Linked Open Data eröffnet neue Wege in der Forschung und Lehre an Universitäten
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Linked Open Data eröffnet neue Wege
in der Forschung und Lehre an Universitäten
Ausarbeitung zur Seminarreihe
„Semantische Technologien“
Julia Retzlaff, B. Sc.
Betreut durch:
Prof. Dr. Norbert Luttenberger
Arbeitsgruppe Kommunikationssysteme,
Institut für Informatik
September 2013
Christian- Albrechts- Universität, Kiel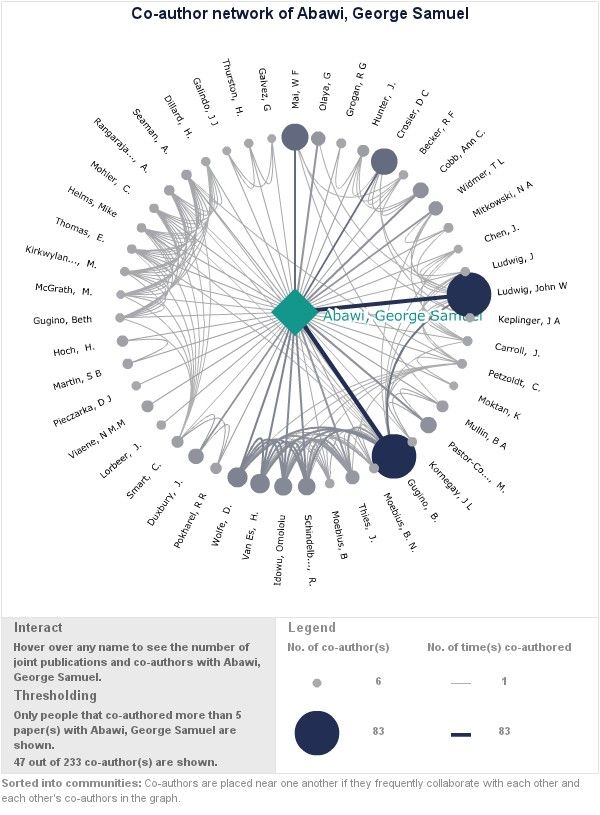
1 Einleitung
Daten bilden die Grundlage der Wissenschaft. Sie sind das Ergebnis von
wissenschaftlichen Experimenten. Sie dienen als Beleg für Annahmen. Der Begriff Daten
ist in diesem Fall sehr umfassend zu verstehen, so zählen auch wissenschaftliche
Ausarbeitungen, und nicht zuletzt die Informationen über die Forscher selbst zu den
Daten, die von den Universitäten erhoben und verwaltet werden.
Der Zugriff auf diese Daten, sowie die Speicherung dieser stellt eine große Hürde
für die Wissenschaft dar. Oft existieren innerhalb einer Fakultät Absprachen über die
Speicherung der Daten, jedoch nicht über diesen Rahmen hinaus. So ist es
beispielsweise mit großem Aufwand verbunden, als Informatiker an die
Forschungsdaten der Biologen zu gelangen. Gerade die Verknüpfung
fächerübergreifender Inhalte und die Zugänglichkeit der Daten sowohl
fakultätsübergreifend als auch universitätsübergreifend ist für die Entwicklung der
Forschung und die Erschließung neuer Forschungsgebiete wichtig. Um dieses Ziel zu
erreichen, kann das Prinzip der Linked Open Data genutzt werden.
2 Linked Open Data
Mit dem Begriff Linked Open Data bezeichnet man Daten, die einer offenen Lizenz
unterliegen und nach vorgegebenen Prinzipien (s. 2.1) untereinander verbunden sind.
Sie werden im Internet publiziert und auf diese Weise öffentlich zugänglich gemacht.
Das Prinzip der Linked Open Data ist ein Bestandteil im semantischen Web. Unter dem
Begriff des semantischen Webs versteht man die Weiterentwicklung des World Wide
Webs von dem Web of Documents hin zu dem Web of Data.
Der Unterschied zwischen diesen Arten des Webs sind die Zielgruppen, für
welche die Inhalte verständlich sein sollen. Während die Inhalte im Web of Documents
nur für Menschen interpretierbar sind, sollen im Web of Data Inhalte sowohl von
Menschen als auch von Maschinen interpretierbar sein. Im Web of Documents ist das
Verlinken ganzer Dokumente die übliche Verfahrensweise, um Zusammenhänge
zwischen Dokumenten herzustellen. Für das Web of Data ist diese Herangehensweise
nicht ausreichend. Um die Bedeutung (Semantik) des beschriebenen Gegenstandes
maschineninterpretierbar darzustellen, ist eine weitergefasste Verfahrensweise
anzuwenden. Um die Vorgehensweise für eine große Zahl von Anwendern des Webs
einfach und einheitlich zu halten, formulierte Sir Tim Berners-Lee, der Begründer des
World Wide Web und Erfinder des Hypertext Markup Language(HTML), im Jahr 2006 die
Linked Data Principles.
2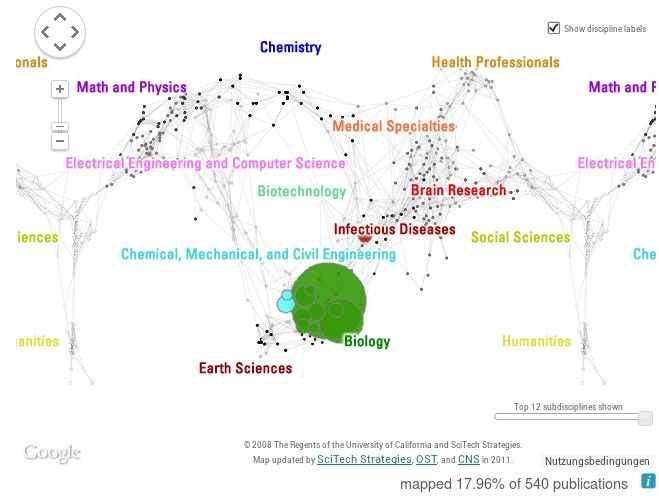
2.1 Linked Data Principles
Tim Berners-Lee formulierte die Linked Data Principles als Leitlinien für die
Veröffentlichung von Daten im Web of Data. In vier Schritten erklärt Berners-Lee die
Grundlagen von Linked Data: Zugrunde liegt die Vorstellung, dass man ein Objekt neu als
Linked Data beschreiben möchte.
Der erste Schritt basiert auf der Nutzung eines Uniform Resource Identifiers
(URI's) für das beschriebene Objekt. Der URI identifiziert das zu beschreibende Objekt.
Im zweiten Schritt wird die Empfehlung auf einen http:// URI weiter
eingeschränkt. Das Hypertext Transfer Protocol (HTTP) kann deferenziert werden. Das
Objekt, welches durch einen http://URI identifiziert wird, kann von jedem Benutzer des
Webs und auch von Maschinen nachgeschlagen werden.
Als dritten Schritt schlägt Tim Berners-Lee das Hinzufügen weiterer
Informationen vor. Dies kann beispielsweise eine Beschreibung zu den dargestellten
Objekten sein. Zur Beschreibung dient das Format des Ressource Description
Frameworks (RDF). Das RDF ist ein Datenmodell für Metadaten, welches durch das
World Wide Web Consortium (W3C) spezifiziert wurde. Es wurde entwickelt um
Informationen für Computer interpretierbar zu machen. Durch vorgegebene
Annotationen im RDF/XML Format wird eine Bedeutung zu Daten hinzugefügt.
Im letzten Schritt der Linked Open Data Principles werden Verlinkungen zu
anderen bereits nach diesen Prinzipien beschriebenen Objekten eingefügt. Durch dieses
Vorgehen entsteht ein Verlinkungsnetz(Graph), welches die
Bedeutungszusammenhänge enthält und maschineninterpretierbar ist.
2.1.1 Beispiel für die Anwendung der Linked Data Principles
Als Beispielobjekt soll diese Ausarbeitung dienen. Sie soll als Linked Open Data
veröffentlich werden. Zur Umsetzung des ersten und zweiten Schrittes muss eine
http://URI erstellt werden. Unter diesem URI wird die Ausarbeitung abgelegt.
Beispielsweise könnte im Namensraum der Arbeitsgruppe Kommunikationssysteme
unter dem Identifier http://comsys.informatik.uni-
kiel/teaching/semantic_technologies/#data dieses Dokument erreichbar sein.
Schritt 3 sieht das Hinzufügen von Informationen zu der Ausarbeitung vor. Diese
werden im RDF Format hinzugefügt unter zur Hilfenahme des Vokabulare Dublin Core.
Vokabulare, wie Dublin Core, Friend-of-a-Friend oder SKOS, bilden einen Wortschatz, der
nach dem Modell von RDF gebildet wurde und von einer großen Gruppe von
Programmierern verstanden wird. Die Angabe des Titels dieser Ausarbeitung „Linked
Open Data eröffnet neue Wege in der Forschung und Lehre an Universitäten“ ist ein
Beispiel für eine zusätzliche Information zu der Ressource. Diese Information wird mit
der Annotation dc:title versehen, welches die Bedeutung angibt, dass es sich um den
Titel handelt bei der angegeben URI. Ein weiteres Beispiel dafür kann eine Annotation
sein, in welcher angegeben wird, dass es sich um einen Foliensatz handelt, der zur
3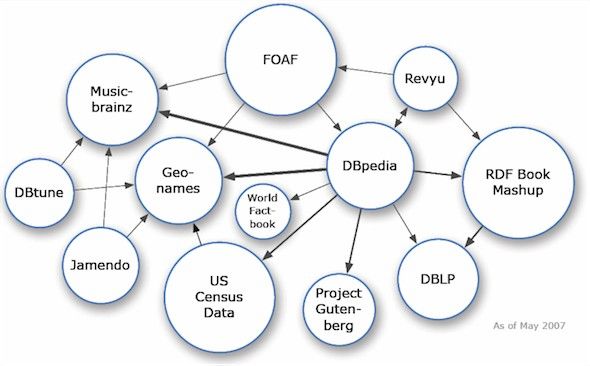
Seminarreihe „Semantische Technologien“ gehört. Um den letzten Schritt der Prinzipien
von Tim Berners-Lee umzusetzen, können Verlinkungen durchgeführt werden: Zum
einen die Angabe, dass es sich bei der Autorin der Präsentationsfolien um Julia Retzlaff
handelt. Wobei zur Identifikation der Person eine http://URI genutzt wird. Und zum
anderen wird der Foliensatz mit einer bestehenden Datenmenge verlinkt. In diesem Fall
mit der dbpedia.org http://URI hinter welcher sich die Beschreibung des Hauptthemas
des Foliensatzes, nämlich „Linked Open Data“ befindet.
Ausarbeitung zur Seminarreihe Linked Open Data eröffnet neue Wege in
„Semantische Technologien“ der Forschung und Lehre an Universitäten
dc:description dc:title
http://comsys.informatik.uni-kiel/teaching/semantic_technologies/#data
dc:subject dc:author
http://dbpedia.org/resource/ http://www.siezgelegenheit.de/
Linked_Open_Data julia_retzlaff.xhtml
Bild 1: Diese Ausarbeitung veröffentlich mit Hilfe der Linked Data Principles.
2.2 Linked Open Data Cloud
Die Linked Open Data Cloud ist das sichtbarste Produkt der Weiterentwicklung des Web
of Documents hin zum Web of Data. Unter diesem Begriff fasst man alle Daten
zusammen, die unter Anwendung der Linked Data Principles in Kombination mit einer
offenen Lizenz publiziert wurden.
Die Linked Open Data Cloud ist ein Produkt des Linked Open Data Projects.
Dieses Projekt wurde im Januar 2007 gegründet. Es wird vom W3C unterstützt und ist
offen, das heißt jeder kann an diesem Projekt teilnehmen. Die Mitglieder des Projektes
unterstützen Menschen bzw. Organisationen bei der Veröffentlichung ihrer Daten in der
Linked Open Data Cloud. Ziel ist es möglichst viele Daten für jeden frei zugänglich zu
machen.
Bereits fünf Monate nach der Gründung des Projektes bestand die Linked Open
Data Cloud aus 12 Datenmengen. Die Datenmengen waren untereinander noch wenig
verlinkt. In den folgenden Jahren wuchs die Anzahl der Datenmengen und auch die Zahl
der Verlinkungen zwischen den Datenmengen stieg stark an.
4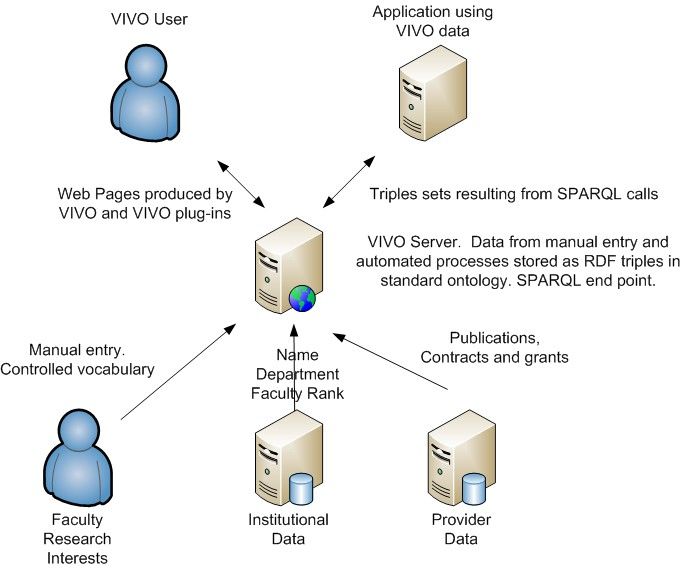
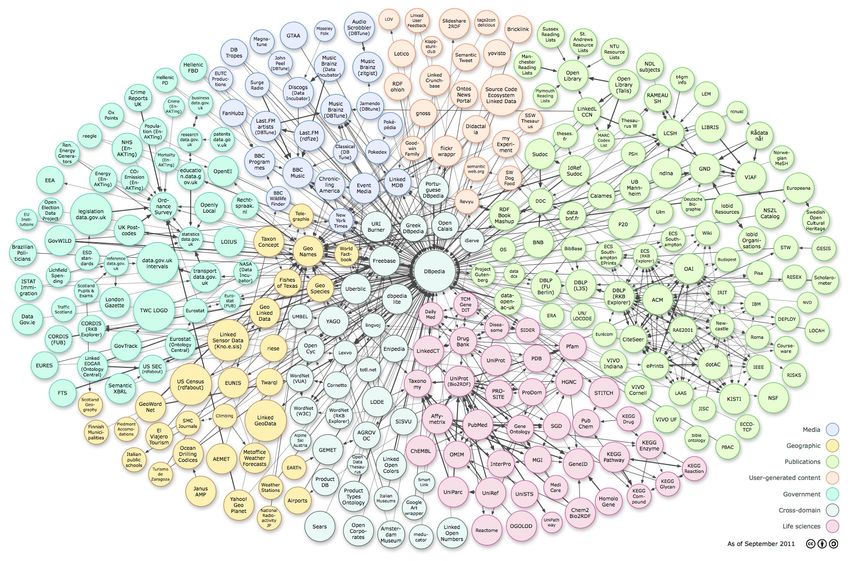
Bis zum September 2011 wuchs die Linked Open Data Cloud auf 295 Datensets.
Sie unterteilt sich zurzeit in 7 inhaltliche Gruppen: Der Bereich „Goverment Data“
enthält Daten über Bevölkerungsentwicklung und Bevölkerungszusammensetzung.
Diese Daten werden von den Regierungen der betreffenden Länder veröffentlicht. Im
Medienbereich befinden sich unter anderem Verzeichnisse über Sänger und Interpreten.
Im Publikationsbereich haben viele Bibliotheken ihre Datenbanken geöffnet. Die „Life
Science Data“ enthält beispielsweise Forschungsdaten aus Versuchen der
Pharmaindustrie. In dem Bereich der „Cross- Domain“ findet sich als bekanntestes
Dataset die Dbpedia. Diese ist eine semantifizierte Version der Wikipedia. Im kleinen
Bereich des „user-generated Content“ befinden sich Datenmengen von einzelnen
Benutzern. Viele stammen noch aus den Anfängen des Web of Data und enthalten
beispielsweise semantifizierte Blogeinträge. Der Bereich Geographie bietet mit
Geonames eine Datenmenge, die Städtenamen mit Ihren Koordinaten verbindet.
Grundsätzlich sind die inhaltlichen Bereiche der veröffentlichten Daten genauso
vielfältig, wie die Daten selbst.
Im August 2013 umfasste die Cloud bereits 337 Datenmengen und es ist
anzunehmen, dass die Cloud noch weiter wachsen wird. Tim Berners-Lee macht in
einem Vortrag bei TED im Februar 2009 deutlich, dass der Nutzen der Linked Open Data
umso größer wird, je mehr Daten in der Linked Open Data Cloud veröffentlicht werden.
Bleibt die Frage, welchen Nutzen uns die veröffentlichten Datenmengen in der Linked
Open Data Cloud bieten und wie wir diese für die Forschung und Lehre an Universitäten
einsetzen können.
Bild 2: Abbild der Linked Data Cloud vom Mai 2007
5Bild 3: Abbild der Linked Data Cloud vom September 2011
3 Zugriff auf Linked Open Data
Eine Datenmenge der Linked Open Data Cloud kann man aus der Programmierer Sicht
als Datenbank oder als Dokument begreifen. Daraus resultieren zwei unterschiedliche
Zugriffsmechanismen auf die Datentriple innerhalb einer Datenmenge: die
Dereferenzierung der URI's und die Anfrage mit SPARQL. Bevor man jedoch auf die
Linked Open Data zugreift und die Daten extrahiert, um beispielsweise eine
Webapplikation mit Inhalten aus der Linked Open Data Cloud anzureichern, muss man
den richtigen Ansatzpunkt finden, in welchem Datensatz man die gewünschten
Informationen findet.
3.1 Online Tools zur Orientierung in der Linked Open Data Cloud
Um in der Linked Open Data Cloud die gewünschten Inhalte zu finden, gibt es eine Reihe
von Online Tools: sindice, sig.ma und relfinder sind Beispiele dafür.
6Exemplarisch wird hier das Tool Sindice näher betrachtet. In der
Benutzeroberfläche von Sindice gibt es die Möglichkeit, nach einem oder mehreren
Begriffen zu suchen. Das Ergebnis zu dieser Anfrage ist eine Liste von http://URIs. In
dieser wird die Anzahl der Triple angegeben, die zu diesem Thema innerhalb der URI
annotiert wurden. Zusätzlich bietet Sindice verschiedene Sichten auf die Datenmengen,
die in der Ergebnisliste auftauchen. Beispielsweise lassen sich die Triple, welche zum
Suchwort passen, zum einen als Liste anzeigen. Eine andere Ansicht ist die Graph Ansicht
der Triple. Außerdem wird eine Liste der von dieser Datenmenge verwendeten
Ontologien angezeigt. Damit kann der Suchende sich ein Bild über den beschriebenen
Inhaltsbereich machen.
Ist die passende Datenmenge gefunden, beispielsweise die dbpedia.org, so stellt
sich vor dem Gebrauch der Inhalte die Frage der Verfügbarkeit dieser Datenmenge.
Denn sowohl eine SPARQL- Anfrage als auch die Dereferenzierung einer http://URI
richten sich immer an einen Server. Damit ist immer auch die Gefahr eines Ausfalls
dieses Servers verbunden. Zur Überprüfung der Verfügbarkeit des betreffenden Servers
bietet sich das Online Tool
[http://labs.mondeca.com/sparqlEndpointsStatus/index.html] an. Es bietet eine
Übersicht über die SPARQL- Endpoint Verfügbarkeit. Das Tool betrachtet die
Verfügbarkeit des jeweiligen Servers im Zeitraum der letzten 24 Stunden und zusätzlich
im Zeitraum der letzten 7 Tage. Bei der Betrachtung der Verfügbarkeit der dbpedia.org,
fällt als erstes auf, das die dbpedia in unterschiedliche SPARQL- Endpoints aufgeteilt ist.
Je nach Region weisen diese SPARQL-Endpoints eine andere Verfügbarkeit auf. Ist ein
verlässlicher Server mit dem passenden Inhalt für die Webapplikation gefunden, muss
sich der Programmierer für eine Zugriffsart entscheiden.
Bild 4: Ausschnitt der Webseite zur Überprüfung der Verfügbarkeit der SPARQL- Endpoints
3.2 Dereferenzierung der http://URI
Entscheidet man sich für eine Dereferenzierung der http://URI durchzuführen, so kann
man dazu beispielsweise das Kommandozeilentool cURL oder die online Variante hURL
7verwenden. Als Beispiel wird hier eine Dereferenzierung mit hURL.it durchgeführt mit
einer DBpedia URL. hURL führt einen HTTP Request mit der angegeben URL durch. Die
Beispiel-URL http://dbpedia.org/resource/Kiel wird dazu in das vorgesehene URL Feld
auf der Oberfläche von hURL.it eingefügt. Außerdem wird die Angabe gemacht, dass der
Inhaltstyp, der bei der Anfrage zurückgegeben wird RDF+XML sein soll. Dies wird
erreicht durch die Verwendung des „Accept“ Feldes bei dem Request. Das Ergebnis
dieser Anfrage sind die RDF Triple, die unter der http://URI verfügbar sind.
3.3 SPARQL- Anfrage
Eine weiter Variante auf die Daten in der Linked Data Cloud zuzugreifen, ist die SPARQL-
Anfrage. Der Begriff SPARQL ist ein rekursives Akronym und ist in der Langform als
Sparql Protocol and RDF Query Language bekannt. SPARQL- Anfragen werden bereits
von vielen gängigen Programmiersprachen, wie Java, PHP, Python oder C/C++
unterstützt. Für Java gibt es beispielsweise das Jena Semantic Web Framework, welches
SPARQL- Anfragen aus einem Programm heraus ermöglicht.
SPARQL ist eine Anfragesprache für RDF, wie man es von SQL für Datenbanken
kennt. Grundsätzlich besteht eine solche Anfrage aus zwei Teilen, einmal aus dem
Schlüsselwort SELECT und dem Schlüsselwort WHERE. Hinter dem WHERE wird das
Anfrage-Pattern eingefügt. Dieses gibt an, was gefragt wird. Der SELECT Teil wird
genutzt, um eine Einschränkung der Ergebnisse zu erwirken. Beispielsweise können die
Anfragen darauf beschränkt sein, nur die Subjekte anzuzeigen. Zusätzlich zu diesen
beiden Hauptbestandteilen einer SPARQL- Anfrage gibt es noch drei weitere Blöcke mit
denen die Anfrage weiter eingegrenzt bzw. spezifiziert werden kann. Diese Teile sind im
Gegensatz zu SELECT und WHERE optional.
Vor dem Schlüsselwort SELECT gibt es die Möglichkeit, eine Prefixdeklaration
vorzunehmen. Innerhalb dieser wird angegeben, mit welchem Vokabular die Anfrage
gestellt wird und wie der Prefix dieses Vokabulares lautet. Vokabulare wie SKOS, FOAF
oder Dublin Core sind zu verstehen als Wortschatz. Sie bilden die Grundlage, um in einer
bestimmten Domaine beschreibende Verknüpfungen für Inhalte zur Verfügung zu
stellen. Diese Vokabulare wurden mit Hilfe von RDF und OWL (Web- ontology Language)
gebildet.
Ein weiteres Pattern der SPARQL-Anfrage kann zwischen dem SELECT und dem
WHERE- Pattern eingefügt werden. Dort kann angegeben werden, von welchem
Datensatz die Anfrage getätigt werden soll, unterstützt durch die zwei Schlüsselwörter
FROM und FROM NAMED .
Hinter dem WHERE-Pattern lassen sich Schlüsselwörter einfügen, mit denen sich
die Frage modifizieren lässt. Beispielsweise kann mit dem Schlüsselwort LIMIT… die
Anzahl der ausgegebenen Antworten begrenzt werden.
Neben der hier beschriebenen Select- Anfrage, welche die Originalwerte vom
SPARQL- Endpoint als Ergebnis in einer Tabelle ausgibt, gibt es noch drei weitere Formen
für SPARQL- Anfragen: die Construct- Anfrage, die Ask- Anfrage und die Describe-
8Anfrage. Jede dieser Anfragearten hat einen eigenen Anwendungsbereich. Die
Construct- Anfrage wird genutzt, um die Informationen aus dem SPARQL- Endpoint in
valides RDF zu transformieren. Die Ask- Anfrage im Gegensatz dazu liefert nur „true“
oder „false“ auf die gestellte Anfrage. Die Describe-Anfrage extrahiert einen RDF-
Graphen aus dem Ergebnis der Anfrage an den SPARQL- Endpoint. Man wählt also die
Struktur der SPARQL- Anfrage nach dem gewünschten Output aus und gelangt so an die
Daten, die von der Datenmenge bereitgehalten werden.
PREFIX foo:
Prefixdeklaration
PREFIX bar:
(optional)
...
SELECT Einschränkung Anfragepattern
Definition Datensatz FROM
(optional) FROM NAMED
WHERE {
Anfrage
}
GROUP BY...
HAVING...
Modifizierer für Anfrage ORDER BY...
(optional) LIMIT...
OFFSET..
BINDINGS...
Bild 5: Struktur einer Select-Anfrage
3.3.1 Beispiel SPARQL- Anfrage an dbpedia.org SPARQL- Endpoint
Es sollen alle Informationen herausgefunden werden, die die dbpedia.org über den Ort
„Kiel“ bereithält. Dazu werden in diesem Beispiel nur die beiden Schlüsselwörter SELECT
und WHERE genutzt. SELECT wird mit dem Sternoperator versehen, das heißt alle durch
das WHERE Schlüsselwort herausgefundenen Ergebnisse werden ausgegeben. Im
Bereich des WHERE- Schlüsselwortes wird das Subjekt, nämlich
angegeben. Dies gibt an nach welchem Subjekt mit
der Anfrage gesucht werden soll. Hinter dem http://URI befindet sich ein ?p und ein ?o,
9die als Platzhalter für die Antworten stehen. Als Ergebnis dieser Anfrage werden alle
Prädikate und Objekte ausgegeben, die mit dem Subjekt „Kiel“ verlinkt sind. Als Ergebnis
auf die wie oben formulierte Anfrage an den SPARQL-Endpoint der dbpedia.org erhalten
wir eine Tabelle, welche die Prädikate und Objekte beinhaltet.
Der Inhalt muss nun noch in eine geeignete Repräsentationsform gebracht
werden, aber die Rohdaten um eine Webapplikation damit zu ergänzen sind mit dieser
Anfrage aus der Linked Open Data Cloud herausgefiltert worden.
SELECT *
WHERE {
?p ?o.
}
Bild 6: Quellcode zur Beispielanfrage aus 3.3.1
4 VIVO Projekt: Anwendung von LOD an Universitäten
Das VIVO Projekt wurde 2003 an der Cornell University Library gegründet und an der
Cornell University implementiert. Es ist eine offene Software. Sie ist darauf ausgerichtet,
Informationen über öffentliche Aspekte der wissenschaftlichen Forschung zu
publizieren. Es verhilft Forschern, Fakultätsmitarbeitern und Studenten die richtigen
Ansprechpartner zu finden und verbessert die Vernetzung der Wissenschaftler
untereinander. Eine interdisziplinäre und fakultätsübergreifende Zusammenarbeit
innerhalb der Universität wird durch VIVO ermöglicht. Bei der Implementierung wurde
ein besonderes Augenmerk auf die Interoperabilität der Daten gelegt. Aus diesem Grund
wurden semantische Technologien bei der Implementierung des Projektes eingesetzt.
4.1 Semantische Webanwendung
VIVO ist ein Open Source Projekt, welches mit Hilfe des Jena Semantic Web Frameworks
implementiert wurde. Es speichert alle Daten unter Verwendung des Ressource
Description Frameworks (RDF) und entspricht damit dem internationalen Standard für
den Austausch von Daten im Internet. Als Basisontologie nutzt das VIVO System die
VIVO Ontologie VITRO. VITRO ist eine Verbindung vieler bereits existierender
Ontologien. Diese Ontologien fokussieren sich darauf, Forscher und ihre
Forschungsaktivitäten sowie ihre sozialen Netzwerke darzustellen. VITRO setzt sich wie
10folgt zusammen: Die Ontologie VIVO CORE bildet die Kernontologie, sie wird erweitert
durch die Ontologien FOAF, EVENT, BIBO, BFO und Science Resources.
Die VIVO-Software bietet drei Werkzeuge für die Datenbearbeitung: den
Ontologie Editor, den Inhaltseditor und die Webseite. Mit dem Ontologie Editor können
neue Ontologien erstellt oder bereits bestehende importiert werden. Der Inhaltseditor
dient dazu, Daten zu integrieren und zu editieren. Die Webseitenansicht präsentiert den
Inhalt, welcher veröffentlicht wurde und lässt authentifizierte Nutzer ihre Inhalte, wie
bei einem Content- Management- System bearbeiten.
4.2 Menschenlesbare Webpage
Sobald die zu veröffentlichenden Daten in das VIVO System eingespeist sind, wird vom
System eine öffentliche Webseite mit Unterseiten erstellt, die beispielsweise die Profile
der Wissenschaftler beinhaltet. Diese menscheninterpretierbare Webpage ist vollständig
anpassbar. Sowohl die angezeigten Themen als auch die Seiteninformationen. Zusätzlich
werden alle Seiteninformationen mit Lucene (lucene.apache.org) indiziert. Die Seiten
werden komplett durchsuchbar.
Die Navigation auf den Webpages des ViVO Systems bietet dem User
verschiedene Ansätze, den gewünschten Content zu finden. Schaut man sich die
typische Aufteilung einer VIVO Webpage an, so offeriert das Hauptmenü Informationen
über Personen, Institute, Forschung und Veranstaltungen. Zusätzlich zu dieser
Navigation wird die oben erwähnte Stichwortsuche angeboten. Gibt man dort einen
Suchbegriff ein, so werden mit dem Stichwort verwandte Beiträge angezeigt. Besonders
zu beachten ist die Möglichkeit, die Suchergebnisse einzuschränken. Am Beispiel des
Cornell University VIVO gibt es die Möglichkeit, die Suchergebnisse auf Personen, Kurse
oder Veranstaltungen zu diesem Begriff einzuschränken. Diese Begrenzung ist nur
möglich, da Annotationen die vorliegenden Texte in ihrer Bedeutung von anderen
abgrenzen. Es handelt sich also um eine Errungenschaft aus der Semantifizierung der
Daten. Eine weitere Methode, welche vom VIVO System erzeugt wurde, um sich auf der
Webpage der Cornell University zurecht zu finden, wird als „Browsen“ bezeichnet. Es
gibt die Möglichkeit zwischen neun Hauptthemen auszuwählen, hinter denen man
jeweils die aktuelle Anzahl der Einträge zu diesem Gebiet sieht. Wählt man zum Beispiel
die Einträge hinter Person, so erscheinen verfeinerte Kriterien, wie beispielsweise
„Faculty Member“ oder „Graduate Student“. Ein Balken zeigt an, wie viele Einträge zu
diesem Bedeutungspunkt vorhanden sind. Die Suchergebnisse des Unterpunktes sowie
alle anderen Webpages kann man sich auch direkt als RDF ausgeben lassen.
Personenprofile sowie Webpages über andere Inhalte können nach einer
Authentifizierung von den „Eigentümern“ selbst bearbeitet werden. So ist eine genaue
Kontrolle und Bearbeitung der veröffentlichten Informationen durch den Forschenden
selbst jederzeit möglich. Das Personenprofil enthält so beispielsweise nur freigegebene
Inhalte des Forschenden. Schauen wir uns als Beispiel das Profil von Professor George
Samuel Abawi von der Cornell University an. Es enthält nicht nur Informationen über
11seinen Werdegang an der Cornell, sondern auch über seine Forschung und Lehre.
Studenten bekommen so die Möglichkeit, sich über seine Lehrveranstaltungen zu
informieren. Institutsfremde finden einen Ansprechpartner, und selbst Informationen
über die einzelnen Publikationen werden bereitgestellt.
Kritisch betrachtet könnte man an diesem Punkt sagen, dass alles ist doch auch
mit einer herkömmlichen HTML basierten Webpage möglich. Eines jedoch hält das VIVO
System noch als herausragende Funktion bereit: die Möglichkeit der Verwendung aller
Daten in anderen Programmen. Diese Funktionalität ergibt sich aus der
maschinenlesbaren Repräsentation der Daten.
Im VIVO System der Cornell University gibt es derzeit drei Arten von
Visualisierungen. Diese werden direkt live auf der Webpage erstellt.
Zum einen ist das die „Co-Autoren“ Visualisierung: Unser Beispiel-Professor hat
540 Publikationen geschrieben mit 47 Co-Autoren. Aus den sematifizierten Daten wird
ein Graph erstellt, welcher von unserem Professoren ausgehend zu den einzelnen Co-
Autoren eine Kante zeichnet. Die Ecke wird umso dicker und farbkräftiger, je mehr
Publikationen der oder diejenige mit unserem Professor zusammen verfasst hat.
Zusätzlich werden auch die Vernetzungen der Co-Autoren untereinander angezeigt. Ein
Export des Graphen ist in GraphML oder als Bild möglich, womit eine Möglichkeit zum
Export der Visualisierung besteht.
Außerdem gibt es bei dieser Anwendung verschiedene weitere Möglichkeiten
die Co-Autoren anzuordnen. Die Visualisierung der Co-Investigatoren ist ganz ähnlich
aufgebaut zu der Visualisierung der Co-Autoren.
Davon unabhängig ist die Visualisierung der „Map of Science“. Diese zeigt durch
eine Landkarte der Forschungsgebiete an, wo das Forschungsgebiet der Person liegt. Die
Landkarte wird aus den Informationen erstellt, welche über die Publikationen gemacht
wurden. Durch farbige Kreise, welche je nach Anzahl der Publikationen in diesem
Bereich auch in der Größe variieren, werden Forschungsschwerpunkte sichtbar.
Visualisierungen, wie die oben aufgeführten, basieren auf den in das System
eingespeisten Daten und es sind noch viele weitere Visualisierungen denkbar. Die
Semantifizierung der Inhalte dient somit nicht nur der Maschinenlesbarkeit, sondern
verbessert auch die Aktualität und Verständlichkeit der Inhalte für den Menschen.
Grafiken werden live erstellt. Sie sind stets aktuell und müssen nicht überarbeitet und
gepflegt werden.
12Bild 7: Abbildung der Co-Authoren live generiert vom VIVO System.
13Bild 8: "Map of Science" aus dem VIVO System der Cornell University.
4.3 Maschinenlesbare Daten
Alle über das VIVO System publizierten Daten sind auch maschinenlesbar. Sie können,
wie oben erwähnt, in anderen Anwendungen verwendet werden. Durch die Anwendung
der Standards der Semantischen Web Technologien, die vom W3C veröffentlicht
wurden, werden die Sachverhalte in ihren Einzelheiten modelliert. Eine Publikation wird
dabei nicht als alleinstehende Entität gesehen, sondern unterteilt sich zum Beispiel in
die Art der Publikation - Buch, Artikel, Journal; in den Autor, Editoren, Übersetzer. All
diese feingliedrigen Einzelheiten bilden eine gut strukturierte Datenbasis. Alle Daten
werden im RDF Format gespeichert. Zusätzlich sorgt das VIVO System dafür, dass für
Daten persistente URI's verwendet werden. Dadurch werden Informationen direkt und
verlässlich verlinkt. Die Benutzung einer VIVO Instanz, um Daten zu veröffentlichen
macht diese Daten im Web feststellbar und nutzbar. Daten mit Hilfe des VIVO Systems
zu veröffentlichen, ist ein Beitrag zur Linked Open Data Cloud.
Die Daten können sowohl von einem anderen Server abgefragt werden über den
SPARQL-Endpoint als auch direkt durch das Speichern der vorliegenden Webpage im
RDF Format. Die RDF- Repräsentation der Daten sind unter derselben http://URI
abgelegt wie die menschenlesbare HTML Version. Die so erlangten Daten können dann
in einer Anwendung weiterverarbeitet werden, da durch die Speicherung im RDF Format
14die Bedeutung der Daten für den Computer erschließbar ist. Beispielsweise kann diese
Vorgehensweise für computergestützte Analysen genutzt werden oder um andere
offene Daten im Web durch den Content zu ergänzen.
4.4 Aufsetzen eines institutseigenen VIVO Systems
Jedes VIVO Projekt unterscheidet sich von jedem anderen. Die Anpassungsmöglichkeiten
und auch die verschiedenen Umfänge der verwendeten Implementierung sind vom
Institut selbst zu wählen. Die bisher an einem Institut bestehenden Datenbanken
können für die Integration der Daten in das VIVO System herangezogen werden. VIVO
zielt darauf ab die Daten aus den bestehenden Systemen des Instituts zu verwenden,
damit kein Mehraufwand bei der Datenpflege entsteht.
Dazu stellt man sich folgenden Aufbau so einer Infrastruktur vor: Es existiert ein
VIVO Server, welcher als Schnittstelle zwischen den inneren Daten und Benutzern und
zwischen den externen Benutzern und anderen Servern steht. Dieser VIVO Server stellt
das System bereit und verarbeitet die gelieferten Daten zu einer menschenlesbaren
Webpage und steht gleichzeitig als SPARQL- Endpoint zur Verfügung, falls ein anderer
Server Daten im RDF Format abrufen möchte.
Die innere Struktur, um dieses System zu speisen, setzt sich wie folgt zusammen:
Zuallererst gibt es die Möglichkeit, Inhalt händisch einzutragen. Dies ist besonders in
kleineren Organisationen und in Organisationen ohne vorhandene maschinenlesbare
Datenhaltung denkbar. In diesem Punkt können beispielsweise die Institutsmitarbeiter
ihre Profile anpassen oder neue Inhalte hinzufügen. Hat die betreffende Organisation
jedoch bereits maschinenlesbare Daten auf anderen Systemen, so können durch
Identifizierung der gebräuchlichen ID's die Daten direkt von diesen inneren Servern vom
VIVO Server abgerufen werden.
Wichtig ist jedoch zu bedenken, welche Informationen nach außen gelangen
sollen bzw. dürfen. Da das VIVO System selbst keine langfristige Datenhaltung betreibt,
muss die Organisation bei der Freigabe ihrer Daten eine Regelung über Identifizierer
innerhalb der internen Datenhaltung finden. Diese müssen angeben, ob die Daten
veröffentlicht werden dürfen.
Jedes VIVO Projekt wird lokal verwaltet. Die offene Software des VIVO Systems,
der Ontologie und die Dokumentationen sind zum Download (unter www.vivoweb.org)
verfügbar. Sie wird ständig weiterentwickelt durch eine offene Community, die sich um
das Projekt herum gegründet hat. Diese Software wird mit der BSD License, der Berkeley
Software Distribution weitergegeben. Dies bedeutet für die Nutzung und
Weiterentwicklung der Software, dass alle Erweiterungen wieder mit dieser Lizenz
weitergegeben werden müssen. Zusätzlich muss die Angabe gemacht werden, dass die
Software ursprünglich von der Cornell University stammt.
15Bild 9: Aufbau einer institutseigenen VIVO Infrastruktur.
4.5 Verbreitung von VIVO
Das VIVO System ist „weltweit“ verbreitet. In 158 Ländern sind VIVO Systeme
vorhanden. Innerhalb dieser Länder sind es zusammen 671 bekannte VIVO Projekte. Die
meiste Anwendung findet diese Open Source Software in Amerika, sowie in Australien.
In Europa hingehen gibt es nur vereinzelte bekannte öffentliche VIVO Systeme. In
England, den Niederladen, Belgien, Polen und Ungarn sind vereinzelt VIVO Systeme
aufgesetzt worden. In Deutschland existiert zurzeit kein öffentliches VIVO System.
5 Bewertung und Ausblick
Das Veröffentlichen von Daten als Linked Open Data bietet dem Nutzer und auch dem
Veröffentlicher selbst viele Vorteile. Im Gegensatz zur herkömmlichen Verfahrensweise
der Veröffentlichung als Dokument, steht die Interpretierbarkeit durch Maschinen bei
16diesem Ansatz im Vordergrund. Die Weiterverarbeitung und auch die Wiederverwertung
der Daten ist durch die von Tim Berners-Lee aufgestellten Linked Data Principles und die
vom W3C herausgegebenen Standards z.B. RDF, möglich. Die einheitliche und
maschineninterpretierbare Struktur der gespeicherten Daten lässt eine
computergestütze Verarbeitung zu. Die offenen Lizenzen, unter denen die Daten
publiziert werden, machen einen Zugriff auf die Daten und deren Verwendung rechtlich
möglich. Diese Vorteile sind besonders für die Daten von Universitäten interessant, da
dort zum einen viele Daten erhoben und gespeichert werden müssen. Außerdem ist in
Universitäten auch ein reger Austausch der Daten zur interdisziplinären
Zusammenarbeit erwünscht. Dieser Austausch fördert die wissenschaftliche Entwicklung
der Universität.
Ein besonderes Augenmerk sollte darauf gelegt werden, welche Daten unter der
offenen Lizenz veröffentlicht werden. Es existieren gerade im Forschungsbereich
sicherheitsrelevante und forschungsrelevante Daten, die nicht ohne weiteres nach
außen gelangen dürfen. Denkbar ist es für diese Art Daten nur eine universitätsinterne
Zugänglichkeit zu gewähren oder die Daten zu einem Zeitpunkt in der Linked Data Cloud
zu veröffentlichen, an dem die eigenen Forschungen bereits weit fortgeschritten oder
abgeschlossen sind.
Eine Anwendung der Linked Open Data an Universitäten ist das VIVO System. Es
erleichtert das Publizieren von Daten in der Linked Open Data Cloud. Es zeigt
eindrucksvoll, wie viele Anwendungsmöglichkeiten es für die nach den Linked Data
Principles von Tim Berners-Lee veröffentlichten Daten geben kann. Es erleichtert die
Suche nach Begriffen auf den Webseiten und ermöglicht eine programmgesteuerte
Analyse von Daten eingebettet in die menschenlesbare Webpage. Diese Software ist
sicherlich auch zur Anwendung an deutschen Universitäten geeignet.
17Literartur- und Quellenverzeichnis
− Heath, T. Hepp, M. and Bicer, C. (eds.). Special Issue on Linked Data,
International Journal on Semantic Web and Information Systems (IJSWIS).
http://linkeddata.org/docs/ijsmis-special-issue
− Tom Heath and Christian Bizer (2011) Linked Data: Evolving the Web into a
Global Data Space (1st edition). Synthesis Lectures on the Semantic Web:
Theory and Technology, 1:1, 1-136. Morgan & Claypool. Chapter 3,6.
− Corson-Rikert, J. , Krafft, D. B., Lowe, B.J.. VIVO: A Semantic Network of
Researchers and Research Information as Linked Open Data
− Corson-Rikert, J.. (2012) VIVO System Architecture and Core Functions, VIVO
Implementation Fest
− Kristi Holmes (2013) VIVO Benefits
https://wiki.duraspace.org/display/VIVO/VIVO+Benefits
− Hausenblas, Dr. Michael (2011) Consuming Linked Open Data from Theory to
Practice, Tutorial at Web Science Doctoral Summer School 2011,
http://webscience.deri.ie
− Berners-Lee, Tim.(2009) The next web.(Vortrag)
http://www.ted.com/talks/tim_berners_lee_on_the_next_web.html
− Krafft, Cappadona, Devare, Lowe (eds.). VIVO: Enabling National Networking of
Scientists
− Hausenblas, M.. Exploiting Linked Data For Building Web Applications, DERI,
National University of Ireland, Galway
18Bildverzeichnis
Bild 1: Diese Ausarbeitung veröffentlich mit Hilfe der Linked Data Principles.
Bild 2: Abbild der Linked Data Cloud vom Mai 2007
http://lod-cloud.net/versions/2007-05-01/lod-cloud.png
Bild 3: Abbild der Linked Data Cloud vom September 2011
http://lod-cloud.net/versions/2011-09-19/lod-cloud_colored.png
Bild 4: Ausschnitt der Webseite zur Überprüfung der Verfügbarkeit der SPARQL-
Endpoints, http://labs.mondeca.com/sparqlEndpointsStatus/index.html
Bild 5: Struktur einer Select-Anfrage
Bild 6: Quellcode zur Beispielanfrage aus 3.3.1
Bild 7: Abbildung der Co-Authoren live generiert vom VIVO System.
http://vivo.cornell.edu/vis/author-network/individual5320
Bild 8: "Map of Science" aus dem VIVO System der Cornell University.
http://vivo.cornell.edu/vis/map-of-science/individual5320
Bild 9: Aufbau einer institutseigenen VIVO Infrastruktur.
Bildauszug aus den Präsentationsfolien von VIVO: Enabling National Networking
of Scientists, Michael Conlon, PhD, Principal Investigator, University of Florida
19Sie können auch lesen

















































