Verteilte Hyperparameteroptimierung für neuronale Netze mit Gearman und Keras
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Masterarbeit Fakultät Informatik Verteilte Hyperparameteroptimierung für neuronale Netze mit Gearman und Keras Studiengang Informatik Vor- und Zuname: Christopher Tent Matrikelnummer: 00069259 Ausgegeben am: 27.01.2021 Abgegeben am: 30.03.2021 Erstprüfer: Prof. Dr. rer. nat. Franz Regensburger Zweitprüfer: Prof. Dr. Munir Georges
Inhalt Erklärung ...................................................................................................................................... iii Abbildungsverzeichnis ................................................................................................................. iv Tabellenverzeichnis ...................................................................................................................... iv Abkürzungsverzeichnis ................................................................................................................. v Listingverzeichnis ......................................................................................................................... v 1 Einleitung.............................................................................................................................. 1 1.1 Aufbau der Arbeit ........................................................................................................ 2 2 Grundlagen ........................................................................................................................... 3 2.1 Neuronale Netze........................................................................................................... 3 2.1.1 Training.................................................................................................................... 5 2.1.2 Drop-out .................................................................................................................. 6 2.2 Konvolutionale neuronale Netze.................................................................................. 6 2.3 Hyperparameteroptimierung ........................................................................................ 8 2.3.1 Grid Search .............................................................................................................. 9 2.3.2 Random Search ........................................................................................................ 9 2.3.3 Hyperband ............................................................................................................... 9 2.3.4 Herausforderung Hyperparameteroptimierung ...................................................... 10 2.4 Statistische Grundlagen ............................................................................................. 11 2.4.1 Normalverteilung ................................................................................................... 11 2.4.2 Messfehler ............................................................................................................. 13 2.5 Regression .................................................................................................................. 13 2.5.1 Bestimmtheitsmaß ................................................................................................. 14 2.5.2 Lineare und nichtlineare Regression ..................................................................... 14 3 Vorstellung der zugrunde liegenden Bachelorarbeit ........................................................... 16 3.1 Aufbau des CNN ........................................................................................................ 16 3.1.1 Verwendeter Bilddatensatz .................................................................................... 16 3.1.2 CNN ....................................................................................................................... 16 3.1.3 Herausforderungen ................................................................................................ 17 4 Entwicklung der verteilten Grid Search Anwendung ......................................................... 18 4.1 Skalierbarkeit ............................................................................................................. 18 4.2 Cluster Computing ..................................................................................................... 18 4.2.1 Clusterarten............................................................................................................ 19 4.3 Vorstellung des Clusters und der verwendeten Technologien .................................... 19 4.3.1 PC-Pool.................................................................................................................. 19 4.3.2 Job-Server .............................................................................................................. 20 4.3.3 Virtualisierung mit Docker .................................................................................... 21 4.4 Finaler Aufbau und Konzeption ................................................................................. 23 4.4.1 Verwendete Bibliotheken und Beschreibung der Images ...................................... 23 i
4.4.2 Ablauf der HPO ..................................................................................................... 24 5 Evaluation der Anwendung................................................................................................. 26 5.1 Bestimmung der Laufzeit auf einem Rechner............................................................ 26 5.1.1 Speedup und Effizienz ........................................................................................... 26 5.1.2 Eliminierung der systematischen Fehler ................................................................ 27 5.1.3 Vorhersage der Laufzeit der HPO .......................................................................... 28 5.2 Durchführung der HPO mit 36 Konstellationen ........................................................ 29 5.2.1 Vorstellung der Hyperparameter ............................................................................ 29 5.2.2 Auswertung............................................................................................................ 29 5.3 Erweiterte HPO .......................................................................................................... 31 5.3.1 Durchführung......................................................................................................... 31 5.3.2 Auswertung............................................................................................................ 32 5.4 Regressionsanalyse .................................................................................................... 34 5.4.1 Messaufbau ............................................................................................................ 34 5.4.2 Bestimmung der Regressionskurve ....................................................................... 35 5.4.3 Auswertung und Interpretation .............................................................................. 37 5.5 Reduzierung der Laufzeit durch vertikale Skalierung ............................................... 39 6 Vergleich mit Keras Tuner .................................................................................................. 42 6.1 Bestimmung der Vergleichskriterien .......................................................................... 42 6.2 Vorstellung des Keras Tuners ..................................................................................... 43 6.3 Umsetzung des Keras Tuners ..................................................................................... 45 6.4 Vergleich der Laufzeit ................................................................................................ 46 6.5 Vergleich der Fehlertoleranz ...................................................................................... 47 6.5.1 Hardwareausfall ..................................................................................................... 47 6.5.2 Softwarefehler ....................................................................................................... 47 6.5.3 Simulieren des Ausfalls eines Workers .................................................................. 48 6.6 Vergleich des Code Aufwands ................................................................................... 48 6.7 Ergebnis ..................................................................................................................... 50 7 Fazit und Ausblick .............................................................................................................. 51 Anhang ........................................................................................................................................ 53 Literaturverzeichnis ..................................................................................................................... 58 ii
Erklärung Ich erkläre hiermit, dass ich die Arbeit selbständig verfasst, noch nicht anderweitig für Prüfungszwecke vorgelegt, keine anderen als die angegebenen Quellen oder Hilfsmit- tel benützt sowie wörtliche und sinngemäße Zitate als solche gekennzeichnet habe. Ingolstadt, den 30.03.2021 Christopher Tent iii

Abbildungsverzeichnis Abbildung 1: Aufbau eines künstlichen Neurons .......................................................................... 3 Abbildung 2: Aktivierungsfunktionen ........................................................................................... 4 Abbildung 3: Vollvernetztes KNN mit zwei verborgenen Schichten ............................................ 4 Abbildung 4: Darstellung des Filters eines Neurons in einem CNN............................................. 7 Abbildung 5: Eingabegröße eines Neurons in einem CNN (siehe Albawi et al. 82017, S. 2) ...... 7 Abbildung 6: Beispiel für einen Hyperparameterraum mit zwei Dimensionen ............................ 8 Abbildung 7: Beispiel für die Durchführung des Hyberband Algorithmus (siehe Li et al. 2018, S. 9) ............................................................................................................................................. 10 Abbildung 8: Normalverteilungskurve ........................................................................................ 11 Abbildung 9: Flächenanteile bei der Normalverteilung (siehe Hedderich und Sachs 2016, S. 264).............................................................................................................................................. 12 Abbildung 10: Regressionsgerade (siehe Adamek 2016, S. 328)................................................ 14 Abbildung 11: Kommunikationsablauf Gearman (gearman 2013) ............................................. 20 Abbildung 12: Ausführung von Containern (siehe Mouat 2016, S. 5) ........................................ 22 Abbildung 13: Docker Images im Cluster ................................................................................... 23 Abbildung 14: Rechenzeit der einzelnen Worker bei der HPO ................................................... 29 Abbildung 16: Zusammenhang zwischen der Anzahl der Neuronen und der Fehlerrate ............ 33 Abbildung 16: Zusammenhang zwischen der Anzahl der Neuronen und der Trainingszeit ....... 33 Abbildung 17: Streudiagramm der gemessenen Worker-Zeit Tupel für die Regressionsanalyse 35 Abbildung 18: Analyse des Einflusses einzelner Punkte auf die Regressionskurve ................... 36 Abbildung 19: Darstellung der Residuen und Vergleich zur Normalverteilung.......................... 37 Abbildung 20: Regressionskurve t_2 .......................................................................................... 37 Abbildung 21: Laufzeit zum Training mehrerer CNN auf der RTX 2070 Super ........................ 40 Abbildung 22: Ablauf der HPO mit Keras Tuner ........................................................................ 44 Abbildung 23: Verteilung der Docker Images für Keras Tuner im Cluster ................................. 45 Tabellenverzeichnis Tabelle 1: Corsos Parameter für die HPO. Es ergeben sich 36 HP-Tupel ................................... 17 Tabelle 2: Rechenzeit 1 hintereinander ausgeführter Trainings ............................................. 28 Tabelle 3: HP-Konstellation für die Messung von 1 .............................................................. 28 Tabelle 4: Die ermittelten CNN mit den geringsten Fehlerraten ................................................. 30 Tabelle 5: Die zehn CNN mit der geringsten Fehlerrate ............................................................. 32 Tabelle 6: Paralleles Trainieren von mehreren CNN auf einer Grafikkarte ................................ 40 Tabelle 7: Vergleichskriterien und Priorisierung ......................................................................... 43 Tabelle 8: Laufzeitergebnisse der HPO ....................................................................................... 47 Tabelle 9: Zusammenfassung der Vergleichsergebnisse .............................................................. 50 iv
Abkürzungsverzeichnis CNN ............................................................................................... Convolutional Neural Network CPU .......................................................................................................... Central Processing Unit CSV ........................................................................................................ Comma-separated values GPU ........................................................................................................Graphics Processing Unit HAC ........................................................................................................ High Availability Cluster HP ..........................................................................................................................Hyperparameter HPC ....................................................................................................... High Performance Cluster HPO ................................................................................................... Hyperparameteroptimierung HTC ......................................................................................................... High Throughput Cluster KNN ................................................................................................... Künstliches neuronales Netz NFS................................................................................................................. Network File System NN ......................................................................................................................... Neuronales Netz ReLU ............................................................................................................. Rectified Linear Unit RPC ............................................................................................................ Remote Procedure Call SH ......................................................................................................................Successive-Halfing SSH.............................................................................................................................. Secure Shell VRAM ............................................................................................ Video Random Access Memory Listingverzeichnis Listing 1:Keras Code zum Erstellen eines CNN (Corso 2019, S. 36) ......................................... 16 Listing 2: Befehl zum Starten des Docker Worker Images ......................................................... 24 Listing 3: Befehl zum Starten des Trainings eines CNN mit übergebenen Hyperparametern .... 24 Listing 4: Anmeldung eines Workers bei dem Gearman Server.................................................. 25 Listing 5: Client startet Training eines einzelnes HP-Tupels über Gearman Server ................... 25 Listing 6: Definition des Hyperparameterraums in Python ......................................................... 29 Listing 7: Definition der Architekturen der CNN abhängig von der Neuronenzahl in Python ... 31 Listing 8: Beispiel für die Umsetzung einer HPO mit Keras Tuner ............................................ 43 v
1 Einleitung In den letzten Jahren hat die künstliche Intelligenz stark an Bedeutung gewonnen. Unter anderem wurden dabei immer mehr Aufgabenbereiche, für die neuronale Netze eingesetzt werden können, erschlossen. Dazu zählen bereits seit 2006 auch komplexere Aufgaben wie die Bilderkennung. Dies wurde durch den von Hinton et al. vorgestellten Algorithmus zum „Deep-Learning“, also dem Trainieren mehrschichtiger neuronaler Netze ermöglicht. Seitdem werden neuronale Netze (NN) in immer mehr Anwendungsgebieten erfolgreich eingesetzt. Eine Prognose von IDC sagt voraus, dass im Jahr 2024 der weltweite Umsatz im Bereich der künstlichen Intelligenz bei über 500 Milliarden US-Dollar liegen wird (vgl. Statista - IDC 2021). Mit der wachsenden Komplexität der Aufgaben steigt auch die Verantwortung, die an die künstliche Intelligenz übertragen wird. Ein Beispiel ist das autonome Fahren (vgl. Huang und Chen 2020, S. 1), also das weitgehend selbstständige Fahren eines Fahrzeuges. Die neuronalen Netze müssen hierbei viele unterschiedliche Aufgabenbereiche erfüllen. Unter anderem spielt das Erkennen und Klassifizieren von Fußgängern und anderen Verkehrsteilnehmern für die Sicherheit eine wichtige Rolle (vgl. Huang und Chen 2020, S. 4–5). Das Nicht-Erkennen eines Fußgängers oder das falsche Erkennen eines Verkehrsschildes kann zu Unfällen und im schlechtesten Fall auch zu dem Tod von Menschen führen. Ein autonom fahrender Volvo überfuhr 2019 bei einer Testfahrt eine Fußgängerin auf dem Zebrastreifen, da sie von der Software als „unbedeutendes Hindernis“, wie eine vorbeifliegende Plastiktüte, erkannt wurde (vgl. Hebermehl 2019). Es ist dementsprechend von höchster Relevanz, dass die Fehlerrate eines neuronalen Netzes für diesen, aber auch für viele weitere Anwendungsfälle möglichst gering ist. Das Ermitteln eines solchen optimalen neuronalen Netzes ist jedoch mit hohem Aufwand verbunden. Problematisch ist, dass die beste zu erreichende Fehlerrate eines Netzes von sehr vielen Parametern, den sogenannten Hyperparametern dieses Netzes abhängt. Diese Eigenschaften des NN richtig zu wählen ist eine große Herausforderung des maschinellen Lernens, da das ndern einer Eigenschaft des Netzes oftmals große Auswirkungen auf die Fehlerrate hat (vgl. Tanay Agrawal 2021, S. 8–11). Aus diesem Grund ist es notwendig, viele neuronale Netze mit unterschiedlichen Parameterkonstellationen zu trainieren und zu evaluieren. Dieser Prozess wird als Hyperparameteroptimierung bezeichnet und erfordert oftmals eine sehr hohe Rechenleistung. Bereits das Trainieren eines einzelnen neuronalen Netzes kann abhängig von der Größe des Trainingsdatensatzes, der Komplexität des Netzes und der verwendeten Rechenkapazität mehrere Stunden, teilweise sogar Tage in Anspruch nehmen. Für die Hyperparameteroptimierung bedeutet dies eine oftmals zu hohe Rechenzeit, um sie durchzuführen. Die Konsequenz ist entweder ein sehr langer Entwicklungsprozess oder eine Reduktion der untersuchten Parameter, was wiederrum negative Auswirkungen auf die Fehlerrate des neuronalen Netzes haben kann. Ziel dieser Masterarbeit ist es eine Anwendung zu entwickeln und zu evaluieren, die die verteilte Hyperparameteroptimierung von neuronalen Netzen im Cluster ermöglicht und somit die benötigte Rechenzeit bedeutend reduziert. Anhand eines Anwendungsbeispiels zur Verkehrsschilderkennung soll gezeigt werden, dass die höhere Rechenleistung durch horizontale Skalierung auch das Auffinden von besser geeigneten Hyperparametern ermöglicht. Bei der Evaluation der Anwendung wird untersucht, wie hoch der Laufzeitgewinn durch das Hinzufügen von weiteren Rechnern ist und ob der horizontalen Skalierung bei der HPO Grenzen gesetzt sind. In einem abschließenden Vergleich der Anwendung mit dem Keras Tuner wird evaluiert, ob die ermittelten Verteilungseigenschaften auch im Vergleich zu einer etablierten Cluster Anwendung für die HPO als positiv angesehen werden können. 1
1.1 Aufbau der Arbeit Zu Beginn werden notwendige Grundlagen bezüglich neuronaler Netze und der Hyperparameteroptimierung (HPO) erklärt sowie die Laufzeit als die Hauptherausforderung eines HPO-Algorithmus aufgezeigt. Die Notwendigkeit für die Verteilung der HPO wird in Kapitel 3Fehler! Verweisquelle konnte nicht gefunden werden. unterstrichen, indem die Arbeit von Frau Corso beschrieben wird, die aufgrund zu geringer Rechenleistung keine HPO durchführen konnte. Hierbei wird auch das für die Verkehrsschildererkennung verwendete neuronale Netz vorgestellt. In dem folgenden Kapitel wird beschrieben, wie die Verteilung der einzelnen Hyperparameter mithilfe eines High Throughput Clusters und dem Job-Server Gearman auf Basis von Docker Containern umgesetzt wurde. In Kapitel 5 wird diese umgesetzte verteilte Grid Search Anwendung evaluiert. Dazu wird zunächst die von Frau Corso vorgeschlagene HPO durchgeführt. Anschließend wird der durchsuchte Hyperparameterraum um einige Parameter vergrößert, um ein neuronales Netz mit einer möglichst guten Performance für die Verkehrsschilderkennung zu entwickeln. Anschließend wird in Kapitel 5.4 die Laufzeit der entwickelten Anwendung, abhängig von der Anzahl der im Cluster verwendeten Rechner, mittels einer Regressionsanalyse untersucht. Der Einfluss der verwendeten Grafikkarte auf die Rechenzeit wird in Kapitel 5.5 betrachtet. Kapitel 6 vergleicht die entwickelte Anwendung mit der Open-Source Anwendung Keras Tuner, welche auch für eine verteilte HPO eingesetzt werden kann. Im Vordergrund stehen dabei die für die Verteilung relevanten Aspekte der beiden Anwendungen. 2
2 Grundlagen 2.1 Neuronale Netze Ein neuronales Netz ermöglicht die Gewinnung von Informationen aus ungenauen und komplexen Daten. Diese Informationen können unter anderem Muster und Trends in den Daten sein (vgl. Axenie 2018). Das Beschaffen solcher Informationen ist durch herkömmliche Lösungsmethoden gar nicht oder nur durch großen Aufwand möglich. Grund hierfür kann eine zu hohe Komplexität, aber auch die Abwesenheit eines bekannten Algorithmus zur Lösung des Problems sein (vgl. Kruse et al. 2015, 2, 8) (vgl. Géron 2020, S. 6–8). Daraus resultierende typische Anwendungsgebiete von neuronalen Netzen sind beispielsweise Objekterkennung und Spracherkennung (vgl. Géron 2020, S. 281). Inspiriert durch das Gehirn, ein biologisches neuronales Netz, bestehen auch künstliche neuronale Netze (KNN) aus vielen einzelnen Neuronen (vgl. Rojas 1993, S. 3). Der Aufbau eines dieser künstlichen Neuronen ist in Abbildung 1 dargestellt. Der Begriff Neuron wird in den weiteren Erklärungen gleichbedeutend zu künstlichem Neuron verwendet. Abbildung 1: Aufbau eines künstlichen Neurons Ein Neuron ist ein Informationsverarbeitungssystem, das beliebig viele Eingangssignale ( 1 bis ) entgegennimmt, ein Ausgangssignal berechnet und zurückgibt (out). Die Berechnung des Ausgangssignals geschieht folgendermaßen: Zunächst wird jedes Eingangssignal ( = 1,2,3 … ) mit dem zugehörigen Gewicht multipliziert. Die einzelnen Ergebnisse werden anschließend summiert und ergeben das Zwischenergebnis net. Im letzten Schritt wird eine sogenannte Aktivierungsfunktion f auf net angewandt und das Ergebnis dieser Funktion wird vom Neuron als Ausgangssignal out zurückgegeben. Mathematisch lassen sich diese Schritte folgendermaßen darstellen: = (∑ ∗ ) =1 Die Wahl der Aktivierungsfunktion ( ) spielt eine entscheidende Rolle für die Eigenschaften des neuronalen Netzes. Grundsätzlich wird für die Aktivierungsfunktion eine nicht-lineare Funktion verwendet, was einem neuronalen Netz das Lösen komplizierterer Probleme ermöglicht (vgl. Géron 2020, S. 293–294). Es gibt viele bekannte Aktivierungsfunktionen. Die derzeit am häufigsten verwendete ist ReLU (Rectified Linear Unit) (vgl. Ramachandran et al. 2017) (vgl. Tanay Agrawal 2021, S. 20). Diese und weitere bekannte Funktionen sind in Abbildung 2 dargestellt. 3
Sigmoid Rectified Linear Unit (ReLU) Tangens hyperbolicus (tanh) Abbildung 2: Aktivierungsfunktionen Ein KNN besteht aus mehreren vernetzen Neuronen. Diese sind normalerweise in mehrere Schichten aufgeteilt. Ein KNN besitzt immer genau eine Eingangsschicht und eine Ausgangsschicht. Zwischen diesen Schichten befinden sich dann beliebig viele verborgene Schichten. Der beispielhafte Aufbau eines KNN mit zwei verborgenen Schichten ist in Fehler! Verweisquelle konnte nicht gefunden werden. zu sehen. Das KNN hat zwei Neuronen in der Eingangsschicht und eines in der Ausgangsschicht. Jedes der gesamt zehn Neuronen ist wie in Abbildung 1 aufgebaut. Jedes Neuron einer Schicht ist vollvernetzt mit allen Neuronen der folgenden Schicht. Das Ausgangssignal eines Neurons dient also als Eingangssignal für alle Neuronen der folgenden Schicht. Da die Signale lediglich in eine Richtung (von links nach rechts) fließen, spricht man bei der Art des KNN auch von einem Feed-Forward-Netz. Abbildung 3: Vollvernetztes KNN mit zwei verborgenen Schichten Einsatzzweck und Funktionsweise eines KNN wird im Folgenden anhand eines Beispiels vorgestellt, das den Kaufpreis eines Gebrauchtwagens vorhersagt. Abhängig von bestimmten 4
Eigenschaften des Autos (z.B. Alter, Fahrleistung) soll das Netz einen angebrachten Kaufpreis bestimmen. Die Ausgabe soll also lediglich eine Zahl sein, dementsprechend reicht in der Ausgangsschicht ein einzelnes Neuron. Dieses Neuron sollte jedoch nicht durch die Aktivierungsfunktion in ihrem Wertebereich zu stark eingeschränkt sein. Tanh und sigmoid ermöglichen beispielsweise nur Ausgaben im Bereich von [-1;1] bzw. [0;1]. Die Anzahl der Neuronen in der Eingangsschicht ist ebenfalls von den Daten abhängig. Wird für das KNN lediglich das Alter und die Fahrleistung benötigt, so sind auch zwei Neuronen in der Eingangsschicht ausreichend. Nach dem initialen Aufbau des KNN ist das Ergebnis, das abhängig von den Eingangssignalen berechnet wird, nur noch abhängig von den Gewichten der Verbindungen zwischen allen Neuronen. Diese Gewichte zu optimieren ist Ziel des Trainings eines neuronalen Netzes. Zu Beginn des Trainings werden die Gewichte zufällig initialisiert. Zunächst berechnet das Netz somit einen zufälligen Preis für das Auto. Schrittweise werden jedoch die Gewichte des KNN so angepasst, dass der Preis immer mehr dem erwarteten Preis entspricht (vgl. Tanay Agrawal 2021, S. 154). Wie die Gewichte angepasst und trainiert werden, wird im folgenden Kapitel erklärt. 2.1.1 Training In dieser Arbeit wird nur die Trainingsart des überwachten Lernens betrachtet. Daneben gibt es das unüberwachte, das halbüberwachte und das verstärkende Lernen (vgl. Géron 2020, S. 9–16). Überwachtes Lernen bezeichnet die Technik ein KNN anhand von bekannten Daten zu trainieren. Diese Beispieldaten umfassen hierbei sowohl mögliche Eingabedaten als auch die erwarteten Ergebnisse, die das KNN liefern soll. Diese erwarteten Ergebnisse werden im Trainingsprozess mit den durch das KNN berechneten Werten verglichen. Anhand des entstehenden Fehlers kann man dann die Gewichte des neuronalen Netzes anpassen, um diesen Fehler zu minimieren. Ein bekannter Algorithmus für das Trainieren eines KNN ist der Backpropagation-Algorithmus (vgl. Géron 2020, S. 290–292). Der Backpropagation-Algorithmus besteht aus drei Phasen. Der erste Schritt ist der sogenannte Forward-Pass (Vorwärtsdurchlauf). Hierbei werden die Trainingseingabedaten in die Eingangsschicht des KNN geschickt und jedes Neuron dieser Schicht berechnet, wie in Abbildung 1 gezeigt wurde, einen jeweiligen Ausgabewert. Die Ausgangssignale werden dann wiederrum zum Eingangssignal der Folgeschicht und der Vorgang wiederholt sich, bis die Ausgangsschicht des KNN ein Ergebnis berechnet hat. Dieser Vorgang entspricht dem Prozess eines neuronalen Netzes Ergebnisse zu berechnen. Dieser Schritt kann sowohl für nur ein Datensatz als auch für mehrere oder alle Testdaten auf einmal durchgeführt werden. Die Größe dieses Datensatzes wird als (Mini-) Batch-Size bezeichnet. Die Batch-Size kann somit maximal so groß sein wie die Gesamtanzahl an Testdaten. In diesem Fall würden somit die Vorhersagen des KNN zu allen Datenpunkten im nächsten Schritt des Backpropagation-Algorithmus verwendet werden (vgl. Géron 2020, S. 130–131). Im zweiten Schritt wird das Ergebnis des Forward-Pass geprüft. Dazu wird das Ergebnis mit dem erwarteten Ergebnis des verwendeten Trainingsdatums verglichen und anhand einer Fehlerfunktion ein Messwert für den Fehler berechnet. Eine bekannte Fehlerfunktion ist der mittlere Quadratische Fehler (vgl. Géron 2020, S. 294). Abhängig von dem berechneten Fehler wird im dritten Schritt versucht, das KNN zu verbessern. Dazu wird das Netz rückwärts durchlaufen (backward pass) und für jedes Verbindungsgewicht in dem Netz wird der Fehlergradient berechnet und die Gewichte im Anschluss leicht in Richtung des negativen Gradienten der Fehlerfunktion angepasst, um den Fehler zu reduzieren (Gradientenabstiegsverfahren) (vgl. Rojas 1993, S. 149). Diese drei Schritte werden bis zu dem Erreichen eines bestimmten Abbruchkriteriums wiederholt. Ein typisches Abbruchkriterium ist die maximale Anzahl an Durchführungen für den gesamten Testdatensatz, auch Epoche genannt. Wurde die vorgegebene Anzahl an Epochen erreicht, so wird der Algorithmus beendet. Ein weiteres, oft zusätzlich verwendetes Abbruchkriterium ist das Erreichen einer bestimmten Güte des KNN und wird als Early Stopping bezeichnet, da die Berechnung schon vor Erreichung der maximalen Epochenzahl abgebrochen wird. 5
Ein wichtiger Parameter bei dem Trainieren eines KNN ist die Lernrate η (engl. Learning rate). Die Lernrate wird im zweiten Schritt mit dem negativen Gradienten multipliziert und ist somit maßgeblich dafür verantwortlich, wie schnell das Training eines KNN die Fehlerrate minimiert (vgl. Géron 2020, S. 124–126). Jedoch führt ein zu hohes η oftmals dazu, dass die Fehlerrate nahe dem globalen Minimum oszilliert. Die Schritte pro Epoche in Richtung Minimum sind dabei zu groß, sodass der Schritt stets an dem Minimum vorbeigeht. Eine zu geringe Lernrate kann dazu führen, dass die Fehlerrate in einem lokalen Minimum festhängt und das globale Minimum somit nicht erreichen kann (vgl. Jin et al. 2000, S. 1647–1648). Bei dem überwachten Lernen wird der vorhandene Beispielsdatensatz in Trainings – und Testdaten (Validierungsdaten) aufgeteilt. Das Training, wie es in Kapitel 2.1.1 erklärt wurde, wird einschließlich mit den Trainingsdaten durchgeführt. Die Validierungsdaten werden im Anschluss an das Training dazu verwendet, das Netz mit Daten zu evaluieren, die neu für das KNN sind. Ziel des Trainings eines KNN ist es, dass es mithilfe von spezifischen Daten generelle Lösungen und Konzepte erlernt (Buch 1993, S.201). Diese Generalisierungsfähigkeit kann sehr gut anhand der Testdaten getestet werden. Dazu wird auch mit diesen Daten ein Vorwärtsdurchlauf durchgeführt und anschließend der Fehler gemessen. Dieser Fehler wird als Validierungsfehler bezeichnet. Zeigt das KNN bei den Trainingsdaten einen geringen Fehler, jedoch einen deutlich höheren Validierungsfehler, so spricht man von Overfitting. Hierbei hat das neuronale Netz die Trainingsdaten zu spezifisch gelernt und weist somit eine schlechtere Generalisierungsfähigkeit auf. Hierbei kann Early Stopping hilfreich sein, da das Training abgebrochen wird, sobald einige Epochen kein oder nur ein geringer Rückgang des Fehlers stattfindet. 2.1.2 Drop-out Bei dem Drop-out handelt es sich um eine weitere Technik, das Overfitting eines KNN zu reduzieren und somit die Generalisierungsfähigkeit zu erhöhen. Bei dem Training gibt es dazu für jedes Neuron eine feste Wahrscheinlichkeit (zum Beispiel 20 %), dass dieses für eine Epoche aus dem Netz entfernt wird. Diese Wahrscheinlichkeit wird auch als Drop-out-Rate bezeichnet. Ein Neuron kann sich somit nie auf die Anwesenheit eines bestimmten Neurons in der Vorgängerschicht verlassen. (vgl. Hinton et al. 2012, S. 1–2). Der Einsatz von Drop-out zeigt deutliche Verbesserungen der Fehlerrate bei vielen Anwendungsfällen, darunter der Spracherkennung, Objekterkennung, aber auch bei einfachen vollvernetzten KNN (vgl. Nitish Srivastava et al. 2014). 2.2 Konvolutionale neuronale Netze Konvolutionale neuronale Netze (CNN, Convolutional Neural Networks) sind inspiriert durch die Funktionsweise des menschlichen visuellen Cortex. Hauptanwendungsgebiet dieser neuronalen Netze ist dementsprechend auch die Bilderkennung (vgl. Géron 2020, S. 449). Vollvernetzte KNN sind für diese Aufgabe eher ungeeignet, da diese eine deutlich zu hohe Anzahl an zu trainierenden Gewichten aufweisen. Geht man beispielsweise von einem Bild mit nur 50 * 50 Pixel aus, so benötigt die Eingangsschicht bei einem Schwarz-Weiß-Bild bereits 2500 Neuronen, da jedes Neuron die Daten eines Pixels erhält. Bei 1000 Neuronen in der ersten verborgenen Schicht benötigt ein vollvernetztes NN somit schon 2,5 Millionen Gewichte, die alle trainiert werden müssen. Dabei handelt es sich jedoch lediglich um ein neuronales Netz mit einer Schicht. In CNN wird dieses Problem gelöst, indem mehrere Neuronen gleiche Gewichte verwenden und auch nicht alle Neuronen vollvernetzt mit den Folgeschichten sind (vgl. Géron 2020, S. 450–451). Im Folgenden wird die Funktionsweise eines CNN anhand der wichtigsten Schicht eines CNN, dem Convolutional Layer, erklärt. Ein künstliches Neuron in einem Convolutional Layer ist nicht von allen Neuronen des vorhergehenden Layer abhängig, sondern nur von einem Teilbereich. 6
Abbildung 4: Darstellung Abbildung 5: Eingabegröße eines Neurons in einem des Filters eines Neurons in CNN (siehe Albawi et al. 82017, S. 2) einem CNN Dies kann sehr anschaulich anhand einer Matrix erläutert werden. In Abbildung 5 ist der Eingabebereich eines Neurons aus der vorherigen Schicht dargestellt. Die rosafarbene Ebene ist dabei die vorherige Schicht. Es wird ein Filter der Größe 3 x 3 verwendet. Jedes Neuron der Folgeschicht betrachtet einen eigenen Bereich der Vorgängerschicht. Die sich am Rand befindenden Neuronen haben in der vorherigen Schicht keine neun Neuronen, die deren Werte es als Eingangssignale erhalten. Die fehlenden Werte werden oftmals durch Nullen gefüllt (zero- padding) (vgl. Albawi et al. 82017, S. 3). In Abbildung 4 ist eine beispielhafte Gewichtsmatrix des blauen Folge-Neurons dargestellt. Die Eingangssignale werden dabei wie in Kapitel 2.1 beschrieben verarbeitet, um ein Ausgabesignal zu berechnen. Dieses reduzieren der 3 x 3 Eingangssignale auf ein Ausgangssignal wird als Faltung (Convolution) bezeichnet (vgl. Géron 2020, S. 451). Abhängig von der Gewichtsmatrix, auch Convolution-Kernel oder Filter genannt, wird sich auf spezielle Eigenschaften des grundlegenden Bildes fokussiert. So gibt es beispielsweise Filter, die besonders gut zum Erkennen von vertikalen oder horizontalen Kanten geeignet sind. Die Filter werden jedoch nicht vom Anwender festgelegt, sondern durch das Training bestimmt (vgl. Albawi et al. 82017, S. 2). In frühen Schichten werden einfache Muster, wie zum Beispiel Kanten, erkannt. Tiefer gelegene Schichten setzen diese Merkmale dann zu komplexeren und übergeordneten Merkmalen zusammen (vgl. Géron 2020, S. 451). Alle Neuronen in einer sogenannten Feature Map verwenden denselben Convolution-Kernel, also dieselben Gewichte. Dies reduziert die Anzahl an zu trainierenden Gewichten deutlich. Ein Convolution Layer setzt sich jedoch im Regelfall aus mehreren Feature Maps zusammen. Eine Feature Map ist somit für das Suchen eines bestimmten Features aus dem vorherigen Convolutional Layer verantwortlich (vgl. Géron 2020, S. 454–456). Diese Arbeit beschäftigt sich insbesondere mit einer Teilaufgabe der visuellen Objekterkennung, der Bildklassifikation. Hierbei besteht die Aufgabe darin, ein Bild einer bestimmten Objektkategorie zuzuordnen, also zum Beispiel das Einordnen eines Tierbildes zu der zugehörigen Tierart. Eine einfache Metrik, um die Erfolgsrate eines Systems bei dieser Aufgabe zu beurteilen, ist die sogenannte Akkuratheit (engl. Accuracy, Genauigkeit), auch Erkennungsrate genannt. Hierbei wird lediglich die Anzahl der vom CNN richtig klassifizierten Bilder in Verhältnis zu der Gesamtzahl der vorhergesagten Bilder gesetzt. Eine Erkennungsrate von 100 % bedeutet somit, dass das CNN die Kategorie aller getesteten Bilder richtig vorhersagen konnte. Auch hierbei unterscheidet man zwischen der Trainingsgenauigkeit und der Testgenauigkeit. Die Testgenauigkeit wird bestimmt, indem das CNN anhand der Validierungsdaten nach dem Training getestet wird. Neben der Bildklassifizierung gibt es im Bereich der visuellen Objekterkennung noch Aufgaben wie das Lokalisieren von Objekten in einem Bild (Objektlokalisierung) und die Semantische Segmentierung, bei der jedem Pixel auf dem Bild eine Klasse zugeordnet wird (vgl. Süße 2014, S. 589–590). 7
2.3 Hyperparameteroptimierung Bei dem Trainieren eines KNN ist es das Ziel, alle Verbindungsgewichte so anzupassen, dass die Fehlerrate der Vorhersage minimal wird. Dafür wird das neuronale Netz zuvor schon festgelegt. So wird beispielsweise entschieden, wie viele Schichten mit jeweils wie vielen Neuronen das NN hat. Es werden die Aktivierungsfunktionen für jedes Neuron festgelegt sowie eine Batch-Size bestimmt. Ist das Training eines NN begonnen, so ändern sich all diese Eigenschaften nicht mehr, es werden nur noch die Gewichte trainiert. Es ist jedoch keineswegs klar, dass die zuvor festgelegten sogenannten Hyperparameter (Aktivierungsfunktion, Zahl der Schichten und Neuronen, …) des NN optimal geeignet sind, um das vorliegende Problem zu lösen. Es kann also dazu kommen, dass das Trainieren eines neuronalen Netzes selbst nach mehreren Versuchen keine bessere Genauigkeit als 80 % erreicht. Fügt man dem KNN jedoch eine verborgene Schicht hinzu, so hat das normalerweise einen Einfluss auf die Genauigkeit. Das neuronale Netz muss jedoch erneut trainiert werden, um herauszufinden, wie groß dieser Einfluss ist. Die Hyperparameter (HP) eines KNN zu optimieren und richtig zu wählen wird als Hyperparameteroptimierung (HPO) bezeichnet. Dabei handelt es sich um einen wichtigen Aspekt, um eine möglichst niedrige Fehlerrate zu erreichen. Grund hierfür ist, dass für unterschiedliche Probleme auch unterschiedliche Hyperparameterkonstellationen zu der besten Lösung führen (vgl. Kohavi und John 1996). Es gibt zwar grundlegende Regeln, die bei der Wahl der HP unterstützen, doch diese sind oft nicht ausreichend, um optimale HP für das KNN zu wählen (vgl. Géron 2020, S. 325–329). Grundsätzlich können HP drei Arten von Variablen sein: diskrete, stetige oder kategorische Variablen (vgl. Luo 2016, S. 5). Kategorische Hyperparameter sind diejenigen, die aus einer endlichen Anzahl von eindeutigen Gruppen bestehen. Ein Beispiel hierfür ist die Aktivierungsfunktion, die Funktionen wie sigmoid, tanh, ReLU, o.ä. annehmen kann. Ein Beispiel für stetige Hyperparameter ist die Learning Rate. Diese kann beliebige Werte zwischen 0 und 1 annehmen. Im Gegensatz dazu kann ein diskreter HP lediglich abzählbar viele Werte annehmen (vgl. Tanay Agrawal 2021, S. 21–24). Die Batch Size kann beispielsweise nur ganzzahlige Werte zwischen 1 und der Anzahl der Trainingsdaten annehmen. Neben den bereits genannten Hyperparametern gibt es viele weitere. Grundsätzlich sind KNN somit sehr flexibel. Die große Anzahl an Kombinationsmöglichkeiten erschwert jedoch gleichzeitig auch die Optimierung, da viele Parameter berücksichtigt werden müssen. Der Prozess der händischen HPO funktioniert wie folgt: Der Entwickler lässt ein KNN mit einer aus seiner Sicht vielversprechenden HP-Konstellation trainieren. Erreicht das KNN nach dem Training die geforderte Genauigkeit, so sind bereits ausreichend gute HP gefunden worden. Bei einer unzureichenden Genauigkeit passt der Entwickler daraufhin einige HP an und wiederholt den Trainingsvorgang. Aufgrund des oftmals sehr großen Hyperparameterraumes, also vielen möglichen Kombination der HP, erfordert es oftmals hunderte, wenn nicht sogar tausende Iterationen. Gleichzeitig erfordert die Auswahl, welche HP mit welchen Abbildung 6: Beispiel für einen Ausprägungen getestet werden sollen, Hyperparameterraum mit zwei Fachkenntnisse (vgl. Luo 2016, S. 3). Dimensionen In Abbildung 6 ist der Hyperparameterraum dargestellt, der entsteht, wenn man lediglich zwei HP betrachtet. In der Horizontalen ist der HP „Aktivierungsfunktion“ mit drei Ausprägungen. In der Vertikalen ist der HP „Anzahl der verborgenen Schichten“ mit vier Ausprägungen. Jeder schwarze Punkt in der Abbildung ergibt somit ein zu testendendes HP-Tupel, also beispielsweise (tanh, 3). Gesamt ergeben sich bereits zwölf unterschiedliche Tupel. Das Hinzufügen eines weiteren HP würde dem HP-Raum eine weitere Dimension hinzufügen und die Anzahl der Tupel erhöhen. HPO-Algorithmen reduzieren dabei den Aufwand der manuellen Durchsuchung des HP-Raumes, indem dieser automatisch nach dem besten Tupel durchsucht wird. Im Folgenden werden drei bekannte HPO Algorithmen vorgestellt. Dabei wird oftmals von dem Trainieren der 8
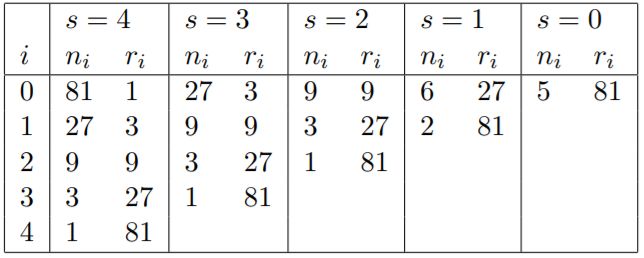
Hyperparameter gesprochen. Dies ist gleich zu verstehen wie das Optimieren von Hyperparameter-Konstellationen (-Konfigurationen) und beschreibt somit das Trainieren einzelner Tupel aus dem HP-Raum. 2.3.1 Grid Search Der Grid Search Algorithmus (Gittersuche, Rastersuche) ist der sicherste Weg, das beste Tupel in dem HP-Raum zu finden. Der Algorithmus durchsucht den Raum vollständig, sodass für den in Abbildung 6 gezeigten HP-Raum mit jedem der zwölf Tupel ein KNN trainiert werden würde. Der Nachteil an Grid Search ist der damit verbundene hohe Rechenaufwand, da mit wachsendem HP-Raum auch der Aufwand das komplette Grid (d. Gitter), also den kompletten HP-Raum, zu durchsuchen stark ansteigt (vgl. Tanay Agrawal 2021, S. 33). Fügt man dem in Abbildung 6 gezeigten Grid zwei HP mit jeweils fünf Ausprägungen hinzu, so ergeben sich bereits 300 (3 * 4 * 5 * 5) zu testende Tupel. Bei einer angenommenen durchschnittlichen Trainingszeit von 5 Minuten pro KNN würde das eine Laufzeit von bereits 25 Stunden bedeuten. Grid Search erlaubt keine stetigen Variablen als HP, da diese auch unendlich viele Ausprägungen annehmen können und somit das Durchsuchen des ganzen Hyperparameterraumes nicht möglich wäre. Aus diesem Grund muss man auch für stetige Parameter diskrete Werte angeben. Viele Bibliotheken bieten beispielsweise die Möglichkeit die Werte in einem Intervall mit einer zugehörigen Schrittgröße anzugeben. 2.3.2 Random Search Bei Random Search (Zufallssuche) gibt der Anwender wie bei Grid Search den Hyperparameterraum vor. Es werden jedoch nicht alle Gitterpunkte getestet, sondern nur einige zufällige. Die maximale Anzahl der zufälligen Iterationen gibt auch der Anwender an. Somit ist die Rechenzeit von Random Search nicht direkt abhängig von der Anzahl der Hyperparameter, sondern nur von der Anzahl der getesteten Tupel. Random Search findet durch die limitierten Trainings oftmals nicht das perfekte Ergebnis, ist aber deutlich schneller darin gute Kandidaten oder vielversprechende Bereiche im HP-Raum zu finden als Grid Search. Zusätzlich haben unwichtige HP, also Parameter, die das Ergebnis des KNN nur minimal oder gar nicht verändern, keine negativen Auswirkungen auf die Laufzeit (vgl. Tanay Agrawal 2021, S. 38–39) (vgl. Géron 2020, S. 324). 2.3.3 Hyperband Die vorherigen Algorithmen gehören zu den sogenannten uninformierten HPO Varianten. Die zu untersuchenden HP sind vollkommen unabhängig von den bereits untersuchten. Es gibt Algorithmen, die die Informationen, die aus den bereits untersuchten HP gewonnen werden, bei der weiteren Suche nutzen. Der im folgenden vorgestellte Hyperband Algorithmus zählt zu den informierten HPO Algorithmen. Der Hyperband Algorithmus basiert auf dem Successive-Halfing-Algorithmus (SH- Algorithmus), der zunächst vorgestellt wird. Beim SH-Algorithmus wird zuerst ein festgelegtes Budget (z.B. Anzahl an Iterationen) benötigt, mit dem eine Menge aus n Hyperparametern evaluiert werden soll. Dieses Budget B wird auf die einzelnen Tupel verteilt, sodass jedem ein Budget von B/n zur Verfügung steht. Nach der Evaluation dieser n Hyperparameter-Tupel wird die schlechtere Hälfte der Tupel entfernt und der Vorgang wiederholt, bis nur noch eine Konstellation übrigbleibt (vgl. Li et al. 2018, S. 6–7). Ein Hauptproblem des SH-Algorithmus ist es, dass der Entwickler bei festgelegtem Budget stets eine Entscheidung treffen muss, wie hoch n gewählt werden soll. Ein hohes n würde viele HP- Konfigurationen testen, aber dementsprechend würde jedem nur sehr wenig Budget zur Verfügung stehen und somit das KNN eventuell nur zu kurz trainiert werden, um zu entscheiden, ob es gut oder schlecht ist. Im Gegensatz dazu würde die Wahl eines niedrigen n nur einen kleineren Suchraum durchforsten, aber dafür längere Trainingszeiten aufweisen. Der Hyperband Algorithmus zielt darauf ab, dieses Entscheidungsproblem zu lösen, indem automatisch unterschiedliche Werte für n genutzt werden, während B konstant bleibt. Der verwendete SH-Algorithmus wird dementsprechend mit unterschiedlichen Werten von n 9
aufgerufen. Ein unterschiedliches n bedeutet, dass die Anzahl an HP-Konfigurationen sich ändert, aber auch, dass diese n Konfigurationen vom Hyperband Algorithmus wieder zufällig aus dem HP-Raum gewählt werden. Dazu muss der Entwickler zwei Werte festlegen: R und η. R ist die Anzahl der maximalen Iterationen (Budget), die eine HP-Konfiguration trainiert werden soll. η ist der Faktor, um den die Anzahl der HP-Konfigurationen pro SH Schritt reduziert wird. Der Algorithmus beginnt mit einem möglichst großen n, sodass im ersten Schritt eine möglichst breite Suche durchgeführt wird. Jede der HP-Konfigurationen wird somit zunächst mit einem niedrigen Budget getestet. Der SH- Algorithmus mit dem verwendeten Faktor η reduziert anschließend die n HP bis nur noch eine HP-Konfiguration übrigbleibt. Anschließend wird in weiteren Schritten dieser Vorgang wiederholt, es wird jedoch ein sukzessive kleiner werdendes n verwendet. Somit wird im nächsten Schritt eine neue Menge mit n/η zufällig gewählten HP- Konfigurationen verwendet und wieder der SH-Algorithmus durchgeführt. Bei der letzten Iteration des Hyperband Algorithmus ist n bereits sehr klein, es werden also nur wenige zufällige Punkte im HP-Raum getestet, jeder dieser Punkte wird aber dementsprechend mit R Iterationen durchgeführt. Diese letzte Iteration entspricht somit einem einfachen Random Search mit nur wenigen getesteten HP-Konfigurationen. Ist die letzte Iteration durchgeführt, so wird das beste bereits gefundene Ergebnis zurückgegeben (vgl. Li et al. 2018, S. 5–12) (vgl. Tanay Agrawal 2021, S. 69–71). In Abbildung 7 ist dieser Vorgang mit R = 91 und η = 3 dargestellt. In der Horizontalen sind die verschieden Hyperband Iterationen zu sehen, während die SH Iterationen in der Vertikalen dargestellt sind. Abbildung 7: Beispiel für die Durchführung des Hyberband Algorithmus (siehe Li et al. 2018, S. 9) Der Hyperband Algorithmus startet fünf unabhängige SH-Algorithmen (s=4 bis s=0) mit unterschiedlichen n und r Werten. Das Budget B ist während jeder dieser SH-Algorithmen stets 5 * R, also 405 Iterationen. Die Zeilen i = 0 bis i = 4 repräsentieren die Schritte des SH-Algorithmus, der nach jeder Berechnung durch η teilt und somit nur die besten HP- Konstellationen in den nächsten Schritt (i+1) übernimmt. Ein einfacher Hyperband Algorithmus ist als Pseudocode in A.1 ersichtlich. Ein Problem von Hyperband sind KNN, die schnell konvergieren, deren Fehlerrate also schon nach wenigen Epochen stark sinkt. Diese haben gegenüber Algorithmen, die nur langsam konvergieren, erstrecht bei den breiteren Suchen (beispielsweise s= 0, 1) einen großen Vorteil. So kann es vorkommen, dass HP-Konfigurationen wegfallen, weil die Fehlerrate beim Training nur langsam sinkt. Ein langsames Abfallen der Fehlerrate heißt jedoch nicht, dass es sich um ein ungeeignetes KNN handelt. Dies zeigt auch die Hyperparameter Lernrate. Je höher die Lernrate ist, umso schneller konvergiert das KNN. Zu hohe Lernraten können jedoch auch dazu führen, dass das Training mit dem Backpropagation Algorithmus nie ein Minimum erreicht (siehe Kapitel 2.1.1). 2.3.4 Herausforderung Hyperparameteroptimierung Ein Entwickler, der ein KNN zur Lösung eines spezifischen Problems entwickelt, nutzt die HPO, um ein KNN zu finden, dass eine möglichst geringe Fehlerrate aufweist. Jedoch muss der Entwickler, um die HPO sinnvoll zu nutzen, gute Kenntnisse im Gebiet des Maschinellen Lernens 10
haben. Es ist entscheidend, dass der Entwickler den Suchraum der HPO geeignet wählt und ihn dabei nicht zu groß werden lässt. Denn das größte Hindernis und die größte Herausforderung bei der HPO ist in all den in dieser Arbeit untersuchten Algorithmen die Rechenzeit. Zwar ist dieser Aspekt bei Grid Search am ausgeprägtesten, da der gewählte Suchraum vollständig durchsucht wird, die beiden anderen Algorithmen treffen jedoch im Vorhinein auch Einschränkungen, die die Laufzeit betreffen. So wird bei Random Search eine Anzahl an maximal zu testenden HP-Konfigurationen festgelegt und bei Hyperband wird ein Budget festgelegt, das nicht überschritten wird. Wie ausführlich die Suche bei den Algorithmen ist, hängt also in jedem Fall von der maximal gewünschten Laufzeit des Nutzers ab. Um die Chance auf das Finden einer guten HP-Konfiguration zu erhöhen, muss auch die eingesetzte Rechenzeit erhöht werden, um mehr Tupel testen zu können. Eine logische Konsequenz der Erhöhung der getesteten Tupel ist auch die Erhöhung der gewonnenen Daten und Informationen. Beim Grid Search mit einem breiten HP-Raum erhält der Nutzer auch Informationen über den gesamten Raum, kann also noch detaillierter Rückschlüsse ziehen, beispielsweise welche Ausprägungen eines Hyperparameters gut abschneiden und welche in egal welcher Kombination schlechte Ergebnisse liefern. Die beschriebenen HPO-Algorithmen können somit alle von einer höheren Rechenleistung profitieren. Das verteilte Ausführen der Algorithmen in einem Cluster ist eine Möglichkeit diese höhere Rechenleistung zu ermöglichen. 2.4 Statistische Grundlagen 2.4.1 Normalverteilung Die Normalverteilung zählt zu den stetigen Verteilungen. Im Gegensatz zu den diskreten Verteilungen haben stetige Verteilung keine abzählbare Anzahl an Ausprägungen. Die Ausprägungen liegen bei stetigen Verteilungen somit in einem Intervall und können alle reellen Zahlen in diesem Intervall annehmen. Ein Beispiel für eine stetige Verteilung ist die Wartezeit der Menschen bei einem Bäcker. Bei diskreten Verteilungen hingegen gibt es eine abzählbare, endliche Anzahl an Ausprägungen. Ein Wurf mit einem Würfel ist ein Beispiel für eine diskrete Wahrscheinlichkeitsverteilung. Die Ausprägungen können nur die natürlichen Zahlen von eins bis sechs annehmen. Die Normalverteilung wird in der Stochastik häufig zur Beschreibung von unabhängigen, zufällig voneinander abweichenden Messwerten verwendet (vgl. Adamek 2016, S. 89). Abbildung 8 zeigt eine Normalverteilungskurve, auch Gaußsche Glockenkurve genannt. Abbildung 8: Normalverteilungskurve Es handelt sich bei dieser Glockenkurve um eine Wahrscheinlichkeitsdichtefunktion. Eine Dichtefunktion gibt an, wie sich die Zufallswerte verteilen. Durch Ablesen der Dichtefunktionen 11
kann man unter anderem auch Häufungen der Zufallswerte erkennen (vgl. Mittag 2016, S. 183– 185). Bei einer Normalverteilung ist die Wahrscheinlichkeit direkt um den Mittelwert µ am höchsten und sinkt, je weiter sich das Intervall von dem Mittelpunkt entfernt, ab. In dem Beispiel erkennt man, dass der Mittelwert der Funktion bei x = 0 liegt. Somit ist die Wahrscheinlichkeit, dass ein Wert in dem Intervall [-0,5; 0.5] liegt deutlich höher als die Wahrscheinlichkeit, dass ein Wert in dem Bereich [2.5, 3.5] liegt. Eine Zufallsvariable X ist somit genau dann normalverteilt, wenn ihre Dichte folgende Form annimmt (vgl. Mittag 2016, S. 189–193): 1 ( − )2 ( ) = exp(− ) √2 2 2 Eine Normalverteilung wird durch ihren Mittelwert µ und die Varianz σ² vollständig beschrieben. Die Wahrscheinlichkeit ( ≤ ) also die Häufigkeit aller Werte, die kleiner sind als x, wird durch die Fläche unter der Kurve f(x) von -∞ bis x beschrieben. Zum Vergleich unterschiedlicher Normalverteilung werden diese oftmals normiert. Durch die Transformation kann für x ein zugehöriger z-Wert ermittelt werden. − = Der z-Wert ist der Abstand vom Mittelwert in Einheit der Standardabweichung . Durch diese z-Transformation kann jede Normalverteilung in die Standardnormalverteilung f(z) umgewandelt werden (vgl. Hedderich und Sachs 2016, S. 260–265). Diese Verteilung hat einen Mittelwert von 0 und eine Varianz von 1. Abbildung 9: Flächenanteile bei der Normalverteilung (siehe Hedderich und Sachs 2016, S. 264) Die Prozentwerte in Abbildung 9 zeigen den prozentualen Anteil der Intervalle in einer Standardnormalverteilung. In dem Intervall von [µ − 1 ∗ ; µ + 1 ∗ ] liegen somit ca. 68.26% aller Werte. Die Dichtefunktion der Standardnormalverteilung ist gemäß der Formel für die Normalverteilung gegeben durch: 1 2 ( ) = ∗ − 2 √2 Für die z-Werte ist es anschließend einfach die Wahrscheinlichkeiten zu bestimmen, da diese bei der Standardnormalverteilung immer gleich sind. Zusätzlich sind die Wahrscheinlichkeiten für sehr viele z-Werte bereits in Tabellen festgehalten, sodass diese nur noch abgelesen werden müssen (vgl. Hedderich und Sachs 2016, S. 262). 12
Sie können auch lesen

















































