BIOMETRISCHE GRUNDLAGEN - BFARM
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Einführung in Planung und
Auswertung klinischer Prüfungen:
Biometrische Grundlagen
PD Dr. Thomas Sudhop
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 1
Klinische Prüfung / Klinische Studie
(Clinical Trials Regulation)
Klinische Studie
Biomedizinisches Experiment mit Arzneimitteln am Menschen zur gezielten
Untersuchung von Wirksamkeit, Sicherheit oder Pharmakokinetik von Arzneimitteln
Klinische Prüfung
Sonderform einer Klinischen Studie mit Abweichungen bzgl. der Behandlungszuweisung
oder der Behandlungsüberwachung von der normalen Behandlungspraxis
Beide Experimentformen versuchen eine Aussage für eine Population zu generieren
anhand von Daten, die (lediglich) aus einer Stichprobe aus der Population ermittelt
wurden.
Grundsätzliche Fragestellungen:
• Ist die Fragestellung von klinischer Relevanz?
• Ist die Stichprobe repräsentativ für die Population?
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 2
1Fragestellungen Klinischer Studien
Explorative Studien
• i.A. keine statistischen Tests
• Methodik kann variabel an die Fragestellung während der Analyse angepasst
werden
• Deskriptive Analytik
• Lagemaße, Streumaße
• Konfidenzintervalle (‐> Übergang in die analytische Statistik)
Konfirmatorische Fragestellungen
• i.A. Anwendung statistischer Tests
• Vorherige Festlegungen erforderlich
• Primäre Zielgröße(n), sekundäre Zielgrößen …
• Irrtumswahrscheinlichkeiten …
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 3
Beispiele für explorative Analysen
Pharmakokinetik
• AUC, Cmax, tmax, t1/2
• Häufig Geometrischer Mittelwert
• Bestimmung aus logarithmierten Werten
Bestimmung einer Wirkdifferenz
• Mittelwert mit Streuungsparameter
Bestimmung eines Verhältnisses
• Odd‘s Ratio
• Risk/Hazard Ratios
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 4
2Konfirmatorische Fragestellungen
• Prüfung einer vorab festgelegten Hypothese
• Entscheidung, ob an der vorab festgelegten Hypothese festgehalten wird
oder diese Hypothese verworfen werden muss, erfolgt auf der Basis einer
experimentellen Beobachtung
• Die Daten der Beobachtungen in einem Experiment sind „Realisationen“
von Zufallsvariablen, die sich bei Wiederholungen des Experiments immer
wieder etwas unterscheiden
• Daher besteht keine absolute Sicherheit, ob die Hypothese tatsächlich
zutrifft oder nicht
• Aber: Mit Hilfe statistischer Tests wird versucht die Wahrscheinlichkeit
von Fehlentscheidungen zu kontrollieren
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 5
Falsifikationismus
Vereinfacht formuliert basiert der Falsifikationismus auf der Annahme, dass sich wissenschaftliche
Hypothesen niemals sicher beweisen lassen, aber gegebenenfalls widerlegen lassen
Beispiel
• Forschungsfrage: „Sind alle Schwäne weiß?“
• Hypothese: „Alle Schwäne sind weiß“ (‐> schwierig alle Schwäne zu sichten)
• Die Hypothese lässt sich aber durch das (Beobachtungs‐)Experiment widerlegen, wenn z.B.
ein schwarzer Schwan gesichtet wird
• Wenn im Experiment also tatsächlich ein schwarzer Schwan gesichtet wurde, muss die
Hypothese „Alle Schwäne sind weiß“ falsch sein
• ‐> Die Alternative „nicht alle Schwäne sind weiß“ muss dann folglich stimmen
Nach diesem Prinzip werden viele statistische Tests in der Medizin durchgeführt:
• Die Widerlegung einer (fehlerhaften) Hypothese führt zur Akzeptanz der Alternativ‐
Hypothese (in einem vollständigen Hypothesenmodell)
• D.h. viele Tests haben nicht den Beweis der Grundhypothese (H0‐Hypothese) zum Ziel,
sondern deren Widerlegung
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 6
3Fragen zum Schwäne‐Experiment
„Wie viele Schwäne muss ich denn beobachten, um sicher zu sein, dass alle
Schwäne weiß sind – oder einer dabei ist, der nicht weiß ist?“
• 5?
• 100?
• 100000?
>>> Fallzahlschätzung für ein Experiment
„Wie sicher bin ich denn, wenn bei 100 Schwänen nur weiße dabei waren, dass
es nicht auch „nicht‐weiße“ Schwäne gibt?“
>>> Irrtumswahrscheinlichkeit
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 7
Hypothese‐Modelle am Beispiel einer
Arzneimittelstudie
0) „Das Arzneimittel wirkt nicht (Falls man einen Effekt sieht, war dieser zufällig)“
1) „Das Arzneimittel wirkt (Die beobachtete Wirkung war systematischer Natur)“
• Die beiden Hypothesen schließen sich aus
• Wenn die Hypothese unter 0) wahr ist, muss die alternative Hypothese unter 1)
falsch sein, und umgekehrt
• Weicher formuliert: Wenn angenommen wird, die Null‐Hypothese (H0) sei falsch,
dann muss daraus gefolgert werden, die Alternativ‐Hypothese (H1 oder HA) ist
wahr
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 8
4Konsequenzen einer Entscheidung für eine
falsche Hypothese: Vergleich zum Justizsystem
0) „Das Arzneimittel wirkt nicht“ => „Der Angeklagte ist nicht schuldig“
1) „Das Arzneimittel wirkt“ => „Der Angeklagte ist schuldig“
Welche Fehlannahme (d.h., welcher Irrtum) ist „schlimmer“?
• In der Rechtsprechung gilt: „In dubio pro reo – Im Zweifel für den Angeklagten“
• Würde fälschlicherweise die obige Hypothese H0 widerlegt (verworfen), würde
deshalb fälschlicherweise die Hypothese H1 als wahr angenommen
Ein Unschuldiger würde fälschlich verurteilt
• Das ist auf jeden Fall zu vermeiden
• Lieber einen Täter im Zweifel „davon kommen lassen“, als einen Unschuldigen zu
verurteilen
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 9
Statistischer Test
Hypothesengenerierung
Untersuchung zum Einfluss einer medizinischen Intervention
• H0: Die Intervention hat keinen Einfluss auf Erkrankungsverlauf
• H1: Die Intervention hat einen Einfluss auf Erkrankungsverlauf
Bezogen auf gemessene Differenzen einer Stichprobe (z.B. vorher‐nachher‐
Vergleich)
• H0: Die Differenz („vorher‐nachher“) ist nicht „0“ verschieden
• H1: Die Differenz ist von „0“ verschieden (d.h. die Intervention hat
Einfluss!)
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 10
5Aufbau eines Testhypothesen‐Modells
• Die Null‐Hypothese (H0) geht von keinem systematischen Unterschied aus.
Falls Unterschiede gefunden werden, werden diese als zufällig und nicht als
systematisch betrachtet
• Die Alternativ‐Hypothese (H1 / HA) ist die logische Umkehrung der Null‐
Hypothese, d.h. es existiert ein systematischer Unterschied
• Gefundene Unterschiede sind nicht zufällig, sondern systematisch
• Null‐ und Alternativ‐Hypothesen müssen sich gegenseitig ausschließen und
alle Möglichkeiten abdecken
• Wenn H0 falsch ist, muss H1 wahr sein
• Wenn H0 wahr ist, muss H1 falsch sein
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 11
Statistische Fehler
Fehler 1. und 2. Art
Wirklichkeit
(objektiv richtig)
AM wirkt! AM wirkt nicht (Zufall)!
(H1ist wahr) (H0 ist wahr)
Falsch
Richtig
AM wirkt! positiv
(H1 ist wahr‐>
positiv
(Fehler 1. Art
H0 ablehnen) (Power = 1‐β)
Testergebnis = α‐Fehler)
(auf der Basis
der Stichprobe) Falsch
Richtig
AM wirkt nicht! negativ
negativ
(H0 beibehalten) (Fehler 2. Art
(1‐α)
= β‐Fehler)
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 12
6Testergebnis und Wirklichkeit
Statistische Fehler
‐Fehler (FALSCH POSITIVES TESTERGEBNIS)
• Eine Wirkung wird angenommen, wo keine ist
• H0‐Hypothese wird abgelehnt, obwohl H0 in Wirklichkeit wahr ist
• Es wird angenommen das Arzneimittel wirkt, obwohl?
‐Fehler (FALSCH NEGATIVES TESTERGEBNIS)
• Eine vorhandene Wirkung wird nicht erkannt
• H0‐Hypothese wird akzeptiert, obwohl H1 in Wirklichkeit wahr ist
• Es wird angenommen das Arzneimittel wirkt nicht, obwohl?
Welcher Fehler ist „schlimmer“ und ist daher eher zu vermeiden?
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 13
Signifikanz‐Niveau
Konsequenzen eines falsch‐positiven Tests
• Uneffektive Behandlung
• Risiko ohne Nutzen („Nihil nocere“)
• Kosten ohne Nutzen
Fazit
• Das Risiko eines falsch positiven Tests ist zwar nicht vermeidbar, sollte aber vorher
bekannt sein und durch vorherige Festlegung eines ‐Niveaus (Signifikanz‐
Niveaus) kontrolliert werden
• Festlegung der maximalen Wahrscheinlichkeit ein falsch positives Testergebnis zu
akzeptieren (Irrtumswahrscheinlichkeit)
• Übliche Werte für
• 0,05 (5%), 0,01 (1%), 0,001 (0,1%) ...
• Das Signifikanz‐Niveau muss vorher im Experimentierplan (Prüfplan) festgelegt
werden
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 14
7Festlegung der Test‐Hypothesen
H0: „AM wirkt nicht“ / H1: „AM wirkt“ und
Festlegung des stat. Verfahrens
Ablauf eines statistischen Tests
Festlegung des Höchstwertes für den Fehlers 1. Art (α‐Fehler)
Üblich α < 0,05 (Statistische Testverfahren
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 17
Zweistichproben‐Tests
Vergleich zweier Gruppen
Parametrische Tests Nicht‐parametrische
Tests
Verbundene Gepaarter Wilcoxon
Daten* (gepaart) t‐Test signed‐ranks Test
unverbundene t‐Test für Mann‐Whitney U
Daten unverbundene Test
Daten
*Verbunden bedeutet: Bestimmte Datenpunkte der beiden Stichproben sind
miteinander korreliert, d.h. sie bilden Datenpaare, z.B. weil sie vom gleichen
Individuum stammen (Beispiel: Vorher/Nachher‐Vergleiche)
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 18
9Parametrische vs. nicht‐parametrische Testung
• Bei der parametrischen Testung wird die gesamte Information der
Stichprobe , d.h. z.B. die absolute Differenz zum Lagemaß (z.B. zum arithm.
Mittelwert), herangezogen
• Bei nicht‐parametrischer Testung werden die Absolutwerte durch z.B.
Rangwerte ersetzt, d.h. es wird nur noch die relative Position in einer
Stichprobe zur Berechnung herangezogen, nicht aber die absolute Lage
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 19
Studie: Neue Tablette zur RR‐Senkung
Diastolischer Blutdruck (mmHg)
vor Behandlung nach Behandlung Differenz Vorzeichen
97 95 ‐2 ‐
96 90 ‐6 ‐
98 94 ‐4 ‐
99 89 ‐10 ‐
90 88 ‐2 ‐
89 82 ‐7 ‐
90 90 0 0
95 85 ‐10 ‐
91 95 4 +
90 90 0 0
94 96 2 +
‐3.18
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 20
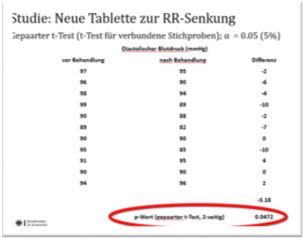
10Studie: Neue Tablette zur RR‐Senkung
Gepaarter t‐Test (t‐Test für verbundene Stichproben); α = 0.05 (5%)
Diastolischer Blutdruck (mmHg)
vor Behandlung nach Behandlung Differenz
97 95 ‐2
96 90 ‐6
98 94 ‐4
99 89 ‐10
90 88 ‐2
89 82 ‐7
90 90 0
95 85 ‐10
91 95 4
90 90 0
94 96 2
‐3.18
p‐Wert (gepaarter t‐Test, 2‐seitig) 0.0472
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 21
Interpretation des p‐Wertes
Im Voraus definiertes Signifikanzniveau = 0,05
Ermittelter p‐Wert im gepaarten t‐Test: p = 0,047 = 4,7/100 = 4,7% = 47/1000
p < 0,05, 5%)
Interpretation des p‐Wertes (p = 0,047)
• Bei 1000‐facher Wiederholung des Experiments würde bei 47 Experimenten eine Differenz von
3,18 mmHg oder mehr im diastolischen Blutdruck zufällig beobachtet werden, ohne dass das
Arzneimittel tatsächlich wirkt
• Die Wahrscheinlichkeit, dass die im Experiment gefundene Differenz von 3,18 mmHg zufälliger
Natur ist und nicht auf einem systematischen Effekt beruht, ist 4,7% (und damit kleiner als das
vorher festgelegte Signifikanzniveau von 5%)
• Da der p‐Wert kleiner als das vorher festgelegte Signifikanzniveau ist, wird der gefundene
Unterschied nicht als zufällig sondern als systematisch betrachtet, d.h. wir sind hinreichend
sicher, dass die gefundene Differenz auf den Effekten der Intervention basiert (Einnahme der
neuen Tablette) und nicht eine zufällige Beobachtung darstellt
• Ein solche Differenz wird „signifikant“ genannt, man spricht von einem „signifikanten
Unterschied“
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 22
11Abhängigkeit des p‐Wertes
Von welchen Parametern wird der p‐Wert beeinflusst?
• Umfang der Stichprobe („Fallzahl“)
• Tatsächlicher Gruppenunterschied in der Stichprobe
• Streuung in der Stichprobe
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 23
Studie: Neue Tablette zur RR‐Senkung
Gepaarter t‐Test (t‐Test für verbundene Stichproben); α = 0.05 (5%)
Vor Therapie Nach Therapie Differenz
97 95 -2
96 90 -6
98 94 -4
99 89 -10
90 88 -2
89 82 -7
90 90 0
95 85 -10
91 95 4
90 90 0
94 96 2
Differenz -3,18
p-Wert (2-seitiger verbundener t-Test) 0,04720228
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 24
12Studie: Neue Tablette zur RR‐Senkung
Gepaarter t‐Test (t‐Test für verbundene Stichproben); α = 0.05 (5%)
Vor Therapie Nach Therapie Differenz
97 95 -2
96 90 -6
98 94 -4
99 89 -10
89 82 -7
90 90 0
95 85 -10
91 95 4
90 90 0
94 96 2
Differenz -3,30
p-Wert (2-seitiger verbundener t-Test) 0,0620570
Entfernung eines Datensatzes aus der Stichprobe führt trotz Zunahme der RR‐Senkung (‐
3,30 vs. ‐3,18) zu einer „Verschlechterung“ des p‐Wertes (p > 0,05): Senkung des RR nicht
mehr statistisch signifikant! ‐> Effekt wird nur als zufällig betrachtet!
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 25
Einfluss der Fallzahl
• Eine zu geringe Fallzahl kann falsch negative statistische Testergebnisse
bewirken (Fehler 2. Art / ‐Fehler)
• Experimente müssen die notwendige statistische Power aufweisen, um
signifikante Ergebnisse liefern zu können
• Fazit: Beim Design eines Experiments ist eine Fallzahlabschätzung
notwendig!
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 26
13‐Fehler und Statistische Power
‐Fehler
• Definition: Wahrscheinlichkeit H0 nicht zu verwerfen, obwohl H0 falsch ist
• „Auf der Basis des Testergebnis halten wir an der Null‐Hypothese fest, dass das
Arzneimittel keine systematische Wirkung hat; die beobachteten Unterschiede
waren zufälliger Natur“ (>>>falsch negatives Ergebnis)
Statistische Power (1‐)
• Definition: Wahrscheinlichkeit H0 zu verwerfen, wenn H0 falsch ist, d.h. die
Wahrscheinlichkeit eine “reale” Differenz auch als solche mit dem Test zu
belegen
• Vereinfacht: Wahrscheinlichkeit ein signifikantes Testergebnis zu erhalten (wenn
ein „wirklicher“ Unterschied besteht)
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 27
Vermeidung von ‐Fehlern
Power‐Schätzung
Power‐Schätzung
• Wenn die statistische Power eines Studiendesigns nur 50% beträgt und
die Fallzahl entsprechend geschätzt wird, wird jede 2. Studie mit dieser
Fallzahl keine signifikanten Unterschiede anzeigen, obwohl eine
systematischer Unterschied existiert
• Konfirmatorische Studien: Power 80%
• Große Phase III Studien: 85‐90%
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 28
14Zusammenhang zwischen
Power & Fallzahl
GPOWER ‐ Version 2.0 Franz Faul & Edgar Erdfelder
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 29
Fallzahl beeinflussende Faktoren
Signifikanz‐Niveau ()
n
• Je niedriger das angestrebte , um so höher die erforderliche Fallzahl
Power (1‐)
• Je größer die gewünschte Power, um so höher die erforderliche
n
Fallzahl
Power
Geschätzte Differenz
n
• Je kleiner die nachzuweisende Differenz, um so höher die
erforderliche Fallzahl µPBO - Z99
Geschätzte Standardabweichung
n
• Je größer die Standardabweichung (SD), um so höher die erforderliche
Fallzahl SD
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 30
15Fallzahlberechnung
(Differenztestung)
1. Festlegung von und gewünschter Power und Festlegung ob ein‐ oder zweiseitig
getestet werden soll und welcher geeigneter Test verwendet werden soll
• z.B. = 0.05 (5%), power = 80%, 2‐seitiger t‐test (two‐tailed)
2. Schätzung der nachzuweisenden Differenz (=Effekt)
• Ist die Schätzung klinisch relevant?
3. Schätzung der erwarteten Varianz/Standardabweichung
• Möglichst realistische Werte aus vorangegangenen Experimenten oder der Literatur
verwenden
4. Effektstärke berechnen
• Effekt / Standardabweichung
5. Fallzahlberechnung durchführen (oder durchführen lassen!)
• Ist die geschätzte Fallzahl klinisch realisierbar?
• Ist die geschätzte Fallzahl adäquat zum klinischen Problem?
• Anpassung der Fallzahl an die geschätzte Drop‐Out‐Rate
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 31
Beispiel einer Fallzahlschätzung
• = 5%, 2‐seitiger t‐Test
• Power = 80%
• Annahmen für geschätzte Differenz der
Gruppenmittelwerte & SD
• Effekt: xPBO ‐ xTestsubstanz ~ 13 mmHg
• SDpooled ~ 16
• Effektstärke = 13/16 = 0,8125
• Fallzahlberechnung
• 2 x n = 50, n = 25
• Ggf. Anpassung an antizipierte „Drop
out“‐Rate
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 32
16Signifikant ≠ Relevant
Unabhängig von der Teststatistik ist die klinische Relevanz der beobachteten
Unterschiede zu bewerten
• Ist eine signifikante Senkung des diastolischen Blutdrucks von 0,9 mmHg
wirklich auch klinisch relevant?
• Wie viele Patienten müssten im obigen Beispiel behandelt werden, um
einen Schlaganfall zusätzlich zu verhindern? (Number‐needed‐to‐treat)
Umgekehrt: Ist ein nicht‐signifikantes Ergebnis ohne Information?
• Ist eine Senkung des diastolischen Blutdrucks um 12 mmHg mit einem p‐
Wert von p=0,055 in einer Studie mit 13 Patienten wirklich ein Beweis,
dass das Arzneimittel nicht den Blutdruck senkt?
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 33
Konfidenzintervalle und
statistische Tests
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 34
17Konfidenzintervalle x = 6 mmHG
• 95%‐KI für einen Mittelwert: Das
3 mmHG 9 mmHG
Intervall, in dem mit 95%iger
Wahrscheinlichkeit der „wahre“
Mittelwert liegt x = 12 mmHG
• 99%‐KI: Das Intervall für einen Wert,
in dem mit 99%iger
Wahrscheinlichkeit der „wahre“ 13 mmHG
1 mmHG
Mittelwert liegt
• Die Breite des KI hängt ab
• Vom Stichprobenumfang: Je kleiner
die Stichprobe umso größer das KI x 1,96 * SEM
• Von der Präzision des KI: 99%‐KI ist
breiter als 95%‐KI SD
SEM
n
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 35
Vergleich p‐Wert eines gepaarten t‐Test mit dem
Konfidenzintervall für Differenz
Beispielstudie zum RR‐Senker
• Mittlere Differenz ‐3,18 mmHg, SD 4,76 mmHg, p=0,0472
• 95%‐Konfidenzintervall der Differenz [‐5,94 ; ‐0,42 mmHg]
Interpretation
• Die wahre RR‐Differenz der Population liegt mit 95%iger Wahrscheinlichkeit in dem Intervall
[‐5,94 ; ‐0,42 mmHg] >> ist also kleiner als Null „0“
• Mit mindestens 95% Wahrscheinlichkeit ist die Null („0“) nicht im Konfidenzintervall
enthalten, d.h. es wird mit 95% Wahrscheinlichkeit ein systematischer Effekt der
Behandlung beobachtet
• Die Wahrscheinlichkeit, dass die beobachtete Differenz nur zufälliger Natur ist, liegt unter 5%
• Es wird daher mit höchstens 5% Irrtumswahrscheinlichkeit angenommen, dass die
beobachtete RR‐Senkung systematischer Natur sei, also das AM die Blutdrucksenkung
hervorgerufen hat
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 36
18Konfidenzintervalle
Beispiel für Verhältnisse
Fiktives Beispiel: Odd‘s Ratio (OR) für Depressionen in Abhängigkeit vom Geschlecht bei 2
verschiedenen Studien
Bedeutung der OR in den Studien
• > 1: Depressionsrisiko für Frauen gegenüber Männern erhöht
• = 1: Risiko für Frauen gleich hoch
• < 1: Risiko für Frauen erniedrigt
Fiktive Studie A
• OR für Depressionen bei Frauen: 2,8 95%KI: [1,4; 4,2]
• >>> „Frauen haben ein erhöhtes Depressionsrisiko“
Fiktive Studie B 1,4 4,2
• OR für Depressionen bei Frauen: 2,8 95% KI:[0,9; 5,7]
0,9 5,7
• >>> „Frauen haben kein erhöhtes Depressionsrisiko“
1,0 2,8
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 37
Vielen Dank für Ihre Aufmerksamkeit!
Kontakt
Bundesinstitut für Arzneimittel und Medizinprodukte
Abteilung 10 „Informationstechnik / Klinische Prüfung“
Kurt‐Georg‐Kiesinger‐Allee 3
53175 Bonn
Ansprechpartner
PD Dr. med. Thomas Sudhop
thomas.sudhop@bfarm.de
www.bfarm.de
Tel. +49 (0)228 99 307‐3424
Thomas Sudhop | Einführung in die Planung Klinischer Studien | 18.01.2022 38
19Sie können auch lesen

















































