ERZEUGUNG SYNTHETISCHER DATEN ZUR ERKENNUNG DER 6-DOF-POSE BEKANNTER OBJEKTE MITTELS DEEP LEARNING - der 6-dof ...
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

E RZEUGUNG SYNTHETISCHER DATEN ZUR E RKENNUNG
DER 6-D O F-P OSE BEKANNTER O BJEKTE MITTELS D EEP
L EARNING
Dustin Spallek
Department of Computer Science
Hamburg University of Applied Sciences
Berliner Tor 7, 20099 Hamburg, Germany
dustin.spallek@haw-hamburg.de
12. Februar 2020
A BSTRACT
Dieser Projektbericht baut auf der in [1] durchgeführten Literaturanalyse auf. Weiter wird
in diesem Projektbericht die praktische Umsetzung der in [1] vorgestellten Ende-zu-Ende
Pipeline zur Objekterkennung und 6-DoF (degrees of freedom, deutsch Freiheitsgrade)
Lagebestimmung mittels Machine Learning erläutert. Dazu gehört die Erstellung von synthe-
tischen Daten mithilfe des Plug-ins für die Unreal Engine namens NVIDIA Deep learning
Dataset Synthesizer zur Erzeugung von beschrifteten Daten. Außerdem wird in diesem
Projektbericht die Durchführung des Trainings eines neuronalen Netzes mithilfe des Deep
Object Pose Estimation Netzes von Jonathan Tremblay et al. [2] beschrieben, welches mit
den selbst erstellten synthetischen Daten trainiert wurde. Die Experimente werden in der hier
zugehörigen Masterarbeit fortgeführt und dort bezüglich der Erfahrungen und Ergebnisse
analysiert.
Keywords Augmented Reality · Deep Learning · Objekterkennung · synthetische Datenerzeugung · sechs
Freiheitsgrade
1 Einleitung
Aufgrund der Notwendigkeit von handbeschrifteten Daten, ist das Training und Testen von Deeplearning-
Systemen laut Xue-Wen Chen [3] eine teure und komplexe Aufgabe. Dies ist, wie Jonathan Tremblay et
al. [2] erklären besonders problematisch, wenn die Aufgabe Expertenwissen oder nicht so offensichtliche
Anmerkungen erfordert, wie z. B. das Hinzufügen von 3D- Rahmen um die zu erkennenden Objekte. So
lassen sich beschriftete Daten für die 3D- Objekterkennung manuell kaum erzeugen, da hierfür erhebliche
Aufwände, wie Messungen des Abstandes zur Kamera oder der Rotation der Objekte aus verschiedenen
Kameraperspektiven, nötig sind. Weiter sind, wie in [1] beschrieben, bei der Erzeugung der realen, als
auch der synthetischen Trainingsmenge viele Einflüsse der Umgebung, wie unter anderem Lichtverhältnisse,
Verdeckungsgrad und variierende Hintergründe zu berücksichtigen. Um diese Einschränkungen zu überwinden,
wird in diesem Artikel die in [1] erläuterte Ende-zu-Ende Pipeline angewendet, die wie in [4, 5] beschrieben
hochgradig randomisierte synthetische Daten verwendet, um Computer Vision Systeme für reale Anwendungen
zu trainieren und somit einen erfolgreichen Domain-Transfer zwischen synthetischer und realer Welt zu zeigen.
Diese Arbeit ist in zwei Abschnitte aufgeteilt. Beginnend mit dem NVIDIA Deep learning Dataset Synthesizer
(NDDS) findet im Folgenden zunächst eine Analyse des von Jonathan Tremblay et al. [2] erzeugten ’Falling
Things’ (FAT)- Datensatz [6] statt. Die Analyse wird weiter als Grundlage für den Aufbau der selbst angelegten
Szenen verwendet, um Rahmenbedingungen zu schaffen, die die Reproduktion einer dem FAT-Datensatz
ähnlichen Trainingsmenge ermöglicht. Anschließend wird detailliert auf den Aufbau der fotorealistischen
12. F EBRUAR 2020
Szenen sowie der randomisierten Bilder eingegangen, worauf eine Beschreibung der Erstellung der eigenen
Trainingsmenge folgt. Zuletzt werden Beispiele der erstellen Trainingsmenge als Ergebnis präsentiert.
Im zweiten Abschnitt wird auf das Training mit Hilfe des in [1] detailliert beschriebenen Deep Object Pose
Estimation (DOPE) Netzes eingegangen. Hierzu gehören die gewonnenen Erfahrungen bei der Durchführung
des Trainings, sowie eine Darstellung der Ergebnisse der erfolgreich trainierten Modelle.
Zuletzt folgt ein Ausblick darauf, was in der an dieser Arbeit anschließenden Masterarbeit weiter behandelt
wird.
2 NVIDIA Deep learning Dataset Synthesizer
Der NVIDIA Deep learning Dataset Synthesizer ist ein von NVIDIA erstelltes Plug-in für die Unreal Engine1 ,
mit dem in der Computer Vision hochwertige synthetische Bilder mit Metadaten erstellt und exportieren werden
können. NDDS unterstützt die Erstellung von Bildern, Segmentierungen, Tiefen, Objektposen, Rahmen-Boxen,
Schlüsselpunkten und benutzerdefinierten Schablonen. Zusätzlich zum Exporter von Metadaten enthält das
Plug-in verschiedene Komponenten zur Erzeugung hochgradig randomisierter Bilder. Diese Randomisierung
umfasst Beleuchtung, Objektpositionen, Kameraposition, Posen, Texturen und Distraktoren. Zusammen
erlauben diese Komponenten, die Erstellung von Szenen zur randomisierten Erzeugung synthetischer Daten
für das Training tiefer neuronaler Netzwerke.
2.1 Planung
Im Folgenden wird der FAT-Datensatz analysiert, um Bedingungen für die Auswahl der zu annotierenden
Objekte und der fotorealistischen Umgebungen abzuleiten.
2.1.1 Analyse des FAT- Datesatzes
Grundsätzlich wurde der "Falling Things" - Datensatz (FAT) [6] zur Weiterentwicklung des Standes der
Technik in der Objekterkennung und 3D- Posenschätzung im Kontext der Robotik entwickelt. Durch die
synthetische Kombination von Objektmodellen und Hintergründen in komplexer Komposition und hoher
grafischer Qualität ist es möglich, fotorealistische Bilder mit exakten 3D-Pose-Annotationen für alle Objekte in
allen Bildern zu erzeugen. Der FAT- Datensatz ist ca. 44 Gigabyte groß und enthält ca. 122.500 kommentierte
Fotos im JPG- Format von 21 Haushaltsgegenständen aus dem YCB- Datensatz [8]. Zu jedem Bild existiert
die 3D-Pose, Klassen-Segmentierung pro Pixel und 2D/3D Rahmen-Box-Koordinaten für alle Objekte. Um
das Testen verschiedener Eingaben zu erleichtern, bietet der FAT- Datensatz Mono- und Stereo-RGB-Bilder,
entlang mit registrierten Bildern in dichter Tiefe.
Für die Erstellung der synthetischen Daten spielen laut Jonathan Tremblay et al. [7] Faktoren wie der Verde-
ckungsgrad, die Texturierung und die Pose von Objekten in Kombination mit verschiedenen Lichtverhältnisse,
zur Verringerung des Reality Gaps, eine wichtige Rolle. Mit diesem Wissen im Hintergrund wurden die
fotorealistischen Szenen nach Beispiel des FAT- Datesatzes [6] von Nvidia erstellt. Hierzu sei erwähnt, dass
die originale Reproduktion des FAT- Datesatzes [6] nicht möglich ist, da Nvidia die original verwendeten
Szenen aus rechtlichen Gründen nicht zur Verfügung stellen kann. Jedoch wurde bei der Erstellung des eigenen
Datensatzes darauf geachtet, die Szenen möglichst nach Vorbild des FAT- Datensatzes anzulegen.
Allgemein beinhaltet der FAT- Datensatz einen "Mixed" und einen "Single"- Ordner mit je drei verschiedenen
Szenen. Der "Mixed"- Ordner beinhaltet Daten mit stets mehreren zufällig durchmischten Objekten und der
"Single"- Ordner beinhaltet für jedes Objekt einen weiteren Ordner mit Dateien aus einer Aufnahmestelle
in einer Szene in dem nur das jeweilige Objekt vorkommt. Pro Aufnahmestelle innerhalb der "Single"-
Ordner werden dabei 200 Schnappschüsse erzeugt. Ein Ordner mit zufälligen Bildern entsprechend des
Ansatzes der "Domain Randomization" von Jonathan Tremblay et al. [2] mit randomisierten Bildern in
denen stets der Hintergrund mit zufälligen Bildern aus dem COCO- Datensatz [9] ausgetauscht wird, ist nicht
vorhanden. Dies entspricht nicht den in [2] genannten Eigenschaften des Datensatz, in dem explizit zwischen
"fotorealistisch" und "Domain Randomized" unterschieden wird.
Innerhalb der einzelnen Szenen wurden jeweils fünf unterschiedliche Aufnahmestellen als Ort für die
zufällige Erscheinung der zu annotierenden Objekte gewählt. Innerhalb des FAT- Datensetzes wurden pro
Aufnahmestelle in einer Szene 16.000 Dateien erzeugt. Diese Dateien sind aufgeteilt in 4000 stereoskopische
1
www.unrealengine.com, 11.01.2020
2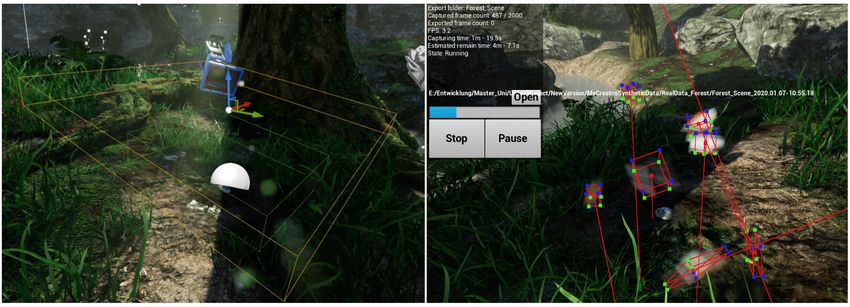
12. F EBRUAR 2020
Schnappschüsse (jeweils 2000 für das rechte und das linke Auge). Pro Schnappschuss existiert zusätzlich ein
Textdokument mit den oben genannten Informationen im JSON- Format, ein Bild mit Tiefeninformationen
und ein Bild mit Segmentierungsinformationen pro Pixel. Die Anzahl der annotierten Objekte pro Bild
variieren jeweils zufällig zwischen zwei und zehn, wobei ein gleiches Objekt mehrfach vorkommen kann.
Die Entfernung zwischen den annotierten Objekten und dem Aufnahmepunkt (Kamera) der Bilder variiert
schätzungsweise zwischen einem und drei Metern.
Somit besteht der Datensatz insgesamt aus ca. 122.500 Schnappschüssen mit unterschiedlichen kom-
mentierten Objekten und Kameraausrichtungen, beziehungsweise ca. 492.000 Dateien (RGB-Bild, Tiefen-Bild,
Segemtierungsbild, JSON- Datei).
2.1.2 Analyse der grafischen Umgebung
Bei der Auswahl der Szenen bedient sich der FAT- Datensatz drei verschiedener fotorealistischer Umge-
bungsassets. Hierzu gehört eine fotorealistische Küche2 (weiter als Raum bezeichnet), eine fotorealistische
Wald-Umgebung3 und ein fotorealistischer Tempel4 . Diese drei Umgebungen weisen eigens markante Charak-
teristiken auf. So enthält der fotorealistische Raum eine für uns Menschen alltägliche Beleuchtungsatmosphäre
mit weniger starken Schatten innerhalb einer kleinen Umgebung, ausgeschmückt mit Objekten aus dem
alltäglichen Leben (Sofa, Stuhl, Tisch, usw.). Die Szene des fotorealistischen Waldes beinhaltet einige Blend-
und Schatteneffekte. Außerdem sind die Trainingsobjekte oftmals von Objekten aus der Umgebung, wie
z. B. Äste von Bäumen oder langen Grashalmen bedeckt. Markant in der fotorealistischen Tempel-Szene
sind eine schlechtere Ausleuchtung der Umgebung und Blendeffekte in Kombination mit Reflexionseffekten.
Durch diese Komposition der Umgebung soll laut Jonathan Tremblay et al. [2] der Reality Gap zwischen
synthetischer und realer Szene verringert werden, da diese Effekte in Bildern auch in der Realität vorkommen.
Unter Berücksichtigung dieser markanten Charakteristiken der Szenen wurden passende Umgebungsassets
für den eigens zu erstellenden Datensatz gesucht. So wurde für die Wald-Szene das Procedural Nature Pack5
und für die Raum-Szene eine frei verfügbare Wohnzimmer-Szene6 der Unreal Engine verwendet. Die Tempel-
Szene hingegen ist frei verfügbar und konnte somit, wie beim FAT- Datensatz [6], zur Erstellung einer Szene
für die Erzeugung des eigenen Datensatzes verwendet werden. Abbildung 1 zeigt eine Gegenüberstellung der
Szenen.
2.2 Durchführung
Nachfolgend wird die Annotation von Objekten sowie der Aufbau der fotorealistischen und der Domain
Randomized Szenen dargestellt. Hierbei fließen die Schlussfolgerungen aus der Analyse des FAT- Datensatze
sowie die in [6] angewendete Methodik zur Erstellung des FAT- Datensatzen ein.
2.2.1 Annotation von Objekten
Bei der Auswahl der innerhalb der 3D- Szenen zu annotierenden Objekte wurden insgesamt 19 verschiedene
Objekte verwendet (Abbildung 2). 16 dieser Objekte sind, wie auch bei dem FAT- Datensatz, gewöhnliche
Haushaltsobjekte aus der YCB- Datenbank7 . Hierzu sei außerdem erwähnt, dass die Objekte zur Erstellung
des eigenen Datensatzes nicht vollständig mit den innerhalb des FAT- Datensatzes verwendeten Objekten
übereinstimmen. Diese Entscheidung hat alleine den Grund der regionalen Zugänglichkeit der echten Objekte.
Die Objekte der YCB- Datenbank wurden speziell für Forschungsarbeiten im Zusammenhang mit Simulationen
erzeugt und sind qualitativ hochwertig aufgrund einer hochauflösenden Detailtiefe der einzelnen Objekte.
Die Erzeugung der Objekte entstand mithilfe von Fotogrammetrie und wird in [10, 11] von Berk Calli et al.
näher erläutert. Neben den Objekten aus der YCB- Datenbank wurden die 3D- Modelle eines Skateboards8 ,
eines Playstation 4 Controllers9 und eines Spielzeug Starwars Tie Fighers verwendet. Die 3D-Modelle des
2
https://www.unrealengine.com/marketplace/archviz-kitchenette, 11.01.2020
3
https://www.unrealengine.com/marketplace/realistic-forest-pack, 11.01.2020
4
https://developer.nvidia.com/ue4-sun-temple, 11.01.2020
5
https://www.unrealengine.com/marketplace/procedural-nature-pack-vol, 11.01.2020
6
https://docs.unrealengine.com/Resources/Showcases/RealisticRendering/index.html, 11.01.2020
7
http://www.ycbbenchmarks.com/object-models/, 11.01.2020
8
https://sketchfab.com/3d-models/skateboard-4b0f217a8b9043b781f23a271ceb2276, 11.01.2020
9
https://sketchfab.com/3d-models/playstation-4-controller-16a3c27778264334a40aa3f9faabe98a,
11.01.2020
3
12. F EBRUAR 2020
Abbildung 1: Gegenüberstellung der Szenen
Skateboard sowie des Playstation 4 Controllers wurden künstlich mithilfe von 3D- Grafiksoftware erzeugt.
Das 3D- Modell des Starwars Tie Fighters wurde selbst mithilfe der freien Fotogrammetrie-Software 3DF
Zephyr10 erzeugt.
Abbildung 2: Alle für die Erstellung des eigenen Datensatzes verwendeten Objekte
Bei der Auswahl der Objekte wurde darauf geachtet, dass die Größen der Objekte sich innerhalb eines für die
Szenen geeigneten Größenrahmens bewegt. Der Größenrahmen wurde nicht fest spezifiziert, jedoch liegt der
10
https://www.3dflow.net/3df-zephyr-free/, 11.01.2020
4
12. F EBRUAR 2020
dieser zwischen dem Skateboard (größtes verwendetes Objekt) und einer Erdbeere (kleinstes verwendetes
Objekt). Im Übrigen sei erwähnt, dass darauf geachtet wurde, dass die Größe der Objekte in den jeweiligen
Szenen der Unreal Engine den Größen der gleichen Objekte in der Realität entsprechen. Dafür wurden in
Parametern der Szene eingestellt, dass eine uu (Unreal Unit) einem realen Meter entspricht. Diese Einstellungs-
möglichkeit ist eine Standardfunktion der Unreal Engine. Die Einbindung der Scripts für die Datenextraktion
kann dem Git- Hub Repository [12] von Trembley et al. entnommen werden.
2.2.2 Szenenaufbau - fotorealistisch
Im Folgenden wird auf die allgemeine Einrichtung einer Aufnahmestelle innerhalb der drei oben genannten
Szenen eingegangen. Hierzu gehört der Bereich innerhalb dessen die zu annotierenden Objekte erscheinen, der
Bereich innerhalb dessen die Kamera ihre Position verändern darf und der Blickpunkt, anhand dessen sich die
Kamera orientiert.
Abbildung 3: Beispiel "fotorealistisch" - Aufnahmestelle (links) und Ausführung (rechts)
Abbildung 3 (links) zeigt eine Beispielaufstellung einer Aufnahmestelle innerhalb der eigens aufge-
stellten Szenen. Zu sehen ist eine Kamera in der oberen Mitte des Bilden, ein weißer Kreis in der Mitte des
Bildes, die gelblich hervorgehobenen Ränder einer Trigger- Box und die grünlich hervorgehobenen Ränder
einer Trigger- Box. Eine Trigger- Box beschreibt hierbei immer einen Bereich, innerhalb dessen beliebige
Objekte zufällig platziert werden können. Für diese Bereiche gilt es einen Rahmen zu definieren, der dem
gewünschten Bereich für die zu lösende Aufgabe der 3D- Posen- Erkennung entspricht. Bei der Einrichtung
der eigenen Aufnahmestellen bewegt sich dieser Rahmen zwischen einer Höhe von 0.25 m bis 1.00 m, einer
Breite von 0. 50 m bis 4. 00 m und einer Länge von 0.50 m bis 4.00 m. Die Trigger- Box für die Kamera
(gelbliche Ränder) ist dabei stets größer als die Trigger-Box für die zu annotierenden Objekte (grünliche
Ränder). Außerdem existiert stets ein Abstand zwischen den beiden Trigger-Boxen, damit die 3D- Modelle
der zu annotierenden Objekte nicht über die Aufnahmeposition der Kamera hinauslaufen, was Fehler in
der Darstellung des zu annotierenden Objektes zur Folge haben würde. Der weiße Kreis in der Mitte des
Bildes beschreibt die Position nach der sich die Kamera orientiert, sodass die Kamera mit jedem Wechsel der
Position stets in die gleiche Richtung ausgerichtet wird. Weiter zeigt die Abbildung 3 (rechts) das Bild einer
Kamera, während der Ausführung der Erstellung einer Teilmenge der Trainingsmenge. Zu sehen sind dabei
Objekte umgeben von Quadraten, die jeweils auf das Objekt angepasst sind. Auf dem Bild sind die Objekte
verschwommen dargestellt, diese sind in der erzeugten Datenmenge jedoch klar zu erkennen. Die weiteren
eingerichteten Aufnahmestellen sind dem Anhang (Abbildung 7) zu entnehmen.
2.2.3 Szenenaufbau - domain randomized
Wie bereits für den Aufbau der fotorealistischen Szenen folgt nun eine Erklärung zur Einrichtung der "Domain
Randomized" -Szene, innerhalb der die zu annotierenden Objekte sowie Distraktoren zufällig erscheinen und
der Hintergrund häufig ausgetauscht wird, um den Ansatz der Data Augmentation [13] für synthetisch erzeugte
Daten zu ermöglichen. Die Einrichtung der "Domain Randomized" -Szene (Abbildung 4 - links) gestaltet sich
5
12. F EBRUAR 2020
Abbildung 4: Beispiel "Domain Randomized" - Aufnahmestelle (links) und Ausführung (rechts)
ähnlich wie die der fotorealistischen Szenen. Hierbei werden auch zwei Trigger- Boxen und eine Kamera
verwendet. Dieses Mal werden die Trigger- Boxen jedoch ineinander verschachtelt. Dabei wird eine kleinere
Trigger- Box vor der Kamera positioniert, welche für die zufällige Positionierung der für die Annotation
vorgesehenen Objekte innerhalb des 3D- Rahmens zuständig ist. Eine größere Trigger- Box umschließt diese
und ist für die zufällige Positionierung von Distraktoren verantwortlich. Die Kamera erhält dieses Mal eine
feste Position am Rand der Distraktoren-Trigger-Box. Durch diese Aufstellung wird sichergestellt, dass die
Distraktoren überall um die zu annotierenden Objekte herum und auch zwischen der Kamera und den Objekten
erscheinen können. Gegenüberliegend zur Kamera existiert ein Hintergrund (in der Abbildung durch rote und
grüne Quadrate dargestellt), der dafür vorgesehen ist, während der Ausführung der Erstellung der eigenen
Trainingsmenge, mit zufälligen Bildern ausgetauscht zu werden (Abbildung 4 - rechts). Außerdem sind wieder
die Quadrate zu erkennen, die jedes Objekt, welches es zu annotieren gilt, umgeben. Die Distraktoren im Bild
werden durch keine Quadrate umgeben und sind zufällig in der Szene verteilt. Der Hintergrund besteht aus
einem 2D- Bild, dessen Licht- und Schattenverhältnisse sich aufgrund der Szenenaufstellung nicht auf die
Objekte in der Szene auswirken.
2.2.4 Erstellung der Trainingsmenge
Bei der Erstellung der Trainingsmenge wird das Unreal Projekt mit dem NDDS- Plugg-in ausgeführt.
Hierbei werden pro Aufnahmestelle jeweils 4000 Schnappschüsse erstellt. Während des Erstellungspro-
zesses springt die Kamera innerhalb des definierten Bereichs zwischen zufälligen Position umher. Dabei
erscheinen die zu annotierenden Objekte zufällig innerhalb des für die Objekte definierten Bereichs mit
jeweils unterschiedlichen Rotationen. Ein neuer Schnappschuss wird nach jedem Positionswechsel der Ob-
jekte und der Kamera erstellt. Die pro Schnappschuss erstellte JSON- Datei enthält dabei folgende Information:
Die für jede Aufnahmeposition erstellen JSON- Dateien, stehen stets in Abhängigkeit zu einer Object-
Settings- Datei, welche die allgemeinen Objekteigenschaften der annotierten Objekte beinhaltet (Tabelle 2).
Für den Erstellungsprozess des eigenen Datensatzes wurde die Auflösung der Kamera in den Szenen auf
960 x 540 Pixel bei einem Sichtfeld von 90◦ eingestellt. Die Anzahl der Möglichkeit von erscheinenden
Annotationsobjekten wurde auf eins bis vier Objekte eingestellt. Die Ober- und Untergrenze von möglichen
Annotationsobjekten in der Szene wurde zwischen mindestens drei und maximal elf eingestellt. Distraktoren
wurden in den fotorealistischen Szenen nicht verwendet, jedoch wurde die Umgebung genutzt, um die zu
annotierenden Objekte zufällig zu verdecken. Die Zeit, wie lange ein Annotationsobjekt bis zum Austausch
in der Szene verbleibt, wurde auf drei Sekunden eingestellt. Während der drei Sekunden wechselt das
Annotationsobjekt mehrfach die Position und die Orientierung. Die Zeit zwischen den Schnappschüssen
wurde auf null Sekunden eingestellt, sodass am Ende jedes erfolgreich Frames ein Schnappschuss entsteht.
Im Gegensatz zu den Ansätzen von Jonathan Tremblay et al. [2] werden die Annotationsobjekte nicht
innerhalb der Szene fallen gelassen, woraufhin diese physikalisch korrekt miteinander interagieren (Falling
Things). Stattdessen schweben die Objekte innerhalb der eingestellten drei Sekunden, währenddessen die
Kamera weiter ihre Position und die Objekte weiter ihre Rotation verändern. Jonathan Tremblay et al. [2]
argumentieren ihr Vorgehen damit, dass das "Fallenlassen" der Objekte mehr Zufall bei der Erzeugung der
6
12. F EBRUAR 2020
Name Beschreibung
Umfasst die Information zur Position (location_worldframe) in
camera_data Abhängigkeit des globalen Koordinatensystems einer Szene und Rotation
(quaternion_xyzw_worldframe) der Kamera zu einer Aufnahmeposition.
Beinhaltet die nachfolgend aufgelisteten Metadaten für jedes
objects
annotierte Objekte in einer Aufnahmeposition.
class Name/ Klasse eines annotierten Objektes.
visibility Transparenzgrad eines annotierten Objektes.
Der Ort eines annotierten Objektes in Abhängigkeit des lokalen
location
Koordinatensystems der Kamera.
quaternion_xyzw Rotation des annotierten Objektes in einer Aufnahmeposition.
Matrix-Darstellung (4x4) der Position und Rotation des annotierten Objektes
pose_transform_permuted
in einer Aufnahmeposition.
Beschreibt den Mittelpunkt des annotierten Objektes in einer
cuboid_centroid
Aufnahmeposition (äquivalent zur Location).
2D-Projektion des Mittelpunktes eines annotierten Objektes in einer
projected_cuboid_centroid
Aufnahmeposition.
2D-Projektion der Rahmen-Box um ein annotiertes Objekt in einer
bounding_box
Aufnahmeposition. Besteht aus zwei Vektoren (top_left & bottom_right).
Quader (3D- Rahmen) eines annotierten Objektes in Matrix-Darstellung
cuboid
(3x8). Jede Zeile der Matrix beschreibt dabei eine Kante des 3D- Rahmens.
projected_cuboid 2D- Projektion des Quaders (3D- Rahmens).
Tabelle 1: Inhalte der JSON-Datei pro Aufnahmeposition mit Beschreibung
Name Beschreibung
Hier werden die Referenzen zu allen Objekten festgehalten, die es zu annotieren
exported_object_classes
gilt.
exported_objects Beinhaltet die Metadaten für jedes der zu annotierenden Objekte.
class Name/ Klasse eines zu annotierenden Objektes.
ID eines der zu annotierenden Objekte, zur Wiedererkennung während des
segmentation_class_id
Trainings.
Transformation des 3D-Modells eines zu annotierenden Objektes in
fixed_model_transform
Abhänigkeit zur Rahmen-Box.
Rahmen- Box, die das zu annotierende Objekt umhüllt. Die Dimensionen
cuboid_dimensions
entsprechen den unterschiedlichen Kantenlängen der umhüllenden Box.
class Name/ Klasse eines zu annotierenden Objektes.
Tabelle 2: Inhalte der JSON-Datei zur allgemeinen Beschreibung der annotierten Objekte mit Erklärung
Datenmenge berücksichtigt. Da der zufällige Wechsel der Kameraposition und die zufällige Positionierung
und Rotation der Annotationsobjekte bereits stark randomisiert ist, wurde sich bei der Erstellung des eigenen
Datensatzes dagegen entschieden. Ob der Ansatz zur Erstellung des eigenen Datensatzes oder Tremblays
Ansatz an dieser Stelle der bessere ist, lässt sich durch die allgemein schon hohe Konstellation von Zufällen
und aufgrund einer fehlenden Vergleichbarkeit zwischen den Datensätzen nur schwer messen.
Speziell bei für die "Domain Randomization" -Szene wurde die Kamera auf den Nullpunkt des globalen
Koordinatensystems der Szene gesetzt. Die Trigger-Box für die zu annotierenden Objekte hat die Maße 2 m
x 2 m x 2 m und der Mittelpunkt ist 1.07 m von der Kamera entfernt. Die Trigger-Box für die Distraktoren
hat die Maße 4 m x 4 m x 4 m und der Mittelpunkt ist 1.71 m von der Kamera entfernt. Die Anzahl an
möglichen gleichzeitigen Distraktoren wurde auf das Intervall zwischen 40 und 60 eingestellt. Der Wechsel des
Hintergrundes erfolgt mit jedem Frame, dabei wird aus einer Teilmenge von 10.000 Bildern des COCO- Daten-
satz [9] zurückgegriffen. Außerdem wird der Hintergrund teilweise mit prozedural generierten mehrfarbigen
Gittermustern ausgetauscht.
Zuletzt sei erwähnt, dass für die Erstellung der eigenen Trainingsdaten ein Desktop PC mit einem AMD
Ryzen 7 1700 mit 8 Kernen und 16 Threads bei maximal 3.7 GHz, einer Nvidia 2080 mit 8 GB RAM und 16
Gigabyte DDR4 Arbeitsspeicher verwendet wurde.
7
12. F EBRUAR 2020
2.3 Ergebnis - NDDS
Die Erzeugung der eigenen Datenmenge verlief erfolgreich. Der Datensatz enthält 127.000 kommentierte Fotos.
Zu jedem Schnappschuss existiert ein RGB-Bild, ein Tiefen-Bild, eine Klassen-Segmentierung sowie die
3D- Pose und 2D/ 3D Rahmen-Box-Koordinaten für alle im Schnappschuss enthaltenen Objekte (Abbildung
5). Ungleich zum FAT- Datensatz [6] enthält der eigens erzeugte Datensatz keine stereoskopischen Bilder.
Diese Entscheidung beruht auf der Intention einzig und alleine eine hohe Qualität bei der Objekterkennung zu
erzielen. Der Ansatz stereoskopische Bilder zu erzeugen ermöglicht laut Jonathan Tremblay et al. [2] nur
die Zurverfügungstellung weiterer Input- Methoden beim Testen des Datensatzes. Die Größe des eigens
Abbildung 5: Beispiel des Datensatzes - RGB (oben), Segmentierung (unten rechts), Tiefen (unten links)
erstellten Datensatzes beträgt ca. 87 Gigabyte. Die benötigte Zeit für die Erstellung der Dateien von 4000
Schnappschüssen pro Aufnahmestelle variiert zwischen ca. 12 und 16 Minuten. Insgesamt benötigt die
Erstellung eines Datensatzes mit der Größe von 127.000 Schnappschüssen ca. 7,5 Stunden.
Bei einem direkten Vergleich der Tempel Szenen aus dem FAT- Datensatz und der eigens erstellten
Szene ist auf den ersten Blick kein großer Unterschied festzustellen (Abbildung 6).
Insgesamt wirken die von Jonathan Tremblay et al. erzeugten Szenen grafisch ein nahezu gleichwertig. Welche
Auswirkung die subjektiv empfundene geringere grafische Qualität auf ein erfolgreiches Training einer künst-
lichen Intelligenz hat, kann im Zuge der Masterarbeit unternommen werden. Weitere Gegenüberstellungen
können aus dem Anhang entnommen werden (Abbildung 8).
3 Deep Object Pose Estimation - Netzwerk
Beim "Deep Object Pose Estimation" - Netzwerk (DOPE) handelt es sich grundsätzlich um ein Paket für das
Robot Operating System (ROS)- Framework11 , zur Erkennung und 6-DoF-Posenschätzung bekannter Objekte
mithilfe einer RGB- Kamera. Das DOPE- Projekt selbst entstammt von NVIDIA, bzw. von Jonathan Tremblay
et al. [2] und wird in dieser Arbeit speziell für das Training zur Erkennung und 6-DoF-Posenschätzung genutzt.
11
https://www.ros.org/, 11.01.2020
8
12. F EBRUAR 2020
Abbildung 6: Gegenüberstellung Bild aus dem FAT-Datensatz (links) und eigens erstelltes Bild (rechts)
Als Datengrundlage für das Training dienen die im zweiten Kapitel beschriebenen selbst erstellten Daten,
sowie der von Jonathan Tremblay et al. [6] zur Verfügung gestellte FAT- Datensatz.
3.1 Planung
Das Trainings des tiefen neuronalen "Object Pose Estimation" - Netzwerks richtete sich an den von Jonathan
Tremblay et al. [2] verwendeten Konfigurationen. Demnach wurde der VGG-19 [15] Datensatz (vortrainiert
auf ImageNet) verwendet und bei der Parametrisierung des neuronalen Netzes eine Laufzeit von 60 Epochen,
bei einer Batch- Größe von 128 und einer Lernrate von 0,0001 (Adam) eingestellt. Der Datensatz bestand aus
ca. 60.000 domain randomisierten Bildern und 60.000 fotorealistischen Bildern und eine Testmenge wurde
dabei nicht definiert. Das Trainings wurde zunächst für zwei Objekte durchgeführt. Einerseits wurde die
Cracker Box aus dem YCB- Datensatz, die auch innerhalb des FAT- Datensatzes vorkommt und andererseits
der TIE Fighter als selbst erstelltes Objekt verwendet.
3.1.1 Hardware
Bei der verwendeten Hardware für die ersten Tests wurde, wie auch bei der Erstellung des synthetisch
erzeugten Datensatzes, ein Desktop PC mit einem AMD Ryzen 7 1700 mit 8 Kernen und 16 Threads bei
maximal 3.7 GHz, einer Nvidia 2080 mit 8 GB RAM und 16 Gigabyte DDR4 Arbeitsspeicher verwendet.
Weiter wurde ein Training mit stark leistungsbeanspruchenden Parameterkonfigurationen auf der Multi-
GPU-Renderfarm der HAW- Hamburg durchgeführt, welche der von Nvidia verwendeten Hardware ähnelt.
Die Hardwarekonfiguration der Renderfarm sowie Benchmarks wurden von Matthias Nitsche und Stephan
Halbritter in [14] beschrieben. Zum Vergleich sei erwähnt, dass die von Jonathan Tremblay et al. verwendete
Hardware für das Training auf einer NVIDIA DGX Workstation12 mit vier bis acht NVIDIA P100 oder V100
GPUs beruht und zum Testen der trainierten Modelle eine NVIDIA Titan X verwendet wurde.
3.2 Durchführung
Bei der Durchführung des Trainings ist es derzeit nur möglich, die Erkennung der 6-DoF-Pose für ein
einzelnes Objekt anzutrainieren. Welche Schichten das neuronale Netz während der Durchführung des
Trainings durchläuft, wurde bereits in [1] beschrieben. Bei den ersten Tests auf dem Desktop PC musste
wegen der schwächeren Hardware die Batch- Größe aufgrund einer geringeren Grafikkarten- Leistung, im
Vergleich zur Renderfarm, auf 12 reduziert werden. Außerdem wurde die Anzahl an Epochen auf eine Epoche
reduziert, weil der Durchlauf nur für den Zweck der Validierung dienen sollte, ob ein Training grundsätzlich
durchgeführt werden kann. Als Trainingsdaten wurde hierbei der eigene sowie der FAT- Datensatz verwendet.
Für das Training von 60 Epochen auf der Renderfarm wurden die Parameter wie eingangs erwähnt
konfiguriert. Das Training dauerte auf der in [14] beschriebenen Hardware ca. sieben Tage. Insgesamt wurden
zur Posen-Erkennung drei Objekte (Skateboard, Tie Fighter und eine Cracker-Box) jeweils 60 Epochen
trainiert. Das Training von mehreren Objekten gleichzeitig ist innerhalb des DOPE-Projektes nicht vorgesehen,
weil dies wesentlich mehr Trainingszeit beanspruchen würde und sich laut Jonathan Tremblay et al. zum
12
https://www.nvidia.com/de-de/data-center/dgx-station/, 11.01.2020
9
12. F EBRUAR 2020
aktuellen Forschungsstand zunächst auf die Qualität und Optimierung bei der Erkennung einzelner Objekte
konzentriert wurde.
4 Ergebnis
Das Training mit dem FAT- Datensatz, als auch mit dem eigens erstellten Datensatz lief erfolgreich. So
zeichnet das laufende Modell Rahmenboxen mit korrekten Größenverhältnissen und Orientierungen um
die zu erkennenden Objekte. Während des Trainings auf der Renderfarm der HAW konnte die gleiche
Parameterkonfiguration, wie von Jonathan Tremblay et al. genutzt werden. Beim Training mittels der acht
Grafikkarten der HAW- Renderfarm konnte somit eine Batch- Größe von 128 erreicht werden. Bei der
Verwendung von weniger Grafikkarten musste die Batch- Größe dementsprechend nach unten angepasst
werden. Dies hatte zur Folge, dass das Training der einzelnen Objekte mehr Zeit in Anspruch nahm. Erste
moderate Erkennungen von Objekten waren, wie bei Jonathan Tremblay et al., ab der 30 Episode zu erkennen.
Für einen ersten empirischen Vergleich wurden die trainierten Modelle der Cracker- Box verwendet. Für
den einfachen Vergleich wurde das Bild einer Webcam abgegriffen. Hierbei wurde die Webcam auf ein
Bild, welches mehrere Cracker- Boxen enthielt (siehe Abbildung 10 im Anhang- Abbildungen), gerichtet.
Beim Vergleich zwischen dem anhand des FAT- Datensatzes selbst trainierten Modells, gegenüber dem
öffentlich zugänglichen trainierten Modell13 konnte ad hoc kein Unterschied beobachtet werden. So wurden in
beiden Fällen ca. fünf Cracker-Boxen gleichzeitig erkannt. Das Modell, welches aus der eigens erstellten
Datenmenge trainiert wurde schnitt dabei mit durchschnittlich ca. sieben gleichzeitig erkannten Cracker-
Boxen etwas besser ab. Jedoch sei an dieser Stelle erwähnt, dass eine Vergleichbarkeit aufgrund der fehlenden
Reproduzierbarkeit des FAT- Datensatzes nicht gegeben ist. Außerdem stehen weitere Analysen bezüglich
der Beurteilbarkeit der Datensätze aus und werden weiter in der auf diese Arbeit aufbauende Masterarbeit
beschrieben.
Weiter konnte zunächst durch empirische Beobachtung bei der Erkennung eines Objektes auf dem
Desktop PC eine Bildwiederholrate von ungefähr 10 bis 12 Bildern pro Sekunde beobachtet werden.
Außerdem ließen sich zur Erkennung mehrerer Objekte gleichzeitig die trainierten Modelle hintereinander
schalten. Dies beanspruchte pro Modell jedoch mehr Leistung des Desktop PC’s auf dem die Tests ausgeführt
wurden. So konnte beobachtet werden, dass sich die Bildwiederholrate bei zwei zu erkennenden Objekten
ungefähr halbierte.
Das "Object Pose Estimation" - Netzwerk wurde erfolgreich für die drei oben genannten Objekte trainiert. Die
Abbildung 7 zeigt dafür einen Bildausschnitt mit zwei erkannten Objekten während der laufenden Erkennung
von zwei trainierten Modellen. Das eine trainierte Modell wurde zur Posen-Schätzung des Tie Fighters (türkis)
trainiert und das andere Modell zur Posen-Schätzung des Skateboards (purpur). Dreidimensionale Quader
erscheinen in der für die Objekte definierten Farbe um die Objekte herum und machen auf dem Bild den
Eindruck, die 6-DoF Posen der Objekte sehr gut zu erkennen.
5 Fazit
In dieser Arbeit wurde die erfolgreiche praktische Umsetzung der in [1] erläuterten Pipeline zur Schätzung
der 6-DoF-Pose von bekannten Objekten beschrieben. Als Datengrundlage diente hierfür der FAT- Datensatz
sowie ein mithilfe des NDDS- Plugins für die Unreal Engine selbst erstellter synthetischer Datensatz. Weiter
wurde für die Erstellung des synthetischen Datensatzes beschrieben, wie sich der Szenenaufbau gestaltet
und welche Bedingungen berücksichtigt wurden, um einen Reality Gap zu verringern. Zu den Bedingungen
zählten unter anderem möglichst natürliche Licht- und Schattenverhältnisse, Blendeffekte und die teilweise
Verdeckung von den Objekten, die es zu annotieren gilt. Bei der Erstellung des synthetischen Datensatzes
konnte eine ähnliche grafische Qualität, wie die des FAT- Datensatzes, erreicht werden. Gleichzeitig bedingt
die vom Zufall bestimmte Häufigkeit, Position und Rotation der zu annotierenden Objekte bei der Erzeugung
des synthetischen Datensatzes, dass die Qualität des erzeugten Datensatzes nur schwer zu beurteilen ist. So
kann es beispielsweise sein, dass ein Objekt zufallsbedingt relativ selten innerhalb eines erzeugten Datensatzes
vorkommt. Auch kann es sein, dass ein Objekt häufig von anderen Objekten abgedeckt wurde. Diese Umstände
wiederum wirken sich auf die trainierte Qualität des Modells zu einem zu erkennenden Objekt aus. Bei der
Wahl der Szenen für die Datenerzeugung ist die Größe der zu annotierenden Objekte zu berücksichtigen, sodass
der Abstand zwischen den Objekten und der Kamera, den erwarteten Verhältnis in der Realität entspricht. Nur
13
https://drive.google.com/drive/folders/1DfoA3m_Bm0fW8tOWXGVxi4ETlLEAgmcg, 11.01.2020
1012. F EBRUAR 2020
Abbildung 7: Schnappschuss bei laufender Erkennung - Tie Fighter (türkis) & Skateboard (purpur)
so ist es möglich, dass erwartete Verhalten mit dem Training des neuronalen DOPE- Netzes auf die Realität zu
übertragen. Somit muss für unterschiedliche Anwendungsfälle ein passender Datensatz erstellt werden. Hierzu
sei erwähnt, dass beim Testen der Modelle die Erkennungsrate innerhalb von 1.0 m - 4.0 m besonders gut war.
Dies entspricht ungefähr den Verhältnissen der Aufnahmestellen aus den Szenen.
Alle bisher getroffenen Aussagen basieren hierbei auf einfachen empirischen Beobachtungen und Vermutungen.
Eine konkrete wissenschaftliche Untersuchungen und Auswertungen folgt in der auf diese Arbeit aufbauende
der Masterarbeit.
6 Ausblick
Die Ausführung der "Object Pose Estimation" - Pipeline warf während der Projektarbeit weitere Forschungs-
fragen auf, die es unter anderem in der an diese Arbeit anschließende Masterarbeit durch wissenschaftliche
Untersuchungen zu beantworten gilt. So ist bislang unklar, wie ausschlaggebend die Verwendung von
fotorealistischen Umgebungen zur Erstellung der synthetischen Datenmenge ist. Hierfür kann beispielsweise
ein Datensatz auf Basis von Low-Poly-Umgebungen für Experimente verwendet werden. In diesem
Zusammenhang wären Experimente interessant, in denen der Anteil an "Domain Randomized" - Daten variiert,
um zu sehen, wie sich die Daten im Vergleich zu [2] auf den Trainingsverlauf des Netzes auswirken. Außerdem
besteht die Frage, für welche Anwendungsfälle sich die Nutzung von fotorealistischen Umgebungen lohnt.
Hierfür könnten zum Beispiel Szenen angelegt werden, die speziell für einen Anwendungsfall erstellt wurden.
Ein Anwendungsfall könnte in diesem Zusammenhang die allgemeine Nutzung innerhalb eines Wohnzimmers
sein. Die Frage, die sich hieraus ergibt, könnte lauten ob Objekte in einer Wohnzimmer-Umgebung besser
erkannt werden, wenn eine synthetisch erzeugte fotorealistische Umgebung zur Erzeugung der Datenmenge
genutzt wurde. Außerdem besteht die Frage, welche Auswirkung die Verwendung von Distraktoren innerhalb
von fotorealistischen Umgebungen hat. Diese Fragen lassen sich einerseits empirisch beantworten, unter der
Berücksichtigung, dass die Erkennung, wie in Kapitel zwei beschrieben, durch viele Faktoren beeinflusst
wird. Ein quantitativer Ansatz wäre andererseits ein Vergleich der Trainingsverläufe bei der Erstellung eines
Modells. Eine weitere Frage, die untersucht werden kann, ist ob sich die Erkennung der 6-DoF-Pose für einen
Anwendungsfall optimieren lässt, indem die Rahmenbedingungen der Aufnahmestellen (Entfernung der
Kamera zu den Objekten), auf einen für den Anwendungsfall entsprechendes Intervall festgelegt werden.
Beispielsweise könnte dazu ein Datensatz erstellt werden, in dem die Objekte immer nur 0.5 m bis 1.0 m
von der Kamera entfernt sind, um später zu prüfen, wie zuverlässig die Objekterkennung in dem kleineren
definierten Bereich funktioniert. Das "Object Pose Estimation" - Netz wurde für die Nutzung innerhalb von
1112. F EBRUAR 2020
Robotik-Systemen für relativ kleine Objekte in einem nahen Bereich erstellt. Aus diesem Grund stellt sich die
Frage, ob das "Object Pose Estimation" - Netz auch trainiert werden kann, um größere und/ oder weit entfernte
Objekte, wie Drohnen, Autos oder Flugzeuge zu erkennen.
Bezüglich der verwendeten Objekte könnte untersucht werden, wie sich die Verwendung von LowPoly-
und HighPoly- Objekt-Modellen auf die Performance bei der Erzeugung der Datenmenge und den
Trainingsverlauf des neuronalen Netzes auswirkt. Zusätzlich ließe sich hierbei untersuchen, wie sich
die Verwendung von verschiedenen Varianten zu einem Objekt auf die Qualität der Posen-Erkennung
und den Verlauf des Trainings des neuronalen Netzes auswirkt. Eine weitere Frage in Bezug auf die
Objekterkennung ist, wie viele unterschiedliche Objekte und wie viele gleiche Objekte gleichzeitig erkannt
werden können. Zur Untersuchung wie viele unterschiedliche Objekte gleichzeitig erkannt werden, können
mehrere Modelle trainiert und für Tests hintereinander geschaltet werden. Hierbei ist interessant, wie sich
die Verwendung von mehreren verschiedenen Modellen auf die Performance und somit die notwendige
Hardware zur 3D-Posen-Erkennung auswirkt. Zur Optimierung der Erkennung der Pose von Objekten könnte
untersucht werden, wie sich unterschiedliche Trainingsparameter oder das Hinzufügen, bzw. das Entfernen
von Schichten aus der Netzarchitektur des "Object Pose Estimation" - Netzes auf den Trainingsverlauf auswirkt.
Zuletzt bleibt die Fragen offen für welche Anwendungsfälle sich der Einsatz des tiefen neuronalen
Pose-Estimation Netzwerks eignet und für welche Anwendungsfälle Alternativen wie OpenCV oder Vuforia
besser geeignet sind. Diesbezüglich ist außerdem ausstehend, wie sich die Informationen von annotierten
Objekten zum Beispiel in einer Augmented Reality Anwendung nutzen lassen und wie sich die Erkennung der
6-DoF-Pose auf leistungsschwächeren Plattformen, wie z. B. Smartphones bringen lässt.
Literatur
[1] Dustin Spallek, Pipeline zur Erkennung und Schätzung der 6-DoF-Pose bekannter Objekte, Hochschule
für Angewandte Wissenschaften, Hamburg, 2019
[2] Tremblay, Jonathan, et al. ’Deep object pose estimation for semantic robotic grasping of household
objects.’ arXiv preprint arXiv:1809.10790 (2018).
[3] Chen, Xue-Wen, and Xiaotong Lin. "Big data deep learning: challenges and perspectives.ÏEEE access 2
(2014): 514-525.
[4] J. Tremblay, T. To, A. Molchanov, S. Tyree, J. Kautz, S. Birchfield. Synthetically Trained Neural Networks
for Learning Human-Readable Plans from Real-World Demonstrations. In International Conference on
Robotics and Automation (ICRA), 2018.
[5] J. Tremblay, T. To, S. Birchfield. Falling Things: A Synthetic Dataset for 3D Object Detection and Pose
Estimation. CVPR Workshop on Real World Challenges and New Benchmarks for Deep Learning in
Robotic Vision, 2018.
[6] Tremblay, Jonathan, Thang To, and Stan Birchfield. ’Falling Things: A Synthetic Dataset for 3D Object
Detection and Pose Estimation.’ Proceedings of the IEEE Conference on Computer Vision and Pattern
Recognition Workshops. 2018.
[7] Tremblay, Jonathan, et al. ’Training deep networks with synthetic data: Bridging the reality gap by domain
randomization.’ Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition
Workshops. 2018.
[8] Calli, Berk, et al. "The ycb object and model set: Towards common benchmarks for manipulation
research."2015 international conference on advanced robotics (ICAR). IEEE, 2015.
[9] T. Lin, M. Maire, S. J. Belongie, L. D. Bourdev, R. B. Girshick, J. Hays, P. Perona, D. Ramanan, P.
Dollar, and C. L. Zitnick. Microsoft COCO: Common objects in context. In CVPR, 2014.
[10] Berk Calli, Aaron Walsman, Arjun Singh, Siddhartha Srinivasa, Pieter Abbeel, and Aaron M. Dollar,
Benchmarking in Manipulation Research: The YCB Object and Model Set and Benchmarking Protocols,
IEEE Robotics and Automation Magazine, pp. 36 – 52, Sept. 2015.
[11] Berk Calli, Arjun Singh, James Bruce, Aaron Walsman, Kurt Konolige, Siddhartha Srinivasa, Pieter
Abbeel, Aaron M Dollar, Yale-CMU-Berkeley dataset for robotic manipulation research, The International
Journal of Robotics Research, vol. 36, Issue 3, pp. 261 – 268, April 2017.
1212. F EBRUAR 2020
[12] Thang To, Jonathan Tremblay, Duncan McKay, Yukie Yamaguchi, Kirby Leung, Adrian Bala-
non, Jia Cheng, William Hodge, Stan Birchfield."NVIDIA Deep Learning Dataset Synthesizer
(NDDS)"https://github.com/NVIDIA/Dataset_Synthesizer, 2018
[13] Van Dyk, David A., and Xiao-Li Meng. "The art of data augmentation."Journal of Computational and
Graphical Statistics 10.1 (2001): 1-50.
[14] Matthias Nitsche, Stephan Halbritter ’Development of an End-to-End Deep Learning Pipeline’. Hoch-
schule für Angewandte Wissenschaften Hamburg (HAW Hamburg), 2019.
[15] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In
ICLR, 2015.
1312. F EBRUAR 2020
7 Anhang - Abbildungen
Abbildung 8: Überblick aller Aufnahmestellen in den Szenen
Abbildung 9: Weitere Beispiele für die Gegenüberstellung der Datensätze
1412. F EBRUAR 2020
Abbildung 10: Grundlage des ersten einfachen empirischen Tests
15Sie können auch lesen

















































