Funktionsweise, Eigenschaften und Anwendung der Microsoft Kinect in der Robotik
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Institut für Verteilte Systeme
Proseminar – Sensorik und Robotik
Funktionsweise, Eigenschaften und Anwendung der Microsoft
Kinect in der Robotik
Sommersemester 2013
Autoren: Silyana Gerova
Vasil Georgiev
Fabian Göcke
Lars Grotehenne
Dominik Hamann
Patrick Hühne
Ben Rabeler
Christian Schildwächter
Professor: Prof. Dr. rer. nat. Kaiser
Betreuer: Sebastian Zug
Betreuer: Christoph Steup
2 Nachname, Vorname: Funktionsweise, Eigenschaften und Anwendung der Microsoft Kinect in der Robotik Proseminar – Sensorik und Robotik, Otto-von-Guericke-Universität Magdeburg, 2013.Institut, Addresse, Jahr
Inhaltsverzeichnis
Abbildungsverzeichnis vi
Tabellenverzeichnis vii
1 Einleitung 3
1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
1.2 Einordnung und Gliederung der Arbeit . . . . . . . . . . . . . . . . . . . . 4
2 RGB-D SLAM 5
2.1 Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2 Grundlagen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2.1 Definition SLAM . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.2.2 Existierende Lösungsansätze . . . . . . . . . . . . . . . . . . . . . 6
2.2.3 Modularer Aufbau . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3 Funktionsweise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.3.1 Definition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.3.2 Ablauf des ICP . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.3.3 RANSAC . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.3.4 KD-Trees . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.3.5 Spezielle Gewichtung . . . . . . . . . . . . . . . . . . . . . . . . 12
2.3.6 Herausforderungen . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3.7 Loop Closing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3.8 Ablauf . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
2.3.9 Einschränkungen der Kinect . . . . . . . . . . . . . . . . . . . . . 14
2.4 Konklusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.4.1 Rückschlüsse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.4.2 Future Work . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3 Lageregelung eines Quadcopters 19
3.1 Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
i
ii Inhaltsverzeichnis
3.2 Funktionsweise . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.2.1 Erkennung der Grundfläche . . . . . . . . . . . . . . . . . . . . . 19
3.2.2 Die Hardware . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
3.2.3 Der Regler . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.3 Ergebnisse . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.4 Fazit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
4 RoboEarth Project 25
4.1 Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 25
4.2 Was ist RoboEarth? . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.3 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.4 Architektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.4.1 Datenbank . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29
4.4.2 Interfaces . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
4.4.3 Generische Komponenten . . . . . . . . . . . . . . . . . . . . . . 34
4.5 Erkennung von Objekten und Positionseinschätzung . . . . . . . . . . . . . 35
4.5.1 Semantische Kartierung . . . . . . . . . . . . . . . . . . . . . . . 35
4.5.2 Schulung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
4.5.3 Aktions - und Situationserkennung und Etikettierung . . . . . . . . 36
4.5.4 Demonstrationen . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
4.6 RoboEarth und Microsoft Kinect . . . . . . . . . . . . . . . . . . . . . . . 40
4.6.1 Einführung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
4.6.2 Wie funktioniert die Erfassung beliebiger Objekte? . . . . . . . . . 41
4.6.3 Objekterkennung und Positionsabschätzung . . . . . . . . . . . . . 41
4.7 Fazit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
5 Detektion von Personen 45
5.1 Abstract . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
5.2 Personendetektion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.2.1 Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.2.2 Related Works . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.2.3 Die Methode . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
5.2.4 2D Kantenmatching . . . . . . . . . . . . . . . . . . . . . . . . . 47
5.2.5 Kopferkennung . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
5.2.6 Konturextraktion . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5.2.7 Experimente . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
Inhaltsverzeichnis iii
5.3 Gestenerkennung am Beispiel des FEMD-Verfahrens . . . . . . . . . . . . 54
5.3.1 Motivation und Probleme in der Gestenerkennung . . . . . . . . . 54
5.3.2 Hand- und Fingerdetektion mit Kinect . . . . . . . . . . . . . . . . 55
5.3.3 Gestenerkennung mit FEMD . . . . . . . . . . . . . . . . . . . . . 56
5.3.4 Experimente und Einordnung . . . . . . . . . . . . . . . . . . . . 57
5.4 Anwendung entsprechender Bibliotheken . . . . . . . . . . . . . . . . . . 58
5.4.1 Kinect-Hacking Geschichte . . . . . . . . . . . . . . . . . . . . . 58
5.4.2 Vergleich verfügbarer Sensoren . . . . . . . . . . . . . . . . . . . 59
5.4.3 Vergleich verfügbarer Bibliotheken . . . . . . . . . . . . . . . . . 60
5.4.4 Frameworks zur Personen-/Gestenerkennung . . . . . . . . . . . . 63
5.5 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63
6 Alternative Sensorsysteme 65
6.1 Einleitung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
6.2 Laserscanner . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
6.2.1 Funktionsweise . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65
6.2.2 Arten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67
6.2.3 Anwendungsgebiete . . . . . . . . . . . . . . . . . . . . . . . . . 67
6.2.4 Vor- und Nachteile . . . . . . . . . . . . . . . . . . . . . . . . . . 68
6.3 PMD Kameras . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
6.3.1 Funktionsweise . . . . . . . . . . . . . . . . . . . . . . . . . . . . 69
6.3.2 Anwendungsgebiete . . . . . . . . . . . . . . . . . . . . . . . . . 70
6.4 Stereoskopie . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
6.4.1 Methoden . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71
6.4.2 Anwendungsgebiete . . . . . . . . . . . . . . . . . . . . . . . . . 75
6.5 Fazit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76
Literaturverzeichnis 86

Abbildungsverzeichnis
1.1 Microsoft Kinect Sensor [Wikipedia] . . . . . . . . . . . . . . . . . . . . . 3
2.1 Übersicht Online Offline SLAM . . . . . . . . . . . . . . . . . . . . . . . 7
2.2 EKF-SLAM Anwendung auf Victoria Park Toronto, E.Nebot . . . . . . . . 7
2.3 Möglicher Ablauf von SLAM . . . . . . . . . . . . . . . . . . . . . . . . 8
2.4 Beispiel für einen 2-dimensionalen Baum, der Koordinaten speichert . . . . 12
2.5 Beispiel Loop-Closing in 2D, Vorher | Nachher . . . . . . . . . . . . . . . 14
2.6 An Quadrocopter montierte Kinect . . . . . . . . . . . . . . . . . . . . . . 15
2.7 Beispiel einer 3D-Karte eines Raumes . . . . . . . . . . . . . . . . . . . . 16
3.1 Gerade in Hessescher Normalform in Bild- und Hough-Raum [SHBS11b] . 20
3.2 Ebene in Hessescher Normalform[SHBS11b] . . . . . . . . . . . . . . . . 20
3.3 Quadcopter . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
3.4 Messergebnisse [SHBS11b] für 0,5m (a) und 1m (b) . . . . . . . . . . . . 24
4.1 Datenaustausch mittel Cloud . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.2 RoboEarth Komponenten . . . . . . . . . . . . . . . . . . . . . . . . . . . 27
4.3 RoboEarth Architektur . . . . . . . . . . . . . . . . . . . . . . . . . . . . 28
4.4 Die Drei-Schichten-Architektur von RoboEarth [www.roboearth.org] . . . . 29
4.5 Die drei Hauptteile der Datenbank von RoboEarth [www.roboearth.org] . . 30
4.6 Objektbeschreibung und Erkennung. [www.roboearth.org] . . . . . . . . . 31
4.7 Ungebungskarte [www.roboearth.org] . . . . . . . . . . . . . . . . . . . . 32
4.8 Die Handlungsanweisungen [www.roboearth.org] . . . . . . . . . . . . . . 33
4.9 RoboEarth - Demontrationsszenario A . . . . . . . . . . . . . . . . . . . . 38
4.10 RoboEarth - Demontrationsszenario B . . . . . . . . . . . . . . . . . . . . 40
5.1 Abbildung 1: Ablauf (vgl. [XCA11]) . . . . . . . . . . . . . . . . . . . . 47
5.2 Zwischenschritte des 2D chamfer match . . . . . . . . . . . . . . . . . . . 48
v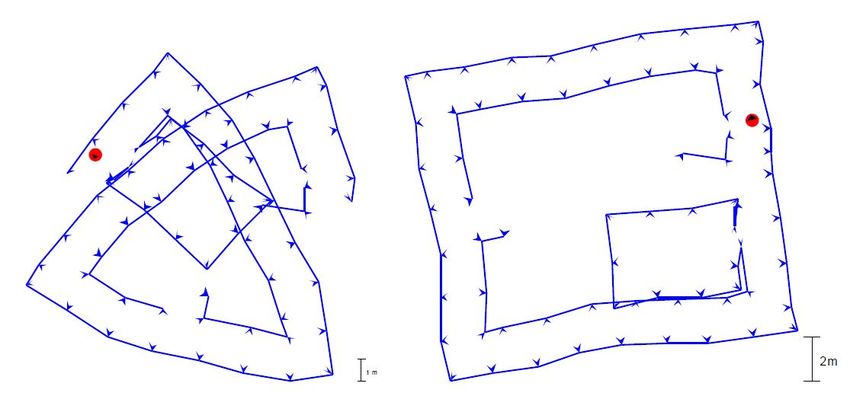
vi Abbildungsverzeichnis
5.3 Nutzen des 3D Modells . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5.4 Konturextraktion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51
5.5 Pseudocode region growing (vgl. [XCA11]) . . . . . . . . . . . . . . . . . 51
5.6 Ergebnisse der Extraktion . . . . . . . . . . . . . . . . . . . . . . . . . . . 52
5.7 Ergebnisse der Personenerkennung [XCA11] . . . . . . . . . . . . . . . . 53
5.8 FN Beispiele . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 53
5.9 Genauigkeiten [XCA11] . . . . . . . . . . . . . . . . . . . . . . . . . . . 54
5.10 Drei schwierige Fälle für die Gestenerkennung ([RMYZ11]) . . . . . . . . 55
5.11 Schritte für die Handerkennung mit Kinect ([RMYZ11]) . . . . . . . . . . 55
5.12 Beispiel für das EMD-Verfahrens . . . . . . . . . . . . . . . . . . . . . . . 56
5.13 Erkennung einer Geste mit Kinect bei vier schwierigen Fällen . . . . . . . 57
5.14 Asus Xtion (Pro) [asu] . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
5.15 Kinect und Xtion Live im Vergleich [kinc] . . . . . . . . . . . . . . . . . . 60
6.1 Abtastsystem eines Laserscanners [www.xdesy.de] . . . . . . . . . . . . . 66
6.2 Laserscan von Mount Rushmore [http://ncptt.nps.gov/] . . . . . . . . . . . 68
6.3 Aufbau eines PMD-Systems . . . . . . . . . . . . . . . . . . . . . . . . . 69
6.4 Farbcodiertes Entfernungsbild (links) und Grauwertbilddarstellung (rechts)
[www.wiley-vch.de] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70
6.5 Spiegelstereoskop . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
6.6 3D-Anaglyphenaufnahme [Wikipedia] . . . . . . . . . . . . . . . . . . . . 73
6.7 Gegenüberstellung von Parallaxenbarrieren- und Linsenrastertechnik [Wi-
kipedia] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74
6.8 Prinzip eines linearen Polarisationsfilters [Wikipedia] . . . . . . . . . . . . 74
6.9 zirkulare Polarisation [Wikipedia] . . . . . . . . . . . . . . . . . . . . . . 75
6.10 Beispiele für 6D-Vision [www.6d-vision.de] . . . . . . . . . . . . . . . . . 76
Tabellenverzeichnis
2.1 Parameter des RANSAC Algorithmus . . . . . . . . . . . . . . . . . . . . 10
2.2 Vergleich zur Neuauflage . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
5.1 Sensoren im Vergleich [sen] . . . . . . . . . . . . . . . . . . . . . . . . . 60
5.2 SDK im Vergleich . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62
vii
Abkürzungen
CL Code Laboratories
EMD Earth Mover Distance
FEMD Fingers Earth Mover Distance
HCI Human Computer Interaction
MEMM hierarchical maximum entropy Markov model
SDK Software Development Kit
SLAM Simultaneous Localization and Mapping
VR Virtual Reality
TOF Time-of-flight
SLAM Simultaneous Localization And Mapping
RGB-D Red-Green-Blue-Depth
ICP Iterative-Closest-Point
GPS Global Positioning System
RANSAC RAndom SAmple Consensus
CAD Computer Aided Design
fps Frames per Second (engl. Bilder pro Sekunde; Einheit der Bildfrequenz)
SIFT Scale-Invariant Feature Transform
EKF Extended Kalman Filter
SURF Speeded Up Robust Features
IEEE Institute of Electrical and Electronics Engineers
LIDAR LIght Detection And Ranging
RGB-D Red-Green-Blue-Depth
ixICP Iterative-Closest-Point GPS Global Positioning System RANSAC RAndom SAmple Consensus CAD Computer Aided Design fps Frames per Second (engl. Bilder pro Sekunde; Einheit der Bildfrequenz) SIFT Scale-Invariant Feature Transform EKF Extended Kalman Filter SURF Speeded Up Robust Features IEEE Institute of Electrical and Electronics Engineers LIDAR LIght Detection And Ranging
Todo list
11 Einleitung
1.1 Motivation
Verglichen mit anderen typischen Sensoren (Laserscanner, PMD-Kameras, hochwertige In-
ertialsysteme), wie sie in der Robotik Einsatz finden, ist die Microsoft Kinect ein vergleichs-
weise preiswertes System, dass verschiedene Möglichkeiten der Umgebungsperzeption bie-
tet. Wichtigste Ausgabegröße ist dabei eine dreidimensionale Punktewolke, die Objekte in
einem Abstand von bis zu 5 Meter in einer veränderlichen Entfernungsauflösung wahr-
nimmt. Die zweite Messgröße ist das Bild einer Webcam, die in die Kinect integriert ist und
eine Auflösung von 960x720 Pixeln liefert. Das dritte Messystem basiert auf einem Mikro-
fonarray, das über Laufzeitunterschiede eine Schallquellenlokalisation umsetzen. Der vier-
te und letzte Sensor, ein Beschleunigungsmesser, mit dem die Neigung des schwenkbaren
Kopfes erfasst wird, ist mit den meisten Treibern nicht erfassbar.
Im Zusammenspiel dieser vier Sensorsysteme lassen sich in spezifischen Robotikanwen-
dungen vielfältige Erkenntnisse über den Zustand des Roboters und Merkmale der Umge-
bung gewinnen. Für fliegende Systeme kann dies beispielsweise die Höhe über dem Grund
sein, die von der Kinect allerdings nur in einem schmalen Korridor bereitgestellt werden
kann. Für den Indoor-Einsatz wird mit dem Kamerabild und der Punktewolke eine drei-
dimensionale Repräsentation der Umgebung berechnet. Für die Interaktion mit dem Men-
schen eignet sich die Kinect wegen der Vielzahl von entsprechenden Bibliotheken zur Ges-
ten und Personenerkennung.
Abbildung 1.1: Microsoft Kinect Sensor [Wikipedia]
34 1 Einleitung 1.2 Einordnung und Gliederung der Arbeit Die vorliegende Arbeit versucht diese Einsatzmöglichkeiten zusammenzufassen und die Grenzen und Möglichkeiten der Kinect in Robotikszenarien zu hinterfragen. Die Ausarbeitung entstand dabei im Rahmen des Proseminars SSensorik und Robotik", das von der Arbeitsgruppe für Eingebettete Systeme und Betriebssysteme im Sommersemester 2013 angeboten wurde. Neben den einzelnen Aufsätzen, die von einzelnen Studenten oder von Studentengruppen erarbeitete wurden, sind auch die entsprechenden Vorträge auf der Webseite der Arbeitsgruppe unter http://eos.cs.ovgu.de/de/lecture/courses/ss13/ proseminar-sensorik-und-robotik/ zu finden. Das Paper selbst gliedert sich folgendermaßen. Zunächst wird im Kapitel 1 die Funktions- weise, die Möglichkeiten und die Grenzen der Kinect als Messsystem untersucht. Im dar- auf folgenden Abschnitt werden die Grundlagen der RGB-D Slam-Techniken vorgestellt und die Anwendbarkeit dieser Methoden auf die Messdaten einer Kinect hinterfragt. Ka- pitel ?? beschäftigt sich mit dem Einsatz des Sensors in fliegenden Roboterapplikationen. Im nächsten Abschnitt wird das Cloud basierte RoboEarth-Projekt vorgestellt und die Ein- bindung von 3d-Sensoren in die Erfassung von Umgebungsobjekten untersucht. Kapitel ?? fasst die Möglichkeiten zur Erfassung von Personen und Gesten zusammen. Zudem werden die entsprechenden Bibliotheken dafür verglichen und charakterisiert. Das letzte Kapitel beschreibt schließlich alternative Sensortechniken.
Dominik Hamann, Patrick Hühne
2 RGB-D SLAM
2.1 Einleitung
Ein Großteil der in der autonomen Robotik stattfindenden Forschung setzt sich mit fol-
genden Fragestellungen auseinander. "Wo bin ich?Wie sieht die Welt um mich herum
aus?"Die Lösung auf beide dieser Fragen liefern Simultaneous Localization And Map-
ping (SLAM)(Simultaneous Localization And Mapping) Algorithmen. Der Grundstein für
SLAM wurde 1986 auf der Institute of Electrical and Electronics Engineers (IEEE) Ro-
botics and Automation Conference in San Francisco von Peter Cheeseman, Jim Crow-
ly,Hugh DurrantWhyte und einigen anderen Wissenschaftler gelegt[DWB06]. Das Akro-
nym "SLAM"wurde erstmals in einem Paper präsentiert welches 1995 auf dem Ïnte-
national Symposium on Robotics Research"[DWB06]vorgestellt wurde. Der essentielle
Teil der Theorie, der Konvergenz und vielen weiteren initialen Ergebnissen wurden von
Csorba[DWB06] erstellt. 1999 fand die erste SLAM Sitzung statt. Auf ihr wurden die
Konvergenzen zwischen Kalman Filtern, probabilistischen Lokalisierung und Kartogra-
phierungsmethoden durch Thrun [DWB06]eingeführt. Seitdem arbeiten verschiedene For-
schungsgruppen an dem Thema SLAM und dessen Anwendungen. Eine dieser Anwen-
dungen ist der RGB-D SLAM mithilfe eines Microsoft Kinect Systems. Dieser Artikel
beschreibt einen Einstieg in dieses Themengebiet. Dazu definieren wir zunächst wichti-
ge Grundlagen und um eine bessere Einführung in RGB-D SLAM zu ermöglichen, gehen
wir im Laufe des Artikels auf den Iterative-Closest-Point (ICP) und den RAndom SAmple
Consensus (RANSAC) Algorithmus ein. Ein großes Problem stellt bei der Kinect der Auf-
nahmebereich dar. Der minimale Abstand zu einem Objekt beträgt 80 cm. Ist ein Objekt
näher, so wird es nicht wahrgenommen und blockiert die Kamera. Der maximale Abstand
hingegen liegt bei 400 cm. Dies führt gerade in der mobilen Anwendung zu Problemen,
da sich die Kinect dementsprechend nur äußerst eingeschränkt für die Nutzung im Nahbe-
reich, wie zum Beispiel zum Kollisionsschutz, eignet. Auch im Fernbereich, beispielsweise
bei der Nutzung der Kinect zur Navigation eines Quadrocopters, ist die Reichweite eine
massive Einschränkung. Im Laufe unserer Recherche sind wir auch auf Arbeiten gestoßen
welche sicherlich weiterverfolgt werden sollten. Eine dieser Arbeiten befasst sich mit dem
56 2 RGB-D SLAM Rat-SLAM Verfahren. Dabei kommt statt der Kinect nur eine einzelne RGB-Kamera zum Einsatz. Mithilfe der vom Roboter genutzten Odometrie und den Informationen aus der Kamera kann so eine verwertbare Karte erstellt werden 2.2 Grundlagen 2.2.1 Definition SLAM SLAM bezeichnet Verfahren aus der Robotik, die es einem Roboter ermöglichen die ei- gene Position zu bestimmen und gleichzeitig eine Karte der Umgebung zu erstellen. Dies ermöglicht die autonome Fortbewegung des Roboters. Bei SLAM spricht man von einem relativen Navigationsverfahren, da nur im Verhältnis zu der (Ausgangs-)Position des Ro- boters gearbeitet wird. Den Gegensatz dazu stellen die absoluten Navigationsverfahren die zum Beispiel mit Global Positioning System (GPS) zur Orientierung nutzen dar. Außerdem wird das SLAM-Verfahren genutzt, um Objekte unabhängig von der Bewegung eines Ro- boters zu kartographieren. Dadurch können schnell und simpel 3D-Modelle erstellt werden. 2.2.2 Existierende Lösungsansätze In der mobilen Robotik existieren zwei Lösungswege zur Kartenerstellung. Bei Offline- SLAM wird die Karte vor der eigentlichen autonomen Fahrt erstellt. Dabei wird die zu erkundende Umgebung zunächst manuell, durch eine oder mehrere Testfahrten/-Scans, kar- tographiert und evtl. durch Zusatzinformationen ergänzt oder berichtigt. Somit ist das er- stellen der Karte von der Verwendung getrennt. Bei dem sogenannten Online-SLAM wird die Karte zeitgleich zu der Lokalisierung erstellt. Diese Verfahren ist wesentlich komple- xer und erfordert Anwendungen, welche mit Sprüngen und Korrekturen umgehen können. Aber dieses Verfahren ermöglicht dynamische Modifikationen und Verbesserung der Karte, was bei dem Offline-SLAM nur während der Kartographierungsphase möglich ist. Folgende Abbildung verdeutlicht nochmal beide Verfahren und stellt sie nebeneinander. Alle existierenden SLAM Algorithmen können diesen beiden Verfahren zugeordnet werden. Im folgenden werden wir auf einige der existierenden Verfahren eingehen und kurz ihre Grundideen erläutern. SLAM Algorithmen können 3 verschiedenen Paradigmen zugeordnet werden.[Wie12] Diese sind: Extended Kalman Filter Einer der ersten SLAM Algorithmen ist der Extended Kalman Filter (EKF)-SLAM. Dieser Algorithmus ist ein reines Online-SLAM Verfahren, welcher sogenannte Landmarken nutzt.
2.2 Grundlagen 7
Abbildung 2.1: Übersicht Online Offline SLAM
Abbildung 2.2: EKF-SLAM Anwendung auf Victoria Park Toronto, E.Nebot
Landmarken sind dabei meist auffällige, permanent wahrnehmbare und damit identifizier-
bare Merkmale der Umgebung, wie zum Beispiel Bäume. Allgemein wird bei EKF-SLAM
noch unterschieden ob die Landmarkenzuordnung bekannt ist oder unbekannt. Ein Nach-
teil des Algorithmus ist das die Komplexität quadratisch mit der Anzahl der Landmarken
wächst. [SK08]Ein Beispiel für die Anwendung des EKF SLAMs ist die Kartierung des
Victoria-Parks in Toronto von E.Nebot, welche in Abb. 2 dargestellt ist [O.B13]
Partikelfilter
Partikelfilter beruhen auf Schätzungen, dabei repräsentiert jeder Partikel eine konkrete Ver-
mutung was der wahre Wert des Zustandes sein kann. Aus einer Sammlung vieler solcher
Partikeln, wählt der Partikelfilter eine repräsentative Stichprobe aus dem letzteren Vorkom-
men und führt damit seine Neuberechnung durch. Das Hauptproblem bei Partikelfiltern ist,
dass diese ein exponentielles Wachstum für jede hinzukommende Dimension besitzen. Ein
Trick dieses Problem zu lösen ist FastSLAM[SK08]8 2 RGB-D SLAM
Abbildung 2.3: Möglicher Ablauf von SLAM
Bei FastSLAM wird die Rao-Blackwellized Partikel Filterung genutzt. Diese beruht auf
Landmarken welche eine 2x2 EKF repräsentieren. Jedes Partikel wiederum besitzt eine
endliche Anzahl dieser EKFs[TM05]. Mit FastSLAM wird nun die aktuelle Position und
der komplette Pfad konkret geschätzt. Bei jeder Bewegungsänderung erfolgt die Schätzung
anhand der Odometrie und einem "Rauschen"welches hinzugefügt wird. Danach werden
die Landmarken gewichtet und das Partikelset neu berechne[MTKW02]. FastSLAM besitzt
dabei eine logarithmische Komplexität .
Graph-basierende Techniken
Bei den Graph-basierten Techniken werden die Odometriedaten und die Daten der Land-
marken mithilfe von RGB-D Informationen verknüpft. Bei RGB-D wird das durch eine Ka-
mera aufgenommene Bild (RGB) um die Entfernungsinformation (D) eines jeden einzelnen
Pixels ergänzt. Der genaue Ablauf von RGB-D SLAM mithilfe einer Kinect-Kamera wird
im Kapitel "3D RGB-D SLAM"behandelt.
2.2.3 Modularer Aufbau
SLAM-Algorithmen folgen in der Regel einem modularem Aufbau, wobei als Herzstück
der Teil angesehen werden kann, der die vorhandenen Daten mit den neuen Daten ergänzt.
In diesem Fall handelt es sich um den ICP. Diesem sind in der Regel allerdings Algorith-
men vorgeschaltet, um die Qualität der Aufnahmen zu verbessern. Die folgende Grafik soll
den Ablauf eines RGB-D SLAM noch einmal in seine Bestandteile zerlegen. Anschließend
werden die einzelnen Module erläutert.2.3 Funktionsweise 9 2.3 Funktionsweise 2.3.1 Definition Der ICP-Algorithmus ist eine bereits etablierte Methode, um Gemeinsamkeiten in ver- schiedenen Datensätzen zu finden und diese Datensätze anhand dieser Gemeinsamkeiten zu verbinden[EEH+ 11]. Im Fall des Red-Green-Blue-Depth (RGB-D) SLAM erhält der Al- gorithmus zwei Punktwolken, die sich überlappende Abbildungen realer Objekte darstellen. ICP kann nun entscheiden, welche Punkte in den beiden Punktwolken identisch sind und sie zu einer konsistenten Wolke zusammenführen. Dadurch entsteht aus mehreren Aufnah- men des gleichen Objekts aus verschiedenen Perspektiven ein Modell. Bei der Aufnahme von Objekten mit einer Kamera wird es immer das Verdeckungsproblem geben. Durch das Zusammenfügen der einzelnen Aufnahmen werden auch die Teile zum Modell hinzugefügt, die bei der ersten Aufnahme verdeckt waren. 2.3.2 Ablauf des ICP Mittlerweile gibt es verschiedene Algorithmen, mit denen das finden von Paaren durch ICP ermöglicht wird. Aber alle lassen sich nach Rusinkiewicz et al. [RL01] auf die 6 folgenden Schritte reduzieren. 1. Selektion von Punkten aus einer oder beiden Punktwolken 2. Matching/Paarung dieser Punkte zu Stichproben in der anderen Punktwolke 3. Gewichtung der zusammengehörenden Paaren 4. Verwerfung einiger dieser Paare 5. Zuweisung einer Fehlermetrik zu den einzelnen Punktpaaren 6. Minimierung dieser Fehlermetrik Eine mögliche Anwendung des ICP zeigt folgender Pseudocode: Beschreibung des ICP in Pseudocode[Nel11]: Bei diesem wird zunächst eine grundlegende Translation berechnet. Dafür wird mithilfe der beiden Punktwolken eine initiale Bewegungsschätzung durchge- führt. Da es sich dabei nur um eine grobe Schätzung handelt, ist auch der initiale Fehler sehr groß. Um diesen zu verringern wird nun in K-Schritten zunächst die berechnete Translation auf die scan-Punktwolke angewendet und in der daraus entstandenen neuen Szene mithilfe der bereits existierenden model-Punktwolke nach Punktpaaren gesucht. Mit den nun be- rechneten Paaren, der Translation und den beiden Punktwolken (model,newscene) wird der Fehler berechnet und die gegebene Translation upgedatet. Durch das mehrfache iterieren über diese 3 Unterfunktionen kann die zunächst grobe Schätzung konkretisiert werden.
10 2 RGB-D SLAM
Input: Point[] model, Point[] scan
trans := InitialTransformationEstimate (model, scan);
for k FROM 1 TO K do
newscene := ApplyTranslation(scan, trans);
pointpairs := GetCorrespondingPoints(model, newscene);
R, t, error := UpdateTranslationEstimate(model, newscene, pointpairs, trans);
end
return trans
Algorithm 1: ICP in Pseudocode
2.3.3 RANSAC
RANSAC ist ein etablierter, stabiler Algorithmus, um bei automatischen Messungen Feh-
ler in Form von Ausreißern, also unnatürlich stark abweichenden Werten, zu entfernen.
RANSAC erhält bei der Verwendung mit ICP folglich eine Punktwolke von dem Aufnah-
megerät, begradigt sie und gibt sie an den ICP weiter. RANSAC verbessert also die Qualität
des Modells, erhöht aber die Laufzeit und folglich die Latenz. Die Funktionsweise wird
analog zum Pseudocode aus [Zha11] grob umrissen. Die Parameter der Funktion sind in der
folgenden Tabelle zusammengefasst:
Tabelle 2.1: Parameter des RANSAC Algorithmus
Input data Datensatz von Messungen
model Ein Modell, das diese Daten darstellen soll
n Mindestanzahl an Daten um ein Modell zu er-
stellen
k Anzahl der Iterationen des Algorithmus
t Schwellenwert, der die Fehlertoleranz angibt
d Weiterer Schwellenwert
Output bestModel Modell, das den Datensatz am besten darstellt
(oder nil, wenn kein Modell zu den gegeben
Kriterien gefunden wurde)
bestConsensusSet Datensatz, aus dem dieses Modell entstanden
ist
bestError Der Fehler des Modells
RANSAC wählt zunächst zufällig Werte aus den übergebenen Daten und behandelt diese als
Fixpunkte. Alle anderen Punkte werden daraufhin mit diesen Punkten verglichen und wer-
den verworfen, falls der berechnete Fehler den festgelegten Schwellenwert übersteigt. Aus
den verbliebenen Punkten wird ein Modell erstellt, welches zusammen mit dem Datensatz
und dem dazugehörigen Fehler zwischengespeichert wird.2.3 Funktionsweise 11
Dieser Vorgang wird k mal durchgeführt, wobei die zwischengespeicherten Werte über-
schrieben werden, wenn das neue Modell einen geringeren Fehler aufweist. Nach Ausfüh-
rung aller Wiederholungen wird dementsprechend das beste der erstellten Modelle ausge-
geben.
Der nachfolgende Pseudocodeausschnitt 2 zeigt die Basisfunktionalität des Algorithmus:
begin initialization
iterations := 0;
bestModel := nil;
bestConsensusSet := nil;
bestError := infinity;
end
while iterations < k do
maybeInliers := n randomly selected values from data;
maybeModel := model parameters fitted to maybeInliers;
consensusSet := maybeInliers;
for every point in data not in maybeInliers do
if point fits maybeModel with an error smaller than t then
add point to consensusSet;
end
end
if the number of elements in consensusS etis > d then
/* this implies that we may have found a good model, now test
how good it is */
thisModel := model parameters fitted to all points in consensusSet;
thisError := a measure of how well thisModel fits these points;
if thisError < bestError then
/* we have found a model which is better than any of the
previous ones, keep it until a better one is found */
bestModel := thisModel;
bestConsensusSet := consensusSet;
bestError := thisError;
end
end
increment iterations;
end
return bestModel, bestConsensusSet, bestError
Algorithm 2: RANSAC-Algorithmus in Pseudocode12 2 RGB-D SLAM
Bei der Verwendung des RANSAC-Algorithmus ist zu beachten, dass die Güte und Perfor-
mance stark von der Wahl der Parameter abhängt. Die Anzahl der Iterationen und die Werte
der verwendeten Grenzwerte sollten dementsprechend an den Anwendungsfall angepasst
werden.
2.3.4 KD-Trees
Bei den k-d-Bäumen handelt es sich um eine mehrdimensionale Datenstruktur bei welcher
ungeordnete Sets von Punkten strukturiert werden und so eine effektive Suche ermöglichen.
Dabei stellt die Wurzel den kompletten Suchraum dar. Die Blätter bilden die Subsets in
welchen nur eine bestimmte Anzahl an Punkten drin ist und die Zwischenknoten unter-
teilen den Suchraum in k-Dimensionen. Aufgrund der Struktur des k-d-Baums ist es dem
ICP-Algorithmus möglich effektiv (Normalfall: O(log(n))) zwei gegebene Punktsets zu ver-
gleichen. Mittlerweile existieren auch für die Verwendung von k-d-Bäumen Verbesserun-
gen, welche eine bis zu 50% Steigerung bei der Anwendung des ICP-Verfahrens darauf
erreichen[NLH07].
Abbildung 2.4: Beispiel für einen 2-dimensionalen Baum, der Koordinaten speichert
2.3.5 Spezielle Gewichtung
Mithilfe von bestimmten Algorithmen können Bilder auf besondere Merkmale untersucht
werden. Punkte, die diese Merkmale aufweisen sind folglich robust gegen Rauschen und an-
dere Fehler, da sie nicht bloß anhand des reinen Tiefen-Bildes festgelegt wurden. Bekannte
Vertreter dieser Verfahren sind der Scale-Invariant Feature Transform (SIFT)[Low04]- und
der Speeded Up Robust Features (SURF)-Algorithmus.2.3 Funktionsweise 13
2.3.6 Herausforderungen
Die Herausforderung liegt letztendlich darin, ein auf den spezifischen Anwendungsfall zu-
rechtgeschnittenes Kompromiss aus Qualität und Geschwindigkeit zu finden. Um die Pro-
blematik an zwei extremen Beispielen zu erläutern:
Ein Roboter, der RGB-D SLAM zur autonomen Navigation nutzt muss in Echtzeit ein Mo-
dell seiner Umgebung erstellen können. Erschwerend kommt hinzu, dass die Rechenleis-
tung bereits durch das Gewicht und den Stromverbrauch der Komponenten stark begrenzt
sein kann. Daher muss in diesem Fall auf einen qualitativ niederwertigen, aber schnelleren
Algorithmus gesetzt werden.
Soll hingegen aus Aufnahmen von einem Objekt ein Computer Aided Design (CAD)-
Modell erstellt werden, das womöglich als Bauteil produziert werden soll, muss der ver-
wendete Algorithmus ein möglichst fehlerfreies Modell erstellen können. In diesem An-
wendungsfall wird die Ausführung des ICP nicht so stark durch die einschränkenden
Faktoren(Gewicht,Rechenleistung, Strom und Zeit) des ersten Beispiels beeinflusst, da man
von einer stationären Anwendung ausgehen kann.
2.3.7 Loop Closing
Erreicht ein Roboter eine Position, die er bereits kennt, so müsste er sich auf seiner Karte
an demselben Ort wiederfinden. Durch den Fehler bei der Erstellung der Karte kann die-
se Position auf der internen Karte allerdings weit von der tatsächlichen Position entfernt
sein. Anhand der Merkmale der bereits bekannten Umgebung muss der Roboter dement-
sprechend seine Position erkennen und seine Karte korrigieren, indem er die Schleife (engl.
loop) schließt. Dieses Unterproblem des SLAM ist als Loop-Closing-Problem[Wie12] be-
kannt.
2.3.8 Ablauf
Der Ablauf jedes offline-SLAM-Algorithmus folgt ungefähr diesem Muster[Neu11]:
Schrittweises Abgleichen Jede neue Aufnahme wird in das bereits bestehende Modell
eingegliedert.
Loop Detection Bei jedem Scan wird überprüft, ob eine Schleife geschlossen wurde, in-
dem zum Beispiel eine 360◦ Drehung vollzogen wurde. Ist dies der Fall, wird die
eigentliche Schließung dieser Schleife initiiert.
Loop Closure Wurde eine geschlossene Schleife erkannt, versucht ein Algorithmus die
eigentliche Positionen der Punkte wiederherzustellen.14 2 RGB-D SLAM
Abbildung 2.5: Beispiel Loop-Closing in 2D, Vorher | Nachher
Überwachung Die vorhergegangenen Schritte sind fehleranfällig und können daher das
Modell verschlechtern. Durch bestimmte Mechanismen können aufgetretene Fehler
erkannt und rückwirkend beseitigt werden.
2.3.9 Einschränkungen der Kinect
Allgemein gelten als einschränkende Faktoren der Kinect die Auflösung, der Aufnahme-
winkel, die Bildrate, die Latenz, die Datenübertragungsgeschwindigkeit an andere Geräte
und die Reichweite.
In der Praxis sollten jedoch hauptsächlich der Aufnahmewinkel und die Reichweite ent-
scheidend sein. Mit einem horizontalen Winkel von nicht einmal 60◦ hat die Kinect ins-
besondere im Vergleich zu einem LIght Detection And Ranging (LIDAR) ein stark einge-
schränktes Blickfeld.
Die Kinect wurde dafür konzipiert als Teil einer Spielekonsole in einem Wohnzimmer ge-
nutzt zu werden. Daher können Objekte nur in einem Abstand zwischen ungefähr 80 cm
und 400 cm erfasst werden. Während diese Einschränkung im Wohnzimmer wohl kaum
auffällt, stellt dies für die autonome Navigation von Robotern die größte Schranke dar. Soll
ein Quadrokopter beispielsweise einen großen Raum kartographieren, so muss er sich ent-
sprechend der Position der einzelnen Objekte ausrichten. Je eingeschränkter der Aufnahme-
bereich, desto mehr Flugoperationen benötigt der Quadrokopter und desto kleiner ist auch
die aufgenommene Fläche. Dadurch erhöht sich enorm das Fehlerpotenzial.
Ein Quadrokopters, der im freien agiert und zum Beispiel ein Haus kartographieren soll,
hätte durch den knapp bemessenen Aufnahmebereich zudem ein besonders hohes Risiko
abzudriften, da der Roboter sich nur anhand seiner eigenen Position und seinen bisherigen
Aufnahmen orientieren kann.
Auf der anderen Seite kann die Kinect kein Objekt erfassen, dass sich näher als 80 cm
am Sensor befindet. In unserem Beispiel könnte das in bestimmten Situationen bereits zum
Totalausfall führen. Gerade zur Kollisionsvermeidung ist die Kinect daher nicht tauglich.2.4 Konklusion 15
Abbildung 2.6: An Quadrocopter montierte Kinect
Ein Roboter sollte daher zu diesem Zweck wenn möglich noch ein redundantes System zur
Abstandsmessung nutzen.
2.4 Konklusion
2.4.1 Rückschlüsse
Grundlegend ist die Güte einer SLAM basierten Karte abhängig von einigen Faktoren. Dar-
unter fallen der verwendete Algorithmus und die Hardware, welche verwendet wurde um
die grundlegenden Daten zu sammeln. Wir kommen aufgrund unserer Recherchen zu dem
Schluss, dass eine mit Hilfe einer Kinect erstellten Karte zwar eine hohe Güte aufweist,
aber nicht an die teurerer Sensoren heranreicht. Insbesondere LIDARs sind um ein Vielfa-
ches präziser. Dabei wirken sich, nach [WWN11] et al.besonders negativ das stark steigende
Messrauschen bei zunehmenden Objektabstand und die Auswertecharakteristik des Sensors
aus. Dadurch ist die Gesamtgenauigkeit limitiert. Aber aufgrund des preislichen Vorteils ist
die Kinect eine gute Alternative zu teureren Sensorsystemen und mithilfe angepasster Kali-
brierungsmöglichkeiten sollte es möglich sein die Güte der berechneten Karte zu erhöhen.
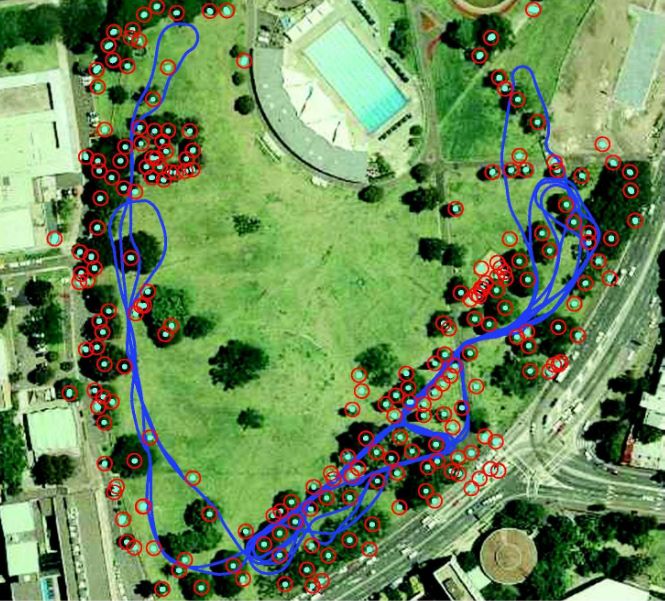
In einigen Versuchen zeigte es sich zum Beispiel als praktikabel Innenräume mit einer Ki-
nect zu kartographieren, wie im folgenden Bild.
Letztlich wird sich die Kinect wohl nicht gegen bereits etablierte Systeme durchsetzen und
vermutlich höchstens für Nischenanwendungen durchsetzen. Die Vorteile für Forschung
und Lehre ein so günstiges Produkt zur Erstellung von 3D-Karten und Modellen zur Verfü-
gung zu haben sind jedoch enorm.16 2 RGB-D SLAM
Abbildung 2.7: Beispiel einer 3D-Karte eines Raumes
2.4.2 Future Work
Die Forschung im Bereich des Maschinellen Sehens ist noch sehr jung und steckt voller
Potenzial. Auch die Möglichkeiten der erst 3 Jahre alte Kinect wurden noch nicht völlig
ausgeschöpft. Im Folgenden wollen wir daher auf interessante Themen eingehen, die zum
jetzigen Zeitpunkt noch unausgereift sind.
Verwendung synchronisierter Kinects
Die Möglichkeit mehrere Kinects gleichzeitig zu benutzen, um das mit ca. 4m2 relativ kleine
Aufnahmefeld zu vergrößern, ist Gegenstand aktueller Forschung. Durch die Verwendung
eines Kinect-Arrays kann der Blickwinkel eines Roboters vergrößert werden, wodurch er
nicht nur mit weniger Navigationsaufwand einen Bereich kartographieren könnte, sondern
auch auf bewegliche Hindernisse reagieren könnte, die nicht direkt vor ihm liegen. Denkbar
wäre sogar ein Kinect-Array, das eine 360◦ -Ansicht liefert. Ein Roboter mit solch einer
Ausstattung hätte in der Ebene praktisch keinen toten Winkel.
Die synchrone Nutzung von zwei Kinect-Sensoren hat sich bei Versuchen im Bereich der
3D-Rekonstruktion von Objekten bereits als möglich erwiesen. Obwohl das strukturierte
Licht der beiden Sensoren teils überlappte gab es keine gravierenden Interferenzen. Größ-
tenteils kann das System erkennen, welche Punkte welcher Kamera zuzuordnen sind. Um
diese Technik zu nutzen, müssen jedoch bestimmte Frameworks und Treiber genutzt wer-
den. Außerdem vergrößert sich der Berechnungsaufwand stark, was besonders bei autonom
navigierenden Robotern ins Gewicht fallen sollte. Trotz der theoretischen Möglichkeit ist
uns für die Verwendung von mehr als zwei Kinect-Sensoren zu diesem Zeitpunkt allerdings
keine Implementierung bekannt.2.4 Konklusion 17
Rat-SLAM
RatSLAM[PMW05] ist ein SLAM-Algorithmus, der in Anlehnung an ein Computermo-
dell des Hippocampus von Nagetieren entstanden ist. Der Hippocampus ist der Teil des
Gehirns, der für den Orientierungssinn zuständig ist. RatSLAM wurde bereits indoor und
outdoor[PMW05] getestet und nutzt im Gegensatz zum RGB-D SLAM als Datenquelle eine
einfache Ein-Linsen-Kamera. Bei der Implementierung von Prasser et al.[PMW05] wurde
zum Beispiel eine Kamera mit 4 Frames per Second (fps) und einer Auflösung von 1024 x
768 Pixeln in Kombination mit einem elektronischen Kompass und einem Odometer ver-
wendet.
Die Ergebnisse von RatSLAM sind gerade in Anbetracht des Inputs beeindruckend. Zum
jetzigen Zeitpunkt sind uns jedoch keine bionisch-orientierten Implementierungen des
RGB-D SLAM bekannt. Obwohl RatSLAM einen grundlegend verschiedenen Ansatz hat,
vermuten wir, dass bionische Ansätze des RGB-D SLAM ein großes Potenzial haben.
Kinect 2.0
Inoffizielle Quellen wie beispielsweise ’vgleaks.com’ berichten über die angeblichen tech-
nischen Daten der neuen Version der Kinect, die noch dieses Jahr zusammen mit der Video-
spielekonsole ’Xbox One’ erscheinen wird. Diese verbesserte Version liefert einige Neue-
rungen, die der Nutzung für RGB-D SLAM zugute kommen.
Zur Übersicht dient diese Tabelle:
Feature Kinect(Xbox 360) Kinect(Xbox One)
Field of View (FOV) 57.5◦ horizontal by 43.5◦ vertical 70◦ horizontal by 60◦ vertical
Resolvable Depth 0.8 m - 4.0 m 0.8 m - 4.0 m
Color Stream 640x480x24 bpp 4:3 RGB @ 30fps 1920x1080x16 bpp 16:9 RGB
640x480x16 bpp 4:3 YUV @ 15fps @ 30 fps
Depth Stream 320x240 16 bpp, 13-bit depth 512x424x16 bpp, 13-bit depth
Infrared (IR) Stream No IR stream 512x424, 11-bit dynamic range
Registration Color < − > depth Color < − > depth & active IR
Audio Capture 4-mic array 48 Hz audio 4-mic array 48K Hz audio
Data Path USB 2.0 USB 3.0
Latency 90 ms with processing 60 ms with processing
Tilt Motor Vertical only No tilt motor
Tabelle 2.2: Vergleich zur Neuauflage
Bei der Präsentation der Xbox One am 21.05.2013 zeigte Microsoft bereits Bilder der neuen
Kinect und bestätigte die Full-HD-Auflösung von 1080p mit 30 fps und eine Datenübertra-
gungsrate von 2 GB/s. Alle weiteren Daten sind bis jetzt reine Spekulation. Als wichtig zu18 2 RGB-D SLAM erachtende Änderungen sind die von 90 ms auf 60 ms gesunkene Latenz und das Upgra- de von USB 2.0 auf USB 3.0. Das ermöglicht eine potenziell schnellere Auswertung der Daten. Außerdem ist der Blickwinkel in der Horizontalen von 57, 5◦ auf 70◦ und in der Vertikalen von 43, 5◦ auf 60◦ angestiegen. Die Auflösung von sowohl der RGB-Kamera, als auch der IR-Kamera ist ebenfalls größer. Dadurch lassen wesentlich präzisere Aufnahmen erstellen. Im Gegensatz zu ihrem Vorgänger enthält die neue Kinect keinen Motor mehr, um zu schwenken. Das könnte einen kleinen Kostenvorteil bedeuten und schränkt die Nutzung für SLAM-Algorithmen nicht ein. Leider ist aber der Aufnahmebereich bei 80-400 cm ge- blieben und schränkt somit die Nutzung der Kinect für SLAM-Algorithmen immer noch stark ein. Abschließend lässt sich sagen, dass die neue Version der Kinect qualitativ hochwertigere Modelle erstellen können wird. Das wird wiederum auch mehr Rechenleistung am nutzen- den Gerät voraussetzen.Außerdem wird man auch von einem etwas höheren Preis ausgehen müssen. Trotzdem wird die Kinect wohl auch in Zukunft für den professionellen Einsatz keine zufriedenstellenden Ergebnisse liefern und daher weiter im Fokus der Forschung und Bastlern sein.
Julian Scholle
3 Lageregelung eines
Quadcopters
3.1 Einleitung
In diesem Kapitel wird die Höhenregelung eines Quadcopters mit Hilfe der Kinect und
der Hough-Transformation beschrieben. Das Vorgehen wurde dabei analog zu [SHBS11b]
beschrieben. Die Microsoft Kinect ist ein kostengünstiges Peripheriegerät, das eine Tie-
fenkarte mit hoher Genauigkeit und Geschwindigkeit berechnet. Durch die randomisierte
Hough-Transformation[XOK90] ist es möglich auf effiziente Art und Weise die Grundplat-
te in dieser Karte zu erkennen. So kann die Kinect als Höhensensor eines Quadcopters
verwendet werden.
3.2 Funktionsweise
3.2.1 Erkennung der Grundfläche
Erkennung von Flächen
Das Problem besteht darin, in einer Punktwolke eine planare Fläche zu erkennen. In diesem
Fall ist das Erkennen der Grundplatte der Schlüssel zum Erfolg. Um Probleme mit unendli-
chen Steigungen zu vermeiden, nutzen wir die Hessesche Normalform, gegeben durch einen
Punkt (p) auf der Ebene und einen Normalenvektor n0 der senkrecht auf der Ebene steht.
Hough-Transformation
Die Hough-Transformation [Hou62] ist eine robuste Methode zum Erkennen von para-
metresierbaren geometrischen Figuren wie Geraden im 2D-Fall oder Ebenen im 3D-Fall.
1920 3 Lageregelung eines Quadcopters
Jeder Punkt im Hough-Raum entspricht einem geometrischen Objekt im ursprünglichen
Bildraum. Bei einer Geraden ist das z.B. der Winkel des Nomalenvektors im Bezug zur x-
Achse und der Abstand zum Nullpunkt. Bei einer Ebene können dies, wie in unserem Fall,
zwei Winkel und der Abstand zum Nullpunkt sein.
Abbildung 3.1: Gerade in Hessescher Normalform in Bild- und Hough-Raum [SHBS11b]
Für eine Gerade in Normalform gilt:
ρ = x cos θ + y sin θ
wobei θ und ρ die Parameter des Hough-Raumes sind. Im R2 wird meist vor der eigentli-
chen Transformation eine Kantendetektion durchgeführt, z.B. “Canny Filter” um die Menge
der Daten zu reduzieren [Jäh05]. Für die Erkennung einer Geraden wird der Hough-Raum
diskretisiert und eine oft “Voting-Matrix”[Jäh05] genannte Datenstruktur angelegt. Dann
werden für jeden Punkt einer möglichen Gerade alle ρ und θ berechnet und in der Voting-
Matrix der entsprechende Eintrag inkrementiert, weshalb die Komplexität des Algorithmu-
ses direkt von der Größe der Voting-Matrix abhängt, also der Diskretisierung von ρ und θ.
Wobei eine zu grobe Einteilung dazu führen kann, dass Geraden “übersehen“ werden, eine
zu feine Einteilung führt jedoch zu einer hohen Laufzeit. Wenn alle Punkte im Bildraum
abgearbeitet sind, stehen die größten Werte in der Voting-Matrix für die wahrscheinlichsten
Geraden.
Analog lässt sich das in den R3 übertragen [AAAA04, VDR+ 01].
Abbildung 3.2: Ebene in Hessescher Normalform[SHBS11b]3.2 Funktionsweise 21
Eine Ebene lässt sich darstellen als:
ρ = p · n~0
ρ = p x n x + py ny + pz nz
ρ = p x cos θ sin φ + py sin θ sin φ + pz cos φ (3.1)
Die Parameter im Hough-Raum sind dann θ,φ und ρ. Für die Erkennung werden dann die
Werte θ,φ und ρ diskretisiert. Die Voting-Matrix speichert dann wieder einen Score für jeden
der Tripel (θ,φ,ρ). Die höchsten Werte der Voting-Matrix stellen dann analog zum R3 die
wahrscheinlichsten Ebenen dar. Wie am Algorithmus leicht zu erkennen ist, ist die Standard
Hough-Transformation auf Grund der hohen Komplexität nicht für Echtzeitanwendungen
geeignet. Weshalb nun eine Abwandlung der Standard Hough-Transformation betrachtet
wird.
Randomisierte Hough-Transformation
Die randomisierte Hough-Transformation [XOK90] basiert darauf, dass sich eine Ebene
durch drei auf ihr liegende Punkte eindeutig definieren lässt. Diese drei Punkte werden
zufällig aus dem diskretisierten Bildraum genommen. Der zugehörige Normalenvektor der
Ebene, welche diese drei Punkte aufspannen, lässt sich durch das Kreuzprodukt berechnen.
n = (p3 − p2 ) × (p1 − p2 ) (3.2)
Der Normaleneinheitsvektor ist:
n
n̂ = (3.3)
||n||
Mit Hilfe von (3.2) und (3.3) ergibt sich ρ durch:
ρ = n̂ · p1 (3.4)
Da n̂ der Normaleneinheitsvektor ist, lässt er sich darstellen als:
cos θ sin φ
sin θ sin φ .
cos φ
Durch Umstellen der Gleichung kommen wir auf folgende Parameter:
φ = arccos nz (3.5)
ny
θ = arcsin (3.6)
sin φ22 3 Lageregelung eines Quadcopters
Mit Hilfe von (3.5),(3.6) und (3.4) lassen sich die Einträge für θ,φ und ρ in der Voting-
Matrix inkrementieren. Eine Ebene gilt als erkannt, wenn ein vorher festgelegter Grenzwert
T A überschritten wird. Wenn nicht, fährt der Algorithmus fort bis alle Punkte berechnet sind
oder eine obere Schranke T I an Iterationen erreicht ist. Die Komplexität die größte Ebene
der Größe m zu finden ist ungefähr O(min(m3 T A , T I )), was unabhängig von der Größe des
Bildraumes[XO93, DPHW05] ist.
Erkennung der Grundfläche
Die größte Ebene hat die höchste Wahrscheinlichkeit erkannt zu werden, da auf ihr die
meisten Punkte liegen. Da die Kinect im 90◦ Winkel nach unten montiert ist, ist die größte
Ebene auch die Grundfläche. Angenommen m1th aller Punkte liegen auf der größten Ebene,
dann ist die Wahrscheinlichkeit, dass die drei zufällig gewählten Punkte auf der größten
Ebene liegen, m13 .
Der Algorithmus ist implementiert wie im vorherigen Abschnitt beschrieben, aber mit fol-
genden Erweiterungen:
• Da wir nur die größte Ebene erkennen wollen, wird der Algorithmus nach dem erst-
maligen erreichen von T A beendet.
• Ein Distanzkriterium nach [N10] wurde eingeführt distmax (p1 , p2 , p3 ) ≤ distmax .
Durch die maximale Distanz von 7 Meter der Kinect, beträgt distmax genau diese 7m.
Nur Werte die kleiner sind als distmax gehen in die Berechnungen mit ein. Dadurch
kann der Rechenaufwand weiter reduziert werden.
• Zusätzlich zu diesem Kriterien wählen wir nur unseren ersten Punkt p1 zufällig aus
unserem gesamten Raum. Die Punkte p2 und p3 werden zufällig aus der näheren Um-
gebung von p1 gewählt. Dies führt dazu, dass weniger Punkte unser Distanzkriterium
verletzten.
3.2.2 Die Hardware
Der Quadcopter ist ein Eigenbau. Er verfügt über einen eingebetteten Echtzeit Lageregler,
implementiert auf einem 32 Bit ARM 7 Microprozessor [SHBS11a] und einen Trägheits-
messsystem, welches einen Bescheunigungssensor, ein Gyroskop und ein Magnetometer
enthält. Die Kinect ist unter dem Schwerpunkt in richtung Boden montiert. Die Kinekt ist
mit einem Laptop verbunden auf dem die Regellung läuft, deshalb ist die Reichweite des
Quadcopters durch die Länge des USB Kabels eingeschränkt.3.3 Ergebnisse 23
Abbildung 3.3: Quadcopter
3.2.3 Der Regler
Leider ist dieser Teil des Ausgangsmaterials[SHBS11b] nur sehr rudimentär beschrieben.
Die Höhe wird von einem Proportional-Integral (PI) Regler, der auf dem Laptop imlemen-
tiert ist geregelt. Davon ausgehend dass die richtige Grundplatte erkannt wurde ist ρ = Pv.
Die Stellgröße c ist gegeben duch:
Z
c = KP ∆ + KI ∆dt
Wobei K p = 5 und KI = 1 und ∆ die Regelabweichung ist. Es wird ein Runge-Kutta
Integrator 4. Ordnung benutzt. Der Regler läuft mit einer Frequenz von 20Hz.
Die Lageregleung läuft auf der eingebetteten Hardware des Quadcopters. In einer anderen
Quelle[GBK11] wird hier ein LQ-Regler genutzt welcher den Vorteil mit sich bringt, dass
Gewichte auf einzelne Regelgrößen gelegt werden können und die Stellgrößen beschränkt
werden können. Das aktuelle Lage (Roll, Nick und Gier) wird über eine Funkverbindung
übertragen, über welche auch Steuersignale zurück an den Quadcopter übertragen werden.
3.3 Ergebnisse
Die randomisierte Hough-Transformation wurde in Matlab entwickelt und dann in C++ im-
plementiert. Dem Quadcopter wurde eine feste Flughöhe vorgegeben. Schwankungen der
Höhe, wie in Abbildung 3.4 zu sehen, zeigten jedoch, dass der PI-Regler für diese Aufgabe
nicht optimal war. Für die Dauer des Teste von 40 Sekunden war dieser allerdings ausrei-
chend. Die Performance der randomisierten Hough-Transformation war hingegen sehr gut.
Mit einem guten Wert für distmax betrug die Ausführungszeit des Algorithmuses rund 10
ms. Dabei wurden im Mittel weniger als 2% aller Bildpunkte getestet.24 3 Lageregelung eines Quadcopters
(a) (b)
Abbildung 3.4: Messergebnisse [SHBS11b] für 0,5m (a) und 1m (b)
3.4 Fazit
Es wurde erfolgreich gezeigt das es auch mit Hilfe der Kinect und der randomisierten
Hough-Transformation möglich ist eine Höhenregelung umzusetzen. Doch diese Lösung
hat einige Einschränkungen. Zum einen ist die maximale Höhe durch die Kinect auf 7
Meter begrenzt. Zum anderen ist die Erkennung der Grundfläche stark vom Untergrund
Abhängig. Nicht zu verachten ist auch das hohe Gewicht der Kinect und die erforderliche
Rechenleistung um die Menge an Daten zu verarbeiten.Silyana Gerova, Vasil Georgiev
4 RoboEarth Project
4.1 Einleitung
Roboter werden zu einem immer größeren Bestandteil des menschlichen Lebens. Sie ver-
fügen über Präzision und eine angemessene Freiheitsgrade für Tätigkeiten in unterschied-
lichen Umgebungen, sogar in solchen, die gefährlich für den Mensch sein können. Zu-
dem haben sie die Möglichkeit Rezeptoren zu benutzen, über die Menschen nicht verfügen.
So können die Roboter in nahe Zukunft zu unentbehrlichen Helfer der Menschen werden.
Für die Umsetzung von Routinearbeiten können die Roboter genutzt werden, so dass die
Menschen die Möglichkeit haben würden, ihr volles Potential auszunutzen und sich auf
Kreativtätigkeiten zu konzentrieren. Bei der Umsetzung dieses Ansatzes gibt es eine große
Herausforderung mit dem Roboter: sie werden modelliert, hergestellt und programmiert um
spezifische Aufgaben auszufüllen und zwar nur solche, die von den Konstrukteuren vorge-
sehen waren. Diese Besonderheit begrenzt das Spektrum der Tätigkeiten, die die Roboter
ausführen können und auch die Sitationen, in denen sie beteiligt werden können. Die Ursa-
che dafür ist, dass das Leben meistens komplizierter und vielfältiger als das Modell, auch
wenn gut geplant ist. Das größte Teil von den bis jetzt existierenden Robotern benutzt man
in der Industrie oder für sehr einfache Arbeiten im Haushalt, wie das Rasenmähen. Ein ak-
tiver Einsatz im Alltag ist noch nicht möglich. Der Mensch als separates Individuum, das
sich nur auf seine eigene Instinkten, Wissen und Erfahrung verlässt, könnte nie ohne die
Kommunikation zwischen den einzelnen Individuen zur dominanten Spezies werden. Die
verstärkte Kommunikation, der Informations-, Erfahrungs- und Gedankenaustausch ist der
entscheidende Vorteil, den der Mensch im Vergleich zu den anderen biologischen Spezies
besitzt. Wenn es gelingt, eine effektive Kommunikation zwischen den Roboter zu orga-
nisieren, würden sich die Effektivität und das Anwendungsfeld der Helfer der Menschen
erheblich vergrößern. Daher würde auch die Integration der Roboter in der zukünftigen Ge-
sellschaft erfolgreicher. Um das zu ermöglichen, soll zuverlässiges, einheitliches System
zum Wissensaustausch zwischen den Roboter erschafft werden, wobei dieses Kodierung,
Austausch, Verwendung, Aktualisierung und Wiederverwendung von Daten einschließt.
2526 4 RoboEarth Project
4.2 Was ist RoboEarth?
Die Basis des RoboEarths ist eigentlich World Wide Web für Roboter – ein große Netzwerk
und Datenbankarchiv, in dem Roboter Informationen über ihr Verhalten und ihre Umgebung
austauschen können und gemeinsames Wissen teilen. Damit gibt es eine neue Bedeutung
für das Sprichwortes „Erfahrung ist der beste Lehrer“. Das Ziel des RoboEarth Projektes is
es, den Roboten die Möglichkeit zu geben, von den Erfahrung anderer Roboten zu lernen,
was den Weg für schnelle Fortschritt in maschinelles Erkennen und Verhalten und sogar für
die schlauere und komplexere Mensch-Maschine Interaktion bahnen würde.
Abbildung 4.1: RoboEarth ermöglicht Austausch und Wiederverwendung von Wissen zwi-
schen unterschiedlichen Arten von Roboten [www.roboearth.org]
RoboEarth bietet mit Cloud-Robotik eine Infrastruktur, welche alles umfasst, was man
braucht, um den Kreis vom Roboter zur Cloud und zurück zum Robot zu schließen. Ro-
boEarth’s World-Wide-Web Datenbank speichert Wissen, gesammelt von Menschen und
Roboten, in Maschinen-lesbaren Format. Die in RoboEarth gespeicherten Informationen
umfassen Softwarekomponenten, Karten für Navigation (z.B. Positionen von Objekten,
Welt-Modelle), Wissen über Tätigkeiten (z.B. Aktionshinweise, Betätigungsstrategien) und
Modelle zur Objekterkennung (z.B. Bilder, Objektmodelle).
Das RoboEarth Cloud Engine bietet den Roboten mächtige Berechnungsmethoden. Sie er-
laubt es, den Roboter zu entlasten und die Computing Umgebung in der Cloud mit mini-
maler Konfiguration zu sichern. Das Cloud Engine’s Computing Umgebung bietet große
Erreichbarkeit auf das RoboEarth-Wissensarchiv, wobei es ermöglicht, dass die Roboten
die Erfahrung von anderen Roboten nutzen.4.3 Motivation 27
Abbildung 4.2: RoboEarth bietet Komponenten für ein ROS kompatibles, Operationssys-
tem auf höhere Ebene, sowie für roboterspezifische Komponenten auf unte-
rer Ebene [www.roboearth.org]
4.3 Motivation
In der Regel sind die Roboter geplant und programmiert, um bestimmte spezifische Aufga-
ben zu erfüllen. Bei der ursprünglichen Programmierung sind alle bekannten Situationen,
Modellen und Aufgaben im Bezug auf die Funktion, die der Roboter ausfüllen soll, in An-
spruch genommen. Aber das Leben ist dynamisch und alles –langsamer oder schneller –
verändert sich mit der Zeit. Manchmal passiert diese Veränderung so schnell, dass bis ein
Roboter produziert und in Betrieb gesetzt wurde, dieser nicht mehr aktuell ist. Zum Beispiel,
wenn die Elemente, die er verarbeiten sollte, ihre Form, Größe und Gewicht verändert haben
oder wenn die Lieferroute schon unterschiedlich ist oder die ganze Situation ist schon völ-
lig anders geworden. Es gibt Anwendungsbereiche, wie zum Beispiel die 3D-Visualisierung
von unbekannten Objekten, bei denen der Informationsaustausch in reeller Zeit von großer
Bedeutung für die Projektdurchführung ist. Es gibt Projekte, bei denen die Roboter selbst
so programmiert sind, dass sie bei derselben Situation unterschiedlich reagieren – „neugie-
riger“ werden, mit dem Ziel, eine maximale Menge an Informationen zu bekommen und
optimale Lösungen zu finden, oder „konservativer“ mit dem Ziel den Roboter als solcher
zu bewahren und nur die Information für das Objekt, die von allen Interessanten (Perso-
nen und Maschinen) gebraucht wurde hochzuladen. Auf diese Weise ist zum Beispiel das
theoretische Programm zur Untersuchung von Jupiter organisiert. Das Internet für Roboter
bietet sich als ausgezeichnetes Mittel, über das die gebrauchte Information in reelle Zeit
ausgetauscht werden kann. Es ist genug, dass ein Roboter tausende Versuche macht, bis er
zu der optimalsten Lösung einer Aufgabe kommt. Dann kann er das neue Wissen in dem
Netz „mitteilen“, so dass jeder folgender Roboter nicht wieder alle Versuche macht, son-Sie können auch lesen

















































