TECHNICAL WHITE PAPER LOBSTER_DATA 2018
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
TECHNICAL WHITE PAPER LOBSTER_DATA 2018
Inhalt
1 Einführung ................................................................................................................................................. 1
1.1 Was ist Lobster_data? ........................................................................................................................... 1
1.2 Für wen ist _data das richtige Werkzeug?....................................................................................... 2
2 Lobster_data Architektur .......................................................................................................................... 3
2.1 Installation ....................................................................................................................................... 3
2.2 DMZ Datenempfang......................................................................................................................... 4
3 Datenkonvertierung nach System – Die Sechs Phasen............................................................................. 5
3.1 Phase 1 – Daten empfangen ............................................................................................................ 6
3.2 Phase 2 – Daten parsen ................................................................................................................... 7
3.3 Phase 3 – Mapping........................................................................................................................... 9
3.4 Phase 4 – Datenbankoperationen (optional) .................................................................................. 12
3.5 Phase 5 – Integration Unit .............................................................................................................. 12
3.6 Phase 6 – Daten versenden ............................................................................................................ 13
4 Kommunikationsprotokolle ..................................................................................................................... 15
5 Unterstütztes Mapping durch Vorlagen und Dokumentationen .............................................................. 17
5.1 Vorlagen ......................................................................................................................................... 17
5.2 Funktionen, Makros und Kontextdokumentationen: ..................................................................... 20
6 Schnittstellen-Monitoring und -Management ........................................................................................ 25
7 Zusatzmodule ......................................................................................................................................... 27
8 Weitergabe ............................................................................................................................................. 28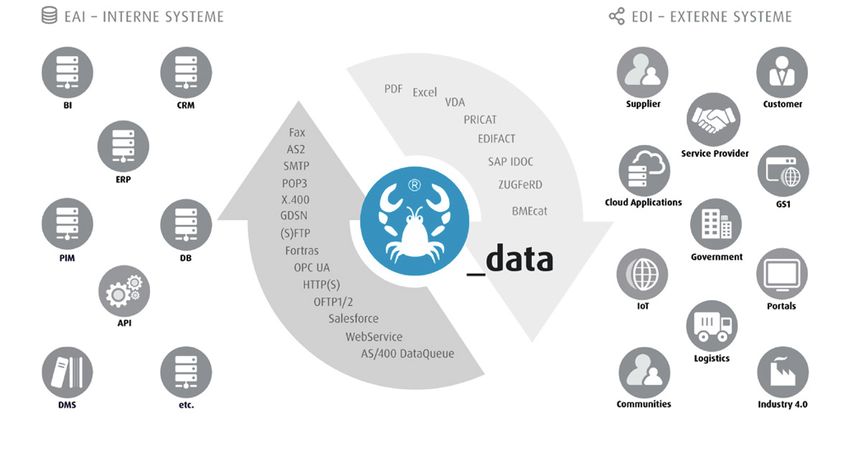
1 Einführung
Lobster_data ist eine intuitiv bedienbare Datenintegrationsplattform. Sie vereinfacht Entwicklung und
Monitoring von Schnittstellen, sowie das Onboarding von Partnern mittels EDI (Electronic Data
Interchange).
1.1 Was ist Lobster_data?
Durch seine grafische Benutzeroberfläche führt _data seine Anwender in einem bewährten sechsstufigen
Prozess durch die „Elektronische Daten- und Applikationsintegration“.
• Integrierte Server-Funktionen
• Kompatibilität mit allen gängigen Industrie-Protokollen
• über 10.000 mitgelieferte Format-Vorlagen und ein
• transparentes Monitoring-Tool
… machen den _data zu einem beliebten Werkzeug, das industrieübergreifend zur Datenkonvertierung
und zum elektronischen Datenaustausch (EDI) verwendet wird.
Ein weiteres Anwendungsgebiet findet sich bei Systemmigrationen zur Applikationsintegration (EAI),
d.h. die Vernetzung unterschiedlicher Ebenen einer Netzwerkhierarchie.
Abbildung 1: Lobster_data transformiert in verschiedenste Formate und wird zur Anbindung von Dienstleistern,
Partnern und Kunden an die eigene IT eingesetzt. Das grafische Baukastensystem (Datendrehscheibe) macht das
Handling von Schnittstellen einfach und auch ohne Programmierkenntnisse möglich.
Technical White Paper Lobster_data 2018 Seite 1 von 28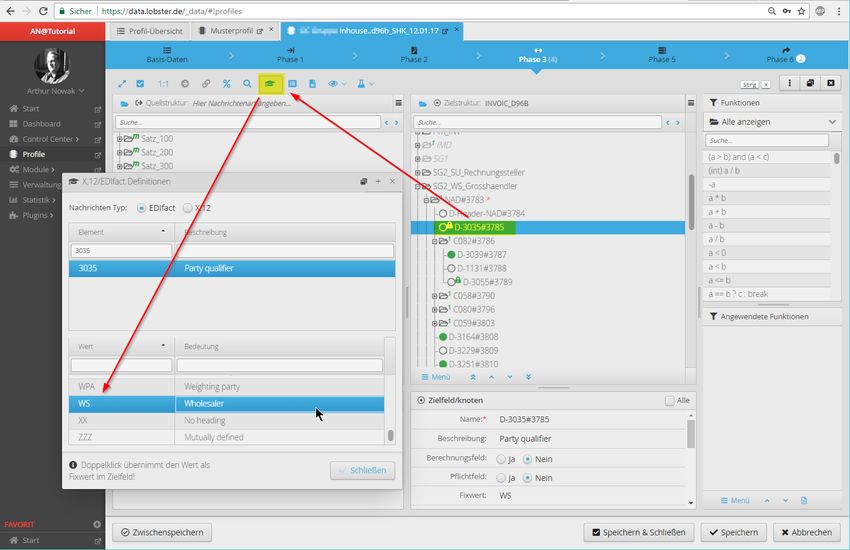
1.2 Für wen ist _data das richtige Werkzeug?
Abbildung 2: Ein Radar-Chart, das veranschaulicht, welche Bedürfnisse _data abdeckt.
_data entflechtet die Schnittstellenentwicklung und führt den Anwender in einem eingängigen, kurzen
Prozess Schritt für Schritt durch die Anbindung.
In der modernen, grafischen Oberfläche findet man sich schnell zurecht, so dass Realisierung,
Verbesserung und Betrieb der Schnittstellen intuitiv wird.
Damit funktioniert die Arbeit mit Lobster_data auch ohne Programmierkenntnisse.
_data ist so entwickelt, dass sich Integrationsszenarien von Anfang bis Ende allein durch Konfigurierung
umsetzen lassen. Das heißt, dass der Anwender mit Auswahlmenüs und Drag and Drop arbeitet, während
_data die Datenströme im Hintergrund entsprechend erstellt.
Lobster_data enthält über 10.000 Vorlagen aller gängigen EDI-Nachrichtenformate und eine Bibliothek aus
ca. 350 vorgefertigten Funktionen. Diese Vorlagen für Bestellungen, Lieferabrufe, Rechnungen, etc.
minimieren Einarbeitungszeiten und Flüchtigkeitsfehler. Damit wird der Start in den elektronischen
Datenaustausch nochmals beschleunigt. Entwicklungs- und Testphasen werden deutlich effizienter.
Technical White Paper Lobster_data 2018 Seite 2 von 28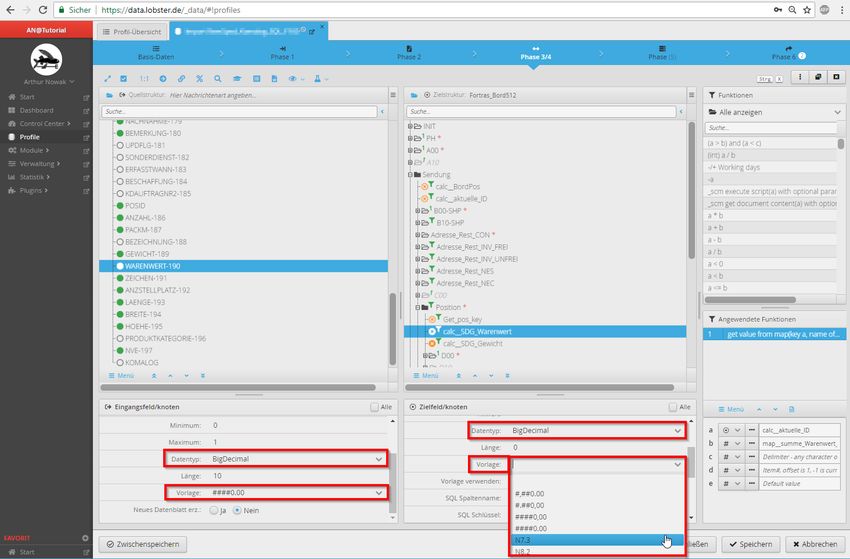
2 Lobster_data Architektur
2.1 Installation
Abbildung 3: Eine Minimal-Installation von _data enthält folgende Systemanbindungen:
Quellsystem, Zielsystem, GUI und Datenbank.
Der _data ist ein auf Java basierendes und damit plattformunabhängiges System, das als Server z.B.
innerhalb eines Rechenzentrums installiert und betrieben wird.
Die Bedienung erfolgt mittels Browser über eine HTML5-Benutzeroberfläche, so dass auch mehrere
Benutzer parallel mit dem Server arbeiten können.
Im Rahmen der Installation wird eine Datenbank angebunden, die dem _data als Repository für
Benutzerdaten, entwickelte Profile etc. dient. Als Profil wird ein konfigurierter Konvertierungsprozess
bezeichnet.
Technical White Paper Lobster_data 2018 Seite 3 von 28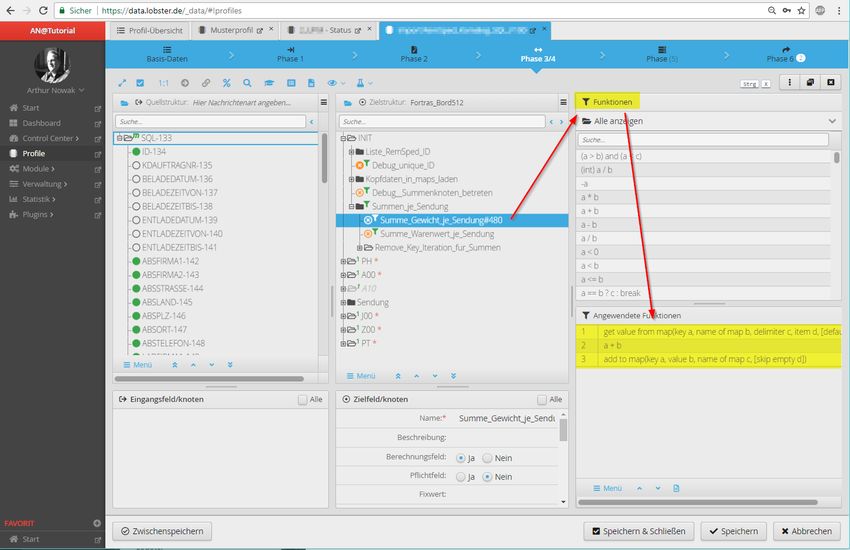
2.2 DMZ Datenempfang
Abbildung 4: Im Zusammenspiel mit einer DMZ-Installation, ist ein _data für den Empfang für Daten vorgesehen.
Der zweite _data, der Prozesse ausführen darf, befindet sich hinter einer zusätzlichen Firewall.
Für den Datenempfang von externen System kann _data in einer DMZ-Umgegbung (DeMilitarisierte Zone)
betrieben werden. Alle mit Dritten stattfindenden Verbindungen werden so an einer vom sensiblen
System getrennten Stelle aufgebaut. Dies erhöht die Sicherheit. Der in der DMZ agierende _data führt
hierbei ausschließlich Kommunikationsaufgaben durch. Die Verarbeitung erfolgt weiterhin auf dem inneren
System.
Der Austausch von Daten erfolgt zwischen den beiden Systemen eventbasiert. Verhindern
Sicherheitsrichtlinien die Verbindungsaufnahme von der DMZ nach Innen, kann eine Reverse-Proxy-
Funktionalität konfiguriert werden (sog. Pushback).
Technical White Paper Lobster_data 2018 Seite 4 von 28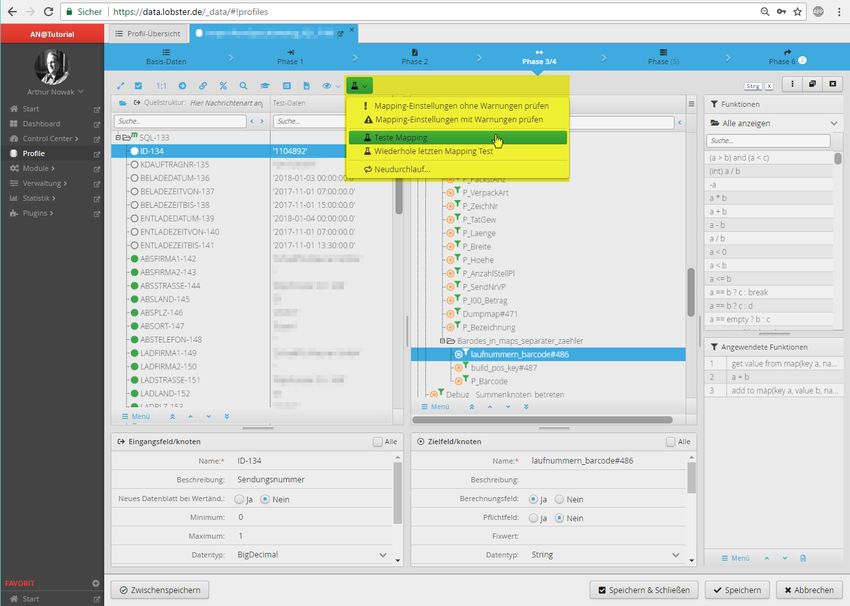
3 Datenkonvertierung nach System – Die Sechs Phasen
Abbildung 5: Eine schematische Darstellung des Mappingprozesses. Die Phasen werden im Folgenden beschrieben.
Technical White Paper Lobster_data 2018 Seite 5 von 28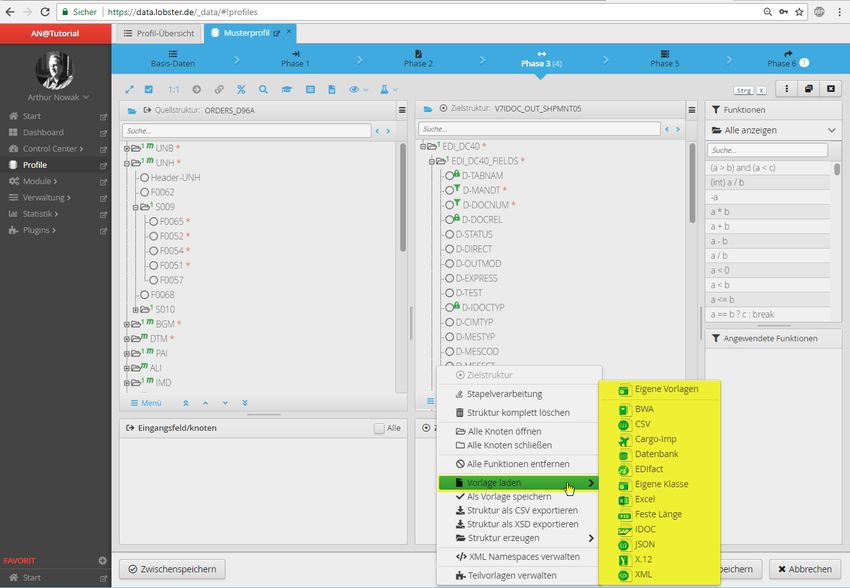
3.1 Phase 1 – Daten empfangen
Abbildung 6: Jeder Eingangsweg benötigt spezielle Einstellungen.
Über diese Kacheln, gelangt man in die gewünschte Maske.
Phase 1 beschreibt den Vorgang des Datenempfangs. Prinzipiell kann hier zwischen zwei Grundprinzipien
unterschieden werden:
• Zeitgesteuertes Prüfen auf neue Daten (Polling) auf lokalen oder entfernten Systemen
• Warten auf Daten, die aktiv in das System eingestellt werden (Push)
Zeitgesteuerte Abrufe sind auf diverse Arten möglich:
• Abruf von Daten in Verzeichnissen (lokal, CIFS)
• Abruf mittels eines Dateitransferprotokolls. Unterstütze Protokolle sind unter anderem FTP(S),
SFTP/SCP, OFTP (Version 1 und 2), HTTP(S), WebService, WebDAV, SAP-RFC-Aufrufe, Mail (POP3,
IMAP) und X.400
• Abruf von Daten aus einer oder mehrerer Datenbanken unter Nutzung von JDBC
Für die Möglichkeit, Daten von Außen direkt eingeliefert zu bekommen (Push) stellt Lobster_data eine
Reihe von integrierten Serverfunktionen bereit. Eine Installation von parallel laufenden Prozessen, wie z.B.
ein FTP-Server, ist hierfür nicht erforderlich. Derzeit nutzbare Protokolle sind unter anderem AMQP, AS2,
IBM DataQueue, FTP(S), HTTP(S), OFTP (Version 1 und 2), OPC(UA), SAP ALE, SMTP und SSH (SFTP und SCP).
Profile von _data können als WebService oder RESTful Service nach Außen bereitgestellt werden, ebenso
ist eine Verkettung von mehreren Profilen möglich.
Technical White Paper Lobster_data 2018 Seite 6 von 28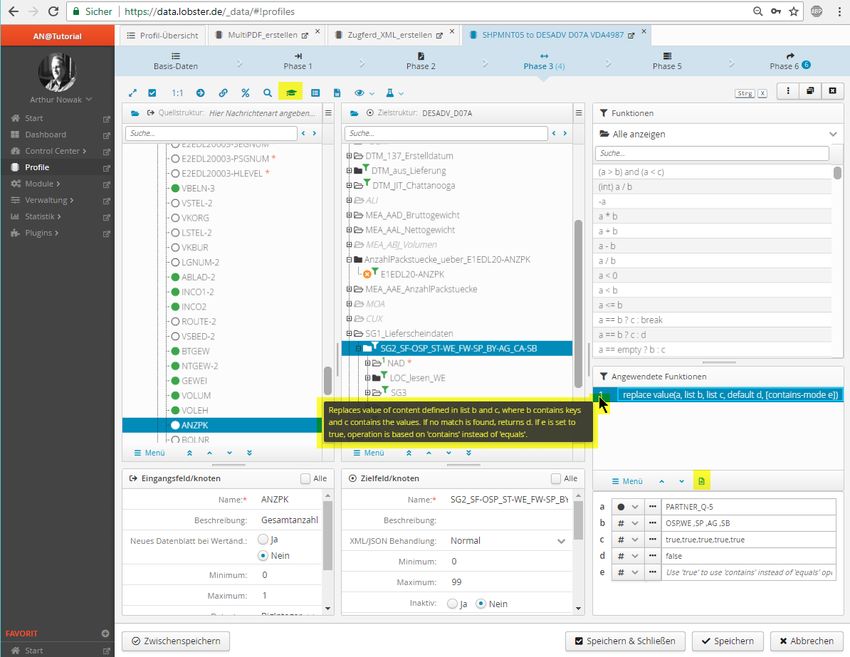
3.2 Phase 2 – Daten parsen
Phase 2 umfasst das Einlesen der Eingangsdaten, d.h. im ersten Schritt die Festlegung des prinzipiell zu
verwendenden Parsers (CSV, XML, …) und das Auswählen der konkreten Eingangsstruktur im weiteren
Verlauf.
Abbildung 7: Hier sehen Sie welche Parser im Standard enthalten sind.
Diese Dateiformate kann _data automatisch in die Quellstruktur laden.
Neben grundsätzlichen Einstellungen zum zu erwartenden Format, können bereits erste Funktionen
verwendet werden, um das Verarbeiten der Daten zu vereinfachen, z.B. das pauschale Entfernen von
führenden und nachfolgenden Leerzeichen. Dies ist sehr praktisch bei Formaten mit Feldern fester Länge
(VDA, Idocs, usw.).
Technical White Paper Lobster_data 2018 Seite 7 von 28
Abbildung 8: Datenbereinigungen wie das Trimmen von Leerzeichen, Prüfungen der Eingangsstruktur etc.
werden hier abhängig vom gewählten Parser ebenfalls angeboten.
Die Quellstruktur, die in Phase 2 befüllt und in der nächsten Phase auf der linken Seite dargestellt wird, ist
eine lebende Schnittstellenbeschreibung. Diese kann man mit Dokumentationen wie Feldbeschreibungen,
Datentypen, Satzkennungen, usw. anreichern und als Excel-Datei, XSD oder RAML (RESTful API Modeling
Language) exportieren.
Für das Aufgliedern der Daten stellt _data bereits Vorlagen für gängige Standards wie EDIFACT, IDoc, XML,
CSV, JSON, Excel, etc. zur Verfügung. Diese enthalten bereits den Algorithmus, wie die eingegangenen
Daten den Feldern im Quellbaum zuzuweisen sind.
Ist das Eingangsformat nicht direkt über einen der vorhandenen Parser lesbar (z.B. ungültiges XML, PDF-
Dateien, mit GZIP komprimierte Dateien, …), kann eine Vorverarbeitung durch einen sogenannten
Preparser vorgeschaltet werden, der hilft die Daten in ein verarbeitbares Format umzuwandeln.
Technical White Paper Lobster_data 2018 Seite 8 von 283.3 Phase 3 – Mapping
Abbildung 9: Der Mapping-Dialog. Hier wählt man die Vorlage der Quell- und Zielstruktur aus und
ordnet die Inhalte per Drag and Drop in das neue Ausgabeformat. Erweiterte Konfigurations-
Einstellungen, der Test-Manager und eine visuelle Aufbereitung der Anpassungen durch grafische
Icons sind hier ebenfalls untergebracht.
Abgesehen von „Datenpumpen“, also Schnittstellen zur reinen Weiterleitung der Nachrichten ohne
inhaltliche oder strukturelle Änderungen, liegt in dieser Phase der Schwerpunkt auf der Konfiguration der
Ausgabeseite.
Profile sind einzelne Konvertierungsprozesse, die den Workflow beschreiben. Sie sind die kleinsten
Bausteine einer _data-Schnittstelle.
In der Mapping-Phase wird die gewünschte Zielstruktur erstellt sowie der Zusammenhang zwischen Quell-
und Zielstruktur konfiguriert (Mapping). Dies geschieht über Feldzuordnungen (per Drag and Drop),
Eintragen von Fixwerten, und Einsatz von ca. 350 Funktionen bzw. einer Kombination davon.
So ist es zum Beispiel möglich, anhand eines Werts der Eingangsseite (Artikelnummer) in einer Datenbank
die Gültigkeit und eventuell Verfügbarkeit eines Artikels zu prüfen, um beim Scheitern der Prüfung das
Mapping mit einer sprechenden Fehlermeldung abzubrechen.
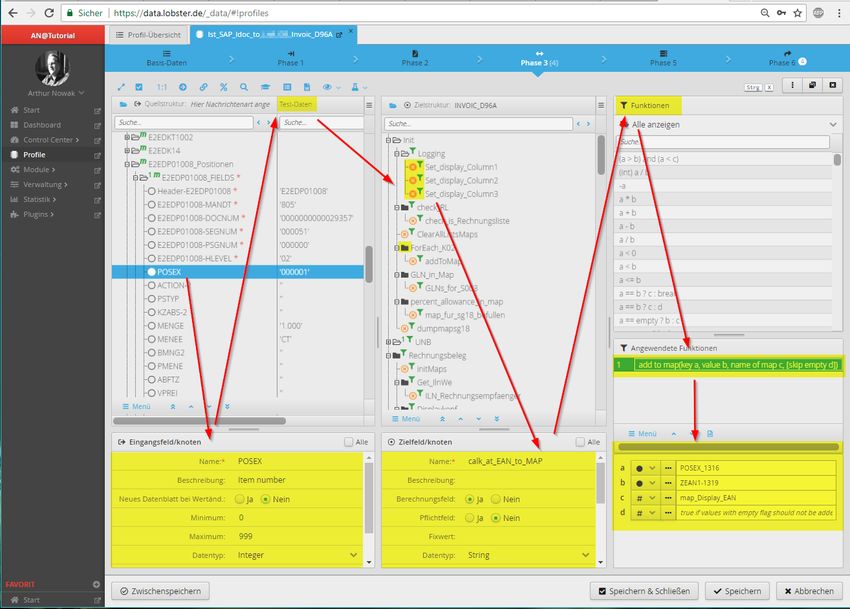
Technical White Paper Lobster_data 2018 Seite 9 von 28Abbildung 10: Der Lebensweg eines Parameters: Feld in der Quellstruktur, in der dieser erscheint; zur
Übersicht kann ein Beispielwert direkt mit angezeigt werden; das Zielfeld, in das der Parameter zu
positionieren ist; und Funktionen zur erweiterten Datenmanipulation, die auf das entsprechende Feld
gelegt werden können.
Als Funktionen steht eine breite Palette an Möglichkeiten zur Verfügung, z.B. die Anreicherung von Daten
aus Drittquellen (DB, WebService, etc.), das Berechnen von Werten (mathematisch, Textmanipulationen,
Datumsberechnungen, etc.) oder auch das Entscheiden von Mappingverläufen anhand von logischen
Bedingungen und vieles mehr. Funktionen können miteinander verkettet werden, so dass sich hierdurch
beliebig komplexe Abläufe abbilden lassen.
Abbildung 11: Will man die eigene Entwicklung testen oder Fehler im produktiven Prozess
analysieren, kann man sich über die „Teste-Mapping“-Funktion die Quelldatei bequem
entschlüsseln. Die Werte werden in die vorgesehenen Felder geladen.
Das Programm springt direkt an die gesuchte Stelle.
Technical White Paper Lobster_data 2018 Seite 10 von 28Abbildung 10: Eine Ansicht des Test-Dialogs: Links die aufbereitete, bezettelte Quelldatei, rechts die
Zielstruktur mit den errechneten Inhalten. Über das Kontextmenü lässt sich ins Log springen, so dass
man Schritt für Schritt die Verarbeitung verfolgen kann und Inhalte von Variablen, Listen und Maps
einsehen kann.
Bei der Erstellung von Mappings ist es wichtig, frühzeitig Feedback darüber zu erhalten, ob man „auf dem
richtigen Weg“ ist. _data unterstützt den Nutzer hierbei auf verschiedene Weise.
Durch Farbkodierungen, Icons auf Feldern und Knoten und andere visuelle Hilfsmittel, wird dem Benutzer
dargestellt, ob es sich z.B. um Felder handelt, die in der Zielstruktur erscheinen sollen oder nur für die
Zwischenberechnung von Werten verwendet werden (Berechnungsfelder). Weitere Visualisierungen
existieren z.B. für Informationen zu Pflichtfeldern, Feldern mit fixen Werten, etc.
Eingangsdaten können als Beispieldaten eingelesen werden. Die ermittelten Werte werden jeweils neben
dem ihnen zugewiesenen Feld angezeigt. Dies erleichtert beim Arbeiten die Wahl des korrekten
Eingangsfeldes bzw. zeigt frühzeitig Fehler in der Eingangsstruktur auf, wenn z.B. ein Feld mit Namen
Dokumentdatum etwas anderes als ein Datum enthält.
Den Fortschritt eines Mappings prüft man mittels der „Teste Mapping“-Funktion. Hierbei wird eine
Eingangsdatei testweise anhand des aktuellen Standes gemappt und das Ergebnis als Baum (vergleichbar
mit der Anzeige der Daten im Eingangsbaum) dargestellt. Dies erlaubt es festzustellen, ob angewendete
Logiken korrekt ausgeführt werden, die Werte in den richtigen Feldern erscheinen und wiederholt
auszuführende Teilbereiche (z.B. Bestellpositionen) auch so oft wie nötig erscheinen.
Werden diese Tests zeitnah nach dem Vornehmen von Änderungen am Mapping durchgeführt, sind
Korrekturen im Falle eines falschen Ergebnisses schneller möglich, da man gedanklich weiterhin mit dem
Teilproblem beschäftigt ist und daher Fehleinstellungen oder falsche Implementierungen von Logiken
schneller erkennt und korrigieren kann.
Technical White Paper Lobster_data 2018 Seite 11 von 283.4 Phase 4 – Datenbankoperationen (optional)
Beim Mappen der Daten können aufgrund von Attributen, die man in Phase 3 gesetzt hat, automatisch
SQL-Statements erzeugt werden.
Über _data lassen sich alle Statements ausführen, die Ihre Datenbank kennt. Zusätzlich gibt es bei
„Inserts“ noch Einstellungen „try update before insert“, „delete before insert“, „only update“ und „only
delete“.
Hier lassen sich auch „stored procedures“, also eine vorher festgelegte Abfolge von
Anweisungen/Berechnungen auf Datenbankebene, aufrufen, sowie mittels Transaktionssteuerung auch
die Häufigkeit der Statements und selektive Zugriffe auf die Datenbank festlegen.
Falls SQL-Anweisungen dynamisch, also abhängig von Variablen, angesprochenen Datenbanken etc.
freigeschaltet werden sollen, lässt sich das in dieser Phase mit wenigen Mausklicks einstellen.
3.5 Phase 5 – Integration Unit
Abbildung 11: Eine Auswahl der mitgelieferten Klassen zur Nachbearbeitung der Zielstruktur.
In diesem Schritt können die Daten aus der Zielstruktur nachbearbeitet werden.
Wenn z. B. PDFs für z.B. Etiketten zu erzeugen sind, lässt sich hier eine Vorlage wählen, die Ihre Daten in
eine Layout-Datei füllt. Weitere häufig verwendete Vorlagen sind Edifact, XML, Excel-Format, etc.
Diese bringen auch formatspezifische, zusätzliche Einstellungsmöglichkeiten mit.
Somit lassen sich Standardeinstellungen wie „Titelzeilen Ein- und Ausblenden“, die gebündelte Ausgabe
von Dateien, benutzerdefinierte Trennzeichen, etc. zentral festlegen.
Technical White Paper Lobster_data 2018 Seite 12 von 283.6 Phase 6 – Daten versenden
Abbildung 12: Wie beim Datenempfang lässt sich hier ein Ausgangsagent festlegen. Je nach dem, wie
die Datei zu übertragen ist, wird eine darauf abgestimmte Konfigurationsmaske erscheinen.
Sollten mehrere Antwortwege hinterlegt sein, findet man hier die Auflistung.
Technical White Paper Lobster_data 2018 Seite 13 von 28Abbildung 13: Beispiel: X.400-Antwortweg; Neben der Empfänger-Adresse (auch wählbar über
Zuordnung eines Partnerkanals, in dem die Daten in einer Art Adressbuch hinterlegt sind), werden
hier auch Inhaltseinstellungen (Komprimieren oder nicht, Nachbearbeitung, ...), Abhängigkeiten vom
Erfolg anderer Antwortwege und die gebündelte Übertragung eingestellt.
Die erstellte Nachricht kann auf beliebig vielen unterschiedlichen Antwortwegen versendet werden. Einer
davon wäre z. B. die automatische Erstellung von Sicherungskopien der Nachrichten.
Neben den gängigen Protokollen wie X.400, AS2, SAP, SAP ALE, Datei, FTP, HTTP(S), Mail(SMTP) werden
auch AS/400, AMQP, SMS, FAX, SCP, WebDAV, Cloud Storage und API unterstützt. Unter diesen befinden
sich Konstrukte wie Trigger für Folge-Schnittstellen, Übergabe der Daten für die gebündelte Versendung
oder an ein Dispatcher-Profil, welches die Daten abhängig vom Inhalt an die richtigen Prozesse leitet.
Antwortwege lassen sich so gestalten, dass sie in Abhängigkeit voneinander ausgeführt werden z. B. bei
Erfolg/Misserfolg oder anhand von im Mapping definierten Variablen. Dies erlaubt es, ein Profil für
verschiedene Empfänger zu verwenden, bei dem die gleiche Art Zieldatei einmal über z.B. FTP an Partner 1
und über AS2 an Partner 2 gesendet wird.
Sollte das Versenden oder Weiterverarbeiten fehlschlagen, erscheint ein Hinweis im zentralen
Monitoring(Control Center-Modul). Dieser Hinweis kann auch als Mail(SMTP) oder auf anderen
Kommunikationswegen mit dem Fehlerlog zugestellt werden. Zum Ergebnis lassen sich so umfangreiche
Eskalationsszenarien festlegen.
Technical White Paper Lobster_data 2018 Seite 14 von 284 Kommunikationsprotokolle
Abbildung 14: Eine Einführung in die wichtigsten Kommunikationsprotokolle, die
_data unterstützt finden Sie wenn Sie „edi-wissen“ googeln.
Als Allround-Plattform macht _data das Thema „elektronischer Datenaustausch“ jedem Nutzer zugänglich.
Auf der Seite edi-wissen.de werden Konzepte wie EAI, EDI, ESB, ETL/ELT, SOA, sowie Datenformate und
Nachrichtenstandards und auch Kommunikationsprotokolle erklärt und anhand von Beispielen
veranschaulicht.
Diese Seite dient zum einen als Unterstützung für EDI-Enthusiasten, beschreibt aber auch in Lobster_data
unterstütze Protokolle und dient als Einstieg in Mapping-Projekte.
Im Standard bringt _data bereits Tools zum Handling von Kommunikationsprotokollen, wie
• AMQP
• AS2
• CommLog
• IBM/AS400
• FAX
• FTP
• http(SOAP, REST)
• (IOT)
• Message(Trigger vorgeschalteter Profile etc.)
• OFTP
• SAP ALE
• SMS
• SMTP
• SSH
• Cloud Storage
Auf www.lobster.de/lobster_data/ finden Sie weitere enthaltene Features, wie
Technical White Paper Lobster_data 2018 Seite 15 von 28• eingebettete AS2- und Odette-Zertifizierungs-Workflows
• Benutzerverwaltung
• automatische Anmeldungen an verschlüsselten Drittsystemen, etc.
• Engdat
• uvm.
Nachrichtenformate, für die bereits Konvertierungs-Vorlagen enthalten sind:
• BWA
• CSV
• Cargo-Imp
• Datenbank
• EDIFACT
• Excel
• Fixrecord (z.B. VDA)
• IDoc
• JSON
• X.12
• XML
• etc.
_data kann auf Wunsch durch seine Release-sicheren API erweitert werden.
Der Lobster_data fügt sich somit nahtlos in bestehende Systemlandschaften ein und automatisiert auf
flexible Weise EDI-Prozesse.
Technical White Paper Lobster_data 2018 Seite 16 von 285 Unterstütztes Mapping durch Vorlagen und Dokumentationen
5.1 Vorlagen
_data enthält viele Elemente, die den Anwender bei der Anbindung von Systemen unterstützen.
Erfahrungen aus 20 Jahren EDI- und Systemintegration bei über 1000 Kunden in allen Industrien sind in den
eingebauten Vorlagen und Funktionen verdichtet.
Durch diese Strukturen lassen sich Fehler beim Mapping und Unsicherheiten bezüglich Anforderungen an
das Zielformat vermeiden.
Zusätzlich wird auch durch enthaltene Schablonen und eingebettete Kontextdokumentationen die
Entwicklungszeit erheblich verkürzt.
Die Philosophie einer fehlertoleranten und unterstützenden Software wurde durch Elemente sichergestellt,
wie
• Profilvorlagen (bereits entwickelte Muster, die als Schablonen für analoge Schnittstellen vererbt
werden können. Das ist z. B. praktisch bei Kunden, die weltweit nur ein Format z. B. IDoc, EDIFACT
verwenden, bei dem sich aber z. B. Quell- und Zielsysteme stellenweise unterscheiden)
• Vorlagen für Quell- und Zielstruktur (da der elektronische Datenaustausch häufig sehr standardisiert
ist, Formate wie IDOCs, VDA, EDIFACT aber komplexe Strukturen haben, die sich auch in
unterschiedlichen Versionierungen unterscheiden, enthält _data bereits vorgefertigte Muster. Diese
enthalten die Standard-Struktur inkl. Hilfe, wie Feldbeschreibungen, Zählervariablen, Zeitstempel,
etc..
Abbildung 15: Vorlagen sind bereits im Standard-_data enthalten. Mit wenigen Klicks lässt
sich die Struktur laden.
Technical White Paper Lobster_data 2018 Seite 17 von 28Abbildung 17: in Nachrichtentyp (hier die Edifact-Rechnung) existiert in unterschiedlichen
Versionen. _data enthält hier viele Vorlagen, so dass Sie sich um den Aufbau von
Segmenten, die Syntax etc. wenig Gedanken machen müssen.
Abbildung 16: Den Feldinhalt kann man konvertieren, indem man die gewünschten Datenformate auswählt und die davon
abhängigen Formatvorlagen auswählt.
• Formatvorlagen für Werte von Zielfeldern: Datenformate zu konvertieren ist eine klassische
Anforderung an einen Konverter. Ein Beispiel ist; einen kommagetrennten Betrag in einen
gerundeten, durch Punkt getrennten Betrag zu überführen. Viele häufig verwendete Vorlagen
erleichtern solche Konvertierungen. Weitere Beispiele sind: Einstellungen zum Auffüllen von Feldern
mit Nullen, dem Umschreiben von Zahlen- oder Datumsformaten nach Bedarf, etc..
Technical White Paper Lobster_data 2018 Seite 18 von 28Abbildung 18: Ein Datum kann z.B. folgendermaßen ausgegeben werden.
HH, dd, … sind Platzhalter, die nach Wunsch kombiniert werden können.
• Vorlagen für Integration Units: Siehe hierzu Seite 12 „3.5 Phase 5: Integration Unit“
• Integrierte Bibliotheken von Codelisten für viele Formate: Edifact-Nachrichten dienen vor allem
dem Informationsaustausch zwischen Maschinen. Informationen wie zum Beispiel Lieferbe-
dingungen, Transportarten, Zusatzinformationen zu Geldbeträgen werden nur noch als Code
übertragen.
Welches Kürzel man braucht, kann man sich einblenden lassen. _data sucht die entsprechende
Codeliste für das verwendete Format und das markierte Feld heraus. So lassen sich Recherchen im
Netz und in Schnittstellendokumentationen auf ein Minimum reduzieren.
Abbildung 19: _data enthält die richtigen Codes bereits in der Strukturvorlage.
Diese sind mit den Feldern verknüpft,
so dass hier Zeit gespart und Fehlern vorgebeugt wird.
Diese Vorlagen sorgen für eine stabile, verlässliche Schnittstelle und verhindern durch Ausblenden falscher
Einstellungen gängige Flüchtigkeitsfehler.
Da lange Nachrichtentypen, in denen Details entscheidend sind (z.B. Rechnungen), alltäglich sind,
ist diese Art der Qualitätssicherung ein großes Plus.
Technical White Paper Lobster_data 2018 Seite 19 von 285.2 Funktionen, Makros und Kontextdokumentationen:
Wenn Sie aber Pionierarbeit leisten und das Rad neu erfinden müssen, hilft _data mit gut durchdachten
Bausteinen.
Neben einer Vielzahl an Standard-Funktionen, die logische Abfragen, Rechenoperationen, String-
Manipulationen etc. durchführen, sind auch exotischere Methoden erhalten, mit denen sich Webservices
aufrufen oder Hashwerte berechnen, Passwörter erstellen, Verzeichnisse durchsuchen lassen, uvm..
Abbildung 20: Die gewünschte Funktion lässt sich aus einer gruppierten und direkt zugänglichen
Auswahl ziehen.
Technical White Paper Lobster_data 2018 Seite 20 von 28Abbildung 21: Berechnungsfelder, die „auszukommentieren“ sind, werden durch ein
orangenes Icon markiert. Funktionen lassen sich nach Belieben verketten.
Durch intensiven Einsatz von Tooltips und Kontext-Dokumentationen findet man sich schnell in der Struktur
zurecht. Lernzeiten und Rechercheaufwände werden damit drastisch verkürzt. Die Orientierung wird
erleichtert.
Technical White Paper Lobster_data 2018 Seite 21 von 28Abbildung 22: Was die Funktion im Detail macht, sieht man an dem Tooltip, der erscheint,
wenn man mit der Maus drüber fährt. Die Art des benötigten Inputs sieht man an den
Beschriftungen der Parameter-Felder. Beispiele finden Sie, wenn Sie auf das Dokument-Icon
klicken.
Technical White Paper Lobster_data 2018 Seite 22 von 28Abbildung 24: Die Dokumentation, inkl. Mappingbeispiele des Parsers, Postexecuters, Integration
Units und Antwortweges, in dem Sie sich gerade befinden, erreichen Sie über den Fragezeichen-
Button.
Abbildung 23: Bespieldokumentation/Hilfe zur Integration-Unit, die die Zielstruktur als XML
aufbereitet.
Technical White Paper Lobster_data 2018 Seite 23 von 28Grundsätzlich hat jede Funktion, Preparser, Postexecuter, Integration Unit und Antwortweg eine an Ort und Stelle verlinkte und über einen Fragezeichen-Button erreichbare Kontext-Dokumentation. Man springt hier ohne lange zu suchen direkt in den Eintrag, der die Funktionsweise beschreibt, Konfigurationsmöglichkeiten empfiehlt und Beispiele enthält. Technical White Paper Lobster_data 2018 Seite 24 von 28
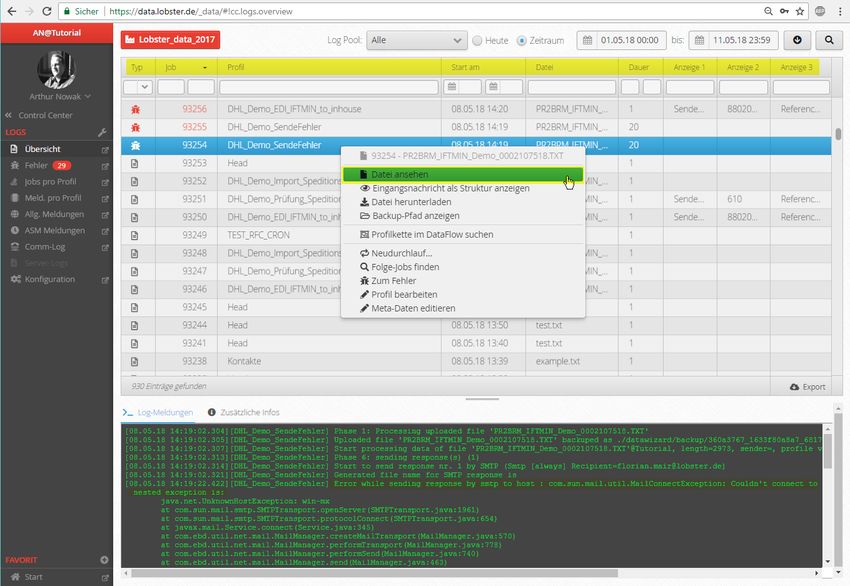
6 Schnittstellen-Monitoring und -Management
Über das Control Center wird der gesamte Schnittstellenbetrieb gemanagt.
Abbildung 25: Über einen Rechtklick auf den Job, lassen sich Quell- und Zieldateien einsehen,
runterladen, Jobs neu starten, etc…
Hier lässt sich nicht nur auf einen Blick sehen, was gerade passiert, sondern es lässt sich aus dieser Ansicht
direkt tiefer in den Prozess springen und direkt eingreifen.
Die wichtigste Ansicht ist die Jobübersicht, die die gelaufenen Jobs darstellt. Abgebrochene Jobs sind sofort
erkennbar. Über das Kontextmenü und das unten eingeblendete Fehlerlog erkennt man schnell, an
welcher Stelle der Fehler lag und was passiert ist. Die Eingangs- und Zieldateien lassen sich mittels
Kontextmenü einsehen.
Somit erspart man sich viele Rückfragen, das Suchen nach Ablageverzeichnissen und das erneute Anfragen
von Eingangsdateien. Eine erweiterte Suchfunktion findet Jobs anhand des Namens, sowie auch anhand
von Dateinamen, Metadaten, Feldwerten etc. Mittels einer „Elastic Search Indizierung“ kann die Suche
auch auf eigene Merkmale erweitert werden.
Auch laufende Jobs, Kommunikations-, SQL-Logs, etc. lassen sich in Echtzeit beobachten. Vertiefende
Überwachungs- und Recherchetools sind ebenfalls untergebracht: Alle Kommunikationslogs,
Jobzusammenfassungen, Fehlerlogs, Tracking-Einstellungen und Systemstatistiken sind in diesem Modul
untergebracht. Über Kontextmenüs springt man direkt in die dahinter stehenden Prozesse und Dateien und
kann diese bearbeiten.
Sobald der Fehler korrigiert ist, lassen sich direkt aus dieser Ansicht Jobs neu auslösen. Durch die schnellen
Verarbeitungszeiten erhält man direktes Feedback. Korrektur- und Entwicklungszyklen werden erheblich
Technical White Paper Lobster_data 2018 Seite 25 von 28vereinfacht. Da man diese Schritte schnell am Stück durchführen kann, entfallen lange Leerlaufzeiten. So wird vermieden, sich mehrfach in ein Thema eindenken zu müssen. Technical White Paper Lobster_data 2018 Seite 26 von 28
7 Zusatzmodule
Für Spezialanforderungen bietet Lobster_data folgende Zusatzmodule:
• Asynchrones Sendemodul (ASM), das Übertragung einer beliebigen Anzahl von Dateien
bündelt
• Managed File Transfer (MFT) für den sicheren und einfachen Datenaustausch
• ContentInspection (CI), die Dateien abhängig vom Inhalt auf unterschiedliche Schnittstellen
verteilen kann und erweiterte Vorverarbeitungsmöglichkeiten bietet
• DataFlow erzeugt automatisch ein Ablaufdiagramm von Profilketten, markiert grafisch die Stelle
von Profilabbrüchen und zeigt Simulationsläufe
• Demilitarisierte Zone (DMZ) schützt das Firmennetzwerk vor öffentlichen Zugängen durch eine
Installation, welche Dateien entgegennimmt und hinter einer zusätzlichen Firewall steht
• Massendatenverarbeitung mit XML verringert die Speicherauslastung und führt zu hoher
Performance
• WebMonitor stellt wichtige Teilinformationen des Lobster_data-ControlCenters übersichtlich in
einem beliebigen Webbrowser zur Verfügung
• Webportal, das Eingangsbäume automatisch in ein HTML-Frontend wandelt, so dass Mitarbeiter,
Partner oder Kunden freigegebene Geschäftsprozesse online abwickeln können
• Prozesslastoptimierung (PLO) für eine optimierte Abarbeitung bei sehr hohem
Prozessaufkommen
• LoadBalancing, das Konvertierungsaufgaben beschleunigt, indem es Jobs auf aktive
Lobster_data-Nodes verteilt
• Salesforce API für die bequeme Anbindung an Salesforce
• TestcaseManager für automatisches Testen aktiver Profile
Technical White Paper Lobster_data 2018 Seite 27 von 288 Weitergabe Copyright für das vorliegende Dokument: © Lobster GmbH, 2018. Eine Weitergabe dieses White Papers ist nur mit ausdrücklicher Genehmigung durch Lobster gestattet. Die Genehmigung muss in schriftlich erfolgen. Technical White Paper Lobster_data 2018 Seite 28 von 28
Sie können auch lesen

















































