Standard-Setting Mathematik 8. Schulstufe - Technischer Bericht
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Standard-Setting Mathematik
8. Schulstufe
Technischer Bericht
(Autor: Roman Freunberger)
BIFIE Salzburg
Zentrum für Bildungsmonitoring & Bildungsstandards
Alpenstraße 121 / 5020 Salzburg
Telefon +43-662-620088-3000 / Fax DW-3900
office.salzburg@bifie.at / www.bifie.at
Jänner 2013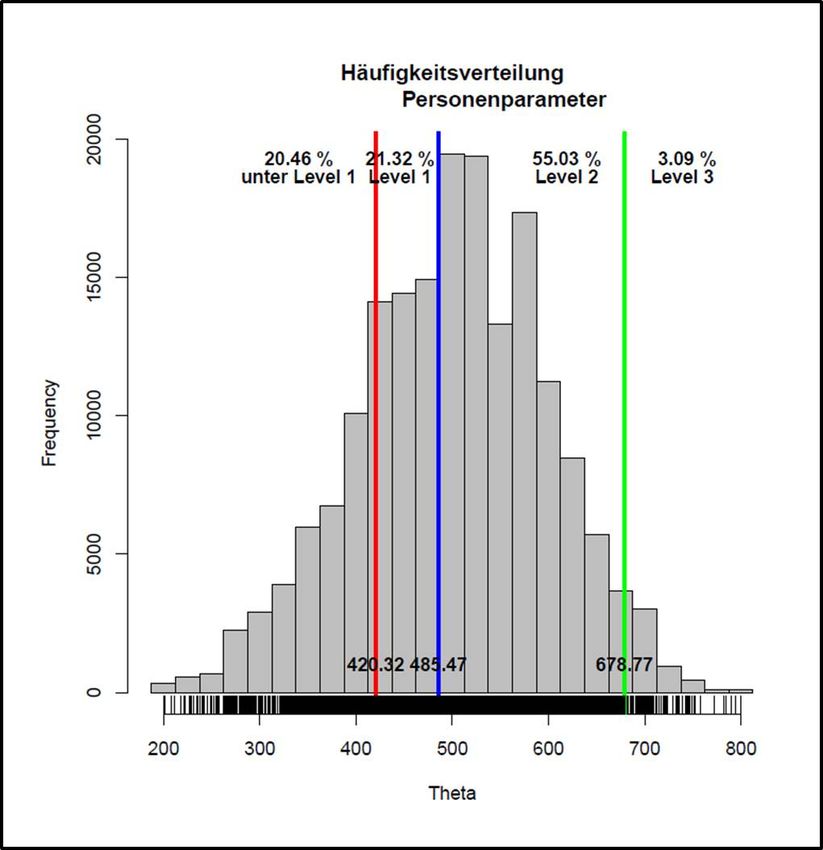
Inhaltsverzeichnis
1 Das Kompetenzstufenmodell 2
2 Phase III: Das Standard-Setting für Mathematik auf der 8. Schulstufe 2
2.1 Die Expertengruppe . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.2 Das Ordered-Item-Booklet . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2.3 Item-Descriptor-Matching-Methode (IDM) . . . . . . . . . . . . . . . . . . . . . . . 5
2.4 Training und Vorbereitung auf den Beurteilungsprozess . . . . . . . . . . . . . . . . 6
2.5 Runde 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.5.1 Aufgabe und Instruktion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.5.2 Auswertung der Ratingdaten . . . . . . . . . . . . . . . . . . . . . . . . . . 6
2.6 Runde 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.6.1 Aufgabe und Instruktion . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.6.2 Bestimmung der Cut-Scores . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.7 Präsentieren der Konsequenzen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.8 Runde 3 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.9 Setzung der Schwelle zu Unter Level 1 . . . . . . . . . . . . . . . . . . . . . . . . . 10
3 Validität und Post-Standard-Setting 11
3.1 Prozessevaluation und Evaluation der Cut-Score-Urteile . . . . . . . . . . . . . . . . 11
3.2 Endgültige M8-Cut-Score-Werte und Standardfehler . . . . . . . . . . . . . . . . . . 12
3.3 Rating-Verhalten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.4 Interrater-Reliabilität . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
4 Phase IIb und Phase IIIb 15
Literatur 16
5 Appendix 18
Standard-Setting Mathematik 8 1
petenzstufen beschrieben, deren inhaltliche und methodische Festlegung durch ein Expertengremium
aus Fachdidaktik und Methodik erfolgte.4 In Abbildung 4 sind die Bezeichnungen, inhaltlichen Be-
schreibungen und Punktbereiche der einzelnen Kompetenzstufen nachzulesen. Die Rückmeldung an-
hand der vorher definierten Kompetenzstufen wird auch als „kriteriale Rückmeldung“ bezeichnet und
ergänzt die Rückmeldung nach erzielten Testpunkten.
Mathematik 8. Schulstufe
BIST-Ü M8 (2012) Beschreibung der Kompetenzstufen
Kompetenzstufen in der kriterialen Rückmeldung
Kompetenzstufen Mathematik Punktskala
Bildungsstandards übertroffen Punktbereich: ab 691 800
höher
Die Schüler/innen verfügen über grundlegende Kenntnisse und Fertigkeiten in allen Teilbereichen des Lehrplans
3 Mathematik und über erweiterte Wissensstrukturen, welche über die Anforderungen der Stufe 2 hinausgehen, 750
insbesondere über stärker ausgeprägtes Abstraktionsvermögen und höhere Kombinationsfähigkeit. Sie können
diese eigenständig in neuartigen Situationen flexibel einsetzen.
700
Bildungsstandards erreicht Punktbereich: 518 bis 690
Die Schüler/innen verfügen über grundlegende Kenntnisse und Fertigkeiten in allen Teilbereichen des Lehrplans
650
Mathematik und können diese flexibel nutzen. Sie können geeignete Lösungsstrategien finden und umsetzen,
2 gewählte Lösungswege beschreiben und begründen. Sie können mit verbalen, grafischen und formalen
Darstellungen mathematischer Sachverhalte flexibel umgehen und diese angemessen verwenden. Sie können
600
relevante Informationen aus unterschiedlich dargestellten Sachverhalten (z. B. Texte, Datenmaterial, grafische
Darstellungen) entnehmen und sie im jeweiligen Kontext deuten. Sie können ihre mathematischen Kenntnisse
Kompetenzen
550
miteinander in Verbindung setzen sowie mathematische Aussagen kritisch prüfen, bewerten und/oder begründen.
Bildungsstandards teilweise erreicht Punktbereich: 440 bis 517 500
1 Die Schüler/innen verfügen über grundlegende Kenntnisse und Fertigkeiten in allen Teilbereichen des Lehrplans
Mathematik und können damit reproduktive Anforderungen bewältigen und Routineverfahren durchführen.
450
400
350
unter 1 Bildungsstandards nicht erreicht Punktbereich: bis 439
300
niedriger
250
200
Abbildung
Abbildung 4: Kompetenzstufen in Mathematik auf
1: Kompetenzstufenmodell der 8. Schulstufe
Mathematik 8.
1 Das Kompetenzstufenmodell
Im Rahmen der Bildungsstandardüberprüfung, beginnend mit 2012 in Österreich, wurde für Mathe-
matik 8. Schulstufe ein Standard-Setting durchgeführt, das insgesamt 3 Phasen umfasst hat. Phase
III beschreibt das eigentliche Standard-Setting und wird im Weiteren näher erläutert. In Phase I und
Phase II wurde durch Fachexperten ein Kompetenzstufenmodell entwickelt das 4 Stufen umfasst und
4
in Abbildung 1 dargestellt ist.
Das Gremium bestand aus Expertinnen und Experten aus Schulpraxis, Fachdidaktik, Pädagogik und Psychologie sowie den Interessenvertretungen
(Eltern, Wirtschafts- und Arbeiterkammer), Abnehmerinstitutionen und dem BMUKK.
2 Phase III: Das Standard-Setting für Mathematik auf der 8. Schul-
stufe
Ziel der Phase III war es Schwellenwerte auf der kontinuierlichen Kompetenzskala zu definieren, welche
es erlauben, die Schüler und Schülerinnen den einzelnen Stufen zuzuordnen. Hierzu wurde die Metho-
dik des Standard-Settings verwendet, was im weiteren Sinne einen komplexen Entscheidungsprozess
beschreibt der möglichst standardisiert durchgeführt werden sollte, um valide Schwellenwertsetzun-
gen zu ermöglichen.
Der eigentliche Standard-Setting-Prozess mit einer Expert/innen-Gruppe soll in der Domäne Mathe-
matik 8. Schulstufe drei Schwellenwerte (Cut-Scores) hervorbringen. Daraus ergibt sich — neben
Standard-Setting Mathematik 8 2
Abbildung 2: Zusammensetzung der Expertengruppe für das Standard-Setting. den drei definierten Stufen — noch die Stufe Unter Level 1. Die Cut-Scores sollen, unter Verwen- dung einer modifizierten Item-Descriptor-Matching-Methode (Ferrara, Perie & Johnson, 2002; Cizek, 1996; Cizek & Bunch, 2007), mit Ordered-Item-Booklets von einer Expert/innen-Gruppe erarbeitet werden. Zusätzlich wird zur Bestimmung des Cut-Scores zu Unter Level 1 eine modifizierte Form der Direct-Consensus-Methode verwendet. Der Workshop zum Standard-Setting fand von 12. 10. – 14. 10. 2011 am BIFIE Salzburg statt. 2.1 Die Expertengruppe Die insgesamt 23 Teilnehmer/innen setzten sich aus unterschiedlichen Teilgruppen zusammen, die ein bestimmtes Spektrum repräsentierten (Abb. 2). Die direkte Auswahl geschah durch das BIFIE in Zusammenarbeit mit den verschiedenen Institutionen und Behörden. Unter den Teilnehmer/innen befanden sich Vertreter der Fachdidaktik (30,43%), der Elternvertretungen (13,04%), verschiedener Abnehmergruppen wie zum Beispiel Berufschulen (17,39%), des Ministeriums (8,70%), praktizieren- de Lehrer/innen für M4 und M8 (13,04%), des Schulrats (8,70%) und der Psychometrie (8,70%). An Tag drei des Workshops mussten 3 Personen aus beruflichen Gründen bzw. krankheitsbedingt ausscheiden. Für Runde 3 des Standard-Settings reduzierte sich die Gruppe somit auf 20 Personen. Laut Einführungsfragebogen waren zum Zeitpunkt des Standard-Settings 95% der Experten/innen mit Schülerleistungsstudien vertraut, 62% waren mit der Konstruktion von Testaufgaben in Kompetenz- messungen vertraut, 76% waren mit den Kompetenzstufen der Bildungsstandards in Österreich für Mathematik 8 vertraut, 67% mit dem Setzen von Standards im Bildungswesen. 2.2 Das Ordered-Item-Booklet Das gereihte Aufgabenheft (Ordered-Item-Booklet, OIB) wurde ursprünglich durch die Bookmark- Methode eingeführt (Karantonis & Sireci, 2006; Mitzel, Lewis, Green & Patz, 1999). Bei der Bookmark- Methode werden die Items nach den ermittelten Schwierigkeiten aufsteigend, von leicht bis schwie- rig, geordnet. Die Itemschwierigkeiten werden durch psychometrische Verfahren der Item-Response- Theorie (IRT) aus den vorhandenen Daten geschätzt. Pro Seite wird ein Item mit der dazugehörigen Schwierigkeit dargestellt. Die Teilnehmer/innen setzen nun unter Berücksichtigung der Schwierig- keiten ein Lesezeichen (Bookmark) an der jeweiligen Stelle, an der sie die Cut-Scores zwischen den unterschiedlichen Kompetenzstufen vermuten. Die Frage, die an die Teilnehmer/innen gestellt wird, lautet (cf., Cizek & Bunch, 2007): ”Ist es Standard-Setting Mathematik 8 3
wahrscheinlich dass ein/e minimalqualifizierte/r Schüler/in bzw. eine Testperson an der
Grenze zwischen den Kategorien X und Y dieses Item richtig beantworten wird?” Der Term
”wahrscheinlich” wird meist mit einer 2/3- oder 67%-Wahrscheinlichkeit festgelegt (Response Pro-
bability, RP = .67), das Item zu lösen (50% bei Wang, 2003). Der/die Teilnehmer/in erhält somit
die Aufgabe jedes Item zu begutachten und sich die Frage zu stellen, ob ein/e minimalqualifizierte/r
Schüler/in in 2 von 3 Fällen die Aufgabe richtig beantworten würde. Kommt der/die Teilnehmer/in
zu einem Item, bei dem die Wahrscheinlichkeit unter 2/3 fallen würde, setzt er/sie dort eine Marke.
Alle Items bis zu dieser Bookmark könnten demnach minimalqualifizierte Testpersonen (mit einer
2/3-Wahrscheinlichkeit) lösen. Hier bleibt zu entscheiden, welche Response Probability man festlegt,
da diese Auswirkungen auf die Cut-Scores hat (Wyse, 2011).
Neben der oft schweren Verständlichkeit des Konzepts der RP, weisenKarantonis und Sireci (2006)
auf einige zusätzliche Schwierigkeiten in der Anwendung der Bookmark-Methode hin:
• Im OIB kann eine Item-Disordinalität auftreten, die den Entscheidungsprozess erheblich er-
schweren kann.
• Es konnte gezeigt werden, dass die Bookmark-Methode Cut-Scores meist etwas unterschätzt
(negativer Bias) und zwar im Vergleich zu anderen Methoden und zu simulierten Daten.
• Generell scheinen Panelisten die Anforderungen in der Bookmark-Methode zu verstehen, das
Ausmaß der kognitiven Komplexität und inwiefern die Urteile tatsächlich valide sind, ist aller-
dings unklar.
• Eine weitere Frage ist, ob der Mittelwert oder Median für die Cut-Score-Berechnung verwen-
det werden sollte. Der Median ist zwar unabhängig von Ausreißern, allerdings könnten solche
Extremmeinungen auch eine wichtige Bedeutung haben.
Für das Standard-Setting in M8 wurde daher die Item-Descriptor-Matching-Methode (s. unten) be-
vorzugt. Diese verwendet ebenfalls ein OIB und das Konzept der RP ist für die Reihung der Items
notwendig, geht allerdings nicht in den Entscheidungsprozess ein. Die Itemschwierigkeiten wurden für
M8 durch das Rasch-Modell (Rasch, 1960) ermittelt, wobei die Lösungswahrscheinlichkeit auf 62,5%
gesetzt wurde. Für das bessere allgemeine Verständnis wurde der Mittelwert der Item- und Personen-
parameterverteilung für das Standard-Setting auf 500 gesetzt. Dieser ist aufgrund von internationalen
Schülerleistungsstudien vertraut. Für die Konsequenzdaten wurde eine gemeinsame Verteilung aus
der Pilotierungsstudie (N = 2530) sowie aus der Baselinestudie (N = 10082) gebildet, diese Vertei-
lung hat einen gewichteten Mittelwert von 516,94. Um einen Mittelwert von 500 zu erhalten wurde
die sich ergebende Differenz von 16,96 von den Item- und Personenparametern subtrahiert. Alle be-
richteten Ergebnisse und Analysen beziehen sich auf Daten dieser korrigierten Verteilung mit einem
Mittelwert von 500. Zur endgültigen Festlegung der Cut-Scores muss diese Differenz allerdings wieder
aufaddiert werden. An den Konsequenzdaten ändert dies dabei nichts.
Aus dem gesamten Itempool wurden durch ein internes Review 80 Items ausgewählt, die das gesamte
Schwierigkeitsspektrum bestmöglich repräsentierten (aus Zeitgründen können nicht alle verfügbaren
Items in den Standard-Setting-Prozess einbezogen werden). Die Items wurden sortiert nach Schwie-
rigkeit (von leicht bis schwierig) in das Ordered-Item-Booklet gegeben, wobei pro Seite nur ein Item
gelistet wurde. Jede Seite enthielt den Itemtext (Itemstamm) und dazugehörige Abbildungen sowie
den Antwort-Schlüssel, den Itemnamen und die Seitennummer. Zusätzlich zum OIB erhielten die Teil-
nehmerinnen ein Ratingsheet (auch als Item-Map bezeichnet) der die Itemnamen mit dazugehöriger
OIB-Seitennummer, ein Feld für Notizen sowie drei Kästchen zum Ankreuzen der unterschiedlichen
Levels enthielt. Der Ratingbogen wurde nach jeder Runde eingescannt und anschließend die Daten
aufbereitet. Die daraus gewonnenen Daten dienten wiederum als Grundlage für die Diskussionen im
Plenum. Insgesamt wurden drei Ratingrunden durchgeführt, die im Nachfolgenden erläutert werden.
Standard-Setting Mathematik 8 42.3 Item-Descriptor-Matching-Methode (IDM) Die IDM-Methode wurde aus der Motivation heraus entwickelt, eine bessere Verlinkung zwischen den PLDs (Performance Level Descriptors = Kompetenzstufenbeschreibungen) und den Cut-Scores zu gewährleisten, was wiederum die Validität der Ergebnisse erhöht (Cizek & Bunch, 2007). Die Metho- de verwendet ebenfalls ein Ordered-Item-Booklet und die einzelnen Testitems werden den einzelnen PLDs zugeordnet (Ferrara et al., 2002). Die Frage, die an das Experten-Panel gestellt wird, ist: ”Welcher PLD repräsentiert am besten die Anforderungen des Items?” Oder genauer: ”Welcher PLD drückt am besten das Wissen, die ver- langte Fähigkeit und kognitiven Prozesse aus, die zur Beantwortung des bestimmten Items gefordert sind?”Die Teilnehmer ordnen danach jedes Item einem bestimmten PLD zu und vermerken dies auf dem Antwortbogen. Der Schwellenwert, der zwei Kompetenzstufen voneinander trennt, wird dort gesetzt, wo der/die Teilnehmer/in kontinuierlich und systematisch von einem Level ins nächste wechselt. Dies spricht für eine sehr flexible Methode, die nicht von einer strengen Sequenzierung (wie bei der Bookmark-Methode) ausgeht und auch etwas Rauschen zulässt. Da die Schwierigkeiten der Items meist durch Schätzungen basierend auf der IRT erfolgen, kann nicht davon ausgegangen werden, dass die Item-Positionen im Booklet unveränderlich sind, sondern auch einem Schätzfehler unterliegen, eine erlaubte Flexibilität entspricht also einem natürlicheren Matching-Prozess (Cizek & Bunch, 2007; Ferrara et al., 2002). In Regionen alternierender Item-PLD-Matches wird der Threshold- Bereich festgelegt (Ferrara et al., 2002). Da es auch in den PLDs keine absolut festsetzbaren Grenzen gibt, sondern auch hier die Übergänge eines PLDs zum nächsten fließend sind, wird dieser Bereich als optimal zur Schwellenwertbestimmung angesehen. Die IDM verwendet eine Start/Stopp-Regel (die laut Autoren ähnlich wie bei IQ und Diagnosetest definiert ist) zur Festlegung der Grenzbereiche. Mindestens drei aufeinanderfolgende gleiche Klas- sifizierungen müssen vorliegen, um den Anfang und das Ende eines Grenzbereichs zu definieren. In diesem Bereich wird der Cut-Score ermittelt. Dies kann ähnlich wie bei einer Bookmark-Methode geschehen, indem man die Teilnehmer/innen nochmals entscheiden lässt, wo genau sich in dieser Region der exakte Übergang zwischen den Kompetenzstufen befindet. Genauer kann man es mit- tels Median oder Mittelwertberechnung erfassen. Im Falle der Mittelwertbestimmung werden nur die Schwierigkeiten der jeweiligen Grenz-Items verwendet (N = 2). Es gibt auch Ansätze, in denen der Schwellenwert mittels logistischer Regression bestimmt wird (Sireci & Clauser, 2001). Die IDM wird grundsätzlich in mehreren Runden durchgeführt, wobei in Runde 1 die Items den PLDs zugeordnet werden, danach werden die Schwellenwert-Regionen durch die Standard-Setters ermittelt (oder auch durch Panelteilnehmer selbst) und rückgemeldet. Diese werden dann im Plenum diskutiert oder in Subgruppen. In Runde 2 wird das Gleiche nochmals durchgeführt, Änderungen können vor- genommen werden und ein erster Cut-Score wird berechnet. In Runde 3 werden die Werte diskutiert und es werden den Teilnehmern/innen zusätzlich Informationen über die Konsequenzen, Mittelwerte, Verteilungen usw. vermittelt. Der endgültige Cut-Score wird danach festgelegt und nochmals zur Begutachtung präsentiert. Zusätzlich könnte die IDM noch durch eine Item-Map ergänzt werden, da eine solche auch Item-Untergruppen besser darstellt (Schulz, Kolen & Nicewander, 1999; Schulz, Lee & Mullen, 2005). Die sogenannten Threshold Regions (TR) sind Bereiche in denen der Match zwischen Item-Anforderung (Wissen, Fähigkeit etc.) und die Anforderungen des Descriptors (PLDs) nicht klar sind. Dies kann mehrere Gründe haben und die Teilnehmer/innen müssen darauf sensibilisiert und trainiert werden. Gründe können sein: • Item Ordering Effects (inkl. methodische Aspekte der OIB-Generierung) • Unklarheit in Beschreibung der PLDs Standard-Setting Mathematik 8 5
• Unsicherheit der Teilnehmer/innen bzgl. Zuordnung In der Originalmethode vermerken Teilnehmer/innen in einem Formblatt ihre jeweiligen TRs, in dem sie einfach die spezifischen OIB-Seitennummern eintragen, Psychometriker können dann die Daten- eingabe leichter vornehmen. Die Teilnehmer/innen werden hier auch gebeten, innerhalb der TR einen Cut-Score zu definieren, der ebenfalls vermerkt wird. Der wesentliche Vorteil der Methode liegt darin, dass der kognitive Anspruch an die Teilnehmer/innen gering gehalten wird (Ferrara et al., 2002). Die Items müssen lediglich den PLDs zugeordnet werden, es bedarf keiner zusätzlichen Instruktion, wie z. B. sich eine bestimmte Schülergruppe vorzustellen, die einer bestimmten Mindestanforderung entspricht. Da Personen generell Probleme haben, Urteile auf Grund von Wahrscheinlichkeitsangaben zu machen (cf., Impara & Plake, 1998; Plous, 1993) bietet diese Methode auch den Vorteil, dass Antwortwahrscheinlichkeiten zwar in die Generierung des OIB miteinfließen, für den Entscheidungsprozess allerdings irrelevant sind (nicht so bei der Bookmark- Methode). 2.4 Training und Vorbereitung auf den Beurteilungsprozess Die Teilnehmer/innen müssen eine umfassende Schulung erhalten, damit sie mit dem Material, der Methode und dem Ablauf vertraut sind. Es ist von enormer Wichtigkeit, dass die Aufgaben ver- standen werden. Cizek und Bunch (2007) geben einen kleinen Leitfaden, an dem der Ablauf des Standard-Settings für M8 ausgerichtet wurde. Am Tag 1 des Workshops wurden die Teilnehmer/innen einen Nachmittag lang geschult. Nach ei- ner ausführlichen Einführung in die Bildungsstandardsüberprüfung sowie zum bisherigen Verlauf des Standard-Setting-Prozesses (Phase I und II) bekamen die Experten einen Übungstest mit 11 Items vorgelegt. Dadurch sollte ihnen eine mögliche Testsituation vermittelt werden und ihnen auch zeit- licher Druck, der in der tatsächlichen Bearbeitung der Items miteinfließt, bewusst gemacht werden. Danach folgte eine Einführung in die Standard-Setting-Methode und den Ratingprozess. Nach genaue- rer Erläuterung der Kompetenzstufenbeschreibungen folgte eine kurze Diskussion in Kleingruppen, in denen die Personen auf Unterschiede zwischen den Stufenbeschreibungen achten und Unklarheiten in den Begrifflichkeiten klären konnten. Anschließend wurde im Plenum nochmals über kritische Punkte diskutiert und erste Ratings anhand von einigen Items in der Gesamtgruppe vorgenommen. Erst am zweiten Tag folgten Runde 1 und Runde 2. 2.5 Runde 1 2.5.1 Aufgabe und Instruktion In Runde 1 wurden die Experten/innen aufgefordert, die Items den Kompetenzstufenbeschreibungen (= PLDs) zuzuordnen. Die genaue Instruktion lautete: ”Beantworten Sie folgende Fragen: Welche Kompetenzanforderung stellt das Item an die Schüler/innen? Welche Kompetenzstufenbe- schreibung drückt das am besten aus?” Die Teilnehmer/innen wurden aufgefordert, das OIB individuell durchzuarbeiten und ihre Entscheidungen in den Ratingbogen einzutragen. Anschließend wurden die Bögen gescannt und ausgewertet. 2.5.2 Auswertung der Ratingdaten Aus dem Scanprozess erhält man eine Datenmatrix mit Panelisten × Items, mit den Werten 1, 2 und 3 (Level-Ratings 1 – 3). Zur Auswertung wurde für jedes Item separat die prozentuelle Häufigkeit der einzelnen Kategorien ermittelt und grafisch aufbereitet (siehe Abb. 3). Dieses Datenblatt diente als Diskussionsgrundlage. Diskussionspunkte waren Items mit hoher Konvergenz bzw. Divergenz, Standard-Setting Mathematik 8 6
augenscheinliche Übergänge zwischen Levels und Abschnitte, die sich bereits als einzelne Levels
herauskristallisierten.
2.6 Runde 2
2.6.1 Aufgabe und Instruktion
Die Diskussion in Runde 1 diente dazu, die Expertengruppe in bestimmten Diskussionspunkten, die für
den Entscheidungsprozess wichtig sind, zu homogenisieren. In Runde 2 arbeiteten die Experten/innen
wiederum individuell das OIB durch und adjustierten ihre Item-PLD-Zuordnungen, sie vermerkten
ihre Urteile wiederum in einem Ratingbogen, der anschließend gescannt wurde. Als Feedback zur
Runde 2 wurden den Experten/innen erneut die Ratingdaten vorgelegt, die in ähnlicher Weise wie
in Runde 1 diskutiert wurden. Zusätzlich wurden hier auch noch die Cut-Scores ermittelt und den
Teilnehmern/innen rückgemeldet.
2.6.2 Bestimmung der Cut-Scores
Die Bestimmung der Cut-Scores erfolgt in mehreren Analyseschritten. Wie bereits erwähnt wurde
eine Methode verwendet, die dem Prozess der IDM (Ferrara et al., 2002) sehr ähnlich ist. Die
Bestimmung der Übergangsbereiche, die in der IDM zur Bestimmung der Cut-Scores definiert sind,
ist praktisch sehr schwierig umzusetzen. Bei größeren Item-Mengen können auch Ausreißer auftreten,
die laut Original-Methode bereits den Beginn oder das Ende eines Grenzbereichs festlegen würden.
Zusätzlich ist die Verwendung der Start/Stopp-Regel kritisch zu hinterfragen. Im Standard-Setting
für M8 verwendeten wir daher eine alternative Strategie zur Auswertung des Ratingverhaltens und
der damit verbundenen Cut-Score-Bestimmung. Ziel der Methode ist es Übergänge zwischen den
einzelnen Levels zu detektieren, was in drei Schritten vorgenommen wurde:
1. Als erster Schritt wird jede individuelle Ratingserie durch einen symmetrischen Moving Average
geglättet ( order = 1, Filterfenster ergibt sich aus 2 ∗ order + 1, ungewichtet). Um in den
Randbereichen keinen Datenverlust durch die Filterung zu erleiden, wurden die mittleren Ra-
tingwerte dem Beginn und Ende der Serie angefügt. Abbildung 4 zeigt die Rating-Serie (series,
obere Graphik) einer Person und die gefilterte Funktion dieser Serie darunter. Die individuelle
Ratingserie besteht aus 80 Werten (pro Item ein Wert). Die Itemnummer entspricht exakt der
Seitenzahl im OIB, die Items sind nach Schwierigkeit geordnet.
2. Die geglättete Funktion jedes Panelisten steigt mit zunehmender Kategorienzahl an. Es wurden
2 Schwellen definiert, die jeweils ersten Werte, die diese Schwellen überschreiten, liefern den
Seiten-Index für den jeweiligen Cut-Score. Die dazugehörige Schwierigkeit des Items auf der
jeweiligen Schwelle definiert des Weiteren den Cut-Score auf der Theta-Metrik. Die Schwellen-
werte wurden auf 1,7 für den ersten Cut und auf 2,4 für den zweiten Cut gesetzt. Diese Werte
ergaben sich aus zusätzlich in einem Probelauf erhaltenen Daten1 .
3. Nach anschließender manueller Kontrolle erhält man pro Teilnehmer/in Index-Werte mit An-
gabe der Seitenzahl des Cut-Score-Items sowie die dazugehörigen Theta-Werte (siehe Abb. 4).
Um einen Gruppen-Wert für die jeweiligen Cut-Scores zu erhalten, wurde der Median über alle
individuellen Cut-Scores berechnet (Abb. 5).
Die Methode erbrachte bei allen Teilnehmern/innen reliable Werte der Übergange zwischen Level 1
und 2. Der Übergang zwischen Level 2 und 3 konnte bei drei Experten nicht genau erfasst werden.
1
Überschreitet — wie in Abbildung 4 — die geglättete Funktion (filtered, mittlere Graphik) den ersten Schwel-
lenwert von 1,7, definiert dieser Punkt den Index für die Seite im OIB. In diesem Fall Seite 20. Dieses Item, mit der
entsprechenden Schwierigkeit (auf Theta-Metrik), liefert den ersten Cut-Score für diese/n Experten/in. Analog verfährt
man mit dem zweiten Cut-Score.
Standard-Setting Mathematik 8 7100
% Häufigkeit
40
0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
Seiten Nr. (ITEM)
% Häufigkeit
80
40
0
21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
Seiten Nr. (ITEM)
% Häufigkeit
40 80
0
41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60
Seiten Nr. (ITEM)
% Häufigkeit
80
40
0
61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80
Seiten Nr. (ITEM)
Abbildung 3: Rating-Daten aus Runde 1, die an die Teilnehmer/innen rückgemeldet wurden. Pro Item
wird die prozentuale Häufigkeit der Zuordnungen pro Level dargestellt. Die Teilnehmer/innen können
dadurch Items mit hoher/niedriger Übereinstimmung erkennen und über diese Items diskutieren (ROT
= Level 1, GRÜN = Level 2, BLAU = Level 3).
Standard-Setting Mathematik 8 8Abbildung 4: Methodik der Cut-Score-Bestimmung. Die oberste Grafik zeigt eine einzelne Ratingserie
einer Person. Darunter ist die geglättete Funktion dieser Serie (unten: Filter-Residuen). Gestrichelte
horizontale Linien zeigen die beiden Schwellenwerte bei 1,7 und 2,4. Vertikale Linien stellen die
Schnittpunkte der geglätteten Funktion mit den Schwellenwerten dar. Aus diesen Punkten kann man
auf der X-Achse die Seitennummer des Items ablesen, das den Cut-Score repräsentiert.
Dies lag entweder an sehr inhomogenen Ratingserien oder wie bei einem Experten daran, dass ledig-
lich ein Item dem Level 3 zugeordnet wurde. Die Filterungs-Methode kann somit keinen Übergang
bestimmen.
Zur Rückmeldung an die Teilnehmer/innen wurde eine Tabelle präsentiert, in der die individuel-
len Cut-Scores mit dazugehöriger OIB-Seitennummer dargestellt wurde (Abb. 5). Da vor allem die
Übergänge zu Level 3 nicht genau erfasst werden konnten, wurde dies als Diskussionspunkt in Run-
de 2 eingebracht, stärker über die Definition von Level 3 sowie über die typische Level-3-Items zu
diskutieren.
2.7 Präsentieren der Konsequenzen
Die Klärung, was Schüler/innen wissen und können sollen, ist sehr wichtig zur genauen Definition
der Cut-Scores. Studien zeigen, dass z. B. die Konsistenz der Einschätzung der Cut-Scores in der
Diskussion von den erhaltenen Informationen abhängt (Jaeger & Mills, 2001; Jaeger, 1990).
Generell sollte man sich Gedanken machen, ob bzw. wann Feedback gegeben und auch welches Feed-
back gegeben werden sollte (Hambleton, Jaeger, Plake & Mills, 2000). Es wird auch berichtet, dass
man durch das Vermeiden von Rückmeldung von genauen Ergebnissen zwischen den Runden des
Standard-Settings statistische Unabhängigkeit der Daten erhält (Reckase, 2006b, 2006a)2 .
2
Kritische Meinungen behaupten auch, dass durch die Rückmeldung über bestimmte Konsequenzen, der Standard-
Standard-Setting Mathematik 8 9Abbildung 5: Feedback in Runde 2 und 3: Deskriptive Statistik der Cut-Scores. Im Standard-Setting für M8 wurde nach einer ersten Diskussionsphase in Runde 2, die lediglich die Itemzuordnungen im Fokus haben sollte, den Teilnehmer/innen die Konsequenzdaten (ähnlich zu Abb. 6 nur ohne unter Level 1 ) präsentiert. Dadurch wurde ermöglicht, dass die Experten die Items und deren Level-Zuordnungen als Hauptaufgabe im Zentrum ihrer Aufmerksamkeit behielten, und erst relativ spät im Prozess die Auswirkungen berichtet bekamen. Durch die Präsentation solcher Konsequenzdaten erkannten die Panelisten die Auswirkungen ihrer Entscheidungen auf die Cut-Score- Setzung. Sie sehen somit die prozentuale Aufteilung der Schüler/innen auf die einzelnen Levels. 2.8 Runde 3 Nach der Diskussion zu Runde 2 wurden die Teilnehmer/innen gebeten, die OIBs ein letztes Mal durchzuarbeiten, die Zuordnungen zu adjustieren und sich auf endgültige Urteile festzulegen. Wie- derum wurden Rückmeldedaten und Konsequenzdaten präsentiert, danach folgte eine abschließende Diskussion und Entscheidung über die Setzung der Cut-Scores. 2.9 Setzung der Schwelle zu Unter Level 1 Nach einer endgültigen Entscheidung über die Cut-Scores zu Level 1–2 und Level 2–3 wurde ab- schließend noch die Grenze zu Unter Level 1 bestimmt. Dazu wurde ein modifizierte Form der Direct-Consensus-Methode verwendet. Es wurde ein absoluter Standard festgelegt, das heißt, es musste darüber entschieden werden, wie viele Items ein/e Schüler/in beantworten muss, um eine bestimmte Kompetenz vorzuweisen bzw. um den Standard zu erfüllen (Norcini, 2003). Dazu wurden den Teilnehmern/innen alle Items, die auf Level 1 liegen, präsentiert (von OIB-Seite 1 bis OIB-Seite 12, siehe Abb. 5, Runde 3). Die Teilnehmer/innen wurden gebeten, sich sogenannte Grenz- oder minimal-kompetente-Schüler/innen vorzustellen, also jene, die gerade noch auf Level 1 liegen würden. Es wurde die Frage gestellt: ”Wie viele Items müssten Grenz-Schüler/innen richtig beantworten, um dem Level 1 zu entspre- chen?” Die Experten/innen gaben ihre Entscheidungen ab und diese wurden wiederum im Plenum präsentiert und diskutiert. Die Experten/innen mussten zu einem endgültigen Entschluss kommen. Setting-Prozess von einem ursprünglich kriteriumsbasierten in ein normreferenziertes Verfahren überführt wird (Impara & Plake, 1997). Standard-Setting Mathematik 8 10
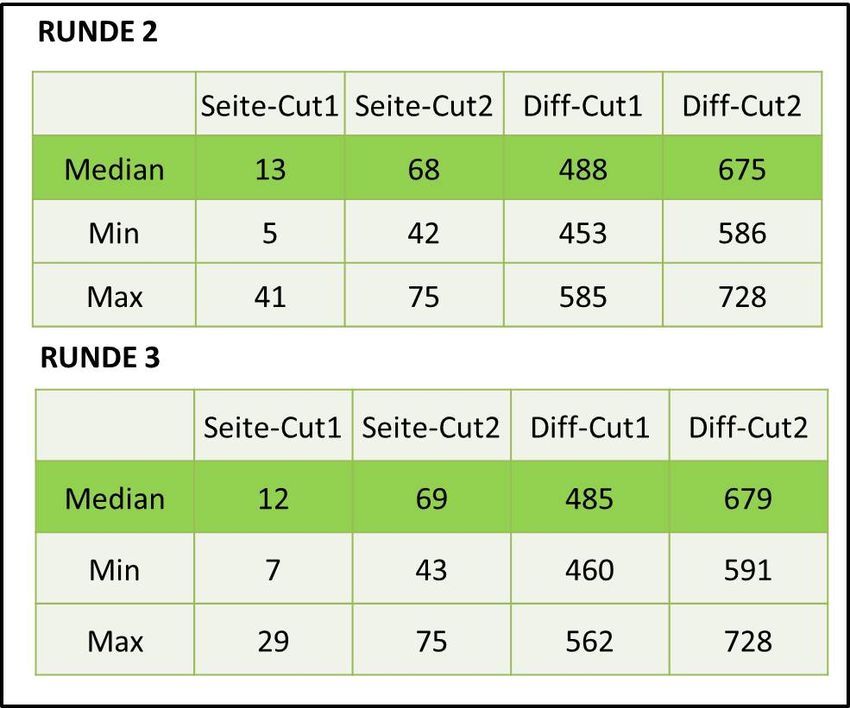
Abbildung 6: Endgültige Cut-Score-Werte für M8 inklusive der Konsequenzdaten. Der Median lag bei 7 Items (von 12), die es zu lösen galt, um auf Level 1 zu kommen. Der Wert von 7 wurde von der Mehrheit akzeptiert und als endgültig festgelegt, dieser entsprach einem Theta-Wert von 420,32 (Abb. 6). 3 Validität und Post-Standard-Setting 3.1 Prozessevaluation und Evaluation der Cut-Score-Urteile Es ist von großer Bedeutung, am Ende wichtiger Entscheidungsrunden interne Evaluationen durchzu- führen (Hambleton, 2001). Mit diesen soll geklärt werden, ob die Teilnehmer/innen alles verstanden haben, ob es Verbesserungsvorschläge für die Vorgehensweise gibt und wie einig man sich bei den Ergebnissen ist (Morgan & Perie, 2004; Raymond & Reid, 2001). Für Cizek, Bunch und Koons (2004) besteht die Evaluation aus mehreren Teilen: nach einer ersten Orientierung wird der Grad des Bereitseins der Experten erhoben (Training, Aufgabenverständnis, Überzeugung gegenüber der Methode). Danach folgt eine Evaluation über das Ergebnis des Standard- Settings (Pitoniak, 2003). Für das M8-Standard-Setting wurde ein Eingangsfragebogen und ein Ab- schlussfragebogen verwendet, sowie ein Fragebogen nach jeder Runde. Aus der Evaluation durch die Experten/innen konnte ebenfalls ein positives Bild des Standard-Setting- Prozesses, hinsichtlich Methodik, Durchführung und Organisation gezeichnet werden. Die ermittelten Cut-Scores wurden großteils (ca. 95%) als verlässlich eingestuft. Viele Personen waren ebenfalls der Meinung, dass die Verteilung, die sich aus den Konsequenzdaten ergab, ein sehr gutes Abbild aus der praktischen Erfahrung wiederspiegelt. Ein einziger Kritikpunkt betraf die Formulierung des PLDs Standard-Setting Mathematik 8 11
Abbildung 7: Cut-Scores wurden mit Median (Md) und Mittelwert (MW) bestimmt, Standardfehler
(SE) durch Jacknife- und Bootstrap-Verfahren.
zu Stufe 3. Die Zustimmung zu der Frage, inwieweit man von den Item-Zuordnungen zu den Levels
überzeugt sei, zeigte für Level 3 deutlich geringere Werte als für Level 1 und Level 2.
3.2 Endgültige M8-Cut-Score-Werte und Standardfehler
Für die Cut-Scores der Runde 3 wurden über Jackknife-3 und Bootstrapping-Verfahren Standardfehler
ermittelt.
Anstelle der Medianberechnung könnte man auch eine Mittelwertsberechnung zur Bestimmung der
Cut-Scores in Betracht ziehen. Hier würden alle Meinungen der Experten gleich einfließen, das heißt,
auch extremere Meinungen (die durchaus wichtig sind) würden in die Cut-Score-Bestimmung mit-
einfließen. Durch den Median würde man solche Meinungen verlieren, da dieser ein robustes Maß
gegenüber Ausreißern darstellt. Aus diesen Gründen wurden daher alle Cut-Scores auch durch eine
Mittelwertberechnung bestimmt und über Jackknife- und Bootstrap-Verfahren die jeweiligen Stan-
dardfehler errechnet (Abb. 7). Zwischen den beiden Methoden gibt es numerisch keine großen Un-
terschiede, die Mittelwertsberechnung liefert allerdings kleinere Standardfehler. Für die Bestimmung
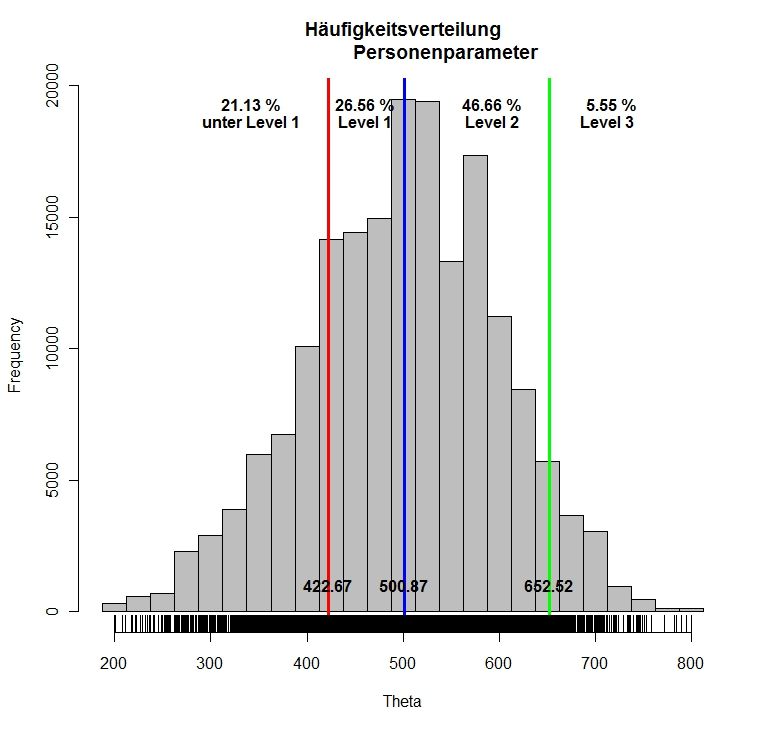
der endgültigen Cut-Scores werden die Mittelwerte herangezogen (siehe Abb. 8).
3.3 Rating-Verhalten
Die Ergebnisse einer 2-faktoriellen Varianzanalyse (Greenhouse-Geisser korrigiert) mit den Faktoren
Runde (1–3) und Cut (Cut-Level 1–2, Cut Level 2–3) zeigten einen Haupteffekt für den Faktor
Cut (F (1, 19) = 182, 85; p < .001; η 2 = .91) sowie eine Interaktion zwischen Runde × Cut
(F (2, 38) = 7, 34; p = .003; η 2 = .23). Der Haupteffekt für Cut zeigt, dass die verwendete Methode
funktioniert hat da die Schwelle zwischen Level 2 und 3 signifikant höher liegt als zwischen Level
1 und 2. Es wäre durchaus problematisch, würden sich die beiden Cut-Scores nicht signifikant von-
einander unterscheiden. Die Interaktion ist interessant, sie zeigt, dass die Experten über die Runden
hinweg ihre Urteile adjustieren, der unterste Cut-Score sinkt über die Runden hinweg leicht ab, der
obere Cut-Score steigt nach Runde 1 an und bleibt dann konstant.
Um festzustellen, ob bestimmte Rater strenger oder milder urteilen, wurde für jede/n Experten/in
(Rater ) der Mittelwert über alle Item-Ratings berechnet. Abbildung 9 zeigt Boxplots für die be-
rechneten individuellen Mittelwerte über die Runden hinweg. Die Streuung nimmt über die Runden
hinweg augenscheinlich ab, eine Person zeigt tendenziell höhere mittlere Ratings im Vergleich zu
3
Da der Median einen Datensatz genau in der Mitte teilt, ergeben sich durch Weglassen eines Werts höchstens zwei
unterschiedliche Mediane aus dem Jackknifing, egal ob die Anzahl an Datenwerten gerade oder ungerade ist. Der Median
ist daher kein ”glatter” Schätzer der Daten, er kann die Daten also nicht linear approximieren. Efron und Tibshirani
(1986) weisen auf diese Problematik hin und empfehlen hier eher ein Bootstrapping-Verfahren zur Berechnung des
Standardfehlers des Medians
Standard-Setting Mathematik 8 12Abbildung 8: Konsequenzdaten für Cut-Scores durch Mittelwertberechnung.
allen anderen Ratern4 . Um zusätzlich Aufschluss über das Rating-Verhalten zu bekommen, wurde in
Runde 3 für jedes Item der Modalwert5 berechnet. Jede individuelle Ratingserie wurde anschließend
mit der Reihe an Modalwerten korreliert. Wie Abbildung 10 zeigt, sind die Korrelationen generell
hoch (von r = 0.54 bis r = 0.84). Vergleicht man die Person mit dem höchsten und dem niedrigsten
Rang sieht man keine auffälligen Rating-Verhalten (Abb. 11). Auf Grund dieser Analysen wurden
daher keine Personen aus dem Standard-Setting-Prozess ausgeschlossen.
3.4 Interrater-Reliabilität
Um Interrater-Reliabilität festzustellen. kann man grundsätzlich zwischen Maßen der Rater-Konsistenz
und der Rater-Übereinstimmung unterscheiden (e. g. Eckes, 2011). Rater-Übereinstimmung (oder
Rater-Konsens) beschreibt hier die exakte Übereinstimmung der einzelnen Ratings zwischen den Ra-
tern. Rater-Konsistenz hingegen gibt an, inwieweit die Rater bestimmte Objekte (Personen, Items
etc.) in eine ähnliche Reihung bringen. Es ist wichtig anzumerken, dass diese Maße zu unterschiedli-
chen Ergebnissen führen können. Die Reihung der bewerteten Objekte kann zum Beispiel gleich sein
(hohe Konsistenz) und die absoluten Ratings aber unterschiedlich (niedriger Konsens). Dies würde
passieren wenn bestimmte Rater generell strengere Urteile abgeben als andere, die Reihung aber
beibehalten. Bewertet zum Beispiel ein Experte drei Items mit 1, 1, 2 und ein anderer Experte mit
2, 2, 3, so hätten diese beiden Rater keine Übereinstimmung, aber eine hohe Konsistenz.
Als erste Analyse der Übereinstimmung der Raterurteile wurde der von Fleiss vorgeschlagene Kappa-
Koeffizient für jede Standard-Setting-Runde berechnet (Fleiss, 1971). Fleiss’ Kappa ist eine Erweite-
4
Es wurden daher alle Cut-Scores erneut berechnet ohne diesen Ausreißer. Die Cut-Scores veränderten sich allerdings
nicht substanziell. Das Rating-Verhalten dieser Person zeigt ebenfalls keinen ungewöhnlichen Verlauf die Person wurde
somit nicht aus dem Standard-Setting-Prozess ausgeschlossen.
5
Der am häufigsten vorkommende Wert.
Standard-Setting Mathematik 8 13Rater−Strenge
●
2.2
●
●
2.0
1.8
1.6
RUNDE 1 RUNDE 2 RUNDE 3
Abbildung 9: Boxplots zu Rater-Strenge/-Milde über die Runden hinweg.
Modalwert − Items
3.0
● ● ● ● ● ● ●
2.5
Mod
2.0
● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●
1.5
1.0
● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ●
0 20 40 60 80
Item−Nr.
Mittelwert − Items
3.0
●
●
● ●
●
●
2.5
●
● ● ●
●
● ● ●
●
● ●
●
MW
● ● ● ● ●
2.0
● ● ● ● ●
● ● ● ● ● ● ●
● ● ● ● ●
● ● ●
● ●
● ●
● ● ● ●
● ● ●
1.5
● ●
● ●
●
● ●
● ● ● ●
●
● ● ●
● ●
● ● ●
●
1.0
● ● ●
● ●
0 20 40 60 80
Item−Nr.
Korrelation mit Modalwert
1.0
SS01
SS16 SS09 SS08 SS12 SS13
SS22 SS07
SS02 SS05 SS11 SS17
SS18 SS15 SS19 SS10
SS04 SS20
SS23 SS06
0.6
Korr.
0.2
5 10 15 20
Experten−ID (gereiht)
Abbildung 10: Modalwerte und Mittelwerte der Itemratings (oben, Mitte). Korrelation der individu-
ellen Ratingserie mit Modalwert (unten). Die Experten-IDs sind aufsteigend nach Korrelationskoeffi-
zient gereiht.
Standard-Setting Mathematik 8 14Rang 1 (geringe Korr.)
3.0
2.5
Ratings
2.0
1.5
1.0
0 20 40 60 80
Item−Nr.
Rang 20 (hohe Korr.)
3.0
2.5
Ratings
2.0
1.5
1.0
0 20 40 60 80
Item−Nr.
Abbildung 11: Ratingserien (schwarze Linien) der Personen mit höchster und geringster Korrelation
mit Modalwert (rote Linien).
rung zu Cohen’s Kappa (Cohen, 1960) bei mehr als 2 Raterurteilen, wobei κ = 1 perfekte Überein-
stimmung bedeutet. Runde 1 ergab für 23 Experten und 80 Items κ = 0.24, bei Runde 2 κ = 0.38
und in Runde 3 für 20 Experten κ = 0.43. Interpretiert man die Werte nach Landis und Koch (1977),
so würden jeweils in den ersten beiden Runden ausreichende (0, 21 < κ < 0, 40) und in Runde 3
mittelmäßige (0, 41 < κ < 0, 60) Übereinstimmungen der Expertenurteile vorherrschen.
Die Intraklassen-Korrelation (intraclass correlation coefficient, ICC) kann auf Basis von verschiedenen
Varianzanteilen sowohl zur Bestimmung von Konsens als auch für Konsistenz eingesetzt werden. Der
ICC beschreibt das Verhältnis der Varianz einer abhängigen Variable (e. g. Ratings) zur Gesamtvari-
anz. Ist die Varianz ausschließlich auf die Items und nicht auf die unterschiedlichen Rater rückführbar,
erreicht der ICC einen Wert von 1 (Bartko, 1966; McGraw & Wong, 1996). Unter der Annahme, dass
sowohl Zeilen als auch Spalten der Datenmatrix (Rater × Items) systematische Variation aufwei-
sen, wurde zur Analyse ein two-way random effects model verwendet, es lassen sich dadurch Maße
zur Konsistenz6 wie auch zur Übereinstimmung ermitteln. Rechnerisch unterscheiden sich die Maße
dahingehend, dass beim ICC für Übereinstimmung auch die mean squares (MS) über die Spalten
miteinberechnet werden. Die Ergebnisse sind in Abbildung 12 zusammengefasst.
4 Phase IIb und Phase IIIb
Aus der Evaluation des Standard-Settings ging hervor, dass vor allem die Zuordnung von Items zu
Level 3 schwierig erschien, da hier die Definition der Kompetenzstufe zu eingeschränkt war (siehe
Kapitel 3.1). Basierend auf dieser Rückmeldung fand am 9. März 2012 ein eintägiger Workshop
(Phase IIb) mit 7 nationalen Experten/innen am BIFIE Salzburg statt. Ziel dieses Workshops war es
— basierend auf den Erfahrungen aus dem Standard-Setting und unter Berücksichtigung der Items
6
Würde man von einem einfaktoriellen Design ausgehen und annehmen die Item-Reihung sei unmatched, könnte
als Konsequenz kein Maß zur Konsistenz berechnet werden. Da die Itemschwierigkeit aber zunimmt, wird hier eine
systematische Varianzquelle postuliert.
Standard-Setting Mathematik 8 15Abbildung 12: Analysen zur Übereinstimmung und Konsistenz der Ratings. ICC = Intraclass correla-
tion coefficient.
Cut uL1-L1 Cut L1-L2 Cut L2-L3
Phase III 439,63 517,82 669,46
Phase IIIb 419,43 506,05 712,35
GESAMT 439,63 517,82 690,91
Abbildung 13: Cut-Scores aus den zwei Standard-Settings (Phase III und Phase IIIb). Zur Bestimmung
des Cut-Scores zwischen Level 2 und 3 wurde der Mittelwert aus den beiden Phasen gebildet.
— die Stufenbeschreibung von Level 3 zu überarbeiten. In Kapitel 1 sind die endgültigen Beschrei-
bungen dargestellt.
Von 28. – 29. September 2012 fand ein abschließender Standard-Setting Workshop (Phase IIIb) mit 10
nationalen Experten/innen statt. Der Prozess wurde vollständig wiederholt, Ziel war es einen Vergleich
zum ersten Standard-Setting herstellen zu können und den Cut-Score zu Level 3, unter Verwendung
der neu definierten Stufenbeschreibung, exakter zu bestimmen. Die Ergebnisse aus Phase III und
Phase IIIb sind in Abbildung 13 dargestellt. Zur Bestimmung des endgültigen Cut-Scores zwischen
Level 2 und Level 3 wurde der Mittelwert aus Phase III und Phase IIIb gebildet.
Literatur
Bartko, J. (1966). The intraclass correlation coefficient as a measure of reliability. Psychological
Reports, 19 , 3-11.
Cizek, G. J. (1996). Standard-setting guidelines. Educational Measurement: Issues and Practice, 15
(1), 13–21.
Cizek, G. J. & Bunch, M. B. (2007). Standard setting: a guide to establishing and evaluating
performance standards on tests. Sage.
Cizek, G. J., Bunch, M. B. & Koons, H. (2004). Setting performance standards: Contemporary
methods. Educational Measurement: Issues and Practice, 23 (4), 31–31.
Cohen, J. (1960). A coefficient of agreement for nominal scales. Educational and Psychological
Measurement, 20 , 37-46.
Eckes, T. (2011). Introduction to many-facet Rasch measurement. Frankfurt: Peter Lang.
Efron, B. & Tibshirani, R. (1986). The bootstrap method for standard errors, confidence intervals,
and other measures of statistical accuracy. Statistical Science, 1 , 1-35.
Ferrara, S., Perie, M. & Johnson, E. (2002, April). Matching the judgemental task with standard
Standard-Setting Mathematik 8 16setting panelist expertise: The item-descriptor (id) matching procedure. Paper presented at
the annual meeting of the American Educational Research Association, New Orleans, LA.
Fleiss, J. (1971). Measuring nominal scale agreement among many raters. Psychological Bulletin,
76(5), 378-382.
Hambleton, R. K. (2001). Setting performance standards on educational assessments and criteria
for evaluating the process. In G. J. Cizek (Hrsg.), (S. 89-116). New York: Routledge.
Hambleton, R. K., Jaeger, R. M., Plake, B. S. & Mills, C. (2000). Setting performance standards
on complex educational assessments. Applied Psychological Measurement, 24 (4), 355-366.
Impara, J. & Plake, B. S. (1997). Standard setting: an alternative approach. Journal of Educational
Measurement, 34 , 353-366.
Impara, J. & Plake, B. S. (1998). Teacher’s ability to estimate item difficulty: A test of the assumption
in the modified angoff standard setting method. Journal of Educational Measurement, 35(1),
69-81.
Jaeger, R. M. (1990). Establishing standards for teacher certification tests. Educational Measure-
ment: Issues and Practice, 9(4), 15-20.
Jaeger, R. M. & Mills, C. (2001). An integrated judgment procedure for setting standards on complex,
large-scale assessments. In G. J. Cizek (Hrsg.), (S. 313-338). NJ: Lawrence Erlbaum.
Karantonis, A. & Sireci, S. G. (2006). The bookmark standard-setting method: A literature review.
Educational Measurement: Issues and Practice, 25 (1), 4–12.
Landis, J. & Koch, G. (1977). The measurement of observer agreement for categorical data.
Biometrics, 33 , 159-174.
McGraw, K. & Wong, S. (1996). Forming inferences about some intraclass correlation coefficients.
Psychological Methods, 1(1), 30-46.
Mitzel, H. C., Lewis, D. M., Green, D. R. & Patz, R. J. (1999). The bookmark standard setting
procedure. Monterey, CA: McGraw-Hill.
Morgan, D. L. & Perie, M. (2004). Setting standards in education: Choosing the best method for
your assessment and population. (note)
Norcini, J. J. (2003, May). Setting standards on educational tests. Med Educ, 37 (5), 464–469.
Pitoniak, M. (2003). Standard setting methods for complex licensure examinations. Unveröffentlichte
Dissertation, University of Massachusetts, Amherst.
Plous, S. (1993). The psychology of judgement and decision making. New York: McGraw-Hill.
Rasch, G. (1960). Probabilistic models for some intelligence and attainment tests. Copenhagen:
Nielsen & Lydiche.
Raymond, M. R. & Reid, J. B. (2001). Who made thee a judge? selecting and training participants
for standard-setting. In G. J. Cizek (Hrsg.), (S. 119-158). New York: Routledge.
Reckase, M. D. (2006a). A conceptual framework for a psychometric theory for standard setting with
examples of its use for evaluating the functioning of two standard setting methods. Educational
Measurement: Issues and Practice, 25 (2), 4–18.
Reckase, M. D. (2006b). Rejoinder: Evaluating standard setting methods using error models proposed
by schulz. Educational Measurement: Issues and Practice, 25 (3), 14–17.
Schulz, E. M., Kolen, M. J. & Nicewander, W. A. (1999). A rationale for defining achievement levels
using irt-estimated domain scores. Applied Psychological Measurement, 23 (4), 347-362.
Schulz, E. M., Lee, W.-C. & Mullen, K. (2005). A domain-level approach to describing growth in
achievement. Journal of Educational Measurement, 42 (1), 1–26.
Sireci, S. G. & Clauser, B. E. (2001). Practial issues in setting standards on computerized adaptive
tests. In G. J. Cizek (Hrsg.), (S. 355-369). New York: Routledge.
Wang, N. (2003). Use of the rasch irt model in standard setting: An item-mapping method. Journal
of Educational Measurement, 40 (3), 231–253.
Wyse, A. E. (2011). The similarity of bookmark cut scores with different response probability values.
Educational and Psychological Measurement, xx, xx-xx.
Standard-Setting Mathematik 8 175 Appendix
1. Agenda Workshop Standard-Setting
2. Fragebogen Einführung
3. Fragebogen Durchführung
4. Fragebogen Abschluss
Standard-Setting Mathematik 8 18Workshop: Standard Setting M8, 12.10.-14.10.2011
Tag 1 Zeit
Präsentation 13:00 Begrüßungsworte und Einleitung
Präsentation 13:45 Einführung in die Methode des Standard Settings
Evaluation 14:45 Bearbeitung Evaluations Fragebogen (vorher)
15:00 Kaffeepause
Bearbeitung 15:20 Bearbeitung eines Übungstests
Diskussion 16:00 Kleingruppendiskussionen zu den Niveaustufenbeschreibungen
Diskussion im Plenum und Zuordnung einzelner Trainings-Items zu den
Diskussion 16:30
Niveaustufenbeschreibungen
17:00 Einsammeln der Materialien
Tag 2
Präsentation 09:00 Rekapitulation der Methode, Diskussion offener Fragen, Verteilung Materialien
Präsentation 09:30 Instruktion zu RUNDE 1
09:45 Kaffeepause
Bearbeitung 10:00 RUNDE 1: Durcharbeiten des gereihten Aufgabenheftes, Zuordnen der Items zu den
Niveaustufenbeschreibungen
12:30 Mittagspause
Präsentation 14:00 Feedback zu RUNDE 1
Diskussion 14:15 Diskussion zu RUNDE 1
Evaluation 15:15 Bearbeitung Evaluations Fragebogen (RUNDE 1)
15:30 Kaffeepause
Präsentation 15:45 Instruktion RUNDE 2
Bearbeitung 16:00 RUNDE 2: Erneutes Durchgehen der gereihten Aufgabenhefte und adjustieren der Zuordnungen
17:00 Einsammeln der Materialien
Tag 3
Präsentation 09:00 Feedback zu RUNDE 2 und Diskussion
Präsentation 09:30 Präsentieren der Konsequenzdaten
Diskussion 09:45 Diskussion der Konsequenzdaten
Evaluation 10:30 Bearbeitung Evaluations Fragebogen (RUNDE 2)
10:45 Kaffeepause
Präsentation 11:00 Instruktion RUNDE 3
Bearbeitung 11:15 RUNDE 3: Erneutes Durchgehen der gereihten Aufgabenhefte und festlegen der Zuordnungen
12:30 Mittagspause
Präsentation 13:30 Präsentation der Konsequenzdaten, Feedbackdaten
Diskussion 13:45 Diskussion und endgültige Entscheidung über die Schwellenwertsetzung
Evaluation 14:30 Bearbeitung Evaluations Fragebogen (RUNDE 3)
14:45 Kaffeepause
Präsentation 15:00 Einführung und Instruktion zur Methode der Schwellentwertbestimmung "Unter Level 1"
Bearbeitung 15:15 Bestimmen der Grenze "Unter Level 1"
Diskussion 15:30 Diskussion und Festlegung der Grenze "Unter Level 1"
Evaluation 16:00 Bearbeitung Evaluations Fragebogen (nachher)
16:30 Verabschiedung und Einsammeln der Materialiena
a
a
a
a
a
a
a a a a
a a a a
a a a a
a a a aa
a
a
a a a a a
a a a a
a a a a
a a a a
a a a a
a a a a
a a a a
a a a a
a a a a
a a a a
a a a aa a a a
a a a a
a a a a
a a a a
a a a a
a a a aa a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a
a a a a a a a a a a a a a a a a
Sie können auch lesen

















































