Informatik Spektrum - Dr. Jekyll, Mr. Hyde und Distributed-Ledger-Technologien Social Machines Digital Literacy - GI Radar
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Organ der Gesellschaft für Informatik e.V. Band 45 • Heft 1 • Februar 2022
und mit ihr assoziierter Organisationen
Informatik
Spektrum
Dr. Jekyll, Mr. Hyde und Distributed-Ledger-Technologien
Social Machines
123 Digital Literacy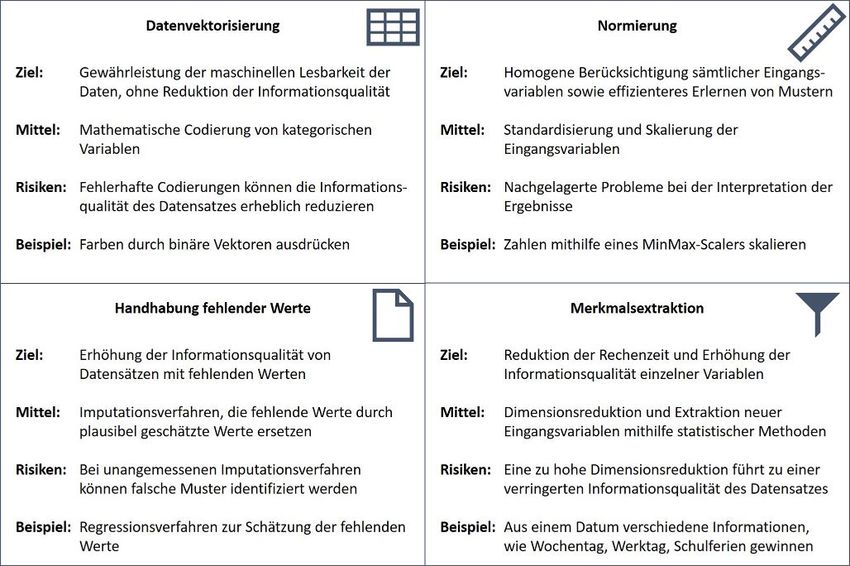
ZUM TITELBILD
Informatik
Spektrum Organ der Gesellschaft für Informatik e. V. und mit ihr assoziierter Organisationen
BEISPIEL ALGORITHMISCHER KUNST
Frieder Nake, Beispiel algorithmischer Kunst aus dem Jahre 1966, ein Ergebnis des Programm-
systems „Walk-through-Raster“ (hier Walk aus der Serie 2.1-4). Das Blatt hat die Größe 40 x 40 cm.
Dem Schema dieses Programmsystem liegt eine gedanklich gerasterte Zeichenfläche zugrunde.
Außerdem steht ein einfaches „Zeichenrepertoire“ zur Verfügung. In diesem Fall besteht es aus
einem kurzen waagerechten und einem senkrechten Strich gleicher Länge (der Größe des Raster-
feldes), sowie dem leeren Feld.
Mit diesen drei Zeichen wird eine Markov-Kette gebildet, die nach einem bestimmten Modus in die
Zeichenfläche übertragen wird. Dieser Modus ist in unserem Fall diagonal hin- und hergehend. Das
nächste Zeichen in der Kette wird nach Übergangswahrscheinlichkeiten zufällig ausgewählt, sein
Erscheinen hängt also vom gerade vorher platzierten Zeichen ab. Die Übergangswahrscheinlich-
keiten sind nicht für das ganze Bild die gleichen. Sie hängen vielmehr vom Ort ab, an dem wir uns
beim Zeichnen befinden.
So kommt es auf einfach zu kontrollierende Weise dazu, dass zu Anfang und gegen Schluss das leere
Feld deutlich häufiger erscheint. – Diese Art von algorithmischer Planung ästhetischer Objekte war,
so kann man recht sicher vermuten, in der Mitte der 1960er Jahre anderswo nicht bekannt. –
Gerechnet auf Telefunken TR4, gezeichnet mit Zuse Graphomat Z64. Programmiert in Algol-60.
Frieder Nake
Universität Bremen, FB3 (Informatik)
E-Mail: nake@uni-bremen.de
A2
INHALT
Informatik
Spektrum
Band 45 | Heft 1 | Februar 2022
Organ der Gesellschaft für Informatik e. V. und mit ihr assoziierter Organisationen
EDITORIAL
Thomas Ludwig · Peter Pagel
1 Editorial 1/22
HAUPTBEITRÄGE
Christoph Lübbert · Thomas Zeh
3 Skizze eines Verfahrens zur Erstellung von Ontologien mittels Formaler
Begriffsanalyse
Marko Kureljusic · Erik Karger
13 Data Preprocessing as a Service – Outsourcing der
Datenvorverarbeitung für KI-Modelle mithilfe einer digitalen Plattform
Arno Rolf
20 Digital Literacy. Wie die digitale Urteilsfähigkeit der Studierenden
gestärkt werden kann
Mathias Ellmann
29 Effektives Lehren und Lernen in der Informatik, Wirtschaftsinformatik
und verwandten Fachgebieten
AKTUELLES SCHLAGWORT
Claude Draude · Christian Gruhl · Gerrit Hornung · Jonathan Kropf · Jörn Lamla ·
Jan Marco Leimeister · Bernhard Sick · Gerd Stumme
38 Social Machines
KOLUMNE
Edy Portmann
43 Dr. Jekyll, Mr. Hyde und Distributed-Ledger-Technologien
NACHRUF
Hans Langmaack · Gunther Schmidt
45 Manfred Paul (1932–2021)
FORUM
Rainer Rehak · Nikolas Becker · Pauline Junginger · Otto Obert
47 Gewissensbits – wie würden Sie urteilen?
Ursula Sury
50 Verträge auf elektronischem Weg
Rolf Windenberg
53 Um etliche Ecken ged8. Gehirn-Jogging auf Basis der math.- und
informatisch-orientierten Rechtschreibreform
MITTEILUNGEN
55 Mitteilungen der GI im Informatik Spektrum 1/2022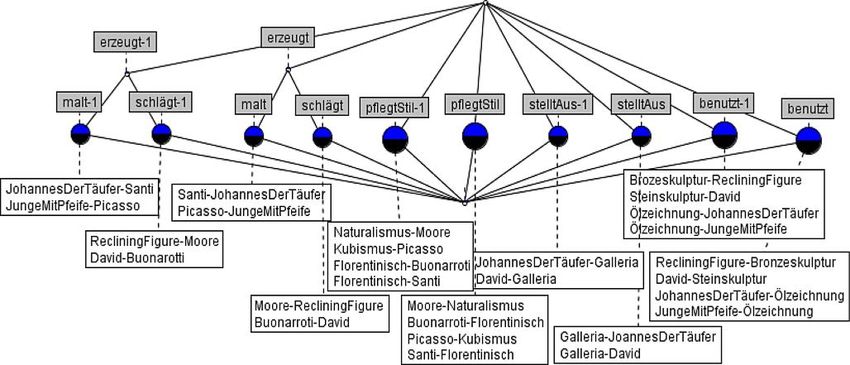
Informatik
Spektrum Organ der Gesellschaft für Informatik e. V. und mit ihr assoziierter Organisationen
Hauptaufgabe dieser Zeitschrift ist die Weiterbil- Gemeinschaft ist, kann unter bestimmten Voraus- Prof. Dr. H. Federrath, Universität Hamburg
dung aller Informatiker durch Veröffentlichung setzungen an der Ausschüttung der Bibliotheks- und Prof. O. Günther, Ph. D., Universität Potsdam
aktueller, praktisch verwertbarer Informationen Fotokopietantiemen teilnehmen. Nähere Einzelhei- Prof. Dr. D. Herrmann,
über technische und wissenschaftliche Fort- ten können direkt von der Verwertungsgesellschaft Otto-Friedrich-Universität Bamberg
schritte aus allen Bereichen der Informatik und WORT, Abteilung Wissenschaft, Goethestr. 49, Prof. Dr. W. Hesse, Universität Marburg
ihrer Anwendungen. Dies soll erreicht werden 80336 München, eingeholt werden. Dr. Agnes Koschmider, Universität Kiel
durch Veröffentlichung von Übersichtsartikeln und Die Wiedergabe von Gebrauchsnamen, Han- Dr.-Ing. C. Leng, Google
einführenden Darstellungen sowie Berichten über delsnamen, Warenbezeichnungen usw. in dieser Prof. Dr. F. Mattern, ETH Zürich
Projekte und Fallstudien, die zukünftige Trends Zeitschrift berechtigt auch ohne besondere Kenn- Prof. Dr. Michael Meier, Uni Bonn,
aufzeigen. zeichnung nicht zu der Annahme, dass solche Namen Lehrstuhls für IT-Sicherheit
Es sollen damit unter anderem jene Leser an- im Sinne der Warenzeichen- und Markenschutz- Prof. Dr. K.-R. Müller, TU Berlin
gesprochen werden, die sich in neue Sachgebiete Gesetzgebung als frei zu betrachten wären und daher Prof. Dr. W. Nagel, TU Dresden
der Informatik einarbeiten, sich weiterbilden, sich von jedermann benutzt werden dürfen. Prof. Dr. E. Portmann, Universität Fribourg
einen Überblick verschaffen wollen, denen aber Prof. Dr. F. Puppe, Universität Würzburg
das Studium der Originalliteratur zu zeitraubend Vertrieb, Abonnement, Versand Prof. Dr. Kai Rannenberg, Uni Frankfurt,
oder die Beschaffung solcher Veröffentlichungen Papierausgabe: ISSN 0170-6012 Mobile Business & Multilateral Security
nicht möglich ist. Damit kommt als Leser nicht nur elektronische Ausgabe: ISSN 1432-122X Prof. Dr. R.H. Reussner, Universität Karlsruhe
der ausgebildete Informatikspezialist in Betracht, Erscheinungsweise: zweimonatlich Prof. Dr. S. Rinderle-Ma, Universität Wien
sondern vor allem der Praktiker, der aus seiner Ta- Prof. Dr. O. Spaniol, RWTH Aachen
gesarbeit heraus Anschluss an die wissenschaftliche Den Bezugspreis können Sie beim Customer Dr. D. Taubner, München (bis 2020: msg systems ag)
Entwicklung der Informatik sucht, aber auch der Service erfragen: customerservice@springernature. Sven Tissot, Iteratec GmbH, Hamburg
Studierende an einer Fachhochschule oder Univer- com. Die Lieferung der Zeitschrift läuft weiter, wenn Prof. Dr. Herbert Weber, TU Berlin
sität, der sich Einblick in Aufgaben und Probleme sie nicht bis zum 30.9. eines Jahres abbestellt wird.
der Praxis verschaffen möchte. Mitglieder der Gesellschaft für Informatik und der Impressum
Durch Auswahl der Autoren und der The- Schweizer Informatiker Gesellschaft erhalten die
men sowie durch Einflussnahme auf Inhalt und Zeitschrift im Rahmen ihrer Mitgliedschaft. Verlag:
Darstellung – die Beiträge werden von mehreren Bestellungen oder Rückfragen nimmt jede Springer, Tiergartenstraße 17,
Herausgebern referiert – soll erreicht werden, dass Buchhandlung oder der Verlag entgegen. 69121 Heidelberg
möglichst jeder Beitrag dem größten Teil der Le- SpringerNature, Kundenservice Zeitschriften,
ser verständlich und lesenswert erscheint. So soll Tiergartenstr. 15, 69121 Heidelberg, Germany Redaktion:
diese Zeitschrift das gesamte Spektrum der Infor- Tel. +49-6221-345-0, Fax: +49-6221-345-4229, Peter Pagel, Vanessa Keinert
matik umfassen, aber nicht in getrennte Sparten e-mail: customerservice@springernature.com Tel.: +49 611 787 8329
mit verschiedenen Leserkreisen zerfallen. Da die Geschäftszeiten: Montag bis Freitag 8–20 h. e-mail: Peter.Pagel@springer.com
Informatik eine sich auch weiterhin Bei Adressänderungen muss neben dem Ti-
stark entwickelnde anwendungsorientierte tel der Zeitschrift die neue und die alte Adresse
Wissenschaft ist, die ihre eigenen wissenschaft- angegeben werden. Adressänderungen sollten Herstellung:
lichen und theoretischen Grundlagen zu einem mindestens 6 Wochen vor Gültigkeit gemeldet Madeleine Schnurr,
großen Teil selbst entwickeln muss, will die Zeit- werden. Hinweis gemäß §4 Abs. 3 der Postdienst- e-mail: Madeleine.Schnurr@springer.com
schrift sich an den Problemen der Praxis orien- Datenschutzverordnung: Bei Anschriftenänderung
tieren, ohne die Aufgabe zu vergessen, ein solides des Beziehers kann die Deutsche Post AG dem Verlag Redaktion Gl-Mitteilungen:
wissenschaftliches Fundament zu erarbeiten. Zur die neue Anschrift auch dann mitteilen, wenn kein Cornelia Winter
Anwendungsorientierung gehört auch die Be- Nachsendeauftrag gestellt ist. Hiergegen kann der Gesellschaft für Informatik e.V. (GI)
schäftigung mit den Problemen der Auswirkung Bezieher innerhalb von 14 Tagen nach Erscheinen Wissenschaftszentrum,
der Informatikanwendungen auf den Einzelnen, dieses Heftes bei unserer Abonnementsbetreuung Ahrstraße 45, D-53175 Bonn,
den Staat und die Gesellschaft sowie mit Fragen widersprechen. Tel.: +49 228-302-145, Fax: +49 228-302-167,
der Informatik-Berufe einschließlich der Ausbil- Internet: http://www. gi.de,
dungsrichtlinien und der Bedarfsschätzungen. e-mail: gs@gi.de
Elektronische Version
springerlink.com
Urheberrecht Wissenschaftliche Kommunikation:
Mit der Annahme eines Beitrags überträgt der Au- Hinweise für Autoren Anzeigen: Eva Hanenberg
tor Springer (bzw. dem Eigentümer der Zeitschrift, http://springer.com/journal/00287 Abraham-Lincoln-Straße 46
sofern Springer nicht selbst Eigentümer ist) das 65189 Wiesbaden
ausschließliche Recht zur Vervielfältigung durch Tel.: +49 (0)611/78 78-226
Druck, Nachdruck und beliebige sonstige Verfahren Hauptherausgeber Fax: +49 (0)611/78 78-430
das Recht zur Übersetzung für alle Sprachen und Prof. Dr. Dr. h. c.mult. Wilfried Brauer (1978–1998) eva.hanenberg@springer.com
Länder. Prof. Dr. Dr. h. c. Arndt Bode,
Die Zeitschrift sowie alle in ihr enthaltenen Technische Universität München (1999–2019)
Prof. Dr. T. Ludwig, Satz:
einzelnen Beiträge und Abbildungen sind urhe- le-tex publishing services GmbH, Leipzig
berrechtlich geschützt. Jede Verwertung, die nicht Deutsches Klimarechenzentrum GmbH, Hamburg
ausdrücklich vom Urheberrechtsgesetz zugelassen (seit 2019)
ist, bedarf der vorherigen schriftlichen Zustim- Druck:
mung des Eigentümers. Das gilt insbesondere für Herausgeber Printforce,
Vervielfältigungen, Bearbeitungen, Übersetzungen, Prof. Dr. S. Albers, TU München The Netherlands
Mikroverfilmungen und die Einspeicherung und Prof. A. Bernstein, Ph. D., Universität Zürich
Verarbeitung in elektronischen Systemen. Jeder Prof. Dr. Dr. h. c. Arndt Bode, Technische springer.com
Autor, der Deutscher ist oder ständig in der Bundes- Universität München
Eigentümer und Copyright
republik Deutschland lebt oder Bürger Österreichs, Prof. Dr. T. Braun, Universität Bern
© Springer-Verlag GmbH Deutschland,
der Schweiz oder eines Staates der Europäischen Prof. Dr. O. Deussen, Universität Konstanz
ein Teil von Springer Nature, 2022
A4
springer.com
Editor-in-Chief:
Dennis-Kenji Kipker
International Cybersecurity
Law Review
Zeitschrift für Cybersicherheit und Recht
International Cybersecurity Law Review -
Zeitschrift für Cybersicherheit und Recht
The International Cybersecurity Law Review (ICLR) is chiefly aimed at professionals
interested in developments in international cybersecurity, data security, technology, law
and regulation. Articles deal with compliance and security regulation, as well as related
issues around the globe. Thus, ICLR is providing crucial and reliable information for anyone
who is doing IT related business internationally.
Die International Cybersecurity Law Review (ICLR) richtet sich vor allem an Fachleute, die
sich für Entwicklungen in den Bereichen internationale Cybersicherheit, Datensicherheit,
Technologie, Recht und Regulierung interessieren. Die Artikel befassen sich mit der
Einhaltung von Vorschriften und Sicherheitsbestimmungen sowie mit verwandten
Themen rund um den Globus. Somit stellt ICLR entscheidende und zuverlässige
Informationen für jeden bereit, der international im IT-Bereich tätig ist.
Jetzt bestellen auf springer.com/shop oder in Ihrer Buchhandlung
A95443
springer.com/informatik
R. Schuhmann, B. Eichhorn (Hrsg.)
Contractual Management
Managing Through Contracts
2020, XXXIII, 404 p. 38 illus., 23 illus. in color. Geb.
€ (D) 53,49 | € (A) 54,99 | *CHF 66.61
ISBN 978-3-662-58481-1
€ 42,79 | *CHF 53.00
ISBN 978-3-662-58482-8 (eBook)
Vertragsmanagement
neu gedacht
• Explores the theoretical foundations of contractual management
• Covers a variety of industries, company sizes, contract types, and
management situations
• Case studies illustrate applications of contract management
The Concept Contractual Management offers a holistic approach to managerial
decision-making based on contracts or business processes that are related to contracts. It
explains management from the point of view of the contract, just as it interprets the
contract from the point of view of management. Thus, the approach highlights the great
inherent potential of contracts for managing companies, transactions and business
relationships. The book addresses students as well as practitioners and gives insights into
the usage of contracts to manage companies or relationships.
Ihre Vorteile in unserem Online Shop:
Über 280.000 Titel aus allen Fachgebieten | eBooks sind auf allen
Endgeräten nutzbar | Kostenloser Versand für Printbücher weltweit
€ (D): gebundener Ladenpreis in Deutschland, € (A): in Österreich. * : unverbindliche Preisempfehlung.
Alle Preise inkl. MwSt.
Jetzt bestellen auf springer.com/informatik oder in der Buchhandlung
A85539
Informatik Spektrum (2022) 45:1–2
https://doi.org/10.1007/s00287-022-01433-8
EDITORIAL
Editorial 1/22
Thomas Ludwig1 · Peter Pagel2
Angenommen: 24. Dezember 2021
© The Author(s), under exclusive licence to Springer-Verlag GmbH Deutschland, ein Teil von Springer Nature 2022
Liebe Leserinnen und Leser, der Pandemie darin besteht, dass viele, die zuvor skeptisch
waren und die Verwendung von Videokonferenz-Software
Sie halten das erste Heft des Jahres 2022 in Händen. Wieder und Ähnlichem teils konsequent verweigerten, sich aus der
liegt ein Jahr mit Corona hinter uns, und was an Varianten- Not heraus dann doch daran gewöhnt haben. Gelernt haben
reichtum vor uns liegt, das wollen wir gar nicht so genau wir dabei, dass diese Hilfsmittel zwar oft sehr nützlich sind,
wissen. Mittlerweile können wir alle G’s schon mindestens aber eben auch, dass sie Treffen im wirklichen Leben nicht
einmal vorweisen – vermutlich ist das bei Ihnen teilweise vollständig ersetzen können. Das wird sicher auch nach der
ebenso – und wenn wir etwas von G’s höre, dann fällt das Pandemie ein Thema bleiben.
schnell in die Kategorie G-enervt. Wie Sie vielleicht bereits erfahren haben, hat sich die
Nun haben wir also ein volles Jahr unter Pandemiebedin- Gesellschaft für Informatik gegen Ende des Jahres 2021
gungen verbracht. Mal mehr, mal weniger eingeschränkt, entschieden, den Vertrag mit Springer Nature [korrekt? Ja,
und immer in der Hoffnung auf Besserung. Meine univer- passt so] ab 2023 nicht mehr fortzusetzen. Das Informatik
sitäre Lehre erfolgt jetzt abwechselnd per aufgezeichnetem Spektrum ist damit nicht länger das Organ der Gesellschaft
Video, als Zoom-Vorlesung oder als Präsenzvorlesung. Lei- für Informatik. Das Erscheinen wird aber normal fortge-
der gibt es in diesem Winter nahezu alle zwei Wochen neue führt. Mögliche Anpassungen der inhaltlichen Ausrichtung
Regularien. Überraschenderweise hatten wir im Frühjahr werden im Jahr 2022 diskutiert werden – was aber auf je-
bei den video-mündlichen Prüfungen festgestellt, dass der den Fall bleiben wird ist, dass das Informatik Spektrum
Lernerfolg bei den Studierenden ausgezeichnet war. Ich hat- auf hohem Niveau über die ganze Bandbreite der Informa-
te mit mehr Teilnehmern ein insgesamt höheres Leistungs- tik berichten wird. Hauptherausgeber ist weiterhin Thomas
niveau festgestellt, und das ist besonders für meine Spezi- Ludwig und ich hoffe, dass die Gruppe der Herausgeberin-
alvorlesung Hochleistungsrechnen doch überraschend. Ich nen und Herausgeber auch weiterhin aktiv zum Gelingen
nehme an, dass die Videos ein konzentrierteres Lernen ge- des Journals beitragen wird. Weitere Informationen werden
statten, da man sich den Stoff in passende Häppchen teilen wir Ihnen im Laufe des Jahres 2022 mitteilen.
kann und insbesondere bei Fragen einfach auch zurück- Wir wünschen allen Leserinnen und Lesern noch alles
setzen kann. Lustiger Nebeneffekt, Fehler im Vortrag sind Gute zum Jahr 2022, und wir hoffen, dass es für alle ein
jetzt eindeutig nachweisbar. „Herr Ludwig hat aber im Vi- glückliches und gesundes Jahr werden möge.
deo gesagt, das geht so und so.“ Herr Ludwig musste dann
Hinweis des Verlags Der Verlag bleibt in Hinblick auf geografische
diese Folie nochmal, und besser, aufzeichnen und in das Vi- Zuordnungen und Gebietsbezeichnungen in veröffentlichten Karten
deo einbauen. Selbes Hemd, selber Dozent – nur die Folie und Institutsadressen neutral.
korrigiert. Merkt man fast nicht. Videolehre hat auch ihre
praktischen Seiten.
Insgesamt lässt sich bei Privatleuten und im professio-
nellen Umfeld beobachten, dass ein positiver Nebeneffekt
Peter Pagel
peter.pagel@springer.com
1
Deutsches Klimarechenzentrum, Hamburg, Deutschland
2
Springer Fachmedien Wiesbaden GmbH, Wiesbaden,
Deutschland
K
2 Informatik Spektrum (2022) 45:1–2
Thomas Ludwig Peter Pagel
K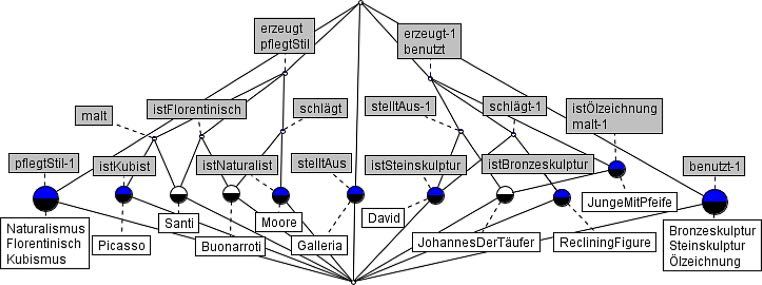
Informatik Spektrum (2022) 45:3–12
https://doi.org/10.1007/s00287-021-01397-1
HAUPTBEITRAG
Skizze eines Verfahrens zur Erstellung von Ontologien mittels Formaler
Begriffsanalyse
Christoph Lübbert1 · Thomas Zeh1
Angenommen: 2. August 2021 / Online publiziert: 22. September 2021
© Der/die Autor(en) 2021
Zusammenfassung
Die Formale Begriffsanalyse vermag aus den Daten zu Gegenständen und deren Merkmalen eine Datenstruktur zu er-
mitteln. Es wird ein weitgehend automatisierbares Verfahren vorgestellt, das ausgehend von Elementarsätzen in Form
von RDF-Tripeln in einem iterativen Bottom-up-Prozess mittels Semantischer Netze und der Formalen Begriffsanalyse zu
einem Ontologieschema führt. Neben der Taxonomie der Klassen wird hierbei auch eine Taxonomie der Relationstypen
erstellt. Die durch die Formale Begriffsanalyse automatisch erstellten Merkmalimplikationen können für die Qualitäts-
sicherung herangezogen werden. Führt diese zu Korrekturen und Erweiterungen der Elementarsätze, wird der Prozess
wiederholt. Das resultierende Ontologieschema wird in ein Entity-Relationship-Diagramm überführt, das die Grundlage
für ein konzeptionelles Datenbankschema liefert. Zur Demonstration des Verfahrens wird exemplarisch eine Ontologie
eines Wissensgebiets erstellt.
Alle Überlegungen zur Erstellung des Ontologieschemas lassen sich prinzipiell auch bei der Erstellung und Ausarbeitung
beliebiger semantischer Datenschemata anwenden. Somit bietet diese Bottom-up-Methode die Chance, die Generierung
des Datenbankschemas algorithmisch durch Beispielsammlungen zu unterstützen. Da jeder Schritt im Verfahren nachvoll-
ziehbar und somit von der Person des Modellierers unabhängig ist, liefert das Verfahren einen Beitrag zur Automatisierung
der Modellierung, insbesondere von Ontologien.
Motivation und Ziel der Entwicklung von Ontologien [2] praktisch genutzt wer-
den können.1
Mit der Formalen Begriffsanalyse (FBA) [1] entfalten sich Anhand eines Beispiels wollen wir ein Verfahren auf-
aus Daten zu Gegenständen und deren Merkmalen automa- zeigen, mit dem das Modellieren weitgehend automatisch,
tisch Begriffe, unter die diese Gegenstände fallen und die nachvollziehbar und somit objektivierbar und weniger per-
diese Merkmale beinhalten. Die FBA liefert somit anhand sonenabhängig gemacht werden kann. Der Artikel richtet
erhobener Daten eine Datenstruktur. Aus Daten lassen sich sich vor allem an Informatiker und Linguisten und an Ent-
also Metadaten generieren, wie sie für semantische Daten- wickler von Datenmodellen sowie an Wissensingenieure,
modelle von Wissensgebieten benötigt werden und die bei die an einer Beschreibung von Weltausschnitten – sei es für
die Schaffung von Anwendungssystemen, sei es für Onto-
logien – interessiert sind.2
Aufgabe und Ausgangssituation
Christoph Lübbert Es gilt, für ein bestimmtes Wissensgebiet anhand von Aus-
christoph.luebbert@t-online.de sagen über einige Instanzen ein zugehöriges Ontologie-
Thomas Zeh
thomas.zeh@t-online.de
1 Eine Aufstellung derartiger Verfahren findet sich bei Priya und Ku-
1
Ernst-Schröder-Zentrum für Begriffliche mar [3].
Wissensverarbeitung, Fachbereich Mathematik, TU 2 Der vorliegende Artikel ist eine Kurzfassung des mathematisch fun-
Darmstadt, Schlossgartenstr. 7, 64289 Darmstadt, dierten Artikels Ein Verfahren zur Erstellung von Ontologien mittels
Deutschland Formaler Begriffsanalyse von den gleichen Autoren [4].
K
4 Informatik Spektrum (2022) 45:3–12
schema zu erstellen. Dies soll auf Basis einer Sammlung Ein Paar (A, B) heißt ein formaler Begriff im formalen
elementarer Sätze der Form Subjekt-Prädikat-Objekt (S-P- Kontext K = (G, M, I), wenn gilt
O) geschehen. Die Elementarsätze liegen in Textform oder
als RDF-Tripel [5] vor als sogenannte Statements oder Ur- A G; B M; A "= B und B #= A:
teile, also für wahr gehaltene Aussagen. Um sachlogische
Zusammenhänge zwischen den Termen der Elementarsätze Dabei heißt A der Umfang, B der Inhalt des formalen
grafisch darzustellen, wird ein Semantisches Netz genutzt. Begriffs (A, B). Die Menge aller formalen Begriffe des for-
malen Kontextes K wird mit B(K) bezeichnet. Auf B(K)
führt man eine Ordnung (reflexive, antisymmetrische, tran-
Formaler Kontext und Begriffsverband sitive binäre Relation) ein durch
Nach DIN 2342 ist ein Begriff „eine Denkeinheit, die aus .A; B/ .A0 ; B 0 / W, A A0
einer Menge von Gegenständen unter Ermittlung der die- .und das gilt genau dann; wenn B 0 B/:
sen Gegenständen gemeinsamen Eigenschaften mittels Ab-
straktion gebildet wird“. Der Gegenstandsbegriff wird hier Die Struktur (B(K), ≤) heißt der Begriffsverband des
sehr weit gefasst. Er umfasst nicht nur materielle und kon- formalen Kontexts K, da diese Struktur mathematisch stets
krete, sondern beliebige Dinge. Die formale Definition des einen Verband darstellt.
Begriffs erfolgt in der Formalen Begriffsanalyse. Die FBA Begriffsverbände können als Liniendiagramme darge-
ist eine auf der Verbandstheorie basierende Methode zur stellt werden. Diese zeigen recht anschaulich die Daten in
Strukturierung von Daten mittels formaler Kontexte und ihrer Struktur.
deren Begriffsverbänden. Sie wurde in den 1980er-Jahren
von Rudolf Wille, Bernhard Ganter und Peter Burmeister
eingeführt. Verfahren
Es folgen einige grundlegende Definitionen.
Gegeben sei eine Menge G, deren Elemente man Ge- Mittels Semantischer Netze und der Formalen Begriffsana-
genstände nennt, und eine Menge M, deren Elemente man lyse wollen wir ein Verfahren vorstellen, das ausgehend von
Merkmale nennt, sowie eine Relation I G × M, die man Elementarsätzen in einem iterativen Bottom-up-Verfahren
Inzidenzrelation nennt. Das Tripel K = (G, M, I) wird dann zu einem Ontologieschema und einem Entity-Relationship-
als formaler Kontext bezeichnet. Für einen Gegenstand Diagramm (ERD) [6] führt. Zur Demonstration des Verfah-
g 2 G und ein Merkmal m 2 M liest man (g, m) 2 I als: rens erstellen wir exemplarisch und im Kleinen eine On-
der Gegenstand g hat das Merkmal m. Ein formaler Kontext tologie eines Wissensgebiets. Wir wählen hierzu das Wis-
(G, M, I) lässt sich in Form einer Kreuzchentabelle darstel- sensgebiet Kunstgeschichte und verwenden das Beispiel aus
len: Trifft (g, m) 2 I zu, so bekommt die Zelle (g, m) der dem Wikipedia-Artikel über Ontologie (Informatik) [7] in
G-M-Tabelle (Inzidenzmatrix) ein Kreuzchen , andern- leicht modifizierter Form. Wir gehen von den Sachverhalten
falls bleibt sie leer. in der Instanzenebene (unterer Teil der Grafik in Abb. 1)
Ist K = (G, M, I) ein formaler Kontext und A G, so aus und werden im Folgenden zeigen, dass das Ontologie-
ist die Menge der Merkmale, die alle Gegenstände von A schema (oberer Teil der Grafik) daraus prinzipiell ableitbar
gemeinsam haben ist. Diese Ontologie kann u. a. der Erstellung eines Infor-
mationssystems für den an Kunstgeschichte interessierten
A "W= fm 2 M j8g 2 A W .g; m/ 2 I g: Laien dienen.
Wir gehen von den folgenden 11 Aussagen aus:
Ist B M, so ist die Menge der Gegenstände, die alle
Santi malt Johannes den Täufer.
Merkmale von B gemeinsam haben
Galleria dell’Accademia stellt Johannes der Täufer aus.
Buonarroti schlägt den David.
B #W= fg 2 Gj8m 2 B W .g; m/ 2 I g:
Galleria dell’Accademia stellt den David aus.
Picasso malt den Jungen mit der Pfeife.
Die Operatoren " und # nennt man Ableitungen im
Picasso ist Kubist.
Kontext K. Durch sie werden Gegenstandsmengen auf
Santi ist Florentiner.
Merkmalsmengen und umgekehrt abgebildet.
Buonarroti ist Florentiner.
Johannes der Täufer ist eine Ölzeichnung.
Der Junge mit der Pfeife ist eine Ölzeichnung.
David ist eine Steinskulptur.
KInformatik Spektrum (2022) 45:3–12 5
Abb. 1 Beispielontologie
Kunstgeschichte mit Instanzen- String String
und Schemaebene. (Mod. nach: erzeugt Name
Name
https://de.wikipedia.org/wiki/
Ontologie_(Informatik)#/media/ Künstler Kunstwerk ausgestellt
Vor- hergestellt
Ontologieschema
Datei:Ontschichten.gif)
String name von
Museum
schlägt Skulptur Name
Bildhauer geschlagen
von String
malt
Maler
gemalt von Bild
Florentinisch Kubist benutzt
Technik Name String
Pablo Vorname malt Name Junge mit
der Pfeife
Picasso Name Maler:I1 Bild:I2benutzt
Name Ölzeich-
benutzt Technik:I3 nung
Instanzen
Michelangelo Vorname
Name David
schlägt
ausgestellt
Buonarroti Name Bild- Skulp-
Galleria dell
hauer:I4 tur:I5 Name Accademia
ausgestellt Museum:I6
Raffaelo Vorname malt
Johannes
Name Maler:I7 Name
Santi Bild:I8 der Täufer
Abb. 2 Semantisches Netz SN1 Buonarroti David Steinskulptur
schlägt benutzt
Florentinisch istFlorentinisch istSteinskulptur
istSteinskulptur
Johannes
DerTäufer GalleriaDell´
Santi
malt Accademia
istFlorentinisch istÖlzeichnung
Junge Ölzeichnung
Kubismus Picasso MitPfeife
pflegtStil malt
istKubist istÖlzeichnung
K6 Informatik Spektrum (2022) 45:3–12
Abb. 3 Leitfaden zur Erstellung
Instanzenebene FBA
des Ontologieschemas
Semantisches Netz SN1 der Instanzen
x
Schritt 1 x
Formale
x x
x x Kontexte
KV, KE
Schritt 4 Schritt 2
Schemaebene
Semantisches Netz SN2 des Schemas
Schritt 3
Liniendia-
gramme für
B(KV), B(KE)
Schritt 5
Ontologieschema als ERD
Diese Aussagen entsprechen denjenigen des Wikipedia- Varianten korrekt sind, modellieren wir sie nach der Devise
Beispiels. Bei den Künstlern haben wir die dort fehlenden nicht entweder-oder sondern sowohl-als auch.
Angaben zum Stil ergänzt. Anders als im Wikipedia-Bei- Am einfachen Beispiel der Abb. 2 wollen wir demons-
spiel gibt es hier auf der Instanzenebene nicht die Begriffe, trieren, wie man, ausgehend von einer Sammlung von Ele-
wie z. B. Maler, Bild, Bildhauer, Skulptur und Museum. Wir mentarsätzen, mithilfe von FBA-Methoden zur Darstellung
werden zeigen, dass diese Begriffe erst anhand der Elemen- eines Ontologieschemas gelangt. Die Elementarsätze wer-
tarsätze durch die FBA ermittelt resp. konstruiert werden den in das Semantische Netz SN1 überführt. Dessen Kno-
und zur Metaebene, also zum Ontologieschema, gehören. ten, Knotenattribute und Kanten werden im Schritt 1 als
Es reicht dem Entwickler, wenn er einige Beispiele er- formale Kontexte der Knoten KV und der Kanten KE in
mittelt hat und sich ein Bild von der „strukturellen Breite“ zwei Tabellen übertragen. Aus diesen Daten der Instan-
der kunstgeschichtlichen Daten gemacht hat. Diese Samm- zenebene werden im Schritt 2 zwei Liniendiagramme mit
lung von Elementarsätzen stellt die Ausgangsdatensituati- den durch die FBA ermittelten Begriffen generiert, die der
on dar. Sollten unter den Termen der Elementarsätze Syn- Schemaebene zuzurechnen sind. Sie werden im Schritt 3
onyma auftauchen, so werden diese durch den Entwickler in das Semantische Netz SN2 der Klassen überführt. Das
bereinigt, indem er einen bevorzugten Term festlegt; Hom- Ontologieschema SN2 wird im Rahmen der Qualitätssiche-
onyme werden von ihm berücksichtigt, indem er sie aufteilt rung überprüft, was im Schritt 4 zu einer Erweiterung und
und sie unterschiedlich benennt. Korrektur der Elementarsätze und somit des Semantischen
Basierend auf diesen Elementarsätzen erstellt der Ent- Netzes SN1 der Instanzen führen kann. In diesem Fall er-
wickler ein Semantisches Netz. Hierbei wird jeder Elemen- folgen die Schritte 1–4 zyklisch. Unser iteratives Bottom-
tarsatz der Form S-P-O auf ein Knotenpaar und eine ge- up-Verfahren endet, sobald das Ontologieschema alle Kri-
richtete Kante überführt. Ein Elementarsatz kann auch zu terien der Qualitätsprüfung erfüllt. Dann kann im Schritt 5
einem Attribut des durch das Subjekt bestimmten Knotens aus SN2 das ERD abgeleitet werden, das die Grundlage für
führen. Die Entscheidung ob Strukturierung mittels Kan- ein Datenbankschema zur Erstellung der Datenbasis für die
ten oder Knotenattributierung ist in dieser Phase der Onto- Ontologie ist.
logieentwicklung meist willkürlich. Beispiel: „Picasso ist Das Vorgehen aus den genannten fünf Schritten ist in
Kubist.“ Soll dieser Elementarsatz als Beziehung pflegtStil Abb. 3 dargestellt.
zwischen den Knoten Picasso und Kubismus oder als At-
tribut istKubist von Picasso modelliert werden? Da beide
KInformatik Spektrum (2022) 45:3–12 7
Abb. 4 Der Knotenkontext KV
Schritt 1: Erstellung der formalen Kontexte zum Streckenzug erreichbar sind. Entsprechend finden wir die
Semantischen Netz der Instanzen Merkmalsmenge eines Begriffs durch die über den Kreisen
stehenden Merkmalsnamen aller aufsteigenden Streckenzü-
Zum vorgegebenen SN1 der Abb. 2 bilden wir die Kreuz- ge. Die Verbandsordnung von B(KV) ist später im Schritt 3
chentabelle des Knotenkontexts KV, wobei die Knoten die als die Klassentaxonomie im Ontologieschema zu interpre-
Gegenstände sind. Merkmale sind die Knotenattribute so- tieren.
wie die Beziehungen, an denen ein Knoten in einer be- Entsprechend erzeugen wir aus dem Kantenkontext
stimmten Rolle – als Subjekt oder als Objekt – beteiligt ist – KE das Liniendiagramm des zugehörigen Begriffsver-
zu anderen Knoten wie auch ggf. zu sich selbst (Abb. 4). bands B(KE). Die Verbandsordnung von B(KE) ist zu
Hiernach bilden wir zum vorgegebenen SN1 der Abb. 2 interpretieren als die Taxonomie der Relationstypen im
die Kreuzchentabelle des Kantenkontexts KE,3 wobei die Ontologieschema, die hier zunächst noch flach ist.
gerichteten Kanten in beide Richtungen die Gegenstände
und die Beziehungstypen die Merkmale sind. Die inverse Schritt 3: Erstellung des Ontologieschemas
Richtung eines Beziehungstyps wird durch ein nachgestell-
tes –1 gekennzeichnet (Abb. 5). Das Liniendiagramm von B(KV) in der Abb. 6 zeigt im
Wesentlichen bereits das Grundgerüst des Ontologiesche-
Schritt 2: Erstellung der Begriffsverbände zu den mas. Die durch die Kreise repräsentierten Begriffe im Li-
formalen Kontexten niendiagramm haben noch keine Bezeichner. Die Namens-
vergabe setzt einen mentalen Akt voraus. Es ist nicht damit
Mit einem bewährten FBA-Tool [10] erzeugen wir aus dem getan, dem Knoten ein „Etikett zu verpassen“, sondern es
Knotenkontext KV das Liniendiagramm des zugehörigen gilt für den Experten des Wissensgebiets anhand der Ge-
Begriffsverbands B(KV) – siehe Abb. 6. Die Kreise im Li- genstandsmenge und der Merkmalsmenge eines jeden Be-
niendiagramm repräsentieren die Begriffe als Paare von Ge- griffs im Begriffsverband einen entsprechenden Begriff aus
genstands- und Merkmalsmengen. Die Gegenstandsmenge dem zu modellierenden Wissensgebiet ausfindig zu machen.
eines Begriffs finden wir anhand der Gegenstandsnamen, Dieser muss alle Gegenstände der Gegenstandsmenge um-
die unter all den Kreisen stehen, die ausgehend von dem fassen und alle Merkmale der Merkmalsmenge aufweisen.
zum Begriff gehörenden Kreis durch einen absteigenden Die Bezeichnung dieses so gefundenen Begriffs kann dann
als Klassenname herangezogen werden.
Nach der Vergabe sprechender Klassennamen folgt die
3 Elemente von Relationen als Gegenstände eines formalen Kontexts Einbettung der Relationstypen. Hierfür sind für einen Re-
zu betrachten, ist eine Anwendung der von Rudolf Wille eingeführten
lationstyp r die jeweils zwei Klassen ausfindig zu machen,
power context families (PCF), die er wie folgt definiert hat: Eine power
context family ist eine Folge K! := (K0, K1, K2, ...) von formalen Kon- zwischen denen der Relationstyp „aufgehängt“ wird, d. h. es
texten Kk := (Gk, Mk, Ik) mit Gk (G0)k für k = 1, 2, ... [8] Die formalen gilt, die zwei vom Umfang kleinsten Klassen zu ermitteln,
Gegenstände von Kk mit k = 1, 2, ... repräsentieren Elemente k-stelliger zwischen deren Instanzen die Beziehung besteht.
Relationen. In unserer Situation haben wir es neben K1 mit K2, also bi-
Dazu helfen die Ableitungsoperatoren " und # der FBA
nären Relationen, zu tun. Bei der Überführung der semantischen Netze
in PCFs wurde von uns der von Eklund und Groh in [9] beschriebene wie folgt:
Algorithmus modifiziert.
K8 Informatik Spektrum (2022) 45:3–12
Abb. 5 Der Kantenkontext KE
Abb. 6 Der Begriffsverband
B(KV)
Ist A eine Menge an Gegenständen, zu der der Begriff sätzen „Henry Moore schlägt Reclining Figure.“, „Henry
mit dem kleinsten Umfang U gesucht wird, der alle Ele- Moore ist Naturalist.“ und „Reclining Figure ist eine Bron-
mente von A enthält, dann ist U = (A")# die Gegenstands- zeskulptur.“.
menge, die zum gesuchten Begriff gehört. Dieser eindeutig Der Schritt 4, also die Überprüfung des Ontologiesche-
bestimmte Begriff entspricht dann der gesuchten Klasse. mas, kann nicht automatisiert werden. Allenfalls können
Damit können wir das Ontologieschema mit den Relations- bei der Überprüfung des Ontologieschemas mithilfe der
typen als Semantisches Netz SN2 erstellen (Abb. 7). Merkmalimplikation (Schlussfolgerungen zwischen Merk-
malen des formalen Kontexts), deren automatisch durch das
Schritt 4: Überprüfung des Ontologieschemas FBA-Programm ConExp erstellten Implikationen als Stütze
dienen. Derartige Implikationen zwischen Merkmalen sind
Die im Semantischen Netz SN1 abgebildeten Elementar- im vorliegenden Kontext beispielsweise:
sätze können durch unzureichende Erhebung unvollständig
istKubist ! malt und istNaturalist ! schlägt.
oder unzutreffend sein. So fällt z. B. auf, dass die Klasse
Skulptur Unterklasse der Klasse Ausstellungsobjekt ist; d. h. Lehnt der Experte eine Implikation ab, dann ist er gefor-
jede Skulptur wird ausgestellt. Der Kunstkenner weiß aller- dert, einen neuen Elementarsatz zu ergänzen (wie es bei der
dings von Fällen, dass es auch Skulpturen gibt, die nicht obigen Klasse Skulptur der Fall war) oder ggf. einen alten
ausgestellt werden, so z. B. die Skulptur Reclining Figure – dann falschen – zu streichen. Um die zweite der beiden
des Naturalisten Henry Moore. Dies führt zu den Elementar- o. a. Implikationen zu widerlegen, reicht es aus, einen neu-
KInformatik Spektrum (2022) 45:3–12 9
Abb. 7 Ontologieschema als Top Class
Semantisches Netz SN2
Kunst-
Künstler werk
Museum stellt aus Ausstellungs-
objekt
Maler malt
Bild
Florentiner
Kubist Bildhauer
schlägt Skulptur
Stil Florenti- Ausstel- Technik
nischer lungsbild
Maler
Bottom Class
Legende
: is-a-Beziehung zur Darstellung der Klassentaxonomie
: Relaonstyp
Abb. 8 Begriffsverband der
Knoten B(KV) nach dem zwei-
ten Durchlauf
en Elementarsatz mit einem Naturalisten aufzunehmen, der Schritt 5: Ableitung des Entity-Relationship-
keine Skulpturen schlägt (Abb. 8). Diagramms
Die FBA liefert im Liniendiagramm der Kanten die
Relationstypen-Taxonomie, welche bei der konventionellen Das Ontologieschema in Abb. 10 kann in ein ERD4 über-
Top-down-Methode meist nicht erkannt oder berücksich- führt werden, wobei nicht alle Knoten und Kanten des SN2
tigt wird. In unserem Fallbeispiel war sie nach dem ersten in das ERD übernommen werden. Kandidaten für Entitäts-
Durchgang trivial; die Hierarchie war flach. Nach dem typen sind solche Klassen, für die es betriebliche Funktio-
zweiten Durchlauf ist das Ergebnis wie folgt (Abb. 9). nen gibt, die sie auch verwenden, und Klassen, die an Re-
Als Ergebnis des 2. Durchlaufs erhalten wir das folgende lationstypen beteiligt sind. Im ERD wird zur Darstellung
Klassendiagramm (Abb. 10). der Kardinalitäten die (min, max)-Notation verwendet. Die
einzelnen Häufigkeitsangaben werden dem aktuellen Da-
tenbestand entnommen. Sie sind bei der Qualitätssicherung
zu überprüfen und deren Ergebnis kann genutzt werden, um
4 Zur Visualisierung des Ontologieschemas kann auch ein UML-Da-
tenstrukturdiagramm genutzt werden.
K10 Informatik Spektrum (2022) 45:3–12
Abb. 9 Begriffsverband der Kanten B(KE) nach dem zweiten Durchlauf
Abb. 10 Ontologieschema als Top Class
Semantisches Netz SN2 nach
dem zweiten Durchlauf Künstler
erzeugt
Kunstwerk
Museum stellt aus
Maler Bild Ausstellungs-
malt objekt
Florentiner Bildhauer schlägt Skulptur
Technik
Stil
Kubist Florentini- Florentinischer Naturalistischer Ausstellungs- Ausstellungs- Bronze-
scher Maler Bildhauer Bildhauer bild skulptur skulptur
Bottom Class
Legende
: is-a-Beziehung zur Darstellung der Klassentaxonomie
: Relaonstyp
das Datenmodell realitätsgetreuer zu gestalten. So kann im können aber als Integritätsbedingungen in das konzeptionel-
Beispiel mit dem Datenbestand nach dem zweiten Durch- le Datenmodell eingehen und in der Ontologie neben den
lauf gefragt werden, ob es zutrifft, dass ein Bildhauer genau Merkmalimplikationen die Inferenzmaschine anreichern.
eine Skulptur schlägt, und ob nicht ein Künstler mehrere Ein Attribut einer Klasse wird demjenigen Entitätstyp
Stile pflegen kann (Abb. 11). zugeordnet, der innerhalb der Entity-Relationship-Ord-
Im ERD lässt sich die Taxonomie der Relationstypen nungsstruktur von unten nach oben gehend erstmalig alle
nicht ohne weiteres darstellen. Entitäten mit den zugehörigen Attributwerten umfasst.
Die Implikationen Aus dem ERD lässt sich dann das konzeptionelle Daten-
bankschema für die Ontologie ableiten.
malt ! erzeugt und schlägt ! erzeugt
KInformatik Spektrum (2022) 45:3–12 11
Abb. 11 Entity-Relationship-
Diagramm mit der (min, max)- stellt Ausstellungs-
Museum
Notation (1,*) aus (1,1) objekt
Künstler erzeugt Kunstwerk
(1,1) (1,1)
(1,1)
(1,1)
Bildhauer Maler Bild Skulptur
pflegt malt benutzt
(1,1) (1,1)
(1,*) (1,*)
(1,1) (1,1)
Stil Technik
schlägt
Legende: Entitätstyp
Relationstyp
Generalisierung/Spezialisierung
Potenziale/Nutzenaspekte dem neue Instanzen zu gegebenen Zeiten gegen das Schema
laufen, das dann im Konfliktfall differenziert und damit er-
Wir sehen in dem weitgehend automatisierbaren Verfahren weitert bzw. um strukturelle Neuheiten ergänzt wird. Damit
eine Möglichkeit, den Modellierungsprozess und die Quali- können die Erweiterung eines Wissensgebietes und auch
tätssicherung zu unterstützen, sowie einen Beitrag zur Kon- ein Strukturwandel in der Ontologie einfacher berücksich-
sensfindung bei den an der Entwicklung von Ontologien Be- tigt werden. Überträgt man diesen Prozess auf zwei oder
teiligten. Die Liniendiagramme zum Knoten- und Kanten- mehr bestehende Ontologien, so kann das Verfahren auch
kontext, das Semantische Netz des Ontologieschemas wie zur Schemaintegration der Ontologien, basierend auf Aus-
auch die automatisch erkannten logischen Zusammenhänge zügen aus deren Datenbeständen, genutzt werden.5
durch die Merkmalimplikation werfen inhaltliche Fragen
Funding Open Access funding enabled and organized by Projekt
auf und unterstützen damit den Entwickler und den Quali- DEAL.
tätssicherer zielführend bei der Konzeption des Ontologie-
schemas. Auch ist jeder Schritt im Verfahren nachvollzieh- Open Access Dieser Artikel wird unter der Creative Commons Na-
mensnennung 4.0 International Lizenz veröffentlicht, welche die Nut-
bar und somit von der Person des Modellierers unabhängig. zung, Vervielfältigung, Bearbeitung, Verbreitung und Wiedergabe in
Alle Überlegungen zur Erstellung des Ontologieschemas jeglichem Medium und Format erlaubt, sofern Sie den/die ursprüng-
lassen sich prinzipiell auch bei der Erstellung und Ausar- lichen Autor(en) und die Quelle ordnungsgemäß nennen, einen Link
beitung beliebiger semantischer Datenschemata anwenden. zur Creative Commons Lizenz beifügen und angeben, ob Änderungen
vorgenommen wurden.
Somit bietet diese Bottom-up-Methode die Chance, die Ge-
nerierung des Datenbankschemas algorithmisch durch Bei- Die in diesem Artikel enthaltenen Bilder und sonstiges Drittmaterial
spielsammlungen zu unterstützen. Auch kann ein auf an- unterliegen ebenfalls der genannten Creative Commons Lizenz, sofern
sich aus der Abbildungslegende nichts anderes ergibt. Sofern das be-
derem Weg erstelltes semantisches Datenschema mit dem treffende Material nicht unter der genannten Creative Commons Lizenz
Ergebnis des FBA-basierten Verfahrens verglichen werden, steht und die betreffende Handlung nicht nach gesetzlichen Vorschrif-
um von den Widersprüchen wie auch den strukturellen Er- ten erlaubt ist, ist für die oben aufgeführten Weiterverwendungen des
gänzungen – z. B. durch neue Begriffe oder Beziehungen – Materials die Einwilligung des jeweiligen Rechteinhabers einzuholen.
zu profitieren. Weitere Details zur Lizenz entnehmen Sie bitte der Lizenzinformation
Da uns nur einige Instanzen aus der Datenbasis zum auf http://creativecommons.org/licenses/by/4.0/deed.de.
Ontologieschema führen, das für alle Daten des Wissens-
gebietes gelten soll, muss das induktiv entstandene Ergeb-
nis durch weitere Elementarsätze auf Plausibilität überprüft 5 Einen FBA-basierenden Bottom-up-Ansatz für den Merge-Prozess
werden. Dies kann zu einem Prozess ausgebaut werden, in- von Ontologien verfolgen auch Stumme und Maedche in [11].
K12 Informatik Spektrum (2022) 45:3–12
Literatur 7. Wikipedia – Die freie Enzyklopädie Ontologie (Informatik). https://
de.wikipedia.org/wiki/Ontologie_%28Informatik%29. Zugegrif-
fen: 30 Apr 2021
1. Ganter B, Wille R (1996) Formale Begriffsanalyse (FBA). Springer,
8. Wille R (1997) Conceptual graphs and formal concept analysis. In:
Berlin, Heidelberg
Lukose D, Delugach H, Keeler M, Searle L, Sowa JF (Hrsg) Con-
2. Busse J, Humm B, Lübbert C, Moelter F, Reibold A, Rewald M,
ceptual structures: fulfilling Peirce’s dream. LNAI, Bd. 1257. Sprin-
Schlüter V, Seiler B, Tegtmeier E, Zeh T (2014) Was bedeutet ei-
ger, Heidelberg, S 290–303
gentlich Ontologie? – Ein Begriff aus der Philosophie im Licht ver-
9. Groh B, Eklund P (1999) Algorithms for Creating Relational Power
schiedener Disziplinen. Informatik Spektrum 37(4):286–297
Context Families from Conceptual Graphs. In: Proceedings 7th-
3. Priya M, Aswani Kumar C (2015) A survey of state of the art of on-
International Conference on Conceptional Structures. LNAI, Bd.
tology construction and merging using formal concept analysis. In-
1640, Springer, Heidelberg, S 389–400
dian J Sci Technol. https://doi.org/10.17485/ijst/2015/v8i24/82808
10. Beschreibungen und Downloadmöglichkeiten von Software zur
4. Lübbert C, Zeh T Ein Verfahren zur Erstellung von Ontologien mit-
FBA. http://www.ernst-schroeder-zentrum.de/sw.html. Zugegrif-
tels Formaler Begriffsanalyse (Publikation vorgesehen)
fen: 28. Apr. 2021
5. Barrasa J Field engineer: RDF triple stores vs. labeled property gra-
11. Stumme G, Maedche A (2001) FCA-merge: a bottom-up approach
phs: what’s the difference? https://neo4j.com/blog/rdf-triple-store-
for merging ontologies. In: Proc. 17th Int’l Joint Conf. Artificial
vs-labeled-property-graph-difference/
Intelligence IJCAI ’01. Morgan Kaufmann, San Francisco
6. Elmasri R, Navathe SB (2015) Fundamentals of database systems.
Addison Wesley, Boston
KInformatik Spektrum (2022) 45:13–19
https://doi.org/10.1007/s00287-021-01420-5
HAUPTBEITRAG
Data Preprocessing as a Service – Outsourcing der
Datenvorverarbeitung für KI-Modelle mithilfe einer digitalen Plattform
Marko Kureljusic1 · Erik Karger1
Angenommen: 5. Oktober 2021 / Online publiziert: 29. Oktober 2021
© Der/die Autor(en) 2021
Zusammenfassung
Sowohl in der Praxis als auch in der Wissenschaft kam es in den vergangenen Jahren zu einem zunehmenden Interesse an
datenintensiven Verfahren, wie der künstlichen Intelligenz. Die Mehrheit dieser Data-Science-Projekte fokussierte sich auf
den Erklärungsgehalt und die Robustheit der Modelle. Vernachlässigt wurde hierbei häufig der Prozess der Datenvorverar-
beitung, obwohl dieser ca. 80 % der Zeit eines Data-Science-Projekts beansprucht. Im Rahmen der Datenvorverarbeitung,
welche auch als Data Preprocessing bezeichnet wird, werden Daten akquiriert, bereinigt, transformiert und reduziert. Das
Ziel dieser Vorgehensweise ist die Generierung eines Datensatzes, welcher sich für Trainings- und Testzwecke der Data-
Science-Modelle eignet. Somit ist das Data Preprocessing ein erforderlicher Prozessschritt, der für das maschinelle Erler-
nen von korrekten Mustern und Zusammenhängen notwendig ist. Häufig scheitern Data-Science-Projekte jedoch an der
mangelhaften Datenvorverarbeitung. So werden beispielsweise fehlerhafte Daten nicht vorab identifiziert, wodurch mögli-
cherweise falsche Zusammenhänge erlernt werden. Dies führt dazu, dass der Erklärungsgehalt der Data-Science-Modelle
signifikant verringert wird. Eine Möglichkeit, dieses Problem zu lösen, ist das Outsourcing der Datenvorverarbeitung an
spezialisierte Fachkräfte. Mithilfe einer Plattform kann ein sicherer und automatisierter Datenaustausch zwischen Kunden
und Dienstleistern gewährleistet werden. Der vorliegende Beitrag thematisiert, wie die Plattform für das Data Preprocessing
genutzt werden kann, um eine effizientere und schnellere Bereitstellung der Daten zu ermöglichen.
Einleitung ta-Science-Projekten. Vor allem das Extrahieren von Merk-
malen aus Daten führt zu einer erhöhten Komplexität und
Mangelnde Datenqualität wird laut aktuellem Stand der einem hohen zeitlichen Aufwand [3]. Um Algorithmen,
Forschung als einer der wichtigsten Gründe für das Schei- wie Machine-Learning-basierte Analyseverfahren, auf den
tern von Data-Science-Projekten angesehen [1]. In den bis- Daten anzuwenden, muss das Data Preprocessing erfolg-
herigen empirischen Studien wird eine Ex-post-Betrachtung reich abgeschlossen sein. Laut aktuellen Umfragen bean-
vorgenommen, indem diese nachträglich die Ursachen für sprucht das Data Preprocessing ca. 80 % der Zeit eines Da-
gescheiterte Projekte untersuchen. Es mangelt an empiri- ta-Science-Projekts und ist maßgeblich für dessen Erfolg
schen Untersuchungen, die aufzeigen, dass eine angemes- [4].
sene Datenvorverarbeitung das Problem der mangelhaften Data Science ist eine multidisziplinäre Wissenschaft, die
Datenqualität eliminieren oder zumindest reduzieren kann. Expertise in verschiedenen Bereichen erfordert. So sind ins-
Jedoch wird dies in der qualitativen Forschung bereits als besondere bei dem Data Preprocessing Kenntnisse der Pro-
elementarer Bestandteil zur Gewährleistung der Datenqua- grammierung, Statistik oder dem Datenmanagement not-
lität angesehen [2]. wendig [8]. Darüber hinaus setzt eine qualitativ hochwerti-
Das Aufbereiten von Rohdaten, welches im Folgenden ge Aufbereitung von Rohdaten voraus, dass deren Herkunft
auch als Data Preprocessing bezeichnet wird, ist in der Pra- und Inhalt verstanden werden. Neben technischer Expertise
xis eine der technisch anspruchsvollsten Aufgaben bei Da- ist daher, je nach Branche, Unternehmen oder Problem-
stellung, auch ein bestimmtes domänenspezifisches Know-
how der Data-Scientists erforderlich. Aufgrund der unter-
Marko Kureljusic
schiedlichen Rahmenbedingungen und Zielsetzungen von
marko.kureljusic@uni-due.de
Data-Science-Projekten gibt es oftmals kein standardisier-
1
Campus Essen, NRW, Universität Duisburg-Essen, tes Vorgehen, auf das bei der Datenvorverarbeitung zurück-
Universitätsstraße 12, 45141 Essen, Deutschland gegriffen werden kann. Aus diesem Grund besteht die Not-
K14 Informatik Spektrum (2022) 45:13–19
wendigkeit, dass das Data Preprocessing durch einen Data- sich strukturierte und unstrukturierte Daten sowie interne
Scientist durchgeführt wird, der auf bestimmte Branchen und externe Daten vorfinden, die gemeinsam für eine Pro-
spezialisiert ist und Inhalt, Struktur sowie Herkunft der blemstellung genutzt werden können. Das Ziel von Data
Daten versteht. Allerdings ist der Markt für spezialisierte Science besteht darin, komplexe Muster und Zusammen-
Fachkräfte sehr kompetitiv, wodurch es für Unternehmen hänge in einem Datensatz zu identifizieren, um wichtige Er-
herausfordernd ist, diese zu akquirieren und zu halten. So kenntnisse aus den Daten zu gewinnen [7]. Die identifizier-
geht aus einer vom Stifterverband und McKinsey durchge- ten Muster bilden die Basis für Machine-Learning-Anwen-
führten Studie hervor, dass bis zum Jahr 2023 ca. 455.000 dungen, welche in der Lage sind, anspruchsvolle Regressi-
zusätzliche Fachkräfte für komplexe Datenanalysen gesucht ons- und Klassifikationsaufgaben zu lösen. Da im Vorfeld
werden [5]. eines Data-Science-Projekts meistens unklar ist, wie stark
Der vorliegende Beitrag stellt mit Data Preprocessing as die Eingangsvariable die Zielvariable beeinflusst, wird häu-
a Service einen neuen, plattformbasierten Ansatz für das fig eine Vielzahl unterschiedlicher Daten verwendet. Mit-
Outsourcing der Datenvorverarbeitung vor. Auf Basis einer hilfe von iterativen Testverfahren können die wesentlichen
Plattform entsteht ein neuer Dienstleistungsmarkt, der es er- Ergebnistreiber im Datensatz identifiziert werden [8]. Dies
möglicht, die Datenvorverarbeitung an spezialisierte Fach- setzt jedoch voraus, dass die Daten maschinell verarbeitbar
kräfte outzusourcen. Hierdurch soll die Datenqualität opti- sind. In den meisten Fällen müssen die Rohdaten erst auf-
miert werden, um die Erfolgswahrscheinlichkeit von Data- wendig angepasst werden, um anschließend Algorithmen
Science-Projekten zu erhöhen. erfolgreich darauf anzuwenden. Die einzelnen Schritte einer
Zunächst werden im zweiten Kapitel die theoretischen Datenvorverarbeitung werden in Anlehnung an einschlägi-
Grundlagen beschrieben, indem auf die Schritte des Data ge Praxishandbücher für Machine Learning, u. a. Géron [9]
Preprocessings sowie auf digitale Geschäftsmodelle einge- und Chollet [10], nachfolgend dargestellt.
gangen wird. Daraufhin wird im dritten Kapitel das Ge- Die Abb. 1 veranschaulicht, dass sämtliche Schritte
schäftsmodell Data Preprocessing as a Service vorgestellt. der Datenvorverarbeitung bei falscher Anwendung Risi-
In Kapitel vier erfolgt eine kritische Diskussion dieses An- ken nach sich ziehen. Um den Erfolg eines Data-Science-
satzes hinsichtlich der praktischen und theoretischen Not- Projekts nicht zu gefährden, sollte das Data Preprocessing
wendigkeit sowie der Nachteile und Risiken, die sich durch daher nicht vernachlässigt werden. Vor dem Hintergrund,
die Anwendung ergeben können. Der Artikel schließt mit dass es mittlerweile AutoML-Tools gibt, die grundsätzlich
einem Fazit in Kapitel fünf, welches die zentralen Aussagen ein End-to-end-Learning ermöglichen, stellt sich jedoch
zusammenfasst. die Frage, welchen Mehrwert eine manuelle Datenvor-
verarbeitung gegenüber AutoML-Tools bietet. Bekannte
Beispiele für AutoML-Tools sind unter anderem Auto-
Theoretische Grundlagen sklearn [11], Hyperopt [12] und Auto-Keras [13]. Das Ziel
sämtlicher AutoML-Tools besteht darin, die Hyperparame-
Im Folgenden wird das Data Preprocessing tiefergehend ter von Machine-Learning-Algorithmen zu optimieren, um
beleuchtet, indem auf sämtliche relevanten Schritte, von so das bestmögliche Ergebnis aus der zugrundeliegenden
der Datensammlung bis hin zur optimalen Datenbereitstel- Datenmenge zu erzielen [14]. Zwar unterstützen AutoML-
lung für Machine-Learning-Anwendungen, eingegangen Tools einige Schritte der Datenvorverarbeitung, wie die
wird. In diesem Zusammenhang wird auch die Relevanz Vektorisierung von kategorialen Variablen, jedoch ersetzen
dieser Schritte thematisiert. Da das Data Preprocessing sie keine vollständige Datenvorverarbeitung durch Data-
in der Praxis aufgrund von zeitlichen, finanziellen oder Scientists [15]. Vor allem ist im Rahmen der Merkmals-
personellen Gründen häufig vernachlässigt wird, stellt sich extraktion ein tiefgründiges Verständnis der Datenmengen
die Frage, welchen Mehrwert es für Data-Science-Projekte und ihrer Zusammenhänge notwendig, um neue Eingangs-
bieten kann. Im Anschluss an die Beantwortung dieser variablen zu kreieren, die das maschinelle Erlernen von
Frage werden sowohl die Grundlagen digitaler Plattformen komplexen Mustern erleichtern [16].
vorgestellt als auch deren Notwendigkeit wissenschafts- Neben AutoML-Tools gibt es auch Machine-Learning-
theoretisch begründet. Dienstleistungen, die auf Basis von Cloud Computing an-
geboten werden. Charakteristisch hierfür ist, dass große Da-
Data Preprocessing tensätze mit modernen Algorithmen analysiert werden kön-
nen, ohne die eigene Hardware zu beanspruchen [17]. Diese
In der Regel werden für Data-Science-Projekte Daten aus werden auch als Machine Learning as a Service bezeich-
unterschiedlichen Ursprungsquellen herangezogen, die sich net. Bekannte Beispiele hierfür sind IBM Watson, Azure,
sowohl von ihrer Struktur als auch ihrer potenziellen In- Google Cloud und AWS. Analog zu AutoML-Tools können
formationsqualität differenzieren [6]. Grundsätzlich lassen im Rahmen von Machine Learning as a Service grundlegen-
KSie können auch lesen

















































