Von der analogen Sammlung zur digitalen Forschungsinfrastruktur - De Gruyter
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Irene Amstutz, Martin Reisacher, Elias Kreyenbühl
Von der analogen Sammlung zur digitalen
Forschungsinfrastruktur
Die IIIF APIs als digitaler Kompass für die Überführung
der historischen Zeitungsausschnittsammlung des SWA
Abstract: The Swiss Economic Archives (SWA) owns a collection of newspaper
clippings on companies, persons, and factual topics related to the Swiss economy,
dating back to the 1850s. The 2.7 million clippings represent a well-used, central
source collection for economic and social history. Already in 2012, a shift from ana-
logue to digital clipping took place. Since then over 180.000 digital-born articles
have been added and made available online as PDFs. Starting 2018, as part of a
still ongoing project, about half of the analogue newspaper clippings have been
digitized and OCRised. This combined digital collection is accessible to Swiss
researchers (upon authentication due to copyright restrictions).
The retrodigitisation project marked the move from digital publication to
digital infrastructure based on the International Image Interoperability Frame-
work (IIIF) standard and its Application Programming Interface (APIs) for ima-
ges, full text, authentication and, last but not least, presentation. Thanks to IIIF
and compliant applications it has been possible to combine the benefits of digi-
tal and analogue collections and provide innovative and flexible access to over
800.000 clipped articles.
However, building and maintaining a digital infrastructure brings new chal-
lenges. When using interoperable standards, persistence, reliability, sustainability
and transparency must be ensured. We recognise this responsibility and look
forward to explore these challenges in depth with the researchers who use
this infrastructure.
Keywords: digitised newspapers clippings, IIIF, interface design
1 Einleitung
Am Anfang steht die etwas altbacken wirkende Sammlung von 2,7 Millionen
Zeitungsausschnitten, die, in grauen Schachteln liegend, vor Ort genutzt wer-
den kann. Am Schluss eine Infrastruktur, die mittels IIIF APIs (Application Pro-
gramming Interface) auch für Laien nutzbar ist, weitgehende Interoperabilität
der Daten schafft und die Möglichkeit, sich seine eigenen virtuellen themati-
Open Access. © 2023 bei den Autoren, publiziert von De Gruyter. Dieses Werk ist lizenziert
unter der Creative Commons Namensnennung - Nicht-kommerziell - Keine Bearbeitung 4.0 International Lizenz.
https://doi.org/10.1515/9783110729214-004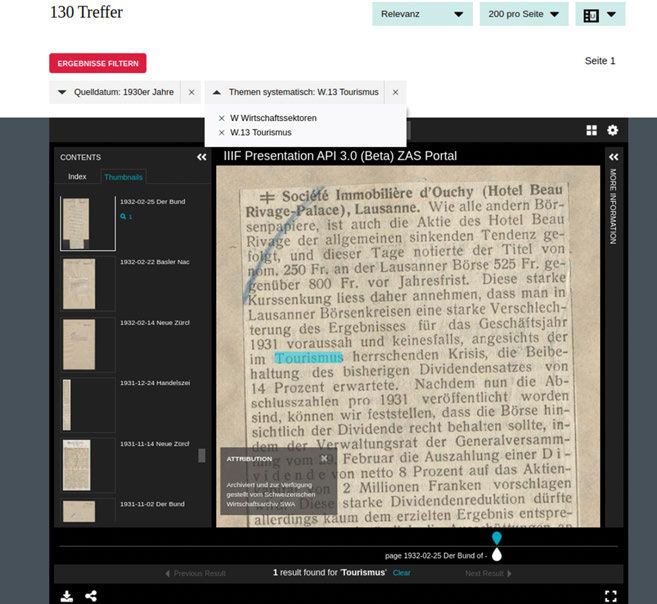
68 Irene Amstutz, Martin Reisacher, Elias Kreyenbühl
schen Sammlungen nachhaltig nutzbar herzustellen. Von den Zwischenschrit-
ten dieses langen Wegs und den zukünftigen Herausforderungen, die damit
verbunden sind, handelt der vorliegende Artikel.
Das Schweizerische Wirtschaftsarchiv SWA verfügt über eine Zeitungsaus-
schnittsammlung zu Firmen, Personen und Sachthemen der Schweizer Wirt-
schaft, die bis in die 1850er-Jahre zurückreicht. Die 2,7 Millionen Ausschnitte
stellen eine gut genutzte, zentrale Quellensammlung dar. Die Artikel sind the-
matisch geordnet und erschlossen: Im Rahmen eines noch laufenden Projekts
wurde die Hälfte der Zeitungsausschnitte digitalisiert und im Volltext auf einer
innovativen IIIF-basierten Oberfläche zur Verfügung gestellt, die neue Einstiege
in die Sammlung bietet.1
2 Die analoge Sammlung: Entstehung
und Nutzung
Seit seiner Gründung 1910 dokumentiert das Schweizerische Wirtschaftsarchiv
SWA die Wirtschaft. Dokumentieren bedeutet im Wesentlichen das gezielte Sam-
meln von meist publizierten Informationen über einen Gegenstand. Eine andere
Art der Quellensicherung stellt das Archivieren dar. Beim Archivieren werden von
einer Person oder Organisation selbst hergestellte Unterlagen von einer Archivin-
stitution übernommen. Die Unterlagen erfahren anlässlich der Übergabe ans Ar-
chiv eine Zweckänderung, vom aktiven Gebrauch zur Erfüllung einer Aufgabe hin
zum Nutzen für die historische Forschung. Für Forschende ist die Unterscheidung
wichtig, denn es spricht eine andere Perspektive aus dem Quellenmaterial. Der Un-
terschied fließt in die Quellenkritik ein. Die Sicherung von Archiven der privaten
Wirtschaft ist in der Schweiz nicht gesetzlich geregelt und deshalb freiwillig. Fir-
men archivieren in unterschiedlichem Ausmaß: Dies reicht von der Nullarchivie-
rung bis zu einigen professionell geführten und umfangreichen Firmenarchiven.
Weil schon zur Gründung des SWA klar war, dass deshalb keine systematische
und nur eine lückenhafte Überlieferung im Wirtschaftsbereich entstehen würde,
legte das SWA eine Wirtschaftsdokumentation an. Diese dokumentiert bis heute
die Wirtschaft in systematischer Weise in Form von einzelnen Dokumentensamm-
lungen: Im Blick steht die gesamte Schweizer Wirtschaft, gesammelt wird Material
https://ub-zas.ub.unibas.ch (zugänglich momentan nur aus dem IP Range der Uni Basel
bzw. zukünftig aus dem Schweizer Hochschulnetz).
Von der analogen Sammlung zur digitalen Forschungsinfrastruktur 69
zu wirtschaftlichen Sachthemen, über Firmen- und Verbände sowie wirtschaftsre-
levante Personen.
Eine Säule der Wirtschaftsdokumentation besteht darin, die wesentlichen
Tages- und Wochenzeitungen der Schweiz hinsichtlich wirtschafts- und wirt-
schaftspolitisch relevanter Artikel auszuwerten.2 Die Auswahl erfolgt intellektu-
ell, selektiv und auf der fundierten Kenntnis der gesamten Sammlung. Vor dem
digitalen Zeitalter wurden die Artikel ausgeschnitten, aufgeklebt und mit Meta-
daten versehen (Zeitungsname, Ausgabe, Signatur). Jeder Artikel wurde inhalt-
lich erschlossen, indem er in einer thematischen Dokumentensammlung, einer
Dokumentensammlung über Firmen und Organisationen oder über eine Person
abgelegt wurde. Die Titel der Dokumentensammlungen können als Schlagworte
betrachtet und verwendet werden, welche die Sammlungen in einer qualitativ
hochwertigen Weise erschließen. In der mehrsprachigen Medienlandschaft der
Schweiz wird hiermit auch eine sprachübergreifende Erschließung nutzbar ge-
macht. Entstanden ist in den vergangenen mehr als hundert Jahren eine her-
ausragende Sammlung von ca. 35.000 Dokumentensammlungen, in denen
ca. 2,7 Millionen Print-Zeitungsausschnitte des Zeitraums von 1850 bis 2012 lie-
gen und die digital weitergeführt wird (siehe unten).
Darüber hinaus enthalten die Dokumentensammlungen „Graue Literatur“,
also nicht von Verlagen publizierte Schriften wie Expertenberichte, Studien,
Statuten, Jahresberichte etc. Zudem liegen darin auch in Verlagen publizierte
Veröffentlichungen, wie etwa Festschriften über Firmen. Heute werden die
Dokumentensammlungen zu nahezu 100% mit digitalen Publikationen ergänzt,
welche online zur Verfügung gestellt werden, lokal abgespeichert, langfristig
archiviert und vom SWA dauerhaft online vermittelt werden. Die historischen
Dokumentensammlungen bestehen aus Schachteln, in denen in Mappen die
einzelnen Teile der Dokumentensammlung strukturiert sind. Eine Dokumenten-
sammlung kann einen Umfang von einer Mappe bis hin zu unzähligen Schach-
teln aufweisen.3 Die Schachteln werden vor Ort im Sonderlesesaal des SWA zur
Einsicht zur Verfügung gestellt (siehe Abb. 1). Die Mappen mit den historischen
Zeitungsausschnitten können ausschließlich vor Ort konsultiert werden.
Katalogisierte Einzelschriften können ausgeliehen werden.
Für weitergehende Informationen zu den ausgewerteten Zeitungstiteln, der Struktur und Er-
schließung der Sammlung etc. siehe Rechercheportal Zeitungsausschnitte – Informationen |
Universitätsbibliothek (https://ub.unibas.ch/de/historische-bestaende/wirtschaftsdokumenta
tion/rechercheportal-zeitungsausschnitte-informationen, Zugriff am 29.06.2022).
So besteht etwa die Zeitungsausschnitte-Sammlung zum „Münz- und Währungswesen im
Allgemeinen“ aus über 8.000 Artikeln.
70 Irene Amstutz, Martin Reisacher, Elias Kreyenbühl
Abb. 1: Die analoge Form der Zeitungsausschnittsammlung und die Schachteln,
die deren Struktur abbilden.
Copyright: Universitätsbibliothek Basel, SWA.
Die Dokumentensammlungen werden stark genutzt und erfreuen sich großer
Beliebtheit. Forschende unterschiedlicher Fächer wie Geschichte und Wirtschaft,
aber auch Medienwissenschaften, Politologie, Soziologie, Geografie, Volkskunde,
Gender Studies u. a. sind daran interessiert. Neben Wirtschaftsfragen im engeren
Sinn lassen sich auch Fragen zu Konsum, Sozialpolitik, Verkehr, Bildung, Raum-
planung, Technik, Architektur, Gleichstellung etc. bearbeiten. Die Zugänglichkeit
ist niederschwellig, da es sich um gedrucktes Material ohne schwer entzifferbare
Handschriften handelt. Zudem liegt die Information häufig in gut aufbereiteter
Form vor (Überblicke, Zusammenfassungen, Berichte, Statistiken). Man kann sich
anhand der Dokumentensammlungen in kurzer Zeit einen guten Überblick über
die Entwicklung einer Firma oder eines Themas aneignen. Gerade die Zeitungsaus-
schnitte bilden den öffentlichen Diskurs zum jeweiligen Thema ideal ab. Der teil-
weise lange Zeitraum der Berichterstattung pro Thema ist ein weiterer Pluspunkt.
Eine umfangreiche Dokumentensammlung stellt aber auch große Anforderungen
daran, den Überblick zu halten. Das analoge Material kann nur zu den Öffnungs-
zeiten eingesehen werden. Reproduktionen müssen extra hergestellt werden.
In der analogen Arbeitsweise musste jedes Dokument zwingend in eine der
Dokumentensammlungen abgelegt werden, auch wenn vom Thema her vielleicht
zwei oder mehr Dokumentensammlungen dafür in Frage gekommen wären. Zum
Beispiel musste der Zeitungsausschnitt, in dem Roche-CEO Severin Schwan über
die Entwicklung eines Medikaments von Roche berichtete und gleichzeitig zu sei-
ner Person befragt wurde, entweder in die Dokumentensammlung über die Firma
Roche oder in diejenige zu seiner Person gelegt werden. Arbeitet man an einem
Thema, muss man sich überlegen, welche Dokumentensammlungen dazu Mate-
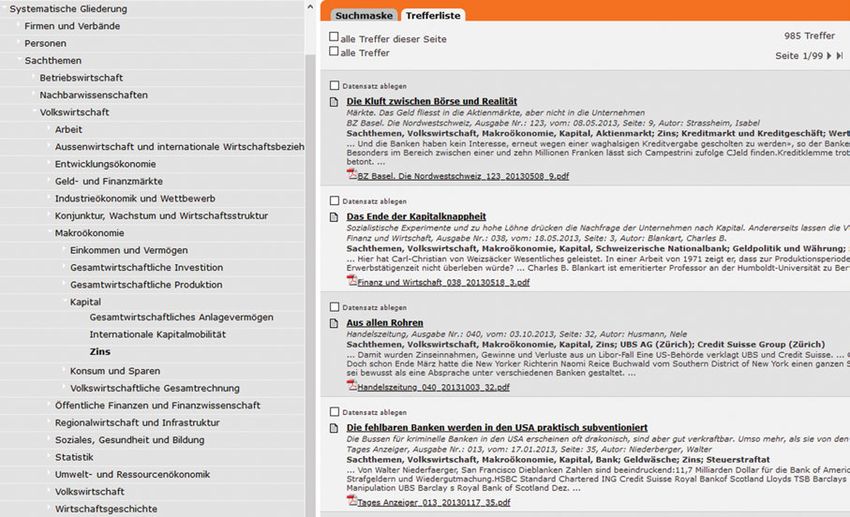
rial bieten könnten. Die Titel der Dokumentensammlungen werden zudem mit derVon der analogen Sammlung zur digitalen Forschungsinfrastruktur 71 Zeit historisch und das Thema kann seine Benennung über die Jahre verändern. So wurde beispielsweise eine Dokumentensammlung über „Reklamewesen“ ange- legt, das heute „Werbung“ oder sogar „PR“ heißt oder „Fremdenverkehr“ wurde zu „Tourismus“.4 Übrigens war die Veränderung der Begriffe auch immer ein Ar- gument dafür, bei der intellektuellen Auswahl der Artikel zu bleiben. So landen auch Zeitungsartikel in einer Dokumentensammlung, welche den Begriff, der für den Titel der Dokumentensammlung verwendet wird, nicht im Inhalt tragen. 3 Erste Schritte in Richtung digitale Transformation 2012 begann mit dem Projekt E-ZAS (Elektronische Zeitungsausschnitt-Samm- lung) eine neue Ära für die Zeitungsausschnitt-Sammlung. Die Artikel werden mittels einer Clipping-Software, die für die kommerzielle Medienbeobachtung entwickelt wurde, aus den als E-Paper zur Verfügung gestellten Zeitungen nach einer halbautomatischen Layout-Erkennung digital ausgeschnitten und mit Me- tadaten versehen. Im Gegensatz zur Print-Sammlung werden zusätzliche Meta- daten erfasst (neu auch Autor, Titel des Artikels, Seitenzahl). Die Artikel stehen in einem Portal online zur Verfügung (siehe Abb. 2). Jeder Artikel wird mit einem Schlagwort des Standard Thesaurus Wirtschaft versehen und damit einer digitalen Dieser Veränderung wurde in der Erschließung in den vergangenen 15 Jahren Rechnung ge- tragen, indem Ontologien und Linked Open Data eingesetzt werden. Die Dokumentensamm- lungen zu Personen sowie über Firmen und Organisationen werden mit dem Namen betitelt. Namenswechsel von Firmen und weiteren Organisationen werden nachgeführt. Firmen und Organisationen sind zudem mit den Normdaten der GND (Gemeinsame Normdatei) verknüpft. Die Dokumentensammlungen zu Wirtschaftsthemen trugen bis 2004 hausintern gewählte, his- torische Titel, z. B. „Gewerbe- und Fabrikinspektionswesen“. 2005 fand eine Revision der Titel statt: Die Anzahl der weiter zu pflegenden Dokumentensammlungen wurde von 3.500 auf 1.200 reduziert; vor allem auf eine starke geografische Gliederung wurde verzichtet. Die neu verwendeten Titel bzw. Begriffe wurden in Anlehnung an den Standard Thesaurus Wirtschaft STW vergeben. Der STW stellt zudem eine hierarchische Gliederung zur Verfügung (Volkswirt- schaft, Betriebswirtschaft etc.), welche für die Implementierung einer systematischen Suche genutzt wird. Die Dokumentensammlungen mit den historischen Benennungen wurden mit den neuen STW-basierten Titeln der Dokumentensammlungen verknüpft. So gelangt man in der Suche mit einem STW-Schlagwort zur historischen Dokumentensammlung. Oft führt ein STW-Schlagwort zu mehreren historischen Dokumentensammlungstiteln. Seit 2020 werden statt der adaptierten STW-Begriffe die Begriffe des originalen STW verwendet (als linked open data-Verknüpfung). Alle früher benutzten Begriffe bzw. Titel von Dokumentensammlungen werden bei einer Suche als Synonyme mitberücksichtigt.
72 Irene Amstutz, Martin Reisacher, Elias Kreyenbühl
Dokumentensammlung zugeordnet (es wird dasselbe Schlagwort wie in der
analogen Sammlung verwendet, siehe dazu auch Fussnote 4). Nun können
pro Artikel mehrere Schlagworte vergeben werden. Somit wird der Artikel in
verschiedenen E-Dokumentensammlungen auffindbar. Auch ist der gesamte
digital gesammelte Bestand texterkannt und kann im Volltext durchsucht
werden. Dies erschließt den Bestand auf völlig neue Art und Weise, worauf
weiter unten näher eingegangen wird. Aktuell umfasst der Bestand an „born
digital“ Zeitungsausschnitten ca. 180.000 Artikel. Pro Jahr kommen zwi-
schen 25.000 bis 30.000 Artikel neu dazu.
Ende 2020 wurde die Clipping-Software abgelöst. Das SWA arbeitet seit 2021
mit der Schweizerischen Mediendatenbank SMD, die alle Artikel der teilnehmenden
Zeitungsverlage enthält und Journalisten und Journalistinnen als Arbeitsinstrument
dient. Die Artikel liegen bereits digital, texterkannt, layouterkannt und metadatiert
vor. Auf diese Weise kann von den dort vorhandenen („Original“-)Daten und
Metadaten bruchlos profitiert werden. Das mühsame „Clippen“, also Schneiden
der Artikel, und das nachträglich händische Metadatieren entfallen. Die zur Verfü-
gung stehende Software ist deutlich ergonomischer in der Bedienung. Wie bis
anhin werden die Artikel lokal gespeichert und lokal langfristig archiviert.
Und ein weiterer Automatisierungsschritt ist in Arbeit. In einem Projekt der
Zürcher Hochschule für Angewandte Wissenschaften (ZHAW) Winterthur wurde
mit Hilfe von Maschinellem Lernen (Deep Learning) ein Algorithmus entwickelt,
der die intellektuelle Beschlagwortung der einzelnen Zeitungsartikel unterstützt.
Das vorhandene digitale Textmaterial der mit der Clipping-Software bearbeiteten
Artikel wurde in Beziehung zu den verwendeten Schlagworten gesetzt. Der Algo-
rithmus ist nun fähig, mit neuem Textmaterial aufgrund der vorhandenen Daten
potenzielle Schlagworte vorzuschlagen.5
Die Online-Zurverfügungstellung barg jedoch die Herausforderung der Ein-
haltung des Urheberrechts. Da die neuen Artikel nicht frei im Internet zugäng-
lich gemacht werden dürfen, wurde eine Login-Funktion programmiert.6
Siehe https://www.zhaw.ch/no_cache/de/forschung/forschungsdatenbank/projektdetail/
projektid/2248 (Zugriff am 29.06.2022).
Unbestritten ist, dass Angehörige von Universitäten und Schulen geschützte Inhalten online
nützen dürfen. Uneinigkeit herrscht darin, ob eine kontrollierte Nutzung (z. B. durch bewusste
Freischaltung von Nutzerinnen und Nutzern) einzelner Artikel (nicht einer ganzen Ausgabe
einer Zeitung) urheberrechtskonform sei. Das SWA hat ein Login für Angehörige von Hoch-
schulen und Schulen programmiert (Angehörige der Universität Basel nutzen VPN), um keine
Urheberrechtsverletzung zu begehen. Alle anderen müssen die Sammlung vor Ort nutzen.Von der analogen Sammlung zur digitalen Forschungsinfrastruktur 73
Abb. 2: Das alte E-ZAS Portal, basierend auf einer kommerziellen Softwarelösung für die Medienbeobachtung.7
Siehe Fußnote 1. Eine Anmeldung um einen Zugang auf E-ZAS – Elektronische Zeitungsaus-
schnittsammlung zur Schweizer Wirtschaft zu erhalten wird hier erklärt: https://ub-easyweb.
ub.unibas.ch/de/news/details/das-zeitungsausschnitt-portal-des-swa/ (Zugriff am 29.06.2022).74 Irene Amstutz, Martin Reisacher, Elias Kreyenbühl
Nach der Umstellung des analogen auf den digitalen Sammlungsprozess
nahm das SWA ein Anschlussprojekt in Angriff: Die historische Sammlung über
2,7 Millionen Zeitungsausschnitte wird retrodigitalisiert. Drei Hauptziele werden
damit verfolgt: Erstens entsteht durch die Digitalisierung eine Schutz- und Siche-
rungskopie. Ein Aspekt, der gerade für das fragile Zeitungspapier erheblich ist.
Zweitens wird die Sammlung damit online zugänglich, digital durchsuchbar und
auf neue Weise präsentierbar. Drittens wird damit der entstandene Medienbruch
zur digitalen Sammlung ab 2012 geschlossen. Das Projekt läuft über mehrere
Jahre und wird zu erheblichen Teilen mit Drittmitteln finanziert. Bis anhin ist die
Hälfte der Artikel retrodigitalisiert worden. Auch diese Artikel haben Texterken-
nung durchlaufen und sind metadatiert. Damit steht nun ein großer Korpus an
digitalen Zeitungsartikeln in hoher Qualität zur Verfügung. Und nun beginnt das
Träumen über Volltextsuchen über das gesamte Material, über virtuelle Doku-
mentensammlungen, über neue Präsentations- und Auswertungsformen und
über Weiternutzungen der Daten in anderen Umgebungen.
4 Aufbruch zur digitalen Forschungsinfrastruktur
4.1 Leitgedanken
Schon bei der Umstellung auf E-ZAS zeigten sich die Möglichkeiten der digita-
len Transformation, war es doch nun möglich, gezielt von zuhause in den Voll-
texten zu recherchieren. Doch das Durchblättern größerer Treffermengen war
aufwendig, musste doch jedes PDF einzeln aufgerufen werden. Interoperabili-
tät, dass also die Artikel auch außerhalb der E-ZAS-Oberfläche nachgenutzt
und eingebunden werden konnten, war nicht gegeben.
Die Entwicklungen in Richtung Infrastruktur war zu Beginn des Projekts weni-
ger von einem detaillierten Konzept geprägt, sondern vielmehr ein Lernprozess,
der besonders durch die begrenzten Projektmittel für die Präsentationskomponen-
ten, aber auch durch die zeitliche Möglichkeit in der Entwicklung innezuhalten
und zu reflektieren, geprägt war.
Und auch der Zufall spielte eine Rolle. Da durch den Umzug des bisherigen
Clipping Dienstleisters nach Indien die Zusammenarbeit äußerst schwierig
wurde, musste überhaupt erst eine eigenständige Lösung außerhalb des alten
E-ZAS Portals gefunden werden. Know-how und Infrastruktur bzgl. Suchtech-
nologie war in der Universitätsbibliothek Basel (UB) als Trägerorganisation desVon der analogen Sammlung zur digitalen Forschungsinfrastruktur 75
SWA insbesondere durch swissbib8 vorhanden und auch ein flexibles Frontend
zur Präsentation von heterogenen Daten bereits in Planung.
Nur für Digitalisate existierte keine Lösung, da diese bislang auf den großen
Schweizer Plattformen e-rara9, e-manuscripta10 und e-codices11 publiziert wur-
den. Mit IIIF (International Image Interoperability Framework) als Standard zur
Präsentation von Digitalisaten waren aber bereits erste Erfahrungen gesammelt
worden. Gerade die Möglichkeiten zur Nachnutzung von IIIF-Komponenten, die
nicht selbst programmiert werden mussten, wie etwa einem Viewer, boten hier
aufgrund der begrenzten Projektressourcen eine interessante Perspektive.
Langsam formten sich daraus grundlegenden Ideen, was bei der Überfüh-
rung dieser analogen Sammlung in den digitalen Raum und bei der Verknüpfung
mit E-ZAS zu berücksichtigen wäre, um für die nächsten Jahre anschlussfähig zu
bleiben. Rückwirkend betrachtet haben die folgenden Thesen die Entwicklung
des ZAS-Projekts maßgeblich geprägt:
– Infrastruktur vor Portal: das Projekt definiert sich stark über die Interope-
rabilität seiner IIIF APIs und nicht primär über seine Oberfläche.
– Nachnutzung durch Standards und Interoperabilität: durch die Stan-
dards profitiert das Projekt von einer großen Community, die Applikationen
rund um IIIF entwickelt bzw. können andererseits die ZAS-Daten von de-
zentralen Forschungsumgebungen genutzt werden
– Easy2Use API: da im IIIF Standard die API auf die Präsentation der Daten
ausgerichtet ist, wird die technische API Spezifikation, gerade bei der Prä-
sentation im Viewer, für den Endnutzer nahezu unsichtbar. Das vereinfacht
auch für technische Laien die Interaktion mit der API.
– „Virtuelle Dokumentensammlungen“: die Möglichkeit über 800.000 Ar-
tikel zu individuellen Datensets zusammenstellen zu können, ist ein zentra-
ler Mehrwert der spezifischen Ausformung der IIIF APIs in diesem Projekt.
– Authentifizierung: da es sich bei der Sammlung primär um urheberrecht-
lich geschützte Materialien handelt, spielt die Authentifizierung eine zent-
rale Rolle.
swissbib war bis Januar 2021 der Metakatalog und Datenhub aller Schweizer Hochschulbi-
bliotheken: https://www.swissbib.ch (Zugriff am 29.06.2022).
https://www.e-rara.ch/ (Zugriff am 29.06.2022).
https://www.e-manuscripta.ch (Zugriff am 29.06.2022).
https://www.e-codices.unifr.ch/de (Zugriff am 29.06.2022).76 Irene Amstutz, Martin Reisacher, Elias Kreyenbühl
4.1.1 Exkurs: IIIF APIs
Viele dieser Leitgedanken trägt der IIIF Standard schon genuin in sich. Das Spe-
zifikum dieses Projekts ist aber die hohe Flexibilität in der Generierung der IIIF-
Datensets, wodurch diese Aspekte noch verstärkt werden. IIIF ist ein Set von
API-Spezifikationen zur Präsentation von Bild und in Zukunft auch AV- bzw. 3D-
Objekten.12 Rund um den Standard hat sich in den letzten Jahren eine starke
Community gebildet, die von zentralen Akteuren im Bibliotheks- und Archivbe-
reich getragen wird. So unterstützen in der Schweiz und weltweit mehrere hun-
dert Institutionen und Portale diesen Standard und stellen zig Millionen Objekte
interoperabel zur Verfügung.
IIIF standardisiert diverse APIs, deren Bedeutung für das Projekt kurz er-
läutert werden soll. Eine Besonderheit ist auch, dass die APIs erst als stabil gel-
ten, sobald es zumindest zwei Umsetzungen gibt. IIIF ist also ein funktionaler
Standard. Folgend werden die zentralen APIs und deren Bedeutung für das Pro-
jekt kurz definiert. So existiert eine IIIF Image API13, die von einer Vielzahl an
Bildservern unterstützt wird.14 Darüber können performant unterschiedliche
Größen von Bildern ausgegeben werden, wie etwa Thumbnails für Voransich-
ten. Es kann aber auch bis ins letzte Detail gezoomt werden. Eine IIIF Search
API15 ermöglicht es, Volltext durchsuchbar zu machen und Text und Bild im
Viewer durch Highlighting miteinander zu verknüpfen. Durch die IIIF Authentica-
tion API16 können selbst in dezentralen Tools von berechtigten Personen Inhalte
angezeigt werden. Dieser Standard kann mit unterschiedlichen Authentifizierungs-
komponenten gekoppelt werden. All diese APIs inkorporiert die IIIF Presentation
API17, die diese Schnittstellen noch mit Metadaten und Strukturinformationen
zum digitalen Objekt verknüpft, damit diese in einem Viewer angezeigt werden
können.
Zentral ist, dass diese Standards alle interoperabel gedacht sind, sprich,
dass die Daten, insbesondere die Bilddaten, auch in anderen Kontexten und
von anderen Institutionen weltweit eingebunden werden können.
Für weitere Informationen zu IIIF für Einsteiger, aber auch Experten siehe https://iiif.io/
community/#how-to-get-involved-1 (Zugriff am 29.06.2022).
https://iiif.io/api/image/3.0/ (Zugriff am 29.06.2022).
Im Projekt wird der vom DHLab in Basel entwickelte IIIF Bildserver Sipi genutzt, wobei
hier von der engen Zusammenarbeit mit dem DHLab profitiert wird: https://github.com/
dasch-swiss/sipi (Zugriff am 29.06.2022).
https://iiif.io/api/search/1.0/ (Zugriff am 29.06.2022).
https://iiif.io/api/auth/1.0/ (Zugriff am 29.06.2022).
https://iiif.io/api/presentation/3.0/ (Zugriff am 29.06.2022).Von der analogen Sammlung zur digitalen Forschungsinfrastruktur 77
4.1.2 Infrastruktur vor Portal
Durch den Fokus auf IIIF steht also auch weniger die Präsentation im Portal,
sondern die Interoperabilität der Daten im Mittelpunkt des Projekts. Soll es
doch der Kreativität der Forschenden überlassen sein, wie die Daten genutzt
und in Forschungstools eingebunden werden. Daher baut die Präsentation der
Digitalisate im Portal auch auf Schnittstellen auf, die nach außen zugänglich
sind. Im Gegensatz zu anderen Portalen ist die IIIF Presentation API nicht nur
ein weiteres Exportformat, sondern auch die Schnittstelle für das Portal zur Prä-
sentation der digitalen Objekte.
Für die wenigsten Forschenden ist eine einzige Datenquelle ausreichend.
Beschäftigt man sich etwa mit der Schweizer Wirtschaftsgeschichte, wird
auch die Perspektive von außen, etwa in internationalen Medien, interessant
sein. Daher ist es zentral, dass Daten aus unterschiedlichen Infrastrukturen
in einem standardisierten Format wie IIIF zur Integration und Nachnutzung
vorliegen, um in externen Tools zusammengeführt werden zu können. Die
Datensammlung des ZAS-Portals versteht sich als ein Baustein einer digitalen
Forschungsinfrastruktur.
4.1.3 Nachnutzung durch Standards und Interoperabilität
Der im Portal für die Präsentation genutzte Viewer ist eine IIIF Applikation.18
Für die Zeitungsausschnittsammlung wurden mehrere Viewer getestet und die
Entscheidung fiel auf den Universal Viewer19, da dieser viele wichtige Funktio-
nalitäten wie die integrierte Volltextsuche am besten abdeckt.
In der Austauschbarkeit der Komponenten zeigt sich aber gerade das Po-
tenzial der digitalen Nachhaltigkeit der IIIF-Schnittstellen. So kann etwa der
funktional sehr beeindruckende, aber optisch möglicherweise schon etwas ver-
altet wirkende Universal-Viewer einfach durch einen neuen Viewer20 ersetzt
Dieser wurde unter anderem von der Agentur digirati für die Wellcome Library, die British
Library und die National Library of Wales (weiter)entwickelt. Durch das einfache Einbinden ist
es möglich, auf all den hier eingeflossenen Erfahrungen dieser Institutionen zur Präsentation
von Digitalisaten aufzubauen.
Siehe https://universalviewer.io/ (Zugriff am 29.06.2022).
So wird etwa bald eine neue Version des Mirador-Viewers(https://projectmirador.org/, Zu-
griff am 29.06.2022) veröffentlicht, der auch gemeinsam von einer Vielzahl an großen Kultur-
einrichtungen entwickelt wird und weitere Funktionalitäten zur Präsentation von Digitalisaten
enthält.78 Irene Amstutz, Martin Reisacher, Elias Kreyenbühl
werden und damit die zentrale Präsentationskomponente im Portal aktualisiert
werden.
Doch die Einbindung der Daten in einen Viewer ist nur der augenschein-
lichste Anwendungsfall. Genauso gut können Forschungstools, die auf externen
Servern laufen, die IIIF-Ressourcen aus dem ZAS-Projekt einbinden. Für For-
schungsprojekte kann daher IIIF die Möglichkeit bieten, dass Tools nicht neu
programmiert werden müssen, sondern nachgenutzt werden können. Durch die
Interoperabilität steht auch weniger im Mittelpunkt, dass ein Tool alle Anforde-
rungen erfüllen muss, sondern je nach Anwendungsfall können unterschiedli-
che, auf IIIF basierende Applikationen genutzt werden.
Unter anderem gibt es zum Beispiel recogito, eine Webanwendung, welche
den DH Award 2018 gewonnen hat und Forschende bei der Annotation und
Auswertung von Karten, die in IIIF verfügbar sind, unterstützt.21 Möchte man
seine Daten hingegen in einer kurzen Ausstellung präsentieren, würde man
wohl auf storiiies22 von cogapp zurückgreifen oder auf Inseri23, eine kollabora-
tive Arbeits- und Präsentations-Umgebung.
Es muss aber erwähnt werden, dass diese IIIF-Applikations-Infrastruktur
für Forschende bis auf Einzelbeispiele noch nicht so einfach zu nutzen ist, wie
dies etwa bei den Präsentationskomponenten (Viewern) der Fall ist. Betrachtet
man allerdings die Dynamik, mit der IIIF voranschreitet, dürfte dies nur eine
Frage der Zeit sein, bis eine niederschwellige Nutzung gang und gäbe ist.
Hier kann auch eine gewisse Trennlinie zwischen Daten-Infrastruktur und
Forschenden gesehen werden. So sind Bibliotheken und Archive oft auch im
digitalen Raum die Infrastruktur, über welche Quellen interoperabel zur Verfü-
gung gestellt werden. Die Tools bzw. dadurch auch die Methoden, mit denen
die Daten bearbeitet und präsentiert werden, könnten allerdings primär von
den Forschenden oder Forschungs-Projekten kommen.
Wobei diese Trennlinie zwischen Infrastruktur und Tools/Methoden frü-
her möglicherweise einfacher zu ziehen war. Heute sind die Methoden abhän-
gig davon, welche Möglichkeiten die Schnittstellen bieten. IIIF ist hier ein
erster Ansatz, aber es wird wahrscheinlich nicht die letzte Schnittstelle blei-
ben, da damit nur Inhalte in einer bestimmten Form abfragbar sind, in deren
Mittelpunkt das digitale Objekt steht.
https://recogito.pelagios.org/ (Zugriff am 29.06.2022).
https://storiiies.cogapp.com/ (Zugriff am 29.06.2022).
https://github.com/nie-ine/inseri (Zugriff am 29.06.2022).Von der analogen Sammlung zur digitalen Forschungsinfrastruktur 79
4.1.4 Easy2Use API
Eine große Stärke von IIIF ist, dass es ein Standard zur Präsentation von Daten
ist. Das bedeutet, dass die API-Komponente nicht abstrakt bleibt, sondern der
Nutzer durch die Darstellung der IIIF-Daten in einem Viewer sieht, welches Da-
tenset er zusammengestellt hat. In diesem kann er auch im Volltext mit Highligh-
ting suchen. Ist das Datenset für seine Forschung relevant, ist es ausreichend,
die Daten per Link in ein anderes IIIF-fähiges Tool einzubinden.
4.2 Konkrete Umsetzung
Was bedeuten diese Leitgedanken aber nun konkret für die digitale Aufberei-
tung der Sammlung? Im Mittelpunkt stand die Frage, wie man das Konzept der
analogen Dokumentensammlung in den digitalen Raum übertragen und um die
digitalen Möglichkeiten erweitern konnte.
Der Schritt zur elektronischen Zeitungsausschnittsammlung 2012 war ein
erster wichtiger Schritt: Der Zugriff von Zuhause, die Zuordnung von Artikeln
zu mehreren Dokumentensammlungen und die so wichtige Volltextsuche war
nun möglich. Im Gegensatz zu den analogen Mappen konnte man aber nicht
mehr in einer Dokumentensammlung rasch von einem Artikel zum nächsten
blättern und sich innerhalb kurzer Zeit einen Überblick verschaffen.
Schon aufgrund der Möglichkeit, dass in E-ZAS die Artikel den Dokumen-
tensammlungen nicht mehr eindeutig zugeordnet werden mussten, aber das
Dossier-Prinzip einen zentralen Charakter der Sammlung bildete, musste eine
Lösung gefunden werden, die weiterhin die Abbildung der Dokumentensamm-
lungen sowie die gemeinsame Darstellung der retrodigitalisierten und digital
born Inhalte ermöglichte.
Es war auch klar, dass die starre Zuordnung zu einem Dossier nicht die For-
schungsrealität abbilden konnte. Können die Forschungsfragen doch quer zu
den Dokumentensammlungen verlaufen, auf Volltextsuchen beruhen oder nur
einen bestimmten Zeitraum betreffen. Perspektivisch betrachtet lässt es sich
auch nicht ausschließen, dass etwa in Zukunft maschinelle Verfahren dyna-
misch Dokumentensammlungen nach neuen Kriterien bilden könnten.
4.2.1 Virtuelle Dokumentensammlungen
Hier setzt das Konzept der virtuellen Dokumentensammlungen an, das zumindest
unserem Wissen nach hinsichtlich der Flexibilität ein Alleinstellungsmerkmal des80 Irene Amstutz, Martin Reisacher, Elias Kreyenbühl
Projekts ist.24 Die Dokumentensammlungen können über die IIIF Presentation API
des Portals komplett dynamisch gebildet werden. Alle Suchmöglichkeiten im Portal
können dafür genutzt werden, sich eine virtuelle Dokumentensammlung zusam-
menzustellen und gleichzeitig persistent verfügbar zu machen. Ob nun die virtuelle
Dokumentensammlung anhand der ursprünglichen Zuordnung zum Thesaurus
durch die Dokumentarin bzw. den Dokumentar erfolgte, die Dokumentensammlun-
gen zukünftig von einer KI gebildet wird oder es eine einfache Volltextsuche im
Portal ist, spielt dabei keine Rolle.
Die virtuellen Dokumentensammlungen stellen also den Versuch dar, die
Vorteile aus der digitalen und analogen Welt zu vereinen: einerseits rasch
durch große Datenmengen blättern zu können, andererseits aber nicht länger
durch die Grenzen der traditionellen Dokumentensammlungen limitiert zu wer-
den und die Daten auch über die API in andere Umgebungen „mitnehmen“
und einbinden zu können (siehe Abb. 3).
Diese Präsentationsform eignet sich, die Treffer aus den diversen Suchein-
stiegen beispielsweise über die Volltexte, aber auch über den Standard Thesau-
rus Wirtschaft (STW) zu kombinieren. Der große Vorteil beim Einstieg über die
Themen-Deskriptoren des STW liegt etwa darin, dass auch alternative Suchfor-
men gefunden werden.
Wie schon erwähnt ist etwa der Begriff „Tourismus“ ein relativ neuer Be-
griff. Sucht man danach in den 1930er-Jahren, erhält man fast keine Treffer.
Hingegen sind dem Sachdeskriptor „Tourismus“ in den 1930er-Jahren 130 Arti-
kel zugeordnet und ermöglichen einen viel breiteren Einstieg in dieses Thema.
Volltextsuche und Deskriptoren können aber gewinnbringend gemeinsam
in der Suche genutzt werde. Gibt man etwa den Begriff „Fremdenverkehr“ in
der Volltextsuche ein, erhält man eine Vielzahl an Treffern. Überraschenderweise
sind die meisten aber nicht dem Deskriptor W13 „Tourismus“ zugeordnet,
sondern W11 „Gastgewerbe“ (mit der Unterkategorie „Hotellerie“), wodurch
man einen weiteren Sucheinstieg erhält, ohne die Struktur des STW vorab bereits
bis ins letzte Detail kennen zu müssen. So kann durch die Nutzung von Volltext-
suche und STW die Suche immer weiter verfeinert oder auch erweitert werden
und ermöglicht auch eine einfachere Nutzung des Thesaurus für Laien (Abb. 4).
Ähnliche Zugänge auf einer IIIF-Meta-Ebene existieren etwa von Intranda im goobi Viewer
(https://iiif.io/news/2020/03/31/newsletter, Zugriff am 29.06.2022), ÖNB Labs (https://labs.onb.
ac.at/en/tool/sacha, Zugriff am 29.06.2022) und Biblissima (https://iiif.biblissima.fr/collections,
Zugriff am 29.06.2022). Bei diesen Beispielen müssen aber jeweils manuell mehrere Manifeste zu
einer IIIF-Collection hinzugefügt werden.Von der analogen Sammlung zur digitalen Forschungsinfrastruktur 81
Abb. 3: Ein Ausschnitt, wie 50 Meter aneinandergereihte Artikel in einem IIIF Viewer aussehen
und einen raschen Überblick über große Datenmengen ermöglichen.
Copyright: Universitätsbibliothek Basel, SWA
4.2.2 Digitaler Zugriff
Bislang war der Zugriff primär auf den IP-Range der Uni Basel beschränkt.25
Das Schweizerische Urheberrecht erlaubt aber sogar eine kontrollierte Nutzung
für den allgemeinen universitären Gebrauch. Auch hier kann Swiss Edu-ID26,
ein zentrales Authentifizierungssystem für den Schweizer Hochschulbereich,
eingesetzt werden. Allerdings muss diese Anbindung an IIIF erst umgesetzt
werden.
Dabei zeigen sich aber auch die Herausforderungen und Abhängigkeiten
für digitale Infrastruktur. Änderungen im Browser Chrome könnten nämlich in
Zukunft dazu führen, dass die reibungslose Interoperabilität, also das Einbin-
den der Daten in andere Applikation nicht mehr so einfach funktioniert, sofern
eine Authentifizierung notwendig ist.27
Auch anderen Nutzenden kann der Zugang gewährt werden. Sie müssen sich anmelden
und frei geschaltet werden. Diese Lösung muss für das neue Portal ebenfalls erst integriert
werden.
Siehe https://projects.switch.ch/eduid/ (Zugriff am 29.06.2022).
Siehe dazu etwa der Blog-Artikel Access Control, Interoperability and Cultural Heritage
von Tom Crane vom 31.1.2021, siehe: https://tom-crane.medium.com/access-control-interopera
bility-and-cultural-heritage-4d3c6241f63f (Zugriff am 29.06.2022).82 Irene Amstutz, Martin Reisacher, Elias Kreyenbühl Abb. 4: Über die Freitextsuche und die Facetten des Portals können individuelle Subsets der insgesamt über 800.000 Artikel (retrodigitalisiert und digital born) im Viewer angezeigt und im Volltext durchsucht werden. Hier wurde eine Auswahl über den STW und die zeitliche Zuordnung getroffen und innerhalb des Subsets eine Volltextsuche durchgeführt. Copyright: Universitätsbibliothek Basel, SWA. 4.3 Herausforderungen Das ZAS-Portal bzw. vielmehr seine API versteht sich nur als kleines Puzzleteil einer dezentralen IIIF Infrastruktur, die von vielen Institutionen wechselseitig bereitgestellt und genutzt werden kann. Vieles ist dabei jedoch noch in Bewe- gung. Auch die Herausforderungen und Versprechungen, die damit verknüpft sind, werden uns sicherlich noch die nächsten Jahre begleiten und sind nicht mit der Publikation der Daten gelöst.
Von der analogen Sammlung zur digitalen Forschungsinfrastruktur 83
4.3.1 Persistenz/Versionierung
Im Gegensatz zum Zettelkatalog, als eine mögliche Form des verlängerten Ge-
dächtnisses des Forschenden, sind es in einer interoperablen Infrastruktur oft
nur mehr flüchtige Links,28 die Quellen repräsentieren. Gerade wenn wir von
Interoperabilität sprechen, ist daher die Persistenz die erste Bedingung, die er-
füllt werden muss, um zu garantieren, dass dezentrale Systeme langfristig funk-
tionieren können.
Oder um es konkret zu formulieren: Wenn wir als UB Basel unser Katalogi-
sierungssystem wechseln, müssen die IDs und Links weiterhin stabil bleiben.
Aber auch auf praktischer Ebene stellen sich bei virtuellen Dokumentensamm-
lungen Fragen hinsichtlich der Persistenz, sofern eine Sammlung noch nicht
abgeschlossen oder fertig digitalisiert ist. Soll etwa ein zukünftiger Aufruf der
virtuellen Dokumentensammlung „Wirtschaftskrise“ nur jene Artikel beinhal-
ten, die zum Zeitpunkt X der Publikation digitalisiert waren oder doch alle, die
zum heutigen Zeitpunkt Y verfügbar sind? Für den Forschenden haben diese
zwar digital nicht existiert, analog wären diese aber vorhanden gewesen.
4.3.2 Zuverlässigkeit
Neben der Persistenz ist beim Zugriff auf externe Daten zentral, dass diese
rasch ausgeliefert werden und die Schnittstellen zuverlässig ohne Unterbre-
chungen funktionieren. Nicht umsonst definieren sich Services von großen An-
bietern durch ihre praktisch hundertprozentige Verfügbarkeit.
4.3.3 Nachhaltigkeit
Es stellt sich auch die Frage, wie man Persistenz und Zuverlässigkeit mit dem
Projektcharakter vieler Initiativen verknüpfen kann. Ist es doch nicht mehr
bloß das Portal, das nach der Projektlaufzeit sanft entschlummern könnte, son-
dern verlieren Forschende den Zugriff auf ihre Daten, wenn gewisse Infrastruk-
turen nicht mehr funktionieren oder nur teilweise gewartet werden würden?
Im Idealfall sind es Persistent Identifier, wie urn, dois oder ark, die durch ein Resolving-
System selbst bei URL-Änderungen stabil bleiben. Aber auch diese bleiben nur bei aktiver
Pflege stabil.84 Irene Amstutz, Martin Reisacher, Elias Kreyenbühl
Aber auch hinsichtlich der notwendigen Schnittstellen für Forschende wer-
den die Entwicklungen nicht stehen bleiben. Momentan spielt IIIF als Schnitt-
stelle eine wichtige Rolle, um (Bild-)Daten nachnutzbar zu machen. Welche
Schnittstellen und Standards benötigten aber etwa in Zukunft Forschungspro-
jekte, die komplexe Volltext-Analysen durchführen wollen? Werden deren Be-
dürfnisse in Zukunft berücksichtigt werden können oder ist es möglicherweise
sogar einfach besser, die „Rohdaten“ zur Verfügung zu stellen?
4.3.4 Transparenz
Transparenz gilt es auf unterschiedlichen Ebenen zu gewährleisten. In Zukunft
wird nicht nur der Forschende seine digitalen Methoden zur Quellenanalyse
reflektieren müssen, sondern auch die Institutionen, die die Daten zur Verfügung
stellen. Es können einfache Fragen sein wie, welcher Teil der Sammlung bereits
digital vorhanden ist und welche Auswirkungen das auf die Nutzung der Quellen
hat. Wahrscheinlich ist, dass jene im Volltext zugänglichen Teile der Sammlung
eine viel stärkere Nutzung erfahren. Die Strategie, welche Teile digitalisiert wer-
den und die Transparenz darüber, spielt dann eine zentrale Rolle.
Aber auch Fragen hinsichtlich der Datenqualität müssen adressiert werden.
Was bedeutet es etwa für einen Teil des Quellenkorpus, wenn die Fraktur-OCR
bei nicht geglätteten Zeitungsartikeln schlechtere Resultate liefert? Solche Qua-
litätskennzahlen zur OCR sind für ZAS-Volltexte jedoch nicht vorhanden. An-
dere Informationen, wie die vom OCR-Prozess erkannte Sprache, die starke
Auswirkungen auf die Qualität hat, existieren hingegen schon.
Dabei muss zwischen Nutzerfreundlichkeit und Transparenz abgewogen
werden. So könnte der Hinweis auf die von der OCR erkannte Sprache (zum Bei-
spiel OldGerman oder GermanNewSpelling) für den normalen Nutzer, der sich
nicht mit methodischen Fragen zur OCR-Qualität auseinandersetzt, zuallererst
Verwirrung stiften.
Es dürfte überhaupt eine Gratwanderung hinsichtlich der Nutzererwartun-
gen sein, wie komplex oder intuitiv die Suchmöglichkeiten sind. Soll es sich bei
diesen Infrastrukturen um Expertentools handeln, bei denen man die ganzen
Möglichkeiten eines Suchservers auf einer Oberfläche abbildet oder soll die
Einstiegshürde möglichst niedrig gehalten werden?
Doch nicht nur die OCR birgt ihre Geheimnisse, auch maschinelle Verfah-
ren, seien es etwa standardisierte Prozesse für das Suchranking oder Machine-
Learning zur Aufbereitung bzw. Strukturierung der Daten, beeinflussen, wie
sich Forschende den Quellen annähern. Bis zu einem gewissen Punkt formen
wir dadurch auch die „Forschungs-Realität“ für die Wissenschaft. Reicht hierVon der analogen Sammlung zur digitalen Forschungsinfrastruktur 85
eine Mischung aus guter alter Quellenkritik und Digital Literacy oder braucht
es doch mehr? Wieviel Transparenz müssen die Institutionen an den Tag legen
und wieviel können sie überhaupt mit ihren Daten und Ressourcen leisten? In
der drastischsten Variante bedeutet das hinsichtlich der Quellen „program or
be programmed“. Die Leerstellen im Code oder die pragmatischen Entscheidun-
gen bei der Datenaufbereitung können wohl, wenn überhaupt, nur jene mit
ausreichendem technischen Grundverständnis nachvollziehen.
Es stellt sich aber die Frage, wie transparent die Aufbereitung und Selek-
tion von Quellen früher war. Weshalb etwa eine Dokumentarin einen Artikel
einer bestimmten Dokumentensammlung zugeordnet hatte, war zu einem ge-
wissen Teil ja eine persönliche Entscheidung, die sich zudem über die Zeit ge-
wandelt haben konnte oder durch einen personellen Wechsel Veränderung
erfahren hat. Aber zumindest konnte man bis zu einem gewissen Grad das Ge-
spräch suchen, die Algorithmen hingegen schweigen (zumindest noch).
5 Resümee
Für Forschende bietet das neue ZAS-Portal einen wertvollen Baustein in ihrer
Recherche zur Schweizer Wirtschafts- und Sozialgeschichte. So wurde unlängst
auf einer Veranstaltung darauf hingewiesen, dass die gesammelten Zeitungs-
ausschnitte für Historiker von großem Wert sind, da Zeitungsartikel eine Ver-
dichtung des Diskurses aus unterschiedlichsten Perspektiven zu einem Thema
darstellen. Noch besser als in Zeitungsarchiven hat man bei Ausschnittsamm-
lungen durch die manuelle Auswahl und Erschließung die Möglichkeit, diesen
Diskurs einfach nachzuverfolgen.
Dass hier eine Zeitungsausschnittsammlung und keine Zeitung digitalisiert
wurde, ist ebenfalls ein Spezifikum. Gibt es doch im deutschsprachigen Raum
unseres Wissens nur wenige digitalisierte Sammlungen29, wobei die Samm-
lung des SWA die einzige sein dürfte, die tatsächlich neben ihren Klassifikations-
kriterien im Volltext und anhand von Facetten durchsuchbar ist.
Gerade diese Suchmöglichkeiten bieten in Verknüpfung mit den IIIF Präsen-
tationskomponenten neue Einstiegspunkte, die zusätzlich zur bisherigen Samm-
So existiert das Innsbrucker Zeitungsarchiv (https://iza-server.uibk.ac.at/adb/index.jsp, Zugriff
am 29.06.2022) und die Pressemappe des 20. Jahrhunderts der Zentralbibliothek Wirtschaft
(http://webopac.hwwa.de/pressemappe20, Zugriff am 29.06.2022). Gerade die Pressemappe des
20. Jh. zeigt auch noch das Potential für die ZAS-Sammlung hinsichtlich der Möglichkeiten der
weiteren Integration von Linked Open Data (LOD).86 Irene Amstutz, Martin Reisacher, Elias Kreyenbühl
lungsbildung verlaufen und den Forschenden viele effiziente neue Möglichkeiten
zur Quellenanalyse und -sammlung und digitalen Nachnutzung geben und die
Besonderheiten einer manuell kuratierten Zeitungsausschnittsammlung auch
digital in den Vordergrund rücken.30
Die Überführung der Zeitungsausschnittsammlung in den digitalen Raum
zeigt aber auch die Bedeutung der manuellen Erschließung über Thesauri und
Normdaten. So streben immer mehr Projekte die Verschlagwortung mit ML-
Verfahren an, um weitere Einstiegspunkte neben den Möglichkeiten (aber auch
Grenzen) der Volltextsuche zu bieten. Dafür braucht es hochqualitative Trai-
ningssets, wofür die Sammlung als Grundlage dienen kann. Andererseits bietet
die Verschlagwortung für die Forschenden auch ein Korrektiv zur reinen Voll-
textsuche. Existiert doch durch die Zuordnung zu einer Dokumentensammlung
ein zusätzlicher Sucheinstieg, über den verwandte Artikel gefunden werden
können, die über eine Volltextsuche nicht auffindbar wären.
Das Aufbauen dieser Infrastruktur für Zeitungsausschnitte ist aber nur ein
erster Schritt. Auch gemeinsam mit der Forschung muss noch das Potential
hinsichtlich der Interoperabilität der Quellen und die Vorzüge einer offenen
Forschungsinfrastruktur erprobt werden, in der Quellen online konsultiert, ge-
sammelt, zitiert und möglicherweise schlussendlich auch im Sinne eines Digi-
tal Life Cycle Managements selbst hinzugefügt und annotiert werden können.
Die Kenntnis von archivischer Erschließung und guter wissenschaftlicher Ar-
beit wird dann auch durch Digital Literacy ergänzt werden müssen. Das Verständ-
nis von Suchalgorithmen, Standards und damit auch die Auslassungen in diesem
Prozess dürfte wohl für die Forschenden ein zentrales Handwerkszeug werden,
um diese Angebote effizient zu nutzen und auch deren Grenzen und Möglichkeiten
beurteilen zu können. So wie es früher Einführungen zum guten wissenschaftli-
chen Arbeiten, zur Recherche und zum Zitieren gab, könnte es in Zukunft Kurse zu
Technologie-Standards geben, um diese neuen Infrastrukturen beurteilen und
Quellenkritik hinsichtlich der Grenzen und Möglichkeiten üben zu können.
Gerade IIIF und die Interoperabilität der Daten ist aber auch eine Chance, in
gewissen Bereichen Rechercheprozesse im digitalen Raum zu vereinfachen. Wo
früher diverse Portale oder Interfaces konsultiert werden mussten, bietet IIIF die
Möglichkeit, Digitalisate aus verschiedensten Quellen in einem einheitlichen Inter-
face (etwa dem Universalviewer) anzeigen zu lassen, um sich wieder weniger auf
die unterschiedlichen Oberflächen als auf die Inhalte konzentrieren zu können.
Einerseits werden die Artikel in einer Ausschnittssammlung dekontextualisiert, da diese
aus der Zeitung ausgeschnitten werden und von den restlichen Artikeln getrennt werden, an-
dererseits werden sie gerade kontextualisiert, da diese in den Sammlungen neben Artikel aus
anderen Zeitungen zum gleichen Thema gestellt werden können.Von der analogen Sammlung zur digitalen Forschungsinfrastruktur 87
Der Schritt in Richtung digitale Forschungsinfrastruktur bietet für Kultur-
einrichtungen und auch den Forschenden viele neue Möglichkeiten, doch gibt
es noch immer eine Reihe an Herausforderungen. So werden wir in einigen Be-
reichen von den Erfahrungen anderer lernen, aber auch unsere eigenen Fehler
machen müssen, um voranschreiten zu können. Daher wird es sicherlich noch
eine Weile dauern, bis wir ohne schlechtes Gewissen das Beta in der Version
entfernen können. Aber bei all dem darf nicht vergessen werden, dass nun eine
Sammlung von momentan gut 1.000.000 der 2,7 Millionen Zeitungsausschnitte
und gut 180.000 Born-Digital-Artikel im Volltext online interoperabel verfügbar
ist und sich dadurch für die Forschung hoffentlich ganz neue Möglichkeiten
und Perspektiven ergeben.
Wir sind daher gespannt, in welche Richtung uns der weitere Austausch
und die Zusammenarbeit mit den Forschenden leiten wird und ob unsere The-
sen zum Umgang mit digitaler Forschungsinfrastruktur rückblickend gehalten
haben, was sie für uns momentan versprechen.Sie können auch lesen

















































