Sachstandsbericht für das SAW-Projekt MathSearch Berichtszeitraum 1.3.2012 31.12.2012
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Sachstandsbericht für das SAW-Projekt MathSearch
Berichtszeitraum 1.3.2012 – 31.12.2012
1. Stand und Entwicklung der durchgeführten Arbeiten
einschließlich Abweichungen vom ursprünglichen Konzept
Das erste Jahr des MathSearch Projekts (Beginn des Projekts war der 1.3.2012) stand im Zeichen
der Entwicklung des inhaltlichen Konzepts und der Schaffung der technischen Grundlagen für den
geplanten Dienst.
Suchmaschinen für Formeln sind weitgehend Neuland: mathematische Symbole und Formeln, im
Folgenden unter dem Term mathematische Formeln zusammengefasst, weisen eine Reihe von
Eigenheiten gegenüber Texten auf. Mathematische Formeln komprimieren komplexe
mathematische Objekte, die Komplexität ist dabei beliebig. Sie sind kein fortlaufender Text und
lassen sich nicht auf eine Dimension reduzieren. Mathematische Symbole können freie Variablen
enthalten, die für die Indexierung und die Suche markiert werden müssen.
Aber, Mathematik teilt auch die Probleme anderer natürlicher Sprachen: dieselben mathematischen
Terme in einer Formel bezeichnen unterschiedliche mathematische Objekte, unterschiedliche
Symbole haben dieselbe Bedeutung.
Die Entwicklung der Formelsuche erfordert also innovative Ansätze.
Im ersten Projektjahr wurden wie geplant Vorarbeiten für den Aufbau des Dienstes MathWebSearch
durchgeführt und konzeptionelle Grundlagen für die Formelsuche geschaffen.
Das erste Projektjahr verlief erfolgreich und führte zu einer deutlichen Präzisierung und partiellen
Erweiterung des Konzepts für die semantische Annotation von Formeln (Aufbau eines
mathematischen Glossar, Kontextanalyse).
Die Standardisierung der Formatierung der zbMATH-Daten im Berichtszeitraum war eine wichtige
und notwendige Vorarbeit für die Aufbereitung der Daten für die Suche.
Werkzeuge für die Weiterverarbeitung der zbMATH-Daten (LaTeXML, Build-System wurden
(weiter-)entwickelt oder angepasst.
Die Arbeiten zu den Schwerpunkten
• Datenpflege und MathML Konvertierung der zbMATH-Daten
• Aufbau eines mathematischen Glossars
• Kontextanalyse
• Formelsuche
werden im Folgenden näher erläutert.
Für das MathSearch Projekt wurden alle mathematischen Formeln in den zbMATH-Daten extrahiert
und abgespeichert. Die Gesamtzahl der Datensätze in zbMATH Anzahl der Dokumente beträgt
derzeit 3.239.415 (11.2.2013).
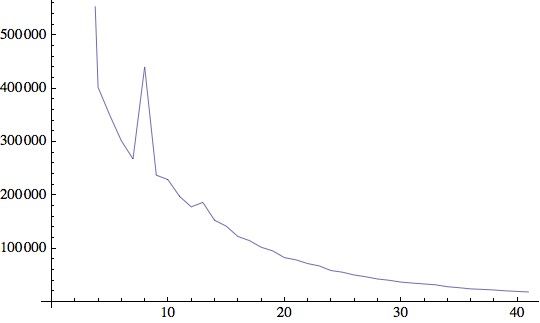
Insgesamt sind in diesen Daten 8.066.377 verschiedene Formeln enthalten. Die Anzahl der Zeichen
pro Formel kann als Indikator für die Komplexität einer Formel dienen. Die folgende Graphik stellt
die Verteilung der Anzahl der Zeichen pro Formel darAnzahl der Dokumente in zbMATH,
die eine Formel der Länge n enthalten
Anzahl der Zeichen pro Formel
Die Formeln sind unterschiedlich auf die verschiedenen mathematischen Gebiete (Klassen der
Mathematics Subject Klassifikation, MSC2010) verteilt. Der Durchschnittswert für den Quotienten
aus Formeln pro Dokument ist wenig aussagefähig. Viele Dokumente, gerade aus dem
Anwendungsbereich, enthalten in den Zusammenfassungen keine Formeln.
Die Verteilung zeigt aber deutlich, dass es sich bei den Formeln in den zbMATH-Daten meist um
relativ einfache mathematische Ausdrücke handelt.
1.1. Ausgangspunkt: Datenpflege und MathML Konvertierung
1.1.2 TeX/LaTeX/sTeX
Mathematische Symbole und Formeln lassen sich in mathematischen Texten einfach erkennen: Für
die Präsentation und die Verarbeitung mathematischer Formeln im Web werden verschiedene
Formate verwendet, die eine Formel eindeutig von dem Text unterscheidbar machen.
TeX hat den Publikationsprozeß in der Mathematik revolutioniert.
Das TeX-Format war das erste Markup-Format in der Mathematik und ist bis heute ein elegantes
und komfortables Werkzeug zur Erstellung (und nach Konvertierung ins PDF-Format auch zur
perfekten Präsentation) mathematischer Texte. In der Standardversion enthält es aber nur in
rudimentärer Form semantische Informationen über eine Formel. TeX wird seit langem auch für die
Erstellung der Datenbank zbMATH verwendet. Meist wird TeX heute in der speziellen Ausprägung
LaTeX von der mathematischen Community zur Publikation ihrer Ergebnisse genutzt.
Es gibt eine Erweiterung von LaTeX, sTeX, die zusätzlich zum Layout eine semantische Annotation
der benutzten Elemente erlaubt, aber zusätzlichen Aufwand für den Autor erfordert und bisher leider
nur in geringem Umfang genutzt wird.
Die zbMATH Daten sind TeX-kodiert, das verwendete TeX-Format ist aber nicht einheitlich und hatsich im Laufe der Jahre verändert. Die Inhomogenität des verwendeten TeX macht eine erste Schwierigkeit des Projekts aus. In der Redaktion der zbMATH-Datenbank erfolgten im Berichtszeitraum Arbeiten, um das TeX-Format der zbMATH-Daten zu vereinheitlichen und in den LaTeX-Standard zu überführen. 1.1.3 MathML und Datenkonvertierung Die eXtensible Markup Language (XML) ist ein universeller graphen-basierter Ansatz, um Informationen darzustellen, automatisch zu verknüpfen und auswertbar zu machen. XML lässt sich flexibel an die spezifischen Anforderungen einzelner Communities, etwa der Mathematiker, anpassen. Für die Mathematik wurden von der mathematischen Community verschiedene XML-Formate entwickelt, insbesondere der W3C-Standard MathML in den zwei Ausprägungen Presentation MathML und Content MathML. Im Projekt ist geplant, Content MathML für die Formelsuche einzusetzen. Für die Konvertierung von TeX nach MathML wurden in den letzten Jahren verschiedene Konverter entwickelt, etwa Tralics: http://www-sop.inria.fr/marelle/tralics/ oder LaTeXML: http://dlmf.nist.gov/LaTeXML, die eine stabile Konvertierung des LaTeX-Formats nach MathML, genauer Presentation MathML, erlauben. Presentation MathML ist für die Formelsuche prinzipiell nicht ausreichend, da es nur Informationen über das Layout enthält. Für die Formelsuche ist Content MathML besser geeignet, weil hier semantische Informationen über die Formeln zur Verfügung stehen. Die Konvertierung der zbMATH Daten nach Content MathML ist eine der zentralen Herausforderungen des Projekts und Voraussetzungen für den Aufbau einer innovativen Formelsuchmaschine. Die Konvertierung nach Conten t MathML geschieht in zwei Schritten: es ist eine Erweiterung des LaTeXML-Konverters in der Entwicklung, an der MathSearch in Person von D. Ginev wesentlich beteiligt ist. Der erweiterte Konverter transformiert die Daten insbesondere nach Content MathML: Dazu werden der Syntaxbaum der mathematischen Formeln analysiert und die möglichen Interpretationen einer Formel im Content MathML generiert. Im Allgemeinen ist das Resultat dieses Konvertierungsprozesses nicht eindeutig: Für jede Formel werden mehrere Interpretationen erzeugt. Eine Disambiguierung der verschiedenen Interpretationen, die wesentlich für die Formelsuche ist, ist nur in einem zweiten Schritt durch zusätzliche Untersuchungen möglich. Die Disambiguierung soll dadurch erfolgen, dass sowohl die Formeln selbst (interne Analyse) als auch der Kontext einer Formel (externe Analyse) benutzt werden. Für die interne Formelanalyse werden in MathSearch Konzepte entwickelt, um die mathematischen Entitäten einer Formel zu identifizieren (Aufbau eines Glossar für mathematische Entitäten). Zusätzlich sollen der (Text- oder Formel-)Kontext einer Formel benutzt werden, um so weit wie möglich Rückschlüsse auf die Semantik einer Formel zu ziehen. Gegenwärtig wird an der Konvertierung der zbMATH Daten mittels des erweiterten LaTeXML Konverters gearbeitet. Für das MathSearch Projekt wurde der LaTeXML-Konverter von D. Ginev um einen Daemon-Mode ergänzt, der die Transformation kleiner Dokumente (Reviews/Abstracts) erlaubt ohne einen Neustart des Programms. Diese Neuerung ermöglicht eine Konversion der zbMath Daten im Stundenbereich (statt Wochen). Der Daemon wurde im Berichstzeitraum zu einem leistungsfähigen Web-Service ausgebaut, um die Integrierbarkeit zu erleichtern. Für die Evaluierung der Datenkonvertierung wurde weiterhin 2012 ein erster Prototyp des sogenannten Build-Systems entwickelt, das den Verlauf der Konvertierung großer Datenmengen wie im Fall der Zentralblatt-Daten analysiert, überwacht und transparent macht. So werden etwa Fehler in der TeX-Kodierung bei diesem Prozess erkannt, was wiederum für die Verbesserung der Qualität der zbMATH Daten genutzt werden kann. Erste Ergebnisse lassen erwarten, dass der Konvertierungsprozeß der zbMATH-Daten ohne größere Schwierigkeiten vonstatten geht und nur eine kleinere Anzahl von Formeln nachbearbeitet werden
muss.
1.2 Aufbau eines Gazetteer/Glossars
Die semantische Analyse komplexer mathematischer Formeln lässt sich wesentlich vereinfachen,
wenn darin bestimmte charakteristische Teile, „Entitäten“, identifiziert werden können. Der Aufbau
einer solchen Liste von Entitäten ist die Idee, die dieser Projektaktivität zu Grunde liegt.
'Entity Recognition' ist in den letzten Jahren für das Retrieval großer Datenmengen zu einem
wichtigen Thema geworden, egal ob es um die Identifizierung von Autoren, Ortsnamen oder wie in
MathSearch um wesentliche mathematische Begriffe oder Symbolkomplexe geht.
Wie in jeder natürlichen Sprache ist auch die Verwendung mathematischer Symbole nicht eindeutig:
verschiedene Symbole können dieselbe Bedeutung haben oder ein Symbol kann in verschiedenen
Bedeutungen verwendet werden. Zusätzlich können die mathematische Formeln freie Parameter
enthalten, die keinen Einfluss auf die Bedeutung der Formel haben.
Aus dem Erkennen einzelner mathematischer Entitäten in (komplexen) mathematischen Formeln
können meist relevante Aussagen zur semantischen Erschließung einer Formel gefolgert werden.
Für den Aufbau eines mathematischen Glossars sind
• Kriterien zur Auswahl der relevanten mathematischen Entitäten (Relevanz der Entitäten für
zbMATH und Mathematik) zu bestimmen,
• die Daten, die über die mathematischen Entitäten bereitgestellt werden sollen, festzulegen.
Die Daten müssen in geeigneter Form bereitgestellt werden, so dass sie technische Barrieren zur
Untersuchung der konvertierten zbMATH-Daten eingesetzt werden können.
Ein erstes Glossar mit mehreren Hundert Einträgen wird im sTeX-Format derzeit von C.
Demirkiran manuell erstellt. Das Glossar soll in Hinblick auf andere Einsatzmöglichkeiten
erweiterbar sein. Das kann durch Hinzunahme weiterer Informationen, etwa den verschiedenen
Darstellungen einer Entität oder der Definition einer Formel erreicht werden.
In einem zweiten Schritt sollen dann Methoden untersucht werden, ob und wie sich der Aufbau
eines mathematischen Glossars automatisieren lässt.
Der explizite Aufbau eines Glossars als wesentlicher Baustein für die Disambiguierung der Formeln
ist ein Ergebnis der intensiven Diskussionen im Projekt und soll im zweiten Projektjahr auf seine
Brauchbarkeit getestet werden und auf eine breitere Basis gestellt werden (z.B. durch crowd-
sourcing über die zbMATH Community).
1.3 Kontextanalyse
Kontextinformationen zu einer Formel liegen in der Datenbank zbMATH in verschiedener Form
vor, es gibt globale Informationen zum Text in Form der Mathematics Subject Classification (MSC)
oder den Keywords einer Publikation.
Zu den globalen Kontextinformationen ist der lokale Kontext zu untersuchen: die links- und
rechtsseitige Umgebung einer Formel sowie mathematische Identitäten, die mit einer Formel oder
einem Teil einer Formel in Verbindung stehen.
Derzeit werden Methoden zur Textanalyse für die Datenbank zbMATH entwickelt. Diese
extrahieren auch Formeln, wenn diese in der Umgebung relevanter Textphrasen auftauchen.
An der JUB wird eine Repräsentationssystem entwickelt, das formale und informelle
(natürlichsprachliche/rhetorische) Aspekte der Bedeutung mathematischer Aussagen und Theorien
vereinheitlicht darstellen kann (vergleiche die Diskussion um Presentation/Content MathML). Wir
hoffen dadurch in der Zukunft den Kontext mathematischer Einheiten und Formeln genauer fassen
zu können.
1.4 Formelsuche
Die JUB hat bereits den Prototyp einer Suchmaschine für die Formelsuche entwickelt, der mit denzbMATH Daten gefüttert werden soll. Da der Index im MWS Daemon speicherresident ist, treten bei größeren Datenmengen Speicherprobleme auf. Im Berichtszeitraum konnte der Speicherverbrauch rund gedrittelt werden, und die Antwortzeiten auf ca. 50 ms. gesenkt werden. Für das zweite Projektjahr ist geplant, eine Arbeitsversion der Formelsuche für die zbMATH-Daten zu implementieren. Die bisherige reine Formelsuche soll zu einer mathematischen Volltextsuche erweitert werden. Allerdings steht bisher für eine (für eine breite Akzeptanz notwendige) öffentliche mathematische Suchmaschinen keine geeignete Hardware zur Verfügung. Dafür wird ein vom Internet zugänglicher Server mit großem Hauptspeicher(ca. 128 GB) benötigt. Dieser kann neben der Suchmaschine auch die Datenkonvertierung übernehmen. Nach der internen Testphase der Suchmaschine sollte entschieden werden, inwieweit Projektmittel dafür umgewidmet werden können. 2. Integration der Kooperationspartner Das Ziel, eine leistungsfähige Formelsuche insbesondere für den zbMATH-Korpus zu entwickeln, ist nur durch die intensive Zusammenarbeit der Projektpartner zu erreichen. Im Berichtszeitraum wurden in einem intensiven Diskussionsprozess nicht nur die Aufgaben sondern auch die Rolle der einzelnen Projektpartnern präzisiert. Das betrifft vor allem die Rolle des FIZ Karlsruhe bei der semantischen Formelanalyse. Hier wird sich das FIZ Karlsruhe wie oben dargestellt auch an der Entwicklung von Werkzeugen für die semantische Analyse engagieren. Beide Partner sind an der Zusammenarbeit sehr interessiert. Das Projekt stärkt die strategische Partnerschaft zwischen FIZ und JUB Forschungsergebnisse in das mathematische Diensteangebot des FIZ zu integrieren. Im Berichtszeitraum fanden zwei Arbeitstreffen in Karlsruhe und Berlin statt. Zudem erfolgten Gastaufenthalte der Projektmitarbeiter des FIZ und der JUB beim anderen Projektpartner. Für die Kontrolle der Projektverlaufs wird ein elektronisches Projektmanagementsystem eingesetzt. 3. Stellenwert der Formelsuche und internationale Kooperation Formelsuche und Information Retrieval für die Mathematik sind noch ein sehr junges Forschungsgebiet mit hohem Anwendungspotential für mathematische Informationssysteme, das zunehmend im den Fokus von Entwicklergruppen in der mathematischen Information gelangt, dessen Methoden und Ergebnisse in der Mathematik aber noch weitgehend unbekannt sind. Außer dem MathSearch Projekt beschäftigen sich derzeit noch weitere Forschungsgrupppen mit dem Thema Formelsuche und Information Retrieval. Auf der CICM-Konferenz 2012 (an der JUB), der führenden internationalen Tagung zur Nutzung von Computern in der mathematischen Information, wurden Formelsuche und Information Retrieval in der Mathematik erstmals in einem separaten Workshop thematisiert: es fand ein Math Information Retrieval Workshop (MIR 2012) und ein MIR Happening statt, auf dem zwei Suchmaschinen in einer öffentlichen Session gegeneinander antraten. Auf der NTCIR-10, eine der beiden grossen Information Retrieval Challenges weltweit, wurde 2012 ein Math Task gegründet. Ziel des Math Tasks ist es, neue Korpora und Formate für mathematische Suchanfragen zu entwickeln und das Evaluierungssystem auf die Verarbeitung mathematischer Texte auszudehnen. Zum NTCIR Math Task haben sich 15 Forschungsgruppen angemeldet. Sechs davon haben Resultate eingereicht, die im Moment evaluiert werden. An der Math Task Initiative beteiligt sich das MathSearch Projekt aktiv: Michael Kohlhase ist Mitglied des Organisationskommittees. Das FIZ-Team hat diesen Prozess mit konkreten Suchanfragen für den Wettbewerb unterstützt und ist an der Evaluation der Resultate beteiligt. Wir erwarten, dass sich der Math Task auf der NTCIR etabliert und ein globales Forum für die Darstellung, Diskussion und Verbreitung der Ergebnisse des MathSearch Projekts bietet.
Sie können auch lesen

















































