Dateiformatidentifizierung - Was, warum, wie, womit, Micky Lindlar 09. Juni 2021 - Langzeitarchivierung
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Dateiformatidentifizierung Was, warum, wie, womit, … Micky Lindlar 09. Juni 2021
Agenda
□ WAS ist Dateiformatidentifizierung?
□ WARUM überhaupt Dateiformatidentifizierung?
□ WIE geht Dateiformatidentifizierung?
□ WOMIT kann ich Dateiformatidentifizierung durchführen?
□ Alles klar! Kann überhaupt noch was schieflaufen ?
Seite 2
Was ist Dateiformatidentifizierung
Dateiformatidentifzierung, die
[daˈtaɪ̯‘fɔʁˈmaːtˈidɛntifiˈt͡siːʁʊŋ]
Datei - format - identifizierung
.. welche bekannt und
zuordnungsbar ist.
… die als Einheit einer bestimmten
Syntax („Grammatik“) und Semantik
(„Inhalt“) folgen, …
Aneinanderreihung
zueinander gehörender
Bits, …
Seite 3
Syntax und Semantik von Formaten !?
Syntax Semantik
• beschreibt Reihenfolge von • beschreibt Regeln für eine
Bytes und Struktur, in der inhaltliche Interpretation
diese angeordnet sein
müssen, um technisch
interpretiert werden zu können
Syntax: Semantik:
Tags erscheinen Im Namespace wird auf
paarweise das Schema verwiesen,
(Anfang/Ende) welches zulässige Elemente
solange deren und deren Beziehung
Werte nicht leer Zueinander beschreibt . Hier:
sind Beschreibung einer Matrix in
MathML.
Image und Beispiel aus: Cotent MathML examples - https://www.w3.org/Math/XSL/csmall2.xml Seite 4
Text-basierte vs. binäre Dateiformate
Textformat
[tɛkst ̯‘fɔʁˈmaːt]
Der Inhalt ist eine sequenzielle Folge von Zeichen eines
Zeichensatzes (z.B. UTF-8). Bytes stehen hier immer für das
selbe Zeichen. Textformate sind besonders robust und ihr Inhalt
ist mit einfachen Editoren (z.B. Notepad, Vi, usw.) lesbar.
Binärformat
[biˈnɛːɐ̯‘fɔʁˈmaːt]
Der Inhalt ist eine beliebige Anordnung von
Bitmustern. Binärformate sind weniger
robust als Textdateien und die
Darstellung des Inhalts erfordert
spezielle Software (z.B. PDF
Reader, IfranView).
Seite 5
Image: ASCII Art Archive https://www.asciiart.eu/computers/other
□ WAS ist Dateiformatidentifizierung?
□ WARUM überhaupt Dateiformatidentifizierung?
□ WIE geht Dateiformatidentifizierung?
□ WOMIT kann ich Dateiformatidentifizierung durchführen?
□ Alles klar! Kann überhaupt noch was schieflaufen ?
Seite 6
Warum überhaupt Dateiformatidentifizierung?
• Datei kann nicht geöffnet werden
− Bestimmung des Dateiformats „Grundwissen“ zur Planung
weiterer Schritte (z.B. Suche nach geeigneter Software zum
ausführen)
• Kontrolle von Ablieferungsformaten
− (erste) Überprüfung, ob Datenlieferant im vereinbarten
Dateiformat geliefert hat (z.B. PDF/A-1b)
• Prozessautomatisierung
− Kenntnis des Dateiformats erlaubt gezielte Weiterleitung an
für das Format geeignete Tools zur Validierung und
Extrahierung technischer Metadaten
• Preservation Watch und Preservation Planning
− Übersicht der Dateiformate hilft Langzeitarchiv, Preservation
Watch und Preservation Planning zu koordinieren
Seite 7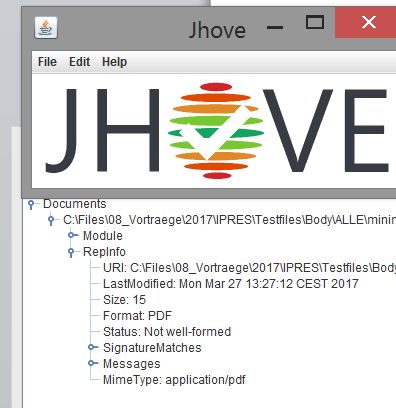
Beispiel der TIB - Formatvielfalt
Abgebildet sind „Top 20“ (ohne TIFF) Dateiformate im Langzeitarchiv,
PDF Formate sind in gelb gekennzeichnet
120000
100000
80000
60000
40000
20000
0
Seite 8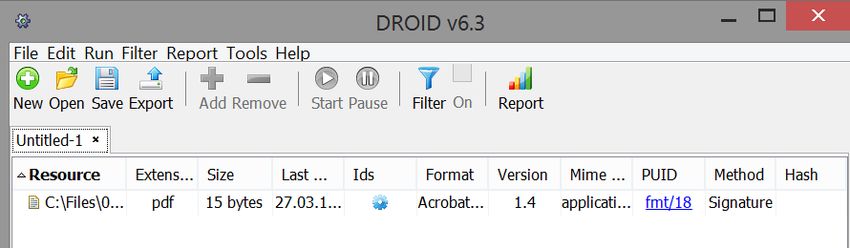
□ WAS ist Dateiformatidentifizierung?
□ WARUM überhaupt Dateiformatidentifizierung?
□ WIE geht Dateiformatidentifizierung?
□ WOMIT kann ich Dateiformatidentifizierung durchführen?
□ Alles klar! Kann überhaupt noch was schieflaufen ?
Seite 9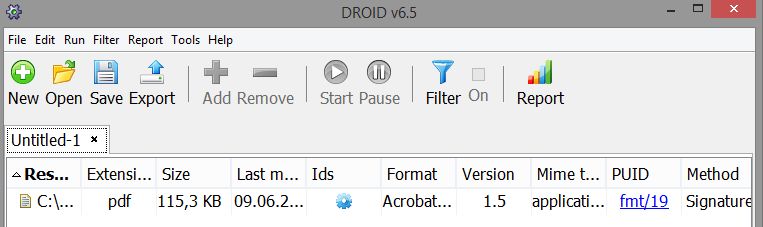
Drei Wege zur Formatbestimmung:
(1) begleitende Metadaten, z.B. MIME-Type
In manchen Fällen finden sich begleitende Information zum
Dateiformat, z.B. der MIME-Type (Multipurpose Internet Mail Extension):
• MIME-Type setzt sich zusammen aus type/subtype, z.B. text/html
• Ca. 130 registrierte MIME-Types, siehe
https://www.iana.org/assignments/media-types/media-types.xhtml
• Ursprung im SMTP Protokoll zur Unterstützung von non-ASCII
Zeichen
• u.a. auch Teil der METS Spezifikation (optionale Angabe in
FileGroup)
• Aber:
− Oftmals nicht vom Produzenten mit übergeben
− In manchen Fällen nicht granular genug (z.B. application/pdf für
alle PDF Profile)
MIME-Type Angabe
aus goobi METS/MODS
Seite 10Drei Wege zur Formatbestimmung:
(2) Dateiendung
Dateiendung / Dateiformaterweiterung kann einen
Anhaltspunkt bzgl. Format geben, ABER:
• Nicht in allen Betriebssystemen eingesetzt (z.B. Linux)
• Wo es eingesetzt wird, dient es der
Verbindung zwischen Datei(format)
und einer Darstellungssoftware
• Kann einfach manipuliert werden
(Umbenennung der Datei)
• Wird, um Manipulation zu
vermeiden, in einigen Standard-
sichten ausgeblendet
• Manche Formate teilen sich
eine Dateiendung (z.B.
gesamte PDF-Familie)
Fazit: Unsicher, höchstens
brauchbar als erster
Anhaltspunkt
Seite 11Drei Wege zur Formatbestimmung:
(3) Interpretation des Datei-Inhalts (Signatur)
Viele Dateiformate verfügen über eine „Magic Number“ -
eine Reihe von Zeichen am Beginn der Bytesequenz - die
das Objekt als ein bestimmtes Format kennzeichnen
• Signaturen erhalten zusätzlich oftmals weitere
Signatursequenzen, z.B. „End-of-File“ Marker
• Signaturen beschreiben, an welcher Stelle innerhalb der Datei
(relativ zum Anfang / Ende oder relativ zu einem anderen
Pattern) ein Pattern erwartet wird
• Identifizierung mittels Signatur ist die gründlichste der
drei Methoden Textdarstellung der Hex-Sequenz
- Aber: Links „%PDF-“ ist die Magic Number
für alle PDF-Versionen. Zusätzlich
- Für nicht alle Dateiformate können Signaturen ist hier die Version 1.4 mit benannt,
geschrieben werden (insb. Textbasierte Was eine Identifizierung auf Versions-
Ebene ermöglicht
Formate problematisch)
Seite 12□ WAS ist Dateiformatidentifizierung?
□ WARUM überhaupt Dateiformatidentifizierung?
□ WIE geht Dateiformatidentifizierung?
□ WOMIT kann ich Dateiformatidentifizierung durchführen?
□ Alles klar! Kann überhaupt noch was schieflaufen ?
Seite 13Persistente Identifier für Formate
Verschiedene Datenbanken erfassen strukturierte
Informationen zu Dateiformaten. Hierzu zählen:
• PRONOM (The National Archive, UK)
− vergibt PUID (PRONOM Unique Identifier) für
Formate
− hoher Nachnutzungsgrad von PUIDs, höchste
Formatabdeckung
• Library of Congress File Format Descriptions
− https://www.loc.gov/preservation/digital/formats/fdd/b
rowse_list.shtml
− vergibt fdd Identifier für Formate
− höchste Informationstiefe
• Wikidata for Digital Preservation
− https://wikidp.org/
− vergibt QID Identifier für Formate
− Linked-Open-Data Wissensbasis zu Dateiformaten
Seite 14Tools, Tools, Tools
• Mehrere Tools für automatische Dateiformatidentifizierung, für
umfangreiche Liste siehe:
https://coptr.digipres.org/index.php/File_Format_Identification
• Einige nutzen die aus der PRONOM Datenbank
erzeugten DROID-Signature Files, z.B. neben DROID selbst:
− Siegfried
− Fido
− Nanite
• Viele Tools nutzen als Identifizierungsmethode
sowohl Signatur als auch Dateiendung
− Höherer Abdeckungsgrad
− Erlaubt Hinweis wenn Erweiterung und Pattern
zu unterschiedlichen Ergebnissen kommen
• Tools unterscheiden sich u.a. durch:
− Pattern-Quelle
− Verknüpfung mit Dateiformat-Identifikatoren
− Informationstiefe des Outputs
Seite 15Tools: file Utility/ libmagic - „das Urgestein“
• Kommandozeilen Tool, Unix
• Open Source - https://github.com/file/file (read-only mirror)
• Features:
− Identifiziert „mehrere tausend“ Dateiformate
− Wird in den meisten UNIX-basierten Systemen
automatisch mit ausgeliefert
− Liefert sowohl MIME-Type als auch beschreibenden
Namen zurück
• Nachteil:
− Keine Persistent Identifier für Formate
− Geringe Informationstiefe des Outputs
Seite 16Tools: DROID – der „Platzhirsch in der LZA“
• Kommandozeilen-Tool und graphische Benutzeroberfläche,
plattformübergreifend
• Open Source - http://digital-preservation.github.io/droid/
• Features:
− Identifiziert ca. 1.800 Dateiformate
− Zeigt Art der Identifizierung (Extension, Signature) an
− Verlinkt PUID für Format
− Erstellung von Reports, Output als csv möglich
• Nachteil:
− Geschwindigkeit (sowohl Tool, als auch Entwicklung)
Seite 17Tools: Siegfried – „New Kid on The Block “
• Kommandozeilentool (+ Website-Demo), plattformübergreifend
• Open Source - https://github.com/richardlehane/siegfried
• Features:
− Zusätzlich zu PRONOM IDs auch
Zuordnung zu Library of Congress Format
Description ID
− Zusätzliche Identifizierung mittels MIME-Type
Tools
− erweiterte Infos zu Offset der Signaturen-Treffer
Seite 18□ WAS ist Dateiformatidentifizierung?
□ WARUM überhaupt Dateiformatidentifizierung?
□ WIE geht Dateiformatidentifizierung?
□ WOMIT kann ich Dateiformatidentifizierung durchführen?
□ Alles klar! Kann überhaupt noch was schieflaufen ?
Seite 19„Mich kennt hier keiner!“ – Format unknown
Dateiformat konnte nicht identifiziert werden - was nun?
• Verschiedene Identifizierungstools laufen lassen
• Datei in Hex-Editor (Binärformat) oder Notepad (Textformat)
betrachten, um Hinweise zu finden
• In gängigen Portalen nach Infos suchen, z.B. „Just Solve the File
Format Problem“
http://fileformats.archiveteam.org/wiki/Main_Page
• Ggf. Signature-Pattern schreiben
• Antrag auf Aufnahme des Dateiformats in PRONOM schreiben
Seite 20„Ich bin so viele!“ Multiple File Format Hits
Dateiformat kann eines von ganz vielen sein! Was nun?
• Mögliche Gründe:
− bei Extension-basierter Identifizierung viele Einträge für
Formaterweiterung
− Ungenaue Signatur
− Fehler in Datei
• Verschiedene Identifizierungstools laufen lassen
• Überprüfen, ob Datei beschädigt ist (Rendering in verschiedenen
Tools, Dateiformatvalidierung)
• Datei „manuell“ identifizieren, d.h. Gegenprüfung des Patterns im
Hex-Editor
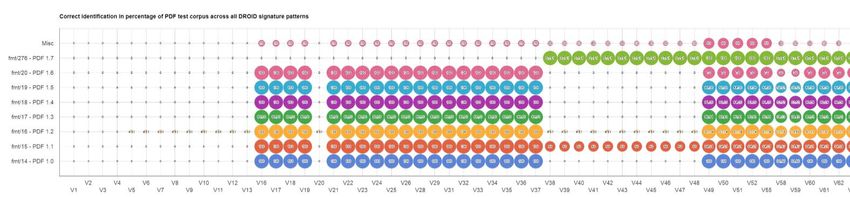
Seite 21Die Auswirkung neuer Signaturen
• Jede Identifizierung ist nur so gut wie die Regeln, gegen
die sie abgleicht
• Beispiel: „PDF-Dark Age“ zwischen DROID v38 und v48
• Umgesetzt war in diesen Pattern-Versionen ein erwarteter
Zeilenumbruch vor dem Dateiende-Marker (%%EOF)
• Einsatz dieser Signature-Pattern führt zu falschen
Identifzierungsergebnissen
• Ebenso können Ergebnisse aber auch über die Zeit genauer
werden, z.B. durch neue PUIDs für Formate, die vorher XML1.0
(fmt/101) zugeordnet wurden
Image: Lindlar, Tunnat „Time-travel with PRONOM – The Fourth Dimension of DROID“ https://doi.org/10.5281/zenodo.3517766
Seite 22Pattern stimmt, aber Ergebnis nicht!
%PDF-1.4
%%EOF
Seite 23□ WAS ist Dateiformatidentifizierung?
□ WARUM überhaupt Dateiformatidentifizierung?
□ WIE geht Dateiformatidentifizierung?
□ WOMIT kann ich Dateiformatidentifizierung durchführen?
□ Alles klar! Kann überhaupt noch was schieflaufen ?
Seite 24Fazit
• Dateiformatidentifizierung ist das Fundament, auf dem
weitere Analyse (Validierung, Extrahierung tech. Metadaten,
Risikoanalyse) aufbaut
• Automatische Dateiformaterkennung ist immer nur so gut wie
die Methode / Signatur, die dahinter steht
• Auch Tools können irren oder wachsen – Fehler in Pattern
oder die Aufnahme neuer Formate können
eine Auswirkung auf bisherige
Identifizierungsergebnisse des bereits
archivierten Bestandes haben
Seite 25Kontakt: M. Lindlar – TIB Hannover Michelle.lindlar@tib.eu 0511 762 19826 Lindlarm mickylindlar
Weiterführende Informationen
Pia Rudnik, Crashkurs Digitale Langzeitarchivierung –
Dateiformate (Video)
https://doi.org/10.5281/zenodo.3985074
Mario Röhrle: DROID Reference Card
https://doi.org/10.5281/zenodo.4593879
Mario Röhrle: Arbeitsweise der Identifikationsmethoden in DROID
https://doi.org/10.5281/zenodo.4593877
Lindlar, Tunnat: Time-travel with PRONOM – The fourth dimension
of DROID
https://doi.org/10.5281/zenodo.3517766
Seite 27Sie können auch lesen

















































