Vorlesung Suchmaschinen - Prof. Dr. Werner Kießling Universität Augsburg Sommersemester 2016 - Uni ...
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Vorlesung Suchmaschinen
Universität Augsburg
Sommersemester 2016
Prof. Dr. Werner Kießling
Institut für Informatik
Lehrstuhl für Datenbanken und Informationssysteme
© Prof. Kießling 2016 Kap. 1 - 1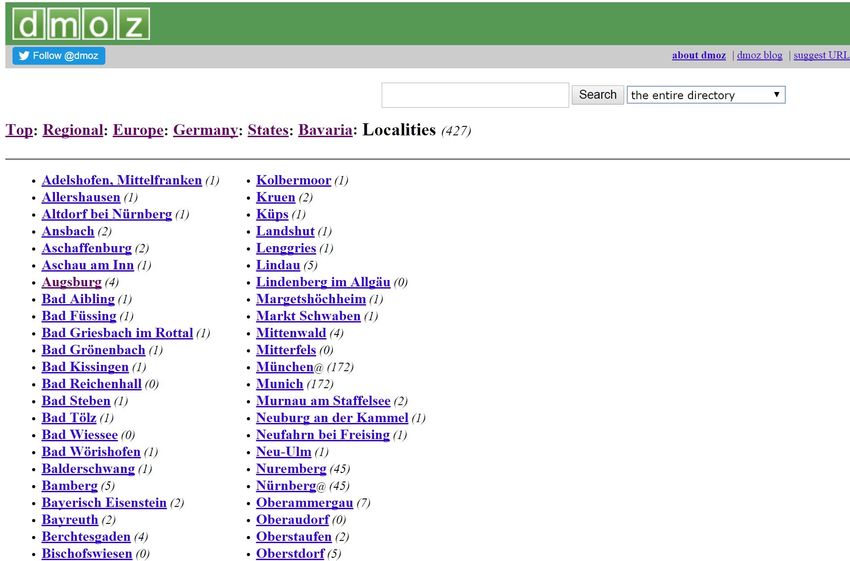
Vorlesungsbetrieb
• Zwei Vorlesungen pro Woche im Hörsaal 2045 (N)
• Dienstag 10:00 – 11:30 Uhr
• Donnerstag 10:00 – 11:30 Uhr
• Folien der Vorlesung sind spätestens am jeweiligen
Vorlesungstag im Internet verfügbar
http://www.informatik.uni-augsburg.de/lehrstuehle/dbis/db/lectures/ss16/se/scripts/
Zugang mit RZ-Kennung
• Regelmäßig nach Aktuellem auf der Homepage schauen!
© Prof. Kießling 2016 Kap. 1 - 2
Kontakt
Prof. Dr. W. Kießling:
Sprechstunde: Donnerstag 11:45-12:15 Uhr (2051 N)
Dr. Florian Wenzel und Lena Rudenko (2001 / 2002 N):
{wenzel, lena.rudenko}@informatik.uni-augsburg.de
© Prof. Kießling 2016 Kap. 1 - 3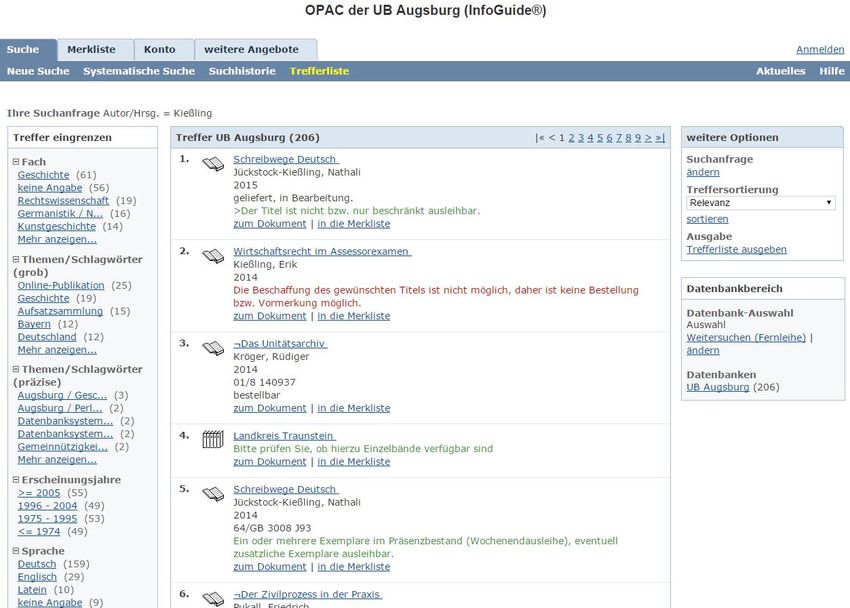
Übungen
● Übungsblätter werden jeweils freitags auf der Homepage veröffentlicht
● Es wird davon ausgegangen, dass die Blätter vor dem Übungstermin
angesehen / bearbeitet werden
● Während der Übung:
● Erarbeitung der wichtigsten Aufgaben in Kleingruppen
● Präsentation und Diskussion der erarbeiteten Ergebnisse
● Keine Punktevergabe, keine Zulassungsbedingung zur Klausur
© Prof. Kießling 2016 Kap. 1 - 4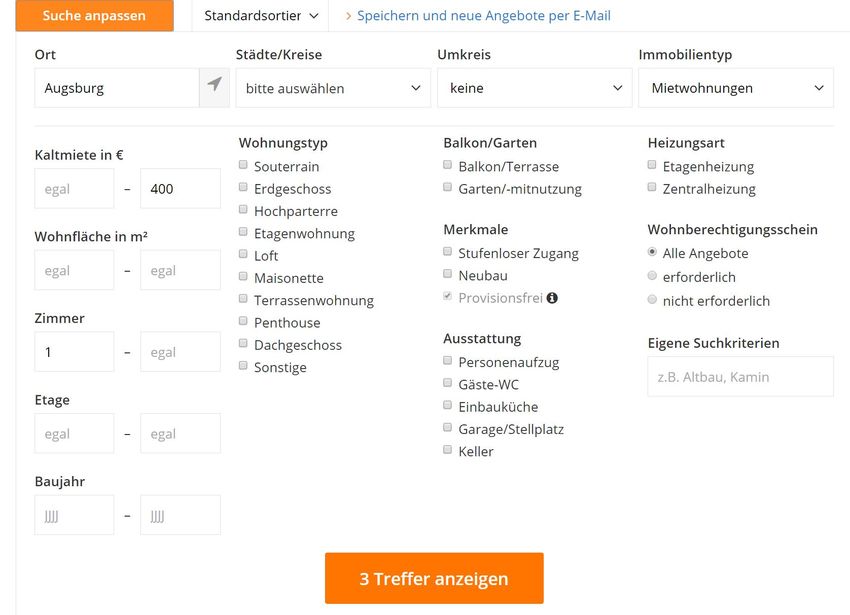
Übungsgruppen
Gruppe Zeit Raum
1 Montag, 12:15 – 13:45 Uhr 2056 (N)
2 Mittwoch, 10:00 – 11:30 Uhr 2056 (N)
3 Mittwoch, 14:00 – 15:30 Uhr 2056 (N)
4 Freitag, 10:00 – 11:30 Uhr 2056 (N)
http://www.informatik.uni-augsburg.de/lehrstuehle/dbis/db/lectures/ss16/se/groups/
Verteilung auf Übungsgruppen: Sonntag, 17.04.16 um 18:00 Uhr
© Prof. Kießling 2016 Kap. 1 - 5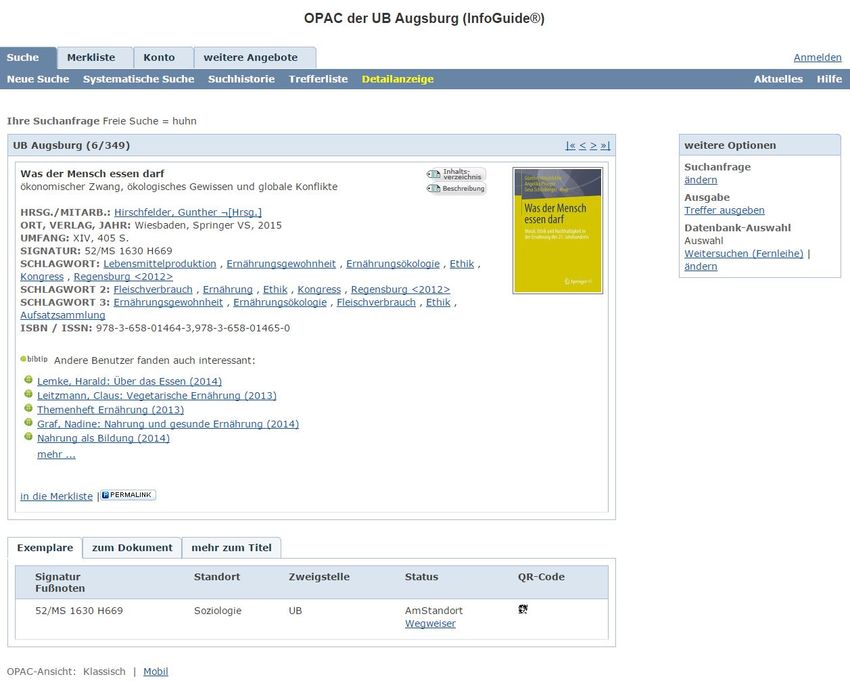
Klausur
Termin: 12.07.16, 17:00 Uhr (Mensa)
Dauer: 90 Minuten
Nur Papierunterlagen sind zugelassen (open book)
Anmeldung bei STUDIS zwingend erforderlich!
Näheres unter:
http://www.informatik.uni-augsburg.de/lehrstuehle/dbis/db/lectures/ss16/se/
exams/
© Prof. Kießling 2016 Kap. 1 - 6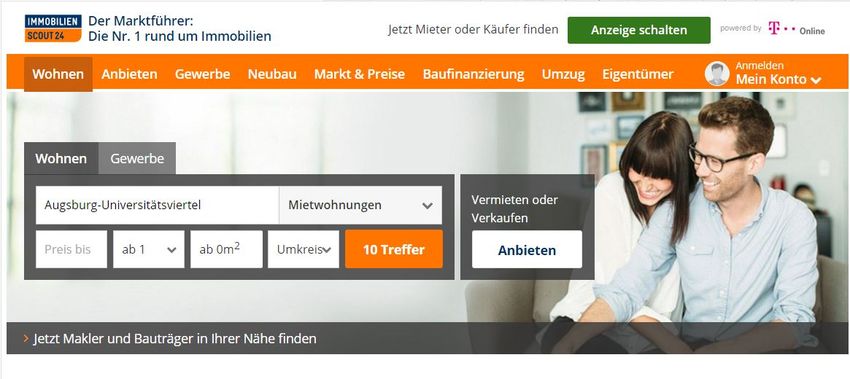
Gliederung
1 Einführung
2 Volltext-Suchmaschinen
3 Präferenz-Theorie
4 Preference SQL-System
5 Implementierung von Präferenz-Querysprachen
6 Top-k-Algorithmen
7 XML-Suchmaschinen
8 Softwareaspekte von SQL-Suchanwendungen
© Prof. Kießling 2016 Kap. 1 - 7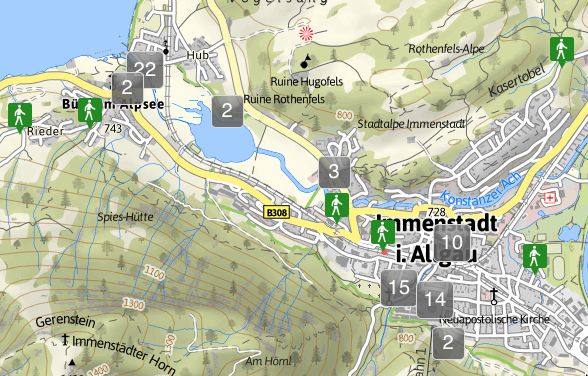
Allgemeine Literatur Dirk Lewandowski (Hrsg.): Handbuch Internet-Suchmaschinen 2: Neue Entwicklungen in der Web Suche Akademische Verlagsgesellschaft AKA GmbH, Heidelberg, 2012; ISBN: 978-3-89838-651-7 Christopher D. Manning, Prabhakar Raghavan, Hinrich Schütze: Introduction to Information Retrieval, Cambridge University Press; 2008; ISBN: 978-0-521-86571-5 Marc Levene: An Introduction to Search Engines and Web Navigation, 2nd Edition, Wiley, 2010; ISBN: 978-0-470-52684-2 Ricardo Baeza-Yates & Berthier Ribeiro-Neto: Modern Information Retrieval, 2nd Edition, New York, NY: ACM Press Books; 2010; ISBN: 978-0-321-41691-9 © Prof. Kießling 2016 Kap. 1 - 8
1 Einführung
1.1 Unterschiedliche Suchverfahren
1.2 Überblick IR-Systeme
1.3 Überblick Web-Suche
1.4 Überblick Attribut-Suche
1.5 Überblick Multimedia-Suche
1.6 Überblick Soziale Netzwerke
1.7 Mobile Dienste
1.8 Metasuchmaschinen
1.9 Google Analytics
1.10 Zusammenfassung
Quelle: http://www.flickr.com/photos/deia/7942538/
„I will use Google before asking dumb questions.“
© Prof. Kießling 2016 Kap. 1 - 9
1.1 Unterschiedliche Suchverfahren
Wichtigste Komponente für ein Such-System ist die Menge der
Dokumente, Korpus genannt, und deren interne Struktur.
Der Korpus kann
unstrukturiert
semi-strukturiert oder auch
strukturiert sein.
Korpus von
Dokumenten
Such-
Anfrage Ergebnis
System
© Prof. Kießling 2016 Kap. 1 - 10Dokumente können sein:
Artefakte (z.B. gescannte Bücher)
Kataloge (z.B. Branchenbücher)
Linksammlungen (Webkataloge)
Videosammlungen (YouTube)
Soziale Daten (z.B. Facebook)
Dateien (z.B. Excel, PDF, Text, HTML, XML, …)
…
© Prof. Kießling 2016 Kap. 1 - 11Beispiel: Suche nach Buch im Antiquariat
1.) Stöbern
Struktur (Sachgebiet, Thema, Autor, …)
Navigation (Teilbereiche, Signaturen, ...)
2.) Dialog
Zweck, Absicht, Ziel
Frage Antiquar
Fragen - Antworten
Benutzer-Modellierung
Hintergrundwissen Empfehlungen
„Gezielte Suche“
Relevanz?
© Prof. Kießling 2016 Kap. 1 - 12Soziale Suche
Mit Hilfe von sozialen Vernetzungen (Freundes-, Kollegenkreis, …) kann ein
Suchvorgang gleichzeitig von mehreren Teilnehmern ausgeführt werden.
Für den Erfolg dieser Vorgehensweise ist wichtig:
Hoher Vernetzungsgrad, verteilter Korpus
Gemeinsamer Code, klare Spezifikation
Terminierung, Qualität und Quantität der Ergebnisse
Anfrage Ergebnis
Freundeskreis als Such-System
© Prof. Kießling 2016 Kap. 1 - 13Beispiel: Wohnungssuche
1.) Suchanfrage über persönliche oder webbasierte soziale Netzwerke
streuen und auf hohen Verbreitungsgrad hoffen.
2.) Gemeinsamer Code (Wohnungen und ihre Eigenschaften)
3.) Klare Spezifikation (Größe, Preis, Typ)
4.) Bewertung der Ergebnisse erfolgt auch nach weiteren (meist nicht
vollständig kommunizierten) weichen Faktoren.
5) Meistens wird man unter den ersten k Rückmeldungen fündig
(Top-k-Suche).
© Prof. Kießling 2016 Kap. 1 - 14Beispiel: Wohnungssuche in Facebook-Gruppe Gemeinsamer Code Spezifikationen weiche Faktoren © Prof. Kießling 2016 Kap. 1 - 15
Eigenschaften von sozialen Netzen:
● Mitglieder von sozialen Netzen können sich ihrerseits auch wieder
auf andere soziale Netze abstützen.
● Mitglieder von sozialen Netzen können aber auch automatische
Suchsysteme, Spezialisten, Bibliotheken, … zu Rate ziehen.
● Die Kommunikation (Aussage, Frage – Antwort) erfolgt
asynchron.
© Prof. Kießling 2016 Kap. 1 - 161.2 Überblick IR-Systeme
Suche nach Information in
Bibliothek
Korpus von
Dokumenten
Information
Anfrage IR- Retrieval
System
Relevanz? 1. Doc1
Gewichtete 2. Doc2
Dokumente 3. Doc3
…
© Prof. Kießling 2016 Kap. 1 - 17Beispiel: Anfrage nach Veröffentlichung in Bibliothek OPAC der UB Augsburg: © Prof. Kießling 2016 Kap. 1 - 18
Eigenschaften von OPAC:
Korpus (Katalog) abgeschlossen, geringe Änderungsrate
Suchmöglichkeiten:
Autor, Schlagwort, … Attributsuche
Logische Verknüpfungen Boolesche Algebra
Trunkierungszeichen Wildcards: “?“, “*“
Freie Suche keine Volltextsuche dank
Digitalisierung des Korpus
Filter / Navigation:
Suche eingrenzen Annotationen, sem. Kategorien
BibTip Andere Benutzer fanden Empfehlungen durch Analyse
auch interessant des Benutzerverhaltens
© Prof. Kießling 2016 Kap. 1 - 19Exemplarische Trefferliste: Autor = Kießling, Navigationshilfen © Prof. Kießling 2016 Kap. 1 - 20
Exemplarischer Treffer: Attribute – digitalisierter Text(ausschnitt) © Prof. Kießling 2016 Kap. 1 - 21
OPAC-Beispiele (Kardinalität der Ergebnismenge aus SS2010, SS2016): ● Freie Suche „Preference und Algebra“ Leere Ergebnismenge (0, 0) ● Freie Suche „Kießling“ Überflutung (283, 400) ● Attributsuche: Autor „Kießling“ Relevanz (171, 206) ● Attributsuche: Autor „Kie?ling“ Korrektheit (-, 29) ● A.-Suche: Autor „Werner Kießling“ Relevanz (25, 31) ● Kießling, Kiessling automat. Graphemerweiterung © Prof. Kießling 2016 Kap. 1 - 22
Digitalisierung von Buchbeständen:
Volltextsuche
Beispiele:
Google Book Search
Search Inside! von Amazon
Rechtliche Probleme bei noch geschützten Werken:
Urheberrechte
Nutzungsrechte, Verwertungsrechte
© Prof. Kießling 2016 Kap. 1 - 23Autoren:
Suche nach Information in
Wikipedia
Korpus von
Dokumenten
Anfrage IR-
System
Relevanz? 1. Doc1
Gewichtete 2. Doc2
Dokumente 3. Doc3
…
© Prof. Kießling 2016 Kap. 1 - 24Beispiel: Anfrage nach Artikel (Konzept) in Wikipedia
Wikipedia
Korpus (Online-Enzyklopädie) geschlossener Korpus bezogen auf
http://de.wikipedia.org/, offener und
„kleiner“ Autorenkreis im sozialem
Netzwerk, Kollaboration [Bearbeiten],
Suchmöglichkeiten:
Artikel (Von A bis Z) Konzeptsuche
Piktogramm Lupe Volltextsuche, Syntax
Verlinkung Semantisches Netzwerk
Links auf diese Seite Verweisstruktur (Backlinks)
© Prof. Kießling 2016 Kap. 1 - 251.3 Web-Suche
Websuche-Technologie stammt ursprünglich von IR-Systemen.
1993: der erste Such-Roboter „The Wanderer“ im WWW
„The Wanderer“ erstellte von 1993 bis 1995 einen Index des zu dieser
Zeit noch übersichtliche Web. Im Juni 1993 gab es nur 130 Webseiten.
Der Index diente der Vermessung des Webs und nicht der Suche.
1994/95: erste Suchmaschinen von kommerziellen Firmen (Lycos,
Infoseek, Alta Vista, …)
1998: Entstehung heutiger marktführender Suchmaschinen (Google,
Bing)
→ Geschichte der Suche im WWW
© Prof. Kießling 2016 Kap. 1 - 261.3.1 Architektur Websuche
Web Spider Korpus von
Dokumenten
Such-
Anfrage
System
Relevanz? Gewichtete
Dokumente
© Prof. Kießling 2016 Kap. 1 - 27Im Unterschied zu einem IR-System, bei dem der Korpus eher geschlossen und statisch ist, wächst das Web kontinuierlich, und auch bereits erfasste Inhalte ändern sich. Der Korpus des Webs ist offen und dynamisch, deswegen werden zusätzliche Komponenten benötigt. Ein Spider (auch "Crawler" oder "Robot" genannt) bewegt sich durch das Verfolgen von Links selbständig durch den Datenbestand des Internets und ermittelt die Inhalte der Webseiten. © Prof. Kießling 2016 Kap. 1 - 28
Verfeinerung Spider
Spider: Web
TODO:
Liste
von
URLs
Auswahl Laden Extraktion
Füge URLs
Seite
von Links
indizieren
hinzu
© Prof. Kießling 2016 Kap. 1 - 29Wichtigstes Merkmal neben der Anzahl der erfassten Seiten ist die Update-Rate, wodurch neuer oder geänderter Inhalt erfasst wird. Bei Google wird dies als „Google Dance“ bezeichnet: Bis 2003 wurden die Suchindizes einmal monatlich neu berechnet. Inzwischen läuft der Update-Prozess kontinuierlich. Trotzdem gibt es Seiten, die nicht erfasst werden bzw. nicht erfasst sein wollen (Deep Web / Dark Web). © Prof. Kießling 2016 Kap. 1 - 30
Exkurs: Deep Web Die Bezeichnung Deep Web bezieht sich auf alle Internet-Inhalte, die aus verschiedenen Gründen von Suchmaschinen nicht indiziert sind oder nicht indiziert werden können, z.B. dynamische Webseiten, geblockte Seiten (erwarten CAPTCHA-Antwort), nicht verlinkte Seiten, ... Der Begriff Deep Web wurde von dem Informatiker Mike Bergman im Jahr 2000 eingeführt. In seiner Veröffentlichung „The Deep Web: Surfacing Hidden Value“ von 2001 weist er darauf hin, dass die Inhalte von Deep Web 400 bis 550 Mal größer sind, als im allgemein zugänglichem Web. © Prof. Kießling 2016 Kap. 1 - 31
Arten des Deep Web
Nach Sherman & Price (2001) unterscheidet man fünf Typen des Deep Web
(Wikipedia):
●
Opaque Web: Webseiten, die generell indiziert werden könnten , es aber
aus technischen Gründen oder Gründen der Leistungsfähigkeit nicht sind.
●
Private Web: Webseiten, die indiziert werden könnten, es auf Grund von
Zugangsbeschränkungen aber nicht werden.
●
Proprietary Web: Webseiten, die erst nach Anerkennung einer
Nutzungsbedingung oder nach einer Identifikation indiziert werden
können.
© Prof. Kießling 2016 Kap. 1 - 32Arten des Deep Web
●
Invisible Web: Webseiten, die indiziert werden könnten, es jedoch aus
kaufmännischen oder strategischen Gründen nicht werden.
●
Truly Invisible Web: Webseiten, die aus technischen Gründen (noch) nicht
indiziert werden können, z.B. nicht-Standardformate (Flash) oder Formate,
die aufgrund ihrer Komplexität nicht erfasst werden können
(Grafikformate).
© Prof. Kießling 2016 Kap. 1 - 33Exkurs: Dark Web Deep Web und Dark Web werden fälschlicherweise oft gleichgesetzt. Eine Gemeinsamkeit ist, dass man auf Inhalte nicht mit kommerziellen Suchmaschinen zugreifen kann. Das Dark Web kann man dabei als Teil von des Deep Web betrachten. Die Seiten des Dark Web werden absichtlich vor dem Zugriff durch Suchmaschinen geschützt, nutzen maskierte IP-Adressen und sind nur mit speziellen Web-Browsern zugänglich. Beiden Begriffe sind der breiten Öffentlichkeit aus den Nachrichten bekannt, als das FBI ein Online Schwarzmarkt „Silk Road“ (2013) und danach auch seinen Nachfolgen „Silk Road 2.0“ (2014) geschlossen hat. © Prof. Kießling 2016 Kap. 1 - 34
Dark Web Zugang Das Tor Projekt stellt mit Hilfe des Tor Browsers eine Möglichkeit zur anonymen Nutzung des Webs zur Verfügung. Auch eine Version für Android ist verfügbar. Anfragen werden dabei innerhalb des Tor Netzwerkes über mehrere Server (mindestens 3) weitergeleitet, um die Identität des Nutzers zu verschleiern. Daten werden dabei verschlüsselt übertragen. Neben gewöhnlichen Webseiten kann mit Tor auch auf sogenannte Hidden Services zugegriffen werden. Diese sind über eine sogenannte “onion address“ erreichbar (Übersicht über legale Services). Für eine detaillierte Beschreibung des Tor Netzwerkes wird auf die Veröffentlichung „Tor: The Second-Generation Onion Router“ von Dingledine, Mathewson und Syverson verwiesen. © Prof. Kießling 2016 Kap. 1 - 35
Nutzen des Dark Web In Ländern mit repressiven Regimen kann das Dark Web für einen politischen Kampf genutzt werden. Facebook hat eine Version der Seite im Dark Web zugänglich gemacht, damit auch aus Ländern, in denen Facebook verboten ist, darauf zugegriffen werden kann. Sie ist nur mit Browsern erreichbar, die Tor unterstützen: https://facebookcorewwwi.onion Im Zuge der Dark Web Debatte wird oft über die dezentrale digitale Währung Bitcoin diskutiert, da sie auch für die anonyme Bezahlung im Dark Web Einsatz findet. Weitere Informationen sind in der Veröffentlichung „Bitcoin: A Peer-to-Peer Electronic Cash System“ von Nakamoto zu finden. © Prof. Kießling 2016 Kap. 1 - 36
Vom Deep Web zurück zum Visible Web In den meisten Fällen ist man natürlich an einer Anmeldung interessiert: • Google (Bekanntmachung für Spider per http://www.google.de/addurl/) • Beschreibung der eigenen Webstruktur z.B. durch Sitemaps Über das Robots Exclusion Protocol kann ausgeschlossen werden, dass Seiten vom Crawler besucht werden. Allerdings können Crawler eine definierte robots.txt Datei, die beschreibt welche Seiten indiziert werden dürfen und welche nicht, ignorieren. Es handelt sich also um eine freiwillige Einhaltung des Protokolls. © Prof. Kießling 2016 Kap. 1 - 37
Um der großen Datenmenge Herr zu werden, extrahiert ein Merkmalsextraktor relevante Merkmale und Texte aus den gefundenen Webseiten. Durch die Merkmalsextraktion wird die Datenmenge bereits deutlich verkleinert (Korpus). Um die grammatikalische Komplexität (Flexion) zu reduzieren, werden Wörter durch Text-Operationen auf ihren Wortstamm zurückgeführt (Stemming). Einer der bekannteste Algorithmen ist der Porter-Stemmer. Zudem werden Füllwörter (Artikel, …) entfernt (Stopword removal), da sie oft nur grammatikalische Informationen tragen. Siehe dazu Kapitel 2 in „Introduction to Information Retrieval“. © Prof. Kießling 2016 Kap. 1 - 38
Um über die Suchbegriffe wieder auf die Originale zurück schließen zu
können, verwaltet der Indexierer die extrahierten Merkmale und Texte
der Dokumente und erlaubt den schnellen Zugriff auf die Originale über
diese Merkmale und Texte.
Dieser Suchindex wird als „Inverted File“ implementiert. Er hat die
gleiche Funktion wie ein Schlagwortregister, das Schlagwörter
denjenigen Buchseiten zuordnet, in denen das Schlagwort vorkommt.
Beispiel:
Di: Unter einem blauen ID Term Dokument : Position
Himmel trafen … …
n blau i : 3, j : 4
Dj: Montags machen n+1 Himmel i : 4, j : 7
viele blau. Unter
freiem Himmel … …
© Prof. Kießling 2016 Kap. 1 - 39Verfeinerung Websuche
Such- Anfrage
System:
Text-Operationen
Logische Sicht Spider
Anfrage- Datenbank-
Indexierung
Operationen Manager
Reformu-
lierung Inverted
File
Suche Index
Dokument
Ergebnis- DB
Bewertete
Dokumente Bewertung menge
© Prof. Kießling 2016 Kap. 1 - 401.3.2 Navigationsanfragen im Web
Beispiel: Navigation per Links
Ziel: Ich will mich über Vorlesungen des Lehrstuhls für „Datenbanksysteme“
informieren.
Einstieg per URL
http://www.informatik.uni-augsburg.de/de/lehrstuehle/
Ergebnis:
Durch die Linkstruktur in HTML werden die Lehrstühle thematisch so strukturiert, dass
die Informationsbedürfnisse der Leser (hoffentlich vollständig) erfüllt werden. Der Leser
erschließt nach den eigenen Bedürfnissen die Struktur der Webseite per Navigation.
Hypertext, HTTP, (X)HTML, serverseitiges Skripting (Java, Servlet, Python,
PHP, …), clientseitiges Skripting (JavaScript, Applet, AJAX)
© Prof. Kießling 2016 Kap. 1 - 41Beispiel: Semantikunterstützte Navigation in a priori definierten
Kategorien per Hierarchischer Suche
Ziel: Ich will mich um eine Urlaubsreise im Sommer kümmern.
Einstieg per Directory:
DMOZ (open directory project):
– Vordefinierte Hierarchien zur Navigation, z.B.
Regional → Europe → Germany → States → Bavaria → Localities
– Begrenzte Auswahl an Ergebnissen da von Menschen erstellt & verwaltet
Kommerzielle Portale (wie z.B. Yahoo) greifen nicht mehr auf diese Directories
zurück, da die Aktualisierung zu aufwändig ist.
© Prof. Kießling 2016 Kap. 1 - 42© Prof. Kießling 2016 Kap. 1 - 43
Ergebnis:
Exploratives Suchen in Kategorien
keine einheitlichen Kategorien und Relationen für die Semantik einer
Applikation
Anzahl der in einer Kategorie gesammelten Konzepte ist angegeben
Hierarchische Suche wird immer mehr durch Volltextsuche verdrängt.
Hierarchische Suche, die einen Bezug zu geographischen Inhalten hat,
wird durch Oberflächenelemente wie interaktive Maps versteckt.
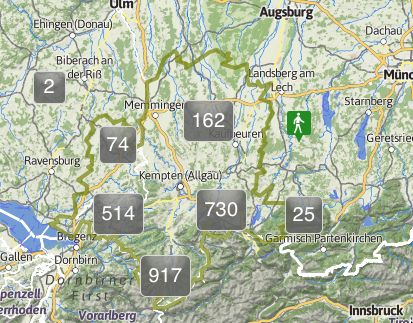
© Prof. Kießling 2016 Kap. 1 - 44Hierarchische Suche mit Hilfe von Karten:
Suche nach Wanderungen im Allgäu →
Zoom zu Wanderungen in Immenstadt
www.outdooractive.com
© Prof. Kießling 2016 Kap. 1 - 451.3.3 Suchanfragen im Web
Korpus (WWW):
Offen
Dynamisch, indizierter Inhalt ändert sich!
Unentdeckte „Kontinente“ (Deep Web)
Suchmöglichkeiten:
Stichwörter für Volltextsuche
Erweiterte Suche: (z.B. Google)
Logische Verknüpfungen
Wildcard-Suche
Zahlenbereiche
Ortsspezifische Suche per Domain-Einschränkung
Leere Ergebnismenge, Überflutung , Relevanz
© Prof. Kießling 2016 Kap. 1 - 46Zipfsches Gesetz
Welche Suchbegriffe muss man wählen, um mit ihnen relevante Quellen
zu finden? Ein Hinweis gibt das Zipfsche Gesetz:
Der Rang i eines Wortes ist indirekt proportional zu seiner rel. Häufigkeit:
Freq(Worti) = i-ϴ x Freq(Wort1),
wobei 1,5 < ϴ < 2 für die meisten Sprachen gilt (Potenzverteilung).
Beispiel:
Freq(Worti) Für ϴ = 1 besitzt das 2. häufigste Wort eine
Häufigkeit von 1/2 des häufigsten Wortes.
• Zone I: Sehr häufige Wörter sind meist
funktionale Wörter (der, die, und, …).
• Zone II: Mittelhäufige Wörter erschließen
einen Text am besten.
Rang i • Zone III: Seltene Wörter sind häufig Tipp-
I II III
fehler oder zu spezifische Wörter (Ranb,
© Prof. Kießling 2016
Freq., Hornussen, …). Kap. 1 - 47Folgerungen aus dem Zipfschen Gesetz: Positiv: Füllwörter machen einen großen Anteil von Texten aus. Die Eliminierung von Füllwörtern hat keinen Einfluss auf das Retrieval, erspart jedoch Speicher. Negativ: Für die meisten Wörter ist eine signifikante statistische Analyse (z.B. Korrelationsanalyse) schwer zu erzielen, da die Wörter in einem Korpus zu selten auftreten. Beispiel: Sprachabhängige Worthäufigkeiten, englische Worthäufigkeiten © Prof. Kießling 2016 Kap. 1 - 48
Beispiel: Verknüpfte Stichwortsuche Welche Zulassungsbedingungen müssen eingehalten werden, um an der Klausur in Datenbanksysteme I teilnehmen zu dürfen? Wunschseite: http://www.informatik.uni-augsburg.de/de/lehrstuehle/dbis/db/lectures/ws1415/datenbanksysteme1/exams/ Suche mit Google (Achtung! Google Suche ist personalisiert.) Ergebnisse aus SS16: Von den 2940 Treffern finden sich auf Position 1 bis 4 Dokumente des Lehrstuhls. Ein Ortsbezug wird automatisch hergestellt. Das gewünschte Dokument ist erst auf Position 3. Fehlende Relevanz © Prof. Kießling 2016 Kap. 1 - 49
2. Änderung: ganz genauen Domänenbezug hinzunehmen
www.informatik.uni-augsburg.de
Suche mit Google
Ergebnisse aus SS16:
Es werden durch die Domain-Einschränkung 7 Treffer angeboten.
Der 2. Treffer bietet das Klausurdatum und die Zulassungsbedingungen korrekt
an.
© Prof. Kießling 2016 Kap. 1 - 501. Änderung: Domänenbezug erzwingen durch Domain-Einschränkung
auf www.uni-augsburg.de
Suche mit Google
Ergebnis:
Die beiden zuvor gefunden Dokumente mit Bezug zum Lehrstuhl werden
nicht mehr gefunden, da sie aus Subdomains der Uni Augsburg stammen.
SS16: keine Treffer
© Prof. Kießling 2016 Kap. 1 - 513. Änderung: Kompositum „Zulassungsbedingung“ semantisch auf
„Zulassung“ reduzieren, kein Domänenbezug
Suche mit Google
Ergebnisse aus SS16:
Es werden insgesamt 8720 Dokumente gefunden. Auf Platz 1+2 befinden
sich Seiten zu DB1 des Lehrstuhls im WS12/13 und WS 09/10. Der
Ortsbezug wird wiederum automatisch hergestellt.
Überflutung, jedoch gutes Ranking
© Prof. Kießling 2016 Kap. 1 - 52Stand der Dinge:
Iteratives Vorgehen
(Suche im „Heuhaufen“ geeignetere (!) Stichwörter,
Filterfunktionen der Suchmaschine wie z.B. Domain)
Solange keine Zufriedenheit mit dem Suchergebnis besteht,
1. Abfrage(re)formulierung,
2. [Selektion],
3. [Navigation].
© Prof. Kießling 2016 Kap. 1 - 53Bei der Stichwortsuche ist ein häufiges Phänomen eine leere
Ergebnismenge (empty result set) bzw. als Alternative eine Überflutung
(flooding effect) durch meist irrelevante Dokumente.
Beide Phänomene erschweren, dass Benutzer relevante Treffer entdecken
können.
Um die Relevanz der Treffer zu erhöhen, bieten sich Modelle an, die
semantische Zusatzinformationen bei der Suche bzw. Navigation ins Spiel
bringen:
Stichwortsuche mit Unterstützung von in Beziehung stehenden
semantischen Kategorien (Semantische Netzwerke, Ontologien,
Taxonomien)
Attributsuche (Schemata)
Präferenzen (Benutzermodelle)
© Prof. Kießling 2016 Kap. 1 - 54Beispiel: Stichwortsuche nach mehrdeutigem Wort „Saturn“ in
verschiedenen Suchräumen
Korpus Treffer (SS07) (SS16)
1. Web, Suche mit Google 54.100.000 107.000.000
2a. Gesamtverzeichnis, Suche mit 66.500 2012: Semantische
Google Suche abgeschaltet
2b. Verzeichnis „Wissenschaft“, 189 2012: Semantische
Suche mit Google Suche abgeschaltet
Ergebnis: Die Suche in Kategorien erhöhte die Relevanz der Treffer, da irreführende
Synonyme ausgeschlossen sind. Das Erstellen von Kategorien sowie die Zuordnung von
Dokumenten zu Kategorien erfordert jedoch redaktionellen Zusatzaufwand bzw.
gemeinschaftliches Indexieren (social tagging, folksonomy).
© Prof. Kießling 2016 Kap. 1 - 55Stichwortsuche mit semantisch richtigen, aber nicht im Korpus
verwendeten Stichwörtern
Beispiele (Ergebnisse aus SS16):
Suche Zahnarzt (458.000) / Dentist (127.000) in Augsburg?
Suche Zahnarzt OR Dentist (463.000) in Augsburg?
Synonymsuche z.B. ~Dentist in Augsburg bei Google (127.000)?
Ergebnis:
Die Suche erfolgt nur anhand von Wörtern nicht Konzepten.
Stichworterweiterung aus Synonymwörterbücher,
VerODERung mit Synonymen oder themenrelevante Vorschläge
© Prof. Kießling 2016 Kap. 1 - 56Beispiele: Stichwortsuche mit Unterstützung durch
semantisches / linguistisches Wissen
Beispiele:
Suche nach Alfons Huhn als Bild bei Flickr
Bis 2013 alternative Vorschläge nach leerer Ergebnismenge
wie “chicken“, 2016 leere Ergebnismenge
Suche nach Information Retrieval bei Ask.com
Bis 2013 Möglichkeit von semantischen Anfrageerweiterungen bzw.
Anfrageeinengungen (wissensbasiert), 2016 statistikbasierte
Termerweiterungen
Ergebnis:
Semantisches / linguistisches Wissen wird durch statistikbasiertes Wissen
ersetzt.
© Prof. Kießling 2016 Kap. 1 - 57Beispiel: Volltextsuche und Plagiarismus
Welchen Autoren lässt sich der Text "Let us exemplify the unsatisfying
state of the art" zuschreiben?
Suche mit Google
Ergebnis:
Textstellen, insbesondere Zitate, lassen sich hervorragend mit Volltext-
suche überprüfen.
Ergebnisse 1 - 1 von ungefähr 1 für "Let us exemplify the unsatisfying
state of the art". (0,27 Sekunden, SS2007)
SS2016: 5 URLs
© Prof. Kießling 2016 Kap. 1 - 581.4 Überblick Attribut-Suche
Voraussetzung für eine Attribut-Suche sind strukturierte Daten. Diese werden
im Normalfall durch Schemata beschrieben. Standardmäßig kommt eine
Datenbank im Backend zum Einsatz:
Im Unterschied zur Stichwortsuche ist bei einer Attributsuche ein
exaktes Daten-Retrieval möglich.
Web-Applikationen verstecken das Datenmodell, die dazu gehörenden
Schemata und die Ablauflogik.
Eingabefelder erlauben die Selektion und Projektion der gewünschten
Daten.
Beispiel: Reiseauskunft bei der DB
© Prof. Kießling 2016 Kap. 1 - 59Bei der Attributsuche mit exakten Treffern (exact match) treten die
bekannten Phänomene auf:
1. Leere Ergebnismenge (empty result set)
2. Überflutung (flooding effect)
3. Eine Bewertung (ranking) ist nicht möglich.
Viele Datenbanksysteme kombinieren die Attribut- mit der Volltextsuche
wie z.B. „Oracle Text“ von Oracle.
© Prof. Kießling 2016 Kap. 1 - 60Bemerkung (Warnung):
Webseiten, die dynamisch durch Attributsuche generiert werden, können nicht
indiziert werden, da der Spider sonst alle möglichen Eingabe-Kombinationen
ausprobieren müsste ( Deep Web).
Die Ergebnisse von Fachdatenbanken mit einem Web-Frontend liegen aus
dem gleichen Grund im Deep Web trotz einer guten Ergebnisqualität.
Die Stichwortsuche kann in diesen Fällen also nur dazu benutzt werden,
geeignete Fachportale zu finden.
„I will use Google before asking dumb questions.“
© Prof. Kießling 2016 Kap. 1 - 61Beispiel: Elektronischer Handel (E-Commerce)
B2C (Business-to-Consumer)
Anfrage Ecommerce- DB
System
Relevanz? 1. Ware1 Kauf!
Gewichtete
2. Ware2 Kauf!
Waren
3. Ware3 Kauf!
…
Kauf!
© Prof. Kießling 2016 Kap. 1 - 62Beispiel 1: Mieten einer Wohnung
Online-Immobilienmakler
Korpus (Immobilienbestand) abgeschlossen, rel. geringe Änderungsrate
Suchmöglichkeiten:
Reiter, Überschriften Kategorien, Navigation
Suchfenster Attributsuche, hierarchische Suche
Hintergrundwissen Geographisches Informationssystem (GIS)
Beispiel: Wohnen, Augsburg … , Mietwohnungen
(SS07) Salomon-Idler, Umkreis Automat. Erweiterung um Univiertel,
ab SS08: „Radius“
(SS16) #Zimmer, Fläche, Preis Leeres Ergebnis bei zu geringem Preis
Parametrische Suche (Synonym Facettensuche)
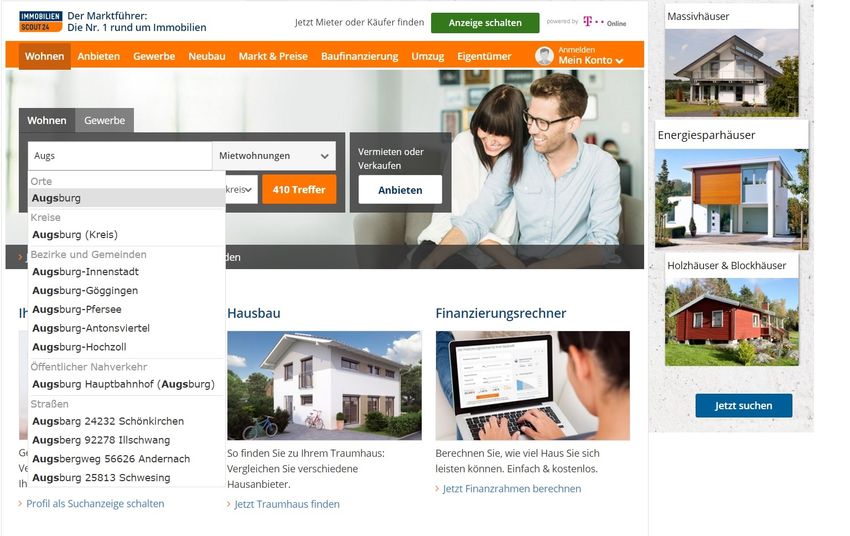
© Prof. Kießling 2016 Kap. 1 - 63Seit SS2013
http://www.immobilienscout24.de/
Vorschläge für Autovervollständigung der Benutzereingabe auf mehreren
geographischen Konzeptebenen:
- Orte, Kreise, Bezirke und Gemeinden, Straßen
Parallele, konzeptspezifische Suche mit Vorschlag von 5 Varianten je Konzept
© Prof. Kießling 2016 Kap. 1 - 64Seit SS2013
Definition von oberer (Preis) oder unterer (Zimmer, Fläche) Grenze für
numerische Parameter.
Umkreis kann in Minuten oder in km angegeben werden.
Dynamische Anzeige der Trefferanzahl in Abhängigkeit von jedem
Parameter.
Frühere attributbasierte Suche ist ersetzt durch Parametrische Suche mit 4
Attributen, wobei WO und WAS für den Anwender als Prefilter wirken.
© Prof. Kießling 2016 Kap. 1 - 65Suche anpassen: Anzeige aller vorhandenen Parameter © Prof. Kießling 2016 Kap. 1 - 66
Beobachtung:
In Abhängigkeit vom Datenbestand und der Anfrage können bei
der Attribut-Suche zwei Phänomene auftauchen:
1. Leere Ergebnismenge (empty result set)
2. Viel zu große Ergebnismenge (flooding effect)
Mit Hilfe der „Parametrischen Suche“ wird der Einfluss von
Attributen auf die Größe der Ergebnismenge visualisiert und damit
dem Benutzer ein Feedback auf seine Aktionen gegeben.
© Prof. Kießling 2016 Kap. 1 - 67Parametrische Suche
Beispiel 2: Auswahl von Elektronikware
Preisvergleich (z.B. Fernseher) bei Idealo
Ergebnis:
Nach einem hierarchischen Suchvorgang gelangt man zu einer Startseite für
eine parametrische Suche. Bei einer parametrischen Suche wird durch die
Benutzerauswahl eines Attributwertes die Ergebnismenge eingeschränkt.
Die Ergebnismenge kann dann durch Auswahl weiterer Attributwerte iterativ
eingeschränkt werden, dabei kann auch eine leere Ergebnismenge auftreten.
Durch Rücknahme von Einschränkungen kann sich die Ergebnismenge wieder
vergrößern. Die Kardinalität der Ergebnismenge der momentanen Selektion ist
(meistens) angegeben.
Die Vorgehensweise entspricht einer iterativen Navigation bezüglich der
Attribute des Suchraums.
© Prof. Kießling 2016 Kap. 1 - 681.5 Übersicht Multimedia-Suche
Suche in Multimediabeständen bestehend aus
Bildern,
Audios,
Videos.
Multimediasuche findet meist in textuell erschlossenen Beständen ab. Die
Erschließung findet in sozialen Netzwerken durch Annotierungen (Tagging)
mit Hilfe eines offenen Vokabulars statt.
Für die professionelle Annotierung existieren z.B. spezifische XML-
Sprachen wie MPEG-7 (siehe Schema).
Beispiele: Videos mit den Annotierungen „Clinton“ „2016“
●
YouTube
●
Yahoo
© Prof. Kießling 2016 Kap. 1 - 69Praktisches Beispiel: Google Bildersuche
Suche Bild aus tz aus der Wochenendausgabe vom 11./12.11.06:
© Prof. Kießling 2016 Kap. 1 - 70Aus dem Zeitungsartikel, in dem das Bild eingebettet ist (Erschließung über
Umgebungstext), kann der Leser folgende Stichwörter entnehmen:
1. Versuch: saturn, ring, earth, cassini
(SS07: 79.400, seit SS13: Anzahl wird nicht mehr angezeigt.)
2. Versuch: saturn, eclipse, 2006-09-15, cassini
(SS07: 215, seit SS13: Anzahl wird nicht mehr angezeigt.)
Aus der Ergebnismenge von Google-Bildsuche kann bislang nur durch
(menschliche) Analyse das gesuchte Bild und seine Quelle gefunden werden.
Quelle: http://photojournal.jpl.nasa.gov/catalog/?IDNumber=PIA08329
© Prof. Kießling 2016 Kap. 1 - 71Die Suche nach ähnlichen Bildern in einem Bildarchiv bzw. die Bild- Annotierung und Suche ausgehend von einem Vergleichsbild ist im Allgemeinen ein kaum zu lösendes Problem. Für stark eingeschränkte Anwendungsdomänen wie z.B. Gesichtserkennung werden Lösungen angeboten. Beispiele: Polar Rose, 2010 gekauft von Apple, bzw. Gesichtserkennung bei Facebook abgeschlossenes Lehrstuhlprojekt: Heron Bildsuchekriterien: z.B. Farbhistogramm (blau/weiß) Textur (Hermelinfell) © Prof. Kießling 2016 Kap. 1 - 72
Ähnlichkeitssuche für Bilder im Web (Reverse Image Search): ● Google Bildersuche ● TinEye ● Yandex Unterschiedliche Güte der Suchergebnisse je nach Suchverfahren. Suche allein auf Bildähnlichkeit basierend liefert ungenügende Ergebnisse. Trefferraten werden durch Metainformationen verbessert. © Prof. Kießling 2016 Kap. 1 - 73
Sie können auch lesen

















































