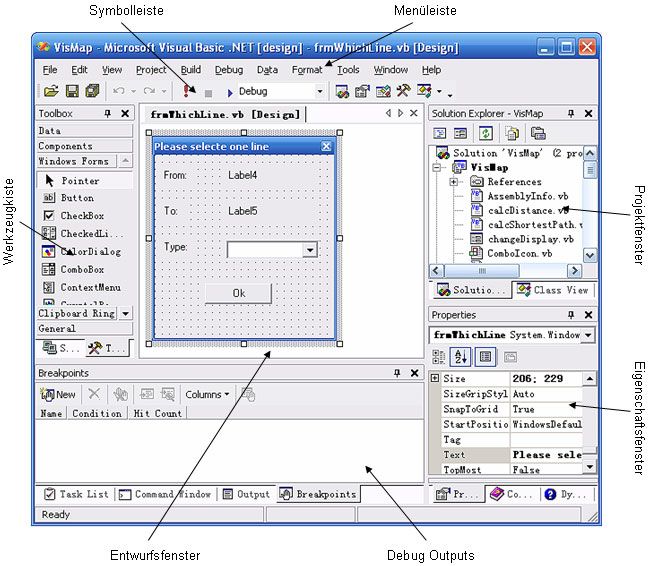
Interaktive Manipulation raumbezogener Datenbanken über 2D-Bildschirmkarten - Diplomarbeit - Universität Bonn
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
RHEINISCHE FRIEDRICH-WILHELMS-UNIVERSITÄT BONN
INSTITUT FÜR INFORMATIK III
Diplomarbeit
Interaktive Manipulation raumbezogener
Datenbanken über 2D-Bildschirmkarten
Vorgelegt von
Zheyi Ji
Bonn, Mai 2005
Betreuer: Prof. Dr. Rainer Manthey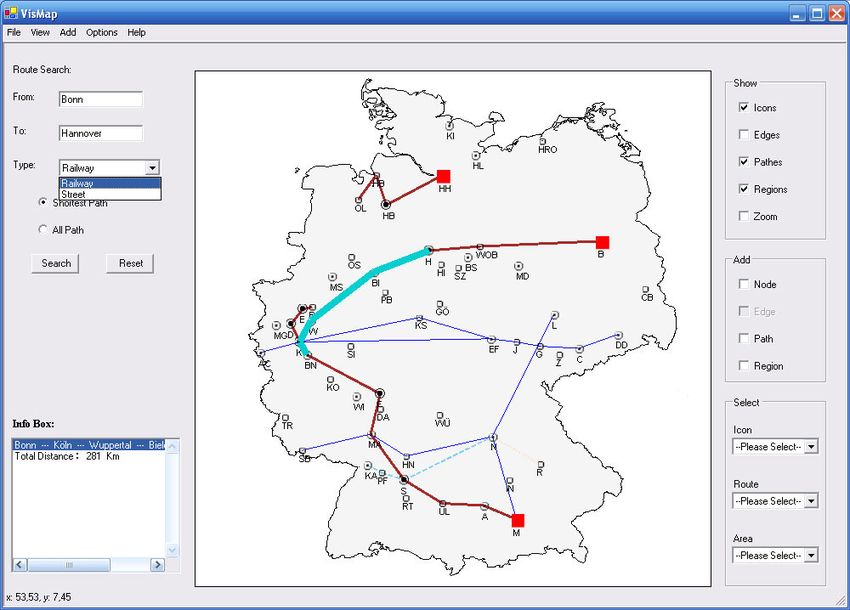
Inhaltsverzeichnis
1. Einleitung ........................................................................................................................ 3
2. Grundlagen relationaler Datenbanken............................................................................ 5
2.1 Datenbankentwurf ................................................................................................. 5
2.2 Das Entity-Relationship-Modell ............................................................................. 8
2.3 Das relationale Modell ......................................................................................... 10
2.4 Normalisierung .................................................................................................... 13
2.5 Grundlagen der SQL ........................................................................................... 15
2.6 Microsoft Access.................................................................................................. 19
3. Visual Basic und Microsoft .NET................................................................................... 22
3.1 Microsoft .Net Framework.................................................................................... 22
3.1.1 Struktur des Microsoft .NET Frameworks.................................................. 23
3.1.2 Kompilierung der .NET-Programme .......................................................... 24
3.2 ADO .NET............................................................................................................ 26
3.3 Visual Basic ......................................................................................................... 28
3.4 Unterschiede zwischen VB und VB .NET ............................................................ 32
4. Geo-Informationssysteme............................................................................................. 33
4.1 Geoobjekte .......................................................................................................... 33
4.2 Modellierung von Geoobjekten ............................................................................ 35
4.3 Präsentation von Geoobjekten ............................................................................ 37
4.4 Kartenprojektion .................................................................................................. 38
5. Modellierung von Geoobjekten in VisMap .................................................................... 41
5.1 Primärmodell der Geoobjekte .............................................................................. 42
5.2 Präsentationsmodell der Geoobjekte................................................................... 46
6. VisMap .......................................................................................................................... 47
6.1 Systemarchitektur................................................................................................ 47
6.2 GUI ...................................................................................................................... 49
6.2.1 Layout der Bildschirmkarte........................................................................ 49
6.2.2 Steuerelemente des Hauptfensters ........................................................... 50
6.2.3 Konfiguration der Bildschirmkarte ............................................................. 52
6.3 Interaktion mit VisMap ......................................................................................... 53
6.3.1 Normalmodus ............................................................................................ 53
6.3.2 Einfügemodus ........................................................................................... 57
6.4 Fenstermanager .................................................................................................. 60
6.4.1 Ereignisinterpretation ................................................................................ 60
6.4.2 Kommunikation mit der Datenbank ........................................................... 62
6.4.3 Pfadsuche ................................................................................................. 66
6.5 Kartengenerator................................................................................................... 67
7. Zusammenfassung und Ausblick .................................................................................. 71
Literaturverzeichnis............................................................................................................... 73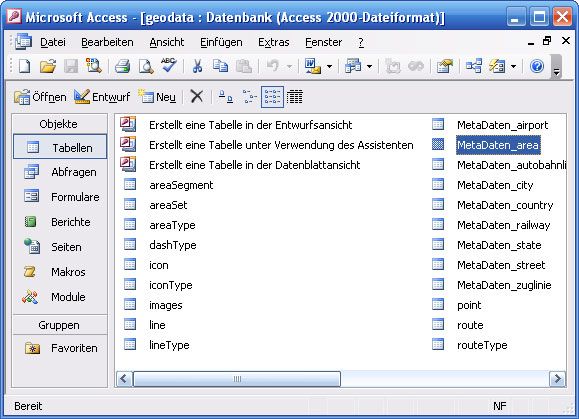
⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯⎯
Ich erkläre hiermit, dass ich die vorliegende Arbeit selbständig verfasst und keine anderen als
die angegebenen Quellen und Hilfsmittel verwendet habe.
Bonn, Mai 2005
2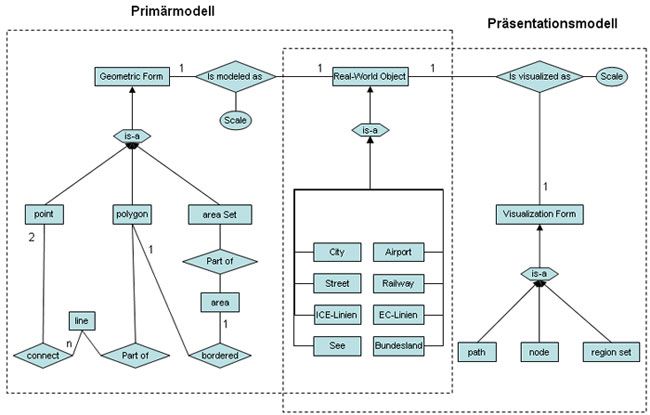
1. Einleitung
Seit Jahrtausenden versuchen die Menschen, visuelle Darstellungen räumlicher Objekte zu
gewinnen. In der alten Zeit lassen sich die Informationen nur analog darstellen, es findet
meistens in Form von Karten statt. Erst seit der Erfindung des Computers ist es möglich,
raumbezogene Informationen in digitaler Form zu speichern. Dies ist ein großer Fortschritt, da
man in digitaler Form Informationen leichter darstellen, verarbeiten und verbreiten kann.
Die Anwendungsmöglichkeiten rechnergestützter Informationssysteme für raumbezogene
Daten sind vielfältig. In der Wirtschaft können sie zur Standortplanung, Ver-/Entsorgung oder
Verkehrsleitung eingesetzt werden. In der wissenschaftlichen Forschungen wie zum Beispiel
Geographie, Klimatologie und Archäologie spielen sie ebenfalls eine wichtige Rolle. Im All-
tagsleben werden sie häufig benutzt für GPS-Navigation, Routenplaner und Stadtpläne. In
dieser Diplomarbeit sowie in ihren zwei Vorgängerarbeiten wird ein 2D-Bildschirm-
karten-System für die automatische Kartenerstellung und interaktive Manipulation raumbe-
zogener Daten entwickelt, das für Landkarten, Stadtpläne oder Routenplaner benutzt werden
kann. Es gibt schon zahlreiche kommerzielle GIS-Anwendungen auf dem Markt, die ebenfalls
Bildschirmkarten als Schnittstellen anbieten. Die Bildschirmkarten solcher Anwendungen ba-
sieren aber meist auf eingescannten analogen Karten, die nicht automatisch vom Programm
erzeugt worden sind. Es ist bei solchen Systemen in der Regel auch nicht möglich, die Geo-
objekte in der Datenbank direkt in der Bildschirmkarte zu bearbeiten. In dieser Arbeit wird die
Bildschirmkarte dagegen automatisch von einem VB-Programm erzeugt, und die Geoobjekte
in der Datenbank können durch Mausklicks auf die Bildschirmkarte leicht bearbeitet werden.
In der Diplomarbeit von Lutz Kunicke [Ku03] sind manche primitive Operationen wie zum
Beispiel das Einfügen der Linienzüge und der Vielecke nicht implementiert worden. Das Da-
taMap-System von Ernest Hadziresic [Ha04] ist eine verbesserte Version von Virtual-
Map-Systems, bietet aber keine Suchfunktionen, und das Bedienungsinterface ist nicht
ausgereift. Beide Systeme nutzen nur einfache Datenbankstrukturen und ihnen fehlt ein all-
gemeines Konzept der Modellierung von Geoobjekten. Das Hauptziel dieser Diplomarbeit ist
es, eine technische, funktionale und konzeptuelle Verbesserung der zwei Vorgängerarbeiten
anzubieten. Dazu wird das VisMap-System entwickelt, das aus einer Datenbank und einem
VB-Programm besteht. Die Datenbank enthält sämtliche Informationen über die räumlichen
Objekte der jeweiligen Anwendung. Das anwendungsunabhängige VB-Programm soll in der
Lage sein, die für eine Visualisierung der Geoobjekte relevanten Informationen aus der Da-
tenbank auszulesen, eine interaktive graphische Darstellung dieser räumlichen Objekte auf
dem Bildschirm zu erzeugen und ein benutzerfreundliches graphisches Interface anzubieten,
um die Informationen in der Datenbank zu manipulieren. VisMap ist kein System für eine be-
stimmte Anwendung, sondern es kann mit einer leichten Anpassungsarbeit in unterschiedli-
chen Anwendungsgebieten eingesetzt werden. Als Anwendungsbeispiel werden in dieser
Diplomarbeit das Eisenbahn- und Autobahnnetz Deutschlands benutzt, die Koordinatendaten
stammen von http://opengeodb.sourceforge.net/.
3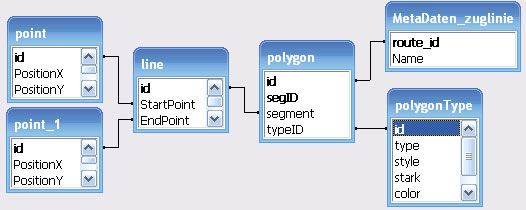
Statt Visual Basic 6, das die zwei Vorgängerarbeiten benutzt haben, wird in dieser Diplom-
arbeit eine echte objektorientierte Erweiterung dieser Sprache verwendet, nämlich Visual
Basic .NET, was zahlreiche Vorteile mit sich bringt. Damit das VB-Programm mit der Daten-
bank kommunizieren und die Daten in der Datenbank manipulieren kann, wird die neue Ver-
sion von ADO, ADO .NET, verwendet. Das zugrunde liegende Datenbanksystem ist wie
bisher Microsoft Access, um den Administrationsaufwand der Datenbank zu verringern. Dank
der vielfältigen Daten-Provider von ADO .NET kann das Programm später sehr einfach um-
wandelt werden, damit es auch z.B. mit Microsoft SQL Server, ORACLE und anderen
ODBC-kompatible Datenbanksystemen arbeiten kann.
Im Kapitel 2 werden die Grundlagen von Datenbanken erläutet. Dabei werden nicht nur das
Konzept des Datenbankentwurfs, das Entity-Relationship-Modell und das relationale Daten-
modell, sondern auch das DBMS Microsoft Access vorgestellt. Im Kapitel 3 werden die
Microsoft .NET-Plattform, Visual Basic .NET, und ADO .NET vorgestellt. Außerdem werden
die Vorteile von VB .NET gegenüber seinen Vorgängerversionen erörtert. Im Kapitel 4 werden
Geoobjekte behandelt, und deren Modellierung und Präsentation erläutet.
Im 5. Kapitel wird der konzeptuelle Entwurf des VisMap-Systems präsentiert. Dabei stehen
die Modellierung der Geoobjekte und der Entwurf der Access-Datenbank im Vordergrund. In
Kapitel 6 wird der Aufbau des VB-Programms von VisMap erläutet. Hier wird vorgestellt, wie
die Schnittstelle gestaltet ist, wie VisMap mit der Datenbank kommuniziert, wie es eine gra-
phische Darstellung der Geoobjekte herstellt, wie es auf die Ereignisse der Steuerelemente
reagiert und welche Funktionen es bietet, um Geoobjekte zu bearbeiten.
4
2. Grundlagen relationaler Datenbanken
Der Inhalt dieses Kapitels orientiert sich am Buch „Datenbanksysteme“ von Alfons Kemper
[KeEi01] und am Vorlesungsskript „Informationssysteme“ von Rainer Manthey [Man03].
Die Datenverwaltung und Speicherung spielen eine zentrale Rolle in einem
Geo-Informationssystem. Nach einer formalen Definition besteht ein Datenbanksystem (DBS)
aus einem Datenbank-Managementsystem (DBMS) und einer oder mehreren Datenbanken.
Das DBMS dient der Verwaltung und Organisation einer Menge von Objekten, der Zusam-
menfassung zu Datensätzen und der Beschreibung von Beziehungen und Abhängigkeiten
zwischen Daten und Datensätzen. Es bildet die funktionale Schnittstelle zwischen dem An-
wender und den Datenbanken, verwaltet den Zugriff auf die Datenbank, kontrolliert die Da-
tenbankkonsistenz und bietet Funktionen, um die Datensätze zu manipulieren. Das DBMS
verfügt über eine Data Definition Language (DDL) und eine Data Manipulation Language
(DML).
Mit der DDL wird die Struktur der abzuspeichernden Datenobjekte definiert. Dabei werden
gleichartige Datenobjekte durch ein gemeinsames Schema beschrieben. Die Strukturbe-
schreibung aller Datenobjekte des betrachteten Anwendungsbereichs nennt man das Da-
tenbankschema. Die DML besteht aus der Anfragesprache (Query Language) und der
Datenmanipulationssprache zur Änderung, Löschen und Einfügen von Abgespeicherten Da-
ten. Die DML kann zwei unterschiedliche Arten genutzt werden: Interaktiv, indem
DML-Kommandos direkt im DBMS eingegeben werden, oder indem sie in einem Programm
eingebettet wird.
Die Datenbanksysteme basieren immer auf einem Datenmodell. Ein Datenmodell besteht aus
einer bestimmten Zusammenstellung von Konzepten zum Modellieren von Daten der realen
Welt und/oder im Rechner. Darüber hinaus stellen Datenbanksysteme Werkzeuge zur Defini-
tion, Generierung, Manipulation und Abfrage von Daten dar. Das heutzutage am meisten
benutzte Datenmodell ist das relationale Datenmodell. Außerdem gibt es auch das hierar-
chische Datenmodell, das objektorientierte Datenmodell und das deduktive Datenmodell.
2.1 Datenbankentwurf
Die ANSI/SPARC schlug bereits 1978 eine konzeptionelle Datenbankarchitektur vor, die auch
heute noch breite Anerkennung findet und in dieser Form die Grundlage der meisten kom-
merziellen und wissenschaftlichen Datenbanksysteme bildet. Diese Drei-Ebenen-Architektur
unterscheidet bei der Modellierung in interne, externe und konzeptuelle Ebene einer Daten-
bank.
5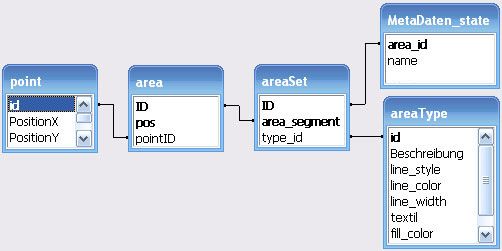
Die interne Ebene liegt am dichtesten am physikalischen Speicher einer Datenbank. Auf
dieser Ebene wird die Speicherorganisation festgelegt. Es wird bestimmt, auf welchem
Speicherort und welchem Speichermedium (Platte, Band) welche Daten wie physisch abge-
legt sind. Die Strukturen dieser Ebene können die Effizienz des gesamten Datenbanksystems
stark beeinflussen.
Die konzeptuelle Ebene liegt oberhalb der internen Ebene. Auf dieser Ebene erstellt man das
organisationsweite Datenmodell sowie das organisationsweite Datenbankschema. Es wird
festgelegt, welche Daten in der Organisation insgesamt von Bedeutung sind und mit welcher
Struktur sie in der Datenbank abgelegt sein sollen.
Die externe Ebene bietet die Schnittstelle zu den Anwendern und Applikationen. Auf dieser
Ebene kann der Anwender Daten in die Datenbank eintragen (INSERT), Daten ändern
(UPDATE, DELETE), Daten aus der Datenbank selektieren (SELECT) und die für sich rele-
vante Aussicht (VIEW) definieren. Man kann sowohl mit einem User Interface (GUI) als auch
mit einer Programmschnittstelle (API) auf die Datenbank zugreifen.
Die oben genannten drei Ebenen kommunizieren ständig miteinander. Bei jedem Zugriff auf
die Datenbank werden die Daten zwischen zwei übereinander liegenden Ebenen bis zum
physikalischen Speicher und wieder zurück – bis zur externen Sicht – übertragen. Die drei
Ebenen und deren gegenseitige Kommunikationen werden von DBMS organisiert.
Benutzer 1 Benutzer 2 Benutzer 3 Benutzer 4
Externe Schicht A Externe Schicht B Externe Schicht C
externe/konzeptuelle Abbildung
Konzeptuelle Schicht DBMS
Konzeptuelle/interne Abbildung
Interne Schicht
Abb. 2.1: Drei-Ebenen-Modell
6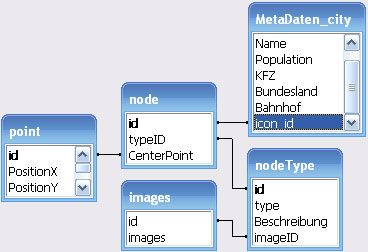
Die Aufgabe des Datenbankentwurfs ist der Entwurf der logischen und physischen Struktur
einer Datenbank so dass die Informationsbedürfnisse der Benutzer in einer Organisation für
bestimmte Anwendungen adäquat befriedigt werden können. Der Datenbankentwurf orientiert
sich an den oben beschriebenen Abstraktionsebenen einer Datenbankanwendung.
Bevor jedem Datenbankentwurf soll eine Anforderungsanalyse durchgeführt werden. In der
Anforderungsanalyse sollen die Abgrenzung und Eingrenzung des zu modellierenden Reali-
tätsausschnittes festgelegt werden. Außerdem wird auch bestimmt, auf welche Weise die
Objekte zu bearbeiten sind. Es sind ggf. Nutzergruppen mit unterschiedlichen Anforderungs-
profilen zu berücksichtigen.
Nach Fertigstellung der Anforderungsspezifikation erfolgt der konzeptuelle Entwurf. In dieser
Phase werden die für die Verarbeitung wesentlichen Merkmale von Objekten und Beziehun-
gen bestimmt. In diesem Entwicklungsschritt wird die Modellierung mit dem „Enti-
ty-Relationship-Modell“ bevorzugt. Im relationalen Datenmodell werden zusätzlich alle Details
zu den „Relationen“ der Datenbasis festgelegt, der so genannte logische Entwurf. Es erfolgt
eine Normierung der Relationen zur Vermeidung von Anomalien bei der Nutzung der Da-
tenbank und zur Beseitigung von Redundanz.
Abb. 2.2: Datenbankentwurf und 3-Ebenen-Architektur [Vo99]
Der letzte Schritt des Datenbankentwurfs, der physische Entwurf, verfolgt das Ziel der Effi-
zienzsteigerung. Im physikalischen Modell werden schließlich die Art der Datenspeicherung
sowie der zugehörige Zugriffsmechanismus festgelegt. Bei manchen Datenbanksystemen
kann dabei auch angegeben werden, welche Datenstrukturen für diese Zugriffspfade (Indi-
zierung) benutzt werden sollen.
7
Für diese Diplomarbeit wird das Entity-Relationship-Modell für den konzeptuellen Entwurf und
das relationale Datenmodell für den logischen Entwurf benutzt, die im nächsten Abschnitt
erklärt werden.
2.2 Das Entity-Relationship-Modell
Das am häufigsten benutzte Modell für den konzeptuellen Entwurf ist das Enti-
ty-Relationship-Modell, das im Jahr 1976 von Peter Chen entwickelt wurde. Es dient als Abs-
traktion eines Ausschnitts der realen Welt. Es ist aus mindestens drei unterschiedlichen
Elementen aufgebaut: aus den so genannten Entitäten (Gegenständen), den Attributen von
Entitäten und den so genannten Relationships (Beziehungen zwischen den Gegenständen).
Entitäten und Attribute
Entitäten sind wohlunterscheidbare physisch oder gedanklich existierende Konzepte der zu
modellierenden Welt. Die einzelnen Entitäten, die ähnlich, vergleichbar oder zusammenge-
hörig sind, werden zu einem Entitätstyp zusammengefasst.
Entitäten besitzen Attribute (Eigenschaften), wobei die konkreten Merkmalsausprägungen als
Attributwerte bezeichnet werden. Die Domäne (Wertebereich) umfasst sämtliche mögliche
oder zugelassene Merkmalsausprägungen.
Im ER-Diagramm werden die Entitätstypen als Rechtecke dargestellt. Die Attribute werden
als Kreise oder Ovale graphisch beschrieben, die durch ungerichtete Kanten mit dem zuge-
hörigen Rechteck verbunden werden.
Stadt Liegt_in Rathaus
id KFZ Stadt Baujahr
Name Population
Abb. 2.3: Entitäten und ihre Attribute
Es gibt nicht nur die Entitäten, die autonom existieren und innerhalb ihrer Entitätsmenge über
die Schlüsselattribute eindeutig identifizierbar sind, sondern auch schwache Entitäten, bei
denen dies nicht gilt. Die schwachen Entitäten sind in ihrer Existenz von einer anderen, ü-
bergeordneten Entität abhängig und oft nur in Kombination mit dem Schlüssel der überge-
ordneten Entitäten eindeutig identifizierbar. Sie werden durch doppelt umrandete Rechtecke
8
repräsentiert. Die Beziehung zu dem übergeordneten Entitätstyp wird ebenfalls durch eine
Verdopplung der Raute und der von dieser Raute zum schwachen Entitätstyp ausgehenden
Kante markiert.
Beziehungen
Zwischen verschiedenen Entitäten können Beziehungen existieren. Beim konzeptuellen Da-
tenbankentwurf sind die Beziehungen zwischen Entitätstypen von Interesse. Die Menge sol-
cher Beziehung nennt man Beziehungstypen. Die Beziehungstypen werden als Rauten mit
entsprechender Beschriftung repräsentiert.
Man kann Beziehungstypen hinsichtlich ihrer Funktionalität charakterisieren. Die Funktiona-
litäten stellen Integritätsbedingungen dar, die in der zu modellierenden Welt immer gelten
müssen. Es gibt 3 Arten von Beziehungstyp. Seien A und B Entitätstypen und R eine Relation
R(a,b), dann gilt:
1: 1 Typ: one-to-one-Relationship
Zu jedem a aus A gibt es genau ein b aus B mit R(a,b) und umgekehrt.
1: n Typ: one-to-many-Relationship
Zu jedem a aus A gibt es ein oder mehrere b aus B mit R(a,b).
n: m Typ: many-to-many-Relationship
Zu jedem a aus A gibt es ein oder mehrere b aus B mit R(a,b) und zu jedem b
aus B gibt es ein oder mehrere a aus A mit R(a,b)
N M
Flächen Begrenzung Kanten
(3,*) (2,2)
Abb. 2.4: Funktionalität der Beziehung und (min, max)-Notation
Bei der Angabe der Funktionalitäten ist für eine Entität nur die maximale Anzahl von Bezie-
hungsinstanzen relevant. Wenn man für eine Entität die präzisen Unter- und Obergrenzen
festlegen will, ist die (min, max)-Notation die richtige Lösung. Die Markierung (mini, maxi) gibt
an, dass es für alle ei∈Ei mindestens mini viele Tupel der Art (...,ei, …) und höchstens maxi
viele solcher Tupel in R gibt.
Um eine weitere Strukturierung der Entitätstypen zu realisieren werden Generalisierung und
Aggregation eingesetzt. Bei der Generalisierung werden die Attribute ähnlicher Entitätstypen
zusammengefasst und einem gemeinsamen Obertyp zugeordnet. Die ähnlichen Entitätstypen,
aus denen diese Eigenschaften faktorisiert werden, heißen Untertypen des generalisierten
Obertyps. Die Untertypen erben die Attribute von Obertypen. Bei dem jeweiligen Untertyp
verbleiben nur die nicht faktorisierbaren Attribute. Somit stellt der Untertyp eine Spezialisie-
9rung des Obertyps dar. Die Generalisierung wird durch eine Beziehung mit dem Namen IS-A
ausgedrückt, welche durch ein Sechseck, verbunden mit gerichteten Pfeilen symbolisiert
wird.
Auto Fahrzeug
IS-A IS-A
PART-OF PART-OF
LKW PKW Auto Auto
Generalisierung Aggregation
Abb. 2.5: Generalisierung und Aggregation
Durch die Aggregation werden einem übergeordneten Entitätstyp mehrere untergeordnete
Entitätstypen zugeordnet. Die unterordneten Entitätstypen bilden in ihrer Gesamtheit den
übergeordneten Entitätstyp. Diese Beziehung wird als PART-OF bezeichnet, um zu betonen,
dass die untergeordneten Entitäten Bestandteile der übergeordneten Entitäten sind.
2.3 Das relationale Modell
Das relationale Datenmodell dient den meisten derzeitigen Datenbanken als Grundlage. In
kommerziellen Datenbanken wird es seit etwa 1981 eingesetzt. Es wurde von E. F. Codd um
1970 vorgestellt mit dem Ziel, die Datenunabhängigkeit zu gewährleisten und basiert auf ei-
ner Variante des mathematischen Konzepts der Relation, in der Relationen auf einfache
Weise als Tabellen interpretiert werden. Es sind im Wesentlichen zwei Gründe, die für das
relationale Datenmodell als logisches Datenbankmodell sprechen: [GI03]
• Einfachheit: die gesamte Information einer relationalen Datenbank wird
einheitlich durch Werte repräsentiert, die mittels eines einzigen Konstrukts
(nämlich der "Relation") strukturiert sind
• Systematik: das Modell besitzt eine fundierte mathematische Grundlage: die
Mengentheorie
Im Gegensatz zum Entity-Relationship-Modell, welches ein konzeptuelles Modell darstellt,
handelt es sich beim relationalen Modell um ein logisches Datenmodell. Es liegt in gewisser
Hinsicht eine Stufe "tiefer". Hier werden keine abstrakten Entitäten oder Entitätstypen mehr
betrachtet, sondern nur noch deren konkrete, datenmäßige Umsetzung. Das Ziel der logi-
10schen Datenmodellierung ist das Anordnen der zu speichernden Informationen mit Hilfe eines
Modells, welches eine möglichst redundanzfreie Speicherung unterstützt und geeignete O-
perationen für die Datenmanipulation zur Verfügung stellt.
In der Regel basiert die logische Datenmodellierung auf einem fertig gestellten konzeptuellen
Schema, das mit Hilfe bestimmter Richtlinien und Regeln in möglichst eindeutiger Weise auf
ein relationales Schema abgebildet wird. Die grundlegende Organisationsform der Daten im
relationalen Datenbankmodell ist die Relation. Das Relationale Datenmodell basiert auf der
mathematischen Definition einer Relation:
Gegeben seien n nicht notwendigerweise unterschiedliche Wertebereiche
(Domänen) D1, D2, …, Dn. Eine Relation R ist dann definiert als eine Teilmenge
des kartesischen Produkts der n Domänen:
R ⊆ D1 × D2 × L × Dn
Eine derartige Relation kann anschaulich durch eine zweidimensionale Tabelle dargestellt
werden, wobei zu beachten ist, dass sich die Definition einer Relation nicht mit der einer Ta-
belle deckt und umgekehrt. Beim relationalen Datenmodell wird also der gesamte Datenbe-
stand durch einfache Tabellen verwaltet, in denen die Daten der Relationen gespeichert
werden. Dabei stellt eine Zeile jeweils einen Datensatz oder ein Tupel dar. Als Beispiel sei
eine einfache Relation Point zur Speicherung punktförmiger Geometrie genannt.
Schema(Point) = (id: LONG, PositionX: SINGLE, PositionY: SINGLE)
Sei ein Relationenschema, dann ist eine gültige Menge von Instanzen gegeben durch:
Point = {(1, 7.21667, 51.4833), (2, 7.1, 50.7333), (3, 8.68333, 50.1167)}
Schlüssel (key) oder Kandidatenschlüssel (candidate key) ist die minimale Kombination
von Attributen, die eine Entität aus einer Entitätsmenge eindeutig identifiziert. Minimal be-
deutet hier, dass man nicht alle Attribute angeben muss, um ein einzelnes Tupel einer Rela-
tion eindeutig zu identifizieren. Die Zahl der notwendigen oder auch hinreichenden Attribute
hängt natürlich stark von den Inhalten ab. Man kann einen der Kandidatenschlüssel als so
genannten Primärschlüssel auswählen. Es gibt im relationalen Modell einen besonderen
Schlüsseltyp, den so genannten Fremdschlüsseln. Mit diesem werden Abhängigkeiten
zwischen verschiedenen Relationen einer Datenbank definiert.
Um ein Entity-Relationship-Modell in ein relationales Datenbankschema umzuwandeln, sollen
acht Abbildungsregeln abgearbeitet werden. Jede Regel wird für alle im zu bearbeitenden
Entity-Relationship-Modell gefundenen und der Regel entsprechenden Entitätstypen (Regel 1,
2, 7 und 8) oder Beziehungen (Regel 3, 4, 5 und 6) angewendet. Man beachte die korrekte
11Reihenfolge der Anwendung der Abbildungsregeln in der Praxis (1, 7, 8, 2, 3, 4, 5 und zum
Schluss 6) [GI03].
Regel 1:
Definiere ein Relationenschema R für jeden starken Entitätstypen G, wobei die Eigenschaften
von G die Attribute von R bilden. Bei mehrwertigen Eigenschaften verfahre nach Regel 7.
Wähle einen Primärschlüssel (Identifikationsschlüssel) aus.
Regel 2:
Für jeden schwachen Entitätstypen S mit Eigentümer G erzeuge ein Relationenschema R,
wobei die Eigenschaften von S die Attribute von R bilden. Bei mehrwertigen Eigenschaften
verfahre nach Regle 7. Übernimm den Primärschlüssel des Relationenschemas, das dem
Eigentümer G entspricht und füge ihn als Fremdschlüssel R hinzu. Wähle eine Attributkom-
bination (Kandidatenschlüssel) aus, die dann zusammen mit diesem Fremdschlüssel den
Primärschlüssel der Relation bildet. Erst die Kombination von Fremdschlüssel- und Kandi-
datenschlüsselattributen bildet den Primärschlüssel von R.
Regel 3:
Suche alle regulären, binären (1,1)(1,1)-, (0,1)(1,1)- und (0,1)(0,1)-Beziehungstypen B. Finde
die Relationenschemata S und T für die beteiligten Entitätstypen. Wähle eines davon (zum
Beispiel S) aus und füge dort den Primärschlüssel von T als Fremdschlüssel sowie die Ei-
genschaften von B als Attribute hinzu.
Regel 4:
Suche alle regulären, binären (1,n)(1,1)-, (0,n)(1,1)-, (1,n)(0,1)- und
(0,n)(0,1)-Beziehungstypen B, sowie die jeweiligen Relationenschemata S und T der betei-
ligten Entitätstypen. Wähle das Relationenschema auf der "(1,1)"/"(0,1)"-Seite (S) aus und
füge dort den Primärschlüssel von T als Fremdschlüssel hinzu. Ausserdem werden allfällige
Eigenschaften von B als Attribute zu S hinzugefügt.
Regel 5:
Suche alle regulären, binären (0,n)(0,n)-, (0,n)(1,n)- und (1,n)(1,n)-Beziehungstypen B, sowie
jeweils die Relationenschemata S und T der beteiligten Entitätstypen. Definiere für jeden Be-
ziehungstyp B ein neues Relationenschema R. Die Primärschlüssel der Relationenschemata
der beteiligten Entitätstypen S und T werden als Fremdschlüssel übernommen. Sie bilden
zusammen den Primärschlüssel des neuen Relationenschemas R. Füge Attribute, die Ei-
genschaften von B entsprechen, zu R hinzu.
Regel 6:
Verfahre für n-stellige Beziehungstypen (n>2) analog zu Regel 5, d.h. bilde sie auf eigen-
ständige Relationenschemas ab und übernimm den Primärschlüssel der Relationenschemas
aller beteiligten Entitätstypen als Fremdschlüssel.
12Regel 7: Definiere für jede mehrwertige Eigenschaft E ein neues Relationenschema R'. R' enthält ein Attribut A, das der Eigenschaft E entspricht und den Primärschlüssel K jenes Relationen- schemas (R), welches dem Gegenstandstyp entspricht, der E enthält. Der Primärschlüssel von R' ergibt sich aus der Kombination von A und K (man beachte, dass R keine Attributent- sprechung für die mengenwertige Eigenschaft besitzt). Regel 8: Definiere ein Relationenschema R für die Superklasse C mit den Attributen A(R) = (K, A1, ..., An). Bestimme K zum Primärschlüssel von R. Definiere weiter ein Relationenschema Ri für jede Subklasse Si, (1
konzeptuellen Schemas sollte sich über die Normalisierungsprinzipien im Klaren sein, um mit
einem korrekten konzeptuellen Schema die Implementierung eines korrekten logischen
Schemas zu erleichtern.
Die Theorie der Normalisierung, die durch E. F. Codd begründet worden ist, besteht aus 9
Regeln, die auch als 1. - 9. Normalform bezeichnet werden, von denen die ersten drei die
wichtigsten sind. Um die Umwandlung der Relationen in die drei Normalformen zu verstehen,
müssen wir zuerst das Konzept der Abhängigkeiten zwischen Attributen dieser Relationen
einführen.
Seien A und B Mengen von Attributen des Relationsschemas R, B ist von A funktional ab-
hängig, wenn zu jedem Wert von A höchstens ein Wert von B auftreten kann. Dies wird wie
folgt dargestellt:
A → B
Die funktionalen Abhängigkeiten stellen eine Verallgemeinerung des Schlüsselbegriffs dar.
Um es zu präzisieren, definieren wir hier den Begriff voll funktional abhängig:
Seien A und B Mengen von Attributen des Relationsschema R, B ist von A
voll funktional abhängig, wenn B von A funktional abhängig aber nicht funk-
tional abhängig von einer echten Teilmenge von A ist. Dies wird wie folgt
bezeichnet:
A →& B
Nun können wir die ersten drei Normalformen definieren:
Erste Normalform:
Eine Relation befindet sich in erster Normalform, wenn jedes Attribut elementar oder atomar,
d.h. unzerlegbar, ist.
Zweite Normalform:
Eine Relation befindet sich in zweiter Normalform, wenn sie die erste Normalform besitzt und
zusätzlich jedes Attribut, das nicht selbst zum Identifikationsschlüssel gehört, voll funktional
vom gesamten Identifikationsschlüssel abhängig ist.
Dritte Normalform:
Eine Relation befindet sich in dritter Normalform, wenn sie die zweite Normalform besitzt und
zusätzlich kein Attribut, das nicht zum Identifikationsschlüssel gehört, transitiv von einem I-
dentifikationsschlüssel abhängig ist.
142.5 Grundlagen der SQL
Der Inhalt dieses Abschnittes orientiert sich stark am „SQL: The Complete Reference“ von
James Groff [GrWe02] und am „Die relationale Anfragesprache SQL“ [GI03].
Man benötigt neben der Strukturbeschreibung auch eine Sprache, mit der man Informationen
aus der Datenbank extrahieren kann. Es gibt zwei formale Anfragesprachen, die für die An-
frageformulierung in relationalen Datenbanken konzipiert wurden: die relationale Algebra und
das Relationenkalkül. In ihrer unmittelbaren Form haben sie heute jedoch als DML stark an
Bedeutung verloren, da sie schwer zu durchschauen sind. Stattdessen hat SQL (structured
query language) sich seit Mitte der 80er Jahre für relationale Datenbanken durchgesetzt. Sie
basiert auf den oben genannten zwei formalen Sprachen und ist eine deskriptive, mengen-
orientierte Sprache. Sie kann sowohl selbständig als auch eingebettet in eine Programmier-
sprache (C, C++, Java, VB, …) verwendet werden. SQL wurde zunächst in den 70er Jahren
von IBM unter dem Namen „SEQUEL“ entwickelt. In den 80ern erfolgte eine allgemeine
Standardisierung dieser Sprache, die jüngste Version ist SQL99.
SQL kann nicht nur benutzt werden, um die Daten in der Datenbank zu manipulieren. Sie
kann in drei konzeptionelle Teile aufgeteilt werden. Die Datenbankschemata können mittels
SQL erzeugt und abgeändert werden, hier wird sie als Datendefinitionssprache (DDL) benutzt.
Am häufigsten werden die SQL-Anweisungen benutzt, um Anfragen an die Datenbank zu
stellen und Tupel in Tabellen zu mutieren (mit den Anweisungen INSERT, DELETE und
UPDATE), hier dient sie als Datenmanipulationssprache (DML). Außerdem kann mittels SQL
die Sicherheit der Datenbanken kontrolliert werden, hier wird sie als Datenkontrollsprache
(DCL) benutzt.
Relation, Tupel und Attribute werden in SQL als „table", „row" und „column" bezeichnet. Durch
die CREATE TABLE-Anweisung wird ein Relationenschema in der Datenbank definiert. Bei
dem Definieren eines Relationenschemas müssen die zur Relation gehörenden Attribute so-
wie deren Domänen angegeben werden. Außerdem kann man auch weitere Deklarationen
wie z.B. Wertebeschränkungen (CHECK-Klausel), Standardwerte oder Primär- und Fremd-
schlüsseldeklarationen angeben.
SQL bietet eine umfangreiche Auswahl der Domänen, Beispiele dafür sind char, number, long
und date. Durch die Deklaration „NOT NULL“ wird festgelegt, dass für das jeweilige Attribut
keine NULL-Werte zulässig sind. Folglich muss beim Einfügen eines Tupels grundsätzlich ein
Wert für dieses Attribut angegeben werden. Primärschlüssel können mit Hilfe der PRIMARY
KEY-Klausel durch eine so genannte „Table Constraint“ deklariert werden. Gefolgt ist ein
Beispiel dafür, wie eine Datenbanktabelle mit Hilfe von SQL definiert werden kann.
CREATE TABLE City
( Name VARCHAR2(35),
15Country VARCHAR2(4),
Province VARCHAR2(32),
Population NUMBER CONSTRAINT CityPop
CHECK (Population >= 0),
CONSTRAINT CityKey PRIMARY KEY (Name, Country, Province)
);
Die Möglichkeiten der Datenmanipulation mit SQL können in zwei Kategorien eingeteilt wer-
den. Die eine sind die Datenbankanfragen, welche Inhalte abfragen, aber keine Änderungen
an der Datenbank vornehmen. Die zweite Gruppe sind die Datenmanipulationen, die die Da-
tenbank verändern, die zum Beispiel Daten einfügen, löschen oder abändern.
Bei den Abfragen mit der SQL werden die Daten des Definitionsbereichs (FROM) mit Hilfe
eines Auswahlkriteriums (WHERE) auf einen Bildbereich (SELECT) abgebildet. Dabei ent-
stehen im Ergebnis grundsätzlich wieder Relationen. Die Standardform einer Datenbankan-
frage mittels SQL ist wie folgt aufgebaut:
SELECT
FROM
WHERE
Wobei die Attributliste aus den Namen der Attribute besteht, deren Werte man durch die An-
frage erhalten möchte; Die Relationenliste ist die Aufführung der Namen der Relationen, die
für die Anfrage gebraucht werden. Die Bedingungen identifizieren die Tupel, die durch die
Anfrage zurückgegeben werden sollen.
Es gibt nun eine Reihe von möglichen Erweiterungen des obigen Grundschemas, welche die
Flexibilität von Anfragen massiv erhöhen:
- mehrere Bedingungen (konjunktiv oder disjunktiv verknüpft)
- komplexere Bedingungen (Unteranfragen, Bereichsanfragen, Verbundoperatoren)
- speziellere Bildbereiche (Verknüpfung von Attributen)
- nicht-relationale Konstrukte (Sortieren, Gruppierungen, Aggregatfunktionen)
- Mengenoperationen (Vereinigung, Durchschnitt, Differenz)
Bedingungen können beliebig durch die Anwendung der logischen Operatoren AND und OR
miteinander verkettet werden. Einzelne Bedingungen können mit dem NOT-Operator negiert
werden. Bedingungen haben prinzipiell die Struktur (z.B. Na-
me=“Zheyi“) wobei die Werte wiederum Attribute, Konstanten oder aber das Resultat von
Unteranfragen sein können, d.h. man muss die Werte von Bedingungen nicht unbedingt fix
definieren, sondern kann sie mittels einer verschachtelten Anfrage generieren. Mit dem Ver-
gleichs-Operator "IN" können Anfragen beliebig tief geschachtelt werden.
16SQL unterstützt eine Reihe von Vergleichs- und Mengenoperatoren. Vergleichsoperatoren
wie =, , , =, BETWEEN können auf zwei Arten verwendet werden. Ist ein Wert
einer Bedingung eine Konstante, so handelt es sich bei dieser Bedingung um eine Restriktion.
Ist der Wert wiederum ein Attribut einer anderen Relation des Definitionsbereichs, so handelt
es sich um eine Verbundbedingung. Mittels Verbundbedingungen können Daten aus mehre-
ren Relationen miteinander verknüpft werden. Es können nur Attribute mit identischen Do-
mänen miteinander verglichen werden. Sie müssen jedoch nicht den gleichen Namen
besitzen.
Im SELECT-Teil kann anstelle einer Attributliste auch ein „*“ geschrieben werden. Der Effekt
besteht darin, dass alle Attribute des Definitionsbereichs gezeigt werden.
Durch den Vergleichsoperator "LIKE" können Teile von Zeichenketten miteinander verglichen
werden. Teile von Zeichenketten werden mit zwei reservierten Zeichen dargestellt: "%" er-
setzt eine unbestimmte Anzahl von Zeichen, während "_" ersetzt ein Zeichen.
Die arithmetischen Standard-Operatoren für Addition (+), Subtraktion (-), Multiplikation (*) und
Division (/) können für alle numerischen Werte oder Attribute mit numerischen Domänen ein-
gesetzt werden.
SQL unterstützt auch Konstrukte, die mit der ursprünglichen relationalen Algebra wenig bis
gar nichts zu tun haben. So besitzt eine Menge per Definition keine Ordnung. Mittels des
Konstrukts "ORDER BY" kann man jedoch eine Ordnung auf der Ergebnisrelation definieren.
Standardmäßig wir absteigend sortiert. Die Schlüsselwörter "ASC" und "DESC" jedoch be-
zeichnen aufsteigende und absteigende Anordnung der Werte im Resultat.
Gruppierungen (GROUP BY-Klausel) dienen dazu, die Menge aller Tupel einer Relation nach
bestimmten Kriterien in Teilmengen zu unterteilen, um für diese Teilmengen bestimmte Sta-
tistiken zu berechnen. Als Gruppierungskriterium dienen die Werte eines bestimmten Attributs.
Alle Tupel, die für dieses Attribut den gleichen Wert besitzen, werden zu einer Gruppe zu-
sammengefasst. Diese Gruppen können dann weiterbearbeitet werden (als Spezialfall auch
durch eine weitere Gruppierung, um Gruppen von Gruppen zu bearbeiten etc.). Dazu dienen
so genannte Aggregatfunktionen, die nur auf numerische Attribute im "SELECT"-Teil ange-
wendet werden können. Folgende Aggregatfunktionen stehen üblicherweise zur Verfügung:
- MIN: Bestimmen des minimalen Wertes eines Attributs
- MAX: Bestimmen des maximalen Wertes eines Attributs
- SUM: Berechnen der Summe aller Werte eines Attributs
- COUNT: Anzahl der Werte eines Attributs (nicht der verschiedenen Werte!)
- AVG: Berechnen des Durchschnitts aller Werte einen Attributs, wobei
NULL-Werte nicht in die Berechnung einfließen
17Mengenoperationen werden verwendet, um Tupel in einer Ergebnisrelation zusammenzu-
fassen, die aus im Grunde verschiedenen Anfragen stammen. Voraussetzung dafür ist natür-
lich, dass die Anzahl der selektierten Attribute jeder beteiligten Anfrage identisch ist.
Außerdem müssen die jeweiligen Domänen kompatibel sein (und zwar jeweils in der selben
Reihenfolge). Für die Verknüpfung von Tupelmengen stehen die üblichen Operatoren zur
Verfügung, wie man sie von der Mengenlehre her kennt:
- UNION: Vereinigung von Tupelmengen
- INTERSECT: Durchschnitt von Tupelmengen
- MINUS: Differenz von Tupelmengen
Um eine Datenbank immer auf dem aktuellen Stand zu halten, müssen von Zeit zu Zeit die
Daten nachgeführt werden (alte, nicht mehr gebrauchte Einträge löschen, neue Einträge er-
fassen oder veränderte Einträge anpassen). In SQL gibt es drei Kommandos um die Daten-
basis zu modifizieren. Diese Kommandos sind Einfügen (INSERT), Löschen (DELETE) und
Ändern (UPDATE).
In seiner einfachsten Form wird durch das Einfügen-Kommando (INSERT INTO) ein Tupel zu
einer Relation hinzugefügt. Form des Statements:
INSERT INTO Relationenname (Liste von Attributen)
VALUES (Liste von Werten);
Wobei die Liste der Attribute nur dann angegeben werden muss, wenn keine vollständigen
Tupel eingegeben werden oder wenn die Werte in einer anderen Reihenfolge erscheinen
sollen als die zugehörigen Attribute bei der Definition der Relation.
Das Löschen-Kommando (DELETE FROM) entfernt ein oder mehrere Tupel aus einer Rela-
tion. Die WHERE-Klausel spezifiziert, welche Tupel betroffen sind. Tupel werden explizit
immer nur aus einer Relation gleichzeitig gelöscht. Bei einer fehlenden WHERE-Klausel
werden alle Tupel aus der angegebenen Relation gelöscht. Form des Statements:
DELETE FROM Relationenname
WHERE Bedingung;
Das Ändern-Kommando (UPDATE) wird gebraucht, um Werte von Attributen von einem oder
mehreren Tupeln zu ändern. Die WHERE-Klausel spezifiziert, welche Tupel von der Ände-
rung betroffen sind. Die SET-Klausel spezifiziert die Attribute, die geändert werden sollen und
bestimmt deren neue Werte. Form des Statements:
UPDATE Relationenname
SET einem oder mehreren Attributen einen Wert zuweisen
WHERE Bedingung;
182.6 Microsoft Access
Access ist ein DBMS für relationale Datenbanken, das seit 1992 von Microsoft entwickelt und
vertrieben wird. Es ist eine wichtige Komponente des Microsoft Office Paketes und zählt
heute zum populärsten DBMS für Desktop-PCs, weil es sehr gut für kleine bis mittlere
DB-Anwendungen ohne große Anforderungen für Mehrbenutzerbetrieb geeignet ist.
Es gibt zwei Typen von DBMS für Access, die Jet Database Engine und die MSDE (Microsoft
SQL Server 2000 Desktop Edition). Microsoft SQL Server 2000 Desktop Edition ist eine
Technologie zur lokalen Datenspeicherung in einem Format, das kompatibel mit Microsoft
SQL Server 2000 ist. MSDE kann auch zur servergestützten Datenspeicherung verwendet
werden. Man kann sich SQL Server 2000 Desktop Edition als Client/Server-Alternative zum
Dateiserver Microsoft Jet-Datenbank-Engine vorstellen, sie bietet mehr Funktionen als die Jet
Database Engine. Das System VisMap ist keine Client/Server Anwendung, die Datenbank-
struktur ist auch relativ einfach. Um die Verwaltungsaufwand für die Datenbank zu minimieren
wird in VisMap die Jet Database Engine benutzt. Die Jet Database Engine ist das traditionale
DBMS für Access. Sie ist einfach zu verwalten und besonderes geeignet für die Datenbank
mit einfacher Struktur. Die Daten werden in einer Datei gespeichert und deswegen einfach zu
transportieren. Die Benutzung der Systemressource ist auch sehr gering.
MS Jet hat erweiterte Kapazitäten, die normalerweise bei Desktop-Datenbanken nicht zur
Verfügung stehen. Diese sind: [Gr02]
• Zugriff auf heterogene Datenquellen. MS Jet unterstützt mit Hilfe von Open Data-
base Connectivity (ODBC)-Treibern den Zugriff auf über 170 verschiedene Daten-
formate einschließlich Borlands dBASE und Paradox, ORACLE von der Oracle
Corporation, den MS SQL Server und IBM DB2. Entwickler können Applikationen
erstellen, in denen die Anwender praktisch jedes Datenformat lesen und verändern
können.
• Referenzielle Integrität und die Gültigkeit von Daten. MS Jet unterstützt sowohl
Primärschlüssel als auch Fremdschlüssel, datenbankspezifische Regeln und das Lö-
schen oder Ändern von Datensätzen in untergeordneten Tabellen. Das bedeutet, dass
der Entwickler diese Regeln nicht mehr selbst entwickeln muss. Die Daten-
bank-Engine enthält die Regeln bereits, so dass sie für jede Applikation verfügbar
sind.
• Erweiterte Sicherheitsmerkmale für Workgroups. MS Jet speichert die Benutzer-
rechte in einer separaten Datenbank, die normalerweise im Netzwerk abgelegt wird.
Zugriffe auf Datenbank-Objekte (z. B. Tabellen oder Abfragen) werden in jeder Da-
tenbank gespeichert. Durch die Trennung von Benutzerrechten und Informationen
über Dateizugriffe erleichtert MS Jet die Administration der Datenbanken im Netzwerk.
19• Veränderbare Datenblattansicht. Im Gegensatz zu vielen Datenbank-Engines, die
Datenbankabfragen in temporären Views oder Snapshots anzeigen, gibt MS Jet eine
Datenblattansicht zurück, die automatisch alle Änderungen, die die Anwender vor-
nehmen, in die Original-Datenbank zurückschreibt. Das heißt, dass alle Ergebnisse
einer Abfrage, auch wenn sie auf verschiedene Tabellen zugegriffen hat, genauso
behandelt werden können wie die Tabellen selber. Außerdem können Abfragen auch
auf anderen Abfragen basieren.
• Abfrage-Optimierung mit der Microsoft RushmoreTM-Technologie. MS Jet enthält
die innovative RushmoreTM-Technologie von MS FoxPro; die Geschwindigkeit der
Abfragen erhöht sich damit erheblich
Die Daten einer Access-Datenbank werden in Tabellen gespeichert. Tabellen sind daher die
Grundlagen einer Datenbank. Wie viele Tabellen eine Datenbank umfasst und in welcher
Weise die Daten der einzelnen Tabellen miteinander verknüpft sind, lässt sich nicht allgemein
sagen. Diese Aufgabe muss bei den Überlegungen zum Datenbankdesign gelöst werden.
Jede einzelne Tabelle ist dagegen in gleicher Weise aufgebaut.
Abb. 2.6: Graphisches Interface von Microsoft Access
Tabellen sind in Zeilen und Spalten organisiert. Jede Zeile stellt einen Datensatz dar, jede
Spalte ein Feld. Ein Feld enthält daher so viele Werte, wie eine Tabelle Datensätze aufweist.
Obwohl die Werte eines Feldes sich im Allgemeinen inhaltlich unterscheiden, sind sie doch
von gleicher Art. So enthält das Feld Name lauter Textwerte, während das Feld Geburtsda-
tum nur Datumswerte aufweist. Für eine effiziente Datenbankverwaltung ist es erforderlich,
dass bei der Definition einer Tabelle für jedes Feld sein Datentyp festgelegt wird.
20Man kann bei dem relationalem Datenmodell die Relationen leicht in Tabellenform umwan-
deln. Die Tabellen lassen sich auch als Relationen formalisieren, wenn man keine Duplikate
zulässt und von der Anordnung absieht. Im Access kann man mit der Entwurfsansicht sehr
leicht das Schema einer Relation (Felder von Tabellen, Feldernamen, Felddatentypen, Be-
dingungen, etc.) festlegen. In der Datenblattansicht der Tabellen kann man die Datensätze
addieren, löschen und aktualisieren.
Nachdem man verschiedene Tabellen zu den einzelnen Themen in der Access Datenbank
angelegt hat, muss er Microsoft Access mitteilen, wie diese Informationen wieder zusam-
mengeführt werden. Der erste Schritt in diesem Prozess besteht darin, Beziehungen zwi-
schen den Tabellen zu definieren. Eine Beziehung ist eine Zuordnung zwischen allgemeinen
Feldern (Spalten), die in zwei Tabellen vorkommen. Eine Beziehung kann vom Typ 1:1, 1:n
oder n:n sein. Anschließend kann man Abfragen, Formulare und Berichte erstellen, um die
Informationen aus verschiedenen Tabellen gleichzeitig anzuzeigen. Eine Beziehung funktio-
niert durch übereinstimmende Daten in Schlüsselfeldern (in der Regel ein Feld, das in beiden
Tabellen denselben Namen besitzt). In den meisten Fällen stellen diese übereinstimmenden
Felder in der einen Tabelle den Primärschlüssel, der einen eindeutigen Bezeichner für jeden
Datensatz enthält, und in der anderen Tabelle einen Fremdschlüssel dar.
Im Abfragenbereich kann man die komplexe Abfragen definieren und speichern. In der Ent-
wurfsansicht kann man mit Hilfe der vordefinierten Formulare unterschiedliche Abfragentypen
definieren: Auswahlabfrage, Kreuztabellenabfrage, Tabellenerstellungsabfrage, Aktualisie-
rungsabfrage, Anfügabfrage und Löschensabfrage. Sie können Abfragen zusammen mit der
Datenbank speichern. Im Allgemeinen enthält eine Datenbank eine Vielzahl von gespeicher-
ten Abfragen, die dann jeweils bei Bedarf aufgerufen oder dauerhaft als Datenherkunft von
Formularen oder Berichten dienen. Obwohl das Abfrageergebnis große Mengen von Daten
beinhalten kann, verbraucht eine gespeicherte Abfrage nur sehr wenig Speicherplatz auf der
Festplatte. Insbesondere ist der benötigte Speicherplatz unabhängig von der im Abfrageer-
gebnis vorhandenen Datenmenge. Dies ist darin begründet, dass Access nur die Abfrage-
formulierung speichert, nicht jedoch das Abfrageergebnis. Die Folge dieses Konzepts ist
natürlich, dass das Abfrageergebnis jedes Mal neu ermittelt werden muss, wenn die Abfrage
benötigt wird. Das kostet mehr oder weniger viel Zeit, hat jedoch den unschätzbaren Vorteil,
dass Abfrageergebnisse stets dem neuesten Datenmaterial der Tabellen entsprechen.
Access bietet zwei grundsätzlich verschiedene Anfragesprachen, die QBE (Que-
ry-by-Example) und die SQL. Mit QBE erhält der Benutzer ein benutzerfreundliches Interface,
um die einfachen Abfragen zu konstruieren. Die komplexen Abfragen können aber nur durch
SQL konstruierbar. Weil man die Datenbank nicht im Access, sondern direkt durch die
Jet-Datenbank-Engine verwaltet und bearbeitet, ist QBE von weniger Bedeutung. Hingegen
sind für diese Diplomarbeit die Abfragen durch die im VB Programm eingebetteten SQL Sta-
tements von großer Bedeutung. Zu beachten ist, dass das von MS Jet Database Engine un-
terstützte SQL keine ANSI-SQL, sondern Jet-SQL von Microsoft ist.
213. Visual Basic und Microsoft .NET
Statt Visual Basic 6 wird die Implementierung des VB-Programms von VisMap mit Visual Ba-
sic .NET entwickelt. Für den Datenzugriff zur Access-Datenbank wird statt ADO ADO .NET
verwendet. Weil Visual Basic .NET und ADO .NET stark abhängig von dem Microsoft .NET
Framework sind, wird in diesem Kapitel zunächst das Microsoft .NET Framework erklärt.
Dann wird erläutet, was ADO .NET ist und seine Fortschritte im Vergleich mit ADO. Danach
wird erklärt, was Visual Basic .NET ist und wie man die Visual Basic .NET Programme
schreiben. Am Ende wird ein Vergleich zwischen Visual Basic und Visual Basic .NET ge-
macht, um die Fortschritte von VB .NET zu erklären. Der Inhalt dieses Abschnittes orientiert
sich am „Database Programming with Visual Basic® .NET and ADO .NET” von Barker
[Bark02], „Programming Visual Basic .NET“ von Liberty [Lib03] und „MSDN for Visual Stu-
dio .NET“ von Microsoft [MSDNLib].
3.1 Microsoft .Net Framework
Im Jahr 2000 hat Microsoft die .NET Plattform angekündigt. .NET ist ein Entwicklungsfra-
mework, das ein neues API (application programming interface) für die Dienste und die APIs
für klassische Windows Betriebssysteme anbietet, besonders für die Windows 2000/XP/2003
Familie. Es kombiniert unterschiedliche Technologien, die von Microsoft während der späten
1990er herausgegeben wurden. Unter letzterem sind die COM+ Komponente-Dienste, das
ASP Web-Entwicklungsframework, die XML, das objektorientierte Design und die Unterstüt-
zung der neuen Web Dienste Protokolle wie SOAP, WSDL und UDDI zufinden.
Der Anwendungsbereich von .NET Framework ist riesig, Die Plattform besteht aus 4 separa-
ten Produktionsgruppen, diese Diplomarbeit betrifft aber nur die erste Gruppe:
- Eine Gruppe von Sprachen, einschließlich Visuell Basic .NET, C#, JScript .NET, und Ma-
naged C++; eine Gruppe von Entwicklungswerkzeugen, einschließlich Visual Studio .NET;
eine umfassende Klassenbibliothek für den Aufbau der Web Dienste und Win-
dows-Anwendungen; und die Common Language Runtime (CLR), um die in diesem
Framework erzeugende Objekte auszuführen.
- Eine Gruppe von .NET Enterprise Server, wie SQL Server 2000, Exchange 2000, BizTalk
2000 usw., die spezialisierte Funktionalität für relationale Datenspeicherung, Email, B2B
Kommerz anbieten.
- Ein Angebot von kommerziellen Webdiensten, .NET My Services; für ein Honorar können
die Entwickler diesen Dienst benutzen, um eigene Programme zu erstellen.
- Neue .NET-enabled non-PC Geräte, von Handy bis zum Spiel-Konsole.
22Das .NET Framework ermöglicht die Zusammenarbeit der unterschiedlichsten Sprachen.
Zusammenarbeit bedeutet dabei nicht nur, dass ein Aufruf von einem Programmcode möglich
ist, der in einer anderen Sprache geschrieben wurde, sondern auch, dass in objektorientierten
Sprachen eine Vererbung von Klassen möglich ist, die in einer anderen objektorientierten
Sprache entwickelt wurden.
Basis für diese Sprachintegration ist einerseits die Zwischensprache MSIL und die CLR und
andererseits die so genannte Common Language Specification (CLS). Die CLS ist ein Re-
gelwerk für Compiler, das festlegt, wie die Umsetzung von sprachspezifischen Konzepten in
die MSIL erfolgen muss. Kern der CLS ist das Common Type System (CTS), das ein einheit-
liches System von Datentypen definiert. Denn nur, wenn die verschiedenen Sprachen die
gleichen Datentypen verwenden, ist eine problemlose Integration möglich.
3.1.1 Struktur des Microsoft .NET Frameworks
Die Ausführung einer .NET-Anwendung setzt eine Laufzeitumgebung voraus, die Common
Language Runtime (CLR) genannt wird. Die CLR stellt den Just-in-Time-Compiler und zahl-
reiche andere Basisdienste bereit, die von allen .NET-fähigen Sprachen verwendet werden.
Dazu gehören zum Beispiel ein Garbage Collector, Exception Handling, ein Sicherheitssys-
tem und die Interoperabilität mit Nicht-.NET-Anwendungen.
Wie in der Abb. 3.1 gezeigt, die „Framework Base Classes“ basiert auf CLR. Oberhalb von
„Framework Base Classes“ ist eine Menge von Klassen, die zusätzliche Funktionen bietet, die
„Data and XML Classes“. Am ganz oben ist eine Menge der Klassen für Web Dienste, Web
Formen und Windows Formen. Insgesamt werden diese Klassen als die Framework Class
Library (FCL) bezeichnet, die eine objektorientierte API für das ganze .NET Framework bietet.
Abb. 3.1: Systemarchitektur des .Net Frameworks [Lib03]
23Die Framework Base Classes, die niedrigste Stufe der FCL, ist ähnlich wie die Java Basis
Klassen. Diese Klassen unterstützen fundamentale Eingabe und Ausgabe, Manipulation der
Strings, Sicherheitsmanagement, Netzkommunikation, Management des Threads, Textma-
nipulation usw.
Die Data and XML Classes sind eine Erweiterung der Framework Base Classes, sie unter-
stützen Datenverwaltung und XML Manipulation. Die Daten-Klassen, die ADO .NET enthält,
unterstützen das persistente Management von Daten, die von den Datenbanken im Hinter-
grund erhalten werden. Diese Klassen umfassen die Structured Query Language Klassen,
damit man durch eine standardmäßige SQL-Schnittstelle die persistente Datenbank manipu-
lieren kann. Das .NET Framework unterstützt auch eine Menge von Klassen, mit denen die
XML Daten bearbeitet und geparst werden können.
Ganz oben steht eine Reihe von Klassen, mit den man mit drei unterschiedlichen Technolo-
gien Anwendungen erzeugen kann: Web-Dienste, Web-Formen, und Windows-Formen. Web
Dienste schließen eine Anzahl von Klassen ein, die die Entwicklung von einfach verteilten
Komponenten unterstützen, die sogar mit Firewall und NAT funktionieren können. Diese
Komponenten unterstützen auch Plug-and-Play, da die Web Dienste HTTP und SOAP als
zugrunde liegende Kommunikations-Protokolle brauchen.
Die Web Formen und Windows Formen ermöglichen eine schnelle Entwicklung von Web- und
Windows-Anwendungen. Mit dem Drag and Drop der Maus kann man einfach die vordefi-
nierten Steuerelemente auf die Formen rüberziehen. Nach dem Einfügen des Steuerele-
mentes kann man die gewünschten Ereignisse von diesem Steuerelement in einer List
auswählen und dafür eigene Programmiercodes schreiben.
3.1.2 Kompilierung der .NET-Programme
Das .NET Framework arbeitet – genau wie die Programmiersprache Java – mit einer Zwi-
schensprache. Ein Compiler einer .NET-Sprache erzeugt also nicht einen prozessorspezifi-
schen Maschinencode, sondern einen plattformunabhängigen Zwischencode, der von CLR
ausgeführt werden kann. Dieser Zwischencode heißt Microsoft Intermediate Language (MSIL)
und bildet eine so genannte Assembly. Die VB .NET erzeugende MSIL Datei ist identisch mit
denen von anderen Sprachen erzeugte MSIL Dateien. Eine wichtige Besonderheit der CLR
ist, dass es allgemein ist. Die gleiche Runtime unterstützt die Entwicklung in Visual
Basic .NET und in C#.
Erst zur Laufzeit wird dieser MSIL-Code in einen prozessorspezifischen Maschinencode (Na-
tive Code) umgewandelt. MSIL-Code wird aber nicht interpretiert, sondern von einem so ge-
nannten Just-in-Time-Compiler Stückchenweise umgewandelt und dann ausgeführt. Der
24Sie können auch lesen

















































