Informelle statistische Inferenz - Manfred Borovcnik Universität Klagenfurt
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Informelle statistische Inferenz
Manfred Borovcnik
Universität Klagenfurt
ÖMG, Fortbildungstag für Lehrkräfte 2021, Wien, 9. 4. 2021• Informelle und „Informal“ Inference
1. Ein elementarer Zugang zum Signifikanz-Test –
Rangtests, Re-Randomisierung und der p-Wert
2. Informelle Inferenz – eine Analogie zur Medizin
3. Informelle Wege zur statistischen Inferenz – Beispiele
4. „Informal Inference“ – Eine vereinfachte Inferenz
5. Resümee – Vereinfachung oder Reduktion
21. Ein elementarer Zugang zum Signifikanz-Test –
Rangtests, Re-Randomisierung und der p-Wert
Aufgabe:
Empirischer Nachweis der Effizienz eines blutdrucksenkenden Medikaments
durch eine placebo-kontrollierte, randomisierte, doppel-blinde klinische Studie
Zielvariable:
Intra-individuelle Differenz des Blutdrucks = sysBasis – sys4.Woche [mm Hg]
Große Werte entsprechen einer starken Wirkung.
Hypothesen:
Nullhypothese (H0): Verum = Placebo
Alternativhypothese: Verum ist besser als Placebo
Wenn Verum besser ist, dann sind große Werte unter der Behandlung
im Vergleich zu Placebo zu erwarten.
Mann-Whitney-Test für unabhängige Stichproben
31.1 Umordnung und Ränge
Originaldaten Geordnet Rang Rangsumme
2,5 0,9 1
0,9 1,8 2
Placebo 1,8 2,5 3
= 10
3,6 3,6 4
3,7 3,7 5 Unter H0 sind
alle
Verum 5,2 4,8 6 = 26 Zuordnungen
4,8 5,2 7
6,1 6,1 8 gleich wahr-
scheinlich!
Anzahl der Umordnungen: ( 84) = ‚8 über 4‘ = 70
Rangsumme 10 11 12 13 … 16 18 … 26
4Verteilung der Rangsumme (n = 70 Umordnungen)
Szenario-Annahme: Es gibt keinen Unterschied zwischen Verum & Placebo
(Nullhypothese)
Schwarz:
p = 2/70 = 0,0286
10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
51.2 Der p-Wert: erste Bedenken
p = Wahrscheinlichkeit für ein beobachtetes Resultat, wenn H0 zutrifft.
Wenn p kleiner als 5% ist, wird die Nullhypothese abgelehnt;
p ist die Wahrscheinlichkeit für eine falsch-positive Aussage,
d.h., der Test ergibt ein signifikantes Ergebnis, wenn das
Droge/Medikament nicht wirksam ist:
p ( Test signifikant | Droge ist nicht wirksam).
Wir haben etwas beobachtet, was weniger Wahrscheinlichkeit als 5% hat,
wenn H0 zutrifft (Droge nicht wirksam).
Aber, wir sind nur an dieser Zahl interessiert :
P (Droge ist wirksam | Test signifikant ) ??
6Formale Methoden und wissenschaftliche Prinzipien
Eine Entscheidung über eine klinische Studie basiert auf statistischen Methoden.
Ärzte sind keine Experten in Statistik und sie müssen es auch nicht sein.
Dennoch sollten sie die Prinzipien wissenschaftlicher Methoden kennen.
No test based upon a theory of probability
can by itself provide any valuable evidence of
the truth or falsehood of a hypothesis.
Neyman J., Pearson E. (1933): On the problem of most efficient tests of
statistical hypotheses. Philos. Trans. Roy. Soc. A, 231, 289-337.
7Ein Dialog dazu zwischen einem Mediziner und einem Statistiker M: Du hast dich so bemüht, mir den statistischen Test zu erklären – aber was bedeutet es, wenn mein Test ein signifikantes Resultat ergibt? Kann ich dann behaupten, dass die Droge wirksam ist? ST: Nein – Du kannst nur berechnen, wie wahrscheinlich solch ein Resultat ist, WENN die Droge tatsächlich nicht wirksam ist. M: Die Ethikkommission hat die Studie über die Wirksamkeit dieser Droge bewilligt. Ich habe dich gefragt, ob man das durch einen statistischen Test beweisen kann. Weil das Resultat signifikant ist, dachte ich, dass die Wahr- scheinlichkeit, dass die Droge wirksam ist, 95% beträgt, weil der p-Wert 5% ist. ST: Du hast mich etwas gefragt, auf das der p-Wert keine Antwort gibt. Die Fehler-Wahrscheinlichkeit für deine Aussage ist höher – dennoch, ich kann das nicht berechnen. M: Du magst ja Recht haben, aber ich habe das getan, wie es alle tun – warum sollte das falsch sein? Das Resultat des statistischen Tests ist signifikant und wird publiziert: Die Droge ist wirksam (p < 0.05). 8
2. Informelle Inferenz –
eine Analogie zur Situation in der Medizin
Wir untersuchen die Situation in der Medizin, wo es immer eine
Entscheidung gibt, die dann zu diversen Fehlern führen kann, wie
auch immer die Entscheidung ausfällt.
Ein diagnostischer Test kann mit einem statistischen Test verglichen
werden:
• Dies dient dazu, statistische Tests besser zu verstehen.
• Dies kann auch dazu dienen, die medizinischen Entscheidung
besser zu verstehen und zu untersuchen.
92.1 Trennung der Verteilung einer Variablen zwischen
gesunden und kranken Menschen
gesund
95 %
Referenzbereich
krank 10Trennung der Gruppen: Diagnostischer Test
– +
gesund
korrekt
negativ
falsch
positiv
Spezifität
falsch
negativ
korrekt
Sensitivität
positiv
krank
11Trennung der Gruppen: Statistischer Test
nicht signifikant signifikant
Droge nicht wirksam
P( Test n.s. |
Droge nicht wirksam)
α Typ-I-Fehler
P( Test sig | Droge nicht wirksam)
β Typ-II-Fehler Power oder Macht
P( Test n.s. | Droge wirksam) P( Test sig. | Droge wirksam )
Droge ist wirksam
12Klinische Versuche von Drogen als statistischer Test
nicht signifikant signifikant
Droge ist nicht wirksam
Eine Wirkung der Droge wird
fälschlicherweise angenommen
5%
Die Wirkung der Droge Power oder Macht
wird nicht erkannt 80%
20%
Droge ist wirksam
132.2 Medizinischer Test als Entscheidung
– 2 Stichproben: Placebo (P) , Verum (V)
– Hypothesen: H0: P = V (Nullhypothese)
HA: P V (Alternativhypothese)
– Entscheidung über H0 oder HA
Wirklichkeit
H0 HA
Droge nicht wirksam Droge wirksam
Testentscheidung
korrekt Falsch-negative Entscheidung
Droge nicht wirksam H0
1– a b Konsumentenrisiko
Falsch-pos. Entscheidung korrekt
Droge wirksam HA
α Produzentenrisiko 1–β Power / Macht
Die Anordnung von H0 und HA und der Entscheidungen ist umgekehrt zu zuvor!
14Die Analogie zwischen diagnostischem und statistischen Test
p ( Test + | krank ) Sensitivität
p ( Test sig. | Droge wirksam ) Power oder Macht
Fehlt: wir haben keinerlei Information über:
p ( krank | Test + ) Positiver
Prädiktiver Wert
p ( Droge wirksam | Test sig. )
Abhängig von der Prävalenz
Abhängig von der Qualität
der Forschungshypothesen
15Das fehlende Bindeglied: Prävalenz und die Bayesformel
Mammographie in radiologischer Klinik und im Screening
Ca No Ca Ca No Ca
+ 80 4 84 + 640 3 968 4 608
Sensitivität Falsch pos.
20 96 116 160 95 232 95 392
– –
Falsch neg. Spezifität
100 100 200 800 99 200 100 000
Prävalenz Klinik 50 % Screening 0.8 %
Sensitivität 80/100 = 80.0% 80.0% P (+| Ca)
Spezifität 96/100 = 96.0% 96.0% P (– | No Ca)
Pos.präd.Wert (PPV) 80/84 = 95.2% 13.9% P (Ca| +)
Neg.präd.Wert (NPV) 96/116 = 82.8% 99.8% P (No Ca| –)
162.3 Trennpunkte, um zwischen den Gruppen von
Gesunden und Kranken zu unterscheiden
Immunchem. faecal occult blood test FOBT ng/ml
Spezifität: 18/20 (90%)
3
richtig falsch
negativ positiv
2 No tumour (n = 20)
1 Tumour (n = 20)
falsch richtig
negativ positiv
0
25 50 75 100 125 150
Sensitivität: 17/20 (85%)
Trennpunkt
Cut Cut Cut
Bei diesem Spezifität Sensitivität Welchen Trennpunkt
sollte man für die
Trennpunkt 18 / 20 (90%) 17 / 20 (85%)
Diagnose verwenden?
171 – b = Sensitivität
Dieser Trennpunkt entspricht dem markierten
Punkt auf der ROC
– + ROC
gesund
korrekt a = 1 – Spezifität
negativ
a
falsch 1 – b = Sensitivität
positiv 1 – a = Spezifität
b
falsch 1–b
negativ korrekt
positiv
krank
181 – b = Sensitivität
Dieser Trennpunkt entspricht dem markierten
Punkt auf der ROC
– + ROC
gesund
korrekt a = 1 – Spezifität
negativ
a 1 – b = Sensitivität
Spezifität falsch
1 – a = Spezifität
positiv
b
falsch
1–b
negativ
korrekt
positiv
Sensitivität
krank 191 – b = Sensitivität
Dieser Trennpunkt entspricht dem markierten
Punkt auf der ROC
– + ROC
gesund
korrekt a = 1 – Spezifität
negativ
a
1 – b = Sensitivität
falsch
positiv 1 – a = Spezifität
b
falsch
1–b
negativ
korrekt
positiv
krank
201 – b = Sensitivität
Verschiedene Krankheiten haben
verschiedene Verteilungen und ROCs
gesund ROC
a = 1 – Spezifität
Je steiler die ROC, umso besser.
Eine diagnostische Prozedur sollte
einem Punkt weit oben links entsprechen.
krank
212.4 Einige Schlüsse aus der Analogie zur Medizin Der p-Wert ist nur schwer sinnvoll zu interpretieren. Diagnose von Krankheiten ist ein Entscheidungsproblem, in welchem man die Verteilungen unter dem Szenario von gesund & krank vergleicht. Es sind immer zwei divergierende Fehler im Spiel: • Diagnose der Krankheit, wenn die Person gesund ist. • Nicht-Erkennen der Krankheit, obwohl die Person diese tatsächlich hat. Verschiedene Trennpunkte zur Trennung von gesund und krank bedingen unterschiedliche Größen dieser Fehler. Es gibt Krankheiten, welche leicht zu diagnostizieren sind. Es gibt einen 3. Fehler: Ob die Entscheidung gut ist, hängt nicht nur von den Trennpunkten ab, sondern auch von der Prävalenz der Krankheit. In vielen Fällen erhalten wir nur schlecht interpretierbare Kenngrößen für die Qualität der Entscheidungen. 22
3. Informelle Wege zur statistischen Inferenz
Beispiele
Zwei verschiedene Methoden zur Messung des Mittelwerts
Unbekannte Wahrscheinlichkeiten messen – Weg zum Gesetz der Großen Zahlen
Kleine Risiken, dass einzelne Daten mehr als 2 SD vom Mittelwert abweichen
Stichprobenverteilung des Mittelwerts
Single-choice-Prüfungen – Erfolg unter verschiedenen Szenarios
Lady tasting tea – Einführung in den Signifikanztest
Trennen von guter und schlechter Qualität – Folge einer Ablehnungszahl
Statistische Prozesskontrolle als Exploration von Szenarios – Informelle Tests
Überdeckungswahrscheinlichkeit von Konfidenzintervallen
Explorationen, um Schlüsselbegriffe kennenzulernen; Meta-Wissen jenseits
der Mathematik. Reduzieren der Komplexität, wobei man den Weg zur all-
gemeinen Situation offenhält.
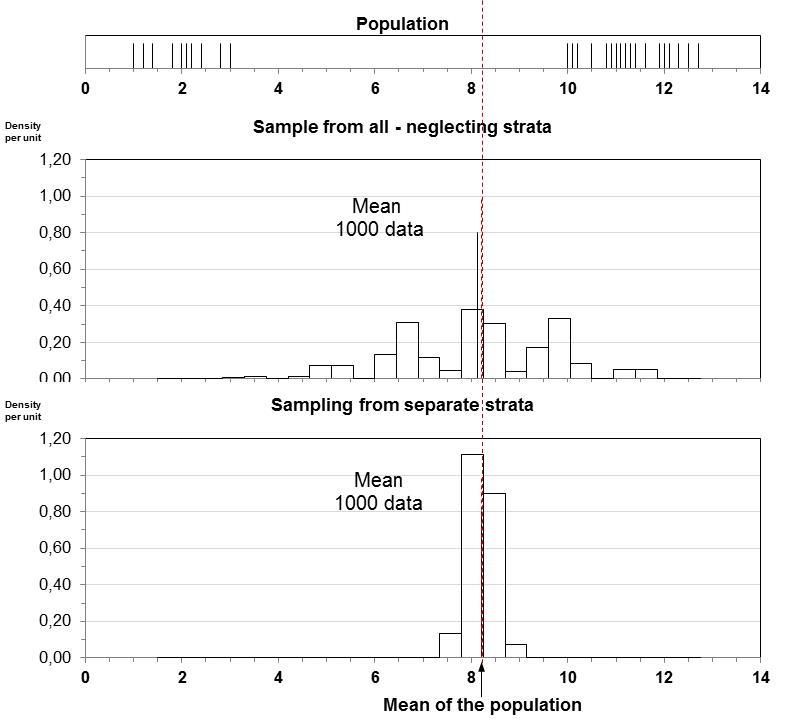
233.1 Zwei Methoden den Mittelwert zu schätzen
Population
0 2 4 6 8 10 12 14
Die Werte der Population sind durch einen Strich dargestellt.
Zwei homogene Schichten werden sichtbar.
Wenn eine solche Schichtung bekannt ist, ist es ratsam, das bei der
Rekrutierung der Stichprobe zu berücksichtigen.
Zufällig: 6 Elemente aus allen, Vernachlässigen der Schichten
Zufällig 2 aus Schicht 1 (kleine Werte) und 4 aus Schicht 2.
Für beide Methoden:
Mittel der simulierten Daten Mittel der Population (unverzerrt).
Schichtenmethode (Methode 2) liefert viel präzisere Ergebnisse.
Die Verbesserung der Schätzung durch die Schichtung im Vergleich
zur einfachen Zufallsstichprobe ist stabil in der Wiederholung. 24Sampling from the population 1. Sample neglecting strata structure of population
Population Size Sample
6
Nr. Strata Data Rd. Nr. Rank Rank Nr. Data
1 1 1,0 0,9 0,2362 18 1 24 11,6
2 1 1,2 0,9 0,3845 12 2 23 11,3
3 1 1,4 0,9 0,1215 26 3 8 2,4
4 1 1,8 0,9 0,2328 19 4 16 10,9
5 1 2,0 0,9 0,1242 25 5 27 12,1
6 1 2,1 0,9 0,6044 10 6 21 11,1
7 1 2,2 0,9 0,1980 22
8 1 2,4 0,9 0,8156 3 Mean 9,90
9 1 2,8 0,9 0,2492 16 St. Dev. 3,698
10 1 3,0 0,9 0,2969 15
11 2 10,0 0,9 0,0758 27
12 2 10,1 0,9 0,0144 30 Parameter of the population
13 2 10,2 0,9 0,6751 7
14 2 10,5 0,9 0,2228 20 Mean 8,21
15 2 10,8 0,9 0,3073 14 St. Dev. 4,457
16 2 10,9 0,9 0,7538 4
17 2 11,0 0,9 0,3248 13 Task
18 2 11,2 0,9 0,2489 17 To estimate the mean of the population by
19 2 11,4 0,9 0,2027 21 the mean of a sample
20 2 11,6 0,9 0,0145 29 The method is judged by the quality of the estimate
21 2 11,1 0,9 0,7024 6 in repeated samples.
22 2 11,2 0,9 0,4284 11
23 2 11,3 0,9 0,9400 2 1000 samples are generated
24 2 11,6 0,9 0,9574 1 To investigate the properties of the estimation.
25 2 11,9 0,9 0,1869 23
26 2 12,0 0,9 0,6579 9 Sampling by drawing without replacement
27 2 12,1 0,9 0,7246 5
28 2 12,3 0,9 0,1400 24
29 2 12,5 0,9 0,0260 28
30 2 12,7 0,9 0,6746 8 25Sampling within strata 1. Sample within strata of population
Population Size Stratum 1 Stratum 2 Sample
6 2 4
Nr. Strata Data Rd. Nr. Rank Rank Nr. Data
1 1 1,0 0,6516 2 Stratum 1 1 10 3,0
2 1 1,2 0,5796 3 2 1 1,0
3 1 1,4 0,2428 7 Stratum 2 1 18 11,2
4 1 1,8 0,3945 6 2 30 12,7
5 1 2,0 0,5015 4 3 13 10,2
6 1 2,1 0,1815 8 4 28 12,3
7 1 2,2 0,4864 5
8 1 2,4 0,1764 9 Mean 8,40
9 1 2,8 0,0709 10 St. Dev. 5,073
10 1 3,0 0,8578 1
11 2 10,0 0,5762 11
12 2 10,1 0,5037 12 Parameter of the population
13 2 10,2 0,8726 3
14 2 10,5 0,6001 10 Mean 8,21
15 2 10,8 0,7414 7 St. Dev. 4,457
16 2 10,9 0,4921 13
17 2 11,0 0,2603 17 Task
18 2 11,2 0,9282 1 To estimate the mean of the population by
19 2 11,4 0,8277 5 the mean of a sample
20 2 11,6 0,2755 16 The method is judged by the quality of the estimate
21 2 11,1 0,2816 15 in repeated samples.
22 2 11,2 0,3335 14
23 2 11,3 0,7034 9 1000 samples are generated
24 2 11,6 0,0229 19 To investigate the properties of the estimation.
25 2 11,9 0,7978 6
26 2 12,0 0,0122 20
27 2 12,1 0,1997 18 Sampling by drawing without replacement
28 2 12,3 0,8321 4
29 2 12,5 0,7215 8 26
30 2 12,7 0,9118 2• Beide Methoden treffen den Parameter im Durchschnitt.
• Die Schichtenmethode liefert viel präzisere Ergebnisse.
273.2 Measuring an unknown probabilityas path to the Law of Large Numbers
3.2 Messen unbekannter Wahrscheinlichkeiten –
Coin Weg
tossing:zu Gesetztheder
investigate GroßenofZahlen
development the relative frequency of heads
n Measure of p
Relative frequencies stabilise 987 0,488
1,0
988 0,489
989 0,488
0,8 990 0,489
991 0,488
0,6 992 0,489
993 0,488
0,4 994 0,489
995 0,488
0,2 996 0,488
997 0,488
0,0 998 0,488
0 200 400 600 800 1000 999 0,487
1000 0,488
The current series can now more fluctuate because of the weight of close to 1000 values.
The limiting curve suggests a great precision of less than 0.5 percentage points of fluctuation.
Yet, a new experiment (F9!) shows another curve with another "limiting point" within +/- 4 % points.
The law of large numbers: relative frequencies "converge" to the unknown probability
The convergence hides: the current results are still completely prone to randomness
What about measuring the unknown probability by short series
and investigate the precision of such a measurement 28Messen einer
Measuring unbekannten
the unknown Wahrscheinlichkeit
probability – Untersuchung
- investigation of the measurement der Präzision
procedure
Series of 5 fluctuate much Series of 10 fluctuate a bit less Series of 20 fluctuate much
1,0 1,0 1,0 less
0,8 0,8 0,8
0,6 0,6 0,6
0,4 0,4 0,4
0,2 0,2 0,2
0,0 0,0 0,0
0 200 400 600 800 1000 0 200 400 600 800 1000 0 200 400 600 800 1000
We see: despite the convergence, the current series of 5 (10, 20) still vary!
This variation decreases if the series of measurement values is longer.
Longer series provide more precise measurements of the unknown probability.
The risk of larger errors decreases with the length of the series. Less values exceed the boundaries.
29Untersuchung der Verteilung der Messfehler
Investigation of the distribution of the measurement errors
Sample size 5 Sample size 10 Sample size 20
Relative frequency
0,4 0,4 0,4
0,2 0,2 0,2
0,0 0,0 0,0
0 0.5 1 0 0.5 1 0 0.5 1
We see the impact of the length of the series. Longer series provide a more reliable measuring "device".
303.3 Small risks that single data are more than two SD away from the mean
3.3 Kleine Risiken, das ein Datum weiter als 2 SD vom Mittel abweicht
Density Normal Distribution - Simulation 1000
per unit First:
0,10 See the great variability in the shape of a normal sample!
0,08
Second:
0,06
Sample Percentage of data within
0,04
size m - 2s and m + 2s:
0,02
1000 95,3%
0,00
-30 -20 -10 0 10 20 30 40 50 50 88,0%
Density Normal Distribution - Simulation 50
per unit
In conclusion:
0,10
about 95% of the data lie within 2 standard deviations
0,08
from the mean; regardless of the values of the parameters.
0,06 If sigma is small, then one piece of data can indicate the
location of the population mean!
0,04
There is a small risk that the distance is larger than
0,02
two standard deviations.
0,00
-30 -20 -10 0 10 20 30 40 50 Third:
For mean values, the normal distribution applies approximately!
31The
3.4 Die sampling distribution ofdes
Stichprobenverteilung the Mittels
mean isist
an artifiziell
artificial distribution
Uniform Population J-Shaped Population
Mean Mean
Population
0 1 2 3 4 5 6 0 1 2 3 4 5 6
Mean Mean
Mean of
Samples
with
5 Data 0 1 2 3 4 5 6 0 1 2 3 4 5 6
Mean Mean
Mean of
Samples
with
20 Data
0 1 2 3 4 5 6 0 1 2 3 4 5 6
The larger the sample, the smaller the variability of the distribution of the mean.
..., the closer the mean of an arbitrary random sample will be to the mean of the population.
32
… the better the normal shape of the distribution of the mean of samples.3.4 Single-Choice Exam
3.5 Single-choice-Prüfungen – Erfolg unter verschiedenen Szenarios
Binomial distribution to model the number of correctly solved items No. Items Success
n Number of Items (questions) n p
p Probability of success (answer the question correctly) 10 0,25 25
Xi i-th item, how is it solved; 1 correct; 0 wrong
P(Xi = 1) = p P(Xi = 0) = 1-p
Distribution of correct answers with 10
Assumptions 0,30= i)
P(X
items
Independence of items; i.e., the probability to answer items Limit to Success at item
pass 0,25
correctly, is independent of answering the other items; e. g.,
P(Xi = 1 and Xj = 1) = p * p 0,20
Success at exam
0,0781
We model answering the items as if we drew balls out of an urn 0,10
N Number of balls in the urn
p Proportion of marked ( = 1 = correct) in the urn
n we draw n balls with replacement 0,00 i
Xi = 1 or 0; depending on ball we draw. 0 10 20
X Xi = number of marked balls = number of correct answers.
X ~ B(n, p) , i. e., is binomially distributed
Plausibility of assumptions
It makes sense to model the number of correctly solved items under the assumption of guessing.
For a learner who has learned relatively much, and should be modelled by a solving capacity p,
the assumptions of the binomial distribution are not really met.
Neither the same solution probability for each item, nor the independence of solving different items.
Yet, as a scenario, the binomial distribution might give insight how to tune the parameters in
a single-choice exam. 33Distribution of correct answers with 10 items Distribution of correct answers with 10 items Distribution of correct answers with 10 items
0,30= i)
P(X 0,30= i)
P(X 0,30= i)
P(X
Limit to Success at item Limit to Success at item Limit to Success at item
pass 0,25 pass 0,55 pass 0,80
0,20 0,20 0,20
Success at exam Success at exam Success at exam
0,0781 0,7384 0,9936
0,10 0,10 0,10
0,00 i 0,00 i 0,00 i
0 10 20 0 10 20 0 10 20
Distribution of correct answers with 20 items Distribution of correct answers with 20 items Distribution of correct answers with 20 items
0,30= i)
P(X 0,30= i)
P(X 0,30= i)
P(X
Limit to Success at item Limit to Success at item Limit to Success at item
pass 0,25 pass 0,55 pass 0,80
0,20 0,20 0,20
Success at exam Success at exam Success at exam
0,0139 0,7507 0,9994
0,10 0,10 0,10
0,00 i 0,00 i 0,00 i
0 10 20 0 10 20 0 10 20
Distribution of correct answers with 100 items Distribution of correct answers with 100 items Distribution of correct answers with 100 items
0,30= i)
P(X 0,30= i)
P(X 0,30= i)
P(X
Success at item Success at item Success at item
0,25 Limit to 0,55 Limit to 0,80 Limit to
pass pass pass
0,20 0,20 0,20
Success at exam Success at exam Success at exam
0,0000 0,8654 1,0000
0,10 0,10 0,10
0,00 i 0,00 i 0,00 i
0 10 20 30 40 50 60 70 80 90 100 0 10 20 30 40 50 60 70 80 90 100 0 10 20 30 40 50 60 70 80 90 100
343.6 Lady tasting tea – Einführung in den Signifikanztest
Eine Dame behauptet, dass sie durch Schmecken erkennen kann, ob Tee
oder Milch zuerst in die Tasse gefüllt wurde.
Wie können wir ein Experiment organisieren, um dies zu prüfen?
Experiment mit 8 Tassen, T und M in zufälliger Reihenfolgen (nicht be-
kannt, wie viele in welcher Reihenfolge) Nullhypothese: Einfach raten.
Ws. für Erfolg (Erraten der Reihenfolge T & M): 1/2 wie beim Münzwerfen.
Wir untersuchen das Experiment
Wir nutzen die Binomialverteilung (n=8, p=0.5).
Oder wir simulieren Werfen einer Münze 8 Mal; und wiederholen
dieses Experiment 1000 Mal und schätzen die Ws. aus den relativen
Häufigkeiten dieses Szenarios.
Wenn wir 6 von 8 Tassen korrekt klassifiziert (75% Erfolg) als Leistung an-
sehen, können wir nun sehen, dass dies ziemlich leicht ist; die Ws. ist 14.5%.
Bei 32 Tassen ist eine Erfolgsrate von 75% und mehr sehr selten: 0.4%.
35Tea-tasting (8 cups) % Number of correct cups by guessing %
Number of correct cups by guessing
No. Proport. abs. rel. 30 30
correct correct frequ. frequ. 8 cups 32 cups
0 0,006 6 0,6
20 20
1 0,125 37 3,7
2 0,250 101 10,1
3 0,375 211 21,1
4 0,500 266 26,6 10 10
5 0,625 241 24,1
6 0,750 110 11,0
7 0,875 24 2,4
8 0,994 4 0,4 0 0
0,00 0,25 0,50 0,75 1,00 0,00 0,25 0,50 0,75 1,00
Total 1000 100
R. A. Fisher arrangierte das Experiment etwas anders.
Er ließ in 4 Tassen zuerst Tee dann Milch eingießen und dann 4 mit Milch
zuerst. Er ordnete die Tassen zufällig an, etwa: TMTT MMTM.
Seine Überlegung beruhte auf einem Re-randomisierungsargument:
Wenn jede Permutation gleich ws. ist – dies entspricht einfach Raten –
dann ist eine von 70 Permutationen korrekt, was bedeutet, es hat eine Ws.
von 1/70 = 1.4%; und 6 oder mehr korrekt entsprechen 4 Mal 1.4 = 5.7%
(es kann nur 8 oder 6 etc. richtige in diesem Arrangement geben).
Fisher begründete den Signifikanztest durch eine Re-randomisierung. 363.7
How Separieren
to separatethe
Investigating guter
good and in
errors &separating
the schlechter
bad quality the Qualitätof–the
- investigation
hypotheses Folgen
of einer
badAblehnungszahl
consequences
good and of a rejection number
quality
Good quality: Process under control Bad quality: Process out of control
Represented by 4% defectives Represented by 10% defectives
We simulate rather than apply the binomial distribution
Null hypothesis 100 B(100, 0.04) Alternative hypothesis 100 B(100, 0.1)
reject if ≥ 8 not reject if ≤ 7
N. of Absolute Relative N. of Absolute Relative
defects frequency frequency defects frequency Frequency
0 68 1,36% 1,36 0,00 0 0 0,00% 0,00% 0,00
1 348 6,96% 6,96 0,00 1 1 0,02% -0,02% -0,02
2 732 14,64% 14,64 0,00 2 5 0,10% -0,10% -0,10
3 991 19,82% 19,82 0,00 3 30 0,60% -0,60% -0,60
4 1015 20,30% 20,30 0,00 4 79 1,58% -1,58% -1,58
5 814 16,28% 16,28 0,00 5 175 3,50% -3,50% -3,50
6 510 10,20% 10,20 0,00 6 311 6,22% -6,22% -6,22
7 296 5,92% 5,92 0,00 7 436 8,72% -8,72% -8,72
8 128 2,56% 2,56 2,56 8 597 11,94% -11,94% -11,94
9 63 1,26% 1,26 1,26 9 678 13,56% -13,56% -13,56
10 25 0,50% 0,50 0,50 10 639 12,78% -12,78% -12,78
11 9 0,18% 0,18 0,18 11 539 10,78% -10,78% -10,78
20 0 0,00% 0,00 0,00 20 5 0,10% -0,10% -0,10
21 0 0,00% 0,00 0,00 21 1 0,02% -0,02% -0,02
5000 100,00% 5000 -20,74
37Investigations of errors in separating the hypotheses of good and bad quality
Fehler beim Separieren der Hypothesen guter & schlechter Qualität
Small sample n = 100 Large sample n = 400
Two types of errors: reject the null even if it applies: not reject the null even if the alternative hypothesis applies
Rejection number currently 8 Rejection number currently 28
Type I error (a) 4,52% Type I error (a) 0,18%
Type II error (b) 20,74% Type II error (b) 1,16%
The rejection number may be shifted to see that the errors are developing in the opposite direction.
The choice of the rejection number balances the diverging interests.
Null hypothesis Null hypothesis
% %
20 Rejection
Rejection 10
10
0
0
-10
No rejection No rejection
-20 -10
0 10 20 0 10 20 30 40 50 60
Alternative hypothesis Alternative hypothesis
38Statistical Process Control as Informal Exploration of Scenarios - Informal Statistical Tests
3.8 Statistische Prozesskontrolle: Exploration von Szenarios – Informelle Tests
Fit to target Deviation from target 20 Deviation from target 40
1100 1100 1100
1050 1050 1050
1000 1000 1000
950 950 950
900 900 900
0 50 100 150 200 0 50 100 150 200 0 50 100 150 200
Scenario 1 Scenario 2 Scenario 3
Deviation from target 0 20 40
SD of process 25 25 25
No of Samples 200 200 200
Within limits W, no W alarm 187 124 6
Within limits C, no C alarm 198 166 32
W alarms rate 0,065 0,380 0,970
C alarm rate 0,010 0,170 0,840
In this scenario, alarms are false alarms. ..., alarms are correct. ..., alarms are correct. wrong
correct
False alarm rate = alpha error False rate of missing = beta error False rate of missing = beta error
39Produktion unter regulären Bedingungen – Alles ist unter Kontrolle
Production under regular conditions - everything is under control, i.e., X ~ N(1000, s2 = 625)
At each control time, inspection involves 5 single items; 200 inspections are simulated (a month).
It is checked how the prescribed control (CL) and warn limits (WL) behave.
Chart for mean values of 5 items Control Limits (CL) Warning limits (WL)
Number of samples 200 200
Samples within the limits, no alarm 199 196
Proportion of samples within the limits, no alarm 0,995 0,980 wrong
Sample rate outside limits, alarm 0,005 0,020 correct
Control chart for mean values of samples of 5 items
1100
1050
CL
WL
1000
WL
CL
950
900
0 20 40 60 80 100 120 140 160 180 200
40Production under deviation from regular conditions - deviation in mean of 20
Produktion unter Abweichungen von regulären Bedingungen – Abweichung im Mittel von 20
At each control time, inspection involves 5 single items; 200 inspections are simulated (a month).
It is checked how the prescribed control (CL) and warn limits (WL) behave.
Chart for mean values of 5 items
Mean values within Control Limits (CL) Warning limits (WL)
Number of samples 200 200
Samples within limits 154 122
Sample rate within limits, no alarm 0,770 0,610 wrong
Sample rate outside limits, alarm 0,230 0,390 correct
Control Chart for Mean Values - Deviation from target value 20
1100
1050
CL
WL
1000
WL
CL
950
900
0 20 40 60 80 100 120 140 160 180 200
41Production under deviation from regular conditions - deviation in mean of 40
Produktion unter Abweichungen von regulären Bedingungen – Abweichung im Mittel von 40
At each control time, inspection involves 5 single items; 200 inspections are simulated (a month).
It is checked how the prescribed control (CL) and warn limits (WL) behave.
Chart for mean values of 5 items
Mean values within Control Limits (CL) Warning limits (WL)
Number of samples 200 200
Samples within limits 30 9
Sample rate within limits, no alarm 0,150 0,045 wrong
Sample rate outside limits, alarm 0,850 0,955 correct
Control Chart for Mean Values - Deviation from target value 40
1100
1050
CL
WL
1000
WL
CL
950
900
0 20 40 60 80 100 120 140 160 180 200
423.9 Überdeckungswahrscheinlichkeit
Demonstration of the coverage probability (confidence von Konfidenzintervallen
coefficient) of confidence intervals
The confidence level (coefficient) relates to the coverage of the unknown parameter if samples are repeated.
Model for the population (single measurement):X ~ N(0, s2 = 16); the variance is unknown.
Repeatedly samples are drawn; i. with 5 data; ii. with 20 data;
for each sample, a confidence interval is calculated for the expected value (which is "known" in the laboratory).
Bars show the repeated confidence intervals. If m (0 in our scenario) lies outside, this will be marked
by a red dot on the axis.
Confidence intervals (CI) based on 5 data - unknown variance % of covering intervals:
10
5
Bar shows CI
ALL SHORT
0
92,5% 80,6%
-5 MIDDLE LONG
-10 97,0% 100,0%
0 50 100 Number of sample150 200
10
Confidence intervals (CI) based on 20 data - unknown variance
ALL SHORT
Bar shows CI
5 95,0% 86,6%
0
MIDDLE LONG
100,0% 98,5%
-5
-10
0 50 100 Number of sample 150 200
The present sample may have an SD above/below average with no clear interpretation of the confidence level.
434. „Informal Inference“ – Eine vereinfachte Inferenz
Inferenz basiert einzig auf vorhandenen Daten – keine theoretische Verteilung
wird unterstellt. Wenn Hypothesen verwendet werden, sind sie “natürlich”.
• Schätzung Bootstrap-Stichproben, um den Fehler zu schätzen
Stichproben aus den Daten mit Zurücklegen.
Anstatt Stichproben aus der wahren Verteilungsfunktion F zu nehmen,
nimmt man sie aus der Schätzung von F, die aus der ersten Stichprobe re-
sultiert.
Bootstrap liefert approximative Intervalle und kann und muss durch andere
Methoden korrigiert werden (BCa, ABC).
• Hypothesentesten Randomisierungstests
Re-randomisierung der Zuordnung zu Gruppen werden verglichen.
Permutationen der Daten oder Stichproben aus den Daten ohne Zurücklegen.
Liefert exakte nonparametrische Tests in einzelnen Fällen.
444.1 Bootstrap-Interval & klassisches Konfidenzintervall
Für das Mittel einer Population
Gegeben: eine Stichprobe vom Umfang n mit Mittel und SD für eine Variable
Wie präzise ist das Mittel aus der Stichprobe als Messung für die Population?
Time = Zeitaufwand für ein Seminar.
Statt wieder aus der Population zu ziehen, was
Raw data 1. Bootstrap
ja unmöglich ist, nehmen wir die Stichprobe aus
Nr Times Nr Times der ersten Stichprobe (mit Zurücklegen).
1 12 10 4
2 2 1 12
3 6 8 4
4 2 9 1 Der erste Bootstrap liefert eine neue Messung
5 19 2 2
6 5 9 1
des Mittels der Population.
7 34 7 34
8 4 5 19
9 1 1 12 Wir wiederholen den Bootstrap und erhalten
10 4 8 4
1000 (oder mehr) artifizielle Messungen.
n Mean Mean
10 8,90 9,30
Wir analysieren diese mit den üblichen
Methoden.
45Bootstrap-Verteilung für das Mittel
Density Bootstrapped means & Bootstrap interval
per unit
95%
0,20
Observed
lower mean upper
0,15
0,10
0,05
0,00
0 5 10 15 20 25
Das ergibt ein Bild der Präzision der Messung des Mittels basierend auf der
ersten Stichprobe. Wir vergleichen die numerischen Resultate mit dem
klassischen Konfidenzintervall.
46Bootstrap-Verteilung für das Mittel
Density Bootstrapped means & Bootstrap interval
per unit
95%
0,20
Observed
95% Bootstrap interval 3,60 15,70
0,15
lower mean upper contains ex. 95% of Bootstrapped means
The Bootstrap interval reflects the precision of
0,10 measurements of the mean of the population
0,05 95% Confidence interval 2,46 15,34
contains population mean in 95% of "repeated"
0,00
0 5 10 15 20 25 samples
Wir sehen eine gute Übereinstimmung beider Methoden.
Natürlich ist die Interpretation ganz unterschiedlich.
474.2 Bootstrap-Intervall für andere Parameter
Der Vorteil des Bootstraps ist, dass die Strategie immer dieselbe bleibt, egal,
um welchen Parameter es sich handelt. Wir zeigen das für die Korrelation.
Gegeben: eine Stichprobe vom Umfang n Paare von Daten. Wie präzise ist
die Korrelation der Stichprobe als Messung für die ganze Population?
Raw data 1. Bootstrap
Statt wieder von der Population zu sampeln,
nehmen wir die Stichprobe aus der ersten
Nr Ca M Nr Ca M
1 105 1247 13 78 1307 Stichprobe (mit Zurücklegen).
2 17 1668 10 84 1359
3 5 1466 11 73 1392
4 14 1800 8 78 1299 Der erste Bootstrap liefert eine neue Messung
5 18 1609 12 12 1755
6 10 1558 7 15 1807 der Korrelation der Population.
7 15 1807 13 78 1307
8 78 1299 9 10 1637
9 10 1637 3 5 1466 Beachte, dass Paare von Daten resampelt
10 84 1359 11 73 1392
11 73 1392 10 84 1359 wurden.
12 12 1755 6 10 1558
13 78 1307 3 5 1466
Wir wiederholen den Bootstrap und erhalten
n r r
13 -0,851 -0,782
1000 (oder mehr) artifizielle Messungen. Wir
analysieren diese mit den üblichen Methoden.
48Bootstrap-Verteilung für die Korrelation
Density Bootstrapped correlations & Bootstrap interval
per unit
8,00
Observed
corr. 95%
lower upper
6,00
4,00
2,00
0,00
-1 -0,8 -0,6 -0,4 -0,2 0 0,2
Das ergibt ein Bild der Präzision der Messung der Korrelation basierend auf
der ersten Stichprobe.
Wir vergleichen die numerischen Resultate mit dem klassischen Konfidenz-
intervall.
49Bootstrap-Verteilung für die Korrelation
Density Bootstrapped correlations & Bootstrap interval
per unit
8,00
Observed
corr. 95% 95% Bootstrap interval -0,97 -0,61
6,00
lower upper
contains ex. 95% of Bootstrapped correlations
The Bootstrap interval reflects the precision of
4,00 measurements of the corr. of the population
2,00
95% Confidence interval -0,95 -0,57
contains population corr. in 95% of "repeated"
0,00
-1 -0,8 -0,6 -0,4 -0,2 0 0,2 samples
Wieder sehen wir eine gute Übereinstimmung beider Methoden. Doch, die
Interpretation unterscheidet sich sehr.
Die Methode des Untersuchens der wiederholten Messungen der Korrelation
durch artifizielle Messungen, die durch Ziehen aus der ersten Stichprobe
entstehen, ist sehr intuitiv.
Was sonst kann man tun, um Hypothesen über die Population zu vermeiden?
504.3 Re-Randomisierungstest für die Differenz von Mitteln
Ist die Behandlung wirksam (im Hinblick auf eine Zielvariable) ? Treatment
group TG bekommt VERUM – control group CG bekommt Placebo.
Re-Randomisierung als Alternative zum Zwei-Stichproben-Test.
Raw data 1. Rerandomisation Unter der Nullhypothesis KEINE DIFF
ist es intuitiv, dass jede Neu-Zuordnung
Nr E Random Nr E
1 69,0 0,48 6 40,0
von Personen zu den Behandlungen
Treatment TG
2 24,0 0,74 5 77,5 KEINEN EFFEKT haben sollte.
new TG
3 63,0 0,17 11 -7,5
4 87,5 0,39 7 9,0
5 77,5 0,26 10 77,5
Daher permutieren wir die Zahlen der
6 40,0 0,36 8 12,0 Personen, sodass die nächste Behand-
7 9,0 0,78 4 87,5
lungsgruppe aus den Personen Nr. 6, 5,
Control CG
8 12,0 0,36 9 36,0
new CG
9 36,0 0,99 1 69,0
10 77,5 0,98 2 24,0
11, 7, 10, und 8 besteht.
11 -7,5 0,16 12 32,5
12 32,5 0,81 3 63,0 Die erste Re-Attribution liefert eine neue
TG 60,17 TG 34,75
Messung der Differenz der Mittel (zur
Mean
CG 26,58 CG 52,00 Messung des Effekts der Behandlung).
Diff 33,58 Effect Diff -17,25
51Re-Randomisierung der Differenz der Mittelwerte unter H0
Density Re-randomisation on the basis of no difference TG
per unit & CG
0,03
0,02
Observed
difference
6,6 %
0,01
0,00
-60 -40 -20 0 20 40 60
Die Verteilung für die Mittelwertdifferenz für die wiederholte Re-attribution
(durch Zufall) ist im Bild enthalten. Sie liefert artifizielle Ergebnisse basie-
rend auf der Hypothese KEINE DIFFERENZ, d.h., der Nullhypothese.
Wir können das Ergebnis der ersten Stichprobe in diese Verteilung einordnen,
um zu unserer Einschätzung zu kommen. 52Re-Randomisierungsverteilung unter der Nullhypothese
Density Re-randomisation on the basis of no difference TG Is the observed difference (of the means) only due to
per unit & CG randomness?
0,03
"what if there is no difference between TG & CG?"
0,02
Observed lower 2.5% upper 2.5% observed p value %
difference
-34,25 35,08 33,58 6,6
6,6 %
two-sided
0,01 t test Welch test
equal unequal variances
2,16 2,16 Test statistic
0,00
-60 -40 -20 0 20 40 60
5,6% 5,9% p value
Wieder ergibt sich eine gute Übereinstimmung mit beiden Methoden.
Die Re-Randomisierung ist überzeugend für die Bedingungen unter der
Nullhypothese.
Aber es gibt keine Möglichkeit, eine Alternativhypothese über die Differenz
im Mittel durch eine Re-Randomisierung zu repräsentieren, weil wir dazu ja
keine Daten haben.
534.4 Re-Randomisierungstest für die Korrelation
Eine Stichprobe für 2 Variable ergibt einen Korrelationskoeffizienten von -0,85.
Können wir behaupten, dass der beobachtete Wert signifikant von Null ver-
schieden ist?
1. Re-sampling based on
Raw data
Corr = 0
Da die Annahme ist, dass
KEINE Korrelation (Corr = 0)
Nr Ca M Rand Rank Ca M
1 105 1247 0,689 4 105 1800 besteht,
2 17 1668 0,489 8 17 1299
3 5 1466 0,919 2 5 1668 können wir die Werte der zweiten
4 14 1800 0,223 13 14 1307 Variablen zur ersten durch eine
5 18 1609 0,541 5 18 1609
6 10 1558 0,303 12 10 1755 Permutation neu zuordnen.
7 15 1807 0,377 11 15 1392
8 78 1299 0,433 9 78 1637
9 10 1637 0,425 10 10 1359 Schon die zweite Neu-Zuordnung
10 84 1359 0,504 7 84 1807 unter Corr = 0 ergibt eine neue
11 73 1392 0,966 1 73 1247
12 12 1755 0,880 3 12 1466 Messung der Korrelation, welche
13 78 1307 0,522 6 78 1558
sehr weit weg ist von der ersten
n r r
13 -0,851 0,384 Stichprobe ist, was andeutet, dass
die Korrelation signifikant ist. 54Re-Randomisierung der Korrelationen unter H0
Re-randomized values for R and 95% intervall
IF R = 0
0,020
initial
0,015 sample
lower upper
0,010
0,005
0,000
-0,90 -0,70 -0,50 -0,30 -0,10 0,10 0,30 0,50 0,70 0,90
Die Verteilung der wiederholten Re-randomierung ist im Bild. Sie zeigt die
artifiziellen Ergebnisse, die auf der Hypothese von KEINE KORRELATION,
d.h., auf der Nullhypothese, basieren.
Wir können das Ergebnis der ursprünglichen Stichprobe in diese Verteilung
einordnen, um unsere Einschätzung zu treffen. 55Re-Randomisierungs-Verteilung unter der Nullhypothese
Re-randomized values for R and 95% intervall
IF R = 0
Distribution of
0,020
re-randomised R's IF Corr = 0
initial
0,015 sample
lower upper 95% Re-random interval -0,56 0,57
0,010
0,005
95% Confid. interval -0,95 -0,57
0,000
-0,90 -0,70 -0,50 -0,30 -0,10 0,10 0,30 0,50 0,70 0,90
Die beobachtete Korrelation liegt weit außerhalb des resampelten Intervalls.
Das klassische Konfidenzintervall ist weit weg von der Null.
Mit beiden Methoden: die Korrelation ist signifikant von Null verschieden!
Die Re-Randomisierung ist überzeugend unter den Bedingungen der Null-
hypothese.
Aber es gibt keine Möglichkeit, die Situation unter irgendeiner Alterna-
tivhypothese über den Wert der Korrelation durch Rerandomisierung zu
repräsentieren. 565. Resümee – Vereinfachung oder Reduktion
“Informal inference” geht viel weiter als informelles Explorieren
stochastischer Modelle durch Simulation; es zielt darauf ab,
traditionelle statistische Inferenz zu ersetzen.
Eine Überlegung zum Ansatz der “Informal Inference”
Konzepte verstehen Lösen von Aufgaben.
Wie soll man mit Wahrscheinlichkeit umgehen? Normalverteilung
weglassen? Und andere Verteilungen (etwa zur Risikoanalyse)? Wie
soll man andere Zugänge und Interpretationen (Bayes) damit verein-
baren, wenn alles durch Simulation erledigt wird.
Modellieren wird in der Simulation absorbiert. Daten werden zu Fak-
ten, während Modelle einem hypothetischen Denken entsprechen.
Re-Randomisierung erlaubt nicht, b-Fehler anzusprechen.
Bootstrap ist intuitiv; aber Korrekturen für die Verzerrtheit der
Schätzungen sind komplex. Bootstrap versagt bei kleinen Wsn.
Wie soll man das Curriculum zu Inferenz / Bayes-Methoden fortsetzen?
Der Zugang engt die Sicht auf Modellieren mit Wahrscheinlichkeiten ein.
57Didaktische Fragen, die durch “Informal Inference” auftauchen:
Die Statistiker nützen immer komplexere Modelle, aber wir haben es
noch nicht geschafft, die einfacheren unter ihnen zu unterrichten.
Wie will man Experten herausfordern, wenn man nur diesen Seiten-
strang statistischer Inferenz kennenlernt?
Soll Statistik für die Sekundarstufe wirklich etwas sein, das nichts
mit Statistik an der Universität und in den vielfältigen Anwendungen,
die in alle Bereiche des öffentlichen und privaten Lebens hereinspie-
len, zu tun hat?
Wollen wir die nächste Generation so ausbilden, dass sie weder die
Expertise wertschätzen noch unsachgemäße Anwendungen kritisie-
ren kann?
Informelle Inferenz
Für exploratorische Wege zum Erforschen der Begriffe in statisti-
scher Inferenz findet man auch Anregungen in Batanero & Boro-
vcnik (2016), oder in meinen statistischen Applets.
ResearchGate: https://www.researchgate.net/profile/Manfred_Borovcnik
Feedback bitte an: manfred.borovcnik@aau.at
58
View publication statsSie können auch lesen

















































