Leitfaden für die Migration von einem RDBMS zu MongoDB - Hinweise und Best Practices November 2017
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Ein Whitepaper von MongoDB Leitfaden für die Migration von einem RDBMS zu MongoDB Hinweise und Best Practices November 2017
Inhaltsverzeichnis Einleitung 1 Erfolg erfordert Organisation 1 Schemadesign 2 Von starren Tabellen zu flexiblen, dynamischen BSON-Dokumenten 2 Modellierung von Beziehungen durch Einbettungen und Verweise 6 Indizierung 7 Design und fortlaufende Weiterentwicklung von Schemata 11 Anwendungsintegration 11 MongoDB-Treiber und die API 12 Die Übertragung von SQL-Befehlen in die MongoDB-Syntax 12 Das MongoDB Aggregation Framework 12 Integration mit Business Intelligence-Lösungen – der MongoDB Connector for BI 13 Atomarität in MongoDB 14 Wahrung der starken Konsistenz 14 Dauerhaftigkeit der Schreibprozesse 14 Implementierung von Validierungsprozessen und Schreibbeschränkungen 15 Views 16 Die Migration von Daten zu MongoDB 17 Flexible, skalierbare Lösungen für den Datenbankbetrieb18 MongoDB Atlas: Database-as-a-Service für MongoDB 18 Wir unterstützung Ihre Migration: MongoDB Services 19 MongoDB University 19 Ressourcen der Nutzer-Community und Beratungsdienste 19 Fazit 19 Wir helfen Ihnen gern! 20 @atlas 20 @stitch 21

Einleitung
Seit über 30 Jahren basiert die Datenverwaltung in des Prozesses mit den einzelnen Schritten finden Sie in
Unternehmen auf relationalen Datenbanken. Abbildung 2.
Doch die modernen Verfahren für die Entwicklung und den Dieser Leitfaden enthält zahlreiche Links, die den Leser an
Betrieb von Anwendungen in Kombination mit der rasant geeignete Online-Ressourcen verweisen. Um die
steigenden Zahl neuer Datenquellen und den immer aktuellsten und ausführlichsten Informationen zu einem
umfangreicheren Workloads der Anwender übersteigen bestimmten Thema zu erhalten, schlagen Sie bitte in der
zunehmend die Möglichkeiten relationaler Datenbanken. Online-Dokumentation nach.
Die dadurch entstehenden Einschränkungen im Hinblick
auf die Flexibilität und Skalierbarkeit sowie die steigenden
finanziellen Belastungen bewegen mehr und mehr Erfolg erfordert Organisation
Unternehmen dazu, zu alternativen Datenbanken wie
MongoDB oder NoSQL zu migrieren.
Der Erfolg einer Migration hängt nicht nur von der Wahl der
Wie Sie Abbildung 1 entnehmen können, haben richtigen Technologie und Architektur ab, sondern auch von
Unternehmen aus vielen verschiedenen Branchen für der rechtzeitigen Einbeziehung aller für die Anwendung
vielfältigste Anwendungen erfolgreich eine Migration von zuständigen Entscheidungsträger und Experten, darunter
relationalen Datenbank-Managementsystemen (RDBMS) Führungskräfte aus den Geschäftsbereichen sowie
zu MongoDB durchgeführt. Entwickler, Datenarchitekten und Datenbank- und
Systemadministratoren. In manchen Unternehmen sind
Dieser Leitfaden wendet sich an Projektteams, die möglicherweise mehrere dieser Rollen in einer Funktion
erfahren möchten, was bei einer Umstellung von einem zusammengefasst.
RDBMS zu MongoDB zu beachten ist. Ein Ablaufdiagramm
1
Unternehmen Früher
rüheres
es DB
DBMMS Anwendung
eHarmony Oracle und Postgres Management und Analyse von Kundendaten
Shutterfly Oracle Web- und mobile Services
Cisco Mehrere verschiedene Analysen, Social Networking
RDBMS
Craigslist MySQL Archiv
Under Armour Microsoft SQL-Server Online-Handel
Foursquare PostgreSQL Plattformen für soziale Medien und mobile Apps
MTV Networks Mehrere verschiedene Zentralisiertes Content-Management
RDBMS
Buzzfeed MySQL Echtzeitanalysen
Verizon Oracle Überblicksansichten, Mitarbeitersysteme
The Weather Channel Oracle und MySQL Plattformen für mobile Apps
Abbildung 1: Fallbeispiele
Bei der Festlegung geschäftlicher und technischer Ziele
Schemadesign
sowie der Zeitpläne und Zuständigkeiten sollte das
Projektteam mit allen Beteiligten zusammenarbeiten und
regelmäßige Treffen abhalten, um den Fortschritt zu Die grundlegendste Änderung bei einer Migration von
überwachen und etwaigen Problemen frühzeitig zu einer relationalen Datenbank zu MongoDB betrifft die Art
begegnen. und Weise der Datenmodellierung.
Selbstverständlich variiert die Datenmodellierung von
MongoDB und die User-Community bieten eine Reihe von
Anwendungsfall zu Anwendungsfall, doch es gibt ein paar
Services und Ressourcen an, die Ihnen dabei helfen
allgemeine Überlegungen, die auf die meisten Projekte zur
können, die notwendigen Kenntnisse und Fertigkeiten für
Schemamigration zutreffen.
die Nutzung von MongoDB aufzubauen, z. B. kostenlose
Online-Schulungen, Support und Beratungsdienste. Bevor Sie sich näher mit dem Schemadesign befassen,
Nähere Informationen dazu finden Sie im Abschnitt über bietet Ihnen Abbildung 3 einen nützlichen Überblick über
MongoDB-Services am Ende dieses Leitfadens. die Analogien einiger wichtiger RDMBS-Fachbegriffe in
der Welt von MongoDB.
Abbildung 2: Ablaufplan einer Migration
2Die Umstellung auf MongoDB erfordert, dass Dagegen wird der Entwicklungsprozess verlangsamt, wenn
Datenarchitekten, Entwickler und Daten aus einem objektorientierten
Datenbankadministratoren beim Schemadesign einen Anwendungsprogramm in der Tabellenstruktur eines
anderen Blickwinkel einnehmen: RDBMS abgebildet werden müssen. Außerdem können
durch die Nutzung eines Tools für die objektrelationale
• weg vom herkömmlichen relationalen Datenmodell, das
Abbildung (Object Relational Mapper, ORM) neue
die Daten in eine starre zweidimensionale
Komplikationen entstehen, da hierdurch die Flexibilität bei
Tabellenstruktur mit Zeilen und Spalten zwängt,
der Anpassung der Schemata an neue
• hin zu einem dynamischen dokumentbasierten Modell Anwendungsanforderungen und bei der
mit eingebetteten Unterdokumenten und Arrays. Abfrageoptimierung eingeschränkt wird.
R DB
DBMMS MongoDB Beim Schemadesign sollte der erste Schritt des
Projektteams in der Analyse der
Datenbank Datenbank
Anwendungsanforderungen bestehen. Darüber hinaus
Tabelle Collection sollte die Datenmodellierung auf eine Art und Weise
erfolgen, die die Vorteile der Flexibilität des
Zeile Dokument
dokumentbasierten Modells in vollem Umfang ausschöpft.
Spalte Feld Bei einer Schemamigration mag es am einfachsten
erscheinen, das flache Schema der relationalen Datenbank
Index Index
im dokumentbasierten Modell nachzubilden. Dieser Ansatz
JOIN Eingebettetes Dokument, ignoriert jedoch die Vorteile, die sich aus den vielfältigen,
Dokumentverweis oder $lookup, um eingebetteten Datenstrukturen des dokumentbasierten
Daten aus verschiedenen Collections zu
verknüpfen Modells ergeben. Stehen zum Beispiel Daten aus zwei
RDBMS-Tabellen in einer Eltern-Kind-Beziehung, werden
Abbildung 3: Terminologische Entsprechungen diese in MongoDB üblicherweise in einem einzigen
Dokument zusammengeführt (eingebettet).
Von starren Tabellen zu flexiblen,
dynamischen BSON-Dokumenten
Viele der Daten, die wir heute verwenden, weisen komplexe
Strukturen auf, die viel effizienter mit JSON-Dokumenten
(JavaScript Object Notation) als mit Tabellen modelliert und
dargestellt werden können.
MongoDB speichert JSON-Dokumente im binären
BSON-Format (Binary JSON). Mit der BSON-Codierung
wird die beliebte JSON-Modellierung auf weitere
Datentypen wie Integer, Long Integer, Decimal und Abbildung 4: relationales Schema, flache 2-D-Tabellen
Gleitkommazahlen ausgedehnt.
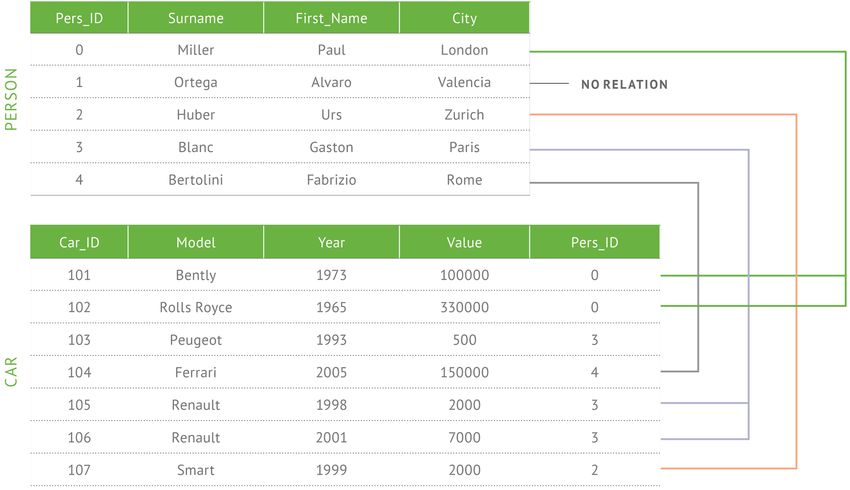
In Abbildung 4 stellt das RDBMS die Verknüpfung
Mit Unterdokumenten und Arrays spiegeln
zwischen den Tabellen „Person“ (Eigentümer) und „Car“
JSON-Dokumente außerdem die Struktur der Objekte auf
(Fahrzeug) über das Feld „Pers_ID“ her, damit die
der Anwendungsebene wider. Dies erleichtert Entwicklern
Anwendung für jedes Fahrzeug den Eigentümer ausgeben
die Verknüpfung der in einer Anwendung verwendeten
kann. Im Gegensatz dazu werden derartige Verknüpfungen
Daten mit dem entsprechenden Dokument in der
im dokumentbasierten Modell durch eingebettete
Datenbank.
Unterdokumente und verschachtelte Arrays hergestellt, das
heißt durch die Zusammenfassung aufeinander bezogener
3Felder in einer einzigen Datenstruktur. Zeilen und Spalten,
die üblicherweise normalisiert und über verschiedene
Tabellen verteilt waren, können nun zusammen in einem
einzigen Dokument gespeichert werden. Dadurch kann die
Anwendung vollständige Datensätze ausgeben, ohne
separate Tabellen mit einer JOIN-Operation verknüpfen zu
müssen.
Das bedeutet: Bei der Modellierung der oben
angesprochenen Fahrzeug- und Eigentümerdaten in
MongoDB kann ein Schema erstellt werden, bei dem ein
Array von fahrzeugspezifischen Unterdokumenten direkt in
das Dokument mit den Personendaten eingebettet wird.
{
first_name: “Paul”,
surname: “Miller”,
city: “London”,
location: [45.123,47.232],
cars: [
{ model: “Bentley”,
year: 1973,
value: 100000, ….},
{ model: “Rolls Royce”,
year: 1965,
value: 330000, ….},
]
}
Abbildung 5:
5:Durch die Zusammenführung der 5
RDBMS-Tabellen in 2 BSON-Dokumenten wird der JOIN
in der Datenbankstruktur abgebildet.
In diesem einfachen Beispiel besteht das relationale
Modell aus nur zwei Tabellen, während die meisten echten
Anwendungen Dutzende, Hunderte oder sogar Tausende
Tabellen benötigen. Dieser Ansatz entspricht nicht der Art
und Weise, wie Architekten mit Daten umgehen oder wie
Entwickler Anwendungen schreiben. Mit dem
dokumentbasierten Modell können Daten viel intuitiver
modelliert werden.
4Anhand des in Abbildung 5 dargestellten Beispiels einer basieren. Zwar ist dafür etwas mehr Speicherplatz
Blogging-Plattform lassen sich die Unterschiede zwischen erforderlich, doch wird dies durch die Effizienzgewinne
dem relationalen und dem dokumentbasierten Modell vereinfachter Lese- bzw. Schreibprozesse mehr als
weiter verdeutlichen. In diesem Beispiel muss die aufgewogen. Allerdings gibt es auch Umstände, unter
Anwendung bei der Erstellung eines Blogbeitrags das denen die Normalisierung der Daten von Vorteil sein kann,
RDBMS anweisen, fünf separate Tabellen durch insbesondere wenn Daten aus verschiedenen Quellen zu
JOIN-Operationen zu verknüpfen. Alternativ lassen sich mit Analysezwecken zusammengeführt werden müssen. Dies
MongoDB alle zur Erzeugung des Blogbeitrags relevanten kann über die Stufe „$lookup“ des MongoDB Aggregation
Daten in einem einzigen Dokument speichern, das mit nur Frameworks erfolgen.
einem weiteren Dokument verknüpft ist: einem
Das Aggregation Framework ist eine Pipeline für die
Nutzerdokument mit Angaben zu den Autoren des
Datenaggregation, die nach dem Vorbild der
Blogbeitrags und der dazugehörigen Kommentare.
Datenverarbeitungspipelines modelliert wurde. Die
Dokumente werden in eine mehrstufige Pipeline
Weitere Vorteile des dokumentbasierten Modells eingespeist, die die in den Dokumenten enthaltenen Daten
in die gewünschte Form aggregiert. Auf jeder Stufe werden
Das dokumentbasierte Modell ermöglicht es nicht nur, die
die Dokumente weiterverarbeitet und verändert.
Daten auf der Datenbankebene in einer intuitiveren Form
abzubilden, sondern bietet darüber hinaus auch Vorteile in Auch wenn „$lookup“ keine so vielseitige Auswahl an
puncto Leistung und Skalierbarkeit: JOIN-Operationen bietet wie manches RDBMS,
ermöglicht es doch LEFT OUTER EQUI-JOINs, die für
• Das vollständige Dokument kann mit einer einzigen
eine Reihe von Anwendungen nützlich sind. Mit LEFT
Anfrage bei der Datenbank angezeigt werden, weshalb
OUTER EQUI-JOIN werden Dokumente in der „rechten“
bei der Bearbeitung einer Abfrage die Notwendigkeit
Collection mit Dokumenten in der „linken“ Collection
entfällt, mehrere Tabellen mithilfe von JOINs
abgeglichen und in diese eingebettet.
miteinander zu verknüpfen. Das MongoDB-Dokument
wird physisch als ein einziges Objekt gespeichert, Enthält zum Beispiel die linke Collection Dokumente des
sodass im Arbeitsspeicher oder auf der Festplatte nur Typs „Bestellung“, die durch eine Warenkorbanwendung
ein einziger Lesevorgang notwendig ist. Demgegenüber generiert werden, dann kann der Operator „$lookup“ die
erfordern RDBMS-JOINs mehrere Lesezugriffe auf Angaben im Feld „Produkt_ID“ in diesen Dokumenten mit
verschiedene physische Speicherorte. der Collection „Produkte“ abgleichen und die
• Da jedes Dokument in sich geschlossen ist, wird die entsprechenden Produktdaten in die Bestellungen
Verteilung der Datenbank über mehrere Nodes (ein als einbetten.
„Sharding“ bezeichneter Vorgang) einfacher, was
Darüber hinaus bietet MongoDB 3.4 eine neue
wiederum schier unbegrenzte Möglichkeiten zur
Aggregationsstufe mit der Bezeichnung „$graphLookup“,
horizontalen Skalierung mit Standardhardware eröffnet.
mit der ein Satz von Dokumenten rekursiv nach
Datenbankadministratoren müssen sich keine Sorgen
spezifischen Beziehungen zu einem Ausgangsdokument
mehr darüber machen, ob die auf verschiedenen Nodes
durchsucht werden kann. Entwickler können die maximale
gespeicherten Daten mit vertretbarer Leistung (oder
Tiefe für derartige rekursive Suchvorgänge festlegen und
überhaupt) durch JOINs zusammengeführt werden
zusätzliche Filter verwenden, um nur die Nodes zu
können.
durchsuchen, die spezifische Bedingungen erfüllen. Mit
$graphLookup können einzelne oder mehrere Collections
Verknüpfung von Collections im Rahmen von abgefragt und rekursiv durchsucht werden.
Abfragen
Ein ausgearbeitetes Beispiel für die Verwendung von
In den meisten Fällen ist es von Vorteil, wenn die für die „$lookup“ sowie anderen Aggregationsstufen findet sich im
Unterstützung von Geschäftsprozessen genutzten Blogbeitrag „JOINS und andere Verbesserungen an der
Datenbanken auf einem denormalisierten Datenmodell Aggregationspipeline“ (auf Englisch).
5Definition des Dokumentschemas Vor
organg
gang R DB
DBMMS-
S-Operation
Operation MongoDB-
MongoDB-Operation
Operation
Das Schemadesign sollte sich an den Produktdatensatz INSERT in (n) insert() in 1
Datenzugriffsmustern der Anwendung orientieren und erstellen Tabellen Dokument
insbesondere die folgenden Punkte berücksichtigen: (Produktbeschreibung,
Preis, Hersteller etc.)
• das Verhältnis der Lese-/Schreibvorgänge im Rahmen
Produktdatensatz SELECT und JOIN find() ein einziges
von Datenbankoperationen und die eventuelle anzeigen von (n) Dokument
Notwendigkeit, die Performance für einen dieser beiden Produkttabellen
Vorgänge zulasten des anderen zu optimieren
Produktrezension INSERT in Tabelle insert() in
• die Arten von Abfragen und Updates, die von der hinzufügen „Rezension“, Collection
Datenbank durchgeführt werden sollen einschließlich „Rezension“,
Fremdschlüssel zu einschließlich Verweis
• der Lebenszyklus der Daten und die Zuwachsrate der Produktdatensatz zu Produktdokument
Dokumente
Weitere …… ……
In einem ersten Schritt sollte das Projektteam die mit den Vorgänge …
Anwendungsdaten durchzuführenden Operationen
Abbildung 6: Analyse der Abfragen zur Ermittlung des optimalen
definieren, um auf dieser Grundlage einen Vergleich Schemas
vorzunehmen:
1. Wie werden diese Operationen derzeit von der Modellierung von Beziehungen durch
relationalen Datenbank umgesetzt? Einbettungen und Verweise
2. Wie könnten sie mit MongoDB umgesetzt werden?
Die Entscheidung, ob es sinnvoller ist, ein Dokument in ein
Abbildung 6 illustriert, wie ein solcher Vergleich aussehen anderes einzubetten oder separate Dokumente in
könnte. verschiedenen Collections zu erstellen und diese durch
einen Verweis zu verknüpfen, hängt von der jeweiligen
Diese Analyse hilft dabei, das ideale Dokumentschema zu Anwendung ab. Einige allgemeinere Überlegungen zum
finden und die Indizes optimal auf die Anwendungsdaten Schemadesign können jedoch bei dieser Entscheidung
sowie die geplanten Workloads, Datenbankabfragen und helfen.
Operationen abzustimmen.
Zusätzlich kann das Projektteam die Protokolle des Einbettung
RDBMS heranziehen, um die häufigsten Abfragen der
Für Daten, die in Beziehungen mit einer Kardinalität von
bestehenden Anwendung zu ermitteln und damit zugleich
1:1 oder 1:n zueinander stehen, bietet sich die Einbettung
die Daten, auf die am häufigsten gemeinsam zugegriffen
in einem einzigen Dokument an (insbesondere, wenn die
wird. Dies gibt Hinweise darauf, welche Daten
„n“ Objekte immer in Zusammenhang mit dem
möglicherweise zusammen in einem MongoDB-Dokument
Elterndokument auftreten bzw. angezeigt werden).
gespeichert werden können. Dieser Prozess wird in
Datenhierarchien und -zugehörigkeiten können ebenfalls
unserem Whitepaper [Die Apollo Group migriert von Oracle
durch Einbettung modelliert werden. Im oben erläuterten
zu MongoDB] (nur auf English verfügbar)
Beispiel mit den Produktdaten sollten die Produktpreise
(http://www.mongodb.com/lp/whitepaper/
(aktuelle und frühere) in das Produktdokument eingebettet
nosql-oracle-migration-mongodb) beispielhaft anhand der
werden, da sie untrennbar zu diesem bestimmten Produkt
Entwicklung einer neuen cloudbasierten Plattform für das
gehören und eine Teilmenge der Produktdaten bilden.
Schulungsmanagement erläutert.
Wenn das Produkt gelöscht wird, werden die
Preisinformationen überflüssig.
6Auch Felder, die stets zusammen modifiziert werden • wenn viele verschiedene Quellen auf ein Objekt
müssen, sollten in dasselbe Dokument eingebettet werden. verweisen
Nähere Informationen dazu finden Sie in diesem Leitfaden • zur Abbildung komplexer n:m-Beziehungen
im Abschnitt „Anwendungsintegration“.
• zur Modellierung großer, hierarchischer Datensätze
Doch nicht alle 1:1- und 1:n-Beziehungen sollten in einem
In der „$lookup“-Stufe der Aggregationspipeline können
einzigen Dokument abgebildet werden. In den folgenden
die in den Dokumenten der ersten Collection enthaltenen
Fällen sind Verweise zwischen Dokumenten in
Verweise mit den „_id“-Feldern der zweiten Collection
unterschiedlichen Collections die bessere Wahl:
abgeglichen und die referenzierten Daten automatisch in
• Wenn ein Dokument häufig gelesen wird, aber ein den Ergebnisdatensatz eingebettet werden.
eingebettetes Unterdokument enthält, das nur selten
aufgerufen wird. Ein Beispiel hierfür wäre ein
Für unterschiedliche Zwecke optimiert
Kundendatensatz, in den Kopien der Jahresberichte
eingebettet sind. Die Einbettung der Berichte vergrößert Der Vergleich der beiden Modellierungsoptionen –
nur den Arbeitsdatensatz der Collection und erhöht Einbettung von Unterdokumenten versus Erstellung von
somit die Anforderungen an den Arbeitsspeicher. Verweisen zwischen Dokumenten – hebt einen
• Wenn ein Teil des Dokuments häufig aktualisiert wird wesentlichen Unterschied zwischen relationalen und
und kontinuierlich an Umfang zunimmt, während der dokumentbasierten Datenbanken hervor:
Rest des Dokuments im Großen und Ganzen
• Ein RDBMS ist vor allem auf die möglichst effiziente
unverändert bleibt.
Nutzung des Datenspeichers ausgelegt, da es aus einer
• Wenn das kombinierte Dokument die von MongoDB Zeit stammt, in der der Speicherplatz die teuerste
vorgegebene Größenbeschränkung von 16 MB Komponente einer Datenbankinfrastruktur war.
überschreiten würde.
• Das dokumentbasierte Modell von MongoDB ist im
Hinblick auf den Datenzugriff durch Anwendungen
Verweise optimiert und trägt der Tatsache Rechnung, dass
Leistung, kurze Entwicklungsprozesse und eine rasche
Verweise ermöglichen die Normalisierung der Daten und Markteinführung heute wichtiger sind als ein
bieten im Vergleich zur Einbettung ein höheres Maß an minimierter Speicherplatzbedarf.
Flexibilität. Allerdings muss die Anwendung zur Auflösung
von Verweisen Nachfolgeabfragen initiieren, wodurch Weitere Überlegungen, Muster und Beispiele zur
zusätzliche Serveranfragen erforderlich werden. Datenmodellierung einschließlich ausführlicherer
Informationen zur Einbettung und zu Verweisen finden Sie
Verweise werden üblicherweise in einem „_id“-Feld1 in der Dokumentation.
abgebildet, das in einem oder mehr Dokumenten erscheint.
Wird ein solches Dokument im Rahmen einer Abfrage
aufgerufen, führt die Anwendung eine zweite Abfrage Indizierung
durch, um auch die darin referenzierten Daten auszugeben.
Bei jeder Datenbank hängt die Performance entscheidend
In den folgenden Fällen sollten Verweise verwendet von den verwendeten Indizes ab. Dadurch wird die
werden: Festlegung und Feinabstimmung der Indizes zu einem
wesentlichen Teil des Schemadesigns.
• bei 1:1- oder 1:n-Beziehungen, wenn die Vorteile, die
die Einbettung in puncto Leseperformance bietet, die Indizes in MongoDB entsprechen im Großen und Ganzen
Auswirkungen der Datenduplizierung nicht aufwiegen den Indizes einer relationalen Datenbank. MongoDB
würden. verwendet B-Baum-Indizes und ist von Haus aus auf die
1. Hierbei handelt es sich um ein erforderliches eindeutiges Feld, das in einem MongoDB-Dokument als Primärschlüssel verwendet wird. Es wird
entweder automatisch vom Treiber erzeugt oder vom Anwender eingegeben.
7Unterstützung sekundärer Indizes ausgelegt. Daher wird es werden, die in Abhängigkeit von diesen drei Werten den
allen, die sich mit SQL auskennen, sofort geläufig sein. Datensatz der entsprechenden Person ausfindig
machen. Ein zusätzlicher Vorteil eines derartigen
Bei der Auswahl der Indizes sollten die Art und Häufigkeit
zusammengesetzten Indexes besteht darin, dass er
der durch die Anwendung initiierten Abfragen die
auch für Abfragen verwendet werden kann, die nur die
ausschlaggebenden Faktoren sein. Wie bei allen
bei der Indexerzeugung zuerst genannten Felder
Datenbanken hat die Indizierung ihren Preis: Sie führt zu
betreffen. Dadurch werden eventuell Indizes, die nur auf
zusätzlichen Arbeitslasten bei Schreibvorgängen und einer
einem Feld basieren, überflüssig. Im zuvor genannten
gesteigerten Ressourcenauslastung (Festplatte und
Beispiel würde der zusammengesetzte Index auch
Arbeitsspeicher).
Abfragen beschleunigen, bei denen Kundendaten nur
anhand des Nachnamens oder anhand des
Indexarten Nachnamens und des Vornamens (ohne
Berücksichtigung des Wohnsitzlandes) gesucht wird.
MongoDB verfügt über ein funktionsreiches
Abfragemodell, das flexible Zugriffsmöglichkeiten auf die • Eindeutige Indizes: Wird ein Index als eindeutig
Daten bietet. Standardmäßig erstellt MongoDB einen Index definiert, blockiert MongoDB das Einfügen neuer
für das Primärschlüsselfeld („_id“) der Dokumente. Dokumente oder die Aktualisierung bestehender
Dokumente, falls dadurch Doppelungen bei den Werten
Alle anwenderdefinierten Indizes sind Sekundärindizes. des indizierten Feldes entstehen würden. Wird ein
Sekundärindizes können für beliebige Felder eingerichtet zusammengesetzter Index als eindeutig definiert, muss
werden, einschließlich für Felder in Unterdokumenten und die Kombination der Werte eindeutig sein.
eingebetteten Arrays.
• Array-Indizes: Bei Feldern, die ein Array enthalten, wird
MongoDB bietet unter anderem die folgenden jeder Arraywert als eigener Indexeintrag gespeichert.
Indexoptionen: Zum Beispiel enthalten Dokumente mit
Produktbeschreibungen möglicherweise ein Array mit
• Indexverknüpfung und zusammengesetzte Indizes: den wichtigsten Eigenschaften. Wenn es einen Index
Durch die Nutzung der Möglichkeit zur Verknüpfung von des Eigenschaftenfeldes gibt, wird jedes Attribut einzeln
Indizes lassen sich in MongoDB Abfragen erstellen, bei indiziert und Abfragen des Eigenschaftenfeldes können
denen mehrere Indizes zur Identifizierung und Ausgabe über diesen Index optimiert werden. Zur Erstellung
der gewünschten Daten herangezogen werden. Diese eines Array-Index ist keine spezielle Syntax erforderlich
Funktion ist nützlich für Ad-hoc-Abfragen, da deren – wenn das Feld ein Array enthält, wird es als
Datenzugriffsmuster im Allgemeinen nicht im Voraus Array-Index indiziert.
bekannt sind. Wenn jedoch im Voraus bekannt ist,
• TTL
TL-Indizes:
-Indizes: In manchen Fällen sollen Daten
welche Prädikate im Rahmen von Abfragen für den
automatisch entfernt werden. Mit Time-To-Live-Indizes
Datenzugriff verwendet werden und welche Sortierung
(TTL) kann der Anwender einen Zeitraum bestimmen,
gewünscht ist, bietet sich die Verwendung
nach dessen Ablauf die Daten automatisch aus der
zusammengesetzter Indizes an. Diese Indizes fassen
Datenbank gelöscht werden. Eine gängige Verwendung
mehrere Felder in einer linearen Indexstruktur
von TTL-Indizes sind Anwendungen, die ein
zusammen und bieten gegenüber der Indexverknüpfung
kontinuierlich aktualisiertes Fenster mit einer Chronik
Vorteile in puncto Performance. Nehmen wir zum
des Clickstreams und anderer Nutzeraktionen (zum
Beispiel eine Anwendung zur Verwaltung von
Beispiel der letzten 100 Tage) enthalten.
Kundendaten. Eine solche Anwendung muss unter
anderem in der Lage sein, Kunden anhand des • Geoindizes: MongoDB ermöglicht die Nutzung von
Nachnamens, Vornamens und Land des Wohnsitzes zu Geoindizes, um ortsbezogene Abfragen in einem
finden. Durch die Nutzung eines zusammengesetzten zweidimensionalen Raum zu optimieren, zum Beispiel
Indexes, der auf den Feldern Nachname, Vorname und für Projektionssysteme für die Erde. Mithilfe dieser
Land des Wohnsitzes basiert, können Abfragen initiiert Indizes kann MongoDB Abfragen optimieren, mit denen
8nach Dokumenten gesucht wird, die ein Polygon oder Alle MongoDB-Datenbank-Engines unterstützen alle
Punkte enthalten, die am nächsten an einem Indexarten und die Indizes können für jeden Teil eines
angegebenen Punkt oder einer Linie liegen oder JSON-Dokuments erstellt werden, auch basierend auf
innerhalb eines Kreises, Rechtecks oder Vielecks liegen Unterdokumenten und Array-Elementen. Dadurch sind sie
oder einen Kreis, ein Rechteck oder ein Vieleck viel leistungsfähiger als die Indizes in RDBMS.
schneiden.
• Gestr
Gestreute
eute Indizes (Sparse Indexes): Gestreute Leistungsoptimierung mit Indizes
Indizes enthalten nur Einträge für Dokumente, die ein
bestimmtes Feld enthalten. Da in MongoDB das MongoDB verfügt über einen Abfrageoptimierer, der die
Datenmodell von Dokument zu Dokument variieren Auswahl des Index auf der Basis empirischer
kann, ist es nicht ungewöhnlich, dass manche Felder Leistungsdaten vornimmt, indem er von Zeit zu Zeit
nur in einer Teilmenge aller Dokumente vorkommen. alternative Abfragepläne verwendet und den Plan mit der
Gestreute Indizes bieten die Möglichkeit schlankerer, kürzesten Antwortzeit auswählt. Mit der Methode
effizienterer Indexstrukturen, wenn die zu indizierenden „cursor.hint()“ kann der Abfrageoptimierer übergangen
Felder nicht in allen Dokumenten vorhanden sind. werden.
• Partielle Indizes: Partielle Indizes können als eine Wie bei einer relationalen Datenbank kann der
flexiblere Weiterentwicklung des gestreuten Index Datenbankadministrator Abfragepläne einsehen und
betrachtet werden. Sie eröffnen dem sicherstellen, dass für gängige Abfragen wohldefinierte
Datenbankadministrator die Möglichkeit, einen Indizes verwendet werden. Dazu gibt es die Funktion
Ausdruck festzulegen, der geprüft wird, um darüber zu „explain()“, die Auskunft darüber gibt ...
entscheiden, ob ein Dokument in einen bestimmten
• wie viele Dokumente ausgegeben wurden,
Index aufgenommen werden soll. Z. B. wird in einer
Collection „Bestellungen“ ein Index des Status und • welcher Index verwendet wurde bzw. ob überhaupt ein
Lieferanten nur für offene Bestellungen benötigt. Der Index verwendet wurde,
Index könnte also die Bedingung „{orderState: "active"}“ • ob das Abfrageergebnis bereits gespeichert war, sodass
enthalten und so die Belastung von Arbeitsspeicher und die Ergebnisse ausgegeben werden konnten, ohne
Speicherplatz sowie die Schreibleistung reduzieren und dass Dokumente gelesen werden mussten,
Suchabfragen der offenen Bestellungen weiter
• ob eine Sortierung im Arbeitsspeicher erfolgt ist (was
optimieren.
darauf hinweist, dass ein Index von Vorteil wäre),
• Hash-Indizes: Hash-Indizes berechnen für den Wert in
• wie viele Indexeinträge durchsucht wurden,
einem Feld einen Hashwert, den sie dann indizieren.
Derartige Indizes werden vor allem für das hashbasierte • wie viele Dokumente gelesen wurden,
Sharding eingesetzt und ermöglichen eine einfache und • wie viel Zeit zur Bearbeitung der Abfrage benötigt
gleichmäßige Verteilung von Dokumenten auf die wurde (in Millisekunden),
Shards.
• welche alternativen Abfragepläne geprüft und
• Volltextindizes: MongoDB bietet einen speziellen verworfen wurden.
Index für Textsuchen, der komplexe, sprachspezifische
linguistische Regeln für die Stammformreduktion, Es ist zwar nicht unbedingt notwendig, die Datenbank
Tokenisierung und Stoppwörter verwendet. Abfragen, gleich zu Projektbeginn auf mehrere Shards zu verteilen,
die den Volltextindex verwenden, geben die Dokumente doch ist es immer ratsam, davon auszugehen, dass zu
nach ihrer Relevanz geordnet aus. Zu jeder Collection einem späteren Zeitpunkt skaliert werden muss, z. B.
darf es höchstens einen Volltextindex geben, doch kann infolge wachsender Datenvolumen oder Nutzerzahlen. Die
dieser mehrere Felder enthalten. Definition der Indexschlüssel im Rahmen des
Schemadesigns hilft auch dabei, Schlüssel zu identifizieren,
die zur anwendungstransparenten Skalierung mithilfe der
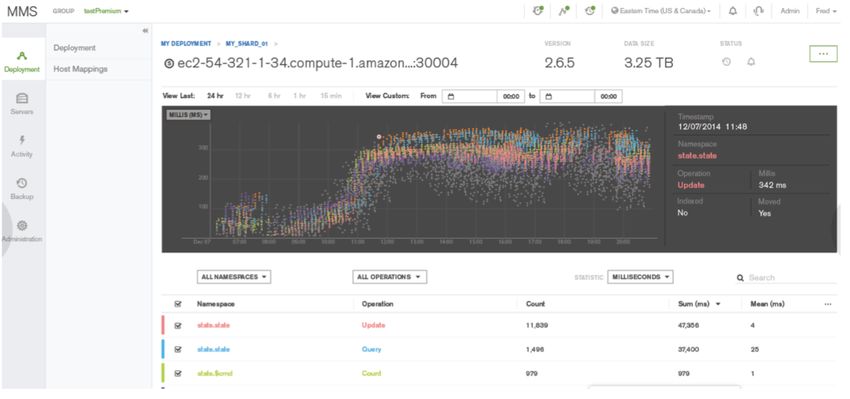
9Abbildung 7: Visualisiertes Abfrageprofil in MongoDB Ops Manager
Auto-Sharding-Funktion von MongoDB genutzt werden somit die Erkennung von langsameren Abfragen mit
können. gängigen Zugriffsmustern und Eigenschaften sowie von
Latenzspitzen.
MongoDB verfügt über eine Reihe von Protokollierungs-
und Überwachungstools, die dafür sorgen, dass Collections Der Visual Query Profiler analysiert die erfassten Daten
in geeigneter Weise indiziert und Abfragen optimiert und liefert Empfehlungen für neue Indizes, die zur
werden. Diese Tools sollten sowohl in der Verbesserung der Abfrageleistung eingerichtet werden
Entwicklungsphase als auch beim geschäftlichen Einsatz können. Der Ops bzw. Cloud Manager bietet die
der Anwendungen genutzt werden. Möglichkeit zur automatisierten Implementierung
vorgeschlagener Indizes in das Produktionssystem. Dies
Der MongoDB Database Profiler wird überwiegend für
geschieht mittels eines schrittweisen Erstellungsprozesses,
Belastungstests und bei der Fehlersuche genutzt. Er
durch den jegliche Beeinträchtigung der Anwendung
protokolliert wahlweise alle Datenbankoperationen oder
vermieden wird.
nur die Ereignisse, deren Bearbeitung einen festgesetzten
Schwellenwert überschreitet (die Voreinstellung ist 100 MongoDB Compass bietet visuelle Darstellungen der
ms). Profildaten werden in einer größenbegrenzten Abfrageprozesse. Sie enthalten die wichtigsten
Collection („Capped Collection“) gespeichert und können Informationen darüber, wie Abfragen ausgeführt und
dort mühelos nach relevanten Ereignissen durchsucht bearbeitet werden. Zum Beispiel geht aus ihnen hervor, wie
werden – oft ist eine Abfrage dieser Collection einfacher viele Dokumente als Antwort auf eine Abfrage
als das Parsen der entsprechenden Logdateien. ausgegeben wurden, wie lange die Ausführung der
Abfrage gedauert hat und ob bzw. welche Indizes dabei
Der neue Visual Query Profiler ist Bestandteil der
genutzt wurden. Jede Stufe der Abfragepipeline wird als
MongoDB-Plattformen Ops Manager und Cloud Manager.
Knoten eines Baums dargestellt. Auf diese Weise
Er bietet Ihren für den Datenbankbetrieb und die
entstehen aussagekräftige Übersichten über
Datenbankadministration zuständigen Experten schnelle
Abfrageprozesse, in die mehrere Nodes einbezogen
und bequeme Funktionen für die Analyse bestimmter
wurden.
Datenbankabfragen oder Abfragetypen. Der Visual Query
Profiler (Abbildung 7) zeigt an, wie Abfrage- und
Schreiblatenzen im Laufe der Zeit variieren, und erleichtert
10Design und fortlaufende einige Tage, doch häufig nimmt dieser Schritt Wochen oder
Weiterentwicklung von Schemata Monate in Anspruch.
Das dynamische Schema von MongoDB bietet gegenüber Mit MongoDB können Entwickler das Schema in einem
relationalen Datenbanken erhebliche Vorteile. schrittweisen und agilen Prozess aufbauen. Sie können
sofort damit beginnen, Code zu schreiben, und neu
Zur Erstellung von Collections ist es nicht erforderlich, generierte Objekte sofort in die Datenbank einspeisen.
zunächst ihre Struktur, d. h. Dokumentfelder und Auch wenn sie weitere Funktionen hinzufügen, speichert
Datentypen, festzulegen. Darüber hinaus müssen die MongoDB die aktualisierten Objekte, ohne dass teure
Dokumente in einer Collection nicht alle dieselben Felder „ALTER TABLE“-Operationen durchgeführt oder Schemata
enthalten. Und schließlich lässt sich die Struktur der komplett neu entworfen werden müssen.
Dokumente einfach durch Hinzufügen neuer Felder bzw.
durch das Löschen bestehender Felder ändern. Diese Vorteile bestehen auch bei der Pflege der
Anwendung nach der Produktivsetzung. Wenn dagegen
Diese Vorteile lassen sich besonders gut am Beispiel der eine relationale Datenbank verwendet wird, kann durch das
verschiedenen Datensätze in einer Kundendatenbank Upgrade einer Anwendung die Notwendigkeit entstehen,
veranschaulichen: Felder hinzuzufügen oder anzupassen. Solche Änderungen
erfordern ein konzertiertes Vorgehen von
• Manche Kundenunternehmen haben mehrere
Datenbankadministratoren, Entwicklern und der für den
Geschäftsstellen und -bereiche, andere nicht.
Datenbankbetrieb zuständigen Teams, die sich für ein
• Die Anzahl der Kontaktpersonen und synchrones Upgrade der Anwendung und der Datenbank
Kommunikationskanäle kann von Kunde zu Kunde darüber abstimmen müssen, wann die notwendigen
variieren. „ALTER TABLE“-Operationen durchgeführt werden sollen.
• Für diese verschiedenen Personen und Kanäle können
Da MongoDB eine dynamische Weiterentwicklung der
unterschiedliche Informationen abgelegt sein, z. B.
Schemata unterstützt, muss für solche Operationen
unterhalten einige Social-Media-Feeds, deren
lediglich die Anwendung aktualisiert werden; in der Regel
Verfolgung nützlich sein kann, und andere nicht.
sind keine Maßnahmen in MongoDB erforderlich. Die
• Jeder Kunde bezieht vom Anbieter unterschiedliche Weiterentwicklung von Anwendungen ist einfach und
Services, für die wiederum jeweils eigene Verträge Projektteams können die Flexibilität verbessern und die
bestehen. Zeit bis zur Marktreife verkürzen.
Im starren, zweidimensionalen Schema einer relationalen Wenn ein Datenbankadministrator oder Entwickler
Datenbank ist die Modellierung dieser enormen Bandbreite entscheidet, dass bestimmte Beschränkungen der
von Konstellationen kompliziert und umständlich. Dagegen Dokumentstruktur vorgenommen werden müssen, können
ist die Möglichkeit zur nahtlosen Erstellung von jederzeit Regeln für die Dokumentvalidierung hinzugefügt
Datenbanken aus verschiedenartigen Dokumenten einer werden. Nähere Informationen dazu finden Sie weiter
der grundlegenden Vorteile der BSON-Dokumente in unten in diesem Leitfaden.
MongoDB.
Die flexiblen und dynamischen Schemata von MongoDB
ermöglichen die einfache Entwicklung und laufende
Anwendungsintegration
Weiterentwicklung der Schemata. Im Unterschied dazu
müssen Entwickler und Datenbankadministratoren bei der Nachdem das Schemadesign festgelegt wurde, kann die
Verwendung einer relationalen Datenbank im Rahmen Anwendung mit der Datenbank verknüpft werden. Hierzu
eines neuen Entwicklungsprojekts zunächst das bietet MongoDB vielseitige Treiber und Tools.
Datenbankschema festlegen, bevor sie überhaupt die erste
Datenbankadministratoren können MongoDB außerdem so
Zeile Code schreiben können. Im besten Fall dauert dies
konfigurieren, dass die Anforderungen der Anwendung
11hinsichtlich Datenkonsistenz und -dauerhaftigkeit erfüllt Beispielen, die bei der Umstellung auf die Struktur und
werden. Diese Aspekte werden im Folgenden erläutert. Semantik der MongoDB-Abfragesprache helfen.
Außerdem bietet MongoDB einen umfangreichen Katalog
fortgeschrittener Abfrageoperatoren.
MongoDB-Treiber und die API
MongoDB ist unter anderem auf maximale
Das MongoDB Aggregation Framework
Anwenderfreundlichkeit und Entwicklerproduktivität
ausgelegt. Die Aggregation von Daten innerhalb einer Datenbank ist
eine wichtige Funktion und eine der Stärken von RDBMS.
Ein entscheidender Unterschied zwischen einem
SQL-basierten RDBMS und MongoDB besteht darin, dass Viele NoSQL-Datenbanken haben keine
die MongoDB-Schnittstelle in Form von Methoden (oder Aggregationsfunktionen. Das führte in der Vergangenheit
Funktionen) im API einer bestimmten Programmiersprache dazu, dass Entwickler bei der Migration zu einer
implementiert ist und nicht in einem API, das auf einer NoSQL-Datenbank Behelfslösungen finden mussten, wie
eigenen textbasierten Sprache basiert, wie dies in SQL der beispielsweise:
Fall ist. Zusammen mit der Affinität zwischen dem
1. Die Erstellung eigener Aggregationsfunktionen und
BSON-Dokumentmodell von MongoDB und den in
deren Einbettung in den Anwendungscode: Dies führt
modernen Programmiersprachen verwendeten
zu mehr Komplexität und Performancedefiziten.
Datenstrukturen erleichtert dies die
Anwendungsintegration beträchtlich. 2. Die Übermittlung eines Datenbankexports an Hadoop,
um dort MapReduce-Operationen durchzuführen: Auch
MongoDB bietet Treiber für die gängigsten hierdurch nimmt die Komplexität deutlich zu. Zudem
Programmiersprachen, darunter elf von MongoDB werden Daten über mehrere Speicherorte dupliziert und
entwickelte und unterstützte Treiber (z. B. für Java, Python, Echtzeitanalysen sind nicht möglich.
.NET, PHP) und über 30 von der Community unterstützte
3. Falls möglich, die Durchführung nativer
Treiber.
MapReduce-Operationen innerhalb der
Die MongoDB-Treiber für spezifische NoSQL-Datenbank selbst:
Programmiersprachen reduzieren die Einarbeitungszeit für
MongoDB stellt zu diesem Zweck das in die Datenbank
neue Entwickler auf ein Minimum und vereinfachen die
integrierte Aggregation Framework bereit, das ähnliche
Anwendungsentwicklung. Zum Beispiel können
Funktionen wie „GROUP BY“, „JOIN“ und vergleichbare
Java-Entwickler Code für MongoDB direkt in Java
schreiben. Gleiches gilt für Ruby-Entwickler, SQL-Befehle bietet.
PHP-Entwickler usw. Die Treiber werden von Mit dem Aggregation Framework durchlaufen Dokumente
Entwicklungsteams erstellt, die Experten in ihrer jeweiligen aus einer Collection eine Aggregationspipeline und werden
Programmiersprache sind und die bevorzugten dort in Stufen verarbeitet. Die verschiedenen Ausdrücke
Arbeitsmethoden von Programmierern in dieser Sprache führen Rechenoperationen mit den in den
kennen. Eingabedokumenten enthaltenen Daten durch und
generieren entsprechende Ausgabedokumente. Die in der
Stufe „$group“ verwendeten Akkumulatorausdrücke
Die Übertragung von SQL-Befehlen in die
ermitteln Statusinformationen (z. B. Gesamtsummen,
MongoDB-Syntax
Maximal-, Minimal- und Durchschnittswerte sowie
Für Entwickler, die mit SQL vertraut sind, ist es nützlich, Standardabweichung und ähnliche Daten) und bewahren
nachvollziehen zu können, wie zentrale SQL-Befehle wie diese auf, während die Dokumente die Pipeline
„CREATE“, „ALTER“, „INSERT“, „SELECT“, „UPDATE“ und durchlaufen.
„DELETE“ in der MongoDB-API abgebildet werden.
Außerdem kann das Aggregation Framework mithilfe von
Unsere Dokumentation enthält eine Vergleichstabelle mit
Projektionen, Filtern, Redacts, Lookups (JOINs) und
12rekursiven graphLookups Dokumente bearbeiten und SQL-basierte BI-Tools wie Tableau benötigen eine
kombinieren. Datenquelle mit einem festen, tabellarischen Schema. Für
Nutzer von MongoDB mit seinem dynamischen Schema
Die Tabelle zur Übersetzung von SQL-Befehle in
und den vielfältigen, mehrdimensionalen Dokumenten stellt
Aggregationen-Operatoren enthält eine Reihe von
dies eine Herausforderung dar. Damit BI-Tools MongoDB
Beispielen, die illustrieren, wie sich SQL-Abfragen in das
als Datenquelle für ihre Abfragen nutzen können, dient der
MongoDB Aggregation Framework übertragen lassen. Für
BI-Konnektor als Vermittler:
komplexere Analysen unterstützt MongoDB außerdem
MapReduce-Operationen in Collections – unabhängig • Er liefert dem BI-Tool ein Schema der
davon, ob diese auf mehrere Shards verteilt sind oder nicht. MongoDB-Collections, die visualisiert werden sollen.
Nutzer können das ausgegebene Schema überprüfen,
um sicherzustellen, dass Datentypen, Unterdokumente
Integration mit Business und Arrays korrekt dargestellt werden.
Intelligence-Lösungen – der MongoDB
• Er übersetzt vom BI-Tool ausgegebene
Connector for BI SQL-Anweisungen in die entsprechenden
Infolge des wachsenden Bedarfs an Tools für MongoDB-Abfragen, die dann zur Bearbeitung an
Self-Service-Datenanalysen, die schnellere MongoDB weitergeleitet werden.
Datenauffindung und zur Erstellung von Prognosen auf der • Er wandelt die empfangenen Ergebnisse in das vom
Grundlage von Echtzeitdaten zum operativen Geschäft BI-Tool benötigte Tabellenformat um, sodass die Daten
sowie aufgrund der Notwendigkeit, multistrukturelle entsprechend den Nutzeranforderungen angezeigt
Datensätze und Streaming-Daten in Analyseprozesse werden können.
einzubeziehen, sind BI- und Analyseplattformen eines der
am schnellsten wachsenden Segmente des Außerdem haben zahlreiche Anbieter von BI-Lösungen
Softwaremarktes. Konnektoren entwickelt, mit denen neben den
herkömmlichen relationalen Datenbanken auch MongoDB
In MongoDB gespeicherte Daten aus modernen mit ihrer jeweiligen Suite integriert werden kann, ohne dass
Anwendungen können einfach mit branchenüblichen, dafür SQL genutzt werden muss. Durch die Integration von
SQL-basierten BI- und Analyseplattformen untersucht MongoDB mit BI-Tools erhalten die Nutzer Funktionen für
werden. Mit dem BI-Konnektor können Analysten, die Erstellung von Berichten, Ad-hoc-Analysen und
Datenexperten und geschäftliche Nutzer jetzt die Dashboards sowie zur Visualisierung und Analyse von
gängigsten, in Millionen von Unternehmen verwendeten Daten aus verschiedenen Datenquellen. Hierfür sind Tools
BI-Tools nutzen, um halbstrukturierte und unstrukturierte von einer ganzen Reihe von Anbietern verfügbar, darunter
Daten in MongoDB gemeinsam mit Daten aus ihren Actuate, Alteryx, Informatica, JasperSoft, Logi Analytics,
herkömmlichen SQL-Datenbanken zu visualisieren. MicroStrategy, Pentaho, QlikTech, SAP Lumira und Talend.
13Abbildung 8: Gewinnen Sie neue, tiefere Einblicke mit den leistungsfähigen Visualisierungsfunktionen von MongoDB
Atomarität in MongoDB Wahrung der starken Konsistenz
Relationale Datenbanken bieten typischerweise Standardmäßig leitet MongoDB alle Lesezugriffe an die
ausgereifte Funktionen zur Sicherstellung der Primary Nodes, um für eine starke Konsistenz zu sorgen.
Datenintegrität, wie ACID-Transaktionen und die Ebenfalls standardmäßig erfolgt die Synchronisierung der
Durchsetzung von Beschränkungen. Anwender möchten zu Secondary Nodes innerhalb eines Replica Sets in
Recht vermeiden, dass ein Wechsel zu einem anderen MongoDB zeitverzögert – ganz ähnlich wie bei der
Datenbanktyp zulasten der Datenintegrität geht. Mit Master-Slave-Replikation in relationalen Datenbanken.
MongoDB profitieren sie von vielen diesbezüglichen
Administratoren können durch die Festlegung von
Funktionen relationaler Datenbanken, auch wenn die
Lesepräferenzen für die Secondary Nodes steuern, wie die
technische Umsetzung möglicherweise anders ausfällt.
Leseoperationen der Clients zu den Servern eines Replica
Schreibvorgänge in MongoDB haben auf Dokumentebene Sets geroutet werden.
ACID-Eigenschaften – und ermöglichen dadurch sogar die
atomare Aktualisierung eingebetteter Arrays und
Unterdokumente. Durch die Einbettung
Dauerhaftigkeit der Schreibprozesse
zusammengehöriger Felder in ein- und dasselbe Dokument In MongoDB stehen verschiedene Write Concerns zur
genießen die Anwender dasselbe Maß an Sicherheit Verfügung, mit denen sich festlegen lässt, welche Art von
hinsichtlich der Integrität wie bei einem herkömmlichen Rückmeldung auf einen Schreibvorgang erfolgt bzw. mit
RDBMS, das jedoch seinerseits rechenintensive welcher Sicherheit ein initiierter Schreibvorgang
ACID-Operationen synchronisieren und über separate durchgeführt wird. Die Optionen reichen von
Tabellen hinweg die referenzielle Integrität bewahren muss. Schreibanfragen ohne jegliche Empfangs- oder
Erfolgsbestätigung bis hin zu mehrstufigen
Durch die Atomarität auf Dokumentebene ist in MongoDB
Schreibprozessen, die erst dann abgeschlossen werden,
sichergestellt, dass Dokumente bei einer Aktualisierung
wenn eine Erfolgsbestätigung mehrerer Nodes
vollständig isoliert sind. Tritt ein Fehler auf, wird der
eingegangen ist.
Vorgang rückgängig gemacht. So erhalten Clients stets
eine konsistente Sicht des Dokuments. Bei der Auswahl des schwächsten Write Concerns sendet
die Anwendung die zu schreibenden Daten an MongoDB
Allerdings kann es Anwendungsfälle geben, in denen
und bearbeitet dann weitere Anfragen, ohne auf eine
ACID-Transaktionen für mehrere Dokumente gleichzeitig
Antwort der Datenbank zu warten. Dadurch wird die
nötig sind. Für solche Fälle gibt es verschiedene Ansätze.
Performance optimiert. Diese Option ist nützlich für
Einer basiert auf dem Befehl „findAndModify“, mit dem ein
Anwendungen im Bereich Protokollierung, wo Nutzer
Dokument atomar aktualisiert und im gleichen Vorgang
typischerweise Trends in den Daten analysieren und nicht
zurückgegeben werden kann. „findAndModify“ ist ein
einzelne Ereignisse.
leistungsfähiger Grundbaustein, auf dem Nutzer
komplexere Transaktionsprotokolle aufbauen können. Zum Bei stärkeren Write Concerns sind keine weiteren
Beispiel erstellen Nutzer häufig atomare Soft-State-Locks, Schreibvorgänge möglich, bis MongoDB den Vorgang
Job-Queues, Zähler und Zustandsmaschinen, die dabei durchgeführt und den Erfolg bestätigt hat (oder eine
helfen können, komplexere Prozesse zu koordinieren. Eine entsprechende Fehlermeldung vorliegt). Dies ist die
Alternative besteht in der Implementierung von Standardeinstellung von MongoDB. Es existieren
Zwei-Phasen-Commit. In unserer Dokumentation wird zahlreiche Möglichkeiten zur Feineinstellung der
beschrieben, wie dies in MongoDB umgesetzt werden Dauerhaftigkeit der Schreibprozesse. Diese basieren
kann und was bei der Verwendung unbedingt beachtet darauf, dass der Erfolg der Replikation der zu schreibenden
werden sollte. Daten an eine der folgenden Bedingungen geknüpft wird:
14• Der Schreibvorgang war auf einem einzigen Secondary Dokumentation enthält ausführlichere Informationen über
Node erfolgreich. Write Concerns.
• Der Schreibvorgang war auf der Mehrzahl der MongoDB befolgt das WAL-Prinzip (write-ahead logging)
Secondary Nodes erfolgreich. und protokolliert Vorgänge vor dem eigentlichen
• Der Schreibvorgang war auf einer festgelegten Anzahl Schreibvorgang in einem Journal auf der Festplatte.
von Secondary Nodes erfolgreich. Dadurch lassen sich die Dauerhaftigkeit von
Schreibvorgängen und ein hohes Maß an Robustheit bei
• Der Schreibvorgang war auf allen Secondary Nodes
Ausfällen sicherstellen.
erfolgreich – auch wenn diese in verschiedenen
Rechenzentren eingerichtet sind (in diesem Fall sollten Bevor eine Änderung in der Datenbank vorgenommen wird
Nutzer die Auswirkungen auf die Netzwerklatenz – unabhängig davon, ob es sich um einen Schreibvorgang
sorgfältig abwägen). oder eine Indexmodifizierung handelt –, hält MongoDB den
Änderungsvorgang im Journal fest. Falls ein Server ausfällt
oder ein Fehler in MongoDB auftritt, bevor die Änderung
vom Journal in die Datenbank übertragen wurde, kann der
protokollierte Vorgang erneut durchgeführt werden. Auf
diese Weise wird nach der Wiederherstellung des Servers
für einen konsistenten Status der Datenbank gesorgt.
Implementierung von
Validierungsprozessen und
Schreibbeschränkungen
Fremdschlüssel
Wie bereits dargelegt werden viele JOINS durch das
dokumentbasierte Modell von MongoDB JOINs
überflüssig, weil die zu verknüpfenden Daten in einem
einzigen, atomar aktualisierbares BSON-Dokument
eingebettet werden. Dadurch werden gleichzeitig viele
Fremdschlüssel und die Regeln zur Sicherstellung ihrer
Integrität überflüssig.
Wenn Sie jedoch Fremdschlüssel nutzen und Funktionen
zu deren Verwaltung benötigen, können Sie Frameworks
Abbildung 9: Konfiguration der Dauerhaftigkeit von
Schreibvorgängen von Drittanbietern wie Mongoose oder PyMODM
verwenden.
Mit einem Write Concern kann auch sichergestellt werden,
dass die Änderung auf der Festplatte gespeichert wurde, Dokument-Validierung
bevor sie bestätigt wird.
Dynamische Schemata bieten in puncto Flexibilität große
Der Write Concern wird über den Treiber konfiguriert und Vorteile, doch zugleich ist es wichtig, dass Kontrollen zur
ist äußerst granular: Die Einstellungen können Wahrung der Datenqualität implementiert werden können,
vorgangsspezifisch, für eine bestimmte Collection oder für insbesondere wenn die Datenbank als Basis für mehrere
die gesamte Datenbank vorgenommen werden. Unsere Anwendungen dient oder in eine umfassendere
Datenmanagementplattform integriert ist, die Daten in vor-
15und nachgelagerte Systeme speist. Anstatt die db.runCommand({
collMod: "contacts",
Durchsetzung dieser Kontrollen wieder in den validator: {
Anwendungscode zu verlagern, bietet MongoDB $and: [
{year_of_birth: {$lte: 1994}},
Funktionen zur Dokumentvalidierung in der Datenbank.
{$or: [
Damit können Nutzer dafür sorgen, dass die {phone: { $type: "string" }},
Dokumentstruktur, die Datentypen und -bereiche sowie {email: { $type: "string" }}
]}]
das Vorhandensein von Pflichtangaben überprüft werden. }})
Auf diese Weise können DBAs Richtlinien für den Umgang
mit Daten implementieren, während Entwickler weiterhin Um Validitätsprüfungen für eine Collection einrichten zu
von den Vorteilen eines flexiblen Dokumentmodells können, müssen sich Entwickler oder DBAs, die mit
profitieren. MongoDB vertraut sind, nicht erst lange einarbeiten, da die
Dokumentvalidierung die Standardabfragesprache von
MongoDB bietet flexible Optionen, mit denen sich
MongoDB verwendet.
individuell festlegen lässt, welche Teile eines Dokuments
bei dessen Aufnahme in eine bestimmte Collection Validierungsregeln können über Compass verwaltet,
überprüft werden und welc
welche
he nic
nicht
ht – im Gegensatz zu erzeugt und modifiziert werden. Dazu steht eine einfach zu
einem RDBMS, in dem alles definiert und überprüft bedienende Oberfläche zur Verfügung. Außerdem werden
werden muss. Für jeden Schlüssel empfiehlt es sich, die in Compass alle Dokumente angezeigt, die gegen die
folgenden Punkte zu überprüfen: Validierungsregeln verstoßen. DBAs können dann die von
Compass unterstützten CRUD-Operationen benutzen, um
• dass er existiert, die betreffenden Dokumente einzeln zu bearbeiten und so
• dass der ihm zugeordnete Wert vom richtigen Typ ist, Probleme mit der Datenqualität zu beheben.
• dass der Wert ein bestimmtes Format hat (so kann etwa
durch die Verwendung regulärer Ausdrücke überprüft Die Nutzung von Indizes zur Durchsetzung von
werden, ob der Inhalt eines Strings einem bestimmten Regeln
Muster entspricht und z. B. das Format einer korrekten
E-Mail-Adresse aufweist), Wie im Abschnitt über das Schemadesign beschrieben,
unterstützt MongoDB nativ eindeutige Indizes. Dadurch
• dass der Wert innerhalb eines festgelegten Bereichs
kann MongoDB Eingabevorgänge identifizieren, bei denen
liegt.
ein Wert doppelt in das eindeutig indizierte Feld einer
Beispielsweise könnte es nötig sein, die Dokumente in der Collection eingefügt werden soll, und eine entsprechende
Collection „Kontakte“ anhand folgender Kriterien zu Fehlermeldung ausgeben. Auf unserer Website steht ein
überprüfen: Tutorial zur Verfügung, in dem beschrieben wird, wie
eindeutige Indizes erstellt und auf welche Weise mehrfach
• Das Geburtsjahr darf nicht später als 1994 sein. vorhandene Einträge in dem zu indizierenden Feld aus
• Das Dokument enthält mindestens eine Telefonnummer bestehenden Collections entfernt werden können.
oder E-Mail-Adresse.
• Falls vorhanden, sind Telefonnummern und Views
E-Mail-Adressen Strings.
Datenbankadministratoren können nicht-materialisierte
Dies lässt sich mithilfe der folgenden Regel für die Views definieren, die nur einen Teil der in einer Collection
Dokumentvalidierung umsetzen: enthaltenen Daten umfassen, beispielsweise Views, in
denen bestimmte Felder herausgefiltert werden. Sie
können eine View für eine Collection definieren, die auf der
Aggregation von Daten anderer Collections oder Views
basiert. Die Zugriffsrechte auf einen View werden separat
16Sie können auch lesen

















































