OBJEKTERKENNUNG IN BIM-REGISTRIERTEN VIDEOS ZUR ZUSTANDSERFASSUNG IM INNENAUSBAU
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Objekterkennung in BIM-registrierten
Videos zur Zustandserfassung im
Innenausbau
Christopher Kropp
Ruhr-Universität Bochum, Lehrstuhl für Informatik im Bauwesen
Christian Koch
Ruhr-Universität Bochum, Lehrstuhl für Informatik im Bauwesen
Abstract: Die automatische Erfassung des Bauzustands im Innenausbau von Bauprojekten ist aufgrund
der komplexen Umgebung eine große Herausforderung. Um komplexe Aktivitäten mit Computer
Vision und maschinellem Lernen erkennen zu können, ist es hilfreich, zuerst die Präsenz involvierter
Objekte nachzuweisen. In diesem Beitrag wird ein Ansatz vorgestellt, der vorhandene Daten aus BIM-
Modellen, Zeitplänen und bewegungsregistrierten Videos zur Verbesserung und Ermöglichung von
Objekterkennung beinhaltet. Es wird ein simples 2D-Klassifikations-Problem für ungesteuerte Aufnahmen
des Innenausbaus geschaffen, indem Bilddaten durch mehrere Filter vorverarbeitet werden. Dieser
Ansatz wird anhand eines Beispiels für die Erkennung von Heizkörpern unter der Nutzung von HOG-
Features und einem SVM-Klassifikator evaluiert. Es wird gezeigt, dass dieser Ansatz nur eine geringe
Anzahl echter und modellgenerierter Bilder zur Erzielung hoher Genauigkeit bei der Objekterkennung
benötigt.
Schlüsselwörter: Bauzustandserkennung, BIM, Objekterkennung, Computer Vision, maschinelles Lernen
1. Einleitung
Bei der Durchführung von Innenausbauarbeiten entstehen häufig Abweichungen vom
ursprünglichen Bauablaufplan. Dies liegt einerseits an den inhärenten Unsicherheiten der
Planung, als auch an unvermeidbaren Störungen. Aus diesem Grund ist eine kontinuierliche
Erfassung des tatsächlichen Bauzustands von großer Bedeutung, da die gewonnenen Werte
für eine schnelle und angemessene Entscheidungsfindung für Gegenmaßnahmen benötigt
werden. Derzeit ist die Zustandserfassung aufgrund der manuellen Registrierung ein sehr zeit-
und arbeitsintensiver, als auch stark subjektiv geprägter Prozess.
359
2. Hintergrund
Mehrere Ansätze wurden bereits vorgestellt, die auf eine automatische Zustandserfassung
von Bauprojekten abzielen. In Lukins und Trucco (2007) wird die Zustandserfassung des
Rohbaus durch Beobachtungen einer fixen Kamera durchgeführt und durch Berechnung der
Unterschiede in aufeinanderfolgenden Einzelbildern untersucht. Golparvar-Fard et al. (2009)
erzeugen mit Einzelbildaufnahmen 3D-Rekonstruktionen der Gebäudestruktur des im Rohbaus
befindlichen Gebäudes, um Punktwolken des Ist-Zustandes zu erhalten. Der Zustand wird dabei
aus der Präsenz der Objekte, wie beispielsweise Träger, Wände oder Stützen abgeleitet, indem
das Gebäudemodell über die Punktwolke überlagert wird und das Vorhandensein von Punkten
in den entsprechenden Objekten zur Aussage der Präsenz führt. Evaluierungen bestehender
Ansätze zeigen, dass sie in Außenbereichen anwendbar sind. Jedoch ist aufgrund der hohen
Komplexität von Szenen im Innenausbau eine Übertragung dieser Techniken nicht möglich
(Roh et al., 2011). Zur Abschätzung des detaillierten Zustands von Innenausbauobjekten
werden andere Methoden benötigt. Deshalb wird in Roh et al. (2011) eine Zustandserfassung
durchgeführt, bei der Computer Vision und maschinelle Objektklassifizierung eingesetzt wird,
um Objekte zu erkennen. Jedoch können bei diesem Ansatz die erkannten Objekte keinen
Instanzen des geplanten Modells des Building Information Modeling (BIM) zugeordnet werden.
Um diese Nachteile bei der Zustandserkennung im Innenausbau zu beheben, wurde in Kropp
et al. (2012) ein Konzept entwickelt, das automatisch Verzögerungen im Innenausbau anhand
des Vergleichs von Ist-Videodaten und Soll-Planungsdaten vorhersagt. Dieses Konzept
beinhaltet eine Bewegungsabschätzung eines mobilen Geräts und die Erkennung des
aktuellen Baufortschritts durch den Einbezug von Informationen eines BIM-Modells mitsamt
des dazugehörigen Bauablaufplans (4D-BIM), als auch dessen Aktualisierung. Das mobile
Gerät wird durch das Bauwerksinnere geführt. Dabei werden durch integrierte Sensoren des
Mobilgeräts, Video-Daten und Daten einer Inertial Measurement Unit (IMU) aufgezeichnet. Die
Erkennung des Bauzustands einer Aktivität beinhaltet einerseits die Erkennung veränderlicher
Bauobjekte, andererseits auch bei Bedarf die Abschätzung des Grades der Vervollständigung.
In Savarese und Fei-Fei (2010) wurde ein Überblick von Ansätzen zur Lösung des Problems
der Objekterkennung in Bildern mit unbekannten Kameraperspektiven erstellt. Laut dieser
Untersuchung, existieren drei verschiedene Kategorien von Modellen zur Lösung des
Erkennungsproblems für eine gegebene Bildaufnahme, Single-View-2D-Modelle, Single-
Instance-3D-Modelle und Multi-View-Modelle (Savarese und Fei-Fei, 2010). Ansätze mit Single-
View-2D-Modellen behandeln verschiedene Perspektiven unabhängig voneinander, ohne, dass
360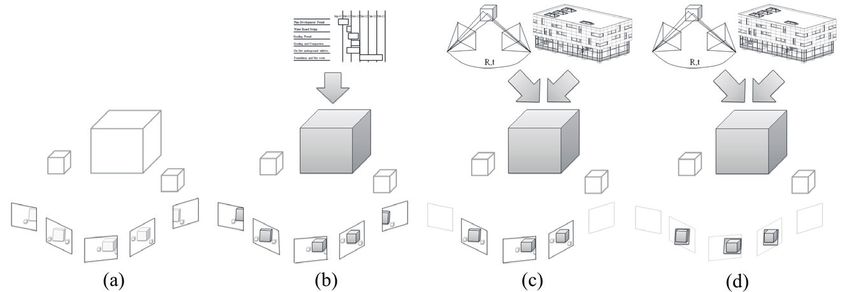
ein gemeinsames Modell zugrunde liegt und sind in der Regel nicht fähig die Lage eines Objekts
relativ zur Kamera zu ermitteln. Da die Lage des Objekts nicht verfügbar ist, können darauf
aufbauende Methoden nicht angewandt werden. Im Gegensatz dazu sind Single-Instance-
3D-Modelle dazu fähig, anhand von lokalen 3D-Features einer Objektinstanz sehr genaue
Angaben über die Lage eines Objekts bereitzustellen, lassen jedoch keine Klassenzuordnung
zu. Des Weiteren scheitern diese Ansätze oft daran, dass homogene Oberflächentexturen
im Innenausbau keine ausreichend große Feature-Menge und Oberflächenmuster mehrfach
auftreten. Aus diesem Grund kann das Matching lokaler Features zwischen zwei Ansichten
mehrdeutig sein. Besonders schwierig ist dies auch bei wechselndem Kontrastverhältnis durch
Gegenlicht oder fehlender künstlicher Lichtquellen mangels elektrischer Infrastruktur. Mit Multi-
View-Modellen wird versucht, die Vorteile der ersten beiden beschriebenen Ansätze zu vereinen,
indem die Charakteristiken eines Objekts aus mehreren Ansichten in ein kohärentes Modell
einfließen (Savarese und Fei-Fei, 2010). Abgesehen von anderen Ansätzen dieser Kategorie
wurden Ansätze vorgestellt, die dreidimensionale Computer Aided Design-Modelle (CAD)
zur Objekterkennung verwenden. In Xiang und Savarese (2012) werden Ebenen der Objekte
aus Punktwolken extrahiert. In dem zugrunde liegenden Modell wird für jede so ermittelte
Ebene eine Repräsentation erzeugt. Die Ebenen werden anhand einer homographischen
Transformation normalisiert, damit sie der Frontansicht der Ebene entsprechen. Anschließend
werden Features durch Histogram of Oriented Gradients (HOG) extrahiert, um damit eine
Support Vector Machine (SVM) zu trainieren und später zur Klassifikation zu nutzen. Neben der
Voraussetzung, dass identifizierte Teile manuell identifiziert wurden, wird das Modell nur von
3D-Punktinformationen abgeleitet.
3. Methodik
Die Identifizierung von Objekten in 2D-Bildern einer 3D-Szene stellt eine große Herausforderung
dar. Innerhalb des vorgestellten Konzepts beinhaltet die 3D-Szene ein ganzes Bauprojekt.
Die 2D-Bilder sind Teile eines während der Ausbauphase aufgezeichneten Videos. Dadurch
können einerseits viele Bilder entstehen, die das zu identifizierende Objekt beinhalten,
andererseits kann die Diversität der in einer Bildsequenz erscheinenden Objekte sehr hoch sein.
Unsicherheiten wie unkontrollierte Kamerabewegungen, verschiedene Aufnahmeperspektiven
auf Objekte (Rotation, Transition, Skalierung), sowie unvorteilhafte und wechselnde
Lichtbedingungen (Gegenlicht, Schatten, fehlende künstliche Lichtquellen während des
Innenausbaus) beeinflussen die Identifizierung von Objekten innerhalb der Zustandserkennung
im Innenausbau. Nicht zuletzt muss die zu erkennende Objektinstanz zu einem Objekt im
BIM-Modell zuzuordnen sein, obwohl mehrere Instanzen eines Objekts in einem Bild oder
361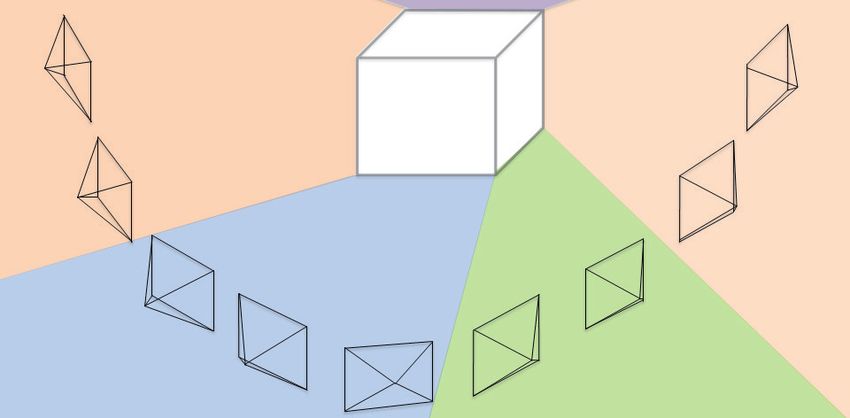
Video vorhanden sein können. Der hier vorgestellte Ansatz behandelt die Beschränkungen
und Voraussetzungen, die durch diese Herausforderungen aufgestellt wurden. In Abbildung 1
wird veranschaulicht, dass schon vorhandene Modellinformationen, Daten des BIM-Modells,
Bewegungsinformationen und zuvor gewonnene Bilddaten genutzt werden, um eine genaue
und verlässliche Objekterkennung mit den aktuellen Bilddaten zu ermöglichen. Das BIM-
Modell besteht aus einem Gebäudemodell (Objekte, Geometrie, …) und einem Ablaufplan.
Bewegungsinformationen beinhalten die Kameraposition und Perspektive, die für jedes Bild in
dem Gebäudemodell registriert ist.
Abbildung 1: Übersicht des vorgestellten Ansatzes
Im ersten Schritt wird die immense Menge der Bilddaten auf für die Objekterkennung
relevante Daten reduziert. Danach werden die verschiedenen Ansichten auf ein Objekt
gruppiert. Anschließend erfolgt eine Gruppierung der Bilder anhand ihrer Perspektive auf
das zu untersuchende Objekt. Innerhalb der Gruppen werden die Bilder durch projektive
Transformation und Kontrastverbesserung normalisiert, um eine kanonische Form für jedes
Bild in einer Gruppe zu. Nach diesen vorbereitenden Maßnahmen findet die Anwendung
eines Objekterkennungsalgorithmus zur Bestimmung der Präsenz des Objekts statt, so dass
anschließend die Zustandsuntersuchung auf einer höheren Ebene fortgesetzt werden kann.
Ohne weiteren Einbezug von Kontextwissen, könnte jedes Objekt in jedem Teil eines jeden
Bildes in jeglicher Rotation, Translation und Skalierung im Bezug zur Kamera auftauchen. Aus
diesem Grund werden Informationen der Objekte, die in den Bildaufnahmen erscheinen auf
einfache Weise abgeleitet werden. In Abbildung 2(a) wird eine Bildsequenz aufgezeigt, die
einige Objekte aufnimmt. Da keine Relation zwischen Bildinhalt und Objekten bekannt ist,
verbleiben alle Objekte und ihre Projektionen auf den Kamerabildern farblos. In diesem sehr
362großen Suchraum ist eine annehmbare maschinelle Objekt-Erkennung nicht vertretbar, da die
Komplexität zu hoch ist und eine Vollständigkeit schwer zu erreichen ist. Da der Zeitpunkt
der Videoaufnahme bekannt ist, kann der Ablaufplan des BIM-Modells untersucht werden. Es
kann bestimmt werden, welche Aktivitäten laut Plan ausgeführt werden und welche baulichen
Veränderungen erkannt werden müssen. In Abbildung 2(b) wird die Auswahl eines relevanten
Objekts dargestellt. Ein relevantes Objekt wird durch Untersuchung des Ablaufplans nach
Aktivitäten für die gegenwärtige Überwachung ausgewählt. Sobald die zu überwachenden
Objekte bekannt sind, ist es möglich, eine Menge an Bildern zu bestimmen, in denen die
Objekte sichtbar sind. Dies wird durch die Nutzung der Informationen der Objektgeometrie und
der mit dem BIM-Modell registrierten Kamerabewegung erreicht (siehe Abbildung 2(c)). Danach
wird eine virtuelle Ansicht innerhalb des Gebäudemodells erzeugt, die die Kameraansicht
auf die Szene repräsentiert. Wenn volle Sichtbarkeit eines Objekts in der virtuellen Ansicht
sichergestellt ist, kann die korrespondierende Kameraansicht zu der Bildmenge hinzugefügt
werden (Abbildung 2(c)). Für jedes relevante Objekt wird somit eine Bildmenge erzeugt, die
Bilder mit vollständiger Sichtbarkeit unabhängig von der Aufnahmeperspektive enthält.
Abbildung 2: (a) Bildaufnahmen ohne abgeleitete Informationen, (b) Auswahl des Objekts für weitere Untersuchung, (c)
Bildmenge, in der Objekt erscheint, (d) beschnittene relevante Bildregionen
Die Ermittlung der Region eines Bildes, die das Objekt begrenzt, ist wichtig zur effizienten
Anwendung von Computer Vision. Für die Bildmenge, die das Objekt beinhaltet, kann eine
Region of Interest (ROI) ermittelt werden. Die ROI berücksichtigt die 3D-Stuktur des Objekts
und seine Lage zur Kamera. Zur weiteren Vorverarbeitung des Bildmaterials wird eine
perspektivische Transformation dieser Region durchgeführt. Dadurch kann der Suchraum
für die Erkennung von Objekten auf nur eine bestimmte Region eingeschränkt werden
(siehe Abbildung 2(d)). Das Erscheinungsbild von Objekten ist signifikant abhängig von der
Perspektive, von der sie betrachtet werden. Die Sichtbarkeit der Objektoberfläche kann
von bestimmten Perspektiven aus verborgen sein und die Form der Erscheinung kann sich
363von Perspektive zu Perspektive stark verändern. Hingegen ergeben Perspektiven, die sich
ähneln, ein ähnliches Erscheinungsbild. Der vorgestellte Ansatz nimmt davon Gebrauch, dass
räumlich benachbarte Perspektiven verglichen werden und somit klassifiziert werden können.
Anschließend unterteilt der Ansatz Perspektiven in Gruppen (siehe Abbildung 3). Abhängig
davon, wie Objekte in der Aufnahmeszene verteilt sind, beeinflusst dies die Gruppierung.
Beispielsweise sind spezielle Perspektiven aufgrund von Verdeckungen durch permanente
Hindernissen nicht zulässig. Eine kleinere Anzahl an Gruppenelementen führt zu einer höheren
Erkennbarkeit, da Unterschiede in den Erscheinungsbildern verringert werden, jedoch auch
dazu, dass mehr Aufwand beim Training entsteht und eine höhere Anzahl Trainingsbilder
bereitstehen muss. Aus diesem Grund kann nur schwerlich eine allgemeingültige Aussage über
eine feste Einteilung der Perspektiven für alle Objekte erfolgen. Für die Perspektiveneinteilung,
wird für diesen Ansatz vorgeschlagen, dass jedes Bild in einer Gruppe die gleiche Menge
an Oberflächen aufzeigt. Ebene Flächen bei Objekten können nur schwer bestimmt werden.
Aus diesem Grund wird der Ansatz vereinfacht. Um eine Approximation zu erzielen, wird ein
umschließender Quader mit minimalem Volumen (O’Rourke, 1985) um jedes Objekt erzeugt
und nur die Flächen des Quaders für die Gruppeneinteilung der Perspektiven berücksichtigt.
Lediglich drei Seiten eines Quaders von einer Perspektive aus können daher sichtbar sein. In
der Anwendung sind installierte Objekte im Innenausbau aufgrund der baulichen Restriktionen
nicht von allen Seiten aus zu betrachten, weswegen die Anzahl der Gruppen in der Praxis
gering ausfällt.
Abbildung 3: Einteilung der Perspektiven
Aufgrund der abweichenden Aufnahmeperspektiven innerhalb der Perspektivengruppen,
sind die Erscheinungsbilder eines Objekts gegebenenfalls nicht immer vergleichbar, was die
Erkennung des Objekts negativ beeinflussen kann. Deshalb werden mit der vorliegenden
Information über Struktur und Layout eines Objekts und der bekannten Aufnahmeperspektive
die Bilder innerhalb der Perspektiveneinteilung perspektivisch transformiert. Dadurch wird eine
Reduzierung auf ein simples 2D-Klassifikations-Problem zu erreichen. Aus dieser kanonischen
Form können Bildfeatures extrahiert und verglichen werden. Die Transformation kippt die ROI
364so, dass alle ROIs einer Perspektivengruppe in eine homogene frontale Form gebracht werden.
Belichtungsbedingungen in Bildaufnahmen des Innenausbaus stellen eine große Herausforderung
für die maschinelle Objekterkennung dar. Es existieren inhomogene Belichtungsverhältnisse,
da die elektrische Infrastruktur noch nicht besteht und künstliche Lichtquellen oft nicht
verfügbar sind. Um dem entgegenzuwirken, wird die Belichtung von Objekten mittels einer
Kontrastverstärkung, basierend auf einer Analyse des Helligkeitshistogramms des Bildes,
normalisiert. Dies verbessert das Erscheinungsbild der Objekte, damit die charakteristischen
Objekteigenschaften besser extrahiert werden können.
Anschließend werden zur Objekterkennung Klassifikatoren mit Bildfeatures erlernt. Für jede
Perspektivengruppe wird ein eigener Klassifikator erstellt. Abhängig von der Objektpräsenz
erfolgt eine Kennzeichnung der Bilder als positiv oder negativ. Die Anwendung der
Vorverarbeitung reduziert sich nicht auf positive Beispiele. Auch negative Beispiele ohne
Objektpräsenz werden so behandelt. Schlechte Lichtbedingungen führen teilweise zu nicht
nutzbaren Bildern mit schlechter Qualität. Deshalb können Objekte nicht immer korrekt
dargestellt werden. Aus diesem Grund reicht es nicht aus, nur ein Bild einer Sequenz zu
untersuchen, um damit auf die Präsenz eines Objektes zu schließen. Daher wird nach der
Klassifikation eine Abstimmung für jedes Objekt durchgeführt und die endgültige Aussage
formuliert, ob ein Objekt präsent ist.
4. Evaluation
Zur Gewinnung von Testdaten wurde für einige Zeit der Verlauf des Innenausbaus eines
Bauprojektes mit Kameras dokumentiert. Dabei wurden Aufnahmen von verschiedenen
Aktivitätszuständen akquiriert und Bilder einer Aktivität, die die Montage eines Heizkörpers
beinhaltet, wurden in einem Testdatensatz zusammengetragen. In den durchgeführten Tests
wurde versucht, Heizkörper mit der in diesem Beitrag vorgestellten Methode zu erkennen. In
Abbildung 4 wird exemplarisch ein vorverarbeitetes Bild dargestellt. Die Aktivität ist Teil eines
Bauprojekts, das die Errichtung eines Bürogebäudes verfolgt. Übereinanderliegende Räume
sind sehr stark ähnelnd aufgebaut und ausgestattet und unterscheiden sich nur geringfügig
in den Fensterrahmen, so dass die Durchführung der Aktivität über mehrere Stockwerke
beobachtet werden konnte. Ein Bauwerksmodell stand zur Zustandsüberwachung des
Soll-Zustands zur Verfügung. Die Bildaufnahmen wurden durch eine in einem Tablett-PC
integrierte Kamera in Form von Videos erstellt, die durch das Gebäudeinnere des Bauwerks
geführt wurde. Aus Gründen der Genauigkeit, wurden die Bewegungsinformationen der
365Kamera manuell durch 2D-Bild- 3D-Gebäudemodell-Korrespondenzen hergestellt. Nach der
perspektivischen Transformation erfolgte die Reduzierung der Bildgröße auf 128x32 Pixel. Ein
Ablaufplan zur Überwachung der Aktivität des Anbringens des Heizkörpers wurde erstellt und
beinhaltete drei verschiedene Zustände. Neben dem Zustand, bei dem der Heizkörper schon
montiert ist, werden auch zwei vorherige Zustände, bei dem die Wand hinter dem Heizkörper
verputzt und noch unverputzt ist berücksichtigt (siehe Abbildung 5).
Abbildung 4: Beispiel eines vorverarbeiteten Bildes von der Identifikation des minimalen Quaders zur normalisierten ROI
Abbildung 5: Verschiedene Aktivitätszustände der Testkonfiguration
Die Evaluation beinhaltet verschiedene Konfigurationen, bei denen HOG-Features extrahiert
und eine SVM trainiert wurde, um die Objekterkennung zu testen. Bilder mit Positiv-Beispielen
des installierten Heizkörpers und Negativ-Beispielen der zukünftigen Heizkörperposition wurden
aus den Videodaten entnommen und mit dem vorgestellten Ansatz vorverarbeitet. Aufgrund
teilweise geringer Kamerabewegung wurden nicht alle Einzelbilder extrahiert, was letztendlich
in 445 positiven und 702 negativen Beispielen resultierte. In einem ersten Testdurchlauf wurde
die SVM mit dem gesamten Testdatensatz unter Verwendung verschiedener Vektorgrößen
trainiert. Zur Demonstration der Effektivität des Filterungsprozesses wurde ein Testdurchlauf
mit einem 5-Fold-Cross-Validation-Ansatz durchgeführt. Der Testdatensatz ist dabei in fünf
disjunkte Untermengen unterteilt. Es wird dabei fünf Mal, abwechselnd eine Teilmenge als
Anfragemenge und der Rest als Trainingsmenge verwendet. Tabelle 1 beinhaltet die Ergebnisse
für jeden Test (siehe Abbildung 6 für Beispielbilder). Die falsch positiven (FP) und falsch negativen
(FN) Resultate werden für jeden Test aufgeführt. Die Gesamtgenauigkeit (richtig Positive / (FP
+ richtig Positive)) und die Trefferquote (richtig Negative / (FN + richtig Negative)) sind in den
letzten beiden Spalten der Tabelle dargestellt. Die Ergebnisse zeigen, dass eine relativ geringe
366Feature-Vektor-Länge von 108 Elementen schon eine gute Genauigkeit hervorruft. Untersucht
man die Resultate der falsch erkannten Objekte, zeigt dies, dass sie hauptsächlich durch stark
unterbelichtete Bildregionen, die nicht durch eine Kontrastnormalisierung verbessert werden
konnten, hervorgerufen werden (siehe Abbildung 6(e)). Diese Ungenauigkeiten könnten durch
den abschließenden Abstimmungs-Schritt bei Berücksichtigung der gesamten Bildsequenz
behoben werden.
Tabelle 1: Ergebnisse der Klassifikation mit HOG und SVM.
Fold 1 Fold 2 Fold 3 Fold 4 Fold 5
Feature-Vektor-
länge FP FN FP FN FP FN FP FN FP FN Genauigkeit Trefferquote
7812 0 0 0 0 0 3 1 0 0 0 0,9978 0,9933
1620 0 1 0 0 0 1 1 0 0 0 0,9978 0,9955
108 0 3 1 3 0 2 2 0 4 0 0,9843 0,9821
72 7 3 4 5 0 4 20 1 20 0 0,8854 0,9681
18 32 1 32 0 40 0 49 0 56 0 0,5303 0,9958
In einem zweiten Test wurde ein Szenario echter Bedingungen überprüft, wobei auch die
Perspektiveneinteilung berücksichtigt wird. Eine Vektorlänge von 1620 wurde genutzt.
Hierbei wurde auch der Einsatz von Bildern aus dem virtuellen Bauwerkmodell als Ersatz für
gegebenenfalls nicht oder kaum vorhandene Trainingsbilder getestet.
Die Ergebnisse in Tabelle 2 zeigen, dass echte Bilddaten mit der Unterstützung von generierten
Bilddaten aus dem Bauwerksmodell die beste Leistung erreicht. Falls nur virtuell generierte
Bilddaten zur Verfügung stehen, fällt die Leistung jedoch nur leicht ab. Die Perspektiveneinteilung
zeigt in diesem Beispiel nicht viel Einfluss auf. Dies mag daran liegen, dass das Beispiel durch
die große frontale Heizköperfläche nur geringe Einteilungsmöglichkeiten bietet. Zudem kann
für diese Testkonfiguration festgestellt werden, dass nur eine geringe Anzahl an Bilddaten
notwendig ist, um gute Leistungsergebnisse zu erreichen.
Tabelle 2: Ergebnisse der Simulation der Echt-Szenario-Konfiguration.
Ohne Perspektiveneinteilung Mit Perspektiveneinteilung
Genauigkeit Trefferquote Genauigkeit Trefferquote
Nur echte Bilddaten 0,9306 0,9802 0,9603 0,9916
Mit virtuellen Bilddaten 0,9411 0,9901 0,9923 1,0000
Nur virtuelle Bilddaten 0,9565 0,9687 0,9670 0,9887
367Abbildung 6: Erkennungsbeispiele: (a-d) richtig negative, (e) falsch negative, (f-h) richtig positive Ergebnisse
5. Zusammenfassung und Ausblick
In diesem Beitrag wurde ein Ansatz vorgestellt, der die Präsenz von Objekten zur Unterstützung
der Zustandsüberwachung im Innenausbau erkennt. Dieser Ansatz basiert stark auf der
Nutzung von Daten von Bauwerksmodellen, deren Zeitplänen und bewegungsregistrierten
Videos, um eine Objekterkennung auf ein simples 2D-Klassifizierungsproblem reduzieren
zu können. Es wurde gezeigt, dass nur eine kleine Menge an Trainingsdaten nötig ist,
wenn Wissen von vorherigen Begehungen mit einbezogen wird. Zudem wird gezeigt, dass
die perspektiven-sensitive Verarbeitung von Bildaufnahmen einen Vorteil erzielen kann. Der
Versuch, aus Bauwerksmodellen gewonnene Bilddaten in den Lernprozess einzubeziehen,
stellt sich als erfolgreich heraus. Eine Aussage bezüglich der Allgemeinheit des vorgestellten
Ansatzes kann noch nicht erfolgen. Dazu sind zukünftig weitergehende Tests mit komplexeren
Objekten durchzuführen.
Literatur
Golparvar-Fard M, Peña-Mora F, Endowed G, Savarese S und Arbor A (2009) D4AR – A 4-Dimensional augmented reality
model for automating construction progress monitoring data collection, processing and communication. Journal of Informa-
tion Technology 14: 129-153.
Kropp C, Koch C, Brilakis J und König M (2012) A Framework for automated delay prediction of finishing works using video
data and BIM-based construction simulation. Proceedings of the 14th International Conference on Computing in Civil and
Building Engineering, 2012, Moskau, Russland
Lukins T C, Trucco E (2007) Towards Automated Visual Assessment of Progress in Construction Projects. Proceedings of
the British Machine Vision Conference, 2007, Coventry, England
368O’Rourke J (1985) Finding Minimal Enclosing Boxes. International Journal of Computer and Information Sciences 14(3):
183–199
Roh S, Aziz Z, Peña‐Mora F (2011) An object-based 3D walk-through model for interior construction progress monitoring.
Automation in Construction 20(1): 66-75
Savarese S, Fei-Fei L (2010) Multi-view Object Categorization and Pose Estimation. Studies in Computational Intelligence -
Computer Vision. 285, Springer, 2010
Xiang Y, Savarese S (2012). Estimating the aspect layout of object categories. Conference on Computer Vision and Pattern
Recognition, 2012, Providence, Rhode Island, USA.
369370
Sie können auch lesen

















































