Finaler Bericht der dritten Projektphase - Wasserstandsvorhersage mit Hilfe von Deep Learning - Intelligente Systeme
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
– Finaler Bericht der dritten Projektphase –
Wasserstandsvorhersage mit Hilfe von Deep
Learning
Michel Spils1 , Simon Reichhuber2 , Sven Tomforde3 , Ralf Hach4 , Henke Hund5
Intelligent Systems, Christian-Albrechts-Universität zu Kiel
1
stu127161@mail.uni-kiel.de
2
sir@informatik.uni-kiel.de
3
st@informatik.uni-kiel.de
Landesamt für Landwirtschaft, Umwelt und ländliche Räume
4
Ralf.Hach@llur.landsh.de
5
Henke.Hund@llur.landsh.de
Zusammenfassung. Die dritte Projektphase der Zusammenarbeit zwi-
schen der Arbeitsgruppe Intelligente Systeme an der Christian-Albrechts-
Universität zu Kiel und dem Landesamt für Landwirtschaft, Umwelt und
ländliche Räume umfasst architektonische Erweiterungen zum Vorher-
sagemodell zu dem aus der zweiten Projektphase bekannten1 Pegeln
Willenscharen, Tarp, Treia und Hollingstedt sowie zum weiteren Pegel
Föhrden-Barl.
Schlüsselwörter: Wasserpegelvorhersage, Deep Learning, Zeitreihen-
vorhersage
1 Einleitung
Auch in der dritten Projektphase ging es darum, mit Hilfe von neuronalen Net-
zen Wasserstände für die nächsten 24 beziehungsweise 48 Stunden vorherzusa-
gen. Dafür haben wir verschiedene LSTM-Modelle für die Pegel Willenscharen,
Tarp, Treia und Hollingstedt optimiert und initial auch für den Pegel Föhrden-
Barl erstellt. Neue Aspekte in dieser Arbeitsphase waren unter anderem die Be-
trachtung von weiteren Metriken und Kennwerten, Bayesische Hyperparameter-
Optimierung, sowie eine höhere räumliche Auflösung der Niederschlags-Daten.
Weiterhin haben wir damit begonnen, räumlich extrem hoch aufgelöste Radar-
Daten des DWD zu verarbeiten, um diese in Zukunft als Niederschlagsvorhersage
nutzen zu können.
Im folgenden Kapitel 2 wird der neu betrachtete Pegel Föhrden-Barl beschrie-
ben und auf seine Besonderheiten genauer eingegangen. Darauf folgend wird
über die Erweiterungen auf Benutzerseite des Modells in Kapitel 3 eingegangen.
Anschließend wird auf die Erweiterungen bezüglich der Hyperparametersuche
1
https://www.ins.informatik.uni-kiel.de/en/projects/llur/final-report-water-level-
prediction-with-deep-le-1.pdf
2 M. Spils, S. Reichhuber, S. Tomforde, R. Hach, H. Hund in Kapitel 4, der Eingabedaten in Kapitel 5 und bezüglich des Netzwerktyp- sin Kapitel 6 eingegangen. Darauf folgend werden die Ergebnisse im Kapitel 7 zusammengetragen und interpretiert. In Kapitel 8 werden die Erkenntnisse zusammengefasst und Konsequenzen abgeleitet. 2 Einbeziehen des neuen Pegelstands Föhrden-Barl Neben dem Pegel Willenscharen aus der ersten Projektphase und den Pegeln Hollingstedt, Tarp und Treia widmeten wir uns in der dritten Projektphase zu- sätzlich dem Pegel Föhrden-Barl. An diesem Pegel liegen Messdaten zum Pe- gelstand des Gewässers Bramau, einem Nebenfluss der Stör, weitere Pegel- und Abflussmessungen oberhalb gelegener Stationen sowie hydrologisch relevanten Messdaten vor. Die oberhalb gelegenen Stationen Bad Brahmstedt/Ohlau, Bad Brahmstedt/Osterau, und Bad Brahmstedt/Schmalfelder Au decken sowohl Pe- gelstand als auch Abfluss aller Zuflüsse der Bramau ab. Des Weiteren wurden zu diesen Zuflüssen eine Einteilung des ca. 458.6 km2 Einzugsgebietes in drei Niederschlagsgebiete vorgenommen (siehe Abbildung 1). Ähnlich wie zu den be- reits bekannten Pegeln wurden auch die hydrologisch relevanten Messungen des Luftdrucks, der Lufttemperatur, der Luftfeuchte und der Bodenfeuchte mitein- bezogen. Eine genaue Liste der jeweils zur Verfügung stehenden Messwerte zum Pegel Föhrden-Barl findet sich in Tabelle 1. Tabelle 1: Sensordaten des Modells Föhrden-Barl. 1) Bodenfeuchte von 0 bis 60 cm unter Erdoberfläche.
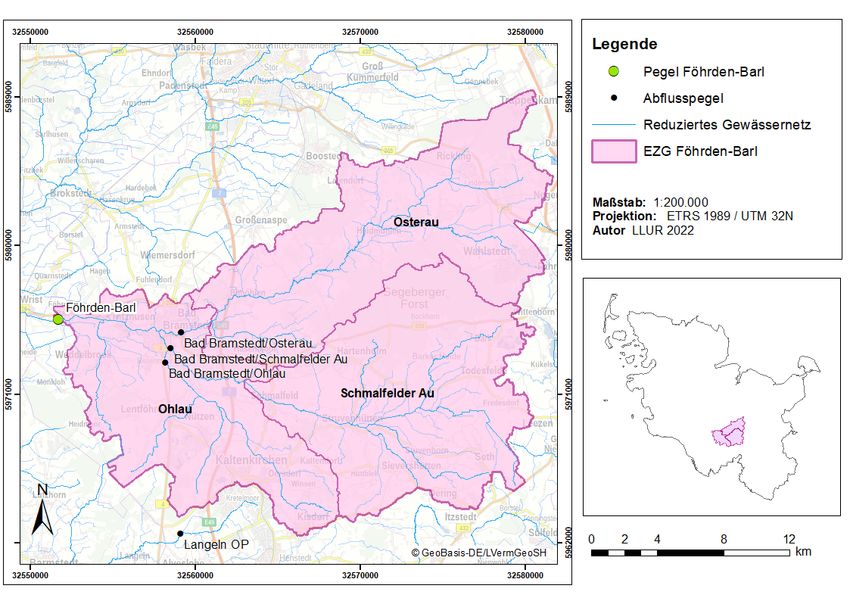
Wasserstandsvorhersage mit Hilfe von Deep Learning 3
Abb. 1: Einzugsgebietskarte des Pegels Föhrden-Barl
3 Benutzerseitige Anpassungen
3.1 Benutzerseitige Modellgenerierung
Mit Zunahme neuer Pegel konnten einige Arbeitsschritte automatisiert und ma-
nuelle Anpassungen auf die Benutzerseite ausgelagert werden. Hierzu gehört ein
wiederholtes Training der Modelle mit aktualisierten Messdaten. Wegen der ho-
hen Entwicklungskomplexität für Vorhersagemodelle der ersten Pegel, die sich
beispielsweise aus Fragen über die Architektur des Netzwerks oder die Form
der Sensoreingabe und deren Vorverarbeitung für das Netzwerk ergab, mussten
viele manuelle Schritte teilweise in Form von Programmierung in der Entwick-
lungsebene stattfinden. Auch die Vielzahl von möglichen Hyperparameterkonfi-
gurationen führte zu einem intensiven Gebrauch von leistungsstarken Servern,
die auf Anwenderseite nicht zur Verfügung standen. Die Schritte Datenaquise
und Preprocessing, Hyperparameter-Loop und Training fanden daher in der Ar-
beitsgruppe Intelligenten Systeme statt. Wie in Abbildung 2 dargestellt, gibt es
drei größere Prozessschritte zum Finden eines optimierten Vorhersagemodells für
einen neuen Pegel. Datenaquise und Preprocessing bezeichnet das Identifizieren
relevanter Messdaten und deren Weiterverarbeitung, um diese für das Training
eines Neueronalen Netzes einzusetzen. Im Schritt Hyperparameter-Loop wird
dann über Netzwerke mit unterschiedlicher Hyperparameterkonfiguration ite-
riert und mithilfe einer Validierungsmetrik, in diesem Fall Mean-Squared-Error4 M. Spils, S. Reichhuber, S. Tomforde, R. Hach, H. Hund des Vorhersagebereichs, ein optimiertes Modell erzeugt. Mithilfe diesen Modells können anschließend unter Eingabe neuer Messdaten Vorhersagen erzeugt wer- den. Lediglich diese Erzeugung der Vorhersagen lag auf Benutzerseite, weswegen die Gültigkeit der Vorhersagen von Modellen, deren Trainingsdaten weiter in der Vergangenheit liegen, stetig eingeschränkt wurde. Da eine einzelne Trai- ningsiteration in wenigen Minuten durchgeführt werden kann, wurde hier ein Mechanismus etabliert, der es auch dem Anwender erlaubt, neue Netze mit neu verfügbaren Trainingsdaten zu erzeugen. Abb. 2: Prozessschritte zum Finden eines optimierten Vorhersagemodells für einen neuen Pegel. 3.2 Plausibilitätschecks und Warnungen Um den Anwender genau über Datenlücken in der Eingabe für die Vorhersa- ge zu warnen, wurden Warnmeldungen eingeführt, die eine Liste der fehlenden Zeiträume, sowie die sensorabhängige Interpolationsmethodik angeben. Hierzu sei erwähnt, dass für jeden Sensor eine bestimmte Interpolationsmethodik ein- geführt wurde, wie sie in Tabelle 2 zu sehen ist. Außerdem muss darauf geachtet werden, ob der Zeitraum, in der die Interpolation statt findet, nicht zu groß ist. Beispielsweise kann bei fehlenden Lufttemperaturwerten in einem Zeitraum von 5 h davon ausgegangen werden, dass der Wert sich in einem linearen Ver- lauf angepasst hat, wohingegen eine zwei-Tages-Lücke bei Niederschlagsdaten plausibler durch den Wert Null ergänzt werden kann. Einstellbar sind 2 Größen, ab der ersten Größe wird gewarnt, dass die Ergebnisse weniger zuverlässig sind, ab der zweiten werden keine Ergebnisse mehr geliefert. Die Extrapolation von fehlenden Daten in jüngster Vergangenheit wird in jedem Fall durch Wiederho- lung des letzten Werts garantiert. Eine zu große Extrapolation sollte allerdings benutzerseitig ausgeschlossen werden.
Wasserstandsvorhersage mit Hilfe von Deep Learning 5
Sensor Interpolationsmethodik Default maximale
Interpolationslänge
Wasserstand linear 12 h
Durchfluss linear 12 h
Niederschlag konstanter Wert: 0 ∞
Bodenfeuchte linear 12 h
Lufttemperatur linear 12 h
Luftdruck linear 12 h
Luftfeuchte linear 12 h
Niederschlagsvorhersage konstanter Wert: 0 ∞
Tabelle 2: Interpolationsmethodiken der verschiedenen Sensoren.
4 Hyperparametersuche
Neben den historischen Sensordaten wird zum Training der Modelle eine Viel-
zahl von sogenannten Hyperparametern benötigt. Die Bestimmung dieser wird
dabei mit Hilfe eines Hyperparameteroptimierers vollzogen. Die Suche erfolgte
unter Eingabe minimaler und maximaler Werte der Hyperparameter (siehe Ta-
belle3) mithilfe der Bayesian Optimisation [1]. In mindestens 100 und höchstens
500 Schritten wurden dabei je Pegel die Hyperparameter angepasst bis keine
Verbesserung mehr zu erwarten war.
Parameter Typ Wertebereich
first_layer_units Integer [50, 1000]
hidden_layer_units Integer [50, 1000]
lstm_layer_count Diskret [1, 2]
dense_layer_count Integer [0, 3]
batch_size Diskret [64, 128, 256, 512]
learning_rate Float [0.0001, 0.01] (logarithmisch)
activiation Kategorisch [linear, leaky_relu]
dropout Float [0.1, 0.5]
in_size Integer [48, 240]
Tabelle 3: Wertebereich für die Hyperparametersuche mittels Bayesian Optimi-
sation
5 Änderung der Eingabedaten
5.1 Wettervorhersagen
Eine weitere wichtige Eingabegröße, die wegen fehlender Historie vorerst nicht
betrachtet wurde, sind Wettervorhersagedaten. Hierbei wurden zuerst die zu-
künftige Niederschläge der nächsten zwei Tage stundenweise betrachtet. Um6 M. Spils, S. Reichhuber, S. Tomforde, R. Hach, H. Hund
einen Aussage über die Verbesserung der Modelle durch diese Eingangsdaten
zu bekommen, wurde hier mit einem vereinfachten Verfahren gearbeitet. Echt
gemessene Daten aus der Historie wurden als Vorhersagedaten ausgezeichnet.
Auch wenn dieses Vorgehen die Unsicherheit aus den echten Wettervorhersa-
gedaten umgeht, gibt es dennoch einen Aufschluss über eine obere Grenze des
Verbesserungspotential.
5.2 Das Format GRIB 2
Das General Regularly-distributed Information in Binary-Format (kurz: GRIB
2 Format) ist ein Datenformat, dass meteorologische Inhalte komprimiert und
strukturiert zusammenfasst. Neben Wettervorhersagedaten können hier Gebiete
definiert werden, um den gefallenen Niederschlag in etwa 4.84 km2 großen Zel-
len abzurufen2 . Des Weiteren enthält das Format auch Wettervorhersagedaten,
was die Datenaquise zukünftiger Trainingsdaten deutlich erleichtert und die Be-
trachtung der Niederschlagvorhersage für beliebige Einzugsgebiete ermöglicht.
Weiter gilt zu erforschen, inwiefern die verschiedenen Vorhersageprodukte, die
im GRIB 2 auslesbar sind, dem Modell nützlich sind. Auch das vom DWD an-
gebotene Vorhersagemodell für hydrologische Daten ICON-D2 kann aus dem
Format GRIB 2 ausgelesen werden3 .
Änderung des Zeithorizonts der Eingabesequenz
Die optimale Länge der Eingabezeitreihe ist nicht mit Sicherheit zu bestimmen4 .
Die Bayesische Hyperparameteroptimierung und zahlreiche Experimente deuten
allerdings je nach Pegel auf eine Länge von 100 h bis 140 h. Dieser Wert könnte
jedoch je nach Architektur und Komplexität der verwendeten Netzwerke stark
schwanken. Die Zeitreihe sollte allerdings zur einfacheren Verwendung mindes-
tens die Länge der Niederschlagvorhersage haben.
Eingrenzung des betrachteten Niederschlaggebietes
Anders als in der ersten Projektphase werden die Niederschlagsgebiete über dem
Einzugsgebiet, wie in Kapitel 2 schon erwähnt, nun aufgeteilt. Grund dafür ist,
dass die lokalen Verteilungen des Niederschlags und deren Auswirkung auf den
Pegel besser abbgebildet werden können.
Verwenden von Hochwasserannotationen
Die in der letzten Projektphase verwendete experimentelle Gewichtung der Ein-
gangsdaten wurde in dieser Projektphase verworfen. Die Ergebnisse der Modelle
ließen sich durch eine einfach statische Gewichtung abhängig vom Anteil der
2
https://www.dwd.de/DE/leistungen/modellvorhersagedaten/
modellvorhersagedaten.html (aufgerufen am 05.04.2022)
3
https://www.dwd.de/SharedDocs/downloads/DE/modelldokumentationen/nwv/
icon/icon_dbbeschr_aktuell.pdf (aufgerufen am 11.04.2022)
4
optimal wird hier als die Länge der Eingabezeitreihe angesehen, wodurch ein Modell
trainiert werden kann, das den Validierungsfehler minimiert.Wasserstandsvorhersage mit Hilfe von Deep Learning 7
Zielwerte einer Hochwasserschwelle nicht verbessern. Die gesammelten Hoch-
wasserannotationen könnten allerdings zur Erstellung bestimmter hochwasser-
sensibler Netzwerke relevant werden, die ausschließlich auf dieser Art von Daten
trainiert werden. Die Verwendung eines Ensembles von Modellen war allerdings
nicht Gegenstand dieser Projektphase.
6 Architektonische Änderungen des Vorhersagemodells
In der ersten Projektphase wurden relativ kleine LSTM, Convolutional und voll-
ständig verbundende Architekturen benutzt. In der zweiten Projektphase haben
wir primär weiterhin LSTMs benutzt, geeignetere Varianten von Convolutional
entwickelt und Echo State Networks (ESN) getestet. Für die aggregierten Daten
musste die LSTM-Architektur entsprechen angepasst werden.
Auch in der zweiten Projektphase lieferten LSTMs die besten Ergebnisse.
Dabei wurden auch Echo-State Netze getestet, die aber schlechtere Ergebnisse
als LSTM und eine der Convolutional Architekturen lieferten. In der dritten
Projektphase wurden primär LSTMS verwendet, allerdings wurde die Größe und
die Anzahl der Lagen variiert. Eine Erweiterung war die zusätzliche Nutzung von
diversen statistischen und temporalen Features. Diese konnten die Vorhersagen
leicht verbessern, sind aber deutlich rechenintensiver und anfällig für fehlerhafte
Messwerte und Sprünge in den Daten. Aus Platzgründen sind im Appendix einige
der konkret getesteten Architekturen zu sehen.
7 Ergebnisse der Experimente
Die Experimente konnten durch veränderte Netzwerkarchitekturen für alle Pegel
bessere Modelle und Vorhersagen generieren als bisher. Mehrere LSTM-Lagen
hintereinander wirkten sich oft positiv aus. Die Modelle für Föhrden-Barl un-
terscheiden sich kaum von den bisher bekannten Modellen und Ergebnissen. Die
aus den ICON-D2 Vorhersagen gesammelten Werte unterscheiden sich etwas von
den aus den historischen Daten generierten Vorhersagen. Das Ausmaß der Ab-
weichung lässt sich allerdings erst feststellen, wenn die entsprechenden Daten
über einen längeren Zeitraum vorliegen.8 M. Spils, S. Reichhuber, S. Tomforde, R. Hach, H. Hund
Föhrden-Barl Hollingstedt Willenscharen Tarp Treia
p10 12 h 0.98 6.86 1.56 0.32 0.15
p10 24 h 2.13 19.34 2.83 1.57 0.37
p10 48 h - - 5.11 9.02 2.46
p20 12 h 0.06 0.36 0.26 0.02 0
p20 24 h 0.35 2.59 0.87 0.18 0.008
p20 48 h - - 1.43 1.54 0.46
train_loss 0.004 0.026 0.019 0.009 0.015
val_loss 0.003 0.025 0.011 0.018 0.011
Tabelle 4: Ausgewählte Metriken der jeweils besten LSTM-Modelle verschiedener
Pegel auf die Testdatensätze
8 Zusammenfassung
Die Ergebnisse der früheren Projektphasen ließen sich durch komplexere Ar-
chitekturen erneut verbessern. Die bei neuronalen Netzen inhärenten Probleme
sind auch weiterhin vorhanden. Strukturelle Änderungen oder Wetterereignisse,
die in diesem Ausmaß bisher nicht vorkamen, wurden von den Modellen nicht
oder nur schlecht gelernt. Letzteres führt zu der Notwendigkeit größere Daten
aufzunehmen, die auch eine Vielzahl extremer (beispielsweise sog. Jahrhundert-
hochwasser) Wetterereignisse enthalten.Wasserstandsvorhersage mit Hilfe von Deep Learning 9
9 Appendix
Abb. 3: Vorhersage vom Weihnachtshochwasser 2014 (In den Trainingsdaten)
9.1 Messstationen der Pegel
Willenscharen
Treia
Tarp
bf10 Bodenfeuchte Station Schleswig
bfwls Bodenfeuchte Station Schleswig
airpress Luftdruck Station Schleswig
airtemp Temperatur Station Wagersrott
airhumidity Luftfeuchte Station Wagersrott
waug Wasserstand Augaard
qaug Abfluss Augaard
wmueh Wasserstand Mühlenbrück
qmueh Abfluss Mühlenbrück
wsolm Wasserstand Sollerupmühle
Tarp_radar_mm Niederschlag (Radar) Tarp
Tarp_pegel_cm Wasserstand Tarp10 M. Spils, S. Reichhuber, S. Tomforde, R. Hach, H. Hund
Abb. 4: Vorhersage vom Hochwasser im Februar 2022 (Dem Model unbekannt)
Hollingstedt
bf10 Bodenfeuchte Station Schleswig
bfwls Bodenfeuchte Station Schleswig
airpress Luftdruck Station Schleswig
airtemp Temperatur Station Wagersrott
airhumidity Luftfeuchte Station Wagersrott
waug Wasserstand Augaard
qaug Abfluss Augaard
wmueh Wasserstand Mühlenbrück
qmueh Abfluss Mühlenbrück
wtarp Wasserstand Tarp
wegg Wasserstand Eggebek
wsolm Wasserstand Sollerupmühle
wtarp Wasserstand Tarp
wtreia Wasserstand Treia
wwohl Wasserstand Wohlde
wfrie Wasserstand Friedrichstadt
qfrie Abfluss Friedrichstadt
n1 Tarp
n2 Jerrisbek
n3 Bollingstedter Au
n4 Treia bis Sollerup
n5 Sollerup bis Tarp
n6 Hollingstedt bis Treia
n_vh_mm Vorhersage Treene
Holl_pegel_cm Wasserstand HollingstedtWasserstandsvorhersage mit Hilfe von Deep Learning 11
9.2 Detaillierte Netzwerkstruktur
Layer Größe Details
Inputlayer n*m
LSTM 200 Zusätzliche Dropout-Layer
Dense 48
Tabelle 5: LSTM
Layer Größe Details
Inputlayer n∗m
SeparableConv1D 8 kernel_size,64 filter,8 depth_multiplier,2 strides,valid padding
MaxPooling1D Pool Größe: 3
Flatten
Dense 200
Dense 48
Tabelle 6: Convolution 2
Layer Größe Details
Inputlayer n∗m
SeparableConv1D 8 kernel_size,32 filter,8 depth_multiplier,4 strides,valid padding
MaxPooling1D Pool Größe: 3
Flatten
Dense 200
Dense 200
Dense 48
Tabelle 7: Convolution 312 M. Spils, S. Reichhuber, S. Tomforde, R. Hach, H. Hund
Layer Größe Details
Inputlayer n*m
ESN 500
Dense 48
Tabelle 8: Echo State Network
Absolute energy Mean absolute deviation Peak to peak distance
Area under the curve Mean absolute diff Positive turning points
Centroid Mean diff Root mean square
ECDF Percentile Count 0,1 Median Signal distance
ECDF Percentile 0,1 Median absolute deviation Skewness
Entropy Median absolute diff Slope
Histogram 0-9 Median diff Variance
Interquartile range Min Zero crossing rate
Kurtosis Negative turning points
Max Neighbourhood peaks
Tabelle 9: Genutzte temporale und statistische FeaturesWasserstandsvorhersage mit Hilfe von Deep Learning 13
14 M. Spils, S. Reichhuber, S. Tomforde, R. Hach, H. Hund
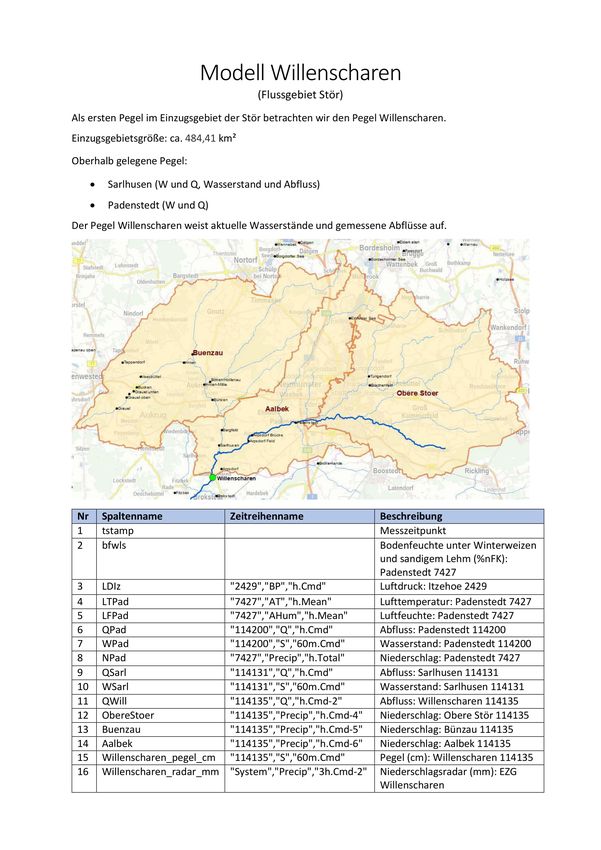
Modell Treia
(Flussgebiet Treene)
Als zweiten Pegel im Einzugsgebiet der Treene (nach Tarp) betrachten wir den Pegel Treia
Einzugsgebietsgröße: ca. 481 km²
Oberhalb gelegene Pegel:
Mühlenbrück (W und Q, Wasserstand und Abfluss)
Augaard (W und Q)
Tarp (W)
Eggebek (W)
Sollerupmühle (W)
Der Pegel Treia weist aktuelle Wasserstände und gemessene Abflüsse auf.Wasserstandsvorhersage mit Hilfe von Deep Learning 15 Abb. 5: Architektur für aggregierte Zeitreihen
16 M. Spils, S. Reichhuber, S. Tomforde, R. Hach, H. Hund Abb. 6: Architektur mit statistischen und temporalen Features. Der zweite Ein- gang des Modells setzt sich aus temporalen und statistischen Features der nor- malen Eingänge zusammen, gefiltert nach Korrelationen und Varianz 9. Diese Modell entspricht 24_large.
Wasserstandsvorhersage mit Hilfe von Deep Learning 17 Abb. 7: Architektur für Standard LSTM Modelle
18 M. Spils, S. Reichhuber, S. Tomforde, R. Hach, H. Hund Literatur 1. Pelikan, M., Goldberg, D.E., Cantú-Paz, E., et al.: Boa: The bayesian optimization algorithm. In: Proceedings of the genetic and evolutionary computation conference GECCO-99. vol. 1, pp. 525–532. Citeseer (1999)
Sie können auch lesen

















































