ALICE-TRD digital chip - Inhalt
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
ALICE-TRD digital chip
Falk Lesser
Kirchhoff Institut für Physik
lesser@kip.uni-heidelberg.de
Inhalt
• Ziele des ALICE-Experiments
• Das TRD-System
• Lineare Regression
• Implementierungsansätze
• Der Prozessorkern femtoJava 1
• Projekt-Status
2
1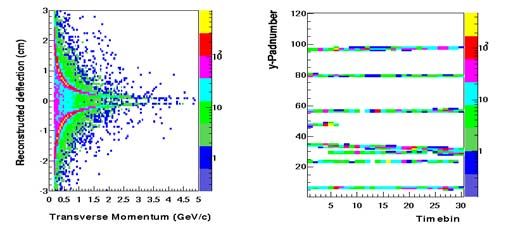
Ziele des ALICE-Experiments
• ALICE ist eines der vier großen Experimente am LHC
• Studien am Quark Gluonen Plasma (QGP)
• Ereignisrate beträgt 4*103 Kollisionen pro Sekunde (Pb + Pb)
• Teilchenmultiplizität von etwa 16000 Teilchen in der Akzeptanz des
Detektors (zentrales Event)
• Suche nach high pt Elektron-Positron Paaren (e+ e-)
– Teilchen mit einem Transversalimpuls ≥ 3 GeV/c
– 5 % aller zentralen Pb + Pb beinhalten e+e- -Paare
– Identifizierung der Teilchen über die Ablenkung in r/ϕ -Ebene
– Ablenkung der gesuchten Teilchen < 2.0 mm bei pt ≥ 3 GeV/c
– ohne Trigger jährliche Produktion Y = 1000
• Trigger auf interessante Ereignisse
3
Gesamtübersicht des Detektor
• TRD umgibt die TPC
• TRD ist der Level 0 Trigger der TPC
• TPC besitzt sehr lange Latenzzeiten
• Anforderung: Gute Spurauflösung, schnelle Triggerentscheidung
• Pionenunterdrückung
• Verarbeitet Daten aus 1.2 Millionen Kanälen (occupancy = 12 %)
4
2
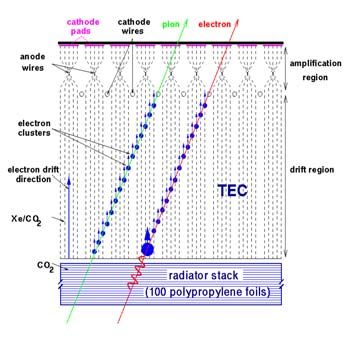
Der Detektor
Pionenunterdrückung:
• (TR) -Photonen werden emittiert beim Übergang
eines Teilchens durch zwei Medien unter-
schiedlicher Dielektrizitätskonstanten ε1 => ε2
• Intensität der Übergangsstrahlung ∝ | ε2 - ε1 |
• Abgestrahlte Intensität ∝ Lorentzfaktor γL
(Identifikation); Hochrelativistisch γL >> 1
• Elektronen γL = 2000 (Größenordnung)
Track-Detection:
• Partikel ionisieren Gas (Xe/CO2 oder Xe/C4H10)
und setzen freie Elektronen ab
• Elektronen driften entlang eines elektr. Feldes
• Detektion am Auslesepad
• Insgesamt 1.2 Millionen Auslesekanäle
5
Zeitablauf
• Alle e+ e- mit minimaler Ablenkung sollen gefunden werden
• Ermittlung der Position, Winkel und Amplitude aller high pt tracks Infos
zur Track Matching Unit (TMU).
• Datenreduktion von 1800 Hz (clean min bias) auf 40 Hz (e+ e-)
Ereignisrate
• Selektion der steifen Tracks über lin. Regression parallel für alle Lagen
• Berechnung der Regressionsparameter in Echtzeit
• Berechnung charakteristischer Werte mit Hilfe einer microCPU
• Berechneten Werte in 32 Bit-Wert zusammenfassen und an TMU
übergeben
• TMU korreliert Spursegmente und fällt Triggerentscheidung
6
3
Datenauslese
Amplitude
Pad
timebin
• 12 % Occupancy bei Detektoroberfläche von 108 m2 (plane 1)
• 200 000 Pads/Lage => 4,5 cm2 pro Pad
• Ladungsteilung zwischen benachbarten Pads
• Ortsauflösung von 200 μm
7
Simulation
• Teilchenmultiplizität von etwa 16000 Teilchen/s (Pb + Pb)
• Anzahl der Kanäle 1.200.000
• 30 Werte pro Kanal (Timebins)
• Sampling rate 15-20 MHz
• Auflösung der ADCs 8 Bit
• Gesamtaufkommen an Rohdaten 36 MByte
Erste Simulation:
8
4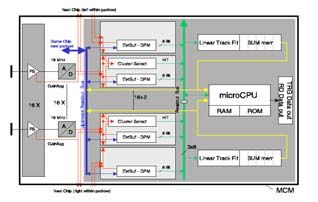
Datenaufkommen
Datenformat: 8 Bit/pro Timebin und Kanal
.
.. Berechnungsdauer: 2 μs Driftzeit
. .
timebin Rohdaten: 30 Bytes pro Ereignis
Daten: 30 Bytes x 1.2 Millionen Kanäle = 36 MByte
Insgesamt : 18 TByte/s
Elektronik: Auf dem Detektor
9
Datenanalyse
Pad-No.
30
timebin
a
b
10
5Algorithmus
• Insgesamt 5 μs Verarbeitungsdauer davon 2 μs Driftzeit
• Positionen und Fit-Parameter während der Driftzeit bestimmbar
• Stichprobenwerte (xi, yi): i = 1, 2, ... N
• x-Wert ist diskret (timebin), y-Wert ist gemessene Position (Spur + Meßfehler)
n
• KQ-Methode: ∑ [ y − (a + bx )]
i =1
i
i
2
= min
• Zu Berechnen sind die Erwartungswerte für a, b
N ∑yi xi - ∑xi ∑yi yi =
AP+1 - AP-1
b=
N ∑xi2 - (∑xi)2 AP-1 + AP + AP+1
∑yi ∑xi2 - ∑yi xi ∑xi
a= χ2= N-1 ∑ [yi - ( a + bx)]2
N ∑xi2 - (∑xi)2
Regressionsgerade: y(x) = a + bx
11
Anforderungen
Während der Driftzeit: Nach der Driftzeit:
N = Hitcount A = Achsenabschnitt
yi = Ort B = Steigung
∑xi = Summe Timebin
Allg. Größen = f(∑ yi, ∑xi)
∑yi = Summe Ort
χ2 = Qualitätsmaß für den Fit
∑ xi yi = Summe Ort * Timebin
Keine Iteration notwendig am Ende der Driftzeit! Zeitersparnis 2 μs
Pipelineverarbeitung in Hardware: 64
Do 64 Di
Calculate Calculate fit Calculate sums
∑ xi y'i < 15377
AP+1 8
∑ y'i2 < 30753
∑ xi2 < 10417
Position summands 15
AP 8
∑y'i < 993
∑xi < 497
5 +1
AP+1 - AP-1 14 +1 3
yi = yi2 ∑xi ∑ xi2
AP-1 8 AP-1 + AP + AP+1 14 ∑yi ∑ yi2
xi yi xi2
∑ xi yi
12 4 Op. 3 Op. 6 Op. 12 Op. Sum Memory
6Rechenleistung im Vergleich
Notwendige Operationen: Lineare Regression
Ziel: Geradengleichung y(x) = a + b x
Regressionsparameter : 25 Operationen pro Timebin
30 Werte pro Track: 750 Operationen pro Track
Werte a, b: 11 Operationen für jeden Parameter
Wert χ2 : 30 Operationen
Insgesamt: 791 Arithmetische Operationen (AOPS)
16 000 Tracks: 12,656 * 106 Arithmetische Operationen
Rechenzeit 2 μs 6,328 * 1012 AOPS insgesamt
13
Lösungsansatz
Problem: Gesamtaufkommen an Daten: 18 TByte/s
Erforderliche Rechenleistung: 6,328 * 1012 AOPS
Lösung: Netzwerk aus 75 000 CPUs
Jeder Kanal berechnet die Regressionsparameter
microCPU verarbeitet die Daten von 16 Kanälen
I II III
• 16 (18) Verarbeitungskanäle
auf jedem Chip
• 16 HSLP-ADCs für jeden Chip
• Funktionseinheiten von 16
Kanäle auf MCM
• Algorithmen in Java-Bytecode
• AMS035 CMOS-Technologie
14
7I/O-Daten der Fit-Logik
• Input-Daten
– 8 Bit (256 Quantisierungsstufen)
– 16 Datenkanäle + 2 benachbarte Kanäle
– Samplingrate 15-20 MHz (62,5 - 50 ns)
• Output Daten
– 32 Bit Ausgabedaten teilen sich auf in
• rφ Position 11 Bits
• Korrigierter φ-Winkel bzw. Displacement 5 Bit
• z-Position 6 Bits (Position aus Chip-Nummer, Padrow, Sektor)
• Amplitude 8 Bits
• TR-Qualität 2 Bits
15
Implementierungsansätze
Pad 1 Pad 2 Pad 3 Pad 8 Pad 9 Pad 10 Pad 16
TH-Logic
TH-Logic
TH-Logic
TH-Logic
TH-Logic
TH-Logic
TH-Logic
Evt. Buffer
Zentr. Zentr.
Selektion der Operanden Selektion der Operanden
A1 ..A4 A5 ..A8 A9 ..A12 A13 ..A16
Sub Sub Sub Sub
∑A1 ... ∑A4 ∑A5 ... ∑A8 ∑A9 ... ∑A12 ∑A13 ... ∑A16
Shift Shift Shift Shift
Reg Reg Reg Reg Reg Reg Reg Reg
Div Div Div Div
16 Reg y Reg y Reg y Reg y
8Ausschnitt aus der TH-Logik
Pad 1 Pad 2 Pad 3 Pad 8 Pad 9 Selektion der ADC-Werte:
∑ ∑ ∑ • AP-1 + AP + AP+1 > TH
• (AP-1 < AP) & (AP+1 < AP)
TH TH TH
Comp Comp Comp Comp Comp
Datenreduktion:
& & & & Faktor 4
Sum Sum
(30 x 1 Byte => 4 x 1 Byte)
& & &
Zentr. Zentr. Zentr.
Sum
17
Die virtuelle Java Maschine
Kompilierte Programme
Quellprogramme
A.class B.class C.class
A.java B.java C.java A.class B.class C.class
A.java B.java C.java
Class-Loader
Java Java
Java
Compiler Execution Engine Virtual
Compiler
Machine
A.class B.class C.class X.class Y.class Z.class
A.class B.class C.class X.class Y.class Z.class
Kompilierte Programme Standard Java-Klassen (API)
• Definition eines abstrakten Maschinenmodells
• Funktionale Verhalten ist genau spezifiziert
• Spezifikation der JVM ist von Implementierungsdetails entkoppelt
• Flexibler Triggercode
• Ideal spezifizierter Prozessor
9Spezifikation der JVM
• Befehlssatz besteht aus 201 Opcodes
• Laden/Speichern
• Arithmetische/Logische Befehle
• Typumwandlungsbefehle
• Befehle zur Verwaltung des Operandenstapels
• Kontrolltransferbefehle
• Befehle zum Erzeugen und Manipulieren von Objekten
• Spezialbefehle:
– N ∑yi xi - ∑xi ∑yi
– N ∑xi2 - (∑xi)2
• Befehlsformat 8 Bit
• Datenformat 32 Bit (hier 16 Bit)
19
Hardwarestruktur des femtoJava 1
Data-Memory
Data-Memory
Verarbeitungsdaten Kontrollsignale femtoJava 1
Reset
Initialisierung
Pipe
Pipe11 Pipe
Pipe22 Pipe
Pipe33(4)
(4)
Kontrollsignale
Instr.-Memory
Instr.-Memory
Instruktionen
• Dreistufige Pipelinestruktur
• Fetch/Decode (Pipe 1)
• Fetch Operands, Execute Control, Write Back (Pipe 2)
• Execute (Pipe 3)
10Die erste Pipelinestufe
Aktivität an
Pipelinestufe 2 Pipelinestufe22
Pipelinestufe
Reset Clk
Go
Go Anweis
Anweis Const
Const Code
Code Temp
Temp11 Temp
Temp22
idle
idle Read_instr
Pipe
Pipe 22
Start Instr_ready
Neuer LZ
Instr_addr 300 301 302
Opcode/Data
fetch
fetch
Opcode goto Op 1 Op2
LZ fortsetzen
1. LZ
LZ fortsetzen Code goto
Befehls
Befehls Addr. Instruktions
Instruktions
decode
decode temp1 Operand 1 Decoder
Decoder Speicher
Speicher
PC-
PC-
Logik
Logik
temp2 Operand 2 Kontroll-
Kontroll-
2. LZ Einheit
Einheit
LZ fortsetzen Instruktionswort zu goto
anweisung
fetch2
fetch2 Konstante zu goto
const
Decode
abgeschlossen
Kontrolleinheit Datenpfad
21
Kontrolleinheit der zweiten Stufe
Execute
Execute Zeitgleich zum WB
ALU-Ctr
ALU-Ctr nächsten Fetchzyklus
Pipe 1
Readdecode
Readdecode Executedecode
Executedecode Writedecode
Writedecode
Read_ix8
Read_ix8 Read_ix
Read_ix Write_ix8
Write_ix8 Write_ix_1
Write_ix_1 Write
Write _ix
_ix
Read_ix8_2
Read_ix8_2 Read_ix_2
Read_ix_2 Write_ix8_d1
Write_ix8_d1 Write_ix1_d1
Write_ix1_d1 Write
Write _ix_d1
_ix_d1
Read_ix_2d1
Read_ix_2d1 Write_ix8_d2
Write_ix8_d2 Write_ix1_d2
Write_ix1_d2 Write
Write _ix_d2
_ix_d2
Read_ix_2d2
Read_ix_2d2
Write
Write _ix1_3_1
_ix1_3_1 Write
Write _ix1_3_2
_ix1_3_2 Write
Write _ix1_3_3
_ix1_3_3
• Readdecode: Daten laden
Write
Write _ix1_4_1
_ix1_4_1 Write
Write _ix1_4_2
_ix1_4_2 Write
Write _ix1_4_3
_ix1_4_3
• Executedecode: Operationen der ALU steuern
• Writedecode: Speichern von Daten Write
Write _ix1_4_6
_ix1_4_6 Write
Write _ix1_4_5
_ix1_4_5 Write
Write _ix1_4_4
_ix1_4_4
22
11Datenpfad der zweiten Stufe
Pipelinestufe 3
Funktion:
R1
R1 R2
R2 R4
R4 R5
R5
• Vorverarbeitung der geladenen
Daten und Operanden Daten
Daten
Speicher
Speicher
• Laden und Speichern von Daten
• Zusammensetzen geladener Add
Add
vars
vars
Daten Add
Add
Kontroll
Kontroll
Einheit
Einheit
• Alle Datenpfade sind vollständig Extension
Extension
voneinander entkoppelt
Optop
Vorzeichen
Optop
Vorzeichen
Check Add
Add
Check Add
Add
anweisung
anweisung const
const opcode
opcode Temp
Temp 11 Temp
Temp 22
Pipelinestufe 1
23
Kontrolleinheit der dritten Stufe
Readdecode
Readdecode
Funktion: Executedecode
Executedecode Writedecode
Writedecode
Nächster Fetch
Execute Ready
• Steuerung der ALU-Operation
• Decodierung des ALU- Freigabe Register
Lmul1
Lmul1 Lmul3
Lmul3
Steuerwortes
• Freigabe des Ausgangsregisters Go_
Go_
Lmul2 WB
WB
Lmul2
ALU
ALU
idle
idle
ALU-Operation selektieren
ALU-Operation selektieren
24
12Datenpfad der dritten Stufe
R6
R6
C1 C2
Funktion:
C3
• ALU verarbeitet 44 Befehle
Ass
Ass
• 17 Vergleichsoperationen
• 16 Arithmetische/Logische Temp
Temp Reg
Reg
Shift
Shift Add/Sub
Add/Sub Boolsche
Boolsche
• 6 Schiebeoperationen MAC
MAC
• 5 Typkonvertierungen
Assemble Typkonv.
• 42 Befehle werden innerhalb Assemble Typkonv.
eines Taktes verarbeitet
• Aufwendige Befehle (64 Bit Mul)
werden innerhalb von drei Takten
R1 R2 R4 R5
verarbeitet R1 R2 R4 R5
Pipelinestufe 2
25
Hardwaresynthese
Xilinx FPGA-Bibliothek:
• Gesamtentwurf umfaßt 3615 CLBs
• Kritische Pfad besitzt Signallaufzeit von 254 ns (ca. 4 MHz)
AMS08 Standardzellenbibliothek
• Gesamtentwurf umfaßt 38,63 mm2 Chipfläche
• Kritische Pfad besitzt Signallaufzeit von 62 ns (ca. 16 MHz)
• Gatteräquivalent von 29834 Gatter
Test-Layout des femtoJava 1
AMS035 Standardzellenbibliothek
• Gesamtentwurf umfaßt 7,27 mm2 Chipfläche (femtoJava 2)
• Kritische Pfad besitzt Signallaufzeit von 19 ns (ca. 52 MHz)
26
13Projektstatus
• Implementierung der „Linear track fit engine“
– Simulationsmodel liegt vor und wird iterativ verbessert
– Werte aus Simulation bestimmen die Implementierungsstruktur
der Hardwarerealisierung
• Erster Prototyp der microCPU ist vorhanden
– Hardwarerealiesierung der LTFE liegt vor (VHDL-Modell)
– Tape out Q1 `00
– Nächster Designschritt der microCPU Q2 `00
27
14Sie können auch lesen

















































