ANALYSE DER SENSORABH ANGIGKEIT EINER LIDAR-BASIERTEN OBJEKTERKENNUNG MIT NEURONALEN NETZEN
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Analyse der Sensorabhängigkeit einer
LiDAR-basierten Objekterkennung mit
neuronalen Netzen
Bachelorarbeit
für die Prüfung zum
Bachelor of Science
im Studiengang Angewandte Informatik
an der Hochschule Ruhr West
von
Niclas Hüwe
Matrikelnr. 10007508
Erstprüfer Prof. Dr.-Ing. Anselm Haselhoff
Zweitprüfer M. Sc. Fabian Küppers
Bottrop, 18.05.2020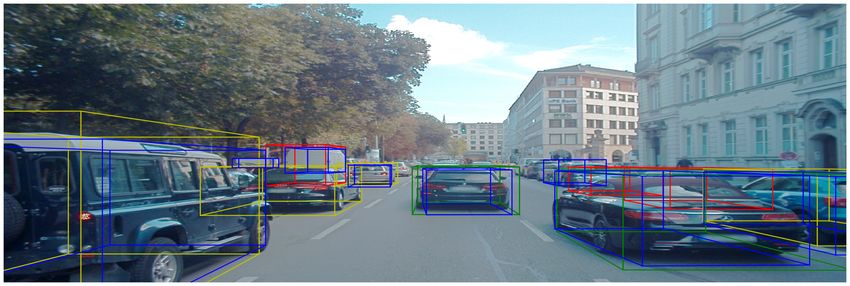
Eidesstattliche Erklärung
Hiermit versichere ich, dass ich
die vorliegende Arbeit selbstständig und nur unter
Verwendung der angegebenen Quellen und
Hilfsmittel angefertigt habe.
Bottrop, 18. Mai 2020
II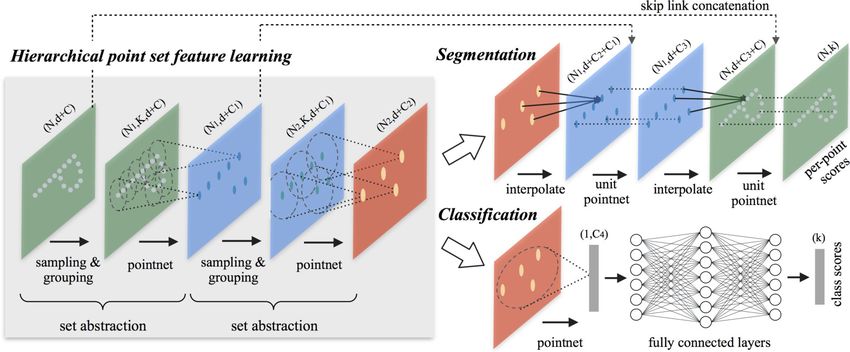
Kurzfassung
Die Aufgabe der Objekterkennung im Automobilbereich kann durch Auswertung verschiedener
Sensordaten durchgeführt werden. Die Auswertung von LiDAR Daten zur Detektion von Objekten
stellt eine besondere Herausforderung dar, für die Systeme mit neuronalen Netzen genutzt werden
können. Diese neuronalen Netze werden mit Hilfe eines Datensatzes trainiert. Falls man das Netz
mit eigenen Aufnahmen oder einem anderen Datensatz verwenden möchte, ist es wichtig zu
wissen, wie gut diese Systeme im Zusammenhang mit Daten eines anderen Sensors funktionieren.
Dadurch lassen sich die Ergebnisse im Vorhinein abschätzen und mit den Ergebnissen aus vorherigen
Versuchen vergleichen.
In dieser Arbeit soll die Sensorabhängigkeit einer LiDAR basierten Objekterkennung mit neuronalen
Netzen analysiert werden. Als Detektor wird in dieser Arbeit PointRCNN [1] verwendet, welcher
für den KITTI Datensatz [2] konzipiert wurde. Um die Sensorabhängigkeit zu überprüfen, wurde
als weiterer Datensatz der ’AEV Autonomous Driving Dataset’ (A2D2) Datensatz [3] ausgewählt.
Nach einer Vorstellung von PointRCNN und dessen Funktionsweise werden beide Datensätze
hinsichtlich ihrer Daten analysiert. Anschließend werden die Daten des zweiten Datensatzes in das
Format des KITTI Datensatzes portiert, sodass diese mit PointRCNN verwendet werden können.
Durch verschiedene Versuche mit variierenden Kombinationen von Trainings- und Validierungsdaten
soll untersucht werden, inwiefern trainierte Modelle auf anderen Sensordaten bzw. Datensätze
übertragen werden können. Somit soll untersucht werden, wie stark die Abhängigkeit des Detektors
(PointRCNN) von den jeweils verwendeten Sensoren ist.
Die Auswertung dieser Ergebnisse zeigt, dass PointRCNN mit einem anderen Datensatz als dem
Trainings-Datensatz evaluiert werden kann und dabei Objekte erkannt werden. Für die Qualität der
Erkennung spielt die Punktdichte der Datensätze eine entscheidende Rolle. Daher lässt sich sagen,
dass PointRCNN eine Sensorabhängigkeit besitzt, die mit der Beschaffenheit der Punktwolke und
ihrer Dichte variiert.
Schlagwörter: LiDAR-Daten, 3D Objekterkennung, Laser-Scanner, Sensorabhängigkeit,
PointRCNN, PointNet++, PointNet, KITTI Datensatz, AEV Autonomous Driving Dataset, A2D2
Datensatz
III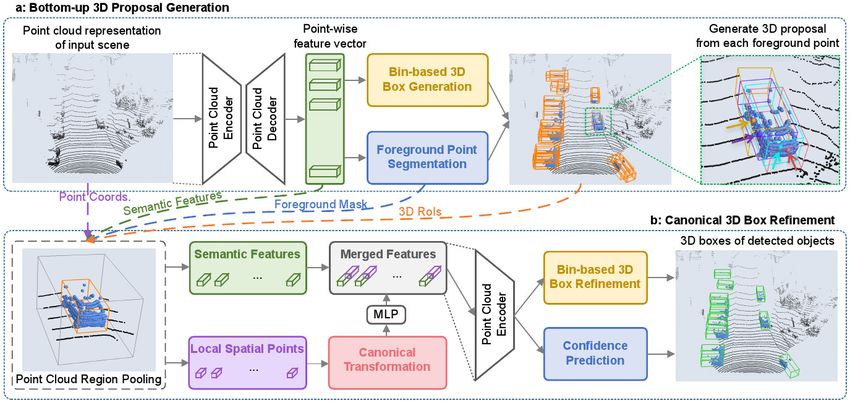
Abstract
The task of object detection in the automotive sector can be performed by evaluating various
sensor data. The evaluation of LiDAR data for the detection of objects is a special challenge for
which systems with neural networks can be used. These neural networks are trained by means of a
data set. If you want to use the net with your own recordings or another data set, it is important
to know how well these systems work in combination with data from another sensor. This allows
the results to be estimated in advance and compared with the results of previous experiments.
In this work the sensor dependence of a LiDAR based object recognition with neural networks
will be analysed. The detector used in this work is PointRCNN [1], which was designed for the
KITTI dataset [2]. To check the sensor dependency, the ’AEV Autonomous Driving Dataset’
(A2D2) dataset [3] was selected as a further dataset. After an introduction to PointRCNN and its
functionality, the data of both datasets are analysed. Then the data of the second dataset will be
ported into the format of the KITTI dataset so that they can be used with PointRCNN. Through
experiments with varying combinations of training and validation data it shall be investigated to
what extent trained models can be transferred to other sensor data or datasets. Therefore, it shall
be investigated how strong the dependence of the detector (PointRCNN) on the used sensors is.
The results show that PointRCNN can be evaluated with a different dataset than the training
dataset while still being able to detect objects. The point density of the datasets plays a decisive
role for the quality of the detection. Therefore it can be said that PointRCNN has a sensor
dependency that varies with the nature of the point cloud and its density.
Keywords: LiDAR data, 3D object recognition, laser scanner, sensor dependency, PointRCNN,
PointNet++, PointNet, KITTI Dataset, AEV Autonomous Driving Dataset, A2D2 Dataset
IV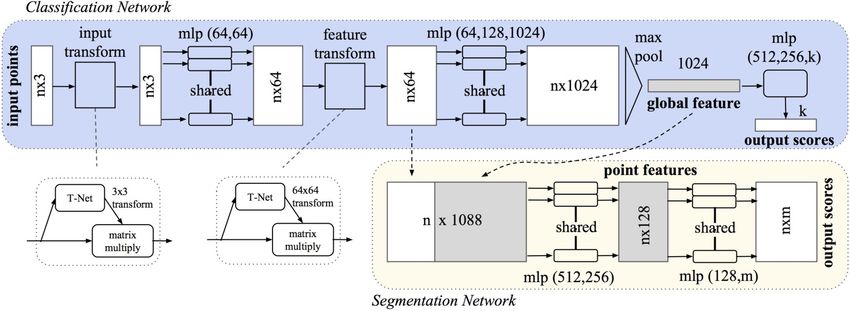
Inhaltsverzeichnis
Abbildungsverzeichnis VII
1 Einleitung 1
1.1 Problemstellung und Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.2 Fragestellung, Anforderungen und Ziele . . . . . . . . . . . . . . . . . . . . . . . 1
1.3 Wahl des Detektors in Abhängigkeit vom Stand der Technik . . . . . . . . . . . 2
1.4 Aufbau der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Vorstellung der PointRCNN-Struktur 4
2.1 PointNet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.1 Klassifizierungsnetzwerk . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.2 Segmentierungsnetzwerk . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2 PointNet++ . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2.1 Set-Abstraction Ebene . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2.2 Feature Propagation Ebene . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.2.3 Robustheit gegen Inkonsistenz der Punktdichte . . . . . . . . . . . . . . 7
2.3 PointRCNN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3.1 Bottom-Up Vorschlagsgenerierung . . . . . . . . . . . . . . . . . . . . . 9
2.3.2 Kanonische 3D Box Verbesserung . . . . . . . . . . . . . . . . . . . . . 12
3 Analyse verschiedener Datensätze 15
3.1 KITTI-Datensatz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.1.1 LiDAR-Daten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.1.2 Bilddaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.1.3 Kalibrierungsdaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.1.4 Annotierte Daten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.2 AEV Autonomous Driving Dataset . . . . . . . . . . . . . . . . . . . . . . . . . 21
3.2.1 Koordinatensystem des Datensatzes . . . . . . . . . . . . . . . . . . . . 22
3.2.2 LiDAR-Daten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2.3 Kameradaten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.2.4 Datenformat der Kalibrierungsdaten . . . . . . . . . . . . . . . . . . . . 24
3.2.5 Annotierte Daten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.3 Portierung des A2D2 Datensatzes in das Format des KITTI Datensatzes . . . . . 26
3.3.1 Definition der Validierungs- und Trainingsdaten . . . . . . . . . . . . . . 26
3.3.2 Portierung der LiDAR-Daten . . . . . . . . . . . . . . . . . . . . . . . . 26
3.3.3 Portierung der Bilddaten . . . . . . . . . . . . . . . . . . . . . . . . . . 26
3.3.4 Portierung der Kalibrierungsdaten . . . . . . . . . . . . . . . . . . . . . 26
3.3.5 Portierung der annotierten Daten . . . . . . . . . . . . . . . . . . . . . . 27
V
Inhaltsverzeichnis
3.3.6 Portierung des Alpha Winkels . . . . . . . . . . . . . . . . . . . . . . . . 29
4 Analyse der Sensorabhängigkeit von PointRCNN 31
4.1 Vergleich der Datensätze im Bezug auf die LiDAR-Daten . . . . . . . . . . . . . 31
4.1.1 Vergleich der verwendeten Sensoren . . . . . . . . . . . . . . . . . . . . 31
4.1.2 Vergleich der Punktwolken . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.2 Anpassungen des PointRCNN . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.2.1 Anpassung des Samplings . . . . . . . . . . . . . . . . . . . . . . . . . . 32
4.2.2 Anpassung für größere Datenmengen . . . . . . . . . . . . . . . . . . . . 33
4.2.3 Anpassung der Evaluierung . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.3 Evaluierung des A2D2 Datensatzes mit Hilfe von PointRCNN . . . . . . . . . . . 33
4.3.1 Auswertungsmethode . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.3.2 Versuch 1: Evaluierung des KITTI Datensatzes auf KITTI trainiertem Netz 34
4.3.3 Versuch 2: Evaluierung des A2D2 Datensatzes auf KITTI trainiertem Netz 35
4.3.4 Versuch 3: Evaluierung des A2D2 Datensatzes auf A2D2 trainierten Netzen 36
4.3.5 Versuch 4: Evaluierung des KITTI Datensatzes auf A2D2 trainiertem Netz 42
4.4 Auswertung der Versuche . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
5 Zusammenfassung und Ausblick 45
5.1 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.2 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
Literaturverzeichnis IX
VI
Abbildungsverzeichnis
2.1 Architektur des PointNet Netzwerks [4, Abb. 2]: Es wird sowohl das Klassifizierungs-
netzwerk als auch das Segmentierungsnetzwerk dargestellt sowie die Verbindung zwi-
schen diesen. Zusätzlich wird die Architektur der Input- und Feature-Transformation
aufgezeigt, die jeweils ein kleines vereinfachtes Netzwerk (T-Net) verwendet. . . 4
2.2 Architektur des PointNet++ Netzwerks [5, Abb. 2]: Darstellung des hierarchischen
Aufbaus der Set-Abstraction Ebenen, die für das Lernen der Features verantwortlich
sind, sowie die darauf folgende Klassifizierung oder Segmentierung der Punkte. . 6
2.3 Vereinfachte Darstellung der Grouping-Methoden [5]: (a) beschreibt das Multi-Scale
Grouping, bei dem verschiedene Skalen angewendet werden, während in (b) das
Multi-Resolution Grouping dargestellt wird, bei der auf Features der Unterregionen
zugegriffen wird. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.4 Architektur des PointRCNN Netzwerks [1]: Darstellung der Bottom-Up Vorschlags-
generierung (a) sowie der kanonischen 3D Box Verbesserung (b). Darüber hinaus
werden alle relevanten Verarbeitungsschritte grafisch repräsentiert und die Ver-
bindungen zwischen den Stufen aufgezeigt. Sowohl in a) als auch in b) wird
PointNet++ als Backbone-Netzwerk verwendet. . . . . . . . . . . . . . . . . . . 9
2.5 Darstellung der Standortbestimmung von Objekten durch eine Einteilung der Region
um jeden Vordergrundpunkt in Bins entlang der x- und z-Achse. . . . . . . . . . 11
3.1 Übersicht der Sensorverteilung des Fahrzeuges zur Aufnahme des KITTI-Datensatzes
[6, Abb. 3]: Platzierung der 4 verschiedenen Kameras und des Laser-Scanners sowie
die Benennung von Größen und Abständen und die Darstellung der verschiedenen
Koordinatensysteme und Transformationen. . . . . . . . . . . . . . . . . . . . . 16
3.2 Verteilung der Anzahl von Punkten pro Aufnahme im KITTI-Datensatz. . . . . . 17
3.3 Heatmap aus der Vogelperspektive. . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.4 Heatmap des Querschnitts entlang der x-Achse. . . . . . . . . . . . . . . . . . . 17
3.5 Darstellung der Transformation vom LiDAR-Koordinatensystem (links) in das
Kamerakoordinatensystem (rechts). . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.6 Übersicht der Sensorverteilung des Fahrzeuges zur Aufnahme des A2D2 Datensatzes
[3]: Platzierung der 6 verschiedenen Kameras und der 5 Laser-Scanner. . . . . . 22
3.7 Koordinatensystem der Front-Kamera bzw. des verwendeten A2D2 Datensatzes. . 22
3.8 Verteilung der Anzahl von Punkten pro Aufnahme im A2D2-Datensatz. . . . . . 23
3.9 Heatmap aus der Vogelperspektive. . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.10 Heatmap des Querschnitts entlang der x-Achse. . . . . . . . . . . . . . . . . . . 24
3.11 Rotationswinkel aus der Vogelperspektive (blau: KITTI, rot: A2D2). . . . . . . . 30
VII
Abbildungsverzeichnis
4.1 Vergleich der Anzahl an Punkten pro Punktwolke nach Filterung der Punkte. Es ist
deutlich zu sehen, dass der KITTI Datensatz mehr Punkte pro Punktwolke besitzt
als der A2D2 Datensatz. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
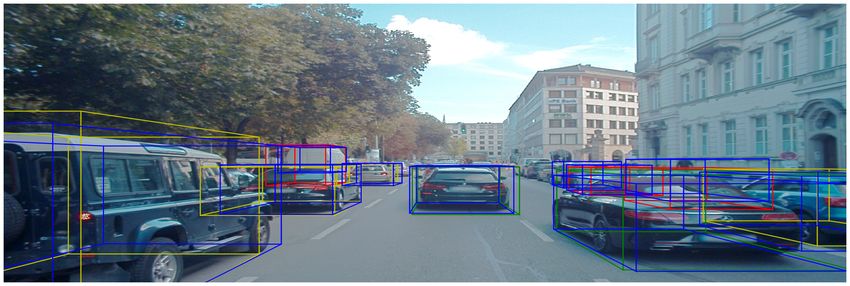
4.2 Resultierende 3D Boxen aus der Evaluierung des ersten Versuches: blau = detektierte
Autos, grün = annotierte Autos, die nicht verdeckt sind; gelb = annotierte Autos,
die etwas verdeckt sind; rot = annotierte Autos, die stark verdeckt sind. . . . . . 35
4.3 Resultierende 3D Boxen aus der Evaluierung des zweiten Versuches unter Verwen-
dung der Standardeinstellungen: Es ist erkennbar, dass bereits die Mehrheit der
Fahrzeuge erkannt wird, jedoch die detektierten Boxen nicht von hoher Qualität sind. 36
4.4 Resultierende 3D Boxen aus der Evaluierung des dritten Versuches unter Ver-
wendung der Standardeinstellungen: Im Vergleich zum zweiten Versuch wurden
etwas mehr Objekte detektiert. Die Qualität der Boxen hat sich zudem auch etwas
verbessert. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.5 Veranschaulichung der Verbesserung gegenüber dem zweiten Versuch. Bild (a)
repräsentiert die Ergebnisse des zweiten Versuches während Bild (b) die Ergebnisse
aus Versuch 3.1 darstellt. Beim direkten Vergleich dieser fällt auf, dass mehr Objekte
in Bild (b) detektiert wurden. Dies zeigt den positiven Einfluss, wenn das Netz auf
demselben Datensatz trainiert wurde, auf dem es evaluiert wird. . . . . . . . . . 38
4.6 Verteilung der Punkte des A2D2 Datensatzes entlang der x-Achse. . . . . . . . . 39
4.7 Verteilung der Punkte des A2D2 Datensatzes entlang der y-Achse. . . . . . . . . 39
4.8 Verteilung der Punkte des A2D2 Datensatzes entlang der z-Achse. . . . . . . . . 40
4.9 Resultierende 3D Boxen aus der Evaluierung des vierten Versuches: Es werden
die gleichen Objekte wie im ersten Versuch erkannt, jedoch gibt es Abweichungen
bezüglich der Überlappung der Boxen. Darüber hinaus kann man erkennen, dass
auch falsche Regionen als Auto detektiert wurden. . . . . . . . . . . . . . . . . . 43
VIII
1 Einleitung
Heutzutage werden Automobile mit immer mehr Sensoren ausgestattet, um mehr Komfort und
Sicherheit zu gewährleisten. Hierbei spielt das Erfassen anderer Objekte im Straßenverkehr eine
wichtige Rolle. Durch das Erkennen anderer Verkehrsteilnehmer können Unfälle antizipiert werden,
mit dem Ziel einen möglichen Schaden zu minimieren. Neben einer Erfassung von Objekten über
Kamerabilder werden auch Laser-Scanner für diese Aufgabe verwendet. Zur Auswertung der durch
Laser-Scanner entstandenen Punktwolken können neuronale Netze verwendet werden. Für das
Erstellen von 3D Objektdetektoren werden meist bereits vorhandene Datensätze genutzt, da das
Aufnehmen und Auswerten von Punktwolken zur Generierung von Trainings- und Validierungsdaten
sehr zeitaufwendig ist. Die trainierten Modelle sind somit genau auf die Beschaffenheit und die
verwendete Sensorik des verwendeten Datensatzes abgestimmt. Als Basis wurde für diese Arbeit
der KITTI Datensatz [2] verwendet, da für diesen Datensatz eine Vielzahl an Detektoren existieren.
1.1 Problemstellung und Motivation
Ein Detektor, der für den KITTI Datensatz konzipiert wurde, setzt gewisse Daten (LiDAR-Daten,
Kamera-Daten, Kalibrierungsdaten und annotierte Daten) mit gewissen Eigenschaften voraus. Um
einen anderen Datensatz oder eigene Aufnahmen mit solch einem Detektor zu testen, müssen
alle dafür notwendigen Daten gegeben sein. Da jeder Datensatz mit einer individuellen Zusam-
menstellung von Sensoren aufgenommen wurde, ist die Beschaffenheit der Daten, insbesondere
der Punktwolken, verschieden. Eine solch andere Beschaffenheit der Punktwolken kann zu einer
Abweichung der Leistung des Detektors führen.
1.2 Fragestellung, Anforderungen und Ziele
In dieser Arbeit soll die Leistung eines für den KITTI Datensatz konzipierten Detektors unter
Verwendung eines anderen Datensatzes getestet werden. Ziel hierbei ist es zu untersuchen, inwiefern
die durch die Verwendung verschiedener Laser-Scanner sich unterscheidenden Punktwolken Einfluss
auf das Ergebnis des Detektors nehmen. Zuerst muss ein Detektor auf Basis des KITTI Datensatzes
gewählt werden. Für diesen Anwendungsfall wurde PointRCNN [1] gewählt, da dieser aufgrund
seiner Architektur besonders robust für verschiedene Datensätze erscheint. Im nächsten Schritt
muss ein KITTI-fremder Datensatz ausgewählt werden, der alle notwendigen Informationen enthält,
die der Detektor benötigt. Hierfür wird als Datensatz der ’AEV Autonomous Driving Dataset’
[3] verwendet, weil dieser alle notwendigen Daten für ein Zusammenspiel mit PointRCNN liefert.
Es soll durch verschiedene Versuche untersucht werden, wie gut die Leistung des Detektors auf
diesem Datensatz ist und ob sich diese durch veränderte Einstellungen verbessern lässt. Ziel ist es
1
1 Einleitung
eine abschließende Aussage über die Abhängigkeit des Detektors von dem verwendeten Sensor
treffen zu können.
1.3 Wahl des Detektors in Abhängigkeit vom Stand der Technik
In diesem Unterkapitel wird der akutelle Stand der Technik im Bereich der 3D Objekterkennung
auf LiDAR-Daten anhand von drei Detektoren, die für den KITTI Datensatz konzipiert wurden,
aufgezeigt. Anschließend wird die Wahl des Detektors begründet, der im Rahmen dieser Arbeit
verwendet wird.
SECOND / PointPillars
Diese Methode der Objekterkennung wurde im Dezember 2018 vorgestellt [7] und verfolgt den
Ansatz der Konvertierung der Punktwolken in ein 2D Pseudo-Image. Hierbei werden die Punktwolken
in Säulen zusammengefasst und anschließend aneinander gereiht. Die aus diesen zusammengefassten
Säulen entstehenden Features werden in ein 2D Pseudo-Image zurückgeführt. Dadurch können
durch ein 2D Convolutional Neuronal Network Features für den abschließenden Single Shot
MultiBox Detector [8] erzeugt werden. Als Backbone Netzwerk wird ein angepasstes VoxelNet [9]
verwendet.
PointRCNN
PointRCNN ist ein im Mai 2019 vorgestellter Detektor [1], der aus zwei verschiedenen Stufen
besteht. In der ersten Stufe wird ein Region Proposal Network genutzt. Hierbei werden die durch
ein Backbone Netzwerk erlernten Features für eine Segmentierung der Punkte und zur Generierung
von 3D Box Vorschlägen genutzt. In der zweiten Stufe wird ein Region-based Convolution Neuronal
Network (RCNN) genutzt, um die 3D Box Vorschläge durch das Erlernen von lokalen Features
mittels Backbone Netzwerk zu verbessern. Zum Schluss erhält man die verbesserten Vorschläge
sowie eine Einschätzung der Genauigkeit (Confidence Prediction) der einzelnen Vorschläge. Als
Backbone Netzwerk kommt hierbei PointNet++ [5] zum Einsatz.
Frustum ConvNet
Frustum ConvNet [10] ist ein weiterer Detektor zur Erkennung von 3D Objekten in Punktwolken
und wurde im Mai 2019 vorgestellt. Dieser Detektor teilt den zu betrachtenden Ausschnitt
einer Punktwolke in Frustums ein. In diesem Fall beschreibt ein Frustum einen Auschnitt aus
dem dreidimensionalen pyramidalen Sichtfeld eines Sensors. Diese Methode findet bereits in der
21 Einleitung
Auswertung von 2D RGB-Bildern Anwendung und wurde in diesem Detektor auf den 3D Raum
übertragen. Zum Lernen der Punktfeatures wird PointNet verwendet [4].
Wahl des Detektors
Die Leistungen aller vorgestellten Detektoren weichen im Benchmark des KITTI Datensatzes nur
minimal voneinander ab. SECOND und Frustum ConvNet können im Vergleich zu PointRCNN
aufgrund ihrer Architektur auf Methoden von 2D Detektoren zurückgreifen. Die Wahl des Detektors
zur Nutzung in dieser Arbeit fiel allerdings auf PointRCNN. Dieser bietet im Gegensatz zu
SECOND einen zum Paper passenden Quellcode und benutzt im Vergleich zu Frustum ConvNet
das weiterentwickelte PointNet++ als Backbone Netzwerk. Der Vorteil von PointNet++ ist das
robuste Lernen von Features bei abweichender Punktwolkendichte [5, 3.3].
1.4 Aufbau der Arbeit
Als Erstes wird der ausgewählte Detektor und dessen Funktionsweise vorgestellt. Anschließend wird
der KITTI Datensatz analysiert, um festzustellen, welche Daten der KITTI Datensatz beinhaltet
und in welcher Form diese gespeichert und ausgelesen werden können. Für den KITTI-fremden
Datensatz kommt der Datensatz ’AEV Autonomous Driving Dataset’ zum Einsatz, der ebenfalls
analysiert wird. Anschließend wird eine Portierung des Datensatzes in das Format des KITTI
Datensatzes durchgeführt. Mit dem daraus generierten portierten Datensatz kann der ausgewählte
Detektor trainiert, getestet und hinsichtlich der Sensorabhängigkeit analysiert werden. Abschließend
findet eine Diskussion der Ergebnisse sowie eine Zusammenfassung der Arbeit statt.
32 Vorstellung der PointRCNN-Struktur
PointRCNN [1] ist ein regionenbasiertes Convolutional Neuronal Network (R-CNN) zur Erkennung
von Fahrzeugen in Punktwolken. Es verwendet als Backbone Netzwerk PointNet ++[5], welches
aus einer hierarchischen Struktur mehrerer PointNets [4] besteht. Aus diesem Grund wird zuerst
der Aufbau von PointNet und PointNet++ betrachtet und erst im Anschluss die Struktur von
PointRCNN.
2.1 PointNet
PointNet [4] ist ein neuronales Netzwerk, welches aus Punktwolken eine Klassifizierung über die
gesamte Eingabe ausgibt und alternativ auch zur Segmentierung der Punkte verwendet werden
kann. Hierfür besitzt es ein Klassifizierungsnetzwerk sowie ein Segmentierungsnetzwerk. Letzteres
wird als Erweiterung des Klassifizierungsnetzwerks genutzt. Während das Klassifizierungsnetzwerk
einen Vektor ausgibt, der die Punktwolke bezüglich jeder Kategorie mit einem Score bewertet, wird
bei der Segmentierung jeder Punkt separat bewertet, sodass Segmente aus zusammenhängenden
Punkten mit ähnlichen Scores entstehen. Die detaillierte Struktur beider Netzwerke wird in [4,
Abb. 2] beschrieben und kann aus Abbildung 2.1 entnommen werden.
Abbildung 2.1: Architektur des PointNet Netzwerks [4, Abb. 2]: Es wird sowohl das Klassifi-
zierungsnetzwerk als auch das Segmentierungsnetzwerk dargestellt sowie die
Verbindung zwischen diesen. Zusätzlich wird die Architektur der Input- und
Feature-Transformation aufgezeigt, die jeweils ein kleines vereinfachtes Netzwerk
(T-Net) verwendet.
2.1.1 Klassifizierungsnetzwerk
Das Klassifizierungsnetzwerk nutzt die gesamte Punktwolke mit n Punkten mit ihren entsprechenden
Koordinaten im dreidimensionalen Raum. Das Klassifizierungsnetzwerk nutzt sowohl eine Input-
als auch eine Feature-Transformation mit dem Ziel, die Genauigkeit der Klassenvorhersagen zu
42 Vorstellung der PointRCNN-Struktur
verbessern [4, Abschnitt 5.2]. Diese Transformationen bestehen aus einem kleinen Netzwerk (T-Net),
welches genutzt wird um eine Transforamtionsmatrix vorherzusagen, und einer Matrix Multiplikation,
die die Transformation direkt auf die Eingabe anwendet. Wie auch in [11] beschrieben, kann eine
Transformation der Eingabe-Daten zu einer Reduzierung von Fehlern bei der Vorhersage führen.
Das Klassifizierungsnetzwerk erstellt globale Features, mit denen klassenspezifische Scores generiert
werden. Als Ausgabe des Klassifizierungsnetzwerkes erhält man k Scores. Hierbei beschreibt k die
Größe des Output-Layers und gleichzeitig die Anzahl der Klassen.
2.1.2 Segmentierungsnetzwerk
Das Segmentierungsnetzwerk dient dazu, jedem einzelnen Punkt eine semantische Unterkategorie
zuzuordnen. Hierzu greift es auf die erlernten Features des Klassifizierungsnetzwerks zurück. Die für
jeden Punkt individuellen lokalen Features, die durch die Feature-Transformation entstanden sind,
werden mit den globalen Features für jeden Punkt zusammengefasst, sodass n × 1088 Features
entstehen. Aus diesen Features werden für n Punkte jeweils m individuelle Scores bezüglich der
semantischen Unterkategorien generiert.
2.2 PointNet++
PointNet++ ist das Backbone-Netzwerk, welches von PointRCNN verwendet wird und das auf dem
PointNet Netzwerk aufbaut. Zur Vorstellung von PointNet++ wird als Erstes der hierarchische
Aufbau der Set-Abstraction Ebenen erläutert, die zum Erlernen von Features verwendet werden.
Zur semantischen Segmentierung der Eingangspunkte N ist es notwendig, diese erlernten Features
wieder auf die ursprünglische Anzahl an Eingangspunkten N abzubilden. Hierzu wird eine Feature
Propagation Ebene verwendet, die ebenfalls eine hierarchische Struktur aufweist. Zum Schluss
werden Gruppierungsverfahren betrachtet, die eine gute Robustheit bei variierenden Punktdichten
versprechen und im Zusammenhang mit den Set-Abstraction Ebenen in verschiedenen Auflösungen
verwendet werden. Der hierarchische Aufbau der Set-Abstraction Ebenen kann in Abbildung 2.2
betrachtet und nachvollzogen werden.
2.2.1 Set-Abstraction Ebene
Eine Set-Abstraction Ebene wird verwendet, um auf Basis von Eingangspunkten neue Features zu
berechnen. Auf jeder Set-Abstraction Ebene wird eine Menge an Eingabepunkten verarbeitet und
abstrahiert, sodass eine neue Menge mit weniger Punkten erzeugt wird. Dadurch können unter
Verwendung von PointNet [5] lokale Features bei verschiedenen Skalen entdeckt werden. Eine
Set-Abstraction Ebene besteht aus einem Sampling, Grouping und PointNet Layer. Während N für
die Anzahl der eingehenden Punkte steht, beschreibt N ′ die Anzahl an ausgehenden gesampelten
52 Vorstellung der PointRCNN-Struktur
Abbildung 2.2: Architektur des PointNet++ Netzwerks [5, Abb. 2]: Darstellung des hierarchi-
schen Aufbaus der Set-Abstraction Ebenen, die für das Lernen der Features
verantwortlich sind, sowie die darauf folgende Klassifizierung oder Segmentierung
der Punkte.
Punkten. Die Variable d beschreibt die Dimension der Koordinaten und C sowie C ′ die Dimension
des Feature-Vektors.
Der Sampling Layer dient der Reduzierung der Anzahl an Punkten durch Verwendung von
Sampling. Auf eine Eingabe x1 , x2 , ..., xg wird ein iteratives Farthest Point Sampling (FPS) [12]
angewendet. Wir erhalten als Subset eine Menge xi1 , xi2 , ..., xih . Für einen Punkt xij , der Element
dieser Menge ist, gilt, dass er den größten Abstand hat zu den Punkten xi1 , xi2 , ..., xij−1 und noch
nicht in der Menge enthalten ist. Durch die Verwendung von FPS wird eine größere Abdeckung
der Punktwolke ermöglicht als bei einer zufälligen Auswahl, wo eine großflächige Abdeckung nicht
immer gewährleistet ist. Die durch das Sampling erhaltene Auswahl N ′ der Punkte definiert lokale
geometrische Schwerpunkte.
Der Grouping Layer dient der Erfassung von lokalen Punkten um die zuvor bestimmten geome-
trischen Schwerpunkte der Größe N ′ × d. Bei dieser Erfassung werden die lokalen Punkte aus
der Menge aller Punkte N × (d + C) bezogen. Durch den Einsatz einer Ball Query [13] erhält
man alle Punkte K innerhalb eines bestimmten Radius um den entsprechenden Schwerpunkt
aus N ′ . Für die Anzahl der aus diesem Verfahren resultierenden Punkte kann eine Obergrenze
in den Einstellungen definiert werden. Als Output erhält man die entsprechenden Gruppen von
Punkte-Mengen, sodass sich unsere Matrix auf N ′ × K × (d + C) erweitert.
Hierbei ist zu beachten, dass K je nach Gruppe variiert und keinen fixen Wert hat. Diese Variation
wird in der folgenden PointNet Schicht abgehandelt, die aus einer beliebigen Anzahl von Punkten
einen Feature Vektor mit einer festen Größe herausgibt. Eine Alternative zur Ball Query wäre die
Implementierung eines k-nearest-neighbour Algorithmus. Im Vergleich ist jedoch die Ball Query
eine bessere Wahl, da eine fixe Regionsgröße verwendet wird, die für das Lernen von lokalen
Features von Vorteil ist.
62 Vorstellung der PointRCNN-Struktur
Die einzelnen Gruppen werden am Ende der Set-Abstraction Ebene in einem PointNet Layer
verwendet, um lokale Features zu generieren. Die Input-Matrix einer Set-Abstraction Ebene hat
eine Größe von N × (d + C) und einen Output der Größe N ′ × (d + C ′ ).
2.2.2 Feature Propagation Ebene
Durch die hierarchischen Set-Abstraction Ebenen wird die Anzahl der Punkte von Ebene zu Ebene
verringert. Für die Segmentierung benötigen wir jedoch die Punkt-Features für alle ursprünglichen
Punkte. Daher werden die Features der kleineren Punktmengen auf die ursprünglichen Punkte
propagiert. In einer Feature Propagation Ebene werden die punktspezifischen Features, die in
Nl ×(d+C) beschrieben werden, auf die Punkte Nl−1 propagiert. Nl−1 beschreibt hierbei die Anzahl
an Punkten am Input einer Set-Abstraction Ebene, während Nl die Menge an gesampelten Punkten
nach einer Set-Abstraction Ebene l darstellt, für die, bedingt durch das Sampling, Nl ≤ Nl−1
gilt. Für die Propagation werden die Features der Nl Punkte auf Nl − 1 interpoliert. Hierbei
wird eine inverse Distanzgewichtung zur Interpolation genutzt, basierend auf dem Durchschnitt
der nächsten benachbarten Punkte. Anschließend werden die interpolierten Features mit Punkt
Features der entsprechenden Set-Abstraction Ebene kombiniert und in ein ’unit pointnet’ geleitet.
Dieses ähnelt einer 1 × 1 Faltung eines CNNs und verringert somit die Größe der Feature Vektoren.
Dieser Vorgang wird für jede Set-Abstraction Ebene durchgeführt, bis schließlich am Ende für
jeden ursprünglichen Punkt die entsprechenden Features vorliegen.
2.2.3 Robustheit gegen Inkonsistenz der Punktdichte
Da die Beschaffenheit der Punktwolken bezüglich ihrer Punktdichte stark variieren kann, stellen
diese Unterschiede ein Problem für das Lernen von Features dar. So können zum Beispiel Features,
welche in Regionen mit hoher Dichte gelernt wurden, nicht auf Regionen mit weniger Punkten
übertragen werden. Dadurch können Modelle, die auf spärlichen Punktwolken trainiert wurden,
Schwierigkeiten bei Punktwolken mit einer hohen Punktedichte haben. Während man bei einer
hohen Dichte sehr genau im nahen Umfeld nach regionalen feinen Features suchen sollte, führt
dies bei Regionen mit geringer Dichte zu falschen Ergebnissen. Diese sollten mit einem größeren
Umfeld nach gröberen Strukturen untersucht werden. Das Grouping Layer nutzt jedoch nur eine
Skala bei der Gruppierung und Generierung der Features und wird daher Single-Scale Grouping
genannt.
Aus diesem Problem heraus ergibt sich der Lösungsansatz, die PointNet Schichten von der
Dichte abhängig zu machen. Dies ermöglicht es, die Features von Regionen unter Betrachtung
verschiedener Skalen zu kombinieren, falls sich die Dichte unterscheidet. Hierfür erzeugen die
Set-Abstraction Ebenen die lokale Features in verschiedenen Skalen, um diese anschließend in
Abhängigkeit der lokalen Punktdichte zu kombinieren. PointNet++ bietet dafür die Möglichkeit, die
72 Vorstellung der PointRCNN-Struktur
beiden Methoden ’Multi-Scale Grouping’ und ’Multi-Resolution Grouping’ anzuwenden. Beim Multi-
Scale Grouping werden Grouping Layer mit verschiedenen Skalen auf die Punktwolke angewendet,
gefolgt von PointNet Layern, um für jede dieser Skalen Features zu generieren. Dadurch lernt
das Netz auf Basis von Punktwolken mit verschiedenen Punktdichten. Beim Multi-Resolution
Grouping bilden zwei Vektoren die Merkmale einer Region von einer Set-Abstraction Ebene Li .
Der erste Vektor setzt sich aus den Features der relevanten Unterregionen zusammen, die man aus
der vorherigen Set-Abstraction Ebene Li−1 erhält. Für den zweiten Feature-Vektor werden alle
Punkte der Region und nur ein PointNet genutzt. Je nach Punktdichte werden diese Vektoren
unterschiedlich gewichtet. Sollte die Punktdichte einer lokalen Region niedrig sein, so wird der
zweite Vektor höher gewichtet, andernfalls der erste Vektor.
Das Multi-Scale Grouping ist dabei im Vergleich rechenaufwändiger, da hierbei auch lokale
PointNet Netze für Skalen mit großem Umkreis für jeden Schwerpunkt genutzt werden. Vor
allem bei der ersten Set-Abstraction Ebene, bei der die Anzahl der Schwerpunkte sehr hoch ist,
beeinträchtigt dieses Verfahren die Laufzeit. Beiden Verfahren werden in Abbildung 2.3 vereinfacht
bildlich dargestellt.
Abbildung 2.3: Vereinfachte Darstellung der Grouping-Methoden [5]: (a) beschreibt das Multi-
Scale Grouping, bei dem verschiedene Skalen angewendet werden, während in
(b) das Multi-Resolution Grouping dargestellt wird, bei der auf Features der
Unterregionen zugegriffen wird.
2.3 PointRCNN
PointRCNN ist aufgeteilt in zwei Stufen: in eine Bottom-Up Vorschlagsgenerierungsstufe und in
eine kanonischen 3D Box Verbesserungsstufe. In der ersten Stufe werden Features auf Grundlage
der Punktwolke durch das Backbone Netzwerk gelernt, um Vorschläge für 3D Bounding Boxen
zu erzeugen sowie eine Segmentierung der Punkte durchzuführen. Die zweite Stufe betrachtet
82 Vorstellung der PointRCNN-Struktur
die lokalen Regionen im Umfeld der generierten Vorschläge der ersten Stufe um weitere Features
zu erzeugen. Diese werden für eine Verbesserung der 3D Bounding Boxen genutzt und um eine
Aussage über die Klassen dieser zu treffen. Zur Vorstellung von PointRCNN wird im Folgenden die
Funktionsweise des Netzwerkes aufgezeigt.
Abbildung 2.4: Architektur des PointRCNN Netzwerks [1]: Darstellung der Bottom-Up Vor-
schlagsgenerierung (a) sowie der kanonischen 3D Box Verbesserung (b). Darüber
hinaus werden alle relevanten Verarbeitungsschritte grafisch repräsentiert und die
Verbindungen zwischen den Stufen aufgezeigt. Sowohl in a) als auch in b) wird
PointNet++ als Backbone-Netzwerk verwendet.
2.3.1 Bottom-Up Vorschlagsgenerierung
Die erste Stufe des PointRCNN erzeugt aus einer Punktwolke Vorschläge für 3D Bounding Boxen,
die die Position und Orientierung der zu erkennenden Objekte beschreiben. Zunächst werden im
Backbone-Netzwerk punktspezifische Features gelernt. Dazu werden die Punkte einer Punktwolke
durch Subsampling ausgewählt, die in das PointNet++ Backbone-Netzwerk eingelesen werden.
Dies sorgt dafür, dass das Backbone-Netzwerk immer eine gleich große Menge an Input-Daten hat.
Wie in [1] erwähnt, können auch andere Netzwerke anstelle von diesem als Backbone-Netzwerk
eingesetzt werden.
Das verwendete PointNet++ Netzwerk besteht aus vier Set-Abstraction Ebenen mit Multi-Scale
Grouping. Diese führen ein Subsampling der Punkte durch. Weitere vier Feature Propagation
Layers werden genutzt, um punktspezifische Features zu lernen. PointNet++ benötigt lediglich
die Position der einzelnen Punkte im euklidischen Koordinatensystem, um die punktspezifischen
Feature-Vektoren zu erzeugen. Da Vordergrundpunkte Informationen zur Position und zur Ori-
entierung des zugehörigen Objektes enthalten, können diese für die Vorhersage von 3D Boxen
für entsprechende Objekte genutzt werden. Die resultierenden Feature Vektoren werden in zwei
Heads weiterverarbeitet: Einer dient der Segmentierung der Vordergrundpunkte und einer dient
92 Vorstellung der PointRCNN-Struktur
dem Erzeugen von 3D Box Vorhersagen.
Segmentierung der Vordergrundpunkte
Aus der Segmentierung der Vordergrundpunkte lässt sich eine Maske erstellen. Die Segmentie-
rungsmasken für das Training ergeben sich automatisch aus den annotierten 3D Boxen, da diese
Boxen im Gegensatz zu Daten aus der Bilderkennung ausschließlich Punkte enthalten, die sich im
Vordergrund befinden. Da die Anzahl an Vordergrundpunkten bei großflächigen Szenen deutlich
kleiner als die der Hintergrundpunkte ist, wird eine Focal Loss [14] Funktion verwendet, welche
in Gleichung 2.1 beschrieben wird. Diese kompensiert die Ungleichheit zwischen der Anzahl an
Vorder- und Hintergrundpunkten. Die Formel
Lfocal = −αt (1 − pt )γ log(pt ) (2.1)
(
p für Vordergrundpunkt
mit pt = (2.2)
1 − p sonst
beschreibt eine modifizierte Kreuzentropie, welche eine beliebte Kostenfunktion darstellt und
durch log(pt ) repräsentiert wird. Der Wert p ∈ [0, 1] beschreibt die vorhergesagte Sicherheit, dass
der aktuell betrachtete Punkt im Vordergrund liegt. Die Formel kann über die beiden Parameter α
und γ angepasst werden. Der Wert α stellt eine Gewichtung dar, durch die Vordergrundpunkte
stärker gewichtet werden. Durch γ kann der Ausdruck (1 − pt )γ angepasst werden, der dafür
verantwortlich ist, dass einfach zu erkennende Vordergrundpunkte (z.B. p = 0.9) deutlich weniger
stark gewichtet werden.
Bin-basierte 3D Box Erstellung
Der Box Regression Head nutzt die Informationen der Vordergrundsegmentierung um 3D Box
Vorhersagen zu treffen. Eine 3D Box wird durch (x, y, z, h, w, l, θ) beschrieben, wobei (x, y, z) die
Position, (h, w, l) die Dimensionen und θ die Rotation aus der Vogelperspektive beschreiben. Um
die Anzahl der 3D Boxen zu begrenzen, werden bin-basierte Kostenfunktionen zur Vorhersage
der 3D Objektboxen genutzt. Für jeden Vordergrundpunkt wird die Position des Objektzentrums
geschätzt. Dafür wird sowohl für die x-Achse als auch die z-Achse ein Suchbereich S definiert,
welcher entlang der entsprechenden Achse in diskrete, äquidistante Bins der Länge δ aufgeteilt
wird, die verschiedene Objektmittelpunkte repräsentieren. Dieses Verfahren wird in folgender
Abbildung 2.5 anhand einer Skizze dargestellt:
102 Vorstellung der PointRCNN-Struktur
Abbildung 2.5: Darstellung der Standortbestimmung von Objekten durch eine Einteilung der
Region um jeden Vordergrundpunkt in Bins entlang der x- und z-Achse.
Die Nutzung von bin-basierter Klassifikation (dargestellt in Gleichung 2.3) mit Kreuzentropie als
Kostenfunktion für eine Regression (dargestellt in Gleichung 2.4) sorgt für eine genaue und robuste
Lokalisierung des Mittelpunktes bezüglich x- und z- Achse. Für die y-Koordinate des Mittelpunktes
wird eine lineare L1 Verlustfunktion für die Regression genutzt, da sich die y-Werte nur in einem
kleinen Wertebereich befinden. Die Verlustfunktion für die Regression der y-Koordinaten wird in
Gleichung 2.5 beschrieben.
Wir nehmen an, dass u ∈ {x, z}, dann gilt
$ %
up − u(p) + S
bin(p)
u = , (2.3)
δ
1 δ
res(p)
u = p (p) (p)
u − u + S − binu · δ + , (2.4)
C 2
res(p) p (p)
y =y −y . (2.5)
Hierbei sind x(p) , y (p) , z (p) die Koordinaten des aktuellen Vordergrundpunktes und xp , y p , z p die des
(p)
entsprechenden Objektmittelpunktes. binu beschreibt das entsprechende Bin des Mittelpunktes
(p)
bezüglich des Vordergrundpunktes p, während das Residuum resu vom Mittelpunkt einer besseren
Lokalisierung innerhalb des entsprechenden Bins dient.
Die Klassifizierung der Orientierung θ ist ebenfalls bin-basiert, bei der ein Vollkreis (2π) in
gleichgroße Bins eingeteilt wird. Die Objektdimensionen (h, w, l) gehen hingegen aus einer direkten
Regression hervor, bei der die Residuen aus der Differenz gegenüber den durchschnittlichen
112 Vorstellung der PointRCNN-Struktur
Dimensionswerten des kompletten Trainingssets berechnet werden.
In der Inferenz-Ebene wird für die Bestimmung von (x, z, θ) die Mitte des Bins mit der höchsten
Sicherheit ausgewählt und eine Korrektur durch Addieren des prognostizierten Residuums durch-
geführt. Diese Korrektur wird durch Anwendung der Formel
X
(p)
Lbin = c (p) , bin(p) ) + Freg (c
(Fcls (bin res(p) (p)
u u u , resu )) (2.6)
u∈{x,z,θ}
durchgeführt. Für die Parameter (y, h, w, l) wird das prognostizierte Residuum durch Verwendung
der Formel
(p)
X
Lres = res(p)
Freg (c (p)
v , resv ) (2.7)
v∈{y,h,w,l}
auf den ursprünglichen Wert addiert, da hier nur eine direkte Regression genutzt wird. Daraus
ergibt sich
1 X (p) (p)
Lreg = Lbin + Lres (2.8)
Npos p∈pos
als Kostenfunktion für eine Regression bezüglich der gesamten 3D Box. Npos ist die Anzahl der
Vordergrundpunkte, während binc (p) und rces(p) den prognostizierten Bin sowie dessen prognos-
u u
tiziertes Residuum für den Vordergrundpunkt p beschreiben. Fcls ist die Kreuzentropie, die als
Verlustfunktion für die Klassifikation verwendet wurde, während Freg die L1 Verlustfunktion zur
Regression beschreibt. Da bei diesem Verfahren viele 3D Box Vorschläge entstehen, wird ein
Intersection over Union (IoU) Schwellwert gesetzt und durch Non-maximum supression (NMS) die
Anzahl der 3D Box Vorschläge auf die mit dem besten Score reduziert.
2.3.2 Kanonische 3D Box Verbesserung
In der zweiten Stufe des PointRCNN Netzwerks werden die zuvor generierten 3D Box Vorschläge
bezüglich Position und Orientierung verbessert. Durch eine Transformation der Punkte in das
kanonische Koordinatensystem werden neue lokale Features erlernt und mit den Features aus der
ersten Stufe verbunden. Anschließend werden die 3D Box Vorschläge mit Hilfe eines weiteren
PointNet++ Netzwerks verbessert und es wird eine Klassenvorhersage getroffen. Beim Training
der zweiten Stufe von PointRCNN wird durch Anwendung von Data Augmentation die Zahl der
Trainingsdaten künstlich vergrößert.
122 Vorstellung der PointRCNN-Struktur
Zusammenfassen der Punktwolkenregionen
Die Punkte aus der vorherigen Stufe [Unterabschnitt 2.3.1] sowie deren Features werden den
Vorschlägen entsprechend mittels Pooling zusammengefasst. Um weitere kontextuelle Informationen
zu jedem 3D Box Vorschlag bi = (xi , yi , zi , hi , wi , li , θi ) zu erhalten, werden diese um einen
konstanten Wert η zu bei = (xi , yi , zi , hi + η, wi + η, li + η) vergrößert. Die Punkte in der
vergrößerten Box bei sowie deren entsprechenden Informationen werden zur Verbesserung der Box bi
genutzt. Ein Punkt p besitzt neben den Positionsdaten (x(p) , y (p) , z (p) ) und der Reflexionsintensität
des Laser-Scanners r(p) auch die Segmentierungsmaske m(p) ∈ {0, 1} und die C-dimensionale
Darstellung der gelernten Punktfeature f(p) ∈ RC aus der ersten Stufe.
Kanonische Transformation
Alle Punkte eines Vorschlags werden in das entsprechende kanonische Koordinatensystem trans-
formiert, um besser lokale Features zu lernen. Für jeden Punkt p wird nun eine entsprechende
Rotation und Translation angewendet, sodass man einen Punkt p̃ im kanonischen Koordinaten-
system erhält. Der Bezugspunkt ist hierbei der Ursprung des kanonischen Koordinatensystems,
welcher im Mittelpunkt der Bounding Box liegt.
Erlernen von Features für die 3D Box Verbesserung
Da bei dieser Transformation die Informationen bezüglich der Tiefe der Punkte verloren gehen,
p
erhält jeder Punkt p die euklidische Distanz zum Sensor d(p) = (x(p) )2 + (y (p) )2 + (z (p) )2
als weiteres Feature. Die lokalen Features p̃ und die weiteren Features [r(p) , m(p) , d(p) ] werden
zusammengeführt und durch mehrere vollverknüpfte Schichten auf dieselbe Dimension gebracht,
wie die der globalen Features f(p) . Die verknüpften Features gelangen dann in ein PointNet++. Als
Eingabe erhält das Netzwerk 512 zufällige Punkte je Vorschlag. Mit Hilfe von drei Set-Abstraction
Ebenen mit Single-Scale Grouping wird ein Feature Vektor für die Klassifikation und für die
Verbesserung der Box erzeugt.
Bin-basierte 3D Box Verbesserung
Das verwendete Netzwerk nutzt ebenfalls bin-basierte Regression Verlustfunktionen. Hierbei wird
eine Box aus den annotierten Daten einer vorhergesagten Box zugeordnet, falls deren IoU Score
mehr als 0.55 beträgt. Durch Transformation beider Boxen in das kanonische Koordinatensystem
erhalten wir aus den beiden Boxen
bi = (xi , yi , zi , hi , wi , li , θi ) (2.9)
bgt
i = (xgt gt gt gt gt gt gt
i , yi , zi , hi , wi , li , θi ) (2.10)
132 Vorstellung der PointRCNN-Struktur
die transformierten Boxen
b˜i = (0, 0, 0, hi , wi , li , 0) (2.11)
˜
bgt gt gt gt gt gt gt gt
i = (xi − xi , yi − yi , zi − zi , hi , wi , li , θi − θi ). (2.12)
Zur Berechnung der entsprechenden Bins und Residuen werden die gleichen Formeln wie in
Abschnitt 2.3.1 verwendet, jedoch mit verkleinerter Suchweite S.
Bei der Verbesserung der Orientierung wird angenommen, dass der Winkel der vorhergesagten Box
und der Winkel der annotierten Box im Bereich von [− π4 , π4 ] voneinander abweichen können. Für
π
die anschließende Berechnung wird 2 in äquidistante Bins der Größe ω eingeteilt. Daraus ergeben
sich die Formeln
$ %
θigt − θi + π4
bini∆θ = , (2.13)
ω
2 gt π ω
resi∆θ = θi − θi + − bini∆θ · ω + . (2.14)
ω 4 2
Die Verlustfunktion dieses Unternetzwerkes lässt sich durch
1 X 1 X (i) (i)
Lrefine = Fcls (probi , labeli ) + (L̃bin + L̃res ) (2.15)
||B|| ||Bpos ||
i∈B i∈Bpos
beschreiben. Hierbei ist B die Menge aller Vorschläge aus der ersten Stufe des PointRCNN Netz-
werks, während Bpos die positiven Vorschläge beinhaltet. probi ist die Wahrscheinlichkeit, dass
(i) (i)
der i-te Vorschlag der Klasse labeli zuzuordnen ist. Die Ausdrücke L̃res und L̃bin bezeichnen die
Verlustfunktionen auf Grundlage der korrigierten Bins. Um nun überlappende Boxen zu eliminie-
ren, wird NMS mit einem Schwellwert von 0.01 zur Entfernung aller, aus der Vogelperspektive
überlappender, Boxen angewandt. Dadurch wird sichergestellt, dass pro Objekt nur eine finale Box
erzeugt wird.
143 Analyse verschiedener Datensätze
Die Nutzung von Datensätzen ermöglicht das Arbeiten mit einer großen Menge an bereits an-
notierten und ausgewerteten Daten. Dabei stehen Sensordaten von verschiedenen Sensoren wie
Kamera, LiDAR oder GPS zur Verfügung sowie Daten zu Objekten, die mit hohem Zeitauf-
wand ausgewertet wurden. Die hier aufgeführten Datensätze sind frei zugänglich und bieten
die Möglichkeit, aufgenommene Daten für eigene Forschungszwecke zu verwenden. Neben den
eigentlichen LiDAR-Daten sind auch die Label-Daten wichtig, um einen Detektor entsprechend
zu trainieren sowie Bilddaten, um die Ergebnisse repräsentativ im Bild anzeigen zu können. Die-
ses Ziel der Repräsentation benötigt Kalibrierungsdaten der Kamera und des Laser-Scanners,
um eine entsprechende Koordinatentransformation vom Lidar- zum Kamerakoordinatensystem
durchzuführen.
Der erste Datensatz, der in diesem Kapitel analysiert wird, ist der KITTI Datensatz [2], auf dessen
Grundlage PointRCNN entwickelt wurde. Anschließend wird der Datensatz ’AEV Autonomous
Driving Dataset’ der Firma Audi [3] analysiert. Ziel hierbei ist es, alle nötigen Informationen, die
im KITTI-Datensatz enthalten sind, auch in dem Datensatz von Audi wiederzufinden, sodass eine
anschließende vollständige Portierung stattfinden kann.
3.1 KITTI-Datensatz
Die KITTI Vision Benchmark Suite [2] entstand aus einer Kooperation des Karlsruhe Institute
”
of Technology“ und des Toyota Technological Institute at Chicago“. Die ersten Aufnahmen des
”
Datensatzes fanden im Jahr 2011 im Raum Karlsruhe statt. Hierfür wurde ein VW Passat mit
entsprechenden Sensoren und Hardware ausgestattet:
• 2 × PointGray Flea2 Graustufenkamera (FL2-14S3M-C), 1.4 Megapixel, 1/2” Sony ICX267
CCD, globaler Shutter
• 2 × PointGray Flea2 Farbkamera (FL2-14S3C-C), 1.4 Megapixels, 1/2” Sony ICX267 CCD,
globaler Shutter
• 4 × Edmund Optics lenses, 4mm, horizontaler Öffnungswinkel: ∼ 90◦ , vertikaler Öffnungswinkel
der region of interest (ROI): ∼ 35◦
• 1 × Velodyne HDL-64E rotierender 3D Laserscanner, 10 Hz, 64 Strahlen, Winkelauflösung:
0.09◦ , Distanzgenauigkeit: 2cm, erfasst ∼ 1.3 Millionen Punkte pro Sekunde, field of view
(FOV): 360◦ horizontal und 26.8◦ vertikal, Reichweite: 120 m
• 1 × OXTS RT3003 Trägheits- und GPS Navigationssystem, 6 Achsen, 100 Hz, L1/L2 RTK,
Auflösung: 0.02m / 0.1◦
153 Analyse verschiedener Datensätze
Abbildung 3.1: Übersicht der Sensorverteilung des Fahrzeuges zur Aufnahme des KITTI-
Datensatzes [6, Abb. 3]: Platzierung der 4 verschiedenen Kameras und des
Laser-Scanners sowie die Benennung von Größen und Abständen und die Darstel-
lung der verschiedenen Koordinatensysteme und Transformationen.
Die Aufteilung der Sensoren ist in Abbildung 3.1 dargestellt. KITTI stellt sowohl Rohdaten als
auch bereits verarbeitete Daten zur Verfügung. Der Vorteil der aufbereiteten Daten ist, dass die
Daten des 360◦ Laserscanners bereits angepasst und den entsprechenden Bilddaten zugeordnet
wurden. Hierfür wurden die einzelnen Aufnahmen mit einem Zeitstempel versehen und einander
zugeordnet. Darüber hinaus sind Objekte in den aufbereiteten Daten bereits annotiert.
Für diese Arbeit wurden die aufbereiteten Daten der ’3D Object Evaluation 2017’ [2] mit 7481
Trainings- und 7518 Testbildern verwendet. Bei beiden sind Bild-, LiDAR- und Kalibrierungsdaten
vorhanden. Darüber hinaus sind für die Trainingsdaten annotierte Daten vorhanden, die die Objekte
in den jeweiligen Aufnahmen beschreiben.
3.1.1 LiDAR-Daten
Die LiDAR-Daten liegen sowohl für die Tranings- als auch Testbilder in binärer Form vor. Das
Histogramm in Abbildung 3.2 zeigt die Verteilung der Anzahl der Punkte pro Aufnahme. Im
Durchschnitt hat jede Aufnahme 119790.54 Punkte, dabei jedoch mindestens 78596 und maximal
128467 Punkte.
163 Analyse verschiedener Datensätze
Abbildung 3.2: Verteilung der Anzahl von Punkten pro Aufnahme im KITTI-Datensatz.
Jeder Punkt wird durch seine Koordinaten in kartesischer Darstellung sowie seinem Reflexionswert
beschrieben. Die Koordinaten liegen in der Einheit Meter vor, während sich der Reflexionswert in ei-
nem Bereich zwischen 0 und 1 befindet. Zur Veranschaulichung wird in Abbildung 3.3 die Verteilung
der Punkte aus der Vogelperspektive dargestellt sowie in Abbildung 3.4 der Querschnitt entlang
der x-Achse. Beide Heatmaps beschreiben die Verteilung der Punkte im LiDAR-Koordinatensystem.
Der Sensor befindet sich bei beiden im Punkt (0, 0).
Abbildung 3.3: Heatmap aus der Abbildung 3.4: Heatmap des Querschnitts
Vogelperspektive. entlang der x-Achse.
3.1.2 Bilddaten
Die Bilddaten der KITTI-Datenbank wurden mit vier Kameras aufgenommen. Hierbei wurden
zwei Stereosysteme verwendet, eines für Farb- und eines für Graustufenbilder. Da bei der 3D
173 Analyse verschiedener Datensätze
Objekterkennung die Bilddaten nur zur späteren Visualisierung Gebrauch finden, wird in den
meisten Fällen nur das Bild der linken Farbkamera verwendet. Die Bilddateien sind im verlustfreien
.png Format und haben eine Auflösung von 1224 × 370 (Bildbreite × Bildhöhe in Pixel).
3.1.3 Kalibrierungsdaten
Für jede Aufnahme des KITTI-Datensatzes existiert eine eigene Textdatei mit den Kalibrierungs-
informationen, um die verschiedenen Koordinatensysteme von Kamera und LiDAR in Relation
zueinander setzen zu können. Jede Zeile repräsentiert eine Matrix, die für die Umrechnung von
Koordinatensystemen benötigt wird. Als Erstes werden die vier Projektionsmatrizen der einzelnen
Kameras erläutert.
Projektionsmatrizen P0 , P1 , P2 und P3
Die ersten vier Zeilen der Textdatei beschreiben die Projektionsmatrizen der einzelnen Kameras.
Diese werden benötigt um einen Punkt aus dem 3D Raum einer Kamera in die zweidimensionale
Bildebene zu transformieren. Der jeweilige Index steht für eine der für die Aufnahme verwendeten
Kameras. Eine Projektionsmatrix
h i f 0 hx t x
Pi = C t = 0 f hy ty (3.1)
0 0 1 tz
setzt sich zusammen aus der Kalibrierungsmatrix C, welche die intrinsischen Parameter der Kamera
enthält, und einem Translationsvektor t. Die intrinsischen Parameter setzen sich zusammen aus
einem Brenntpunkt f und dem Bildmittelpunkt (hx , hy ). Der Translationsvektor beschreibt den
Versatz der einzelnen Kameras zum Referenzsystem, welches das der ersten Kamera ist. Daher ist
der Translationsvektor der ersten Projektionsmatrix ein Nullvektor. Da für die Visualisierung der 3D
Objekterkennung das Farbbild der linken Farbkamera verwendet wird, ist nur die Projektionsmatrix
P2 von Interesse.
Rotationsmatrix R0
Die Rotationsmatrix mit den Dimensionen 3×3 ermöglicht eine Rotation vom Referenzkamerako-
ordinatensystem in das rektifizierte Kamerakoordinatensystem.
183 Analyse verschiedener Datensätze
Transformationsmatrix vom LiDAR- in das Kamerakoordinatensystem
Die Transformationsmatrix
h i
T rv2c = R t (3.2)
der Größe 3×4 besteht aus einer Rotationsmatrix R und einem Translationsvektor t und ermöglicht
die Umrechnung vom Lidarkoordiantensystem in das Kamerakoordinatensystem. Die Darstellung
der beiden Koordinatensysteme ist in Abbildung 3.5 dargestellt.
z
z
x
x T rv2c
−−−→
y
y
Abbildung 3.5: Darstellung der Transformation vom LiDAR-Koordinatensystem (links) in das
Kamerakoordinatensystem (rechts).
3.1.4 Annotierte Daten
Für jede Aufnahme aus den Trainingsdaten gibt es eine Textdatei mit Informationen zu den
in der Szene befindlichen Objekten. Jede Zeile in einer Datei beschreibt dabei ein Objekt mit
Informationen, welche durch Leerzeichen voneinander separiert sind. In Tabelle 3.1 sind diese der
Reihenfolge nach erklärt.
193 Analyse verschiedener Datensätze
Tabelle 3.1: Übersicht der KITTI Objektdaten.
Position Bezeichnung Wertebreich Beschreibung
Klassennamen der KITTI-Datenbank.
{’Car’, ’Van’, ’Truck’,
Objekte der Klasse ’DontCare’ sind
’Pedestrian’,
nicht relevant, da sie zum Beispiel zu
1 Klassenname ’Person sitting’,
weit entfernt sind. Unter der Klasse
’Cyclist’, ’Tram’,
’Misc’ versteht man Objekte wie
’Misc’, ’DontCare’}
Anhänger oder Segways.
Bei 0 ist das Objekt vollständig im
Bild enthalten und je näher der Wert
2 Truncation [0..1] an der 1 liegt, desto mehr
überschreitet das Objekt die
Bildkante.
Beschreibt, wie stark ein Objekt
verdeckt ist:
0 = komplett sichtbar
3 Occlusion {0, 1, 2, 3}
1 = teilweise sichtbar
2 = stark verdeckt
3 = unbekannt
Der Betrachtungswinkel α gibt den
Betrachtungswin- Winkel zwischen der z-Achse des
4 kel [−π..π] Kamerakoordinatensystems und dem
α Vektor vom Ursprung zur
Objektmitte wieder.
Beschreibt zwei Punkte durch die
Koordinaten x1,y1,x2,y2 im Bild, die
5-8 2D Box
eine zweidimensionale Box um das
Objekt erzeugen.
Dimensionen des Objektes in Metern:
9 - 11 3D Boxgröße
Höhe, Breite, Länge
x, y und z Koordinaten, die den
Standort des Objektes im
Kamerakoordinatensystem
12 - 14 3D Objektstandort
beschreiben. x und z sind jeweils
mittig und y der unterste Punkt des
Objektes.
203 Analyse verschiedener Datensätze
Gibt den Rotationswinkel um die
y-Achse (Gierwinkel) im
15 Rotationswinkel [−π..π] Kamerakoordinatensystem an. Dieser
ist 0, falls das Objekt parallel zur
x-Achse liegt.
Dieser Eintrag findet sich nur bei den
Output-Daten wieder und beschreibt
16 Score float wie sicher das Objekt detektiert
wurde. Je höher der Wert, desto
sicherer die Detektion.
Es fällt auf, dass nur eine Rotation um die y-Achse vermerkt ist. Dies liegt daran, dass die
Rotationen um die beiden anderen Achsen aufgrund ihres geringen Wertes vernachlässigt werden
und für die der Wert 0 angenommen wird [6].
3.2 AEV Autonomous Driving Dataset
AEV Autonomous Driving Dataset [3] (im Folgenden A2D2 genannt) ist ein Datensatz der
Audi Electronics Venture GmbH, welcher veröffentlicht wurde, um die Forschung sowie Start-Up
Unternehmen im Bereich des autonomen Fahrens zu unterstützen. Folgende Sensoren wurden
dabei verwendet:
• 5 × LiDAR, 16 Kanäle, Reichweite: 100m, 3cm Genauigkeit, 10 Hz Rotationsrate, 360◦
horizontal, 30◦ vertikal
• 1 × zentrale Frontkamera, Auflösung: 1920 × 1208, horizontaler Öffnungswinkel: 60◦ ,
vertikaler Öffnungswinkel 38◦ , Bildrate: 30 fps
• 5 × Surround-Kamera, Auflösung: 1920 × 1208, horizontaler Öffnungswinkel: 120◦ , vertikaler
Öffnungswinkel: 70◦ vertical, Bildrate: 30 fps
• 1 × Bus Gateway, welches mit dem eingebauten Auto-Gateway verbunden ist, Verbindungen
zu allen Bus-Systemen und deren Sensoren im Auto, Übermittlung und Zeiterfassung über
Ethernet
Eine Übersicht über die Verteilung der genutzten Sensoren ist in Abbildung 3.6 zu finden.
213 Analyse verschiedener Datensätze
Abbildung 3.6: Übersicht der Sensorverteilung des Fahrzeuges zur Aufnahme des A2D2 Daten-
satzes [3]: Platzierung der 6 verschiedenen Kameras und der 5 Laser-Scanner.
In dieser Arbeit werden die aufbereiteten Daten aus dem ’3D Bounding Box’ Datensatz zur 3D
Objekterkennung genutzt.
3.2.1 Koordinatensystem des Datensatzes
In dem verwendeten A2D2 Datensatz sind die Daten einer Szene immer der Frontkamera zugeordnet.
Daher sind neben den Bildern auch die für die Frontkamera relevanten LiDAR-Daten der fünf
Laser-Scanner dem selben Koordinatensystem zugeordnet. Das Kamerakoordinatensystem ist in
Abbildung 3.7 dargestellt.
z
x
y
Abbildung 3.7: Koordinatensystem der Front-Kamera bzw. des verwendeten A2D2 Datensatzes.
3.2.2 LiDAR-Daten
Die LiDAR-Daten sind im .npz Format gespeichert. Dies ist ein spezielles Format der Python
Bibliothek NumPy und beinhaltet ein Wörterbuch, welches Listen mit punktspezifischen Informa-
tionen enthält. Jeder Punkt Qi lässt sich durch die Daten der Listen an i-ter Stelle beschreiben.
22Sie können auch lesen

















































