Entwicklung eines Regressionsmodells für die Vollständigkeitsanalyse des globalen OpenStreetMap-Datenbestands an Nahverkehrs-Busstrecken - gis.Point
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Full Paper 239 Entwicklung eines Regressionsmodells für die Vollständigkeitsanalyse des globalen OpenStreetMap- Datenbestands an Nahverkehrs-Busstrecken Development of a Regression Model for the Analysis of Local Bus Route Data Completeness on OpenStreetMap Oliver Fritz1,2, Michael Auer2, Alexander Zipf1,2 1Universität Heidelberg 2Heidelberg Institute for Geoinformation Technology (HeiGIT) · oliver.fritz@heigit.org Zusammenfassung: Die Qualität der Geodaten auf OpenStreetMap (OSM) zeichnet sich durch Hete- rogenität aus. Ergebnisse herkömmlicher Ansätze zur Qualitätsbewertung, die auf dem Vergleich mit Referenzdaten beruhen, können nicht auf den gesamten Datenbestand übertragen werden. Daher wer- den für die Vollständigkeitsanalyse von OSM-Daten zumeist intrinsische Methoden verwandt. Hier wird ein neuer Ansatz vorgeschlagen, bei dem Referenzdaten über ein Regressionsmodell erzeugt wer- den. Mittels demografischer und sozioökonomischer Indikatoren sowie sporadisch verfügbarer GTFS- Daten wird die Anzahl von Nahverkehrs-Busstrecken auf die Zellen eines globalen Hexagon-Rasters vorhergesagt, um die Ergebnisse mit dem OSM-Datenbestand abzugleichen. Schlüsselwörter: Geodatenqualität, OpenStreetMap, ÖPNV, VGI Abstract: The quality of geodata on OpenStreetMap (OSM) is characterized by heterogeneity. Results of conventional approaches of quality assessment based on the comparison with reference data can thus not be applied to the entire dataset. Hence, the completeness of OSM data is usually analysed using intrinsic methods. Here, we propose a novel approach that consists in the generation of reference data via a regression model. Using demographic and socio-economic raster datasets and sporadically available GTFS data, the number of local bus routes is predicted on the cells of a global hexagon grid. The results are compared with the OSM dataset. Keywords: Geodata quality, OpenStreetMap, Public Transport, VGI 1 Motivation Ziel dieser Analyse ist, mittels eines Regressionsmodells Werte für die Anzahl von Nahver- kehrs-Busstrecken in einzelnen Betrachtungsgebieten vorherzusagen. Durch Vergleich der vorhergesagten Werte mit der Anzahl der entsprechenden in OSM erfassten Relationen kön- nen Aussagen zur Objektvollständigkeit getroffen werden. Die Verfügbarkeit von Geodaten zum öffentlichen Personennahverkehr (ÖPNV) ist die Vor- aussetzung für die Bearbeitung einer Vielzahl gesellschaftsrelevanter räumlicher Fragestel- lungen. Diese Daten bilden die Grundlage für die (multi-modale) Navigation, für Erreichbar- keitsanalysen oder für die Optimierung von Streckenführungen und Fahrplänen. Der Nutzen ist besonders groß, wenn sie offen vorliegen und ohne Weiteres in Anwendungen und Ana- lysen Dritter eingebunden werden können. Derzeit ist nur ein Bruchteil der weltweiten Geo- daten zum ÖPNV offen verfügbar (Colpaert & Rojas Meléndez, 2019). Eine Lösung für die Erfassung und Bereitstellung von Daten zu ÖPNV-Netzen ist das Crowdsourcing. Open- AGIT ‒ Journal für Angewandte Geoinformatik, 7-2021, S. 239-248. © Wichmann Verlag, VDE VERLAG GMBH · Berlin · Offenbach. ISBN 978-3-87907-707-6, ISSN 2364-9283, eISSN 2509-713X, doi:10.14627/537707025. Dieser Beitrag ist ein Open-Access-Beitrag, der unter den Bedingungen und unter den Auflagen der Creative Commons Attribution Lizenz verbreitet wird (http://creativecommons.org/licenses/by-nd/4.0/).
240 AGIT – Journal für Angewandte Geoinformatik · 7-2021 StreetMap (OSM) bietet sich als globale Plattform für Volunteered Geographic Information (VGI; Goodchild, 2007) an: OSM ist universell und für die Erfassung jeglicher Objekte mit einer verifizierbaren Position auf der Erde geeignet (Minghini et al., 2019). ÖPNV-Daten können daher mit vorhandenen Geo-Objekten in Beziehung gesetzt werden (z. B. Busstrecken mit den Straßenabschnitten, auf denen sie verlaufen). OSM verfügt über ein flexibles Daten- modell, das durch tags (d. h. Schlüssel-Wert-Paare) beliebig erweitert und an regionale Ge- gebenheiten angepasst werden kann, aber auch tagging schemes als De-facto-Standards für Anwendungsfälle wie den ÖPNV bereithält. In OSM gespeicherte Daten verbleiben im Be- sitz der Gemeinschaft der Mitwirkenden und sind über eine offene Lizenz zugänglich. Die Gemeinschaft kann gezielt mobilisiert werden (Scholz et al., 2018), um Lücken im Datenbe- stand zu schließen – ggf. unter Einsatz von Werkzeugen zur Synchronisierung von existie- renden GTFS-Daten mit OSM (siehe z. B. Tran et al., 2013). Obwohl VGI von hoher Qualität sein können, zeichnen sie sich zumeist durch eine beträcht- liche Heterogenität insbesondere in der Objektvollständigkeit aus (Ballatore & Zipf, 2015; Gröchenig et al., 2014; Neis et al., 2012). Die Abhängigkeit der Qualität von VGI vom je- weiligen konkreten Betrachtungsgebiet (Roick et al., 2011) ist in diversen Untersuchungen bestätigt worden (z. B. Girres & Touya, 2010; Haklay, 2010; Zielstra & Zipf, 2010). Die Datenqualität ist im Allgemeinen im städtischen Raum besser als im ländlichen (Neis & Ziel- stra, 2014). Sie unterscheidet sich von Land zu Land (Ma et al., 2015) und selbst innerhalb von Städten nach Beliebtheit der Stadtteile (Costa Fonte et al., 2017). Qualitätsunterschiede stehen oft in Zusammenhang mit sozioökonomischen Rahmenbedingungen (Ballatore & Zipf, 2015). Je nach Gebiet unterscheidet sich die Anzahl der potenziellen Mitwirkenden, die über den technischen Zugang, über notwendiges Wissen und Fertigkeiten sowie über Zeit und Muße für Beiträge zu VGI-Projekten verfügen (Costa Fonte et al., 2017). Die herkömmliche extrinsische Qualitätsbewertung von VGI beschränkt sich auf Regionen, für die brauchbare Referenzdaten vorliegen (z. B. Cipeluch et al., 2010; Forghani & Delavar, 2014; Graser et al., 2015; Zielstra & Zipf, 2010). Da die Qualität der OSM-Daten nicht ho- mogen ist, können Ergebnisse solcher Analysen nicht auf andere Gebiete oder den globalen Gesamtbestand übertragen werden. Oft besteht die Lösung in der Anwendung intrinsischer Methoden, bei denen die Qualität aus den zu bewertenden Daten selbst, aus deren Bearbei- tungshistorie und aus dem Verhalten der Bearbeitenden ermittelt wird (Minghini & Frassi- nelli, 2019). Hier wird ein Ansatz vorgeschlagen, der auf der Erzeugung globaler Referenz- daten über ein Regressionsmodell aus weltweit vorliegenden demografischen und sozioöko- nomischen Indikatoren beruht. 2 Methode 2.1 Regelmäßige Aufteilung des Raums Um die Heterogenität der Objektvollständigkeit im globalen Datenbestand angemessen ab- bilden zu können, wurde ein globales Raster in der Icosahedral Snyder Equal Area Aperture 3 Hexagon-Projektion (ISEA3H; Sahr, 2019) der Auflösungsstufe 10 erstellt, das die Erd- oberfläche in 590.492 Hexagone zerlegt. Die resultierenden Hexagone sind mit einer Fläche von je 863,80 km2 gleich groß. Ermittelte Zählwerte können daher ohne weitere Normalisie- rung verglichen werden. Die Hexagon-Größe der gewählten Auflösungsstufe entspricht am ehesten der durchschnittlichen Fläche eines Busnetzwerkes in den extrahierten GTFS-Daten.
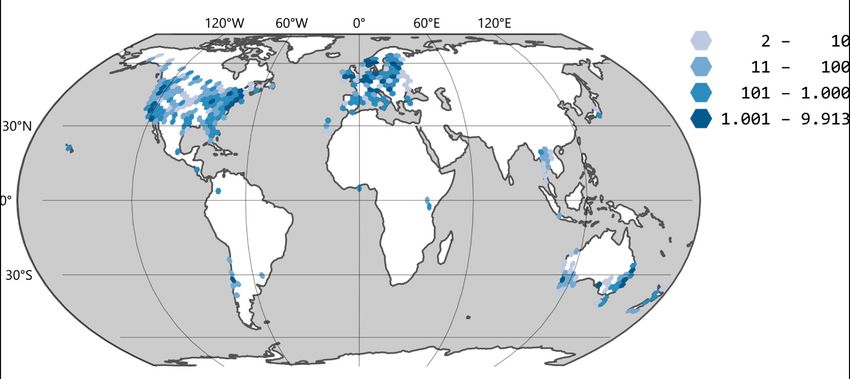
O. Fritz et al.: Regressionsmodell für die Vollständigkeitsanalyse des OSM-Datenbestands 241 Für die Vorhersage der Anzahl der Busstrecken wurden nur Hexagone mit Landanteil (An- zahl: 180.978) berücksichtigt. 2.2 Datengrundlage 2.2.1 OpenStreetMap Für die Aggregation der Zählwerte der OSM-Objekte auf die Betrachtungsgebiete wurde die ohsome API verwendet (Auer et al., 2018), welche Zugang zu den Daten der OpenStreetMap History Database (OSHDB; Raifer et al., 2019) per GET- oder POST-Anfragen bietet. Es wurde die Anzahl der Busstrecken für ISEA3-Hexagone der Auflösungsstufe 10 (s. oben) und einen einzelnen Datenbank-Zeitpunkt („2020-06-01”) ermittelt. 2.2.2 GTFS Die General Transit Feed Specification (GTFS) ist ein De-Facto-Standard für die interope- rable Veröffentlichung von Daten zum öffentlichen Verkehr (Braga et al., 2014). Aus offenen GTFS-Daten der Kataloge von OpenMobilityData 1 und Transitland 2 wurden Geometrien von insgesamt 126.600 Nahverkehrs-Busstrecken aus 886 verschiedenen ÖPNV-Netzwerken weltweit extrahiert. Die Anzahl der Busstrecken wurde auf die ISEA3-Hexagone der Auflö- sungsstufe 10 aggregiert (vgl. Abb. 1). Busstrecken, die mehrere Hexagone schneiden, wur- den dabei mehrfach gezählt. Abb. 1: Anzahl der extrahierten Busstrecken je ISEA3-Hexagon (hier: Auflösungsstufe 6) Die Verwendung der Daten als Referenz ist nicht unproblematisch: Sie sind nicht Ergebnis einer Zufallsauswahl, sondern einer Auswahl des Verfügbaren, in der beispielsweise Regio- nen in Ländern mit hohem Einkommen überrepräsentiert sind. Der jeweilige räumliche Gel- tungsbereich eines GTFS-Datensatzes kann nicht präzise ermittelt werden. Es kann nicht zweifelsfrei davon ausgegangen werden, dass ein GTFS-Datensatz für die ÖPNV-Infrastruk- tur eines bestimmten Gebietes vollständig ist. Vor allem aber fehlt es an gesicherten Infor- 1 https://openmobilitydata.org/ 2 https://www.transit.land/
242 AGIT – Journal für Angewandte Geoinformatik · 7-2021 mationen über Gebiete, die nicht durch ÖPNV erschlossen sind, da für diese keine GTFS- Daten vorliegen. 2.2.3 Demografische und sozioökonomische Indikatoren Es ist anzunehmen, dass die ÖPNV-Infrastruktur einer Region u. a. von der Bevölkerungs- zahl, Urbanität und Wirtschaftsleistung abhängt. Es wurde daher nach in globalen Rasterda- tensätzen frei zur Verfügung stehenden demografischen und sozioökonomischen Indikatoren gesucht. Die im Folgenden beschriebenen Datensätze wurden auf die ISEA3-Hexagone ag- gregiert, auf tatsächliche Korrelation mit der Anzahl der Busstrecken geprüft und als Regres- soren im Regressionsmodell eingesetzt: WorldPop (2018) bietet Bevölkerungsschätzwerte in einem globalen Rasterdatensatz mit 30 Bogensekunden Auflösung. Die Daten beruhen auf einer dasymetrischen Umverteilung von Zensusdaten auf Grundlage eines Random-Forest- Modells, in das eine Vielzahl von unterschiedlichen Geodaten einfließt, wodurch eine hohe Genauigkeit erreicht wird (Stevens et al., 2015). Verwendet wurde der aktuellste Datensatz (Stand 2020). Nächtliche anthropogene Lichtemission ist ein Proxy-Indikator für Urbanität, Bevölkerungsdichte und wirtschaftliche Aktivität (Mellander et al., 2015). Verwendet wurde ein globales Jahreskomposit (Stand 2016) der Black-Marble-Produktserie, die eine verbes- serte Filterung von Lichtemissionen nicht-menschlichen Ursprungs bietet (Román et al., 2018). Der Global Human Settlement Layer (GHSL, 2019) bietet aktuelle globale Rasterda- ten zur Bebauungsdichte, die in der die Aggregation vereinfachenden flächentreuen Moll- weide-Projektion zur Verfügung stehen. Verwendet wurde ein Landsat-basierter Datensatz mit für diese Zwecke ausreichender Auflösung von 1 km. Die Kohlenstoffdioxid-Emission aus der Verbrennung fossiler Brennstoffe ist ein weiterer Proxy-Indikator für menschliche Aktivität und insbesondere für Verkehr. Das Fossil Fuel Data Assimilation System (FFDAS; Asefi-Najafabady et al., 2014) stellt einen weltweiten Rasterdatensatz in der Auflösung von einem Zehntelgrad zur Verfügung. Da dieser auch Emissionen aus dem internationalen Flug- verkehr und aus Kraftwerken berücksichtigt, kann es zwar zu örtlichen Verzerrungen kom- men. Insgesamt verbessert der Einbezug dieser Daten aber die Vorhersagequalität des Mo- dells. 2.3 Regressionsmodell Auf Grundlage der nicht flächendeckend verfügbaren GTFS-Daten und der in globalen Ra- stern verfügbaren demografischen und sozioökonomischen Indikatoren wurde ein Modell zur Vorhersage der realen weltweiten Verbreitung von Busstrecken entwickelt. Damit sollten die großen Lücken in der Verfügbarkeit von Referenzdaten durch Verwendung von vorherge- sagten Werten geschlossen und eine Vollständigkeitsanalyse für den globalen Datenbestand ermöglicht werden. Für 3.438 ISEA3-Hexagone der Auflösungsstufe 10 konnte die Anzahl der Busstrecken aus GTFS-Daten extrahiert werden. In drei Fällen fehlt der Wert mindestens einer der unabhängigen Variablen. Die verbliebenen 3.435 Hexagone (ca. 1,9 % aller Hexa- gone mit Landanteil) wurden in einen Trainings- (n = 2.750; 80 %) und einen Testdatensatz (n = 685; 20 %) aufgeteilt. Es wurden fünf unterschiedliche Regressionsmodelle zur Vorher- sage der Anzahl der Busrouten angepasst. Zwei einfache generalisierte lineare Modelle je- weils für eine Quasi-Poisson (GLM-QP) und eine negative Binomialverteilung (GLM-NB) in der Antwortvariable (Zeileis et al., 2008) dienen als Benchmark. Um den möglichen Effekt der Kollinearität der Regressoren (vgl. Abb. 2) zu minimieren, wurde ein regularisiertes ge- neralisiertes Modell (GLMNET, Simon et al., 2011) angepasst. In den vorgenannten Fällen wurden die Regressoren einer Yeo-Johnson-Power-Transformation (Yeo & Johnson, 2000)
O. Fritz et al.: Regressionsmodell für die Vollständigkeitsanalyse des OSM-Datenbestands 243
unterzogen, um sie der Normalverteilung anzunähern. Weder das generalisierte additive Mo-
dell (GAM; Wood, 2017) noch das Random-Forest-Modell (RF; Wright & Ziegler, 2017)
benötigen diese Transformation. Beim GAM-Modell ist die Antwortvariable linear von Glät-
tungsfunktionen der Regressoren abhängig. RF-Modelle beruhen auf Ensembles aus einer
Vielzahl von Entscheidungsbäumen. Sie setzen nicht die Linearität der Variablenbeziehun-
gen voraus, sind robust, aber weniger unmittelbar interpretierbar als lineare Regressionsmo-
delle. Die Anpassung der Modelle erfolgte jeweils durch Optimierung der Wurzel der mitt-
leren Fehlerquadratsumme (RMSE) im Rahmen einer fünfmal wiederholten zehnfachen
Kreuzvalidierung (CV). Im Anschluss wurden die Modelle durch Vorhersage auf die Test-
daten geprüft.
3 Ergebnisse
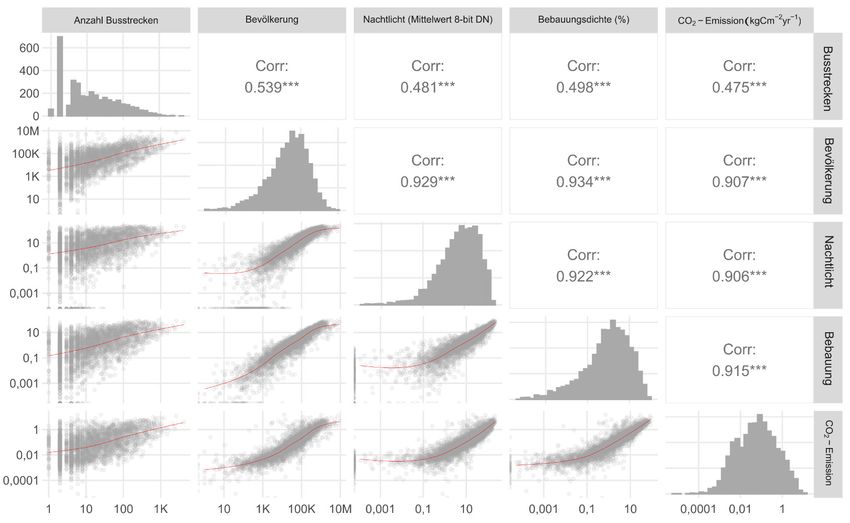
Es bestehen jeweils statistisch signifikante und moderat starke Korrelationen zwischen den
unabhängigen und der abhängigen Variable (Abb. 2), welche die Hypothese eines Zusam-
menhangs der ÖPNV-Infrastruktur mit Bevölkerungszahl, Urbanität und Wirtschaftsleistung
untermauern.
Abb. 2: Korrelations- und Streudiagrammmatrix (Spearman-Korrelation, logarithmische
Transformation)
Die Beziehungen erscheinen nach logarithmischer Transformation als annähernd linear. Die
starke Korrelation der unabhängigen Variablen untereinander ist sachlich plausibel und auch
dadurch bedingt, dass diese Datensätze ihrerseits Ergebnisse von Modellen sind, in die meist
mehrere der jeweils anderen Variablen eingeflossen sind.244 AGIT – Journal für Angewandte Geoinformatik · 7-2021
Tabelle 1 gibt eine Zusammenfassung der Ergebnisse der Regressionsmodelle wieder. Auf-
grund der stark rechtsschiefen Verteilung der Antwortvariablen ist der RMSE-Wert der Mo-
delle allein wenig aussagekräftig, da er übermäßig durch große absolute Abweichungen der
Vorhersagewerte in Gebieten mit ungewöhnlich vielen Busstrecken beeinflusst wird. Als
Grundlage für die Vorhersage der Anzahl der Busstrecken wird daher das RF-Modell ausge-
wählt, das bessere Ergebnisse in der Wurzel der mittleren logarithmischen Fehlerquadrat-
summe (RMSLE) erreicht, die Aufschluss über den relativen Vorhersagefehler gibt.
Tabelle 1: Zusammenfassung der Regressionsmodelle
Modell Hyperparameter RMSE RMSE RMSLE
(in-sample CV) (out-of-sample) (out-of -sample)
GLM-QP – 140,80 181,59 1,50
GLM-NB – 154,21 182,63 1,47
GLMNET alpha = 1 141,07 187,61 1,73
lambda = 0,1
GAM select = TRUE 138,58 187,86 –
method = GCV.Cp
RF mtry = 2 134,17 185,67 1,42
splitrule = extratrees
min.node.size = 5
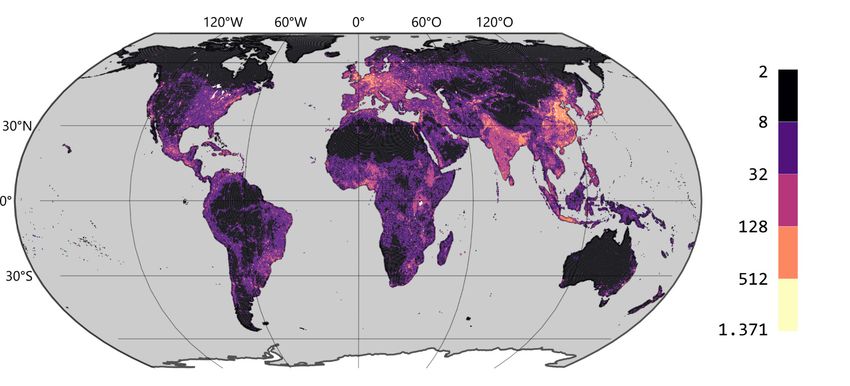
Auf Grundlage des ausgewählten Regressionsmodells kann die Anzahl der Busstrecken je
ISEA3-Hexagon vorhergesagt werden (Abb. 3). Zu beachten ist, dass sich wegen der fehlen-
den Gebiete ohne ÖPNV in den Trainingsdaten eine Mindestanzahl von zwei Busstrecken
ergibt. Für die Ableitung von Aussagen zur Vollständigkeit im OSM-Datenbestand bedeutet
dies, dass diese gerade in Gebieten, in denen sie aufgrund der Nichtexistenz entsprechender
Objekte in der Realität erreicht ist, stark unterschätzt wird.
Abb. 3: Vorhergesagte Anzahl der Busstrecken je ISEA3-HexagonO. Fritz et al.: Regressionsmodell für die Vollständigkeitsanalyse des OSM-Datenbestands 245
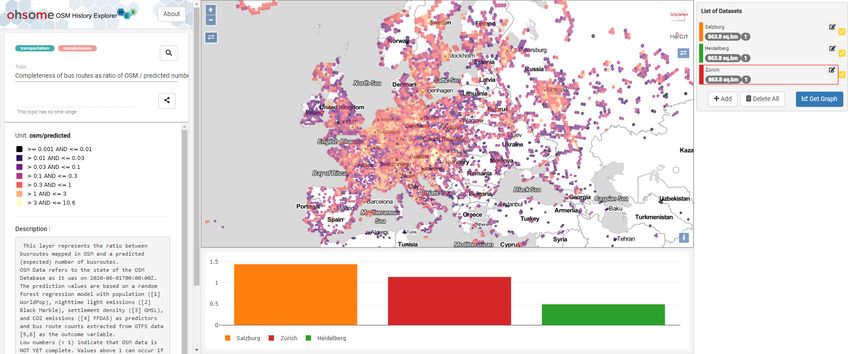
Nach Erzeugung der flächendeckenden Referenzdaten kann die Vollständigkeit des OSM-
Datenbestands beurteilt werden, indem die Anzahl der OSM-Objekte mit der vorhergesagten
Objektzahl abgeglichen wird. Neben der einfachen Differenzbildung bietet sich die Ermitt-
lung des Verhältnisses zwischen OSM-Datenbestand und Vorhersage für den Vergleich an,
zumal dies die relevantere relative Abweichung wiedergibt. Die Ergebnisse können in der
Webapplikation ohsome History Explorer 3 (ohsomeHeX) erkundet werden (Abb. 4). Die in-
teraktive Visualisierung vermag einen Überblick darüber zu geben, wo und in welchem Maße
Lücken im OSM-Datenbestand anzunehmen sind. Die Ergebnisse stehen so zur Qualitätsein-
schätzung und zur Planung gezielter Datenerfassung durch die Gemeinschaft der OSM-
Mitwirkenden zur Verfügung.
Abb. 4: Visualisierung des Verhältnisses der OSM-Busstrecken zur vorhergesagten Anzahl
(Screenshot ohsomeHeX)
4 Diskussion
Mittels in weltweiten Rasterdatensätzen verfügbarer demografischer und sozioökonomischer
Indikatoren sowie sporadisch verfügbarer Ground Truth ist es möglich, über ein Regressi-
onsmodell Referenzdaten für die Vollständigkeitsanalyse zu erzeugen. Damit besteht neben
den üblichen intrinsischen Methoden ein alternativer Ansatz für die Vollständigkeitsbewer-
tung von VGI. Das konkrete hier entwickelte Modell zur Vorhersage der realen Verteilung
von Busstrecken erlaubt zwar bereits Rückschlüsse auf die Vollständigkeit des OSM-Daten-
bestands, hat allerdings noch Schwächen, die sich auf die verfügbaren GTFS-Daten zurück-
führen lassen. Diese stellen keine Zufallsstichprobe aus den realen global bestehenden ÖPNV-
Netzwerken dar. Vielmehr sind Daten u. a. aus Ländern hohen Einkommens stark überreprä-
sentiert. Verwendete unabhängige Variablen wie Nachtlicht- und Kohlenstoffdioxidemission
haben zwar das Potenzial, als Indikatoren für regional unterschiedliche ökonomische Rah-
menbedingungen zu fungieren. Aufgrund der nur sehr sporadisch verfügbaren GTFS-Daten
aus Ländern mit niedrigem und mittlerem Einkommen ist allerdings fraglich, ob der Vorher-
sagefehler räumlich gleichmäßig verteilt ist. Darüber hinaus leidet das Modell unter der Ab-
3 https://ohsome.org/apps/osm-history-explorer246 AGIT – Journal für Angewandte Geoinformatik · 7-2021 wesenheit von gesicherten Daten zu nicht durch ÖPNV erschlossenen Gebieten, weshalb un- ter Umständen besser geeignete Hürdenmodelle (Cameron & Trivedi, 2005) nicht verwendet werden können. Vielversprechend wäre daher die Anwendung der auf Regressionsmodellierung basierenden Vollständigkeitsanalyse auf andere Objektarten. Zum einen könnten dies Objekte sein, die anders als ÖPNV-Strecken nicht obskur, also potenziell mit Mitteln der Fernerkundung er- fassbar sind, wie z. B. Strommasten oder Windräder. In solchen Fällen wäre es möglich, Ground Truth durch die gezielte Erfassung der Objekte in zufällig ausgewählten Gebieten zu schaffen. Dadurch würde sowohl die Verzerrung durch Über- oder Unterrepräsentation be- stimmter Regionen vermieden als auch sichergestellt, dass ausreichend Daten zu Gebieten in das Modell einfließen, in denen entsprechende Objekte abwesend sind. Eine weitere Mög- lichkeit bestünde in der Anwendung auf Objektarten, für die bereits räumlich ausgeglichener verteilte Ground Truth zur Verfügung steht, z. B. Gesundheits- oder Bildungseinrichtungen. Danksagung Die Autoren danken den OSM-Mitwirkenden, sowie Sven Lautenbach, Lukas Loos und Mo- hammed Rizwan Khan für ihre Kommentare und Beiträge. Diese Arbeit wurde von der Klaus Tschira Stiftung (KTS) unterstützt. Literatur Asefi-Najafabady, S., Rayner, P. J., Gurney, K. R., McRobert, A., Song, Y., Coltin, K., Huang, J., Elvidge, C., & Baugh, K. (2014). A multiyear, global gridded fossil fuel CO2 emission data product: Evaluation and analysis of results: GLOBAL FOSSIL FUEL CO2 EMISSIONS. Journal of Geophysical Research: Atmospheres, 119(17), 10,213–10,231. https://doi.org/10.1002/2013JD021296. Auer, M., Eckle, M., & Fendrich, S. (2018). Ohsome – eine Plattform zur Analyse raumzeit- licher Entwicklungen von OpenStreetMap-Daten für intrinsische Qualitätsbewertungen. AGIT Journal, 4-2018. doi:10.14627/537647020. Ballatore, A., & Zipf, A. (2015). A Conceptual Quality Framework for Volunteered Geo- graphic Information. In: S. I. Fabrikant, M. Raubal, M. Bertolotto, C. Davies, S. Freund- schuh, & S. Bell (Eds.), Spatial Information Theory (Vol. 9368, pp. 89–107). Cham: Springer International Publishing. https://doi.org/10.1007/978-3-319-23374-1_5. Braga, M., Santos, M. Y., & Moreira, A. (2014). Integrating Public Transportation Data: Creation and Editing of GTFS Data. In Á. Rocha, A. M. Correia, F. B. Tan, & K. A. Stroetmann (Eds.), New Perspectives in Information Systems and Technologies, Volume 2 (Vol. 276, pp. 53–62). Cham: Springer International Publishing. https://doi.org/10.1007/978-3-319-05948-8_6. Cameron, A. C., & Trivedi, P. K. (2005). Microeconometrics: Methods and Applications (1st Ed.). Cambridge University Press. https://doi.org/10.1017/CBO9780511811241. Cipeluch, B., Jacob, R., Winstanley, A., & Mooney, P. (2010). Comparison of the accuracy of OpenStreetMap for Ireland with Google Maps and Bing Maps. Colpaert, P., & Rojas Meléndez, J. (2019). Open Data and Transport. https://doi.org/10.5281/zenodo.2677833.
O. Fritz et al.: Regressionsmodell für die Vollständigkeitsanalyse des OSM-Datenbestands 247 Costa Fonte, C., Anoniou, V., Bastin, L., Estima, J., Arsanjani, J. J., Laso Bayas, J.-C., See, L., & Vatseva, R. (2017). Assessing VGI Data Quality. In University of Nottingham, GB, G. Foody, L. See, International Institute for Applied Systems Analysis (IIASA), AT, S. Fritz, P. Mooney, Maynooth University, IE, A.-M. Olteanu-Raimond, Paris-Est, LASTIG COGIT, FR, C. C. Fonte, & University of Coimbra, PT (Eds.), Mapping and the Citizen Sensor (pp. 137–163). Ubiquity Press. https://doi.org/10.5334/bbf.g. Forghani, M., & Delavar, M. (2014). A Quality Study of the OpenStreetMap Dataset for Tehran. ISPRS International Journal of Geo-Information, 3(2), 750–763. https://doi.org/10.3390/ijgi3020750. GHSL (2019). GHSL data package 2019: Public release GHS P2019. Publications Office. https://data.europa.eu/doi/10.2760/290498. Girres, J.-F., & Touya, G. (2010). Quality Assessment of the French OpenStreetMap Dataset: Quality Assessment of the French OpenStreetMap Dataset. Transactions in GIS, 14(4), 435–459. https://doi.org/10.1111/j.1467-9671.2010.01203.x. Goodchild, M. F. (2007). Citizens as sensors: The world of volunteered geography. GeoJour- nal, 69(4), 211–221. https://doi.org/10.1007/s10708-007-9111-y. Graser, A., Straub, M., & Dragaschnig, M. (2015). Is OSM Good Enough for Vehicle Rout- ing? A Study Comparing Street Networks in Vienna. In G. Gartner & H. Huang (Eds.), Progress in Location-Based Services 2014 (pp. 3–17). Cham: Springer International Pub- lishing. https://doi.org/10.1007/978-3-319-11879-6_1. Gröchenig, S., Brunauer, R., & Rehrl, K. (2014). Estimating Completeness of VGI Datasets by Analyzing Community Activity Over Time Periods. In J. Huerta, S. Schade, & C. Granell (Eds.), Connecting a Digital Europe Through Location and Place (pp. 3–18). Cham: Springer International Publishing. https://doi.org/10.1007/978-3-319-03611-3_1. Haklay, M. (2010). How Good is Volunteered Geographical Information? A Comparative Study of OpenStreetMap and Ordnance Survey Datasets. Environment and Planning B: Planning and Design, 37(4), 682–703. https://doi.org/10.1068/b35097. Ma, D., Sandberg, M., & Jiang, B. (2015). Characterizing the Heterogeneity of the Open- StreetMap Data and Community. ISPRS International Journal of Geo-Information, 4(2), 535–550. https://doi.org/10.3390/ijgi4020535. Mellander, C., Lobo, J., Stolarick, K., & Matheson, Z. (2015). Night-Time Light Data: A Good Proxy Measure for Economic Activity? PLOS ONE, 10(10), e0139779. https://doi.org/10.1371/journal.pone.0139779. Minghini, M., & Frassinelli, F. (2019). OpenStreetMap history for intrinsic quality assess- ment: Is OSM up-to-date? Open Geospatial Data, Software and Standards, 4(1), 9. https://doi.org/10.1186/s40965-019-0067-x. Minghini, M., Kotsev, A., & Lutz, M. (2019). Comparing INSPIRE and OpenStreetMap Data: How to Make the Most out of the Two Worlds. ISPRS – International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, XLII-4/W14, 167–174. https://doi.org/10.5194/isprs-archives-XLII-4-W14-167-2019. Neis, P., Goetz, M., & Zipf, A. (2012). Towards Automatic Vandalism Detection in Open- StreetMap. ISPRS International Journal of Geo-Information, 1(3), 315–332. ttps://doi.org/10.3390/ijgi1030315. Neis, P., & Zielstra, D. (2014). Recent Developments and Future Trends in Volunteered Geographic Information Research: The Case of OpenStreetMap. Future Internet, 6(1), 76–106. https://doi.org/10.3390/fi6010076.
248 AGIT – Journal für Angewandte Geoinformatik · 7-2021 Raifer, M., Troilo, R., Kowatsch, F., Auer, M., Loos, L., Marx, S., Przybill, K., Fendrich, S., Mocnik, F.-B., & Zipf, A. (2019). OSHDB: A framework for spatio-temporal analysis of OpenStreetMap history data. Open Geospatial Data, Software and Standards, 4(1), 3. https://doi.org/10.1186/s40965-019-0061-3. Roick, O., Hagenauer, J., & Zipf, A. (2011). OSMatrix – Grid based analysis and visualiza- tion of OpenStreetMap. State of the Map EU, Wien. Román, M. O., Wang, Z., Sun, Q., Kalb, V., Miller, S. D., Molthan, A., Schultz, L., Bell, J., Stokes, E. C., Pandey, B., Seto, K. C., Hall, D., Oda, T., Wolfe, R. E., Lin, G., Golpaye- gani, N., Devadiga, S., Davidson, C., Sarkar, S., … Masuoka, E. J. (2018). NASA’s Black Marble nighttime lights product suite. Remote Sensing of Environment, 210, 113–143. https://doi.org/10.1016/j.rse.2018.03.017. Sahr, K. (2019). DGGRID version 7.0: User documentation for discrete global grid software. https://github.com/sahrk/DGGRID/blob/master/dggridManualV70.pdf. Scholz, S., Knight, P., Eckle, M., Marx, S., & Zipf, A. (2018). Volunteered Geographic In- formation for Disaster Risk Reduction – The Missing Maps Approach and Its Potential within the Red Cross and Red Crescent Movement. Remote Sensing, 10(8), 1239. https://doi.org/10.3390/rs10081239. Simon, N., Friedman, J., Hastie, T., & Tibshirani, R. (2011). Regularization Paths for Cox’s Proportional Hazards Model via Coordinate Descent. Journal of Statistical Software, 39(5), 1–13. Stevens, F. R., Gaughan, A. E., Linard, C., & Tatem, A. J. (2015). Disaggregating Census Data for Population Mapping Using Random Forests with Remotely-Sensed and Ancil- lary Data. PLOS ONE, 10(2), e0107042. https://doi.org/10.1371/journal.pone.0107042. Tran, K., Barbeau, S., Hillsman, E., & Labrador, M. A. (2013). GO_Sync – A Framework to Synchronize Crowd-Sourced Mapping Contributors from Online Communities and Transit Agency Bus Stop Inventories. International Journal of Intelligent Transportation Systems Research, 11(2), 54–64. https://doi.org/10.1007/s13177-013-0056-x. Wood, S. N. (2017). Generalized Additive Models: An Introduction with R (2nd Ed.). Chap- man and Hall/CRC. WorldPop (2018). Global 1km Population [Data set]. University of Southampton. https://doi.org/10.5258/SOTON/WP00647. Wright, M. N., & Ziegler, A. (2017). ranger: A Fast Implementation of Random Forests for High Dimensional Data in C++ and R. Journal of Statistical Software, 77(1), 1–17. https://doi.org/10.18637/jss.v077.i01. Yeo, I.-K., & Johnson, R. A. (2000). A New Family of Power Transformations to Improve Normality or Symmetry. Biometrika, 87(4), 954–959. Zeileis, A., Kleiber, C., & Jackman, S. (2008). Regression Models for Count Data in R. Jour- nal of Statistical Software, 27(8). http://www.jstatsoft.org/v27/i08/. Zielstra, D., & Zipf, A. (2010). A Comparative Study of Proprietary Geodata and Volun- teered Geographic Information for Germany.
Sie können auch lesen

















































