Teil IX Eigenschaften und Entwurf von Algorithmen
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Teil IX
Eigenschaften und Entwurf von
Algorithmen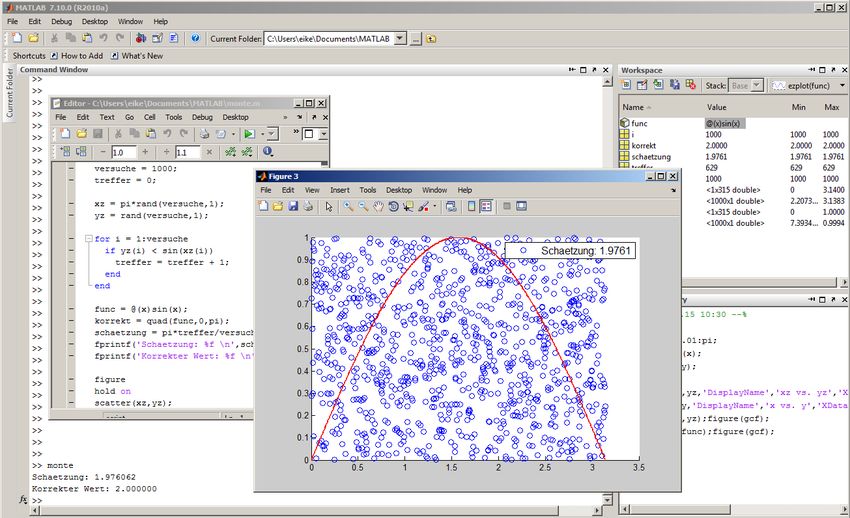
Überblick
1 Einführung
2 Grundlegende Eigenschaften von Algorithmen
3 Zeitkomplexität von Algorithmen
4 Zeitkomplexität am Beispiel von Sortieralgorithmen
5 Typische Algorithmenmuster
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 426/713Algorithmen
Zur Erinnerung:
Definition (Algorithmus)
Ein Algorithmus ist eine eindeutige Beschreibung eines in
mehreren Schritten durchzuführenden Vorgangs zur Lösung
einer bestimmten Klasse von Problemen.
Bisher:
Sehr einfache Algorithmen, z.B.
Matrizenmultiplikation durch geschachtelte Schleifen
Einfügen in eine Datenstrukur (einfach verkettete Liste)
Steuerung der Nutzerinteraktion
Möglichkeiten der Umsetzung in C/C++
Nur: Umsetzbarkeit von Algorithmen!
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 427/713Eigenschaften von Algorithmen
Jetzt: ist der Algorithmus ein „guter“ Algorithmus? →
Eigenschaften von Algorithmen
Effektivität: berechnet der Algorithmus, was er berechnen
soll?
Kommt er unter allen Umständen irgendwann zu einem
Ergebnis? → Terminiertheit
Berechnet er das richtige? → Korrektheit
Berechnet er für identische Eingaben immer dasselbe
Ergebnis? → Determiniertheit
Effizienz:
Liefert der Algorithmus (auch bei Eingabe beliebig großer
Datenmengen) möglichst schnell das Ergebnis? →
Zeitkomplexität
Eigenschaften von Algorithmen werden oft durch die
Eigenschaft des zu lösenden Problems bestimmt →
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 428/713Eigenschaften von zu lösenden Problemen
Kann für das Problem überhaupt ein Algorithmus angegeben
werden, welcher das Problem (für alle Eingaben) löst? →
Berechenbarkeit, Entscheidbarkeit
Wie schnell könnte der bestmögliche Algorithmus für dieses
Problem arbeiten? → Komplexitätsklassen
Kann für das Problem ein Algorithmus angegeben werden, der
(auch bei Eingabe beliebig großer Datenmengen) nach
„vertretbarer“ Zeit zu einem Ergebnis kommt? → Praktische
Berechenbarkeit, Komplexitätsklasse P (polynomiale
Zeitkomplexität)
Kann für das Problem kein solcher Algorithmus angegeben
werden? → Komplexitätsklasse EXP (exponentielle
Zeitkomplexität), NP-Vollständigkeit
Fragen bzgl. Eigenschaften von Algorithmen und Problemen
stehen im Mittelpunkt der Betrachtungen für Theoretische
Informatik
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 429/713Warum ... sind Eigenschaften von Algorithmen
für Ingenieure von Bedeutung?
In der Anwendung von Software und der Entwicklung von Produkten
kann ein Ingenieur in verschiedenen Bereichen auf Probleme der Ei-
genschaften von Algorithmen treffen, z.B.
1 Bei der Entwicklung von Steuerungsalgorithmen von
eingebetteten Systemen ist deren Korrektheit und
Terminiertheit von extrem großer Bedeutung. Selbst wenn ein
Ingenieur in deren Implementierung nicht direkt involviert ist, so
entwickelt er durch die notwendige Spezifikation doch die
Grundlagen für die Überprüfung.
2 Effizienzprobleme bei zu entwickelnder Software können
grundlegenden Anforderungen für den Einsatz entgegenstehen.
Beispiel Echtzeitfähigkeit: Automotive-Systeme wie ABS und
EPS müssen so schnell zu einem Ergebnis kommen, dass der
Steuerungsvorgang (Bremsen, Beschleunigen, etc.) nicht zu
spät gestartet werden kann.Grundlegende Eigenschaften von Algorithmen
Im Folgenden:
Terminiertheit
Determiniertheit
Korrektheit
Weitere Eigenschaften
Berechnungsmodell/Paradigma: zum Beispiel C/C++ mit
imperativen, funktionalen und rekursiven
Berechnungskonzepten (Alternativen: logische oder
nicht-deterministische Berechnungsmodelle)
Umsetzung bestimmter Algorithmenmuster (→)
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 431/713Eigenschaften von Algorithmen: Terminiertheit
Definition (Terminiertheit)
Ein Algorithmus heißt terminierend, wenn er (bei jeder
erlaubten Eingabe von Parameterwerten) nach endlich vielen
Schritten abbricht.
Beispiel einer nicht-terminierenden Berechnungsvorschrift
aus der Mathematik
∞
1 1 1 X 1
e = 1 + + + + ··· =
1! 2! 3! n!
n=0
Terminiertheit nicht immer erwünscht: Endlosschleifen in
Betriebsystemen, GUI-Anwendungen (siehe GLUT Main
Loop bei Grafikprogrammierung), Server-Programmen,
etc. → theoretisch endlose Laufzeit möglich, Abbruch
durch Ereignissteuerung bzw. externer Abbruch des
Prozesses
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 432/713Halteproblem
Bedeutendes Problem in der theoretischen Informatik mit
wichtigen Konsequenzen für die Praxis:
Halteproblem: gibt es ein Verfahren (Algorithmus!), mit dem
man für jeden Algorithmus entscheiden kann, ob dieser
terminiert?
Ein solches Verfahren wäre sehr nützlich: z.B. könnte ein
Compiler oder Verifizierer für Programme Warnungen ausgeben,
wenn diese (unter bestimmten Bedingungen) nicht terminieren
Dieses Problem ist aber NICHT ENTSCHEIDBAR! → es kann
kein Programm existieren, so dass ein Computer mit einem
anderen Programm als Eingabe berechnen kann, ob dieses
Programm unter allen Umständen terminiert
Halteproblem ist ein klassisches Beispiel (von vielen) für ein
nicht entscheidbares/berechenbares Problem
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 433/713Terminiertheit in der Praxis
Auch wenn kein allgemeines Verfahren existiert:
Terminierheit kann nachgewiesen werden für
Spezielle Algorithmen
Klassen von Algorithmen
Spezielle Programstrukturen (z.B. Schleifen) etc.
Untersuchungen zur Terminiertheit von Programmen
können im Rahmen der Verifizierung von Programmen
durchgeführt werden
Nicht-Entscheidbarkeit verbleibt als „Grauzone“ zwischen
eindeutig terminierenden und eindeutig
nicht-terminierenden Algorithmen
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 434/713Terminiertheit: Beispiel Ackermann-Funktion
Terminiert folgender Algorithmus für alle (m,n)?
int f1(int m, int n) {
if (m == 0)
return n+1;
else if (m > 0 && n == 0)
return f1(m-1, 1);
else if (m > 0 && n > 0)
return f1(m-1, f1(m, n-1));
else
return -1;
}
Ackermann-Funktion: häufig untersuchtes Beispiel
Sehr berechnungsaufwändig schon für kleine Parameter
Problematisch für Computer: Speicherüberlauf wegen
hoher Rekursionstiefe
Aber: Terminiertheit wurde nachgewiesen
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 435/713Terminiertheit: Collatz-Problem
Terminiert folgender Algorithmus für alle n?
int f2(int n) {
if (n < 1) return -1;
while (n != 1) {
if (n%2 == 0) n=n/2;
else n=3*n+1;
}
return n;
}
Collatz-Folge
1 Starte mit einer beliebigen natürlichen Zahl n
2 Ist diese gerade, halbiere sie, andernfalls berechne 3n + 1
3 Wiederhole ab Schritt 2
Vermutung: Folge endet immer mit Zyklus (4,2,1)* →
konnte bisher weder bewiesen noch widerlegt werden
Deshalb: Terminiertheit nicht bewiesen
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 436/713Terminiertheit: Fehlerhafte
Abbruchbedingungen
Terminiert folgender Algorithmus für alle n?
int f3(int n) {
while (n != 0) {
n = n%7;
n = n-1;
}
return n;
}
Algorithmus terminiert nicht für
Vielfache von 7
Negative Eingaben
→ Endlosschleife
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 437/713Eigenschaften von Algorithmen:
Determiniertheit
Definition (Determiniertheit)
Ein Algorithmus ist determiniert, wenn dieser bei jeder
Ausführung mit gleichen Startbedingungen und Eingaben
gleiche Ergebnisse liefert.
Entspricht mathematischem Konzept der Funktion als
eindeutig Abbildung von Eingaben(-mengen) auf
Ausgabe(-mengen)
Alternative: zufallsbasierte (auch stochastische,
randomisierte) Algorithmen → Einsatz ebenfalls unter
vielen Bedingungen sinnvoll:
Berechnungen (z.B. Monte-Carlo-Verfahren)
Optimierungsprobleme (z.B. Genetische Algorithmen →)
Nutzerinteraktion, Spiele, etc.
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 438/713Beispiel: Zufallsbasierte Algorithmen
Rπ
Näherungsweise Berechnung von 0 sin(x) durch
Monte-Carlo-Verfahren
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 439/713Monte-Carlo-Verfahren für Integralberechnung
/1
#include
#include
#include
#include
using namespace std;
#define PI 3.14159265358979
#define VERSUCHE 10000000
int main() {
float x,y;
int treffer;
srand(time(NULL));
...
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 440/713Monte-Carlo-Verfahren für Integralberechnung
/2
...
for (int i=0; i < VERSUCHE; i++) {
x = rand()%100000*PI/100000.0;
y = rand()%100000/100000.0;
if (y < sin(x)) treffer++;
}
float flaeche = PI * treffer / VERSUCHE;
coutMonte-Carlo-Verfahren für Integralberechnung
/3
Erläuterungen zum Algorithmus
Zufällige Erzeugung von Testpunkten (x, y) ∈ R2 im
Bereich 0 ≤ x ≤ π (Integrationsbereich) und 0 ≤ y ≤ 1
(Wertebereich der Funktion in diesem Bereich)
Ist der Testpunkt unterhalb der Kurve, ist er Teil der Fläche
und somit ein Treffer
Fläche unter Kurve kann damit über Verhältnis von Treffern
zu Gesamtversuchen mal der Versuchsfläche 1 ∗ π
berechnet werden
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 442/713MATLAB: Monte Carlo-Verfahren /1
versuche = 100;
treffer = 0;
xz = pi*rand(versuche,1);
yz = rand(versuche,1);
for i = 1:versuche
if yz(i) < sin(xz(i))
treffer = treffer + 1;
end
end
func = @(x)sin(x);
korrekt = quad(func,0,pi);
schaetzung = pi*treffer/versuche;
fprintf(’Schaetzung: %f \n’,schaetzung);
fprintf(’Korrekter Wert: %f \n’,korrekt);
...MATLAB: Erläuterungen zum Hauptprogramm Zufällige Punkte werden über rand()-Funktion als Felder erzeugt Da Matlab im Gegensatz zu C++ symbolische Mathematik unterstützt, kann der korrekte Wert durch Integration mittels der quad()-Funktion berechnet werden func = @(x)sin(x); korrekt = quad(func,0,pi);
MATLAB: Monte Carlo-Verfahren /2
...
figure
hold on
scatter(xz,yz);
x = 0:0.01:pi;
plot(x,sin(x),’Color’,’red’,’LineWidth’,2);
legend([’\fontsize{18} Schaetzung: ’ num2str(schaetzung)]);
hold off
Program beinhaltet einfache grafische Ausgabe
Scatter Plot für Zufallspunkte
Funktionsplot von sin(x)MATLAB: Ausgabe des Programms
Eigenschaften von Algorithmen: Korrektheit
Allgemein betrachtet: die Korrektheit eines Algorithmus besteht
darin, dass „er berechnet, was er berechnen soll“ → entspricht
Bedeutung (Semantik) des Verfahrens
Test auf Korrektheit erfordert
vollständige und korrekte Darstellung der Semantik
Verfahren zum Nachweis
Ist so allgemein (wie Terminiertheit) nicht entscheidbar!
Deshalb eingeschränkte Sicht auf
Definition (Korrektheit)
Unter der Korrektheit eines Algorithmus versteht man die
Eigenschaft, einer Spezifikation (formale Beschreibung der
Semantik) zu genügen.
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 447/713Eigenschaften von Algorithmen: Korrektheit /2
Verifikation: formaler Beweis der Korrektheit bezüglich einer
formalen Spezifikation
Validation: (nicht-formaler) Nachweis der Korrektheit bezüglich
einer informellen oder formalen Spezifikation (etwa
systematisches Testen)
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 448/713Vor- und Nachbedingungen
Möglichkeit der Spezifikation durch Angabe von Vor- und
Nachbedingungen für Programmtext (Algorithmus,
Funktion, Abschnitt, ...)
{ VOR } Programmtext { NACH }
VOR und NACH sind dabei Aussagen über den Zustand
vor bzw. nach Ausführung der Anweisungen
Aussage bedeutet: Gilt VOR unmittelbar vor der
Ausführung und terminiert der Programmtext, so gilt NACH
unmittelbar nach Ausführung.
Kann oft formal verifiziert bzw. durch Tests evaluiert
werden
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 449/713Effizienz von Algorithmen
Effizienz von Algorithmen betrifft eigentlich verschiedene
Kriterien
Laufzeiteffizienz: das Ergebnis soll so schnell wie möglich
geliefert werden
Effizienz der Ressourcen-Nutzung: das Ergebnis soll
unter möglichst geringer Nutzung von Ressourcen (vor
allem Speicher: Haupt- und Festplattenspeicher) berechnet
werden
Meist Trade-Off (Kompromiss) zwischen beiden Kriterien
möglich, zum Beispiel
Vorberechnung und Speicherung von
(Zwischen-)Ergebnissen
Speicherung von Zugriffspfaden für Daten (Indexe →
Datenstrukturen, Datenbanken)
Ressourcen werden jedoch oft als gegeben betrachtet,
deshalb:
Fokus auf Laufzeiteffizienz!
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 450/713Laufzeiteffizienz von Algorithmen
Laufzeiteffizienz drückt ein optimales temporales
Verhalten eines Algorithmus aus (möglichst hohe
Geschwindigkeit, möglichst geringe Bearbeitungszeit)
Tatsächliche Ausführungszeit kann für eine konkrete
Programmausführung von zahlreichen Faktoren abhängen
Wie gut/schnell ist die Hardware (CPU, Festplatten, ...)?
Welche Programmiersprache wurde verwendet?
Laufen parallel andere Prozesse, die die Rechenzeit
beeinflussen?
etc. und ist deshalb als Maß für die Effizienz des
Algorithmus wenig geeignet
Abstraktion: wie verändert sich die Anzahl der
notwendigen Bearbeitungsschritte in Abhängigkeit von der
„Größe“ des zu lösenden Problems →
Zeitkomplexität!
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 451/713Zeitkomplexität
Definition (Zeitkomplexität)
Die Zeitkomplexität eines Algorithmus ist eine Abschätzung
der Anzahl der durchzuführenden Berechnungsschritte
f (n, m, ...) in Abhängigkeit von der Größe der Eingabe(n)
n, m, ....
Weitere Unterteilung möglich:
Best Case-Komplexität: nach wie vielen Schritten beendet
der Algorithmus im günstigsten Fall seine Ausführung
Average Case-Komplexität: nach wie vielen Schritten
beendet der Algorithmus im durchschnittlichen Fall seine
Ausführung
Worst Case-Komplexität: nach wie vielen Schritten
beendet der Algorithmus im ungünstigsten Fall seine
Ausführung
Normalerweise Average Case- (und zum Teil Worst Case-)
Komplexität von Bedeutung
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 452/713Zeitkomplexität: einfaches Beispiel
Suche einer Zahl x in einem Feld der Größe n:
int suche(int x, int feld[], int feld_groesse) {
for (int i=0; i < feld_groesse; i++)
if (x == feld[i])
return 1;
return 0;
}
Gezählt werden jetzt nur die Vergleiche V in Abhängigkeit von
der Feldgröße n:
Best Case: gleich das erste Element im Array ist das gesuchte
→ Anzahl der Vergleiche ist V(n) = 1
Average Case: im Durchschnitt finden wir das gesuchte
Element, nachdem wir das halbe Feld durchsucht haben
(Voraussetzung: einmalige Feldwerte, Suchwerte im selben
Wertebereich) → Anzahl der Vergleiche ist V(n) = n2
Worst Case: das gesuchte Element ist garnicht oder erst als
letztes im Feld → Anzahl der Vergleiche ist V(n) = n
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 453/713Zeitkomplexität: Analyse des Beispiels
Gesamtaufwand f (n) ist bestimmt von der Anzahl der
Vergleiche V(n) etwa über einen konstanten Faktor cop ,
welcher den Aufwand für einen Vergleich und abhängige
Operationen (z.B. Iterationschritte) einschließt, d.h.
f (n) ∼ cop ∗ V(n)
wobei es Abweichungen vor allem für kleine n gibt, durch
Mehraufwand für Programmstart etc.
Für den mittleren und schlechtesten Fall gilt: wenn sich die
Problemgröße „n“ um einen Faktor csize ändert, so
verändert sich auch die Anzahl der Vergleiche und somit
der Aufwand um diesen Faktor
f (csize ∗ n) ∼ cop ∗ csize ∗ V(n)
Entfernung (irrelevanter) konstanter Faktoren über
asymptotische Abschätzung →
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 454/713O-Notation: Asymptotische Abschätzung
O-Notation (auch Landau-Notation) beschreibt
Größenordnung bzw. Wachstumsgeschwindigkeit der
Funktion
Idee: Angabe einer einfachen und intuitiv verständlichen
Vergleichsfunktion g : N → N für Aufwandsfunktion f mit
f (n) = O(g(n))
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 455/713O-Notation: Asymptotische Abschätzung /2
Beispiel Suchfunktion: der Aufwand wächst linear mit der
Größe des Problems
f (n) = O(n)
d.h. Vergleichsfunktion g(n) = n
Rechnen in Größenordnungen erlaubt Vereinfachungen:
Weglassen von konstanten Faktoren: O(c ∗ n) = O(n)
Basis des Logarithmus ist unerheblich:
O(log2 (n)) = O(log(n))
Beschränkung auf höchsten Exponenten:
O(n2 + n + 1) = O(n2 )
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 456/713O-Notation (formal)
Formale Definition:
f (n) = O(g(n)) : ⇔ ∃c, n0 ∀n ≥ n0 : f (n) ≤ c · g(n)
f (n)
ist für genügend große n durch eine Konstante c
g(n)
beschränkt, d.h. f wächst nicht schneller als g
6 c · g(n)
f (n)
-
n0 n
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 457/713Komplexitätsklassen
Komplexitätsklassen erlauben Zusammenfassen von
Algorithmen mit typischen Aufwandsabschätzungen
Auch Probleme können danach in Komplexitätsklassen
eingeteilt werden: durch den besten (bekannten)
Algorithmus zur Lösung des Problems
O(1) konstanter Aufwand
O(log n) logarithmischer Aufwand
O(n) linearer Aufwand
O(n · log n)
O(n2 ) quadratischer Aufwand
O(nk )für ein k ≥ 0 polynomialer Aufwand
Problemklasse P
O(2n ) exponentieller Aufwand
Problemklasse EXP bzw.
NP-vollständiges Problem
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 458/713Wachstum
f (n) n=2 24 = 16 28 = 256 210 = 1024 220 = 1048576
log n 1 4 8 10 20
n 2 16 256 1024 1048576
n · log n 2 64 2048 10240 20971520
n2 4 256 65536 1048576 ≈ 1012
n3 8 4096 16777200 ≈ 109 ≈ 1018
2n 4 65536 ≈ 1077 ≈ 10308 ≈ 10315653
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 459/713Wachstum /2 Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 460/713
Problemklassen und typische Probleme
Aufwand Typische Probleme
O(1) Einige Suchverfahren für Tabellen (Hashing)
O(log n) Allgemeine Suchverfahren für Tabellen
(Baum-Suchverfahren)
O(n) Sequenzielle Suche, Suche in Texten
O(n · log n) Sortieren
O(n2 ) Einige dynamische Optimierungsverfahren
(z.B. optimale Suchbäume), Multiplikation
Matrix-Vektor (einfach)
O(n3 ) Matrizen-Multiplikation (einfach)
O(2n ) Zahlreiche Optimierungsprobleme
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 461/713Zeitkomplexität am Beispiel von
Sortieralgorithmen
„Computer verbringen im Durchschnitt 25% ihrer
Rechenzeit mit Sortieren.“
Oft zitiert,
Quelle: ???
Grundlegende Aufgabe: Schaffung einer (Halb-)Ordnung
von Daten, so dass sie auf- oder absteigend nach
ausgewählten Eigenschaften angeordnet sind
Sortierung von Daten von großer Bedeutung für
Effizienz zahlreicher Algorithmen, z.B. Suche von Daten,
Optimierung, etc.
Nutzbarkeit der Daten durch Anwender (z.B. Sortierung
nach Präferenzen, Relevanz, etc.)
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 462/713Sortieralgorithmen
Klasse von Algorithmen mit gleichen Schnittstellen
Eingabe: unsortiertes Feld (Liste, Menge), ggf. Sortier-
bzw. Ordnungskriterium (z.B. welches Attribut, auf- oder
absteigend, etc.)
Ausgabe: sortiertes Feld (Liste)
Zahlreiche existierende Implementierungen mit sehr
verschiedenen Eigenschaften
BubbleSort (hier vorgestellt)
MergeSort (hier vorgestellt)
QuickSort
HeapSort
...
Typischer Algorithmentyp, der für grundlegende
Betrachtungen zu Algorithmeneigenschaften
herangezogen wird (Komplexität, Speicherverbrauch,
Berechnungsmodell, etc.)
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 463/713BubbleSort
Sehr einfacher, aber auch wenig effizienter
Sortieralgorithmus
Idee: Verschieden große aufsteigende Blasen („Bubbles“)
in einer Flüssigkeit sortieren sich quasi von allein, da
größere Blasen die kleineren „überholen“.
Umsetzung als Algorithmus:
1 Durchlaufe das Feld und tausche dabei das aktuelle
Element mit dem folgenden, wenn diese nicht in
Sortierreihenfolge sind
2 Wiederhole das komplette Durchlaufen des Feldes so
lange, bis bei einem Durchlauf keine Vertauschungen mehr
durchgeführt wurden
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 464/713BubbleSort: Beispiel
1. Durchlauf 5 1 8 3 9 2
1 5 8 3 9 2
1 5 3 8 9 2
2. Durchlauf 1 5 3 8 2 9
1 3 5 8 2 9
3. Durchlauf 1 3 5 2 8 9
4. Durchlauf 1 3 2 5 8 9
5. Durchlauf 1 2 3 5 8 9
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 465/713BubbleSort: Optimierung
Größte Zahl rutscht in jedem Durchlauf automatisch an
das Ende der Liste
im Durchlauf k reicht die Untersuchtung bis Position n − k
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 466/713BubbleSort in C++
void bubblesort (int feld[], int feld_groesse) {
bool swapped;
int max = feld_groesse - 1;
do {
swapped = false;
for (int i = 0; i < max; i++) {
if (feld[i] > feld[i + 1]) {
swap (feld, i, i + 1);
swapped = true;
}
}
max--;
} while (swapped);
}
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 467/713BubbleSort in C++ - Erläuterungen
Erläuterungen zum Code
Variable swapped beendet Algorithmus, wenn bei einem
Durchlauf keine Vertauschung mehr durchgeführt wurde
Variable max setzt Optimierung um, dass bei Durchlauf k
nur bis n − k verglichen werden muss
Hilfsfunktion swap() tauscht zwei Elemente in einem Feld
Vollständiger Quelltext auf der Web-Seite zur Vorlesung
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 468/713Analyse von BubbleSort
Gezählt werden wieder Vergleiche
Bester Fall:
Die Liste ist sortiert, was nach einem Durchlauf mit n − 1
Vergleichen festgestellt werden kann: O(n)
Mittler und schlechtester Fall:
Mit der Optimierung müssen wir in den einzelnen
Durchläufen n − 1, n − 2, n − 3 ... 1 Vergleiche Durchführen
Laut Summenformel:
n−1
X (n − 1)(n − 2) n2 − 3n + 2
i= =
2 2
i=1
und damit O(n2 )
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 469/713MergeSort: Prinzip
Relativ effizienter und oft verwendeter Sortieralgorithmus
Beruht auf grundlegendem Algorithmenmuster (→): Teile
und Herrsche
Idee:
1 Teile die zu sortierende Liste in zwei gleich große Teillisten
2 Sortiere diese durch rekursive Anwendung desselben
Verfahrens (wird zurückgeführt auf trivialen Fall der Liste
mit einem Element, welche immer sortiert ist)
3 Mische die sortierten Teilergebnisse und setze so das
Gesamtergebnis zusammen
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 470/713MergeSort: Beispiel
Split 5 1 8 3 9 2
5 1 8 3 9 2
5 1 8 3 9 2
5 1 9 3
Merge
1 5 3 9
1 5 8 2 3 9
1 2 3 5 8 9
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 471/713MergeSort in C++ /1
Zerlegung des Problems durch rekursive Teilung des zu
sortierenden Feldes
void msort (int feld[], int feld_groesse, int l, int r) {
int i, j, k;
int* b = new int[feld_groesse]();
if (r > l) {
int mid = (r + l) / 2;
msort (feld, feld_groesse, l, mid);
msort (feld, feld_groesse, mid + 1, r);
...
Rekursiver Aufruf mit oberer und unter Grenze der
Array-Elemente, die betrachtet werden sollen
Rekursion bricht ab, wenn Grenzen gleich, d.h. nur ein
Element im betrachteten Bereich
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 472/713MergeSort in C++ /2
Merge-Schritt: sortierte Teillisten werden zusammengesetzt
...
for (i = mid + 1; i > l; i--)
b[i - 1] = feld[i - 1];
for (j = mid; j < r; j++)
b[r + mid - j] = feld[j + 1];
for (k = l; kAnalyse von MergeSort
Anzahl der Aufrufe der rekursiven Funktionen für jeden
Pfad (Aufruftiefe): ca. log2 n, zum Beispiel
Feldlänge n = 8 = 23 : 3 Aufrufebenen für Teilfelder mit
Längen 4, 2 und 1
Feldlänge n = 16 = 24 : 4 Aufrufebenen für Teilfelder mit
Längen 8, 4, 2 und 1
...
Auf jeder Ebene müssen für alle n Elemente alle 3
Schleifen durchlaufen werden, d.h. Faktor 3 · n
Gesamtaufwand ca. 3 · n · log2 n
Asymptotische Abschätzung: O(n · log n)
Gleich für besten, mittleren und schlechtesten Fall
D.h. im besten Fall (vorsortierte Liste) nicht so gut wie
BubbleSort
Aber: es sind keine Sortieralgorithmen bekannt, die für
den durchschnittlichen und schlechtesten Fall eine bessere
Komplexitätsabschätzung als O(n · log n) haben!!!
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 474/713Zusammenfassung: Zeitkomplexität
Laufzeit von Algorithmen/Programmen kann von
zahlreichen Faktoren (Hardware, Programmiersprache,
Laufzeitumgebung) abhängen
Deshalb: Zeitkomplexität wichtigstes Kriterium für die
Effizienz eines Algorithmus
Abschätzung des Rechenaufwands in Abhängigkeit von
der Problemgröße über eine Vergleichsfunktion, welches
das Wachstum beschreibt → O-Notation
Typische Probleme können durch schnellste bekannte
Algorithmen in Komplexitätsklassen eingeordnet werden
Beispiel Sortieralgorithmen: beste Algorithmen =
Komplexitätsklasse = O(n · log n)
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 475/713Typische Algorithmenmuster
Allgemeine Beschreibung der Aufgaben von
Algorithmen: aus Eingabedaten bzw. einer großen Anzahl
daraus abgeleiteter möglicher Lösungen sollen alle oder
eine korrekte, optimale oder hinreichende Lösung(en)
abgeleitet werden
Effiziente Algorithmen folgen dabei oft gleichartigen
Mustern oder Strategien für die Lösung des Problems
Systematische Anwendung dieser Muster beim
Entwurf → deshalb auch als Entwurfsparadigmen oder
Entwurfsprinzipien von Algorithmen bezeichnet
Kenntnis erleichtern Umsetzung effizienter Algorithmen
Einführung am Beispiel:
Rucksackproblem: optimales Packen eines Rucksacks
2 Lösungen: Greedy-Algorithmus, Backtracking
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 476/713Rucksackproblem /1 Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 477/713
Rucksackproblem /2
Eingabe:
Ein leerer Rucksack mit einer maximalen Kapazität
(Maximalgewicht)
Eine Auswahl an möglichen Gegenständen, wobei jeder
Gegenstand eine Gewicht und einen Nutzen hat
Zu lösendes Problem: packe den Rucksack so, dass
das Gesamtgewicht der eingepackten Gegenstände die
Kapazität nicht übersteigt
der Nutzen der eingepackten Gegenstände optimal, d.h.
maximal, ist
Klassisches Optimierungsproblem, auf welches zahlreiche
andere Auswahlprobleme abgebildet werden können
In der Informatik häufig untersucht
Komplexitätsklasse O(2n ) (n ist Anzahl der wählbaren
Gegenstände), d.h. NP-vollständiges Problem mit
exponentiellem Berechnungsaufwand
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 478/713Rucksackproblem: Lösung mit
Greedy-Algorithmus
Idee: man packe den Rucksack, indem man jeweils den
aktuell besten Gegenstand auswählt, z.B.
den mit dem höchsten Nutzen,
den mit dem geringsten Gewicht oder
den mit dem besten Verältnis von Nutzen und Gewicht.
Wiederhole diese Auswahl, bis der Rucksack voll ist bzw.
nur noch Gegenstände übrig sind, die nicht mehr in den
Rucksack passen
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 479/713Algorithmenmuster: Greedy-Algorithmus
Greedy=Gierig
Grundprinzip: Finden einer Lösung, indem bei jedem
Entscheidungsschritt die lokal optimale Entscheidung
getroffen wird
Dadurch findet man für viele Probleme (inklusive dem
Rucksackproblem) aber nicht die global optimale
Lösung
Trotzdem oft verwendet, da bei günstigem Sortierkriterium
meist eine hinreichend gute Lösung mit sehr geringem
Aufwand O(n) gefunden wird
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 480/713Greedy-Algorithmus in C++
Hinweise zur Implementierung
Gegenstände und Rucksäcke sind als einfache Klassen
umgesetzt
Hier nur Auszüge aus dem Quelltext → der vollständiger
Quelltext ist auf der Web-Seite zur Vorlesung zu finden
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 481/713Beispiel: Gegenstand als C++-Klasse
class Gegenstand {
public :
Gegenstand() {
gewicht = 1+rand()%MAX_GEWICHT;
nutzen = 1+rand()%MAX_NUTZEN;
};
int gewicht;
int nutzen;
};
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 482/713Beispiel: Rucksack als C++-Klasse
class Rucksack {
public :
int gesamtnutzen();
int gesamtgewicht();
bool einpacken(Gegenstand*);
void ausgabe();
private :
set inhalt;
};
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 483/713Anmerkung: Templates und die STL in C++
Anmerkung zum Quelltext
Programm verwendet Template-Klassen aus der STL
(Standard Template Library)
Templates ... erlauben (u.a.) „Klassenschablonen“ mit
Typparametern zur Implementierung generischer Klassen,
welche mit konkreten Typen wiederverwendet werden
können
Die STL ... bietet nützliche Klassenschablonen für häufig
verwendete Datenstrukturen sowie Funktionen dazu
Programm verwendet:
set - Menge (ungeordnet)
list - geordnete Liste (mit Methode zur Sortierung)
vector - vergleichbar Array, kann aber dynamisch
wachsen
Iteratoren zum Durchlaufen aller Elemente in den zuerst
genannten Strukturen
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 484/713Beispiel: Vergleichsfunktionen in C++
Sortierung der Gegenstände über Vergleichsfunktion
1. Alternative: Sortierung absteigend nach Nutzen
bool vergleichsfunktion(Gegenstand* g1, Gegenstand* g2) {
if (g1->nutzen > g2->nutzen) return true;
if (g1->nutzen == g2->nutzen && g1->gewicht < g2->gewicht)
return true;
return false;
}
2. Alternative: Sortierung nach Verhältnis Nutzen/Gewicht
liefert bessere Ergebnisse
bool vergleichsfunktion2(Gegenstand* g1, Gegenstand* g2) {
if ((float)g1->nutzen/g1->gewicht >
(float)g2->nutzen/g2->gewicht) return true;
return false;
}
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 485/713Beispiel: Greedy Algorithmus zur Auswahl in
C++
Rucksack packenGreedy(list auswahl) {
Rucksack rs;
auswahl.sort(vergleichsfunktion);
list::const_iterator pos;
for (pos = auswahl.begin();
rs.gesamtgewicht() < KAPAZITAET
&& pos != auswahl.end(); pos++) {
Gegenstand* g = *pos;
rs.einpacken(g);
}
return rs;
}
Sortieren der Liste nach Greedy-Präferenz
(Vergleichsfunktion)
Dann entsprechend dieser Reihenfolge „in den Rucksack
stopfen“
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 486/713Rucksackproblem mit Backtracking
Idee: man versuche, systematisch alle möglichen
Packungen des Rucksacks zu testen:
1 Man teste für den ersten Gegenstand Rucksäcke in denen
dieser enthalten bzw. nicht enthalten ist
2 Für diese beiden Möglichkeiten, teste für den 2.
Gegenstand alle Rucksäcke ...
3 usw.
Gib von allen untersuchten Rucksäcken den mit dem
besten Nutzen zurück
Weitere Möglichkeiten müssen ggf. nicht untersucht
werden, wenn der Rucksack aus dem vorhergehenden
Schritt schon gefüllt ist
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 487/713Entwurfsprinzip: Backtracking
Backtracking: Zurückverfolgen, Rücksetzverfahren
Verfahren das systematisch alle Lösungen testet, und
schlechte Lösungen verwirft und mit guten Lösungen
weiterarbeitet
Garantiert optimale Lösung
Meist durch Rekursion umgesetzt: erzeugt baumartige
Aufrufstruktur
Durch vollständige Untersuchung sehr
berechnungsaufwändig mit O(2n )
Optimierung durch „Abschneiden von Suchpfaden“
möglich → spezifische Abbruchkriterien für konkretes
Problem (z.B. Rucksack voll)
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 488/713Backtracking in C++ /1
Umsetzung als rekursive Funktion
Eine weitere Funktion setzt Einstieg in Rekursion um, da
rekursive Funktion spezielle Parameter benötigt
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 489/713Backtracking in C++ /2
Rucksack packenBacktracking(list auswahl) {
vector* v =
new vector(auswahl.begin(),auswahl.end());
Rucksack rs;
rs = packenRekursiv(rs,v,0);
return rs;
}
Rekursionseinstieg
Kopieren der Liste in einen Vektor erlaubt Zugriff über
Position wie bei einem Array
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 490/713Backtracking in C++ /3
Rucksack packenRekursiv(Rucksack rs,
vector* auswahl, int pos) {
if (pos < auswahl->size() && rs.gesamtgewicht() < KAPAZITAET) {
Rucksack rs1 = packenRekursiv(rs,auswahl,pos+1);
rs.einpacken((*auswahl)[pos]);
Rucksack rs2 = packenRekursiv(rs,auswahl,pos+1);
if (rs1.gesamtnutzen() > rs2.gesamtnutzen()) return rs1;
return rs2;
}
return rs;
}
Rekursiv werden jeweils alle Rucksäcke mit UND ohne den
Gegenstand an der aktuellen Position in der Auswahl
berechnet
Nur die beste wird jeweils zurückgegeben
So werden systematisch alle Lösungen getestet
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 491/713Weitere Algorithmenmuster
Teile und Herrsche
Dynamische Programmierung
Genetische Algorithmen
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 492/713Algorithmenmuster: Teile und Herrsche
Teile und Herrsche=Divide et Impera
Idee:
Man zerlege ein komplexes Problem in kleinere
Teilprobleme
Man zerlege so lange, bis man bei einer Problemgröße
angekommen ist, bei der die Lösung trivial ist
Man setze die Lösungen der Teilprobleme umgekehrt
schrittweise zur Gesamtlösung zusammen
Ebenfalls häufig rekursiv umgesetzt
Z.B. MergeSort (→) und viele andere Sortieralgorithmen
(QuickSort, HeapSort)
Typische Komplexitätsklassen: O(n · log n) und O(log n)
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 493/713Algorithmenmuster: Dynamische
Programmierung
Idee: systematisches Zusammensetzen einer
Gesamtlösung aus häufig auftretenden Teillösungen
Funktioniert bottom up (von unten nach oben): kleinste
Teillösungen werden zuerst berechnet und aufgehoben,
um daraus dann schrittweise komplexere
zusammenzusetzen
Vermeidet durch Abspeichern der Teillösungen
Mehrfachberechnungen
Beispiel: für Rucksackproblem existiert unter der Annahme
ganzzahliger Gewichte und Nutzen ein sehr effizienter
Algorithmus mit Dynamischer Programmierung, indem
optimale „Teilrucksäcke“ für verschiedene Kapazitäten
kleiner der Maximalkapazität berechnet werden, um dann
schrittweise „zusammengesetzt“ zu werden
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 494/713Algorithmenmuster: Genetische Algorithmen
Beispiel für Muster zufallsbasierter Algorithmen
Idee: Nachbildung der natürliche Auslese nach
Evolutionstheorie von Darwin
Erzeuge initiale Lösungen mit einfachem Verfahren
(Greedy, Zufall) → Gen-Pool
Bewerte Lösungskandidaten mit einer Überlebensfunktion
Erzeuge neue Lösungen aus den besten Kandidaten durch
Kreuzung (Kombination von Lösungen) oder Mutation
(zufällige Veränderung)
Wiederhole dies über eine feste Anzahl von Schritten
(Generationen) oder bis Lösung bestimmte Qualität hat
(z.B. verbessert sich kaum noch im Vergleich zur
Vorgängergeneration)
Aufwand (meist O(n) oder O(1)) kann sehr präzise
gesteuert werden
Auch hier: garantiert nicht das Finden der optimalen
Lösung
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 495/713Zusammenfassung: Algorithmen
Grundlegende Eigenschaften von Algorithmen
Terminiertheit
Determiniertheit
Korrektheit
Zeitkomplexität als wichtiges Maß für Effizienz von
Algorithmen
Effiziente Algorithmen verwenden meist typischen
Algorithmenmuster
Eike Schallehn, FIN/ITI Grundlagen der Informatik für Ingenieure 496/713Sie können auch lesen

















































