Grid Computing, eine Einf uhrung
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Grid Computing, eine Einführung
Johann Siegele
14. November 2004, Innsbruck
640K ought to be enough for anybody.“
”
Bill Gates, 1981
Seminararbeit für das Seminar “Grid Computing “(LV.Nr 703404)
Lehrveranstaltungsleiter: T. Fahringer
Geschrieben von: Johann Siegele (Mat.Nr. 0016995)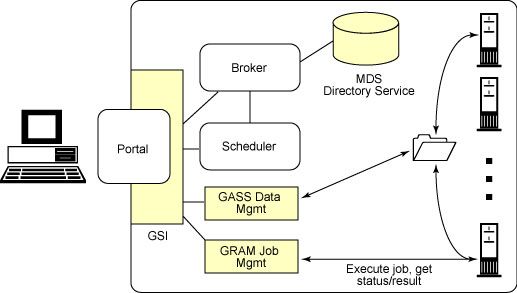
Seminar “Grid Computing “ WS 2004/05
Inhaltsverzeichnis
1 Kurzfassung 3
2 Einleitung 3
3 Grid Computing 5
3.1 Geschichte . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5
3.2 Anwendungstypen des Grids . . . . . . . . . . . . . . . . . . . 9
3.2.1 Rechen-Grids . . . . . . . . . . . . . . . . . . . . . . . 9
3.2.2 Daten Grids . . . . . . . . . . . . . . . . . . . . . . . . 10
3.2.3 Kollaborative Grid Computing . . . . . . . . . . . . . . 11
3.3 Komponenten des Grid Computing . . . . . . . . . . . . . . . 13
3.3.1 Portal/User interface . . . . . . . . . . . . . . . . . . . 13
3.3.2 Security im Grid . . . . . . . . . . . . . . . . . . . . . 13
3.3.3 Broker . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.3.4 Scheduler . . . . . . . . . . . . . . . . . . . . . . . . . 15
3.3.5 Datenmanagement . . . . . . . . . . . . . . . . . . . . 15
3.3.6 Job und Ressourcemanagement . . . . . . . . . . . . . 17
3.4 Anwendungsbeispiele für Grids . . . . . . . . . . . . . . . . . 18
3.5 Probleme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.6 Ausblick in die Zukunft . . . . . . . . . . . . . . . . . . . . . . 19
4 Zusammenfassung 20
2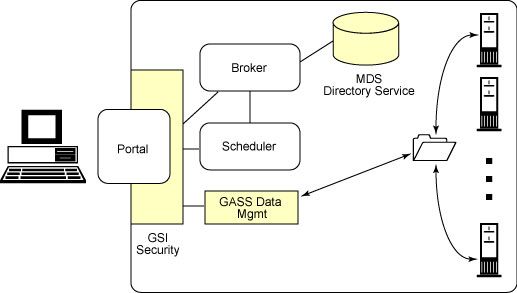
Seminar “Grid Computing “ WS 2004/05
1 Kurzfassung
Dieses Dokuments soll einen ersten Einblick / Überblick geben, was hinter
dem Schlagwort Grid Computing eigentlich genau steckt. Nach einer kurzen
Einleitung, welche die Motivation um so ein Projekt, wie Grid-Computing,
auf die Beine zustellen, erklären soll werde ich einen geschichtlichen Über-
blick über die Entstehung des Computers bis hin zum Grid-Computing ge-
ben. Aber es werden auch aktuelle Anwendunungen des Grid-Computing
angeführt, sowie die Unterscheidungen der verschiedenen Gridtypen, welche
wären, Rechen-Grids, Daten-Grids und Koloberative-Grids. Weiters wird der
Aufbau und somit die Komponenten des Grid Computing beschrieben. Was
ist zum Beispiel ein Broker oder ein Scheduler und wer sorgt dafür, dass
meine Anwendung läuft. Wie sieht es mit der Sicherheit im Grid Computing
aus, welche Rolle spielt diese. Aber es nicht alles Gold was glänzt und so
werde ich auch einige Probleme beschreiben. Und zuguterletzt wird noch ein
Blick in die Zukunft des Grid-Computing gewagt.
2 Einleitung
Zurzeit stellen rund 5,2 Millionen Menschen, in mehr als 200 Ländern, ihre
freien Rechenkapazitäten via Web der Suche nach ausserirdischer Intelligenz
tagtäglich zurverfügung. Statt zwischen zwei Anwendungen den Computer
im Leerlauf dösen zulassen, verschenken sie ihre Ressourcen an das seit Mai
1999 bestehende kalifornische Forschungsprojekt SETI@home 1 . Für dieses
Projekt werten diese Computer Radioteleskop-Daten aus dem Weltall, wel-
che sehr groß sind, nach Auffälligkeiten aus.
Einige Daten zum SETI@home Projekt: siehe Tabelle 1, Seite 18.
Auch 42382 Österreicher [16] beteiligen sich an der Suche nach E.T.
Nicht nur Weltraumforscher und Alien-Sucher haben Bedarf an großen
Rechenressourcen angemeldet. Nein, die Ansprüche an Leistungskraft und
Arbeitsspeichern von Maschinen wachsen überall. Insbesonders in der Wis-
senschaft, Produktionsentwicklung, Betriebswirtschaft (z.B: Risikoberechnun-
gen) und vielen anderen Bereichen. Die Zeit ist vorbei wo 640 KBytes alles
1
Search for Extraterrestrial Intelligence. Mehr Info unter:
http://setiathome.ssl.berkeley.edu/
3Seminar “Grid Computing “ WS 2004/05
sind, was man benötigt.
Obwohl jeder nach mehr Leistungskraft und Arbeitsspeicher schreit liegt
Weltweit sehr, sehr viel davon brach und wird nicht genutzt. Beispiele: UNIX
Server “serving“etwa nur 10% der Zeit. Und die meisten Desktop-Maschinen
stehen bis zu 95% der Zeit ohne Arbeit da.
SETI hat “Distributed Computing“populär gemacht. Es verteilt die Re-
chenarbeiten online und bündelt diese. Schnell fanden sich natürlich Nachah-
mer. Die Technik des vernetzten Rechnens ist inzwischen jedoch einen Schritt
weiter, sie erlaubt über die Arbeitsteilung hinaus, Computerkraft, Daten und
Anwendungen nach dem Peer-to-Peer 2 Prinzip allgemein zugänglich, und je
nach Bedarf abrufbar zumachen. Dieses Verfahren nennt sich Grid Com-
puting.
[..]The concept of Grid computing is simple: With Grid compu-
ting you can unite pools of servers, storage systems and networks
into one large system to deliver non-trivial qualities of service. To
an end user or application, it looks like one big virtual computing
system.[..] [14]
Das Wort Grid wird dabei vom “Strom-Netz“abgeleitet. Das Ziel ist es,
dass diese Ressourcen so einfach verfügbar sind, wie der Strom aus der Steck-
dose.
2
Peer-to-Peer (engl. peer “Gleichgestellter“, “Ebenbürtiger“oder “Altersgenosse/in“).
In Peer-to-Peer-Systemen ist diese Rollenverteilung aufgehoben. Jeder Host in einem Com-
puternetzwerk ist ein peer, denn er kann Client und Server gleichzeitig sein.
4Seminar “Grid Computing “ WS 2004/05
3 Grid Computing
3.1 Geschichte
Zuerst möchte ich eine kurze geschichtliche Übersich über die Entwicklung
des Computers, der Supercomputer und die Entstehung des Internets geben.
3000 v. Chr. Die Erfindung des Abakus in Babylon. Das Prinzip war es
Steine in Rillen im Sand zulegen. Diese Form änderte sich im Laufe der
Zeit (2500 Jahre) zu Stäbchen und Perlen in einem Holzgehäuse.
1644 n. Chr. - 1672 Blaise Pascal entwicketlte 1644 eine einfache mecha-
nische Maschine zum Addieren von Zahlen. Ungefähr 1672 entwickel-
te Gottlieb Leibnitz eine mechanische Rechenmaschine, die die vier
Grundrechnungsarten beherrschte.
18. Jh. Alessandro Volta entdeckte den elektrischen Strom.
1876 erfand Alexander Graham Bell das Telefon
19. Jh. Neben der Entdeckung des Stroms, bildet die von Georg Boole ent-
wickelte boolsche Algebra einen der Grundsteine für die heutige Com-
putertechnologie.
1936 - 1945 1936 stellte Konrad Zuse die erste binär arbeitende, programm-
gesteuerte Rechenmaschinen mit den Namen Z1(mechanisch), Z2 und
Z3 (elektrisch)vor. 1943 entstand “Colossus“, er war der erste elek-
tronische Digitalcomputer. Er bestand aus 1500 Vakuumröhren. 1945
wurde dann 18000 Elektronenröhren für “ENIAC 3“verwendet. Mit
Hilfe dieses Monstrums konnten einige hundert Multiplikationen pro
Sekunde durchgeführt werden. Die Programmierung erfolgt durch um-
stecken und umlöten von Drähten.
1956 Durch die Entwicklung des Transistors in den Bell Laboratorien wurde
eine Verkleinerung des Computers eingeläutet.
1957 Schoss die Sowjetunion den Sputnik-Satelliten ins All. Heutzutage
spielt die Datenübertragung per Satellit eine große Rolle.
3
(Electronic Numerical Integrator And Computer)
5Seminar “Grid Computing “ WS 2004/05
1958 Der erste voll transistorisierte Supercomputer Cray CDC 1604 wird
von Seymour Cray (1925 - 1996) vorgestellt.
1966 - 1969 plante das zur ARPA4 , welches vom US - Verteidigungsmini-
sterium ins Leben gerufen wurde, gehörige IPTO 5 alle Computerzen-
tren der ARPA miteinander zu verbinden. Im Herbst 1969 gelang dies
dann. Das Netz wurde ARPANET genannt und bestand aus vier Kno-
ten. Das dies gelungen war macht es für das heutige Internet so wichtig,
weil es geschafft wurde Rechner unterschiedlicher Art miteinander zu
verbinden.
1970 - 1975 1971 produziert Intel seinen ersten Mikrochip für Taschen-
rechner. 1974 wird der erste Home-Computer mit dem Namen ALTAIR
mit Intels 8080-Chip ausgestattet. Ebenfalls wurde da “Transmission
Control Protocol / Internet Protocol“enwickelt und wurde 1975 erst-
mals eingesetzt.
1981 Am 12.8 stellte IBM den ersten PC vor. Er enthielt den 8088-Chip von
Intel mit einer Taktfrequenz von 4,77 MHz und 64 KByte RAM, was
man für mehr als genug hielt. Das Betriebssystem kam von der Firma
Microsoft und hieß MS-DOS.
1982 - 1984 1982 stellt Intel den 80286 vor, welcher 1984 vom AT-PC ab-
gelöst wird, dieser enthielt einen 80286-Chip von Intel und eine 20 MB
Festplatte. 1985 kam dann der 386er von Intel auf den Markt, welcher
aber 1989 durch den 80486 wiederum abgelöst wurde.
1985 wurde der Multiprozessor Supercomputer Cray 2 mit 1,9 Giga-Flops
vorgestellt.
1990 Tim Berners-Lee und Robert Cailiau nehmen ein hausinternes Tele-
fonbuch in Betrieb. Damit legten sie den Grundstein für ein Medium,
dass aus der heutigen Zeit nicht mehr wegzudenken ist. Das World
Wide Web, auch Internet genannt. Tim Berners-Lee entwickelte das
Hyperlink-System, um Dokumente mit einem Inhalt, allen zugänglich
zu machen. Das surfen im Netz war erfunden.
4
( Advanced Research Projects Agency )
5
(Information Processing Techniques Office)
6Seminar “Grid Computing “ WS 2004/05
1991 stellte der Finnische Student Linus Torvalds den ersten Linux-Kernel
ins Internet.
1992 bring Microsoft Windows 3.1 auf den Markt. Bill Gates legte damit
seinen Grundstein zum Multimillionär.
1993 - 1997 Der Netscape Browser wurde erfunden. Die Kommerzialisiung
des Internets erhielt eine neue Komponente. Jeder konnte diesen bedie-
nen. Intel bring den Intel Pentium mit 60 MHZ auf den Markt welcher
bis 1997 auf 233 MHZ hochgetaktet wird. Windows NT kommt 1993
auf den Markt, 1995 Windows 95. 1996 hat das Internet bereits 50
Millionen Nutzer.
1998 - 2003 1998 kommt Windows 98 auf den Markt, Bill Gates vermögen
beläuft sich auf 60 Milliarden Dollar. 2000 - 2002 ist der schnellste Su-
percomputer der IBM ASCO white mit 12,3 Tera-Flops (Spitze). 2002
wurde in Japan dann der bis dahin schnellste Supercomputer gebaut,
der “Earth Simulator“, er kommt auf eine Leistung von 35,86 Tera-
Flops.
2004 Die Benutzeranzahl im Internet steigt täglich. Intel ist mit dem Pentim
4 auf dem Markt, getaktet bis 3,6 GHZ. Am Fr. 05.11.2004 wurde be-
kannt, dass der neue Supercomputer Blue-Gene/L-System einen neuen
Rekord mit 70,72 Tera-Flops aufstellte. Der Supercomputer ist zurzeit
erst zu einem Viertel fertig. Soll wenn er fertig ist auf 300 Tera-Flops
kommen.
Zurück zum Grid Computing. Seinen Ursprung nimmt das Grid Compu-
ting 6 in den 90er Jahren. Die Anfänge des Grid Computing liegen in den
rechnerintensiven Bereichen, High-Performance-Computing (HPC) 7 .
Bald sah man aber in den Supercomputern nicht mehr das Ultimative, man
suchte nach neuen möglichkeiten mehr Rechenleistung zurverfügung zu ha-
ben. Die Lösung sah man im Grid Computing
6
(englisch: “Gitter-Berechnung“)
7
Hochleistungsrechnen (englisch: high performance computing HPC) versteht man
alle Rechenanwendungen, deren Komplexität oder Umfang eine Berechnung auf einfachen
Arbeitsplatzmaschinen unsinnig macht.
7Seminar “Grid Computing “ WS 2004/05
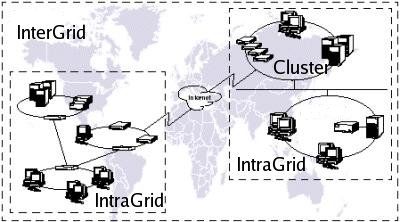
Es gibt 3 Ausbaustufen des Grids:
Cluster sind laut Definition von IBM kein Grid
What’s not a grid? A cluster, a network attached storage de-
vice, a scientific instrument, a network; these aren’t grids.
Each might be an important component of a grid, but by itself,
it doesn’t constitute a grid.[14]
Aber dennoch kann diese Art von kein Grid herangezogen werden um
Grid Sofware zutesten.
Intragrid ist die erste Richtige Ausbaustufe des Grids. Hier werden hetero-
gene Netze aufgebaut. Das Problem, welches hierbei entsteht ist, dass
• Verschiedene Prozessortypen
• Verschiedene Betriebsysteme
• Unterschiedliche Kapazitäten
• Unterschiedliche Geräte sind verfügbar
• ...
zusammenwirken müssen. Diese Unterschiede müssen gehandelt wer-
den, um zu einem Grid zusammengeschlossen werden. So können bei-
spielsweise Rechner eines Unternehmens vernetzt werden und einfache
Scheduling Mechanismen implementiert werden.
Intergrid Ist eine weitere Ausbaustufe des Intragrid. Hier werden immer
mehr Computer Weltweit mit in das Grid aufgenommen. Ab dieser
Ausbaustufe kommen weitere Factoren mit ins Spiel, wie Sicherheit,
Policies und Scheduling.
8Seminar “Grid Computing “ WS 2004/05
Abbildung 1: Die 3 Stufen des Grids (Quelle: adapidert von
Computerbild.de)
3.2 Anwendungstypen des Grids
3.2.1 Rechen-Grids
Rechen-Grids 8 ist der Begriff denn man für den Zusammenschluss der Re-
chenleistung vieler high-performance servern, denn der Großteil eines Rechen-
Grid besteht aus solchen, verwendet. Wie schon in der Einleitung erwähnt
dösen viele Server die meiste Zeit nur vor sich hin. Genau da setzt das Rechen-
Grid an. Das Rechen-Grid macht sich diese Server, welche gerade keine Arbeit
haben, zunutze und verwendeten ihre Ressourcen für rechenintensive Anwen-
dungen, welche selbst mit einem Supercomputer schwer zu handhaben wären.
Natürlich sind einige Dinge zuberücksichtigen:
• Ähnlich dem parallelen Rechnen, darf durch die Übertragung der Daten
kein höherer Zeitaufwand entstehen. Das heißt, mit Übertragung der
Daten und Berechnung sollte ich schneller zum Ergebnis kommen als
sonst.
8
(eng. computational grid) wird aber auch verteiltes Supercomputing genannt
9Seminar “Grid Computing “ WS 2004/05
• Natürlich muss der Rechner, auch die ihm gestellte Aufgabe Hardware
und Softwaretechnisch lösen können.
Das Ziel, die Anwendungen nicht nur von einem Rechner im Grid lösen zu-
lassen, sondern von mehreren. Wer sich beim parallelen Rechnen auskennt,
weiß, dass der folgende Satz nicht zwangsläufig stimmen muss. Wenn ich
die Aufgabe auf 12 Maschinen verteile, bekomme ich das Ergebnis 12 mal so
schnell als sonst. Was hier berücksichtig werden muss, ist die Kommunika-
tion zwischen den “Jobs“, der zugriff auf gemeinsame Daten und somit die
Abhängigkeit der einzelnen “Jobs“zueinander. Was hier zum Problem wer-
den kann ist, zB. das Nutzen gemeinsamer Daten, oder der Algorithmus ist
nicht an beliebig viele “Jobs“aufteilbar. Hier spricht man dann von der Ska-
lierbarkeit einer Anwendung.
Wie sehen nun solche geeigneten Anwendungen aus? Sie sollten sein:
• Rechnerintensive Anwendungen, die einzelne Rechner überfordert.
• Die Anwendung muss gut unterteilbar sein.
• Keine Benutzerinteraktionen notwendig
• Der genaue Durchsatz ist schwer vorhersagbar, daher muss entweder
genug Kapazität vorhanden sein oder die Anwendung sollte nicht zeit-
kritisch sein.
• Es sollten möglichst wenig bwz. kleinere Datenzugriffe notwendig sein.
• Es sollten möglichst in sich abgeschlossene Anwendung sein.
Diese und weitere Anforderungen an eine Anwendung finden sie hier: [10].
3.2.2 Daten Grids
“Access to distributed data is typically as important as access to
distributed computational ressources.“[7]
Für einige wissenschaftlichen Anwendungen werden einige Gigabyte oder so-
gar Petabyte an Daten benötigt. Um diesen Zugang zu den Daten zu ermögli-
chen gibt es das Daten Grid. In diesem Grid stellt jeder Benutzer Speicher-
platz für die Daten anderer User zurverfügung. Auf diese Daten kann dann
durch das Grid zugegriffen werden, wobei wieder der Sicherheitsgedanke im
10Seminar “Grid Computing “ WS 2004/05
Vordergrund steht, denn nicht jeder will, dass jeder auf seine Daten Zugriff
hat. Dies muss im Daten-Grid genauso gemanagt werden wie der Austausch
der Daten.
Datensicherung
Wo Daten sind, können Daten verloren gehn. Um dem Vorzubeugen können
Daten mehrfach im Grid abgelegt werden, und bei Verlust einer “Datenbank
“greift man auf die Nächste zu. Ein entscheidender Vorteil, der sich aus der
Mehrfachenablage der Daten im Netz ergibt ist, dass die Daten nicht über
das gesamte Netzwerk übertragen werden müssen, sondern von einer nahe
liegenden Maschine bezogen werden können.
Anwendung
Ein Beispiel für die wissenschaftliche Anwendung findet sich bei der Atom-
physikergemeinschaft CERN. Diese will ab 2007 im Rahmen des Large-Hardon-
Collider-Projectes (LHC) enorm große Datenmengen verarbeiten. Es wird
von 12 bis 14 Petabyte Daten pro Jahr gesprochen, dies entspricht 20 Millio-
nen Cds. Beim LHC handelt es sich um den bislang leistungsfähigsten Teil-
chenbeschleuniger, welche Aufschlüsse über den Ursprung des Universums
liefern soll. Bei solchen Datenmengen ist natürlich auch die Übertragungsra-
te wichtig, so wurden in 30 Minuten mehr als 1 TeraByte an Daten über eine
große Entfernung übertragen. Auch wurde mit einer Geschwindigkeit von 1
GigaByte pro Sekunde auf ein Band gesichert. Mehr Information finden sie
hier [8] und hier [9].
3.2.3 Kollaborative Grid Computing
Neben Großrechnern in Firmen und wissenschaftlichen Einrichtungen, stehen
aber weltweit auch Millionen von Desktop-Maschinen mit Anschluss zum In-
ternet in Haushalten und Betrieben. Wie in der Einleitung gezeigt, befinden
sich hier, durchschnittlich die Maschinen bis zu 95% der Zeit am Tag im
Leerlauf. Das Projekt SETI@home (siehe Einleitung), macht sich eben diese
leerstehenden Ressourcen zueigen und nutzt diese zur Suche nach ET. Dieses
Projekt arbeitet nach dem Prinzip des Kollaborativen-Grids.
Aber es müssen nicht nur Desktop-Maschinen, sein welche zusammengefaßt
werden. Nein es können ebenso Spezialgeräte integriert sein, wie Elektronen-
mikroskope, vielleicht sogar der Teilchenbeschleuniger aus dem LHC Projekt.
Auf einigen Maschinen ist eventuell teure Software, welche benutzt werden
11Seminar “Grid Computing “ WS 2004/05
kann. Auf all diese Ressourcen kann aus dem Kollaborativen-Grid heraus zu-
gegriffen werden.
All dies kann natürlich nicht willkürlich benutzt werden, sondern es braucht
eine Organisation, eine so genannte virtuelle Organisation (VO) welche die
Ressourcen kontrolliert und deren Austausch überwacht. Was hier natürlich
wieder eine wichtige Rolle spielt ist die Sicherheit, unter anderem ist wichtig,
dass die Organisation keine Information, Daten und Ressourcen nach außen
dringen läßt, sprich in sich geschlossen ist. Jeder Benutzer des Kollaborativen-
Grids, gehört einer solchen virtuellen Organisation an, welche wiederum ein
Teil eines noch größeren Grids sein kann. Solche virtuelle Organisationen
haben nach Ian Foster 9 eine besondere Bedeutung so sagt er:
“It is our belief that VOs have the potential to change dramati-
cally the way we use computers to solve problems, much as the
web changed how we exchange information “
Neben den Ressourcen auf die zugegriffen werden kann, kann natürlich jeder
User auch auf die Daten im Grid zugreifen, womit sich ein Daten-Grid eben-
so ergibt.
Diese Form des Grids, ist jene, die uns Allen ermöglichen soll das Grid-
Computing zunutzen. Damit stellt sich jedoch gleich die nächste Frage, wer
kontrolliert den Zugriff auf die Ressourcen.
Es stehen hier verschiedene Methoden zur verfügung um “Jobs “für die zur-
verfügung stehenden Ressourcen zu organisieren und zu überwachen.
• Reservation, der Gebrauch der Ressource wird einfach reserviert. Der
Zugriff erfolgt dann zu dem Zeitpunkt an dem die Ressource reserviert
wurde.
• Scheduling, wird später noch erklärt. Nur soviel, die benötigte Res-
source wird selbständig im Grid gesucht. zb: eine Maschine die gerade
nichts zutun hat.
• Scavening hier sendet eine Maschine ihren Status an eine zentrale
Instanz. Auf diese Art können sich Maschinen melden, die gerade local
nichts zutun haben und können in der Zwischenzeit einen Job aus dem
Grid übernehmen.
9
Chefs der Mathematik- und Informatikabteilung am Argonne-Nationallaboratorium
und Professor für Informatik an der Universität Chicago
12Seminar “Grid Computing “ WS 2004/05
3.3 Komponenten des Grid Computing
Im nachfolgenden möchte ich einen Überblick über die verschiedenen Kompo-
nenten eines Grids geben, einige der hier aufgelisteten Komponenten werden
nicht immer benötigt, dies hängt von der Architektur des Grids ab. So kann
zB. der Scheduler wie oben beschrieben durch verschiedene andere Techniken
ersetzt werden. Es soll aber dazudienen um generell einen Überblick über die
Komponenten und deren Funktion im Grid zubekommen.
3.3.1 Portal/User interface
Ein Endbenutzer des Grids will sich nicht mit Quellcode herumschlagen,
um mit dem Grid arbeiten zu können, er will sich nicht zuerst sein eigenes
Programm schreiben müssen. Nein er will den Stecker in die Dose stecken
und will dann seine Applicationen laufen lassen können. Ähnlich wie beim
Internetsurfen.
Ein Grid Portal kann ihm das ermöglichen. Er kann durch das Portal, die ihm
zurverfügung stehenden Ressourcen nutzen. Somit sieht der Nutzer ähnlich
wie beim Strom aus der Steckdose nicht woher die Energie kommt. Um solche
Portale zuerzeugen steht beispielsweise Grid Portal Toolkit 3 zuverfügung.
Weiter Informationen finden sie hier: [12]
Abbildung 2: Portal/User interface (Quelle: [1])
3.3.2 Security im Grid
Angesichts der Möglichkeiten die das Grid seinen Benutzern bieten kann, hat
eine Frage oberste Priorität. Wie sorge ich dafür, dass nicht jeder beliebige
auf die vorhandenen Daten, Rechenleistungen, usw. zugreifen kann und sich
diese somit zunutze machen kann. Vielleicht wüerde jemand sogar auf die Idee
13Seminar “Grid Computing “ WS 2004/05
kommen diese gewaltige Rechenkraft dazu zu verwenden um Sicherheitssy-
steme zuhacken. Nicht nur Hacker Attacken sondern auch Betriebsspionage
hindert die meisten Betriebe und Forschungsgruppen daran, ihr Grid aufs
Internet auszuweiten. So sagt zum Beispiel Harald Lesch, Astrophysiker an
der Universität München: “Allein der letzte Hackerangriff aus Bulgarien auf
unser Intranet verbietet es, externe Pcs in das Fakultäts-Grid mit einzube-
ziehn.“
Diese Securitymechanismen müssen Authentifizierung, Autorisierung und so-
weiter unterstützen. Eines der Tools überhaupt im Grid ist Globus Toolkit.
Dies Tool bietet auch eine GSI 10 , welches ein sehr guter security mechanis-
mus ist.
[..]The GSI includes an OpenSSL implementation. It also provi-
des a single sign-on mechanism, so that once a user is authen-
ticated, a proxy certificate is created and used when performing
actions within the grid. [..] The portal will then be responsible
for signing in to the grid, either using the user’s credentials or
using a generic set of credentials for all authorized users of the
portal.[..] [1]
Abbildung 3: Security im Grid (Quelle: [1])
3.3.3 Broker
Wenn sich nun ein Benutzer erfolgreich ins Grid eingeloggt hat, will er natürlich
seine Anwendung laufen lassen. Um dies tun zukönnen muss er zuerst her-
ausfinden welche Ressourcen überhaupt vorhanden sind und welchen Status
diese haben. Hierfür gibt es MDS 11 . Dieses System ist wiederum Teil des
10
Grid Security Infrastructure
11
Monitoring and Discovery System
14Seminar “Grid Computing “ WS 2004/05
Globus Toolkits.
MDS kann eben dazu verwendet werden, um herauszufinden welche Res-
sourcen überhaupt vorhanden sind und welchen Status diese haben. Weitere
Informationen finden sie hier: [17]
Abbildung 4: Broker (Quelle: [1])
3.3.4 Scheduler
Ein Scheduler findet die Maschine, welche vom User ausgewählt wurde, oder
sucht sich selber die passende Maschine für den Job aus. Weiters wird er
dazu verwendet um die Ausführung des Jobs zu überwachen und bei nicht
korrekter Ausführung, diesen an eine andere Maschine zuübermitteln.
Abbildung 5: Scheduler (Quelle: [1])
3.3.5 Datenmanagement
Wenn zB. eine Application (z.B: ein Java Programm) zu einer Maschine im
Grid gesendet werden muss, um dieses dort auszuführen, braucht es auch hier
ein Management. Dieses Daten management muss die Sicherheit aufrecht er-
halten, muss dafür sorgen, dass die Daten an ihren angegeben Platz kommen.
Globus Toolkit 2.0 bietet auch hier Lösungen an:
15Seminar “Grid Computing “ WS 2004/05
• GridFTP, baut auf dem bekannten FTP12 Protokol aus dem Internet
auf. Doch es hat einige Erweiterungen gegenüber dem FTP Protokol,
so verwendet es zB. GSI 13 welche für die Identifizierung des Users
zuständig ist. Weiters können auch von Server zu Server Daten übert-
ragen werden (third-party), sowie parallele und partielle Datenübert-
ragung ist möglich.
• Data Replication, es gibt 2 Tools um verschiedene Kopien von Da-
ten, gespeichert in verschiedenen Systemen, verteilt auf das Grid, zu
managen. Einmal Replica Catalog und zum anderen Replica Ma-
nagement.
• GASS 14 , erlaubt zB. einer Application mittels eines URLs, welcher
auch in Form eines HTTP Url angegeben werden kann, auf Daten,
verteilt im Grid, Zugriff.
Weiter Informationen finden zum Datenmanagement in Globus Toolkit 2.0
finden sie hier: [4]
Globus Toolkit 2.0 ist natürlich nur eine Möglichkeit, so steht auch zB. das
Globus Toolkit 3.2 zuverfügung. Information zum Thema Datenmanagement
in Globus Toolkit 3.2 finden sie hier: [3]
Abbildung 6: Datenmanagement (Quelle: [1])
12
File transfer Protocol
13
Grid Security Infrastructure
14
Globus Access to Secondary Storage
16Seminar “Grid Computing “ WS 2004/05
3.3.6 Job und Ressourcemanagement
Wenn wir uns nun erfolgreich im Grid angemeldet haben, unsere Maschinen
gefunden haben, die wir brauchen, all unsere Daten (zB. ein Java Programm)
an die Maschinen geschickt haben, welche diese benötigen, wollen wir nun
unseren “Job “ausführen. Um diesen Job auszuführen, hilft uns GRAM15 .
GRAM kann auf einer Maschine im Grid einen Job starten, dessen Status
abfragen und uns das Resultat zurücksenden, wenn der Job fertig ist. Für
mehr Informationen zu GRAM lesen sie hier [5] nach.
Abbildung 7: Job und Ressource management (Quelle: [1])
15
Grid Ressource Allocation Manager
17Seminar “Grid Computing “ WS 2004/05
3.4 Anwendungsbeispiele für Grids
Hier einige Grid Projekte:
Seti@home Seti@home war der erste Versuch die nicht genutzeten Re-
chenleistungen und Ressourcen, dazu zunutzen um rechenintesive An-
wendungen laufen zulassen. Seti@home ist auf der Suche nach unre-
gelmässigkeiten im All. Seti@home habe ich schon näher in der Einlei-
tung beschrieben (siehe Kapitel 2, Seite 3).
Hier einige Daten zum Projekt:
Total Letzten 24 Stunden
Benutzer 5236846 970
zurückgesendete 1627790254 1452015
Ergebnisse
Totale CPU zeit 2117874,146 Jahre 1071,240 Jahre
Floating Point Opera- 5.932567e+21 5.662858e+18(65.54
tions TeraFLOPs/sec)
durchschnittliche 11 hr 23 min 50.6 sec 6 hr 27 min 46.0 sec
CPU Zeit pro Ar-
beitsstation
Tabelle 1: Statistik SETI@home [16], Stand 07.11.04
Large-Hardon-Collider-Projectes (LHC) Dieses Projekt wird von der
Atomphysikergemeinschaft CERN, CERN wo unter anderem auch das
Internet seinen Ursprung hat, betrieben. Hier wird das Grid dazu ver-
wendet um riesige Datenmengen zuverarbeiten, welche der bisher lei-
stungsfähigste Teilchenbeschleuniger der Welt erzeugt. Das Ziel der
Projektes ist es, den Ursprung des Universums zu entschlüsseln. (siehe
Kapitel 3.2.2, Seite 10);
GIMS Great Internet Mersenne Prime Search, hier kann man mithelfen
mögliche Mersenne-Primzahlen zufinden.
Compute Against Cancer Wird von der Firma Parabon betrieben, und
will damit die Krebsforschung beschleunigen. Bei diesem Projekt wird
simuliert wie die Krebszellen auf die verschiedene Medikamente reagie-
ren.
18Seminar “Grid Computing “ WS 2004/05
Dies sind nur ein kleiner Bruchteil, der Projekte, die gerade laufen. Wei-
tere Projekte finden sie hier [15].
3.5 Probleme
Eines der größten Probleme, mit dem das Grid Computing zukämpfen hat
ist, dass die Grid Standardisierung langsam voran geht. Um das zusammen-
fassen von unzähligen Rechnern, Datenbanken, und Speicherkomponenten zu
einem riesigen, virtuellen Computer gewährleisten zukönnen, bedarf es einer
ausgeklügelten Middleware und stabiler Standard-Schnittstellen.
“Im Prinzip muss die Grid-Infrastruktur den heutigen Web-Services ähneln“,
sagt dazu Joseph Reger16 . Die Entwicklung geht sehr schleppend voran, die
Probleme sind neben den anspruchsvollen technischen Rahmenbedingungen
auch firmenpolitische Interessenslagen. “Vor Ende 2006 wird es keine allge-
mein akzeptierten Standardschnittschnellen im Grid-Bereich geben“, so Re-
gers Einschatzung.
Das nicht-vorhandensein von Grid-Standards heißt natürlich nicht, dass es
noch keine Grid-ähnliche Struktur gibt. Es existieren solche Strukturen in
Wissenschaftsgemeinschaften wie auch auf dem freien Markt.
Ein weiteres Problem werden die befürchteten Hacker-Attacken darstellen.
Sehen sie dazu, unter Kapitel. 3.3.2 nach, Sicherheit im Grid.
3.6 Ausblick in die Zukunft
Zurzeit dient das Internet vorwiegend als Transportmittel, Informationsspei-
cher. Das soll sich ändern, es soll nicht nur mehr Datenaustausch betrieben
werden, vielmehr soll die ganze Rechenleistung gebündelt werden und zu ei-
nem riesigen, virtuellen Computer mit verteilten Rechner - und Speicherka-
pazität werden. Dies wird jetzt schon als die nächste Generation des Internets
gesehen. Die dadurch enstehenden Rechenleitung für die Wissenschaft und
Forschung wäre durch einen Supercomputer nicht einmal annähernd zu errei-
chen. Diese Leistungen, Rechenleistung, Speicherkapazität oder Anwendun-
gen, sollten, so wird es immer wieder in der Literatur erwähnt, wie Strom
aus der Steckdose Unternehmen zurverfügung stehen.
Das dies nicht nur Zukunftsmusik bleibt sorgt unter anderem auch die Eu-
ropäische Kommision, dies fördert nämlich mit 52 Millionen Euro zwölf EU
16
Chief Technology Officer bei Fujitsu Siemens Computers
19Seminar “Grid Computing “ WS 2004/05
- Forschungsprojekte, die Grid Technologie für Hochleistungs - Rechennetze
aus den Forschungslabors in die Unternehmen bringen wollen.
Neben den Technischen Aspekten, darf man eines nicht aus den Augen ver-
lieren, und das ist die Nutzung des Grids als kommerzielles Gut. Grid Lei-
stung soll in Zukunft, wie schon öfter gesagt, wie Strom aus der Steckdose,
verfügbar sein, dass heißt das jeder, genau wie beim Internet, Zugriff darauf
hat. Daraus folgt, dass sich Betreiber und Anbieter finden werden die ge-
gen Bezahlung die Nachfrage nach Ressourcen erfüllen. Welcher Markt sich
hier auftun kann, ist schwer einzuschätzen, aber man kann annehmen, dass
es dem Internet in nichts nachstehen wird.
4 Zusammenfassung
Ich persönlich sehe auch im Grid Computing eine große Chance. Dies be-
zieht sich nicht nur auf die Entdeckung von ET oder des Ursprungs des
Universums. Nein, mit der Möglichkeit des Grids ist es zB. einer kleinen For-
schungsgruppe möglich, zugriff auf für sie zuteure Geräte zuhaben, denn nicht
jeder kann sich einen Teilchenbeschleuniger leisten. Aber auch riesige Daten-
mengen wären für solche Forschungsgruppen zugänglich. Wer weiss vielleicht
wird mit Hilfe des Grid Computing wirklich einmal Krebs ausgerottet. Worin
ich aber eines der größten Probleme sehe, ist die Absicherung des Grids vor
Hackern. Es ist ja schon das Internet ein gefundenes Fressen für viele Hacker,
wie ist es dann erst, wenn sie die möglichkeit haben Teilchenbeschleuniger
zu steuern, oder Elektronenmikroskope verwenden können. Hier verstehe ich
absolut den Zweifel jener Firmen und Forschungsgruppen, die den Schritt
vom Intragrid zum Intergrid noch nicht wagen. Das Grid Computing steckt
noch in den Kinderschuhen, und bis es aus der Steckdose zu uns kommt wird
es wohl noch einige Jahre dauern.
Literatur
[1] Bart Jacob, IBM Grid computing: What are the key
components, zu finden auf der Homepage: http://www-
106.ibm.com/developerworks/grid/library/gr-overview/. Technical
report, 2003.
20Seminar “Grid Computing “ WS 2004/05
[2] CHIP Online, Kim Kranz Das Internet als
Superrechners, zu finden auf der Homepage:
http://www.chip.de/artikel/c artikel 10837960.html?tid1=19508&tid2=0.
Technical report, 2003.
[3] the Globus Alliance. Data Management Documentation, zu
finden auf der zu finden auf der Homepage: http://www-
unix.globus.org/toolkit/docs/3.2/datamanagement.html. Techni-
cal report, 2004.
[4] the Globus Alliance. Data Management, zu finden auf der Homepa-
ge: http://www.globus.org/toolkit/data-management.html. Tech-
nical report, 2003.
[5] the Globus Alliance. GRAM: Key Con-
cepts, zu finden auf der Homepage: http://www-
unix.globus.org/toolkit/docs/3.2/gram/key/index.html. Technical
report, 2004.
[6] the Globus Alliance. The Globus Data Grid Effort, zu finden auf
der Homepage: http://www.globus.org/datagrid/. Technical re-
port, 2002.
[7] the Golem.de. CERN: Fortschritte beim Grid-Computing, zu finden
auf der Homepage: http://www.golem.de/0407/32225.html. Tech-
nical report, 2004.
[8] the Golem.de. CERN: Weltweites wissenschaftliches
Datengrid geht online, zu finden auf der Homepage:
http://www.golem.de/0310/27790.html Technical report, 2003.
[9] the Golem.de. CERN: Fortschritte beim Grid-Computing, zu finden
auf der Homepage: http://www.golem.de/0407/32225.html. Tech-
nical report, 2004.
[10] Grohmann Ralf, Dr. Wedeniwski Sebastian Die
IBM ZetaGrid Lösugn: zu finden auf der Homepage:
http://www.zetagrid.net/zeta/ZetaGRID4customers de.pdf.
Technical report, 2004.
21Seminar “Grid Computing “ WS 2004/05
[11] Heidenblut Norbert. Grid-Computing: zu fin-
den auf der Homepage: http://www.mathematik.uni-
ulm.de/sai/ss03/inetsem/src/heidenblutharbeit.pdf. Technical
report, 2003.
[12] Maytal Dahan, Mary Thomas, Akhil SethEric, Ro-
berts Jay Boisseau Build grid portals with Grid Por-
tal Toolkit 3, zu finden auf der Homepage: http://www-
106.ibm.com/developerworks/grid/library/gr-gridport/. Technical
report, 2003.
[13] Jürgen Höling. Es wird gridisiert - obwohl die Standards noch dau-
ern, Zu finden auf derHomepage: http://www.silicon.de/cpo/hgr-
csh/detail.php?nr=16062. Technical report, 2004.
[14] IBM. So what is grid computing anyway, zu finden auf der
Homepage: http://www-106.ibm.com/developerworks/library/gr-
starthere.html. Technical report, 2004.
[15] Rechenkraft.net. Du kannst der medizinischen Forschung helfen,
zu finden auf der Homepage: http://rechenkraft.net/indexjs.html.
Technical report, 2004.
[16] SETI@home. Statistic, zu finden auf der Homepage:
http://setiathome.ssl.berkeley.edu/totals.html. Technical re-
port, 07.11.2004.
[17] Vladimir Silva . Querying the Grid with the Globus Toolkit
Monitoring and Discovery Service, zu finden auf der Homepa-
ge: http://www-106.ibm.com/developerworks/grid/library/gr-
mds.html. Technical report, 01.04.2003.
[18] Besonderen Dank, von meiner Seite aus, an Google.at. Zu finden
auf der Homepage: http://www.google.at.
22Sie können auch lesen

















































