HPC Einführungsveranstaltung - Hochleistungsrechnen @ RZ CAU 18.03.2021 - RZ Uni Kiel
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Hochleistungsrechnen @ RZ CAU
Rechenzentrum
HPC Einführungsveranstaltung
18.03.2021
18.03.2021 1
HPC Einführung: Überblick
Rechenzentrum
• Einleitung
• HPC Support Team
• HPC Dienste
• Hochleistungsrechner: Definition und Arbeitsweise
• Vorstellung der verfügbaren HPC-Systeme
• Lokale Installationen
• Linux Cluster (caucluster)
• NEC HPC-System (nesh)
• Hochleistungsrechner Nord (HLRN)
• Arbeiten auf HPC-Systemen
• Accountbeantragung
• Login und Dateisysteme
• Software und Batchbetrieb
• Vortragsfolien:
• https://www.rz.uni-kiel.de/de/angebote/hiperf/hpc-kurse
18.03.2021 2
Ansprechpartner
Rechenzentrum
• HPC Support Team
• Benutzerberatung
• Dr. Karsten Balzer
• Dr. Michael Kisiela
• Dr. Simone Knief
• Systemadministration
• Dr. Cebel Kücükkaraca
• Dr. Holger Naundorf
• Mailingliste/Ticketsystem
• hpcsupport@rz.uni-kiel.de
18.03.2021 3
Hochleistungsrechnen @ RZ CAU
Rechenzentrum
• Bereitstellung von Rechenressourcen unterschiedlicher
Leistungsklassen
• HPC Support
18.03.2021 4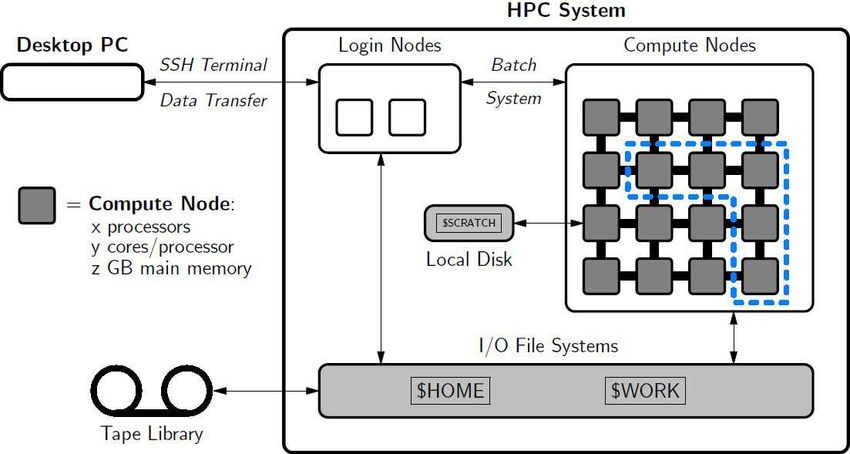
Hochleistungsrechnen @ RZ CAU
Rechenzentrum
• Bereitstellung von Rechenressourcen unterschiedlicher
Leistungsklassen
• lokale Hochleistungsrechner
• caucluster: Linux-Clustersystem
• hybrides NEC HPC-System (nesh):
• NEC HPC-Linux Cluster
• NEC SX-Aurora TSUBASA
• GPU-Komponente (NVIDIA Tesla V100 Grafikkarten)
• Hochleistungsrechner Nord (HLRN)
18.03.2021 5
Hochleistungsrechnen @ RZ CAU
Rechenzentrum
• Bereitstellung von Rechenressourcen unterschiedlicher
Leistungsklassen
• lokale Hochleistungsrechner
• caucluster: Linux-Clustersystem
• hybrides NEC HPC-System (nesh):
• NEC HPC-Linux Cluster
• NEC SX-Aurora TSUBASA
• GPU-Komponente (NVIDIA Tesla V100 Grafikkarten
• Hochleistungsrechner Nord (HLRN)
Ressourcen stehen allen CAU- und GEOMAR-Angehörigen zur Verfügung
18.03.2021 6
Hochleistungsrechnen @ RZ CAU
Rechenzentrum
• Bereitstellung von Rechenressourcen
• HPC Support
• Unterstützung bei Nutzung lokaler und dezentraler HPC-Ressourcen
• Auswahl der geeigneten Rechnerarchitektur
• Hilfe bei der Portierung von Programmen
• Unterstützung bei der Programmoptimierung
• Auswahl geeigneter Compiler und deren Optionen
• Optimierung von Programmcodes (Algorithmenauswahl)
• Hilfe bei Parallelisierung und Vektorisierung von Programmen
• Installation von Benutzerprogrammen auf unseren Systemen
• Hilfestellung bei Anfertigung von Projektanträgen für HLRN-Rechner
18.03.2021 7
Rechenzentrum
Hochleistungsrechner
18.03.2021 8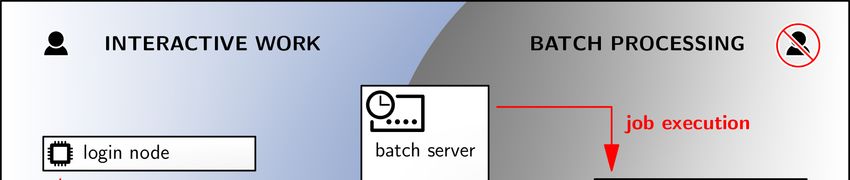
Was sind Hochleistungsrechner?
Rechenzentrum
• keine eindeutige Formulierung möglich
• = computer aided computation
• Hochleistungsrechnen ist heute praktisch identisch mit parallelem Rechnen
• Architektur ist auf parallele Verarbeitung ausgerichtet
18.03.2021 9
Hochleistungsrechner: Definition
Rechenzentrum
• keine eindeutige Formulierung möglich
• = computer aided computation
• Hochleistungsrechnen ist heute praktisch identisch mit parallelem Rechnen
• Architektur ist auf parallele Verarbeitung ausgerichtet
• aktuelle PCs mit Multi-Core Prozessoren (kleine Parallelrechner)
• Leistungssteigerung ist jedoch begrenzt
18.03.2021 10Hochleistungsrechner: Definition
Rechenzentrum
• keine eindeutige Formulierung möglich
• Hochleistungsrechnen ist heute praktisch identisch mit parallelem Rechnen
• Architektur ist auf parallele Verarbeitung ausgerichtet
• aktuelle PCs mit Multi-Core Prozessoren (kleine Parallelrechner)
• Leistungssteigerung ist jedoch begrenzt
• Hochleistungsrechner:
• hochparallele Rechencluster
• große Anzhal von Rechenknoten ausgestattet mit Multi-Core CPUs
• schnelles Verbindungsnetzwerk
• leistungsfähige I/O-Dateisysteme (für Lese- und Schreibprozesse)
• Rechnersysteme mit einer hohen Hauptspeicherausstattung (>1TB)
• Rechnersysteme mit spezieller Architektur (z.B. Vektorrechner)
18.03.2021 11Prozessorarchitekturen
Rechenzentrum
• skalare CPUs
• sequentiell arbeitende Prozessoren
• alle Befehle werden nacheinander ausgeführt
• jede Rechenoperation arbeitet mit einzelnen Daten
• Erweiterung zur Verarbeitung mehrerer Anweisungen
• SIMD (single instructions multiple data)
• ein Befehl arbeitet parallel mit mehreren Daten
• AVX (advanced vector extensions)
18.03.2021 12Vektorrechner
Rechenzentrum
• spezielle Bauweise eines Prozessors
• parallele Verarbeitung findet auf dem Prozessor (Core) statt
• Vektorregister
• Instruktionen werden auf eindimensionalem Feld (Vektor) ausgeführt
• ↔ Skalarrechner arbeiten mit einzelnen Daten; Parallelisierung:
Nutzung mehrerer Cores
• geeignet für Programme, bei denen viele gleichartige Daten auf gleiche Art
und Weise bearbeitet werden müssen, z.B. Matrixoperationen
18.03.2021 13Vektorrechner
Rechenzentrum
• Beispiel: Z =a*X+Y
• X,Y,Z: Vektoren gleicher Länge; a: skalare Größe
• Fortran-Code:
do i=1,64
Z(i)=a*X(i)+Y(i)
enddo
• C-Code:
• for (i=0;iVektorrechner
Rechenzentrum
do i=1,64
Z(i)=a*X(i)+Y(i)
enddo
• Arbeitschritte: Skalarprozessor
Skalar a laden
X(1) laden
a*X(1) bilden
Y(1) laden
a*X(1)+Y(1) bilden
Z(1) speichern
…
X(64) laden
a*X(64) bilden
Y(64) laden
a*X(64)+Y(64) bilden
Z(64) speichern
64*5+1=321 Schritte
18.03.2021 15Vektorrechner
Rechenzentrum
do i=1,64 do i=1,64
Z(i)=a*X(i)+Y(i) Z(i)=a*X(i)+Y(i)
enddo enddo
• Arbeitschritte: Skalarprozessor • Arbeitschritte: Vektorprozessor
Skalar a laden Skalar a laden
X(1) laden Vektor X
A*x(1) bilden Vektor-Skalar Multiplikation
Y(1) laden Vektor Y laden
A*x(1)+y(1) bilden Vektoraddition
Z(1) speichern Vektor Z speichern
…
6 Schritte
X(64) laden
A*x(64) bilden
Y(64) laden
A*x(64)+y(64) bilden
Z(64) speichern
64*5+1=321 Schritte
18.03.2021 16Parallelrechner @ RZ CAU
Rechenzentrum
• 5/1999-06/2002: CRAY T3E
• 18 CPUs mit 256MB Hauptspeicher
• Peak Performance: 22GFlops
• 6/2002-12/2006: SGI Altix 3700
• 128 CPUs mit 512GB Hauptspeicher
• Peak Performance: 664GFlops
• seit 2005
• kontinuierlicher Ausbau unseres Linux-Clusters (rzcluster, caucluster)
• Flops= Floating Point Operations per Second
• Gleitkommaoperationen pro Sekunde
• Maß für Leistungsfähigkeit von Prozessoren/Computern
18.03.2021 17Vektorrechnersysteme @ RZ CAU
Rechenzentrum
1987 CRAY X-MP 1/8 470 MFlops
1994 CRAY Y-MP/M90 666 MFlops
1996 CRAY T94 7.2 GFlops
2002 NEC SX-5 64 GFlops
2005 NEC SX-8 640 GFlops
2007 NEC SX8 + SX8R 1.2 TFlops
2009 NEC SX-9 8.2TFlops
2014 NEC SX-ACE 65.5 TFlops
2018 NEC SX-Aurora TSUBASA 137,6 TFlops
• Flops= Floating Point Operations per Second
• Gleitkommaoperationen pro Sekunde
• Maß für Leistungsfähigkeit von Prozessoren/Computern
• 138 TFlops = 138 * 1012 Gleitkommaberechnungen pro Sekunde
18.03.2021 18Hybrides NEC HPC-System
Rechenzentrum
• seit 2012 Betrieb eines hybriden NEC HPC-Systems
• NEC SX-Vektorrechnersystem
• NEC SX-Aurora TSUBASA
• skalarer NEC HPC Linux-Cluster
• GPU-Komponente (seit 2021)
• einheitliche Systemumgebung
• Login-Knoten
• gemeinsame Dateisysteme
• ein Batchsystem zur Verwaltung der Berechnungen
18.03.2021 19Hybrides NEC HPC-System
Rechenzentrum
• seit 2012 Betrieb eines hybriden NEC HPC-Systems
• NEC SX-Vektorrechnersystem
• NEC SX-Aurora TSUBASA
• skalarer NEC HPC Linux-Cluster
• GPU-Komponente (seit 2021)
• einheitliche Systemumgebung
• Login-Knoten
• gemeinsame Dateisysteme
• ein Batchsystem zur Verwaltung der Berechnungen
Nutzung unterschiedlicher Architekturen ohne Datentransfer
18.03.2021 20HPC-Systeme (Aufbau allgemein)
Rechenzentrum
18.03.2021 21HPC-Systeme (Aufbau allgemein)
Rechenzentrum
18.03.2021 22Linux-Cluster (caucluster)
Rechenzentrum
18.03.2021 23Linux Cluster (caucluster)
Rechenzentrum
• Hardware
• Login-Knoten
• 16 Cores und 128GB Memory
• 90 Batchknoten mit 1900 Cores (Intel und AMD CPUs)
• 16 – 64 Cores, Hauptspeicher: 64GB bis 1TB
• 4 x Intel Sandy Bridge (16 Cores, 256GB RAM)
• 48 x Intel Sandy Bridge (16 Cores, 128GB RAM)
• 4 x Intel Ivy Bridge (16 Cores, 64GB RAM)
• 2 x Intel Ivy Bridg (32 Cores, 1TB RAM)
• 7 x Intel Haswell (40 Cores, 256GB RAM)
• 4 x Intel Haswell (32 Cores, 256GB RAM)
• 3 x Intel Haswell (16 Cores, 128GB RAM)
• 5 x Intel Haswell (16 Cores, 256GB RAM)
• 2 x Intel Broadwell (24 Cores, 1TB RAM)
• 4 x AMD Epyc Naples (32 Cores, 256GB RAM)
• 3 X AMD Epyc Rome (64 Cores, 512GB RAM)
18.03.2021 24caucluster
Rechenzentrum
• Betriebssystem
• CentOS 7.x
• Dateisysteme
• HOME-Verzeichnis
• 22TB für alle Nutzer
• WORK-Verzeichnis
• 350TB BeeGFS paralleles Dateisystem
• Zugriff auf Tape-Library
• Batchsystem
• SLURM Workload Manager
• Simple Linux Utility for Resource management)
• Resourcenverteilung über Fair-Share Algorithmus
• Fair-Share ≠ First In – First Out (FiFO)
• Berücksichtigung von Core- und Hauptspeichernutzung
18.03.2021 25Hybrides NEC HPC-System
Rechenzentrum
18.03.2021 26NEC HPC-System (nesh)
Rechenzentrum
• Hybrides HPC-System
• skalarer NEC HPC-Linux Cluster
• NEC SX-Aurora TSUBASA
• GPU Subsystem (seit 2021)
• 4 gemeinsame Vorrechner (HPC-Login)
• globale (gemeinsame) Dateisysteme für $HOME und $WORK
• ein gemeinsames Batchsystem: SLURM
• Resourcenverteilung über Fair-Share Algorithmus
kein Datentransfer für die Nutzung unterschiedlicher Hardwarearchitekturen
erforderlich
18.03.2021
27NEC HPC-System
Rechenzentrum
• 4 gemeinsame Vorrechner (HPC-Login)
• Skylake-SP Prozessoren (2,1GHz)
• 32 Cores pro Knoten und 768GB Hauptspeicher
• Login-Name: nesh-fe.rz.uni-kiel.de
• interaktives Arbeiten sowie Pre- und Postprocessing
18.03.2021 28NEC HPC-Linux Cluster
Rechenzentrum
• 464 Knoten mit insgesamt 14848 Cores (Compute)
• 284 Knoten mit jeweils
• 2 Intel Xeon Gold 6226R (Cascade Lake): 32 Cores pro Knoten und
192 GB Hauptspeicher bzw. 1.5TB (4 Knoten)
• 180 Knoten mit jeweils
• 2 Intel Xeon Gold 6130 (Skylake-SP): 32 Cores pro Knoten und 192
GB Hauptspeicher bzw. 384GB (8 Knoten)
• Batchknoten mit schnellem EDR-InfiniBand vernetzt
• Übertragungsrate: 100Gbit/s
• Betriebssystem: Red Hat Enterprise Linux (Release 8.2)
• Batch-Knoten (Compute) nur über Batchsystem erreichbar, kein
interaktives Einloggen
18.03.2021 29NEC SX-Aurora TSUBASA
Rechenzentrum
• NEC SX-Aurora TSUBASA
• 8 Vektorhosts (VH) mit jeweils:
• 8 Vektor-Engines (VE, Vektor-Karten) mit jeweils 8 Vektor-Cores, 48
GB Speicher, 64 logische Vektor-Register pro Core (Länge 256 x 64
Bits)
• VE-Anbindung an Vektorhost über PCIe
• 1,2 TB/s Speicherbandbreite
512
512 SX-Aurora Vektor-Cores
18.03.2021 30NEC SX-Aurora TSUBASA
Rechenzentrum
Speicherbandbreite Vektorhost:
1,2 TB/s
18.03.2021 31GPU Subsystem
Rechenzentrum
• 2 Knoten ausgestattet mit jeweils
• GPU-Host
• 2 Intel Xeon Gold 6226R (Cascade Lake): 32 Cores,192GB RAM
• 4 NVIDIA Tesla V100 GPU-Karten
• 5120 NVIDIA CUDA Cores und 32GB GPU RAM
• 900GB/s Speicherbandbreite
18.03.2021 32NEC HPC-System
Rechenzentrum
• Betriebssystem
• Betriebssystem: Red Hat Enterprise Linux (Release 8.2)
• Dateisysteme
• HOME-Verzeichnis
• 300TB NEC GxFS
• WORK-Verzeichnis
• 5PB NEC GxFS (in Kürze 10PB)
• Zugriff auf Tape-Library
• Batchsystem
• SLURM Workload Manager
• Simple Linux Utility for Resource management)
• Resourcenverteilung über Fair-Share Algorithmus
18.03.2021 33HLRN Verbund
Rechenzentrum
18.03.2021 34HLRN-Verbund
Rechenzentrum
• 7 Bundesländer – 2 Standorte – 1 Supercomputer
• Zusammenschluss der 7 norddeutschen Bundesländer
• Berlin, Brandenburg, Bremen, Hamburg, Mecklenburg-Vorpommern,
Niedersachsen und Schleswig-Holstein
• Norddeutscher Verbund für Hoch- und Höchstleistungsrechnen
• HLRN: Hochelistungsrechner Nord
• besteht seit 2001
• Ziele:
• Gemeinsame Beschaffung und Nutzung von HPC-Systemen
• Bearbeitung von Grand Challenges
• Aufbau und Weiterentwicklung eines HPC-Kompetenznetzwerkes
• https://www.hlrn.de
18.03.2021 35HLRN-Systeme: Historie
Rechenzentrum
• HLRN-I:
• Laufzeit: Mai 2002 bis Juli 2008
• IBM p690-System (IBM Power4-Prozessoren)
• Peak-Performance: 5.3TFlops
• HLRN-II:
• Laufzeit: Juli 2008 bis November 2013
• SGI Altice ICE (Intel Harpertown und Nehalem Prozessoren)
• Peak-Performance: 329 TFlops
• HLRN-III:
• Laufzeit: September 2013 bis Oktober 2019
• CRAY XC30/XC40-System
• Peak-Performance: 2.6 PFlops
• HLRN-IV:
• Inbetriebnahme 2018 (GWDG Göttingen) bzw. 2019 (ZIB Berlin)
• Intel CPUs (Firma Atos)
• Peak-Performance (2.Stufe): 16PFlops; ca. 244.000 Cores (Intel-CPUs)
18.03.2021 36Hochleistungsrechner Nord (HLRN IV)
Rechenzentrum
Berlin (Lise) Göttingen (Emmy)
1270 Knoten (121.920 Cores) 974 Knoten (93.504 Cores)
• 1236 Knoten, 384GB RAM • 956 Knoten, 384GB RAM
• 32 Knoten, 768GB RAM • 16 Knoten, 768 GB RAM
• 2 Knoten, 1,5TB RAM • 2 Knoten, 1.5TB RAM
• 2 Intel Cascade Lake CPUs • 2 Intel Skylake CPUs
• 48 Cores/CPU • 48 Cores/CPU
Intel Omni-Path Vernetzung 448 Knoten (17920 Cores)
• 432 Knoten, 192GB RAM
• 16 Knoten 768GB RAM
• 2 Intel Skylake CPUs
• 20 Cores pro CPU
1 GPU Knoten
• 4 NVIDIA Tesla V100
(32GB) Grafikkarten
• 2 Intel Skylake CPUs
• 40 Cores/CPU, 192GB
RAM
18.03.2021 37Rechenzentrum 18.03.2021 38
Lokale HPC-Systeme
Rechenzentrum
18.03.2021 39Hochleistungsrechnen @ RZ CAU
Rechenzentrum
• Arbeiten auf unseren lokalen HPC-Systemen
• Accountbeantragung
• Einloggen und Datentransfer
• Dateisysteme und Datensicherung
• Compiler und Software
• Interaktives Arbeiten und Batchbetrieb
18.03.2021 40HPC-Systeme: Zugang
Rechenzentrum
• Rechnerzugang kann jederzeit beantragt werden
• Formular 3: Antrag auf Nutzung eines Hochleistungsrechners
• https://www.rz.uni-kiel.de/de/ueber-
uns/dokumente/formulare/anmeldung/form3.pdf
• ausgefüllt an die RZ-Benutzerverwaltung schicken
• https://www.rz.uni-kiel.de/de/ueber-uns/dokumente/formulare/anmeldung/rz-
antraege-waehrend-corona
• mit Accounteintragung: Aufnahme in 2 Mailinglisten
• nesh_user@lists.uni-kiel.de bzw. rzcluster_user@lists.uni-kiel.de
• rechnerspezifische Informationen:
• Betriebsunterberechnungen, Probleme, neue Software, …
• hpc_user@uni-kiel.de
• allgemeine Informationen
• Kurse, Infoveranstaltung, Rechnerbeschaffungen, …
18.03.2021 41HLRN: Zugang
Rechenzentrum
• Nutzung für alle Mitarbeiter der Universitäten und Hochschulen in
Schleswig-Holstein möglich
• 2 Phasen der Rechnernutzung
• Beantragung einer Schnupperkennung
• Beantragung eines Großprojektes
18.03.2021 42HLRN-Schnupperkennung
Rechenzentrum
• dient zur Vorbereitung eines Großprojektes
• Beantragung ist jederzeit möglich (WWW-Formular)
• begrenzte Laufzeit von 3 Quartalen
• begrenztes Kontingent an Rechenzeit:
• 10.000 NPLs pro Quartal (erweiterbar auf max. 40.000 NPLs)
• Definition NPLs:
• NPL=Norddeutsche Parallelrechner-Leistungseinheit
• 1 Knoten für 1 Stunde: 6 bis 28 NPLs (abhängig von Knotenart)
18.03.2021 43HLRN-Großprojekt
Rechenzentrum
• dient zur Durchführung von größeren Forschungsvorhaben
• Antragsfrist endet jeweils ca. 2 Monate vor Quartalsbeginn:
• 28.1., 28.4., 28.7. und 28.10.
• Anträge werden durch den wissenschaftlichen Ausschuss begutachtet
• Kontingente werden jeweils für ein Jahr bewilligt und quartalsweise zugeteilt
• Angaben, die für einen Antrag erforderlich sind:
• Kurzbeschreibung des Projektes bzw. Statusbericht
• nachvollziehbare Abschätzung der benötigten Betriebsmittel
• Rechenzeit, Hauptspeicher, Plattenspeicherbedarf
18.03.2021 44Rechenzentrum
Nutzung
unserer lokalen
HPC-Systeme
18.03.2021 45HPC-Systeme: Zugang
Rechenzentrum
• interaktives Einloggen nur auf Vorrechner (Login-Knoten) möglich
• direkter Zugriff nur über IP-Adressen aus dem CAU- und GEOMAR-Netz bzw. UKSH-
Netz
• Zugriff aus anderen Netzen nur über eine VPN-Verbindung
• VPN-Verbindung mit su- bzw. smomw-Kennung aufbauen (nicht mit stu-
Account)
• CAU Nutzer: CAU VPN, GEOMAR-Nutzer GEOMAR-VPN
• Aufbau einer ssh-Verbindung über ssh-Client vom lokalen PC aus:
• MAC und Linux: ssh-Client in Standarddistributionen enthalten
• Windows-Clients:
• putty:
• http://www.putty.org/
• kein Arbeiten mit einer grafischen Benutzeroberfläche möglich
• MobaXterm:
• https://mobaxterm.mobatek.net/
• SmarTTY:
• http://smartty.sysprogs.com/ (ssh client mit scp Möglichkeit)
• X-Win32:
• https://www.rz.uni-kiel.de/de/angebote/software/x-win32/X-Win32
18.03.2021 46HPC-Systeme: Zugang
Rechenzentrum
• Zugriff auf Login-Knoten NEC HPC-System
• ssh –X username@nesh-fe.rz.uni-kiel.de
• -X Option aktiviert X11-Forwarding
• Nutzung einer grafischen Benutzeroberfläche
• Zugriff auf caucluster Login-Knoten
• ssh –X username@caucluster.rz.uni-kiel.de
• ssh-Kommando auf lokalem PC ausführen
18.03.2021 47HPC-Systeme: Datentransfer
Rechenzentrum
• Linux und MAC:
• scp-Kommando:
• scp dateiname username@nesh-fe.rz.uni-kiel.de:/verzeichnisname
• rsync-Kommando:
• rsync -av dateiname username@nesh-fe.rz.uni-kiel.de:/verzeichnisname
• Windows:
• WinSCP (grafischer scp-Client)
• https://winscp.net/eng/docs/lang:de
• SmarTTY:
• http://smartty.sysprogs.com/ (ssh client mit scp Möglichkeit)
• scp-, rsync-Kommando bzw. WinSCP-Aufruf auf lokalem PC ausführen
18.03.2021 48HPC-Systeme: Editoren
Rechenzentrum
• Verfügbare Editoren auf HPC-Systemen (Vorrechner, HPC-Login)
• vi
• Emacs
• nedit
• nano
• Arbeiten mit Dateien, die unter Windows erzeugt/bearbeitet wurden
• nur als reine ASCII-Dateien abspeichern auf lokalem PC
• vermeidet Fehlermeldung
• /bin/bash^M: bad interpreter: no such file or directory
• Kommando dos2unix dateiname entfernt Steuerzeichen
• dos2unix-Kommondo auf Vorrechner (HPC-Login) ausführen
18.03.2021 49HPC-Systeme: Passwörter
Rechenzentrum
• Benutzerkennung erhalten Sie per E-Mail
• Passwortverwaltung über das CIM-Portal
• https://cim.rz.uni-kiel.de/cimportal
• Setzen eines Wunschpasswortes vor dem ersten Einloggen
• Passwortänderungen auch über CIM-Portal
18.03.2021 50Hochleistungsrechner
Rechenzentrum
Dateisysteme
und
Datensicherung
18.03.2021 51HPC-Rechner: Dateisysteme
Rechenzentrum
• Vier verschiedene Dateisysteme nutzbar
• HOME-Verzeichnis
• WORK-Verzeichnis
• lokaler Plattenplatz an den Rechenknoten
• Zugriff auf Tape-Library (Magnetband-Robotersystem)
18.03.2021 52HOME-Verzeichnis
Rechenzentrum
• Login-Verzeichnis
• erreichbar über die Umgebungsvariable $HOME
• verfügbarer Plattenplatz (für alle Nutzer)
• NEC HPC-System: 300TB
• caucluster: 22TB
• global verfügbar an allen Knoten
• tägliche Datensicherung durch das Rechenzentrum
• Quoten für nutzbaren Plattenplatz pro Benutzer
• Verzeichnis für wichtige Daten, die gesichert werden müssen
• Skripte, Programme und kleinere Ergebnisdateien
• nicht für die Durchführung von Batchjobs verwenden
• langsame Zugriffszeiten
18.03.2021 53Work-Verzeichnis
Rechenzentrum
• globales paralleles Dateisystem
• Dateisystem für die Durchführung von Batchberechnungen
• erreichbar über
• $WORK-Umgebungsvariable
• keine Datensicherung durch das Rechenzentrum
• verfügbarer Plattenplatz (für alle Nutzer insgesamt)
• NEC HPC-System: 5 PB GxFS (in Kürze: 10 PB)
• caucluster: 350 TB BeeGFS
• Quoten für nutzbaren Plattenplatz pro Benutzer
18.03.2021 54$WORK: Plattenplatzkontingent
Rechenzentrum
• NEC HPC-System
• $WORK Standardkontingente
• Nutzbarer Speicherplatz
• Softlimit: 1.8TB (CAU) bzw. 4.5TB (GEOMAR)
• Hardlimit: 2.0TB (CAU) bzw. 5.0TB (GEOMAR)
• $HOME Standardkontingent
• Nutzbarer Speicherplatz: 150GB Soft- und 200GB Hardlimit
• caucluster
• $WORK Standardkontingent:
• Speicherplatz: 1TB
• Inode-Einträge: 250.000
• $HOME Standardkontingent:
• Speicherplatz: 100GB Soft- und 150GB Hardlimit
• Kommando zur Quotenabfrage: workquota
18.03.2021 55Lokaler Plattenplatz
Rechenzentrum
• erreichbar über Umgebungsvariable
• $TMPDIR
• lokaler temporärer Plattenplatz am jeweiligen Batchknoten
• nur innerhalb eines Batchjobs verfügbar
• schnelle Zugriffszeiten: wichtig für I/O intensive Berechnungen (viele Lese-
und/oder Schreibprozesse in kurzer Zeit)
18.03.2021 56TAPE-Library
Rechenzentrum
• Plattenspeicher mit angeschlossenem Magnetbandrobotersystem
• erreichbar über
• Umgebungsvariable $TAPE
• nur lokal auf Vorrechnern verfügbar
• Speicherung von aktuell nicht benötigten Daten
• erstellen von tar-Dateien (max. 1TB; empfohlene Größe: zwischen 3
und 50GB)
• langsamer Zugriff: kein direktes Arbeiten mit Dateien auf Band
• kein Archivierungssystem
• irrtümlich gelöschte Daten können nicht wieder hergestellt werden
18.03.2021 57Datensicherung
Rechenzentrum
• HOME-Verzeichnis
• tägliche Sicherung
• Datensicherungen werden 8 Wochen aufbewahrt
• für die letzten 2 Wochen ist eine tagesaktuelle Wiederherstellung
möglich
• ältere Datensicherungen stehen in Wochenabständen zur Verfügung
• $WORK:
• keine Sicherung durch das Rechenzentrum
• TAPE-Library
• keine Backup, d.h. irrtümlich gelöschte Daten nicht wieder herstellbar
• Daten nur verfügbar solange ein Account aktiv ist
• keine Langzeitarchivierung durch das Rechenzentrum
18.03.2021 58Arbeiten mit den Dateisystemen
Rechenzentrum
• wichtige Daten, die gesichert werden müssen auf $HOME
• Batchberechnungen
• starten und Ausführen auf $WORK
• Nutzung von $TMPDIR für I/O intensive Berechnungen
• $TAPE-Verzeichnis
• aktuell nicht benötigte Daten auf Magnetband auslagern
• bevorzugt große Datenpakete abspeichern
• eigenen Datenbestand von Zeit zu Zeit überprüfen
18.03.2021 59Rechenzentrum
Anwendersoftware
und
Programmübersetzung
18.03.2021 60HPC-Rechner: Software
Rechenzentrum
• Compiler
• Gnu-Compiler
• Intel-Compiler
• SX-Crosscompiler für Nutzung der NEC SX-Aurora TSUBASA Knoten
• NVIDIA Cuda Toolklt für GPU Nutzung
• MPI-Implementierung
• Intel-MPI (Linux-Cluster)
• spezielles SX-MPI (für SX-Aurora TSUBASA)
• Bibliotheken
• netCDF, HDF5, FFTW, MKL, PETSc …
• Anwendersoftware:
• Python, Perl, R, Matlab, Gaussian, Turbomole, ….
18.03.2021 61HPC-Rechner: Software
Rechenzentrum
• Compiler
• Gnu-Compiler
• Intel-Compiler
• SX-Crosscompiler für Nutzung NEC SX-Aurora TSUBASA
• NVIDIA Cuda Toolklt für GPU Nutzung
• MPI-Implementierung
• Intel-MPI (Linux-Cluster)
• SX-MPI (NEC SX-Aurora TSUBASA)
• Bibliotheken
• netCDF, HDF5, FFTW, MKL, PETSc, …
• Anwendersoftware:
• Python, Perl, R, Matlab, Gaussian, Turbomole, ….
Bereitstellung über ein Module-Konzept
18.03.2021 62Module-Konzept
Rechenzentrum
• ermöglicht Nutzung bereits global installierter Software
• Softwareverzeichnis nicht im Standardsuchpfad
• nach dem Laden eines Softwaremodules:
• Programm ohne weitere Pfadanpassungen nutzbar
• einfaches Setzen/Umsetzen von Suchpfaden:
• $PATH, $LD_LIBRARY_PATH, $MANPATH
18.03.2021 63Modules: Kommandos
Rechenzentrum
• module avail
• liefert Überblick über bereits installierte Softwarepakete
• module load name
• lädt Module mit dem Name name; alle Einstellungen für die
Programmnutzung werden vorgenommen
• module list
• listet alle Module auf, die aktuell geladen sind
• module unload name
• entfernt das Module name, d.h. alle Einstellungen werden rückgängig
gemacht
• module purge
• entfernt alle bisher geladenen Module, d.h. module list Kommando
liefert keine Einträge mehr
• module show name
• zeigt Pfadänderung an, die das Module durchführt
18.03.2021 64Modules: Beispiele
Rechenzentrum
• Nutzung Programmpaket Matlab
• module load matlab/2020b (CAU-Nutzer)
• module load matlab_geomar/2020b (GEOMAR-Nutzer)
• Programmaufruf mit Kommando matlab –nodisplay starten
• Programmübersetzung mit Intel-Compiler
• module load intel/20.0.4 (Compileraufruf: ifort, icc oder icpc)
• module load intel/20.0.4 intelmpi/20.0.4
• Compileraufruf: mpiifort, mpiicc oder miicpc
• Programmübersetzung SX-Aurora TSUBASA
• module load ncc/3.1.0 (Compileraufruf: nfort, ncc oder n++)
• Programmübersetzung GPU NVIDIA Karten
• module load cuda/11.1.0 (compileraufruf: nvcc)
18.03.2021 65Hochleistungsechner
Rechenzentrum
Interaktives Arbeiten
und
Batchbetrieb
18.03.2021 66HPC-System
Rechenzentrum
18.03.2021 67Arbeiten auf den HPC-Systemen
Rechenzentrum
• Interaktives Arbeiten
• nur auf auf den Login-Knoten (HPC-Login)
• Datentransfer: PC ↔ HPC-Login ↔ Tape-Library
• Programmübersetzung, kurze Testberechnungen
• Erstellung der Batchskripte
• Abgabe und Kontrolle von Batchjobs
• keine längeren Berechnungen über Batchsystem
18.03.2021 68Arbeiten auf den HPC-Systemen
Rechenzentrum
• Interaktives Arbeiten
• nur auf auf den Login-Knoten
• Datentransfer: PC ↔ HPC-Login ↔ Tape-Library
• Programmübersetzung, kurze Testberechnungen
• Erstellung der Batchskripte
• Abgabe und Kontrolle von Batchjobs
• Keine längeren Berechnungen über Batchsystem
• Batchbetrieb
• Berechnungen werden auf den Compute-Knoten ausgeführt
• kein direkter Zugriff auf ausführende Knoten
18.03.2021 69HPC-Systeme: Batchbetrieb
Rechenzentrum
• Vorteil
• Rechenressourcen können effektiver genutzt werden
• höherer Durchsatz
• gerechte Verteilung auf alle Benutzer
• jeder Benutzer kann mehrere Berechnungen gleichzeitig ausführen
• angeforderte Ressourcen sind während der Laufzeit garantiert
• Nachteil
• zunächst etwas ungewohntes Arbeiten
18.03.2021 70HPC-Systeme: Batchbetrieb
Rechenzentrum
• Benutzer startet sein Programm nicht direkt in der Konsole
• schreibt eine kleine Batchskript-Datei
• enthält Informationen über die angeforderten/benötigten Ressourcen
• Core-Anzahl, Hauptspeicherbedarf, Rechenzeit, ….
• enthält den eigentlichen Programmaufruf
• Batchskript-Datei wird vom Login-Knoten an den Batchserver übergeben
• durchsucht alle Knoten nach freien Ressourcen
• Job startet sofort oder wird in eine Warteschlange gestellt
• Batchsystemsoftware: SLURM
18.03.2021 71HPC-Systeme: Batchbetrieb
Rechenzentrum
18.03.2021 72SLURM-Batchskript (NEC Linux Cluster) serielle Berechnung Rechenzentrum #!/bin/bash #SBATCH --nodes=1 #SBATCH --tasks-per-node=1 #SBATCH --cpus-per-task=1 #SBATCH --time=01:00:00 #SBATCH --mem=10000mb #SBATCH --partition=cluster #SBATCH --job-name=testjob #SBATCH --output=testjob.out #SBATCH --error=testjob.err #Laden der Softwareumgebung module load intel/20.0.4 # Programmstart ./prog # Ausgabe der verbrauchten Ressourcen (Rechenzeit, Hauptspeicher des Jobs) jobinfo 18.03.2021 73
SLURM-Batchskript (NEC Linux Cluster) serielle Berechnung Rechenzentrum #!/bin/bash Shell-Definition #SBATCH --nodes=1 #SBATCH --tasks-per-node=1 #SBATCH --cpus-per-task=1 #SBATCH --time=01:00:00 #SBATCH --mem=10000mb #SBATCH --partition=cluster #SBATCH --job-name=testjob #SBATCH --output=testjob.out #SBATCH --error=testjob.err #Laden der Softwareumgebung module load intel/20.0.4 # Programmstart ./prog # Ausgabe der verbrauchten Ressourcen (Rechenzeit, Hauptspeicher des Jobs) jobinfo 18.03.2021 74
SLURM-Batchskript (NEC Linux Cluster) serielle Berechnung Rechenzentrum #!/bin/bash Shell-Definition #SBATCH --nodes=1 Anzahl benötigter Rechenknoten #SBATCH --tasks-per-node=1 #SBATCH --cpus-per-task=1 #SBATCH --time=01:00:00 #SBATCH --mem=10000mb #SBATCH --partition=cluster #SBATCH --job-name=testjob #SBATCH --output=testjob.out #SBATCH --error=testjob.err #Laden der Softwareumgebung module load intel/20.0.4 # Programmstart ./prog # Ausgabe der verbrauchten Ressourcen (Rechenzeit, Hauptspeicher des Jobs) jobinfo 18.03.2021 75
SLURM-Batchskript (NEC Linux Cluster) serielle Berechnung Rechenzentrum #!/bin/bash #SBATCH --nodes=1 #SBATCH --tasks-per-node=1 Anzahl MPI-Prozesse pro Rechenknoten #SBATCH --cpus-per-task=1 Anzahl Tasks pro Knoten (z.B. OpenMP Parallelisierung) #SBATCH --time=01:00:00 #SBATCH --mem=10000mb #SBATCH --partition=cluster #SBATCH --job-name=testjob #SBATCH --output=testjob.out #SBATCH --error=testjob.err #Laden der Softwareumgebung module load intel/20.0.4 # Programmstart ./prog # Ausgabe der verbrauchten Ressourcen (Rechenzeit, Hauptspeicher des Jobs) jobinfo 18.03.2021 76
SLURM-Batchskript (NEC Linux Cluster) serielle Berechnung Rechenzentrum #/bin/bash #SBATCH --nodes=1 #SBATCH --tasks-per-node=1 #SBATCH --cpus-per-task=1 #SBATCH --time=01:00:00 angeforderte Rechenzeit (Verweilzeit) #SBATCH --mem=10000mb #SBATCH --partition=cluster #SBATCH --job-name=testjob #SBATCH --output=testjob.out #SBATCH --error=testjob.err #Laden der Softwareumgebung module load intel/20.0.4 # Programmstart ./prog # Ausgabe der verbrauchten Ressourcen (Rechenzeit, Hauptspeicher des Jobs) jobinfo 18.03.2021 77
SLURM-Batchskript (NEC Linux Cluster) serielle Berechnung Rechenzentrum #!/bin/bash #SBATCH --nodes=1 #SBATCH --tasks-per-node=1 #SBATCH --cpus-per-task=1 #SBATCH --time=01:00:00 #SBATCH --mem=10000mb max. benötigter Hauptspeicher pro Knoten #SBATCH --partition=cluster #SBATCH --job-name=testjob #SBATCH --output=testjob.out #SBATCH --error=testjob.err #Laden der Softwareumgebung module load intel/20.0.4 # Programmstart ./prog # Ausgabe der verbrauchten Ressourcen (Rechenzeit, Hauptspeicher des Jobs) jobinfo 18.03.2021 78
SLURM-Batchskript (NEC Linux Cluster) serielle Berechnung Rechenzentrum #!/bin/bash #SBATCH --nodes=1 #SBATCH --tasks-per-node=1 #SBATCH --cpus-per-task=1 #SBATCH --time=01:00:00 #SBATCH --mem=10000mb #SBATCH --partition=cluster Partition auf der Job laufen soll (hier x86 Linux cluster) #SBATCH --job-name=testjob #SBATCH --output=testjob.out #SBATCH --error=testjob.err #Laden der Softwareumgebung module load intel/20.0.4 # Programmstart ./prog # Ausgabe der verbrauchten Ressourcen (Rechenzeit, Hauptspeicher des Jobs) jobinfo 18.03.2021 79
SLURM-Batchskript (NEC Linux Cluster) serielle Berechnung Rechenzentrum #/!bin/bash #SBATCH --nodes=1 #SBATCH --tasks-per-node=1 #SBATCH --cpus-per-task=1 #SBATCH --time=01:00:00 #SBATCH --mem=10000mb #SBATCH --partition=cluster #SBATCH --job-name=testjob Name des Batchjobs #SBATCH --output=testjob.out #SBATCH --error=testjob.err #Laden der Softwareumgebung module load intel/20.0.4 # Programmstart ./prog # Ausgabe der verbrauchten Ressourcen (Rechenzeit, Hauptspeicher des Jobs) jobinfo 18.03.2021 80
SLURM-Batchskript (NEC Linux Cluster) serielle Berechnung Rechenzentrum #!/bin/bash #SBATCH --nodes=1 #SBATCH --tasks-per-node=1 #SBATCH --cpus-per-task=1 #SBATCH --time=01:00:00 #SBATCH --mem=10000mb #SBATCH --partition=cluster #SBATCH --job-name=testjob #SBATCH --output=testjob.out Dateiname für Standardausgabe #SBATCH --error=testjob.err Dateiname für Fehlerausgabe #Laden der Softwareumgebung module load intel/20.0.4 # Programmstart ./prog # Ausgabe der verbrauchten Ressourcen (Rechenzeit, Hauptspeicher des Jobs) jobinfo 18.03.2021 81
SLURM-Batchskript (NEC Linux Cluster) parallele MPI Berechnung Rechenzentrum #!/bin/bash #SBATCH --nodes=2 Anforderung von 2 Rechenknoten #SBATCH --tasks-per-node=32 auf jedem Knoten werden 32 Cores benötigt #SBATCH --cpus-per-task=1 #SBATCH --time=01:00:00 #SBATCH --mem=10000mb #SBATCH --partition=cluster #SBATCH --job-name=testjob #SBATCH --output=testjob.out #SBATCH --error=testjob.err #Laden der Softwareumgebung module load intel/20.0.4 intelmpi/20.04 # Programmstart mpirun –np 64 ./prog # Ausgabe der verbrauchten Ressourcen (Rechenzeit, Hauptspeicher des Jobs) jobinfo 18.03.2021 82
SLURM-Batchskript (NEC Linux Cluster) parallele OpenMP Berechnung Rechenzentrum #!/bin/bash #SBATCH --nodes=1 Anforderung von 1 Rechenknoten #SBATCH --tasks-per-node=1 #SBATCH --cpus-per-task=16 auf dem Knoten sollen 16 OpenMP Threads laufen #SBATCH --time=01:00:00 #SBATCH --mem=10000mb #SBATCH --partition=cluster #SBATCH --job-name=testjob #SBATCH --output=testjob.out #SBATCH --error=testjob.err #Laden der Softwareumgebung und Programmstart module load intel/20.0.4 export OMP_NUM_THREADS=16 ./prog # Ausgabe der verbrauchten Ressourcen (Rechenzeit, Hauptspeicher des Jobs) jobinfo 18.03.2021 83
SLURM-Batchskript (SX-Aurora TSUBASA)
Rechenzentrum
#!/bin/bash #!/bin/bash
#SBATCH --nodes=1 #SBATCH --nodes=1
#SBATCH –gres=ve:1 #SBATCH –gres=ve:1
#SBATCH --tasks-per-node=1 #SBATCH --tasks-per-node=1
#SBATCH --cpus-per-task=1 #SBATCH --cpus-per-task=1
#SBATCH --time=01:00:00 #SBATCH --time=01:00:00
#SBATCH --mem=10000mb #SBATCH --mem=10000mb
#SBATCH --partition=vector #SBATCH --partition=vector
#SBATCH --job-name=testjob #SBATCH --job-name=testjob
#SBATCH --output=testjob.out #SBATCH --output=testjob.out
#SBATCH --error=testjob.err #SBATCH --error=testjob.err
export VE_PROGINF=DETAIL export VE_PROGINF=DETAIL
export OMP_NUM_THREADS=8 module load necmpi/2.11.0
./vector.x source necmpivars.sh
mpirun -nn 1 -nnp 8 -ve 0-0 ./vector.x
18.03.2021 84SLURM-Batchskript (SX-Aurora TSUBASA)
Rechenzentrum
#!/bin/bash
#SBATCH --nodes=1
#SBATCH –gres=ve:8
#SBATCH --tasks-per-node=1
#SBATCH --cpus-per-task=1
#SBATCH --time=01:00:00
#SBATCH --mem=10000mb
#SBATCH --partition=vector
#SBATCH --job-name=testjob
#SBATCH --output=testjob.out
#SBATCH --error=testjob.err
export VE_PROGINF=DETAIL
module load necmpi/2.11.0
source necmpivars.sh
mpirun -nn 1 -nnp 64 -ve 0-7 ./vector.x
18.03.2021 85SLURM-Batchskript (GPU-Knoten)
Rechenzentrum
#!/bin/bash
#SBATCH --nodes=1
#SBATCH --tasks-per-node=1
#SBATCH --cpus-per-task=1
#SBATCH –gpus-pernode=1
#SBATCH --time=01:00:00
#SBATCH --mem=10000mb
#SBATCH --partition=gpu
#SBATCH --job-name=testjob
#SBATCH --output=testjob.out
#SBATCH --error=testjob.err
module load intel/19.0.4
time ./prog
jobinfo
18.03.2021 86SLURM-Batchskript (caucluster)
Rechenzentrum
#!/bin/bash
#SBATCH --nodes=1
#SBATCH --tasks-per-node=1
#SBATCH --cpus-per-task=1
#SBATCH --time=01:00:00
#SBATCH --mem=10000mb
#SBATCH --partition=all
#SBATCH --job-name=testjob
#SBATCH --output=testjob.out
#SBATCH --error=testjob.err
module load intel/19.0.4
time ./prog
jobinfo
18.03.2021 87SLURM: Abgabe/Kontrolle von Batchjobs
Rechenzentrum
• Kenntnis weniger Kommandos ausreichend
• sbatch jobskript
• Abgabe einer Batchberechnung
• squeue
• Auflistung aller Jobs im System
• squeue –u username
• Auflistungen der eigenen Jobs
• scancel jobid
• Beenden eines laufenden bzw. entfernen eines wartenden Jobs
• scontrol show job jobid
• liefert Details über einen bestimmten Job
• sinfo
• Zeigt Informationen über verfügbare Partitionen an
18.03.2021 88SLURM: weitere Kommandos
Rechenzentrum
• max. Rechenzeit per Default: 48 Stunden
• #SBATCH --qos=long Rechenzeit bis 10 Tage möglich
• Für längere Rechenzeiten extra Validierung erforderlich
• benötigte CPU-Art genauer spezifizieren
• sinfo --Node -o "%20N %20c %20m %20f %20d"
• z.B. NEC-Cluster: Skylake oder Cacade Lake CPU
• #SBATCH --constraint=cascade
• z.B. caucluster: Intel oder AMD CPU
• #SBATCH --constraint=intel
18.03.2021 89SLURM: jobinfo-Ausgabe
Rechenzentrum
- Requested resources: - Important conclusions and remarks:
Timelimit = 10-00:00:00 ( 864000s ) * !!! Please, always check if the
number of requested cores and
MinMemoryNode = 180000M ( nodes matches the need of your
180000.000M ) program/code !!!
* !!! Less than 20% of requested
NumNodes = 1 walltime used !!! Please, adapt your
batch script.
NumCPUs = 32
* !!! Less than 20% of requested main
NumTasks = 1 memory used !!! Please, adapt your
batch script.
CPUs/Task = 32
- Used resources:
RunTime = 1-01:29:57 ( 91797s )
MaxRSS = 31857880K ( 31111.211M )
====================
18.03.2021 90Interaktive Batchjobs
Rechenzentrum
• Möglichkeit interaktiv auf Batchknoten zu arbeiten
• caucluster:
srun --pty –nodes=1 –cpus-per_task=1 –time=1:00:00 partition=all
/bin/bash
• NEC HPC-System
srun --pty --nodes=1 --cpus-per-task=1 --mem=1000mb --time=00:10:00 --
partition=cluster /bin/bash
srun --pty --nodes=1 --cpus-per-task=1 --mem=1000mb --time=00:10:00 --gres=ve:1 –
partition=vector /bin/bash
18.03.2021 91Arbeiten mit dem Batchsystem
Rechenzentrum
• nicht mehr Knoten und Cores anfordern als benötigt werden
• benötigte Rechenzeit und Hauptspeicher möglichst genau angeben
• höherer Durchsatz und kürzere Wartezeiten
• Zwischenergebnisse abspeichern (insbes. bei sehr langen Laufzeiten)
• Standardausgabedatei möglichst klein halten
• Ausgaben evtl. direkt in WORK-Verzeichnis umleiten
18.03.2021 92Dokumentation und Kontakt
Rechenzentrum
• WWW-pages:
• HPC-Angebote:
• https://www.rz.uni-kiel.de/de/angebote/hiperf
• NEC HPC-System:
• https://www.rz.uni-kiel.de/de/angebote/hiperf/nesh
• caucluster:
• https://www.rz.uni-kiel.de/de/angebote/hiperf/caucluster
• Vortragsfolien:
• https://www.rz.uni-kiel.de/de/angebote/hiperf/hpc-kurse
• Maillingliste/Ticketsystem
• hpcsupport@rz.uni-kiel.de
18.03.2021 93Sie können auch lesen

















































