Persistent Identifier für wissenschaftliche Einrichtungen
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Fachbereich Informationswissenschaften
Studiengang Bibliotheksmanagement
Persistent Identifier für wissenschaftliche
Einrichtungen
Bachelorarbeit
zur Erlangung des akademischen Grades
Bachelor of Arts (B.A.)
eingereicht von: Laura Rothfritz
Matrikelnummer: 13817
Gutachter/innen: Prof. Dr. rer. nat. Heike Neuroth
Dipl. Bib. Heinz Pampel
eingereicht am: 27. Januar 2018 verteidigt am: 7. Februar 2018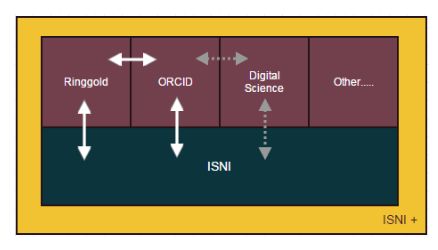
Selbstständigkeitserklärung Ich erkläre hiermit, dass ich die vorliegende Arbeit selbstständig verfasst und noch nicht für andere Prüfungen eingereicht habe. Sämtliche Quellen einschließlich Internetquellen, die unverändert oder abgewandelt wiedergegeben werden, insbesondere Quellen für Texte, Grafiken, Tabellen und Bilder, sind als solche kenntlich gemacht. Mir ist bekannt, dass bei Verstößen gegen diese Grundsätze ein Verfahren wegen Täuschungsversuchs bzw. Täuschung eingeleitet wird. Berlin, den 26. Januar 2018
Abstract In der vorliegenden Arbeit werden Probleme bei der eindeutigen Identifizierung wissenschaftli- cher Einrichtungen aufgezeigt, Persistent Identifier als Lösung dieser Probleme vorgeschlagen und bereits bestehende Lösungsansätze in Form von Identifikatorensystemen für wissenschaft- liche Einrichtungen ausgewertet. Außerdem werden Anwendungsszenarien für die eindeutige Identifikation wissenschaftlicher Einrichtungen und bisherige Lösungen vorgestellt. Die be- trachteten Identifikatorensysteme werden bewertet und aus den Anwendungsfällen Kriterien für Persistent Identifier für wissenschaftliche Einrichtungen herausgearbeitet. Offene For- schungsinfrastrukturen als Organisationsform für ein Identifikatorensystem bieten hierfür die Grundlage. Bisher erfüllen keine der betrachteten Identifikatoren die Kriterien für Persistent Identifier und können nicht als diese bewertet werden. Es bestehen jedoch Anwendungsfälle, für die Persistent Identifier zur eindeutigen, anhaltenden Identifizierung von Einrichtung sowie dem automatisierten Austausch von Metadaten sehr gut geeignet sind. Dieses Werk ist unter einer Creative Commons Lizenz vom Typ Namensnennung 2.0 Deutsch- land zugänglich. Um eine Kopie dieser Lizenz einzusehen, konsultieren Sie http://creativecommons.org/licenses/by/2.0/de/ oder wenden Sie sich brieflich an Creative Commons, Postfach 1866, Mountain View, California, 94042, USA.
Inhaltsverzeichnis 1 Einleitung 1 2 Forschungsstand 4 2.1 Persistent Identifier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4 2.2 Bestehende Identifikatorensysteme . . . . . . . . . . . . . . . . . . . . . . . 7 2.3 Projekte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8 3 Methode 12 4 Identifikatoren für wissenschaftliche Einrichtungen 14 4.1 Die Gemeinsame Normdatei (GND) . . . . . . . . . . . . . . . . . . . . . . 14 4.2 Der International Standard Name Identifier (ISNI) . . . . . . . . . . . . . . 15 4.3 Ringgold Identifier . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17 4.4 Die Global Research Identifier Datenbank (GRID) . . . . . . . . . . . . . . . 19 4.5 Identifikatoren der Deutschen Forschungsgemeinschaft (DFG ID) . . . . . . 20 4.6 Participant Identification Code (PIC) . . . . . . . . . . . . . . . . . . . . . 21 4.7 Scopus Affiliation ID . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 4.8 CrossRef Funder ID . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22 5 Nutzung von Identifikatoren 25 5.1 Drittmittelanträge (Forschende) . . . . . . . . . . . . . . . . . . . . . . . . 25 5.2 Aggregation und Reporting (Forschungsinfastrukturen) . . . . . . . . . . . . 25 5.3 Automatisierung von Datenflüssen (Forschungsinfrastrukturen) . . . . . . . . 27 5.4 Tracking (Forschungsförderung) . . . . . . . . . . . . . . . . . . . . . . . . 28 5.5 Gutachtenverfahren für Anträge (Forschungsförderung) . . . . . . . . . . . . 30 5.6 Open-Access-Monitoring und APC-Management . . . . . . . . . . . . . . . 31 6 Diskussion 33 6.1 Einordnung der Identifikatorensysteme . . . . . . . . . . . . . . . . . . . . . 33 6.2 Anforderungen an Metadaten . . . . . . . . . . . . . . . . . . . . . . . . . 38 6.3 Bewertung der Anwendungsfälle . . . . . . . . . . . . . . . . . . . . . . . . 40 6.4 Offene Forschungsinfrastrukturen . . . . . . . . . . . . . . . . . . . . . . . 41 7 Fazit und Ausblick 44 A Anhang 54 A.1 Anwendungsfälle für OrgIDs . . . . . . . . . . . . . . . . . . . . . . . . . . 55 A.2 IDs für das GeoForschungsZentrum Potsdam in Scopus . . . . . . . . . . . . 57 A.3 Antworten zum RFI der Organization Identifier Working Group . . . . . . . . 60 B Abbildungen 86
Tabellenverzeichnis
1 Bereits durchgeführte Projekte, Untersuchte Identifier und Ergebnisse . . . . 11
2 Korrelierende Anwendungsfälle in jeweils mind. 2 Studien . . . . . . . . . . . 13
3 Unterschiede zwischen einfachen, eindeutigen und Persistent Identifiern . . . 33
4 Bewertung der untersuchten Identifikatoren . . . . . . . . . . . . . . . . . 35
Abbildungsverzeichnis
1 ISNI+ als hybrider Organizational Identifier. Aus: Ferguson, Moore und Schmol-
ler, 2014, S. 19 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 86
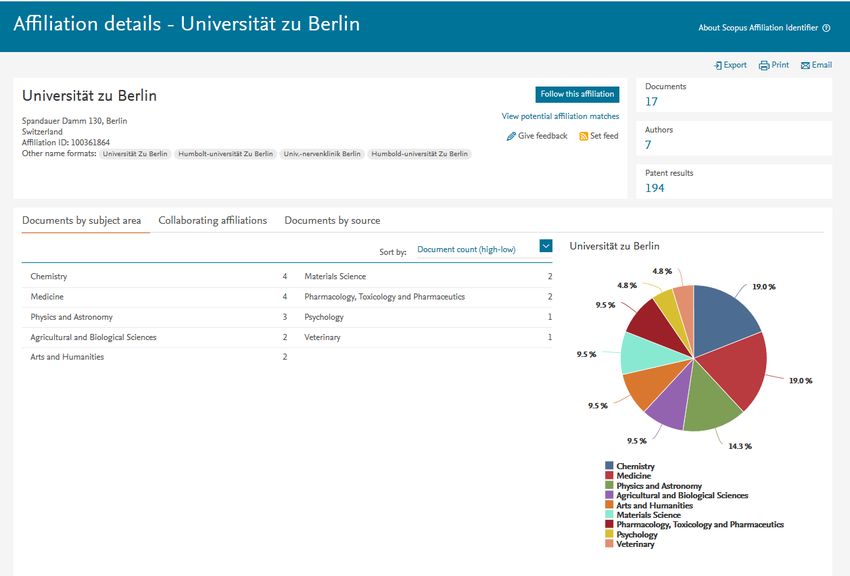
2 Affiliation Profile der Universität zu Berlin in Scopus . . . . . . . . . . . . . 86Einleitung
1 Einleitung
Kommunikationsprozesse in der Wissenschaft bilden sich in Informationsflüssen zwischen den
unterschiedlichen Akteursgruppen ab und münden in messbaren Produkten, dem Output
der Wissenschaft. Die Identifizierung, Benennung und Verknüpfung von Forschenden, For-
schungsinfrastrukturen, Forschungsförderern und Forschungsoutputs kann dabei zu einem
nachvollziehbaren Netzwerk führen, welches den wissenschaftlichen Fortschritt trägt und
vorantreibt. Dennoch ist gerade im digitalen Austausch von Informationen über Beteiligte
am Forschungsprozess und die entstandenen Ergebnisse diese Identifizierung nicht immer
eindeutig und leicht durchführbar.
Fehlerhafte Namen von wissenschaftlichen Einrichtung in Zitationsdatenbanken führen bei
bibliometrischen Auswertungen von Zitationsdaten unter Umständen zu falschen Ergebnissen
(vgl. De Bruin und Moed, 1990). Nicht standardisierte Benennungen von wissenschaftlichen
Einrichtungen beruhen auf Namensvarianten, Schreibfehlern, unterschiedlichen Benennungen
in verschiedenen Sprachen, Abkürzungen, semantischen Fehlern oder unklaren Hierarchieebe-
nen (vgl. Huang u. a., 2014). Zudem verändern Institutionen mit der Zeit häufig ihre Struktur
durch Zusammenlegungen, Aufsplittung in distinkte Einrichtungen, Übernahme durch größere
Einrichtungen usw. (vgl. Hood und Wilson, 2003). Sind Adress- oder Namensfelder unzurei-
chend formatiert, entstehen auch durch die automatische Indexierung von Einrichtungsnamen
und -adressen Fehler in der eindeutigen und korrekten Bezeichnung der Körperschaft (vgl.
Taşkın und Al, 2013).
Der Prozess der Auflösung doppeldeutiger Zeichenketten zur Benennung von Entitäten wird
als Disambiguierung benannt. Im Mittelpunkt stehen dabei zwei Formen von mehrdeutigen Be-
ziehungen zwischen Zeichenketten und Entitäten: Synonyme bezeichnen zwei unterschiedliche
Zeichenketten, die die selbe Entität identifizieren, zum Beispiel wenn eine wissenschaftliche
Einrichtung unterschiedliche Benennungen hat. Homonyme sind zwei oder mehr gleiche Zei-
chenketten, die verschiedene Bedeutungen haben. Beispielsweise können zwei unterschiedliche
Einrichtungen unter dem selben Akronym bekannt sein. Wenn wissenschaftliche Einrichtungen
eindeutig identifiziert werden sollen, müssen auch sogenannte „Sektorenhybride” (Einrichtun-
gen, die aus Einrichtungen unterschiedlicher Sektoren entstehen)1 oder „An-Institute”, die an
Universitäten angegliedert sind, aber rechtlich eigenständig agieren2 , korrekt zugeordnet und
benannt werden (vgl. Winterhager, Schwechheimer und Rimmert, 2014). In der Bibliometrie
wurden dafür einige Lösungen entwickelt, die auf der automatischen Indexierung mit Hilfe
von Named-Entity Recognition Verfahren beruhen.3
Um der Problematik der uneinheitlichen Bezeichnung von Konzepten in der außersprachli-
1
Beispiel: Das KIT Karlsruhe, entstanden aus einer Ausgliederung der Universität Karlsruhe und des For-
schungszentrum Karlsruhe.
2
Beispiel: Das Leibniz-Institut für Arterioskleroseforschung (LIFA) an der Universität Münster - aber nicht
Teil der Universität Münster.
3
Unter Named-Entity Recognition wird die automatisierte Erkennung und Klassifikation von Eigennamen
bei Informationsextraktion aus Texten verstanden. Dieses Verfahren wird häufig in der Computerlinguistik
verwendet (vgl. hierzu Jiang, 2012). Beispiele für die Anwendung zur automatischen Erkennung von Namen
wissenschaftlicher Einrichtungen sind Enhanced Finite-State Transducer in Galvez und Moya-Anegón,
2007 oder Nooj Transducer in Taşkın und Al, 2013.
1Einleitung
chen Realität entgegenzuwirken entwickelten sich im bibliothekarischen Bereich sogenannte
Verzeichnisse für Normdaten. In diesen werden Personen, Körperschaften, Geografika und
Sachverhalte durch normierte Benennungen identifiziert und Publikationen zugeordnet. In
Deutschland wird die Gemeinsame Normdatei (GND) als Werkzeug für die eindeutige Zuord-
nung von Namen verwendet, ein weiteres Beispiel ist die Name Authority Files der Library of
Congress in den USA (vgl. Wiechmann, 2014).
Zunehmend wird versucht, das Problem durch die Vergabe von eindeutigen Kennungen zu
lösen: „[N]ame forms are being replaced by universal registered identifiers for individuals in
these records, and internation registration agencies for such identifiers are being formed”
(Zhao und Strotmann, 2015, S.101-102).
Im Kontext der eindeutigen Identifikation von Forschenden trotz Namensgleichheiten werden
Identifikatoren für Personen als eine gute Lösungsmöglichkeit angesehen. Um wissenschaftliche
Publikationen eindeutig mit ihren Autor*inen zu verknüpfen, existieren eine Reihe von Diensten,
wie die Researcher ID von Thomas Reuters/Web of Science, den Scopus Author Identifier und
Author Profile von Elsevier oder das Virtual International Authority File (VIAF) (vgl. Walker
und Armstrong, 2014). In den letzten Jahren hat sich die Open Research Contributer iD
(ORCID) als globaler non-profit Anbieter für eindeutige, gleichbleibende und durch Internet-
browser auflösbare Identifikatoren (Persistent Identifier ) für Personennamen etabliert. ORCID
verzeichnet mittlerweile über 4 Millionen IDs4 , welche jedoch nur für individuelle Personen
und nicht für wissenschaftliche Einrichtungen vergeben werden. Persistent Identifier (PID)
haben zwei grundlegende Eigenschaften: Sie identifizieren ein Informationsobjekt eineindeutig
zur Unterscheidung von anderen Objekten und sie ermöglichen die langfristige Auffindbar-
keit von Objekten im digitalen Raum, unabhängig davon, an welchem Ort sie gespeichert
sind (vgl. Lynch, 1998). Diese Arbeit wird sich vorrangig mit der eindeutigem Bezeichnung
von wissenschaftlichen Einrichtungen befassen, die mit Hilfe von Persistent Identifiern in
unterschiedlichen Nutzungsszenarien erfolgen kann. Die Nutzung von Persistent Identifiern
führt dazu, dass der Informationsfluss zwischen unterschiedlichen Stakeholdern und Entitäten
des Forschungsprozesses vereinfacht wird: „Tracking information flows between researcher,
facilities and publishers requires a common understanding and use of specific data fields and
associated persistent identifiers” (Haak, 2017). Für die Verbreitung von und das Vertrauen in
Persistent Identifier werden offene Forschungsinfrastrukturen nach Bilder, Lin und Neylon als
zuträglich angesehen.
Ziel dieser Arbeit ist es, einen Überblick über bisherige Lösungen für die eindeutige Identi-
fizierung von Institutionen mit Hilfe von Identifikatoren zu schaffen, Nutzungsszenarien zu
diskutieren und Vorschläge für die Entwicklung von Persistent Identifiern für wissenschaftliche
Einrichtungen zu entwickeln. Dafür wird in Kapitel 2 zunächst der Forschungsstand zu Persis-
tent Identifiern und bereits durchgeführten Projekten zu Identifikatoren für Organisationen
umrissen. Nach der Klärung der Methode in Kapitel 3 erfolgt in Kapitel 4 eine Analyse
bestehender Identifier sowie in Kapitel 5 ein exemplarische Analyse von Anwendungsfällen. In
Kapitel 6 werden die Ergebnisse diskutiert. Es werden folgende Aspekte genauer betrachtet:
4
Siehe: https://support.orcid.org/knowledgebase/articles/150557-number-of-orcid-ids
(Abgerufen am 26. Januar 2018).
2Einleitung
1. Welche Möglichkeiten zur eindeutigen Identifizierung von wissenschaftlichen Einrichtun-
gen bestehen bereits?
2. Wie lassen sich bestehende Lösungen einordnen und bewerten?
3. Welche Anforderungen an Persistent Identifier für wissenschaftliche Einrichtungen gibt
es?
4. Welche konkreten Anwendungsfälle ergeben sich für diese Persistent Identifier im
Forschungsprozess?
3Forschungsstand
2 Forschungsstand
2.1 Persistent Identifier
Im Zuge der Zugänglichkeit zu wissenschaftlicher Literatur über das Internet stellt sich
die Herausforderung, wie digitale Informationsobjekte eindeutig und langfristig identifizierbar
bleiben können, um das Auffinden und die zuverlässige Referenzierbarkeit von wissenschaftlichen
Ergebnissen zu garantieren. Seit Anfang der 2000er Jahre erfolgte eine Reihe von Studien, die
die mangelnde Persistenz von Belegen und Referenzen in wissenschaftlichen Publikationen
aufzeigen (vgl. Lawrence u. a., 2001; Dellavalle, 2003; Hennessey und Ge, 2013). Das Ergebnis
dieser Studien zeigt, dass die Referenzierung digitaler Informationsobjekte über einen Uniform
Resource Locator (URL) keine langfristig verlässlichen Belege liefern kann, da URLs keine
eineindeutige Bezeichnung für ein Objekt darstellen, sondern nur einen „Weg” hin zu einem
Objekt beschreiben (vgl. Lynch, 1998). Wenn das referenzierte Objekt verschoben oder
gelöscht wurde, der Service des Anbieters (Domain oder Host) nicht mehr existiert oder das
Objekt umbenannt wurde, können URLs nicht mehr verarbeitet und das Objekt nicht mehr
erreicht werden. Das „verschwinden” von digitalen Objekten aufgrund nicht funktionaler Links
wird als Link Rot bezeichnet; im Kontext des Verweisens auf Quellen in wissenschaftlichen
Publikationen spricht man von Reference Rot (vgl. Klein u. a., 2014). Ein Hauptproblem
besteht darin, dass URLs sowohl ein Objekt identifizieren, als auch seinen Speicherort im
Internet beschreiben (vgl. Dellavalle, 2003).
Um die Zugänglichkeit und Auffindbarkeit sowie Zitierbarkeit von wissenschaftlicher Literatur
im Internet sicherzustellen, etablierten sich seit Mitte der 1990er Jahre unterschiedliche Verweis-
und Identifikatorensysteme, die unter dem Oberbegriff Persistent Identifier zusammengefasst
werden.5 Die Research Data Alliance (RDA) definiert den Terminus Persistent Identifier als:
„[A] long-lasting ID represented by a string that uniquely identifies a DO6 and
that is intended to be persistently resolved to meaningful state information
about the identified DO. An identifier should have an unlimited lifetime, even
if the existence of identified entity ceases. This aspect of an identifier is called
persistency ” (Berg-Cross, Ritz und Wittenburg, 2015).
Ein Persistent Identifier bezeichnet ein bestimmtes Informationsobjekt, beispielsweise ein
Dokument. Informationsobjekte (oder Teile von Objekten) können mit unterschiedlichen PIDs
beschrieben werden, jedoch ist einem Identifier immer nur ein Objekt zugeordnet. Es besteht
somit eine 1:n-Beziehung zwischen Informationsobjekten und Persistent Identifiern. Ändert
sich das Objekt oder verschwindet es, bleibt der Identifier bestehen und wird nicht wieder
verwendet. Persistent Identifier haben demnach zwei grundlegende Eigenschaften:
5
Siehe hierzu Sollins, Masinter (1994): Functional Requirements for Uniform Resource Names (RFC 1737).
https://www.ietf.org/rfc/rfc1737.txt (Abgerufen am 26. Januar 2018).
6
Digital Object, also ein Objekt im digitalen Raum/Internet.
4Persistent Identifier
1. Sie sind eineindeutig und einzigartig und
2. sie sind beständig unabhängig von dem Objekt, auf das sie verweisen.
Identifiziert werden die Objekte an sich, Metadaten zu den Objekten und Zugriffswege auf das
Objekt. Die Metadaten zu den Objekten werden in sogenannten PID Records gespeichert:
„A PID record contains a set of attributes stored with a PID describing DO
properties” (Berg-Cross, Ritz und Wittenburg, 2015).
Der Unterschied zwischen PIDs und URLs liegt darin, dass PIDs auf ein identifiziertes Objekt
unabhängig davon, wo es zu einem Zeitpunkt gespeichert ist, verweisen. Persistent Identifier
an sich beinhalten nur Informationen über das Objekt, unter anderem seinen Speicherort.
PIDs werden über ein Resolver System zu dem digitalen Objekt geleitet (vgl. Tonkin, 2008).
Die RDA definiert dies als Resolution System:
„[A resolution system] is a globally available infrastructure system that has the
capability to resolve a PID into useful, currentstate information describing the
properties of a DO” (Berg-Cross, Ritz und Wittenburg, 2015).
Überlegungen zur Trennung von Identifikatoren und tatsächlichen Informationsobjekten stam-
men aus Konzeptionen zur Architektur von digitalen Bibliotheken. Objekte in einer digitalen
Bibliothek müssen durch „Namen” und Identifikatoren eindeutig identifizierbar und auffindbar
sein, ähnlich wie Buchbestände in einer analogen Bibliothek über eine Signatur gekennzeichnet
sind. Diese Namen müssen durch ein administratives System verwaltet werden, welches auf
Änderungen der Objekte reagiert und ihren aktuellen Ort langfristig dokumentiert (vgl. Arms,
1995). Persistent Identifier als Identifikatorensysteme im Internet geben über den Resolving
Service die Möglichkeit, auf eine Repräsentation des Informationsobjektes im digitalen Raum,
welche Informationen über das Objekt bereithält, zuzugreifen (vgl. Car, Golodoniuc und Klump,
2017). Der Resolving Service sorgt auch dafür, dass der Identifier eindeutig mit dem Informa-
tionsobjekt verbunden bleibt (vgl. Askitas, 2010). Der Resolver identifiziert Informationen
über das Informationsobjekt (Metadaten) und zeigt dabei auf seinen Speicherort. Bei der
Auflösung des PID werden Informationen (Metadaten, Location URL) zum bezeichneten
Objekt zurückgegeben und Anfragende zum Objekt selbst oder einer sogenannten Landing
Page weitergeleitet. Dieser zweischichtige Aufbau führt dazu, dass, wenn sich der Speicherort
des Informationsobjektes ändert, nur die Verknüpfung zwischen dem Identifikator und dem
Informationsobjekt geändert wird. Für Nutzer*innen des PID bleibt der Identifikator gleich.
PIDs ermöglichen, dass Informationsobjekte und ihre unterschiedlichen Versionen ohne die
Gefahr der Verwechslung identifiziert werden können. Sie helfen beim Auffinden und Referen-
zieren von Informationsobjekten im Internet und sorgen dafür, dass wissenschaftlicher Output
(Publikationen, Daten...) verlässlich zitierbar ist. Viele Identifikatorensysteme ermöglichen
zudem, über die ihnen zugrundeliegenden Metadaten, die Interoperabilität mit anderen Identi-
fiern und somit die Darstellung von Relationen zwischen Objekten (vgl. Davidson, 2006).
5Persistent Identifier
Im wissenschaftlichen Bereich haben sich im Laufe der letzten 20 Jahre unterschiedliche
Systeme für Identifier etabliert.7 Dabei haben sich vor allem der Digital Object Identifier
(DOI), Handle PIDs, Persistent URL (PURL), Uniform Ressource Name (URN) und Archival
Resource Key (ARK) durchgesetzt.
Klump und Huber untersuchten das Repository-Verzeichnis re3data auf die Nutzung von
PID Typen. DOIs wurden in den meisten Repositories als Identifier benutzt (vgl. Klump und
Huber, 2017). Sie können mittlerweile als ein quasi-Standard für Identifier für wissenschaftliche
Publikationen angesehen werden. DOIs werden zudem nicht nur für traditionelle Publikationen
in Schriftform vergeben, sondern auch für andere Formen von wissenschaftlichem Output, wie
zum Beispiel Forschungsdaten. Für die Zitierung quantitativer Daten wird als Minimalanforde-
rung das Vorhandensein eines Persistent Identifiers genannt (vgl. Altman und King, 2007).
Die Verlinkung und Interoperabilität zwischen den unterschiedlichen Identifier Systemen,
die für die Entitäten bereits bestehen, fördern einen Informations- und Datenfluss über den
gesamten Forschungszyklus und für alle Stakeholder. Die Nutzung von interoperablen PID
Systemen ermöglicht die Auffindbarkeit von wissenschaftlichem Output, die richtige Zuordnung
von Ergebnissen zu ihren Urheber*innen, nachvollziehbare Provenienz von nachgenutzten
Quellen oder Daten und verbesserte Metadatenqualität über die Verknüpfung unterschiedlicher
Metadatenquellen (vgl. Dappert u. a., 2017). Neuere Entwicklungen zielen darauf ab, PIDs
für alle Entitäten im wissenschaftlichen Forschungskontext zu vergeben, um Interoperabilität
zwischen ihnen zu schaffen. Folgende Entitäten werden von Dappert u. a. identifiziert:
• Agents: Individuelle Forschende, Organisationen und Konsortien
• Resources: Publikationen, Forschungsdaten, Software, Forschungsinstrumente, Laborbü-
cher...
• Rights statements: Lizenzen, Förderungsmaßnahmen, Patente
• Events: Vorgänge, die die Provenienz von wissenschaftlichem Output beschreiben
(Erstellung, Kuration, Updates, Zugriff, Claiming, Zitation, Review)
• Derived entities: Entitäten wie Projekte, die aus Verbindungen von allen oben genannten
Entitäten entstehen oder diese erschaffen
Eindeutige, meist numerische Identifikatoren existieren auch außerhalb des Internets um
Objekte (beispielsweise Bücher durch eine ISBN) oder Personen (beispielsweise Bürger eines
Landes durch die Passnummer) zu identifizieren. Für die eindeutige Identifizierung von
Personen findet seit ihrer Gründung 2012 die ORCID iD immer weitere Verbreitung. Diese Art
der Selbst-Identifizierung von Personen in der Form eines offenen Infrastrukturservices wird in
Deutschland durch das von der Deutschen Forschungsgemeinschaft (DFG) geförderte Projekt
ORCID DE8 unterstützt. Das Ergebnis einer 2016 durch ORCID DE durchgeführten Umfrage
ergab für eine Mehrzahl der Befragten einen sehr hohen bis hohen Bedarf an persistenten
Identifikatorensystemen für wissenschaftliche Institutionen, Forschungsinfrastrukturen und
Förderorganisationen (vgl. Fuchs, Pampel und Vierkant, 2017, S. 53). Die Nutzung von
7
Einen guten Überblick geben Hilse und Kothe, 2006: Implementing persistent identifiers: overview of
concepts, guidelines and recommendations.
8
Siehe: http://www.orcid-de.org/ (Abgerufen am 26. Januar 2018).
6Bestehende Identifikatorensysteme
Identifikatoren für Organisationen ist bisher in Deutschland jedoch nicht sehr weit verbreitet
(vgl. Bryant, Dortmund und Malpas, 2017, S. 42).
2.2 Bestehende Identifikatorensysteme
Für die eindeutige Identifikation von wissenschaftlichen Einrichtungen bestehen bereits eine
Reihe Identifikatorensysteme, die im Kapitel 4 näher analysiert werden. Im bibliothekarischen
Kontext werden zur eindeutigen Identifizierung von Entitäten Normdaten, die in Normdateien
gespeichert sind, verwendet. Sie werden aufgrund einer Ontologie gebildet und dienen zur Un-
terscheidung von Konzepten und aus der bibliothekarischen Tradition heraus zur Erleichterung
des Sucheinstiegs, indem Namensvarianten zusammengeführt werden (vgl. Wiechmann, 2014).
Normdateien werden landesintern durch nationale Informationsinfrastruktureinrichtungen,
meist Nationalbibliotheken, gepflegt. In Deutschland wird die Gemeinsame Normdatei (GND)
verwendet. Das Virtual International Authority File (VIAF) führt unterschiedliche nationale
Normdateien zusammen.9 Ein ISO-Standard (ISO-Standard 27729) für die Identifizierung
von Personen und Organisationen ist der International Standard Name Identifier (ISNI).10
Es werden Personen, Körperschaften oder fiktionale Charaktere identifiziert. Ringgold ist
ein Unternehmen, welches seit 2003 Identifikatoren speziell für Organisationen vergibt. Das
Identify Database 11 verzeichnet über 480.000 Organisationen (Stand: 26. Januar 2018), die
meisten davon aus Nordamerika (ca. 47 %) und Westeuropa (ca. 25%)12 . Die Global Research
Identifier Database13 (GRID) ist ein von der Firma Digital Science entwickeltes Identifier-
System, welches wissenschaftliche Einrichtungen auf der ganzen Welt erfassen will. Entwickelt
wurde das System 2015 von Digital Science, um die Firma bei ihren Reporting Aktivitäten zu
unterstützen. Der GRID Identifier wird u.a. von Altmetrics und Figshare verwendet. Forschungs-
förderungseinrichtungen vergeben Forschungsgelder an Projekte, die an wissenschaftlichen
Einrichtungen angesiedelt sind. Die DFG verzeichnet in ihrer Datenbank GEPRIS14 (Geför-
derte Projekte Informationssystem) Förderprojekte und die durchführenden Personen und
Institutionen. Institutionen erhalten innerhalb von GEPRIS eine DFG ID. Der Wissenschafts-
rat empfiehlt in seinen Empfehlungen zum Kerndatensatz Forschung, die Verwendung der
Instituts-ID der DFG und des DAAD, welche über den Research-Explorer15 , dem Verzeichnis
der Forschungsstandorte in Deutschland, abgefragt werden kann (vgl. Wissenschaftsrat, 2016,
S. 60). Für die Antragstellung und spätere Förderung werden von Institutionen Antragsdoku-
mente ausgefüllt in die verantwortliche Institutionen eingetragen werden müssen. Für Projekte
im Zuge des EU-Rahmenprogramm Horizon 2020 ist eine eindeutige Identifikationsnummer
9
Siehe: https://viaf.org/ (Abgerufen am 26. Januar 2018).
10
Siehe: http://www.isni.org/ (Abgerufen am 26. Januar 2018).
11
Siehe: https://www.ringgold.com/ringgold-identifier (Abgerufen am 26. Januar 2018).
12
Siehe: https://support.ringgold.com/wp-content/uploads/2018/01/Ringgold_Infographics_
2018_Jan.pdf (Abgerufen am 26. Januar 2018).
13
Siehe: https://grid.ac/ (Abgerufen am 26. Januar 2018).
14
Siehe: http://gepris.dfg.de/gepris/OCTOPUS (Abgerufen am 26. Januar 2018).
15
Siehe: http://www.research-explorer.de/research_explorer.de.html (Abgerufen am 26. Januar
2018).
7Projekte
für wissenschaftliche Einrichtungen für die Antragstellung gefordert. Diesem Teilnehmercode
(Participant Identification Code (PIC))16 hinterliegen alle Angaben zu den Institutionen.
Um Forschungsförderer eindeutig zu identifizieren und das Tracking der wissenschaftlichen
Ergebnisse zu erleichtern, wurde 2013 durch die DOI-Registrierungsagentur Crossref das Open
Funder Registry17 (ursprünglich FundRef genannt) gegründet. Es handelt sich hierbei um eine
normalisierte Liste von Forschungsförderern aus aller Welt, die durch eine DOI identifiziert
werden. In Literatur- und Zitationsdatenbanken werden Publikationsdaten sowohl Personen als
auch wissenschaftlichen Einrichtungen zugeordnet. Die Datenbank Scopus der Firma Elsevier
vergibt jeder Affiliation in ihrer Datenbank eine eindeutige Nummer, die sie Affiliation-ID
nennen, um zwischen Organisationen zu unterscheiden und Publikationen zusammenzufassen,
die zu einer Organisation gehören (vgl. Elsevier, 2018a).
2.3 Projekte
Identifier für Organisationen werden idealerweise zur Vereinfachung von Workflows innerhalb
der digitalen Forschungsinfrastruktur verwendet:
„Identifiers are useful for disambiguating, consolidating and establishing a hierarchy
view. They enforce uniqueness as they disambiguate institutional records, eradicate
duplication of data, ensure correct delivery, entitlement and access rights, improve
trust in data and map institutions into their hierarchy ” (Amante u. a., 2017, S.
139).
Ein Anwendungsgebiet ergibt sich im Bereich der Zugehörigkeit (Affiliation) von Forschen-
den zu ihren Einrichtungen. Bereits seit 2008 wird für die vom Verlag Elsevier geführte
bibliografische Datenbank Scopus ein Affiliation Identifier angeboten, der die Angabe von
Zugehörigkeiten normiert und es ermöglicht, alle Publikationen einer Einrichtung aggregiert
anzuzeigen (vgl. Haerter, 2008).
Der Journal Supply Chain Efficiency Improvement Pilot der National Information Standards
Organisation (NISO) identifiziert die Erleichterung von Transaktionsprozessen und Infor-
mationsflüssen zwischen Verlagen und Bibliotheken als ein weiteres Anwendungsgebiet für
eindeutige Identifier für Organisationen (vgl. Chvatal, 2008). Eine Bewertung von bereits
bestehenden Identifikatorensystemen ergab, dass ISNI als einziges System weitestgehend
diese Anforderungen erfüllt, jedoch das verwendete Metadatenschema noch nicht vollständig
ausgereift ist. Die Working Group gab dementsprechende Empfehlungen an ISNI weiter.
In Großbritannien wurde zwischen 2013 und 2014 eine umfangreiche Studie zur Organizational
Identifiern in Großbritannien durch das Joint Information Systems Committee (Jisc) und das
16
Siehe: http://www.horizont2020.de/projekt-teilnehmercode.htm (Abgerufen am 26. Januar
2018).
17
Siehe: https://www.crossref.org/services/funder-registry/ (Abgerufen am 26. Januar 2018).
8Projekte
Consortia Advancing Standards in Research Administration Information (CASRAI) durchge-
führt (vgl. Hammond und Curtis, 2013). Die Studie ergab, dass keiner der 23 identifizierten
und geprüften Identifikatoren als ausreichend „autoritativ” angesehen wird, die Identifikato-
rensysteme ISNI und UKPRN18 jedoch am positivsten beurteilt werden. Ein hybrider Ansatz
mit ISNI als „bridging Identifier ” (Brückenidentifier) wird von der Working Group als optimal
angesehen (vgl. Brown, 2015).
Aufbauend auf den Ergebnissen des Jisc/CASRAI Projektes evaluierte ein von OCLC geleitetes
Projekt die Vergabe von ISNI Nummern anhand unterschiedlicher Anwendungsfälle. Diese
bezogen sich auf folgende Akteure innerhalb der wissenschaftlichen Community: Administrative
Mitarbeiter*innen, Forschungsförderer, Verlage, Verwaltungen, Forschende und Gruppen von
Forschenden, Informationsspezialist*innen Softwareentwickler*innen und Rechtsabteilungen
(vgl. Smith-Yoshimura u. a., 2016). Das Projekt zeigt anhand von Szenarien, wie innerhalb
ISNI mit Herausforderungen bei der Identifizierung von wissenschaftlichen Einrichtungen
umgegangen wird. Diese beinhalten Namensänderungen, genaue Angabe eines bevorzugten
Namens, die Abbildung von Hierarchien in den Metadaten mit Hilfe von Beziehungsbeschrei-
bungen, die Restrukturierung von wissenschaftlichen Einrichtungen, Fälle von Übernahmen
oder Zusammenlegungen und der Umgang mit Forschungsgruppen und Konsortien. Hieraus
ergeben sich Empfehlungen, die das Projekt an ISNI abgeben konnte.
Das Konzept von ISNI als Brückenidentifier ist in Portugal für die Entwicklung eines Identifi-
kators für Organisationen innerhalb des nationalen Forschungsinformationssystems PTCRIS
angewendet worden (vgl. Amante u. a., 2017). Der Identifier ist mit ISNI, bzw. auf ISNI
gemappte Ringgold-Identifier interoperabel und dient zur Disambiguierung von Organisationen
innerhalb von PTCRIS.
Das Projekt THOR befasste sich von 2016 bis 2017 mit der Interoperabilität und Verlinkung
von Persistent Identifiern für die wissenschaftliche Infrastruktur (vgl. Fenner u. a., 2016),
wobei es sich vor allem auf die Relationen zwischen Identifiern für Forschungsschaffende und
Forschungsoutputs konzentrierte. Persistent Identifier für Organisationen werden bislang wenig
genutzt. Obwohl es bereits eine Reihe von Identifikatorensystemen gibt, hat sich bisher keines
in der wissenschaftlichen Community durchgesetzt:
„The use of persistent identifiers for organisations lags behind the use of persistent
identifiers for research outputs and people. Despite the work by ISNI, FundRef
and others, community uptake is still low. In addition, for some of these orga-
nizational identifiers (e.g. FundRef) there is no openly available central service
that systematically collects links to other identifiers” (Fenner u. a., 2015, S. 19).
Das Organization Identifier Projekt verfolgt das Ziel, ein Identifikatorensystem für Organisa-
tionen zu schaffen, welches den „Principles for open scholarly infrastructures” (vgl. Bilder, Lin
18
UK Provider Reference Number, beispielsweise verwendet von der Higher Education Statistics Agency
(HESA) in der UK. Siehe: https://www.hesa.ac.uk/support/providers (Abgerufen am 26. Januar
2018).
9Projekte
und Neylon, 2015) entspricht. Dabei geht es vor allem um das Vertrauen in die Governance,
Nachhaltigkeit und die Ansiedlung der Infrastruktur in der Community. Bestehende Organiza-
tional Identifier, so die Arbeitsgruppe, seien diesen Prinzipen bisher nicht gewachsen: „Among
the gaps that have been identified during our consultations this year are transparent, non-profit
governance and the ability for organizations to manage their own records” (Cruse, Haak und
Pentz, 2016, S. 1). Die Arbeitsgruppe stellte eine Liste von Anforderungen an ideale Organi-
zational Identifier zusammen, wobei sie sich auf die vorangegangenen Studien bezog. Anders
als bei diesen Studien liegt hier der Fokus weniger auf dem Verbreitungsgrad der bisherigen
Lösungen sondern auf Offenheit (öffentliche API-Schnittstellen), Transparenz (getragen durch
gemeinnützige Organisationen) und Nachnutzbarkeit (Daten sind nicht proprietär und liegen
unter einer Lizenz vor, die die Nachnutzbarkeit ermöglicht). Die Arbeitsgruppe identifizierte
folgende Anforderungen an Organizational Identifier:
• Unique: Die Identifier sind global eineindeutig, unabhängig davon wie groß ihre Anzahl
ist.
• Stable: Die Identifier garantieren Funktionalität.
• Discoverable: Die Identifier können leicht gefunden werden.
• Resolvable: Die Identifier können im Browser aufgelöst werden.
• Not recycled: Im Falle der Obsoleszenz eine identifizierten Objektes wird der Identifier
nicht wieder verwendet.
• Documented: Die Funktionsweise des Identifiersystems ist offen dokumentiert.
• Have appropriate metadata: Die Identifier sind mit für die Identifizierung und Beschrei-
bung wissenschaftlicher Einrichtungen angemessenen Metadaten versehen.
• Interoperable: Die Identifier sind mit anderen Identifiern über Metadaten, die ihre
Relationen beschreiben verknüpfbar.
• Can be merged/split: Die Identifier können im Falle struktureller Veränderungen von
Einrichtungen zusammengeführt oder aufgeteilt werden.
• Expressed as HTTP(S) URIs: Die Identifier werden als URI, die über das HTTP(S)-
Protokoll im Internet ausgeführt werden kann, ausgedrückt.
• Support content negotiation for machine representations: Die Identifier unterstützen
das System der Inhaltsausgabe19 um die bestmögliche Darstellung der Informationen zu
ermöglichen.
• Support discovery APIs: Das Identifiersystem kann über eine Programmierschnittstelle
(API) abgefragt werden.
• Have transparent, non-profit governance: Die Identifier werden von einer non-profit
Organisation mit einer transparenten Verwaltungsstruktur angeboten.
• Offer the ability for organizations to manage their own records: Die Identifier und die
Metadaten können von den identifizierten Einrichtungen selber verwaltet werden.
Bisher erfüllt kein Identifier diese Anforderungen. Kritikpunkte an der ISNI beziehen sich auf das
Business-Model (Kosten für die Benutzung/Registrierung), fehlende offene Lizenzen, fehlender
19
Siehe hierzu: Holdman und Mutz (1998): RFC 2295. Transparent Content Negotiation in HTTP. https:
//tools.ietf.org/html/rfc2295 (Abgerufen am 26. Januar 2018).
10Projekte
Fokus auf Organisationen, fehlende Transparenz im Government und fehlende Nutzbarkeit der
Daten in maschinenlesbarer Form für die Öffentlichkeit. Außerdem sieht die Arbeitsgruppe
aufgrund von Vertrauen und Nutzbarkeit einen Mehrwert in offenen Identifikatorensystemen
(vgl. Bilder, Brown und Demeranville, 2016).
Überblick
Projekt Untersuchte Identifier Ergebnis
I2 Working Group ISNI, MARC, SAN, DUNS ISNI mit angepasstem Meta-
datenschema
Landscape Study 23 Identifikatoren ISNI
Jisc CASRAI ISNI, Digital Science (jetzt ISNI+ als „Brücke” mit ange-
GRID), Ringgold, UKPRN passtem Metadatschema
OCLC ISNI ISNI+ möglich, aber Anpas-
sungen im Metadatenformat
notwendig, Nutzung muss ver-
breitet werden
ORCID Open Funder Registry, ISNI, Kein offenes Identifikatoren-
Ringgold, Publisher Solutions system vorhanden
International, GRID, LEI, Or-
gRef
Tabelle 1: Bereits durchgeführte Projekte, Untersuchte Identifier und Ergebnisse
11Methode
3 Methode
Das Hauptziel dieser Arbeit besteht darin, einen Überblick über bisherige Lösungen für die
eindeutige Identifizierung von wissenschaftlichen Einrichtung mit Hilfe von Identifikatoren zu
schaffen. Dabei werden im ersten Schritt bereits bestehende Identifikatorensysteme betrach-
tet. Die Auswahl der Identifikatoren erfolgt anhand einer Recherche nach Identifikatoren für
wissenschaftliche Einrichtungen und den Beispielen aus den genannten Studien. Der Begriff
Identifikator wird dabei als „eindeutige Kennung, die eine auf eine Entität verweist” verwendet.
Die Auswahl der Identifikatoren ist zudem auf ihre mögliche Anwendung im deutschsprachigen
Raum beschränkt. Dies spiegelt sich unter anderem darin, dass im Zuge der Betrachtung
von Normdaten nur die GND ausgewählt wurde. Andere Normdatendateien, wie das Name
Authority File der Library of Congress in den USA oder das international übergreifende VIAF
wurden nicht näher betrachtet. Die GND ID und die ISNI ID sind zwei Identifikatorensysteme
in der Auswahl, die nicht ausschließlich wissenschaftliche Einrichtungen beschrieben, sondern
deren Anwendungsgebiete auch auf Personen (ISNI, GND) und Orte, sowie Sachverhalte
(GND) bezogen werden. Da die GND als Normdatensatz die Grundlage der bibliothekarischen
Disambiguierung legt und die ISNI in bereits durchgeführten Studien sehr gut bewertet wurde,
werden die beiden Identifier trotzdem betrachtet und nur auf ihre Anwendung für wissen-
schaftliche Einrichtungen bzw. Körperschaften untersucht.
Zuerst werden bereits verwendeten Identifikatoren kurz beschrieben und darauf hin untersucht,
welche Informationen zu den Einrichtungen in welcher Form abgebildet werden, welche Rela-
tionen zwischen Einrichtungen untereinander und ggf. zu Personen bestehen können, ob die
Identifikatoren im Internet anwendbar sind und in wie fern sie zugänglich und nachnutzbar sind.
Dabei werden induktiv Kriterien für Persistent Identifier für wissenschaftliche Einrichtungen
abgeleitet.
Innerhalb der bisherigen Studien zu Identifikatoren für wissenschaftliche Einrichtungen wurden
Anwendungsszenarien entwickelt. Dafür wurden die besprochenen Anwendungsfälle zunächst
Oberthemen zugeordnet, wie im Anhang dargestellt. Die Anwendungsszenarien, die in je-
weils mindestens einer Studie besprochen wurden, sind in Tabelle 2 noch einmal dargestellt.
Dabei werden die Anwendungsszenarien aus der NISO-Studie nicht berücksichtigt, da die
Anwendungsfälle hier sehr spezifisch auf ein fiktives Konsortium zugeschnitten sind. Für
den Anwendungsfall der konsistenten und zeitunabhängigen Zuweisung von Affiliationen
wird keine Lösung recherchiert, da dieses Anwendungsgebiet im Zuge der Untersuchung der
Metadaten aufgegriffen wird. Der Anwendungsfall für das Open-Accesss-Monitoring und APC-
Management konnte nur in einem Projekt identifiziert werden. Aufgrund seiner Aktualität und
angenommenen Nützlichkeit wird dieser mögliche Einsatz von Identifikatoren für wissenschaft-
liche Einrichtungen dennoch behandelt. Die Anwendungsfälle werden daraufhin untersucht,
welche Lösungen (im deutschsprachigen Raum) im Sinne der eindeutigen Identifizierung von
wissenschaftlichen Einrichtungen bisher erfolgt sind. Aufgrund des eingeschränkten Umfangs
der Arbeit, kann keine vollständige Erhebung zu Lösungen durchgeführt werden. Stattdes-
sen wird für jeden Anwendungsfall beispielhaft nach Lösungen bzw. bestehenden Workflows
recherchiert. Diese werden in Kapitel 5 vorgestellt.
12Methode
Auswahl der Anwendungsfälle
Kategorie Landscape Study Jisc/CASRAI OCLC
für Jisc/CASRAI
Forschende Drittmittel- Drittmittel- Drittmittel-
förderung (An- förderung (An- förderung (Grup-
trag) trag) pen)
Forschungsinfrastruktur Reporting Reporting (For- Aggregation und
schungsergebnis- Reporting
se/Drittmittel)
Automatisierung Automatisierung
von Datenflüssen von Datenflüssen
Forschungsförderung Tracking Tracking Tracking
Gutachtenverfahren Gutachtenverfahren
(Anträge) (Anträge)
Open Access Mo-
nitoring und APC-
Management
Tabelle 2: Korrelierende Anwendungsfälle in jeweils mind. 2 Studien
Die Diskussion der Ergebnisse erfolgt anhand von vier Kriterien:
1. Definition von Kriterien für Persistent Identifier für wissenschaftliche Einrichtungen und
Kategorisierung Kategorisierung der untersuchten Systeme im Bezug auf diese Kriterien.
2. Anforderungen an Metadaten für PIDs für wissenschaftliche Einrichtungen im Bezug
auf die untersuchten Anwendungsfälle.
3. Bewertung der Anwendungsfälle im Bezug auf den Nutzen von Persistent Identifiern.
4. Einschätzungen zu Organisationsansätzen für ein Identifiersystem für wissenschaftliche
Einrichtungen im Bezug auf offene Forschungsinfrastrukturen.
Durch die Diskussion werden die Ergebnisse der Analyse der Identifikatoren und die Recherche
nach Lösungen zusammengeführt und in einen gemeinsamen Kontext, der Entwicklung eines
Persistent Identifiers für wissenschaftliche Einrichtungen basierend auf offenen Forschungsin-
frastrukturen gebracht.
13Identifikatoren für wissenschaftliche Einrichtungen
4 Identifikatoren für wissenschaftliche Einrichtungen
4.1 Die Gemeinsame Normdatei (GND)
Für Körperschaften entstand in den 1970er Jahren die GKD (Gemeinsame Körperschaftdatei),
die aus Körperschaftsdaten der Zeitschriftendatenbank hervorging und 2012 in die Gemeinsame
Nordatei (GND) aufging. Körperschaften werden definiert als „Eine Organisation oder Gruppe
von Personen und /oder Organisationen, die mit einer bestimmten Bezeichnung identifiziert
wird, und die als Einheit handelt” (Patton u. a., 2010, S. 27f.). Dazu gehören auch Tagungen,
Kongresse, Konferenzen, Messen und weitere kurzzeitige vorhandene Organisationen, die noch
bestehen oder in der Vergangenheit bestanden haben.
Innerhalb des Modells der Funktionalen Anforderungen an bibliografische Datensätze (FRBR)
werden Körperschaften als separate bibliografische Entitäten behandelt, deren Bezeichnungen
mit Normdaten kontrolliert und deren Datensätze mit anderen Datensätzen verlinkt werden
können (Ebd., S. 17f.). Beziehungen zwischen Körperschaften sind in FRBR als hierarchische
Beziehungen (untergeordnet, übergeordnet) oder (temporale) Folge-Beziehungen (Namens-
änderungen, gesplittete Körperschaft, fusionierte Körperschaft) modelliert (Ebd., S. 77f.).
Kernelemente eines Normdatensatzes für Körperschaften sind nach dem Resource Description
and Access (RDA) Standards, der seit 2015 für die GND gilt: Name, bevorzugter Name, Ort,
der mit der Körperschaft in Verbindung steht (Ort einer Konferenz, Ort des Hauptsitzes),
Datum, das mit der Körperschaft in Verbindung steht (Datum der Konferenz, Gründungsda-
tum, Auflösungsdatum), in Verbindung stehende Institution (bei Konferenzen), sonstige zur
Körperschaft gehörende Kennzeichnung (Art, sonstige Kennzeichnung) und Identifikator für
die Körperschaft (RDA, S. 545ff.). Mit Identifikatoren sind externe Identifikatoren gemeint,
die mit der vergebenden Stelle in den Datensatz übernommen werden. Jeder Datensatz in
der GND erhält eine Nummer (Identifikator), die diesen Datensatz eindeutig bezeichnet. Die
Fachhochschule Potsdam hat beispielsweise die GND-Nummer 5105272-6.20 GND-Datensätze
können auch im Marc21-XML21 und RDF (Resource Description Framework)22 Format herun-
ter geladen werden. Der RDF-Datensatz zeigt die Properties, die von der GND verzeichnet
werden.
a gndo:CorporateBody ;
foaf:page ;
gndo:gndIdentifier "5105272-6" ;
gndo:oldAuthorityNumber "(DE-588)4492533-5" ;
owl:sameAs ;
dnbt:deprecatedUri "http://d-nb.info/gnd/4492533-5" ;
gndo:oldAuthorityNumber "(DE-588c)4492533-5" , "(DE-588b)5105272-6" ;
gndo:variantNameForTheCorporateBody "FHP","University of Applied Sciences
Potsdam","FHP (Fachhochschule, Potsdam)" ;
gndo:preferredNameForTheCorporateBody "Fachhochschule Potsdam" ;
20
Siehe: http://d-nb.info/gnd/5105272-6.
21
Machine-Readable Cataloging, ein Datenformat für den Austausch bibliografischer Daten. Siehe: https:
//www.loc.gov/marc/bibliographic/ (Abgerufen am 26. Januar 2018).
22
Ein Datenformat zur Modellierung von semantischen Aussagen (Subjekt-Prädikat-Objekt) im Internet.
14Der International Standard Name Identifier (ISNI)
gndo:gndSubjectCategory ;
gndo:geographicAreaCode ;
gndo:homepage ;
gndo:dateOfEstablishment "1991" ;
gndo:placeOfBusiness
Im Datensatz sind keine Relationen zu verwandten Organisationen verzeichnet, obwohl die-
se als „untergeordnet” erfasst sind. Für die Fachhochschule Potsdam sind dies insgesamt
13 untergeordnete Einrichtungen: fünf Fachbereiche, das Usbekisch-Deutsche Zentrum für
Architektur und Bauwesen23 , die Gleichstellungsbeauftragte24 , die Potsdam School of Archi-
tecture25 , das Informationszentrum für Informationswissenschaft und -praxis (Potsdam)26 und
das Institut für Information und Dokumentation (Potsdam)27 . Zudem bestehen Datensät-
ze für die vorherige Benennung des Fachbereichs Informationswissenschaften (Fachbereich
Archiv-Bibliothek-Dokumentation28 ) und dem Fachbereich Sozialwesen29 . Der Datensatz des
Fachbereichs Archiv-Bibliothek-Dokumentation verweist auf den neuen Datensatz des neu
benannten Fachbereichs, und ist im RDF-Datensatz über
gndo:succeedingCorporateBody
definiert. Der Datensatz für den Fachbereich Sozialwesen beinhaltet keine Relationen zu
anderen GND-Datensätzen.
Für Organisationen sind in der GND folgende Rollen vorgesehen: „Urheber von”, „Beteiligt an”
und „Thema in”. Körperschaften sind sowohl Thema von Publikationen als auch geistige Schöp-
fer von Werken.30 In der GND gibt es keine Relationen zwischen Personennormdaten und Kör-
perschaftsnormdaten, also keine Möglichkeit, Affiliationen auszudrücken. Die Datensätze sind
einheitlich über eine URL nach dem Schema
aufrufbar. Es gibt kein Resolving System. Der Datensatz ist in Linked Data Anwendungen
über die Einbindung der GND-Ontologie vernetzbar aber in den öffentlichen Datensätzen sind
keine weiteren externen Identifikatoren eingebunden.
4.2 Der International Standard Name Identifier (ISNI)
Der International Standard Name Identifier (ISNI) identifiziert Personen oder Organisationen,
die an der Herstellung und/oder Distribution von medialen Inhalten beteiligt sind (vgl. DIN
ISO, 2012). Der Identifikator soll als Brückenidentifikator fungieren und die Nutzung anderer
Identifier erleichtern. Daher enthalten die Datensets nur Kerndaten zur Disambiguierung von
Identitäten und verlinken auf andere Systeme, die mehr Informationen bereit halten. ISNI hat
23
Siehe: http://d-nb.info/gnd/1069427608.
24
Siehe: http://d-nb.info/gnd/10026349-5.
25
Siehe: http://d-nb.info/gnd/16086296-6.
26
Siehe: http://d-nb.info/gnd/5105274-X.
27
Siehe: http://d-nb.info/gnd/5129722-X.
28
Siehe: http://d-nb.info/gnd/5253999-4.
29
Siehe: http://d-nb.info/gnd/2160393-5.
30
Lt. RDA 19.2.1.1.1 (RDA, S. 660f.).
15Der International Standard Name Identifier (ISNI)
zum Ziel, die Auffindbarkeit von Informationsressourcen zu erleichtern, die Disambiguierung
von Namen zu unterstützen und eine Infrastruktur zu stellen, die die Informationsdistribution
für Organisationen erleichtert (vgl. ISNI, 2018a). ISNI führt die Daten zu Identitäten aus
unterschiedlichen Datenbanken aus der ganzen Welt zusammen (vgl. ISNI, 2018b).
Die Kernelemente der Datensätze sind über die Suche in der ISNI Datenbank einsehbar.
Angegeben werden Name, Location/Nationality, Creation Class, Creation Role, Related Names
und Titles (Titel von Publikationen). Zudem können Notes vergeben werden. Unter Sources
wird angezeigt aus welchen Quellen die Informationen stammen. Es kann eine Liste der
Datenelemente auf der ISNI Website31 heruntergeladen werden (vgl. ISNI, 2014). In der
neusten Version von 2014 sind bereits einige der Vorschläge aus durchgeführten Studien zur
Identifikatoren für wissenschaftliche Einrichtungen integriert. Für Organisationen können im
MARC-Feld 710$q Angaben zu organisationType gemacht werden. Eine Liste von Typen
wurde von ISNI definiert. Aus dieser Liste können auch Konsortien, Forschungsgruppen oder
Subscription Services ausgewählt werden. Namen werden in Feld 710 $3 mit folgenden
Attributen aufgenommen: legalName, acronym, nickname, assignedName, transliteratedName,
difusedName, commonForm (default). Zwischen Personen und Organisationen können folgende
Relationen definiert werden:
• isRelatedTo
• isMemeberof / hasMember
• isAffiliatedWith / hasEmployee
• contact, no relation oder undefined
Organisationen untereinander können eine Reihe von Relationen haben:
• isMemberOf / hasMember
• isUnitOf / hasUnit
• isSupersededBy / supersedes
• isAffiliatedWith
• isRelatedTo
• formerName
• laterName
In der ISO-Norm für die ISNI ist festgelegt, dass, wenn Namensänderungen von Körperschaf-
ten durch Aufteilung oder Zusammenführung geschehen, diese Körperschaften eine neue
ISNI-Nummer erhalten (DIN ISO, 2012, S. 5). Jedoch können Namensänderungen über die
Relationsattribute formerName und laterName nachvollzogen werden.
Aus dem Metadatenschema der ISNI wird nicht ersichtlich, welche Rollen eine Körperschaft
einnehmen kann. Die Suche in der Datenbank ergibt eine Reihe von Titeln, die mit der
Körperschaft assoziiert sind. Da die ISNI vor allem dazu dient, Namen zu disambiguieren,
scheint kein großer Wert auf die Auszeichnung von Rollen für Körperschaften gelegt zu werden,
sie sind meistens creator. Relationen können in der ISNI sowohl zwischen Organisationen
untereinander als auch zwischen Personen und Organisationen angegeben werden. Dadurch
31
Siehe: http://www.isni.org/content/documents-related-data-submission (Abgerufen am
26. Januar 2018).
16Ringgold Identifier
lassen sich Affiliationen darstellen. Auch Namensänderungen für Organisationen lassen sich
über Relationen nachvollziehen. ISNIs sind einfache numerische Kennzahlen, bestehend aus
16 Zahlen. Sie enthalten keine semantischen Merkmale.32 ISNIs werden als persistente URIs
ausgedrückt, nach dem Schema .33 Für den
Zugriff ist kein Resolver Service vorgesehen. ISNI-Daten können als MARC21 Code und Linked
Data heruntergeladen werden. Die Daten sind unter einer „Open License” lizensiert.34
4.3 Ringgold Identifier
Ringgold ist ein Unternehmen, welches Identifikatoren für Einrichtungen aus einem breiten
Spektrum von Sektoren, beispielsweise auch Krankenhäuser (Typ hospital) oder Verwaltungs-
einrichtungen (Typ govt) anbietet (Delpeuch, 2017). Das Identifiersystem wurde begründet,
um eine Best-Practice-Lösung für die Disambiguierung von Organisationen durch Verlage
zu schaffen (vgl. Ringgold, 2018d). Dabei ging es vor allem um die korrekte Zuordnung
von Transaktionsdaten im Subskriptionsprozess. Das Unternehmen ist eine Registrierungs-
einrichtung für ISNI. Ringgold IDs werden auf ISNI-IDs gemapped und wenn neue Ringgold
IDs erstellt werden, werden diese mit der ISNI Datenbank abgeglichen und ggf. eine neue
ISNI hinzugefügt (vgl. Ringgold, 2018b). ORCID verwendet Ringgold IDs für die Angabe von
Affiliationen. Die Identify Datenbank kann gegen Bezahlung von Organisationen lizensiert
werden. Sie bietet Zugang zu den IDs, zu Zusatzinformationen und zu Datenhierarchien. Für
einen limitierten Gast-Zugang kann sich jeder registrieren35 , über die Kosten für den vollen
Zugriff gibt es auf der Webseite keine genaueren Angaben.
Ringgold IDs sind speziell dafür ausgelegt, Organisationen zu identifizieren. Eine öffentlich
zugängliche Version des Schemas der Datensätze gibt es nicht, jedoch werden Elemente der
Identify Datenbank dokumentiert.36 Standard Kernelemente beinhalten Name, Alternativer Na-
me, Adresse (Ort, Postleitzahl, Region, Land). Ringgold kategorisiert Arten von Organisationen
nach einem eigenen Standard (vgl. Ringgold, 2018f). Alternative Namen von Organisationen
werden mit Hilfe eines Kürzels in verschiedene Arten geordnet, Beispielsweise in Akronyme,
vorherige Namen, Transliterierte Namen, Zusammengelegte Namen. Organisationen werden
nach Sektoren und Typen geordnet. Sektoren sind academic, corporate, government (central
government), hospital, other (non-profit institutions), public (local government), school oder
consortium. Diese werden wiederum in Typen bzw. Schwerpunkte aufgeteilt. Somit ist die
Typisierung sehr granulär. Ein zweites von Ringgold entwickeltes Klassifizierungsschema ist die
Einordnung von Organisationen in Tiers (Ebenen/Stufen) (vgl. Ringgold, 2018e). Auch hier
werden Sektoren angegeben und mit dem Scope (Größe/Reichweite) der Organisation gepaart.
Diese bleiben äquivalent zu den Ringgold Types, es wird jedoch nicht nach Schwerpunkten
sondern nach Größe (anhand der Anzahl von Mitarbeitenden für Wirtschaftliche Einrichtungen)
oder Reichweite (anhand der Menge an Forschungsoutput für akademische Einrichtungen) ge-
32
Zum Beispiel ist die ISNI für die Fachhochschule Potsdam: 0000 0001 0680 6484.
33
Beispiel für die Fachhochschule Potsdam: http://isni.org/isni/0000000106806484.
34
Siehe: Open License, Version 1.0 (2011): http://ddata.over-blog.com/xxxyyy/4/37/99/26/
licence/Licence-Ouverte-Open-Licence-ENG.pdf (Abgerufen am 26. Januar 2018).
35
Siehe: https://www.ringgold.com/identify-online-guests (Abgerufen am 26. Januar 2018).
36
Siehe: https://support.ringgold.com/ (Abgerufen am 26. Januar 2018).
17Sie können auch lesen

















































