On HPC Systems: Current Trends and Developments - Proceedings of the 3rd Seminar - mediaTUM
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Technical University of Munich
Ludwig-Maximilians-University Munich
Proceedings of the 3rd Seminar
on HPC Systems: Current
Trends and Developments
Winter Semester 2017/2018
January 30-31
Frauenchiemsee, Germany
Eds.: Karl Fürlinger, Josef Weidendorfer, Carsten Trinitis, Dai Yang
TUM University Library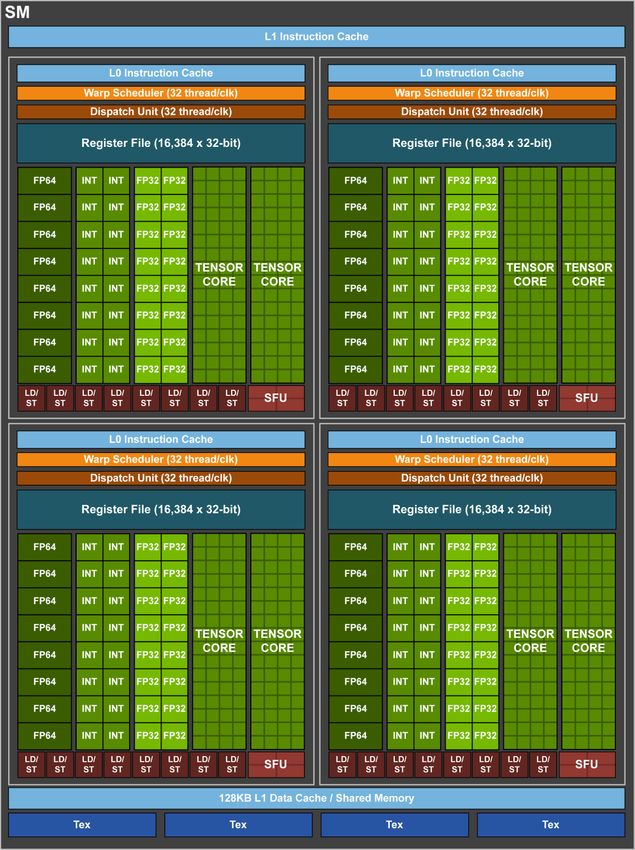
Proceedings of the 3rd Seminar on HPC Systems: Current Trends and Developments Winter Semester 2017/2018 Editors: Karl Fürlinger, Ludwig-Maximilians-University Munich Carsten Trinitis, Technical University of Munich Josef Weidendorfer, Technical University of Munich Dai Yang, Technical University of Munich Cataloging-in-Publication Data Seminar High Performance Computing: Current Trends and Developments Proceedings of the 3rd Seminar on HPC Systems: Current Trends and Developments WS2017/2018 30-31.01.2018 Frauenchiemsee & Munich, Germany DOI: 10.14459/2018md1430700 Published by TUM University Library Copyright remains with authors. © 2018 Chair of Computer Architecture, Technical University of Munich © 2018 Munich Network Management Team, Ludwig-Maximilians-University Munich Seminar: HPC Trends and Developments 2 DOI: 10.14459/2018md1430700
Preface The hardware and software requirements for High Performance Computing (HPC) Systems is demanding and versatile. Due to its large scale, even the smallest improvement in efficiency and performance may have great impact on these systems, which eventually leads to higher cost efficiency. Therefore, cutting-edge technologies are often deployed rapidly on HPC- Systems. This unique character challenges users and programmers of HPC-systems: how can these new functionalities be efficiently used? In the joint seminar “High Performance Computing: Current Trends and Developments” students worked on recent publications and research in HPC technologies. New developments and trends in both hardware and software have been discovered and discussed. The seminar features a technical committee of active HPC researchers from Technical University of Munich, Ludwig-Maximilians-University Munich, and various industry partners. Eight students participated in the seminar and submitted a peer-reviewed seminar paper. An academic conference, in which the students present their work in a 30-minute talk, was held at Abtei Frauenwörth on the island of Frauenchiemsee in January 2018. These are the first proceedings of our seminar series. By publishing the seminar work, we intend to spread the knowledge on recent developments in HPC-Systems and make HPC related education and research more interesting to a broader audience. Karl Fürlinger, Carsten Trinitis, Josef Weidendorfer and Dai Yang 08.02.2018 in Munich, Germany Seminar: HPC Trends and Developments 3 DOI: 10.14459/2018md1430700
Seminar Lecturers Professors Martin Schulz, Technical University of Munich Dieter Kranzlmüller, Ludwig-Maximilians-University Munich Seminar Chairs Karl Fürlinger, Ludwig-Maximilians-University Munich Josef Weidendorfer, Technical University of Munich Carsten Trinitis, Technical University of Munich Advisors David Büttner, Siemens AG Roger Kowalewski, Ludwig-Maximilians-University Munich Matthias Maitert, Intel & Leibniz Super Computing Center Dai Yang, Technical University of Munich Homepage http://www.nm.ifi.lmu.de/teaching/Seminare/2017ws/HPCTrends/ https://www.lrr.in.tum.de/lehre/wintersemester-1718/seminare/hochleistungsrechner- aktuelle-trends-und-entwicklungen/ Seminar: HPC Trends and Developments 4 DOI: 10.14459/2018md1430700
Master-Seminar: Hochleistungsrechner -
Aktuelle Trends und Entwicklungen
Aktuelle GPU-Generationen (NVidia Volta, AMD Vega)
Stephan Breimair
Technische Universität München
23.01.2017
Abstract 1 Einleitung
GPGPU - General Purpose Computation on Graphics Grafikbeschleuniger existieren bereits seit Mitte der
Processing Unit, ist eine Entwicklung von Graphical 1980er Jahre, wobei der Begriff GPU“, im Sinne der
”
Processing Units (GPUs) und stellt den aktuellen Trend hier beschriebenen Graphical Processing Unit (GPU)
bei NVidia und AMD GPUs dar. [1], 1999 von NVidia mit deren Geforce-256-Serie ein-
Deshalb wird in dieser Arbeit gezeigt, dass sich GPUs geführt wurde.
im Laufe der Zeit sehr stark differenziert haben. Im strengen Sinne sind damit Prozessoren gemeint, die
Während auf technischer Seite die Anzahl der Transis- die Berechnung von Grafiken übernehmen und diese in
toren stark zugenommen hat, werden auf der Software- der Regel an ein optisches Ausgabegerät übergeben. Der
Seite mit neueren GPU-Generationen immer neuere und Aufgabenbereich hat sich seit der Einführung von GPUs
umfangreichere Programmierschnittstellen unterstützt. aber deutlich erweitert, denn spätestens seit 2008 mit
Damit wandelten sich einfache Grafikbeschleuniger zu dem Erscheinen von NVidias GeForce 8“-Serie ist die
”
multifunktionalen GPGPUs. Die neuen Architekturen Programmierung solcher GPUs bei NVidia über CUDA
NVidia Volta und AMD Vega folgen diesem Trend (Compute Unified Device Architecture) möglich.
und nutzen beide aktuelle Technologien, wie schnel- Da die Bedeutung von GPUs in den verschiedensten
len Speicher, und bieten dadurch beide erhöhte An- Anwendungsgebieten, wie zum Beispiel im Automobil-
wendungsleistung. Bei der Programmierung für heu- sektor, zunehmend an Bedeutung gewinnen, untersucht
tige GPUs wird in solche für herkömmliche Grafi- diese Arbeit aktuelle GPU-Generationen, gibt aber auch
kanwendungen und allgemeine Anwendungen differen- einen Rückblick, der diese aktuelle Generation mit vor-
ziert. Die Performance-Analyse untergliedert sich in hergehenden vergleicht. Im Fokus stehen dabei die ak-
High- und Low-Level-Analyse. Entscheidend für das tuellen Architekturen, deren technische Details bezie-
GPU-Profiling ist, ob Berechnungskosten Speicherkos- hungsweise die Programmierung sowie Performance-
ten verdecken beziehungsweise umgekehrt oder man- Analyse von und für GPUs.
gelnde Parallelisierung vorliegt. Im Abschnitt 2 wird dementsprechend diskutiert, wie
Insgesamt konnte mit dieser Arbeit dargelegt wer- sich GPUs seit ihrer Einführung in den Markt der
den, dass die aktuellen GPU-Architekturen eine weitere elektronischen Rechenwerke, entwickelt und speziali-
Fortführung der Spezialisierung von GPUs und einen siert haben. Abschnitt 3 gibt einen tieferen Überblick
anhaltenden Trend hin zu GPGPUs darstellen. Allge- über die Architekturen aktueller GPUs von NVidia und
meine und wissenschaftliche Anwendungen sind heute AMD, technische Details und die Leistungsfähigkeit.
also ein wesentliches Merkmal von GPUs geworden. Anschließend werden in Abschnitt 4 Möglichkeiten der
Seminar: HPC Trends and Developments 5 DOI: 10.14459/2018md1430700
Programmierung für GPUs vorgestellt. Da es jedoch Fähigkeiten (FP64), wozu bis zu Kepler separate ALUs
auch im GPU-Bereich nötig beziehungsweise sinnvoll verbaut waren. Dies geschah vermutlich aus Platz-
ist, eine Performance-Analyse durchzuführen, soll dies gründen. [2] Während Double-Precision-Operationen
im Abschnitt 5 genauer auf verschiedenen Leveln dis- für 3D-Anwendungen wie Spiele nicht benötigt wurden,
kutiert werden. machte das Fehlen von Double-Precision-Fähigkeiten
Insgesamt liegt der Fokus dieser Arbeit aber auf aktuel- den Einsatz in den professionelleren Tesla-Karten
len Architekturen für technische und wissenschaftliche unmöglich. Deshalb wurde dort mit GK210 eine ver-
Berechnungen. Herkömmliche Grafikprogrammierung, besserte Variante der älteren Kepler-Architektur ein-
wie zum Beispiel mit C++ und DirectX oder OpenGL, gesetzt. Dies kann als Beginn einer echten Differen-
sollen deshalb nur am Rande Erwähnung finden. zierung der GPUs betrachtet werden. Auch die zwei-
te Generation der Maxwell-Architektur (GM204) wies
2 Entwicklung der GPUs eine zu geringe Double-Precision-Leistung auf, um in
Dieser Abschnitt gibt einen Überblick über die Ent- den Tesla-Karten zum Einsatz zu kommen, wo also
wicklung der GPUs seit ihrer Einführung. weiterhin die Kepler-Architektur verwendet wurde. Die
GeForce-10-Serie für den Desktop- und Workstation-
2.1 Rückblick [13] Bereich nutzt die Pascal-Architektur im 16 nm Ferti-
Die ersten Jahre der GPUs sind in Tabelle 1 abgebildet. gungsprozess. Die Ausbaustufen reichen von GP108
Bei AMD folgten danach bis heute (Stand 12.2017) bis GP100, wobei sich der größte GP100-Chip stark
noch die HD Radeon-R200-Serie, die Radeon-R300- von den restlichen unterscheidet. Durch den kleine-
Serie, die Radeon-400 und Radeon-500-Serie. Bei die- ren Fertigungsprozess entfielen die Limitierungen we-
sen ist die erstmalige Verwendung von HBM-Speicher gen zu großer Die-Fläche, wie die zu geringe Double-
mit dem Fiji-Grafikprozessor in der Radeon R9 Fury Precision-Leistung, allerdings entschied sich NVidia
X (gehört zur Radeon-R300-Serie) hervorzuheben. Au- wieder, für die professionellen Tesla-Karten einen eige-
ßerdem nutzten die Polaris-Grafikchips (Radeon-400- nen, nämlich den sich stark unterscheidenden GP100-
Serie) bereits die GCN 4.0 Architektur, wodruch die Chip, einzusetzen. Dort wurden ein anderer Cluster-
Effizienz gesteigert werden konnte. Allerdings war be- aufbau, High Performace Computing Fähigkeiten und
ziehunsweise ist diese Generation und auch die nach- ein ECC-HBM2-Speicherinterface verwendet. Die noch
folgende Rebrand-Generation (Radeon-500-Serie) nicht aktuellere Volta-Architektur ist derzeit (Stand Dezem-
in der Lage die Leistung des Konkurrenten NVidia ber 2017) nur für die Tesla-Karten verfügbar und erhöht
zu erreichen. Die neueste Grafikkarten-Serie (Stand durch ein Schrumpfen des Fertigungsprozesses von 16
12.2017) seitens AMD ist die Radeon-Vega-Serie, die nm auf 12 nm und eine Vergrößerung der Die-Fläche die
die GCN-Architektur bereits in der 5. Ausbaustufe ver- Transistorenzahl auf 21 Milliarden (gegenüber 15 Mil-
wendet und DX 12.1, OpenGL 4.5, Open CL 2.0+ sowie liarden bei Pascal). Weitere Details zur aktuellen Volta-
Vulkan 1.0 unterstützt sowie 12,5 Milliarden Transis- Architektur finden sich in Unterunterabschnitt 3.1.1.
toren besitzt. Für weitere Details zum Vega-Grafikchip Die Separierung in Desktop- bzw. Workstation-Karten
siehe Unterunterabschnitt 3.1.2. und Tesla-Karten umfasst jedoch nicht die ganze vor-
Neben AMD und NVidia existierten beziehungsweise handene Differenzierung von GPUs. Mit NVidia Qua-
existieren noch andere Grafikchip-Hersteller mit teil- dro existieren GPU-Karten, die den Desktop- bzw.
weise eigenen technischen Neuerungen, die aber hier Workstation-Pendants sehr ähneln und sogar die glei-
der Übersichtlichkeit halber keine Erwähnung finden chen Treiber verwenden, allerdings durch eine ande-
sollen. re Beschaltung eine andere Chip-ID erhalten, was wie-
derum den Treiber veranlasst spezielle Funktionen für
2.2 Differenzierung der GPUs professionelle Anwendungen im CAD-, Simulations-
Der größte Ausbau der Maxwell-Architektur (GM200) und Animationsbereich freizuschalten. Von ATI bezie-
von NVidia verfügte gegenüber dem Vorgänger (Kep- hungsweise AMD existieren entsprechende Karten un-
ler) aber nicht mehr über erweiterte Double-Precision- ter den Bezeichnungen FireGL- und FirePro bezie-
Seminar: HPC Trends and Developments 6 DOI: 10.14459/2018md1430700
Jahr Produkt / Serie Transistoren CUDA-Kerne Besondere Technologie(n) / Besonder-
heiten
1990er - Entwicklung dedizierter GPUs beginnt
1997 NV Riva 128 3 Millionen - Erster 3D-Grafikbeschleuniger
1995-98 ATI Rage 8 Millionen - Twin Cache Architektur
2000 NV GeForce 256 17 Millionen - Erste, echte GPU; DX7, OpenGL
2000 ATI Radeon-7000 30 Millionen - Effizienzsteigerungen (HyperZ)
2000 NV GeForce 2 25 Millionen - Erste GPU für Heimgebrauch
2001 NV GeForce 3 57 Millionen - Erste programmierbare GPU; DX8,
OpenGL; Pixel- u. Vertex-Shader
2002 ATI Radeon-9000 >100 Millionen - Einstieg ATIs in High-End-Markt
2003 NV GeForce FX 135 Millionen - 32-bit floating point (FP) programmierbar
2004 NV GeForce 6 222 Millionen - GPGPU-Cg-Programme; DX9; OpenGL;
SLI; SM 3.0
2006 NV GeForce 8 681 Millionen 128 Erste Grafik- und Berechnungs GPU; CU-
DA; DX10; Unified-Shader-Architektur
2007 NV Tesla GPUs für wissenschaftliche Anwendungen
2008 NV GeForce-200 240 CUDA; OpenCL; DirectCompute
2008 ATI-Radeon-HD-4000 - GDDR5; Übernahme ATIs durch AMD
2009 NV Fermi / GeForce-400 3 Milliarden 512 Zunehmende GPGPU-Bedeutung; C++
Unterstützung; DX11; ECC-Speicher;
64-bit Addressierung
2010 ATI-Radeon-HD-5000 ∼2 Milliarden - Terrascale-Architektur; Optimierungen für
GPU-Computing
2012 NV Kepler / GeForce-600 ∼3,5 Milliarden 1536 GPU-Boost; Graphics Processing Cluster
(GPCs)
2012 AMD-Radeon-HD-7000 4,3 Milliarden - Neue GCN-Architektur; Vulkan-API
Tabelle 1: Entwicklung der GPUs
hungsweise seit der 4. Generation der GCN Architektur Laut NVidia [3] kombiniert die Plattform Deep Lear-
unter dem Namen Radeon Pro. ning, Sensorfusion und Rundumsicht, was sogar Level-
5, also vollständige, Fahrzeugautonomie bieten soll.
2.3 Spezialisierung der GPUs Darüber hinaus bietet NVidia mit NVidia DGX-1 eine
Hinsichtlich Spezialisierung von GPUs, sind die bereits Plattform für die KI-Forschung und den KI-Einsatz in
aus den vorhergehenden Abschnitten bekannten Diffe- Unternehmen. Letztendlich kommt aber hierbei eben-
renzierungen, wie Tesla- und Quadro-Karten, zu nen- falls eine aktuelle Tesla V100 und spezialisierte Soft-
nen. ware zum Einsatz. [4]
Allerdings geht die Differenzierung von GPUs inzwi- Zuletzt existiert unter dem Namen NVidia Tegra auch
schen soweit, dass von Spezialisierung auf einzelne An- ein komplettes System-on-a-Chip (SoC) für mobile
wendungsgebiete gesprochen werden muss. Für autono- Geräte, aber auch Autos, das neben der Grafikeinheit
mes Fahren bietet NVidia beispielsweise Drive PX an, auch ARM-Kerne, Chipsatz, teilweise ein Modem und
ein Fahrzeugcomputer mit künstlicher Intelligenz, der weiteres enthält. Dieses SoC trägt bei NVidia den Na-
bezüglich Umfang von Einzelprozessoren für einzel- men Tegra, das in der aktuellen Generation (Tegra X1)
ne Fahrzeugfunktionen bis zu Kombinationenen mehre- allerdings nur eine Mawell-Grafikeinheit enthält. Her-
rer Grafikprozessoren für autonome Robotertaxis reicht. vorzuheben ist jedoch, dass trotz des mobilen Anwen-
Seminar: HPC Trends and Developments 7 DOI: 10.14459/2018md1430700
dungsfokus CUDA unterstützt wird. und CPU-Systeme. Deshalb unterstützt Volta GV100
bis zu sechs NVLinks mit einer Gesamtbandbreite von
3 Architekturen aktueller GPUs 300 GB/s.
Nachdem im vorhergehenden Abschnitt die Entwick- Das Subsystem für die HBM2-Speicherverwaltung er-
lung der GPUs dargelegt wurde, sollen im folgen- reicht laut NVidia eine Spitzenleistung von 900 GB/s
den die technischen Details der aktuellen Architekturen Speicherbandbreite. Durch die Kombination des neuen
von NVidia und AMD, sowie deren Leistungsfähigkeit, Volta-Speichercontrollers und einer neuen Generation
Kosten und Anwendungsgebiete dargestellt werden. Samsung HBM2-Speichers, erreicht Volta insgesamt ei-
ne 1,5-fache Speicherbandbreite gegenüber Pascal.
3.1 Technische Details Der Volta Multi-Prozess Dienst (MPS) hardware-
Bei den aktuellen Architekturen soll bei NVidia der Fo- beschleunigt kritische Komponenten des CUDA-MPS-
kus auf der Volta-Architektur in Form der Tesla V100 Servers, wodurch eine bessere Leistung, Entkopplung
GPU, die auf eben dieser Architektur basiert, und bei und besseres QoS erreicht wird, wenn mehrere Anwen-
AMD auf Vega-Chips liegen, der 5. Ausbaustufe der dungen für wissenschaftliche Berechnungen die GPU
GCN-Architektur. teilen müssen. Dadurch steigt die erlaubte Anzahl an
3.1.1 NVidia Tesla V100 GPU [14] MPS-Clients von 16 bei Pascal auf nun 48.
Verbesserte Unified Memory- und Address Translation-
Die Volta-Architektur wird gegenwärtig nur in Form
Dienste erlauben eine genauere Migration der Speicher-
der Tesla V100 GPU (GV100) umgesetzt, die unter an-
seiten zu demjenigen Prozessor, der diese am häufigsten
derem die folgenden Neuerungen und Verbesserungen
nutzt. Dadurch wird erneut die Effizienz beim Zugriff
mitbringt:
auf Speicherbereiche, die von mehreren Prozessoren
• Neue Streaming Multiprozessor (SM) Architektur verwendet werden, erhöht. Auf der sogenannten IBM-
für Deep Learning Power-Plattform gestattet es eine entsprechende GPU-
• NVLink 2.0 seitige Unterstützung derselben auf die Seitentabellen
• HBM2 Speicher mit höherer Effizienz der CPU direkt zuzugreifen.
• Volta Multi-Prozess Dienst (MPS) Die Thermal Design Power (TDP) von Volta ist mit
• Verbesserte Unified Memory and Address Transla- 300 Watt spezifiziert, die jedoch nur im Maximum-
tion Dienste Performance-Mode genutzt wird, wenn Anwendun-
• Modi für maximale Performance und Effizienz gen höchste Leistung und höchsten Datendurch-
• Cooperative Groups and Launch APIs satz benötigen. Dagegen eignet sich der Maximum-
• Für Volta optimierte Software Efficiency-Mode für Datencenter, die die Leistungsauf-
• Weitere, wie zum Beispiel unabhängiges Thread- nahme regulieren und die höchste Leistung pro Watt er-
Scheduling zielen wollen.
Daneben enthält die Tesla-GPU 21,1 Milliarden Tran- Mit NVidia CUDA 9 wurden Cooperative Groups (ko-
sistoren auf einer Die-Fläche von 815 mm2 und wird im operative Gruppen) für miteinander kommunizierende
TSMC 12 nm FFN (FinFET NVidia) Fertigungsprozess Threads eingeführt. Mithilfe der Cooperative Groups
hergestellt. können Entwickler die Granularität bestimmen mit
Durch die neue Streaming Multiprozessor (SM) Ar- welcher Threads kommunizieren, worduch effizientere,
chitektur ist diese 50% energieeffizienter als dieje- parallele Dekompositionen von Anwendungen erstellt
nige in der Pascal-Architektur, bei gleichzeitig deut- werden können. Alle GPUs seit Kepler unterstützen die-
lich erhöhter FP32- und FP64-Leistung. Mithilfe neuer se Gruppen, Pascal und Volta aber auch die Launch-
Tensor-Kerne steigt die Spitzen-TFLOPS-Leistung auf APIs, die die Synchronisation zwischen CUDA-Thread-
das Zwölffache für das Training und das Sechsfache bei Blöcken ermöglichen.
der Inferenz. Der Aufbau einer Volta-GPU besteht aus sechs GPU
NVLink 2.0 ermöglicht eine höhere Bandbreite, mehr Processing Clusters (GPCs), die jeweils über sieben
Links und eine bessere Skalierbarkeit für Multi-GPU- Texture Processing Clusters (TPCs) und 14 Strea-
Seminar: HPC Trends and Developments 8 DOI: 10.14459/2018md1430700
ming Multiprozessoren (SMs) verfügen. Jeder Strea-
ming Multiprozessor hat dabei:
• 64 FP32 Kerne
• 64 INT32 Kerne
• 32 FP64 Kerne
• 8 Tensor Kerne
• Vier Textureinheiten
Insgesamt verfügt jede volle GV100 GPU also über
5376 FP32- und INT32-, 2688 FP64-, 672 Tensor-
Kerne und 336 Textureinheiten. Zusätzlich besitzt eine
vollständige GV100-GPU acht 512-bit Speichercontrol-
ler mit insgesamt 6144 KB L2 Cache.
Die Anzahl der Streaming Multiprozessoren hat sich ge-
genüber der GP100, die auf der Pascal-Architektur auf-
baut, nicht nur von 56 auf 80 erhöht, sondern diese ent-
halten nun auch erstmalig 8 Tensor-Kerne, die explizit
für Deep Learning vorgesehen sind.
In Abbildung 1 ist ein einzelner Streaming Multiprozes-
sor einer Volta GV100 dargestellt.
Wie leicht zu erkennen ist, nehmen die Tensor-Kerne ei-
ne nennenswerte Fläche innerhalb des Streaming Mul-
tiprozessors ein, was insofern bemerkenswert ist, als
dass es sich um die erste GPU-Generation überhaupt
handelt, die diese Tensor-Kerne beinhaltet. Von die-
sen Tensor-Kernen ist jeder in der Lage 64 floating Abbildung 1: Volta GV100 Streaming Multiprocessor
point fused multiply-add (FMA) Operationen pro Takt (SM) [14]
durchzuführen. Diese Berechnungsmethode unterschei-
gleichzeitig besserer Bandbreite. Shared Memory bie-
det sich von der herkömmlichen Berechnungsmethode
tet hohe Bandbreite, geringe Latenz und konstante Per-
für Addition und Multiplikation dadurch, dass die Be-
formance, muss jedoch bei der CUDA-Programmierung
rechnung mit voller Auflösung durchgeführt wird und
explizit verwaltet werden. Bei der Kombination von Ca-
eine Rundung erst am Ende erfolgt. [16] Wie bereits
che und Shared-Memory wird fast die gleiche Leistung
erwähnt ist Tesla V100 mithilfe der Tensorkerne in
erreicht (ca. 7% weniger), jedoch ohne die Notwendig-
der Lage 125 Tensor-TFLOPS für Training- und Infe-
keit dies in Anwendungen manuell zu steuern.
renzanwendungen zu liefern.
Neben den bereits teilweise zuvor erwähnten neu-
Jeder Tensor-Kern rechnet auf einer 4 × 4-Matrix und
en Funktionalitäten, ist die Volta-Architektur im Ge-
führt die Operation D = A × B + C auf dieser
gensatz zu Pascal zuletzt in der Lage FP32- und
aus, wobei A, B, C und D 4 × 4 Matrizen sind. In
INT32-Operationen gleichzeitig auszuführen, da sepa-
der Praxis werden mit den Tensor-Kernen Operatio-
rate FP32- und INT32-Kerne vorhanden sind, wodurch
nen auf größeren, auch mehrdimensionalen, Matrizen
sich zum Beispiel bei FMA Geschwindigkeitsvorteile in
durchgeführt, die hierzu in diese 4 × 4 Matrizen zer-
bestimmten Anwendungsszenarien ergeben können.
legt werden. Volta Streaming Multiprozessoren besit-
zen zudem ein verbessertes L1 Datencache- und Sha- 3.1.2 AMD [10]
red Memory-System, das die Effizienz steigern und die Auch wenn von AMD selbst als Vega-Architektur be-
Programmierbarkeit vereinfachen soll. Durch die Kom- zeichnet, so handelt es sich bei Vega streng genommen
bination in einem Block verringert sich die Latenz bei um die 5. Ausbaustufe der GCN-Architektur. Im Fol-
Seminar: HPC Trends and Developments 9 DOI: 10.14459/2018md1430700
genden werden diese Begrifflichkeiten jedoch der Ein-
fachheit halber synonym verwendet.
Für diese neue Architektur beziehungsweise Ausbau-
stufe sind verschiedene Implementierungen geplant,
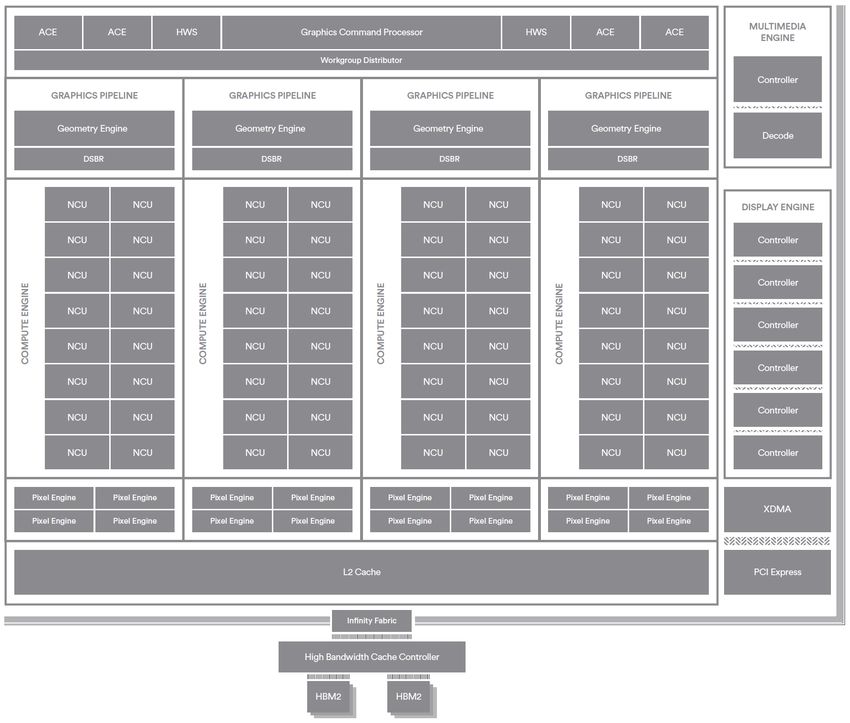
wobei die aktuelle als Vega 10 bezeichnet wird. Ab-
bildung 3 zeigt die im 14 nm LPP FinFet Fertigungs-
prozess hergestellte Architektur Vega 10 mit ihren 12,5
Milliarden Transistoren. Durch das kleinere Fertigungs-
verfahren beträgt der Boost-Takt nun 1,67 Ghz ge-
Abbildung 2: Systemspeicherarchitektur mit SSG [9]
genüber 1 Ghz bei Produkten mit Architekturen, die im
28 nm Verfahren hergestellt wurden. Bei Vega werden
deutlich kleiner als die kompletten Ressourcen sind und
als Zielgruppen Gaming, Workstation, HPC und Machi-
folglich schnell vom neuen Controller für hohe Band-
ne Learning genannt.
breite (HBCC), einem neuen Bestandteil der Speicher-
Mit 64 Rechneneinheiten der nächsten Generation
controllerlogik, kopiert werden können.
(Next-generation compute units (NCUs)) besitzt Ve-
ga 10 4096 Stream-Prozessoren, deren Anzahl bisheri- [9] Davon profitiert insbesondere die neue Radeon Pro
gen Radeon GPUs ähnelt, die aber aufgrund des Takts SSG, eine GPU mit Solid State Disk (SSD), die La-
und der Architekturverbesserungen Instruktionsanwei- tenz und CPU-Overhead deutlich reduzieren soll. Diese
sungen schneller ausführen. Dadurch sind diese in der spezielle GPU verhält sich, als besäße sie ein Terabyte
Lage 13,7 Teraflops von Berechnungen einfacher Ge- lokalen Videospeichers. Bei der bisher üblichen Syste-
nauigkeit und 27,4 Teraflops mit halber Genauigkeit marchitektur für Massenspeicher in einem CPU-GPU-
durchzuführen. Die neue Architektur ist in Abbildung 3 System erfolgt die Datenübertragung zwischen zwei
dargestellt. Endpunkten gewöhnlich in den folgenden drei Schrit-
Des weiteren bietet Vega sogenanntes Infinity Fabric ten: Zuerst werden die Daten von einem PCIe-Endpunkt
mit geringen Latenzen, das Logikeinheiten innerhalb in den System-Cache gelesen und anschließend von dort
des Chips verbindet und gleichzeitig Quality of Service in den Prozesscache kopiert, von wo sie zuletzt zum an-
und Sicherheitsapplikationen zur Verfügung stellt. deren PCIe-Endpunkt kopiert werden.
Ebenfalls neu in der Vega-Architektur ist eine neue Abbildung 2 zeigt wie die Systemspeicherarchitektur
Speicherhierarchie mit einem Cache Controller für ho- mit der Radeon Pro SSG aufgebaut ist. Dort werden
he Bandbreite (HBCC). Üblicherweise werden Daten sogenannte Ende-zu-Ende Leseoperationen ermöglicht,
von den Registern der Rechenelemente aus dem L1- indem zunächst, über PCIe exponierter, Videospeicher
Cache bezogen, der seinerseits den L2-Cache nutzt. reserviert wird, anschließend die SSD angewiesen wird
Dieser L2-Cache wiederum stellt einen Zugriff mit ho- eine Leseoperation durchzuführen und zuletzt die Da-
her Bandbreite und geringer Latenz auf den Videospei- ten auf der GPU verarbeitet werden. Dies hat auch
cher der GPU bereit. Dabei müssen das gesamte Da- den Vorteil, dass die CPU, sobald der Pfad zwischen
tenset und alle Ressourcen im Videospeicher gehalten GPU und NVMe-Speicher hergestellt ist, zum Daten-
werden, da es ansonsten zu Einschränkungen bezüglich transfer nicht mehr benötigt wird und folglich für an-
der Bandbreite und Latenz kommt. Bei Vega verhält dere Aufgaben verwendet werden kann, was die Sy-
sich der Videospeicher nun seinerseits wie eine Art letz- stemperformance weiter erhöht, da Datensätze nur so
ter Cache, wozu dieser Speicherseiten, die noch nicht schnell von der GPU verarbeitet werden können, wie
im GPU-Speicher vorliegen, selbst über den PCIe Bus diese dieser zur Verfügung stehen. Die Größe solcher
bezieht und im Cache mit hoher Bandbreite speichert. Datensätze nimmt bei modernen Anwendungen konti-
Bisher wurde stattdessen die komplette Berechnung der nuierlich zu, was jedoch durch immer schnellere GPU-
GPU verzögert, bis der Kopiervorgang abgeschlossen Architekturen kompensiert wird. Allerdings wird dann
war. Diese Neuheit der Speicherhierarchie bei der Vega- häufig die Datenübertragung zur GPU zum Flaschen-
Architektur ist möglich, da die Speicherseiten meist hals, der mit der CPU-GPU-Systemarchitektur der Ra-
Seminar: HPC Trends and Developments 10 DOI: 10.14459/2018md1430700Abbildung 3: AMD Vega 10 Architektur [10]
deon Pro SSG entfällt. Learning und Videoverarbeitung eingeführt, wobei 16-
Zur Vega 10-Archiektur zurückkommend gilt es weiter- bit Datentypen, wie float und Integer, zum Tragen kom-
hin hervorzuheben, dass alle Grafikblöcke nun Clients men. Dies ist ebenso Bestandteil der Vega NCU wie
des gemeinsamen L2-Cache sind, womit Datenredun- die Unterstützung neuer Instruktionen, zum Beispiel die
danz verringert wird. Aus diesem Grund wurde der L2- Summe der absoluten Differenzen (SAD), die häufig in
Cache mit 4 MB gegenüber der Vorgängergeneration Video- und Bildverarbeitung benötigt wird.
verdoppelt. Nicht zuletzt wurde auch die Pixel-Engine der Vega-
Außerdem wird eine Geometrie-Engine der nächsten Architektur überarbeitet, unter anderem in Form
Generation (NGG) in Vega integriert, die einen viel des Draw-Stream Binning Rasterizers (DSBR), der
höheren Polygon-Durchsatz pro Transistor erreicht. unnötige Berechnungen und Datentransfer vermeiden
Hierzu werden primitive“ Shader unterstützt, womit soll. Beim Rendern des Bildes wird dieses hierbei
”
Teile der Geometrie-Pipeline mit einem neuen Shader- zunächst in ein Gitter von Kacheln aufgeteilt, wobei
Typ kombiniert und ersetzt werden. In üblichen Sze- Stapel von Primitiven gebildet werden. Der DSBR tra-
narien wird rund die Hälfte sogenannter Primitiven der versiert anschließend diese Stapel nacheinander und
Geometrie verworfen, was bisher durch die Geometrie- überprüft, welche vollständige oder Teile von Primiti-
Pipelines erst nach der Vertex-Verarbeitung geschehen ve enthalten. Dadurch und durch weitere Maßnahmen
konnte, nun aber früher erfolgen kann. Dadurch errei- soll die Leistungsaufnahme verringert und höhere Bild-
chen die vier Geometrie-Engines von Vega 10 nun 17 wiederholungsraten erreicht werden.
statt nur 4 Primitive pro Takt. Abschließend werden mit der Vega Architektur DirectX
Ebenfalls mit Vega wird sogenanntes Rapid Packed in Feature Level 12.1, verbesserte Stromsparfunktionen
”
Math“ für spezialisierte Anwendungen wie Machine und Display- und Multimediaverbesserungen wie HDR
Seminar: HPC Trends and Developments 11 DOI: 10.14459/2018md1430700integriert beziehungsweise unterstützt. ware. Die programmierbaren Einheiten einer GPU ver-
folgen dabei ein single-program multiple-data (SPMD)
3.2 Leistungsfähigkeit Programmiermodell, was bedeutet, dass eine GPU aus
Dieses Kapitel beschreibt die Leistungsfähigkeit aktu- Effizienzgründen parallel mehrfach das gleiche Pro-
eller GPU-Architekturen und deren Umsetzungen. Ein gramm auf verschiedenen Elementen ausführt. Deshalb
direkter Vergleich ist jedoch schwierig beziehungsweise sind Programme für GPUs auch immer derart struktu-
selten möglich, da die Architekturen zum einen sehr neu riert, dass es mehrere gleichzeitig zu verarbeitende Ele-
sind (Stand 12.2017) und zum anderen deren Umsetzun- mente und parallele Verarbeitung dieser Elemente von
gen unterschiedliche Andwenundgsfokusse haben. einem einzigen Programm gibt.
3.2.1 NVidia Tesla V100 GPU [14] Die Programmierung für Grafikanwendungen unter-
Der Vergleich zwischen Pascal und Volta zeigt, dass die scheidet sich dabei von der Programmierung für allge-
Matrixmultiplikation von 4 × 4 Matrizen und die dazu meine Anwendungen. Erstere erfolgt dabei folgender-
nötigen 64 Operationen von Volta zwölfmal so schnell maßen:
berechnet werden. In cuBlAS, einer Bibliothek für Be- 1. Der Programmierer spezifiziert die Geometrie, die
rechnungen der linearen Algebra, die auf CUDA auf- eine bestimmte Region des Bildschirms abdeckt.
baut, weist Volta gegenüber Pascal bei einfacher Genau- Der Rasterer generiert daraus an jeder Pixelstelle
igkeit eine bis zu 1,8-fach und bei gemischter Genauig- ein Fragment, das von der Geometrie abgedeckt ist.
keit (FP16 Input, FP32 Output) bis zu 9,3-fach höhere 2. Jedes Fragment wird von einem Fragment-
Geschwindigkeit auf. Programm bearbeitet.
3.2.2 AMD [10] 3. Das Fragment-Programm berechnet dabei den
Die Radeon Pro SSG besitzt in einem CPU-GPU- Wert des Fragments mithilfe einer Kombination
System gegenüber einem herkömmlichen CPU-GPU- aus mathematischen Operationen und der globale
System eine rund fünf Mal höhere Performance bei Speicher liest von einem globalen Texturspeicher.
der Videoverarbeitung in 8K. Weiterhin ist Vega, 4. Das resultierende Bild kann dann als Textur in wei-
mithilfe der neuen Geometrie-Engine der nächsten teren Durchläufen innerhalb der Grafik-Pipeline
Generation (NGG) und Fast Path, in der Lage über 25 weiter verwendet werden.
Gigaprimitive, gegenüber ca. 5 bei Fiji, zu verwerfen. und für allgemeine Anwendungen wie folgend:
Obwohl die GPUs von NVidia und AMD aufgrund 1. Der Programmierer spezifiziert direkt den Berech-
der Spezialisierung nicht vollständig vergleichbar sind, nungsbereich als strukturiertes Raster von Threads.
existieren Bechmarks, wie der PassMark Benchmark 2. Ein SPMD-Progamm für allgemeine Anwendun-
[5], die die verschiedenen Karten dennoch vergleichen. gen berechnet den Wert jedes Threads.
In besagtem PassMark Benchmark (Stand 14.12.2017) 3. Der Wert wird dabei erneut durch eine Kombi-
führt die Titan V100 das Testfeld mit 16,842 Punkten nation mathematischer Operationen, sowie lesen-
mit einigem Vorsprung an. Eine GeForce GTX 1080 Ti, dem und schreibendem Zugriff auf den globa-
die zweithöchste Ausbaustufe der Pascal-Architektur, len Speicher berechnet. Der Buffer kann dabei
erreicht dagegen nur 13,634 Punkte, ist damit aber sowohl für lesende und schreibende Operationen
immer noch deutlich schneller als die schnellste Radeon verwendet werden, um flexiblere Algorithmen zu
Vega Karte im Test mit 11,876 Punkten. Damit wäre die ermöglichen (z.B. In-Place-Algorithmen zur Redu-
aktuelle Umsetzung der Tesla-Architektur circa 50% zierung der Speichernutzung).
schneller als diejenige der Vega-Architektur. 4. Der resultierende Buffer im globalen Speicher
kann wiederum als Eingabe für weitere Berech-
4 Programmierung für GPUs nungen genutzt werden.
Dieser Abschnitt beschreibt übliche Vorgehensweisen Früher musste bei der Programmierung der Um-
bei der GPU-Programmierung und dazu nötige Soft- weg über geometrische Primitive, den Rasterer und
Seminar: HPC Trends and Developments 12 DOI: 10.14459/2018md1430700Fragment-Programme, ähnlich wie bei der Grafikpro- ben. Auch wenn moderne Profiler Nebenläufigkeit un-
grammierung, gegangen werden. terstützen, so stellt diese enorme Anforderungen an et-
Dies legt bereits nahe, dass als Softwareumgebung für waige Analysetools. Schon bei einer Threadanzahl wie
die GPGPU-Programmierung früher direkt die Grafik- sie bei einer CPU vorkommt kann es zu Schwierigkei-
API genutzt wurde. Auch wenn dies vielfach erfolgreich ten bei der Erkennung von Laufzeitproblemen, wie etwa
genutzt wurde, unterscheiden sich, wie bereits oben durch Deadlocks, kommen.
erwähnt, die Ziele herkömmlicher Programmiermodelle
und einer Grafik-API, denn es mussten Fixfunktionen, 5.1 High-Level Analyse
grafik-spezifische Einheiten, wie zum Beispiel Textur- Als High-Level wird im Folgenden die Analyse der
filter und Blender, verwendet werden. GPU-Performance mit Softwaretools bezeichnet, wel-
Mit DirectX 9 wurde die high-level shading langua- che aber oft ihrerseits Low-Level-Analyse nutzen und
ge (HLSL) eingeführt, die es erlaubt die Shader in diese in Form einer API oder Ähnlichem dem Program-
einer C-ähnlichen Sprache zu programmieren. NVidi- mierer zur Verfügung stellen. Die einzelnen Tools und
as Cg verfügte über ähnliche Fähigkeiten, war aller- ihre Funktionsweise ist genauer in Unterabschnitt 5.3
dings in der Lage für verschiedene Geräte zu kompi- beschrieben.
lieren und stellte gleichzeitig die erste höhere Spra- Als Beispiel, wie High-Level-Analyse durchgeführt
che für OpenGL bereit. Heute ist die OpenGL Shading werden kann, soll die Arbeit von Sim, Dasgupta, Kim
Language (GLSL) die Standard-Shading-Sprache für und Vuduc [17] dienen, die feststellen, dass es sich
OpenGL. Nichtsdestotrotz sind Cg, HLSL und GLSL äußerst schwierig gestaltet, bei Plattformen mit vielen
immer noch Shading-Sprachen, wobei die Programmie- Kernen die Ursachen für Engpässe festzustellen. Des-
rung grafikähnlich erfolgen muss. halb stellen die genannten Autoren ein Framework na-
Inzwischen gibt es deshalb sowohl von NVidia, als mens GPUPerf Framework vor, das solche Engpässe
auch von AMD, spezielle GPGPU Programmiersyste- aufdecken soll. Es kombiniert ein genaues analytisches
me. NVidia stellt hierzu das bekannte CUDA-Interface Modell für moderne GPGPUs und gut interpretierba-
zur Verfügung, das wie Cg über eine C-ähnliche Syn- re Metriken, die direkt die möglichen Performance-
tax besitzt, über zwei Level von Parallelität (Daten- Verbesserungen für verschiedene Klassen von Optimie-
Parallelität und Multithreading) verfügt und nicht mehr rungstechniken zeigen. Das zugrunde liegende analyti-
grafikähnlich programmiert werden muss. sche Modell, das als MWP-CWP-Modell (siehe Abbil-
AMD bietet Hardware Abstraction Layer (HAL) und- dung 4) bezeichnet wird, nutzt folgende Eingaben: An-
Compute Abstraction Layer (CAL). Außerdem wird zahl der Instruktionen, Speicherzugriffe, Zugriffsmuster
OpenCL unterstützt, das seinerseits von CUDA inspi- sowie architekturelle Eigenschaften wie DRAM-Latzen
riert wurde und auf einer großen Bandbreite von Geräte und -Bandbreite.
genutzt werden kann. Bei OpenCL erfolgt die Program- Auf der einen Seite beschreibt der Memory
mierung in OpenCL C, das zusätzliche Datentypen und Warp Parallelism (MWP) die Anzahl an Warps,
Funktionen für die parallele Programmierung bereit- Ausführungseinheiten einer GPGPU, pro Streaming-
stellt. Es handelt sich also wie bei der Programmierung Multiprozessor (SM), die gleichzeitig auf den Speicher
von CUDA um eine C-ähnliche Syntax. [15], [13] zugreifen können. Auf Ebene des Speichers spiegelt
MWP also Parallelität wider. MWP ergibt sich dabei als
Funktion aus Speicherbandbreite, Parameter von Spei-
5 Performance-Analyse bei GPUs cheroperationen, wie Latzenz und der aktiven Anzahl
Progammierwerkzeuge zur Laufzeitanalyse werden im von Warps in einem SM. Das Framework modelliert die
allgemeinen Profiler genannt, die den Programmierer Kosten von Speicheroperationen durch die Anzahl von
dabei unterstützen ineffiziente Programmteile zu iden- Anfragen über MWP. Auf der anderen Seite entspricht
tifizieren. Der Fokus liegt hierbei auf Funktionen, die Computation Warp Parallelism (CWP) der Anzahl von
am häufigsten durchlaufen werden, da diese den größten Warps, die ihre Berechnungsperiode innerhalb einer
Einfluss auf die Gesamtlaufzeit eines Programms ha- Speicherwarteperiode plus eins abschließen können.
Seminar: HPC Trends and Developments 13 DOI: 10.14459/2018md1430700Abbildung 4: MWP-CWP-Modell, links: MWP <
CWP, rechts: MWP > CWP [17]
Eine Berechnungsperiode ergibt sich dabei aus den
durchschnittlichen Berechnungszyklen pro Speicher-
instruktion. Das MWP-CWP-Modell dient dazu, zu
identifizieren, welchen Kosten durch Multi-Threading
verborgen werden können. Dazu wird in drei Fälle
unterschieden: Abbildung 5: Potentieller Performance-Gewinn [17]
1. MWP < CWP: Die Kosten einer Berechnung wer- Berechnungen ideal entfernt werden. In der Praxis
den durch Speicheroperationen verdeckt. Die ge- können hier keine 100% erreicht werden, da der
samten Ausführungskosten ergeben sich durch die Kernel immer auch Operationen wie Datentransfer
Speicheroperationen. (vgl. Abbildung 4, links) haben muss.
2. MWP ≥ CWP: Die Kosten der Speicheroperatio- • Bserial : zeigt die Kosteneinsparung, wenn Over-
nen werden durch die Berechnung verdeckt. Die head durch Serialisierungseffekte wie Synchroni-
gesamten Ausführungskosten ergeben sich aus der sation und Ressourcenkonflikte entfernt werden.
Summe der Berechnungskosten und einer Spei-
cherperiode. (vgl. Abbildung 4, rechts) Neben allgemeiner High-Level-Analyse gibt es auch
3. Nicht genug Warps: Aufgrund mangelnder Paral- Performance-Modellierung und -Optimierung, die sich
lelisierung werden sowohl Berechnungs- als auch auf spezielle Operationen bezieht. Guo, Wang und
Speicherkosten verdeckt. Chen [11] stellen zum Beispiel ein Analysetool
vor, das Sparse-Matrix-Vektor-Multipliktion auf GPUs
Das Framework enthält nun einen sogenannten optimieren kann. Dazu stellt es, unter Verwen-
Performance-Advisor, der Informationen über dung einer integrierten analytischen und profilbasier-
Performance-Engpässe und möglichen Performance- ten Performance-Modellierung, ebenfalls verschiedene
Gewinn durch Beseitigung dieser Engpässe bereitstellt. Performance-Modelle bereit, um die Berechnungsdauer
Dazu nutzt dieser Advisor eben obiges MWP-CWP- präzise vorherzusagen. Außerdem ist in dem genannten
Modell und stellt vier Metriken bereit, die sich Tool ein automatischer Selektionsalgorithmus enthal-
entsprechend Abbildung 5 visualisieren lassen. Die vier ten, der optimale Sparse-Matrix-Vektor-Multiplikation-
enthaltenen Metriken sind: Werte hinsichtlich Speicherstrategie, Speicherformaten
• Bitilp : zeigt den potentiellen Performance-Gewin und Ausführungszeit für eine Zielmatrix liefert.
durch Erhöhung der Inter-Thread Parallelität auf Weitere Frameworks sind in Unterabschnitt 5.3 be-
Instruktionslevel. schrieben.
• Bmemlp : zeigt den potentiellen Performance-
Gewin durch Erhöhung der Parallelität auf Spei- 5.2 Low-Level Analyse
cherlevel. Auf GPU-Basis ist die Low-Level Analyse mithilfe so-
• Bf p : spiegelt den potentiellen Performance- genannter Performance-Counter und anderen Methoden
Gewinn wider, wenn die Kosten für ineffiziente noch relativ neu. Verschiedene Hersteller wie NVidia
Seminar: HPC Trends and Developments 14 DOI: 10.14459/2018md1430700(The PAPI CUDA Component) und IBM (Parallel En- stark der entsprechende GPU-Teil genutzt wird; er spie-
vironment Developer Edition) stellen Technologien be- gelt die aktive Zeit der entsprechenden GPU-Einheit wi-
reit, die es ermöglichen auf Hardware-Counter inner- der. Letzterer zeigt welchen zeitlichen Anteil eine GPU-
halb der GPU zuzugreifen. Prinzipiell ist der Übergang Einheit einen Engpass darstellt. Es kann eine große An-
und die Definition von High- und Low-Level Analyse zahl an verschiedenen GPU-Counter untersucht werden.
aber natürlich fließend. Der AMD Radeon GPU Profiler stellt Low-Level
[6] Der Einsatz der GPU-Counter soll anhand der Per- Timing-Daten für Barriers, Warteschlangensignale,
formance API (PAPI) gezeigt werden, die daneben Wellenfront-Belegung, Event-Timings und weitere be-
aber auch noch sehr viele weitere Performanceanalyse- reit. [7]
Funktionen bereitstellt. PAPI bietet hierzu ein Counter- Ebenfalls für AMD Chips steht die AMD CodeXL Ent-
Interface, das den Zugriff, das Starten, Stoppen und wicklungssuite bereit, die neben einem CPU-Profiler,
Auslesen von Countern für eine spezifizierte Liste einem GPU debugger, einem statischen Shader/Kernel
von Events ermöglicht. Die Steuerung beziehungswei- Analysator auch einen GPU Profiler beinhaltet. Die-
se Programmierung von PAPI erfolgt mittels C oder ser sammelt Daten von den Performance-Countern,
Fortran. Außerdem kann PAPI sogenannte benutzerde- vom Anwendungsablauf, Kernelbelegung und bietet ei-
finierte Gruppen von Hardware-Events namens Event- ne Hotspot-Analyse. Der Profiler sammelt Daten der
Sets verwalten, was für Programmierer einem fein- OpenCL Runtime und von der GPU selbst und dient
granulares Mess- und Kontrollwerkzeug gleichkommen ebenfalls zur Reduzierung von Engpäassen und der Op-
soll. timierung der Kernel-Ausführung. [8]
Auch die Umsetzung beziehungsweise Implementie- Die Autoren Zhang und Owens [19] schlagen ein quan-
rung des zuvor genannten GPUPerf Frameworks kann titatives Performance-Analyse-Modell basierend auf ei-
als Low-Level Analyse bezeichnet werden. nem Microbenchmark-Ansatz vor, das den nativen In-
Zuletzt gibt es auch Empfehlungen und Vorgehens- struktionssatz einer GPU nutzt.
weisen, beispielsweise von NVidia selbst [12], für Daneben existiert natürlich noch eine Vielzahl weite-
Performance-orientierte Implementierungen. Allgemei- rer Frameworks und Tools, die zum GPU Profiling ein-
ne Empfehlungen sind in diesem Kontext zum Beispiel, gesetzt werden können, aber hier der Übersichtlichkeit
mit 128-256 Threads pro Threadblock zu sarten, nur halber keine Erwähnung finden sollen. Es ist stets eine
Vielfache der Warpgröße (32 Threads) zu nutzen und Vergleichbarkeit mit CPU-Profiling gegeben, mit dem
als Rastergröße 1000 oder mehr Threadblöcke einzuset- Unterschied, dass Parallelität bei GPUs naturgemäß ei-
zen. ne viel entscheidendere Rolle spielt.
5.3 Hilfsmittel (Tools)
Zur Analyse der Laufzeit gibt es auch bei GPUs ei-
6 Zusammenfassung
ne Reihe von Profiling-Tools. Neben den bereits, zur Mit dieser Arbeit konnte zu Beginn dargelegt wer-
Veranschaulichung von High- und Low-Level Analyse, den, wie sich Graphical Processing Units (GPUs). Seit
vorgestellten Frameworks, ist eines dieser Tools NVidia dem Beginn der Entwicklung dedizierter Grafikchips
PerfKit. [18] hat sich der Funktionsumfang dieser kontinuierlich er-
Durch die enthaltene PerfAPI werden in PerfKit weitert und die Transistorenzahl stark erhöht. Außer-
Performance-Counter zugänglich, die aufzeigen, wie dem konnte ein Wandel von reinen Grafik-Chips hin zu
ein Programm die GPU nutzt, welche Performance- multifunktionalen GPGPUs identifiziert werden, der mit
Probleme vorliegen und ob nach einer Veränderung dem Einzug von Programmierschnittstellen wie CUDA
diese Probleme gelöst wurden. PerfKit kann dedi- seinen Anfang fand. Immer umfangreichere und effizi-
zierte Experimente auf individuellen GPU-Einheiten entere Programmierschnittstellen wie OpenGL, DirectX
ausführen, worduch Performance-Charakteristiken ge- und die Vulkan API werden in ihren neuen Versionen in
wonnen werden, nämlich der Speed of Light (SOL)- und der Regel mit neueren Architekturen der Grafik-Chips
Bottleneck-Wert. Ersterer gibt im Allgemeinen an, wie integriert. Die Leistungsfähigkeit der GPUs hat im Lau-
Seminar: HPC Trends and Developments 15 DOI: 10.14459/2018md1430700fe der Zeit stark zugenommen, wobei diese heute primär Literatur
vom Anwendungsgebiet abhängt.
[1] https://www.duden.de/rechtschreibung/GPU_
Die neuen Architekturen von NVidia und AMD,
Grafikprozessor_EDV (aufgerufen am 06.12.2017).
nämlich Volta und Vega, haben gemeinsam, dass sie [2] http : / / www . 3dcenter . org / artikel / launch -
schnellen HBM2 Speicher verwenden. Bei den Neu- analyse-nvidia-geforce-gtx-titan-x (aufgeru-
heiten der Volta-Architektur sind besonders die neue fen am 06.12.2017).
[3] https://www.nvidia.de/self- driving- cars/
Streaming-Multiprozessor-Architektur mit Tensor- drive-px/ (aufgerufen am 06.12.2017).
Kernen für Matrixmultiplikationen und bei der AMD [4] https://www.nvidia.de/data- center/dgx- 1/
Vega-Architektur die 64 Next-generation compute (aufgerufen am 07.12.2017).
units (NCUs) und eine neue Speicherhierarchie mit [5] https://www.videocardbenchmark.net/high_
end_gpus.html (aufgerufen am 14.12.2017).
eine Cache Controller für hohe Bandbreite (HBCC) [6] http://icl.cs.utk.edu/projects/papi/wiki/
hervorzuheben. Counter_Interfaces (aufgerufen am 14.12.2017).
Die Leistungsfähigkeit profitiert von diesen [7] https : / / gpuopen . com / gaming - product /
Architektur-Veränderungen zum Teil erheblich. radeon - gpu - profiler - rgp/ (aufgerufen am
14.12.2017).
Neben allgemeinen Geschwindigkeitsvorteilen in [8] https : / / gpuopen . com / compute - product /
Benchmarks, erreicht die AMD Radeon Pro SSG, eine codexl/ (aufgerufen am 14.12.2017).
auf Vega basierende GPU mit eigener SSD, eine rund [9] A. —. R. T. Group. RADEON PRO - Solid State Graphics
fünfmal höhere Performance als eine herkömmliche (SSG) Technical Brief. Techn. Ber. https : / / www . amd .
com / Documents / Radeon - Pro - SSG - Technical -
Systemarchitektur, wodurch ein flüssiges Videoproces- Brief.pdf (aufgerufen am 26.11.2017).
sing bei 8K ermöglicht wird. NVidias Volta erreicht [10] A. —. R. T. Group. Radeon’s next-generation Vega architec-
mithilfe der Tensor-Kerne bei der Matrixmultiplika- ture. Techn. Ber. https://radeon.com/_downloads/
vega - whitepaper - 11 . 6 . 17 . pdf (aufgerufen am
tion gegenüber der Vorgängergeneration Pascal eine
26.11.2017). Juni 2017.
zwölffache Geschwindigkeit. [11] P. Guo, L. Wang und P. Chen. “A performance modeling and
Bei der Programmierung, wie diese Arbeit darlegt, muss optimization analysis tool for sparse matrix-vector multiplica-
heute sehr stark in Programmierung für herkömmliche tion on GPUs”. In: IEEE Transactions on Parallel and Distri-
buted Systems 25.5 (2014), S. 1112–1123.
Grafikanwendungen und allgemeine Anwendungen dif- [12] P. Micikevicius. “GPU performance analysis and optimizati-
ferenziert werden. on”. In: GPU technology conference. Bd. 84. 2012.
Die Performance-Analyse erfolgt auch bei GPUs mithil- [13] J. Nickolls und W. J. Dally. “The GPU computing era”. In:
fe von Profilern, die im Wesentlichen eine High-Level IEEE micro 30.2 (2010).
[14] NVidia. NVIDIA TESLA V100 GPU ARCHITECTURE. THE
Analyse für den Programmierer bereitstellen, indem sie WORLD’S MOST ADVANCED DATA CENTER GPU”. Techn.
selbst zum Teil eine Low-Level Analyse durchführen. Ber. http : / / www . nvidia . com / object / volta -
Entscheidend für das GPU-Profiling ist, ob Berech- architecture - whitepaper . html (aufgerufen am
nungskosten Speicherkosten verdecken beziehungswei- 26.11.2017). Aug. 2017.
[15] J. D. Owens, M. Houston, D. Luebke, S. Green, J. E. Stone
se umgekehrt oder mangelnde Parallelisierung vorliegt. und J. C. Phillips. “GPU computing”. In: Proceedings of the
Weiterer Forschungsbedarf besteht zum Beispiel in der IEEE 96.5 (2008), S. 879–899.
Performance-Analyse bei Machine-Learning, insbeson- [16] E. Quinnell, E. E. Swartzlander und C. Lemonds. “Floating-
dere bei und in Kombination mit den neuen Tensor- point fused multiply-add architectures”. In: Signals, Systems
and Computers, 2007. ACSSC 2007. Conference Record of the
Kernen der Volta-Architektur. Forty-First Asilomar Conference on. IEEE. 2007, S. 331–337.
Insgesamt zeigt sich mit den aktuellen GPU- [17] J. Sim, A. Dasgupta, H. Kim und R. Vuduc. “A performan-
Architekturen eine weitere Fortführung der Spe- ce analysis framework for identifying potential benefits in
GPGPU applications”. In: ACM SIGPLAN Notices. Bd. 47. 8.
zialisierung von GPUs und ein anhaltender Trend hin
ACM. 2012, S. 11–22.
zu GPGPUs, wobei inzwischen sogar der Hauptfokus [18] N. P. Toolkit. “NVIDIA PerfKit”. In: (2013).
auf wissenschaftlichen und allgemeinen Anwendungen [19] Y. Zhang und J. D. Owens. “A quantitative performance ana-
zu liegen scheint. lysis model for GPU architectures”. In: High Performance
Computer Architecture (HPCA), 2011 IEEE 17th Internatio-
nal Symposium on. IEEE. 2011, S. 382–393.
Seminar: HPC Trends and Developments 16 DOI: 10.14459/2018md1430700Seminar HPC Trends
Winter Term 2017/2018
New Operating System Concepts for High
Performance Computing
Fabian Dreer
Ludwig-Maximilians Universität München
dreer@cip.ifi.lmu.de
January 2018
Abstract 1 The Impact of System Noise
When using a traditional operating system kernel
When running large-scale applications on clusters, in high performance computing applications, the
the noise generated by the operating system can cache and interrupt system are under heavy load by
greatly impact the overall performance. In order to e.g. system services for housekeeping tasks which is
minimize overhead, new concepts for HPC OSs are also referred to as noise. The performance of the
needed as a response to increasing complexity while application is notably reduced by this noise.
still considering existing API compatibility.
Even small delays from cache misses or interrupts
can affect the overall performance of a large scale
In this paper we study the design concepts of het- application. So called jitter even influences collec-
erogeneous kernels using the example of mOS and tive communication regarding the synchronization,
the approach of library operating systems by ex- which can either absorb or propagate the noise.
ploring the architecture of Exokernel. We sum- Even though asynchronous communication has a
marize architectural decisions, present a similar much higher probability to absorb the noise, it is
project in each case, Interface for Heterogeneous not completely unaffected. Collective operations
Kernels and Unikernels respectively, and show suffer the most from propagation of jitter especially
benchmark results where possible. when implemented linearly. But it is hard to anal-
yse noise and its propagation for collective oper-
ations even for simple algorithms. Hoefler et al.
Our investigations show that both concepts have [5] also suggest that “at large-scale, faster networks
a high potential, reduce system noise and outper- are not able to improve the application speed sig-
form a traditional Linux in tasks they are already nificantly because noise propagation is becoming a
able to do. However the results are only proven by bottleneck.” [5]
micro-benchmarks as most projects lack the matu-
rity for comprehensive evaluations at the point of Hoefler et al. [5] also show that synchronization
this writing. of point-to-point and collective communication and
Seminar: HPC Trends and Developments 17 DOI: 10.14459/2018md1430700OS noise are tightly entangled and can not be dis- geneous architectures with different kinds of mem-
cussed in isolation. At full scale, when it becomes ory and multiple memory controllers, like the recent
the limiting factor, it eliminates all advantages of a Intel Xeon Phi architecture, or chips with different
faster network in collective operations as well as full types of cores and coprocessors, specialized kernels
applications. This finding is crucial for the design might help to use the full potential available.
of large-scale systems because the noise bottleneck
We will first have an in-depth look at mOS as at
must be considered in system design.
this example we will be able to see nicely what as-
Yet very specialized systems like BlueGene/L [8] pects have to be taken care of in order to run dif-
help to avoid most sources of noise [5]. Ferreira ferent kernels on the same node.
et al. [3] show that the impact is dependent on
parameters of the system, the already widely used
concept of dedicated system nodes alone is not suf- 2.1 mOS
ficient and that the placement of noisy nodes does
matter. To get a light and specialized kernel there are two
methods typically used: The first one is to take
a generic Full-Weight-Kernel (FWK) and stripping
This work gives an overview of recent developments
away as much as possible; the second one is to build
and new concepts in the field of operating systems
a minimal kernel from scratch. Either of these two
for high performance computing. The approaches
approaches alone does not yield a fully Linux com-
described in the following sections are, together
patible kernel, which in turn won’t be able to run
with the traditional Full-Weight-Kernel approach,
generic Linux applications [4].
the most common ones.
The rest of this paper is structured as follows. We Thus the key design parameters of mOS are:
will in the next section introduce the concept of run- full linux compatibility, limited changes to Linux,
ning more than one kernel on a compute or service and full Light-Weight-Kernel scalability and perfor-
node while exploring the details of that approach at mance, where performance and scalability are pri-
the example of mOS and the Interface for Hetero- oritized.
geneous Kernels. Section 3 investigates the idea of To avoid the tedious maintenance of patches to the
library operating systems by having a look at Ex- Linux kernel, an approach inspired by FUSE has
okernel, one of the first systems designed after that been taken. Its goal is to provide internal APIs
concept, as well as a newer approach called Uniker- to coordinate resource management between Linux
nels. Section 4 investigates Hermit Core which is a and Light-Weight-Kernels (LWK) while still allow-
combination of the aforementioned designs. After ing each kernel to handle its own resources indepen-
a comparison in Section 5 follows the conclusion in dently.
Section 6.
“At any given time, a sharable resource is either
private to Linux or the LWK, so that it can be
managed directly by the current owner.” [11] The
2 Heterogeneous Kernels resources managed by LWK must meet the follow-
ing requirements: i) to benefit from caching and
The idea about the heterogeneous kernel approach reduced TLB misses, memory must be in phys-
is to run multiple different kernels side-by-side. ically contiguous regions, ii) except for the ones
Each kernel has its spectrum of jobs to fulfill and its of the applications no interrupts are to be gener-
own dedicated resources. This makes it possible to ated, iii) full control over scheduling must be pro-
have different operating environments on the parti- vided, iv) memory regions are to be shared among
tioned hardware. Especially with a look to hetero- LWK processes, v) efficient access to hardware must
Seminar: HPC Trends and Developments 18 DOI: 10.14459/2018md1430700be provided in userspace, which includes well-per- Linux [11].
forming MPI and PGAS runtimes, vi) flexibility in
The capability to direct system calls to the cor-
allocated memory must be provided across cores
rect implementor (referred to as triage). The idea
(e.g. let rank0 have more memory than the other
behind this separation is that performance critical
ranks) and, vii) system calls are to be sent to the
system calls will be serviced by the LWK to avoid
Linux core or operating system node.
jitter, less critical calls, like signaling or /proc re-
mOS consists of six components which will be in- quests handles the local Linux kernel and all opera-
troduced in one paragraph each: tions on the file system are offloaded to the operat-
ing system node (OSN). But this hierarchy of sys-
According to Wisniewski et al. [11], the Linux run-
tem call destinations does of course add complexity
ning on the node can be any standard HPC Linux,
not only to the triaging but also to the synchroniza-
configured for minimal memory usage and without
tion of the process context over the nodes [11].
disk paging. This component acts like a service
providing Linux functionality to the LWK like a An offloading mechanism to an OSN. To remove
TCP/IP stack. It takes the bulk of the OS adminis- the jitter from the compute node, avoid cache pol-
tration to keep the LWK streamlined, but the most lution and make better use of memory, using a dedi-
important aspects include: boot and configuration cated OSN to take care of I/O operations is already
of the hardware, distribution of the resources to the an older concept. Even though the design of mOS
LWK and provision of a familiar administrative in- would suggest to have file system operations han-
terface for the node (e.g. job monitoring). dled on the local linux, the offloading mechanism
improves resource usage and client scaling [11].
The LWK which is running (possibly in multiple
instantiations) alongside the compute node Linux. The capability to partition resources is needed for
The job of the LWK is to provide as much hardware running multiple kernels on the same node. Mem-
as possible to the applications running, as well as ory partitioning can be done either statically by
managing its assigned resources. As a consequence manipulating the memory maps at boot time and
the LWK does take care of memory management registering reserved regions; or dynamically mak-
and scheduling [11]. ing use of hotplugging. These same possibilities are
valid for the assignment of cores. Physical devices
A transport mechanism in order to let the Linux will in general be assigned to the Linux kernel in
and LWK communicate with each other. This order to keep the LWK simple [11].
mechanism is explicit, labeled as function ship-
ping, and comes in three different variations: via We have seen the description of the mOS architec-
shared memory, messages or inter-processor inter- ture which showed us many considerations for run-
rupts. For shared memory to work without major ning multiple kernels side-by-side. As the design
modifications to Linux, the designers of mOS de- of mOS keeps compatibility with Linux core data
cided to separate the physical memory into Linux- structures, most applications should be supported.
managed and LWK-managed partitions; and to al- This project is still in an early development stage,
low each kernel read access to the other’s space. therefore an exhaustive performance evaluation is
Messages and interrupts are inspired by a model not feasible at the moment.
generally used by device drivers; thus only send-
ing an interrupt in case no messages are in the
queue, otherwise just queueing the new system call 2.2 Interface for Heterogeneous
request which will be handled on the next poll. This Kernels
avoids floods of interrupts in bulk-synchronous pro-
gramming. To avoid jitter on compute cores, com- This project is a general framework with the goal
munication is in all cases done on cores running to ease the development of hybrid kernels on many-
Seminar: HPC Trends and Developments 19 DOI: 10.14459/2018md1430700Sie können auch lesen

















































