High Performance Realtime Vision for Mobile Robots on the GPU - Eine Implementierung für den Robocup Weingarten
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

High Performance Realtime Vision
for Mobile Robots on the GPU
- Eine Implementierung für den
Robocup Weingarten -
Diplomarbeit
Christian Folkers
Angewandte Informatik
Hochschule Ravensburg-Weingarten
Aufgabensteller: Prof. Dr.- Ing. Franz Brümmer
Betreuer: Prof. Dr. Wolfgang Ertel
Bearbeitungszeitraum: xx.xx.20xx - xx.xx.200x
10. August 2008
2
Erklärung
Ich versichere, dass ich die Arbeit ohne fremde Hilfe und ohne Benutzung anderer
als der angegebenen Quellen angefertigt habe und dass die Arbeit in gleicher oder
ähnlicher Form noch keiner anderen Prüfungsbehörde vorgelegen hat und von
dieser als Teil einer Prüfungsleistung angenommen wurde. Alle Ausführungen, die
wörtlich oder sinngemäß übernommen wurden, sind als solche gekennzeichnet.
12. Mai 2008
34
Zusammenfassung Ziel dieser Diplomarbeit ist es, eine vollständige Bildverarbeitung für den Robo- cup Weingarten zu entwickeln. Der Robocup Weingarten nimmt an der MiddleSize- Liga teil. In dieser Liga ist jeder Roboter vollständig autonom und verfügt über eine eigene Kamera. Das Weingartener Team hat sich dabei auf den Torwart spezialisiert. Dieses Anwendungsgebiet stellt besondere Anforderungen an die Bildverarbei- tung, wie zum Beispiel Echtzeitfähigkeit. Um die benötigte Rechenleistung auf einem mobilen System zu erreichen, nutzt die Implementierung die Grafikkarte. Auf Basis der Low-Level Algorithmen der Grafikkarte ist eine High-Level Bild- verarbeitung, welche Aufgaben wie die Objekterkennung mit Hilfe der Ontologie und die Kantendetektion zur Lokalisierung bereitstellt, implementiert. Die Imple- mentierung ist vollständig auf Parallelität ausgelegt und folgt einer modularen Softwarearchitektur. Der gesamte Quellcode steht unter der GPL Lizenz. Über die Implementierung der Bildverarbeitung auf der Grafikkarte wurde in diesem Zusammenhang eine Fachpublikation auf der internationalen Bildverar- beitungskonferenz VISAPP veröffentlicht. Die entstandene Implementierung wurde bereits auf einigen Veranstaltungen des Robocups erfolgreich eingesetzt.
6
Inhaltsverzeichnis
1 Einleitung 13
1.1 Robocup Weingarten . . . . . . . . . . . . . . . . . . . . . . . 13
1.2 Anforderungen . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2 Globale Architektur 15
3 Kamera Ansteuerung 17
3.1 Kamera Daten/Fakten . . . . . . . . . . . . . . . . . . . . . . . 17
3.2 Bayer Farbschema . . . . . . . . . . . . . . . . . . . . . . . . 17
3.3 Automatische Kalibrierung . . . . . . . . . . . . . . . . . . . . 18
3.4 Performance . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.5 Test-Kameramodul . . . . . . . . . . . . . . . . . . . . . . . . 20
4 Low-Level Bildverarbeitung 21
4.1 Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21
4.2 GPU Alternativen . . . . . . . . . . . . . . . . . . . . . . . . . 21
4.3 Architektur der GPU/Grafikkarte . . . . . . . . . . . . . . . . . 22
4.4 GPU(Fragmentprozessor) vs. CPU . . . . . . . . . . . . . . . . 23
4.5 GPU Programmierung . . . . . . . . . . . . . . . . . . . . . . 25
4.5.1 Fragmentprozessor Programmierung . . . . . . . . . . . 26
4.6 API Referenz . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.6.1 UML Klassendiagramm . . . . . . . . . . . . . . . . . 27
4.6.2 Funktionsreferenz . . . . . . . . . . . . . . . . . . . . 28
4.7 Code-Beispiel . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
5 High-Level Bildverarbeitung 37
5.1 Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.2 Ontologie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
5.3 HSV-Farbraum . . . . . . . . . . . . . . . . . . . . . . . . . . 38
5.4 Farbsegmentierung . . . . . . . . . . . . . . . . . . . . . . . . 39
5.4.1 Globales Hue-Histogramm . . . . . . . . . . . . . . . . 40
5.5 Objekterkennung . . . . . . . . . . . . . . . . . . . . . . . . . 41
7Inhaltsverzeichnis
5.5.1 Blockbasiertes Hue-Histogramm . . . . . . . . . . . . . 41
5.5.2 Objektattribute . . . . . . . . . . . . . . . . . . . . . . 43
5.5.3 Border Tracing . . . . . . . . . . . . . . . . . . . . . . 43
5.6 Lokalisierung . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5.6.1 Sobel-Operator . . . . . . . . . . . . . . . . . . . . . . 44
5.6.2 Canny Edge Detection . . . . . . . . . . . . . . . . . . 46
5.6.3 Eckendetektion . . . . . . . . . . . . . . . . . . . . . . 47
5.7 API Referenz . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5.7.1 UML Klassendiagramm . . . . . . . . . . . . . . . . . 50
5.7.2 Multithreading . . . . . . . . . . . . . . . . . . . . . . 50
5.7.3 Funktionsreferenz . . . . . . . . . . . . . . . . . . . . 52
6 Systemanforderungen 59
6.1 Hardwareanforderungen . . . . . . . . . . . . . . . . . . . . . 59
6.2 Softwareanforderungen . . . . . . . . . . . . . . . . . . . . . . 59
6.3 Kompilieren . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
6.4 Ausführen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
7 Systemperformance 61
8 Qualitätsanalyse 63
8.1 Praxisvorführungen . . . . . . . . . . . . . . . . . . . . . . . . 64
9 Fehlersuche 65
9.1 Interne Debug-Optionen . . . . . . . . . . . . . . . . . . . . . 66
9.1.1 Low-Level Bildverarbeitung . . . . . . . . . . . . . . . 66
9.1.2 High-Level Bildverarbeitung . . . . . . . . . . . . . . . 68
9.1.3 Kamera . . . . . . . . . . . . . . . . . . . . . . . . . . 70
10 Mögliche Erweiterungen 73
11 Lizenz 75
8Abbildungsverzeichnis
1.1 Roboter Torwart. . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.1 Softwarearchitektur. . . . . . . . . . . . . . . . . . . . . . . . . 16
3.1 Das 8 bpp Bayer Pattern. . . . . . . . . . . . . . . . . . . . . . 18
3.2 Die vier möglichen Bayer Fälle. . . . . . . . . . . . . . . . . . 18
4.1 Harware Architektur. . . . . . . . . . . . . . . . . . . . . . . . 23
4.2 GPU und CPU Speicherbandbreiten vergleich. . . . . . . . . . . 24
4.3 Das Canny Edge Detection GLSL Programm. . . . . . . . . . . 27
4.4 Klassendiagramm der ONG Bibliothek. . . . . . . . . . . . . . 28
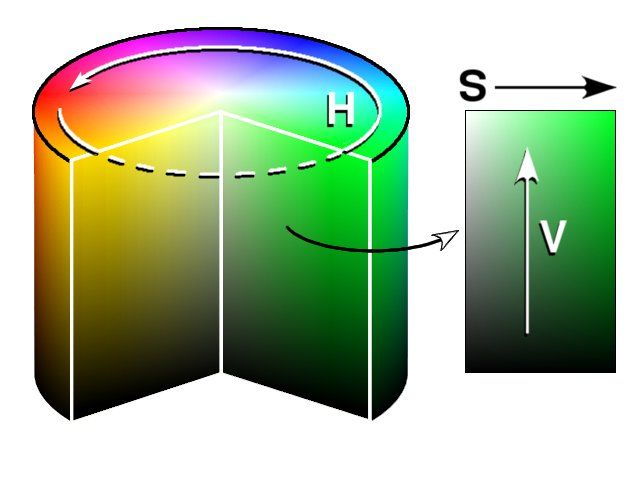
5.1 HSV Farbraum [Wik]. . . . . . . . . . . . . . . . . . . . . . . 38
5.2 Beispiel einer HSV Dekomposition (RGB, Hue, Saturation, Value). 39
5.3 Hue Binarisierung. . . . . . . . . . . . . . . . . . . . . . . . . 41
5.4 Beispiel einer erfolgreichen Farbsegmentierung. . . . . . . . . . 42
5.5 Convolution Maske eines Sobel-Operators in X und Y Richtung. 45
5.6 Originalbild und Ergebnis des Sobel-Operators. . . . . . . . . . 45
5.7 Eine exakt einen Pixel breite, gerade Linie mit eingezeichneten
Gradienten. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.8 Eine exakt einen Pixel breite, abgeknickte Linie mit eingezeich-
neten Gradienten. . . . . . . . . . . . . . . . . . . . . . . . . . 48
5.9 Das Ergebnis einer erfolgreichen Ecken detektion. . . . . . . . . 49
5.10 Klassendiagramm der High-Level Bildverarbeitung. . . . . . . . 50
9.1 Beispiel Kamerabild. . . . . . . . . . . . . . . . . . . . . . . . 72
9Abbildungsverzeichnis 10
Tabellenverzeichnis
3.1 Kameradaten. . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4.1 GPU(FP) und CPU vergleich. . . . . . . . . . . . . . . . . . . . 24
7.1 Systemspezifikationen. . . . . . . . . . . . . . . . . . . . . . . 61
7.2 Messergebnisse (für die CPU jeweils mit und ohne speichern der
Gradienten). . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
11Tabellenverzeichnis 12
1 Einleitung
1.1 Robocup Weingarten
Im Jahr 2004 wurde von Prof. Ertel das Robocup Team an der Hochschule
Ravensburg-Weingarten initiiert. Ziel dieses Projektes ist es, einen Torwart in der
MiddleSize-Liga für andere Teams bereitzustellen (siehe Abbildung 1.1). Nach
einigen Versuchen an der fertig verfügbaren Plattform Volksbot vom Fraunhover
Institut wurde beschlossen eine eigene Soft- und Hardware zu entwickeln.
Ziel dieser Diplomarbeit ist es, eine Bildverarbeitung für diesen Torwart zu
entwickeln und zu Implementieren.
1.2 Anforderungen
Die letzten Meisterschaften haben gezeigt, dass eine hochperformante und zu-
verlässige Bildverarbeitung im Robocup über Sieg oder Niederlage entscheidet.
Dazu kommt, dass die Anforderungen der MiddleSize-Liga sehr hoch sind, da
zum Beispiel jeder Roboter auf dem Feld seine eigene Kamera/Bildverarbeitung
lokal besitzt, was zu Platz und Energieproblemen (verursacht durch Akkuspei-
sung) führt. Eine weitere Schwierigkeit besteht in der Kalibrierung, die bei vielen
Teams langwierig und fehleranfällig, kurz vor dem Spiel, für alle Roboter manuell
durchgeführt werden muss. Alles in allem stellt die Bildverarbeitung im Robocup
eine zentrale und interessante Herausforderung dar, die bisher nur teilweise gelöst
wurde.
Daraus ergeben sich folgende Anforderungen an das System:
1. Ausführung in Echtzeit (24 Bilder/sek. oder mehr)
2. Hohe Kamera Auflösung von mindestens 640x480
3. Geringer Energieverbrauch und geringe Wärmeentwicklung
131 Einleitung
Abbildung 1.1: Roboter Torwart.
4. Automatische Kalibrierung
5. Hohe Zuverlässigkeit auch unter schlechten Bedingungen
6. Anpassbarkeit an zukünftige Reglementierungen oder anderer Aufgabenbe-
reiche
142 Globale Architektur
Die hier beschriebene Bildverarbeitung folgt einer Modularen Softwarearchitektur
(siehe Abbildung 2.1). Die einzelnen Module kommunizieren dabei über fest
definierte Schnittstellen. Ziel dieser Modularisierung ist es, die Hardware zu
abstrahieren und so die Komplexität der Implementierung zu senken. Aufgrund der
Unabhängigkeit der Module voneinander, können einzelne Module losgelöst vom
Rest verwendet werden. So ist es zum Beispiel möglich, nur das Framegrabber
Interface mit der Firewire Kamera Implementierung und der darin enthaltenen
Autokalibrierung zu verwenden, ohne die restliche Bildverarbeitung zu benötigen.
Ein weiterer Vorteil ist die gute Erweiterbarkeit. Die Low-Level Bildverarbeitung
kann über zusätzliche Job Implementierungen in ihrem Funktionsumfang beliebig
erweitert werden, ohne die bestehende Schnittstelle verändern zu müssen.
Es können auch bestehende Module ersetzt werden. Dies ist vor allem beim Fra-
megrabber sinnvoll und ermöglicht zum Beispiel die saubere Anbindung anderer
Kamerasysteme, ohne dabei auf das bestehende Modul gänzlich verzichten zu
müssen. Die verschiedenen Framegrabber Implementierungen bleiben dank der
gemeinsamen Schnittstelle jederzeit austauschbar.
Die drei Hauptmodule Bildverarbeitung, Framegrabber und Ontologie werden
durch die Anwendung miteinander verbunden.
Um die Vorteile dieser Architektur nutzen zu können ist es unerlässlich, dass die
vollständige Trennung der einzelnen Module gewahrt wird. Aus diesem Grund
sind selbst Funktionen, die nur zum Debuggen verwendet werden, in der Low-
Level Bildverarbeitung als Jobs implementiert.
Die Diplomarbeit folgt in ihrem Aufbau den einzelnen Modulen und beschreibt in
dieser Reihenfolge Firewire Kamera, Low-Level Bildverarbeitung, High-Level
Bildverarbeitung und die Ontologie.
152 Globale Architektur
Applikation
High-Level Vision Framegrabber Ontology
Low-Level Vision Job Jobs ... Camera1394 Bildverarbeitung
OpenGL libdc1394 Betriebssystem
GPU i1394 Kamera Hardware
Abbildung 2.1: Softwarearchitektur.
163 Kamera Ansteuerung
3.1 Kamera Daten/Fakten
Als Kamera wird eine DBK 31AF03 FireWire Bayer Kamera mit einem 1/3" Sony
CCD verwendet [Net]. Diese Kamera kommt im Progressive-Scan auf 1024x768
Pixel bei bis zu 30 Bildern pro Sekunde. Die Bilder werden unkomprimiert im
Bayer Modus übertragen. Die genauen technischen Daten der Kamera sind in
Tabelle 3.1 zusammengefasst dargestellt.
3.2 Bayer Farbschema
Das Bayer Farbschema [Sil] ist ein von Kodak entwickeltes Muster, das es erlaubt
die Farbkomponenten Rot, Grün und Blau auf einer Fläche nebeneinander zu se-
rialisieren. Dadurch wird der Aufbau des Sensors in der Kamera stark vereinfacht,
weil sich nicht 3 Sensoren am physikalisch selben Ort befinden müssen.
Des Weiteren reduziert dieses Farbschema die zur Übertragung benötigte Daten-
rate um einen Faktor drei, ohne dabei die Farbauflösung stark zu verschlechtern.
Auflösung: 1024x768
Frame rate: 30 fps
Farbschema: Bayer
Bits/Pixel: 8bit
Schnittstelle: FireWire 1394
Datenrate: 190Mbit/sek.
Software API: libdc1394
Modus: raw1394 (dma)
Tabelle 3.1: Kameradaten.
173 Kamera Ansteuerung
Abbildung 3.1: Das 8 bpp Bayer Pattern.
Abbildung 3.2: Die vier möglichen Bayer Fälle.
Dieser Umstand macht sich vor allem bei der Farbsegmentierung positiv bemerk-
bar.
Der grüne Farbkanal wird dabei bevorzugt, denn auf ihn entfallen die Hälfte aller
Pixel, wohingegen auf den rot und blau Kanal nur jeweils 1/4 der Pixel verwendet
werden.
Die Farbe Grün wurde ausgesucht, weil in einer Vielzahl von realen Bildern im
Grünanteil der stärkste Kontrast zu finden ist.
Um vom Bayer Bild zu einem vollen RGB zu kommen, müssen jeweils die zwei
fehlenden Farbkomponenten pro Pixel aus der benachbarten Region Interpoliert
werden. Dabei gibt es die folgenden vier Fälle.
Bei der Konvertierung zum RGB Bild kann es an Kanten mit einem starken
hell/dunkel Kontrast zu fehlerhaften Farbwerten kommen, da ein Teil der zur
Interpolation benutzten Pixel auf der „hellen“ und ein anderer auf der „dunklen“
Seite liegen.
3.3 Automatische Kalibrierung
Eine Anforderung des Robocups ist es, das System unter hektischen und unbe-
kannten Bedingungen und Umgebungen in kürzester Zeit stabil zum Einsatz zu
183.4 Performance
bringen. Zusätzlich entfällt bei vielen Robocup Teams ein Großteil der Probleme
vor und während eines Spiels auf die Bildverarbeitung.
Diese Probleme sind größtenteils auf die umständliche, langwierige und statische
Kalibrierung zurückzuführen. Dabei kommt es immer wieder zu Fehlern oder Ab-
weichungen, die durch geringfügige Änderungen der Lichtverhältnisse während
dem Spiel verursacht werden.
Die hier beschriebene Bildverarbeitung hat den Vorteil, dass keinerlei manuelle
Kalibrierung zum Betrieb notwendig ist!
Dieses Ziel wird mit Hilfe eines automatischen Weißabgleichs realisiert. Als
Referenz dient dabei eine weiße Markierung, die sich am Roboter außerhalb des
Spiegelbereiches befindet (siehe Abbildung 9.1).
Beim Starten der Bildverarbeitung wird automatisch eine Luminanz- und Farb-
kalibrierung durchgeführt. Diese Kalibrierung arbeitet nach dem Verfahren der
Proportionalregelung und versucht das Kamerabild in maximal 20 Schritten dem
Sollwert bis auf eine fest definierte Genauigkeit anzugleichen.
3.4 Performance
Um die, mit den in Tabelle 3.1 angegebenen Kameradaten entstehende Datenrate
von 1024*768 * 8 * 30 = 190 Mbit/sec. schritthaltend einlesen zu können, wird
ein raw DMA (Direct Memory Access) Modus verwendet. Dieser Modus benötigt,
aufgrund der damit verbundenen Risiken das Betriebssystem zum Absturz zu
bringen, administrative Rechte. In diesem Modus ist es möglich die Kameradaten
ohne Systemaufrufe und unnötige Belastung der CPU vom Firewire Bus direkt
auf die Grafikkarten zu transferieren. Dabei wird nur das zentrale Quadrat von
768x768 Pixel übertragen, weil die Randbereiche aufgrund des runden Spiegels
keine relevante Bildinformation enthalten.
Sowohl die Übertragung, als auch das Abschneiden der Randbereiche wurde
nach dem Zero-Copy-Prinzip implementiert um die Bilddaten nicht unnötig im
Arbeitsspeicher kopieren zu müssen. Dies garantiert optimale Performance bei
geringstmöglicher CPU Belastung.
193 Kamera Ansteuerung 3.5 Test-Kameramodul Um die Bildverarbeitung auch auf Entwicklungsrechnern ohne Kamera ausführen und testen zu können, enthält die Quellcode Distribution ein Test-Kameramodul. Mit Hilfe dieses Moduls ist es möglich gespeicherte Bilddateien anstelle einer Kamera zu verwenden. Die Bilder müssen im BMP-Format mit 8 bit Farbtiefe als Bayer Grauwertbild abgelegt werden. Unter der Verwendung dieses Moduls ent- fallen neben der libdc1394 Abhängigkeit auch die Kalibrierung und die benötigten administrativen Rechte. 20
4 Low-Level Bildverarbeitung
4.1 Einleitung
Das OrontesNG Low-Level Vision Modul, kurz ONG Vision Modul, ist dafür
entwickelt, Low-Level Verarbeitungsschritte der Bilderkennung in Echtzeit zu
realisieren. Diese Aufgaben erfordern in der Regel wenig Logik, dafür aber enor-
me Rechenleistung, da sie vollständig auf der Pixel-Ebene stattfinden. Beispiele
hierfür sind unter anderem Farbsegmentierung, “Canny Edge Detection”, “Gaus-
sian Blur”, “RGB Color Normalization”, oder auch die einfache Umwandlung
von RGB in HSV.
Um diesen Anforderungen nachzukommen, benutzt das ONG Vision Modul, nicht
wie sonst üblich die CPU, sondern arbeitet mit Hilfe der GPU. Die sich in den
meisten heutigen Rechnern auf einer Zusatzkarte (der “Grafikkarte”) befindet und
von Herstellern wie nVidia oder ATI angeboten wird. Normalerweise wird dieser
extra Prozessor zum Berechnen der enormen Pixelmengen heutiger Videospiele
genutzt.
Da sich die GPU stark in der Entwicklung befindet und neue Feature auf älteren
Modellen meist nicht verfügbar sind (und auch nicht per Software nachgerüstet
werden können), liegen die Mindestanforderungen zum ausführen des ONG Vision
Moduls bei einer nVidia GeForce 6xxx oder ATI 9600.
Diese Software ist kein eigenständiges Programm, sondern nur eine in C++ ge-
schriebene Bibliothek mit einer Schnittstelle, welche von Programmen zur gene-
rellen Bildverarbeitung für die oben genannten Aufgaben genutzt werden kann.
4.2 GPU Alternativen
Da passiv gekühlte Grafikkarten mit ausreichender Rechenleistung und Program-
mierbarkeit erst seit kurzem verfügbar sind und es besondere Kenntnisse erfordert,
214 Low-Level Bildverarbeitung diese für die Bildverarbeitung einzusetzen, gibt es bisher noch kaum/keine ver- gleichbaren Bibliotheken. Die einzigen Alternativen bestehen aus den herkömmlichen, vollständig auf der CPU ausgeführten Bibliotheken wie z.B. die LTI-Lib, welche aber im wesentli- chen zu langsam sind und somit nicht echtzeitfähig. OpenVIDIA [Fun05] ist ein Forschungsprojekt mit dem Ziel, eine vollständige High-Level Bildverarbeitung auf der Grafikkarte in Echtzeit zu realisieren. Dies ist im Moment aber nur mit sechs Parallel geschalteten Grafikkarten möglich und somit zumindest in naher Zukunft nicht auf mobilen Systemen anwendbar. Die einzige praktikable Alternative, die auch im Robocup Verwendung findet, sind speziell für eine Aufgabe programmierte FPGA’s(Field Programmable Ga- te Array). Diese frei programmierbaren Logikschaltkreise ähneln vom Aufbau her einer älteren Grafikkarte. Mit dem Unterschied, dass sie nicht direkt mit dem Mainboard über einen internen Bus verbunden sind, sondern über externe Schnittstellen angesprochen werden müssen. Ein weiterer Unterschied ist das Speicherinterface, welches auf der Grafikkarte stark parallelisiert und mit Hilfe von speziellen Caches hoch optimiert, auf einer Platine untergebracht wird. Wohin- gegen ein FPGA meist gar keinen externen Speicher, oder nur langsamen, seriell angesprochenen Speicher besitzt. FPGA´s sind nicht Bestandteil handelsüblicher PC´s so wie Grafikkarten und sind damit auch keine Massenprodukte. 4.3 Architektur der GPU/Grafikkarte Bei der GPU handelt es sich um eine eigene Prozessoreinheit, welche sich auf einer Zusatzkarte (der „Grafikkarte“) befindet und über eine AGP oder PCI-Express Schnittstelle mit dem Mainboard verbunden ist. Die GPU unterscheidet sich im Aufbau wesentlich von der CPU und ist speziell für rechenintensive Aufgaben auf Basis von Fließkomma-Vektoren konzipiert [KR05]. Dabei wird der Grafikkarte einmal ein Programm übermittelt, welches dann von der GPU automatisch für alle Pixel eines Bildes ausgeführt wird. Ein solches Programm heißt Fragmentprogramm und hat die Einschränkung, dass es nicht auf die Zwischenergebnisse oder Ergebnisse anderer Instanzen (des selben Programms nur für andere Pixel des Bildes) zugreifen kann. Dadurch ergibt sich die Möglichkeit, solche Programme 100%ig zu parallelisieren. Heutige Grafikkarten besitzen zwischen 8 und 24 Pixel-Pipelines, mit denen dann genau so viele Pixel zugleich berechnet werden können, wie Pipelines vorhanden sind. 22
4.4 GPU(Fragmentprozessor) vs. CPU
4GB/s 4GB/s
CPU North Bridge RAM
PCI-Express 16x
8GB/s
Graphics Board
GPU
Vertex Fragment 25GB/s VRAM
Processor Processor
Abbildung 4.1: Harware Architektur.
Um die dabei stark anfallenden Speicherzugriffe nicht zum Flaschenhals werden
zu lassen, ist die GPU ohne Sockel direkt auf die Grafikkarte montiert und mit
einem zwischen 128 und 256bit breitem Bus an den Speicher angebunden. In
Zusammenhang mit dem dabei eingesetzten Speicher (DDR2 oder sogar DDR3
mit RAMDAC´s zwischen 400 und 1200MHz) ergeben sich Transferraten von 20
bis 50 GB/sek.
Da die Speicherzugriffe in der Regel coherent sind, weil sie von verschiedenen
Instanzen des selben Programms benachbarter Pixel stammen, werden sie mittels
eines speziellen Caches stark optimiert. Dieser Cache-Algorithmus unterscheidet
sich sehr von Standardverfahren und ist in der Hardware fest eingebaut. Also nicht
vom Programmierer zu beeinflussen.
Eine weitere Besonderheit ist, dass der Fragmentprozessor native mit vierdimen-
sionalen Vektoren (bestehend aus 32bit Fließkomma-zahlen) arbeitet und auch
die Register diese Breite haben.
4.4 GPU(Fragmentprozessor) vs. CPU
Da sich die GPU, wie schon im vorherigen Kapitel 4.2 aufgezeigt, in der Archi-
tektur grundlegend von der CPU unterscheidet, ist ein direkter Vergleich kaum
möglich. Deshalb wird in der folgenden Tabelle die CPU mit dem Fragmentprozes-
sor(FP), welcher nur ein Bestandteil der GPU ist, verglichen. Dabei entsprechen
234 Low-Level Bildverarbeitung
GPU(FP) CPU
Architektur: SIMD CISC
Anzahl Instruktionen: 33 400
Prozessor in MHz: 350-400 2500-3500
Parallelität: 8x-16x 3x
Rechenleistung in GFLOPS: 40-53 12
Speicher in MB: 128-256 512-1024
Speicher in MHz: 800-1000 400-533
Sp. Bandbreite in GB/sec. 16-35 4-6
Tabelle 4.1: GPU(FP) und CPU vergleich.
35
"Memory Bandwidth"
30
25
GB/sec.
20
15
10
5
0
cache seq. rand cache seq. rand
GeForce 6800 Pentium 4 (3GHz)
Abbildung 4.2: GPU und CPU Speicherbandbreiten vergleich.
die Werte der CPU in etwa denen eines Pentium 4 Prozessors und die der GPU
einer GeForceFX 5900 bis 6800 Grafikkarte.
Neben der Parallelität (siehe Kapitel 4.3), ist der größte Unterschied die Architek-
tur des Prozessors, welche sich auch bei der Programmierung stark bemerkbar
macht.
Zum Beispiel: Um einen vierdimensionalen Vektor mit einer 4x4 Matrix zu
multiplizieren, braucht eine Hochsprache auf einer CPU etwa 100 einzelne As-
semblerbefehle. Für die selbe Aufgabe benötigt die Grafikkarte dagegen nur genau
4 Instruktionen.
Folgendes 4D-Vektor Skalarprodukt:
244.5 GPU Programmierung
C.x = A.x*B.x + A.y*B.y + A.z*B.z + A.w*A.w;
ist auf der GPU mit nur einer Instruktion zu berechnen:
DP4 C.x, A, B;
Auf diese Weise können vor allem bei Vektor basierten mathematischen Berech-
nungen eine erhebliche Anzahl an Prozessorzyklen eingespart werden. Dieser
Vorteil macht sich auch bei der Implementierung einer Low-Level Bildverarbei-
tung positiv bemerkbar, da Farben, Gradienten und Filterkerne sehr gut durch
Vektor und Matrix dargestellt werden können.
Es gibt aber auch Nachteile der SIMD Architektur, wie zum Beispiel die kompli-
ziertere Programmierung und die starken Einschränkungen der Kontrollstrukturen.
So ist es mit einer GPU kaum möglich einfache Algorithmen, die auf der Rekursi-
on, oder auf stark verschachtelten Schleifen beruhen, zu implementieren [gpg].
4.5 GPU Programmierung
Zur Ansprechung der GPU wird beim ONG Vision Modul OpenGL [ogla] ver-
wendet, welches eine freie, standardisierte und herstellerunabhängige Grafik-
Bibliothek von SGI ist. OpenGL wird über ein besonderes Modell erweitert. Es
gibt zum einen OpenGL Versionen (1.1 – 2.0) und zum anderen Version unab-
hängige Erweiterungen. Das ONG Vision Modul benötigt mindestens Version 1.1
und folgende Erweiterungen:
• GL_ARB_fragment_program
• GL_ARB_shader_objects
• GL_ARB_fragment_shader
• GL_ARB_texture_rectangle
• GL_EXT_framebuffer_object
Wobei der Präfix GL anzeigt, dass es sich um eine Erweiterung der plattformun-
abhängigen OpenGL-API handelt. ARB bedeutet das diese Erweiterung von der
gleichnamigen Organisation standardisiert wurde und auch herstellerübergreifend
verfügbar sein sollte. Mit EXT werden Erweiterungen bezeichnet die zwar her-
stellerübergreifend verfügbar sind, aber noch nicht standardisiert wurden. Des
254 Low-Level Bildverarbeitung weiteren gibt es noch firmenspezifische Erweiterungen, wie zum Beispiel NV, ATI und SGI [oglb]. Welche Grafikkarte welche Erweiterung unterstützt und auch umgekehrt, kann man auf folgender Internetseite nachschlagen: http://www.delphi3d.net/hardware/index.php Die meisten Erweiterungen können nicht per Software/Treiber-update nachgerüs- tet werden, da sie spezielle Hardwareänderungen erfordern. 4.5.1 Fragmentprozessor Programmierung Über die GL_ARB_fragment_program Erweiterung kann der Fragmentprozessor der Grafikkarte per Assembler programmiert werden. Diese Art der Programmie- rung ist sehr zeitaufwändig und skaliert auch nicht mit Neuerungen der Grafikkar- ten. Deshalb wurde für die meisten Programme dieses Moduls eine High-Level „C ähnliche“ Sprache, die GLSL (OpenGL Shading Language) verwendet, welche durch die Erweiterung GL_ARB_fragment_shader bereitgestellt wird. Diese Hochsprache wurde von 3Dlabs entwickelt und danach von der ARB (Ar- chitecture Review Board) zum Standard ernannt. Eine umfangreiche Spezifikation ist im Internet verfügbar [Kes06]. Eine Besonderheit dieser Sprache ist, dass die Programme erst zur Laufzeit vom Treiber der Grafikkarte übersetzt werden. Dadurch besteht die Möglichkeit, dass durch Updaten der Treiber auch „alte“ Programme noch von neuen Hardware Möglichkeiten oder besseren Kompilieren profitieren können. 4.6 API Referenz Die API des ONG Vision Moduls ist in C++ geschrieben und objektorientiert aufgebaut. Die Struktur der API ist in Kapitel 4.6.1 mittels eines UML Klassen- diagramms dargestellt. Alle Funktionen der API (bis auf die Init() und Destroy() Methoden der Klasse ONG_Vision) sind „thread-safe“. Eine Anwendungsmöglichkeit dessen, ist zum Beispiel das Hochladen von neuen Bildern und das Ausführen von Jobs auf diesen Bildern aus zwei verschiedenen Threads heraus zu steuern. Dadurch kann die Zeit, 26
4.6 API Referenz
uniform sampler2DRect inputImg;
void main()
{
const vec2 offset = {1.0, 0.0};
vec2 gradient;
gradient.x = texture2DRect(inputImg, gl_TexCoord[0].xy + offset.xy).y
- texture2DRect(inputImg, gl_TexCoord[0].xy - offset.xy).y;
gradient.y = texture2DRect(inputImg, gl_TexCoord[0].xy - offset.yx).y
- texture2DRect(inputImg, gl_TexCoord[0].xy + offset.yx).y;
gl_FragColor.xyz = vec3(l engt h(gradient.xy) * 0.707107,
gradient.xy * 0.5 + 0.5);
}
Abbildung 4.3: Das Canny Edge Detection GLSL Programm.
die die Kamera zum Transferieren der Bilder benötigt, noch im anderen Thread
für die Berechnungen der High-Level Bildverarbeitung genutzt werden.
Nachdem das Modul initialisiert wurde, können Jobs erzeugt und per Invoke()
Funktion gestartet werden. Die gestarteten Jobs werden dann nacheinander (FIFO)
abgearbeitet, wobei einmal gestartete Jobs nicht vorzeitig abgebrochen werden
können.
Es gibt zwei unterschiedliche Methoden, auf die Fertigstellung eines Jobs zu
„warten“. Einmal die des Pollings, wobei während der Wartezeit noch andere
Aufgaben erledigt werden können und zwischen diesen Aufgaben nur kurz und
nicht „blockend“ der Status des Jobs mittels der Funktion HasFinished() abgefragt
wird. Und zum Zweiten die des blockenden Wartens, welche durch die Funktion
WaitUntilFinished() realisiert wird. Diese Funktion hat gegenüber einer Polling-
schleife den Vorteil einer geringeren Auslastung des Prozessors und eines kürzeren
Delays.
4.6.1 UML Klassendiagramm
Das UML-Klassendiagramm in Abbildung 4.4 stellt die Schnittstellen der Low-
Level Bildverarbeitung grafisch dar. Die internen Member und Methoden der
Klasse wurden aus Gründen der Übersichtlichkeit weggelassen.
274 Low-Level Bildverarbeitung
Abbildung 4.4: Klassendiagramm der ONG Bibliothek.
4.6.2 Funktionsreferenz
Representation von Bildern im Speicher Die Adresse des Bildes zeigt stets
auf das erste Pixel in der oberen linken Ecke des Bildes. Am Ende einer Zeile folgt
kein padding. Bei Bildern die als Eingabe übergeben werden kann die Anzahl an
Bytes einer Zeile mit angegeben werden.
ONG_Vision:
class ONG_Vision
static ONG_Vision* getSingletonInst()
bool init(unsigned int maxWidth, unsigned int maxHeight)
void destroy()
class ONG_Vision
Diese Klasse bildet die Basis der GPU gestützen Bildverarbeitung. Sie ist nach
dem Singleton Designpattern entworfen und kann nur eine Instanz haben.
static ONG_Vision* getSingletonInst()
284.6 API Referenz
Die statische Funktion getSingletonInst gibt die einzige Instanz dieser Klasse
zurück.
bool init(unsigned int maxWidth, unsigned int maxHeight)
Die Methode init initialisiert die Bildverarbeitung. Diese Methode ist nicht
„thread-safe“ und sollte nur genau einmal aufgerufen werden.
void destroy()
Die Methode destroy deinitialisiert die Bildverarbeitung und gibt alle benötigten
Resourcen wieder frei. Diese Methode ist nicht „thread-safe“ und sollte nur genau
einmal aufgerufen werden.
ONG_VisionJob:
class ONG_VisionJob
ONG_VisionJob()
virtual ~ONG_VisionJob()
virtual int getJobID() = 0
virtual bool invoke()
bool hasFinished()
bool waitUntilFinished()
class ONG_VisionJob
Die Klasse ONG_VisionJob definiert ein gemeinsames Interface für alle Jobs, die
auf die GPU ausgelagert werden können. Alle für die GPU implementierten Jobs
müssen von dieser Klasse abgeleitet werden und deren Interface implementieren.
Auf diese Weise kann das Bildverarbeitungsmodul und der darin implementierte
Scheduler, sowie die Synchronisationslogik für alle GPU Implementierungen
verwendet werden.
ONG_VisionJob()
Dieser Konstruktor wird nur zur Initialisierung der abstrakten Klasse ONG_VisionJob
verwendet.
294 Low-Level Bildverarbeitung
virtual ~ONG_VisionJob()
Virtueller Destruktor der garantiert, dass bei einem delete Aufruf auf die Basis-
klasse der Konstruktor der abgeleiteten Klasse mit aufgerufen wird.
virtual int getJobID()
Die Methode getJobID gibt die Job ID zurück. Diese Id wird per Implementierung
vergeben. Alle Aufträge eines Jobs, wie zum Beispiel der Canny Edge Detection,
erhalten die selbe Id.
virtual bool invoke()
Die Methode invoke meldet einen Job für die Bearbeitung am Scheduler an. Dieser
Methodenaufruf ist Asynchron. Wenn der Aufruf returned, ist nicht garantiert das
der Job bereits ausgeführt wurde.
bool hasFinished()
Die Methode hasFinished gibt zurück, ob der Job bereits fertiggestellt wurde.
Diese Methode kann verwendet werden, um parallel zur GPU auf der CPU
solange Berechnungen durchzuführen, bis der GPU Job fertiggestellt wurde.
bool waitUntilFinished()
Die Methode waitUntilFinished blockt solange, bis der Job fertiggestellt wurde
und returned erst dann. Diese Methode garantiert eine ideale Antwortzeit und sehr
geringe CPU Belastung.
ONG_VJobPostImage:
class ONG_VJobPostImage : public ONG_VisionJob
ONG_VJobPostImage(int width, int height,
int rowLength, ONG_BYTE* data)
virtual ~ONG_VJobPostImage()
int getImageWidth()
int getImageHeight()
304.6 API Referenz
int getImageRowLength()
ONG_BYTE* getImageData()
int getReturnCode()
int getJobID()
class ONG_VJobPostImage
Die Klasse ONG_VJobPostImage implementiert einen VisionJob zum Transfer
von Bildern auf die GPU.
ONG_VJobPostImage(int width, int height,
int rowLength, ONG_BYTE* data)
Dieser Konstruktor erzeugt einen neuen Job vom Typ ONG_VJobPostImage zum
Transfer des übergebenen Bildes. Der angegebene Speicherbereich muss über die
gesamte dauer der Bearbeitung hin gültig sein und wird nicht automatisch wieder
freigegeben.
width Gibt die Breite des Bildes in Pixel an.
height Gibt die Höhe des Bildes in Pixel an.
rowLength Gibt die Anzahl an Bytes einer Reihe an.
data Gibt die Anfangsposition des Bildes im Speicher an.
virtual ~ONG_VJobPostImage()
Virtueller Destruktor der garantiert, dass bei einem delete Aufruf auf die Basis-
klasse der Konstruktor der abgeleiteten Klasse mit aufgerufen wird.
int getImageWidth()
Die Methode getImageWidth gibt die Breite des Bildes in Pixel zurück.
int getImageHeight()
314 Low-Level Bildverarbeitung
Die Methode getImageHeight gibt die Höhe des Bildes in Pixel zurück.
int getImageRowLength()
Die Methode getImageRowLength gibt die Anzahl an Bytes einer Reihe zurück.
ONG_BYTE* getImageData()
Die Methode getImageData gibt einen Pointer auf die Bilddaten zurück.
int getReturnCode()
Die Methode getReturnCode gibt den Rückgabewert des Jobs zurück.
ONG_VJobHueConv:
class ONG_VJobHueConv : public ONG_VisionJob
ONG_VJobHueConv()
virtual ~ONG_VJobHueConv()
int getImageWidth()
int getImageHeight()
ONG_BYTE* getHueImage()
Die Klasse ONG_VJobHueConv implementiert einen VisionJob zum Konvertieren
des aktuellen Bildes in den HSV-Farbraum.
ONG_VJobHueConv()
Dieser Konstruktor erzeugt einen neuen Job vom Typ ONG_VJobHueConv zum
Konvertieren des aktuellen Bildes in den HSV-Farbraum.
~ONG_VJobHueConv()
Virtueller Destruktor der garantiert, dass bei einem delete Aufruf auf die Basis-
klasse der Konstruktor der abgeleiteten Klasse mit aufgerufen wird.
324.6 API Referenz
int getImageWidth()
Die Methode getImageWidth gibt die Breite des Ergebnisbildes zurück.
int getImageHeight()
Die Methode getImageHeight gibt die Höhe des Ergebnisbildes zurück.
ONG_BYTE* getHueImage()
Die Methode getHueImage gibt einen Pointer auf das Ergebnisbild zurück. Die-
ser Pointer ist über die Lebenszeit der Instanz gültig und wird mit der Instanz
freigegeben. Das Bild enthält pro Pixel ein Byte, welches den Hue-Wert angibt.
Die Werte von 0 bis 253 entsprechen den Hue-Winkeln von 0 bis 360 Grad.
Der Wert 254 steht für ein nicht farbiges Pixel mit einer Helligkeit von über
50%.
Der Wert 255 steht für ein nicht farbiges Pixel mit einer Helligkeit von unter 50%.
Die Bildreihen folgen im Speicher direkt aufeinander.
ONG_VJobEdgeDetect:
class ONG_VJobEdgeDetect : public ONG_VisionJob
ONG_VJobEdgeDetect()
virtual ~ONG_VJobEdgeDetect()
int getImageWidth()
int getImageHeight()
ONG_BYTE* getEdgeImage()
Die Klasse ONG_VJobEdgeDetect implementiert einen VisionJob zum Erkennen
von Kanten.
ONG_VJobEdgeDetect()
virtual ~ONG_VJobEdgeDetect()
334 Low-Level Bildverarbeitung Virtueller Destruktor der garantiert, dass bei einem delete Aufruf auf die Basis- klasse der Konstruktor der abgeleiteten Klasse mit aufgerufen wird. int getImageWidth() Die Methode getImageWidth gibt die Breite des Ergebnisbildes zurück. int getImageHeight() Die Methode getImageHeight gibt die Höhe des Ergebnisbildes zurück. ONG_BYTE* getEdgeImage() Die Methode getEdgeImage gibt einen Pointer auf das Ergebnisbild zurück. Die- ser Pointer ist über die Lebenszeit der Instanz gültig und wird mit der Instanz freigegeben. Das Bild enthält pro Pixel ein Byte welches die Steigung der Kante angibt. Der Wert 0 steht für keine Kante und der Wert 255 gibt die maximale Kantenstärke an. Die Bildreihen folgen im Speicher direkt aufeinander. Achtung: In neueren Testversion mit aktivierter Eckendetektion ist der Wert 255 für eine Ecke reserviert. 34
4.7 Code-Beispiel
4.7 Code-Beispiel
#include "ONG_Vision.h"
/ / Pseudocode zur Fr ame Abf r age
ONG_BYTE* getFrame(int width, int height);
int main()
{
int width;
int height;
ONG_BYTE* inputImg = getFrame(&width, &height);
/ / I ni t i al i si er ung der Bi l dver ar bei t ung
ONG_Vision* vision = ONG_Vision::getSingletonInst();
vision->init(width, height);
/ / Hochl aden des Bi l des
ONG_VJobPostImage* newImgPostJob;
newImgPostJob = new ONG_VJobPostImage(width, height, width, inputImg);
newImgPostJob->invoke();
newImgPostJob->waitUntilFinished();
del et e newImgPostJob;
/ / Ausf ühr en ei ner Hue Konver t i er ung ( Bayer nach Hue)
ONG_VJobHueConv* hueConvJob = new ONG_VJobHueConv();
hueConvJob->invoke();
hueConvJob->waitUntilFinished();
/ / Pseudocode zum Schr ei ben des er gebni s Bi l des
writeImageFile(hueConvJob->getImageWidth(), hueConvJob->getImageHeight(),
hueConvJob->getHueImage());
}
354 Low-Level Bildverarbeitung 36
5 High-Level Bildverarbeitung
5.1 Einleitung
Die High-Level Bildverarbeitung stellt auf Basis der Low-Level Bildverarbeitung
allgemeine Funktionen zur Kanten und Objekterkennung bereit. Sie ist im Gegen-
satz zur Low-Level Bildverarbeitung vollständig auf der CPU Implementiert.
5.2 Ontologie
Die Ontologie beschreibt die Beschaffenheit der Welt und die der darin enthal-
tenen Objekttypen. Die Ontologie verhält sich dabei zum Weltmodell, wie eine
Klasse zur Instanz. Damit beschreibt die Ontologie nicht die konkret vorhandenen
Objekte sondern nur deren Struktur.
Die Ontologie ist in dieser Bildverarbeitung als Liste von Objektbeschreibungen
implementiert. Eine Objektbeschreibung enthält je nach Objekttyp verschiedene
Attribute. Die Objektbeschreibung des Balls könnte zum Beispiel folgendermaßen
aussehen:
id Ball
Formfaktor Kreis
Farbe Rot
Ein konkretes Ballobjekt im Weltmodell könnte hingegen so aussehen:
Typ Ball
Position 100, 140
Radius 20
375 High-Level Bildverarbeitung
Abbildung 5.1: HSV Farbraum [Wik].
Das Typfeld assoziiert das Ballobjekt mit der Ballbeschreibung in der Ontolo-
gie.
Die genaue Struktur der Ontologie wird in Kapitel 5.7.3 beschrieben.
5.3 HSV-Farbraum
Der HSV-Farbraum (siehe Abbildung 5.1) beschreibt einen zylindrischen RGB
Farbraum. Die Farbe wird hier nicht aus den drei Grundfarben zusammengesetzt
sondern durch ihre Attribute definiert. Als Attribut wird der Farbton (englisch
hue), die Farbsättigung (englisch saturation) und die Helligkeit (englisch value)
genommen. Damit ergeben sich die folgende drei Achsen:
Farbton: 0 – 359
Sättigung: 0 – 100
Helligkeit: 0 – 100
Der HSV Farbraum ähnelt dem menschlichen Sehen und den physikalischen
Parametern.
Die Umrechnung folgt dem Formelsatz von Gonzalez und Woods.
385.4 Farbsegmentierung
Abbildung 5.2: Beispiel einer HSV Dekomposition (RGB, Hue, Saturation, Va-
lue).
5.4 Farbsegmentierung
Bei einer Segmentierung werden viele ähnliche Pixel zu einigen wenigen Seg-
menten zusammengefasst. Damit stellt die Binarisierung eine Segmentierung mit
nur zwei Segmenten dar. Die Schwierigkeit bei der Segmentierung besteht darin,
dass Maß der Ähnlichkeit zu definieren.
Bei der Farbsegmentierung versucht man Pixel mit ähnlicher Farbe zu einem
Segment zusammen zu fassen. In dieser Implementierung wird dazu die Differenz
des Hue-Wertes verwendet (siehe Kapitel 5.3). Dieser Prozess lässt sich in die
folgenden drei Schritte unterteilen.
1. Im ersten Schritt wird das RGB Bild in den HSV Farbraum umgerechnet.
In diesem Farbraum ist es, im Gegensatz zum RGB Farbraum, möglich die
drei Kanäle des Bildes einzeln zu betrachten. Hierbei muss man beachten,
dass die Umrechnung von RGB nach HSV nicht linear ist und von gewissen
physikalischen Gegebenheiten des Lichtspektrums Gebrauch macht. Ein
weiteres Problem bei der Umrechnung ist die numerische Genauigkeit. Da
die Wertebereiche nicht uniform auf die Achsen des Raumes fallen, kann es
durch die Quantisierung der HSV Werte zu Qualitätsverlust kommen. Dies
ist in der Praxis bei 8bit pro Kanal aber kaum messbar.
Desweiteren ist eine Sonderbehandlung für die Fälle in denen die Sättigung
oder Helligkeit nahe an Null ist nötig. Wenn Sättigung oder Helligkeit nach
der Quantisierung exakt Null sind ist der Farbwert undefiniert.
2. Im HSV Farbraum lassen sich die für die Farbsegmentierung interessanten
Pixel vom Rest sehr gut trennen. Die zwei wichtigen Kriterien hierbei sind
die Sättigung und die Helligkeit. Liegt die Sättigung unter 50% gilt das
Pixel als nicht farbig. Liegt die Helligkeit unterhalb von 10% gilt das Pixel
395 High-Level Bildverarbeitung
als schwarz. Dies spart nicht nur Berechnungen sondern führt auch zu einem
genaueren Farbhistogramm in Schritt 3.
3. Es wird ein Histogramm über den Farbkanal aufgestellt. In diesem Histo-
gramm ist für jeden Farbwert von 0 bis 255 die Anzahl an Pixel im Bild
mit genau diesem Farbwert eingetragen. Da der Farbwert eines Pixels an
Aussagekraft verliert wenn die Helligkeit oder die Sättigung abnimmt, ist
es sinnvoll, Pixel mit zu geringer Helligkeit oder Sättigung nicht in das
Histogramm mit einzubeziehen.
5.4.1 Globales Hue-Histogramm
Ein rotes Objekt auf dem Bild sollte idealerweise eine ein Farbwert breite Säule
im Histogramm ergeben. Weil das Histogramm durch die Kameraaufnahme,
die Umrechnung, eventueller Bildkompression und auch realen Faktoren in der
Szenerie verrauscht ist, ergibt sich eine Normalverteilung um den Rotwert des
Objektes herum. Um nun das Objekt vom Rest des Bildes zu separieren muss man
die Grenzen dieser Verteilung ermitteln (siehe Abbildung 5.3).
Um die Grenzen zwischen den einzelnen Anhäufungen im Histogramm besser
detektieren zu können, wird das Histogramm zunächst geglättet. Dies geschieht
mit Hilfe einer Gaußglocke.
Glättet man das Histogramm zu stark entfallen zunehmend, von der Fläche her
kleine Objekte.
Glättet man dagegen zu schwach werden größere Objekte, anstatt in ein Segment,
in mehrere unterteilt. In der Praxis ist es leicht möglich einen allgemeingültigen
Wert zu finden, weil Objekte bei einer hohen Bildauflösung von der Größe einiger
weniger Pixel nicht relevant sind.
Nach der Glättung werden die lokalen Minima des Histogramms berechnet. Je-
weils der Zwischenraum zwischen zwei Minima definiert den Hue-Bereich eines
Segmentes. Dabei ist zu beachten, dass der Hue-Kanal kreisförmig schließt und
deshalb auch Segmente über die Ansatzstelle (bei 0 beziehungsweise 360 Grad)
hinweg, zusammenhängend betrachtet werden müssen.
405.5 Objekterkennung
Abbildung 5.3: Hue Binarisierung.
5.5 Objekterkennung
Bei der Objekterkennung werden Gruppen von zusammenhängenden Pixeln des
selben Segments, anhand der Objektbeschreibung in der Ontologie, klassifiziert.
Anschließend werden zusätzliche Attribute des Objektes, wie zum Beispiel Positi-
on und Fläche, ermittelt.
Es ist üblicherweise sehr zeitaufwendig zusammenhängende Pixelgruppen in
Bildern zu detektieren. Aus diesem Grund wird in dieser Implementierung eine
blockbasierte Annäherung eingesetzt.
5.5.1 Blockbasiertes Hue-Histogramm
Um das blockbasierte Hue-Histogramm zu erstellen wird das Kamerabild zu-
nächst in 64x64 Pixel große Blöcke eingeteilt. Bei einer nutzbaren Auflösung von
768x768 Pixeln ergeben sich so 144 Blöcke. Für jeden dieser Blöcke wird nun ein
Hue-Histogramm, wie in Kapitel 5.4 beschrieben erstellt. In der Implementierung
lässt sich dieser Schritt mit der Generierung des globalen Histogramms zusam-
menfassen und kann so nahezu ohne extra Zeitaufwand ausgeführt werden.
Wird nun eine Pixelgruppe mit einem bestimmten Hue-Bereich im Bild gesucht,
ermittelt man zunächst für jeden Block die Anzahl an Pixel dieses Hue-Bereichs.
Dieser Füllwert wird berechnet indem man die Histogrammwerte innerhalb des
Hue-Bereichs aufsummiert. Auf diese Weise können Blöcke die nahezu keine
Pixel des gesuchten Hue-Bereichs enthalten bei der Suche vernachlässigt werden.
Bei größeren Objekten reicht es oft schon, nur die Blöcke und deren Füllmenge
zu betrachten.
415 High-Level Bildverarbeitung
Abbildung 5.4: Beispiel einer erfolgreichen Farbsegmentierung.
425.6 Lokalisierung
5.5.2 Objektattribute
Um die Objektattribute wie zum Beispiel Fläche, Position und genaue Farbe zu
bestimmen, reicht es aus, die Histogramme der entsprechenden Blöcke aus Kapitel
5.5.1 zu betrachten.
Die Fläche des Objektes lässt sich grob über die Summe der Füllmengen der
Blöcke annähern. Wenn man die Blockpositionen anhand der Füllmengen gewich-
tet mittelt, erhält man eine ungefähre Position des Objektes. Durch mitteln der
Histogrammwerte innerhalb des Hue-Bereichs der Blockhistogramme erhält man
einen sehr genauen Farbwert für das Objekt.
5.5.3 Border Tracing
Benötigt man weitere Objektattribute wie zum Beispiel den Umfang, oder eine
genauere Position bei Objekten unterhalb der Blockgröße, reicht die Information
der Blockhistogramme alleine nicht mehr aus.
In diesem Fall muss die Pixelgruppe detektiert und genauer ausgewertet werden.
Zu diesem Zweck werden die ausgewählten Blöcke sequentiell gescannt bis das
erste Pixel des angefragten Segmentes gefunden werde. Danach läuft eine Border
Tracer um das Objekt herum. Aus der Umrandung des Objektes können nun
weitere Attribute gewonnen werden. In der aktuellen Implementierung ist diese
Funktionalität nicht aktiviert, weil sie noch unzureichend getestet wurde.
5.6 Lokalisierung
Eine der Hauptschwierigkeiten der Robotik besteht darin den Roboter zu lokali-
sieren, also seine Position relativ zum Modell der Welt zu ermitteln.
Es gibt mehrere grundlegend verschiedene Herangehensweisen an dieses Problem.
Eine der einfachsten und zugleich sehr effektiven besteht in der Odometrie. Bei
der Odometrie wird die bei Bewegungen in der Welt zurückgelegte Wegstrecke,
gemessen. Dieses geschieht im Robocup meist über Encoder an den Rädern des
Roboters. Diese Encoder liefern eine sehr präzise Auskunft über die erfolgte
Drehung des Rades. Summiert man all diese kleinen Bewegungen auf und addiert
die Startposition hinzu, erhält man die aktuelle absolute Position in der Welt.
435 High-Level Bildverarbeitung Die Methode der Odometrie liefert auf kurze Distanzen noch exakte Ergebnisse. Durch Messungenauigkeit und Radschlupf entsteht bei jeder Messung jedoch ein kleiner Fehler. Wird der zurückgelegte Weg länger nimmt die Genauigkeit aufgrund von Fehlerakkumulation schnell ab. Die berechnete Position driftet über die Zeit immer weiter von der Realen Position ab. Aufgrund dieses Verhaltens kann die Odometrie nicht alleine zur Lokalisierung verwendet werden. Es besteht jedoch die Möglichkeit sie in Verbindung mit anderen Lokalisierungsverfahren einzusetzen. Eine weitere Methode der Lokalisierung besteht in der Bildverarbeitung. Hierbei besteht das Grundprinzip darin die Welt vom aktuellen Standpunkt aus aufzuneh- men und mit einem bekannten Modell der Welt zur Deckung zu bringen. Anhand der relativen Transformation kann somit die aktuelle Position bestimmt werden. Das zur Berechnung der relativen Transformation benutze Verfahren nennt man Matching-Verfahren. Es gibt eine Vielzahl von Modellen und Matching-Verfahren die je nach Anwen- dungsgebiet mehr oder weniger geeignet sind. Das nächstliegendste Verfahren ist das Bild zu Bild Matching. Hierbei wird die relative Transformation zwischen zwei Bildern berechnet. Ein solches Matching-Verfahren ist das des Optischen Flusses von Horn und Schunk. Die Nachteile von Matching-Verfahren dieser Art in Bezug auf den Robo- cup besteht darin, dass ein Referenzbild der Welt nur schwer zu erstellen ist und mit dem aktuellen Bildausschnitt des Roboters nur teilweise übereinstimmen wür- de. Die Unterschiede der beiden Bilder sind hauptsächlich auf bewegte Objekte wie z.B. andere Spieler aber auch durch die starke Verzerrung des Kamerabildes zurückzuführen. Aufgrund dieser Probleme ist man im Robocup dazu übergegan- gen nicht zwei Bilder miteinander zu vergleichen, sondern anstelle dessen nur die Merkmale dieser Bilder. Diese Implementierung setzt dabei auf Kanten als Merkmale weil die Spielfeldlinien einen guten Anhaltspunkt bei der Lokalisierung bieten. 5.6.1 Sobel-Operator Beim Sobel-Operator handelt es sich um einen in der Bildverarbeitung weit ver- breiteten Filter zur Kantendetektion. Dieser Filter führt eine diskrete Ableitung des Bildes durch. Der Sobel Operator wird durch eine Convolution Maske (sie- he Abbildung 5.5) abgebildet. Eine solche Sobel Maske führt nur eine partielle Ableitung, in diesem Beispiel eine Ableitung in der X-Achse, durch. Um eine 44
5.6 Lokalisierung
Abbildung 5.5: Convolution Maske eines Sobel-Operators in X und Y Richtung.
Abbildung 5.6: Originalbild und Ergebnis des Sobel-Operators.
455 High-Level Bildverarbeitung vollständige Ableitung zu erhalten muss man mehrere Sobel Operationen durch- führen. Auf einem zweidimensionalen Bild sind zwei Operationen erforderlich. Eine für die X-Achse und eine für die Y-Achse. Das zweidimensionale Ergebnis dieser Operation stellt den Gradienten dar. Der Gradient besteht auf einer Richtung welche den Normalen und einer Länge welche die Stärke der Kante angibt. Für die Kantenerkennung kann die Normale vorerst vernachlässigt werden. In Abbildung 5.6 ist ein Beispiel Bildausschnitt und die dazugehörige Länge der Gradienten als Graufstufenbild abgebildet. Das Gradientenbild ist nahezu schwarz und nur die Kanten im Ausgangsbild zeichnen sich durch mehrere Pixel breite helle Linien im Gradientenbild ab. Die Breite der Linie variiert je nach Kontrast und schärfe der Kante. Ein solches Bild stellt zwar für einen Menschen eine gute Repräsentation der Kanten im Bild dar, ist aber von einem Algorithmus nur sehr schlecht auszuwerten. Dies liegt an der breite der Linien und dem stetigen hell zu dunkel Übergang in Richtung des Normalen. 5.6.2 Canny Edge Detection Weil das Ergebnis der Sobel Operation zum Detektieren der Kanten nicht geeignet ist muss noch ein weiterer Schritt aufgeführt werden. In diesem Schritt der Non- Maximum-Suppression wird die mehrere Pixel breite Linie des Sobel-Operators auf eine genau einen Pixel breite Linie reduziert [Can86]. Dies wird dadurch erreicht, dass alle Pixel, die nicht das Lokale Maximum an Steigung der Kante darstellen ausmaskiert beziehungsweise unterdrückt werden. Das Maximum der Kante ist durch ein Lokales Maxima in Richtung des Normalen definiert. Der Normale der Kante ergibt sich aus dem normalisierten Gradienten und zeigt quer zur Kante. Es existiert ein lokales Maxima wenn die Ableitung in Richtung des Normalen gleich Null ist. Diese exakte mathematische Definition kann nicht direkt verwendet werden da aufgrund der diskreten Positionen der Pixel in der Praxis nahezu alle Pixel der Kante unterdrückt würden. Dies ist damit zu erklären das die Pixel Positionen nur sehr selten auf dem exakten kontinuierlichen Verlauf der Kante liegen. Um jedes Pixel entlang der Kante zu erkennen muss die mathematische Definition folgendermaßen angepasst werden. Ein lokales Maxima existiert, wenn das Pixel vor und hinter dem aktuellen, in Richtung des Normalen einen geringeren Steigungswert enthält. Abbildung 5.9 zeigt ein mit diesem Non- Maximum-Suppression Filter gefiltertes Ergebnis einer Sobel Operation. Es ist gut zu erkennen das die breiten Kanten des Sobel Operators bis auf einen genau 1 Pixel breiten Grad ausgedünnt wurden. Ein solches Bild ist zur Kantendetektion optimal geeignet. 46
5.6 Lokalisierung
Abbildung 5.7: Eine exakt einen Pixel breite, gerade Linie mit eingezeichneten
Gradienten.
5.6.3 Eckendetektion
Bei der Kantendetektion werden die zusammenhängenden Pixel einer Kante
durch einen Vektor ersetzt. Ein solcher Vektor besteht aus einer Start und einer
End Position und ist deshalb nicht in der Lage Bögen zu beschreiben. Da das
Kamerabild im Robocup aufgrund der Spiegelgeometrie der OmniVideo stark
verzerrt ist werden die geraden Spielfeldlinien die zur Lokalisierung besonders gut
geeignet sind gebogen abgebildet. Bei Umwandeln der Pixel Linien in Vektoren
entstehen aus diesem Grund große Abweichungen. Diese Abweichungen sind
aber zu vernachlässigen da die Vektoren anschließend von Bildkoordinaten auf
Spielfeldkoordinaten umgerechnet werden. Bei dieser Umrechnung werden die
Linien wieder gerade und die Abweichungen entfallen. Dies geschieht natürlich
nur wenn die wirkliche Linie in Spielfeldkoordinaten eine Gerade ist. Wenn nun
mehrere Geraden, verbunden durch rechte Winkel, durch einen Vektor ersetzt
werden, entsteht ebenfalls eine Abweichung. Diese Abweichung entfällt jedoch
nicht bei der Umrechnung in Spielfeldkoordinaten. Aus diesem Grund dürfen
Linien nicht über Ecken hinweg durch einen Vektor ersetzt werden. Um dieses
Verhalten zu erreichen müssen die Kanten an den Ecken unterbrochen werden.
Aus diesem Grund ist es nötig die Ecken zu detektieren.
Bei näherer Betrachtung einer durch einzelne Pixel angenäherten Linie sieht
man, dass die Winkel zwischen den Pixeln nur Werte von 0, 45 und 90 Grad
annehmen können. Es fällt auch auf, dass die Winkel als solche in Bezug auf die
Detektion von Ecken, nicht aussagekräftig genug sind da selbst 90 Grad Winkel
an fast geraden Stellen der Kante auftreten. Es gibt drei Methoden zusätzliche
Information über den realen Winkel einer Linie zu erhalten.
• Die erste Methode besteht darin, die einzelnen Winkel zwischen den Pixeln
über einen Bereich der Linie zu betrachten. Die so gewonnene Menge an
Winkeln kann zu einem Winkel gewichtet werden. Die Summe der Winkel
über einen Abschnitt der Kante ergibt die relative Richtung vom Endstück
zum Anfang des Abschnitts. Diese relative Ausrichtung kann auf einem
475 High-Level Bildverarbeitung
Abbildung 5.8: Eine exakt einen Pixel breite, abgeknickte Linie mit eingezeich-
neten Gradienten.
nahezu geraden Abschnitt mit geringem Rauschen bereits bis zu 180 Grad
betragen (siehe Abbildung 5.7) und ist deshalb kein zuverlässiges Attribut
für eine Ecke. Auch eine Gaußgewichtung der einzelnen Winkel behebt
dieses Problem nicht.
• Eine weitere Methode der Eckendetekion besteht in dem maximalen Ab-
stand des Linienabschnitts zur gradlinigen Verbindung von Anfangs und
Endpunkt. Mithilfe dieser Methode lassen sich Ecken zuverlässig detek-
tieren solange die Länge des Abschnitts und der Schwellenwert für den
maximalen Abstand gut gewählt werden. In der Praxis ist es aber nicht
möglich allgemeingültige Werte hierfür zu finden weil diese stark von der
Länge und Form der Linie abhängen.
• Da die einzelnen Winkel weder alleine noch über einen Abschnitt hinweg
ausreichen Ecken zuverlässig zu detektieren, verwendet diese Bildverarbei-
tung zusätzlich die Gradienten der Linienpixel. Die Gradienten enthalten
zusätzliche Informationen weil sie vor der Non-Maximum-Suppression
berechnet wurden und so den "weichen" Verlauf der Linie mit berücksich-
tigen. Dies macht sich besonders in folgendem Beispiel bemerkbar (siehe
Abbildung 5.7). Hier wurde eine nahezu gerade Linie, generiert durch einen
Sobel Operator, mithilfe der Non-Maximum-Suppression auf eine diskrete
genau 1 Pixel breite Linie reduziert. Dabei sind einzelne Winkel von bis
zu 90 Grad entstanden. Die Gradienten der Pixel sind durch einen Pfeil
dargestellt. Sie weisen selbst an der Stelle, an der die Pixellinie einen 90
Grad Knick macht keine Unregelmäßigkeit auf. Im Falle einer Ecke ver-
halten sich die Gradienten wie in Abbildung 5.8 dargestellt. Es ist gut zu
erkennen wie die Gradienten sich über die diskreten Pixel hinweg stetig
in der Ausrichtung ändern. Diese Stetigkeit hat neben dem Vorteil, dass
Störungen durch Diskretisierung ausbleiben, aber auch den Nachteil, das
Ecken sich nicht über eine abrupte Änderung sondern über einen Abschnitt
48Sie können auch lesen

















































