Angriffe auf Kubernetes Cluster mithilfe von Schwachstellenscannern
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Bachelorarbeit
Angriffe auf Kubernetes Cluster mithilfe von
Schwachstellenscannern
vorgelegt von: Volker Weyandt
Fakultät: Informatik/Mathematik
Studiengang: Informatik (B. Sc.)
Matrikelnummer: 43874
Erstbetreuer: Prof. Dr.-Ing. Jörg Vogt
Zweitbetreuer: Dipl.-Ing.(BA) Jan Starke
Abgabedatum: 27.05.2021
Inhaltsverzeichnis
Inhaltsverzeichnis
Abkürzungsverzeichnis IV
Glossar VI
Abbildungsverzeichnis XI
Tabellenverzeichnis XII
1 Einleitung 1
1.1 Zielsetzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
2 Grundlagen 4
2.1 Kubernetes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.1 Architektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.1.2 Kubernetes Objekte . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.3 Komponenten . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.1.4 API Groups . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.1.5 Authentifizierung . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.1.6 Autorisierung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.1.7 Network Policies . . . . . . . . . . . . . . . . . . . . . . . . . . 18
2.2 Schwachstellenscanner . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
2.2.1 Definition und Funktionsweise . . . . . . . . . . . . . . . . . . . 19
2.2.2 Schwachstellenscanner im Kubernetes Umfeld . . . . . . . . . . 20
3 Aufbau und Methoden des Tests 24
3.1 Aufbau des Testclusters . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.2 Methodik des Tests . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.3 Auswahl der Schwachstellenscanner . . . . . . . . . . . . . . . . . . . . 25
3.4 Bewertung der Scanergebnisse . . . . . . . . . . . . . . . . . . . . . . . 25
4 Angriffsvektoren auf Kubernetes Cluster 26
4.1 Kubernetes Threat Matrix . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.1.1 Initial Access . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.1.2 Execution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
4.1.3 Persistence . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
IInhaltsverzeichnis
4.1.4 Privilege Escalation . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.1.5 Defense Evasion . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.1.6 Credential access . . . . . . . . . . . . . . . . . . . . . . . . . . 41
4.1.7 Discovery . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
4.1.8 Lateral Movement . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.1.9 Collection . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
4.1.10 Impact . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5 Ergebnisse und Diskussion 55
5.1 Ergebnisse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55
5.1.1 Kube-hunter . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56
5.1.2 Kube-bench . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57
5.1.3 Kubeaudit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
5.1.4 Kube-Scan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
5.1.5 Kube-Score . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60
5.2 Diskussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61
5.2.1 Sicht des Angreifers . . . . . . . . . . . . . . . . . . . . . . . . 61
5.2.2 Sicht des Verteidigers . . . . . . . . . . . . . . . . . . . . . . . . 62
5.2.3 Sicht eines Penetrationstesters . . . . . . . . . . . . . . . . . . . 63
6 Zusammenfassung und Ausblick 64
Literatur 65
A Anhang 1
A.1 Kubernetes Threat Matrix . . . . . . . . . . . . . . . . . . . . . . . . . . 1
A.1.1 Bereinigte Threat Matrix . . . . . . . . . . . . . . . . . . . . . . 1
A.2 Kube-Proxy Modes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
A.2.1 user space proxy mode . . . . . . . . . . . . . . . . . . . . . . . 2
A.2.2 iptables proxy mode . . . . . . . . . . . . . . . . . . . . . . . . 2
A.2.3 IPVS proxy mode . . . . . . . . . . . . . . . . . . . . . . . . . . 3
A.3 Authorization Modes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
A.4 YAML-Dateien . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
A.4.1 Labels und Selectors . . . . . . . . . . . . . . . . . . . . . . . . 5
A.4.2 RBAC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
A.5 Vagrant Skripte zur Clustererstellung . . . . . . . . . . . . . . . . . . . . 7
IIInhaltsverzeichnis
A.6 Praktikumsversuch . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
A.6.1 Aufgaben . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
A.6.2 Zusatzaufgaben . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
Erklärung
IIIAbkürzungsverzeichnis Abkürzungsverzeichnis ABAC Attribute Based Access Control. 3, 17 ACI Application Centric Infrastructure. 11 ACR Azure Container Registry. 51 AKS Azure Kubernetes Service. 15, 21, 31, 38, 57 Amazon EKS Amazon Elastic Kubernetes Service. 21 AWS Amazon Web Services. 1 CA Certification Authority. 17 CIS Center for Internet Security. 19, 21, 25, 36, 57, 62, 64 CLI Command Line Interface. 21 CN Common Name. 3, 15 CNI Container Networking Interface. XI, 11, 12, 19, 48, 49 CSR Certificate Signing Request. 15 CSV Comma-separated values. 15, 20 CVE Common Vulnerabilities and Exposures. 29, 64, Glossar: CVE CVSS Common Vulnerability Scoring System. Glossar: CVSS ECR Amazon Elastic Container Registry. 51 ESXi Elastic Sky X integrated. 7, 24, Glossar: ESXi GKE Google Kubernetes Engine. 15, 21, 24, 39, 46, 51, 57 IaC Infrastructure as Code. 24, Glossar: IaC IAM AWS Identity and Access Management. 51, Glossar: IAM ICMP Internet Control Message Protocol. 48 IMDS Instance Metadata Service. 43, 46, 47, Glossar: IMDS IPVS IP Virtual Server. 3, 11 JSON JavaScript Object Notation. 20, 22 JWT JSON Web Token. 15, 16, Glossar: JWT K8s Kubernetes. 4 KCCSS Kubernetes Common Configuration Scoring System. 22, Glossar: KCCSS LDAP Lightweight Directory Access Protocol. 16 LVS Linux Virtual Server. 3, Glossar: LVS IV
Abkürzungsverzeichnis
MITM Man-in-the-Middle-Angriff. 48, Glossar: MITM
MVC Model-View-Controller. 4
NDP Neighbor Discovery Protocol. 49
NIC Network Interface Controller. 53
NVD National Vulnerability Database. 29, Glossar: NVD
OPA Open Policy Agent. 4
PSS Pod Security Standard. 30, 32, 37, 42, 57, 61, Glossar: PSS
RBAC Role Based Access Control. 4–6, 17, 18, 23, 31, 36, 38, 41, 42
RCE Remote Code Execution. 29, 32, Glossar: RCE
RST Reset. 20, Glossar: RST
SEND Secure Neighbor Discovery. 49
SYN Synchronization. 20, Glossar: SYN
SYN/ACK Synchronization Acknowledged. 20, Glossar: SYN/ACK
TCP Transmission Control Protocol. 3, 45
UDP User Datagram Protocol. 3
VETH Virtual Ethernet Device. 12, 48, Glossar: VETH
XDP Express Data Path. 53, Glossar: XDP
YAML YAML Ain’t Markup Language. 6, 13, 18, 22, Glossar: YAML
VGlossar
Glossar
Ansible Ein Open-Source Automatisierungstool zur Softwareverteilung, Kommandoaus-
führung und Konfigurationsmanagement und soll das Design Infrastructure as code
(IaC) umsetzen. 1, 24
ARP Poisoning Bezeichnet einen Netzwerkangriff bei dem gefälschte ARP-Pakete ge-
sendet werden. Dies erfolgt mit dem Ziel, dass die ARP-Tabellen im Netzwerk ver-
ändert werden sollen um den Datenverkehr zwischen zwei Mitgliedern des Netzes
manipuliert werden kann. 1, 48, 49
Bearer Token Ein Bearer Token ist nicht an ein Objekt oder eine Identität gebunden, der
Besitzer des Tokens gilt unmittelbar als Inhaber. 1, 15, 16, 28, 41, 42, 61
Bootstrap Token Ein Bootstrap Token ist ein als Secret im kube-system Namespace
gespeichertes Token. Diese werden vom TokenCleaner Controller einem Controller
innerhalb des Controller Manager dynamisch erstellt und entfernt. Ein Bootstrap
Token besitzt die folgende Form: [a-z0-9]{6}.[a-z0-9]{16}. Der Token
ist in zwei punktgetrennte Komponenten geteilt, der erste Teil beinhaltet die ID die
zweite das Secret[26]. 1, 15
Cgroup Mithilfe von CGroups lassen sich, unter Linux Betriebssystemen, Ressourcen
von Prozessen oder Threads administrativ beschränken. 1, 7
CI/CD-Pipeline Eine CI/CD (Continuous Integration/Continuous Delivery) Pipeline stellt
im Bereich DevOps den gesamten Prozess von der Softwareentwicklung bis zur
Softwarebereitstellung dar. 1, 64
ConfigMap Ein Kubernetes Objekt das verschiedene Konfigurationen für Applikatio-
nen speichert. Es enthält beispielsweise bei einer Datenbankanbindung die Verbin-
dungsparameter oder zusätzliche Umgebungsvariablen. 1, 8, 49
Container Registry Eine Container Registry ist ein Dienst der alle Arten von Container
Images speichert und verwaltet. Sie sind nicht zu verwechseln mit einem Contai-
ner Repository, bei dem es sich um eine Sammlung von Images mit dem gleichen
Namen aber unterschiedlichen Tags handelt. 1, 5, 27, 28, 50, 51
Container Runtime Eine Container Runtime ist eine Software die benutzt wird, um Con-
tainer Images auszuführen. Die bekanntesten Beispiele hierfür sind die Docker
Runtime oder die Containerd Runtime. 1, 50, 52
CoreDNS Ein Kubernetes Plugin, welches die Kubernetes DNS-Based Service Discove-
ry Specification implementiert. 1, 49
VIGlossar
CVE Das Common Vulnerabilities and Exposures (CVE) ist ein Industriestandard der
eine einheitliche Namenskonvention für Sicherheitslücken und Schwachstellen im
IT-Umfeld umsetzt. 1, 29
CVSS Das Common Vulnerability Scoring System (CVSS) ist der Industrie-Standard für
die Risikobewertung von Schwachstellen. 1
DeamonSet Ein Kubernetes Objekt, welches eine Pod Definition enthält und ermöglicht,
diese automatisch auf jedem Node auszuführen zu lassen. 1, 10, 11, 40
DevOps Ansatz wie die Softwareentwicklung „Dev“ (Development) und der IT-Betrieb
„Ops“ (IT-Operations) kombiniert werden kann. 1, 4
ESXi Beim VMware Elastic Sky X integrated (ESXi) handelt es sich um einen Typ1-
Hypervisor also einem Bare-Metal-Hypervisor der das VMkernel Betriebssystem
nutzt und damit unabhängig von anderen Betriebssystemen eingesetzt werden kann.
1, 24
False Positive Test- oder Scanergebnisse bei denen fälschlicherweise ein positives Er-
gebnis beim Testen von Kriterien oder Zuständen angezeigt wird.. 1, 20
Helm Ein weit verbreiteter Package Manager für Kubernetes der von der Cloud Native
Computing Foundation (CNCF) gepflegt wird. 1
Hypervisor Als Hypervisor wird eine Software bezeichnet, die es ermöglicht virtuelle
Maschinen, die unabhängig vom Betriebssystem des physischen Computers sind,
auszuführen. 1, 24
IaC Infrastructure as Code (IaC) nennt man den Ansatz bei dem mithilfe von Code als ei-
nem beschreibenden Modell, bei jedem Ausrollen, analog zu dem Kompilieren von
Quellcode bei dem die gleiche Binärdatei erzeugt wird, jedes mal eine identische
Infrastrukturumgebung erstellt wird[17]. 1, 24
IAM Eine Identity and Access Management (IAM) Rolle wird in der AWS Cloud ver-
wendet um Identitäten bestimmten Berechtigungen zuzuweisen. 1, 51
IMDS Ein Instance Metadata Service (IMDS) stellt Metadaten in Cloud Umgebungen zur
Verfügung. 1, 43
IP Spoofing Ist eine Angriffsmethode mit der versucht wird die Absenderkennung in IP-
Datenpaketen zu verändern. Damit soll es für den Angreifer möglich werden, sich
als ein vertrauenswürdiger Rechner zu tarnen. 1, 48, 49
VIIGlossar
JWT JSON Web Token (JWT) ist ein auf JSON basierendes genormtes Access-Token. 1,
15
KCCSS Des Kubernetes Common Configuration Scoring System (KCCSS) ist ein Open-
Source Framework zur Sicherheits-Risikobewertung in Kubernetes Clustern. Die
Bewertung drückt sich in einem Wert von 0 (Kein Risiko) bis 10 (Hohes Risiko)
aus und ähnelt dem Common Vulnerability Scoring System (CVSS)[20]. 1, 22
Kerberos Ein Authentifizierungsprotokoll für Computernetzwerke. Kerberos ist beispiels-
weise der Standard Authentifizierungsdienst in Microsoft Active Directory-basierten
Netzwerken. 1, 16
Kubeconfig Hierbei handelt es sich um eine Kubernetes Konfigurationsdatei die Daten
über die Benutzer Authentifizierung, beispielsweise den Pfad zu den Zertifikaten
des jeweiligen Benutzers, enthält. Diese werden beim Aufruf von kubectl abge-
rufen. 1, 16, 28
kubectl Command Line Tool für Kubernetes Anfragen an den Kube-API Server. 1, 16
LVS Linux Virtual Server (LVS) ist eine Linux-Kernel Erweiterung zur Lastverteilung
durch die transparente Zuweisung von Anfragen an verschiedene Server über den
Netzwerkstack. 1, 3
MITM Ein Man-in-the-Middle-Angriff (MITM) ist eine Angriffsmethode innerhalb von
Rechnernetzen. Dabei befindet sich der Angreifer zwischen zwei Kommunikations-
partnern innerhalb eines Computernetzwerkes und ist in der Lage den Datenstrom
zwischen diesen Partnern abzuhören oder zu manipulieren. 1, 48
Netfilter Softwareschicht innerhalb des Kernel space, die Kernel Modulen erlaubt call-
back Funktionen für den Kernel Netzwerk Stack aufzurufen. Es ermöglicht bei-
spielsweise Paketfilterung, Network Address Translation (NAT) oder Portweiterlei-
tung. 1–3
Nmap „Network Mapper“ (Nmap) ist ein Open Source Werkzeug zum Portscan und ist
zudem in der Lage Informationen über die Hostattribute oder die ausgeführte Ap-
plikation zu sammeln. 1, 29, 33, 45, 61
Node Ein Node ist ein physischer oder virtueller Server auf dem Kubernetes Komponen-
ten ausgeführt werden.. 1, 3, 5, 8, 17, 35
NVD Die National Vulnerability Database (NVD) ist das Repository der US-Regierung
für standardbasierte Schwachstellenmanagementdaten[18]. 1, 29
VIIIGlossar
On-Premises Cluster Ein On-Premises Cluster oder auch On-Prem Cluster ist ein Clus-
ter, der im Gegensatz zur Cloud Infrastruktur innerhalb des eigenen Rechenzen-
trums betrieben wird. 1, 7, 50, 62
Pretexting Beschreibt einen Social Engineering Angriff bei dem das Opfer meist durch
ein fiktives Szenario manipuliert werden soll, vertrauliche Daten preiszugeben oder
den Angreifer Zutritt zu zugriffsbeschränkten Systemen zu gewähren. 1, 26
Privilege Escalation Beschreibt einen Angriff bei dem durch die Ausnutzung eines Bugs,
eines Konfigurations- oder Designfehlers, der Angreifer in der Lage ist, sich höhere
Rechte wie zum Beispiel root Rechte zu verschaffen. 1, 21
PSS Ein Pod Security Standard (PSS) beschreibt sicherheitsrelevante Bedingungen, die
eine Pod Definition erfüllen muss und ersetzt die in älteren Versionen von Kuberne-
tes bekannten Pod Security Policies (PSP). Pod Security Standards werden mithilfe
von Admission Controllern durchgesetzt. 1, 30
RCE Remote Code Execution (RCE) nennt man eine Sicherheitslücke von IT-Systemen
die es Angreifern erlaubt, beliebigen Code auf dem Host Rechner auszuführen. 1,
29
ReplicaSet Ein Kubernetes Objekt, das Pods die redundant vorgehalten werden sollen
gruppiert. Wird automatisch bei der Erstellung von Deployments angelegt, falls die
Option replicas mit einem gültigen Wert gesetzt ist. 1, 8, 10, 40
RST Ein RST (Reset) TCP-Paket, dass zum Zurücksetzen der Verbindung beim TCP-
Handshake genutzt wird. 1, 20
Secret Ein Secret ist ein Kubernetes Objekt in dem vertrauliche Informationen wie Pass-
wörter, OAuth Tokens oder SSH Keys gespeichert werden können[35]. 1, 8, 41–43,
50
ServiceAccount Ein eingeschränkter Maschinenaccount, der für Pods erstellt wird, die
Anfragen an den API-Server stellen müssen. 1, 8, 14–16, 18, 23, 41, 42, 61
SessionAffinity ist eine Lastverteilungsstrategie bei der ein HTTP Request analysiert
wird und versucht wird die Session an den gleichen Pod weiterzuleiten. 1, 2
SYN Ein SYN (Synchronization) TCP-Paket bei dem das Synchronization-Bit gesetzt ist
und bei einem TCP-Handshake den initialen Verbindungswunsch darstellt. 1, 20
SYN/ACK Ein SYN/ACK (Synchronization Acknowledged) TCP-Paket, das als positi-
ve Bestätigung des SYN-Paketes vom Server an den Client während des TCP-
Handshakes gesendet wird. 1, 20
IXGlossar
TLS termination Proxy Dient als Vermittlungs- oder Endpunkt beim Einrichten von TLS-
Tunneln zwischen Server- und Clientanwendungen. 1, 13
Vagrant Ist ein von HashiCorp entwickeltes Tool zur Automatisierung des Bauens und
Verwaltens von Virtual Maschine (VM) Umgebungen mithilfe von Skripten[12]. 1,
24
VETH virtuelle Ethernet Schnittstellen (VETH), die als Tunnel zwischen Netzwerk Na-
mespaces fungieren. 1, 12
XDP Der Express Data Path (XDP) ist eine programmierbare Netzpaketverarbeitung die
meist zum schnellen Filtern von Paketen verwendet wird. Dabei werden die Da-
tenpakete nicht entpackt und ausgewertet sondern nur die wichtigsten Felder im
IP-Header ausgelesen. 1, 53
YAML YAML Ain’t Markup Language (YAML) dient ähnlich wie JSON zur Serialisie-
rung und Speicherung von Daten in einfacher menschenlesbarer Form. 1, 6
XAbbildungsverzeichnis
Abbildungsverzeichnis
1.1 Marktanteil von Orchestration Plattformen[8] . . . . . . . . . . . . . . . 1
1.2 Kubernetes Threat Matrix[38] . . . . . . . . . . . . . . . . . . . . . . . 2
2.1 Security als TOP-Herausforderung in Container Umgebungen[13] . . . . 5
2.2 Kubernetes Architektur im Überblick . . . . . . . . . . . . . . . . . . . 6
2.3 Übersicht zweier durch CNI verbundenen Nodes[36] . . . . . . . . . . . 12
2.4 Zwei Applikationen werden über Ingress veröffentlicht . . . . . . . . . . 13
2.5 Aufbau von API-Groups in Kubernetes . . . . . . . . . . . . . . . . . . . 14
2.6 Authentifizierung mithilfe von OpenID Connect Tokens[26] . . . . . . . 16
2.7 Übersicht der Kubernetes X.509 TLS-Authentifizierung . . . . . . . . . . 17
XITabellenverzeichnis
Tabellenverzeichnis
1 Scanergebnisse Kube-hunter (Version 0.5.0) bei Scan innerhalb des Clusters 56
2 Auswertung Kube-hunter . . . . . . . . . . . . . . . . . . . . . . . . . . 56
3 Scanergebnisse Kube-bench (Version 0.6.0) . . . . . . . . . . . . . . . . 57
4 Auswertung Kube-bench . . . . . . . . . . . . . . . . . . . . . . . . . . 57
5 Scanergebnisse Kubeaudit (Version 0.14.0) . . . . . . . . . . . . . . . . 58
6 Auswertung Kubeaudit . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
7 Scanergebnisse Kube-Scan (Version 20.5) . . . . . . . . . . . . . . . . . 59
8 Auswertung Kube-Scan . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
9 Scanergebnisse Kube-Score (Version 1.11.0) . . . . . . . . . . . . . . . . 60
10 Auswertung Kube-Score . . . . . . . . . . . . . . . . . . . . . . . . . . 60
XII1 Einleitung
Die Containervirtualisierung spielt in immer mehr IT-Infrastrukturen eine zentrale Rolle.
Unternehmen werden hierdurch befähigt, eine hohe Flexibilität, Skalierbarkeit und Dyna-
mik durch die Verbindung verschiedener Technologien über den gesamten Lebenszyklus
ihrer Anwendungen hinweg zu erreichen.
In einer Architektur, die auf Container-Deployments basiert, den sogenannten Microser-
vices werden Anwendungen unabhängig von ihrer jeweiligen Systemumgebung.
1.1 Zielsetzung
Kubernetes ist eine sogenannte Orchestration Software. Diese dient zur automatisierten
Bereitstellung, Skalierung und Verwaltung von Container Anwendungen.
Da Kubernetes in Zusammenarbeit mit der Container Virtualisierungslösung Docker den
de-facto Industrie Standard für solche Lösungen darstellt, gewinnt es immer mehr an Ver-
breitung. Sämtliche führenden Cloud-Plattformen wie z.B. Microsofts Azure, Amazon
Web Services, Google Cloud Platform oder IBM Cloud unterstützen die Orchestrierung
mittels Kubernetes.
Abbildung 1.1: Marktanteil von Orchestration Plattformen[8]
Daraus abgeleitet bietet Kubernetes also aus der Sicht eines Angreifers ein potenziell
lohnendes Angriffsziel. Daher ist es für Unternehmen die Kubernetes Cluster einsetzen
11 Einleitung
entscheidend, die Komplexität des Systems zu verstehen sowie die damit einhergehenden
Sicherheitsrisiken.
Die T-Systems Multimedia Solutions GmbH, an der diese Bachelorarbeit entsteht, bietet
in ihrem Leistungsportfolio Penetrationstests an. Da Kunden vermehrt Kubernetes einset-
zen und im Rahmen des Tests auch die Sicherheit ihres Clusters überprüft werden soll,
benötigen die Penetrationstester möglichst automatisierte Werkzeuge, um in dem meist
knappen Testzeitraum in der Lage zu sein, ein solch komplexes System vollumfänglich
testen zu können.
Hierzu hat Microsoft im Jahre 2020 nach Vorlage des MITRE ATT&CK® Frameworks
der Mitre Corporation die erste Version einer Matrix1 erstellt, die einerseits Ziele eines
potenziellen Angreifers aufzeigt als auch mögliche Angriffsvektoren, um diese zu errei-
chen. Schon im Jahre 2021 wurde die zweite Version dieser Matrix veröffentlicht. Dies
verdeutlicht zusätzlich die rasante Entwicklung im Umfeld von Kubernetes besonders in
Bezug auf Security.
Abbildung 1.2: Kubernetes Threat Matrix[38]
1 Siehe A.1
21.1 Zielsetzung
In dieser Arbeit soll durch eine quantitative Literaturrecherche Open Source Schwach-
stellenscanner als Werkzeuge identifiziert, die Funktionsweise von Kubernetes sowie von
darauf ausgelegten Schwachstellenscannern ergründet und dadurch prinzipielle Möglich-
keiten eines Angriffes auf Kubernetes Cluster gezeigt werden.
Um herauszufinden, ob die in der Matrix genannten Schwachstellen durch die Werkzeuge
gefunden werden, wird eine qualitative Untersuchung durchgeführt, bei der die praktische
Anwendung der Werkzeuge auf verwundbaren Clustern gezeigt werden soll.
Die Ergebnisse sollen zeigen, ob aktuelle Schwachstellenscanner in der Lage sind, die in
der Matrix aufgestellten Sicherheitslücken zu erkennen. Auf Grundlage dieser Daten soll
diskutiert werden, inwiefern deren Einsatz die Erfolgsaussichten eines Angriffes oder der
Abwehr eines solchen erhöht.
32 Grundlagen 2 Grundlagen 2.1 Kubernetes Kubernetes (griechisch für ’Steuermann’, auch als K8s bezeichnet) wurde zunächst von Google entwickelt und zum Zeitpunkt der Veröffentlichung der Version 1.0, am 21. Ju- li 2015, an die Cloud Native Computing Foundation gespendet.[24] Bei der Entwicklung wurde es stark durch die Google interne Cluster-Management Software Borg beeinflusst.[6] Das Hauptziel der Entwicklung war es, den Nachteilen der klassischen monolithischen Architektur durch möglichst hohe Flexibilität und Erweiterbarkeit zu begegnen. Obwohl auch traditionelle Software meist auf Basis von Model-View-Controller (MVC) Modellen entwickelt wird und damit grundsätzlich modular gestaltet ist, werden die Kom- ponenten durch die Art ihres Einsatzes zu einer monolithischen Applikation. Dies macht es schwierig die eingesetzten Systeme zu pflegen und zu erweitern. Da bei der Änderung eines Moduls die komplette Applikation angepasst werden muss. Kubernetes als Orchestrator für Microservices versetzt DevOps Teams in die Lage, die einzelnen Komponenten einer Anwendung Hochverfügbar und einzeln skalierbar zur Ver- fügung zu stellen. Beispielsweise können auch Updates meist ohne Downtime durch so- genannte Rolling Updates eingespielt werden.[29] Beim Einsatz von Microservices fallen unter anderem die Betriebskosten für unnötige Hardwareressourcen und Lizenzen, bei Inbetriebnahme und Skalierung, geringer aus als bei nicht modularen Umgebungen.[10] Zudem kann es zu Performancegewinn kommen, da Kubernetes mithilfe von Lastverteilung gewährleistet, dass Anfragen immer an Res- sourcen mit ausreichender Kapazität weitergeleitet werden. Die gewonnene Flexibilität wird allerdings durch einen hohen Grad an Komplexität er- kauft. Dadurch wird nicht nur tiefes Verständnis über die Konfiguration und Verwaltung der Umgebung für die Administratoren vorausgesetzt, es wirft auch große Schwierigkei- ten in der Härtung dieser Umgebungen auf. Schon im Jahr 1999 schrieb Bruce Schneier in seinem Essay „A Plea for Simplicity“ den unter Sicherheitsforschern gern zitierten Satz, „Complexity is the worst enemy of security“[21] und sah damit die Cybersecurity Probleme der Gegenwart, die auch auf Kubernetes zutreffen, korrekt voraus. 4
2.1 Kubernetes
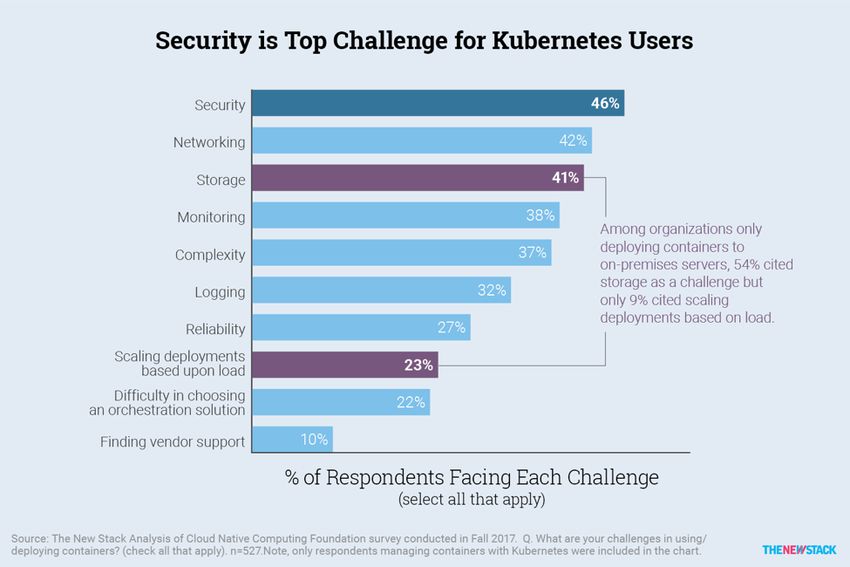
Da die auf Hochverfügbarkeit ausgelegten Cluster meist die kritische Infrastruktur für die
Unternehmen bereitstellen, wächst auch die Sorge der Kubernetes Nutzer um die Sicher-
heit ihrer Systeme. Wie eine Umfrage an Nutzer von Container Umgebungen ergab.
Abbildung 2.1: Security als TOP-Herausforderung in Container Umgebungen[13]
Im folgenden wird die Kubernetes Architektur sowie die einzelnen Standard Komponen-
ten vorgestellt.
2.1.1 Architektur
Kubernetes besteht aus einer Menge an Nodes, diese unterteilen sich wiederum in Master-
und Worker-Nodes.
Zur Verwaltung des Clusters führt der Master-Node unter anderem folgende Aufgaben
aus:
• Planung auf welchen Worker-Nodes die Container ausgeführt werden sollen.
• Ablaufplanung (Scheduling)
52 Grundlagen
• Vorhalten von Informationen über die aktuelle und maximal mögliche Last der
Worker-Nodes
• Monitoring der einzelnen Kubernetes Objekte
• Clusterinterne Kommunikation aufrecht erhalten
Dazu führt er die zentralen Kubernetes Komponenten wie etcd oder den API-Server aus,
auf die in Kapitel 2.1.3 noch näher eingegangen wird. Worker-Nodes führen die eigentli-
chen Applikationen aus, die durch Kubernetes zur Verfügung gestellt werden sollen.
Kubernetes Architektur
User / Service Account
Kube-Proxy
Worker-Node
Container Runtime
Master-Node
Kubelet
Kube-Scheduler Kube-API Server
Container
Controller-Manager
Kube-Proxy
Worker-Node
etcd
Container Runtime
Kubelet
Container
Abbildung 2.2: Kubernetes Architektur im Überblick
Die einzelnen Kubernetes Objekte werden mithilfe von YAML Ain’t Markup Language
(YAML)-Dateien beschrieben. Auf einige der wichtigsten dieser Objekte wird im folgen-
den eingegangen.
62.1 Kubernetes
2.1.2 Kubernetes Objekte
2.1.2.1 Pod
Ein Pod ist die kleinste Instanz innerhalb einer Kubernetes Infrastruktur. Pods bilden ei-
ne Abstraktionsebene über einzelne oder mehrere Container. Diese sollten allerdings nur
dann mehrere Container beinhalten, wenn diese gemeinsam skalieren oder Ressourcen
gemeinsam nutzen müssen.[30] Die Container innerhalb eines Pods benutzen dieselben
Netzwerk- und Storage-Ressourcen und kommunizieren daher über eine IP-Adresse, die
Standardmäßig im gesamten Cluster erreichbar ist. Dies wird durch die gemeinsame Nut-
zung von Cgroups und Namespaces erreicht.[34]
2.1.2.2 Services
Kubernetes Services definieren wie auf eine Gruppe von Pods zugegriffen wird. Die
Zuordnung zu welchen Pods der Service gehört wird meist mithilfe von Labels in den
YAML-Definitionen der Pods vorgenommen1 . Bei der Erstellung eines Services wird ei-
ne virtuelle IP-Adresse, eine sogenannte ClusterIP im Cluster für diesen Service erstellt.
Diese ist allerdings weder einer Netzwerkschnittstelle noch einem Namespace zugewie-
sen. Services wirden mithilfe von ServiceTypes definiert.
ClusterIP: ist ein ServiceType, der eine Cluster interne IP-Adresse erstellt, diese einem Service
zugeordnet und nicht von außerhalb des Clusters erreichbar ist.
NodePort: Erstellt eine ClusterIP und öffnet zusätzlich einen statischen Port, der standardmä-
ßig im Bereich 30000-32767 liegt, an der physischen Netzwerkschnittstelle jedes
Nodes. Mithilfe der Kubernetes Komponente Kube-Proxy wird erreicht, dass ei-
ne Anfrage auf die jeweilige IP:Port Adresse immer auf die Adresse eines aktiven
Pods der Applikation weitergeleitet wird. Kube-Proxy wird in Kapitel 2.1.3.6 näher
behandelt.
LoadBalancer: Erstellt einen NodePort und macht den Service außerdem einer externen LoadBa-
lancer Lösung des Cloud Dienstleisters bekannt.[27] Diese werden meist nur inner-
halb von Cloud Umgebungen angetroffen. Es existieren allerdings auch Lösungen
wie metalLB zum Einsatz bei On-Premises Clustern.
1 Siehe auch: A.4
72 Grundlagen
2.1.2.3 Deployments
Deployments sind die standardmäßige Methode Applikationen im Cluster auszurollen.
Die Erstellung von Pods, ReplicaSets sowie diverser weiterer Konfigurationen wie bei-
spielsweise die Anzahl der redundanten Pods werden hierbei kombiniert. Deployments
beschreiben dabei einen angestrebten Status der ständig mit dem Ist-Zustand der beschrie-
benen Applikation verglichen wird. Falls der aktuelle Status nicht der YAML-Definition
des Deployments entspricht, wird versucht durch Maßnahmen wie zum Beispiel dem Star-
ten oder Beenden von Pods einen erstrebten Status herzustellen. Dadurch können zudem
einfache Änderungen oder Updates durchgeführt werden, da hierfür eine Änderung der
YAML-Datei genügt.
2.1.3 Komponenten
Im folgenden werden nur die wichtigsten Kubernetes Komponenten dargestellt. Alle Kom-
ponenten sind modular und können individuell angepasst oder komplett ersetzt werden.
2.1.3.1 etcd
etcd ist ein key-value Store, der den aktuellen Clusterstatus sowie die Kubernetes Konfi-
guration vorhält. Dazu gehören unter anderem Daten über die aktuellen:
• Nodes
• Pods
• Deployments
• Secrets
• ConfigMaps
• Benutzer und ServiceAccounts
• Roles/Rolebindings
• ...[11]
Alle Informationen, die mit dem Kommando kubectl get oder per API Request vom Kube-
API Server abgefragt wurden, sind dadurch vom Benutzer indirekt durch den API Server
vom etcd Store abgerufen worden.
82.1 Kubernetes
2.1.3.2 Kube-API Server
Der Kube-API Server verarbeitet sämtliche Anfragen der einzelnen Komponenten oder
der Benutzer1 . Diese können entweder indirekt über kubectl oder direkt mithilfe der
REST-API gestellt werden. Der API-Server arbeitet zur Unterscheidung der Anfragen
mit sogenannten API Groups. Diese werden in Kapitel 2.1.4 näher behandelt. Bei der
Erstellung eines Pods führt Kube-API beispielsweise folgende Vermittlungsfunktionen
durch:
1. Benutzer authentifizieren
2. Anfrage validieren
3. Autorisierung prüfen
4. Benötigte Daten zum Erstellen des Containers abrufen (Images,...)
5. Update etcd
6. Scheduler geeigneten Node ermitteln lassen
7. Beauftragung an das Kublet des Nodes, die Pods zu erstellen.[16]
2.1.3.3 Kube-scheduler
Der Scheduler plant die Erstellung von Pods und wählt die Nodes anhand ihrer verfügba-
ren Ressourcen, Mindestanforderungen der Applikation oder anderer Restriktionen wie
etwa taints oder affinities aus.
2.1.3.4 Kube-Controller Manager
Dieser überwacht den Cluster anhand der aktuelle Konfiguration, welche im etcd Store
gespeichert ist, auf Konsistenz und Erreichbarkeit. Der Controller Manager besteht aus
einer Gruppe von mehreren Controller Komponenten dazu gehören unter anderem:
• Node-Controller: Prüft standardmäßig alle 5 Sekunden die aktiven Nodes im Clus-
ter (Node Monitor Period). Falls ein Node 40 Sekunden (Node Monitor Grace Pe-
riod) nicht antwortet wird er als UNREACHABLE gekennzeichnet. Nach Ablauf
von weiteren 5 Minuten (POD Eviction Timeout) werden die Pods auf einem ande-
ren Knoten neu gestartet.
1 Einen groben Überblick darüber zeigt die Abbildung 2.2
92 Grundlagen
• Replication Controller: Überwacht ob zu jeder Zeit die angestrebte Anzahl an
Redundanzen der Applikationen vorgehalten wird und startet und beendet falls nö-
tig Pods innerhalb eines ReplicaSets.
• Admission Controller: Es existieren vorwiegend zwei Arten von Admission Con-
trollern:
– Validating Admission Controller
Prüft gesendete Anfragen an den API-Server auf Übereinstimmung mit vorher
eingesetzten Regeln (Policies) für dieses Objekt. Eine Regel könnte zum Bei-
spiel vorschreiben, dass Deployments immer mindestens 2 Replicas besitzen
müssen.
– Mutating Admission Controller
Dieser Controller ist in der Lage die Anfrage an den API-Server anzupassen.
Diese Art von Admission Controllern werden meist genutzt um Default Ein-
stellungen beim Erstellen einer Ressource nicht immer manuell eintragen zu
müssen. Beispielsweise Quotas für CPU Ressourcen beim Erstellen von De-
ployments.
Admission Controller werden meist mithilfe von Webhooks verwaltet.
2.1.3.5 Kubelet
Kubelets sind die zentralen Komponenten eines Worker Node. Sie erhalten Befehle vom
API-Server um beispielsweise Pods zu starten oder zu beenden. Außerdem sind sie zu-
ständig dafür aktuelle Monitoring Informationen zu den Komponenten und Ressourcen
des Nodes an den API-Server zu senden. Sie können analog zu Kapitänen eines Schiffes
(Nodes) in einem Flottenverband (Cluster) gesehen werden. Kubelets werden im Gegen-
satz zu den meisten anderen Kubernetes Komponenten nicht automatisch beim Erstellen
oder Hinzufügen des Nodes an den Cluster zur Verfügung gestellt sondern müssen im
Vorfeld manuell installiert werden.
2.1.3.6 Kube-Proxy
Im Gegensatz zu den anderen zuvor vorgestellten Komponenten läuft Kube-Proxy auf
jedem Node innerhalb des Clusters1 . Er ist dafür zuständig, den ankommenden Traffic
1 Wird mithilfe von DeamonSets erreicht
102.1 Kubernetes
in Richtung der Services (virtuelle IP-Adresse) an die Pods (eigentliche IP-Adresse), die
von diesem Service erreichbar sein sollen, weiterzuleiten. Dies wird in den meisten Fällen
mithilfe der Aktualisierung von iptables erreicht. Es gibt allerdings drei grundlegende
Modi die Kube-Proxy anbietet:
• user space proxy mode
• iptables proxy mode (Default)
• IP Virtual Server (IPVS) proxy mode
Eine Unterscheidung der einzelnen Modi sind im Anhang unter Kapitel A.2 zu finden.
2.1.3.7 CNI-Network
Eine Container Networking Interface (CNI) Lösung implementiert das Netzwerk Modell
in Kubernetes. Da diese auch von anderen Orchestrator Lösungen wie Mesos oder rkt ver-
wendet werden aber alle das grundsätzlich gleiche Ziel verfolgen, eine Netzwerklösung
für Clusterkomponenten zu implementieren, werden diese von Drittanbietern bereitge-
stellt. Dadurch wird erreicht das die gleiche Codebasis und Normen verwendet werden
und so zusätzliche Kompatibilität sichergestellt wird. In Kubernetes werden CNI mithil-
fe von DeamonSets im Cluster ausgerollt. Bekannte CNI Produkte sind unter anderem:
Weave Net, Flannel, Calico oder Application Centric Infrastructure (ACI). Diese sollten
vor dem Hinzufügen von Nodes zum Cluster installiert werden.
112 Grundlagen
Abbildung 2.3: Übersicht zweier durch CNI verbundenen Nodes[36]
Um dies zu erreichen werden grob folgende Schritte unternommen:
1. Erstellen eines Network Namespaces
2. Erstellen eines Bridge Network Interfaces
3. Erstellen eines Virtual Ethernet Device (VETH) Pairs (Pipe oder Virtual Cable)
4. Anhängen des VETH an den erstellten Namespace
5. Anhängen des anderen VETH an die Bridge
6. Zuweisen von IP-Adressen
7. Netzwerkschnittstellen hochfahren
8. NAT / IP Masquerade einschalten[16]
2.1.3.8 Ingress
Ein Ingress Controller kann als zusätzlicher Layer 7 LoadBalancer gesehen werden. Als
Beispiel für einen Ingress Controller kann der Nginx Ingress Controller genannt wer-
den. Der Controller besteht aus Nginx als reverse proxy und LoadBalancer[33] Dieser
erlaubt es, dass Services nicht mehr nur durch Aufruf der IP:Port Adresse erreicht werden
122.1 Kubernetes
können, sondern auch durch name-based virtual hosting ähnlich zu den server blocks in
Nginx oder virtual hosts in Apache Webservern.
Zusätzlich fungiert er als TLS termination Proxy[31]. Ingress Objekte können wie al-
le anderen Kubernetes Objekte mithilfe von YAML-Definitionen konfiguriert werden. In
Abbildung 2.4 wird dargestellt wie die Applikationen myApp sowie myStream über die
Domain mycompany.com/appname mithilfe von Ingress veröffentlicht werden. Dazu
werden Regeln im jeweiligen Ingress Objekt hinterlegt.
https://mycompany.com/myApp https://mycompany.com/myStream
Ingress
31080 31081
(NodePort) (NodePort)
myApp- myApp-
Service Service
(NodePort) (NodePort)
10.96.1.2 (ClusterIP) 10.95.1.1 (ClusterIP)
TLS Termination
myApp myStream
POD
Postgres- Service
Service(ClusterIP) (ServiceType)
10.96.1.1 (ClusterIP)
Deployment
Postgres
Ingress
Abbildung 2.4: Zwei Applikationen werden über Ingress veröffentlicht
132 Grundlagen
2.1.4 API Groups
Alle Ressourcen von Kubernetes sind in die sogenannten API Groups unterteilt. Dadurch
erkennt der Kube-API Server den Kontext der Anfrage. Eine Übersicht mit den wichtigs-
ten API Groups zeigt Abbildung 2.5.
API Groups
/apps /authentication.k8s.io /certificates.k8s.io /extensions /networking.k8s.io ...
/v1 /v1 /v1 /v1
/tokenreviews /certificatesigningrequests /networkpolicies
/controllerrevisions
create
/deamonsets
delete
/deployments
get
/replicasets
list
/statefullsets update
...
Resources Verbs
Abbildung 2.5: Aufbau von API-Groups in Kubernetes
API Groups besitzten eine Menge an Resources die wiederum eine Menge an Verbs ent-
halten. Dabei steht Verbs für die jeweilige Methode die auf dieser Ressource ausgeführt
werden soll.
2.1.5 Authentifizierung
Jede Komponente, Benutzer oder ServiceAccount muss sich gegen die Server authentifi-
zieren, bevor Anfragen bearbeitet werden. In Kubernetes erfolgt die Authentifizierung für
den Zugriff auf den Cluster ausschließlich über den Kube-API Server. Kubernetes selbst
142.1 Kubernetes
stellt hierfür allerdings keine Benutzerverwaltung im klassischen Sinne zur Verfügung.
Nur ServiceAccounts werden von Kubernetes verwaltet. Mögliche Authentifizierungs-
mechanismen sind:
• Static Token Files:
Dabei handelt es sich um einfache CSV Dateien die wie folgt aufgebaut sind:
1 token,user,uid,"group1,group2,group3"
2
Der Token ist ein einfacher JSON Web Token (JWT) Bearer Token. Bei einer Au-
thentifizierung über einen HTTP header erwartet der API Server einen Authoriza-
tion Header mit dem Wert Bearer . Seit Version 1.18 ist auch die Ver-
wendung von Bootstrap Tokens möglich.[26]
• X.509 Zertifikate:
Im Beispiel einer Authentifizierung mithilfe von X.509 Zertifikaten muss, damit
ein neuer Benutzer authentifiziert werden kann, zunächst ein Zertifikat, mit dem
gewünschten Benutzernamen im CN Feld, ausgestellt und anschließend das Kuber-
netes Objekt Certificate Signing Request (CSR) erstellt und von einem Administra-
tor mit ausreichenden Rechten signiert werden.
• OpenID Connect Tokens:
Bei OpenID Connect handelt es sich um eine Erweiterung von OAuth2, welche
häufig bei Cloud Diensten wie GKE oder AKS anzutreffen ist. Die eigentliche Er-
weiterung zu OAuth2 ist, dass ein weiteres Feld (ID Token) hinzugefügt wurde das
einen JWT enthält, der vom OAuth2 Identity Provider signiert wurde. In Abbildung
2.6 ist zu sehen wie die Authentifizierung abläuft.
152 Grundlagen
User Identity Provider Kubectl API Server
1. Login to IdP
2. Provide access_token,
id_token, and refresh_token
3. Call Kubectl
with --token being the id_token
OR add tokens to .kube/config
4. Authorization: Bearer...
5. Is JWT signature valid?
6. Has the JWT expired? (iat+exp)
7. User authorized?
8. Authorized: Perform
action and return result
9. Return result
User Identity Provider Kubectl API Server
Abbildung 2.6: Authentifizierung mithilfe von OpenID Connect Tokens[26]
• Service Account Tokens:
Dies sind automatisch von Kubernetes erstellte Tokens, die für die Authentifizie-
rung von ServiceAccounts genutzt werden. Der „default“ ServiceAccount des Na-
mespaces1 in dem sich der Pod befindet sowie das dazugehörigen Tokens wer-
den in der Standardkonfiguration automatisch beim Erstellen eines Pods mithil-
fe des Service Account Admission Controller an den Pod gebunden
und dort gemountet. Bei diesen Token handelt es sich ebenfalls um JWT Bearer
Token.
• Außerdem können weitere externe Authentifizierungsmechanismen wie zum Bei-
spiel LDAP, Kerberos oder Webhook verwendet werden.
Um die Authentifizierung bei einem Nutzer nicht bei jedem kubectl Aufruf manuell ange-
ben zu müssen, werden diese in der Kubeconfig Datei gespeichert. Alternativ kann auch
ein sogenannter Kubectl Proxy verwendet werden. Dieser sollte nicht mit der Komponen-
te Kube-Proxy verwechselt werden. Bei einer curl Anfrage, die an Kubectl Proxy gestellt
wird, leitet dieser die Anfragen an den API-Server mitsamt den entsprechenden Zertifika-
ten weiter. Interne Komponenten von Kubernetes wie etwa etcd oder der Kube-Scheduler
1 Dieser ServiceAccount wird beim Erstellen des Namespaces automatisch durch den API-Server
erstellt.
162.1 Kubernetes
arbeiten mithilfe von X.509 TLS Server- und Clientzertifikaten die von einer vertrauten
Certification Authority (CA) zertifiziert wurden. Auch der Kube-API Server selber au-
thentifiziert sich mithilfe solcher Zertifikate.
ca.crt ca.key
Kubernetes Zertifikate
CERTIFICATE AUTHORITY (CA) apiserver.crt apiserver.key
apiserver-etcd- apiserver-etcd-
client.crt client.key
admin.crt admin.key
kubectl KUBE-API
REST API etcdserver.crt etcdserver.key
Server ETCD
Admin Server
apiserver-kubelet-
client.crt
scheduler.crt scheduler.key
apiserver-kubelet-
KUBE-
client.key
SCHEDULER
kubelet- kubelet-
client.crt client.key
controller- controller-
manager.crt manager.key
KUBE-
CONTROLLER-
MANAGER
kubelet.crt kublet.key
Kubelet
Server
kube- kube-
proxy.crt proxy.key
KUBE-PROXY
Abbildung 2.7: Übersicht der Kubernetes X.509 TLS-Authentifizierung
2.1.6 Autorisierung
Es gibt verschiedene Rechteverwaltungsmodi in Kubernetes dazu gehören:
• Node
• Attribute Based Access Control (ABAC)
• Role Based Access Control (RBAC)
• Webhook
• AlwaysAllow
• AlwaysDeny
Die aktiven Modi werden in der Konfiguration des API-Servers gesetzt. RBAC ist die
vorwiegend verwendete Methode in Kubernetes Clustern.[25] Daher wird sie nachfolgend
näher behandelt. Die restlichen Modi können unter A.3 nachgelesen werden.
172 Grundlagen
2.1.6.1 RBAC
Die Verwendung von RBAC ermöglicht, eine Rechteverwaltung auf Basis von Rollen-
konzepten. In Kubernetes werden diese mithilfe von YAML Dateien definiert. Darin wer-
den die Zugriffsberechtigungen auf die jeweiligen API Groups definiert. Die einzelnen
Berechtigungen werden additiv festgelegt. Daraus folgt, dass keine „Deny“ Rules exis-
tieren. Im Kubernetes Role Based Access Control (RBAC) Modell existieren zwei Arten
von Rollen denen Benutzer oder ServiceAccounts zugewiesen werden können.
• Role und
• ClusterRole
Im Gegensatz zur ClusterRole wird eine Role Regel immer nur auf einen einzigen Name-
space angewendet. ClusterRole Regeln werden immer dann verwendet, wenn die Rechte
auf Objekte zu vergeben sind, die entweder
• sich auf Clusterweite Ressourcen wie Nodes beziehen,
• es sich um Endpunkte handelt die keine Ressourcen darstellen wie /healthz oder
• sie sich bei Namespace gebundenen Ressourcen über alle Namespaces erstrecken
sollen[28].
Um Benutzer einer Rolle zuweisen zu können, muss ein RoleBinding oder ClusterRole-
Binding Objekt erstellt werden, indem definiert ist welche Benutzer einer Role/Cluster-
Role zugewiesen werden sollen. Beispielkonfigurationen hierzu können im Anhang unter
A.4.2 gefunden werden.
2.1.7 Network Policies
Im Grundzustand erlaubt Kubernetes die OSI-Layer 3 und 4 Kommunikation sämtlicher
internen Clusterkomponenten untereinander. Daraus resultiert, dass einem Pod einer Ap-
plikation Netzwerkzugriff auf Pods von anderen Applikationen gewährt wird, auch wenn
zwischen diesen keine Kommunikation vorgesehen ist.[32] Dies stellt eine Sicherheits-
lücke dar. Um das zu unterbinden sollten Network Policies angelegt werden. Diese Poli-
cies verhalten sich ähnlich zu Firewall Regeln und unterscheiden dabei zwei Arten von
Traffic:
1. Ingress
182.2 Schwachstellenscanner
2. Egress
Bei Ingress handelt es sich um ankommende Verbindungen, bei Egress um ausgehende
Verbindungen. Die Betrachtung erfolgt immer von dem Pod aus, auf dem die Network
Policy angewendet wird. Zu beachten ist, dass nicht alle CNI Anbieter diese durchsetzen.
Darum sollte darauf geachtet werden, dass falls diese genutzt werden sollen ein geeignetes
CNI ausgewählt wird.
2.2 Schwachstellenscanner
2.2.1 Definition und Funktionsweise
Ein Schwachstellenscanner identifiziert und klassifiziert Schwachstellen von Software,
Computer-, Netzwerk- oder anderen IT-Komponenten. Sie sind meist außerdem in der
Lage, Host und Hostattribute des jeweiligen Ziels zu erkennen. Beim Scan greift der
Schwachstellenscanner meist auf eine interne Datenbank mit bekannten Sicherheitslücken
oder Skripte zurück, um die Schwachstellenerkennung durchzuführen.[19, S. 4-4] Scan-
ner können deshalb eingesetzt werden, um:
• Die Einhaltung von Security Benchmarks wie die des CIS Benchmarks zu überwa-
chen.
• Informationen für einen Penetrationstest zu erhalten.
• Hinweise zu erhalten, welche Schwachstellen in einem System vorhanden sind und
wie diese behoben werden können[19, S. 4-5].
• Eine Risikobewertung der einzelnen aufgedeckten Schwachstellen zu erhalten oder
erstellen zu können.
Scans werden zudem in authentifizierte, bei denen der Scan mit privilegierteren Rechten
erfolgt und in nicht authentifizierte sowie in lokale und netzwerkbasierte Scans unter-
schieden. Bei Netzwerkbasierten unauthentifizierten Scans handelt es sich meist um erste
Informationsbeschaffungsmaßnahmen über das Ziel. Um die maximal erreichbare Erken-
nungsquote von Sicherheitslücken mithilfe von Schachstellenscannern zu erreichen ist
es notwendig, sowohl Netzwerkbasierte Tests als auch interne Tests durchzuführen[19,
S. 4-5]. Deren Anwendung eignet sich also als einfaches Mittel für Administratoren Si-
cherheitslücken aufzudecken und zu schließen oder für Angreifer diese auszunutzen, um
192 Grundlagen
mögliche Angriffsvektoren zu erkennen. Die Güte eines Scanners bemisst sich nicht nur
anhand der möglichen erkennbaren Schwachstellen, sondern auch anhand ihrer Sensitivi-
tät und Spezifität, also einer möglichst geringen Anzahl an sogenannten False Positives
und False Negatives. Zudem ist eine gut parsebare Ausgabe der Scanergebnisse in Forma-
ten wie Comma-separated values (CSV) oder JavaScript Object Notation (JSON) wichtig,
um die Ergebnisse später in Berichte oder Übersichten einzubauen.
Beispiele für verbreitete Schwachstellenscannerlösungen aus dem nicht Kubernetes Um-
feld sind beispielsweise Tenable Nessus, Micro-Focus Fortify oder OpenVAS.
2.2.2 Schwachstellenscanner im Kubernetes Umfeld
Da Kubernetes auf Grund seines geringen Alters, ist die schiere Zahl an relevanten Schwach-
stellenscannern speziell für Kubernetes noch relativ überschaubar. In dieser Arbeit sollen
zudem ausschließlich OpenSource Schwachstellenscanner betrachtet werden.
2.2.2.1 Kube-hunter
Kube-hunter ist ein auf Python basierender Schachstellenscanner von Aqua Security.
Möglichkeiten der Ausführung sind:
1. außerhalb des Clusters (netzwerkbasierter Scan),
2. auf einem Nodes des Clusters oder
3. auf einem Pod innerhalb des Clusters.
Zudem kann mithilfe des Modus „Active Hunting“, versucht werden, Schwachstellen so-
fort automatisch auszunutzen um dadurch weitere zu finden. Dies kann allerdings poten-
tiell schädlich sein, da dadurch möglicherweise Objekte des Clusters verändert werden
könnten[4]. Kube-hunter benutzt defaultmäßig die SYN (Synchronization) Scanmethode
um offene Ports zu erkennen. Dabei sendet der Angreifer ein SYN Paket. Antwortet der
Server mit einem SYN/ACK (Synchronization Acknowledged)-Paket, so handelt es sich
bei dem gescannten Port um einen offenen Port und der Client antwortet mit einem RST
(Reset)-Paket. Antwortet der Server auf das SYN-Paket mit einem RST-Paket, wird der
Port als offen gelistet.
202.2 Schwachstellenscanner
Reporting: Kube-hunter bietet die Möglichkeit Reports in parsebaren Formaten (json,yaml)
auszugeben, die auch an eine REST-API per POST-Request weitergeleitet werden kann.
Hierfür stellt Aqua Security ein optionalles Closed Source Reporting Tool zum Auswer-
ten der Ergebnisse zur Verfügung. Dazu werden allerdings die Ergebnisse des Tests auf
die Server von Aqua Security übertragen[3], dies ist bei internen vertraulichen Daten si-
cherlich nicht immer gewünscht und muss deshalb im Einzelfall geprüft werden.
2.2.2.2 Kube-bench
Kube-bench ist ein ebenfalls von Aqua Security in Go entwickelter Schwachstellenscan-
ner. Dieser prüft hauptsächlich auf die Einhaltung der im CIS Kubernetes Benchmark
definierten Sicherheitsstandards. Kube-bench kann nur innerhalb des Clusters ausgeführt
werden. Dabei wird es entweder als
• installiertes Binary auf einem Node
• Docker-Container auf einem Node oder
• Pod innerhalb des Clusters
zur Verfügung gestellt.
Der CIS Benchmark für Kubernetes[9] enthält die jeweiligen Shell Befehle für das Audit
der jeweiligen Sicherheitslücke. Diesen führt Kube-bench aus und überprüft die Ausgabe
des Kommandos mit seiner internen Datenbank die den Benchmark abbildet und prüft auf
Bestehen des Tests.
Es ist zu beachten, dass Kube-bench nicht in der Lage ist, Master Nodes von „Managed
Clustern“ in den meisten Cloud Infrastrukturen wie Google Kubernetes Engine (GKE),
Azure Kubernetes Service (AKS) oder Amazon Elastic Kubernetes Service (Amazon
EKS) zu testen, da die Anwender von Managed Clustern auf die Master Nodes keinen
Zugriff haben[2].
2.2.2.3 Kubeaudit
Kubeaudit ist ein Command Line Interface (CLI) Tool auf Basis von Go und wurde von
Shopify entwickelt. Kubeaudit besteht aus verschiedenen Testmodulen, die Auditors
genannt werden.[23] Beispielsweise überprüft der Auditor „privesc“, ob Privilege Esca-
lation auf einem Container möglich ist. Dabei prüft er ob in der Konfiguration des Pods
212 Grundlagen die Einstellung allowPrivilegeEscalation auf true gesetzt ist. Dadurch könnte es dem Container potentiell möglich sein höhere Rechte als sein Elternprozess zu erlan- gen. Kubeaudit kann mithilfe einer Konfigurationsdatei gestartet werden in dem die jeweiligen Auditoren eingetragen werden können. Reporting: Der Scanner ermöglicht auch die Ergebnissausgabe im JavaScript Object No- tation (JSON) Format. 2.2.2.4 kube-Scan Kube-Scan von Octarine ist ein in Go geschriebenes Tool für die Risikobewertung von Kubernetes Workloads. Kube-Scan besteht aus einer Client/Server Struktur bei dem der Client die Scans im Cluster durchführt und anschließend die Ergebnisse an den Server weiterleitet. Anhand der im Kubernetes Common Configuration Scoring System (KC- CSS) festgelegten Regeln scannt Kube-Scan den Cluster beim ersten Starten und anschlie- ßend alle 24 Stunden erneut. Reporting: Die erstellten Risikobewertungen können anschließend auf dem Server ein- gesehen werden. Auch eine zeitliche Entwicklung der Bewertung kann nachvollzogen werden. 2.2.2.5 kube-score kube-score ist ein Tool zur statischen Code Analyse der YAML Definitionsdateien. Nach der Analyse gibt der Scanner Empfehlungen zur Härtung der Objekte aus [39]. Dadurch können Schwachstellen innerhalb dieser Konfigurationsdateien entdeckt werden. Dieser bietet auch eine Online Version des Scanners unter https://kube-score.com/ an. Hierbei ist allerdings zu beachten, dass dies nur zu Testzwecken genutzt werden sollte, da dabei möglicherweise sensible Daten auf den Webserver hochgeladen werden. 2.2.2.6 Spezialisierte Schwachstellenscanner Zudem gibt es einige Schwachstellenscanner die sich auf bestimmte Aspekte in Kuberne- tes, wie beispielsweise Network Policies, beschränken. 22
2.2 Schwachstellenscanner
illuminatio - The Kubernetes network policy validator illuminatio beschränkt sich auf
das Testen von Network Policies und scannt diese anhand der jeweiligen Konfiguration
und validiert diese.[15]
KubiScan KubiScan überprüft die Berechtigungen im Kubernetes Role Based Access
Control (RBAC) Autorisierungsmodell. Dabei analysiert es die Rechte von Benutzern,
ServiceAccounts oder roles/rolebindings auf mögliche Fehlkonfigurationen oder unnötig
hohe Rechte.
233 Aufbau und Methoden des Tests
3 Aufbau und Methoden des Tests
Um ein zuverlässiges und vergleichbares Ergebnis der Evaluation der Schwachstellens-
canner zu erhalten ist es erforderlich, dass die Testumgebung immer unter den selben
Voraussetzungen aufgebaut ist. Damit ist gewährleistet, dass immer eine identische Um-
gebung für alle Scanner zur Verfügung steht. Damit dies erreicht werden kann, wird der
Cluster immer mithilfe von Infrastructure as Code (IaC) Tools erstellt, also mit den glei-
chen Betriebssystem Images gestartet und anschließend mithilfe von Vagrant und Bash
oder Ansible konfiguriert und installiert. Um falls nötig Cloudbasierte Managed Clus-
ter spezifische Test durchführen zu können wird eine Google Kubernetes Engine (GKE)
Lösung verwendet.
3.1 Aufbau des Testclusters
Die Testumgebung wird virtuell auf einem VMware Elastic Sky X integrated (ESXi) Ser-
ver aufgebaut. Für die Erstellung des Kubernetes Clusters wird Vagrant mit dem Plugin
vagrant-vmware-esxi[22] verwendet, um ESXi als Hypervisor für die Bereitstel-
lung durch Vagrant nutzen zu können. Die Vagrant Skripte für die Erstellung des Clusters
sind unter A.5 einsehbar. In den Skripten1 können die Spezifikationen für die einzelnen
Maschinen und Konfigurationen eingetragen und nachgelesen werden. Der Cluster wurde
mit der Kubernetes Version 1.20.2 bereitgestellt.
3.2 Methodik des Tests
Die jeweiligen Sicherheitslücken, die in der Threat Matrix aufgelistet sind, sollen auf
dem Testcluster jeweils einzeln nachgebildet werden. Dazu werden die Schwachstellen,
die in Kapitel 4.1 näher betrachtet werden, in der beschriebenen Form implementiert und
von den Schwachstellenscannern jeweils einzeln gescannt. Anschließend wird der Cluster
zurückgesetzt und der Vorgang mit der nächsten Schwachstelle wiederholt.
1 Siehe: A.5
243.3 Auswahl der Schwachstellenscanner
3.3 Auswahl der Schwachstellenscanner
Bei der Auswahl der Schwachstellenscanner wird berücksichtigt, dass diese möglichst
unterschiedliche Schwerpunkte abdecken, um zu erkennen, ob eine breitere Auswahl an
Scannern die Wahrscheinlichkeit für eine größere Abdeckung bei der Erkennung der Si-
cherheitslücken erhöht. Deshalb werden hierfür die Schwachstellenscanner, die in Kapitel
2.2.2 betrachtet wurden, ausgewählt1 .
Eine breitere Auswahl kommt dadurch zustande, dass sich diese Scanner in ihrer Ziel-
setzung unterscheiden. Während Kube-hunter eher als allgemeiner Schwachstellenscan-
ner einzuordnen ist, beschränken sich Kube-bench und Kubeaudit darauf, anhand von
Benchmarks wie dem Center for Internet Security (CIS) Benchmark die Konfiguration
des Clusters zu prüfen. Außerdem werden kube-Scan als Scanner zur Risikobewertung
und kube-score als Scanner, der auf Basis von statischer Code Analyse arbeitet, mit in die
Evaluation einbezogen.
3.4 Bewertung der Scanergebnisse
Die Ergebnisse der Scans werden in drei Bewertungsgruppen eingeteilt.
1. vollständig erkannt: Der Scanner hat die Sicherheitslücke korrekt erkannt und ex-
plizit aufgezeigt. Das bedeutet, dass eine Behebung der im Scanner angezeigten
Lücke direkt zur Behebung der Schwachstelle führt.
2. teilweise erkannt: Der Scanner erkennt die Sicherheitslücke nicht explizit. Es wer-
den allerdings Schwachstellen, die auf einer ähnlichen Grundlage basieren, ent-
deckt. Durch die gegebenen Hinweise des Scanners kann in den meisten Fällen das
Sicherheitsproblem indirekt gelöst werden.
3. nicht erkannt: Der Scanner war nicht in der Lage, die zu Grunde liegende Sicher-
heitslücke zu erkennen und die Schwachstelle bleibt unentdeckt.
Die Bewertungskriterien sind in Bezug auf die jeweiligen Angriffsvektoren nochmals ge-
nauer in Kapitel 4.1 definiert.
1 mit Ausnahme der spezialisierten Scanner aus Kapitel 2.2.2.6
25Sie können auch lesen

















































