OCR-BW Kompetenzzentrum - Volltexterkennung und Transkription - Zenodo
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

OCR-BW
Kompetenzzentrum
Volltexterkennung und Transkription
Stefan Weil, Jan Kamlah
Universitätsbibliothek Mannheim
19.02.2020
OCR-BW Projektziele „Aufbau eines Kompetenzzentrums Volltexterkennung von handschriftlichen und gedruckten Werken“ UB Tübingen: Volltexterkennung (OCR) von Autographen, Handschriften und Inkunabeln UB Mannheim: Volltexterkennung (OCR) von Druckwerken Das Projekt OCR-BW unterstützt Archive, wissenschaftliche Bibliotheken und andere Institutionen in Baden-Württemberg bei der Volltexterkennung ihrer digitalisierten Werke. ➢ https://ocr-bw.bib.uni-mannheim.de 19.02.2020 2
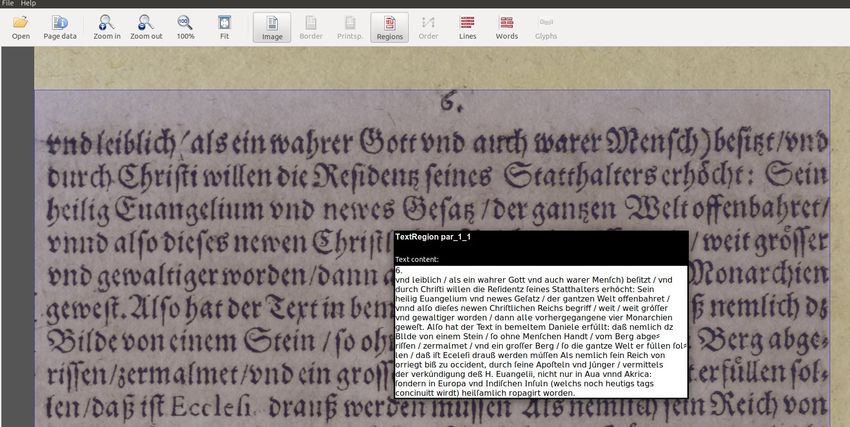
OCR-BW Arbeitsbeispiele für Volltexterkennung Print • Karteikarten der ethnologischen Sammlungen des Museums der Universität Tübingen • Historische Zeitungen für das Stadtarchiv Ladenburg und das MARCHIVUM • Entwicklung neuer Software-Werkzeuge zur Evaluierung und Verbesserung der OCR-Qualität. 19.02.2020 3

OCR-BW
Automatische Texterkennung
von Druckwerken mit Tesseract
Stefan Weil, Jan Kamlah
Universitätsbibliothek Mannheim
19.02.2020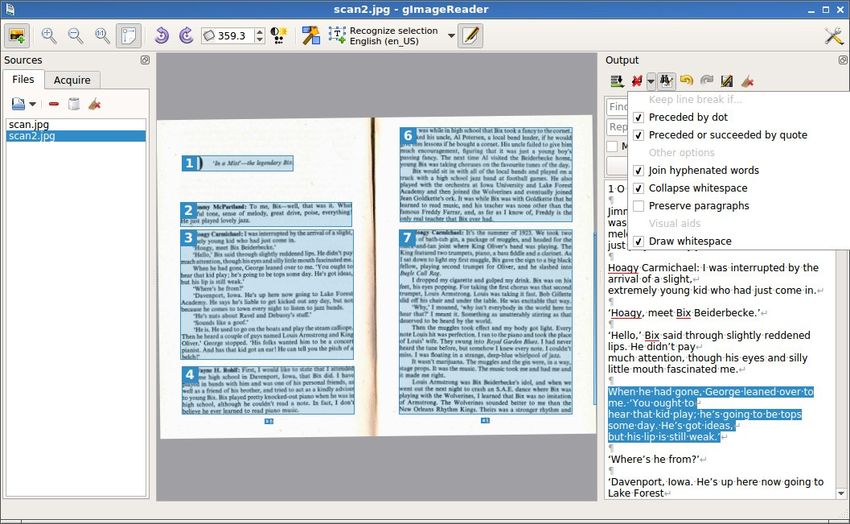
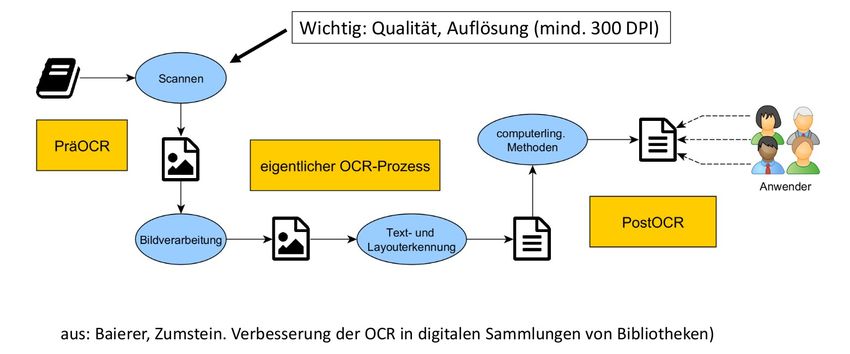
Vom Werk zum Digitalisat mit Volltext 19.02.2020 5

OCR Software (Übersicht)
kommerzielle fett = eingesetzt in Bibliotheken
Software
Transkribus Tesseract freie Software
ABBYY Finereader OCRopus / Kraken /
BIT-Alpha Calamari
Readiris CuneiForm
… …
Adobe Acrobat
CorelDraw ABBYY Cloud OCR
Microsoft OneNote Google Cloud Vision
… Microsoft Azure Computer Vision
OCR.space Online OCR …
Cloud OCR
19.02.2020 6
Tesseract in Kürze • Open Source • Komplettlösung „All-in-1“ • Kommandozeilenprogramm (CLI) • Dient als Kernkomponente in vielen OCR-Applikationen • Mehr als 100 Sprachen / mehr als 30 Schriften • Liest Bilder in allen gängigen Formaten (nicht PDF!) • Erzeugt Text, PDF, hOCR, ALTO, TSV • Große, weltweite Anwender-Community • Technologisch aktuell (Texterkennung mit neuronalem Netz) 19.02.2020 7
Tesseracts Geschichte
Entwicklung der Software
➢ 1985-1994 Ray Smith bei Hewlett-Packard (HP)
➢ 1994-2005 Keine Weiterentwicklung
➢ 2005-2018 Wiederaufnahme durch Ray Smith bei Google
➢ Seit 2018 Weiterentwicklung des Quellcodes durch die
Open-Source-Community auch im Rahmen von OCR-D
Meilensteine
➢ 1995 Einer der drei präzisesten Testkandidaten (UNLV-Test)
➢ 2006 Verwendung bei Google Books
➢ Ende 2016 Einführung von neuronalen Netzen mit Version 4
19.02.2020 8
Tesseract Fraktur OCR 2018
• Drei Modelle zur Auswahl: deu_frak, frk, Fraktur
14. Juni 2018: Tesseract schneidet im Frakturtest
von Jochen Barth (UB Heidelberg) im Vergleich
zu ABBYY FineReader schlecht ab:
https://github.com/tesseract-ocr/tessdata/issues/102
• Ligaturen wie ch und ck werden häufig als
Kleiner- bzw. Größerzeichen erkannt und
weitere systematische Erkennungsfehler
19.02.2020 9
Tesseract Fraktur OCR 2019
• 16. November 2019: Tesseract (grün) schlägt
ABBYY (rot) in Jochen Barths neuem Test
deutlich (trotz noch vorhandener Schwächen
in der Zeilenerkennung):
https://digi.ub.uni-heidelberg.de/diglitData/v/abby12r3-OldGerman-vs-Fraktur5000000_0.466_II.png
• Wichtigste Änderung ist dabei ein neues
Frakturmodell
19.02.2020 10Tesseract Fraktur-Modelle der UB Mannheim
• UB Mannheim benötigt Fraktur OCR u. a. für die
historische Zeitung Deutscher Reichsanzeiger
und Preußischer Staatsanzeiger (ursprünglich
Allgemeine Preußische Staatszeitung)
• Training neuer Fraktur-Modelle aus publizierten
Ground-Truth-Daten seit September 2019:
– GT4HistOCR (Springmann et al.)
– Austrian Newspapers (Mühlberger et al.)
https://github.com/tesseract-ocr/tesstrain/wiki
• Zeichenerkennung besser als 97,5 %,
Worterkennung bei 93 % für Austrian Newspapers
19.02.2020 11Tesseract Fraktur-Training
Beispiele für Zeilen aus GT4HistOCR
Beispiele für Zeilen aus Austrian Newspapers
19.02.2020 12Evaluierung des neuen Modells Vergleich der Modelle: GT4HistOCR, Fraktur, frk Testdaten: Antiqua 17. und 18. Jhd. Fraktur 16., 17. und 19. Jhd. Character Error Rate (CER) Gesamt Fraktur Modell 3.8 % 3.0 % script/GT4HistOCR 8.6 % 10.8 % script/Fraktur 9.9 % 11.3 % frk 19.02.2020 13
Tesseract im Einsatz
OCR
OCR
19.02.2020 14Tesseract – Installation Linux Tesseract 4 ist Bestandteil der gängigen Linux-Distributionen Tesseract 4.1: https://launchpad.net/~alex-p/+archive/ubuntu/tesseract-ocr • Windows Tesseract-Installer der Universitätsbibliothek Mannheim https://github.com/UB-Mannheim/tesseract/wiki • macOS Installation über MacPorts oder Homebrew • Beschreibung: https://tesseract-ocr.github.io/tessdoc/ 19.02.2020 15
Tesseract – Sprachen und Schriften
Tesseract 4 unterscheidet zwischen „Sprachen“ und „Schriften“:
– Eine Sprache wie beispielsweise deu kennt die typischerweise im Deutschen verwendeten
Schriftsymbole und enthält u. a. ein deutsches Wörterbuch.
– Eine Schrift wie beispielsweise script/Latin kennt idealerweise alle Schriftsymbole dieser
Schrift und ein Wörterbuch verschiedener Sprachen, die diese Schrift nutzen.
Das ist neu in Tesseract 4 und bietet Vorteile in vielen typischen Texten.
• Übersicht: Kapitel „Languages and Scripts“ im Tesseract-Handbuch
https://digi.bib.uni-mannheim.de/tesseract/manuals/tesseract.1.html
• Drei Ausprägungen für jede Sprache bzw. Schrift:
– Optimiert für Geschwindigkeit: https://github.com/tesseract-ocr/tessdata_fast
– Genauigkeit + Training: https://github.com/tesseract-ocr/tessdata_best
– Zwei OCR-Erkennungsalgorithmen: https://github.com/tesseract-ocr/tessdata
19.02.2020 16Tesseract Beispiel
OCR
tesseract -l model input output
19.02.2020 17Tesseract – Support
• Dokumentation
– Tesseract: https://tesseract-ocr.github.io/
– UB Mannheim Wiki: https://github.com/UB-Mannheim/tesseract/wiki
– Handbuchseiten: https://digi.bib.uni-mannheim.de/tesseract/manuals/
• Anwenderforum: http://groups.google.com/group/tesseract-ocr
• Entwicklerforum: http://groups.google.com/group/tesseract-dev
• Ticketing-System (in der Regel für Fehlermeldungen)
– Tesseract: https://github.com/tesseract-ocr/tesseract/issues
– Tesseract für Windows: https://github.com/UB-Mannheim/tesseract/issues
19.02.2020 18Nützliche Werkzeuge 19.02.2020 19
ScanTailor
OCR Vorverarbeitungstool
• Zerteilen von Seiten
• Neigungskorrektur
• Entzerrung
• Binarisierung
https://github.com/scantailor/scantailor
19.02.2020 21gImageReader
Einfache GUI mit Nachbearbeitungsmöglichkeiten
• direktes Einlesen vom Scanner
https://github.com/manisandro/gImageReader
19.02.2020 22OCRmyPDF
Automatische Texterkennung für PDF-Dateien
• Erzeugt durchsuchbare PDF/A Dateien
• Kommandozeilenprogramm
• Vorverarbeitungsoptionen wie Neigungskorrektur
• Integrierte Validierung der Ausgabedateien
https://github.com/jbarlow83/OCRmyPDF
19.02.2020 23Poppler-utils (PDF-Werkzeuge)
Eine Sammlung von Kommandozeilen-Programmen für PDF-Dateien
• pdftotext – Entnahme von Text
• pdfunite – Werkzeug für das Zusammenfügen von Dokumenten
• pdfimages – Entnahme von Bildern (-list zeige Bildinformationen)
• pdfinfo – Dokumentinformationen
• pdfseparate – Werkzeug zur Entnahme von Seiten
• pdftohtml – Umwandlung von PDF nach HTML
• pdftoppm – Umwandlung von PDF nach PPM/PNG/JPEG
https://wiki.ubuntuusers.de/poppler-utils/
19.02.2020 24PAGE Viewer
Betrachter für PAGE XML, ALTO und hOCR
https://www.primaresearch.org/tools/PAGEViewer
19.02.2020 25hOCRjs Visualisierung des erkannten Layouts, überlagerte Darstellung von Digitalisat und erkanntem Text Website: http://kba.cloud/hocrjs/ https://digi.bib.uni-mannheim.de/periodika/reichsanzeiger/ocr/film/tesseract-4.0.0-20181201/139-9547/0316.hocr?overlay=1 19.02.2020 26
OCR-D https://ocr-d.github.io/de/ Schaffung eines flexiblen optimierbaren Workflows zur automatischen Volltexterkennung für Alte Drucke • Frei wählbare Module („Prozessoren“) für jeden Arbeitsschritt • Integration in bestehende Arbeitsabläufe durch Nutzung des Standardformats METS • Definition von Ground-Truth-Erfassungsregeln und Bereitstellung von GT-Korpora • Langzeitarchivierungsmöglichkeiten 19.02.2020 27
OCR-D Beispiel
Installation: https://github.com/OCR-D/ocrd_all
Workflow für eine Einzelseite:
# Step 0: Create Workspace & METS file
mkdir -p ~/projects/OCR-D/workshop/2020_02_19/
cd ~/projects/OCR-D/workshop/2020_02_19/
# Create workspace including METS file
ocrd workspace init OCRbw_workspace && cd OCRbw_workspace
# Step 1: Download jpg image
mkdir ./OCR-D-IMG && \
wget -O ./OCR-D-IMG/Fraktur_1621.jpg \
https://digi.bib.uni-mannheim.de/~jkamlah/OCRbw-Workshop-2020-02-19/example/ocrd/MAX/Fraktur_1621.jpg
# Step 2: Add image to METS
# Be aware, that the ID and the GROUPID have to identical if the referenced image represents the original image
ocrd workspace add --file-grp OCR-D-IMG --file-id Fraktur_1621 --page-id OCR-D-IMG_0001 --mimetype image/jpg ./OCR-D-
IMG/Fraktur_1621.jpg
# Install OCR model into Tesseract datapath
apt-get install tesseract-ocr-script-frak
# Step 3: Run the workflow (processors)
ocrd process \
'tesserocr-segment-region -I OCR-D-IMG -O OCR-D-SEG-BLOCK' \
'tesserocr-segment-line -I OCR-D-SEG-BLOCK -O OCR-D-SEG-LINE' \
'tesserocr-recognize -I OCR-D-SEG-LINE -O OCR-D-OCR-TESSEROCR -p {\"model\":\"frk\",\"textequiv_level\": \"word\"} '
19.02.2020 28Literatur
• Springmann, U., Reul, Ch., Dipper, S., & Baiter, J. (2018). GT4HistOCR: Ground Truth for
training OCR engines on historical documents in German Fraktur and Early Modern Latin
(Version 1.0) [Data set]. Zenodo. http://doi.org/10.5281/zenodo.1344132
• Mühlberger, G. & Hackl, G. (2019). NewsEye / READ OCR training dataset from Austrian
Newspapers (19th C.) [Data set]. Zenodo. http://doi.org/10.5281/zenodo.3387369
• Weil, S. (2019). Training Fraktur. GitHub.
https://github.com/tesseract-ocr/tesstrain/wiki
• Metzger, N. & Weil, S. (2019). Optimierter Einsatz von OCR-Verfahren -
Tesseract als Komponente im OCR-D-Workflow.
https://nbn-resolving.org/urn:nbn:de:bsz:180-madoc-522132
• Weil, S. (2019). Vom Bild zum Text.
Automatisierte Texterkennung in historischen Drucken mit der freien Software Tesseract.
https://nbn-resolving.org/urn:nbn:de:0290-opus4-163511
• Weil, S., & Zumstein, P. (2016). Mit freier Software Text in Digitalisaten erkennen.
https://speakerdeck.com/zuphilip/mit-freier-software-text-in-digitalisaten-erkennen-ocr-pra
xis-an-der-ub-mannheim
19.02.2020 29Bildquellen
• Titelseite:
https://pixabay.com/photos/letter-handwriting-written-ink-447577/
https://pixabay.com/photos/wash-angle-hook-book-printing-705674/
• Vektorgrafiken:
https://pixabay.com/de/vectors/flach-design-symbol-icon-www-2126884/
https://pixabay.com/de/vectors/flach-design-symbol-icon-www-2126884/
https://pixabay.com/de/vectors/flach-design-symbol-icon-www-2126880/
https://pixabay.com/de/vectors/werkzeug-schraubenschl%C3%BCssel-3456474/
• Abbildungen von Jochen Barth, UB Heidelberg:
https://digi.ub.uni-heidelberg.de/diglitData/v/abby12r3-OldGerman-vs-Fraktur5000000_0.466_II.png
https://camo.githubusercontent.com/47ac160cf86bb8f69fe98677112e5597a46da3ed/687474703a2f2f646967692e
75622e756e692d68656964656c626572672e64652f6469676c6974446174612f762f6162627979313172382d76732
d746573736572616374342e6a7067
• ScanTailor Logo: https://github.com/scantailor/scantailor
• OCRmyPDF Logo: https://github.com/jbarlow83/OCRmyPDF
• gImageReader: https://github.com/manisandro/gImageReader
• GitHub Logos: https://github.com/logos
• Tux: https://de.wikipedia.org/wiki/Linux#/media/Datei:Tux.svg
• Win10: https://commons.wikimedia.org/wiki/File:Windows_10_Logo.svg
• Mac Logo: https://commons.wikimedia.org/wiki/File:Apple_logo_black.svg
19.02.2020 30
• OCR-D Logo: http://www.ocr-d.de/Sie können auch lesen

















































