Potenzial von Machine Learning bei der kurzfristigen Leistungsprognose innerhalb einer Laufkraftwerkskette
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Originalarbeit
Österr Wasser- und Abfallw 2022 · 74:224–240
https://doi.org/10.1007/s00506-022-00849-6
Potenzial von Machine Learning bei der kurzfristigen
Leistungsprognose innerhalb einer Laufkraftwerkskette
Christoph Klingler · Moritz Feigl · Thomas Linsbichler · Simon Frey · Karsten Schulz
Angenommen: 27. Januar 2022 / Online publiziert: 18. Februar 2022
© Der/die Autor(en) 2022
Zusammenfassung Da die Leistung sene Abfluss- und Leistungswerte von tional use for power forecasting. How-
eines Laufkraftwerks ohne Schwallbe- stromauf liegenden Laufkraftwerken ever, this solution still has some deficits
trieb nicht gesteuert werden kann, sind und Pegeln als Eingangsdaten heran- especially in the case of ascending and
möglichst präzise Leistungsprognosen gezogen. Die erzielten Ergebnisse zei- descending power curves. We therefore
nötig, um die generierte elektrische gen, dass ML im Anwendungsbereich evaluate the potential of machine learn-
Energie bestmöglich am internationa- der kurzfristigen Leistungsprognose ing (ML) methods for short-term (up
len Strommarkt verwerten zu können. innerhalb einer Laufkraftwerkskette to 4 h) power forecasting at the run-of-
Derzeit befindet sich beim österreichi- sinnvoll eingesetzt werden kann. So river power plants Braunau-Simbach,
schen Wasserkraftwerksbetreiber Ver- konnte beim Grenzkraftwerk Braun- Aschach and Greifenstein during five
bund AG für den Zweck der Leistungs- au-Simbach der Modellfehler in Form hydrologically interesting periods. The
prognose eine Kombination aus hy- der Wurzel der mittleren quadratischen used input variables for ML consist of
drologischen und hydrodynamischen Abweichung (RMSE) im Vergleich zu measured discharge and power from
Modellen (PW) im operativen Betrieb, PW bei der 4-Stunden-Prognose sowie upstream run-of-river power plants
welche aber insbesondere bei an- so- über die fünf ausgewählten Zeitfenster and gauges. The obtained results show
wie absteigenden Leistungsverläufen um rund 63 % verringert werden. Beim the advantages of applying ML in the
noch Defizite aufweist. Deshalb wird Kraftwerk Aschach wurde eine Reduk- domain of short-term power predic-
in dieser Studie an den Laufkraftwer- tion von 30 % erzielt, während beim tion within a run-of-river power plant
ken Braunau-Simbach, Aschach und Kraftwerk Greifenstein der RMSE mit chain. The model error, represented by
Greifenstein das Potenzial von Machine ML um mehr als 50 % reduziert wur- the root mean squared error (RMSE),
Learning (ML) Verfahren bei der kurz- de. Es hat sich bei ML zudem gezeigt, at the power plant Braunau-Simbach
fristigen (bis 4 h) Leistungsprognose in dass mit kürzerer Prognosezeit auch was reduced in the 5 selected periods
fünf hydrologisch interessanten Zeit- die Prognosequalität deutlich verbes- by approximately 63% compared to PW
fenstern eruiert. Dafür werden gemes- sert wird, während sich diese bei PW in in the 4-hour forecast. At Aschach a re-
einem deutlich geringeren Ausmaß mit duction of 30% was achieved, while the
der Prognosezeit ändert. Es ist daher RMSE at Greifenstein was reduced by
Anmerkungen Die Gegenüberstellung absehbar, dass ab einer bestimmten more than 50% when using ML. It could
der Zeitreihen für alle Prognosezeit PW gegenüber ML wieder also be shown that the quality of the
Vorhersagestufen (4 bis 1 h) und im Vorteil ist. Nichtsdestotrotz könnte ML forecast is strongly dependent on
Validierungsperioden (Val1 bis Val5) bei längerer Vorhersagezeit aber durch the lead time. The forecast quality of
sowie die „Feature Importance“, die Nachkopplung eines ML-Modells ML increases significantly with shorter
also die Relevanz der einzelnen an PW die Prognosequalität weiter ver- lead times, while this dependency is
Prädiktoren bei den ML-Modellen bessert werden. much weaker at the benchmark model
Random Forest sowie XGBoost, PW. It is therefore expectable that PW
werden als Online-Material zur Schlüsselwörter Kurzfristige will have an advantage over ML beyond
Verfügung gestellt. Leistungsprognose · Laufkraftwerk · a certain lead time. Nevertheless, it
Zusatzmaterial online Zusätzliche Machine Learning is possible that post-coupling an ML
Informationen sind in der model to PW could further improve
Online-Version dieses Artikels Performance of Machine the forecast quality in applications with
(https://doi.org/10.1007/s00506-022- Learning in short-term power longer lead times.
00849-6) enthalten. forecasting within a run-of-river
power plant chain Keywords Short-term power
DI C. Klingler () · DI M. Feigl, B.Sc. ·
forecasting · Run-of-river power plant ·
Univ.-Prof. Dipl.-Geoökol. Dr. K. Schulz
Abstract The output of a run-of-river Machine Learning
Department für
power plant cannot be controlled with-
Wasser-Atmosphäre-Umwelt, Institut
out surge operation. Therefore, precise 1 Einleitung
für Hydrologie und Wasserwirtschaft,
Universität für Bodenkultur Wien,
power forecasts are necessary in order
Muthgasse 18, 1190 Wien, Österreich to optimize sales of the generated elec- Der österreichische Wasserkraftwerks-
christoph.klingler@boku.ac.at trical energy on the international elec- betreiber Verbund AG hat als Stromer-
tricity market. Currently, the Austrian zeuger die Aufgabe, die erzeugte und
Dr. T. Linsbichler · Dr. S. Frey hydropower plant operator Verbund AG verbrauchte Energie an den verfüg-
VERBUND Energy4Business GmbH, uses a combination of hydrological and baren Handelsbörsen zu vermarkten.
Am Hof 6a, 1010 Wien, Österreich hydrodynamic models (PW) in opera- Insbesondere wird angestrebt, dass
224 Potenzial von Machine Learning bei der kurzfristigen Leistungsprognose innerhalb einer Laufkraftwerkskette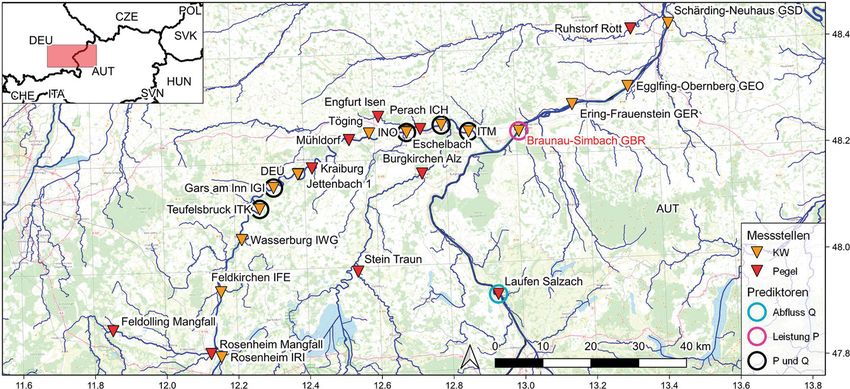
Originalarbeit
die tatsächlich erbrachte Energie der dessen meteorologische-Eingangsda- Li et al. 2021). Obwohl die Eignung
vermarkteten Menge entspricht, um ten die wichtigste Komponente dar. von ML für die (hydrologische) Zeitrei-
die ansonsten entstehenden Kosten Obwohl die Wahl des hydrologischen henvorhersage außer Frage steht, läuft
für verursachte Ausgleichsenergie zu Modells eine relevante Rolle in Be- derzeit eine aktive Diskussion über die
minimieren (Meeus et al. 2020). Für zug auf Prognoseunsicherheiten spielt Einstufung sowie den Wert von ML für
Laufkraftwerke stellt dies eine Her- (Plate und Shahzad 2015), ist die Un- den wissenschaftlichen Bereich (z. B.
ausforderung dar, da die Leistung nur sicherheit bedingt durch die meteoro- Nearing et al. 2021). Die Anwendung
sehr eingeschränkt gesteuert werden logischen Eingangsdaten im Vergleich von ML bei der kurzfristigen Leistungs-
kann und daher prognostiziert werden größer (Ramos et al. 2010; Zappa et al. prognose wurde beispielsweise schon
muss. Prognoseabweichungen können 2010). Die Prognosen mittels der Kom- für Windkraft- und Photovoltaikanlagen
zwar durch flexible Speicherkraftwerke bination COSERO und FluxDSS/DESIGNER/ (z. B. Colak et al. 2012; Heinermann und
kompensiert werden, dies widerspricht FLORIS2000 (im Folgenden als PW-Mo- Kramer 2016; Wang et al. 2019) oder für
aber oftmals den Interessen der Spei- dell bezeichnet) weisen derzeit an eini- die Last im Stromnetz (z. B. Jin et al.
cheroptimierung. Durch die steigende gen Laufkraftwerken insbesondere bei 2021) untersucht. Zur Evaluierung des
Bedeutung des Intraday-Marktes (EEX an- sowie absteigenden Leistungsver- Potenzials von ML bei der kurzfristi-
2019) können auch Prognosen kurz läufen immer noch Defizite auf, obwohl gen Leistungsprognose innerhalb einer
vor der Lieferung in der Vermarktung diese durch die Implementierung der Laufkraftwerkskette sind aber noch kei-
besser verwertet werden. Daraus ergibt hydrodynamischen Modellierung teil- ne vorhandenen Arbeiten bekannt.
sich das Interesse an möglichst präzi- weise bereits deutlich reduziert werden Deshalb stützen wir uns bei dieser
sen kurzfristigen Leistungsprognosen konnten. Arbeit auf die Annahme, dass inner-
für Laufkraftwerke. Machine Learning (ML)-Modelle un- halb eines Flussabschnitts mit größe-
Bei Verbund AG befinden sich für terscheiden sich grundsätzlich von pro- rem Einzugsgebiet bzw. innerhalb einer
mehrere Laufkraftwerksketten (Do- zessbasierten Modellen, welche häu- Laufkraftwerkskette (nicht-)lineare Zu-
nau, Inn, Mur) prozessbasierte Mo- fig bei hydrologischen Anwendungen sammenhänge bestehen. Der Kern der
delle zur Leistungsprognose im ope- verwendet werden. Während prozess- vorliegenden Untersuchung liegt darin
rationellen Betrieb, welche auf einer basierte Modelle eine Struktur und zu verifizieren, ob mittels ML-Modellen
Kombination aus dem hydrologischen Parametrisierung aufweisen, die ein diese Zusammenhänge in den Zeitrei-
Modell COSERO (COntinuous SEmi- physikalisches System widerspiegelt, hen von flussauf liegenden Kraftwerken
distributed RunOff ) und dem hydro- bestehen ML-Modelle aus flexiblen ma- und Pegeln erkannt sowie generalisiert
dynamischen Modell FluxDSS/DESIGNER/ thematischen Strukturen, welche an die werden können – und in weiterer Folge
FLORIS2000 (siehe z. B. Reichel et al. verfügbaren Daten angepasst werden. zu einer besseren kurzfristigen Leis-
2000; Reichel 2001) basieren. Das pro- Dementsprechend gibt es unterschied- tungsprognose (bis 4 h) führen. Dazu
zessbasierte Modell COSERO wurde liche Vor- und Nachteile beider Ansätze, werden die ML-Modelle a) schrittweise
am Institut für Hydrologie und Was- genauso wie unterschiedliche Anwen- multiple lineare Regression (stepLM),
serwirtschaft (HyWa, früher IWHW) dungsgebiete. Während prozessbasierte b) Random Forest (RF; Breiman 2001)
der Universität für Bodenkultur Wien Modelle eine klare Darstellung und In- sowie c) eXtreme Gradient Boosting
zur Abflussvorhersage in alpinen Ein- terpretation des Systems zulassen, gibt (XGBoost; Chen und Guestrin 2016)
zugsgebieten von Nachtnebel et al. es immer noch Schwierigkeiten bei der herangezogen. Die Ergebnisse dieser
(1993) entwickelt. COSERO zeichnet konsistenten Modellparametrisierung ML-Modelle werden an drei Laufkraft-
sich durch räumlich verteilte meteoro- speziell auf regionaler Ebene (z. B. Feigl werken bei verschiedenen hydrologi-
logische Eingangsdaten, (semi-)empi- et al. 2020; Klotz et al. 2017; Mizuka- schen Situationen den Prognosen des
rische Abbildungen diverser physikali- mi et al. 2017) und Ungewissheit über PW-Modells gegenübergestellt. Damit
scher Prozesse, (nicht-)lineare Speicher die Gesetzmäßigkeiten in Abhängigkeit können wir schlussendlich das Poten-
sowie verschiedene Routingansätze aus. von der Betrachtungsskala (z. B. Blöschl zial von ML-Modellen für die kurzfristi-
Eine kontinuierliche Weiterentwicklung et al. 2019; Hrachowitz et al. 2013; Kle- ge Leistungsprognose charakterisieren
sowie Validierung von COSERO erfolgte meš 1983). ML-Modelle weisen keiner- und Empfehlungen für die Anwendung
unter anderem im Rahmen von was- lei physikalisch interpretierbare interne geben.
serwirtschaftlichen Studien (Nachtne- Strukturen auf und können potenziell
bel und Fuchs 2004; Eder et al. 2005; auch unrealistische Ergebnisse liefern, 2 Methodik
Kling und Nachtnebel 2009a, b; Stan- haben aber den Vorteil, dass sie durch
zel und Nachtnebel 2010; Herrnegger ihre Flexibilität komplexe Zusammen- 2.1 Benchmark-Modell PW –
et al. 2012, 2015, 2018; Kling et al. 2012; hänge, Strukturen und Muster in Daten Kombination COSERO mit
Frey und Holzmann 2015; Klingler et al. sehr gut abbilden können. In den letz- FluxDSS/DESIGNER/FLORIS2000
2020, 2021; Wesemann et al. 2018), der ten Jahren konnte gezeigt werden, dass
Erstellung operationeller Prognosesys- sich diese Flexibilität für eine Reihe Um Durchflussprognosen mit COSERO
teme (Stanzel et al. 2008; Schulz et al. von hydrologischen Problemstellungen an einem bestimmten Pegel erstellen zu
2016; Wesemann et al. 2018) sowie bei – vor allem für kurzfristige Progno- können, stehen mehrere Möglichkeiten
der Verwendung in klimatischen Studi- sen – eignet und deshalb ML-Modelle zur Verfügung: a) das gesamte fluss-
en (Kling et al. 2012,2015; Mehdi et al. anstelle von oder in Kombination mit aufwärtsgelegene Einzugsgebiet wird
2021). Da die prognostizierte Leistung prozessbasierten Modellen für manche explizit mit COSERO modelliert, oder
bei Laufwasserkraftwerken stark vom Anwendungen die derzeit besten Er- b) an definierten Modellrändern wird
prognostizierten Durchfluss abhängig gebnisse liefern (z. B. Feigl et al. 2021; die Prognose eines (anderen) hydrologi-
ist, stellt das hydrologische Modell und Kratzert et al. 2021; Lees et al. 2021; schen Modells als Eingang zu COSERO
Potenzial von Machine Learning bei der kurzfristigen Leistungsprognose innerhalb einer Laufkraftwerkskette 225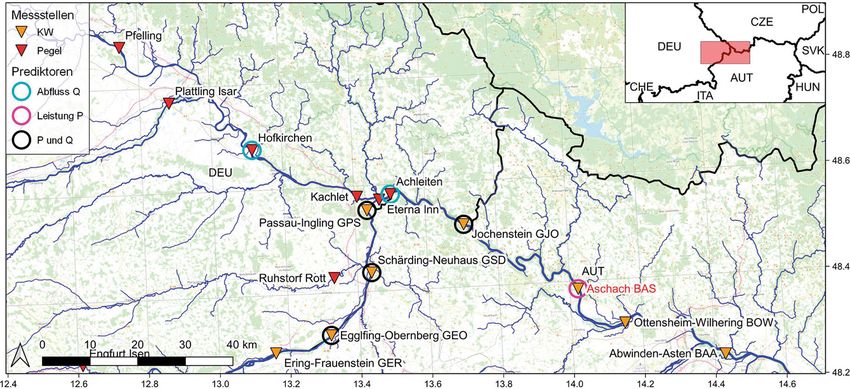
Originalarbeit
Tab. 1 Technische Daten der ausgewählten Laufkraftwerke, Verbund AG/viadonau GmbH
Braunau-Simbach Aschach Greifenstein
Abkürzung GBR BAS BGS
Gewässer Inn Donau Donau
Kilometrierung [km] 61,1 2162,67 1949,18
Seehöhe Oberwasser [m Mh] 349 280 177
Einzugsgebiet [km2] 22.895 78.192 100.342
MQ [m3 s–1], 2016–2020 689 1305 1788
Mq [l s–1 km–2] 30,1 16,7 17,8
Ausbaudurchfluss [m3 s–1] 1070 2480 3150
Mittl. Rohfallhöhe [m] 12,1 15,3 12,6
Engpassleistung [MW] 100 324 293
Regelarbeitsvermögen [GWh a–1] 550 1662 1717
Schleusenvolumen [m3] – 2 × je 93.942 2 × je 80.327
Füllzeit einer Schleusenkammer [min] – ca. 13 ca. 15
Leistungsverlust durch Füllung einer Schleusenkammer [MW]a – ca. 14,5 ca. 8,8
a
Annahme ηges = 80 %
verwendet. Bei VERBUND BAP wurde ARMA-Filters (siehe Broersen 2002; Kay Bei der schrittweisen multiplen linea-
die Variante b) gewählt, wobei alle ein- und Marple 1981; Terminologie XX.AR) ren Regression wird durch eine itera-
zelnen Gebiete mit COSERO modelliert korrigiert. Die Leistung am Kraftwerk tive Variablenselektion ein multiples
werden. An den Modellgrenzen wird hängt maßgeblich vom Durchfluss so- lineares Regressionsmodell generiert,
flussabwärts im Analyselauf der Mess- wie der Fallhöhe ab (siehe z. B. Dorn welches die Daten bestmöglich abbil-
wert, sofern vorhanden, und in der et al. 2016). Die Fallhöhe wird entweder det. Random Forest (Breiman 2001) ist
Vorhersage die Prognose des flussauf- a) mit einer kraftwerksspezifischen PQ- ein Klassifikations- und Regressions-
wärtsgelegenen Einzugsgebietes über- Beziehung abgeschätzt (Terminologie verfahren und basiert auf der Mittelung
geben. Die Modellerstellung gestaltet PW.PQ), oder b) hydrodynamisch pro- der Vorhersagen von mehreren unab-
sich hierbei einheitlich und basiert gnostiziert (Terminologie PW). Im Fall hängigen Regressionsbäumen. Jedem
auf physikalisch abgeleiteten Parame- von b) bekommt das hydrodynamische Regressionsbaum wird durch Bagging
tern der Landnutzung (CORINE, siehe Modell FluxDSS/DESIGNER/FLORIS2000 sei- (Breiman 1996) nur eine Bootstrap-
Feranec 2016), des digitalen Gelände- ne Zuflüsse am Modellrand einerseits Stichprobe der gesamten Trainings-Da-
modells (siehe Farr und Kobrick 2000), aus gemessenen Zeitreihen (in der ten zugeteilt, des Weiteren verwendet
sowie aus geologischen und Boden- Vergangenheit) und andererseits aus jeder Regressionsbaum nur eine indi-
karten aus dem hydrologischen Atlas mittels COSERO modellierten Zufluss- viduelle und zufällige Anzahl an Prä-
Österreichs (BMLFUW 2007). Auf de- Zeitreihen (in der Prognose sowie an diktoren. XGBoost (Chen und Guestrin
ren Basis werden a-priori Parameter Zubringern, die nicht über Pegelmess- 2016) basiert so wie auch RF auf Re-
geschätzt. Anschließend wird COSERO stellen verfügen). Auch die Ergebnisse gressionsbäumen, nur sind diese nicht
mittels SCE-UA (siehe z. B. Duan et al. der berechneten Leistung basierend mehr unabhängig und parallel, sondern
1993) kalibriert, wobei als Zielfunktion auf der hydrodynamischen Modellie- seriell (also aufeinander aufbauend)
die Kling-Gupta Efficiency (Gupta et al. rung werden mit demselben ARMA- strukturiert. Aufgrund der seriellen Ar-
2009) dient. Als meteorologischer Input Filter unter Verwendung der gemesse- chitektur sowie einer erhöhten Anzahl
(Temperatur und Niederschlag) wird nen Leistung korrigiert. an Hyperparametern nimmt das Trai-
mit INCA (Haiden et al. 2011) dersel- In diesem Beitrag werden nur Ergeb- ning des Netzwerks bei XGBoost im
be Datensatz verwendet, der auch im nisse der Modellkonfiguration Vergleich zu RF deutlich mehr Zeit in
operativen Betrieb eingesetzt wird. PW.INCA.AR (meteor. INCA-Progno- Anspruch. Für eine genauere Beschrei-
Operativ wird COSERO kontinuier- sedaten, hydrodynamische Modellie- bung der ausgewählten ML-Modelle
lich eingesetzt. Dies bedeutet, dass rung der Fallhöhe sowie Korrektur der möchten wir auf Feigl et al. (2021),
laufend Analyseläufe, sogenannte Up- Prognose mit ARMA-Filter) dargestellt, Abschn. 2.4.1 (stepLM), Abschn. 2.4.2
dateläufe, durchgeführt werden, um da einerseits INCA aufgrund der Ar- (RF) sowie Abschn. 2.4.3 (XGBoost) ver-
immer einen aktuellen Systemzustand chitektur sowie der hohen zeitlichen weisen.
zur Verfügung zu haben. Die Progno- Auflösung die stets aktuell verfügba-
sen werden mit verschiedenen me- re Prognose darstellt und PW.INCA.AR 2.3 Kraftwerksfestlegung- und
teorologischen Inputs (GFS, AROME, zumindest bei den untersuchten Kraft- Prädiktorenauswahl für die
INCA, ECMWF etc.) durchgeführt. Der werken und Zeiträumen im Mittel auch Prognose mit ML
kontinuierliche Betrieb von COSERO die besten Ergebnisse liefert.
führt dazu, dass der modellierte Ab- In der vorliegenden Untersuchung wird
fluss auch in der Analyse nicht exakt 2.2 Machine-Learning-Modelle das Augenmerk auf das Innkraftwerk
mit dem gemessenen Abfluss über- Braunau-Simbach sowie die beiden
einstimmen muss. Daher werden die Im Folgenden sollen kurz die verwende- Donaukraftwerke Aschach und Grei-
Ergebnisse von COSERO mittels eines ten ML-Methoden beschrieben werden. fenstein gelegt, um eine große Distanz
226 Potenzial von Machine Learning bei der kurzfristigen Leistungsprognose innerhalb einer Laufkraftwerkskette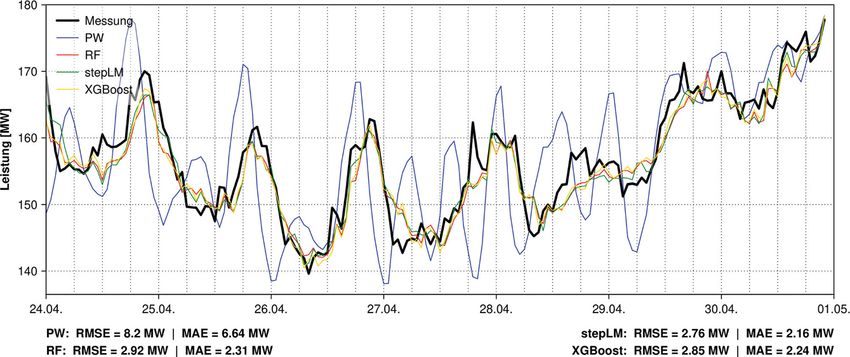
Originalarbeit
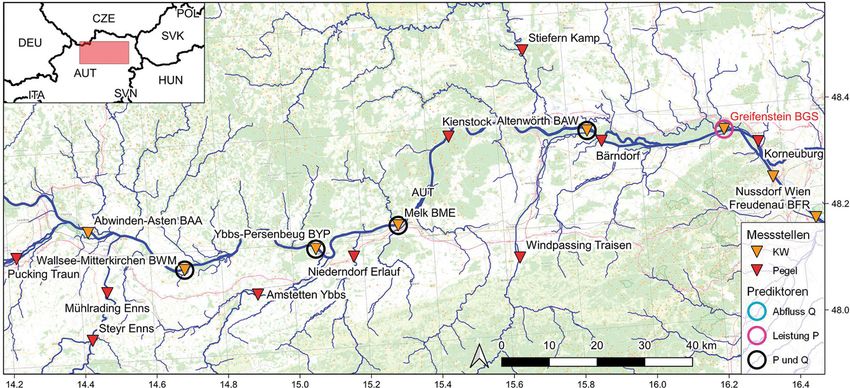
Abb. 1 Übersicht KW Braunau-Simbach, Messnetz: Verbund AG, Gewässernetz: EU-Hydro – River Network Database (EEA 2019),
Hintergrundkarte: OpenStreetMap, Staatsgrenzen: ©EuroGeographics, Koordinaten: WGS84, Prädiktorenauswahl entspricht Aus-
wahl GBR6 in Tab. 2
Abb. 2 Übersicht KW Aschach, Messnetz: Verbund AG sowie GKD Bayern, Gewässernetz: EU-Hydro – River Network Database
(EEA 2019), Hintergrundkarte: OpenStreetMap, Staatsgrenzen: ©EuroGeographics, Koordinaten: WGS84, Prädiktorenauswahl ent-
spricht Auswahl BAS3 in Tab. 3
zwischen den Kraftwerken zu gewähr- stromauf des betreffenden Kraftwerks diktoren stehen bei Kraftwerken grund-
leisten. Grundlegende technische Da- sowie teilweise auch Informationen be- sätzlich die Messgrößen Abfluss und
ten dieser zur Verbund AG zugehörigen treffend der Jahres- („fuzzy months“) Leistung (bei Donaukraftwerken auch
Laufkraftwerke sind in Tab. 1 aufgelis- als auch Tageszeit („fuzzy daytime“) als Wasserstand des Ober- und Unterwas-
tet. Prädiktoren verwendet. Unter „fuzzy“ sers sowie der Wehrüberfall) sowie bei
Im Gegensatz zu COSERO werden wird die Transformation von diskre- Pegeln der Abfluss zur Verfügung. Ei-
bei der kurzfristigen Leistungsprognose ten Zeitpunkten zu kontinuierlichen ne Übersicht der zur Verfügung ste-
mit ML keine meteorologischen Vor- Werten (z. B. über Sinusfunktion) ver- henden Kraftwerke und Pegel ist in
hersagen, sondern primär die gemesse- standen, um Sprünge zum Jahres- oder Abb. 1, 2 und 3 ersichtlich. Die Prä-
nen Werte von Kraftwerken und Pegeln Tageswechsel zu vermeiden. Als Prä- diktorenauswahl für die ML-Modelle
Potenzial von Machine Learning bei der kurzfristigen Leistungsprognose innerhalb einer Laufkraftwerkskette 227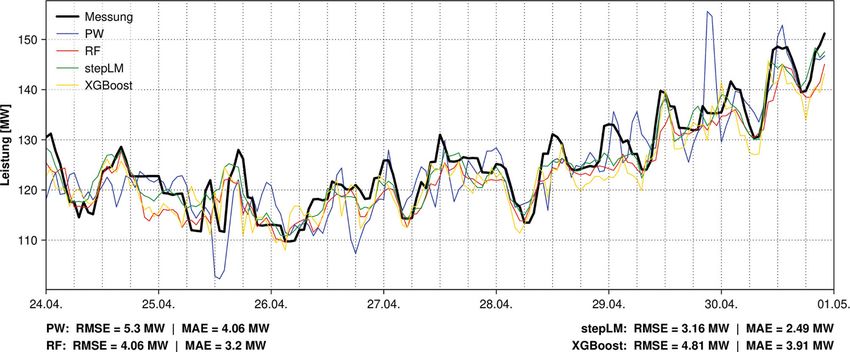
Originalarbeit Abb. 3 Übersicht KW Greifenstein, Messnetz: Verbund AG, Gewässernetz: EU-Hydro – River Network Database (EEA 2019), Hinter- grundkarte: OpenStreetMap, Staatsgrenzen: © EuroGeographics, Koordinaten: WGS84, Prädiktorenauswahl entspricht Auswahl BGS3 in Tab. 4 wird grundsätzlich so ausgelegt, dass bei dieser Optimal-Konfiguration (siehe zum KW Braunau-Simbach (GBR) auf- einerseits so viele Prädiktoren für ei- Tab. 7, 8 und 9) noch getestet, ob die gelistet. Die Messstellen Jettenbach 1 ne ausreichend zuverlässige Prognose Erweiterung der Prädiktoren um „fuzzy & 2, Kraiburg, Mühldorf sowie Töging wie notwendig, aber andererseits auch months“ (Indikatoren für die Jahres- (Abb. 1) werden nicht herangezogen, so wenige wie möglich implementiert zeit), „fuzzy daytime“ (Indikatoren für da diese von der ca. 23 km langen Aus- werden, um die Komplexität des trai- die Tageszeit) oder „lags“ (Werte eines leitung des Innwerkkanals (Ausbau- nierten Modells zu begrenzen sowie Messwerts aus der Vergangenheit) eine durchfluss ca. 340 m3 s–1) maßgebend die Anfälligkeit gegenüber technischen zuverlässigere Prognose ermöglicht. beeinflusst sind. Als die am weitesten Störungen (z. B. Datenübertragung) zu stromauf gelegene Messstelle wurde minimieren (für Prognoseberechnung 2.3.1 Grenzkraftwerk Braunau-Simbach am Inn das KW Rosenheim (IRI) ausge- müssen Werte für alle Prädiktoren vor- (GBR) wählt, welches 126,45 km stromauf von liegen). Da die Anzahl an möglichen GBR liegt, während der Pegel Laufen Kombinationen für die Prädiktorenaus- Das Grenzkraftwerk Braunau-Simbach Salzach im vorliegenden Versuch die wahl sehr hoch ist (zahlreiche Messstel- (GBR, Abb. 1) ist das erste Laufkraft- einzige Messstelle an der Salzach ist len flussauf des jeweiligen Kraftwerks, werk flussab der Einmündung der und sich ca. 54,6 Fließ-km oberhalb eine Vielzahl an möglichen „lags“ – also Salzach (MQ 252 m3 s–1, Pegel Burg- von GBR befindet. Werte der Prädiktoren aus der Vergan- hausen, 1901–2006) in den Inn (MQ genheit, z. B. 1 h vor dem Zeitpunkt der siehe Tab. 1.1). Das erste Laufkraft- 2.3.2 Laufkraftwerk Aschach (BAS) Prognoseberechnung, „fuzzy months“, werk flussauf der Salzach-Mündung „fuzzy daytime“), würde sich eine au- ist das Innkraftwerk Stammham, wel- Das Laufkraftwerk Aschach (BAS, Abb. 2) tomatisierte Suche nach der bestmögli- ches auch den Innzubringer Alz (exkl. ist das erste Donau-Laufkraftwerk, wel- chen Kombination der Prädiktoren als Alzkanal) abarbeitet. Im Unterlauf der ches zur Gänze auf österreichischem sehr rechenintensiv gestalten. Deshalb Alz wird jedoch der überwiegende An- Staatsgebiet liegt, und ist ca. 62,6 wird die Prädiktorenauswahl nach ei- teil in den Alzkanal (Ausbaudurchfluss Fließ-km unterhalb von Passau sta- nem möglichst systematischen „Trial ca. 90 m3 s–1, MQ 57 m3 s–1, Pegel Guffl- tioniert, wo der Inn (MQ 740 m3 s–1, und Error“-Verfahren festgelegt. Die ham, 1973–2011) eingespeist, welcher Pegel Passau Ingling, 1921–2006) sowie Kombination der Eingangsgrößen bei nach energetischer und thermischer die Ilz (MQ 16,1 m3 s–1, Pegel Kalten- den einzelnen durchgeführten Versu- Nutzung bei Burghausen in die Salzach eck, 1921–2012) in die Donau münden. chen wird in Tab. 2, 3 und 4 indiziert. eingeleitet wird. Da das Triebwasser für Zubringer stromab des nächst oberlie- Dabei sind die Kombinationen der den Alzkanal jedoch flussauf des Pegels genden Donaukraftwerks Jochenstein einzelnen Versuche so festgelegt, dass Burgkirchen entnommen wird, steht – und damit nicht messtechnisch für die zunehmend mehr Prädiktoren imple- keine Information über den Gesamtzu- Leistungsprognose verfügbar – sind die mentiert werden und somit die bereits fluss der Alz für die Leistungsprognose Ranna (MQ 3,1 m3 s–1, Pegel Oberkap- beschriebene optimale Konfiguration – des KW Braunau-Simbach zur Verfü- pel, 1951–2010), die kleine Mühl (MQ aus so vielen Prädiktoren wie notwen- gung. 3,3 m3 s–1, Pegel Obermühl, 1976–2011) dig, aber so wenigen wie möglich – In der Tab. 2 sind die Prädiktoren- sowie die große Mühl (MQ 8,6 m3 s–1, gefunden werden kann. Zusätzlich wird Kombinationen der einzelnen Versuche Pegel Teufelmühle, 1951–2011), wobei 228 Potenzial von Machine Learning bei der kurzfristigen Leistungsprognose innerhalb einer Laufkraftwerkskette
Originalarbeit
Tab. 2 Prädiktoren-Kombination der einzelnen Versuche für die kurzfristige Leistungsprognose beim KW Braunau-Simbach
(GBR)
GBR1 p_GBR
GBR2 p_ITM | p_GBR
GBR3 pr_ITM | p_GBR
GBR4 pr_INO | pr_ICH | pr_ITM | p_GBR
GBR5 r_LS | pr_INO | pr_ICH | pr_ITM | p_GBR
GBR6 pr_ITK | pr_IGI | r_LS | pr_INO | pr_ICH | pr_ITM | p_GBR
GBR7 pr_IWG | pr_ITK | pr_IGI | r_LS | pr_INO | pr_ICH | pr_ITM | p_GBR
GBR8 pr_IRI | pr_IFE | pr_IWG | pr_ITK | pr_IGI | r_LS | pr_INO | pr_ICH | pr_ITM | p_GBR
GBR9 Prädiktoren von GBR6 sowie fm | fd
GBR10 Prädiktoren von GBR6 sowie jeweils lag4-Daten
Abkürzung: p Leistung, r Abfluss, pr Leistung und Abfluss, lag4 Wert des Prädiktors 1 h (4 × 15 min) vor dem Zeitpunkt der Prognoseberechnung, fm „fuzzy
months“ (12 Prädiktoren), fd „fuzzy daytime“, IRI KW Rosenheim, IFE KW Feldkirchen, IWG KW Wasserburg, ITK KW Teufelsbruck, IGI KW Gars am Inn, INO KW
Neuötting Inn, ICH KW Perach, ITM KW Stammham, GBR KW Braunau-Simbach, LS Pegel Laufen Salzach (Zeitreihenbeginn Mitte April 2013).
Tab. 3 Prädiktoren-Kombination der einzelnen Versuche für die kurzfristige Leistungsprognose beim KW Aschach (BAS)
BAS1 pr_GJO | p_BAS
BAS2 pr_GPS | r_AD | pr_GJO | p_BAS
BAS3 r_HD | pr_GEO | pr_GSD | pr_GPS | r_AD | pr_GJO | p_BAS
BAS4 pr_GER | r_HD | pr_GEO | pr_GSD | pr_GPS | r_AD | pr_GJO | p_BAS
BAS5 r_PD | r_PI | pr_GER | r_HD | pr_GEO | pr_GSD | pr_GPS | r_AD | pr_GJO | p_BAS
BAS6 Prädiktoren von BAS3 sowie fm | fd
BAS7 Prädiktoren von BAS3 sowie jeweils lag4-Daten
Abkürzung: p Leistung, r Abfluss, pr Leistung und Abfluss, lag4 Wert des Prädiktors 1 h (4 × 15 min) vor dem Zeitpunkt der Prognoseberechnung, fm „fuzzy
months“ (12 Prädiktoren), fd „fuzzy daytime“, GER KW Ering-Frauenstein, GEO KW Egglfing-Obernberg, GSD KW Schärding-Neuhaus, GPS KW Passau-Ingling,
GJO KW Jochenstein, BAS KW Aschach, PD Pegel Pfelling Donau (GKD 2021), PI Pegel Plattling Isar (GKD 2021), HD Pegel Hofkirchen Donau (Zeitreihenbeginn
Mitte August 2016), AD Pegel Achleiten Donau (Zeitreihenbeginn Mitte August 2016).
Tab. 4 Prädiktoren-Kombination der einzelnen Versuche für die kurzfristige Leistungsprognose beim KW Greifenstein (BGS)
BGS1 pr_BAW | p_BGS
BGS2 pr_BYP | pr_BME | pr_BAW | p_BGS
BGS3 pr_BWM | pr_BYP | pr_BME | pr_BAW | p_BGS
BGS4 pr_BAA | pr_BWM | pr_BYP | pr_BME | pr_BAW | p_BGS
BGS5 Prädiktoren von BGS3 sowie r_ME
BGS6 Prädiktoren von BGS3 sowie r_SK | r_WT
BGS7 Prädiktoren von BGS3 sowie fm | fd
BGS8 Prädiktoren von BGS3 sowie jeweils lag4-Daten
Abkürzung: p Leistung, r Abfluss, pr Leistung und Abfluss, lag4 Wert des Prädiktors 1 h (4 × 15 min) vor dem Zeitpunkt der Prognoseberechnung, fm „fuzzy
months“ (12 Prädiktoren), fd „fuzzy daytime“, BAA KW Abwinden-Asten, BWM KW Wallsee-Mitterkirchen, BYP KW Ybbs-Persenbeug, BME KW Melk, BAW KW
Altenwörth, BGS KW Greifenstein, ME Pegel Mühlrading Enns, SK Pegel Stiefern Kamp (Zeitreihenbeginn Mitte August 2016), WT Pegel Windpassing Traisen.
diese in Relation zur Donau (MQ siehe 2.3.3 Laufkraftwerk Greifenstein (BGS) der Donau (MQ siehe Tab. 1.3) beträgt
Tab. 1.2) im Mittel sehr kleine Zubringer ca. 1,4 %, wobei die Abflüsse am Pegel
sind. Das Laufkraftwerk Greifenstein (BGS, Stiefern sowie Windpassing als Prädik-
Die Kombinationen der Prädiktoren Abb. 3) ist das vorletzte Donaukraftwerk toren implementiert werden können
zum KW Aschach (BAS) sind in Tab. 3 auf österreichischem Territorium und (Abb. 3).
aufgelistet. Der Pegel Pfelling ist dabei liegt ca. 16 km stromauf von Wien (KW Tab. 4 zeigt die Auflistung der ge-
in der Untersuchung die am weitesten Nussdorf ). Größere Zubringer, welche wählten Prädiktoren-Kombinationen
entfernte Messstelle an der Donau, wel- nicht beim nächst stromauf liegen- zum KW Greifenstein (BGS). Das am
che 142,86 Fließ-km stromauf von BAS den Donaukraftwerk Altenwörth erfasst weitesten stromauf gelegene Donau-
stationiert ist, während das am wei- werden, sind linksufrig der Kamp (MQ Laufkraftwerk in Tab. 4 ist dabei das KW
testen entfernte implementierte Inn- 8,9 m3 s–1, Pegel Stiefern, 1983–2007) Abwinden-Asten, welches 170,27 Fließ-
KW Ering-Frauenstein (GER) ca. 110,6 und die Krems (MQ 1,9 m3 s–1, Pegel km oberhalb von BGS liegt. Getestet
Fließ-km oberhalb von BAS liegt. Imbach, 1981–2011) sowie rechtsuf- wird bei der optimalsten Prädiktoren-
rig die Traisen (MQ 14,2 m3 s–1, Pegel Kombination (Tab. 9) auch, ob die
Windpassing, 1981–2011). Das Verhält- zusätzliche Implementierung der Ab-
nis der Summe der Mittelwerte dieser flusswerte der Pegel Mühlrading Enns,
drei Zubringer zum mittleren Abfluss Stiefern Kamp sowie Windpassing Trai-
Potenzial von Machine Learning bei der kurzfristigen Leistungsprognose innerhalb einer Laufkraftwerkskette 229Hier steht eine Anzeige. K
Hier steht eine Anzeige. K
Originalarbeit
Tab. 5 Trainings- und Validierungsperioden
Zeitraum Hydrologische Situation
Trn 01.01.2013a 00:00 bis 30.04.2019 23:00 –
Val 01.05.2019 00:00 bis 30.04.2021 23:00 –
Val1 10.05.2019 00:00 bis 16.05.2019 23:00 Bereich zw. Mittelwasser und kleinerem Hochwasser
Val2 01.03.2020 00:00 bis 07.03.2020 23:00 Mittelwasser
Val3 01.08.2020 00:00 bis 07.08.2020 23:00 Kleineres Hochwasser, Zufluss übersteigt Ausbaudurchfluss der Kraftwerke in Tab. 1
Val4 25.11.2020 00:00 bis 01.12.2020 23:00 Niederwasser
Val5 24.04.2021 00:00 bis 30.04.2021 22:00 ausgeprägter Tagesgang durch Schneeschmelze, unterhalb Mittelwasser
a
Abhängig vom spätesten Beginn der Zeitreihe eines ausgewählten Prädiktors
Tab. 6 Trainingsdauer [min] sowie maximale RAM Auslastung [GB] bei den verschiedenen ML-Modellen, 4 h Prognosezeit
Anzahl stepLM RF XGBoost
Prädiktoren Dauera [min] RAMb [GB] Dauera [min] RAMb [GB] Dauera [min] RAMb [GB]
2 0,15 | 0,02 14 5,21 | 0,06 43 173,37 | 0,03 25
6 0,61 | 0,03 16 16,57 | 0,1 49 242,71 | 0,22 26
a
Training (Trn) | Validierung (Val)
b
Basisauslastung von 10 GB inkludiert
sen als Prädiktoren zu geringeren Re- Prognose kein Mitglied des Eingangs- sowie XGBoost (6 Hyperparameter) sind
siduen in der Prognose führen (BGS5 Ensembles – welches die Werte für die kongruent mit der Untersuchung von
und BGS6 in Tab. 4). definierten Prädiktoren umfasst – einen Feigl et al. (2021), welche im dortigen
fehlenden Wert aufweisen darf. Ent- Anhang aufgelistet sind.
2.4 Training und Validierung der ML- sprechende Ensembles werden daher Die Validierung erfolgt in fünf ver-
Modelle aus den Trainings-Daten entnommen schiedenen Perioden mit jeweils ei-
und verkürzen den Trainingszeitraum ner 1-wöchigen Dauer (Tab. 5), wobei
Obwohl die vorhandenen Zeitreihen dementsprechend. Das Ende der meis- das Augenmerk bei der Evaluierung
überwiegend eine 15-minütige Auflö- ten Zeitreihen liegt bei Ende April 2021 aus Gründen der Übersichtlichkeit auf
sung aufweisen, erfolgt das Training und ist andernfalls ebenfalls indiziert. den Vorhersagen jener Modelle mit der
(das Anpassen an die Daten) der ML- Alle ML-Modelle werden mit der längsten untersuchten Vorhersagezeit
Modelle auf Stundenbasis. Einerseits Zielfunktion RMSE (Root Mean Squa- (4 h) gelegt wird, da davon auszugehen
liefert eine 15-minütige Auflösung spe- re Error; Gl. 1) sowie einer 10-fachen ist, dass bei dieser Stufe die Residuen
ziell bei den Pegelwerten gegenüber Kreuzvalidierung trainiert. Um eine im Mittel am größten sind. Zeitreihen
der stündlichen Auflösung meist kei- differenzierte Handhabung zu ermögli- für alle vier Vorhersagestufen inklusive
nen Mehrwert, da diese teilweise vorab chen, wird für jede einzelne Vorhersa- der dabei erzielten Gütemaße werden
auf Basis der Stundenwerte interpo- gestufe (1/2/3/4 h) ein eigenes Modell jedoch als Online-Material zur Verfü-
liert wurden und andererseits kann erstellt. Bei den ML-Modellen RF so- gung gestellt. Für die Validierung der
mit dieser Maßnahme die Gefahr der wie XGBoost müssen vor dem Start des ML-Modelle als auch des Benchmark-
Überanpassung der Modelle an die Trainings sogenannte Hyperparame- Modells PW kommt neben dem RMSE
Trainingsdaten (Overfitting) sowie die ter – welche Grundeigenschaften des auch der MAE (Mean Absolute Error;
Ressourcenauslastung des Rechensys- Modells definieren – festgelegt werden. Gl. 2) zur Anwendung. Aufgrund der
tems reduziert werden. Der Beginn der Häufig werden diese einfach mit „Stan- im Vergleich zu den anderen ML-Mo-
Zeitreihen der meisten Laufkraftwerke dardwerten“ belegt oder anhand eines dellen deutlich längeren Trainingszeit
ist Anfang Januar 2013. Nur beim Do- „Trial und Error“-Verfahrens festgelegt. bei XGBoost wird dieses Modell aus-
nau-KW Jochenstein ist es Mitte Juli Da die Festlegung der Hyperparameter schließlich mit der optimalen Prädikto-
2016 und bei den Inn-KW Oberaudorf- jedoch einen großen Einfluss auf die ren-Konfiguration (Tab. 7, 8, 9) trainiert
Ebbs, Nussdorf, Braunau-Simbach, Er- Modellgüte des trainierten Netzwerks und die dabei erzielte Modellgüte vali-
ing-Frauenstein Egglfing-Obernberg, haben kann (Claesen und De Moor diert.
Schärding-Neuhaus, Passau-Ingling 2015; Feigl et al. 2021), werden die-
liegt dieser bei Anfang April 2015. Der se in der vorliegenden Untersuchung 1
n 2
RM SE = y i − yi (1)
Beginn der Abfluss-Zeitreihen der Pegel mit der Bayes’schen Optimierungsme- n i =1
liegt in der Bandbreite von Anfang Janu- thode (Kushner 1964; Močkus 1975, 1 n
M AE = y i − yi (2)
ar 2013 bis Mitte August 2016 und wird 1989; Močkus et al. 1978; Zhilinskas n i =1
daher – falls der entsprechende Pegel 1975) systematisch per Algorithmus
als Prädiktor ausgewählt wurde und der bestimmt. Für eine Beschreibung der In Gl. 1 sowie 2 stellt n die Stich-
jeweilige Beginn nach Anfang Januar Bayes’schen Methode möchten wir auf probengröße (Anzahl der Zeitschritte),
2013 liegt – im Zusatz zu Tab. 2, 3, 4 Feigl et al. (2021) verweisen. Die An- yi die vorhergesagte sowie yi die beob-
indiziert. Dies ist insofern relevant, da wendungsbereiche sowie Grenzwerte achtete (gemessene) Leistung des Kraft-
sowohl beim Training eines Modells als der Hyperparameteroptimierung bei werks zum Zeitpunkt i dar.
auch bei der späteren Berechnung der den Modellen RF (2 Hyperparameter)
232 Potenzial von Machine Learning bei der kurzfristigen Leistungsprognose innerhalb einer LaufkraftwerksketteOriginalarbeit
Tab. 7 Gütemaße der unterschiedlichen Modelle sowie Versuche für 4 h Prognosezeit bei GBR [MW]
c
PW (PW.INCA.AR) stepLM Random Forest XGBoost
RMSE MAE RMSE MAE RMSE MAE RMSE MAE
GBR1a d d
5,78 3,14 6,02 3,48 – –
GBR2a – – 5,77 3,13 5,81 3,25 – –
GBR3a – – 5,71 3,12 6,43 3,27 – –
GBR4a – – 4,97 2,89 5,71 3,06 – –
GBR5a – – 5,54 2,91 5,32 2,47 – –
GBR6a 8,43 4,65 3,51 2,28 3,14 2,02 3,16 2,11
GBR7a – – 3,42 2,16 3,1 1,99 – –
GBR8a – – 4,22 2,37 3,13 1,97 – –
GBR9a – – – – 3,44 2,21 – –
GBR10a – – – – 3,0 1,92 – –
GBR6b – – 2,97 2,04 0,89 0,55 1,31 0,96
a
Zeitfenster Val1 bis Val5 in Tab. 5
b
Trainingszeitraum Trn lt. Tab. 5 für Optimal-Konfiguration. c Abkürzung siehe Tab. 2
d Die Gütemaße von PW werden nur bei der optimalen Prädiktoren-Kombination für ML als Benchmark angegeben
Tab. 8 Gütemaße der unterschiedlichen Modelle sowie Versuche für 4 h Prognosezeit bei BAS [MW]
c
PW (PW.INCA.AR) stepLM Random Forest XGBoost
RMSE MAE RMSE MAE RMSE MAE RMSE MAE
BAS1a d d
19,33 9,6 11,51 7,66 – –
BAS2a – – 11,47 7,22 10,62 7,64 – –
BAS3a 10,63 7,43 62,88 16,6 8,38 5,62 10,98 6,92
BAS4a – – 90,03 21,17 8,18 5,27 – –
BAS5a – – 77,24 17,85 7,35 4,76 – –
BAS6a – – – – 8,21 5,73 – –
BAS7a – – – – 8,49 5,52 – –
BAS3b – – 7,47 4,85 2,79 1,75 0,44 0,34
a
Zeitfenster Val1 bis Val5 in Tab. 5
b
Trainingszeitraum Trn lt. Tab. 5 für Optimal-Konfiguration
c
Abkürzung siehe Tab. 3
d
Die Gütemaße von PW werden nur bei der optimalen Prädiktoren-Kombination für ML als Benchmark angegeben
3 Ergebnisse und Diskussion der Methodik der Leistungsprognose die Trainings- und Validierungsdauer
mittels ML an anderen Kraftwerken auf sowie die maximale RAM-Auslastung
3.1 Aufwand der Modellerstellung die optimale Auswahl der Prädiktoren. (3 s Abtastintervall, Basisauslastung in-
Trainierte Modelle können als Files ex- kludiert) für 2 sowie 6 Prädiktoren – für
Die Aufbereitung und Homogenisie- portiert und auf andere Rechensysteme welche auch Daten für den vollständi-
rung der Eingangsdaten – welche im transferiert werden. Im operativen Be- gen Trainings- sowie Validierungszeit-
vorliegenden Fall die Zeitreihen der trieb sind dann nur noch wenige Zeilen raum (Tab. 5, Trn bzw. Val) vorliegen –
Prädiktoren darstellen – war unproble- Code für die Ausführung mittels R er- in Tab. 6 aufgelistet.
matisch, da die Rohdaten bereits in ein- forderlich. Die unterschiedliche Architektur von
heitlicher Form von der Verbund AG zur RF sowie XGBoost spiegelt sich auch in
Verfügung gestellt wurden. Der Haupt- 3.2 Testsystem und Tab. 6 anschaulich wider: Die seriel-
aufwand bei der Umsetzung der kurz- Ressourcenauslastung le Struktur der Regressionsbäume bei
fristigen Leistungsprognose mit ML lag XGBoost führt im Gegensatz zur paral-
bei der Erstellung der Algorithmen für Als Berechnungssystem kommt für das lelen Struktur eines RF zu einer geringe-
das Training der verschiedenen Model- Training der ML-Modelle ein Server-PC ren maximalen RAM-Auslastung, dafür
le, wobei die frei verfügbare Software R zur Anwendung, welcher über 16 CPU- aber auch zu einer deutlich längeren
(R Core Team 2020) mit Implementie- Kerne mit jeweils 2,3 GHz sowie 256 GB Trainingszeit (Multi-Core-Prozessoren
rung von einigen ebenfalls frei verfüg- RAM verfügt. Grundsätzlich ist die Trai- verlieren dabei ihren Vorteil). Multi-
baren Packages (z. B. Caret, Kuhn 2019; ningsdauer sowie die maximale RAM- ple lineare Regression ist zwar ein sehr
data.table, Dowle et al. 2014; XGBoost, Auslastung bei allen untersuchten ML- einfaches Modell, welches schnell pa-
Chen et al. 2016) verwendet wurde. So- Modellen vom Umfang der Trainings- rametrisiert werden kann, jedoch steigt
bald die erstellten Algorithmen nach Daten (Anzahl Eingangs-Ensembles so- bei stepLM die Trainingszeit exponen-
intensiver Prüfung voll funktionstüch- wie auch deren Mitglieder) abhängig. tiell mit der Anzahl der Prädiktoren an
tig sind, verlegt sich der Schwerpunkt Um den Unterschied zwischen den und liegt z. B. bei 18 Prädiktoren (GBR8
des Arbeitsaufwands bei Anwendung ML-Modellen zu zeigen, wird jeweils in Tab. 2) aufgrund der großen Zahl
Potenzial von Machine Learning bei der kurzfristigen Leistungsprognose innerhalb einer Laufkraftwerkskette 233Originalarbeit
Tab. 9 Gütemaße der unterschiedlichen Modelle sowie Versuche für 4 h Prognosezeit bei BGS [MW]
c
PW (PW.INCA.AR) stepLM Random Forest XGBoost
RMSE MAE RMSE MAE RMSE MAE RMSE MAE
BGS1a d d
7,34 4,87 7,23 4,71 – –
BGS2a – – 6,64 3,83 4,36 3,11 – –
BGS3a 8,21 6,1 8,58 4,03 4,15 2,99 3,94 2,94
BGS4a – – 6,52 3,47 4,06 2,97 – –
BGS5a – – 8,33 3,95 4,08 2,96 – –
BGS6a – – 5,98 3,58 4,56 3,08 – –
BGS7a – – – – 4,06 3,02 – –
BGS8a – – – – 3,97 2,97 – –
BGS3b – – 3,97 2,78 1,38 0,95 1,1 0,83
a
Zeitfenster Val1 bis Val5 in Tab. 5
b
Trainingszeitraum Trn lt. Tab. 5 für Optimal-Konfiguration.
c
Abkürzung siehe Tab. 4. d Die Gütemaße von PW werden nur bei der optimalen Prädiktoren-Kombination für ML als Benchmark angegeben
an theoretisch möglichen Kombinatio- noch eine marginale Reduktion der bei den ML-Modellen anschaulich dar-
nen (218–1) bereits bei 401 min. Des- mittleren Residuen zeigt. Ausgehend gestellt wird.
halb werden die Versuche GBR9 (225–1 von GBR6 kann durch die Hinzunah- Die Zeitreihen der 4-h-Prognose des
Kombinationsmöglichkeiten), GBR10 me von Informationen für die Jahres- Benchmark-Modells PW sowie der ML-
(224–1) in Tab. 2; BAS6 (224–1), BAS7 sowie Tageszeit als Prädiktoren (GBR9) Modelle (GBR6) werden der gemesse-
(222–1) in Tab. 3 sowie BGS7 (222–1), die Qualität der Prognose mit RF nicht nen Kraftwerksleistung im Zeitraum
BGS8 (218–1) in Tab. 4 mit stepLM nicht verbessern, während die zusätzliche Val5 in Abb. 4 gegenübergestellt. Um
durchgeführt. Bei allen Tests liegt die Einbindung der Werte der Prädiktoren den 27.04.2021 zeigen die Zeitreihen
Berechnungsdauer für die Validierung von GBR6 jeweils 1 h vor dem Zeitpunkt der ML-Modelle eine Lücke, da die
(Prognose) deutlich unter jener für das der Prognoseberechnung (GBR10) nur Abflusszeitreihe des Pegels Laufen Salz-
Training. Im operationellen Betrieb liegt zu einer geringfügigen Reduzierung der ach – welcher bei GBR6 als Prädiktor
die Berechnungsdauer eines Prognose- mittleren Fehler führt. Da sich durch implementiert ist – in diesem Zeit-
Ensembles (1/2/3/4 h) bei allen unter- die Hinzunahme der „lags“ bei GBR10 raum keine Werte beinhaltet und in
suchten ML-Modellen im Bereich von jedoch die Anzahl der Prädiktoren ver- weiterer Folge auch keine Leistungs-
ca. 5 s, sofern die trainierten Netzwerke doppelt und damit eine deutlich höhe- prognose berechnet werden kann. Ins-
einmal in den RAM geladen sind. Eine re Ressourcenauslastung beim Training gesamt zeigt sich sowohl grafisch als
Vorhersage mit der Modellkombination der ML-Modelle sowie eine höhere auch bei Betrachtung der in Abb. 4
PW benötigt zum Vergleich operativ Anfälligkeit im operationellen Betrieb angeführten Gütemaße eine genauere
mehrere Minuten. Erwähnenswert ist folgt, wird die Optimal-Konfiguration Prognose der Kraftwerksleistung mit
allerdings, dass hier a) eine längere mit GBR6 definiert. Der RMSE von ML. Einerseits werden mit ML die an-
Zeitreihe prognostiziert wird und b) die GBR6 liegt mit RF bei 3,14 MW, mit und absteigenden Äste des Leistungs-
Ergebnisse vollverteilter hydrologischer XGBoost bei 3,16 MW und mit stepLM verlaufes exakter in puncto Zeitpunkt
Prozesse in Form von Rastern geschrie- bei 3,51 MW. Der RMSE des Benchmark- sowie Amplitude prognostiziert und
ben werden. Diese können dann zur Modells beträgt zum Vergleich 8,43 MW, andererseits sind auch die maximalen
Plausibilisierung der Ergebnisse heran- und zeigt damit einen höheren Fehler Residuen nur halb so groß. Der RMSE
gezogen werden. bei der Prognose als die ML-Modelle im liegt in Val5 mit RF bei 1,78 MW, mit
Untersuchungszeitraum Val1 bis Val5. stepLM bei 2,06 MW sowie mit XGBoost
3.3 Grenzkraftwerk Braunau-Simbach Aufgrund der Vielzahl an Plots (vier bei 2,23 MW, während PW diesbezüg-
(GBR) Prognosestufen, fünf Zeitfenster) wird lich einen Vergleichswert von 3,83 MW
im Rahmen dieses Artikels bei allen drei aufweist.
Tab. 7 zeigt die Auflistung der erziel- untersuchten Kraftwerken (GBR, BAS,
ten Gütemaße RMSE sowie MAE über BGS) nur jener der 4-h-Prognosestufe 3.4 Laufkraftwerk Aschach (BAS)
alle fünf Validierungsperioden Val1 bis – welche vor allem bei den ML-Model-
Val5 (Tab. 5) für die 4-h-Prognosestufe. len meist den höchsten Unsicherheits- Die erzielten Gütemaße RMSE sowie
An dieser Stelle wird noch einmal die grad aufweist – für das Zeitfenster Val5 MAE über alle fünf Validierungspe-
Engpassleistung des betreffenden Kraft- – welches die höchste Variabilität der rioden Val1 bis Val5 (Tab. 5) kön-
werks GBR von 100 MW (Tab. 1) ange- jeweiligen Kraftwerksleistung beinhal- nen der Tab. 8 entnommen werden.
führt. Sowohl bei stepLM als auch bei tet – dargestellt und diskutiert. Die Die Engpassleistung des betreffenden
RF ist eine deutliche Verbesserung der restlichen Plots werden für die jeweils Kraftwerks BAS liegt zum Vergleich bei
Prognose ausgehend von der Kombina- „optimalste“ Prädiktoren-Kombinati- 324 MW (Tab. 1). Im besten Fall konnte
tion GBR5 auf GBR6 (Tab. 2) erkennbar, on (Bezeichnung in der letzte Reihe in mit dem ML-Modell RF und der Prä-
wohingegen sich bei zusätzlicher Im- Tab. 7, 8, 9) darüber hinaus als Online- diktoren-Kombination BAS5 (Tab. 3)
plementierung von weiter stromauf Material zur Verfügung gestellt, worin eine Reduktion des RMSE von 10,63
gelegenen Kraftwerken als Prädiktoren auch die Verbesserung der Prognose zu 7,35 MW im Vergleich zum Bench-
(GBR7, GBR8) zumindest bei RF nur mit zunehmend kürzerer Prognosezeit mark-Modell PW erzielt werden. Da
234 Potenzial von Machine Learning bei der kurzfristigen Leistungsprognose innerhalb einer LaufkraftwerksketteOriginalarbeit Abb. 4 Gegenüberstellung der 4-h-Prognosen für GBR6 im Zeitfenster Val5 Abb. 5 Gegenüberstellung der 4-h-Prognosen für BAS3 im Zeitfenster Val5 bei BAS5 aber die Abflussdaten der Ergebnisse von Val3 ausgeklammert en erzielt werden, wobei mit allen ML- Pegel Pfelling Donau sowie Plattling werden, liegt der RMSE/MAE für ste- Modellen der RMSE als auch der MAE Isar als Prädiktoren implementiert pLM zum Vergleich bei 5,56/3,94 MW im Vergleich zu PW verringert werden wurden – welche derzeit noch nicht und würde somit das beste Ergebnis konnte. Die Modellgüte der Prognosen für den operativen Betrieb zur Verfü- über alle Modelle darstellen. Mit BAS6 von RF und XGBoost liegen in Val5 zwi- gung stehen –, wird die Kombination (BAS3 + zusätzlich Indikatoren für Jah- schen stepLM und PW, wobei RF mit BAS3 mit RF als optimale Konfigura- res- sowie Tageszeit als Prädiktoren) einem RMSE von 4,06 MW einen ge- tion festgelegt. Bei BAS3 erzielen PW sowie BAS7 (BAS3 + zusätzlich Werte ringeren mittleren Fehler im Vergleich sowie XGBoost in etwa dieselbe Mo- der Prädiktoren aus der Vergangenheit) zu XBG mit 4,81 MW erzielt. Auffällig dellgüte, während stepLM mit einem lassen sich keine besseren kurzfristigen ist, dass die PW-Zeitreihe vereinzelt RMSE von 62,88 MW deutlich davon ab- Leistungsprognosen erzielen. „Ausreißer“ nach oben und unten be- weicht. Begründet werden können die Abb. 5 zeigt eine Gegenüberstellung inhaltet, während bei den Zeitreihen schlechten Ergebnisse mittels stepLM der Zeitreihen der einzelnen Model- der ML-Modelle derart hohe Residu- durch die hohen Residuen (> 100 MW) le in der Validierungsperiode Val5 der en (> 10 MW) nicht inkludiert sind. Ein in Val3, welche durch ein prognosti- Prognosestufe 4 h. In diesem Zeitfens- Grund dafür ist unter anderem die ziertes aber nicht durchgeführtes Ab- ter können mittels stepLM mit einem Hinzunahme der Leistung des betref- schalten des Kraftwerks verursacht wer- RMSE von 3,16 MW (unterer Teil der fenden Kraftwerks BAS als Prädiktor, den (siehe Online-Material). Wenn die Grafik) die geringsten mittleren Residu- womit der Leistungsprognose mittels Potenzial von Machine Learning bei der kurzfristigen Leistungsprognose innerhalb einer Laufkraftwerkskette 235
Originalarbeit
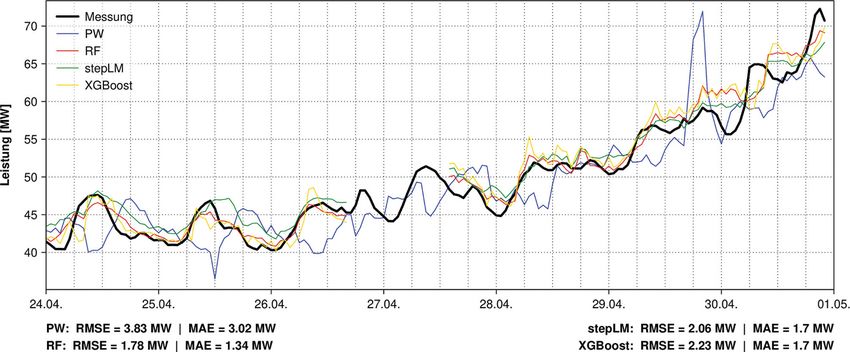
Abb. 6 Gegenüberstellung der 4-h-Prognosen für BGS3 im Zeitfenster Val5
ML ein solider Ausgangswert zur Ver- ten (Tab. 6) zukünftig schneller adap- Prognose in Val3 (nach Scheitelwert
fügung steht und die Bandbreite der tiert werden kann. Die Kombination Leistungsrückgang wegen Hochwasser)
möglichen Leistungsentwicklung in- BGS3 bietet gegenüber der Kombinati- wahrscheinlich aufgrund einer Überan-
nerhalb der nächsten 4 h – und damit on BGS5 den Vorteil, dass im operativen passung (Overfitting) an die Trainings-
auch die potenzielle Abweichung zum Betrieb weniger Prädiktoren implemen- daten erklärt werden.
Messwert – reduziert werden kann. tiert werden müssen, wodurch in wei- In Abb. 6 werden die Zeitreihen
terer Folge die Ausfallsicherheit erhöht in der Validierungsperiode Val5 der
3.5 Laufkraftwerk Greifenstein (BGS) wird. Bei Anwendung von RF mit der Prognosestufe 4 h gegenübergestellt –
Prädiktoren-Kombination BGS6 wird wobei grafisch veranschaulicht wird,
Die Ergebnisse der ML-Modelle für ein im Vergleich zu BGS3 schlechteres dass die verschiedenen ML-Modelle
die einzelnen Versuchskonfigurationen Ergebnis erzielt, da der Pegel Stiefern einerseits untereinander ähnliche Er-
(Tab. 4) sowie des Benchmark-Modells Kamp erst Abflusswerte ab Mitte Au- gebnisse liefern und andererseits deut-
PW sind in Tab. 9 aufgelistet. Die an- gust 2016 aufweist und dadurch die lich bessere Prognosen erzielen als das
gegebenen Modellgüten sollten dabei Trainingsdaten um über 3,5 Jahre re- Benchmark-Modell PW. Dies spiegelt
zur besseren Einstufung in Relation duziert – also nahezu halbiert – wird. sich auch in den angeführten Modell-
zur Engpassleistung des Kraftwerks von Bei der Hinzunahme von Prädiktoren güten RMSE sowie MAE (im unteren
293 MW (Tab. 1) gesetzt werden. Mit bezüglich der Jahres- und Tageszeit Teil des Plots) wider. Während die ML-
der Konfiguration BGS3 und XGBoost (BGS7) werden zwar der RMSE so- Modelle im Zeitraum Val5 einen RMSE
konnte der RMSE im Vergleich zum wie der MAE in der Trainingsperiode von ca. 3 MW aufweisen, liegt der Ver-
Benchmark von 8,21 auf 3,94 MW so- etwas verbessert – über die fünf Vali- gleichswert von PW bei über 8 MW.
wie der MAE von 6,1 auf 2,94 MW im dierungsperioden können mit diesen Ausschlaggebend dafür ist die exaktere
Zeitfenster der fünf Validierungsperi- Erweiterungen jedoch keine markanten Prognostizierung der Zeitpunkte und
oden (Tab. 5) reduziert werden. Dies Verbesserungen im Vergleich zu BGS3 Amplituden der Leistungsschwankun-
entspricht sowohl beim RMSE als auch erzielt werden. Ein ähnliches Bild zeigt gen. Speziell in der ersten Hälfte von
beim MAE ungefähr einer Halbierung sich, wenn ausgehend von der Konfigu- Val5 zeigen die Zeitreihen von PW eine
der mittleren Residuen im besten Test- ration BGS3 zusätzlich jeweils die Werte Phasenverschiebung zu den gemesse-
fall. Ein nahezu identes Ergebnis wurde von 60 min aus der Vergangenheit als nen Peaks von ungefähr drei Stunden,
bei Anwendung des ML-Modells RF Prädiktoren verwendet werden (BGS8). während die Zeitreihen der ML-Mo-
mit der Konfiguration BGS5 erzielt. Bei Mittels stepLM konnten mit fast allen delle die Peaks im Hinblick auf Zeit-
BGS5 wurde im Vergleich zu BGS3 der Konfigurationen zuverlässigere kurz- punkt und Höhe gut darstellen. Abb. 6
Abfluss des Pegels Mühlrading Enns fristige Prognosen (4 h) als mit dem zeigt auch, dass PW teilweise auch
zusätzlich als Prädiktor implementiert. Benchmark-Modell PW erzielt werden, Leistungsanstiege und -abstiege mit ei-
Als optimale Konfiguration wurde je- jedoch fällt die Verbesserung gerin- ner Amplitude im Größenbereich von
doch BGS3 mit dem Modell RF gewählt, ger als mit den ML-Modellen RF und 20 MW prognostiziert, welche später
da damit einerseits nur ein marginal XGBoost aus. Die Verschlechterung des am Kraftwerk nicht gemessen wurden.
schlechteres Ergebnis in der Validie- Ergebnisses von BGS2 auf BGS3 bzw. Zwar werden mit den ML-Modellen
rung wie mit dem Modell XGBoost er- von BGS4 auf BGS5 bei stepLM kann – auch nicht alle gemessenen Leistungs-
zielt wird und andererseits das Modell obwohl dabei jeweils zusätzliche Prä- spitzen in puncto Höhe und Zeitpunkt
RF im Vergleich zu XGBoost aufgrund diktoren implementiert wurden – mit perfekt abgebildet, allerdings sollte die
der deutlich geringeren Trainingszei- einer deutlichen Verschlechterung der Skalierung der Ordinate sowie die Re-
236 Potenzial von Machine Learning bei der kurzfristigen Leistungsprognose innerhalb einer LaufkraftwerksketteOriginalarbeit
lation der Abweichung (max. ca. 7 MW) mit zunehmender Prognosezeit meist Eine – im Vergleich zum hier ange-
zur Engpassleistung von BGS beachtet auch abschwächen –, während bei PW wendeten „Trial und Error“-Ansatz –
werden. die Unsicherheit der Leistungsprogno- systematischere (auf Algorithmen ba-
se zu einem wesentlichen Teil von den sierende) Prädiktorenauswahl (z. B.
4 Schlussfolgerung und Ausblick Unsicherheiten der meteorologischen Chen et al. 2014) könnte wahrschein-
Prognose sowie der konzeptuellen Mo- lich zu einer weiteren Verbesserung
Bei allen untersuchten Laufkraftwer- dellierung abhängig ist. der Leistungsprognose führen. Es ist
ken konnten die Modellgüten bei der Es hat sich herausgestellt, dass die dabei jedoch davon auszugehen, dass
kurzfristigen Leistungsprognose (bis zu zusätzliche Einbeziehung von „fuzzy- aufgrund der Vielzahl an Kombinati-
4 h) durch Anwendung von ML-Mo- months“ (Indikatoren für die Jahres- onsmöglichkeiten sehr hohe Rechen-
dellen verbessert werden. Dabei erziel- zeit) sowie „fuzzy-daytime“ (Indikator kapazitäten erforderlich sind. Diesbe-
ten generell die ML-Modelle RF sowie für die Tageszeit) als Prädiktoren – mög- züglich würde sich hier ein sinnvoller
XGBoost die zuverlässigeren Progno- licherweise aufgrund einer Überanpas- Anknüpfungspunkt für weitere Unter-
sen, wobei mittels XGBoost trotz der sung in der Trainingsperiode – teil- suchungen bzw. Forschungsarbeiten
deutlich längeren Trainingszeit (Tab. 6) weise sogar zu einer Reduzierung der ergeben.
gegenüber RF bei der vorliegenden Un- Modellgüte führte. Daher kann davon Deep Learning (DL) ist ein spe-
tersuchung meist keine Verbesserung ausgegangen werden, dass eine über zieller Teilbereich von ML und kann
erzielt werden konnte. Überraschend den vollständigen Trainings- und Vali- durch den mehrschichtigen, neurona-
genau sind in Anbetracht der Einfach- dierungszeitraum gültige systematische len Netzaufbau („deep“) ein verbesser-
heit des Konzepts und der Annahmen jahres- oder tageszeitabhängige Verzer- tes Systemverständnis erlangen. LSTMs
der multiplen linearen Regression auch rung der Kraftwerksleistung zumindest (Long Short-Term Memory), welche zur
die Prognosen des ML-Modells ste- in den Daten nicht vorhanden ist. Die Gruppe der RNNs (Recurrent Neural
pLM, wobei die erzielte Modellgüte Füllungen der Schleusenkammern bei Networks) gehören, können sich auf-
in den meisten Fällen zwischen je- den Donau-Kraftwerken Aschach und grund der Netzwerkarchitektur mit den
ner der komplexeren ML-Modellen RF Greifenstein verursachen aufgrund des internen dedizierten Speicherbaustei-
bzw. XGBoost sowie des Benchmark- reduzierten Turbinendurchflusses ei- nen bestimmte Information über einen
Modells PW liegt. Beim Kraftwerk Brau- ne Reduktion der Leistung und sind längeren Zeitraum merken. Feigl et al.
nau-Simbach wurde durch RF mit der meist zufällige Events, da nur nach Be- (2021) und Kratzert et al. (2021) konn-
Prädiktoren-Kombination GBR6 in den darf geschleust wird. Diese Zufälligkeit ten beobachten, dass diese Fähigkeit
fünf definierten Validierungszeiträu- ist mittels ML-Verfahren grundsätzlich speziell bei der Modellierung von Pro-
men (Tab. 5) eine Reduktion der RMSE- nicht erlernbar. Bezüglich der Einbe- zessen mit längeren Abhängigkeiten
Werte um rund 63 % im Vergleich zum ziehung von zusätzlichen „lags“ – also (z. B. hohe Konzentrationszeit in einem
Benchmark-Modell PW erzielt. Für das Werte eines Prädiktors aus der Vergan- großen Einzugsgebiet, Niederschlags-
Kraftwerk Aschach konnten mit RF und genheit – als Prädiktor ist grundsätz- speicherung in Form von Schnee) ge-
der Prädiktoren-Konfiguration BAS5 der lich eine außerordentlich hohe Anzahl genüber anderen ML-Modellen vor-
RMSE um etwa 30 % verringert werden, an Auswahlmöglichkeiten gegeben, da teilhaft sein kann. Aufgrund der Be-
während beim KW Greifenstein mittels dafür im Prinzip alle vergangenen Zeit- schränkung auf kurze Prognosezeiten
ML der RMSE mehr als halbiert wer- schritte gewählt werden können und (max. 4 h) sowie dem eher gering ausge-
den konnte. Die Zeitreihen der Modelle die Auswahl diesbezüglich auch für prägten Translations- sowie Retentions-
mit der optimalen Prädiktoren-Konfi- jeden Prädiktor unterschiedlich ausfal- verhalten zwischen den ausgewählten
guration gemäß Tab. 7, 8, 9 werden für len kann. Aufgrund der angewendeten Prädiktoren wird jedoch nicht davon
alle fünf Validierungsperioden sowie für „Trial und Error“-Methode bei der Aus- ausgegangen, dass LSTMs zu einer
die vier Prognosestufen (4 bis 1 h) als wahl der Prädiktoren wurde nur ein deutlich zuverlässigeren kurzfristigen
Online-Material zur Verfügung gestellt. sehr kleiner Auszug der möglichen Op- Leistungsprognose beim vorliegenden
Dort ist klar ersichtlich, dass bei den tionen getestet, wobei die Qualität der Anwendungsfall führen. Letzten Endes
ML-Modellen die Leistungsprognose Leistungsprognose für das KW Braunau bleibt diese Frage aber noch ungeklärt.
mit einer kürzeren Prognosezeit auch sowie Greifenstein durch die Imple- Da ML-Modelle ausschließlich aus
zunehmend kleinere Residuen aufweist, mentierung der „lags“ von 1 h für alle den Daten im Training lernen können,
während sich beim Benchmark-Mo- Prädiktoren geringfügig und für das KW ist die erzielte Modellgüte zu einem
dell PW die Metriken mit zunehmend Aschach bei Verwendung von RF nicht sehr wesentlichen Anteil von der Va-
geringerer Prognosestufe meist nicht gesteigert werden konnte. Die Relevanz riabilität sowie der Qualität (z. B. Mess-
oder nur marginal verbessern. Daraus der einzelnen Prädiktoren für die ML- fehler, Lücken) der verwendeten Daten
lässt sich schließen, dass der Vorteil Modelle RF sowie XGBoost werden im abhängig. Das ML-Modell RF mit der
von ML-Modellen bei der kurzfristi- Online-Material zusätzlich dargestellt. jeweils optimalen Prädiktoren-Konfigu-
gen Leistungsprognose innerhalb einer Dabei zeigt sich, dass für RF die Leis- ration wird derzeit im operationellen
Laufkraftwerkskette mit längerer Pro- tung des betreffenden Laufkraftwerks Betrieb ausführlich getestet. Bei diesen
gnosezeit auch zunehmend geringer sowie die Leistung der nächst stromauf Modellen wurde das Ende der Trai-
wird und ab einer bestimmten Stu- gelegenen Kraftwerke tendenziell am ningsperiode vom 30.04.2019 auf den
fe (z. B. 8 h) nicht mehr vorhanden ist. höchsten gewichtet werden, während 18.04.2021 ausgedehnt, um die Varia-
Dies lässt sich dadurch begründen, dass für XGBoost im Hinblick auf die Re- bilität der Trainings-Daten zu erhöhen
mit den ML-Modellen Zusammenhän- levanz der Prädiktoren keine Tendenz und in weiterer Folge die Prognose zu
ge zwischen den Prädiktoren und der erkennbar ist. verbessern. Im operationellen Betrieb
Zielgröße gelernt werden – welche sich müssen die Messwerte aller Prädiktoren
Potenzial von Machine Learning bei der kurzfristigen Leistungsprognose innerhalb einer Laufkraftwerkskette 237Sie können auch lesen

















































