Planning in the real world - Marco Füllemann - BERNER FACHHOCHSCHULE
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

BERNER FACHHOCHSCHULE
Planning in the real world
Marco Füllemann
25. Mai 2015
Betreuer: Dr. Jürgen Eckerle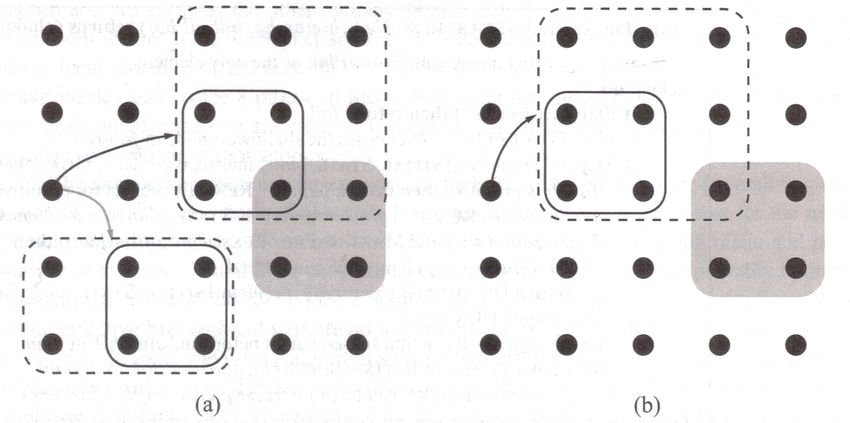
Inhaltsverzeichnis
Inhaltsverzeichnis
1 Einleitung 4
2 Planning Domain Definition Language (PDDL) 5
2.1 States . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.2 Actions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
2.3 Planning-Domain . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
3 Forward state-space search 9
4 Heuristiken 10
4.1 Ignore Precondition Heuristik . . . . . . . . . . . . . . . . . . . . . . . . . . 10
4.2 Decomposition . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
5 Hierarchisches Planen 12
5.1 High-level Actions und Refinement . . . . . . . . . . . . . . . . . . . . . . . 12
5.2 Suche nach primitiven Lösungen . . . . . . . . . . . . . . . . . . . . . . . . 13
5.3 Suche nach abstrakten Lösungen . . . . . . . . . . . . . . . . . . . . . . . . 15
6 Fazit 20
2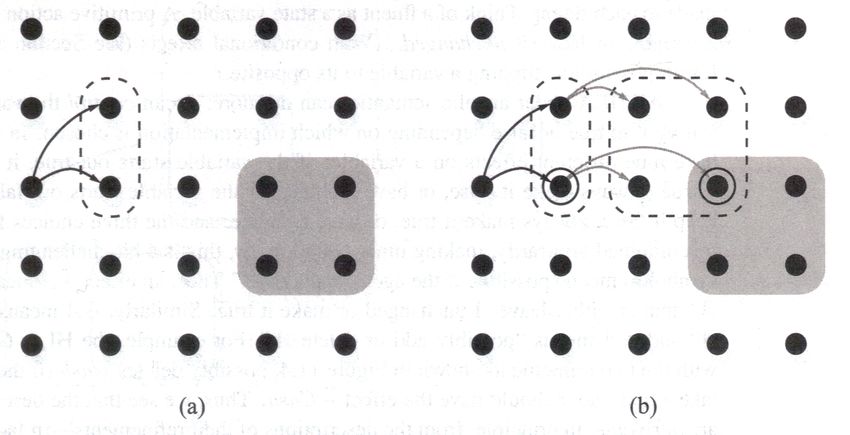
Abbildungsverzeichnis
Abbildungsverzeichnis
1 "Blocks-World"Problem grafisch [Nor] . . . . . . . . . . . . . . . . . . . . . 7
2 "Blocks-World"Problem als Planungs-Problem [RN10] . . . . . . . . . . . . 7
3 State-Space des “Blocks-World“-Problems . . . . . . . . . . . . . . . . . . . 9
4 Mögliche Refinements für eine high-level Action [RN10] . . . . . . . . . . . 12
5 Hierarchische Breitensuche [RN10] . . . . . . . . . . . . . . . . . . . . . . . 14
6 Schematische Darstellung der “Reachable Sets“ [RN10] . . . . . . . . . . . . 16
7 Schematische Darstellung der optimistischen und pessimistischen “Reacha-
ble Sets“ [RN10] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
8 “Angelic-Search“ [RN10] . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3
1 Einleitung
1 Einleitung
Planen ist ein Gebiet der künstlichen Intelligenz und beschäftigt sich mit der Umset-
zung von Strategien, deren Ausführungen von Agenten realisiert werden. Es beschreibt
ein Verfahren, um von einer Menge von Weltzuständen zu definierten Zielzuständen zu
kommen. Planen unterscheidet sich vom klassischen Problemlösen insofern, dass mehrere
Weltzustände, Zielzustände und Pläne zugelassen werden, sodass die Palette an Algorith-
men, die den Suchraum auflösen deutlich grösser ist. Weiter ergibt sich dadurch auch ein
mehrdimensionaler Lösungsraum, in welchem die Lösungen gesucht und optimiert werden
müssen. Mit der Beschreibung einer Ausgangslage (Initial-State) und einem Zielzustand
(Goal-State), soll mit gegebenen Aktionen (Actions) eine Sequenz von Actions gefunden
werden, die einen Plan generiert, der zum gewünschten Ziel führt. Mit einer geeignet Pla-
nungssprache wird der Weltzustand definiert und erlaubt so eine übersichtliche Darstellung
des Problems.
Diese Arbeit erläutert in einem ersten Schritt die Darstellung von Plänen anhand der
Planungssprache PDDL. Anschliessend werden klassische Methoden zur Lösung von Plä-
nen beschreiben. Zum Schluss wird anhand des hierarchischen Planens eine Möglichkeit
aufgezeigt, um mit Plänen Realweltprobleme zu lösen.
42 Planning Domain Definition Language (PDDL)
2 Planning Domain Definition Language (PDDL)
PDDL ist eine Sprache, die es erlaubt alle Actions und States in einem Schema darzustellen.
Daraus ergibt sich die Planning-Domain, welche den für den Plan relevanten Weltzustand
aufzeigt.
2.1 States
Jeder State wird als Verbindung von Eigenschaften dargestellt und beschreibt den aktu-
ellen Zustand. Sie sind atomar, verfügen über keinerlei Funktionalität und dürfen keine
Variablen enthalten. Ein State eines Transportunternehmens könnte zum Beispiel wie folgt
lauten:
At(T ruck1 , London) ∧ At(T ruck2 , Edinburgh)
Folgende Elemente sind in States unzulässig:
• At(x, y), weil Variablen enthalten sind
• ¬P oor, weil es einen Negation ist
• At(F ather(F red), Sydney), weil eine Funktion verwendet wird
Bei der Beschreibung eines States gilt die closed world assumption. Dies bedeutet, dass
für jede nicht genannte Eigenschaft die Negation gilt.
2.2 Actions
Actions werden in Action-Schemen dargestellt und stellen implizit die Funktionen ACTIONS(s)
und RESULT(s, a) zur Verfügung. Diese werden für die Problemlösungssuche benötigt. Sie
beschreiben eine Änderung eines States in einen anderen. In den Actions werden nur Ele-
mente beschreiben, die ändern. Alle übrigen Elemente behalten ihren bisherigen Zustand.
Dies hat den Vorteil, dass nicht nochmals der komplette Weltzustand beschrieben werden
muss. Im folgenden Beispiel wird eine Action beschrieben, um ein Flugzeug von einem
Flughafen zu einem anderen zu fliegen.
Action ( Fly ( p , from , t o ) ,
Precond : At ( p , from ) ∧ Plane ( p ) ∧ A i r p o r t ( from ) ∧ A i r p o r t ( t o ) ,
Effect : ¬At ( p , from ) ∧ At ( p , t o ) )
52 Planning Domain Definition Language (PDDL)
Die Precondition beschreibt die States, die im Weltzustand gelten müssen, damit die Ac-
tion ausgeführt werden kann. Im Effect sind die resultierenden States sichtbar, wenn die
Action ausgeführt wurde. Die negierten Elemente im Effect werden in einem resultieren-
den State gelöscht, diese werden als Delete-List bezeichnet. Die positiven Elemente werden
hinzugefügt und gehören zur Add-List. Dieses Beispiel ist eine generelle Darstellung des
Action-Schemas, da die Elemente durch Variablen repräsentiert werden. Die Variablen
können durch beliebige Werte ersetzt werden, welche die Vorgaben erfüllen, sodass zum
Beispiel folgendes Schema entstehen kann.
Action ( Fly ( P1 , SFO, JFK) ,
Precond : At ( P1 , SFO) ∧ Plane ( P1 ) ∧ A i r p o r t (SFO) ∧ A i r p o r t (JFK) ,
Effect : ¬At ( P1 , SFO) ∧ At ( P1 , JFK ) )
Diese Definition ermöglicht auch eine Action F ly(P1 , JF K, JF K), was keine Änderung des
States zur Folge haben sollte. Jedoch führt dies zum Effect ¬At(P1 , JF K) ∧ At(P1 , JF K),
was einen Widerspruch erzeugt. Oftmals werden diese ignoriert, da sie selten zu fehlerhaf-
ten Plänen führen. Korrekterweise werden der Precondition entsprechende Constraints
(Ungleichungen) hinzugefügt, um dies zu verhindern. Das angepasste Action-Schema sieht
nun wie folgt aus.
Action ( Fly ( p , from , t o ) ,
Precond : At ( p , from ) ∧ Plane ( p ) ∧ A i r p o r t ( from ) ∧ A i r p o r t ( t o )
∧ ( from6= t o ) ,
Effect : ¬At ( p , from ) ∧ At ( p , t o ) )
2.3 Planning-Domain
Die Definition einer Planning-Domain besteht aus einer Menge von Actions, einem Initial-
State und einem Goal-State und beschreibt so den Weltzustand. Dies soll am bekannten
Beispiel Blocks-World erläutert werden, welches in Abbildung 1 dargestellt ist.
Die Domain besteht aus Blöcken, die auf einem Tisch liegen. Die Blöcke können aufein-
ander gestapelt werden, jedoch kann jeweils nur ein Block auf einem anderen liegen. Ein
Roboterarm kann einen Block aufheben und entweder auf einen anderen Block heben oder
auf den Tisch legen. Es kann jeweils nur ein Block verschoben werden. Somit kann der
Roboter keinen Block verschieben, auf dem ein anderer liegt. Im folgenden Szenario ist das
62 Planning Domain Definition Language (PDDL)
Ziel, Block A auf B und Block B auf C zu verschieben, so dass der abgebildete Goal-State
entsteht. Abbildung 2 zeigt die dazugehörige Planning-Domain.
Abbildung 1: "Blocks-World"Problem grafisch [Nor]
I n i t (On(A, Table ) ∧ On(B, Table ) ∧ On(C, A) ∧ Block (A) ∧ Block (B)
∧ Block (C) ∧ C l e a r (B) ∧ C l e a r (C) )
Goal (On(A, B) ∧ On(B, C) )
Action ( Move ( b , x , y ) ,
Precond : On( b , x ) ∧ C l e a r ( b ) ∧ C l e a r ( y ) ∧ Block ( b ) ∧ Block ( y )
∧ ( b6= x ) ∧ ( b6= y ) ∧ ( x6= y ) ,
Effect : On( b , y ) ∧ C l e a r ( x ) ∧ ¬On( b , x ) ∧ ¬ C l e a r ( y ) )
Action ( MoveToTable ( b , x ) ,
Precond : On( b , x ) ∧ C l e a r ( b ) ∧ Block ( b ) ∧ ( b6= x )
Effect : On( b , Table ) ∧ C l e a r ( x ) ∧ ¬On( b , x ) )
Abbildung 2: "Blocks-World"Problem als Planungs-Problem [RN10]
Mit On(b, x) wird dargestellt, dass ein Block b auf x liegt. Dabei kann x ein anderer Block
oder der Tisch sein.
Um einen Block b von x nach y zu bewegen wird die Action M ove(b, x, y) verwendet. Eine
Precondition dieser Move-Action ist, dass kein Block auf b liegen darf. In der Prädika-
tenlogik würde dies mit ¬∃x On(x, b) dargestellt. Da Quantoren in PDDL nicht erlaubt
sind, wird anstelle davon das Prädikat Clear(x) verwendet. Dieses ist wahr, wenn kein
Gegenstand auf x liegt.
Die Move-Action bewegt einen Block b von x nach y, falls x und y frei sind. Nach Abschluss
72 Planning Domain Definition Language (PDDL)
der Action sind b und x frei aber y nicht mehr. Dieses Verhalten ist korrekt solange x und
y Blöcke sind. Sobald aber eines von beiden der Tisch ist, ist der Clear-Wert nicht mehr
korrekt. Wenn x der Tisch ist, so ist der Effekt der Action Clear(T able), der Tisch ist
aber nicht leer. Wird für y der Tisch gewählt, so ist die Precondition Clear(T able), was
aber nicht der Fall sein muss. Um das Problem zu lösen wird die Action M oveT oT able
eingeführt, die einen Block b von x auf den Tisch verschiebt. Weiter wird Clear(x) so
interpretiert, dass auf x Platz ist, um einen Block abzustellen. Somit trifft Clear(T able)
immer zu.
Ein mögliche Lösung für das in Abbildung 1 gezeigte Planungsproblem ist folgende Se-
quenz.
[M oveT oT able(C, A), M ove(B, T able, C), M ove(A, T able, B)]
83 Forward state-space search
3 Forward state-space search
Der Forward-search ist ein Algorithmus, bei dem vom Initial-State aus gesucht wird, bis
ein State gefunden wird, der den Goal-State erfüllt. Zu diesem Zweck wird auf dem aktu-
ellen State jede für diesen State mögliche Action ausgeführt. Für jede Action ergibt sich
daraus einen neuen State, auf dem der Algorithmus rekursiv angewandt wird, bis der State
gefunden ist, der dem Goal-State entspricht.
Das Problem des Forward-Searchs ist, dass oft irrelevante Actions erkundet werden. Ein
weiteres Problem ist, dass bereits bei geringer Anzahl an Elementen grosse State-Spaces
entstehen können. Dies ist der Fall, weil der branching-factor sehr gross werden kann. Wie
in Abbildung 3 sichtbar, erreichen wir beim simplen “Blocks-World“-Problem bereits auf
der dritten Ebene 10 States. Wenn bei diesem Problem noch einige Blöcke hinzugefügt
werden, wird schnell sichtbar, dass das Problem auf Grund der Grösse des State-Spaces
nicht mehr lösbar ist. Es ist somit nötig, dass eine geeignete Heuristik angewandt wird,
um das Problem lösbar zu machen.
On(A, Table)
On(B, Table)
On(C, Table)
MoveToTable(C, A)
On(A, Table) Move(C, A, B) On(A, Table)
On(B, Table) On(B, Table)
On(C, A) On(C, B)
Move(B, Table, C)
On(A, Table)
On(B, C)
On(C, A)
Abbildung 3: State-Space des “Blocks-World“-Problems
94 Heuristiken
4 Heuristiken
Eine Heuristik-Funktion h(s) schätzt die Distanz von einem State s zum Goal-State und
ist einfacher zu berechnen als die effektive Lösung. Eine Heuristik ist nur dann anwendbar,
wenn die geschätzte Distanz kleiner oder gleich der effektiven optimalen Distanz ist. Damit
haben wir die Möglichkeit bei jedem State abzuschätzen, welcher Nachfolge-State uns
näher ans Ziel bringen wird. Eine mögliche Heuristik kann erzeugt werden, in dem das
aktuelle Problem vereinfacht wird und gewisse Restriktionen weggelassen werden (relaxed
problem). Somit erhält man ein Problem, das einfacher zu lösen ist.
4.1 Ignore Precondition Heuristik
Bei dieser Heuristik werden die Preconditions aller Actions gelöscht. Somit sind alle Actions
auf jeden State anwendbar. Dies bedeutet, dass ein einzelnes Element eines Goal-States
nun durch eine einzige Action erzeugt werden kann. Ist keine Action vorhanden, die dies
tun kann, so ist das Problem unlösbar.
Es scheint so, als entspreche bei diesem vereinfachten Problem die Anzahl Actions der
Anzahl Elemente im Goal-State, die noch nicht erfüllt wurden. Dies ist aber nicht der
Fall, denn es gibt Actions, die in mehreren Elementen Goal-States erzeugen und es gibt
Actions, die Effekte wieder rückgängig machen. Um dieses Problem zu beheben werden alle
Elemente des Effects gelöscht, die nicht im Goal-State enthalten sind. Anschliessend wird
die minimale Anzahl an Actions berechnet um den Goal-State zu erreichen. Das Problem
an dieser Heuristik ist, dass sie trotzdem NP-schwer ist.
4.2 Decomposition
Die Heuristiken, die ein vereinfachtes Problem verwenden, bieten eine Funktion um die Di-
stanz abzuschätzen. Meistens ist diese jedoch teuer. Viele Planungsprobleme haben einen
so grossen State-Space, dass eine Simplifikation der Actions nur geringfügig zur Vereinfa-
chung des Problems beiträgt, da die Anzahl States nicht verringert werden.
Decomposition ist ein weiterer Ansatz um Heuristiken zu definieren. Dabei wird ein Pro-
blem in Teilprobleme aufgeteilt und unabhängig von einander gelöst. Anschliessend wer-
den die Teilziele kombiniert. Die Kosten um eine Verbindung von Teilzielen zu lösen, wird
durch die Summe der Kosten approximiert, die jedes Teilziel hat, wenn es unabhängig von
104 Heuristiken
den anderen gelöst wird. Es wird angenommen, dass die Teilziele unabhängig sind. Dies
bedeutet, dass sie keinen Einfluss auf andere Teilziele haben. Diese Eigenschaft wird als
“subgoal indipendance assumption“ bezeichnet. Diese ist optimistisch falls negative Inter-
aktionen zwischen den Teilplänen auftreten. Dass heisst zum Beispiel, wenn ein Teilplan
ein Element eines Goal-States löscht, welches durch einen anderen Teilplan erstellt wurde.
Sie ist pessimistisch, wenn Teilpläne redundante Actions enthalten, was bedeutet, dass sie
im zusammengefügten Plan durch eine einzelne Action ausgetauscht werden können. Ist
sie pessimistisch, so ist die Heuristik nicht anwendbar, denn die berechneten Kosten sind
höher als die der optimalen Lösung. Es ist somit notwendig zu wissen, dass die Teilpläne
untereinander unabhängig sind, um diese Heuristik anwenden zu können.
115 Hierarchisches Planen
5 Hierarchisches Planen
In den vorhergehenden Kapitel wurden jeweils Pläne mit atomaren Actions betrachtet.
In Realweltproblemen kann es häufig vorkommen, dass die Komplexität des Problems so
gross ist, dass eine Lösung tausende von Actions enthalten kann. Beispielsweise für Pläne
die vom menschlichen Hirn ausgeführt werden, sind atomare Actions Muskelbewegungen.
Würde daraus ein detaillierter Plan für eine Ferienreise nach Hawaii gebaut, würde dieser
geschätzte 1010 Actions enthalten. Es ist somit nötig, das Planen auf einem höheren Ab-
straktionslevel durchzuführen. Dies führt zu einem hierarchisch strukturierten Plan, was
ihn auch für Menschen besser lesbar macht. Daraus entsteht ein “Hierarchical Task Net-
work“ (HTN). Eine mögliche Abstraktion für die Ferienreise könnte wie folgt lauten: Gehe
zum Flughafen San Francisco, fliege nach Hawaii, mache Ferien für drei Wochen, fliege
zurück zum Flughafen San Francisco, gehe nach Hause. Die Action “gehe zum Flughafen
San Francisco“ bildet wiederum einen eigenen Plan mit seinen Subtasks.
5.1 High-level Actions und Refinement
Beim hierarchischen Planen handelt es sich bei der Action “gehe zum Flughafen San Fran-
cisco“ somit um eine high-level Action (HLA). Jede HLA kann durch ein Refinement in
eine Sequenz von Actions umgewandelt werden. Jede dieser Actions kann entweder eine
HLA oder eine primitive Action sein. Auf eine primitive Action kann kein Refinement
mehr angewandt werden. Jede HLA kann mehrere mögliche Refinements haben. Dies wird
sichtbar am folgenden Beispiel der Action “gehe zum Flughafen San Francisco“, die formal
als GO(Home, SF O) beschrieben wird.
Refinement (Go(Home , SFO) ,
Steps : [ Dri ve (Home , SFOLongTermParking ) ,
S h u t t l e ( SFOLongTermParking , SFO) ] )
Refinement (Go(Home , SFO) ,
Steps : [ Taxi (Home , SFO) ] )
Abbildung 4: Mögliche Refinements für eine high-level Action [RN10]
An diesem Beispiel wird sichtbar, dass das Refinement einer HLA beschreibt, wie ein
Task umgesetzt werden soll. Dabei kann ein Refinement auch Preconditions enthalten. So
125 Hierarchisches Planen
könnte zum Beispiel das Taxi-Refinement die Precondition “Cash“ haben. Somit kann der
Agent dieses Refinement nur wählen, wenn er Geld hat. Ein Refinement, das nur primi-
tive Actions enthält wird Implementation genannt. Eine Implementation eines high-level
Plans ist somit die Konkatenation der Implementationen jeder HLA im Plan. Anhand
der primitiven Actions ist es nun möglich zu bestimmen, ob eine Implementation eines
high-level Plans zum gewünschten Goal-State führt. Daraus folgt, dass von einem State
in einem high-level Plan der Goal-State nur dann erreicht werden kann, wenn mindestens
eine seiner Implementation den Goal-State von diesem State aus erreichen kann. Es ist
nicht nötig, dass alle Implementationen den Goal-State erreichen, denn der Agent wählt
die Implementation aus, die er ausführen will. Gibt es für eine HLA mehrere Implemen-
tationen, so gibt es zwei Möglichkeiten, wie verfahren wird. Die erste ist, dass man unter
den möglichen Implementationen diejenige sucht, die zielführend ist. Dies bedeutet, dass
man alle HLAs durch die zielführenden Refinements zu primitiven Actions umwandelt.
Die zweite Möglichkeit ist, dass direkt auf der Stufe der HLAs entschieden wird, ob die
Action zielführend ist. Dies ermöglicht eine Anpassung eines abstrakten Plans ohne dass
die Refinements der HLAs berücksichtigt werden müssen.
5.2 Suche nach primitiven Lösungen
Bei dieser Suche wird mit einer einzelnen top-level Action begonnen, die Act genannt
wird. Das Ziel dabei ist eine Implementation für den Act zu finden, die den Goal-State
erreicht. Daraus ergibt sich ein rekursiver Algorithmus, der solange eine HLA im aktuellen
Plan sucht und diese mit einem ihrer Refinements austauscht, bis der Plan den Goal-
State erreicht. Es handelt sich hierbei um eine hierarchische Forward-Suche. Eine mögliche
Implementation dieser Suche ist eine hierarchische Breitensuche, die wie folgt umgesetzt
wird.
135 Hierarchisches Planen
Abbildung 5: Hierarchische Breitensuche [RN10]
Als initialer Plan wird dem Algorithmus Act übergeben. Die Funktion “Refinements“ gibt
für jedes Refinement der HLA eine Sequenz von Actions zurück, falls der angegeben State
die Precondition des jeweiligen Refinements erfüllt. Besteht die Sequenz nur noch aus
primitiven Actions, so wird überprüft, ob diese den Goal-State des Problems erfüllen.
Anhand dieses Beispiels wird sichtbar, dass diese Art der hierarchischen Suche im Raum
der Refinements sucht. Es wird somit das bestehende Wissen (wie einen HLA gelöst wird,
auch HLA-Library) durchsucht. Dabei gilt es zu beachten, dass das Wissen nicht nur
in den Sequenzen der Actions (Steps) steckt, sondern dass auch ein grosser Teil in den
Preconditions steckt, denn diese ermöglichen, dass ein Refinement frühzeitig ausgeschlossen
werden kann.
Die Zeitersparnis bei der Berechnung eines hierarchischen Plans gegenüber der klassischen
Methode wird von [RN10] (Seite 409) wie folgt angegeben:
“An folgendem idealisierten Beispiel wird sichtbar, welchen Vorteil die hierarchische Su-
che auf die Berechnung eines Plans hat. Angenommen ein Planungsproblem hat eine Lö-
sung, die d primitive Actions beinhaltet. Bei einer nicht hierarchischen Forward-Suche
mit b zulässigen Actions pro State betragen die Kosten O(bd ). Für den HTN-Planer
wird angenommen, dass jede HLA r mögliche Refinements hat, die k Actions auf dem
nächst tieferen Level erzeugen. Da d Actions auf dem primitiven Level sind, so gibt es
logk d Levels unter dem Root-Knoten. Somit ist die Anzahl an internen Refinements
1 + k + k 2 + ... + k logk d−1 = (d − 1)/(k − 1). Da jeder Node r mögliche Refinements hat,
145 Hierarchisches Planen
ergibt dies r(d−1)/(k−1) mögliche Decomposition-Trees. Anhand dieser Formel ist sichtbar:
Wenn r klein und k gross ist, wird die Zeitersparnis sehr gross. Denn es wird Wurzel-k der
nicht hierarchischen Zeit benötigt, sofern d und r vergleichbar sind.“
Ist ein solches Verhältnis nicht vorhanden und daher die Zeitersparnis eher gering, ist
eine weitere Möglichkeit, eine Plan-Library zu erstellen. Diese enthält bereits bekannte
Implementationen von komplexen HLAs. Bei der Erstellung einer solchen Library ist es
wichtig generalisierte Lösungen zu speichern und dabei nur Elemente zu behalten, die
wichtig für den Plan sind. Das bedeutet, dass Elemente weggelassen werden sollten, die
problemspezifisch sind und keinen Einfluss auf die Lösung haben.
5.3 Suche nach abstrakten Lösungen
Bei der Suche nach primitiven Lösungen ist es jeweils nötig jede HLA mit einem Refinement
zu ersetzen, bis nur noch primitive Actions vorhanden sind um festzustellen, ob ein Plan
zielführend ist. Dies widerspricht der Grundsatzidee der Abstraktion. Beispielweise sollte
es möglich sein anhand folgender HLA-Sequenz zu sehen, dass dieser Plan einen von zu
Hause an den Flughafen bringt ohne die genaue Route zu kennen.
[ Drive (Home , SFOLongTermParking ) ,
S h u t t l e ( SFOLongTermParking , SFO) ]
Somit kann man nun auf dem high-level Plan überprüfen, ob er zum Goal-State führt
ohne eine HLA durch ein Refinement zu ersetzen. Dadurch wird der State-Space um ein
exponentielles reduziert. Wenn man davon ausgehen kann, dass ein high-level Plan zum
Goal-State führt, bleibt nur das Problem auf jeden Planungsschritt ein Refinement an-
zuwenden. Es ist notwendig, dass jeder high-level Plan der vorgibt, den Goal-State zu
erreichen dies auch tut. Dies bedeutet, dass mindestens eine Implementation den Goal-
State erreicht. Diese Eigenschaft wird “downward refinement property“ genannt.
Das Verfahren bei HLAs mit mehreren Implementation wird an folgendem Beispiel erläu-
tert. Für die HLA Go(Home, SF O) besteht die Möglichkeit mit dem Auto zum Flughafen
zu fahren oder das Taxi zu nehmen. Angenommen die Taxi-Action hätte die Precondition
Cash und diese würde nicht erfüllt, so wäre das Resultat der Action At(Agent, SF O) nicht
möglich. In diesem Fall würde der Agent die Implementation mit dem Auto wählen. Der
Agent wird also seine Implementation selbst wählen, was als “Angelic Nondeterminism“
bezeichnet wird.
155 Hierarchisches Planen
Bei einem gegebenen State s kann für eine HLA h nun das “Reachable Set“ (RS) berechnet
werden, dieses wird mit Reach(s, h) bezeichnet. Es beschreibt die Menge von States, die
durch irgendeine der Implementationen erreicht werden. Da der Agent seine Implementa-
tion selbst wählt, ist eine HLA mit mehreren möglichen Refinements deutlich mächtiger
als eine mit wenigen. Das RS kann auch für einen high-level Plan (Sequenz von HLAs)
berechnet werden. Beispielsweise ist das RS einer Sequenz [h1 , h2 ] die Vereinigung von
allen RS, die wir erhalten, wenn h2 auf jeden State im RS von h1 angewendet wird.
Reach(s0 , h2 )
S
Reach(s, [h1 , h2 ]) =
s0 ∈Reach(s,h1 )
Daraus folgt: Wenn das RS eines high-level Plans sich mit den Goal-States überschneidet,
so kann dieser den Goal-State erreichen. Weiter ergibt sich, dass wenn keine Überschnei-
dung stattfindet der Plan auf keinen Fall lösbar ist. Dies soll am folgenden Beispiel grafisch
erläutert werden.
Abbildung 6: Schematische Darstellung der “Reachable Sets“ [RN10]
Die möglichen Goal-States sind grau hinterlegt. Die schwarzen und grauen Pfeile zeigen
mögliche Implementationen der HLAs h1 und h2 . In (a) werden die möglichen Imple-
mentationen der HLA h1 gezeigt. Abbildung (b) zeigt das RS der Sequenz [h1 , h2 ]. Die
Überschneidung zeigt, dass der Goal-State erreicht wird. Daraus ergibt sich ein Algorith-
mus, in dem die high-level Pläne durchsucht werden bis einer gefunden wird, dessen RS
die Goal-States überschneidet. Sobald dieser gefunden ist, gilt es den Refinement-Prozess
165 Hierarchisches Planen
anzuwenden.
Oftmals kann ein RS nicht ganz eindeutig definiert werden. Beispielsweise ist es möglich
dass die HLA Go(Home, SF O) das Cash-Element löscht oder das Element
At(Car, SF OLongT ermP arking) hinzufügt, je nachdem welche Implementation der Agent
wählt. Zu diesem Zweck wird im Effect einer HLA angegeben wie sich das Attribut mög-
licherweise verändern wird. Folgende Operatoren werden dazu verwendet:
• +A:
e fügt A möglicherweise hinzu
• −A:
e löscht A möglicherweise
• ±A:
e löscht oder fügt A möglicherweise hinzu
Somit ergibt sich für die HLA Go(Home, SF O) die Definition mit folgendem Effect.
Action (Go(Home , SFO) ,
Effect : ¬At ( Agent , Home) ∧ At ( Agent , SFO) ∧ −Cash
e ∧
+At
e ( Car , SFOLongTermParking ) )
Da der Effect nun nicht mehr eindeutig ist, werden zwei Approximationen des RS verwen-
det. Eine optimistische (Reach+ (s, h)), die das RS überschätzt und eine pessimistische
(Reach− (s, h)), die das RS unterschätzt. Dass heisst, die optimistische Approximation
nimmt an, dass alle Elemente, die möglicherweise eintreffen dies tun und die pessimis-
tische nimmt an, dass diese nicht eintreffen. Daraus ergibt sich, dass das effektive RS
zwischen beiden Approximationen liegt, was in der Mengendarstellung wie folgt definiert
werden kann.
Reach− (s, h) ⊆ Reach(s, h) ⊆ Reach+ (s, h)
Die Approximationen verlangen nun, dass die Bewertung des RS angepasst wird. Falls das
optimistische RS die Goal-States nicht überschneidet, so kann der Plan nicht funktionieren.
Überschneidet der pessimistische Plan die Goal-States, so ist gewährleistet, dass der Plan
umsetzbar ist. Falls das optimistische RS die Goal-States überschneidet, das pessimistische
aber nicht, so kann nicht gesagt werden, ob der Plan zum Ziel führt. Tritt dieser Fall ein, so
bedarf es ein weiteres Refinement der HLAs. In Abbildung 7 wird dies grafisch dargestellt.
175 Hierarchisches Planen
Abbildung 7: Schematische Darstellung der optimistischen und pessimistischen “Reachable
Sets“ [RN10]
Die Goal-States sind grau hinterlegt. Die optimistischen RS haben einen gestrichelten und
die pessimistischen einen gezogenen Rahmen. Im Beispiel (a) führt der Plan mit dem
schwarzen Pfeil definitiv zum Goal-State, der Plan mit dem grauen Pfeil definitiv nicht.
In der Abbildung (b) ist ein Plan sichtbar, bei dem weitere Refinements benötigt werden
um zu ermitteln, ob er zum Goal-State führt.
Der Algorithmus in Abbildung 8 implementiert das beschriebene Verhalten bei der Ver-
wendung von approximierten RS. Er basiert auf der hierarchischen Breitensuche aus Ab-
bildung 5. Dabei werden die Schnittmengen von optimistischen und pessimistischen RS
mit dem Goal-State verglichen. Wird dabei ein lösbarer, abstrakter Plan gefunden, so wird
die Decompose-Methode aufgerufen. Diese löst für jeden Planungsschritt das Problem in
Subprobleme auf. Die Making-Progress-Methode stellt sicher, dass keine unendliche
Regression der Refinements entsteht.
Da Angelic-Search die Möglichkeit hat bereits high-level Pläne auszuschliessen, hat es
einen deutlich geringeren Rechenaufwand als die hierarchische Suche und die Breitensuche.
185 Hierarchisches Planen
Abbildung 8: “Angelic-Search“ [RN10]
196 Fazit
6 Fazit
Planen bietet die Möglichkeit diverse Arte von Problemen übersichtlich darzustellen und zu
lösen. Die Verwendung von Heuristiken kann den Rechenaufwand zum Teil schon deutlich
reduzieren und gewisse Probleme lösbar machen. Das hierarchische Planen ermöglicht eine
Abstraktion, um auch komplexe Realweltprobleme zu lösen. Die Verwendung von high-
level Actions ermöglicht es, bestehendes Wissen zu nutzten und bereits erstellte Lösungen
mehrfach zu verwenden. Die Vorgehensweise erinnert stark an die des Menschen bei solchen
Problemstellungen.
20Literatur
Literatur
[Nor] Northwood, Chris: Logic Programming and Artificial Intelligence.
http://www.pling.org.uk/cs/lpa.html, . – Besucht: 2015-04-10
[RN10] Russel, Stuart ; Norvig, Peter: Artificial Intelligence a modern approach. 3rd
Edition. Pearson, 2010. – ISBN 978–0–13–207148–2
21Sie können auch lesen

















































