Masterarbeit HOCHSCHULE MÜNCHEN - ELIB-DLR
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
HOCHSCHULE MÜNCHEN
Masterarbeit
Automatische Generierung von
Softwarebeschreibungen aus Source Code
Elias Porcio
31.08.2021
Fachbereich: Fakultät für Informatik und Mathematik
Prüfer: Prof. Dr. Alfred Nischwitz
Zweitprüfer: Prof. Dr. David Spieler
Betreuer (DLR): Dr. Tobias Hecking
Anmeldedatum: 01.03.2021
Inhalt
1 Einleitung 7
1.1 Motivation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
1.2 Ziel . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2 Grundlagen 8
2.1 Stand der Technik . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.2 Neural code representation . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.1 Embeddings . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
2.2.2 Sequence-to-Sequence Modelle . . . . . . . . . . . . . . . . . 9
2.2.3 code2vec . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.2.4 code2seq . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12
2.3 Textähnlichkeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3.1 BLEU . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
2.3.2 ROUGE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.4 Zentralitätsmetriken . . . . . . . . . . . . . . . . . . . . . . . . . . 16
2.4.1 Eigenvektor-Zentralität . . . . . . . . . . . . . . . . . . . . . 16
2.4.2 Katz-Zentralität . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.5 Transformer Architekturen . . . . . . . . . . . . . . . . . . . . . . . 18
3 Umsetzung 22
3.1 Inlining-Ansatz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.1.1 Datensatz . . . . . . . . . . . . . . . . . . . . . . . . . . . . 24
3.1.2 Call-Graph Erstellung . . . . . . . . . . . . . . . . . . . . . 25
3.1.3 Call-Graph Zentralität . . . . . . . . . . . . . . . . . . . . . 27
3.1.4 Clustering . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31
3.1.5 Inlining . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32
3.1.6 Parsing . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33
3.1.7 Erstellung der Zielsequenzen . . . . . . . . . . . . . . . . . . 35
3.2 Summary-Ansatz . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.2.1 Datensatz . . . . . . . . . . . . . . . . . . . . . . . . . . . . 37
3.2.2 Textzusammenfassung . . . . . . . . . . . . . . . . . . . . . 38
3.3 Erkennung von Lizenzen und Autoren . . . . . . . . . . . . . . . . . 40
3.4 Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 41
1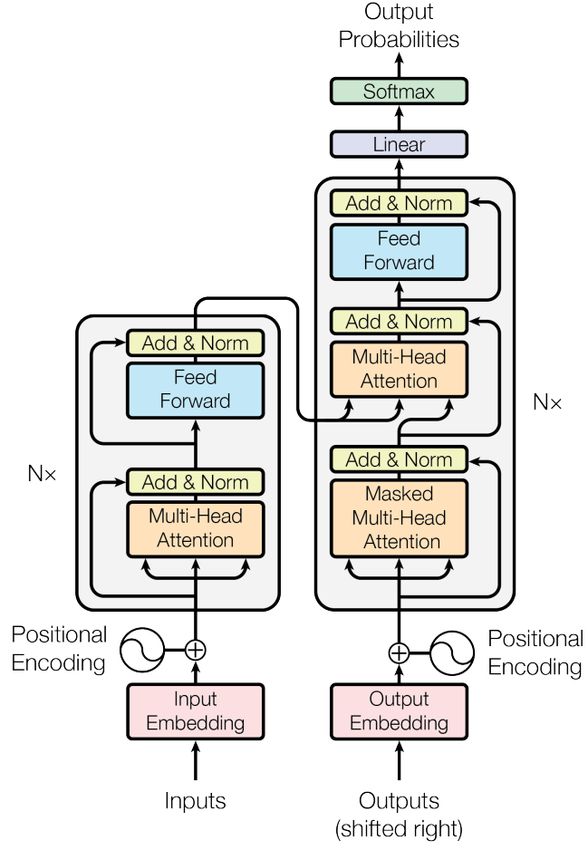
4 Ergebnisse 43
4.1 Inlining-Ansatz . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43
4.2 Summary-Ansatz . . . . . . . . . . . . . . . . . . . . . . . . . . . . 46
4.2.1 Docstring Generierung . . . . . . . . . . . . . . . . . . . . . 46
4.2.2 Textzusammenfassung . . . . . . . . . . . . . . . . . . . . . 47
4.3 Diskussion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 50
5 Schlussfolgerung / Ausblick 51
2
Abbildungen
2.1 Beispiel für die Übersetzung eines englischen Satzes mithilfe eines
Sequence-to-Sequence Modells. [1] . . . . . . . . . . . . . . . . . . . 10
2.2 Beispiel für einen Path-Kontext, der aus dem Ausdruck “x = 7;”
entstanden ist. [2] . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.3 Übersicht über die Datenverarbeitung bei code2vec. . . . . . . . . . 11
2.4 Übersicht über die Datenverarbeitung bei code2seq. . . . . . . . . . 12
2.5 Beispiel zur Generierung eines Satzes mit code2seq. [3] . . . . . . . 13
2.6 Formel zur Berechnung von BLEUs Strafe für zu kurze Übersetzun-
gen. BP: Brevity Penalty; c: Länge der zu bewertenden Übersetzung;
r: Länge der Referenzübersetzung [4] . . . . . . . . . . . . . . . . . 14
2.7 Formel zur Berechnung des BLEU-Scores mit Sequenzlänge 1 und
einer Referenzübersetzung. BP: brevity penalty; Text: zu bewertende
Übersetzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15
2.8 Formel zur Berechnung des ROUGE-1-Scores mit einer einzigen
Referenzzusammenfassung. . . . . . . . . . . . . . . . . . . . . . . . 15
2.9 Intuitive Formel zur Berechnung der Eigenvektor-Zentralität. x:
Eigenvektor-Zentralität; A: Adjazenzmatrix des Graphen . . . . . . 16
2.10 Definition eines Eigenvektors bzw. der Eigenvektor-Zentralität. x:
Eigenvektor-Zentralität; A: Adjazenzmatrix des Graphen; λ: Eigenwert 16
2.11 Formel zur Berechnung der Katz-Zentralität. xi : Katz-Zentralität von
Knoten i; α: Gewichtungsfaktor; A: Adjazenzmatrix des Graphen; n:
Anzahl Knoten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.12 Self-Attention-Matrix eines Transformers über einen Inputsatz. [5] . 18
2.13 Transformer Architektur in der Übersicht. [6] . . . . . . . . . . . . . 20
2.14 Attention-Matrix zwischen Encoder und Decoder eines Transformers
bei einer Übersetzung von Englisch nach Spanisch. [7] . . . . . . . . 21
3.1 Übersicht über den Inlining-Ansatz. . . . . . . . . . . . . . . . . . . 22
3.2 Übersicht über den Summary-Ansatz. . . . . . . . . . . . . . . . . . 23
3.3 Ausschnitt aus dem Call-Graph des Projekts “TwitterTap”. Die Größe
der Knoten entspricht ihrer Zentralität. Blätter sind ausgegraut.
Core-Funktionen sind rot. . . . . . . . . . . . . . . . . . . . . . . . 26
3.4 Java AST für den Ausdruck “x = 1” (links), sowie der von astminer
verwendete Python AST für denselben Ausdruck (rechts). . . . . . . 34
3Tabellen
3.1 Einige Pyan Funktionen, sortiert nach ihrer Eigenvektor-Zentralität
im ungerichteten Call-Graph. Dunkelgrün: sehr wichtig; grün: wichtig;
weiß: neutral; rot: unwichtig . . . . . . . . . . . . . . . . . . . . . . 27
3.2 Einige Pyan Funktionen, sortiert nach ihrer Katz-Zentralität im
transponierten Call-Graph. Dunkelgrün: sehr wichtig; grün: wichtig;
weiß: neutral; rot: unwichtig . . . . . . . . . . . . . . . . . . . . . . 28
3.3 Verschiedenen Zentralitätsmetriken sowie die Scores die sie durch
den Bewertungsalgorithmus erhalten. . . . . . . . . . . . . . . . . . 30
3.4 Die ersten zwei Sätze der “What”-Sektion der Readme-Dateien einiger
GitHub Repositories, sowie deren About-Texte. . . . . . . . . . . . 36
3.5 Vergleich von PEGASUS’ Vokabular mit dem Output-Vokabular des
Docstring-Generators bzw. dem Output-Vokabular von code2seq aus
dem Inlining-Ansatz. . . . . . . . . . . . . . . . . . . . . . . . . . . 39
4.1 Hyperparameter und Evaluationsergebnisse verschiedener Trainings-
durchläufe des Inlining-Ansatzes. . . . . . . . . . . . . . . . . . . . 43
4.2 Originale GitHub About-Texte einiger Repositories, sowie die Be-
schreibungen, die vom code2seq Modell generiert wurden. . . . . . . 44
4.3 Umfrageergebnisse des Inlining-Ansatzes. . . . . . . . . . . . . . . . 44
4.4 Statistiken über die Generierung von Readme-Dateien für 20 ausge-
wählte Projekte mit gutem Ergebnis, sowie für den ganzen Validie-
rungsdatensatz. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45
4.5 Hyperparameter und Evaluationsergebnisse des Docstring Trainings. 46
4.6 Einige vom code2seq Modell generierte Docstrings, sowie die zuge-
hörigen Originale. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47
4.7 Hyperparameter und Evaluationsergebnisse verschiedener Trainings-
durchläufe des Textzusammenfassers für den Summary-Ansatz. . . . 48
4.8 Einige Beispiele für generierte Texte des Textzusammenfassers, sowie
die zugehörigen Zielsequenzen. . . . . . . . . . . . . . . . . . . . . . 48
4.9 Umfrageergebnisse des Summary-Ansatzes. . . . . . . . . . . . . . . 49
4.10 Statistiken über die Generierung von Readme-Dateien für 20 ausge-
wählte Projekte mit gutem Ergebnis, sowie für den ganzen Validie-
rungsdatensatz. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49
4Abkürzungen
AST Abstract syntax tree
BERT Bidirectional Encoder Representations from Transformers
BLEU Bilingual evaluation understudy
DLR Deutsches Zentrum für Luft- und Raumfahrt
LSTM Long short-term memory
MST Minimum spanning tree
PEGASUS Pre-training with Extracted Gap-sentences for Abstractive
Summarization
RNN Recurrent neural network
ROUGE Recall-Oriented Understudy for Gisting Evaluation
5Zusammenfassung
In dieser Arbeit geht es darum, mithilfe von neuronalen Netzen Readme-Dateien
automatisch aus dem Sourcecode von Projekten zu erstellen. Die Readme-Dateien
sollen den Zweck des Projekts beschreiben und als Basis für Sourcecode-Retrieval
Systeme geeignet sein. Das vereinfacht den Umgang mit undokumentierter Software,
insbesondere wenn man mit großen Mengen davon konfrontiert ist.
Zur Umsetzung werden zwei verschiedenen Ansätze verfolgt. In beiden werden
zunächst die wichtigsten Funktionen des Projekts bestimmt, indem der Call-Graph
des Projekts erstellt und die zentralsten Knoten in diesem ermittelt werden. Im sog.
Inlining-Ansatz werden die wichtigsten Funktionen ineinander geinlined, sodass
eine einzige Funktion entsteht, die das gesamte Projekt repräsentiert. Diese dient
anschließend als Input für code2seq - einem neuronalen Netz, das Beschreibungen
für einzelne Funktionen erstellen kann. Der so entstandene Text wird dann als
Readme verwendet.
Im sog. Summary-Ansatz generiert code2seq für die wichtigsten Funktionen zuerst
einen Docstring. Die Docstrings werden konkateniert und mithilfe von PEGASUS
zu einem Readme zusammengefasst. PEGASUS ist ein neuronales Netz, das auf
Textzusammenfassung trainiert ist. In beiden Ansätzen wird ein Fine-Tuning der
Netze auf ihre neue Aufgabe durchgeführt.
Die Ergebnisse werden bewertet, indem sie mit den originalen Readme-Dateien
verglichen werden. Dazu kommen die Metriken ROUGE und BLEU, sowie ein
BERT-Modell zur Bewertung semantischer Ähnlichkeit zum Einsatz. Zum Schluss
wird die Qualität auch durch eine Umfrage unter Softwareexperten bewertet.
Das Generieren von sinnvollen Readme-Dateien gelingt mit beiden Ansätzen in
seltenen Fällen. Bei den meisten Projekten fehlt den generierten Beschreibun-
gen ein inhaltlicher Bezug zum tatsächlichen Projekt. Deshalb wäre eine weitere
Verbesserung der Ansätze nötig, bevor sie für die genannten Zwecke einsetzbar
sind.
61. Einleitung
1.1 Motivation
Readme-Dateien sind ein wichtiges Element der Dokumentation von Softwareprojek-
ten. Sie geben einen Überblick darüber, welchen Zweck die Software erfüllt und wie
sie bedient wird. Außerdem spielen sie eine wichtige Rolle in Sourcecode-Retrieval
Systemen. Entwickler, die nach bestimmten Funktionalitäten suchen, formulieren
ihre Anfragen in natürlicher Sprache. Um gute Suchergebnisse zu erzielen, sollte der
Software deshalb immer eine Beschreibung in natürlicher Sprache beiliegen.
Leider wird die Dokumentation von Software oft vernachlässigt, sodass man mit
Projekten ohne Readme-Datei konfrontiert wird. In diesem Fall muss man mühsam
den Sourcecode lesen, um ein Verständnis für das Projekt zu erhalten. Auch das
Sourcecode-Retrieval könnte nur auf Basis bestimmter Keywords im Sourcecode
funktionieren.
1.2 Ziel
Ziel dieser Arbeit ist es zu untersuchen, ob es möglich ist, Readme-Dateien automa-
tisch zu generieren. Als Basis hierfür soll nur der Sourcecode des Projekts verwendet
werden. Dazu werden verschiedene neuronale Netze eingesetzt. Die Readme-Dateien
sollen geeignet sein, um Entwicklern des Projekts eine Basis zum Verfassen ei-
nes ausführlichen Readmes zu liefern, um fremde Entwickler über den Zweck des
Projekts zu informieren und um Sourcecode-Retrieval zu ermöglichen.
Diese Arbeit ist eine Kooperation mit dem Deutschen Zentrum für Luft- und
Raumfahrt (DLR). Auf Wunsch des DLR soll die Generierung der Readme-Dateien
anhand von Python Projekten demonstriert werden.
72. Grundlagen
2.1 Stand der Technik
Es existieren bereits mehrere Projekte, deren Ziel es ist, Readme-Dateien zu
generieren. Nennenswerte Beispiele sind hier readme-md-generator [8] und generate-
readme [9]. Beide Projekte erstellen Readme-Dateien für Javascript Projekte und
arbeiten auf dieselbe Weise. Der Nutzer wird in der Kommandozeile aufgefordert,
die relevanten Daten einzugeben, welche dann in ein festes Template eingefügt
werden. Soweit möglich werden dabei automatisch Vorschläge gemacht, indem
auch Teile des Projekts analysiert werden. Vor allem die “package.json”-Datei
enthält viele relevante Informationen über das Projekt, wie beispielsweise den
Projektnamen, Version, Autoren und eine kurze Beschreibung. Eine inhaltliche
Analyse des Sourcecodes findet jedoch nicht statt.
Für das Generieren von Softwarebeschreibungen aus Sourcecode existieren bereits
Ansätze, die einzelne Funktionen beschreiben. Ein Beispiel hierfür ist code2seq
[3], welches viele Teile aus dem Abstract syntax tree (AST) einer Java oder C#
Funktion sampelt und anschließend mit einem Long short-term memory (LSTM)
weiterverarbeitet. code2seq wird in Kapitel 2.2.4 ausführlich vorgestellt. Daneben
gibt es auch DeepCom [10], das auf eine ähnliche Weise funktioniert. Statt ein-
zelne Teile des ASTs zu verarbeiten wird dieser aber serialisiert und als ganzes
verarbeitet.
Die oben beschriebenen Projekte unterscheiden sich von dieser Arbeit, da keins
davon dazu in der Lage ist, eine Beschreibung für ein ganzes Projekt durch Analyse
des Sourcecodes automatisch zu generieren. Ein existierendes Projekt, das dazu in
der Lage ist, ist dem Verfasser nicht bekannt.
82.2 Neural code representation
2.2.1 Embeddings
Machine Learning Modelle verarbeiten Daten in Form von ein- oder mehrdimen-
sionalen Vektoren. Andere Datenformen wie Sourcecode oder natürliche Sprache
in Textform müssen daher zuerst in eine Vektorrepräsentation überführt werden.
Diese Repräsentation in Vektorform nennt man Embedding.
Bei Text wird dazu in der Regel eine Embedding-Matrix verwendet. Jede Zeile der
Embedding-Matrix repräsentiert ein zu übersetzendes Wort. Die transponierte Zeile
ist dann der zum Wort gehörige Vektor. Um die Größe der Matrix in Grenzen zu
halten, enthält sie meist nicht alle existierenden Wörter, sondern beschränkt sich
auf ein Vokabular mit sinnvoller Größe. Für alle nicht erfassten Wörter enthält das
Vokabular ein Spezielles “UNK” (“Unknown”) Symbol. Die Werte der Matrix werden
durch einen Trainingsprozess iterativ angepasst. Embedding-Matrizen können
auch zur Repräsentation von Code genutzt werden, indem man statt Wörtern die
einzelnen Token der Programmiersprache übersetzen lässt.
2.2.2 Sequence-to-Sequence Modelle
Mithilfe von Embedding-Matrizen lassen sich jedoch nur einzelne Token übersetzen.
Möchte man die Bedeutung eines ganzen Satzes oder einer Funktion erfassen,
sind komplexere Modelle notwendig, da Embedding-Matrizen die große Menge
an möglichen Token-Kombinationen nicht mehr abbilden können. Dazu werden
häufig Sequence-to-Sequence Modelle [11] verwendet, die eine Sequenz von Token
in eine andere Sequenz überführt, beispielsweise zur Übersetzung von natürlichen
Sprachen.
Die Token werden hierfür mithilfe einer Embedding-Matrix in Vektoren umge-
wandelt und nacheinander von einem Encoder-LSTM, eingelesen. LSTMs sind
neuronale Netze, die Sequenzen von Vektoren verarbeiten, wobei sie mithilfe eines
internen Zustandsvektors Informationen speichern und so einen Bezug zwischen
Elementen an verschiedenen Positionen in der Inputsequenz herstellen. Die Ausga-
ben des Encoder-LSTMs werden verworfen, nur der Zustandsvektor am Ende der
Sequenz wird behalten. Er kann als Embedding für die ganze Sequenz betrachtet
werden und dient als Anfangszustand für ein weiteres LSTM, dem Decoder, dessen
Output schließlich die Zielsequenz ist. Neben dem Anfangszustand liest der Decoder
das Wort ein, das er je zuletzt produziert hat. Abbildung 2.1 zeigt diesen Prozess
an einem Beispiel.
9Abb. 2.1: Beispiel für die Übersetzung eines englischen Satzes mithilfe eines
Sequence-to-Sequence Modells. [1]
2.2.3 code2vec
code2vec [2] ist eine Technik, die ein Embedding für ganze Sourcecode-Funktionen
erstellt. Als naiven Ansatz für dieses Problem könnte man eine Programmiersprache
genau so wie eine natürliche Sprache behandeln und die Token der Programmier-
sprache als Wörter auffassen. Der Nachteil dieses Ansatzes ist jedoch, dass das
Modell dabei die Syntax der Programmiersprache erlernen muss. code2vec ver-
ringert diesen Aufwand, indem es den Code zunächst von einem Parser in einen
Abstract-Syntax-Tree (AST) umwandeln lässt und diesen weiterverarbeitet. Wie in
Abbildung 2.2 zu sehen ist, enthält der AST beispielsweise bereits die Information,
dass es sich bei “x = 7;” um eine Zuweisung handelt.
Um den AST zu verarbeiten, werden zunächst zwei Blätter ausgewählt und der Pfad
zwischen ihnen ermittelt. Blätter und Pfad bilden ein 3-Tupel, den sogenannten
Path-Kontext. Abbildung 2.2 zeigt ein Beispiel hierzu.
Abb. 2.2: Beispiel für einen Path-Kontext, der aus dem Ausdruck “x = 7;” entstanden
ist. [2]
Mit zufällig ausgewählten Blättern werden bis zu 200 dieser Path-Kontexte erstellt,
die gemeinsam eine ausreichende Repräsentation der ganzen Funktion darstellen
sollen. Eine Besonderheit ist hier, dass die Funktion nicht sequenziell von vorne nach
hinten verarbeitet wird. Stattdessen spielt die Reihenfolge der zufällig erstellten
Path-Kontexte keine Rolle.
10Die Blätter jedes Path-Kontexts werden nun mit einer Embedding-Matrix in
Vektoren umgewandelt. Auch für Pfade gibt es eine eigene Embedding-Matrix.
Wegen der großen Anzahl an möglichen Pfaden ist dieses Vorgehen ungewöhnlich.
Um die Größe der Path-Embedding-Matrix in Grenzen zu halten, darf der Pfad
eine bestimmte Länge an Token nicht überschreiten.
Anschließend werden die drei Vektoren des Path-Kontexts konkateniert und einer
Fully-connected-Layer übergeben, deren Output als Combined-Context-Vector
bezeichnet wird. Eine Fully-connected-Layer ist eine Schicht in einem neuronalen
Netz, in der jedes Neuron eine direkte Verbindung zu jedem Neuron der vorherigen
Schicht besitzt. Die bis zu 200 Combined-Context-Vectors sollen danach zu einem
einzigen Vektor vereint werden. Da nicht alle dieser Kontexte gleichermaßen wichtig
sind, sollten sie vom Netzwerk unterschiedlich stark berücksichtigt werden. Hierfür
dient ein Attention-Mechanismus.
Attention-Mechanismen finden in verschiedenen neuronalen Netzen Anwendung,
funktionieren jedoch nicht immer auf die gleiche Weise. code2vec besitzt einen
globalen Attention-Vektor, dessen Werte als Teil des Trainingsprozesses angepasst
werden. Um zu bestimmen welcher der Kontexte besonders wichtig ist, wird das
Skalarprodukt der Combined-Context-Vectors mit dem Attention-Vektor berechnet.
Das Skalarprodukt wird nun als Gewicht zur Berechnung eines gewichteten Mit-
telwerts aller Combined-Context-Vectors verwendet. Dieser gewichtete Mittelwert
ist schließlich das Embedding der verarbeiteten Funktion. Abbildung 2.3 zeigt den
ganzen Prozess noch einmal in der Übersicht.
Über das bloße Embedding hinaus kann code2vec einer Funktion auch Tags zuord-
nen, die ihren Nutzen beschreiben. Hierzu trainiert man eine Embedding-Matrix
mithilfe der Funktionsnamen und verwendet diese umgekehrt.
Abb. 2.3: Übersicht über die Datenverarbeitung bei code2vec.
112.2.4 code2seq
code2seq [3] ist eine Technik, die auf code2vec beruht und die natürliche Sprache
aus Sourcecode generiert. Der generierte Text beschreibt die Funktion und kann
beispielsweise zur Dokumentation genutzt werden.
Der Ablauf der Datenverarbeitung ähnelt stark dem von code2vec, jedoch werden
die Pfade mit einem bidirektionalem LSTM encoded, statt mit einer Embedding-
Matrix. Genauso wird die Output-Sequenz nicht mit einer Matrix, sondern durch
ein bidirektionales LSTM erzeugt.
Außerdem kommt bei code2seq Subtokenization zum Einsatz. Das bedeutet, dass
Token wie “toString” anhand der Camel-Case Schreibweise in die Subtoken “to” und
“String” aufgeteilt werden. Die Subtoken werden mithilfe der Embedding-Matrix in
Vektoren übersetzt und anschließend addiert.
Abb. 2.4: Übersicht über die Datenverarbeitung bei code2seq.
Abbildung 2.5 zeigt ein Beispiel zur Generierung eines Satzes mit code2seq. Die
generierten Wörter sind im unteren Satz eingefärbt. Im Code sind in gleicher
Farbe die Path-Kontexte eingezeichnet, die bei der Generierung des zugehörigen
Wortes laut Attention-Mechanismus die höchste Relevanz hatten. Die AST-Pfade
der Path-Kontexte gehen aus diesem Bild nicht direkt hervor, die eingekreisten
Blätter scheinen aber gut zum jeweils generierten Wort zu passen.
12Abb. 2.5: Beispiel zur Generierung eines Satzes mit code2seq. [3]
132.3 Textähnlichkeit
Im Bereich Natural-Language-Processing werden häufig Metriken benötigt, die
die Ähnlichkeit zweier Texte bewerten. Sie kommen beispielsweise bei Problemen
wie Dokumentenclustering oder der Erstellung von Textzusammenfassungen zum
Einsatz [12]. In dieser Arbeit werden sie in Kapitel 3.4 verwendet, um die Qualität
der generierten Readme-Dateien zu bewerten. Im Folgenden werden zwei solcher
Metriken vorgestellt.
2.3.1 BLEU
BLEU [4] ist eine Metrik, die die Ähnlichkeit einer computergenerierten Überset-
zung mit einer oder mehreren korrekten Referenzübersetzungen vergleicht, um die
Qualität der generierten Übersetzung zu bewerten. Die grundlegende Idee besteht
darin, die Übersetzung wie einen binären Klassifikator zu bewerten, wobei ein Wort
aus der Übersetzung als richtig positiv gilt, wenn es auch in der Referenzübersetzung
enthalten ist und als falsch positiv, wenn nicht. Anschließend wird die Accuracy
der Übersetzung berechnet.
Um ein gutes Maß für die Qualität der Übersetzung zu erhalten, muss die Formel zur
Berechnung der Accuracy jedoch noch erweitert werden. Zu kurze Übersetzungen
müssen bestraft werden, da sonst ein einziges korrektes Wort bereits als perfekte
Übersetzung gewertet wird. Hierzu dient die Formel in Abbildung 2.6.
Abb. 2.6: Formel zur Berechnung von BLEUs Strafe für zu kurze Übersetzungen.
BP: Brevity Penalty; c: Länge der zu bewertenden Übersetzung; r: Länge der
Referenzübersetzung [4]
Außerdem darf ein korrektes Wort, das Mehrfach in der Übersetzung vorkommt, nur
so häufig als korrekt gewertet werden, wie es in der Referenzübersetzung vorkommt.
Dadurch wird verhindert, dass eine Übersetzung aus einem einzigen korrekten Wort,
welches sich ständig wiederholt, gut bewertet wird.
Schließlich ist es auch wichtig, dass sich die Wörter in der Übersetzung in der rich-
tigen Reihenfolge befinden. Um das sicherzustellen, berechnet BLEU die Accuracy
nicht nur mit einzelnen Wörtern, sondern auch mit kurzen Wortsequenzen, die
nur dann als korrekt gelten, wenn die gesamte Sequenz übereinstimmt. Genauer
berechnet BLEU die Accuracy N-mal für Sequenzen der Länge 1 bis N und bildet
zum Schluss das geometrische Mittel. Die Formel zur Berechnung des BLEU-Scores
mit Sequenzlänge 1 ist in Abbildung 2.7 dargestellt.
14P
Satz∈T ext AnzahlKorrekteW örter(Satz)
BLEU1 (T ext) = BP ∗ P
Satz∈T ext AnzahlW örter(Satz)
Abb. 2.7: Formel zur Berechnung des BLEU-Scores mit Sequenzlänge 1 und einer
Referenzübersetzung. BP: brevity penalty; Text: zu bewertende Übersetzung
2.3.2 ROUGE
ROUGE [13] ist ein Satz von Metriken, der entwickelt wurde, um die Qualität
von Textzusammenfassungen zu bewerten. Ähnlich wie bei BLEU werden dazu die
Wörter aus der zu bewertenden sowie einer oder mehrerer Referenzzusammenfas-
sungen verglichen. Statt auf Accuracy beruhen die meisten ROUGE Metriken aber
auf dem Recall und einige weitere auf der längsten übereinstimmenden Sequenz.
ROUGE-1 beispielsweise berechnet den Recall mit einzelnen Wörter, wohingegen
ROUGE-S ihn mit Skip-Grams berechnet. Skip-Grams sind Paare aus Wörtern die
zwar in der richtigen Reihenfolge stehen müssen, die aber nicht direkt aufeinander
folgen müssen.
Bei der Berechnung von ROUGE wird die Länge der Zusammenfassung nicht
betrachtet. Es muss also anderweitig sichergestellt werden, dass die Zusammen-
fassung nicht zu lang ist. Im Vergleich zu BLEU enftällt bei ROUGE auch die
Unterteilung in Sätze, da Zusammenfassungen diese frei festlegen können, während
sie bei Übersetzungen durch den Originaltext relativ eindeutig vorgegeben ist.
AnzahlKorrekteW örter
ROU GE1 =
AnzahlW örterInRef erenz
Abb. 2.8: Formel zur Berechnung des ROUGE-1-Scores mit einer einzigen Referenz-
zusammenfassung.
152.4 Zentralitätsmetriken
Zentralitätsmetriken messen wie zentral sich ein Knoten in einem Graph befindet.
In Kapitel 3.1.3 werden Zentralitätsmetriken in Verbindung mit dem Call-Graph
genutzt, um die wichtigsten Funktionen eines Projekts zu bestimmen. Folgendes
Kapitel stellt zwei Zentralitätsmetriken vor.
2.4.1 Eigenvektor-Zentralität
Nach der Eigenvektor-Zentralität ist ein Knoten sehr zentral, wenn er viele Nach-
barn hat und diese Nachbarn ihrerseits sehr zentral sind. Intuitiv lässt sich diese
Idee mit der rekursiven Formel in Abbildung 2.9 beschreiben. x ist ein Vektor, der
aus den Eigenvektor-Zentralitäten der einzelnen Netzwerkknoten besteht. A ist
die Adjazenzmatrix, die die Kanten des Graphen durch Einsen an den Positionen,
die zu den entsprechenden Knoten gehört, darstellt. Durch die Matrixmultiplika-
tion Ax werden für jeden Knoten die Eigenvektor-Zentralitäten seiner Nachbarn
aufsummiert.
xt+1 = Axt
Abb. 2.9: Intuitive Formel zur Berechnung der Eigenvektor-Zentralität. x:
Eigenvektor-Zentralität; A: Adjazenzmatrix des Graphen
Damit x nach genügend Iterationen konvergiert und nicht divergiert, muss noch
ein konstanter Faktor λ hinzugefügt werden. Der Bezug zu Eigenvektoren wird
offensichtlich, wenn x konvergiert, sodass näherungsweise gilt xt+1 = xt = x. Damit
ergibt sich die Gleichung in Abbildung 2.10, welche der Definition eines Eigenvektors
entspricht.
λx = Ax
Abb. 2.10: Definition eines Eigenvektors bzw. der Eigenvektor-Zentralität. x:
Eigenvektor-Zentralität; A: Adjazenzmatrix des Graphen; λ: Eigenwert
Darüber hinaus soll die Eigenvektor-Zentralität nicht negativ sein. Nach dem Satz
von Perron-Frobenius ist diese Bedingung für den betragsmäßig größten Eigenwert
erfüllt.
16Für gerichtete Graphen funktioniert die Eigenvektor-Zentralität nur eingeschränkt.
Bei einem gerichteten azyklischen Graph sind beispielsweise alle Eigenvektor-
Zentralitäten 0 und sind damit kein Maß für die Zentralität der Knoten mehr.
2.4.2 Katz-Zentralität
Die Katz-Zentralität ähnelt der Eigenvektor-Zentralität, funktioniert aber auch
mit gerichteten Graphen. Sie zählt die Anzahl der Pfade, die zu einem bestimmten
Knoten führen, wobei längere Pfade niedriger gewichtet werden als kürzere. Die
Formel für die Katz-Zentralität ist in Abbildung 2.11 zu sehen.
n
∞ X
X
xi = (αk ∗ Ak )i,j
k≥1 j=1
Abb. 2.11: Formel zur Berechnung der Katz-Zentralität. xi : Katz-Zentralität von
Knoten i; α: Gewichtungsfaktor; A: Adjazenzmatrix des Graphen; n: Anzahl Knoten
k ist die Länge der Pfade, die betrachtet werden. Der Gewichtungsfaktor α liegt
zwischen 0 und 1 und wird durch die Potenzierung mit k immer kleiner, je länger
die betrachteten Pfade werden. Die mit k potenzierte Adjazenzmatrix A beschreibt
wie viele Pfade der entsprechenden Länge es von einem Knoten zu einem anderen
gibt.
172.5 Transformer Architekturen
Ein Transformer [6] ist eine sequence-to-sequence Architektur, die für eine beson-
ders gute Parallelisierbarkeit sorgt. Sequence-to-sequence Architekturen benutzen
normalerweise rekurrente neuronale Netze (RNNs), welche neben dem aktuellen In-
putvektor der Sequenz auch den vorangegangenen Outputvektor verarbeiten, sodass
eine parallele Berechnung unmöglich wird. Bei Transformern werden stattdessen
Fully-connected-Layer mit einem komplexen Attention-Mechanismus verbunden.
Transformer gehören besonders bei der Verarbeitung natürlicher Sprache zum
Stand der Technik und bilden die Grundlagen für bekannte Techniken wie BERT
[14].
LSTMs eignen sich normalerweise deshalb gut zur Verarbeitung von Sequenzen, weil
sie durch ihren Zustandsvektor einen Bezug zwischen verschiedenen Elementen der
Inputsequenz herstellen können. Transformer nutzen stattdessen Scaled Dot-Product
Attention. Dieser Attention-Mechanismus bestimmt nicht (nur) die allgemeine
Wichtigkeit der Inputelemente, sondern gibt mithilfe einer Matrix an wie stark der
Bezug eines Elements zu jedem anderen Element ist. Dazu wird ein Inputelement
von drei unterschiedlichen Fully-connected-Layern in je einen Key-, Value- und
Query-Vektor umgewandelt. Der Query-Vektor eines Elements gibt an, welche
Eigenschaften ein anderes Element haben muss, um einen Bezug zu diesem Element
zu haben. Der Key-Vektor encoded eben diese Eigenschaften, die das Element
besitzt. Alle Query- und Key-Vektoren werden in je einer Matrix zusammengefasst
und diese Matrizen miteinander multipliziert. Durch diese Multiplikation von Query-
und Key-Vektoren unterschiedlicher Elemente entstehen hohe Werte also dann,
wenn sich beide Vektoren ähneln. Abbildung 2.12 zeigt ein Beispiel für die so
entstandene Matrix. Erwartungsgemäß zeigen die hohen Werte auf der Diagonalen,
dass jedes Wort einen starken Bezug zu sich selbst hat.
Abb. 2.12: Self-Attention-Matrix eines Transformers über einen Inputsatz. [5]
18Der Value-Vektor beinhaltet schließlich die Daten, die Weiterverarbeitet werden
sollen. Eine Matrix aus Value-Vektoren wird mit der soeben berechneten Matrix
multipliziert, sodass jeder Value-Vektor auch Informationen von anderen Wörtern
mit hohem Bezug erhält.
Tatsächlich findet dieser Prozess nicht nur einmal statt, sondern mehrmals parallel
mit unterschiedlichen Fully-connected-Layern. Dieses Vorgehen ähnelt Convolutional-
Layern, die mehrere Filterkerne parallel anwenden und nennt sich Multi-Head
Attention.
Auch Transformer besitzen einen Encoder und einen Decoder. Jede Schicht des
Encoders berechnet einen Vektor, der Input für die entsprechende Schicht des
Decoders ist. Der Decoder erhält als Input, neben dem Output des Encoders, das
je zuletzt generierte Element der Sequenz. Damit ist der Decoder bei der Inferenz
nicht parallelisierbar, sondern nur während des Trainings, wo die gewünschte
Output-Sequenz als Input für den Decoder dienen kann.
Abbildung 2.13 zeigt eine Übersicht über die Architektur von Transformer-Netzen.
Die grau eingerahmten Elemente stellen je eine Schicht des Encoders (links) bzw.
Decoders (rechts) dar und wiederholen sich mehrfach. Das “Positional Encoding”
nutzt Sinusfunktionen, um die Vektoren mit Informationen über die Positionen des
entsprechenden Wortes in der Sequenz anzureichern.
19Abb. 2.13: Transformer Architektur in der Übersicht. [6]
20Wie die Abbildung zeigt, wird der Attention-Mechanismus auf den Input jeder
Schicht des Encoders und Decoders angewendet. Beim Decoder gibt es zwei Beson-
derheiten: bei der Masked Multi-Head Attention wird eine Maske angewendet, um
zu verhindern, dass der Transformer auf nachfolgende Wörter zugreift. Diese sind
nur durch die Label der Trainingsdaten bekannt und werden bei der Inferenz fehlen.
Im mittleren Teil der Decoder Schicht bekommt die Unterteilung in Query- und
Key-Vektoren eine besondere Relevanz, da hier die Query-Vektoren aus dem Deco-
der und die Key-Vektoren des Encoders verwendet werden. Abbildung 2.14 zeigt
eine Attention-Matrix wie in Abbildung 2.12 bei einer Übersetzung von Englisch in
Spanisch. Hierbei werden die englischen Wörter aus dem Encoder, den spanischen
Wörtern im Decoder zugeordnet.
Abb. 2.14: Attention-Matrix zwischen Encoder und Decoder eines Transformers
bei einer Übersetzung von Englisch nach Spanisch. [7]
213. Umsetzung
Um Readme-Dateien zu generieren werden in dieser Arbeit zwei Ansätze verfolgt.
Der erste wird als Inlining-Ansatz bezeichnet. Er sieht vor, das zunächst die
wichtigsten Funktionen eines Projekts bestimmt werden. Dem Call-Graph des
Projekts entsprechend, werden diese Funktionen dann ineinander geinlined, sodass
eine lange Funktion entsteht, die das ganze Projekt repräsentieren soll. Anschließend
wird ein code2seq Modell darauf trainiert aus dieser Funktion ein Readme zu
generieren. Das liegt nahe an seiner originalen Aufgabe des Code-Captioning.
Der zweite Ansatz wird Summary-Ansatz genannt. Auch hier werden zunächst die
wichtigsten Funktionen eines Projekts bestimmt. Danach wird mithilfe von code2seq
je ein Docstring erstellt, der die einzelnen Funktionen beschreibt. Die Docstrings
werden anschließend zu einem Text konkateniert. Das neuronale Netz PEGASUS,
welches normalerweise Textzusammenfassungen erstellt, wird dann darauf trainiert
aus den konkatenierten Docstrings eine Readme-Datei zu erstellen.
Die Abbildungen 3.1 und 3.2 zeigen beide Ansätze im Überblick. In diesem Kapitel
werden die Ansätze ausführlich vorgestellt.
Abb. 3.1: Übersicht über den Inlining-Ansatz.
22Abb. 3.2: Übersicht über den Summary-Ansatz.
233.1 Inlining-Ansatz
3.1.1 Datensatz
Als Basis für den Datensatz des Inlining-Ansatzes wird GHTorrent [15] verwendet.
GHTorrent sammelt seit 2013 umfangreiche Metadaten zu GitHub Repositories
und bietet einen entsprechenden Datensatz zum Download an. Aus diesem Daten-
satz werden die Links zu Repositories, die überwiegend Python Code beinhalten
extrahiert und die Repositories anschließend von GitHub heruntergeladen.
Kalliamvakou et. al [16] haben einige Gefahren bei der Verwendung des GHTorrent
Datensatzes bzw. von GitHub als Datenquelle allgemein identifiziert. Da diese
Arbeit nicht an der Analyse von Metadaten interessiert ist, sind die meisten dieser
Gefahren hier unproblematisch. Ein relevanter Punkt ist jedoch, dass nicht jedes
Repository auch ein Projekt ist. Laut den Autoren sieht ein beliebter Workflow vor,
dass Entwickler ein Repository forken, den Code bearbeiten und danach wieder
einen Pull-Request stellen. Dies könnte ein Problem darstellen, da hierdurch viele,
beinahe identische Repositories heruntergeladen werden. Diese zusätzlichen Kopien
bieten keinen Mehrwert, sondern erhöhen den Rechenaufwand bei der Verarbeitung
des Datensatzes. Um dieses Problem zu beheben, werden aus dem Datensatz alle
Projekte gefiltert, die ein Fork eines anderen Projektes sind.
Eine weiteres Problem das die Autoren erwähnen ist, dass nur ca. 63% der Repo-
sitories tatsächlich für Softwareentwicklung genutzt werden. Die anderen Zwecke
beinhalten beispielsweise das Speichern persönlicher Daten oder das Bearbeiten
von Studienaufgaben an Universitäten. Solche Repositories sollen gefiltert wer-
den, indem nur Repositories mit mindestens zehn Watchers in den Datensatz mit
aufgenommen werden. Ein Watcher ist ein GitHub-Nutzer, der regelmäßig über
Neuerungen im Projekt informiert werden möchte. Wenn sich viele Nutzer für ein
Projekt interessieren, ist es außerdem wahrscheinlich, dass Code und Readme-Datei
eine hohe Qualität haben, was das Training von neuronalen Netzen auf diesen
Daten begünstigt.
Da die generierten Readme-Dateien englisch sein sollen, werden zuletzt auch nicht
englische Projekte gefiltert. Aus 80% der übrig gebliebenen Projekten wird der
Trainingsdatensatz erzeugt. Test- und Validierungsdatensatz bestehen aus jeweils
10% der Daten.
243.1.2 Call-Graph Erstellung
Die verwendeten Technologien zur semantischen Analyse von Sourcecode arbeiten
für gewöhnlich mit Inputdaten von begrenzter Größe. code2seq beispielsweise wurde
von den Autoren mit bis zu 30 Zeilen langen Funktionen getestet und zeigte bei
einer Länge zwischen 9 und 30 Zeilen annähernd konstant gute Ergebnisse [3]. Die
in dieser Arbeit verarbeiteten Projekte können jedoch sehr groß sein. Damit dies
die Qualität des Outputs nicht beeinflusst, soll die Größe der verarbeiteten Daten
begrenzt werden. Hierzu werden die Projekte nicht vollständig analysiert, sondern
nur deren jeweils wichtigste Funktionen. Diese Funktionen werden im Folgenden
als “Core-Funktionen” bezeichnet.
Die Schwierigkeit besteht darin, die Wichtigkeit einer Funktion automatisiert zu
bestimmen. In Anbetracht der beiden vorgesehenen Ansätze bezeichnet “wichtig”
dabei, inwieweit Funktionen aufgrund ihres Namens bzw. Docstrings einen Rück-
schluss auf den Zweck des Projekts zulassen oder eine Funktionalität umsetzt,
die elementar für den Zweck des Projekts ist. Da der Zweck eines Projekts zum
Zeitpunkt der Verarbeitung noch nicht bekannt ist, ist die Wichtigkeit nicht direkt
bestimmbar.
Als Heuristik für die Wichtigkeit kann jedoch die Zentralität im Call-Graph ver-
wendet werden. Für gewöhnlich bauen Funktionen in Projekten aufeinander auf:
diejenigen am Rand des Call-Graphen erfüllen kleine, spezifische Aufgaben und
werden von Funktionen im Inneren des Call-Graphen aufgerufen, welche überge-
ordnete Funktionalitäten umsetzen, die einen direkteren Bezug zum Zweck des
Projekts selbst haben.
Call-Graphen können entweder dynamisch oder statisch generiert werden. Bei
dynamischen Call-Graphen wird der Code ausgeführt und tatsächliche Funktions-
aufrufe aufgezeichnet. Dies ist für diese Arbeit nicht praktikabel, da nicht immer
alle Dependencies eines Projekts installiert werden können und außerdem nicht
bekannt ist, welche Inputdaten für ein Projekt sinnvoll sind. Zur Generierung stati-
scher Call-Graphen wird der Code eines Projektes analysiert, um zu bestimmen
welche Funktionsaufrufe theoretisch möglich sind. Das Erstellen eines statischen
Call-Graphen ist in Python aufgrund seiner dynamischen Typisierung ebenfalls
nicht trivial. Wenn es mehrere Funktionen mit gleichem Namen gibt, kann nicht
ohne weiteres bestimmt werden, welche davon aufgerufen wird. Das Projekt Pyan
[17] ist in der Lage durch Analyse des Codes auch in solchen Fällen häufig noch
eine korrekte Zuordnung durchzuführen.
Für die Zwecke dieses Projekts muss Pyan noch wie folgt modifiziert werden:
• Das Importieren von externen Modulen und Funktionen wird nicht mehr als
Funktionsaufruf gewertet
• Das Aufrufen von geerbten Methoden erzeugt einen einzigen Knoten, statt
mehrere
25• Konstruktoraufrufe erzeugen einen einzigen Knoten, statt mehrere
• Importierte externe Funktionen werden dem korrekten Modul zugeordnet
Problematisch ist, dass Pyan nur Python3 Projekte verarbeiten kann. Bei Syntax-
fehlern während der Call-Graph Erstellung wird deshalb versucht, das verarbeitete
Projekt von Python2 zu Python3 zu konvertieren. Python3 enthält ein Tool namens
2to3, das diese Konversion automatisiert. Sollte danach immer noch ein Syntaxfehler
erkannt werden, muss das Projekt aus dem Datensatz entfernt werden.
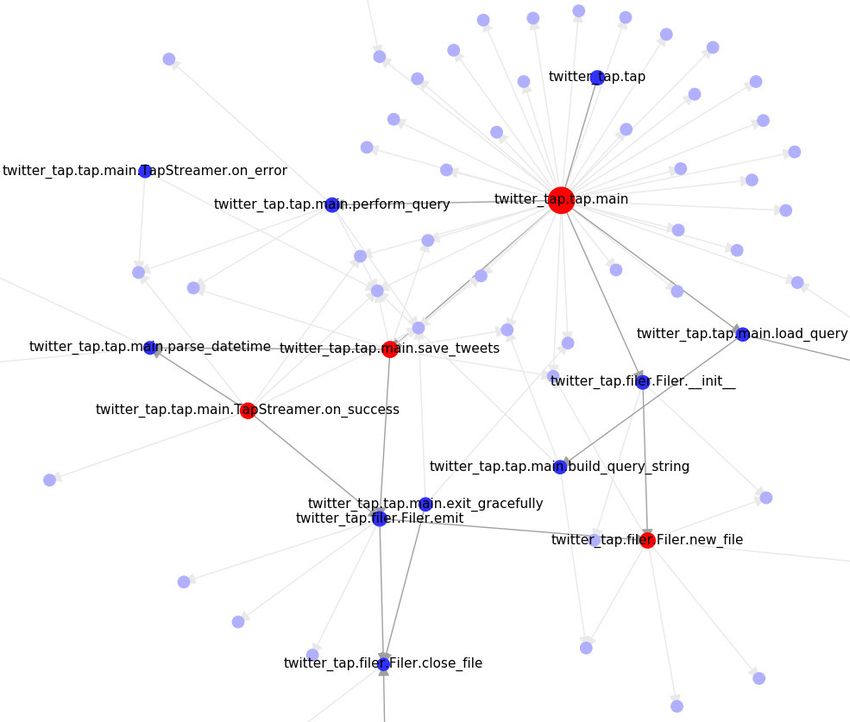
Abb. 3.3: Ausschnitt aus dem Call-Graph des Projekts “TwitterTap”. Die Größe
der Knoten entspricht ihrer Zentralität. Blätter sind ausgegraut. Core-Funktionen
sind rot.
Abbildung 3.3 zeigt einen Ausschnitt aus dem Call-Graph des Projekts “TwitterTap”
[18]. Zur besseren Übersicht wurden Funktionen, die keine anderen Funktionen
aufrufen ausgegraut und nicht beschriftet.
263.1.3 Call-Graph Zentralität
Als Heuristik für die Wichtigkeit einer Funktion soll ihre Zentralität im Call-Graph
gemessen werden. Zu bestimmen wie zentral sich ein Knoten in einem Graph
befindet, ist in der Graphentheorie ein gut untersuchtes Problem. Da der Begriff
“zentral” nicht fest definiert ist, gibt es eine Vielzahl an Metriken, die unterschiedliche
Eigenschaften der Knoten betrachten, um zu bestimmen wie zentral sie sind. Je
nach Anwendungsfall können unterschiedliche Zentralitätsmetriken die “Wichtigkeit”
eines Knotens unterschiedlich gut widerspiegeln. Welche Metrik für diese Arbeit
am geeignetsten ist, soll deshalb empirisch bestimmt werden.
Dazu werden die Funktionen von fünf Python Projekten manuell in die Kategorien
“Sehr wichtig”, “Wichtig”, “Neutral” und “Unwichtig” eingeteilt. Anschließend wird
mit Pyan der Call-Graph der Projekte erstellt und die Zentralität aller Funktionen
mit den zu testenden Metriken berechnet. Tabelle 3.1 zeigt einige Funktionen
sortiert nach der Eigenvektor-Zentralität. Das analysierte Projekt ist hier ebenfalls
Pyan.
eigenvector_centrality Score: 5
1 0.291
2 0.216
3 0.199
4 0.197
5 0.196
6 0.195
7 0.184
8 0.184
9 0.179
10 0.173
11 0.169
12 0.168
13 0.168
14 0.146
15 0.145
16 0.144
17 0.139
Tab. 3.1: Einige Pyan Funktionen, sortiert nach ihrer Eigenvektor-Zentralität im
ungerichteten Call-Graph. Dunkelgrün: sehr wichtig; grün: wichtig; weiß: neutral;
rot: unwichtig
27Tabelle 3.1 zeigt, dass einige Funktionen wie logger.debug von Pyan nicht zugeordnet
werden konnten und deshalb nur als *.debug bezeichnet werden. Bei der Eigenvektor-
Zentralität, die hier auf dem ungerichteten Call-Graphen berechnet wurde, sieht
man außerdem, dass relativ viele unwichtige Utility-Funktionen hohe Positionen
besetzen. Das liegt daran, dass Utility-Funktionen wie logger.debug von sehr vielen
Funktionen benutzt werden und deshalb sehr viele Nachbarn im Call-Graphen
haben. Um das zu verhindern, macht es Sinn der Anzahl der Funktionen die eine
Funktion aufruft (Ausgangsgrad) eine höhere Relevanz beizumessen, als der Anzahl
der Funktionen von der eine Funktion aufgerufen wird (Eingangsgrad).
reverse_katz_centrality Score: 12
1 0.171
2 0.134
3 0.128
4 0.121
5 0.114
6 0.113
7 0.111
8 0.106
9 0.104
10 0.102
11 0.098
12 0.097
13 0.096
14 0.092
15 0.091
16 0.090
17 0.087
Tab. 3.2: Einige Pyan Funktionen, sortiert nach ihrer Katz-Zentralität im trans-
ponierten Call-Graph. Dunkelgrün: sehr wichtig; grün: wichtig; weiß: neutral; rot:
unwichtig
Die in Tabelle 3.2 gezeigte Reverse Katz centrality berechnet die Katz-Zentralität
auf einem transponierten Call-Graphen. Transponiert bedeutet, dass die Richtung
aller Kanten umgekehrt wurde. Obiger Überlegung entsprechend berücksichtigt die
Katz-Zentralität auf diese Weise nicht mehr die Anzahl der Pfade, die zu einem
Knoten führen, sondern die, die an dem Knoten beginnen.
28Um zu messen wie gut eine Metrik mit der manuellen Bewertung der Funktionen
übereinstimmt, wird ein Score berechnet. Dazu wird den sehr wichtigen, wichtigen,
neutralen und unwichtigen Funktionen je ein Wert von 2, 1, 0 und -1 Punkten
zugewiesen und anschließend die Punkte der Funktionen, die die Metrik für die
zentralsten hält, aufsummiert. Wie viele Funktionen eines Projekts später sinnvoll
verarbeitet werden können steht zum Zeitpunkt dieser Analyse noch nicht fest.
Schätzungsweise liegt der Wert jedoch bei 5 - 15 Funktionen. Tabellen 3.1 und 3.2
zeigen den Score, der anhand der Top 15 Funktionen berechnet wurde.
Nun sollen die Scores der Metriken über die fünf bewerteten Projekte hinweg vergli-
chen werden. Die berechneten Scores sind unter den verschiedenen Projekten nicht
direkt vergleichbar, da sie eine unterschiedliche Anzahl wichtiger und unwichtiger
Funktionen haben und die Scores entsprechend zu hohen oder niedrigen Werten
neigen. Stattdessen werden pro Projekt die drei Metriken mit den höchsten Scores
betrachtet.
Die Berechnung wird dreimal wiederholt, wobei die zentralsten 15, 10 und 5 Funk-
tionen berücksichtigt werden. Mit diesen drei Kategorien und den fünf untersuchten
Projekten kann eine Metrik also bis zu 15-mal den ersten Platz belegen. Bei gleichem
Score Teilen sich die Metriken den jeweiligen Platz. Besonders bei der Betrachtung
der fünf zentralsten Funktionen kommt das häufig vor, da dort der Wertebereich
der erreichbaren Scores am kleinsten ist.
Genauso wie oben ein Score für die Metriken berechnet wurde, lässt sich nun ein
Gesamtscore anhand der belegten Platze einer Metrik berechnen. Dabei werden
erster, zweiter und dritter Platz je mit 3, 2 und 1 Punkten bewertet und über alle
Kategorien und Projekte aufsummiert.
Tabelle 3.3 zeigt die Scores, die die Metriken nach dieser Berechnung erzielen.
“Reverse” bedeutet dabei, dass der Call-Graph vor der Berechnung der Metrik
transponiert wurde. “Inverse” bedeutet, dass die Werte die die Metriken berechnen
mit -1 potenziert wurden.
29Reverse Katz centrality 24
Outdegree centrality 23
Reverse closeness centrality 22
Local reaching centrality 17
Pagerank 9
Degree centrality 9
Inverse harmonic centrality 8
Inverse second order centrality 4
Eigenvector centrality 1
Reverse pagerank 0
Degeneracy 0
Katz centrality 0
Harmonic centrality 0
Closeness centrality 0
Second order centrality 0
Tab. 3.3: Verschiedenen Zentralitätsmetriken sowie die Scores die sie durch den
Bewertungsalgorithmus erhalten.
Die Reverse Katz centrality erzielt hier den höchsten Score. Da eine Objektive
Beurteilung der Eignung der Metriken für dieses Projekt nicht möglich ist, wur-
den bei der Bewertung der Metriken einige subjektive Einschätzungen getroffen,
beispielsweise die Einteilung der Funktionen in Wichtigkeitsklassen. Nachdem die
Differenz unter den besten Metriken sehr knapp ausfällt, kann nicht mit Sicherheit
gesagt werden, dass die Reverse Katz centrality tatsächlich die beste Metrik ist.
Die Berechnung zeigt aber, dass sie für dieses Projekt geeignet ist.
Abbildung 3.3 zeigt den Call-Graph eines Projekts, in dem die Reverse Katz
centrality als Größe der Knoten dargestellt wird.
303.1.4 Clustering
Nachdem die Core-Funktionen bestimmt wurden, muss festgestellt werden in
welcher Reihenfolge diese geinlined werden. Häufig rufen sich Core-Funktionen nicht
gegenseitig auf, sondern sind im Call-Graph weit voneinander entfernt. Statt einem
Inlining werden diese Funktionen konkateniert. Ein Inlining wird durchgeführt,
wenn es einen Pfad zwischen zwei Funktionen gibt, der höchstens zwei Knoten lang
ist.
Nun werden die Core-Funktionen in Cluster von Funktionen unterteilt, die gein-
lined werden können. Später werden die Funktionen, die durch das Inlining aller
Funktionen eines Clusters entstehen konkateniert.
Nachdem die Cluster erstellt wurden, wird die Inlining Reihenfolge innerhalb des
Clusters bestimmt. Dazu wird zuerst ein Subgraph erstellt, der die Knoten des
Clusters und deren Nachbarn beinhaltet. Anschließend wird ein Minimum-Spanning-
Tree erstellt, der alle Funktionen des Clusters umfasst. Ein solcher MST, der nicht
alle Knoten des Graphen, sondern nur eine bestimmte Menge enthält, ist auch
als Steiner-Tree bekannt [19]. Der Steiner-Tree definiert schließlich die Inlining
Reihenfolge, wobei jede Funktion in ihren Elternknoten geinlined wird.
313.1.5 Inlining
Die Readme-Datei soll in diesem Ansatz durch code2seq erstellt werden. code2seq
kann jedoch nur einzelne Funktionen verarbeiten. Damit also alle relevanten In-
formationen aus den Core-Funktionen verarbeitet werden können, müssen sie in
eine einzige Funktion kombiniert werden. Um das zu erreichen, ohne dabei die
Semantik zu verändern, sollen die Core-Funktionen ineinander geinlined werden.
Wie im Vorangegangenen beschrieben, ist das natürlich nicht immer möglich. Zum
Inlining einer Python Funktion in eine andere sind folgende Schritte nötig:
1. Extraktion des Sourcecodes der aufrufenden und aufgerufenen Funktion
2. Ermitteln der Stelle des Funktionsaufrufs in der aufrufenden Funktion
3. Anpassen der Einrückung des Codes der aufgerufenen Funktion an die Stelle
des Funktionsaufrufs
4. Entfernen von Return-Statements aus der aufgerufenen Funktion
5. Einfügen des Codes vor die Zeile des Funktionsaufrufs
6. Ersetzen des Funktionsaufrufs mit dem Rückgabewert der Funktion
Für die Umsetzung des Inlinings müssen an mehreren Stellen Kompromisse ein-
gegangen werden. Im 2. Schritt kann es sein, dass die Funktion gleich mehrfach
aufgerufen wird. In diesem Fall wird nur der erste Aufruf geinlined, um der ein-
gesetzten Funktion keine zu hohe Bedeutung zukommen zu lassen. Außerdem ist
ein Inlining streng genommen nur dann möglich, wenn die aufgerufene Funktion
höchstens ein Return-Statement besitzt. In Schritt 4 werden jedoch alle Return-
Statements außer dem Letzten entfernt. Damit wird eine Veränderung der Semantik
in Kauf genommen, um dennoch ein Inlining durchführen zu können. Um evtl.
entstehende Grammatikfehler zu vermeiden, werden die Return-Statements durch
ein “pass”-Statement ersetzt.
Zudem wird nicht darauf geachtet, ob es durch die Vereinigung der Namespaces zu
Konflikten kommt. Eine entsprechende Umbenennung von Variablen wäre allerdings
auch nicht sinnvoll, da code2seq ein Token-Vokabular besitzt, das die Bedeutung
einer Variable anhand ihres Namens bestimmt. Die Interpretation des Codes durch
code2seq würde deshalb durch eine Umbenennung stärker verändert werden, als
durch die doppelte Verwendung eines Namens.
323.1.6 Parsing
Nachdem das Inlining durchgeführt wurde, ist für jedes Projekt eine Funktion
entstanden, die das gesamte Projekt repräsentieren soll. Bevor code2seq mit dieser
trainiert werden kann, muss ein AST erstellt und Path-Kontexte aus diesem ge-
sampelt werden, wie es in Kapitel 2.2.3 beschrieben wurde. code2seq bietet einen
entsprechenden Präprozessor nur für Java und C# an, verweist jedoch auf einen
Präprozessor von JetBrains namens “astminer” [20], der für Python verwendet
werden kann. Obwohl dieser Präprozessor eine Funktion für code2seq bietet, ist sein
Output mit code2seq nicht kompatibel und muss im Anschluss noch umformatiert
werden.
Ein weiteres Problem besteht darin, dass der AST, aus dem der astminer die
Path-Kontexte sampelt, alle Knoten enthält, die Pythons Grammatik spezifiziert.
Typischerweise werden irrelevante Knoten nicht in einem AST dargestellt. Bei
Python ist das besonders problematisch, da durch Pythons Grammatik sehr lange
Ketten von Knoten entstehen, die keinen klaren Bezug zum Code haben. Abbildung
3.4 verdeutlicht dieses Problem. Die linke Seite zeigt den AST für den Ausdruck “x
= 1” in Java, wie er von code2seq verwendet wird. Die rechte Seite zeigt den AST
für den gleichen Ausdruck in Python, wie der astminer ihn verwendet. Um das
Problem zu beheben, werden Sequenzen von Knoten mit nur einem Kindknoten
nachträglich entfernt.
33Abb. 3.4: Java AST für den Ausdruck “x = 1” (links), sowie der von astminer
verwendete Python AST für denselben Ausdruck (rechts).
Die Anzahl der Path-Kontexte die vom Parser gesampelt werden sollen, lässt sich
variieren. Durch das Inlining mehrerer Funktionen ist eine besonders lange Funktion
entstanden. Entsprechend macht es Sinn, auch die Anzahl der Path-Kontexte zu
erhöhen. Neben dem ursprünglichen Wert von 200 wird deshalb in einem weiteren
Trainingsdurchlauf getestet, ob sich die Ergebnisse mit 400 Path-Kontexten pro
Funktion verbessern.
343.1.7 Erstellung der Zielsequenzen
Zum Training von code2seq muss für jede Funktion auch eine Zielsequenz vorgegeben
werden. Das Readme eines Projekts ist meist zu lang, um ein neuronales Netz
sinnvoll darauf zu trainieren. Außerdem enthält es oft Informationen, die nicht aus
dem Sourcecode hervorgehen wie bspw. die Lizenz oder Links auf die Webseite der
Autoren.
Um eine sinnvolle Zielsequenz zu erstellen wird der READMEClassifier [21] verwen-
det. Der READMEClassifier ist ein neuronales Netz, das Sektionen von Readme-
Dateien in bestimmte Klassen einteilt. Zu diesen Klassen gehört beispielsweise
“What”, wo Einleitung und Hintergrund beschrieben wird, oder “Who”: Namen und
Kontaktdaten von Autoren.
Als Zielsequenz wird die “What”-Sektion des Readmes verwendet, da diese meistens
den Zweck des Projekts beschreiben. Da diese Sektionen mitunter auch sehr lang
sein können, werden nur die ersten Sätze verwendet. In verschiedenen Trainings-
durchläufen werden hier einmal die ersten zwei und einmal die ersten zehn Sätze
verwendet.
Bei vielen Projekten kann der READMEClassifier keine “What”-Sektion identifi-
zieren. Auf GitHub kann für jedes Projekt neben einer Readme-Datei auch ein
About-Text angegeben werden, der den Inhalt des Projekts prägnant wiedergibt.
Diese About-Texte werden als Zielsequenz verwendet, wenn der READMEClassifier
keine “What”-Sektion identifizieren kann. Sollte auch kein About-Text existieren,
muss das Projekt aus dem Datensatz entfernt werden. In einem weiteren Trainings-
durchlauf werden ausschließlich die About-Texte als Zielsequenzen verwendet.
Der Datensatz, der bis zu zehn Sätze der Readme “What”-Sektion als Zielsequenz
enthält, verwendet ersatzweise keine GitHub About-Texte. Letztere sind meist nur
einen Satz lang, sodass der Längenunterschied zu groß ist, um noch ein angemessener
Ersatz für die “What”-Sektion zu sein.
35Projektname Readme “What”-Sektion GitHub About-Text
Overview Surprise is a Python scikit for
building and analyzing recommender
systems that deal with explicit rating data. A Python scikit for building and analyzing
Surprise
Surprise was designed with the following recommender systems
purposes in mind: Give users perfect control
over their experiments.
I’ve noticed that many people have
machine
out-of-date forks. Thus, I recommend not A collection of machine learning examples
learning
forking this repository if you take one of my and tutorials.
examples
courses.
30 seconds of code Short Python code
snippets for all your development needs
30 seconds of Python implementation of
Visit our website to view our snippet
python code 30-seconds-of-code
collection. Use the Search page to find
snippets that suit your needs.
Extending and consolidating hosts files from
This repository offers 15 different host file
a variety of sources like adaway.org,
variants, in addition to the base variant.
mvps.org, malwaredomains.com,
The Non GitHub mirror is the link to use
hosts someonewhocares.org, yoyo.org, and
for some hosts file managers like Hostsman
potentially others. You can optionally
for Windows that don’t work with GitHub
invoke extensions to block additional sites
download links.
by category.
percol is an interactive grep tool in your
terminal. percol receives input lines from
stdin or a file, lists up the input lines, waits adds flavor of interactive filtering to the
percol
for your input that filter/select the line(s), traditional pipe concept of UNIX shell
and finally outputs the selected line(s) to
stdout.
Tab. 3.4: Die ersten zwei Sätze der “What”-Sektion der Readme-Dateien einiger
GitHub Repositories, sowie deren About-Texte.
Tabelle 3.4 zeigt einige Beispiele für “What”-Sektion und About-Texte. Die meisten
Sonderzeichen wurden entfernt.
363.2 Summary-Ansatz
3.2.1 Datensatz
Um den Datensatz für den Summary-Ansatz zu erstellen, muss code2seq zuerst
darauf trainiert werden, Docstrings für eine Funktion zu generieren. Da code2seq
jedoch normalerweise nur mit Java und C# arbeitet, ist ein Finetuning mit dem
Checkpoint, den die Autoren bereitstellen, nicht möglich. Zwar sorgt der Parser für
einen gewissen Grad an Abstraktion, das Vokabular der AST-Knoten unterscheidet
sich bei den Sprachen jedoch zu stark.
Stattdessen wird ein neues Vokabular erstellt und ein neues code2seq Modell
trainiert. Hierzu wird der Datensatz von CodeSearchNet [22] verwendet. Dieser
enthält etwa 2 Mio. Funktionen sowie deren Docstrings. Davon sind rund 535.000
Python Funktionen.
Sobald das Training des neuen Modells abgeschlossen ist, kann der Trainingsda-
tensatz für den Textzusammenfasser erstellt werden. Dabei kommt wieder der
GHTorrent Datensatz zum Einsatz. Genau wie beim Inlining-Ansatz wird dazu der
Call-Graph erstellt und die Core-Funktionen bestimmt. Für die Core-Funktionen
wird dann je ein Docstring erstellt und diese konkateniert. Die Docstrings die-
nen dann als Input für den Textzusammenfasser. Die Docstrings sind nach ihrer
Erstellung absteigend nach Zentralität der zugehörigen Funktion sortiert. Diese
Sortierung wird beibehalten.
Die Zielsequenzen werden wie beim Inlining-Ansatz mithilfe des READMEClassifiers
erstellt.
37Sie können auch lesen