Technische Infos Kategorie: Software und Technik
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Die Zeichensatzproblematik - Software und Technik - Technische Infos - Hostpoint
Technische Infos
Kategorie: Software und Technik
Häufig ist für die Installation und den Betrieb von Software und Webappliaktionen detailiertere Kennis
der Umgebung nötig. Lernen Sie mehr über die Konfiguration der Dienste wie den Apache Webserver
oder PHP und wie Sie diese anpassen können.
Die Zeichensatzproblematik
Wir erklären Ihnen nachfolgend die Hintergründe von Zeichensätzen, Probleme die in diesem
Zusammenhang auftreten können und deren Lösungen.
1. Zeichensalat - Datenbanken und Zeichensätze
2. Entstehung und Aufbau der Zeichensätze
3. Die gebräuchlichsten Zeichensätze
ISO-8859-1 oder latin-1
ISO-8859-15 oder latin-9
UTF-8
4. Probleme
5. Text in Datenbanken
6. Zugriff auf Text in Datenbanken: Die Datenbank Library
7. Die Web-Applikation
Zeichensatz per HTTP-Header definieren
Charset in HTML definieren
Definieren des Charsets von Formularen
8. Fehlerfälle
Deklarierter und tatsächlicher Zeichensatz in Datenbank stimmen nicht überein
Daten werden doppelt oder falsch konvertiert
Charset zur Anzeige der Daten im Browser wird nicht oder falsch gesetzt
9. Zusammenfassung: Best Practises
10. Problembehebung: Wenn der Salat schon angerichtet ist
Browser verwendet falsches Charset
-1-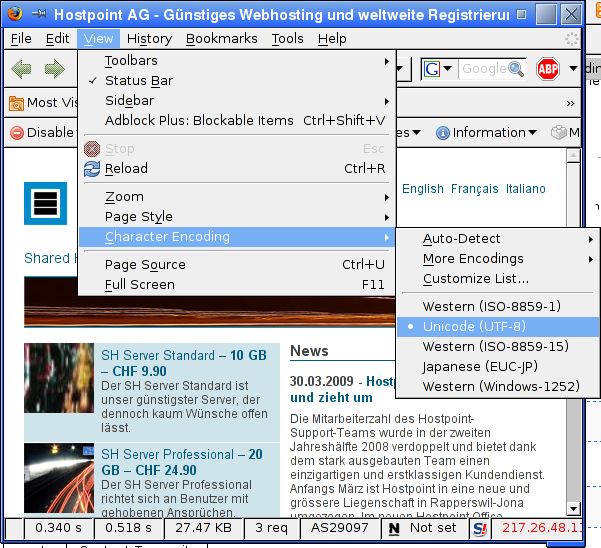
Die Zeichensatzproblematik - Software und Technik - Technische Infos - Hostpoint
1 Zeichensalat - Datenbanken und Zeichensätze
Die Zeit, als Computer noch teure, raumfüllende Apparaturen waren ist schon lange vorbei. Was
ursprünglich einer kleinen Elite und nur in Englisch zur Verfügung stand kann heute beinahe jeder und in
jeder Sprache haben. Doch die beinahe unüberschaubare Anzahl an Sprachen, Schriften und damit die
vom ursprünglich englischen Standard abweichenden Schriftzeichen bereiten immer wieder Probleme.
Dieser Artikel erklärt, wie die Datenbank MySQL das Problem angeht und wie man leidige Probleme mit
Umlauten und Sonderzeichen vermeiden und lösen kann.
2 Entstehung und Aufbau der Zeichensätze
Am Anfang war alles US-ASCII. Beinahe. Seit den 1960er Jahren verwenden Computer als kleinste
Speichereinheit 8 bit (8 Bit = 1 Byte). 8 Bit entsprechen den Zahlen von 0 bis 255. Damit Computer Text
darstellen konnten wurden diesen Zahlen Text-Zeichen zugeordnet. Um Kompatibilität zwischen den
verschiedenen damals verwendeten Systemen zu schaffen standardisierte man 1969 das ASCII Format:
Den 7 ersten Bit-Kombinationen wurden Zeichen zugeordnet- das erste "Charset" war geboren
("Character-Set", engl. Zeichensatz). So entspricht die Zahl 65 zum Beispiel dem Buchstaben ’A’.
Damit Raum für Entwicklungen und neue Zeichen (z.B. das Euro Zeichen) blieb, wurde nur die Hälfte der
256 Zeichen als US-ASCII fest definiert. In diesen Zeichen waren sämtliche englischen Schriftzeichen
enthalten. Symbole, Umlaute und Sonderzeichen anderer Sprachen mussten damit in der zweiten Hälfte
der 256 Zeichen erweitert werden. Da es weltweit jedoch wesentlich mehr als 256 verschiedene
Textzeichen gibt (man denke z.B. an die chinesischen Schriftzeichen) gibt es bis heute viele verschiedene
solcher Erweiterungen für alle möglichen Sprachen. Die für Europa wichtigsten sind die Zeichensätze der
ISO-8859 Familie. Erst zu Beginn der 90er Jahre wurde mit Unicode ein Konzept vorgestellt, dass alle
Zeichensätze abbilden konnte. Bis heute wurde jedoch Unicode noch nicht bei allen Betriebssystemen und
Anwendungen konsequent eingeführt.
Bild 1: Zeichentabelle mit Beispielen aus den Zeichensätzen ISO-8859-1, ISO-8859-6 und UTF-8
3 Die gebräuchlichsten Zeichensätze
In den folgenden Abschnitten wird kurz auf die für westeuropäische Sprachen gebräuchlichsten
Zeichensätze eingegangen.
-2-Die Zeichensatzproblematik - Software und Technik - Technische Infos - Hostpoint
ISO-8859-1 oder latin-1
Dieser Zeichensatz verwendet eine feste Breite von 8 bit um die Zeichen zu codieren. Die mit den ersten 7
Bit (0-127) codierbaren Zeichen entsprechen dem US-ASCII Zeichensatz. Die zweite Hälfte (128-255)
enthalten die gebräuchlichen Zeichen für Westeuropa, Amerika, Australien und Teilen Afrikas. Das Euro
Zeichen ist darin nicht enthalten.
ISO-8859-15 oder latin-9
Dieser Zeichensatz verwendet eine feste Breite von 8 Bit um die Zeichen zu codieren. Die mit den ersten
7 Bit (0-127) codierbaren Zeichen entsprechen dem US-ASCII Zeichensatz. Die zweite Hälfte (128-255)
enthalten die gebräuchlichen Zeichen für Westeuropa inklusive Euro-Zeichen mit kompletter
Unterstützung von Französisch, Englisch (US), Australien und Teilen Afrikas.
UTF-8
Dieser Zeichensatz wurde entwickelt um für alle Sprachen einen einheitlichen Zeichensatz verwenden zu
können. Aus diesem Grund ist die Codierung etwas komplizierter.
UTF-8 verwendet eine variable Breite für die Speicherung der Zeichen. US-ASCII ist in den ersten 7 Bits
enthalten. US-ASCII Zeichen können damit in einem Byte gespeichert werden. Sämtliche weiteren
Zeichen wie Umlaute benötigen 2 oder mehr Bytes (ISO-8859-x benötigt dafür nur 1 Byte).
UTF-8 unterstützt nahezu alle weltweit verwendeten Schriftzeichen.
4 Probleme
Mit diesem US-ASCII Grundzeichensatz und den vielen unterschiedlichen sprachspezifischen
Erweiterungen kann nun der Grossteil der existierenden Zeichen abgebildet werden. Voraussetzung ist
jedoch, dass definiert wurde in welchem Zeichensatz ein Text geschrieben wurde. Wenn diese
Information nicht vorhanden ist, kann der Computer nicht entscheiden ob er das Zeichen Nummer 196
nun als ein ISO-8859-1 ’Ä’ oder ein ISO-8859-6 ’?’ darstellen soll. MS-DOS-Benutzer kennen das
Problem möglicherweise auch noch von den Text-Rahmen von Anwendungen die eben nicht immer als
Rahmen sondern mitunter als rechteckiger Buchstabensalat angezeigt wurden. Das selbe Problem betrifft
auch Unicode: Wenn nicht klar ist, dass es sich bei einem Text um Unicode handelt wird aus einem ’Ä’
plötzlich eine Hieroglyphe aus zwei seltsamen Zeichen (da Unicode sämtliche nicht-US-ASCII Zeichen in
2 oder mehr Bytes speichert).
5 Text in Datenbanken
Auch Datenbanken können Texte speichern. Bei datenbankbasierten Webseiten ist das sogar deren
vorrangige Aufgabe. Damit das Problem des Zeichensalates gelöst werden kann, bieten Datenbanken an,
für jedes Textfeld das dazu gehörige Charset zu definieren. Damit kann beim schreiben oder späteren
lesen das richtige Zeichen ausgegeben werden. Folgender Dump soll dies zeigen:
-3-Die Zeichensatzproblematik - Software und Technik - Technische Infos - Hostpoint
/*!40101 SET NAMES utf8 */;
CREATE TABLE ‘user‘ (
‘Id‘ INT NOT NULL AUTO_INCREMENT,
‘User‘ VARCHAR(255) CHARSET=latin1 NOT NULL default ,
‘Occupation‘ VARCHAR(255) NOT NULL default ,
PRIMARY KEY (‘Id‘,‘User‘)
) ENGINE=MyISAM DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT=’Users’;
Diese simple Datenbank speichert in einer Tabelle drei Felder:
Feldname Typ Zeichensatz
Id INT (Zahl) Keiner (Zahl)
User VARCHAR (Text) latin-1 (spezifisch nur für dieses Feld)
Occupation VARCHAR (Text) UTF-8 Standard für diese Tabelle)
* Diese Tabelle verwendet standardmässig UTF-8 als Zeichensatz. (DEFAULT CHARSET=utf8 auf der
letzten Zeile)
* Das Feld "User" wird jedoch als latin-1 gespeichert. (CHARSET=latin1 auf der 4. Zeile)
* Der gesamte Dump selbst liegt in UTF-8 vor. (Definiert durch das "SET NAMES utf8" Statement im
Kommentar, 1. Zeile.)
* Die Collation definiert die Sortierreihenfolge innerhalb des Alphabets und nicht den Zeichensatz, wie
häufig vermutet wird. (COLLATE=utf8_bin auf der letzten Zeile)
Für diesen Dump wurde also das ’User’ Feld von der datenbankinternen Repräsentation in latin-1 nach
UTF-8 konvertiert. latin-1 lässt sich vollständig in UTF-8 abbilden. Das Feld ’User’ wird beim Einlesen
des Dumps von UTF-8 wieder zurück in den ursprünglichen latin-1 Zeichensatz konvertiert.
6 Zugriff auf Text in Datenbanken: Die Datenbank Library
Der Text in Datenbanken kann also mit einem fest definierten Zeichensatz gespeichert werden. Zwischen
der Datenbank und der Applikation vermittelt eine Programmbiliothek, auch "client library" oder einfach
"library" genannt, welche den Austausch der Daten regelt.
-4-Die Zeichensatzproblematik - Software und Technik - Technische Infos - Hostpoint
Bild 2: Schematischer Ablauf und Zusammenspiel der Komponenten einer Webseite mit DB.
-5-Die Zeichensatzproblematik - Software und Technik - Technische Infos - Hostpoint
Diese Programmbibliothek kann Daten entweder 1:1, so wie diese in der Datenbank gespeichert sind
weitergeben, oder aber sie konvertiert die Daten von einem Charset in ein anderes (zB. latin-1 nach
UTF-8). Wenn das Programm, welches die Bibliothek benutzt, nicht definiert welches Verhalten
gewünscht ist müssen Sie davon ausgehen, dass willkürlich ein Verhalten gewählt wird. Wenn nicht
definiert ist in welchem Zeichensatz die Daten ausgetauscht werden sollen, ist nicht gewährleistet, dass
Texte richtig dargestellt oder abgespeichert werden.
Der für die Verbindung verwendete Zeichensatz wird in MySQL mit folgendem Statement festgelegt:
/*!40101 SET NAMES utf8 */;
In Ihrem PHP Code könnte das so aussehen:
$DB->query("SET NAMES ’utf8’");
oder:
mysql_query("SET NAMES ’utf8’",$connection);
7 Die Web-Applikation
Wenn bis hier hin der ganze Pfad von der Datenbank über die "library" mit dem korrekten Zeichensatz
stattgefunden hat, ist es an der Web-Applikation die Daten mit dem korrekten Charset an den Browser zu
übermitteln. Der Zeichensatz der im generierten HTML verwendet wird muss entweder per META-Tag
im HTML-Header oder im HTTP-Header bei der Übermittlung der Daten deklariert werden. Auch hier
führt eine falsche Deklaration zu Zeichensalat mit allen nicht-US-ASCII Zeichen wie den Umlauten.
Zeichensatz per HTTP-Header definieren
Üblicherweise wird das Charset im HTTP-Header bei der Übermittlung der Daten angegeben. Mit
folgendem HTTP-Header wird UTF-8 als Charset definiert:
Content-Type: text/html; charset=utf-8
In Ihrer PHP-Applikation könnte der PHP-Code um dies zu definieren etwa so aussehen:
header(’Content-Type: text/html; charset=utf-8’);
Charset in HTML definieren
Das Charset kann auch per "http-eqiv"-Meta-Tag direkt im HTML definiert werden. Der HTML Code
sieht dabei etwa so aus:
-6-Die Zeichensatzproblematik - Software und Technik - Technische Infos - Hostpoint
Definieren des Charsets von Formularen
Umgekehrt muss beim übermitteln von Text in Formularen an ihre Applikation das akzeptierte Charset
klar definiert werden. Ansonsten kann der Text der vom Browser gesendet wird einen beliebigen
Zeichensatz haben. Wenn Ihre Web-Applikation in so einem Fall nicht vorsichtig analysiert,
gegebenenfalls konvertiert, ist es reine Glücksache ob die Zeichenfolge in der Datenbank tatsächlich in
dem Charset geschrieben werden, welches auch in der Datenbank definiert wurde.
Beispiel für ein Formular mit genau definierten Charset für die Textfelder:
Name:
Nachname:
8 Fehlerfälle
Die Varianten Zeichensatz-Salat zu produzieren sind beinahe unerschöpflich. Es gibt aber folgende drei
Hauptkategorien:
Deklarierter und tatsächlicher Zeichensatz in Datenbank stimmen nicht
überein
Solche Daten gelangen beispielsweise in die Datenbank wenn ein Browser Daten eines Textfeldes in
einem Formular aufgrund einer fehlenden accept-charset="ISO-8859-15" Anweisung als UTF-8
übermittelt und die Applikation die Daten ungeprüft in ein latin-1 deklariertes Feld der Datenbank
schreibt. Das geht so lange gut, wie der Charset der Datenbank-Verbindung gleich bleibt. Falls dies nicht
definiert ist, können bei einem Wechsel des Anbieters, der DB-Version oder bei einem Update des Servers
plötzlich Probleme auftreten.
Daten werden doppelt oder falsch konvertiert
Textdaten aus einem Formular werden (wie per HTML definiert) im UTF-8 Zeichensatz übermittelt und
sollen in ein UTF-8 deklariertes Feld in der Datenbank geschrieben werden. Allerdings wurde bei der
Datenbankverbindung kein oder ein falsches Charset mit SET NAMES definiert. Damit werden die
UTF-8 Zeichen von einem anderen Zeichensatz erneut in UTF-8 konvertiert. Im ungünstigsten Fall
werden so sämtliche nicht-US-ASCII Zeichen zerstört.
Auch beim Ausgeben von Texten aus der Datenbank kann dies geschehen: In einer latin-1 deklarierten
Datenbank sind fälschlicherweise UTF-8 Texte gespeichert. Wenn die Datenbankverbindung z.B. so
eingestellt ist, dass alle Texte in UTF-8 ausgeliefert werden, versucht die Library den vermeintlichen
latin-1 Text erneut in UTF-8 zu konvertieren. Auch hier wird Zeichensalat produziert.
-7-Die Zeichensatzproblematik - Software und Technik - Technische Infos - Hostpoint
Charset zur Anzeige der Daten im Browser wird nicht oder falsch gesetzt
Der Fehler, der am einfachsten zu korrigieren ist. Die Daten werden mit durchgängig definiertem Charset
abgelegt und ausgelesen aber das verwendete Charset wird im HTTP oder HTML Header nicht definiert.
In so einem Fall versuchen die meisten Browser das Charset zu erraten und sind damit mehr oder weniger
erfolgreich. Da die Daten in der Applikation und in der Datenbank konsistent abgelegt sind, lässt sich
dieses Problem mit einem einfachen php oder HTML statement beheben. (siehe oben)
9 Zusammenfassung: Best Practises
Zusammengefasst ergeben sich folgende Richtlinien für ein "zeichensatzproblemfreies" Leben mit
Datenbanken:
1. Deklarieren Sie für jedes Textfeld, Tabelle oder Datenbank einen Zeichensatz! Es darf keine Textfelder
ohne Definition des Charsets geben.
2. Deklarieren Sie für jede MySQL Verbindung den Zeichensatz mit SET NAMES.
3. Deklarieren Sie das Charset Ihrer Seiten per HTTP oder im HTML Header.
4. Deklarieren Sie für jedes Formular die akzeptierten Zeichensätze. Seien Sie sich aber bewusst, dass ein
Browser trotzdem Daten in einem falschen Zeichensatz senden kann.
5. Achten Sie darauf, dass Sie sowohl beim Einlesen als auch beim Erstellen eines Dumps immer einen
einzigen Zeichensatz per SET NAMES angegeben haben.
10 Problembehebung: Wenn der Salat schon angerichtet ist
Ausgangslage für einen Rettungsversuch ist die Problemanalyse: Sie müssen wissen welche Fehler Sie in
Ihrer Applikation oder den Daten in der Datenbank haben. Sofern der Fehler nur an einer der möglichen
Stellen vorliegt, befolgen Sie folgende Reihenfolge um das Problem zu finden und zu lösen.
Browser verwendet falsches Charset
Überprüfen Sie zuerst, ob Ihr Browser das richtige Charset auswählt. Dazu können Sie in den meisten
Browsern das verwendet Charset einsehen und manuell ändern. Entspricht das Charset dem von Ihnen
Beabsichtigten? Für europäische Webseiten sind die Charsets der ISO-8859 Familie, insbesondere
ISO-8859-1, ISO-8859-15 und UTF-8 üblich und sinnvoll.
-8-Die Zeichensatzproblematik - Software und Technik - Technische Infos - Hostpoint
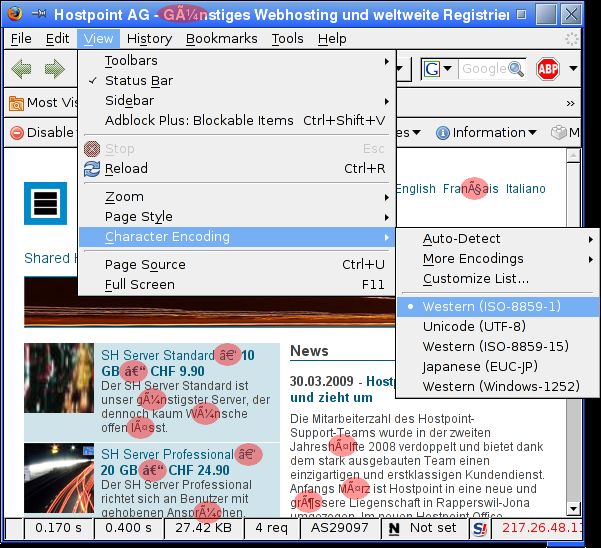
Bild 3: Hostpoint Webseite mit falschen Charset dargestellt: ISO-8859-1 (latin-1) anstelle von UTF-8.
-9-Die Zeichensatzproblematik - Software und Technik - Technische Infos - Hostpoint
Bild 4: Hostpoint Webseite mit richtigem Charset dargestellt: UTF-8.
Tipp: UTF-8 verwendet zur Speicherung von Umlauten und Sonderzeichen zwei Bytes. Werden an Stelle
von Umlauten zwei falsche Zeichen dargestellt (vgl. Bild 3), liegt die Vermutung nahe, dass die Daten
oder dieser Teil der Daten in UTF-8 vorliegt, jedoch ein Zeichensatz aus der IS0-8859-Familie zu
Darstellung im Browser verwendet wird.
Werden anstelle von Umlauten keine oder Komma-ähnliche Zeichen dargestellt, liegt der Fall
wahrscheinlich umgekehrt: Zeichen aus den ISO-8859 Zeichensätzen werden vom Browser als UTF-8
dargestellt.
- 10 -Die Zeichensatzproblematik - Software und Technik - Technische Infos - Hostpoint
Lösung: Stellen Sie sicher, dass Sie im HTTP Header und im HTML Code das korrekte Charset angeben.
Copyright © 2001-2012 - Alle Rechte vorbehalten
- 11 -Sie können auch lesen

















































