Lastvorhersage in einer Cloud mit einem Bayes'schen Klassifizierer.
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Lastvorhersage in einer Cloud mit einem
Bayes’schen Klassifizierer.
basierend auf der Arbeit
”Host Load Prediction in a Google Compute
Cloud with a Bayesian Model”.
von Sheng Di, Derrick Kondo und Walfredo
Cirne. [2]
Seminar aus Informatik,
Universität Salzburg
betreut von Univ.-Prof. Dr. Wolfgang Pree
David Herzog-Botzenhart und Johannes Priewasser
18. Juli 2013
1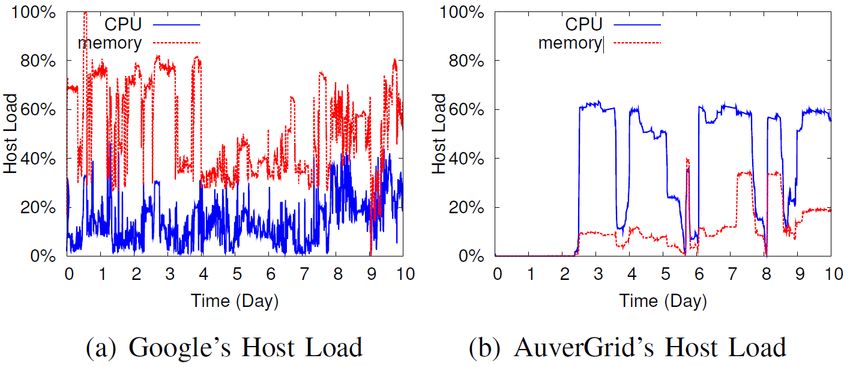
Inhaltsverzeichnis
1 Vorwort. 2
2 Abstract 2
3 Einführung 3
3.1 Die Deplyoment Modelle . . . . . . . . . . . . . . . . . . . . . 4
3.2 Service Modelle . . . . . . . . . . . . . . . . . . . . . . . . . . 4
3.3 Essentielle Charakteristiken von Cloud-Infrastrukturen . . . . 5
4 Lastvorhersage in Cloud basierten Systemen 5
4.1 Lastvorhersagen in Grid, HPC und Cloud Systemen . . . . . . 6
5 Verbesserung der Voraussagen durch das Baye’sche Modell 6
5.1 Datenbasis für die Auswertung . . . . . . . . . . . . . . . . . . 6
5.2 Berechnung der Last . . . . . . . . . . . . . . . . . . . . . . . 7
5.3 Exponentiell segmentiertes Muster ESP
Exponentially segemented Patern . . . . . . . . . . . . . . . . 8
6 Bayes’sches Modell 11
6.1 Klassifizierung . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
6.2 Risikofunktion . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
6.3 Mittlere quadratische Abweichung . . . . . . . . . . . . . . . . 13
6.4 Beweisfenster (Evidence window) . . . . . . . . . . . . . . . . 14
6.5 Merkmale (Features) . . . . . . . . . . . . . . . . . . . . . . . 14
6.6 Merkmalskorellation . . . . . . . . . . . . . . . . . . . . . . . 16
7 Experimentelle Ergebnisse 17
1
1 Vorwort.
Diese Arbeit entstand im Zuge einer Ausarbeitung einer Präsentation auf
Grundlage der Arbeit und des Studiums jener von Sheng Di, Derrick Kon-
do und Walfredo Cirne Host Load Prediction in a Google Compute Cloud
with a Bayesian Model. Das präsentierte Verfahren und die Auswertung der
Feldversuche entstammen eben genau dieser Arbeit von Sheng Di et.al. [2]
2 Abstract
Sheng Di, Derrick Kondo und Walfredo Cirne untersuchten die Verwendung
eines Bayes’schen Klassifizierers mit Hilfe von 9 dafür entwickelten Features
für die Lastvoraussage. Vor allem eine adequate Langzeitvoraussage war das
Ziel. Hierzu verwendeten Sie die Daten der Aufzeichnung eines Google Da-
ta Centers mit über 670.000 Jobs, 40 Millionen Tasks verteilt auf 12.000
Maschinen mit der Auflösung von einer Minute über ein ganzes Monat. Eine
Motivation der Arbeit ist der Vergleich der Charakteristiken von Lastvoraus-
sagen in Clouds mit jener von Grids. Unter Verwendung der aufgezeichneten
Daten erzielten sie vor allem bei Langzeitvoraussagen im Vergleich zu an-
deren gängigen Lösungen (Gleitender Durchschnitt moving averages, Auto-
Regression und/oder Rausch Filter) eine Verbesserung von 5.6% bis 50%[2].
Bei unserem Studium der Arbeit vermissten wir zeitbasierte Features, in de-
nen die Tageszeit oder Zeitzone mit einfließen. Es fiel uns auch der Umstand
auf, dass die Messwerte sowohl zum Lernen als auch als Datengrundlage für
die Auswertung herangezogen wurden und auf ein Monat begrenzt waren.
2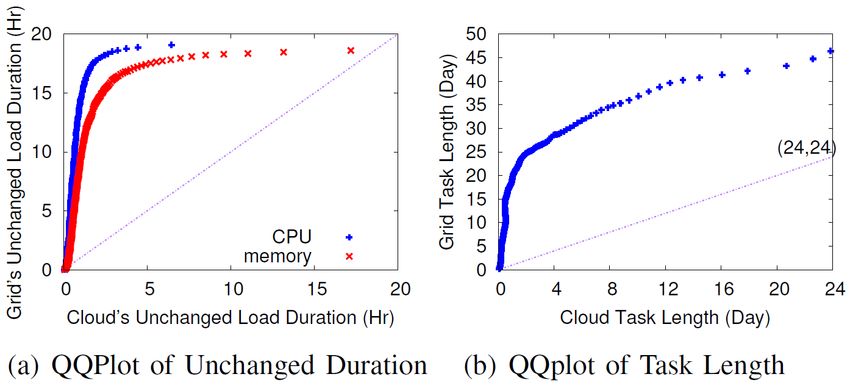
3 Einführung
Cloud Computing hat in den letzten fünf Jahren extrem an Bedeutung zugenom-
men. Im Unterschied zu GRID Computing bei dem eine homogene Lastverteilung
und eine meist gut vorhersehbare Last zu verarbeiten sind, stellt Cloud Com-
puting die Branche vor die Aufgabe, komplexe Lastfluktuationen verarbeiten
zu müssen.
Eine typische Cloud Architektur ist in Abbildung 1 dargestellt.
USERS
LOAD BALANCER
HOST HOST HOST HOST HOST
Abbildung 1: Host Load Verteilung in einer Cloud.
Definition 3.1 Cloud Computing ermöglicht einen einfachen netzbasierten
Zugriff auf Abruf (on-demand) auf einen Pool geteilter und verteilter Com-
puter Resourcen. Der Begriff Resourcen umfasst Netzwerke, Speicher, An-
wendungen und Dienste. Diese Resourcen müssen mit geringen Managemen-
taufwand und minimaler Service Provider Interaktion, schnell zur Verfügung
gestellt, beziehungsweise released werden können .[1, NIST]
Das Cloud Computing Model von Badger et al. unterscheidet fünf essen-
tielle Charakteristiken, drei Service Charakteristiken und vier Deployment
Charakteristiken.[1, NIST]
3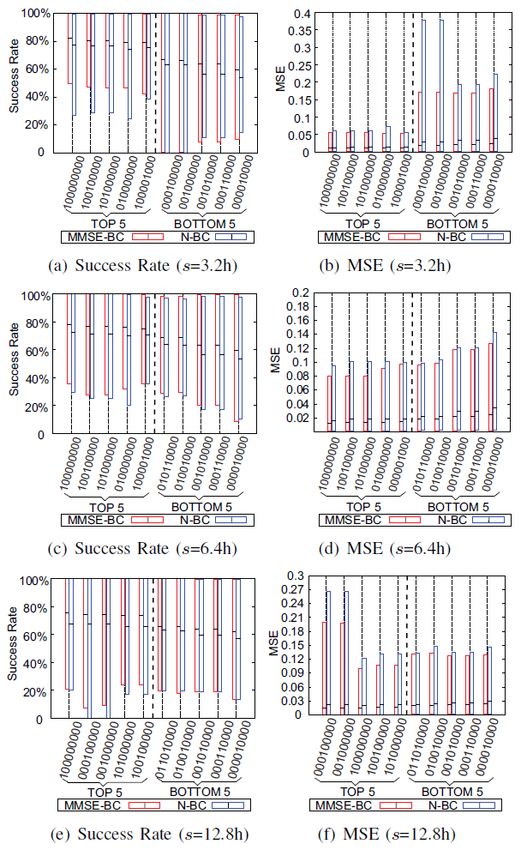
3.1 Die Deplyoment Modelle
Die Deployment Modelle:
1. Private Cloud (private cloud ) Die Verwendung ist exklusiv für eine
einzelne Organisation bestimmt. Sie kann aber von Dritten zur Verfügung
gestellt werden.
2. Gemeinschaftscloud (community cloud ) Die Cloud Infrastruktur wird
von Konsumenten jener Organisationen geteilt, welche die selben Inter-
essen teilen. (Zum Beisiel Projektmanagement, Sicherheitsverbesserung,
etc.)
3. Öffentliche Cloud(public cloud ) Die Cloud Infrastruktur wird für die
Öffentlichkeit zur Verfügung gestellt.
4. Hybridcloud(hybrid cloud )
3.2 Service Modelle
Badger et al. [1, NIST] unterscheiden drei Arten von Service Modellen.
1. Cloud Software als Dienst (SaaS Cloud Software as a Service)
Der Konsument nutzt Applikationen des Anbieters aus der Infrastruk-
tur.
2. Cloud Platform als Dienst (PaaS Cloud Platfom as a Service)
Der Konsument verteilt und betreibt eigene oder Applikationen Dritter,
unter Verwendung der Werkzeuge die der Infrastruktur Provider zur
Verfügung stellt.
3. Cloud Infrastruktur als Dienst (IaaS Cloud Infrastructure as a Service)
Der Konsument erhält die Möglichkeit fundamentale Resourcen zu nutzen.
Dazu können unter anderem Betriebssysteme der Rechner, Speicher,
Netzwerke, Verteilung der Applikationen und limitierter Zugriff auf
Firewalls gehören. Der Konsument darf aber nicht die Cloud Infras-
truktur als solche kontrollieren.
4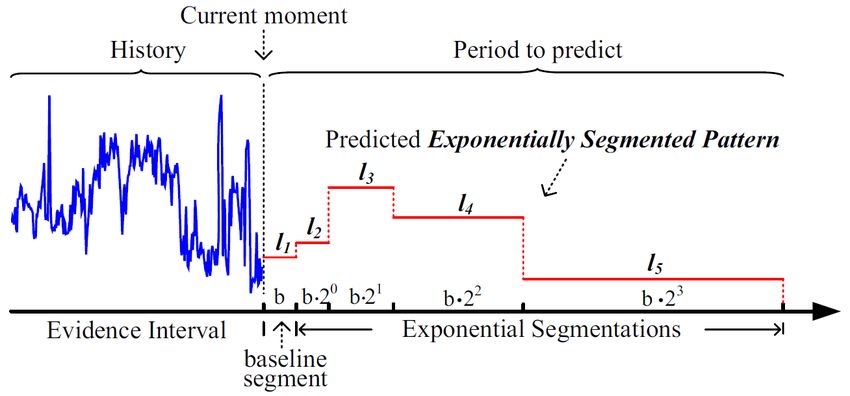
3.3 Essentielle Charakteristiken von Cloud-Infrastrukturen
Badger et al. unterscheiden fünf essentielle Charakteristiken. (On-demand
self-service, Broad network acces, Resource pooling, Rapid elasticity und Mea-
sured Service). Vorallem die Charakteristiken Rapid elasticity und Measured
Service verlangen nach einer möglichst genauen Lastvoraussage um einerseits
SLA’s (Service Level Agreements) und andererseits die Verfügbarkeit QoS
(Quality of Service) garantieren zu können. Dies wiederum ermöglicht es den
Aufwand und die daraus folgenden Kosten abschätzen und kontrollieren zu
können.
1. Rapid elasticity (Schnelle und elastische Kapazitätsanpassung.) Bedeutet
das Kapazitäten schnell und elastisch, zumeist automatisiert, zur Verfügung
gestellt werden können. Es kann sowohl nach Innen als auch nach Außen
skaliert werden. Dem Konsumenten erscheinen die bereitstellbaren Re-
sourcen unendlich und deren Verfügbarkteit zeitlich unabhängig.
2. Measured Service (Überwachte Dienste) Cloud Systeme kontrollieren
und optimieren die Resourcen unter Verwendung von Metriken welche
auf den Typ der zur Verfügung gestellten Resourcen angepasst ist. Die
Verwendung der Resourcen kann überwacht, kontrolliert und zurückgemeldet
werden.
Die größte Herausforderung für Cloud Service Anbieter ist eben der Kom-
promiss (trade-off) zwischen Kundenzufriedenheit und Profit.[3] Daher wurde
in den letzten Jahren intensiv untersucht, welche Voraussagesysteme für die
Auslastung bei Cloud Computing am besten einzusetzen sind. Es wurden
auch adaptive Systeme untersucht, in denen die Kapazitätsplanung abhängig
von SLA’s und QoS erfolgt.
Sheng Di et al. [2] untersuchten den Bayes’schen Klassifizierer und die für
die Untersuchung nötigen unabhängigen Features.
4 Lastvorhersage in Cloud basierten Syste-
men
Die Lastvorhersage in cloud basierten Systemen verglichen mit klassischen
Grid und High Performance Computing (HPC) Systemen stellt eine größere
Herausforderung dar, da die Last in der Cloud stärker fluktuiert. Diese Fluk-
tuation ist die Folge von kürzeren Jobdauern und mehr interaktiven Jobs. Die
5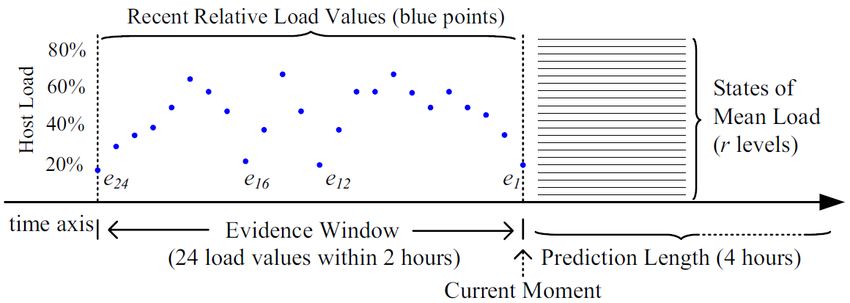
1 1
Jobdauer in der Google Cloud beträgt nur [ 20 , 2 ] verglichen mit der Jobdauer
im AuverGrid System, was zu einer feingranulareren Resourcenreservierung
im Google Daten Center führt.
4.1 Lastvorhersagen in Grid, HPC und Cloud Syste-
men
Bisherige Arbeiten zum Thema Lastvorhersage in Grid und HPC Syste-
men haben sich hauptsächlich auf Methoden fokussiert die auf dem gleiten-
dem Mittelwert, autoregressiven Modellen oder Rauschfiltern basieren. Diese
Methoden erzielen in Cloudsystemen nicht unbedingt brauchbare Genauigkeit-
en. Zum Beispiel würden durch das Filtern von Rauschen in den Lastaufze-
ichungen wichtige Daten von tatsächlichen hohen Fluktuationen verloren
gehen. Des weiteren konzentrieren sich diese Methoden eher auf kurzfristige
Vorhersagen und lassen längere Vorhersageintervalle außer Acht.
5 Verbesserung der Voraussagen durch das
Baye’sche Modell
Durch die Anwendung des bayes’schen Modells sollen Voraussagen zur mit-
tleren Auslastung in einem Zeitintervall von bis zu 16 Stunden, sowie auf
mehreren aufeinander folgenden Zeitintervallen getroffen werden können. Das
Modell verwendet dazu voraussagenden Merkmale (features) die die Erwartung,
Voraussagbarkeit, Tendenzen und Muster in den Lastaufzeichnungen erfassen.
Wichtige Informationen über Fluktuationen und Rauschen werden bei diesem
Ansatz beibehalten. Die mittlere quadratische Abweichung (mean squared
error, MSE) beträgt 0.0014 für ein einzelnes Zeitintervall und ≤ 10−5 für
mehrere aufeinander folgende Zeitintervalle (pattern). Die Vorhersagegenauigkeit
verbessert sich verglichen mit anderen Methoden um 5.6-50%.
5.1 Datenbasis für die Auswertung
In den Lastaufzeichnungen werden die CPU und die Speicherauslastung er-
fasst, welche die zwei wichtigen Metriken für das System darstellen. Die zu-
grunde liegenden Daten wurden über einen Zeitraum von einem Monat in
einem Produktivsystem von Google mit über 12,000 Rechnern aufgezeich-
net. Die Benutzer senden dabei ihre Aufträge (jobs) an einen gebündelten
6Planungsprozess (batch scheduler). Jeder Auftrag besteht aus einer Menge
von Aufgaben (tasks) und einer Menge an Resourcenbeschränkungen. Der
Planungsprozess weist die einzelnen Aufgaben an die zur Vergügung ste-
henden Rechner des Systems zu. In diesem Monat wurden über 670,000
Aufträge und über 40 Millionen Aufgaben abgearbeitet. Die Last in dem
System ist darstellbar als Funktion von den eingehenden Aufträgen und der
Planungsstrategie (scheduling strategy).
5.2 Berechnung der Last
Die Last zu einem bestimmten Zeitpunkt auf einem bestimmten Rechner
besteht aus der Gesamtlast aller laufenden Aufgaben auf diesem Rechner.
Die relative Last errechnet sich durch die Division von der absoluten Last
durch die vorhandene Kapazität. Dieser Wert liegt dann zwischen 0 und 1.
Die Lastdaten werden diskretisiert durch die Berechnung der relativen Last
jedes Rechners über aufeinanderfolgende Zeitintervalle mit einer festgelegten
Länge von ein paar Minuten. Die diskretisierten Daten bilden die Basis der
Arbeit.
Mit der selben Vorgehensweise wurden auch die relativen Lastdaten zu
jeder Periode von AuverGrid’s Lastaufzeichnungen berechnet. Damit konnte
das höhere Rauschen in den Daten von Google verglichen mit AuverGrid ver-
ifiziert werden. Das minimale/mittlere/maximale Rauschen der CPU Last-
daten wurde mit einem Mittelwertfilter berechnet und beträgt jeweils
• AuverGrid: 0.00008, 0.0011, 0.0026
• Google: 0.00024, 0.028, 0.081
7Abbildung 2: Lastvergleich zwischen Google und AuverGrid
Die Verteilung der Lastdaten von Google und AuverGrid wird gegenübergestellt
in einem Quantile-Quantile-Plot. Dazu wird der Bereich der Lastdaten gle-
ichmäßig aufgeteilt in fünf Teilbereiche. Die Lastdauer ist definiert als die Zeit
in der die Last auf einem Rechner konstant in einem der fünf Teilbereiche
bleibt. Die Verteilung der Lastdauern wird miteinander verglichen.
Abbildung 3: Quantile-Quantile Plot der Dauer and Aufgabenlänge
5.3 Exponentiell segmentiertes Muster ESP
Exponentially segemented Patern
Vorhergesagt wird die mittlere Last über ein einzelnes Zeitintervall zu einem
bestimmten Zeitpunkt t0 . Auf dieser Basis wird die mittlere Last für mehrere
8aufeinander folgende Zeitintervalle vorhergesagt. Um die Fluktuation über
eine Zeitperiode zu charakterisieren, wird ein exponentiell segmentiertes Muster
(exponentially segmented pattern, ESP) eingeführt. Das Vorhersageintervall
wird aufgeteilt in eine Menge von aufeinander folgende Segmente, deren
Länge exponentiell zunimmt. Ermittelt wird die mittlere Last in jedem dieser
Segmente.
Abbildung 4: Illustration des exponentiell segmentierten Musters
Die Gesamtlänge des Vorhersageintervalls wird bezeichnet mit s. Das er-
ste Segment (s1 ) wird als Basislinie (baseline) mit der Länge b bezeichnet
und startet vom aktuellen Zeitpunkt t0 und endet bei t0 + b. Die Länge jedes
weiteren Segments (si ) berechnet sich mit b ∗ 2i−2 |i = 2, 3, 4, .... Wird zum
Beispiel b auf 1 Stunde gesetzt, so errechnet sich für die das vorherzusagende
Intervalls eine Gesamtlänge s von 16 Stunden (=1+1+2+4+8). Die Mittel-
werte werden bezeichnet mit li |i = 1, 2, 3, .... Die Vorhersagegenauigkeit ist
besser für kurzfristige Vorhersagen als für langfristige.
9Abbildung 5: Induktion der segmentierten Auslastung
Es wird der Vektor von Lastdaten (l = (l1 , l2 , ..., ln )T ) vorhergesagt, wobei
jeder Wert den Mittelwert über ein bestimmtes Segment repräsentiert. Das
Zeitintervall welches die aktuell erfassten Lastdaten einschließt wird als Be-
weisfenster (evidence window) bezeichnet. Die Vorhersage für jedes einzelne
Segment ist der Schlüsselschritt für die gesamte Vorhersage.
Die Last korelliert stark zwischen benachbarten Segementen und korelliert
nicht für nicht benachbarte Segmente. Die Darstellung der Segmente wird in
eine andere Darstellung transformiert, in der jedes Intervall das vorherge-
sagt werden soll an das Beweisfenster angrenzt. Dann wird eine Menge aus
mittleren Lastvorhersagen für die Intervalle verschiedener Länge berechnet,
wobei jedes Intervall zum aktuellen Zeitpunkt t0 startet. Das Ergebnis da-
raus wird bezeichnet mit η1 , η2 , ..., ηn |ηi+1 = 2ηi . Das Ziel ist es einen Vektor
η = (η1 , η2 , ..., ηn )T vorherzusagen, und nicht den Vektor l.
Der Vektor l kann durch folgende Induktion aus dem Vektor η berechnet
werden:
• Der aktuelle Zeitpunkt ist t0
• Es wurden bereits zwei Lastvorhersagen (ηi−1 and ηi ) über zwei Inter-
valle, [t0 , ti−1 ] und [t0 , ti ] berechnet
• Die zwei Flächen (S1 and S2 ) werden einandern angeglichen
• Die Ableitung der Lastvorhersage [ti−1 , ti ] wird berechnet
10• li ist die vorhergesagte mittlere Last in dem neuen Segment [ti−1 , ti ],
dargestellt als rote Linie in der Grafik
ti−1 − t0
li = ηi + (ηi − ηi−1 ) (1)
ti − ti−1
Dies vereinfacht und verallgemeinert die Implementierung eines Prädiktors,
da jeder Prädiktor der ein einzelnes Intervall voraussagen kann in einen
Prädiktor der ein ESP voraussagen kann, verwandelt werden kann. Dadurch
ergibt sich die Möglichkeit ein einzelnes oder mehrere aufeinander folgende
Intervalle ohne Mehraufwand vorauszusagen.
Die zwei Schlüsselschritte des Algorithmus:
• mittlere Lastvorhersage (Zeile 1-5)
• Segment Transformation (Zeile 6)
Jedes Intervall startet zum aktuellen Zeitpunkt, im Gegensatz zu den vorhin
definierten Segmenten in der Vektorräpresentation l.
Abbildung 6: Pseudo-code der Cloud Lastmustervorhersage
6 Bayes’sches Modell
Zur Laufzeit wird das Beweisfenster mit den kürzlich aufgetretenen Fluktu-
ationen aktualisiert. Es wird die A-posteriori Wahrscheinlichkeit aus der A-
priori Wahrscheinlichkeitsverteilung berechnet, wobei ein Bayes Klassifikator
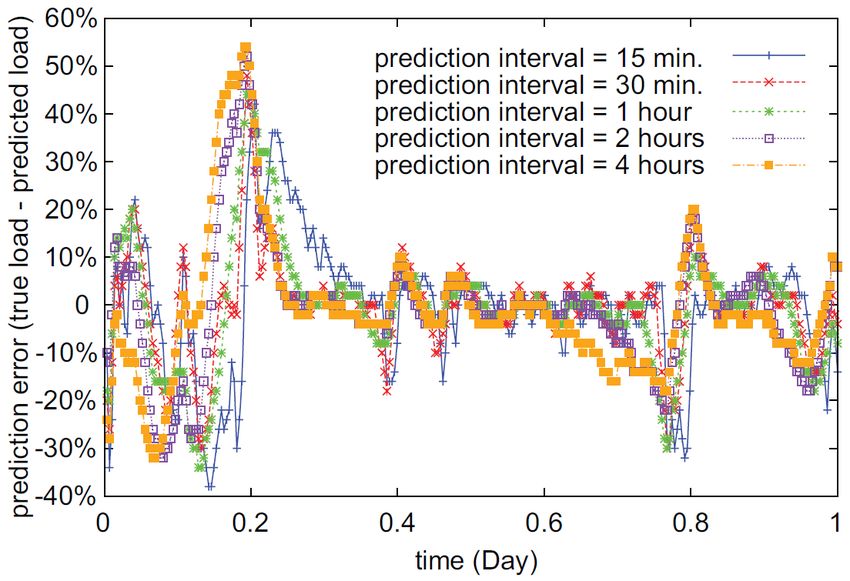
11Abbildung 7: Vorhersagefehler mit unterschiedlichen Vorhersagelängen
einbezogen wird. Ein Bayes Klassifikator ist ein klassischer Klassifikator wie
er auch beim Data Mining beim überwachten Lernen zum Einsatz kommt.
6.1 Klassifizierung
Die Klassifizierung besteht aus fünf Schritten:
1. • Bestimme die Menge an Zielzuständen (W = (ω1 , ω2 , ..., ωm )T ,
mit m als Anzahl der Zustände)
• Beweisvektor mit h voneinander unabhängigen Merkmalen (χ =
(x1 , x2 , ..., xh )T )
2. Berechne die A-priori Wahrscheinlickkeitsverteilung, P (ωi ), basierend
auf den Beweisdaten
3. Berechne die multivariate Wahrscheinlichkeitsverteilung (joint proba-
bility) p(χ|ωi ) für jeden Zustand ωi
4. Berechne die A-posteriori Wahrscheinlichkeit basierend auf den Beweis-
daten
12p(xj |ωi )P (ωi )
P (ωi |xj ) = Pm (2)
k=1 p(xj |ωk )P (ωk )
5. Triff eine Entscheidung basierend auf der Risikofunktion λ(ω̂i , ω̇i ), wobei
ω̂i und ω̇i den tatsächlichen und den vorhergesagten Wert des Zustandes
darstellen
Es gibt zwei Verfahren basierend auf verschiedenen Risikofunktionen um
Entscheidungen zu treffen, unter Verwendung des
• Naiven Bayes-Klassifikators (N-BC) und des auf der
• minimierten quadratischen Abweichung (minimized mean square error,
MMSE) basierten Bayes-Klassifikator (MMSE-BC)
6.2 Risikofunktion
Die entsprechenden Risikofunktionen davon sind:
(
0 |ω̇i − ω̂i | < δ
λ(ω̇i , ω̂i ) = (3)
1 |ω̇i − ω̂i | ≥ δ
λ(ω̇i , ω̂i ) = (ω̇i − ω̂i )2 (4)
Der vorhergesagte Wert für den Zustand (ω̂i ) wird ermittelt durch den
minimalen Fehler:
ω̂i = arg max p(ωi |xj ) (5)
6.3 Mittlere quadratische Abweichung
Mittlere quadratische Abweichung (MSE):
m
X
ω̂i = ωi p(ωi |xj ) (6)
i=1
Der Zielzustandsvektor und der Vektor generiert aus den Lastdaten des Be-
weisfensters sind die beiden kritischsten Faktoren für eine genaue Vorhersage.
13Die Lastdaten werden aufgeteilt in kleinere Bereiche, wobei jeder Bereich ein-
er gewissen Auslastungsstufe entspricht. Die Anzahl der Bereiche im Last-
datenbereich [0,1] wird mit r bezeichnet. Wird zum Beispiel r = 50 gesetzt
ergeben sich daraus die 50 Teilbereiche [0, 0.02), [0.02, 0.04), ..., [0.98, 1].
6.4 Beweisfenster (Evidence window)
Die Länge des Beweisfensters (evidence window) wird auf die Hälfte der
Länge des vorherzusagenden Intervalls gesetzt. Wenn das Vorhersageinter-
vall zum Beispiel 8 Stunden beträgt, wird das Beweisfenster auf die letzten
4 Stunden gesetzt. Mit dieser Vorgehensweise konnte in experimentellen Re-
sultaten das genaueste Ergebnis erzielt werden. Das Beweisfenster wird in
eine Menge von gleich großen Segmenten unterteilt. 48 (= 4∗60 5
) aufeinan-
derfolgende Lastzustände (mit einer Segmentgröße im Beweisfenster von 5
Minuten) bilden in dieser Periode die Ausgangsdaten für die Vorhersage.
Wenn das Vorhersageintervall zum Beispiel auf 4 Stunden gesetzt wird, be-
trägt die Länge des Beweisfensters 2 Stunden und es gibt 24 Auslastungswerte
im Beweisfenster.
Abbildung 8: Illustration des Beweisfensters und den Zielzuständen
6.5 Merkmale (Features)
Der Lastzustandsvektor im Beweisfenster wird defininiert durch e = (e1 , e2 , ..., ed )T
wobei d die Anzahl der Teilsegmente im Beweisfenster darstellt, auch Fen-
stergröße (window size) genannt. Die Elemente in dem Vektor sind zeitlich
sortiert, beginnend mit dem aktuellsten Wert.
14Das Merkmal mittlere Auslastung (mean load, Fml (e))) ist der Mittel-
wert des Lastzustandsvektors e:
d
1X
Fml (e) = ei (7)
d i=1
Der Wertebereich der mittleren Auslastung befindet sich in [0,1]. Dieser
Bereich wird wiederum aufgeteilt in r gleich große Teilbereiche, wobei wieder
jeder Teilbereich einen Lastzustand darstellt. Das Ergebnis der mittleren
Auslastung ist also einer dieser Teilbereiche.
Die gewichtete mittlere Auslastung ist der linear gewichtete Mittel-
wert des Lastzustandsvektores e mit:
Pd d
i=1 (d − i + 1)ei 2 X
Fwml (e) = Pd = (d − i + 1)ei (8)
i=1 i d(d + 1) i=1
Bei diesem Merkmal werden die aktuelleren Lastzustände stärker gewichtet
als ältere. Auch dieses Merkmal befindet sich im Bereich [0,1], wobei der
Bereich wiederum aufgeteilt wird auf r Teilbereiche.
Der Gerechtigkeitsindex (fairness index, Ff i (e))) wird verwendet um
den Grad an Lastfluktuation im Beweisfenster zu charakterisieren. Die Formel
dafür lautet:
( di=1 ei )2
P
Ff i (e) = Pd 2 (9)
d i=1 ei
Das Ergebnis ist normalisiert im Bereich [0,1]. Ein höherer Wert deutet auf
eine stabilere Lastfluktuation hin. Der Wert beträgt 1, genau dann wenn
alle einzelnen Lastzustände gleich sind. Nachdem der Zielzustand in diesem
Modell die mittlere Auslastung im vorherzusagenden Intervall ist, scheint das
Merkmal der mittleren Auslastung wichtiger zu sein als der Gerechtigkeitsin-
dex. Wenn allerdings die Last im vorherzusagenden Intervall ähnlich fluk-
tuiert wie im Beweisfenster, kann der Gerechtigkeitsindex die Vorhersage
verbessern.
Der rauschunterdrückte Gerechtigkeitsindex (noise-decreased fair-
ness index, Fndf i (e)) wird ebenfalls mit der Formel des Gerechtigkeitsindizes
berechnet. Gibt es allerdings ein oder zwei Ausreißer in den Beweisdat-
en (load outliers) die den Gerechtigkeitsindex maßgeblich verschlechtern, so
werden diese nicht in die Berechnung miteinbezogen. Solche Ausreißer sind
höchstwahrscheinlich Rauschen oder irreguläre Jitter.
15Das Zustandsstatus Merkmal (type state, Fts (e)) wird verwendet um
den Lastzustandsbereich im Beweisfenster, sowie den Grad an Jitter zu charak-
terisieren. Es ist definiert als zweiertupel α, β, wobei α die Anzahl an in-
volvierten Zuständen und β die Anzahl an Zustandsänderungen darstellt.
Liegt zum Beispiel ein Lastzustandsvektor von (0.023,0.042,0.032,0.045,0.056,0.036)
vor, so gibt es nur zwei Zustände die involviert sind, nämlich [0.02,0.04)
und [0.04,0.06), sowie vier Zustandsänderungen 0.023 → 0.042, 0.042 →
0.032, 0.032 → 0.045, 0.056 → 0.036. 0.056 ist keine Zustandsänderung, nach-
dem der vorhergehende Zustand in den selben Lastzustandsbereich fällt.
Das Erste-Letzte Last Merkmal (first-last, Ff ll (e)) wird verwendet um
grob den Trend der Auslastung in der jüngeren Vergangenheit zu charak-
terisieren. Es ist definiert als Zweiertupel τ, υ, wobei τ den ersten und υ
den letzten Lastzustand aus dem Beweisfenster darstellt. Dieses Merkmal ist
praktisch nur brauchbar in Kombination mit anderen Merkmalen.
Das N-Segment Muster (N-segment pattern, FN −sp (e)) charakterisiert
die Segmentmuster basierend auf dem Beweisfenster. Das Beweisfenster wird
wieder gleichmäßig aufgeteilt auf Teilbereiche, wobei jeder Teilbereich eine
mittlere Auslastung beinhaltet. Beträgt die Länge des Beweisfensters zum
Beispiel 4 Stunden (mit einer Fenstergröße von 48), dann besteht das 4-
Segment Muster aus einem Vierertupel dessen Elemente die folgenden mit-
tlere Auslastungswerte beinhaltet: [e1 , e12 ], [e13 , e24 ], [e25 , e36 ], [e37 , e48 ]. N wird
jeweils auf 2, 3 und 4 gesetzt, sodass sich daraus eigentlich vier Merkmale
mit dem N-Segment Muster ergeben.
6.6 Merkmalskorellation
Einige der Merkmale sind untereinander abhängig. Dies widerspricht der An-
nahme des Bayes Theorems, dass alle Merkmale voneinander unabhängig
sind. Die Merkmale die in Formel (3) verwendet wurden, sollten voneinan-
der unabhängig sein. Der Gerechtigkeitsindex und der rauschunterdrückte
Gerechtigkeitsindex sind vermutlich voneinander abhängig. Daher wurde un-
tersucht welche Merkmale miteinander linear korellieren und welche nicht.
16Abbildung 9: Kompatibilität der Merkmale
Nachdem 9 Merkmale (Fml , Fwml , Ff i , Fndf i , Fts , Ff ll , F2−sp , F3−sp , F4−sp )
identifiziert wurden, ist die maximale Anzahl an Kombinationen 29 . Um
diese Zahl zu verkleinern wurden die Merkmale in 4 Gruppen unterteilt:
{Fml , Fwml , F2−sp , F3−sp , F4−sp }, {Fndf i , Ff i }, {Fts }, {Ff ll }. Elemente der sel-
ben Gruppe dürfen nicht mehrfach in einer Kombination vorkommen. Die
Anzahl an kompatiblen Kombinationen (number of compatible combinations,
NCC) beträgt 6, 3, 2, 2. NCC(9) = NCC(Gruppe 1) * NCC(Gruppe 2)
* NCC(Gruppe 3) * NCC(Gruppe 4) = 6 * 3 * 2 * 2 = 72. Dabei wird
noch der Fall abgezogen in dem kein Merkmal verwendet wird, was zu einer
Gesamtanzahl an 71 gültigen und sinnvollen Kombinationen führt.
7 Experimentelle Ergebnisse
Die einmonatige Datenaufzeichnung wurde in zwei Datensätze aufgeteilt, ein-
mal in eine Lernperiode von Beginn der Aufzeichung bis zu Tag 25, und ein-
mal in eine Testperiode von Tag 26 bis zum Ende der Aufzeichnung. Die
Lernperiode wurde dazu verwendet um das Modell mit Daten zu füttern, al-
so zum Beispiel um die A-priori Wahrscheinlichkeit P (ωi ) und die abhängige
Wahrscheinlichkeit p(xj |ωk ) zu berechnen.
Die für die Vorhersage zu verwendenden Merkmale werden in einer Binärdarstellung
selektiert. Die Reihenfolge der Merkmale ist festgelegt und ein Merkmal wird
selektiert indem die entsprechende Stelle auf 1 gesetzt wird. Es stellte sich
heraus, dass die beste Kombination an Merkmalen immer 100000000 Fml
und die schlechteste immer 000010000 Fts ist, unabhängig von der Länge des
vorherzusagenden Intervalls. Die Vorhersage unter Verwendung des MMSE-
BC ist immer genauer als unter Verwendung von N-BC. Der MMSE-BC Klas-
17sifikator adaptiert den mathematisch erwarteten Wert des vorhergesagten
Lastzustands, der die höchste Wahrscheinlichkeit aufweist in den tatsächlichen
Lastdaten vorzukommen. Der N-BC Klassifikator verwendet den Lastzustand
mit der höchsten A-posteriori Wahrscheinlichkeit als Ergebnis der Vorher-
sage. Abschließend werden die besten und schlechtesten fünf Ergebnisse und
deren Fehlerraten präsentiert.
Abbildung 10: Erfolgsrate und MSE des Bayes Klassifikators
18Literatur
[1] L. Badger, T. Grance, L. Badger, T. Grance, R. Patt-corner, J. Voas,
and P. D. Gallagher. Cloud computing synopsis and recomendations,
nist special publication 800-14, May 2012.
[2] S. Di, D. Kondo, and W. Cirne. Host load prediction in a google com-
pute cloud with a bayesian model. In Proceedings of the International
Conference on High Performance Computing, Networking, Storage and
Analysis, page 21. IEEE Computer Society Press, 2012.
[3] Y. Kouki and T. Ledoux. Sla-driven capacity planning for cloud appli-
cations. In Cloud Computing Technology and Science (CloudCom), 2012
IEEE 4th International Conference on, pages 135–140. IEEE, 2012.
Abbildungsverzeichnis
1 Host Load Verteilung in einer Cloud. . . . . . . . . . . . . . . 3
2 Lastvergleich zwischen Google und AuverGrid . . . . . . . . . 8
3 Quantile-Quantile Plot der Dauer and Aufgabenlänge . . . . . 8
4 Illustration des exponentiell segmentierten Musters . . . . . . 9
5 Induktion der segmentierten Auslastung . . . . . . . . . . . . 10
6 Pseudo-code der Cloud Lastmustervorhersage . . . . . . . . . 11
7 Vorhersagefehler mit unterschiedlichen Vorhersagelängen . . . 12
8 Illustration des Beweisfensters und den Zielzuständen . . . . . 14
9 Kompatibilität der Merkmale . . . . . . . . . . . . . . . . . . 17
10 Erfolgsrate und MSE des Bayes Klassifikators . . . . . . . . . 18
Wir weisen ausdrücklich darauf hin, dass die Abblidungen 2,3,4,5,6,7,8,9
und 10 aus der Arbeit[2] von Sheng Di, Derrick Kondo und Walfredo Cirne
übernommen wurden.
Copyright notice: The figures 2,3,4,5,6,7,8,9 and 10 have been taken from
the paper[2] of Sheng Di, Derrick Kondo and Walfredo Cirne.
19Sie können auch lesen