Data Mining Praktikum - Wintersemester 2019/20 - Abteilung Datenbanken Leipzig
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Data Mining
Praktikum
Wintersemester 2019/20
Abteilung Datenbanken, Universität Leipzig
http://dbs.uni-leipzig.de
Data Mining Praktikum 1
Einführung
• Implementierung von Data-Mining-Algorithmen mit Java und Spark
• Begleitend zur Vorlesung “Data Mining”
• Einschränkungen:
– Verwendung von Apache Spark
– Schreiben der Programme in Java (nicht Scala, Python, R, oder SQL)
– Umsetzung der Algorithmen mit RDDs (nicht DataFrames oder Datasets)
• Durchführung in Gruppen zu je 2 Studierenden
• Praktikumsleistung: 3 Testate
– Testat 1: bis 29. November 2019
– Testat 2: bis 31. Januar 2020
– Testat 3: bis 31. März 2020
Wichtige Informationen: https://dbs.uni-leipzig.de/stud/2019ws/dwhdmprak
Data Mining Praktikum 2Themen
• K-Means Clustering
– Gruppierung von Datenpunkte in Cluster
• Mitglieder eines Cluster haben geringe paarweise Distanz
• Mitglieder verschiedener Cluster haben hohe paarweise Distanz
– Beispiele
• Gruppierung von Musikalben nach Käufern
• Gruppierung von Dokumenten nach Thema
• Segmentierung von Bildern
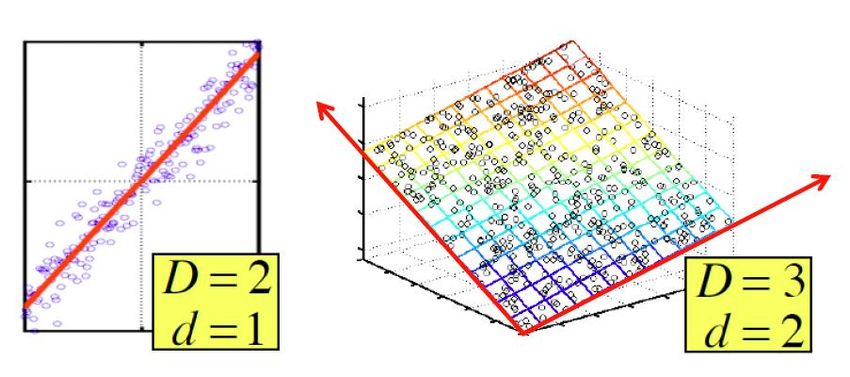
• Dimensionsreduktion
– Datenpunkte eines
D-dimensionalen Raumes liegen
vorrangig in der Nähe eines
d-dimensionalen Unterraumes
– Reduzierung der Punkte auf
deren Projektionen im Unterraum
Data Mining Praktikum 3Themen
• Empfehlungssysteme Avatar LotR Matrix Pirates
– Schätzung unbekannter Bewertungen Alice 10 2
– Verschiedene Herangehensweisen Bob 5 3
• Kollaboratives Filtern Carol 1 5
• Latentes Variablenmodell
David 4
• Assoziationsregeln
Warenkörbe
Brot, Cola, Milch
Milch, Windeln Assoziationsregeln:
Bier, Cola, Windeln, Milch {Milch} → {Cola}
{Windeln, Milch} → {Bier}
Bier, Brot, Windeln, Milch
Cola, Windeln, Milch, Bier
Data Mining Praktikum 4Themen
• MinHashing & LSH
– Finde ähnliche Paare in einer riesigen Menge von hochdimensionalen Daten
– Berechnung in linearer statt quadratischer Zeit
Lorem ipsum dolor sit amet, consectetur
Lorem ipsum
adipiscing dolor
elit, sed do sit amet, consectetur
eiusmod tempor
Lorem
adipiscing
incididunt ipsum
ut labore dolor
elit, sedet do sit amet,
eiusmod
dolore magna consectetur
tempor
aliqua.
Ut enim ad minim veniam, quis nostrud Lorem ipsum dolor sit amet, consectetur
adipiscing
incididunt elit, sed
ut labore et do eiusmod
dolore magna tempor
aliqua.
exercitation ullamco laboris nisi ut aliquip Lorem
adipiscing ipsum
elit, seddolor
do sit amet,
eiusmod consectetur
tempor
incididunt ut
Ut enim adadipiscing
minim labore
veniam, et dolore
quis magna
nostrud aliqua.
ex ea commodo consequat. Lorem
incididunt ut ipsum
elit, sed
labore dolor
et do sit amet,
eiusmod
dolore magna consectetur
tempor
aliqua.
Ut enim ad
exercitation minim
ullamco
adipiscing veniam,
laboris quis
nisi
elit, sed ut nostrud
aliquip
do eiusmod tempor
incididunt ut labore et dolore magna aliqua.
Lorem ipsum dolor sit amet, consectetur eaUt enim ad
ex exercitation
commodo minim laboris
ullamco
consequat.
incididunt
veniam,nisi
ut labore
quis
et
nostrud
utdolore
aliquipmagna aliqua.
adipiscing elit, sed do eiusmod tempor eaUt enim ad
ex exercitation
commodo minim laboris
ullamco
consequat.veniam,nisi quisut nostrud
aliquip
Ut enim
exercitation ad minim
ullamco
ex ea commodo consequat. veniam,
laboris quis
nisi ut nostrud
aliquip
incididunt ut labore et dolore magna aliqua. Ut enim
exercitation ad minim
ullamco
ex ea commodo consequat. veniam,
laboris quis
nisi ut nostrud
aliquip
exercitation ullamco
ex ea commodo consequat. laboris nisi ut aliquip
ex ea commodo consequat.
• Supervised Machine Learning Age Male Class Survived
– Auffinden eines möglichst akkuraten Child True 1 Yes
Modells zur Vorhersage eines Attributs
Adult True 2 No
– Logistische Regression, SVM
Adult False 1 Yes
– Entscheidungsbäume und Random Forests
Child True 3 No
… … … …
Data Mining Praktikum 5Themen
• Analyse von Graphen
– Soziales Netzwerk: Empfehlungen
von Freunden
– PageRank: Wichtigkeit von Webseiten
für die Reihenfolge von Suchergebnissen
• Datenströme
– Stetiges Erheben von Daten (z.B. Sensoren, Interaktionen im WWW)
– Beispiel: Zählen von Wörtern
• Beschränkung auf die neuesten N Elemente
• Exponentially Decaying Window
qwertyuiopasdfghjklzxcvbnm
Data Mining Praktikum 6Einführung zu Spark
• Einschränkungen von MapReduce:
– Schwierige Programmierung: Viele Probleme sind nicht (so einfach) als MapReduce-
Prozedur beschreibbar
– Oft müssen mehrere MapReduce-Schritte kombiniert werden
– Leistungsengpässe: Speicherung auf Festplatte ist wesentlich langsamer als die
Arbeit im Hauptspeicher
• Erweiterung: Workflow Systeme
– Verteilte Verarbeitung
– Weitere Operationen neben
Map und Reduce
– Azyklisches Datenfluss-Netzwerk
– Effiziente Verarbeitung von Daten durch
Vermeidung des Speicherns von
Zwischenergebnissen auf Festplatte
• Beispiele: Spark, Flink, TensorFlow
Data Mining Praktikum 7Spark
• Datenstruktur: Resilient Distributed Dataset (RDD)
– Datenmenge aus Objekten eines Types (z.B. String, Menge, Schlüssel-Wert-Paar)
– Repliziert und verteilt über Cluster
– Unveränderbar
• RDDs werden über Hadoop geladen oder aus einer anderen RDD erstellt
• Transformationen: Umwandlung eines RDD in eine neue RDD
– z.B. map, flatMap, filter, join, groupByKey, …
– Lazy Evaluation: Keine Berechnung
• Aktionen: Berechnung eines Wertes oder Exportierung des RDD
– z.B. count, take, collect, reduce, saveAsTextFile, …
– Aktionen erzwingen Berechnungen und geben Werte aus bzw. exportieren Daten
Data Mining Praktikum 8Spark: map()
Anwendung einer Funktion auf jedes Element einer RDD und Rückgabe
einer neuen RDD mit den Ergebnissen als Elemente
JavaRDD lines = sc.textFile(args[0]);
JavaRDD wordsArrays = lines
.map(line -> line.split(" "));
JavaRDD numbers = wordsArrays
.map(wordsArray -> wordsArray.length);
// nur eine Zeile:
JavaRDD numbers = sc.textFile(args[0])
.map(line -> line.split(" "))
.map(wordsArray -> parts.length);
Data Mining Praktikum 9Spark: flatMap()
Anwendung wie map(), doch jedes Element kann auf eine Menge von neuen
Elementen abgebildet werden
JavaRDD lines = sc.textFile(args[0]);
JavaRDD words = lines
.flatMap(line ->
Arrays.asList(line.split(" ")).iterator());
// Action:
int numberOfWords = words.count()
Data Mining Praktikum 10Spark: mapToPair()
Anwendung einer Funktion auf jedes Element einer RDD und Rückgabe
einer neuen PairRDD mit den Ergebnissen als Elemente
JavaPairRDD pairs = words
.mapToPair(w -> new Tuple2(w, 1));
• PairRDD ist RDD aus Schlüssel-Wert-Paaren
• Spark bietet für PairRDDs einige zusätzliche Funktionen an:
– groupByKey()
– reduceByKey()
– sortByKey()
– join()
– cogroup()
– mapValues()
– …
Data Mining Praktikum 11Spark: PairRDD
JavaPairRDD grouped =
pairs.groupByKey();
JavaPairRDD counts = pairs
.reduceByKey((n1, n2) -> n1 + n2);
JavaPairRDD wordLength = words
.distinct()
.mapToPair(w -> new Tuple2(w, w.length()));
JavaPairRDD res =
wordLength.join(counts);
Data Mining Praktikum 12Spark
• Download und Dokumentation:
https://spark.apache.org/
• Bibliotheken:
• Praktische Einführung und Aufgaben des Praktikums:
https://git.informatik.uni-leipzig.de/dbs/dataminingpraktikum
Data Mining Praktikum 13Sie können auch lesen

















































