Verbesserung und Evaluation eines Modell-Ensembles für die Vorhersage von Unfalldaten anhand synthetischer Daten
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Fakultät Verkehrswissenschaften „Friedrich List“ Institut für Automobiltechnik Dresden – IAD Lehrstuhl Kraftfahrzeugtechnik Verbesserung und Evaluation eines Modell-Ensembles für die Vorhersage von Unfalldaten anhand synthetischer Daten Haoyuan Chen Diplomarbeit zur Erlangung des akademischen Grades Diplomingenieur (Dipl.-Ing.) Betreuer Dipl.-Ing. Maximilian Bäumler, MBA Betreuender Hochschullehrer Prof. Dr.-Ing Günther Prokop Eingereicht am: 29. September 2021
TECHNISCHE
UNIVERSITÄT
DRESDEN
- LKr
Fakultät Verkehrswissenschaften „Friedrich List" - Institut für Automobiltechnik Dresden - IAD
Professur für Kraftfahrzeugtechnik
Aufgabenstellung für eine Diplomarbeit (DAK 2021-08)
Bearbeiter: Haoyuan Chen
Matrikelnr.:
Studiengang: Maschinenbau, Kraftfahrzeugtechnik DPO 2014
Thema: Verbesserung und Evaluation eines Modell-Ensembles für die
Vorhersage von Unfalldaten anhand synthetischer Daten
lmprovement and evaluation of a model ensemble for the prediction of
accident data by means of synthetic data
Zur effizienten Absicherung automatisierter Fahrfunktionen gewinnt das szenarienbasierte Testen
an Bedeutung. Ein Ansatz um umfangreiche, repräsentative Szenarienkataloge zu erreichen ist es,
Szenarien aus verschiedenen Datenquellen mittels Datenfusion zu kombinieren. Hierfür stehen
neben Methoden des Statistical Matchings auch Verfahren des maschinellen Lernens zur Verfügung,
um fehlende Merkmale der Szenarien anhand von Trainingsdaten vorherzusagen.
Ziel dieser Diplomarbeit ist es, die Performance von bestehenden Modell-Ensembles aus Machine
Learning- und Hot-Deck-Verfahren für die Fusion von Unfalldaten zu steigern und anhand
synthetisch generierter Daten zu evaluieren. Als Erstes sind hierfür basierend auf vorhandenen
Unfalldaten neue synthetische Datensätze zu generieren. Anschließend sollen auf den bereits
vorhandenen und den neu generierten Datensätzen bestehende Modell-Ensembles evaluiert und
weiterentwickelt werden. Abschließend sind die Ergebnisse zu diskutieren und ein Ausblick zu
geben.
Folgende Schwerpunkte sind zu bearbeiten:
■ Literaturrecherche zur synthetischen Datengenerierung sowie zu Ensemble-Techniken
■ Generierung synthetischer Unfalldaten anhand einer ausgewählten Methode
■ Vorhersage mittels bestehender Modell-Ensembles
■ Verbesserung bestehender Ensembles inkl. Evaluation
■ Diskussion und Dokumentation der Ergebnisse
Die von der Professur für Kraftfahrzeugtechnik erlassenen Richtlinien zum Anfertigen
wissenschaftlicher Arbeiten sind einzuhalten.
Betreuer: Dipl.-Ing. Maximilian Bäumler, MBA
Ausstelldatum: 29.04.2021
Abgabedatum: 29.09.2021
Prof. Dr.-lng. Günther Prokop
Studienrichtungsleiter und betreuender Hochschullehrer
DAK-2021-08 Selbstständigkeitserklärung
Selbstständigkeitserklärung
Ich versichere, dass ich die vorliegende Arbeit selbstständig verfasst und keine anderen als die angegebenen
Quellen und Hilfsmittel benutzt habe. Ich reiche sie erstmals als Prüfungsleistung ein. Mir ist bekannt,
dass ein Betrugsversuch mit der Note „nicht ausreichend“ (5,0) geahndet wird und im Wiederholungsfall
zum Ausschluss von der Erbringung weiterer Prüfungsleistungen führen kann.
Name: Chen
Vorname: Haoyuan
Matrikelnummer: 4737910
Dresden, den 29.09.2021, ...............................................
Haoyuan Chen
IAD-TU Dresden IDAK-2021-08 Kurzreferat Kurzreferat Ziel dieser Arbeit ist es, robuste und performante Algorithmen für die Fusion von polizeilichen Unfalldaten zur Testszenariengenerierung im Rahmen der Absicherung automatisierter Fahrfunktionen zu generieren. In dieser Arbeit werden Methoden zur Datenfusion in Kombination mit generativen und Klassifikations-modellen untersucht. Eine spezifische Variable vom Empfänger wird während des Datenfusionsverfahrens im Voraus entfernt. Ein Spender mit den gemeinsamen Variablen wird verwendet, um die Vorhersage für die fehlende spezifische Variable im Empfänger zu erhalten. Als Methode werden Ensembles aus Distance-Hot-Deck und Machine-Learning Verfahren für die Vorhersage verwendet. Nach der Vorhersage werden die Ergebnisse anhand ausgewählter Bewertungsmetriken bewertet. Darüber hinaus werden zwei generative Modelle eingeführt, um Datensätze unterschiedlicher Qualität zu synthetisieren. Ziel ist es, die Robustheit der Ensembles mit den synthetisierten „Rauschdaten“ zu testen und die Performance von En-sembles mit den synthetisierten Daten hoher Qualität zu verbessern. Schließlich können Erkenntnisse darüber gewonnen werden, welche Ensembles die besten Ergebnisse für die Datenfusion liefern. Abstract In this thesis, methods for data fusion in combination with generative and classification models are investigated. A specific variable from receiver is removed in advance before the fusion. A donor with the common variables is used to obtain the prediction for the missing specific variable in receiver. Ensembles of distance hot deck and machine learning methods are used as the method for this prediction. After the prediction process, the results are evaluated using selected evaluation metrics. In addition, two generative models are introduced to synthesise datasets with different quality. The aim is to test the robustness of ensembles with the synthesised noise data and to improve the performance of ensembles with the synthesised high quality data. In the end, the conclusion can be drawn as to which Ensembles deliver the best results for data fusion. IAD-TU Dresden II
DAK-2021-08 Inhaltsverzeichnis
Inhaltsverzeichnis
Selbstständigkeitserklärung I
Kurzreferat II
Abbildungsverzeichnis VI
Tabellenverzeichnis VIII
Formelzeichenverzeichnis IX
Indizes X
Abkürzungsverzeichnis XI
1 Einleitung 1
2 Grundlagen 3
2.1 Datenfusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.2 Klassifikationsverfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2.1 Statistical-Matching-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2.2 Machine-Learning Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.3 Generative Modelle für synthetische Daten . . . . . . . . . . . . . . . . . . . . . . . . 10
3 Randbedingungen 14
3.1 Unfalldaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.1.1 Auswahl der Variablen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.1.2 Auswahl der Datensätze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.2 Erweiterung der Daten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.3 Modell-Ensembles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4 Vorgehensweise 23
4.1 Datensatzvorbereitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.1.1 Datensatzaufteilung und Verteilungsvergleich . . . . . . . . . . . . . . . . . . 25
4.1.2 Dimensionsreduzierung der Variablen . . . . . . . . . . . . . . . . . . . . . . 26
4.2 Datengenerierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.2.1 Reversible Datentransformationen (RDT) . . . . . . . . . . . . . . . . . . . . 29
4.2.2 Bewertungskriterien für synthetische Datensätze . . . . . . . . . . . . . . . . 29
4.2.3 Nachfrageorientiertes Modelltuning . . . . . . . . . . . . . . . . . . . . . . . 31
4.2.4 Datensatzvorbereitung für Robustheitstests . . . . . . . . . . . . . . . . . . . 34
IAD-TU Dresden IIIDAK-2021-08 Inhaltsverzeichnis
4.2.5 Datensatzvorbereitung für Daten-Augmentierung . . . . . . . . . . . . . . . . 34
4.3 Bewertungskriterien für Datenfusion . . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.3.1 Validitätsebenen nach Rässler . . . . . . . . . . . . . . . . . . . . . . . . . . 35
4.3.2 Robustheitsbewertung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.4 Modelltuning . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.5 Modell-Ensembling . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38
4.5.1 Paralleles Ensemble . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.5.2 Sequentielles Ensemble . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
4.5.3 Ensemble mit Daten-Augmentierung . . . . . . . . . . . . . . . . . . . . . . 47
5 Ergebnisse 49
5.1 DHD- und einzelnes ML-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
5.2 Ensembling-Verfahren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
5.3 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
6 Diskussion und Ausblick 67
Literaturverzeichnis XII
Anhang XVII
A.1 Anhang zur Messung der Wichtigkeit von Variablen . . . . . . . . . . . . . . . . . . . XVII
A.2 Anhang zum Stacking . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . XX
A.3 Anhang zur Basisklassifikatoren . . . . . . . . . . . . . . . . . . . . . . . . . . . . . XXI
A.4 Anhang zur Hyperparameter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . XXII
A.5 Anhang zum Verteilungsvergleich . . . . . . . . . . . . . . . . . . . . . . . . . . . . XXIII
A.6 Anhang zur Erstellung von Boxplots für Randverteilungen . . . . . . . . . . . . . . . XXIV
IAD-TU Dresden IVDAK-2021-08 Abbildungsverzeichnis
Abbildungsverzeichnis
2.1 Schematische Darstellung der Datenfusion nach D’Orazio et al. [7] . . . . . . . . . . 4
2.2 Probabilistische grafische Darstellung von VAE nach P.Kingma [44, S. 2] . . . . . . . 12
3.1 Überblick des Rahmens der Datenaufbereitung nach Siedel [3] . . . . . . . . . . . . . 16
3.2 Die Struktur vom parallelen Ensemble (Darstellung nach Siedel [3, S. 55]) . . . . . . 21
3.3 Die Struktur vom Stacking (Darstellung nach Siedel [3, S. 55]) . . . . . . . . . . . . . 22
4.1 Überblick der Vorgehensweise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.2 Die Struktur des Parallelen Ensembles mit Soft-Voting (eigene Darstellung) . . . . . . 41
4.3 Die Struktur des Blending-Ensembles (eigene Darstellung) . . . . . . . . . . . . . . . 43
4.4 Die Struktur des Blending-Ensembles mit Undersampling-Verfahren (eigene Darstellung) 45
4.5 Die Struktur des Blending-Ensembles mit Daten-Augmentierung (teilweise) (eigene
Darstellung) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.6 Die Struktur des Ensembles mit Daten-Augmentierung (eigene Darstellung) . . . . . . 47
5.1 Trefferrate von Basisklassifikatoren in verrauschten Datenumgebungen . . . . . . . . 49
5.2 Distanz gemeinsame Verteilungen Gruppe 1 von Basisklassifikatoren in zwei verrauschten
Datenumgebungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5.3 Distanz gemeinsame Verteilungen Gruppe 2 von Basisklassifikatoren in zwei verrauschten
Datenumgebungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5.4 Distanz gemeinsame Verteilungen Gruppe 3 von Basisklassifikatoren in zwei verrauschten
Datenumgebungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5.5 Distanz Gesamtverteilung von Basisklassifikatoren in zwei verrauschten Datenumgebun-
gen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5.6 Distanz Randverteilungen von Basisklassifikatoren in zwei verrauschten Datenumgebun-
gen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
5.7 Trefferrate von Basisklassifikatoren mit Daten-Augmentierung . . . . . . . . . . . . . 53
5.8 Distanz gemeinsame Verteilungen Gruppe 1 von Basisklassifikatoren mit Daten-Augmentierung 53 53
5.9 Distanz gemeinsame Verteilungen Gruppe 2 von Basisklassifikatoren mit Daten-Augmentierung 54 54
5.10 Distanz gemeinsame Verteilungen Gruppe 3 von Basisklassifikatoren mit Daten-Augmentierung 54 54
5.11 Distanz Gesamtverteilung von Basisklassifikatoren mit Daten-Augmentierung . . . . 55
5.12 Distanz Randverteilungen von Basisklassifikatoren mit Daten-Augmentierung . . . . 55
5.13 Trefferrate von Ensembles in zwei verrauschten Datenumgebungen . . . . . . . . . . 56
5.14 Distanz gemeinsame Verteilungen Gruppe 1 von Ensembles in zwei verrauschten Daten-
umgebungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
5.15 Distanz gemeinsame Verteilungen Gruppe 2 von Ensembles in zwei verrauschten Daten-
umgebungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
IAD-TU Dresden VDAK-2021-08 Abbildungsverzeichnis
5.16 Distanz gemeinsame Verteilungen Gruppe 3 von Ensembles in zwei verrauschten Daten-
umgebungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
5.17 Distanz Gesamtverteilung von Ensembles in zwei verrauschten Datenumgebungen . . 58
5.18 Distanz Randverteilungen von Ensembles in zwei verrauschten Datenumgebungen . . 59
5.19 Trefferrate von Ensembles mit Daten-Augmentierung . . . . . . . . . . . . . . . . . . 59
5.20 Distanz gemeinsame Verteilungen Gruppe 1 von Ensembles mit Daten-Augmentierung 60
5.21 Distanz gemeinsame Verteilungen Gruppe 2 von Ensembles mit Daten-Augmentierung 60
5.22 Distanz gemeinsame Verteilungen Gruppe 3 von Ensembles mit Daten-Augmentierung 61
5.23 Distanz Gesamtverteilung von Ensembles mit Daten-Augmentierung . . . . . . . . . 61
5.24 Distanz Randverteilungen von Ensembles mit Daten-Augmentierung . . . . . . . . . 62
IAD-TU Dresden VIDAK-2021-08 Tabellenverzeichnis
Tabellenverzeichnis
3.1 Die Merkmalsausprägung der einstelligen Unfalltyp und deren Beschreibung [49] . . . 16
3.2 33 direkt verwendbare binäre Variablen . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.3 Ergebnisse für die 10 diskretisierten numerischen Variablen . . . . . . . . . . . . . . 18
3.4 Ergebnisse für die 4 dekodierte Multinominal-Variablen . . . . . . . . . . . . . . . . 18
4.1 Ergebnisse des Verteilungsvergleiches . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.2 55 nach RFE ausgewählte gemeinsamen Variablen (nomiert) . . . . . . . . . . . . . . 28
4.3 Häufigkeit des Unfalltyps und die numerische Ausdrücke in [0, 1] . . . . . . . . . . . 29
4.4 Zielwerte für das nachfrageorientierte Modelltuning der Hyperparameter von generativen
Modelle . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.5 Hyperparameter der verwendeten generativen Modelle . . . . . . . . . . . . . . . . . 33
4.6 Ergebnisse der synthetischen Daten . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.7 Bewertungsergebnisse für die gemischten Datensätze . . . . . . . . . . . . . . . . . 34
4.8 Bewertungsergebnisse für den gemischten Datensatz zur Daten-Augmentierung . . . 35
4.9 Variablengruppen zur Auswertung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.10 Bewertungsmetriken der Qualität von Datenfusion für dieser Arbeit . . . . . . . . . . 37
4.11 Bewertungsmetriken für Robustheitstest in dieser Arbeit . . . . . . . . . . . . . . . . 37
4.12 Übersicht der Ensembles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.13 Balanced-Accuracy des Unfalltyps . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.14 Ergebnisse des Verteilungsvergleiches für Zwischen-Spender . . . . . . . . . . . . . . 44
5.1 Ergebnisse für maximale Verlustwerte von Basisklassifikatoren in verrauschten Daten-
umgebungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
5.2 Ergebnisse für minimale Verlustwerte von Basisklassifikatoren in verrauschten Datenum-
gebungen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
5.3 Ergebnisse für maximale Verbesserung von Basisklassifikatoren in der augmentierten
Datenumgebung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
5.4 Ergebnisse für maximale Verlustwerte von Ensembles in verrauschten Datenumgebungen 64
5.5 Ergebnisse für minimale Verlustwerte von Ensembles in verrauschten Datenumgebungen 65
5.6 Ergebnisse für maximale Verbesserung von Ensembles in der augmentierten Datenumge-
bung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
A.1 Zwischenergebnisse für VIM . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . XVII
A.2 33 gemeinsame Variablen für das DHD im Stacking . . . . . . . . . . . . . . . . . . XX
A.3 Rechenzeit der Basisklassifikatoren auf dem Originaldatensatz . . . . . . . . . . . . . XXI
A.4 Zwischenergebnisse von RFE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . XXI
A.5 Hyperparameter für Basismodelle in der R-Sprachumgebung . . . . . . . . . . . . . . XXII
IAD-TU Dresden VIIDAK-2021-08 Tabellenverzeichnis A.6 Hyperparameter für RF bei Blending-Ensemble in der R-Sprachumgebung . . . . . . XXII A.7 Verteilungsvergleich für augmentierten Spender . . . . . . . . . . . . . . . . . . . . XXIII A.8 26 Randverteilungen für alle Klassifikatoren in der originalen Datenumgebung . . . . XXIV A.9 26 Randverteilungen für alle Klassifikatoren in der Datenumgebung +10% Rauschen . XXV A.10 26 Randverteilungen für alle Klassifikatoren in der Datenumgebung +20% Rauschen . XXVI A.11 26 Randverteilungen für alle Klassifikatoren in der augmentierten Datenumgebung . . XXVII IAD-TU Dresden VIII
DAK-2021-08 Formelzeichenverzeichnis Formelzeichenverzeichnis Zeichen Einheit Erklärung A - Spenderdatensatz dieser Arbeit B - Empfängerdatensatz dieser Arbeit a - Variable a in Datensatz A b - Variable b in Datensatz B D - Diskriminator Dn - Normierter Wert von dn dn - Teststatistik von Kolmogorow-Smirnow-Test E - Erwartungswert Fn - Kumulative Verteilungsfunktion der Variable n F1 - F1-Score fo - Beobachtete Häufigkeit fe - Tatsächliche Häufigkeit G - Generator HD - Hellinger-Distanz IG - Gesamtwichtigkeit gemeinsamer Variablen IMDA - Normierter Wert der MDA IMDG - Normierter Wert der MDG IROC - Normierter Wert der ROC-Importance K - Variable K KS − Test - Kolmogorow-Smirnow-Test L - Variational lower bound qφ - Verteilung mit Parameter φ P - Anzahl der gemeinsamen Variablen pθ - Verteilung mit Parameter θ V - Verlustfunktion χ2 - Pearsons Chi-Quadrat X - Gemeinsame Variablen für die Datenfusion Y - Spezifische Variable Y für die Datenfusion Z - Spezifische Variable Z für die Datenfusion IAD-TU Dresden IX
DAK-2021-08 Indizes Indizes Zeichen Bedeutung l Merkmalsausprägungen einer Variablen m Gemeinsame Variablen n Variable n (KS-Test) IAD-TU Dresden X
DAK-2021-08 Abkürzungsverzeichnis Abkürzungsverzeichnis Abkürzung Beschreibung AUC Area Under Curve BE 1 Blending-Ensemble normal BE 2 Blending-Ensemble mit Undersampling-Verfahren BE D Blending-Ensemble mit Daten-Augmentierung (teilweise) CIA Conditional Independence Assumption DHD Distance-Hot-Deck EDA Explorative Datenanalyse EUSka Elektronische Unfalltypensteckkarte GAN Generative Adversarial Networks MDA Mean Decrease Accuracy MDG Mean Decrease Gini ML Machine Learning MLP Multilayer perceptron NNET Neuronale Netze PE 1/2/3 Paralleles Ensemble 1/2/3 PE S Paralleles Ensemble mit Softvoting-Verfahren RF Random Forest RFE Recursive Feature Elimination ROC Receiver Operating Characteristic VAE Variational Autoencoders VIM Variable Importance Measurement SVM Support Vector Machines XGBoost eXtreme Gradient Boosting IAD-TU Dresden XI
DAK-2021-08 Einleitung 1 Einleitung Mit der neuen Energiewende und dem technologischen Fortschritt bewegt sich die Automobilindustrie schrittweise in Richtung Elektrifizierung, Intelligenz und Automatisierung [1]. Im Bereich des autonomen Fahrens werden die Ansprüche an Funktionalität und Sicherheit immer höher. Bei der Absicherung der Funktionen und Sicherheit des autonomen Fahrens spielt ein vollständiger und umfassender Katalog der Verkehrsszenarien eine entscheidende Rolle. Unter diesen Szenarien besitzen die Unfallszenarien die wichtigste Bedeutung. Daten von Unfallszenarien können aus vielen Datenbanken stammen, und die Erfassungsmethoden jeder Datenbank können unterschiedlich sein. Um verschiedene Informationsquellen voll auszuschöpfen und eine einheitliche und umfassende Datenbasis zu erhalten, ist die Datenfusion eine notwendige und praktikable Lösung. Da die Merkmale aus verschiedenen Datenbanken nicht gleich sind, ist es notwendig, durch sinnvol- le Datenaufbereitung und Feature-Engineering gemeinsame Merkmale mit hohem Informationsgehalt auszuwählen und dann die nicht gleichzeitig beobachteten Merkmale bestmöglich zueinanderzupassen. Basierend auf der Arbeit von Bäumler et al. [2] und Siedel [3] werden in dieser Arbeit zwei grundlegende Methoden zur Ergänzung dieser fehlenden Merkmale weiter nutzen. Eines ist das Statistical Matching und die andere ist Machine Learning (ML)-Algorithmen. Bäumler et al. [2] führten eine simulierte Datenfusion mit Distance-Hot-Deck (DHD) und Random Forest beruhend auf der EUSka (Elektronische Unfalltypensteckkarte)-Datenbank durch. Auf dieser Grundlage testete und verglich Siedel [3] DHD und mehrere Basisklassifikatoren mit verschiedenen Datenaufbereitungen und kombinierte sie zu Ensembles. Hinterher wurden die Ergebnisse der Datenfusion verbessert. Um die Methoden für die Datenfusion von Unfalldaten eine bessere Universalität gegenüber unterschiedlichen Datensätzen in der Zukunft zu verleihen und bessere Performance anzustreben, ist es förderlich, die Methoden unter Zuhilfenahme von Daten mit variierten Eigenschaften, die auf Basis der Deep-Learning-Methode (GAN/VAE) synthetisiert wurden, zu testen sowie gezielte Verbesserungen vorzunehmen. Das spezielle Ziel dieser Arbeit besteht darin, verschiedene Ensembles mit Hilfe der durch die generativen Modelle synthetisierten Daten zu testen und zu bewerten und allseitige Modifizierungen bei der Struktur von Ensembles vorzunehmen, damit die Ensembles bessere Ergebnisse für die Datenfusion verschaffen können. Diese Prozesse werden auch mithilfe der simulierten Datenfusion durchgeführt. In Kapitel 2 werden die theoretischen Grundlagen dieser Arbeit vorgestellt, einschließlich Datenfusion, grundlegende Klassifikationsverfahren sowie häufig verwendete generative Modelle zur Datengenerierung. IAD-TU Dresden 1
DAK-2021-08 Einleitung In Kapitel 3 werden die in dieser Arbeit verwendeten Datenquellen, die Erweiterung der Daten und die Methodik von Ensemble beschrieben, die der Ausgangspunkt dieser Arbeit sind. Die konkrete Vorgehensweise der Zielerreichung wird in Kapitel 4 beschrieben. Zunächst werden 3 neue Datensätze mittels der generativen Modelle basierend auf den bestehenden Unfalldaten synthetisiert und die Unterschiede zwischen dem neuen Datensatz und dem originalen Datensatz werden anhand ausgewählter Bewertungsmetriken verglichen, einschließlich statistischer Unterschiede und Unterschiede bei der Performance des maschinellen Lernens. Anschließend werden Verbesserungen an der Struktur der Ensembles vorgenommen. Einerseits wird neue Variante aus Kombination bestehender einfachen Klassifikatoren konstruiert. Andererseits wird das wahrscheinlichkeitsbasierte Abstimmungsverfahren dazu eingeführt. Außerdem werden neue Ensembles erstellt werden, um das bestehende Datenleckproblem vom Stacking Ensemble zu vermeiden. In Kapitel 5 werden die Performance zwischen den bestehenden Ensembles und den neuen Ensembles auf die neuen und alten Datensätze verglichen. Daraus kann die Performance und Robustheit der verschiedenen Ensembles abgelesen werden. In Kapitel 6 werden die Erfolge und die Mängel dieser Arbeit diskutiert und ein Ausblick im nächsten Forschungsschritt auf mögliche Verbesserungen gegeben. IAD-TU Dresden 2
DAK-2021-08 Grundlagen
2 Grundlagen
Wie im ersten Kapitel erwähnt, werden in dieser Arbeit EUSKa-Daten und künstliche synthetische
Datensätze verwendet, die aus verschiedenen generativen Modellen generiert werden, um eine neue
simulierte Datenfusion durchzuführen. Einer der Ziele ist es, die vorhandenen Fusionsmethoden auf
verschiedenen Datensätzen weiter zu testen und zu bewerten. Die zweite besteht darin, die Schwächen
der alten Methode zu verbessern, um eine bessere Leistung zu erzielen. Die Methode der Datenfusion
verwendet hier hauptsächlich eine Reihe von Klassifikationsverfahren und deren Kombinationen, also
Ensembles. Die Bewertung dieser Ensembles sollte nicht nur auf bestehenden Datensätzen, sondern auch
auf verschiedene Datensätze erfolgen. Dies bezieht sich auf die absolute Performance und die Robustheit
der Ensembles.
In diesem Kapitel werden die Grundlagen der Verfahrensweisen aufgezeigt, die in dieser Arbeit involviert
sind.
2.1 Datenfusion
In dem allgemeinen Sinn wird die Integration von Daten und Wissen aus unterschiedlichen Quellen
als Datenfusion bezeichnet [4]. Manchmal wird es auch als Informationsfusion definiert, was sich auf
eine Reihe von Prozessen der Fusion verschiedener Sensoren und Informationsquellen bezieht [4]. Kiesl
und Rässler definieren die Datenfusion als „Techniken, Datensätze aus mindestens zwei verschiedenen
Erhebungen mit teilweise nicht identischen Variablenmengen so zu verknüpfen, dass jeder Beobachtung
der einen Erhebung Daten derselben Beobachtungseinheit (bei Datenintegration) oder einer ‚ähnlichen‘
(bei Datenfusion) aus den anderen Erhebungen hinzugefügt werden“ [5]. Bezüglich der Beziehung
zwischen den Eingabedaten schlägt Durrant Whyte [6] die folgenden drei Arten der Datenfusion vor:
• Komplementär: Die Informationen der Eingabedaten repräsentieren verschiedene Teile derselben
Szene und können verwendet werden, um umfassendere globale Informationen zu erhalten [4,
S. 95] Beispielsweise ergänzen sich in einem visuellen Sensornetzwerk die Daten, die von zwei
Kameras erhalten werden, die dasselbe Ziel aus unterschiedlichen Aspekten beobachten [4, S. 95]
• Redundant: Zwei oder mehr Eingabedatenquellen liefern Informationen über dasselbe Ziel und
können fusioniert werden, um die Glaubwürdigkeit zu erhöhen [4, S. 95].
• Kollaborative: Mehrere Eingabedaten können kombiniert werden, um viel komplexere Informatio-
nen als die ursprünglichen Quellen zu bekommen [4, S. 96].
Zusammenfassend lässt sich feststellen, dass die oben genannten drei Arten der Datenfusion folgenden
Zwecken entsprechen [4]:
IAD-TU Dresden 3DAK-2021-08 Grundlagen
• Komplementär: Erhalten der umfassenderen globalen Daten
• Redundant: Erhöhung der Glaubwürdigkeit der Daten
• Kollaborative: Dateninformationen erweitern
Konkretisierung des Fusionsverfahrens auf dieser Arbeit, bei dem zwei Datensätze, die Unfallszenarien
beschreiben, Informationen über dieselben Informationseinheiten austauschen, um fehlende Informations-
einheiten zu ergänzen. Dieser Prozess ist eine typische komplementäre Datenfusion.
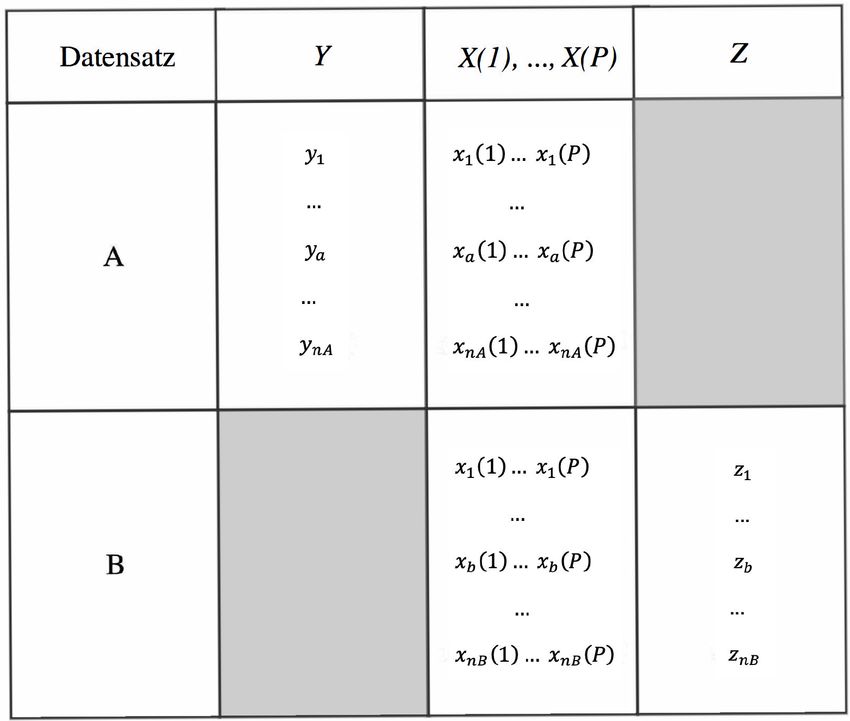
Wie in Abbildung 2.1 dargestellt, werden Unfallszenarien gleichzeitig durch die Datensätze A und B
beschrieben, die beiden Datensätze haben gemeinsame Variablen X und die im Graubereich dargestellten
spezifischen Variablen Y und Z. In jedem Datensatz gibt es n Beobachtungseinheiten und jede Beob-
achtungseinheit hat Variablen Y , X(1), . . . , X(P) oder Z, X(1), . . . , X(P). Diese Variablen werden als
Merkmale einer Einheit definiert. Jede Variante eines Merkmals werden als Merkmalsausprägungen oder
Kategorien bezeichnet. Beide Datensätze haben Variablen, die dem anderen nicht zur Verfügung stehen.
Das Ziel der Datenfusion besteht hier darin, die fehlenden Variablen durch Informationsaustausch zu
ergänzen.
Abbildung 2.1: Schematische Darstellung der Datenfusion nach D’Orazio et al. [7]
Im Datensatz A sind die spezifische Variable Y und die gemeinsame Variablen X bekannt, und es wird
das Beziehungsmodell zwischen den beiden Variablensätzen erstellt. Mit diesem Beziehungsmodell und
der Variablen X im Datensatz B als Modelleingabe, kann der graue Teil Y ergänzt werden. Dabei wird
Datensatz A Spender, Datensatz B mit fehlender Variable Y Empfänger, benennen. Bei der Suche nach
Variable Z ist Datensatz B Spender und Datensatz A Empfänger.
Vor dem Fusionsverfahren müssen die spezifischen Variablen Y und Z die bedingte Unabhängigkeitsannah-
me erfüllen, im Englischen Conditional Independence Assumption (CIA) [8], d.h., dass Y und Z gegeben
IAD-TU Dresden 4DAK-2021-08 Grundlagen
der gemeinsamen Variablen X unabhängig voneinander sein müssen [8][3]. Andernfalls kommt es nach
Abschluss der Fusion zu einem systematischen Fehler in der gemeinsamen Verteilung(X,Y , Z). Die Haupt-
ursache ist, dass das zur Vorhersage der spezifischen Variablen X oder Z verwendete Beziehungsmodell
(Y , Z) oder (Y , X) nicht die gemeinsamen Verteilungsinformationen von (X, Z) enthält.
Unter der obigen Annahme lassen sich die spezifischen Methoden der Datenfusion in Makroansatz und
Mikroansatz unterteilen [7]. Beim Makroansatz wird kein vollständiger Datensatz erzeugt, sondern nur die
Eigenschaften der Gesamtverteilung der Variablen im Spender und Empfänger vergleichend abschätzen
werden, welche nicht gemeinsam beobachtet wurden [7]. Beim Mikroansatz müssen die konkreten Werte
aller fehlenden Variablen ergänzt werden, um einen vollständigen Datensatz zu bekommen [7]. Aufbauend
auf der vorangegangenen Forschungsarbeit von Bäumler et al. [2] und Siedel [3] etabliert diese Arbeit die
simulierte Datenfusion auf Basis von Daten aus EUSKa und künstlichen synthetischen Datensätzen aus
generativen Modellen mit dem Ziel, die Datenfusionsmethode werter zu untersuchen und zu verbessern.
Die Charaktere der in dieser Arbeit durchgeführten simulierten Datenfusion sind:
• Datensatz A und B stammen beide aus derselben Datenquelle, haben eine gemeinsame Datenbasis
und dieselbe Variablenverteilung
• Als komplementäre Datenfusion behält diese Arbeit nur eine spezifische Variable Y bei
• Diese Arbeit verwendet Mikroansatz, um die spezifischen Variablen jeder Beobachtungseinheit
vorherzusagen und auszufüllen.
Das Verfahren der Datenfusion besteht im Wesentlichen darin, ein Modell der Beziehung zwischen
gemeinsamen Variablen X und spezifischer Variable Y mithilfe des Spenders zu erstellen und dieses Modell
zu verwenden, um den fehlenden Wert der spezifischen Variable Y im Empfänger zu ergänzen. Dieses
Modell kann ein statistisches Modell, ein mathematisches Modell oder ein Modell von maschinellem
Lernen sein. In dieser Arbeit wird das Hot-Deck-Verfahren in Kombination mit der Methoden von
maschinellem Lernen verwendet, um eine Datenfusion zu erreichen.
2.2 Klassifikationsverfahren
Das Verfahren der komplementären Datenfusion in dieser Arbeit ist der Prozess, die spezifische Variable
„Unfalltyp“ (siehe Kapitel 3.1.1) des Empfängers anhand der Informationen vom Spender vorherzusagen,
also zu klassifizieren.
Aus den vergangenen Forschungsarbeiten von Siedel [3] kann zusammengefasst werden, dass die Me-
thoden zur Klassifizierung des Unfalltyps beim Datenfusionsverfahren in „Statistical Matching“ und
Machine-Learning Verfahren unterteilt werden können.
2.2.1 Statistical-Matching-Verfahren
Beim Statistical Matching werden parametrische und nichtparametrische Methoden unterschieden [9].
Bei der parametrischen Methode wurde bereits die Verteilung der Daten angenommen und dient dazu,
IAD-TU Dresden 5DAK-2021-08 Grundlagen die gemeinsame Verteilung in diese angenommene Verteilung einzuordnen [9]. Repräsentative davon sind die Maximum-Likelihood-Schätzung und das Conditional Mean Matching. Im Unterschied zum parametrischen Verfahren wird bei der nichtparametrischen Methode die Verteilung der Daten nicht im Voraus angenommen. Die mathematische Beschreibung der Verteilung und deren Parameter werden beim Matching-Verfahren anhand der Daten vom Spender angepasst. Daher ist das nichtparametrische Verfahren ein robusteres und allgemeineres Verfahren [10, S. 68]. Ein typischer Vertreter zum Ziel der Datenfusion sind Hot-Deck-Verfahren, welche nach der Vorgehensweise der Ergänzung der fehlenden Einheiten im Empfänger weiter in drei Modi eingeteilt werden können [10, S. 53]: • Rank-Hot-Deck • Random-Hot-Deck • Distance-Hot-Deck Die Kernidee von Hot-Deck-Verfahren besteht darin, reale Beobachtungen eines vollständigen Datensatzes zu verwenden, um fehlende Einheiten in einem anderen Datensatz zu ergänzen. Beim Rank-Hot-Deck Verfahren werden zuerst die gemeinsamen Variablen ausgewählt, und dann werden die beiden Datensätze nach diesen Variablen sortiert [9]. Die Werte der fehlenden Einheiten können anhand der Rangposition aus einem anderen Datensatz ermittelt werden [9]. Je nachdem, ob die Größen der beiden Datensätze gleich sind, kann die Rangposition direkt oder durch die empirische kumulative Verteilungsfunktion bestimmt werden [9]. Im Gegensatz zu ersterem hängt das Random-Hot-Deck Verfahren nicht von der Rangposition ab. Die zu ergänzenden Werte der Einheiten im Empfänger werden zufällig oder in nach der Merkmalausprägungen homogene eingeteilte Spendergruppen angepasst [9]. Beim Distace-Hot-Deck müssen auch zuerst die gemeinsamen Variablen bestimmt werden. Dann ergeben sich die Verteilungsfunktionen der gemeinsamen Variablen für Spender und Empfänger [9]. Die Grundlage für die Ergänzung der fehlenden Einheitswerte im Empfänger besteht darin, die beiden Verteilungen möglichst ähnlich zu machen [9]. Je nach den rechnerischen Methoden und verwendeten Variablenarten stehen viele verschiedene Distanzmaße zur Berechnung der Ähnlichkeit wie Gower-Distanz, Manhattan- Distanz, Euklid-Distanz, Chebyshev-Distanz usw. zur Verfügung [11]. In Anlehnung an frühere Forschungen von Bäumler et al. [2] und Siedel [3] wird mithilfe des „StatMatch“ -Pakets [12] in RStudio das Distance-Hot-Deck zum Aufbau der Ensembles für diese Arbeit weiterhin verwendet. Aufgrund des Normalisierungsvorteils [12] der Gower-Distanz zu verschiedenen Skalen von Variablen wird dieser Maßstab als Distanzmaß beim DHD-Verfahren ausgewählt. 2.2.2 Machine-Learning Verfahren Maschinelles Lernen bezieht sich auf Wissen, das künstlich aus Erfahrung gewonnen wird [13]. Der Ursprung des maschinellen Lernens lässt sich bis ins 17. Jahrhundert zurückverfolgen [13]. Die Ableitung der kleinsten Quadrate aus Bayes und Laplaces, und die Markov-Kette, bilden die Werkzeuge und IAD-TU Dresden 6
DAK-2021-08 Grundlagen Grundlagen, die beim maschinellen Lernen weit verbreitet sind [14]. Heute hat das maschinelle Lernen als ein Teilgebiet der künstlichen Intelligenz eine große Entwicklung erreicht. Anders als die strenge Abhängigkeit beim Distance-Hot-Deck Verfahren von der Distanzfunktion, die die Ähnlichkeit der Verteilungen beider Datensätze beschreibt, konstruiert Maschine-Learning die Be- ziehung zwischen Eingangsdaten und Ergebnisse von selbst, und die Ausdrucksform der Daten und das Lernverfahren können zu unterschiedlichen Endergebnissen führen. Nach Lernmechanismen lässt sich maschinelles Lernen in überwachtes Lernen, unüberwachtes Lernen und Reinforcement- Lernen einteilen [15]. Überwachtes Lernen lernt aus Trainingsdaten und erstellt ein Lernmodell, um neue Exemplare vorherzusagen [14]. Die Trainingsdaten bestehen aus den Eingabedaten und der erwarteten Ausgabe mit korrekten Labels (gekennzeichnete Datenpaare) [14]. Ist die erwartete Ausgabe des Lernmodells ein kontinuierlicher Wert, wird das Modell für die Aufgabe der Regression verwendet, und wenn das Lernmodell für die Klassifikation angewandt wird, ist die Ausgabe Kategorie [14]. Im Vergleich zum überwachten Lernen enthalten die Trainingsdaten beim unüberwachten Lernen keine vorgegebenen Labels [14]. Daher wird das unüberwachte Lernen häufig bei Clustering-Aufgaben verwendet. Reinforcement Learning erfordert auch keine gekennzeichneten Datenpaare [14]. Es führt einen Belohnungs- und Bestra- fungsmechanismus für Umweltfeedback ein, der beschäftigt sich damit, wie das Modell sich basierend auf der Umwelt verhält, um den erwarteten Nutzen zu maximieren [14]. In dieser Arbeit wird das überwachte Lernen für die Datenfusion angewendet. Dabei werden die Daten mit mehreren Merkmalen im Spender als Eingabedaten verwendet und der für jede Daten entsprechende Unfalltyp, ist deren Label. Nach dem Training mit Spenderdaten können die Unfalltypen der Einträge im Empfänger vorhergesagt werden, und eine komplementäre Datenfusion wird so erreicht. Bäumler et al. [2] wandt Random Forest an, um das Klassifikationsproblem über Unfalltyp zu lösen, und erreichte eine höhere Trefferrate als Distanz-Hot-Deck Verfahren. Siedel [3] testete das DHD-Verfahren und überwachte Lernmodelle gemeinsam und gestaltete sie zum Ensemble. Im Vergleich zu einem einzelnen Lernmodell erzielte Siedel in seiner Arbeit eine bessere Performance bei der Trefferrate von Vorhersage des Unfalltyps und der Reproduktionsfähigkeit der Verteilung. Es gibt viele Algorithmen für überwachtes Lernen, aber für ein konkretes Problem kann man im Voraus nicht wissen, welches Modell die besten Ergebnisse erzielen kann. No-Free-Lunch-Theorie besagt, dass „ohne spezifisches Wissen um ein Problem kein einzelnes Vorhersagemodell als das beste Modell vorhergesagt werden kann“ [16]. Für die Modellauswahl von Klassifikationsproblemen schlug Ho und Basu [17] Metriken der Komplexität von ML-Problemstellungen vor. Aber diese Metriken erwiesen sich aus Zeit- und Datengründen im Umgang mit dem Klassifikationsproblem des Unfallszenarios nicht praktikabel [3]. Seidel [3] hat aus vielen Forschungsbeispielen neun Klassifikationsmodelle abgeleitet, von denen vier Modelle, Random Forest (RF), eXtreme Gradient Boosting (XGBoost), Neuronale Netze (NNET) und Support Vector Machines (SVM) in allen Fällen die höchste Rate, die besten Ergebnisse zu erzielen haben. Diese vier Basismodelle sind auch möglichst untereinander heterogen und können Leistungsunterschiede aufweisen, die den Anforderungen des Aufbaus von Ensemble entsprechen [14][18]. Aufgrund des IAD-TU Dresden 7
DAK-2021-08 Grundlagen gleichen Themengebiets und des gemeinsamen Ziels der Datenfusion werden diese vier Grundmodelle in dieser Arbeit auch verwendet. Der Fokus in dieser Arbeit liegt auf der strukturellen Innovation von Ensemble. Random Forest (RF) Das Konzept des Random Forest wurde erstmals 1995 von Ho vorgeschlagen [19]. 2001 entwarf Leo Breiman den Random Forest-Algorithmus und setzte ihn sehr erfolgreich ein, um die Klassifikations- und Regressionsprobleme zu lösen [20]. Ein Random Forest wird aus vielen Entscheidungsbäumen gebildet, und nach der Mehrheitsabtimmung dieser Entscheidungsbäume wird das Endergebnis von Random Forest bestimmt. Der Trainingssatz jedes Entscheidungsbaums ist eine Unterstichprobe, die durch zufällige Ersetzungsstichproben im vollständigen Trainingssatz erhalten wurden [20]. Im abschließenden Abstimmungsprozess kann diese Zufälligkeit jedes Entscheidungsbaums den Generalisierungsfehler des gesamten Modells reduzieren [14]. Dies ist auch die Kernidee des 1996 von Breiman [21] vorgeschlagenen Bagging-Algorithmus, also ist Random Forest eine Form von „Bagging Decision Trees“ [21]. Der Entscheidungsbaum ist eine Klassifikationsmethode des überwachten Lernens, der ein Binärbaum oder ein Mehrfachbaum sein kann [14]. Jeder interne Knoten des Entscheidungsbaums stellt eine Beurteilung für ein Merkmal in dem Variablenraum dar und dessen Abzweigungen sind die Ausgaben der Beurteilungsergebnisse. Das Ziel der Abzweigungen ist, die Kategorien der Zielvariablen möglichst gut zu ordnen bzw. abzutrennen [15]. Verschiedene Entscheidungsbaummodelle basieren auf unterschiedlichen Metriken für die Abzweigung, die die Entropie oder Gini-Koeffizient sein können [14]. Zwei klassische Vertreter, die Entropie als Abzweigungsbasis im Random Forest verwenden, sind ID3- und C4.5-Algorithmen [22]. Der in dieser Arbeit verwendete Entscheidungsbaum im Random Forest basiert auf dem Gini-Koeffizienten. Für die Klassifizierung führt Random Forest eine implizite Merkmalsauswahl durch und verwendet nur eine kleine Anzahl „starker Variablen“ für die optimale Abzweigung, welcher nach Gini-Verunreinigung (gini-impurity) bestimmt wird [22]. In dieser Arbeit werden das „Caret“-Paket [23] und das „randomforest“- Paket [24] in Rstudio verwendet, um die Klassifizierung vom Unfalltyp und die frühe Auswahl der Variablen nach ihrer Wichtigkeit zu implementieren. eXtreme Gradient Boosting (XGBoost) XGBoost ist ein verbesserter Gradient-Tree-Boosting Algorithmus [25]. Die Hauptidee des Gradient-Tree- Boosting besteht darin, schwache Klassifikatoren mithilfe eines additiven Modells linear zu kombinieren, wobei die schwachen Klassifikatoren Entscheidungsbäume sind [26]. In jeder Iteration beim Gradient-Tree-Boosting erhalten Klassifikatoren mit geringeren Fehlerquoten eine höhere Gewichtung, während Klassifikatoren mit hohen Fehlerquoten eine entsprechend geringere Gewichtung erhalten [27]. Gleichzeitig werden die Gewichte der Trainingsdaten in jeder Iteration geändert, wobei die schwächeren Klassifikatoren, die die Proben in der vorherigen Iteration falsch eingeschätzt haben, höhere Gewichte erhalten, damit sich das Modell in der nächsten Runde mehr auf die Vorhersagen mit größeren Gewichten konzentrieren kann [27]. Nach jeder Iteration werden die Restfehler des Modells IAD-TU Dresden 8
DAK-2021-08 Grundlagen
summiert und verwendet, um den schwachen Klassifikator erneut zu trainieren und das Modell zu aktuali-
sieren, damit die Verlustfunktion minimiert werden kann [27]. Hier schlug Friedman die Verwendung
des negativen Gradienten der Verlustfunktion als Annäherung an die Restfehler im Grandient Boosting
Algorithmus vor [27, S. 3].
Im Vergleich zum traditionellen Grandient-Boosting-Algorithmus hat XGBoost die folgenden Verbesse-
rungen vorgenommen:
• Es wurde eine Taylor-Erweiterung zweiter Ordnung für die Fehlerfunktion eingeführt, so dass
genauere Verluste ermittelt werden können [25, S. 2];
• Es wurde einen Regularisierungsterm für die Verlustfunktion eingeführt, um die Modellkomplexität
zu kontrollieren, damit die Überanpassung verringert werden kann [25, S. 2];
• Lernrate („Shrinkage“) eingeführt [25, S. 3]
• Es wurde eine ähnliche Strategie wie bei Random Forests angewandt, die ein „Sub-Sampling“ der
Daten ermöglicht, damit kann es in einigen Fällen die Effektivität und Geschwindigkeit verbessern
und die Überanpassung reduzieren [25, S. 3];
• Bei spärlichen Trainingsdaten ist es möglich, die Richtung der Verzweigung für fehlende Werte
oder bestimmte Werte festzulegen, was die Effizienz des Algorithmus verbessern kann [25, S. 5].
Die Aufgabe der Klassifizierung des Unfalltyps wurde in dieser Arbeit mithilfe des „xgboost“-Paket [28]
in Rstudio umgesetzt.
Support Vector Machines (SVM)
Der SVM-Algorithmus wurde erstmals von Vapnik und Chervonenkis im Jahr 1963 vorgeschlagen
[29]. Der klassische SVM-Algorithmus wurde zur Lösung binärer Klassifizierungsprobleme verwendet.
1992 ermöglichten Boser et al. die Multi-Klasse-Klassifizierung, indem sie einen „Kernel-Trick“ in die
SVM einführten [30] . Die Idee der SVM ist es, die Hyperebene im Parameterraum zu finden, die den
Datensatz korrekt aufteilen kann und die größte geometrische Trennung zwischen den beiden Datenklassen
aufweist [14]. Diese Ebene wird mithilfe von „Support Vector“ bestimmt, welche sich auf die wenigen
Trainingsprobenpunkte beziehen, die der Hyperebene am nächsten liegen und bestimmte Bedingungen
erfüllen [14].
SVMs werden in lineare und nicht-lineare Algorithmen unterteilt [15]. Wenn der Datensatz linear teilbar
ist, dann können die beiden Datenklassen in der zweidimensionalen Ebene durch eine gerade Linie
korrekt klassifiziert werden, die durch die Bedingung „Maximale geometrische Trennung“ eindeutig
bestimmt ist [15]. Wenn der Datensatz in der 2D-Ebene nicht linear trennbar ist, kann die 2D-Ebene
durch eine nichtlineare Abbildung mit dem „Kernel-Trick“ in einen 3D-Parameterraum erweitert wer-
den, in dem die beiden Datenklassen des Datensatzes durch eine 2D-Ebene, die auch durch die Bedin-
gung „Maximale geometrische Trennung“ eindeutig bestimmt ist, korrekt klassifiziert werden können
IAD-TU Dresden 9DAK-2021-08 Grundlagen [15]. Für Multi-Klassifizierungsprobleme kann dies durch die Methoden „one-against-one“ [31], „one- against-all“ [32] sowie „one-against-the rest“ [33] erweitert werden, deren Grundidee darin besteht, das Multi-Klassifizierungsproblem in mehrere binäre Klassifizierungsprobleme zu zerlegen und damit die Endergebnisse zu erhalten. In dieser Arbeit wurde die auf der „one-against-one“-Strategie basierende Multiklasse-SVM für die Vorhersage des Unfalltyps verwendet, die in Rstudio unter Verwendung des „Radial-Basis-Funktions- Kernel“ aus dem „kernlab“-Paket [34] implementiert ist. Neuronale Netze (NNET) WMCulloch und Pitts entwickelten 1943 ein mathematisches Modell der Neuronen, das so genannte MP-Modell [35]. Sie schlugen eine formale mathematische Beschreibung von Neuronen und eine Me- thode zur Bildung des Netzwerks mithilfe des MP-Modells vor und zeigten, dass einzelne Neuronen logische Funktionen ausführen können [35]. Wie geschrieben, ist die Grundeinheit eines neuronalen Netzes das Neuron. Ein Neuron kann mehrere Eingänge haben [36, S. 3], von denen jeder zwei Parameter enthält, ein Gewicht und ein Bias [36, S. 7 ff.]. Die Summe der Eingabewerte wird durch eine Aktivie- rungsfunktion geleitet, um eine Ausgabe im Bereich von 0 bis 1 zu erhalten [36, S. 7 ff.]. Eine gängige Aktivierungsfunktion hier ist die Sigmoid-Funktion. Ein Netz aus miteinander verknüpften Neuronen wird als neuronales Netz bezeichnet, und seine Grundstruktur besteht aus einer Eingabeschicht, einer verborgenen Schicht und einer Ausgabeschicht [36, S. 11]. Ein neuronales Netz kann mehrere verborgene Schichten enthalten. Die Ausgabe eines Knotens ist die Summe aller Eingabewerte innerhalb dieses Knotens nach einer Aktivierungsfunktion [36]. In der Ausgabeschicht gibt jedes Neuron die Wahrschein- lichkeit für den entsprechenden Merkmalswert aus [14]. Der Trainingprozess eines neuronalen Netzwerks ist ein Optimierungsprozess für die Verlustfunktion. Eine gängige Verlustfunktion ist eine Funktion der mittleren quadratischen Abweichung zwischen den vorhergesagten und den realen Werten [14]. Das Ziel der Optimierung ist es, die Verlustfunktion über Iterationen zu minimieren, indem die Gewichte und Bias der einzelnen Neuronen verändert und das Trainingsmodell aktualisiert werden [14]. In dieser Arbeit entsprechen die Neuronen in der Ausgabeschicht jedem Unfalltyp, und das trainierte Modell kann für jeden Unfalltyp einen eindeutigen Unfalltyp oder eine Wahrscheinlichkeit für jeden Unfalltyp für jede Eingabedaten erhalten. In dieser Arbeit werden neuronale Netze mit dem Paket „nnet“ [37] in RStudio implementiert. 2.3 Generative Modelle für synthetische Daten In der Wahrscheinlichkeitstheorie bezieht sich ein generatives Modell auf ein Modell, das zufällig Beobachtung X nach der gegebenen Zielvariable Y generieren kann [38]. Im Gegensatz dazu wird das Diskriminanzmodell verwendet, um den Wert der Zielvariablen Y unter einer gegebenen Beobachtung X zu bestimmen [38]. Der Random Forest, XGBoost, die Support Vector Machine und das neuronale Netzwerk, die im vorherigen Kapitel erwähnt wurden, sind typische Diskriminanzmodelle, und die in diesem Kapitel besprochenen GAN und VAE sind zwei Vertreter des generativen Modells. IAD-TU Dresden 10
DAK-2021-08 Grundlagen
Generative Adversarial Networks (GAN)
Der Grundrahmen der GAN wurde 2014 von lan Goodfellow vorgeschlagen [39]. Im GANs-Framework
gibt es zwei Teile: Generator und Diskriminator, die beide aus mehrschichtigen Perzeptronen (Muti-Layer
Perception, MLP) bestehen [40]. Darin werden gleichzeitig ein generatives Modell G und ein Diskrimi-
nanzmodell D traniert. Das generative Modell G wird verwendet, um die Verteilung von Trainingsdaten
zu erfassen und daraus neue Daten zu synthetisieren, während das Diskriminanzmodell D verwendet
wird, um die Daten des generativen Modells G von den realen Trainingsdaten zu unterscheiden [40].
Der Trainingsprozess von G soll die Wahrscheinlichkeit maximieren, dass D Fehler erzeugt, während
der Trainingsprozess von D die Wahrscheinlichkeit einer korrekten Unterscheidung zwischen realen
Samples und synthetischen Samples maximieren soll [40]. Daher kann die Verlustfunktion des gesamten
Trainingsprozesses ausgedrückt werden als [40]:
min(G) max(D)V (D, G) = Ex [log(D(x))] + Ez [log(1 − D(G(z)))] (2.1)
Dabei sind D(x) und (1 − D(G(z))) jeweils die Wahrscheinlichkeit, dass der Diskriminator die realen
Daten als wahr beurteilt, und die Wahrscheinlichkeit, dass der Diskriminator die synthetische Daten als
falsch beurteilt. G(z) ist die Ausgabe des Generators bei einem Rauschen z. Der Zweck dieses Rauschens
z besteht darin, dem Generator Zufälligkeit zu verleihen [40]. Ex ist der Erwartungswert aller realen Daten
und Ez ist der Erwartungswert aller von G(z) erzeugten Daten. Der Trainingsprozess des Generators
und des Diskriminators ist ein kontradiktorischer Prozess, wobei für Diskriminator die Maximierung
von logD(x) und log(1 − logD(G(z))) angestrebt wird, während für Generator die Minimierung von
log(1 − logD(G(z)) gewünscht ist [40]. Darauf aufbauend entwickelten Mirza und Osindero [41] das
bedingte GANs (Conditional Generative Adversarial Nets) weiter, so dass die Eingabe in den Generator
zusätzlich zur potenziellen Verteilung der realen Daten auch eine bedingte Variable enthält. Dies bedeutet,
dass es durch Hinzufügen zusätzlicher Informationen zum Modell möglich ist, die Richtung der durch das
Modell erzeugten Daten zu steuern [41], z. B. indem das Modell dazu gebracht wird, Daten zu erzeugen,
die eines bestimmten Lables entsprechen. Xu et al. [42] verwenden in ihrer Arbeit bedingtes GAN, um
die Modellierung von Daten in Tabellenform zu implementieren. Dadurch ist es möglich, für diese Arbeit
eine kontradiktorische Generierung von Verkehrsunfalldaten durchzuführen.
Variational Autoencoders (VAE)
VAE wurden im Jahr 2013 von Diederik P. Kingma und Max Welling [43] eingeführt. Es setzt sich aus
zwei Teilen zusammen, dem Encoder und dem Decoder, die beide neuronale Netzwerkmodelle sind [43,
S. 3]. Der Encoder modelliert die Parameter der Verteilung der Trainingsdaten und erhält den versteckten
Variablenraum z [44]. Der Decoder tastet dann die neuen Daten aus der erstellten Verteilung ab. Das dabei
verwendete probabilistische grafische Modell ist in der Abbildung 2.2 dargestellt. Die Daten x werden
durch die versteckte Variable z erzeugt, die der Verteilung pθ (z) mit dem Parameter θ gehorcht [44, S. 2].
Da aber pθ (x) und pθ (z|x) schwer zu schätzen sind und somit der Parameter θ nur schwer direkt optimiert
werden kann, wird ein weiterer Parameter φ und die entsprechende Verteilung qφ (z|x) eingeführt, die
eine mathematisch leicht zu berechnende Verteilung, φ durch x, verwendet, um eine Annäherung an
die wahre Kausalität z− > x zu erhalten [43][44, S. 2]. Der Trainingsprozess des gesamten Systems ist
IAD-TU Dresden 11DAK-2021-08 Grundlagen
eigentlich ein Verfahren der Variationsapproximation von eingeführter Verteilung qθ (z|x) an die posteriore
Wahrscheinlichkeitsverteilung pθ (z|x) [44]. Wenn die Kullback-Leibler-Divergenz verwendet wird, um
die Nähe zweier Verteilungen auszudrücken, dann kann die Randwahrscheinlichkeit eines Datenpunkts
während des gesamten Trainingsprozesses als Formel 2.2 [44, S. 3] ausgedrückt werden.
logpθ (x(i) ) = DKL (qφ (z|x(i) ))||pθ (z|x(i) ) + L(θ , φ ; x(i) ) (2.2)
In dieser Gleichung stellt die linke Seite die Randwahrscheinlichkeit eines Datenpunktes dar und die
Kullback-Leibler-Divergenz des ersten Terms auf der rechten Seite stellt die Annäherung von qφ (z|x) an
pθ (z|x) dar, die minimiert werden sollte [44, S. 3]. Der zweite Term L wird „variational lower bound“
genannt und stellt die Variationsuntergrenze der Randwahrscheinlichkeit dieses Datenpunktes dar [44, S.
3]. Das Ziel der Optimierung ist es, L so zu maximieren, dass die Kullback-Leibler-Divergenz minimiert
werden kann, während die linke Seite unverändert bleibt, d.h. die Verteilung der beiden am ähnlichsten
ist. Aus Sicht eines neuronalen Netzwerks entsprechen φ und θ jeweils den Parametern der neuronalen
Netzwerkeinheiten des Encoders und Decoders [43, S .5 ff.]. Der Prozess der Gewinnung der Verteilung
qφ (z|x) durch x und dann z wird als Codierung bezeichnet, während der Prozess der Gewinnung von x aus
dem verborgenen Variablenraum z durch die pθ (x|z)-Verteilung als Decodierung bezeichnet wird [43, S.
6].
Abbildung 2.2: Probabilistische grafische Darstellung von VAE nach P.Kingma [44, S. 2]
In dieser Arbeit werden GAN und VAE für die künstliche Synthese von Verkehrsunfalldaten für drei
Zwecke verwendet:
• Synthetische Daten mischen sich unter den originalen Datensatz, die sich etwas von der Ver-
teilung des Originaldatensatzes unterscheiden, um die Performance des Basis-Klassifikatoren,
DHD-Verfahrens, und der Ensembles in Anwesenheit von externen Störungen („Rauschen“) zu
bewerten.
• Kombination mit dem Ensemble-Verfahren als Mittel zur Daten-Augmentierung für alle Unfalltypen,
um die Performance der Ensembles unter den Bedingungen begrenzter Eingabedaten zu verbessern.
• Vergrößerung der Datenmenge für unausgewogene Klassenstichproben, um die gesamte Klassifizie-
rungsperformance der Basisklassifikatoren und Ensembles zu verbessern.
IAD-TU Dresden 12DAK-2021-08 Grundlagen Patki et al. haben das System „The Synthetic data vault (SDV)“ entwickelt [45]. Mit diesem System ist es möglich, Zieldatensätze mithilfe von GAN und VAE zu modellieren und bei Bedarf neue Daten zu generieren. Mithilfe der „CouplaGAN“-Funktion und der „TVAE“-Funktion dieses Systems in „SDV“- Paket [46] wurde in dieser Arbeit die Modellierung der tabellarischen Daten von Verkehrsunfallszenarien und daraus die Probenahme von synthetischen Daten in Umgebung von Python umgesetzt. IAD-TU Dresden 13
DAK-2021-08 Randbedingungen
3 Randbedingungen
In diesem Kapitel werden die in dieser Arbeit verwendeten Datenquellen, die Grundlage für die Aus-
wahl der Variablen, der Forschungsrahmen und der Umfang der Forschung, den diese Arbeit erweitert,
beschrieben.
Dziuba-Kaiser [47] erörterte in ihrer Arbeit ausführlich die Verwendung statistischer Methoden für
die Datenfusion und Bäumler et al. [2] stellten in ihrer Arbeit Random Forest als Vertreter der ML-
Algorithmen für die Datenfusion vor und verglichen die Ergebnisse mit statistischen Methoden. Siedel [3]
verwendete und bewertete in seiner Arbeit vier ML-Modelle und verglich sie mit einer der statistischen
Methoden, DHD-Verfahren. Sie wurden dann weiter zu Ensembles kombiniert.
Diese Arbeit baut auf den Erfahrungen der oben genannten Forschungsarbeiten auf und bewertet sowie
entwickelt neue Methoden der Modell-Ensembles. Zusätzlich zu den neuen Ensemblesvarianten werden in
dieser Arbeit auch generative Modelle im Ensemble als Mittel zur Daten-Augmentierung eingeführt. Ein
neues Stichprobenverfahren wird auch verwendet, um die Performance für die Vorhersage des Unfalltyps
bei unausgewogenen Stichproben der Originaldaten zu verbessern.
Die Gemeinsamkeiten und Unterschiede zwischen dem Inhalt und dem Umfang dieser Arbeit und den
vergangenen Forschungsarbeiten sind wie folgt:
• Auf der Datenebene sind die Datenbasis, die Auswahl der Variablen und die Skala der Variablen in
dieser Arbeit an Siedel [3] angeglichen. Für die wenigen Klassen des Unfalltyps werden ein neues
Stichprobenverfahren und ein Verfahren von Daten-Augmentierung eingeführt.
• Auf der Ebene des Datensatzes bleibt die Proportion der Datensatzaufteilung in dieser Arbeit
derselbe wie in Siedel [3], aber die für diese Arbeit spezifische Ensemble-Struktur wird eine neue
Aufteilung für Zwischen-Spender haben.
• Auf der Ebene des Basisklassifikators werden die fünf in Kapitel 2 beschriebenen Klassifikations-
verfahren beibehalten, wobei die Hyperparameter der ML-Modelle in der Ensemble-Struktur dieser
Arbeit neu angepasst werden.
• Auf der Ebene des Ensembles werden vier neue Ensembles entwickelt und in der Datenumgebung
dieser Arbeit bewertet sowie verglichen. Darüber hinaus wird eine neue Bewertung der bestehenden
Ensembles in derselben Datenumgebung vorgenommen. Die bestehenden Ensembles werden dann
noch mithilfe der Daten-Augmentierung verbessert.
• Auf der Bewertungsebene folgt dieser Arbeit der Validitätsebene nach Rässler [5] für die Bewertung
der Qualität von Datenfusion (siehe Kapitel 4.3). Für die Bewertung der Qualität des synthetischen
IAD-TU Dresden 14Sie können auch lesen

















































