AWSPräskriptive Leitlinien - Aktivierung der Datenpersistenz in Microservices
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
AWSPräskriptive Leitlinien
Aktivierung der Datenpersistenz
in MicroservicesAWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
AWSPräskriptive Leitlinien: Aktivierung der Datenpersistenz in
Microservices
Copyright © 2023 Amazon Web Services, Inc. and/or its affiliates. All rights reserved.
Die Handelsmarken und Handelsaufmachung von Amazon dürfen nicht in einer Weise in Verbindung mit nicht von
Amazon stammenden Produkten oder Services verwendet werden, durch die Kunden irregeführt werden könnten oder
Amazon in schlechtem Licht dargestellt oder diskreditiert werden könnte. Alle anderen Marken, die nicht im Besitz von
Amazon sind, gehören den jeweiligen Besitzern, die möglicherweise mit Amazon verbunden sind oder von Amazon
gesponsert werden.AWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
Table of Contents
Einführung ......................................................................................................................................... 1
Gezielte Geschäftsergebnisse ....................................................................................................... 2
Muster für die Aktivierung von Datenpersistenz ....................................................................................... 3
atabase-per-service D-Muster ....................................................................................................... 3
API-Kompositionsmuster .............................................................................................................. 5
CQRS-Muster ............................................................................................................................. 6
Ereignisbeschaffungsmuster ......................................................................................................... 7
Amazon Kinesis Data Streams Implementierung ...................................................................... 8
EventBridge Amazon-Implementierung .................................................................................. 9
SagaMuster .............................................................................................................................. 10
Shared-Database-per-Service-Muster ........................................................................................... 11
Häufig gestellte Fragen ...................................................................................................................... 13
Wann kann ich meine monolithische Datenbank im Rahmen meiner Modernisierungsreise
modernisieren? ......................................................................................................................... 13
Kann ich eine monolithische Legacy-Datenbank für mehrere Microservices behalten? .......................... 13
Was sollte ich beim Entwerfen von Datenbanken für eine Microservices-Architektur beachten? .............. 13
Was ist ein gängiges Muster zur Aufrechterhaltung der Datenkonsistenz über verschiedene
Microservices hinweg? ............................................................................................................... 13
Wie halte ich die Transaktionsautomatisierung aufrecht? ................................................................. 14
Muss ich für jeden Microservice eine separate Datenbank verwenden? ............................................. 14
Wie kann ich die persistenten Daten eines Microservices privat halten, wenn sie alle eine einzige
Datenbank teilen? ..................................................................................................................... 14
Ressourcen ...................................................................................................................................... 15
Verwandte Anleitungen und Muster ............................................................................................ 15
Sonstige Ressourcen ............................................................................................................... 15
Dokumentverlauf ............................................................................................................................... 16
Glossar ............................................................................................................................................ 17
Bedingungen der Modernisierung ................................................................................................ 17
...................................................................................................................................................... xix
iiiAWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
Aktivierung der Datenpersistenz in
Microservices
Tabby Ward, Amazon Web Services (AWS)
Februar 2021 (Dokumentenhistorie (p. 16))
Organizations suchen ständig nach neuen Prozessen, um Wachstumschancen zu schaffen und die
Markteinführungszeit zu verkürzen. Sie können die Agilität und Effizienz Ihres Unternehmens steigern,
indem Sie Ihre Anwendungen, Software und IT-Systeme modernisieren. Die Modernisierung hilft Ihnen
auch dabei, Ihren Kunden schnellere und bessere Dienstleistungen zu bieten.
Die Anwendungsmodernisierung ist ein Tor zur kontinuierlichen Verbesserung für Ihr Unternehmen. Sie
beginnt mit der Umgestaltung einer monolithischen Anwendung in eine Reihe unabhängig entwickelter,
bereitgestellter und verwalteter Microservices. Der Vorgang hat folgende Schritte:
• Zerlegen Sie Monolithe in Microservices — Verwenden Sie Muster, um monolithische Anwendungen in
Microservices zu zerlegen.
• Integrieren Sie Microservices — Integrieren Sie die neu erstellten Microservices in eine Microservices-
Architektur, indem Sie die serverlosen Dienste von Amazon Web Services (AWS) verwenden.
• Datenpersistenz für die Microservice-Architektur aktivieren — Fördern Sie die polyglotte Persistenz Ihrer
Microservices, indem Sie deren Datenspeicher dezentralisieren.
Obwohl Sie für einige Anwendungsfälle eine monolithische Anwendungsarchitektur verwenden können,
funktionieren moderne Anwendungsfunktionen in einer monolithischen Architektur oft nicht. Beispielsweise
kann nicht die gesamte Anwendung verfügbar bleiben, während Sie einzelne Komponenten aktualisieren,
und Sie können einzelne Komponenten nicht skalieren, um Engpässe oder Hotspots (relativ dichte
Bereiche in den Daten Ihrer Anwendung) zu beheben. Monolithen können zu großen, unüberschaubaren
Anwendungen werden, und es sind erhebliche Anstrengungen und Koordination zwischen mehreren
Teams erforderlich, um kleine Änderungen vorzunehmen.
Legacy-Anwendungen verwenden in der Regel eine zentralisierte monolithische Datenbank, was
Schemaänderungen erschwert, zu einer Technologiebindung führt, bei der vertikale Skalierung die einzige
Möglichkeit ist, auf Wachstum zu reagieren, und eine einzige Fehlerquelle darstellt. Eine monolithische
Datenbank verhindert auch, dass Sie die dezentralen und unabhängigen Komponenten erstellen, die für die
Implementierung einer Microservice-Architektur erforderlich sind.
Bisher bestand ein typischer architektonischer Ansatz darin, alle Benutzeranforderungen in einer
relationalen Datenbank zu modellieren, die von der monolithischen Anwendung verwendet wurde. Dieser
Ansatz wurde durch die gängige relationale Datenbankarchitektur unterstützt, und Anwendungsarchitekten
entwarfen das relationale Schema in der Regel in den frühesten Phasen des Entwicklungsprozesses,
erstellten ein stark normalisiertes Schema und schickten es dann an das Entwicklerteam. Dies bedeutete
jedoch, dass die Datenbank das Datenmodell für den Anwendungsfall bestimmte und nicht umgekehrt.
Indem Sie sich für die Dezentralisierung Ihrer Datenspeicher entscheiden, fördern Sie die polyglotte
Persistenz Ihrer Microservices und identifizieren Ihre Datenspeichertechnologie anhand der
Datenzugriffsmuster und anderer Anforderungen Ihrer Microservices. Jeder Microservice hat seinen
eigenen Datenspeicher und kann unabhängig skaliert werden, wobei Schemaänderungen nur geringe
Auswirkungen haben. Die Daten werden über die API des Microservices verwaltet. Der Abbau einer
monolithischen Datenbank ist nicht einfach, und eine der größten Herausforderungen besteht darin, Ihre
Daten zu strukturieren, um die bestmögliche Leistung zu erzielen. Dezentrale polyglotte Persistenz führt in
1AWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
Gezielte Geschäftsergebnisse
der Regel auch zu Datenkonsistenz. Zu den weiteren potenziellen Herausforderungen, die eine gründliche
Bewertung erfordern, gehören die Datensynchronisation während Transaktionen, die Transaktionsintegrität,
Datenduplizierung sowie Verknüpfungen und Latenz.
Dieser Leitfaden richtet sich an Anwendungsinhaber, Geschäftsinhaber, Architekten, technische Leiter und
Projektmanager. Der Leitfaden enthält die folgenden sechs Muster, um die Datenpersistenz zwischen Ihren
Microservices zu ermöglichen:
• atabase-per-service D-Muster (p. 3)
• API-Kompositionsmuster (p. 5)
• CQRS-Muster (p. 6)
• Ereignisbeschaffungsmuster (p. 7)
• SagaMuster (p. 10)
• Schritte zur Implementierung dessaga Patterns mithilfeAWS Step Functions von finden SieAWS Step
Functions auf der WebsiteAWS Prescriptive Guidance unter demsaga Muster Implementieren des
serverlosen Patterns mithilfe.
• Shared-Database-per-Service-Muster (p. 11)
Der Leitfaden ist Teil einer Inhaltsreihe, die den von empfohlenen Ansatz zur Anwendungsmodernisierung
behandeltAWS. Die Serie umfasst auch:
• Strategie zur Modernisierung von Anwendungen in derAWS Cloud
• Stufenweiser Ansatz zur Modernisierung von Anwendungen in derAWS Cloud
• Bewertung der Modernisierungsbereitschaft für Anwendungen in derAWS Cloud
• Zerlegung von Monolithen in Microservices
• Integration von Microservices mithilfeAWS serverloser Dienste
Gezielte Geschäftsergebnisse
Viele Unternehmen stellen fest, dass sich monolithische Anwendungen, Datenbanken und Technologien
negativ auf Innovationen und die Verbesserung der Benutzererfahrung auswirken. Veraltete Anwendungen
und Datenbanken reduzieren Ihre Möglichkeiten zur Einführung moderner Technologie-Frameworks
und schränken Ihre Wettbewerbsfähigkeit und Innovation ein. Wenn Sie jedoch Anwendungen und
ihre Datenspeicher modernisieren, lassen sie sich einfacher skalieren und schneller entwickeln. Eine
Strategie für entkoppelte Daten verbessert die Fehlertoleranz und Widerstandsfähigkeit, wodurch die
Markteinführung Ihrer neuen Anwendungsfunktionen beschleunigt wird.
Von der Förderung der Datenpersistenz in Ihren Microservices sollten Sie die folgenden sechs Ergebnisse
erwarten:
• Entfernen Sie veraltete monolithische Datenbanken aus Ihrem Anwendungsportfolio.
• Verbessern Sie die Fehlertoleranz, Resilienz und Verfügbarkeit Ihrer Anwendungen.
• Verkürzen Sie Ihre Markteinführungszeit für neue Anwendungsfunktionen.
• Reduzieren Sie Ihre gesamten Lizenzkosten und Betriebskosten.
• Nutzen Sie Open-Source-Lösungen (zum Beispiel MySQL oder PostgreSQL).
• Entwickeln Sie hoch skalierbare und verteilte Anwendungen, indem Sie aus mehr als 15 speziell
entwickelten Datenbank-Engines in derAWS Cloud wählen.
2AWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
atabase-per-service D-Muster
Muster für die Aktivierung von
Datenpersistenz
Die folgenden Muster werden verwendet, um Datenpersistenz in Ihren Microservices zu ermöglichen.
Themen
• atabase-per-service D-Muster (p. 3)
• API-Kompositionsmuster (p. 5)
• CQRS-Muster (p. 6)
• Ereignisbeschaffungsmuster (p. 7)
• SagaMuster (p. 10)
• Shared-Database-per-Service-Muster (p. 11)
atabase-per-service D-Muster
Die lose Kopplung ist das Kernmerkmal einer Microservice-Architektur, da jeder einzelne Microservice
unabhängig Informationen aus seinem eigenen Datenspeicher speichern und abrufen kann. Durch die
Bereitstellung des database-per-service Musters wählen Sie die Datenspeicher (z. B. relationale oder
nicht-relationale Datenbanken) aus, die für Ihre Anwendung und Ihre Geschäftsanforderungen am besten
geeignet sind. Das bedeutet, dass Microservices keine gemeinsame Datenschicht haben, Änderungen an
der individuellen Datenbank eines Microservices keine Auswirkungen auf andere Microservices haben,
einzelne Datenspeicher nicht direkt von anderen Microservices abgerufen werden können und persistente
Daten nur über APIs abgerufen werden. Die Entkopplung von Datenspeichern verbessert auch die Stabilität
Ihrer Gesamtanwendung und stellt sicher, dass eine einzelne Datenbank keine einzige Fehlerquelle sein
kann.
In der folgenden Abbildung werden verschiedeneAWS Datenbanken von den Microservices „Vertrieb“,
„Kunde“ und „Compliance“ verwendet. Diese Microservices werden alsAWS Lambda Funktionen
bereitgestellt und über eine Amazon API Gateway Gateway-API abgerufen. AWS Identity and Access
Management (IAM) -Richtlinien stellen sicher, dass Daten privat gehalten und nicht an die Microservices
weitergegeben werden. Jeder Microservice verwendet einen Datenbanktyp, der seinen individuellen
Anforderungen entspricht. Beispielsweise verwendet „Sales“ Amazon Aurora, „Customer“ verwendet
Amazon DynamoDB und „Compliance“ verwendet Amazon Relational Database Service (Amazon RDS) für
SQL Server.
3AWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
atabase-per-service D-Muster
Sie sollten die Verwendung dieses Musters in folgenden Fällen in Betracht ziehen:
• Zwischen Ihren Microservices ist eine lose Kopplung erforderlich.
• Microservices haben unterschiedliche Compliance- oder Sicherheitsanforderungen für ihre Datenbanken.
• Eine detailliertere Steuerung der Skalierung ist erforderlich.
Die Verwendung des database-per-service Musters hat die folgenden Nachteile:
• Es kann schwierig sein, komplexe Transaktionen und Abfragen zu implementieren, die sich über mehrere
Microservices oder Datenspeicher erstrecken.
• Sie müssen mehrere relationale und nicht-relationale Datenbanken verwalten.
• Ihre Datenspeicher müssen zwei der Anforderungen des CAP-Theorems erfüllen: Konsistenz,
Verfügbarkeit oder Partitionstoleranz.
4AWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
API-Kompositionsmuster
Note
Wenn Sie das database-per-service Muster verwenden, müssen Sie dasAPI-
Kompositionsmuster (p. 5) oder das bereitstellen, um AbfragenCQRS-Muster (p. 6) zu
implementieren, die sich über mehrere Microservices erstrecken.
API-Kompositionsmuster
Dieses Muster verwendet einen API-Composer oder Aggregator, um eine Abfrage zu implementieren,
indem einzelne Microservices aufgerufen werden, denen die Daten gehören. Anschließend werden die
Ergebnisse kombiniert, indem ein In-Memory-Join ausgeführt wird.
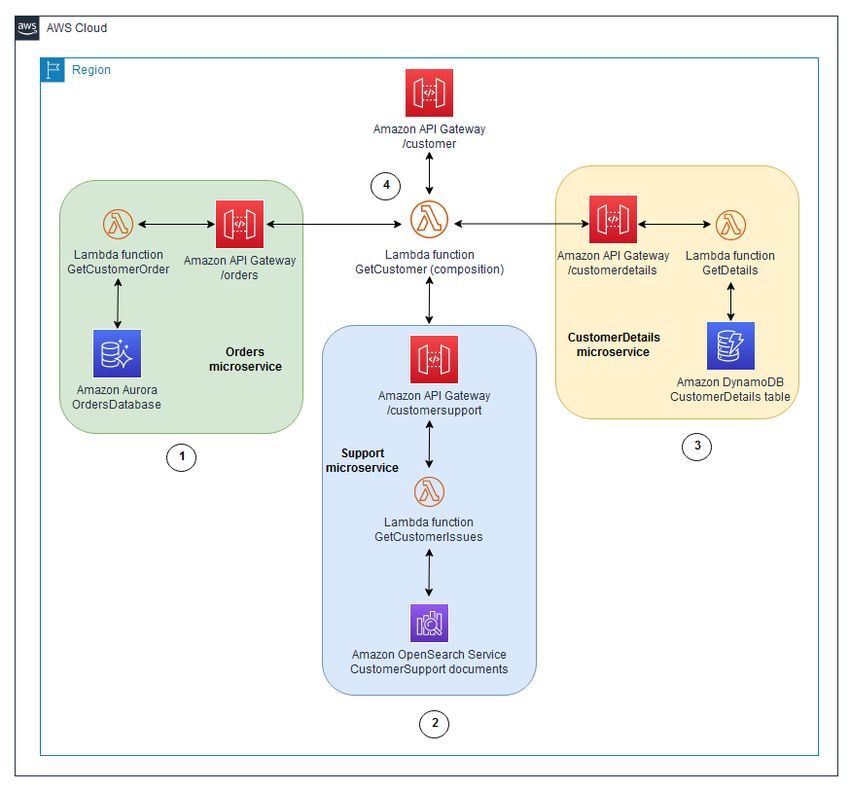
Das folgende Diagramm veranschaulicht, wie dieses Muster implementiert wird.
Das Diagramm zeigt den folgenden Arbeitsablauf:
1. Ein API-Gateway dient der API „/customer“, die über einen Microservice „Orders“ verfügt, der
Kundenbestellungen in einer Aurora-Datenbank nachverfolgt.
5AWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
CQRS-Muster
2. Der Microservice „Support“ verfolgt Probleme mit dem Kundensupport und speichert sie in einer Amazon
OpenSearch Service-Datenbank.
3. Der MicroserviceCustomerDetails "" verwaltet Kundenattribute (z. B. Adresse, Telefonnummer oder
Zahlungsdetails) in einer DynamoDB-Tabelle.
4. Die Lambda-Funktion „GetCustomer“ führt die APIs für diese Microservices aus und führt eine In-
Memory-Verknüpfung der Daten durch, bevor sie an den Anforderer zurückgegeben werden. Auf diese
Weise können Kundeninformationen problemlos in einem Netzwerkaufruf an die benutzerorientierte API
abgerufen werden, und die Benutzeroberfläche ist sehr einfach.
Das API-Kompositionsmuster bietet die einfachste Möglichkeit, Daten aus mehreren Microservices zu
sammeln. Die Verwendung des API-Kompositionsmusters hat jedoch die folgenden Nachteile:
• Es ist möglicherweise nicht für komplexe Abfragen und große Datensätze geeignet, die In-Memory-Joins
erfordern.
• Ihr Gesamtsystem wird weniger verfügbar, wenn Sie die Anzahl der mit dem API Composer verbundenen
Microservices erhöhen.
• Erhöhte Datenbankanforderungen führen zu mehr Netzwerkverkehr, was Ihre Betriebskosten erhöht.
CQRS-Muster
Das CQRS-Muster (Command Query Responsibility Segregation) trennt die Datenmutation oder den
Befehlsteil eines Systems vom Abfrageteil. Sie können das CQRS-Muster verwenden, um Updates und
Abfragen zu trennen, wenn sie unterschiedliche Anforderungen an Durchsatz, Latenz oder Konsistenz
haben. Das CQRS-Muster teilt die Anwendung in zwei Teile auf: die Befehlsseite und die Abfrageseite. Die
Befehlsseite verarbeitetcreateupdate unddelete Anfragen. Auf der Abfrageseite wird dasquery Teil
mithilfe der Read-Replikate ausgeführt.
In der folgenden Abbildung wird ein NoSQL-Datenspeicher wie DynamoDB verwendet, um den
Schreibdurchsatz zu optimieren und flexible Abfragefunktionen bereitzustellen. Dadurch wird eine hohe
Schreibskalierbarkeit für Workloads mit genau definierten Zugriffsmustern erreicht, wenn Sie Daten
hinzufügen. Eine relationale Datenbank wie Aurora bietet komplexe Abfragefunktionen. Ein DynamoDB-
Stream sendet Daten an eine Lambda-Funktion, die die Aurora-Tabelle aktualisiert.
6AWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
Ereignisbeschaffungsmuster
Sie sollten die Verwendung dieses Musters in folgenden Fällen in Betracht ziehen:
• Sie haben das database-per-service Muster implementiert und möchten Daten aus mehreren
Microservices zusammenführen.
• Ihre Lese- und Schreib-Workloads haben unterschiedliche Anforderungen an Skalierung, Latenz und
Konsistenz.
• Eventuelle Konsistenz ist für die gelesenen Abfragen akzeptabel.
Important
Das CQRS-Muster führt in der Regel zu einer eventuellen Konsistenz zwischen den
Datenspeichern.
Ereignisbeschaffungsmuster
Das Event-Sourcing-Muster wird in der Regel verwendet,CQRS-Muster (p. 6) um Lese- und Schreib-
Workloads zu entkoppeln und Leistung, Skalierbarkeit und Sicherheit zu optimieren. Daten werden als eine
7AWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
Amazon Kinesis Data Streams Implementierung
Reihe von Ereignissen gespeichert, anstatt sie direkt in Datenspeichern zu aktualisieren. Microservices
geben Ereignisse aus einem Ereignisspeicher wieder, um den entsprechenden Status ihrer eigenen
Datenspeicher zu berechnen. Das Muster bietet Sichtbarkeit für den aktuellen Status der Anwendung und
zusätzlichen Kontext dafür, wie die Anwendung zu diesem Status gelangt ist. Das Event-Sourcing-Muster
funktioniert effektiv mit dem CQRS-Muster, da Daten für ein bestimmtes Ereignis reproduziert werden
können, auch wenn die Befehls- und Abfragedatenspeicher unterschiedliche Schemata haben.
Wenn Sie dieses Muster wählen, können Sie den Status der Anwendung für jeden Zeitpunkt identifizieren
und rekonstruieren. Dies führt zu einem persistenten Prüfpfad und erleichtert das Debuggen. Die Daten
werden jedoch irgendwann konsistent, und dies ist für einige Anwendungsfälle möglicherweise nicht
geeignet.
Dieses Muster kann entweder mithilfe von Amazon Kinesis Data Streams oder Amazon implementiert
EventBridge werden.
Amazon Kinesis Data Streams Implementierung
In der folgenden Abbildung ist Kinesis Data Streams die Hauptkomponente eines zentralen
Ereignisspeichers. Der Event Store erfasst Anwendungsänderungen als Ereignisse und speichert sie auf
Simple Storage Service (Amazon S3).
Der Workflow besteht aus Folgendem:
1. Wenn bei den Microservices „/withdraw“ oder „/credit“ eine Änderung des Ereignisstatus auftritt,
veröffentlichen sie ein Ereignis, indem sie eine Nachricht in Kinesis Data Streams schreiben.
2. Andere Microservices, wie „/balance“ oder „/CreditLimit“, lesen eine Kopie der Nachricht, filtern sie nach
Relevanz und leiten sie zur weiteren Verarbeitung weiter.
8AWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
EventBridge Amazon-Implementierung
EventBridge Amazon-Implementierung
In der folgenden Abbildung EventBridge wird es als Eventspeicher verwendet. EventBridge bietet einen
Standard-Ereignisbus für Ereignisse, die vonAWS Services veröffentlicht werden, und Sie können auch
einen benutzerdefinierten Ereignisbus für domänenspezifische Busse erstellen.
Der Workflow besteht aus Folgendem:
1. „OrderPlaced“ Ereignisse werden vom Microservice „Orders“ im benutzerdefinierten Event-Bus
veröffentlicht.
2. Microservices, die nach Auftragserteilung Maßnahmen ergreifen müssen, wie z. B. der Microservice „/
route“, werden durch Regeln und Ziele initiiert.
3. Diese Microservices generieren eine Route, um die Bestellung an den Kunden zu versenden, und geben
einRouteCreated "“ -Ereignis aus.
4. Microservices, die weitere Maßnahmen ergreifen müssen, werden ebenfalls durch das "RouteCreated" -
Ereignis initiiert.
5. Ereignisse werden an ein Ereignisarchiv (z. B. Amazon S3 Glacier) gesendet, sodass sie bei Bedarf zur
erneuten Verarbeitung erneut abgespielt werden können.
6. Wenn Ziele nicht initiiert werden, werden die betroffenen Ereignisse zur weiteren Analyse und erneuten
Verarbeitung in eine Warteschlange für tote Buchstaben (DLQ) gestellt.
Sie sollten die Verwendung dieses Musters in folgenden Fällen in Betracht ziehen:
• Ereignisse werden verwendet, um den Status der Anwendung vollständig wiederherzustellen.
• Sie benötigen, dass Ereignisse im System wiederholt werden und dass der Status einer Anwendung zu
jedem Zeitpunkt ermittelt werden kann.
• Sie möchten bestimmte Ereignisse rückgängig machen können, ohne mit einem leeren
Anwendungsstatus beginnen zu müssen.
• Ihr System benötigt eine Reihe von Ereignissen, die leicht serialisiert werden können, um ein
automatisiertes Protokoll zu erstellen.
9AWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
SagaMuster
• Ihr System benötigt umfangreiche Leseoperationen, aber nur geringe Schreibvorgänge. Starke
Leseoperationen können an eine In-Memory-Datenbank weitergeleitet werden, die mit dem
Ereignisstream auf dem neuesten Stand gehalten wird.
Important
Wenn Sie das Event-Sourcing-Muster verwenden, müssen Sie das
bereitstellen,SagaMuster (p. 10) um die Datenkonsistenz zwischen den Microservices zu
gewährleisten.
SagaMuster
Dassaga Muster ist ein Fehlermanagementmuster, das dazu beiträgt, Konsistenz in verteilten
Anwendungen herzustellen und Transaktionen zwischen mehreren Microservices zu koordinieren, um die
Datenkonsistenz zu gewährleisten. Ein Microservice veröffentlicht für jede Transaktion ein Ereignis, und
die nächste Transaktion wird auf der Grundlage des Ergebnisses des Ereignisses eingeleitet. Es kann zwei
verschiedene Wege gehen, abhängig vom Erfolg oder das Fehlschlagen der Transaktionen.
Die folgende Abbildung zeigt, wie dassaga Muster ein Auftragsverarbeitungssystem mithilfe von
implementiertAWS Step Functions. Jeder Schritt (z. B. „ProcessPayment“) hat auch separate Schritte, um
den Erfolg (z. B. "UpdateCustomerAccount„) oder Misserfolg (z. B."SetOrderFailure „) des Prozesses zu
behandeln.
Sie sollten die Verwendung dieses Musters in folgenden Fällen in Betracht ziehen:
• Die Anwendung muss die Datenkonsistenz über mehrere Microservices hinweg aufrechterhalten, ohne
dass eine enge Kopplung erforderlich ist.
10AWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
Shared-Database-per-Service-Muster
• Es gibt langlebige Transaktionen, und Sie möchten nicht, dass andere Microservices blockiert werden,
wenn ein Microservice über einen längeren Zeitraum läuft.
• Sie müssen in der Lage sein, ein Rollback durchzuführen, wenn ein Vorgang in der Sequenz fehlschlägt.
Important
Dassaga Muster ist schwer zu debuggen und seine Komplexität nimmt mit der Anzahl der
Microservices zu. Das Muster erfordert ein komplexes Programmiermodell, das kompensierende
Transaktionen entwickelt und konzipiert, um Änderungen rückgängig zu machen und rückgängig
zu machen.
Weitere Informationen zur Implementierung dessaga Musters in einer Microservice-Architektur finden
Sie im Muster Implementieren des serverlosensaga Musters mithilfeAWS Step Functions auf derAWS
Prescriptive Guidance-Website.
Shared-Database-per-Service-Muster
In dem Shared-Database-per-Service-Muster wird dieselbe Datenbank von mehreren Microservices
gemeinsam genutzt. Sie müssen die Anwendungsarchitektur sorgfältig prüfen, bevor Sie dieses Muster
übernehmen, und sicherstellen, dass Sie Hottables (einzelne Tabellen, die von mehreren Microservices
gemeinsam genutzt werden) vermeiden. Alle Ihre Datenbankänderungen müssen auch abwärtskompatibel
sein. Entwickler können beispielsweise Spalten oder Tabellen nur löschen, wenn Objekte nicht von der
aktuellen und früheren Version aller Microservices referenziert werden.
In der folgenden Abbildung wird eine Versicherungsdatenbank von allen Microservices gemeinsam genutzt,
und eine IAM-Policy bietet Zugriff auf die Datenbank. Dadurch entsteht eine Kopplung der Entwicklungszeit.
Beispielsweise muss eine Änderung im Microservice „Vertrieb“ Schemaänderungen mit dem Microservice
„Kunde“ koordinieren. Dieses Muster reduziert nicht die Abhängigkeiten zwischen Entwicklungsteams und
führt eine Laufzeitkopplung ein, da alle Microservices dieselbe Datenbank verwenden. Beispielsweise
können lang andauernde Verkaufstransaktionen die Tabelle „Kunde“ sperren, wodurch die „Kunden“ -
Transaktionen blockiert werden.
11AWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
Shared-Database-per-Service-Muster
Sie sollten die Verwendung dieses Musters in folgenden Fällen in Betracht ziehen:
• Sie möchten Ihre bestehende Codebasis nicht zu stark überarbeiten.
• Sie stellen Konsistenz, Isolation und Durability, Isolation und Durability, Isolation und Durability, Isolation
und Durability, Durability, Isolation und Durability — ACID) ermöglichen.
• Sie möchten nur eine Datenbank verwalten und betreiben.
• Die Implementierung des database-per-service Musters ist aufgrund der Interdependenzen zwischen
Ihren vorhandenen Microservices schwierig.
• Sie möchten Ihre bestehende Datenschicht nicht komplett neu gestalten.
12AWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
Wann kann ich meine monolithische Datenbank im
Rahmen meiner Modernisierungsreise modernisieren?
Häufig gestellte Fragen
Dieser Abschnitt enthält Antworten auf häufig aufgeworfene Fragen zur Aktivierung der Datenpersistenz in
Microservices.
Wann kann ich meine monolithische Datenbank
im Rahmen meiner Modernisierungsreise
modernisieren?
Sie sollten sich auf die Modernisierung Ihrer monolithischen Datenbank konzentrieren, wenn Sie beginnen,
monolithische Anwendungen in Microservices zu zerlegen. Stellen Sie sicher, dass Sie eine Strategie
erstellen, um Ihre Datenbank in mehrere kleine Datenbanken aufzuteilen, die an Ihren Anwendungen
ausgerichtet sind.
Kann ich eine monolithische Legacy-Datenbank für
mehrere Microservices behalten?
Die Beibehaltung einer freigegebenen monolithischen Datenbank für mehrere Microservices führt zu
einer engen Kopplung, was bedeutet, dass Sie Änderungen an Ihren Microservices nicht unabhängig
voneinander bereitstellen können und dass alle Schemaänderungen zwischen Ihren Microservices
koordiniert werden müssen. Obwohl Sie einen relationalen Datenspeicher als monolithische Datenbank
verwenden können, sind NoSQL-Datenbanken möglicherweise eine bessere Wahl für einige Ihrer
Microservices.
Was sollte ich beim Entwerfen von Datenbanken für
eine Microservices-Architektur beachten?
Sie sollten Ihre Anwendung basierend auf Domänen entwerfen, die mit den Funktionen Ihrer Anwendung
übereinstimmen. Stellen Sie sicher, dass Sie die Funktionalität der Anwendung auswerten und
entscheiden, ob ein relationales Datenbankschema erforderlich ist. Sie sollten auch erwägen, eine NoSQL-
Datenbank zu verwenden, wenn sie Ihren Anforderungen entspricht.
Was ist ein gängiges Muster zur Aufrechterhaltung
der Datenkonsistenz über verschiedene
Microservices hinweg?
Das gebräuchlichste Muster ist die Verwendung einesereignisgesteuerte Architekturaus.
13AWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
Wie halte ich die Transaktionsautomatisierung aufrecht?
Wie halte ich die Transaktionsautomatisierung
aufrecht?
In einer Microservices-Architektur besteht eine Transaktion aus mehreren lokalen Transaktionen, die
von verschiedenen Microservices abgewickelt werden. Wenn eine lokale Transaktion fehlschlägt,
müssen Sie die zuvor abgeschlossenen erfolgreichen Transaktionen rückgängig machen. Sie können
dasSagaMuster (p. 10)um dies zu vermeiden.
Muss ich für jeden Microservice eine separate
Datenbank verwenden?
Der Hauptvorteil einer Microservices-Architektur ist die lose Kopplung. Die persistenten Daten jedes
Microservices müssen privat und nur über die API eines Microservices zugänglich gehalten werden.
Änderungen am Datenschema müssen sorgfältig ausgewertet werden, wenn Ihre Microservices dieselbe
Datenbank teilen.
Wie kann ich die persistenten Daten eines
Microservices privat halten, wenn sie alle eine
einzige Datenbank teilen?
Wenn Ihre Microservices eine relationale Datenbank teilen, stellen Sie sicher, dass Sie private Tabellen
für jeden Microservice haben. Sie können auch einzelne Schemas erstellen, die für die einzelnen
Microservices privat sind.
14AWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
Verwandte Anleitungen und Muster
Ressourcen
Verwandte Anleitungen und Muster
• Strategie zur Modernisierung von Anwendungen in derAWSWolke
• Schrittweiser Ansatz zur Modernisierung von Anwendungen in derAWSWolke
• Bewertung der Modernisierungsbereitschaft für Anwendungen in derAWSWolke
• Zerlegung von Monolithen in Microservices
• Integration von Microservices mithilfe von AWS-Services ohne Server
• Implementieren der ServerlesssagaPattern unter Verwendung vonAWS Step Functions
Sonstige Ressourcen
• Anwendungsmodernisierung mitAWS
• Erstellen Sie hochverfügbare Microservices für Anwendungen jeder Größe und Größenordnung
• Cloud-native Anwendungsmodernisierung mitAWS
• Kostenoptimierung und Innovation: Eine Einführung in die Anwendungsmodernisierung
• -Entwicklerhandbuch: Skalieren mit Microservices
• Verteilte Datenverwaltung —SagaPattern
• Implementierung von Microservice-Architekturen mithilfe von AWS-Services: Muster für die Trennung der
Verantwortlichkeit von Befeh
• Implementierung von Microservice-Architekturen mithilfe von AWS-Services: Ereignismuster
• Moderne Anwendungen: Wertschöpfung durch Anwendungsdesign
• Modernisieren Sie Ihre Anwendungen, fördern Sie das Wachstum und senken Sie die TCO
15AWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
Dokumentverlauf
In der folgenden Tabelle werden wichtige Änderungen an diesem Handbuch beschrieben. Wenn Sie über
future Updates benachrichtigt werden möchten, können Sie einenRSS-Feed.
Änderung Beschreibung Datum
Es wurde ein Link für die Wir haben das 23. Februar 2021
Implementierung dessagamuster aktualisiertHeimatundSagaMusterAbschnitte
mit Step Functions (p. 16) mit dem Link zum
MusterImplementieren der
Serverlesssagamuster unter
VerwendungAWS Step
FunctionsausAWSWebsite für
präskriptive Leitlinien.
Erstversion (p. 16) — 27. Januar 2021
16AWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
Bedingungen der Modernisierung
AWSGlossar für präskriptive Leitlinien
Im Folgenden werden häufig verwendete Begriffe in Strategien, Leitfäden und Mustern aufgeführt, die
vonAWS Prescriptive Guidance bereitgestellt werden. Um Einträge vorzuschlagen, verwenden Sie bitte den
Link Feedback geben am Ende des Glossars.
Bedingungen der Modernisierung
Geschäftsfähigkeit
Was ein Unternehmen tut, um Wert zu generieren (z. B. Vertrieb, Kundenservice oder Marketing).
Microservices-Architekturen und Entwicklungsentscheidungen können von den Geschäftsfähigkeiten
bestimmt werden. Weitere Informationen finden Sie imAWS Whitepaper Running containerized
microservices on, im Abschnitt Organisiert nach Geschäftsmöglichkeiten.
domänengetriebenes Design
Ein Ansatz zur Entwicklung eines komplexen Softwaresystems, bei dem seine Komponenten mit sich
entwickelnden Bereichen oder Kerngeschäftszielen verbunden werden, denen jede Komponente dient.
Dieses Konzept wurde von Eric Evans in seinem Buch Domain-Driven Design: Tackling Complexity in
the Heart of Software (Boston: Addison-Wesley Professional, 2003) vorgestellt. Informationen darüber,
wie Sie domänengetriebenes Design mit dem Strangler-Feigenmuster verwenden können, finden
Sie unter Schrittweise Modernisierung älterer Microsoft ASP.NET (ASMX) -Webdienste mithilfe von
Containern und Amazon API Gateway.
Mikroservice
Ein kleiner, unabhängiger Dienst, der über klar definierte APIs kommuniziert und in der Regel kleinen,
eigenständigen Teams gehört. Ein Versicherungssystem könnte beispielsweise Microservices
beinhalten, die Geschäftsfunktionen wie Vertrieb oder Marketing oder Subdomänen wie Einkauf,
Schadensfälle oder Analytik zuordnen. Zu den Vorteilen von Microservices gehören Agilität, flexible
Skalierung, einfache Bereitstellung, wiederverwendbarer Code und Resilienz. Weitere Informationen
finden Sie unter Integrieren von Microservices mithilfeAWS serverloser Dienste.
Microservices-Architektur
Ein Ansatz zum Erstellen einer Anwendung mit unabhängigen Komponenten, die jeden
Anwendungsprozess als Microservice ausführen. Diese Microservices kommunizieren über eine
klar definierte Schnittstelle mithilfe einfacher APIs. Jeder Microservice in dieser Architektur kann
aktualisiert, bereitgestellt und skaliert werden, um den Anforderungen an bestimmte Funktionen
einer Anwendung gerecht zu werden. Weitere Informationen finden Sie unter Implementieren von
Microservices aufAWS.
Modernisierung
Transformation einer veralteten (veralteten oder monolithischen) Anwendung und ihrer Infrastruktur
in ein agiles, elastisches und hochverfügbares System in der Cloud, um Kosten zu senken, Effizienz
zu steigern und Innovationen zu nutzen. Weitere Informationen finden Sie unter Strategie zur
Modernisierung von Anwendungen in derAWS Cloud.
Einschätzung der Modernisierungsbereitschaft
Eine Bewertung, die dabei hilft, die Modernisierungsbereitschaft der Anwendungen eines
Unternehmens zu ermitteln, Vorteile, Risiken und Abhängigkeiten zu identifizieren und festzustellen,
wie gut das Unternehmen den future Status dieser Anwendungen unterstützen kann. Das Ergebnis
der Bewertung ist ein Entwurf der Zielarchitektur, ein Fahrplan, der die Entwicklungsphasen und
17AWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
Bedingungen der Modernisierung
Meilensteine des Modernisierungsprozesses detailliert beschreibt, sowie ein Aktionsplan zur
Behebung der identifizierten Lücken. Weitere Informationen finden Sie unter Evaluierung der
Modernisierungsbereitschaft für Anwendungen in derAWS Cloud.
monolithische Anwendungen (Monolithe)
Anwendungen, die als ein einziger Dienst mit eng gekoppelten Prozessen ausgeführt werden.
Monolithische Anwendungen haben mehrere Nachteile. Wenn eine Anwendungsfunktion stark
nachgefragt wird, muss die gesamte Architektur skaliert werden. Das Hinzufügen oder Verbessern
der Funktionen einer monolithischen Anwendung wird ebenfalls komplexer, wenn die Codebasis
wächst. Um diese Probleme zu lösen, können Sie eine Microservices-Architektur verwenden. Weitere
Informationen finden Sie unter Decomposing Monoliths into Microservices.
mehrsprachige Persistenz
Unabhängige Auswahl der Datenspeichertechnologie eines Microservices auf der Grundlage
von Datenzugriffsmustern und anderen Anforderungen. Wenn Ihre Microservices über dieselbe
Datenspeichertechnologie verfügen, können sie auf Implementierungsprobleme stoßen oder eine
schlechte Leistung aufweisen. Microservices lassen sich einfacher implementieren und erzielen eine
bessere Leistung und Skalierbarkeit, wenn sie den Datenspeicher verwenden, der ihren Anforderungen
am besten entspricht. Weitere Informationen finden Sie unter Aktivieren der Datenpersistenz in
Microservices.
split-and-seed Modell
Ein Muster für die Skalierung und Beschleunigung von Modernisierungsprojekten. Sobald neue
Funktionen und Produktversionen definiert sind, teilt sich das Kernteam auf, um neue Produktteams
zu bilden. Dies hilft bei der Skalierung der Kapazitäten und Services Ihres Unternehmens, verbessert
die Produktivität der Entwickler und unterstützt schnelle Innovationen. Weitere Informationen finden Sie
unter Stufenweiser Ansatz zur Modernisierung von Anwendungen in derAWS Cloud.
Würger-Feigenmuster
Ein Ansatz zur Modernisierung monolithischer Systeme, bei dem die Systemfunktionen schrittweise
neu geschrieben und ersetzt werden, bis das Altsystem außer Betrieb genommen werden kann.
Dieses Muster verwendet die Analogie einer Feigenrebe, die zu einem etablierten Baum heranwächst
und schließlich seinen Wirt überwindet und ersetzt. Das Muster wurde von Martin Fowler eingeführt,
um das Risiko beim Umschreiben monolithischer Systeme zu managen. Ein Beispiel für die
Anwendung dieses Musters finden Sie unter Inkrementelle Modernisierung älterer Microsoft ASP.NET
(ASMX) -Webdienste mithilfe von Containern und Amazon API Gateway.
Team mit zwei Pizzas
Ein kleines DevOps Team, das Sie mit zwei Pizzen füttern können. Eine Teamgröße von zwei Pizzen
gewährleistet die bestmögliche Gelegenheit für die Zusammenarbeit in der Softwareentwicklung.
Weitere Informationen finden Sie im Abschnitt „Two-Pizza Team“ desAWS Whitepapers Einführung in
ein Team. DevOps
18AWSPräskriptive Leitlinien Aktivierung
der Datenpersistenz in Microservices
Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs
zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von
Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
xixSie können auch lesen