Konzepte der Informatik - Vorkurs Informatik zum WS 2011/2012 26.09 30.09.2011 17.10 - 21.10.2011 Dr. Werner Struckmann / Christoph Peltz
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Konzepte der Informatik
Vorkurs Informatik zum WS 2011/2012
26.09. - 30.09.2011
17.10. - 21.10.2011
Dr. Werner Struckmann / Christoph Peltz
Stark angelehnt an Kapitel 1 aus "Abenteuer Informatik" von Jens Gallenbacher
Vorkurs Informatik 2011 1
Codierung
Verfahren, welches die Symbole einer Nachricht in eine andere Form bringt
ohne den Informationsgehalt einzuschränken.
Codierung wird dazu verwendet, die Informationen von der für Menschen
verständliche Form in eine für Maschinen verarbeitbare und über Netzwerke
kommunizierbare Form umzuwandeln und wieder zurück.
Beispiel: Morsecode
Code verwendet drei Symbole: Punkt (·), Strich (−) und Pause ( )
−− −−− ·−· ··· · −·−· −−− −·· ·
M O R S E C O D E
Quelle: Wikipedia
Vorkurs Informatik 2011 2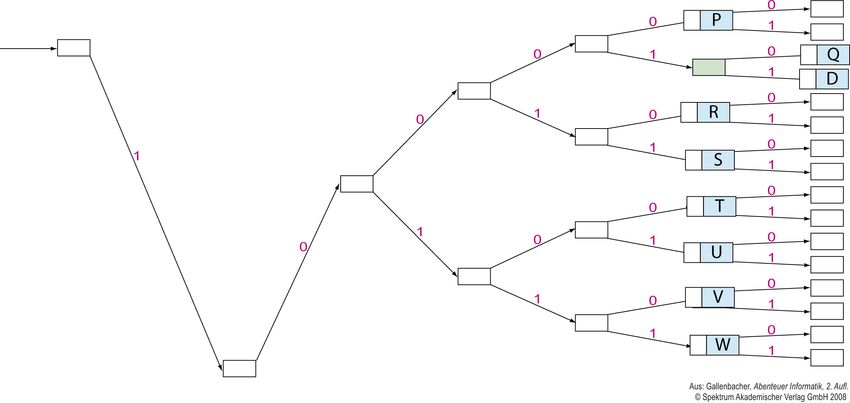
Aspekte der Binär-Codierung
Binärcode
Codetabellen
Codebaum
Einsparung von Bits
Groß- und Kleinschreibung
Informationsgehalt verschiedener Symbole
Präfixbildung
Vorkurs Informatik 2011 3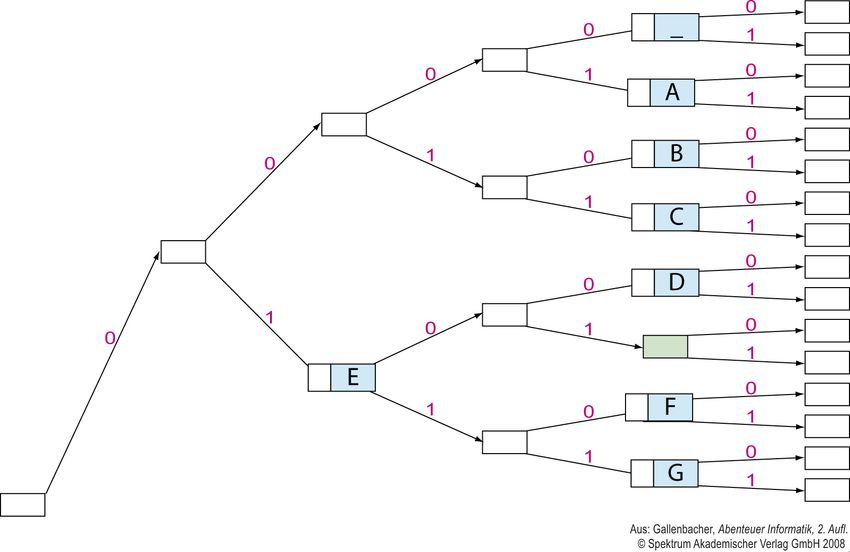
Binärcode
Binärcode / 0/1-Code
Ein Binärcode besteht nur aus zwei Zeichen, 0 und 1.
Diese beiden Zeichen repräsentieren die beiden Zustände „Ausgeschaltet“
und „Eingeschaltet“, welche von einem Computer gut verarbeitet werden
können.
Vorkurs Informatik 2011 4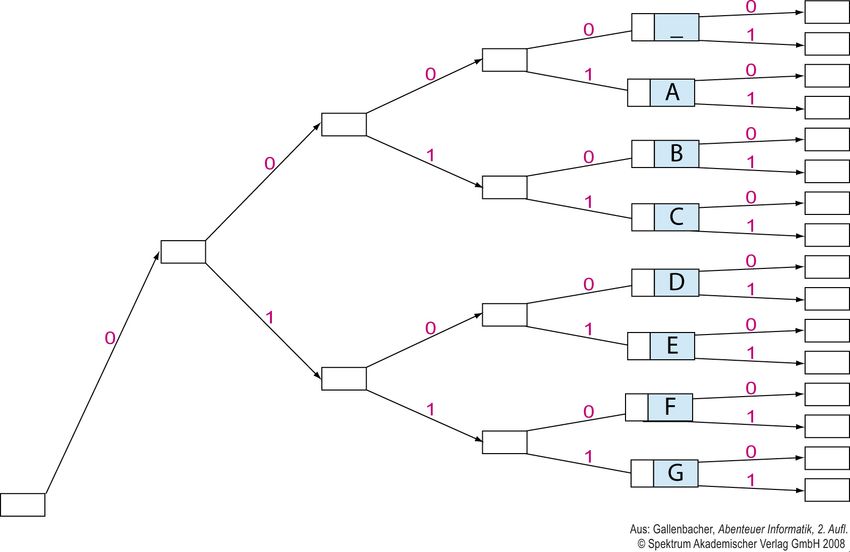
Binärcode
Dualsystem*
Zahlensystem, das nur zwei verschiedene Ziffern zur Darstellung von Zahlen
benutzt
Zahlen werden nur mit Ziffern, welche die Werte Null oder Eins annehmen,
dargestellt
Stellenwertsystem mit der Basis 2
Zahlen 0 bis 8:
Null: 0
Eins: 1
Zwei: 10
Drei: 11
Vier: 100
Fünf: 101
Sechs: 110
Sieben:111
Acht: 1000
* Quelle der Folien 5-14: Wikipedia
Vorkurs Informatik 2011 5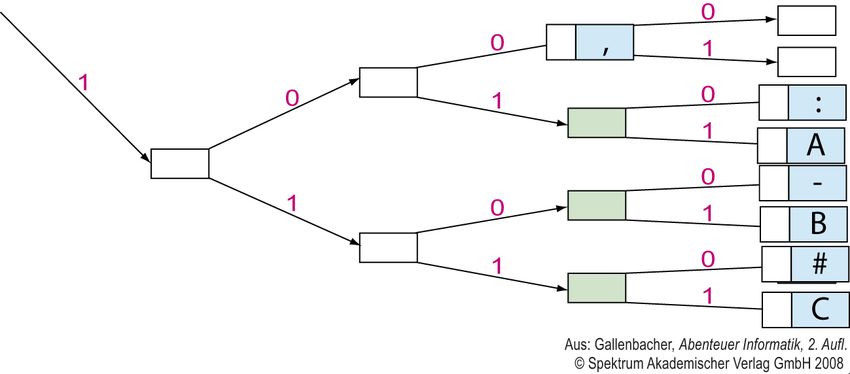
Binärcode
Definition und Darstellung von Dualzahlen
Ziffern zi werden wie im gewöhnlich verwendeten Dezimalsystem ohne
Trennzeichen hintereinander geschrieben.
Beispiel: Dezimalzahl 29
29 = 1 * 24 + 1 * 23 + 1 * 22 + 0 * 21 + 1 * 20 = [11101]2
Vorkurs Informatik 2011 6
Binärcode
Umrechnen von Dezimalzahlen in andere
Stellenwertsysteme
Schreiben Sie die Dezimalzahl 42 als Dual-, Oktal- und als
Hexadezimalzahl.
Dualzahl: 101010
Rechenweg:
42 : 2 = 21 Rest 0
21 : 2 = 10 Rest 1
10 : 2 = 5 Rest 0
5 : 2 = 2 Rest 1
2 : 2 = 1 Rest 0
1 : 2 = 0 Rest 1
Vorkurs Informatik 2011 7
Binärcode
Oktalzahl: 52
Rechenweg:
42 : 8 = 5 Rest 2
5 : 8 = 0 Rest 5
Hexadezimalzahl: 2A
Rechenweg:
42 : 16 = 2 Rest 10
2 : 16 = 0 Rest 2
Vorkurs Informatik 2011 8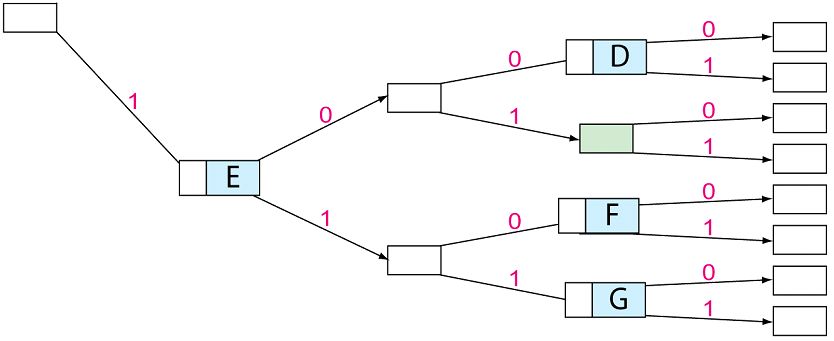
Binärcode
Dualzahlen
Verschiedene Darstellungsformen der Zahl dreiundzwanzig im Dualsystem:
[10111]2
101112
10111(2)
10111B
0b10111
HLHHH
L0LLL
Vorkurs Informatik 2011 9Binärcode
Grundrechenarten im Dualsystem
Addition Beispiel Subtraktion Beispiel
0+0=0 0−0=0
0+1=1 0 − 1 = −1
1+0=1 1−0=1
1 + 1 = 10 1−1=0
Multiplikation Beispiel Division Beispiel
0 0=0 0 / 0 = n.def.
0 1=0 0/1=0
1 0=0 1 / 0 = n.def.
1 1=1 1/1=1
Vorkurs Informatik 2011 10Binärcode
Schriftliche Addition
A = 10011010 (154)
B = 00110110 (54)
Merker = 11111
————————
Ergebnis = 11010000 (208)
‗‗‗‗‗‗‗‗
Vorkurs Informatik 2011 11Binärcode
Schriftliche Subtraktion
Die Subtraktion verhält sich analog zur Addition.
0−0=0
0 − 1 = −1
1−0=1
1−1=0
Eine Zahl im Dualsystem kann von der anderen wie im folgenden Beispiel
dargestellt subtrahiert werden:
Vorkurs Informatik 2011 12Binärcode
Schriftliche Multiplikation
Wird im Dualsystem genauso durchgeführt wie im Dezimalsystem
Beispiel: 1100 * 1101
1100 · 1101
———————————
1100
+ 1100
+ 0000
+ 1100
———————————
10011100
Vorkurs Informatik 2011 13Binärcode
Schriftliche Division
1000010 : 11 = 10110 Rest 0 (= 22 im Dezimalsystem)
− 011
—————
00100
− 011
————
0011
− 011
—————
000
− 00
———
0
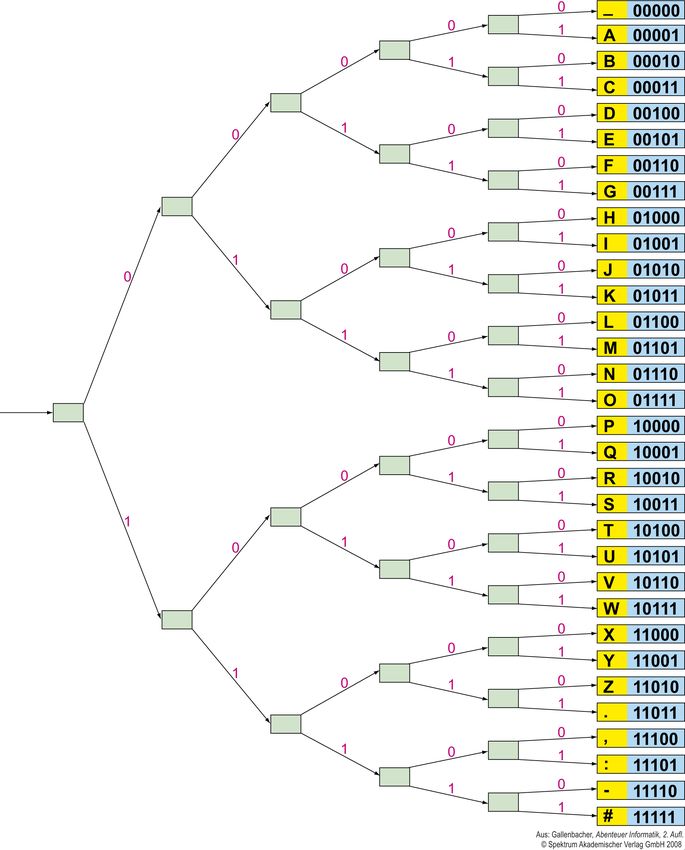
Vorkurs Informatik 2011 14Codetabellen
American Standard Code for Information Interchange
ASCII ist der bekannteste Code. Es handelt sich dabei um eine Tabelle, in der
alle Zeichen des (amerikanischen) Alphabets entsprechenden Sequenzen aus 0
und 1 zugeordnet werden.
_(Leer) 00000 H 01000 P 10000 X 11000
A 00001 I 01001 Q 10001 Y 11001
B 00010 J 01010 R 10010 Z 11010
C 00011 K 01011 S 10011 . 11011
D 00100 L 01100 T 10100 , 11100
E 00101 M 01101 U 10101 : 11101
F 00110 N 01110 V 10110 - 11110
G 00111 O 01111 W 10111 # 11111
Welche Weisheit mag sich wohl hinter dem Code „01001 00011 01000 00000
00100 00101 01110 01011 00101 11100 00000 00001 01100 10011 01111
00000 00010 01001 01110 00000 01001 00011 01000“ verbergen?
Vorkurs Informatik 2011 15Codebaum Ein Codebaum vereinfacht die Decodierung. Man geht einfach entlang des jeweiligen Pfads (0 oder 1) und sobald man an ein Symbol gelangt, schreibt man es auf und beginnt von Neuem. Decodieren Sie „ 01000 00001 01100 01100 01111“. Vorkurs Informatik 2011 16
Bits und Bytes
Byte (engl. „Bissen“) ist sozusagen ein Happen aus dem Datensalat eines
Computers. Es stellt eine kleine Informationseinheit dar.
Bit ist englisch als Verkleinerungsform von Byte zu sehen und auch die
Abkürzung für „Binary Digit“, also deutsch „Ziffer im Binärsystem“. Ein Bit ist
also die kleinste Informationsmenge, die man im Computer identifizieren
kann.
Da alle Symbole die gleiche Anzahl an Bit haben, können wir ganz einfach
berechnen, wie viel Bit eine Nachricht mit 100 Zeichen hat :
100 Zeichen mal 5 Bit pro Zeichen gleich 500 Bit.
Vorkurs Informatik 2011 17Einsparung von Bits Codieren wir zum Beispiel eine Gen-Sequenz „AGATGCCGTTACGA“ mit diesem Code. 000010011100001101000011100011000110011110100101000000100011001110 0001 Das macht genau 70 Bit. Wenn wir aber einen neuen Code hierfür nehmen, lässt sich die Anzahl der Bits auf 28 senken. 0010001110010110111100011000 Vorkurs Informatik 2011 18
Groß- und Kleinschreibung Ohne Groß- und Kleinschreibung: „ICH HABE LIEBE GENOSSEN“ Mit Groß- und Kleinschreibung: „Ich habe liebe Genossen“ & „Ich habe Liebe genossen“ Wenn man die Groß- und Kleinschreibung einführt, enthalten alle Symbole mehr Informationen. Vorkurs Informatik 2011 19
Informationsgehalt verschiedener Symbole „an atte ieen are ei eine eient, a ra er u i ‚err, eine eit it eru, nun ote erne ieer ei u einer utter.‘“ In diesem Text stehen nur die Vokale (A,E,I,O,U) und die Konsonanten N, R und T, die meist verwendeten Buchstaben in unserer Sprache. „Hns htt sbn Jhr b snm Hrrn gdnt, d sprch r z hm ‚Hrr, mn Zt st hrm, nn wllt ch grn wdr hm zu mnr Mttr.‘“ Der gleiche Text, nur fehlen hier alle Vokale. Allerdings ist er deutlich besser lesbar. Hier noch einmal der Originaltext: „Hans hatte sieben Jahre bei seinem Herren gedient, da sprach er zu ihm‚ Herr, meine Zeit ist herum, nun wollte ich gerne wieder heim zu meiner Mutter.‘“ Vorkurs Informatik 2011 20
Informationsgehalt verschiedener Symbole
Wenn man unterschiedliche Buchstaben entfernt, entfernt man also auch
unterschiedlich viel Informationsgehalt. Das Weglassen von Vokalen scheint
nicht so schlimm zu sein wie das von Konsonanten.
Das bedeutet, dass nicht jeder Buchstabe die gleiche Menge an
Informationen enthält. Dann sollte es doch konsequent sein, wenn nicht jeder
Buchstabe die gleiche Anzahl an Bits besäße. Wahrscheinlich könnte man
dadurch auch die Größe einer Nachricht und damit die Übermittlungsdauer
verringern.
Zum Beispiel beim Morsen: der häufigste Buchstabe in unserer Sprache ist
das „E“, dieser wird nur als einzelner kurzer Ton gesendet. Das „Q“ hingegen
wird viel seltener verwendet und besitzt beim Morsen auch einen längeren
Code „lang lang kurz lang“.
Es liegt also nahe, auch bei der Codierung durch diese Methode
Speicherplatz zu sparen.
Vorkurs Informatik 2011 21Codebaum Optimierung Verschieben Sie das „E“ um 2 Stellen nach links. Vorkurs Informatik 2011 22
Codebaum Optimierung Vorkurs Informatik 2011 23
Codebaum Optimierung Jetzt versperren wir mit dem „E“ die Buchstaben „D“, „F“ und “G“ Vorkurs Informatik 2011 24
Präfixbildung
Präfix
Ein Präfix ist ein Wort oder eine Zeichenfolge, die mit dem Anfang einer
anderen Zeichenfolge identisch ist. In der Codierung versucht man Präfixe
zu vermeiden, da man dann codierte Nachrichten nicht mehr direkt
decodieren kann.
„E“ ist mit seinem Code „001“ also die Präfix zu den Buchstaben „D“
(„00100“), „F“ („00110“) und „G“ („00111“).
Vorkurs Informatik 2011 25Präfixbildung
Präfixlösung
Um die drei Buchstaben wieder codierbar zu machen, müssen wir drei anderen
Buchstaben einen längeren Code geben. Zum Beispiel „Q“, „X“ und „Y“, welche
bei der Häufigkeit unter 0,05% liegen und daher nur sehr selten gebraucht
werden.
So erhalten die „D“, „F“ und „G“ sowie „Q“, „X“ und „Y“ einen 6-stelligen Pfad.
Wie viele Bits benötigt man für das Wort „GESELLE“ in den beiden Versionen?
Vorkurs Informatik 2011 26Präfixbildung
Präfixlösung
Das selbe Verfahren lässt sich natürlich auch bei anderen Symbolen
anwenden.
Zum Beispiel bei dem Leerzeichen, welches von allen Symbolen am
häufigsten verwendet wird. Andere Satzzeichen wie Doppelpunkt ( : ),
Gedankenstrich ( - ) oder die Raute ( # ) kommen hingegen nur sehr selten
vor.
Nehmen wir also das Leerzeichen und verschieben es drei Stellen nach
links. Dadurch blockieren die Buchstaben „A“, „B“ und „C“. Dann verschieben
wir die Satzzeichen Doppelpunkt, Gedankenstrich und Raute um eine Stelle
nach rechts und fügen die drei blockierten Buchstaben ein.
Vorkurs Informatik 2011 27Präfixbildung
Präfixlösung
Vorkurs Informatik 2011 28Präfixbildung
Präfixlösung
Allerdings ist „A“ auch ein Buchstabe, der häufig verwendet wird und ist mit
einem 6-stelligen Code denkbar schlecht codiert. Demnach ist dies nicht die
optimale Lösung für das Problem. Es muss also alles etwas freier im
Codebaum getauscht werden.
Am besten wird es wohl sein, wenn das Leerzeichen sowie das „E“ 3 Bits
erhalten, „N“, „I“, „S“ und „R“ jeweils 4 Bit, „A“, „T“, „D“, „H“, „U“, „L“, „C“ und
„G“ 5 Bit, „Q“, Doppelpunkt, Gedankenstrich und Raute 7 Bit und die
restlichen Zeichen 6 Bit erhalten.
Vorkurs Informatik 2011 29Präfixbildung
Präfixlösung
Mit diesem Codebaum lässt sich nun die Bit Anzahl dieses Satzes: „HANS
ZOG EIN TUECHLEIN AUS DER TASCHE, WICKELTE DEN KLUMPEN
HINEIN, SETZTE IHN AUF DIE SCHULTER UND MACHTE SICH AUF DEN
WEG NACH HAUS.“, welcher mit dem Anfangsbaum 670 Bit hätte, auf 552
Bit verringern.
Dieses Verfahren wird für Archive wie Zip, ARJ, RAR usw. genutzt. Diese
Programme nutzen allerdings auch, dass ganze Worte häufig vorkommen
und können somit bis über 90% Speicherplatz sparen.
Andere Verfahren komprimieren ganze Blöcke von Daten (bzip2) oder auch
Teilwörter (LZ77, LZMA).
Vorkurs Informatik 2011 30Moderne Text-Kodierung (UTF-8) In Anbetracht der immer stärkeren Globalisierung und des Wunsches eine Kodierung für alle Sprachen der Welt anzubieten, wurde Unicode entwickelt. Unicode definiert Codepoints für eine vielzahl an Zeichen die benutzt werden (z.B. Griechisch, Arabisch, Chinesisch). Es gibt im aktuellen Standard 6 um die 1.1 Millionen definierte Codepoints. Die effiziente Codierung der Texte ist hier äußerst wichtig. UTF-8 ist in den ersten 128 Codepoints identisch mit ASCII, das bedeutet, dass die weit verbreiteten ASCII-Texte automatisch UTF-8 konform sind. Vorkurs Informatik 2011 31
Moderne Text-Kodierung (UTF-8)
Ein UTF-8 Zeichen, dass mit einer 1 beginnt zeigt an, dass es entweder der
Beginn eines Mehr-Byte-Zeichens oder Teil eines solchen Zeichens ist.
Ein UTF-8 Zeichen kann somit 1 bis 6 Byte lang sein, wobei die am häufigsten
genutzten Zeichen in den unteren Code-Regionen zu finden sind.
Diese Kodierung ist selbstkorrigierend. Falls Teile eines Zeiches verloren gehen,
ist nur das eine Zeichen betroffen, der Beginn eines neuen Zeichens kann ohne
Probleme ermittelt werden.
Quelle (Grafik): Wikipedia
Vorkurs Informatik 2011 32Vielen Dank für Ihre Aufmerksamkeit! Vorkurs Informatik 2011 33
Sie können auch lesen

















































