Paralleles Rechnen: Multicores, Playstation 3, Rekonfigurierbare Hardware - Oliver Sinnen
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Paralleles Rechnen: Multicores, Playstation 3, Rekonfigurierbare Hardware Oliver Sinnen o.sinnen@auckland.ac.nz www.ece.auckland.ac.nz/~sinnen/
Von wo?
● Neuseeland
● Auckland
– Wirtschaftszentrum
– Größte Stadt
● 1,5 Millionen Menschen
im Großraum Auckland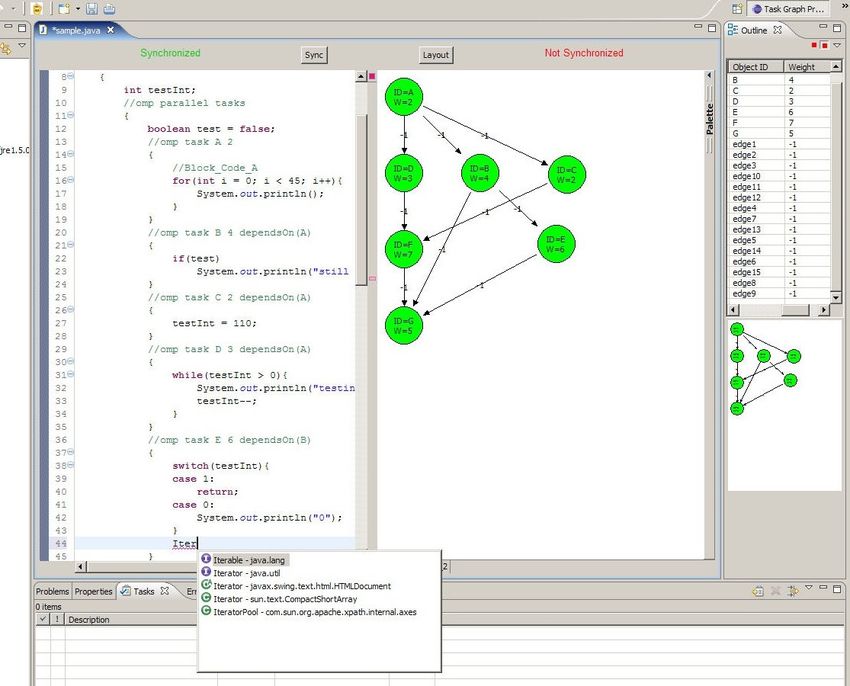
Von wo?
● Senior Lecturer
● Department of Electrical and
Computer Engineering (ECE)
– Mehr als 30 akademische Mitarbeiter
– Sehr international
● University of Auckland
– Größte Universität in Neuseeland
– Weit mehr als 30.000 Studenten
– Unter besten 100 Unis in der Welt
Paralleles Rechnen – Motivation Paralleles Rechnen: ● Mehre Rechenelemente kollaborieren bei der Ausführung von einer Aufgabe oder einem Problem Motivation: ● Höhere Leistung als Einprozessorsystem

Benutzung von Parallelrechnern
● “OK, was ist das Problem? Lass
uns einfach mehrere
Prozessoren für die eine
Aufgabe benutzen!”
● Leider nicht trivial
– Teilung der Aufgabe/des
Programms in Teilaufgaben
● Wie viele? Welche Größe?
– Verteilung auf
Rechenelemente
● Wie?
– Ausführung
● In welcher Reihenfolge? Wie
können sie kommunizieren?
Übersicht ● Aktuelle Rechnertrends ● Hintergrund zum Parallelrechnen Forschung @ ECE, University of Auckland ● Aufgabenablaufplanung (task scheduling) ● Rekonfigurierbares Rechnen ● OpenMP und tasks ● Visualisierungswerkzeuge ● Objektorientierte Parallelisierung

Aktuelle Rechnertrends

Aktuelle Rechnertrends
Parallelrechner bis jetzt
Bis jetzt
● (Sehr) große Rechner
– IBM Blue Gene/L mit mehr als
100.000 Prozessoren
● Mittelgroße Systeme mit
Gemeinsamem Speicher
Blue Gene/L
– Dutzende Prozessoren, world's fastest computer
Gemeinsamer Speicher 2004-8
● PC Cluster
– Unabhängige PCs verbunden
in einem Netzwerk – “low cost”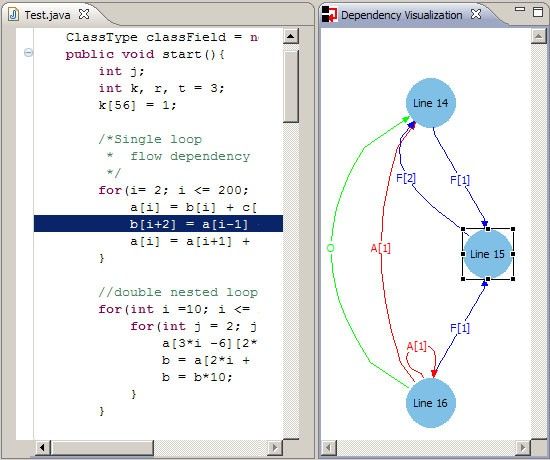
Aktuelle Rechnertrends
Paralleles Rechnen – warum jetzt?
● Paralleles Rechnen gibt es seit Jahrzehnten
● Prozessortechnologie erreicht ein physikalisches Limit –
Taktfrequenz hat sich nicht wesentlich verbessert in den
letzten Jahren!
Multicores überall
● Mehrere Prozessoren auf einem
Chip
● Aktuelle Prozessoren haben 2-4
cores
– Intel Core Duo, AMD
Opteron/Phenom, IBM Power6, die of AMD 'Barcelona' – 1st “real” x86
quad core, launched 10.9.2007
Sony Cell, Sun Niagra T1/T2
● x86 8-cores (!) nächstes Jahr
● Bald noch mehr
Aktuelle Rechnertrends
Spielkonsolen
Spielkonsolen sind parallel
● XBOX360: 3-core PowerPC
● Playstation 3
– Prozessor: Cell Broadband Engine
● 3.2 GHz
● PowerPC Architektur
● Plus 8 Synergistic Processing Elements
(SPE)
– Hauptspeicher: 256 MB
– Unter Linux UbuntuAktuelle Rechnertrends Cell ● Die Foto
Aktuelle Rechnertrends
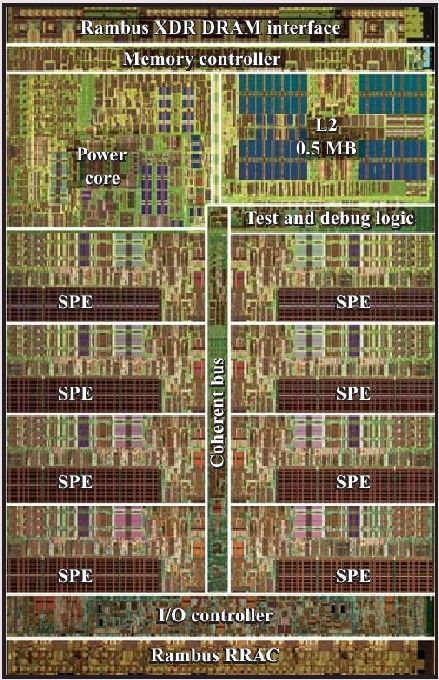
Cell Blockdiagramm
● PPE: power processor
element (PowerPC
instruction set)
● SPE: synergistic processor
element
– DMA: direct memory
access
– LS: local store memory
– SXU: execution unitAktuelle Rechnertrends
Playstation 3 cluster @ ECE
● 8 Playstation 3
● Verbunden durch Ethernet
● In 2007 benutzt für den Graduiertenkurs
SoftEng710
● Beispiel, benutzt für final year project
(~Diplomarbeit):
“Implementing the FDTD Method on the IBM Cell Microprocessor
to Model Indoor Wireless Propagation”, supervisor Dr NeveAktuelle Rechnertrends
Spezialisierte Hardware
● Spezialisierte Hardware benutzen zur Beschleunigung
– Nicht neu, z.B. Grafikkarten
– Aber, GPUs (Graphics Processing Units) werden jetzt
benutzt für andere Rechenaufgaben
● z.B. NVIDIA Compute Unified Device Architecture (CUDA)
● Coprozessoren
– ClearSpeed – PCIexpress board mit zwei
Spezialprozessoren (CSX600) beschleunigt
wissenschaftliche Anwendungen
● Beschleunigungstechnologien/Coprozessoren werden
unterstützt von Prozessorherstellern
– z.B. AMD Torrenza Initiative
● Größte Flexibilität: rekonfigurierbare Hardware
– Rekonfigurierbare Beschleunigungstechnologien auf
FPGA BasisAktuelle Rechnertrends
Rekonfigurierbare Hardware @ ECE
● 2 XD1000 Entwicklungssysteme
– Bald XD2000i
● Normale PCs mit zwei Prozessorsteckplätzen
– Einer für den Prozessor
– Einer für das FGPA (!)
● CPU: AMD Opteron 248 @ 2.2 GHz
● FPGA: Altera Startix II
● RAM: 4GB (CPU), 4GB (FPGA)
● OS: Linux FedoraAktuelle Rechnertrends
Meine Forschung
● Neue Hardware => neue Formen von
Parallelismus
Forschungsfokus
● Fundamentale Probleme des Parallelrechnens
– Aufgabenablaufplanung (task scheduling)
● Visualisierungswerkzeuge für den
Parallelisierungsprozess
Neue Formen von Nebenläufigkeit nutzen
● Desktop Parallelisierung
● Rekonfigurierbares RechnenHintergrund
Hintergrund
Herausforderungen der Parallelen Programmierung
Sequentielle
ProgrammierungHintergrund Herausforderungen der Parallelen Programmierung
Hintergrund Parallelisierungs Beispiel Programm/Aufgabe d = a2+a+1
Hintergrund
Parallelisierungs Beispiel
Teilaufgaben
Programm/Aufgabe A: a = 1
B: b = a+1
d = a2+a+1
Dekomposition C: c = a*a
D: d = b+cHintergrund
Parallelisierungs Beispiel
Teilaufgaben
Programm/Aufgabe A: a = 1
2 B: b = a+1 Abhängigkeits
d = a +a+1 analyse
Dekomposition C: c = a*a
D: d = b+cHintergrund Parallelisierungs Beispiel Teilaufgaben A: a = 1 B: b = a+1 C: c = a*a D: d = b+c
Hintergrund
Parallelisierungs Beispiel
Teilaufgaben
A: a = 1
B: b = a+1
C: c = a*a
D: d = b+c
Ablaufplanung auf 2
Prozessoren (P1, P2)Hintergrund
Parallelisierungs Beispiel
pragma omp parallel tasks
{
#pragma omp task A 2 {
for (i=0; iForschung
Abhängigkeitsanalyse
Abhängigkeitsvisualisierung
Hintergrund: Datenabhängigkeitstypen
● Verschiedene Typen der Abhängigkeit
– Flussabhängigkeit – lesen dann schreiben
● z.B. Zeile 2 liest a, geschrieben in Zeile 1
– Antiabhängigkeit – schreiben dann lesen
● z.B. Zeile 4 überschreibt v nachdem Zeile 3 es liest
– Ausgabeabhängigkeit – schreiben dann schreiben
● z.B. Zeile 2 und 4 beschreiben vAbhängigkeitsvisualisierung
Hintergrund: Abhängigkeit in Schleifen
for(i = 2; i häufig hohe RechenlastAbhängigkeitsvisualisierung Eclipse Plugin für Java
Abhängigkeitsvisualisierung
Eclipse Plugin für Java
● Augenblickliche
Abhängigkeitsanalyse
– Java parser
– Genaue Abhängigkeitstests
● Abhängigkeitsvisualisierung
der Schleife um den Cursor
● Alle
Datenabhängigkeitstypen,
verschiedene Farben
● Interaktion mit Graph und
Code
● Zukunft: Unterstützung für
Abhängigkeitselimination/
transformationAufgabenablaufplanung
-
KommunikationswettstreitAufgabenablaufplanung
Beispiel
Beispiel:
2 Prozessoren
+
NP-hartes
Problem !Aufgabenablaufplanung
Klassisches Systemmodell
Systemmodell Eigenschaften:
● Dediziertes System
● Dedizierte Prozessoren
● Kostenfreie lokale
Kommunikation
● Teilsystem für
Kommunikation
z.B. 8 Prozessoren ● Nebenläufige
Kommunikation
● Vollständig verbundenAufgabenablaufplanung
Kommunikationswettstreit
Wettstreit Beispiel ● Endpunkt Wettstreit
– Um Schnittstelle
● Die meisten
Klassisches Netzwerke sind
Modell nicht vollständig
verbunden
● Netzwerk Wettstreit
– Um
KommunikationskanalAufgabenablaufplanung
Wettstreitsensitive Ablaufplanung
● Zielsystem repräsentiert als Netzwerkgraph
● Integration der Kantenablaufplanung in
Aufgabenablaufplanung
without contention with contentionAufgabenablaufplanung Task scheduling Buch O. Sinnen “Task Scheduling for Parallel Systems” John Wiley, 2007 ● Einführung in Paralleles Rechnen ● Graphenmodelle ● Grundlagen Aufgabenablaufplanung ● Algorithmen ● Fortgeschrittene Aufgabenablaufplanung ● Heterogene Systeme ● Realistische Parallelrechnermodelle
Aufgabenablaufplanung
Wettstreit und Aufgabenduplikation
● Aufgabenduplikation
– die gleiche Aufgabe auf mehr als einem Prozessor
ausführen
● Besonders nützlich gegen Kommunikationswettstreit
● Konzept und Algorithmen entwickelt
P1 P2 P1 P2
0 0
A A A
10 10
B B B
20 20
time C C D
30 D 30
40 40
50 50
Without duplication With duplicationAufgabenablaufplanung
-
Optimaler AlgorithmusAufgabenablaufplanung
Benutzung von A*
Best first Zustandsraum
Suchalgorithmus
Beispiel
● Kürzeste Route von Lyon
nach Paris finden
● Karte modelliert als Graph
– Knoten: Städte
– Kanten: Verbindungen
zwischen den Städten;
Gewicht: gefahrene km
● Geschätzte
Gesamtentfernung f:
– Schon gefahrene Entfernung
+ Luftlinie nach ParisAufgabenablaufplanung
A* für Aufgabenablaufplanung
● Zustand => partieller Ablaufplan
● Kostenfunktion f(s) => Unterschätzung der
Ablauflänge/Ausführungszeit
● Zustand wird erweitert indem ein weiterer Knoten aufgenommen wird
ZustandsbaumAufgabenablaufplanung
A* für Aufgabenablaufplanung
● Erheblich verbesserte Kostenfunktion f(s)
vorgeschlagen
● Neu Beschneidungstechniken für Zustandsbaum
● Umfangreiche experimentelle Resultate mit
überraschenden Ergebnissen
Prozessornormalisierung
normaliseRekonfigurierbares
RechnenRekonfigurierbares Rechnen ● Rekonfigurierbare Rechenwerke können zu extrem hoher Leistung führen – Nebenläufigkeit kann viel höher sein Problem ● Programmierung oder Konfigurierung wesentlich schwieriger – als Parallele Programmierung (!) Idee (Hoffnung ?) ● Benutzung von Hochsprachen und automatischen Werkzeugen
Rekonfigurierbares Rechnen
Java zu Hardware Kompilation
● Hochsprache zu Hardware
– d.h. FPGAs
● Kompilation zu VHDL
– dann Synthese von VHDL, d.h. Konfiguration
von FPGA
Intention
● Beschleunigung von Java Programmen
● In Kombination mit normalem ProzessorRekonfigurierbares Rechnen
Java zu Hardware Kompilation
● Projekt verbindet Parallelrechnen, Eingebettete
Systeme und Software Engineering
Testplattform
XD1000 Systeme
Bieten tiefe Integration von CPU
und FPGA
Leider
schwieriger zu benutzen als
erhofft
● XD2000i hoffentlich einfacherParallele Programmierung Tasks in OpenMP
Parallele Programmierung
OpenMP Direktiven benutzen
OpenMP
● Offener Standard für Programmierung von
Rechnern mit gemeinsamen Speicher
● Compiler Direktiven für FORTRAN, C/C++, Java
● Thread basiert
Beispiele (in C)
#pragma omp parallel for #pragma omp parallel sections
{
for (i=0; iParallele Programmierung
Tasks/Task Direktiven
Einführung neuer Direktiven: tasks/task
● Wie sections mit feinerer Granularität
● Abhängigkeiten und Rechenlast können angegeben werden
#pragma omp parallel tasks
{
#pragma omp task A 1 {
...
}
#pragma omp task B 2 dependsOn(A) {
...
}
...
}
Tasks/task werden umgewandelt in sections/section
mit Hilfe von AufgabenablaufplanungParallele Programmierung
JompX
Source-To-Source Compiler
● Java/OpenMP+task Direktiven => Java/OpenMP
//omp parallel tasks
P1 P2 boolean taskADone = false;
{ 2 0 boolean taskDDone = false;
boolean taskCDone = false;
// omp task A 2 A
{ boolean taskBDone = false;
A boolean taskFDone = false;
Block_Code _A
} //omp parallel sections
// omp task B 4 dependsOn (A) D {
B //omp section
{
Block_Code _B 5 {
} 4 2 3 Block_Code_A
C taskADone = true;
// omp task C 2 dependsOn (A)
{ Block _Code_D
B C D taskDDone = true;
Block_Code _C
} Task Code Block _Code_C
Parsing taskCDone = true;
// omp task D 3 dependsOn (A)
{
Scheduling 10 E
Generation while (!taskBDone ){}
Block_Code _D F Block _Code_E
6 7 while (!taskBDone ){}
}
// omp task E 6 dependsOn (B) while (!taskFDone ){}
{ Block _Code_G
E F
Block_Code _E }
} //omp section
// omp task F 7 dependsOn (C,D) 15 {
{ while (!taskADone ){}
Block_Code _F G Block_Code_B
} 5 taskBDone = true;
// omp task G 5 dependsOn (B,E,F) while (!taskCDone ){}
while (!taskDDone ){}
{ G
Block_Code _G Block _Code_F
} taskFDone = true;
} }
}
Code with tasks directives Tasks Graph representation Schedule of the tasks graph Codes with sections directivesParallele Programmierung
Aufgabengraph Visualisierung in Eclipse IDE
Links
Java Code mit tasks
Rechts:
AufgabengraphObjektorientierte Parallelisierung
Objektorientierte Parallelisierung
Parallel Iterator
● Desktop Programme müssen parallelisiert
werden
– Sonst keine Beschleunigung durch moderne
Prozessoren !
● Meisten Programme sind Objektorientiert (OO)
● Löwenanteil der Rechenlast in Schleifen
● Iteratoren in OO Schleifen
=> Parallele Version von IteratorenObjektorientierte Parallelisierung
Parallel Iterator
Iterator it = collection.iterator();
while ( it.hasNext() ) {
Image image = it.next();
}
resize( image );
...
hasNext() next()Objektorientierte Parallelisierung
Parallel Iterator
Iterator it = collection.iterator();
while ( it.hasNext() ) {
Image image = it.next();
}
resize( image );
...
hasNext() next()
Hohes Potential für
Parallelisierung,
aber wie?Objektorientierte Parallelisierung
Parallel Iterator Problem
hasNext() hasNext()Objektorientierte Parallelisierung
Parallel Iterator Problem
hasNext() next() hasNext()Objektorientierte Parallelisierung
Parallel Iterator Problem
hasNext() next() hasNext() next()Objektorientierte Parallelisierung
Parallel Iterator
Collection collection = ...;
Iterator it = collection.iterator();
ParIterator it = ParIterator.create(collection);
// each thread does this
while (it.hasNext()) {
Image image = it.next();
resize( image );
}Schlusswort
Parallel and Reconfigurable Computing Lab
http://www.ece.auckland.ac.nz/~sinnen/lab.html
Forschung
● Fundamentale Probleme des Parallelrechnens
– Aufgabenablaufplanung
● Visualisierungswerkzeuge für
Parallelisierungsprozess
Neue Formen von Nebenläufigkeit nutzen
● Rekonfigurierbares Rechnen
● Desktop Parallelisierung
– Objektorientierte ParallelisierungSie können auch lesen

















































