MOLZEB - SS2021 BIOINFORMATIK UEBUNGEN - Dietmar Rieder icbi.atcourses/bioinformatics_ex_2021
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
BIOINFORMATIK UEBUNGEN
MOLZEB – SS2021
Dietmar Rieder
icbi.at/courses/bioinformatics_ex_2021/
Organisatorisches
Termine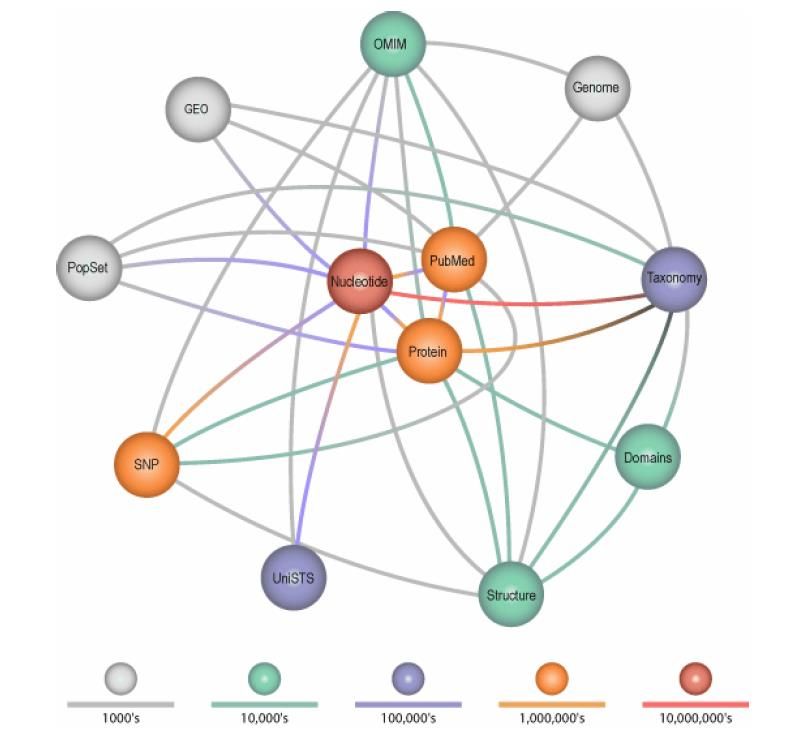
Übungsziele
• Kennlernen biologischer Datenbanken (NCBI, …)
• Arbeiten mit Protein- und DNA/RNA-Sequenzen
• Sequenzalignment (BLAST, ClustalW)
• Arbeiten mit Genome-Browsern (UCSC, Ensembl)
• Arbeiten mit Genexpressions Daten
• Kennenlernen von Clustering Algorithmen
• Finden von TFBS mit Hilfe von PWMs und online tools
• Netzwerkanalyse von Omics Daten
• Klassifikation mittels Gene Ontology
• Selbsttändiges Lösen praktischer Beispiele mit Online-Analyse
Dokumentation der Übung anhand eines Protokolls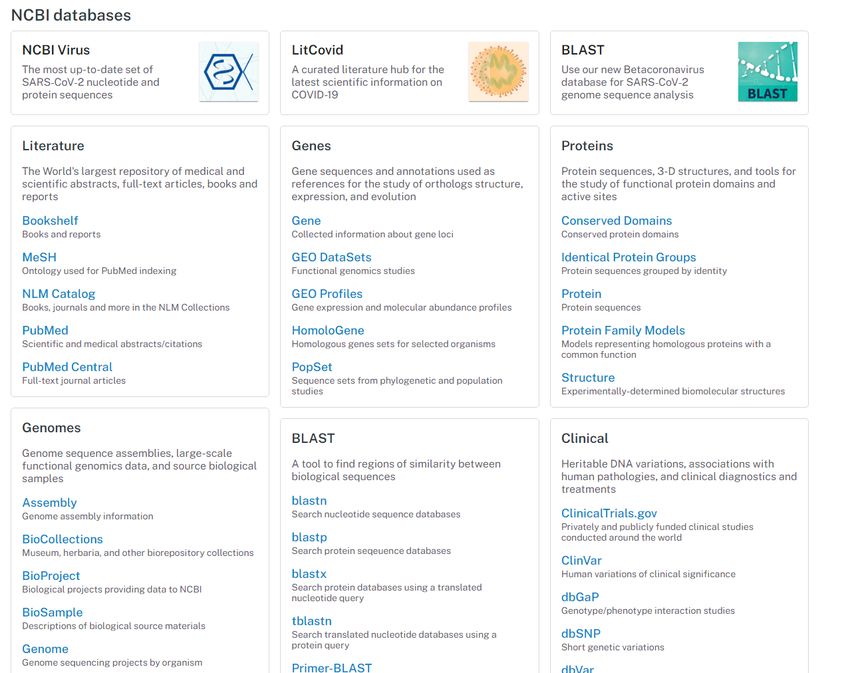
Organisation
• 6 Übungsblöcke
• Kurze Einführung am Beginn eines jeden Blocks
• Erarbeiten der Übungsziele an Hand von Beispielen am
Rechner
• Protokoll:
– 1 Protokoll / 2 Studierende
– Elektronisch als PDF
– Abgabe bis spätestens 11. Juli 2021
– Details siehe:
http://icbi.at/courses/bioinformatics_ex_2021/guidelines.html
Übung I
Einführung, Teil 1
Biologischer Informationsfluss
Biologische Datenbanken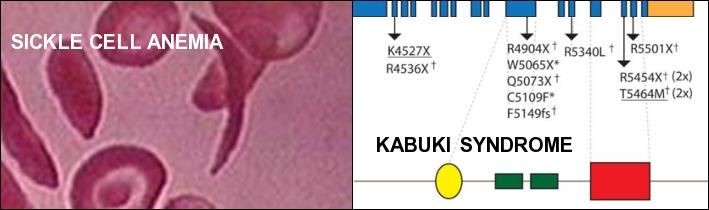
Biologischer Informationsfluss
Biologischer Informationsfluss
...ACCGATGGACCATGACG...
Transkription
...ACCGAUGGACCAUGACG...
Translation
…malwmrllpl lallalwgpd….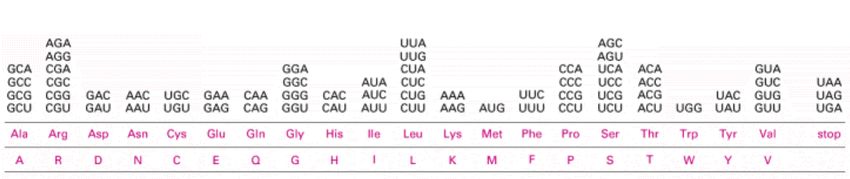
Biologischer Informationsfluss
...ACCGATGGACCATGACG...
Transkription
...ACCGAUGGACCAUGACG...
Translation
…malwmrllpl lallalwgpd….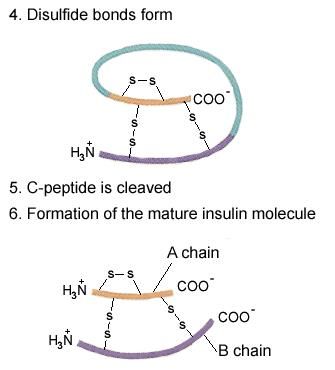
Nomenklatur von Nukleinsäuren Base Symbol Occurrence Adenin A DNA, RNA Guanin G DNA, RNA Cytosin C DNA, RNA Thymin T DNA Uracil U RNA Symbol Meaning Description R A or G puRine Y C or T pYrimidine W A or T Weak hydrogen bonds S G or C Strong hydrogen bonds M A or C aMino groups K G or T Keto groups H A, C, or T (U) not G, (H follows G) B G, C, or T (U) not A, (B follows A) V G, A, or C not T (U), (V follows U) D G, A, or T (U) not C, (D follows C) N G, A, C or T (U) aNy nucleotide
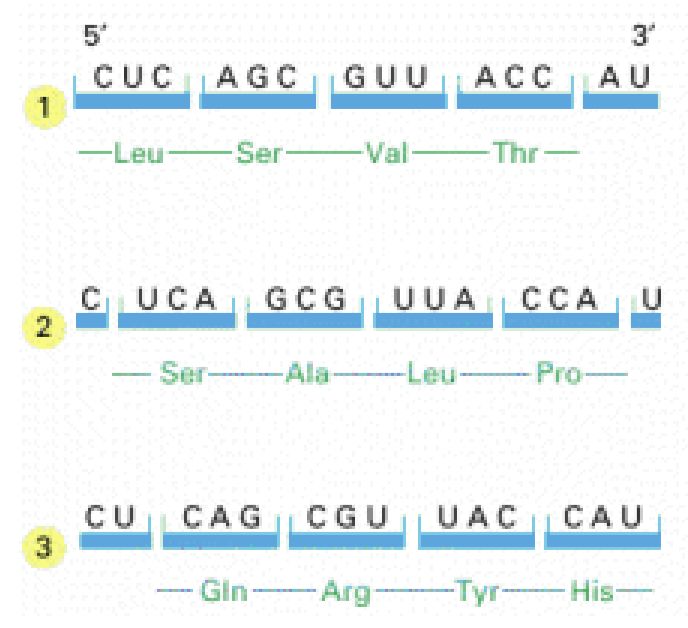
Nomenklatur
DNA sequences are always from 5‘ to 3‘
+ strand 5´-ACGGTCGCTGTCGGTAGC-3´
- strand 3´-TGCCAGCGACAGCCATCG-5´
e.g. in fasta format : >gene sequence|gi12345|chr17|-
GCTACCGACAGCGACCGT
Positions in the genome (genome assembly) are chromosome wise
e.g. human GRCh38/hg38
chr11:1-100 chr11:49,686,777-49,689,777
Positions in the chromosome start for both!! strands from position 1
chr11:1 2523 2529
+ strand 5´-ACGGTCGCTG…………TCGGTAGC-3´
- strand 3´-TGCCAGCGAC…………AGCCATCG-5´
chr11:1 2523 2529Translation, genetic code and reading frames
Peptid chain, amino acid sequence, proteins
backbone
sidechains
Protein sequences are always form N-terminal end to C-terminal end
E.g.. SCD sequence in fasta formatBiologische Datenbanken
OMIM, Locus Link
GenBank (NCBI), DDBJ (CIB), EMBL (EBI)
TRANSFAC, JASPAR
RFAM, RNAdb, clipDB
GenBank (NCBI), SwissPROT, PROSite,
PDB, UniProtBiologische Datenbanken
Weitere Datenbanken:
OMIM, Locus Link
• GeneOntology
GenBank (NCBI), DDBJ (CIB), EMBL (EBI)
• BiologischeTRANSFAC,
PathwaysJASPAR
(Kegg)
• Genexpression (Microarray)
RFAM, RNAdb
• Organismus-spezifisch
• Enzym (Brenda)
• miRNA
GenBankund siRNA
(NCBI), SwissPROT, PROSite, PDB, UniProt
• qPCR primer
• Literatur (Pubmed)National Library of Medicine (NLM)
National Center for Biotechnology Information (NCBI)
• NIH (National Institute of Health)–Campus in Bethesda, Maryland, USA
(gegründet 1836 - Budget ~43 Mrd $ / Jahr)
• NLM weltgrößte med. Bibliothek (budget 2021: 415 Mio. USD)PubMed
• www.pubmed.gov
• Datenbank wurde entwickelt um Zugang zu Zitaten und Abstracts
biomedizinischer Literatur zur Verfügung zu stellen
• 2021 > 32 Mio Einträge von über 5200 Journalen
• > 3.3 Mrd Suchanfragen / Jahr (1.1 Mrd. web, 2.2 Mrd. API)
• PubMed enthält links zu Volltext Artikel
• PubMed ist mit anderen Datenbanken
verlinktGenBank
• Datenbank zur Verwaltung von Sequenzdaten
• Frei zugänglich
• Täglicher Datenaustausch mit EBI und DDBJ (DNA Data Bank of Japan)
• Neuer „Release“ alle zwei Monate
• 2021 > 227 Millionen Sequenzen (>832 Milliarden bp, 2x / 18 Monate)
• > 300.000 Organismen
• > 1150 komplette Genome
• 1987: ̴7 Bände ( ̴ 35 cm) → 2019: ̴ 90,000 Bände ( ̴ 5 km)
Genbank 1987Entrez
Global Query Cross-Database Search System
• Textbasiertes Abfragesystem für > 30 Datenbanken
– PubMed – OMIM
– Nucleotide – Protein
– Gene – dbSNP
– GEO – ...
• Ergebnisse sind vorberechnet und verlinkt
• Mehr als 5.000.000 Suchen pro Tag
• Batchmodus verfügbar
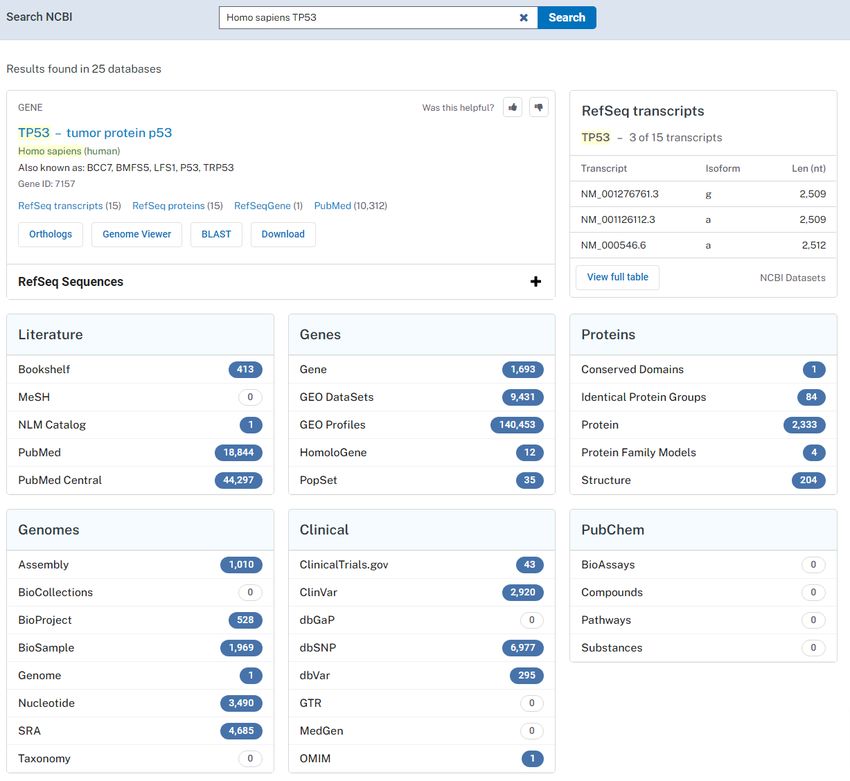
• LinkOut service zu externen DatenbankenSearch (Entrez): Global Query Cross-Database Search System
https://www.ncbi.nlm.nih.gov/search/Search (Entrez): Global Query Cross-Database Search System
RefSeq • Best, comprehensive, non-redundant set of sequences • For genomic DNA (NG_), transcript mRNA (NM_), other RNA (NR_) and protein (NP_) • For major research organisms (91873 organisms present in total) • Based on GenBank derived sequences • Ongoing curation by NCBI staff and collaborators, with review status indicated on each record (computational XM_, XP_)
Gene
• One record represents one single gene from an organism
• Gene-specific information such as map, sequence, expression, structure,
function, homology, publications, links
• Can have one or more Refseq transcripts assigned (NM_)
• Official gene symbol and name, GeneID, aliases and other designationsOMIM • Online Mendelian Inheritance in Men • Bibliographisches, krankheitszentriertes Kompendium • Gene + Phenotypes • Ursprünglich Buchform (MIM, Johns Hopkins University, 1966) • Tägliche Updates • Für Ärzte, Wissenschafter, Studenten und Ausbildner • Links zu vielen Datenbanken (Literatur, Sequenzen...)
Übung I
Einführung, Teil 2
InsulinInsulin
• Polypeptid-Hormon
• Bildung: Betazellen der Langerhansinseln im Pankreas
(Bauchspeicheldrüse)
• 51 Aminosäuren (2 Ketten)
• A mit 21 AS
• B mit 30 AS
• Schweineinsulin (1 AS unterschiedlich)
• Rinderinsulin (3 AS unterschiedlich)
• Glucosetransport in die Zelle und Blutzuckerregulation
• Hemmt in der Fettzelle Lipolyse und fördert Lipogenese
• In Leber und Muskelzelle wird Glykogenaufbau gefördertProinsulin
Vom Preproinsulin zum Insulin
Übung I – Task 1+2 Aufgabenstellungen
Exercise 1 – Task 1: Find difference
between insulin sequence in pig and human
http://icbi.at/courses/bioinformatics_ex_2021/exercise1_task1.htmlExercise 1 - Task 2: Find information on
SICKLE CELL ANEMIA and KABUKI SYNDROM
2.1 Which genes/proteins are involved?
2.2 On which chromosome (arm, cytogenetic band) genes are located?
2.3 What is the position and strand on the human reference genome assembly?
2.4 Can these genes also found in the mouse (location)?
2.5 Are there common mutations i.e. non-synonymous SNPs known?
2.6 What is the function of the encoded proteins?
2.7 Find recent publicationsSie können auch lesen

















































