KI-Einsatz für Effizienzgewinne bei Benchmark-studien im Bereich Transfer Pricing - WTS Global
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
BETRIEBSWIRTSCHAFT Effizienzgewinne durch KI bei Benchmarkstudien im Transfer Pricing
KI-Einsatz für Effizienzgewinne bei Benchmark-
studien im Bereich Transfer Pricing
Mittels Web Crawling und Natural Language Under-
standing
Mittels KI zur Teilautomatisierung des qualitativen Screenings bei der Erstellung von TP Benchmarkstudien
entwickeln die Fachexperten der WTS und das DFKI gemeinsam einen Software-Prototyp – auch um so dem
kompetitiven Umfeld mit einer digitalen Lösung entgegenzutreten.
ses und das hohe Potential von Künstlicher Intelligenz
ALEXANDER BEUTHER, PROF. DR. PETER FETTKE, (KI) in diesem Zusammenhang sorgt hier für euphori-
DR. VANESSA JUST UND ANDREAS RIEDL sche Aussichten.3
1. Einleitung Digitale Technologien haben bereits in vielen Bereichen
„Transfer Pricing – it’s an art, not a science!“ besagt ein Revolutionen ausgelöst. Digitale Fotografie beispiels-
bekanntes Zitat. Die angesprochene Kunst stößt jedoch weise lässt analoge Fotografie antiquarisch wirken. On-
manchmal an äußerst unsanfte Restriktionen. In der Pra- line-Handel hängt den stationären Handel seit Jahren
xis der Verrechnungspreisarbeit gibt es einige Heraus- hinsichtlich des Umsatzwachstums ab. Diese Verände-
forderungen bei der Bestimmung von Fremdvergleichs- rungen haben die jeweiligen Strukturen auf den Märk-
daten. Im Rahmen der Ermittlung angemessener Trans- ten nachhaltig verändert. Auch Steuerabteilungen und
ferpreise ist der international anerkannte Maßstab des Steuerberatungen müssen sich ebenso verändern, um
Fremdvergleichsgrundsatzes anzuwenden. Typischer- wettbewerbsfähig zu bleiben.4 Vor allem bei Verrech-
weise erfordert der Grundsatz des Fremdvergleichs ba- nungspreisen trifft dies besonders zu, da das Volumen
sierend auf § 1 Abs. 1 AStG, dass Transaktionen zwi- interner Transaktionen laut Schätzungen des BMF und
schen verbundenen Unternehmen mit denen von un- der OECD etwa 60 % des weltweiten Handels aus-
abhängigen Unternehmen vergleichbar sind. Die Ana- macht. Es handelt sich um eine signifikant hohe Anzahl
lysen, die in diesem Zusammenhang angefertigt werden, an internen Transaktionen, hohe Volumina und erheb-
stoßen schnell an ihre Grenzen.1 liche Prozesskosten.5 Aufgrund des enormen tech-
nischen Potentials in diesem Zusammenhang erforschen
Ganz konkret geht es um sog. „Benchmarkstudien“. die Autoren innovative Konzepte zur Digitalisierung
In den Studien fällt regelmäßig der größte Teil der aller Aufgaben, die im Zusammenhang mit Verrech-
Arbeit für das manuelle Screening der Vergleichsunter- nungspreisen stehen. Hierzu wurde insbesondere auch
nehmen an. In der Praxis werden Webseiten angesteu- ein Prototyp entwickelt, der basierend auf jahrzehnte-
ert, beurteilt und Screenshots gemacht; nicht selten langer Erfahrung bei der Erstellung von Benchmarkstu-
von mehreren hundert Unternehmen. Dabei ist die dien den Arbeitsschritt des manuellen Screenings unter-
Beurteilung der Webseiten subjektiv und – durch den stützt.
Zeitaufwand für das Screening – die Suchmöglichkei-
ten beschränkt. Insgesamt ist dem Prozess so inhärent,
3 Zur Verbesserung der Qualität hat die OECD ansonsten ein Toolkit
dass die Ergebnisse durch eine Verbesserung des ma- veröffentlicht (A Toolkit for Addressing Difficulties in Accessing Com-
nuellen Screening-Prozesses verbessert werden kön- parables Data for Transfer Pricing Analyses in https://www.oecd.org/
tax/toolkit-on-comparability-and-mineral-pricing.pdf). Die grundsätzli-
nen.2 Gerade die weitere Automatisierung des Prozes- che Problematik im Rahmen des manuellen Screenings wird hierdurch
jedoch nicht beseitigt.
4 Fettke/Herzog/Lahann/Maus/Neumann, Künstliche Intelligenz im Steu-
1 Zu den Grenzen von Benchmarkstudien ua Krüger/Nientimp/Schwarz erbereich: Innovationsstudie zur Digitalisierung und den Potentialen
Ubg 2016, 221. Künstlicher Intelligenz im Bereich Steuer, WTS Group AG Steuerbera-
2 Zu den weiteren Suchkriterien im Rahmen der Erstellung von Bench- tungsgesellschaft, Deutsches Forschungszentrum für Künstliche Intelli-
markstudien ua Vögele/Borstell/Bernhardt, Verrechnungspreise, Kap. H: genz, 2017.
Berechnung, Benchmarking, Profit Split für Gewinnmethoden, 5 Kleinhietpaß/Hanken, Verrechnungspreise – inkl. eBook: im Spannungs-
Rn. 123–125. feld von Controlling und Steuern, 2014, Vol. 1207.
316 beck.digitax 5/2020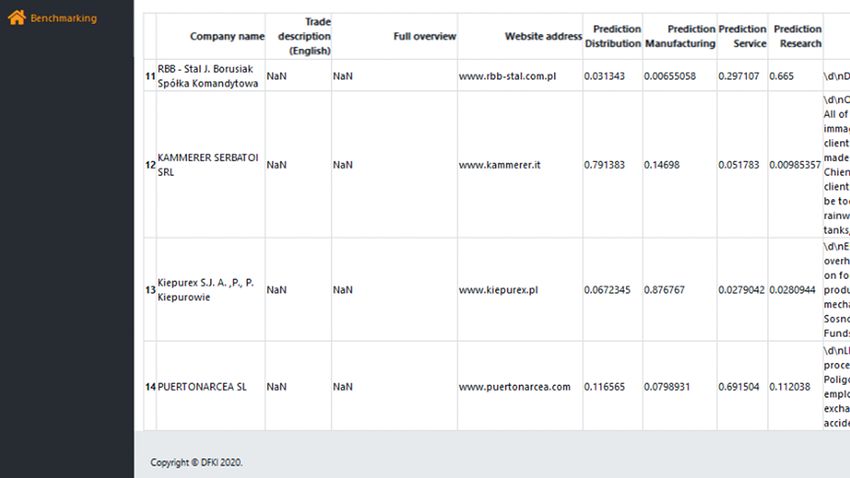
Effizienzgewinne durch KI bei Benchmarkstudien im Transfer Pricing BETRIEBSWIRTSCHAFT
Abb. 1: Überblick global verwendeter Datenbanken
Dieser von DFKI und WTS Service Line Transfer Pricing beteiligt sind. Allerdings umfassen die damit zusammen-
entwickelte Prototyp soll die Benchmarking-Experten hängenden Aufgaben, das sog. Verrechnungspreis-Ma-
der WTS bei der Selektion von vergleichbaren Unterneh- nagement, weitaus mehr als die Festlegung der Methodik
men aus Transfer Pricing-Datenbanken unterstützen, in- oder die Erstellung der Dokumentation. Dies bedeutet,
dem der manuelle Schritt der Bestimmung der Unterneh- dass bei der Digitalisierung der Verrechnungspreise eine
mensfunktion durch eine automatische Textanalyse er- Fülle von Aufgaben und Daten zu berücksichtigen ist.
gänzt wird. Dadurch wird eine Steigerung der Geschwin-
digkeit sowie eine Reduktion von manuellem Aufwand Besonders Verrechnungspreise unterliegen höchsten An-
und damit einhergehend eine Kostenreduktion bei der forderungen an die Steuer-Compliance, da diese Preise
Erstellung von Benchmarkstudien erwartet. von mehreren Parteien, den zwei Ländern, die von der
Transaktion betroffen sind, akzeptiert werden müssen.
Im folgenden Beitrag wird das Vorhaben zuerst in einen Zusätzliche Auflagen durch das BEPS-Projekt, das
größeren wissenschaftlichen Kontext eingeordnet und Country-by-Country-Reporting und ein zunehmender
die Problemstellung beschrieben, anschließend wird ein Fokus auf Vergleichbarkeit bedeuten, dass Steuerzahler
konkreter Anwendungsfall dargestellt, bevor der tech- sicherstellen müssen, dass die internationalen Trans-
nische Prototyp im Allgemeinen und die Technik dahin- aktionen verteidigt werden können. Ansonsten drohen
ter vorgestellt wird. Der Vorstellung schließt sich eine Doppelbesteuerung, Strafzuschläge oder gar strafrecht-
Einordnung des Umgangs in einem Praxisbeispiel sowie liche Verfahren.7 Gleichzeitig existieren aber ein größer
die Evaluation der Methodik an. Anschließend werden werdender Kostendruck und die Erwartung von mehr
besondere neue Nutzungsmöglichkeiten und Herausfor- Leistungen der Steuerfunktion sowie eine zunehmende
derungen dargestellt sowie diskutiert. Deregulierung des Marktes.8
2. Herausforderungen und Problemstellung Eine Möglichkeit zum Nachweis und zur Dokumentati-
Verrechnungspreise sind in steuerlicher Hinsicht „Preise on der Angemessenheit konzerninterner Verrechnungs-
und Konditionen für grenzüberschreitende Geschäfts- preise sind Benchmarkstudien. Die Prüfung und Doku-
beziehungen zwischen verbundenen Unternehmen sowie mentation der Angemessenheit erfolgt dabei ua anhand
zwischen Stammhaus und Betriebsstätte“6; es geht also von GuV-Daten öffentlicher Jahresabschlüsse einer Peer-
speziell um die wertschöpfungsadäquate Allokation des group, denn als Maßstab für den Fremdvergleich (arm’s
Steuersubstrats auf die Staaten, die an einer Transaktion
7 Kleinhietpaß/Hanken (Fn. 5).
8 Fettke, Künstliche Intelligenz für die Digitalisierung der Steuerfunktion,
6 Kleinhietpaß/Hanken (Fn. 5). REthinking: Tax 01/2019, 12–22.
beck.digitax 5/2020 317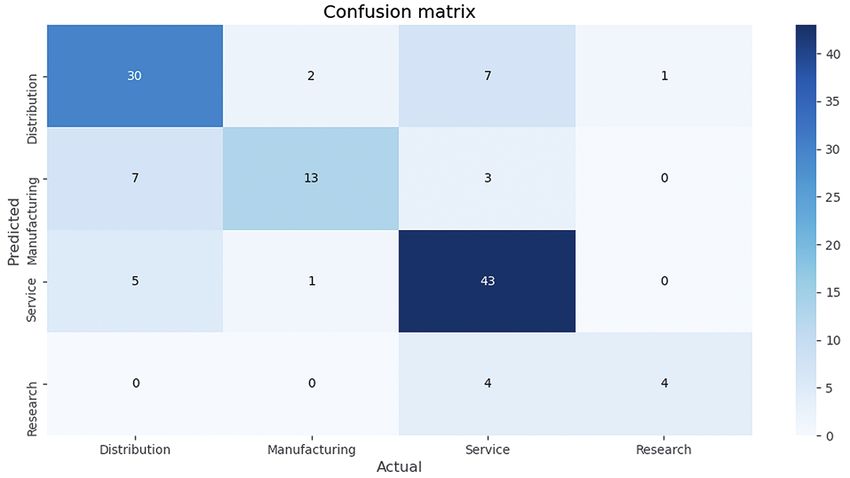
BETRIEBSWIRTSCHAFT Effizienzgewinne durch KI bei Benchmarkstudien im Transfer Pricing
length principle) dienen Finanzkennzahlen vergleich- te Vorlagen verwendet, so dass der Report automatisch
barer Unternehmen. Für die Zugehörigkeit zu einer Peer- generiert werden kann.
group ist eine Vergleichbarkeit in Bezug auf die ausgeüb-
ten Funktionen und Risiken, aber zB auch der angebote- 4. Prototyp – Technische Unterstützung des
nen Produkte und Dienstleistungen erforderlich. Diese Anwendungsfalls
Daten finden sich in Verrechnungspreisdatenbanken,
wie AMADEUS und Royalty Range, müssen aber zu-
sätzlich geprüft werden, da die entsprechenden Einträge
(„Handelsbeschreibung“, „Überblick“) oft unpräzise,
veraltet oder schlicht nicht vorhanden sind. Deshalb
müssen diese Informationen durch eine aufwendige Ana-
lyse externer Quellen beschafft und ausgewertet werden.
Insbesondere, wenn so mehrere hundert Unternehmen
geprüft werden müssen, um einige wenige vergleichbare
Unternehmen zu finden, ergibt sich ein hoher manueller
Aufwand mit entsprechenden Kosten.
3. Ein Anwendungsfall
Der Prozess zur Erstellung von Benchmarkstudien be-
steht aus drei Schritten: Dem quantitativen Screening,
dem qualitativen Screening und der Anfertigung eines
Abb. 2: Konsolidierung zum Fremdvergleich
Reports. Beim quantitativen Screening werden Datensät-
ze aus externen Datenbanken (zB TP Catalyst von Bu-
reau van Dijk) extrahiert. Gefiltert werden diese Daten- Um den Aufwand bei der Erstellung von Benchmark-
sätze nach individualisierten Suchparametern, die an das studien zu reduzieren, liegt es nahe, den manuellen
zu untersuchende Unternehmen des Auftraggebers ange- Screening-Prozess vom Umfang der zu testenden Einhei-
passt werden. Die Datensätze enthalten neben Finanz- ten aus der Datenbanksuche her möglichst klein zu hal-
kennzahlen ua auch Unabhängigkeitskriterien und Un- ten. Dazu muss die Anzahl der zu prüfenden Unterneh-
ternehmensbeschreibungen. Alleinstehend sind diese Da- men weiter reduziert werden. Konkret soll hier eine Vor-
tensätze noch nicht aussagekräftig für eine Benchmark- auswahl getroffen werden, welche Unternehmen eine
studie. Die Vergleichbarkeitsanalyse muss erst noch von der Suche abweichende Unternehmensfunktion be-
durchgeführt werden, und dafür ist ein weiterer Schritt sitzen und diese ausgeschlossen werden. Dadurch
erforderlich. schrumpft die Anzahl möglicher Kandidaten, die manu-
ell geprüft werden müssen, und damit die Arbeitslast der
Im zweiten Schritt erfolgt ein manuelles Screening der
Experten.
gefilterten Datensätze. Der Schwerpunkt liegt dabei auf
der Untersuchung der Webseiten der potentiellen Ver- Diese Reduzierung der möglichen Kandidaten erfolgt
gleichsunternehmen. Das Ziel ist es, Unternehmen zu durch einen Zwischenschritt zwischen Datenbanksuche
finden, deren Spektrum ausgeübter Funktionen und Tä- und manuellem Screening. Dabei werden die gefundenen
tigkeitsschwerpunkte mit der zu testenden Einheit der Kandidaten hinsichtlich ihrer Unternehmensfunktion
Unternehmensgruppe (möglichst weit) übereinstimmen. klassifiziert. Dies erfolgt analog zur manuellen Bearbei-
Diese manuelle Suche nach einer passenden Peergroup tung, die das Aufrufen der Unternehmenswebseite, das
ist derzeit mit einem hohen personellen Aufwand ver- Übersetzen der Inhalte und das Lesen und Verstehen der
bunden. Sowohl das manuelle Aufrufen der Webseiten Webseitentexte, inkl. der Bewertung umfasst. Dazu wird
als auch die Klassifizierung der Unter-
nehmen ist enorm zeitintensiv. Darüber
hinaus muss der gesamte Prozess prü-
fungssicher (zB über das Anfertigen von
Screenshots) dokumentiert werden.
Der dritte Schritt besteht aus der Doku-
mentation des Prozessablaufs und der
gewonnenen Ergebnisse. Für die Erstel-
lung des Reports werden standardisier- Abb. 3: Upload der Input-Daten in den Demonstrator
318 beck.digitax 5/2020
Effizienzgewinne durch KI bei Benchmarkstudien im Transfer Pricing BETRIEBSWIRTSCHAFT
Abb. 4: Tabelle mit beispielhaften Ergebnissen
erst der Datenbankauszug als Excel-Datei in den Pro- den, die bestehende Texte inklusive einer Annotation der
totypen geladen (s. Abb. 3 auf S. 318). Anschließend Unternehmensfunktion enthalten. Dieser Textkorpus
werden die drei Module für jeden Eintrag in der Excel- dient dann als Referenz für eine Unternehmensfunktion.
Datei durchlaufen. Neue, unbekannte Texte können dann anhand ihrer
Ähnlichkeit zu den Texten einer Unternehmensfunktion
Das Modul „Webseiten Aufrufen“ oder auch „Web ebendieser zugeordnet werden.
Crawling“ steuert automatisiert eine Instanz eines de-
Dazu wurden in früheren Benchmarkstudien akzeptierte
finierbaren Browsers, wie Google Chrome, Microsoft
Unternehmen als Referenz für die Unternehmen einer
Edge oder Mozilla Firefox, und imitiert das menschliche
Geschäftsfunktion herangezogen. Die Texte wurden aus
Verhalten, indem die URL aus dem Datenbankauszug
den zugehörigen Webseiten kopiert und dem jeweiligen
kopiert und aufgerufen wird sowie der angezeigte Text
Cluster hinzugefügt. Damit wurde ein Wort-Vektor-Mo-
in den Prototypen kopiert wird. Links zu Unterseiten
dell erstellt, das Merkmale der eingegebenen Texte einer
werden identifiziert, aufgerufen und ebenfalls kopiert.9
Kategorie enthält und mit dessen Hilfe Unternehmen
Das zweite Modul übersetzt maschinell Texte10 und ent-
gleicher Funktion klassifiziert werden können. Grund-
fernt irrelevante Passagen, die zuvor definierte Schlag-
lage dazu sind die Häufigkeiten von Wörtern und das
worte enthalten oder weiteren Selektionskriterien (Zei-
inverse der Dokumentenhäufigkeit.12 Mit diesem Maß
chen- und Wortanzahl, Vorkommen von Zahlen, Son-
von Häufigkeiten von Wörtern und Dokumenten lässt
derzeichen etc) entsprechen.11 Das dritte Modul, das
sich der Abstand von Dokumenten messbar machen.
Lesen und Verstehen der Webseitentexte, ist technolo-
Das nutzen die Modelle, um neue, bisher nicht gesehene
gisch nicht mit dem menschlichen Verstehen von Texten
Texte analysieren und Texte zu der am besten passenden
gleichzusetzen. Es können jedoch Modelle trainiert wer-
Kategorie zuordnen zu können.
9 Vgl. Liu, Web Data Mining: Exploring Hyperlinks, Contents, and Usage
Diese Einschätzung der Unternehmensfunktion soll den
Data, 2007. TP-Spezialisten bei der Selektion von passenden Unter-
10 Hierfür können sowohl kommerziell vorhandene Dienste wie DeepL
oder Google Translate als auch speziell für den Steuerbereich von der
nehmen unterstützen. Dies geschieht mit dem Ergebnis
WTS und dem DFKI entwickelte maschinelle Übersetzer zum Einsatz
kommen.
11 Vgl. Vijayarani/Ilamathi/Nithya, Preprocessing Techniques for Text 12 Vgl. Qaiser/Ali, Text mining: Use of TF-IDF to Examine the Relevance
Mining – an Overview, International Journal of Computer Science & of Words to Documents, International Journal of Computer Applica-
Communication Networks 2015, 5(1), 7–16. tions 2018, 181(1), 25–29.
beck.digitax 5/2020 319BETRIEBSWIRTSCHAFT Effizienzgewinne durch KI bei Benchmarkstudien im Transfer Pricing
der Prototypen in Form einer tabellarischen Auflistung, dungsfall verändert sich, aber die Zahl der zu testen-
die die Datenbankeinträge Unternehmensname, Han- den Unternehmen bleibt gleich.
delsbeschreibung und Überblick sowie die vorhergesag- 3. Der Prototyp schließt selbständig Unternehmen mit
ten prozentualen Werte für die jeweilige Unternehmens- eindeutig nicht passender Unternehmensfunktion aus.
funktion und den aus dem Internet kopierten Text aus- Der Anwendungsfall ändert sich, indem ein Teil des
gibt. manuellen Screenings ersetzt wird. Die Zahl der ma-
nuell zu testenden Unternehmen verringert sich.
Dieser Prototyp soll zwei grundlegende Charakteristika Dadurch wird der außerordentlich zeitintensive manuel-
abdecken: Erstens hat er einen explorativen Charakter le Screening-Prozess zur Auswahl der geeigneten Ver-
und soll dazu dienen, nachzuweisen, dass die verwende- gleichsunternehmen zu einem Großteil durch KI ersetzt.
ten Techniken und zugrunde liegenden Ideen zur Lösung Nach Schätzungen der Mitarbeiter der Service Line wird
des (Teil-)Problems tauglich sind. Zweitens sollen auch eine Zeitersparnis von bis zu 80 % erwartet, denn der
erste praktische Erfahrungen mit dem Prototyp gesam- Spezialist für Transferpricing hat am Ende lediglich die
melt werden, welche dann in umfangreiche Problemana- Aufgabe, das manuelle Screening von ca. 30 Unterneh-
lysen und Systemspezifikationen für die Weiterentwick- men zu verproben, anstatt mehrere hundert Unterneh-
lung eingehen.13 men selbst zu screenen.
5. Praxisbeispiel 6. Evaluation
Im Einsatz des Prototyps in der Praxis wurden eine ak- Die verwendeten Textklassifikationsmodelle nutzen
tuelle Benchmarkstudie auf dem Bereich „Management verschiedene Maße zur Beurteilung der Relevanz von
Services“ herangezogen und die Ergebnisse der manuel- Termen in Dokumenten einer Dokumentensammlung.
len Suche mit den Ergebnissen des Prototyps verglichen. Nach einem Vergleich der Methoden TF, TF-IDF und
Dazu wurde die Benchmarkstudie um eine erste Auswer- Word2Vec erweist sich hier die TF-IDF-Methode am
tung der Ergebnisse erweitert, da in der klassischen Ana- effektivsten. TF steht hierbei für die Term Frequency,
lyse nur das Ergebnis Unternehmensfunktion „stimmt also die (relative) Häufigkeit von Wörtern in einem
überein“ oder „weicht ab“ eingetragen wird. Dazu wur- Text, welche durch Berücksichtigung der inversen Do-
de die gefundene Unternehmensfunktion für jedes zu kumentenhäufigkeit (IDF – Inverse Document Frequen-
testende Unternehmen in das Kommentarfeld eingetra- cy), also der Spezifität eines Terms für die Gesamtmen-
gen. Führen Unternehmen mehrere Unternehmensfunk- ge der betrachteten Dokumente multipliziert wird.
tionen aus, wurden sie im manuellen Screening der Durch diese Verrechnung wird verhindert, dass ein viel-
vermeintlich am stärksten ausgeprägten Funktion zu- fach vorkommender, aber irrelevanter Term nicht auch
geordnet. Als Vergleichswert wurde die von der Text- in gleichem Maße zur Relevanz der Klassifikation bei-
klassifikation am wahrscheinlichsten angesehene Unter- trägt.14
nehmensfunktion verwendet. Die Ergebnisse dieses ers-
ten Tests wurden zur Validierung des Prototyps verwen- Für das Clustern selbst, also die Gruppierung von Tex-
det (siehe Evaluation). ten zu einer Kategorie und auch die gezielte Abgrenzung
zu einer anderen Kategorie, stellten sich nach einem Ver-
Mit dem ersten Einsatz des Prototyps konnten die Fach- gleich der Methoden SVM, KNN, MNB und labled-
experten der WTS-Service Line Transfer Pricing folgen- LDA die „support vector machines“ als besonders geeig-
de drei Möglichkeiten zum Einsatz im Anwendungsfall net heraus. Zur Evaluation wurde der og Trainings-
identifizieren: datensatz in 85 % Trainingsdaten und 15 % Testdaten
1. Die Klassifizierungsergebnisse werden in einer Art aufgeteilt. Damit wurde auf den Trainingsdaten eine
Cockpit angezeigt und bieten einen weiteren Indikator Treffergenauigkeit („accuracy“) von 97 % und eine
zur Bewertung des Sachverhalts. Der Economist der Trefferquote („recall“) von 95 % erreicht. Auf den Test-
Service Line führt weiterhin die manuellen Analysen daten wurde eine Treffergenauigkeit von 80 % und eine
durch. Der Anwendungsfall ändert sich in diesem Fall Trefferquote von 77 % erreicht. Die Analyse der Ergeb-
nicht. nisse ist in der Wahrheitsmatrix (Konfusionsmatrix,
2. Die Klassifizierungsergebnisse werden durch einen „confusion matrix“) in Abb. 5 (S. 321) zu sehen, in der
Fachexperten final genehmigt bzw. eingegrenzt. Hier die Anzahl richtig und falsch klassifizierter Dokumente
führt der Prototyp die Bewertung und ein Fachexperte erkennbar ist. Das zuvor beschriebene Praxisbeispiel
einen Review der Klassifikation durch. Der Anwen-
14 Vgl. Felden/Bock/Gräning/Molotowa/Saat, Evaluation von Algorithmen
13 Vgl. Warfel, Prototyping: A Practitioner’s Guide, 2009. zur Textklassifikation, No. 10/2006, Freiberger Arbeitspapiere.
320 beck.digitax 5/2020Effizienzgewinne durch KI bei Benchmarkstudien im Transfer Pricing BETRIEBSWIRTSCHAFT
Klassifikation zu berechnen. Wei-
ter müssen hier die Umfänge der
einzelnen Kategorien gleich häu-
fig sein, um eine Über- bzw. Un-
terrepräsentation zu vermeiden.
Ebenfalls müssen neue Daten zur
Klassifikation diesen Ansprüchen
in ähnlicher Weise gerecht wer-
den.
H3–H5 betreffen die Extraktion
von Webseiteninhalten von realen
Unternehmenswebseiten. Dabei
sind vor allem sog. „Spider
Traps“ zu beachten, die diesen
Vorgang bewusst verhindern sol-
Abb. 5: Die Wahrheitsmatrix zeigt die richtig und falsch klassifizierten Texte.15
len. Dabei werden beispielsweise
versteckte Texte in den Webcraw-
diente als eine Validierung, und es wurde eine Treffer- ler eingeführt, die irreführende Informationen enthalten
quote von 72 % erreicht. oder falsche Links ausgeben.17 Ein solider Webcrawler
muss diese Manipulationen erkennen und umgehen oder
7. Herausforderungen blockieren können. Zudem ist ein dynamischer Websei-
Der Prototyp hat einen explorativen und experimentel- teninhalt problematisch. Hier wird Inhalt kontextabhän-
len Anspruch, woraus sich Herausforderungen an ver- gig erzeugt und weist mit jedem Aufrufen der Webseite
schiedene Module ergeben. Für eine bessere Übersicht Unterschiede auf. Ein Beispiel sind Online-Shops, die
zeigt Abb. 6 die einzelnen Schritte des Prototyps mit den jedem Kunden andere Produkte auf der Startseite prä-
zugehörigen Herausforderungen in der Praxis an. sentieren. Des Weiteren gibt es Unterschiede in der Qua-
lität und Relevanz von Textpassa-
gen und Unterwebseiten. Hier
muss ein Verfahren irrelevante
und qualitativ weniger gute Pas-
sagen erkennen und ausschließen
(zB AGBs).18
Die Herausforderungen H6–H8
betreffen die Verarbeitung des
Textes in ein einheitliches, ma-
schinell verwertbares Format.
Herausfordernd ist hier eine so-
Abb. 6: Übersicht über aktuelle Herausforderungen lide Übersetzung der Texte in
eine einheitliche Sprache, selbst
Die Herausforderungen H1 und H2 betreffen die Daten, wenn der gesamte Text zwischen unterschiedlichen
die in das System eingegeben werden. Das sind zum Passagen in der Sprache wechselt. In der anschließen-
einen die annotierten Daten zum Training der Modelle, den Vorverarbeitung werden definierte Stoppwörter
zum anderen Daten, die einer Kategorie zugeordnet wer- und Muster ausgeschlossen. Die Wahl der Worte und
den sollen. Es wurde ersichtlich, dass die Daten zum Muster ist hier von entscheidendem Interesse, um irre-
Training hohe Qualitätsanforderungen erfüllen müs- levante Passagen auf sehr feingranularer Ebene aus-
sen16, ua Verfügbarkeit, Umfang und maschinelle Aus- schließen zu können. Zudem müssen die Texte in ein
wertbarkeit, um später für neue Daten eine zuverlässige maschinell verwertbares Format gebracht werden.
15 X-Achse = die tatsächlichen Kategorien; y-Achse = die vorhergesagten 17 Vgl. Pant/Srinivasan/Menczer, Crawling the Web, Web dynamics 2004,
Kategorien. 153–177.
16 Vgl. Knight/Burn, Developing a Framework for Assessing Information 18 Vgl. Hernández/Rivero/Ruiz, Deep Web Crawling: A Survey, World
Quality on the World Wide Web, Informing Science 2005, Vol. 8. Wide Web 2019, 22(4), 1577–1610.
beck.digitax 5/2020 321BETRIEBSWIRTSCHAFT Effizienzgewinne durch KI bei Benchmarkstudien im Transfer Pricing
Hier ist zwischen verschiedenen Repräsentationen zu 3. Die hier vorgeschlagenen Vektor-Modelle zur Text-
wählen.19 verarbeitung betten sich derzeit in die bestehenden
Prozesse ein. Jedoch liegt hier auch das Potential, um
H9–H11 sind Herausforderungen bei der Modellerstel- diese völlig unabhängig von der Unternehmensfunk-
lung. Dafür müssen relevante Qualitäts-Metriken fest- tion anzuwenden. Beispielsweise könnten diese Mo-
gelegt werden20 und verschiedene Klassifizierungsstrate- delle generell zu der zu testenden Entität möglichst
gien und -modelle21 optimiert und verglichen werden, so ähnliche Unternehmen finden. Damit würde die Ähn-
dass die Qualitäts-Metriken bestmögliche Werte messen. lichkeit zwischen zwei Unternehmen für den Fremd-
Die Herausforderung besteht dabei in der geschickten vergleich nicht mehr auf Basis der Datenbanksuche
Parameteroptimierung, um die Verfahren bestmögliche und damit der Branchencodes, sondern auf Basis des
Ergebnisse erzeugen zu lassen. Ebenfalls von hohem In- Wort-Vektors bestimmt werden. Das ist eine radikal
teresse sind hier die Identifikation und Analyse von Do- neue Herangehensweise bei der Suche nach vergleich-
kumenten, die zu einer Kategorie gehören, aber missver- baren Unternehmen.
ständliche Werte liefern, beispielsweise durch eine große 4. Der erzeugte Datensatz ist derzeit stark unterschied-
Distanz zum Cluster. lich verteilt; die Kategorie „Dienstleistungen“ enthält
322 Texte, während die Kategorie „Forschung“ nur
H12–H14 betreffen die Klassifikation von neuen, unbe-
56 Texte umfasst. Das hat zur Folge, dass es zur Über-
kannten Texten. Hier muss die Klassifikation mittels der
bzw. Unterrepräsentation von Kategorien kommt.
vorher definierten Qualitäts-Metriken bestimmt und
evaluiert werden. Ein Feedback bzw. eine Interpretation
über die Ergebnisse vom Anwender (H15) bzgl. der Klas- 9. Resümee
sifikation kann zusätzlich zum Verbessern des Modells Um sich der Herausforderung der Verbesserung des ma-
einfließen (sog. „Reinforcement Learning“). Hier müs- nuellen Screenings bei der Erstellung von Benchmark-
sen auch Erfahrungen darüber gewonnen werden, unter studien via KI zu stellen, wurde ein Webcrawler ent-
welchen Bedingungen gute Ergebnisse erzielt werden wickelt, der die Webseiten der zu untersuchenden Unter-
und wo genau Verbesserungsbedarf besteht. Auch die nehmen eigenständig aufruft und aus dem Text relevante
Ergebnisse, die üblicherweise aus Wahrscheinlichkeiten Inhalte extrahiert. Zusätzlich wurden verschiedene Text-
bestehen, müssen in geeigneter Weise interpretiert wer- klassifikationsverfahren erprobt, die bisher unbekannte
den. Texte automatisiert einer Unternehmensfunktion zuord-
nen sowie deren Klassifikationsleistung miteinander ver-
gleichen. Grundlage waren die Ergebnisse von bereits
8. Diskussion
abgeschlossenen Benchmarkstudien, die jeweils nur Un-
Die vorgestellten Arbeiten sind technisch innovativ und
ternehmen einer bestimmten Unternehmensfunktion ent-
haben einen prototypischen Charakter. Erste Ergebnisse
halten.
sind vielversprechend, und es wird weiter an Verbes-
serungen gearbeitet. Dabei zeigen sich folgende Ergeb- Mit dieser Einschätzung der Unternehmensfunktion und
nisse: einem Webcrawler ist eine erste Einschätzung zur Bewer-
1. Die Unternehmensfunktionen sind nicht einheitlich tung des Sachverhalts möglich und kann direkt durch
definiert. Die hier verwendete Definition entstammt den Webseitentext bestätigt oder im Falle einer Falsch-
der Benchmarking-Praxis und soll hauptsächlich zwi- klassifikation widerlegt werden. Aufgrund dessen wird
schen groben Unternehmensfunktionen unterschei- eine wesentliche Reduktion des Zeitaufwands für die
den. Daneben existieren viele weitere Definitionen, Erstellung von Benchmarkstudien erwartet.
beispielsweise die des Statistischen Bundesamtes. In-
wieweit eine feingranulare Unterteilung weitere Vor- Die durch den KI-Einsatz realisierten Effizienzgewinne
teile bringen könnte, ist zukünftige Forschungsarbeit. im Rahmen der Erstellung von Benchmarkstudien mit-
2. Es ist derzeit noch unklar, ob und wie der maschinelle tels Webcrawler und maschinellem Natural Language
Arbeitsschritt von den Steuerbehörden akzeptiert Understanding im Bereich Transfer Pricing gründen sich
wird. dabei maßgeblich auf die folgenden drei Punkte:
1. erhebliche Zeit- und Kostenersparnis auf Seiten der
19 Siehe Uysal/Gunal, The impact of Preprocessing on Text Classification, steuerlichen Fachkollegen;
Information Processing & Management 2014, 50(1), 104–112.
20 Vgl. Forman, An Extensive Empirical Study of Feature Selection Metrics
2. einheitliche, standardisierte und technologiegestützte
for Text Classification, Journal of Machine Learning Research 2003, 3 Herangehensweise;
(Mar), 1289–1305.
21 Vgl. Aggarwal/Zhai, A Survey of Text Classification Algorithms, Mining 3. Compliance-Anforderungen bleiben gewahrt durch
text data 2012, 163–222. 4-Augen-Prinzip (Maschine-Mensch).
322 beck.digitax 5/2020Effizienzgewinne durch KI bei Benchmarkstudien im Transfer Pricing BETRIEBSWIRTSCHAFT
Derzeit wird eine gute Gesamtgenauigkeit bei der ma- überwindliche „Compliance-Berg“ bezwingbar werden
schinellen Klassifikation erreicht, wobei es sich hierbei könnte – „Step ahead in tax and finance“.
erst um einen aktuellen Arbeitsstand handelt. In der Ent-
wicklung sind zudem noch weitere Ansätze für State-of-
the-Art-Klassifikationsverfahren, die unter Einbeziehung ALEXANDER BEUTHER
externer Daten eine noch höhere Gesamtgenauigkeit er-
warten lassen. Da es sich hierbei um eine kontinuierliche
Weiterentwicklung handelt, werden des Weiteren die
gefundenen Potentiale und Herausforderungen der ein-
Wissenschaftler am Deutschen Forschungs-
zelnen Komponenten weiter ausgenutzt und optimiert.
zentrum für Künstliche Intelligenz (DFKI),
Neben der reinen Zeit- und Kostenersparnis ist somit Saarbrücken.
damit zu rechnen, dass im Bereich der Erstellung von
Benchmarkstudien die Qualität der Ergebnisse erhöht PROF. DR. PETER FETTKE
werden kann. Dadurch, dass durch den KI-gestützten
Screeningprozess deutlich mehr Daten untersucht wer-
den können, steigt auch die Chance auf eine bessere Ver- Professor an der Universität des Saarlandes
gleichbarkeit der finalen Ergebnisse. Langfristig sollte und Leiter des Competence Centers Tax
somit das Risiko steuerlicher Anpassungen im Rahmen Technology am Deutschen Forschungszen-
trum für Künstliche Intelligenz (DFKI), Saar-
von Verrechnungspreisprüfungen gesenkt werden kön-
brücken.
nen. Dies könnte auch den Umgang mit Interquartils-
bandbreiten in der Zukunft verändern.22 Wie allerdings DR. VANESSA JUST
Betriebsprüfer mit KI-gestützten Benchmarkergebnissen
umgehen werden, bleibt in diesem Zusammenhang ab-
zuwarten.
Die Reise ist noch lange nicht zu Ende. Wir werden
weiter mittels der Erforschung innovativer Anwendun-
gen der KI und der Begleitung des Innovationstransfers Geschäftsführerin wtsAI, Hamburg.
zur Gestaltung des Steuerarbeitsplatzes der Zukunft bei-
ANDREAS RIEDL
tragen. Dabei sehen wir in der Zukunft das Potential,
dass wir über hochwertige Massendaten verfügen, um so
die Treffergenauigkeit der eingesetzten Tools weiter zu
erhöhen. Auch der Austausch der interdisziplinären
Fachteams wird eine zusätzliche Bereicherung darstellen.
Gerade in Zeiten von weiteren regulatorischen Verschär- Partner Transfer Pricing und Head of TP
fungen im Bereich der Verrechnungspreise sollten die Technology WTS GmbH, Frankfurt a. M..
vorgestellten Ansätze die Hoffnung vermitteln, dass
Die Autoren danken den Kolleginnen Dr. Birgit Friederike Makowsky
durch zukünftige technische Lösungen der schier un- (Director WTS GmbH), Andrea Groiß (Senior Manager WTS GmbH),
Christina Derer (Manager WTS GmbH) und Lisa Ziegler (Professional
22
WTS GmbH) für ihre wertvollen Beiträge.
Zur Diskussion von Interquartilsbandbreiten ua OECD Guidelines, July
2017, Chapter III, Paragraph 3.57; Heidecke/Sachs IWB 2019, 716; Feedback bitte an digitax@beck.de.
Schwarz/Stein/Flanderova/Hoffmann Ubg 2017, 638.
beck.digitax 5/2020 323Sie können auch lesen

















































