Entity Search Michel Manthey Arne Binder 2013
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Entity Search
Michel Manthey
Arne Binder
2013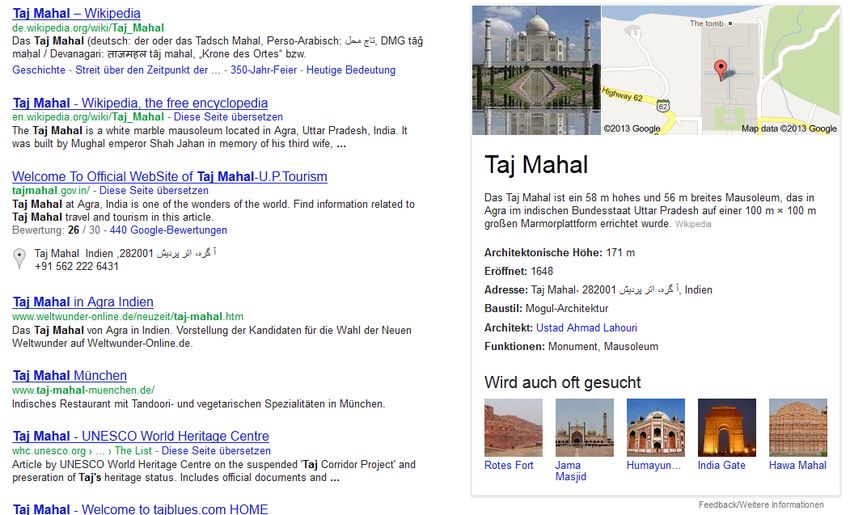
Gliederung • Idee • Herausforderungen • Allgemeine Herangehensweise • Möglichkeiten und angewandte Verfahren • Ausblick • Quellen

Idee
• Bisher: Suche nach
Dokumenten, die am
besten zu einer Menge
von Keywords passen
Idee
• Bisher: Suche nach
Dokumenten, die am
besten zu einer Menge
von Keywords passen
• d.h. alle Dokumente
einsammeln, die die
Keywords enthalten und
dann nach Relevanz
sortieren (PageRank)
Idee
• Bisher: Suche nach
Dokumenten, die am
besten zu einer Menge
von Keywords passen
• d.h. alle Dokumente
einsammeln, die die
Keywords enthalten und
dann nach Relevanz
sortieren (PageRank)
• aber: bei Standardsuche
wird meist nach einer
konkreten Information
gesuchtIdee • diese muss dann händisch aus den zurückgegeben Dokumenten entnommen werden
Idee • diese muss dann händisch aus den zurückgegeben Dokumenten entnommen werden • besser wäre es, wenn direkt die benötigte Information zurückgegeben werden würde
Idee • diese muss dann händisch aus den zurückgegeben Dokumenten entnommen werden • besser wäre es, wenn direkt die benötigte Information zurückgegeben werden würde • eine Information bezieht sich meist auf ein oder mehrere konkrete Objekte und deren Beziehungen
Idee • diese muss dann händisch aus den zurückgegeben Dokumenten entnommen werden • besser wäre es, wenn direkt die benötigte Information zurückgegeben werden würde • eine Information bezieht sich meist auf ein oder mehrere konkrete Objekte und deren Beziehungen • wir wollen also spezielle Entitäten mit bestimmten Eigenschaften finden
Idee • diese muss dann händisch aus den zurückgegeben Dokumenten entnommen werden • besser wäre es, wenn direkt die benötigte Information zurückgegeben werden würde • eine Information bezieht sich meist auf ein oder mehrere konkrete Objekte und deren Beziehungen • wir wollen also spezielle Entitäten mit bestimmten Eigenschaften finden
Herausforderungen • Was sind Entitäten?
Herausforderungen
• Was sind Entitäten?
--> Sinntragende Einheiten
KolibriHerausforderungen
• Was sind Entitäten?
--> Sinntragende Einheiten
Kolibri Golden Gate BridgeHerausforderungen
• falsche/unvollständige Schreibweisen
„Addresse “, „Billiard “, „Imbus(schlüssel) “Herausforderungen
• Mehrdeutigkeit von Wörtern/Phrasen
(Homonymie)
VS.Herausforderungen • viele verschiedene Wörter können auf eine Entität verweisen (Synonymie) „George W. Bush“, „G. Bush“, „GB“, „Bush“, „der ehemalige Präsident der Vereinigten Staaten von Amerika"
Herausforderungen
• Wie lassen sich verschiedene Vorkommen
einer Entität (evtl. in verschiedenen
Dokumenten) vereinigen?
– „Java ist auch eine Insel“
– „…die nun von Oracle weiterentwickelte
Programmiersprache…“
– „Die Programmiersprache Java ist toll.“Herausforderungen • Wann bilden Wortgruppen eine Entität, wann zerfallen sie in mehrere? Was gehört alles dazu? – „big ben“ – „er hat in havanna liebe genossen."
Allgemeine Herangehensweise
1) Entitäten extrahieren
2) Entitäten korpusweit aggregieren
3) Entitäten bzgl. einer Anfrage ranken
4) Beste(s) Ergebnis(se) in strukturierter Form
ausgebenMöglichkeiten und Angewandte
Verfahren
• Extraktion von Entitäten:
– Bestimmung der Kandidaten durch Regex,
Wörterbuch, POS-Tagging etc.
– d.h. Teile der Einheiten ausfindig machen, ist
allerdings niemals 100% korrekt
– Entitäten bestimmen: viele Heuristiken möglich,
z.B. längstes Multitoken ist EntitätMöglichkeiten und Angewandte
Verfahren
• Was wissen wir über die Entität? Können wir
Hintergrundwissen heranziehen?Möglichkeiten und Angewandte
Verfahren
• Entity Rank über textbasierte Methoden
(Benutzung von natural language texts)
1. VSM, Entitäten finden durch Nutzung von Wikipedia-
Artikeln (welche Artikel?)
2. Unterscheidung von Keywords und Entitäten in
Query (Entitäten extra angeben;
z.B. „Ebay Kundenservice #Telefonnummer“)
3. Machine Learning
a. gleiche Idee mit den Wikipedia-Artikeln
b. Feature Vector (Substrings, Abkürzungen,
kontextuelle, semantische Features etc.)Möglichkeiten und Angewandte
Verfahren
• Entity Rank mit Hilfe Strukturierter
Informationen (Graph based)
– Dokumente des Korpus und die Query werden mit
Konzepten einer Ontologie annotiert
– jede Annotation ist zu einer bestimmten
Wahrscheinlichkeit richtig (Score)
– Abhängig beispielsweise von der Ambiguität des
Terms, dem Edit-Abstand und der Überdeckung
des KonzeptnamensMöglichkeiten und Angewandte
Verfahren
• Entity Rank mit Hilfe Strukturierter
Informationen (Graph based)
– die Scores können auf abstraktere Konzepte
(verknüpft mit SubClassOf-Relationen) propagiert
werden
– für jedes Dokument ergibt sich ein Vektor mit
enthaltenen Konzept-Scores
– Winkel zwischen Vektor der Query und Vektoren
der Dokumente führt zu einem Ranking dieserGoogle Knowledge Graph
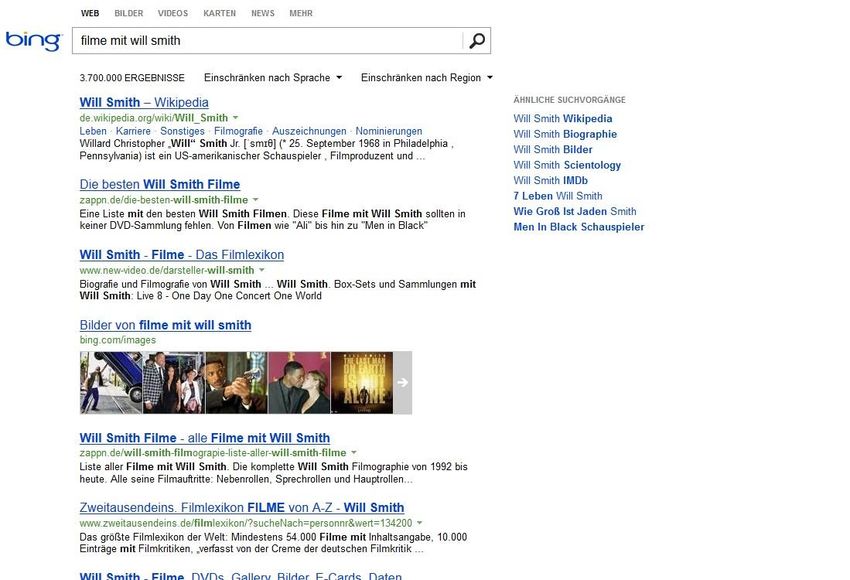
Ausblick • Komplexere Anfragen werden bis jetzt noch nicht beantwortet „10 deepest lakes in the usa“ • „The destiny of search is to become the Star Trek computer, a perfect assistant by my side...“ Amit Singhal, senior vice president and software engineer at Google Inc.
Quellen • Brauer, F., Huber, M., Hackenbroich, G., Leser, U., Naumann, F. and Barczynski, W. (2010). "Graph-Based Concept Identification and Disambiguation for Enterprise Search ". 19th Int. World Wide Web Conference, Raleigh, US. pp 171-180. • Chakaravarthy, V. T., Gupta, H., Prasan, R. and Mohania, M. (2006). "Efficiently linking text documents with relevant structured information". 32nd Int. Conf. on Very Large Data Bases, Seoul, Korea. pp 667 - 678. • Cheng, T., Yan, X. and Chang, K. C. C. (2007). "EntityRank: searching entities directly and holistically". 33rd International Conference on Very Large Data Bases, Vienna, Austria. pp 387-398. • Torsten Huber (2012). „ Entity Linking - A Survey of Recent Approaches“ • Terri Greene, (2012). „Google‘s Knowledge Graph: Semantic Search Results“. http://www.intouchsol.com/insights/articles/08-17- 12/Google_s_Knowledge_Graph_Semantic_Search_Results.aspx
Sie können auch lesen