketteteAttribute)* ":"
ausdrueck=Ausdrueck ':' message=STRING (':'regExp=RegExp)? ;
VerketteteAttribute : '.'attrName=ID;
Ausdrueck:
(vordefinierteFunk=VordefinierteFunk|selbstdefinierteFunk=SelbstdefinierteF
unk);
SelbstdefinierteFunk: funkName=ID ('()'|'('(arg=Argument)(','
args+=Argument)*')') ;
Argument: (idArg=ID|zeichen=STRING|number=INT);
VordefinierteFunk:
(lengthFunkName=LengthFunkName '('lengthArg=LengthArg')'|
matchFunkName=MatchFunkName '('matchArg=MatchArg')'|
numFunkName=NumFunkName (numWert=NumWert|float=Float)|
boolFunkName=BoolFunkName|
datumFunkName=DatumFunkName datumVariante=DatumVariante|
'zwischen' komplexDatumVariante=KomplexDatumVariante) ;
20Enum LengthFunkName: laenge="Laenge"|wertebereich="Wertebereich"|
minLaenge="minimale Laenge"|maxLaenge="maximale Laenge"; //...
Enum MatchFunkName: match="match"|matchMitCase="match mit Case"|
matchOhneCase="match ohne Case";
Enum BoolFunkName: istTrue="ist True"|istFalse="ist False";
Enum NumFunkName: istGroesserAls="ist groesser als"|
istKleinerAls="ist kleiner als"|
istGroessegleich="ist groessergleich"|
istKleinergleich="ist Kleinergleich"|
istGleich="ist gleich"|
istNichtGleich="ist nicht gleich";
Enum DatumFunkName: vor="vor"|nach="nach"|ist="ist den";
LengthArg: (Nmin=INT'-'Nmax=INT)|numWert=NumWert ;
NumWert: wert =INT;
//Argument für Match Funktionen, entweder String oder ein anderes Attribute
MatchArg: st=STRING|id=ID;
RegExp: pruefe="Pruefe Syntax" (exp1=Exp|complexExp1=ComplexExp)
((and="und"|or="oder")
(exp2=Exp|complexExp2=ComplexExp))?
(':' message2=STRING)?;
Enum Exp: nurZiffern="nur Ziffern"|
nurBuchstaben="nur Buchstaben"|
nurKleinbuchstaben="nur Kleinbuchstaben"|
nurGrossbuchstaben="nur Grossbuchstaben"|
email="E-Mail"|
url="URL";
ComplexExp: complexExpName=ComplexExpName "("expArg=STRING")" ;
Enum ComplexExpName: beginntMit="Beginnt mit"|endetMit="Endet mit";
DatumVariante: (date=Date|time=Time|dateUndTime=DateUndTime) ;
KomplexDatumVariante: date1=Date "and" date2=Date|time1=Time "and"
time2=Time|
dut1=DateUndTime "and" dut2=DateUndTime;
Date:"Datum" '('datum=Datum')' ;
Time: "Zeit" '('zeit=Zeit')' ;
DateUndTime: datumUndZeit="Datum&Zeit"'('dDatum=Datum ',' tTime=Zeit ')';
Native Datum:
"'['(('0''1'..'9')|('1'..'2''0'..'9')|('3''0'..'1'))'.'(('0''1'..'9')|('1''
0'..'2'))'.'('1'..'2''0'..'9''0'..'9''0'..'9')']'";
Native Zeit:
"'['(('0'..'1''0'..'9')|('2''0'..'3'))':'('0'..'5''0'..'9')':'('0'..'5''0'.
.'9')']'";
Native Float:
"('-')?('0'..'9')+'.'('0'..'9')+";
21Für bessere Übersicht haben wir den folgenden Graph erstellt:
22(Abbildung 4.1.1 , Graphische Darstellung der DSL)
4.1.2 Constraints
Constraints werden verwendet, um die von dem DSL erhaltene Grammatik zu verfeinern und
zusätzliche Einschränkungen hinzufügen.
In Xtext werden Constraints in der Check-Datei in ähnlicher Sprache als das Object
Constraint Language (OCL) erstellt. Weiterhin können weitere Erweiterungen (Extensions),
die als Hilfsmethoden betrachtet werden können, in der Extensions-Datei implementiert.
Constraints haben die folgende Syntax:
‚context’ ECore-Objekt (‚ERROR’|’WARNING’) Message ‚:’
OCL-Statement ‘;’
Die behandelte Constraints (Inhalt der Check.chk Datei):
import beanvalidationdsl;
extension org::openarchitectureware::util::stdlib::naming ;
extension org::example::dsl::Extensions ;
//untersucht ob eine andere Entitaet derselbe Name als der aktuelle
Entitaetname hat
context EntitaetName ERROR " Duplizierter Entitaetname " + '"'+
entName+'"':
allElements().typeSelect(Entitaet).select(e|e.entitaetName.entName ==
entName).size == 1 ;
//see Extensions
context EntitaetName WARNING "Entitaet soll mit Grossbuchstaben anfangen!"
:
firstLetter();
//see Extensions
context EntitaetName ERROR "Der Entitaetname "+ '"' +entName + '"' +" ist
verboten" :
verboteneSchluesselwoerter();
//untersucht Duplikate im AttributeBlock
context Attribute ERROR "Duplizierter Attributname " + '"' + name +'"' :
getAttrBlock().attribute.select(e|e.name == name).size == 1 ;
//see Extensions
context Attribute WARNING "Attributname soll mit Kleinbuchstaben
anfangen!":
firstLetterSmall();
//untersucht ob es Attribute gibt, die derselbe Name als Entitaet haben
context Attribute ERROR "Attributname ist gleich Entitaetname!" :
allElements().typeSelect(Entitaet).notExists(e|e.entitaetName.entName
== name);
//untersucht ob es selbstdefinierte Attribute gibt, die keine entsprechende
Entitaet haben
context Attribute if(selbstdefinierterAttrTyp != null )
ERROR "Entitaet " + '"' + selbstdefinierterAttrTyp.sdAttrTyp + '"' +
"ist nicht definiert":
allElements().typeSelect(Entitaet).select(e|e.entitaetName.entName ==
selbstdefinierterAttrTyp.sdAttrTyp).size != 0 ;
23//untersucht ob es Attribute in Regelnblock gibt, die nicht im
Attributblock zu finden
context Regel ERROR "Attributname " + '"' + attrName +'"'+ " wuerde nicht
im Attributeblock gefunden!" :
getRegelnBlock().getEntR().attBlock.attribute.select(e|e.name ==
attrName).size != 0 ;
//untersucht ob es verkettete Attribute in Regelnblock gibt, die sich nicht
in den entsprechenden Entitaeten befinden
context Regel if(!verketteteAttribute.isEmpty)
ERROR '"' + verketteteAttribute.first().attrName +'"'+ " koennte
nicht im
Entitaet "+ '"'+ step1().first().selbstdefinierterAttrTyp.sdAttrTyp +
'"' +
" gefunden!" :
step4(step(),verketteteAttribute).size == 1;
/*untersucht ob es verkettete Attribute in Regelnblock gibt, die sich nicht
in den entsprechenden Entitaeten befinden*/
//höhere Verkettungsgrad
context Regel if(verketteteAttribute.size > 1)
ERROR "ein der verketteten Attribute wuerde nicht gefunden!":
stepA(step1(),verketteteAttribute,{}).forAll(e|e == true);
//untersucht ob die minimale Grenze kleiner als die maximale Grenze
context Regel ERROR "Die minimale Grenze ist groesser als die maximale
Grenze!" :
ausdrueck.vordefinierteFunk.lengthArg.Nmin//untersucht ob die verwendete Funktion das verwendete Attribut passt
context VordefinierteFunk if(istFloatFunk2()) ERROR "Der zugewiesene Wert
ist fuer GLEITKOMMAZAHL geeignet nicht fuer NUMBER!" :
stepB(getStep1(),va()).first().vordefinierterAttrTyp.toString() ==
"gleitkommazahl" ;
//untersucht ob die verwendete Funktion das verwendete Attribut passt
context VordefinierteFunk if(istMatchFunk()) ERROR "Attribut " +'"'+
getAttr() + '"'+ " muss vom Typ 'TEXT' sein!" :
getStep1().first().vordefinierterAttrTyp.toString() == "text" ;
//untersucht ob die verwendete Funktion das verwendete Attribut passt
context VordefinierteFunk if(istMatchFunk2()) ERROR "Attribut " +'"'+
getAttr() + '"'+ " muss vom Typ 'TEXT' sein!" :
stepB(getStep1(),va()).first().vordefinierterAttrTyp.toString() == "text" ;
//untersucht ob die verwendete Funktion das verwendete Attribut passt
context VordefinierteFunk if(istLengthFunk()) ERROR "Attribut " +'"'+
getAttr() + '"'+ " muss vom Typ 'TEXT' sein!" :
getStep1().first().vordefinierterAttrTyp.toString() == "text" ;
//untersucht ob die verwendete Funktion das verwendete Attribut passt
context VordefinierteFunk if(istLengthFunk2()) ERROR "Attribut " +'"'+
getAttr() + '"'+ " muss vom Typ 'TEXT' sein!" :
stepB(getStep1(),va()).first().vordefinierterAttrTyp.toString() == "text" ;
//untersucht ob die verwendete Funktion das verwendete Attribut passt
context VordefinierteFunk if(istDatumFunk()) ERROR "Attribut " +'"'+
getAttr() + '"'+ " muss vom Typ 'DATUM' sein!" :
getStep1().first().vordefinierterAttrTyp.toString() == "datum" ;
//untersucht ob die verwendete Funktion das verwendete Attribut passt
context VordefinierteFunk if(istDatumFunk2()) ERROR "Attribut " +'"'+
getAttr() + '"'+ " muss vom Typ 'DATUM' sein!" :
stepB(getStep1(),va()).first().vordefinierterAttrTyp.toString() ==
"datum" ;
//untersucht ob die Funktion "Wertebereich" minimale und maximale Grenze
hat
context VordefinierteFunk if( lengthFunkName.toString() == "wertebereich"
&& lengthArg.Nmax == 0) ERROR "Wertebereichfunktion braucht eine minimale
und maximale Grenze":
false ;
//untersucht ob es eine gueltige Kombination mit "oder" Verknuepfung ist
context RegExp if((or=="oder")&&((complexExp1==null)&&(complexExp2==null)))
ERROR "Ungueltige Kombination " + '"'+ exp1.toString()+ " oder
" + exp2.toString()+'"!' :
exp1.toString()!=exp2.toString();
//untersucht ob es eine gueltige Kombination mit "und" Verknuepfung ist
context RegExp if(and=="und") ERROR "Ungueltige Kombination!" :
exp1.toString()!=exp2.toString() ||
complexExp1.complexExpName!=complexExp2.complexExpName ;
//untersucht ob es eine gueltige Kombination mit "und" Verknuepfung ist
context RegExp if((and=="und")&&((complexExp1==null)&&(complexExp2==null)))
ERROR "Ungueltige Kombination " + '"' + exp1.toString()+ " und " +
25exp2.toString()+'"!' :
false;
//untersucht ob RegExp fuer Zeichenkette verwendet ist
context RegExp ERROR "Pruefe Syntax ist nur fuer Zeichenketten geeignet!" :
getRegel().ausdrueck.vordefinierteFunk.lengthFunkName.toString() !=
"wertebereich" ;
//untersucht ob RegExp fuer Zeichenkette verwendet ist
context RegExp ERROR "Pruefe Syntax ist nur fuer Zeichenketten geeignet!" :
(getRegel().ausdrueck.vordefinierteFunk.lengthArg != null ||
getRegel().ausdrueck.vordefinierteFunk.matchArg != null);
4. 1.3 Extentions
Extentions (Erweiterungen) sind Hilfsmethoden sowohl für die Constraints in der Check-
Datei als auch für die XPand-Templates.
Extensions haben die folgende Syntax:
RückgabeTyp MethodenName ‚(‚ Parameter-1,…, Parameter-n’)’ ‚:’
OCL-Statement ‚;’
Die zugehörige Extensions für die Check-Datei:
import beanvalidationdsl;
extension org::example::dsl::GenExtensions reexport;
//Get-Container methoden
AttributeBlock getAttrBlock(Attribute this):
eContainer ;
RegelnBlock getRegelnBlock(Regel this):
eContainer ;
Entitaet getEntR(RegelnBlock this):
eContainer ;
Entitaet getEntA(AttributeBlock this):
eContainer ;
Modell getModell(Entitaet this):
eContainer;
RegExp getRegExp (ComplexExp this):
eContainer ;
Attribute getAttribute(SelbstdefinierterAttrTyp this):
eContainer;
Regel getRegel(RegExp this):
eContainer;
Ausdrueck getAusdrueckV (VordefinierteFunk this) :
eContainer;
Regel getRegelA ( Ausdrueck this):
eContainer ;
//Liefert True zurueck, wenn der Entitaetname mit Grossbuchstabe anfaengt
Boolean firstLetter(EntitaetName this):
let list
={'A','B','C','D','E','F','G','H','I','J','K','L','M','N','O',
'P','Q','R','S','T','U','V','W','X','Y','Z'}:
list.select(e|e == entName.subString(0,1)).size == 1 ;
26Sie können auch lesen

















































