Bildgenerierung mit Künstlicher Intelligenz
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Bildgenerierung mit Künstlicher Intelligenz
Philipp Nöcker-Prior, 20. März 2023
Hochschule der Medien, Stuttgart, Deutschland
Professor Dr. Koch, Aktuelle Themen, Wintersemester 2022/23
Künstliche Intelligenz, Aktueller Stand und ihre Auswirkungen auf Ihre Zukunft
Mittels Künstlicher Intelligenz (KI) können scheinbar im Handumdrehen beeindruckende
Bilder generiert werden. Durch Eingabe weniger Worte ist es möglich Bilder zu erzeugen, die
eine gewünschte Szene darstellen, beschriebene Details enthalten oder in einem
gewünschten Stil erstellt werden. Möglich machen das verschiedene deeplearning Netzwerke,
die in einem geschickten Zusammenspiel miteinander Informationen austauschen und zu
einem Text-Bild-Modell zur Bildgenerierung verschmelzen.
Text-Bild-Modell einem auf KI basierenden Sprachmodell von
OpenAI, lassen sich dazu Kernaussagen
Um aus Text in natürlicher Sprache Bilder zu
formulieren, die Darstellung, Bedeutung und
generieren, muss der Eingabetext (Prompt)
Betrachter einbeziehen:
mit einem Sprachmodell verarbeitet und in
eine Form gebracht werden, die der Ein Bild ist eine visuelle Darstellung von
Bildgenerator verwenden kann. etwas, das mit einem Medium erstellt wurde,
das Bilder aufnehmen oder produzieren kann,
Für die Bildgenerierung werden zwei
wie beispielsweise eine Kamera oder ein
wesentliche Komponenten benötigt: ein
Pinsel. Ein Bild kann verschiedene Elemente
neuronales Netzwerk, das darauf trainiert
enthalten, darunter Farben, Formen, Linien,
wurde, ein Bild mit einem passenden Text zu
Texturen und Muster. Diese Elemente
verknüpfen, der das Bild beschreibt, sowie ein
können auf verschiedene Arten angeordnet
weiteres Netzwerk, das darauf spezialisiert
werden, um eine bestimmte Botschaft oder
ist, Bilder von Grund auf zu generieren. Die
Wirkung zu vermitteln.
Intention hinter dieser Methode ist, das
zweite neuronale Netzwerk so zu trainieren, Ein Bild kann auch verschiedene Ebenen der
dass es ein Bild erstellt, welches vom ersten Bedeutung haben, die auf der Art des Bildes
Netzwerk als passende Antwort auf die und den Erfahrungen und Überzeugungen
gegebene Anfrage akzeptiert wird. des Betrachters basieren. Es kann eine direkte
Darstellung von etwas sein, das in der realen
Zusammen beschreiben diese drei Haupt-
Welt existiert, wie ein Porträt oder eine
komponenten ein Text-Bild-Modell, wie es
Landschaft. Es kann aber auch abstrakt sein
bei den aktuellen KI-Modellen DALL-E 2,
und sich auf Ideen oder Emotionen beziehen,
Midjourney und Stable Diffusion Anwendung
die durch Farben, Formen oder Linien
findet. [1]
ausgedrückt werden.
Bilder
Insgesamt besteht ein Bild aus einer visuellen
Um zu verstehen, was die Herausforderungen Darstellung von etwas, das auf verschiedene
bei der Bildgenerierung durch eine KI sind, Arten angeordnet sein kann und verschie-
muss zunächst einmal verstanden werden, dene Bedeutungen haben kann, die auf der
was ein Bild ausmacht. Mithilfe von ChatGPT, Perspektive des Betrachters basieren. [2]
1
Die Erstellung von Fotos, handgemalten Es gibt verschiedene Techniken und Algo-
Bildern oder Digital-Art ist ein – oft künst- rithmen, die in NLP-Modellen verwendet
lerisch geprägtes – Handwerk. Neben der ver- werden, um Sprache zu analysieren und zu
wendeten Technik zur Herstellung, be- verstehen. Dazu gehören beispielsweise die
stimmen auch Art, Inhalt und Komposition Aufteilung von Text in Einheiten wie Wörter
der Darstellungen die Wirkung eines Bildes oder Sätze, die Bestimmung der syntak-
für den Betrachter. Eine Zusammenfassung tischen Rolle jedes Wortes in einem Satz und
verschiedener Bilder ist in Genres oder auch die Erkennung von spezifischen Entitäten wie
anhand besonderer Merkmale, die ein Personen, Orte oder Organisationen. Aber
Künstler in seine Werke einfließen lässt, auch die Bestimmung der positiven oder
möglich. Es lassen sich eine Vielzahl verschie- negativen Stimmung eines Textes oder die
dener Informationen über Werke sammeln. automatische Übersetzung von Texten von
Dies trifft auch dann zu, wenn sie nicht mit einer Sprache in eine andere. [3]
dem Anspruch Kunst zu sein, entstanden sind. Insgesamt ermöglichen NLP-Technologien es
Es spielt keine Rolle, ob die Bilder dokumen- KI-Modellen, menschliche Sprache besser zu
tarischer, künstlerischer oder emotionaler verstehen und darauf zu reagieren. Die sog.
Intention entsprungen, noch ob sie profes- Transformer wandeln die Texteingabe in
sionell oder privat erstellt worden sind: verarbeitbare Informationen. In Kombination
Jedem Bild können Merkmale zugesprochen mit den Informationen, die KI aus Daten-
und nach diesen kategorisiert werden. sätzen mit Bildern und beschreibenden
Auf Grundlage dieser Erkenntnis kann die Texten ziehen kann, ist es möglich relevante
Erstellung eines Datensatzes erfolgen, der Informationen aus Texten zu gewinnen, die
Bildern eine kurze und prägnante Textbe- für die Bildgenerierung genutzt werden
schreibung zuordnet. Anhand dieses Daten- können. [4]
satzes kann das neuronale Netz in einem Diffusions-Modell
späteren Schritt trainiert werden.
Bildgenerierung kann durch verschiedenartig
Sprache aufgebaute neuronale Netze realisiert
Eine weitere Herausforderung auf dem Weg werden. Zu den einfacheren Verfahren
vom Text zum Bild ist die Fähigkeit eines gehören Autoencoder, Denoising-Auto-
Systems, Eingaben in natürlicher Sprache encoder (DAE) und Variational Autoencoder
verstehen und verarbeiten zu können. (VAE). Zu den komplexeren Verfahren zählen
Generative Adversarial Networks (GAN) und
KI versteht Sprache mithilfe von sogenannten
Diffusions-Modelle.
Natural Language Processing (NLP) Technolo-
gien. NLP-Technologien ermöglichen es Com- Autoencoder sind neuronale Netze, die
putern, menschliche Sprache zu analysieren, darauf trainiert sind, die zugrunde liegende
zu verstehen und darauf zu reagieren. Struktur eines Bilddatensatzes zu erlernen.
Sie können verwendet werden, um neue
Das Verständnis von Sprache durch KI beginnt
Bilder zu erzeugen, indem sie ein Bild in eine
mit der Verarbeitung von Rohdaten in Form
niedriger dimensionale Darstellung mit
von geschriebenem Text. Anschließend wird
weniger verfügbaren Informationen kodieren
diese Information in Einheiten wie Wörter
und diese dann wieder in ein äquivalentes
oder Sätze aufgeteilt, die dann weiter
Bild dekodieren. [5]
analysiert werden. KI-Modelle können
semantische und syntaktische Beziehungen GANs bestehen aus zwei neuronalen Netzen,
zwischen diesen Einheiten erkennen, um die einem Generator und einem Diskriminator,
Bedeutung und den Kontext der Sprache die so trainiert werden, dass sie gegen-
besser zu verstehen. einander antreten. Der Generator versucht,
2
Bilder zu erzeugen, die dem Diskriminator Sowohl DAEs als auch VAEs können verwen-
vorgaukeln, dass sie echt sind, während der det werden, um die Qualität der erzeugten
Diskriminator versucht, korrekt zu erkennen, Bilder in einem Diffusionsmodell zu verbes-
ob die Bilder echt oder erzeugt sind. Diese sern. Denoising-Autoencoder können helfen,
Architektur weist jedoch Schwächen in das Rauschen aus dem anfänglichen niedrig
kritischen Bereichen des Trainings auf, die das aufgelösten Bild zu entfernen, während VAEs
Framework stagnieren lassen. Ggü. GANs helfen können, die zugrunde liegende
können Diffusions-Modelle bessere Wahrscheinlichkeitsverteilung der Trainings-
Ergebnisse bei Bildbeispielen liefern, sind bilder zu erlernen, was den Realismus der
aber gleichzeitig auch in anderen Punkten erzeugten Bilder verbessern kann.
limitiert. [6]
Die erste Stufe des Diffusions-Models ist in
In den erwähnten aktuellen Text-Bild- der Regel ein einfacher Zufallsrausch-
Modellen finden Diffusions-Modelle Anwen- generator, der ein Bild mit geringer Auflösung
dung. Diese sind eine Art von generativen erzeugt. Die nachfolgenden Stufen, die so
Modellen, die für die Bilderzeugung ver- genannten Diffusionsschritte, werden so
wendet werden können. Sie bestehen aus trainiert, dass sie dem Bild mehr Details
mehreren Stufen, von denen jede für das hinzufügen, indem sie lernen, die Informa-
Hinzufügen weiterer Details zum Bild tionen der vorherigen Stufe zu "verbreiten".
verantwortlich ist. Diffusion vereint DAEs und Bei jedem Diffusionsschritt wird ein neuro-
VAEs in einem Modell. nales Netz, ein so genannter Diffusions-
Ein DAE ist eine Art Autoencoder, der trainiert transformator, auf das Bild angewendet, um
wird, um Rauschen aus einem Bild zu ent- mehr Details hinzuzufügen. Der Diffusions-
fernen. Im Zusammenhang mit einem transformator ist darauf trainiert, die Muster
Diffusionsmodell zur Bilderzeugung kann ein und Merkmale echter Bilder zu lernen, und
DAE als erste Stufe verwendet werden, in der nutzt dieses Wissen, um dem erzeugten Bild
er trainiert wird, um Rauschen aus der realistische Details hinzuzufügen. Das
anfänglichen Zufallsrauscheingabe zu ent- Ergebnis ist im Idealfall ein hochauflösendes
fernen und ein Bild mit niedriger Auflösung zu Bild, das realen Bildern ähnlich ist.
erzeugen. Dieses niedrig aufgelöste Bild wird Im Training wird diesem Netz ein Set an
dann an die nachfolgenden Diffusionsschritte Bildern zugeführt, welches immer weiter
weitergegeben, wo es schrittweise verfeinert verrauscht wird. Das Ergebnis ist eine
wird, um ein hoch aufgelöstes Bild zu automatische Bildgenerierung aus beliebigem
erzeugen. Rauschen. Jedoch kann auf diesen Prozess
VAEs sind eine Art von Autoencodern, die zunächst keinen Einfluss genommen werden.
trainiert werden, um die zugrunde liegende Die Funktionalität der sog. Guided-Diffusion
Wahrscheinlichkeitsverteilung eines Bild- bekommt das Modell, indem eine Anbindung
datensatzes zu lernen. Sie können verwendet des Diffusions-Modells an den Transformer
werden, um neue Bilder durch Stichproben stattfindet. [7]
aus der erlernten Wahrscheinlichkeits-
verteilung zu erzeugen. Im Zusammenhang
mit einem Diffusionsmodell zur Bild-
erzeugung kann ein VAE darauf trainiert
werden, ein Bild mit niedriger Auflösung
auszuwerten und die Wahrscheinlichkeit zu
berechnen, dass ein Pixel eine bestimmte
Farbe hat. Die Engstelle des VAEs ist dabei
stets das Bild der letzten Iterationsstufe.
3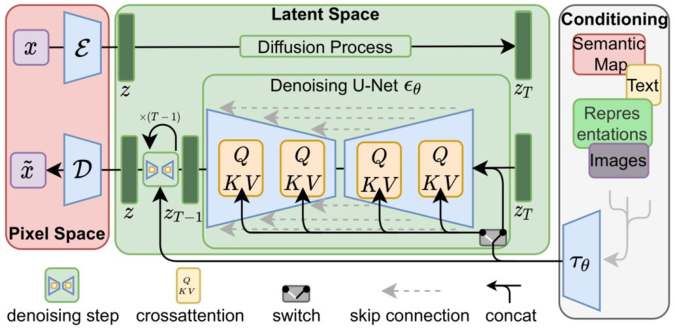
Abbildung 1: Guided Diffusion Framework [8]
Guided Diffusion Dabei wird eine Anfangsbildfolge, die als
Um die Möglichkeit zu erlangen den "Guide" dient, verwendet, um das Modell
Diffusions-Prozess steuern zu können, muss beim Generieren des endgültigen Bildes zu
ein neuronales Netz in die Architektur des lenken. Das Modell berechnet dann iterativ
Text-Bild-Modells integriert werden, welches die Wahrscheinlichkeitsverteilung für jeden
in der Lage ist Bildinhalte zu erkennen und mit Pixel im Bild und generiert das endgültige
textueller Beschreibung zu vergleichen. CLIP Ergebnis durch Abtasten dieser Verteilungen.
(Contrastive Language-Image Pre-Training) ist Ergebnis
ein neuronales Netzwerk von OpenAI. Das
Guided Diffusion hat sich als sehr
CLIP-Modell besteht aus einem bereits leistungsfähig erwiesen, da es in der Lage ist,
trainierten Transformer-Sprachmodell sowie realistisch wirkende Bilder mit hoher
einem Bilderkennungsnetzwerk. Beide Auflösung zu erzeugen. Es hat auch den
Komponenten geben eine Vektorrepräsen- Vorteil, dass es sehr flexibel ist und in der Lage
tation aus, die die Bedeutung des Satzes oder ist, eine Vielzahl von Bildgenerierungs-
des Bildes kodieren soll und deren Länge aufgaben zu bewältigen, wie z.B. die
identisch ist. [5] Generierung von Bildbeschreibungen oder
die Entfernung von Störungen aus Bildern.
Das Ergebnis der Bildgenerierung ist abhängig
von der Qualität des Sprachmodells und der
Verknüpfung von Diffusions-Prozess und dem
Text-Bild-Vergleich. Dabei spielt die Bedeu-
tungsebene eine entscheidende Rolle, da
Sprachmodelle natürliche Sprache zwar
analysieren, aber nicht im engeren Sinne
verstehen. Mit Stable Diffusion 2.0, OpenCLIP
Abbildung 2: Vergleichsmatrix des CLIP [9]
und ChatGPT-4 sind bereits zu Beginn des
Die Wortbedeutung muss mit dem Jahres 2023 erneut performantere und
entstehenden Bildinhalt abgeglichen werden größere KI-Systeme vorgestellt worden, die
und so ein geführter Diffusionsprozess diese Lücke versuchen zu schließen. Eine
ermöglicht werden. Durch dieses Bindeglied Weiterentwicklung dieser Komponenten wird
bekommt das Text-Bild-Modell die Möglich- zukünftig noch stärkere Text-Bild-Anwen-
keit die verarbeiteten Texteingaben in einen dungen ermöglichen. Folgend werden für
Abgleichungsprozess einfließen zu lassen, der zwei Prompts die Ergebnisse von DALL-E 2,
den Diffusionsprozess steuern kann. Midjourney und Stable Diffusion Web gezeigt:
4
Prompt 1 Prompt 2
„robot eating a green cable, digital art“ „ girl standing in a forest, shining light, 4k
photography “
Abbildung 3: Ein Ergebnis von DALL-E 2 zu Prompt 1 Abbildung 6: Ein Ergebnis von DALL-E 2 zu Prompt 2
Abbildung 4: Ein Ergebnis von Midjourney zu Prompt 1 Abbildung 7: Ein Ergebnis von Midjourney zu Prompt 2
Abbildung 5: Ein Ergebnis von Stable Diffusion Web zu Prompt 1 Abbildung 8: Ein Ergebnis von Stable Diffusion Web zu Prompt 2
5
Schlussbetrachtung Literatur
Anhand der dargestellten zufälligen Ergeb- [1] W. D. Heaven, „Wie KI-Bild- und
nisse der drei gewählten Text-Bild-Modelle Textgeneratoren die Kreativ-Branche
ist bereits ersichtlich, dass sich die Qualität umkrempeln,“ MIT Technology Review, 2.
März 2023. [Online]. Available:
der erzeugten Bilder zwischen den https://www.heise.de/hintergrund/Wie-KI-
jeweiligen KIs abhängig vom formulierten Bild-und-Textgeneratoren-die-Kreativ-
Prompt stark unterscheidet. Mit einer Branche-umkrempeln-
größeren Anzahl von Vergleichsbildern der 7489270.html?seite=all. [Zugriff am 10. März
Bildgeneratoren ließe sich dieser Eindruck 2023].
weiter manifestieren. [2] „ChatGPT, Prompt: "Was macht ein Bild
aus?",“ OpenAI, [Online]. Available:
Für Prompt 1 lässt sich feststellen, dass der https://chat.openai.com/chat. [Zugriff am 5. -
gewünschte Stil „digital art“ von jedem 18. März 2023].
Bildgenerator unterschiedlich interpretiert [3] D. W. Otter, J. R. Medina und J. K. Kalita, „A
wurde und sich die Ergebnisse stark unter- Survey of the Usages of Deep Learning in
Natural Language Processing,“ IEEE
scheiden. Inhaltlich lassen sich jedoch transactions on neural networks and learning
Parallelen erkennen. Die geforderte systems, Bd. 32, Nr. 2, pp. 604-624, 2020.
Darstellung eines Roboters, der ein grünes [4] P. Merkert, „KI: So funktionieren künstliche
Kabel frisst („robot eating a green cable“) Sprachsysteme vom Typ "Transformer".,“ c't
wird in allen Ergebnissen umgesetzt. Mit Magazin, 11. Mai 2022. [Online]. Available:
einer Anpassung des Prompts ließen sich https://www.heise.de/hintergrund/KI-So-
funktionieren-kuenstliche-Sprachsysteme-
dahingehend noch exaktere Ergebnisse vom-Typ-Transformer-
erzielen. Das sog. Prompt Engineering, also 7077832.html?seite=all. [Zugriff am 1.
die Entwicklung von Texteingaben für die Dezember 2022].
Erzielung bestimmter Ergebnisse, muss [5] P. Merkert, „KI-Bildgeneratoren: Diese Technik
jedoch für jedes Bild-Text-Modell separat Steckt dahinter.,“ c't Magazin, 18. November
erfolgen, da sie unter-schiedliche Stärken 2022. [Online]. Available:
https://www.heise.de/hintergrund/KI-
aufweisen und dementsprechend jeweils
Bildgeneratoren-Diese-Technik-steckt-
anders optimiert werden müssen. dahinter-7341800.html?seite=all. [Zugriff am
Bei den Ergebnissen für Prompt 2 ist 1. Dezember 2022].
auffällig, dass sowohl DALL-E 2, als auch [6] „ChatGPT, Prompt: "Tell me how GAN based
image generators work.",“ OpenAI, [Online].
Stable Diffusion Web die Umsetzung eines Available: https://chat.openai.com/chat.
fotorealistischen Bildes erbringen. Durch [Zugriff am 5. - 18. März 2023].
den Zusatz „4k photography“ wird den Bild- [7] P. Dhariwal und A. Nichol, „Diffusion Models
generatoren vorgegeben ein hochauf- Beat GANs on Image Synthesis,“ Advances in
lösendes Foto zu generieren. Lediglich Mid- Neural Information Processing Systems, Nr. 34,
journey erstellt auch hier ein Bild, welches pp. 8780 - 8794, 2021.
in das Genre Digital Art einzuordnen ist. [8] R. Rombach, et al., „High-Resolution Image
Synthesis With Latent Diffusion Models,“
Beeinflusst werden die Ergebnisse maß- Proceedings of the IEEE/CVF Conference on
geblich von der gewählten Text-Bild- Computer Vision and Pattern Recognition
Modellarchitektur, sowie dem verwen- (CVPR), pp. 10684-10695, 2022.
deten Trainingsdatensatz. Eine Weiterent- [9] A. Redford, et al., „Learning Transferable
Visual Models From Natural Language
wicklung der Datenbasis ermöglicht über
Supervision,“ Proceedings of the 38th
die o.g. technischen Möglichkeiten hinaus International Conference on Machine
eine Verbesserung der Bildqualität und der Learning, pp. 8748-8763, 2021.
Genauigkeit solcher Bildgeneratoren.
6

Sie können auch lesen

















































