Erzeugung synthetischer Trainingsdaten für die Deep Learning basierte Bestimmung von GPS-Koordinaten aus Fotos am Beispiel der Notre Dame
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

HAUPTPROJEKT
Thomas Kanne-Schludde
Erzeugung synthetischer
Trainingsdaten für die Deep
Learning basierte Bestimmung
von GPS-Koordinaten aus
Fotos am Beispiel der Notre
Dame
FAKULTÄT TECHNIK UND INFORMATIK
Department Informatik
Faculty of Computer Science and Engineering
Department Computer Science
Betreuung durch: Prof. Dr. Kai von Luck
Eingereicht am: 30. September 2020
HOCHSCHULE FÜR ANGEWANDTE
WISSENSCHAFTEN HAMBURG
Hamburg University of Applied Sciences
Inhaltsverzeichnis
Inhaltsverzeichnis
1 Einleitung 1
1.1 Ziel der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.2 Aufbau . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
2 Problemanalyse 3
2.1 Qualität der realen Trainingsdaten . . . . . . . . . . . . . . . . . . . . . . 3
2.2 Synthetische Datengenerierung . . . . . . . . . . . . . . . . . . . . . . . . 4
2.2.1 Domain Randomization (DR) . . . . . . . . . . . . . . . . . . . . . 4
2.2.2 NVIDIA Deep Learning Dataset Synthesizer (NDDS) . . . . . . . . 5
2.2.3 Datensatz: Falling Things Datensatz (FAT) und eigener Datensatz 5
3 Durchführung 7
3.1 Erzeugung eines synthetischen Datensatzes . . . . . . . . . . . . . . . . . . 7
3.1.1 3D-Modell . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3.1.2 Koordinatensystem . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
3.1.3 Synthese-Aufbau . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9
3.1.4 S2-Zellen Integration in das Koordinatensystem . . . . . . . . . . . 11
3.2 Integration in die bestehende Pipeline . . . . . . . . . . . . . . . . . . . . 12
3.2.1 Koordinaten-Import . . . . . . . . . . . . . . . . . . . . . . . . . . 12
3.2.2 Datenverteilung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14
3.3 Training . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.4 Exemplarisches Testen . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
4 Ergebnisdiskussion 18
4.1 Datenverteilung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
4.2 Training . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4.3 Tests der trainierten Modelle . . . . . . . . . . . . . . . . . . . . . . . . . 21
4.4 Fazit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.5 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
5 Anhang 24
Literatur 31
ii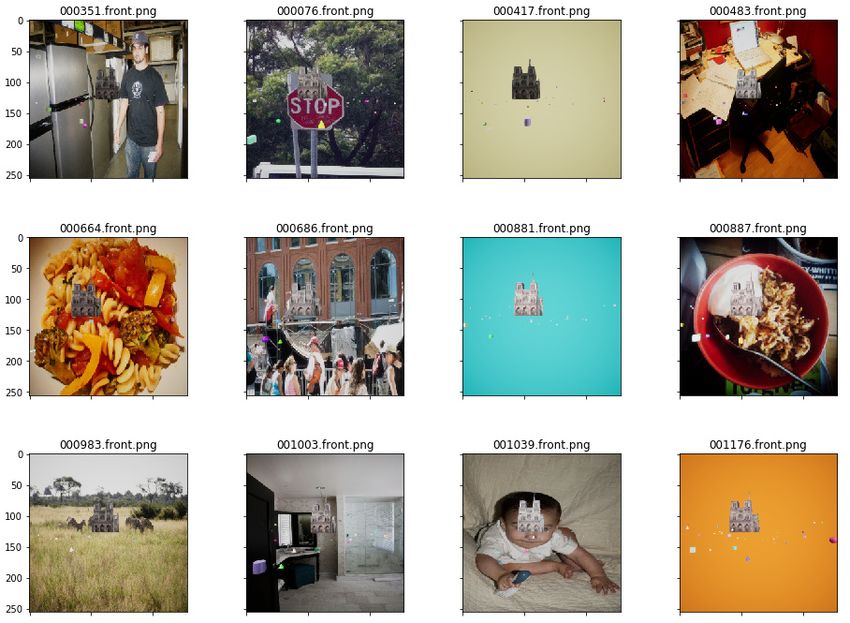
1 Einleitung
In dieser Arbeit wird ein synthetischer Datensatz für das Trainieren eines
neuronalen Netzes zur Bestimmung von GPS-Koordinaten aus Fotos anhand
der Pixel erzeugt. Basierend auf ein 3D-Modell der Kathedrale Notre Dame in
Paris wird mit der Spiel-Engine Unreal Engine 4 ein Trainings-Datensatz er-
zeugt und in eine für diese Arbeit erweiterte Pipeline für die Bestimmung der
GPS-Koordinaten integriert. Durch den gezielt synthetisch erzeugten Trai-
ningsdatensatz soll die Fehlerhaftigkeit der realen Trainings-Fotos aus dem
vorangegangenen Projekt ausgeglichen werden.
1 Einleitung
Wenn mit Deep Learning Algorithmen gearbeitet wird, um Vorhersagen über bestimmte
Daten treffen zu können, ist einer der substantiellsten Faktoren die Qualität der Daten,
mit denen das Modell trainiert wird [3]. In dem dieser Arbeit vorausgehenden Projekt
[5] wurde eine Pipeline zum Trainieren von neuronalen Netzen aufgebaut, mit denen
Geo-Koordinaten von Fotos nur auf Grundlage der Pixel bestimmt werden sollen. In An-
lehnung an [15] wurde ein Klassifikator entwickelt, der ausschließlich mit „geogetaggten“
realen Fotos der Notre Dame in Paris trainiert wurde. Der aus ca. 35.000 Bildern beste-
hende Trainingsdatensatz wurde mithilfe der Flickr-API erzeugt. Mit diesem Datensatz
sollte überprüft werden, ob die Qualität der Fotos ohne aufwändige Nachbearbeitung für
ein erfolgreiches Training ausreichen würde. Mehrere Gründe führten jedoch dazu, dass
sich das Netz kaum an die Trainingsdaten anpassen konnte und der Datensatz faktisch
unbrauchbar ist. Laut Gudivada et al. gibt es einige Mechanismen, wie im Big Data
Kontext Datensätze aufbereitet werden können, was das Training insgesamt allerdings
zu einer sehr komplexen und aufwändigen Angelegenheit macht [1]. Besonders bei der
Objekterkennung haben viele Faktoren wie die Komposition, Belichtung, Abstand der
Objekte zur Kamera etc. großen Einfluss auf die Erkennungsrate und müssen manuell
erarbeitet und markiert werden [7].
Tremblay et al. [13] begegnen diesem Problem mit der Erstellung synthetischer Daten,
bei der durch gezielte Randomisierung der variablen Eigenschaften eines realen Szenari-
os synthetische Trainingsfotos erzeugt und trainiert werden. Durch dieses Vorgehen soll
das Netz gezwungen werden, sich auf die wesentlichen Eigenschaften des zu erkennenden
Objektes zu beschränken.
1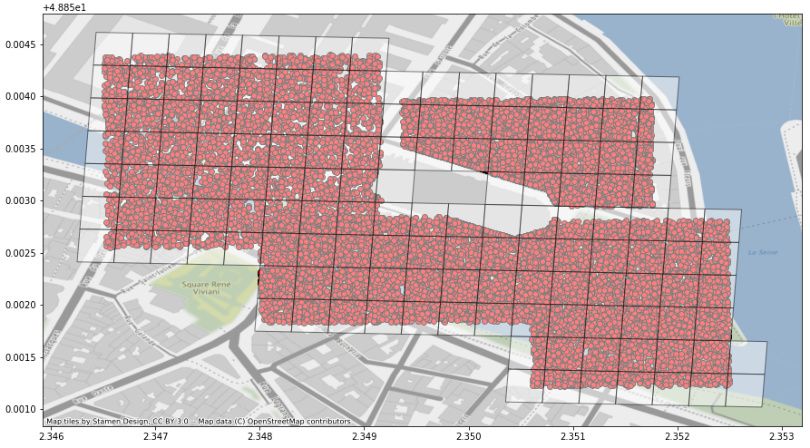
1 Einleitung
1.1 Ziel der Arbeit
Im Zuge dieser Arbeit soll mithilfe der Spiele-Engine Unreal Engine 1 ein synthetischer
Datensatz in Anlehnung an [13] speziell für das Training der Notre Dame Kathedrale er-
stellt und in die Pipeline zur Erkennung von Geodaten aus Fotos aus dem vorangehenden
Projekt [5] integriert werden. Die Pipeline wird dafür so erweitert, dass sowohl synthe-
tische als auch reale Daten erzeugt, aufbereitet und trainiert werden können. Um sich
einen Vorteil gegenüber der arbeitsintensiven Verarbeitung realer Daten zu verschaffen,
ist die Motivation hierbei, den Datensatz möglichst einfach halten zu können, um die
Erstellung auch potenziell für weitere Objekte in Betracht ziehen zu können. Abschlie-
ßend sollen beide Vorgehensweisen verglichen und eine Einschätzung gegeben werden,
inwieweit die Vorgehensweise für die Problemstellung der Ortsbestimmung von Fotos für
weitere Arbeiten behilflich sein kann.
1.2 Aufbau
Zuerst werden in der Problemanalyse die Ergebnisse und damit die noch offenen Heraus-
forderungen der vorangegangenen Arbeit [5] aufgegriffen. Am Beispiel der Arbeiten von
Tremblay et al. [13] wird das Konzept der Datensynthetisierung erläutert und theoretisch
auf die aktuelle Fragestellung angewandt. In der Durchführung wird beschrieben, wie die
synthetischen Fotos des Notre Dame erstellt wurden und welche Anpassungen an die be-
stehende Pipeline nötig waren. Abschließend werden die Ergebnisse präsentiert, bewertet
und Möglichkeiten zur Fortführung dieser Fragestellung skizziert, die dieses Projekt für
folgende Arbeiten eröffnet.
1
https://www.unrealengine.com/, 19.09.20
2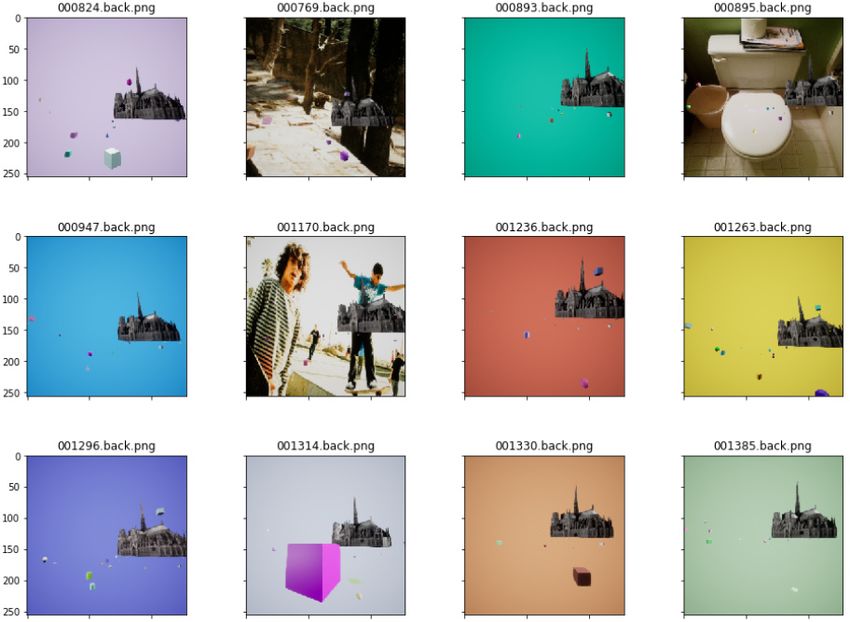
2 Problemanalyse
2 Problemanalyse
Dieses Kapitel behandelt die Herausforderungen, die sich beim Trainieren von Fotos für
neuronale Netze ergeben. Es wird insbesondere auf die vorausgehende Arbeit eingegangen
und mit dem Synthetisieren eines eigenen Datensatzes eine weiterführende Vorgehens-
weise präsentiert.
2.1 Qualität der realen Trainingsdaten
In [5] wurde ein Mehrklassen-Klassifizierungsmodell in Anlehnung an Weyand et al. [15]
auf Basis eines Flickr -Datensatzes von mit Geo-Tags versehenen User-Fotos der Notre
Dame trainiert. Wie dem Ergebnis der Arbeit entnommen werden kann, ist die Aufteilung
der Fotos auf die mit der S2 Geometry Library 2 vordefinierten Klassen im Umkreis von
ca. 4 km um die Notre Dame herum äußerst ungleich (siehe Abbildung 1). Die Nutzung
des S2-Level 18 ergibt schließlich 910 Klassen mit einer Zellengröße3 von ca. 900m2 .
(a) Verteilung der realen Fotos im Umkreis von ca. 4 (b) Darstellung der Verteilung als Balkendiagramm.
km Ein Balken entspricht einer Klasse. y-Achse: An-
zahl der Fotos.
Abbildung 1: Verteilung der realen Testdaten. x-Achse: Längengrad, y-Achse: Breitengrad.
Mit dem in [5] verwendeten Quad-Tree-Verfahren 4 wurde durch eine dynamische Zel-
leneinteilung auf Basis der Anzahl von Fotos die Anzahl der Klassen auf 111 begrenzt.
Zellen mit weniger als 20 Fotos wurden aus dem Datensatz entfernt. Bei einem Datensatz
mit 32.559 Fotos konnte mit diesem Verfahren allerdings nur eine Validierungsgenauig-
keit von 7,47 % erreicht werden. Als hauptsächliche Fehlerquelle konnte der Inhalt der
Flickr-Fotos identifiziert werden: Neben zahlreichen Fotos, die zwar mit dem Titel „Notre
2
S2 Geometry Library: https://s2geometry.io/ (Letzter Zugriff: 18.01.20)
3
https://s2geometry.io/resources/s2cell_statistics, 16.09.20
4
Quad-Tree Wikipedia Artikel: https://de.wikipedia.org/wiki/Quadtree (Letzter Zugriff: 04.09.2020)
3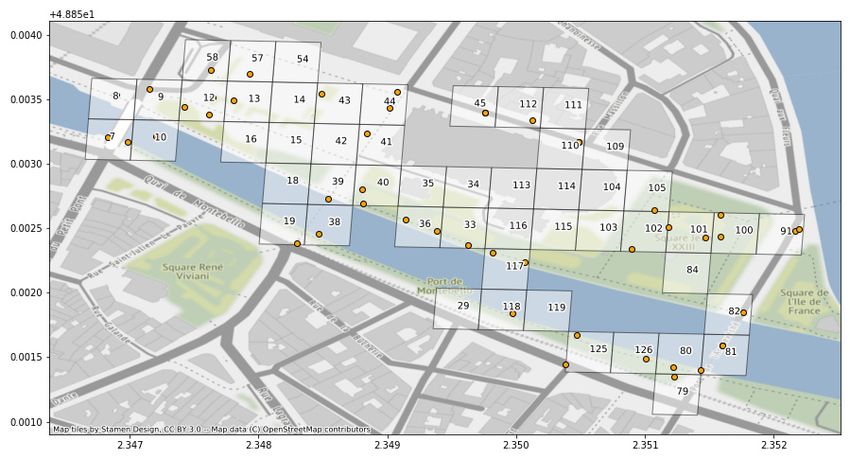
2 Problemanalyse
Dame“ getaggt wurden, jedoch andere Motive wie Pflanzen, Personen oder diverse Ge-
bäude und Gegenstände in der Nähe zeigten, ist ein großer Teil der Geodaten inkorrekt.
Eine Vielzahl der getaggten Koordinaten repräsentieren den Mittelpunkt der Kirche, der
vermutlich in vielen Fällen als Standard gesetzt wurde, wenn die Geodaten nicht auto-
matisch ermittelt werden konnten. Den Großteil machen jedoch Innenaufnahmen aus,
die für dieses Training ignoriert werden sollen, da sich diese Arbeit auf die Außenaufnah-
men konzentrieren soll. Dementsprechend müssen diese Fotos aus dem Trainingsdatensatz
entfernt werden, wofür entweder hoher manueller Aufwand oder Algorithmen zur Unter-
scheidung von Innen- und Außenaufnahmen notwendig wären. Abbildungen 12 und 14
im Anhang gewähren hier einen kleinen Einblick, welche Trainingsfotos sich innerhalb in
einer Klasse befinden.
In dieser Arbeit soll demzufolge ein eigener synthetischer Datensatz erzeugt werden, um
ein von externen Störfaktoren unabhängiges Training zu ermöglichen. In dem Zusam-
menhang soll das bisher verwendete neuronale Netz und die Anzahl der Klassen sowie
die Datenverteilung kritisch hinterfragt und in Hinblick auf bessere Ergebnisse angepasst
werden.
2.2 Synthetische Datengenerierung
Für die Erzeugung des synthetischen Trainingsdatensatzes orientiert sich dieses Projekt
an der Arbeit von Tremblay et al. [13], in der die Autoren eine neuronale Netzarchitek-
tur auf Basis synthetischer Daten trainieren, um die Position und Lage im Raum von
verschiedenen Haushaltsgegenständen - also die Objekt-Pose - innerhalb eines einzigen
Bildes zu bestimmen. Die Erkennung wird schließlich für einen Roboter genutzt, der die
trainierten Haushaltsgegenstände in der Realität in Echtzeit erkennen und greifen kön-
nen soll. Damit unterscheidet sich der Anwendungsfall in großen Teilen von dem dieser
Arbeit. Es soll hier deshalb nicht auf die Details eingegangen, sondern sich die Methodik
der Datenerzeugung zunutze gemacht und überprüft werden, inwiefern sie sich auf den
Anwendungsfall dieser Arbeit übertragen lässt.
2.2.1 Domain Randomization (DR)
Tremblay et al. [13] weisen auf einige vorausgehende Arbeiten hin, bei denen eine große
Problematik der hohe Aufwand beim Annotieren realer Trainingsdaten war. Die dazu-
gehörigen Testdaten ähnelten sich aufgrund der Nutzung gleicher Kameras, Objekte,
4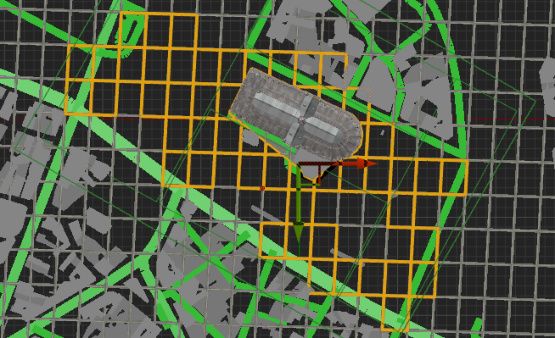
2 Problemanalyse
Lichtverhältnisse etc. stark, wodurch das Netz nur bedingt - nämlich bezüglich der Test-
daten - generalisieren konnte. Aus diesem Grund verweisen sie auf die von Tobin et al.
[12] eingeführte Domain Randomization. Bei diesem Verfahren wird ein synthetischer
Datensatz mit zufälliger Anzahl und Anordnung von verdeckenden Objekten, Texturen,
Position und Orientierung von Kamera und zu trainierenden Objekten sowie wechseln-
den Hintergründen und Lichtverhältnissen bei bewusst niedrig gehaltener Genauigkeit
erzeugt. Somit lässt sich in relativ kurzer Zeit eine enorme variable Datenmenge pro-
duzieren, wodurch das trainierte Modell besser gegenüber realen Daten generalisieren
kann. Dies soll letztendlich dazu beitragen, den sogenannten Reality Gap [4], die Lücke
zwischen Simulation und Realität, zu schließen.
2.2.2 NVIDIA Deep Learning Dataset Synthesizer (NDDS)
Der NVIDIA Deep Learning Dataset Synthesizer (NDDS) ist ein von Thang et al. [11]
für NVIDIA entwickelter Simulator in Form eines Plugins für die Unreal Engine zur Ge-
nerierung synthetischer Daten nach dem Prinzip der Domain Randomization voranging
für das in [13] vorgestellte Projekt zur Erkennung von Position und Pose von Objekten.
Dieses Plugin ermöglicht es, innerhalb einer Szene in der Unreal Engine beliebig viele
Objekte zu platzieren und dann dessen Position, Lage und Aussehen (durch z.B. Aus-
tauschen der Texturen und Verändern von Lichtverhältnissen) zufällig zu verändern. Dies
können sowohl Objekte sein, die vom neuronalen Netz trainiert werden sollen als auch
verdeckende Störobjekte, sogenannte Distraktoren. Zusätzlich lassen sich Kamerabewe-
gungen definieren, sodass diese sich beispielsweise entlang eines vorgegebenen Pfades
oder sich willkürlich innerhalb einer definierten Region bewegt. Mit der Exportfunktion
werden während der Simulation Screenshots des Kamerabildes als png-Dateien expor-
tiert, zu denen zusätzliche Exportbilder optional Tiefeninformationen, Segmentierungen
oder Bounding Boxes 5 enthalten können. In einer JSON -Datei werden pro exportiertem
Bild Metainformationen wie die Position der Objekte und Kamera und diverse weitere
Einstellungen innerhalb der Szene festgehalten.
2.2.3 Datensatz: Falling Things Datensatz (FAT) und eigener Datensatz
Wie ein mit dem NDDS-Plugin erstellter Datensatz aussehen kann, zeigt der Falling
Things (FAT) [14] Datensatz, der gewöhnliche Haushaltsgegenstände sowohl nach dem
5
Bounding Box: Ein Rechteck zum Einrahmen eines Objekts
5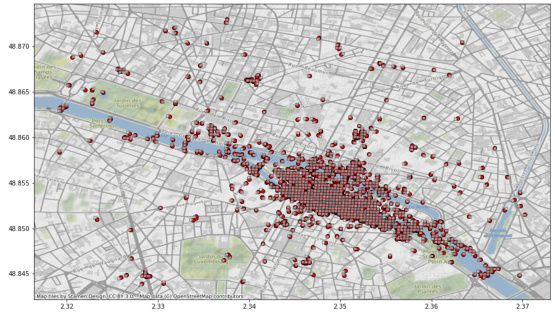
2 Problemanalyse
soeben beschriebenen Domain Randomization Prinzip als auch fotorealistische Umgebun-
gen in verschiedenen Szenen mit je unterschiedlicher Anordnung von Objekten enthält.
In diesem Projekt soll der FAT-Datensatz nur grob als Orientierung dienen, da hier ver-
sucht werden soll, mit einem durch minimalem Aufwand erstellten Datensatz ein zeitlich
effizientes Training zur Bestimmung der Geodaten zu erreichen. Statt einer Auswahl an
Objekten soll hier nur ein Objekt (die Notre Dame) trainiert werden, wodurch die vari-
ierende Anzahl und Komposition von Objekten entfällt. Da die Notre Dame zusätzlich
geografisch an einem statischen Ort gebunden ist, entfallen die zufällige Beweglichkeit des
zu annotierenden Objektes und intuitiv auch die Generierung unterschiedlicher fotorealis-
tischer Umgebungen. Stattdessen sollten sich die synthetischen Bilder auf die Umgebung
aus touristischer Perspektive konzentrieren. Im FAT-Datensatz wurden zudem fünf un-
terschiedliche Positionen für einen kleinen Bereich, in dem sich die Kamera bewegen
kann, definiert - hier soll sie sich allerdings vollständig um das Bauwerk herum bewegen
können.
Da nach [5] die Geopositionen mit einem Klassifikator bestimmt werden und die geografi-
sche Umgebung deshalb mit der S2 Geometry Library in ein Raster eingeteilt wurde, bei
dem jede Zelle einer zu trainierenden Klasse entspricht, soll es auch dementsprechend vie-
le Kamerapositionen geben. Zuletzt soll der hier erstellte Datensatz vorerst ohne Export
von Bounding Boxes, Segmentierung und Tiefeninformation arbeiten, da als Zielwerte
keine Posen oder Positionen des Objektes auf dem Bild, sondern Geo-Zellen verwendet
werden. Durch die reine Generierung synthetischer Momentaufnahmen mit der Hinzu-
nahme von Distraktoren soll eine Vergleichbarkeit zu realen Fotos erzeugt werden.
6
3 Durchführung
3 Durchführung
In diesem Abschnitt wird im Kontext der Erstellung eines eigenen synthetischen Daten-
satzes das NDDS-Plugin näher beschrieben und einige Probleme diskutiert, welche sich
bei der Integration in die bestehende Pipeline ergaben. Um die Nützlichkeit des Daten-
satzes zu ergründen, wird ein Vergleich mit den realen Daten angestrebt und dafür eine
Vergleichbarkeit erzeugt, die im Ergebnisteil in Abschnitt 4 diskutiert wird.
3.1 Erzeugung eines synthetischen Datensatzes
Für die Erzeugung des synthetischen Datensatzes wurde der in Abschnitt 2.2.2 beschrie-
bene NVIDIA Deep Learning Dataset Synthesizer genutzt. Dieses Plugin wird in die
Unreal Engine 4.22 installiert und bietet einige Tools für das Organisieren und Verän-
dern von grafischen Objekten und virtuellen Kameras.
3.1.1 3D-Modell
Für die Erzeugung der Fotos wurde zuerst auf diversen Marktplätzen für 3D-Computer-
grafiken im Internet nach einem qualitativ angemessenem und mit der Unreal Engine
kompatiblem Modell der Notre Dame gesucht. Letztendlich wurde auf dem Webportal
Turbosquid6 ein für diesen Einsatz vorerst ausreichendes 7 Modell8 erworben und in die
Unreal Engine (ab hier mit „UE4“ abgekürzt) importiert.
3.1.2 Koordinatensystem
UE4 arbeitet mit einem eigenen Koordinatensystem, dessen Einheit „Unreal Unit (UU)“
standardmäßig einem Zentimeter entspricht. Alle Objekte und Kameras werden inner-
halb dieses Koordinatensystems - dem „Welt-Koordinatensystem“ - angeordnet, deren
6
https://turbosquid.com - Eines der größten Webportale zum Vertrieb von 3D-Modellen für 3D-
Computergrafik, 09.09.2020
7
Die Bewertung des 3D-Modells mit „vorerst ausreichend“ basiert auf der Grundlage des aktuellen eige-
nen Wissensstandes. An dieser Stelle soll offen bleiben, ob sich bei einer späteren detaillierten Analyse
der trainierten Features des neuronalen Netzes herausstellt, dass das Modell über ungenügende De-
tails verfügt und somit nicht zu zufriedenstellenden Ergebnissen führt.
8
https://www.turbosquid.com/FullPreview/Index.cfm/ID/959011, 09.09.2020
7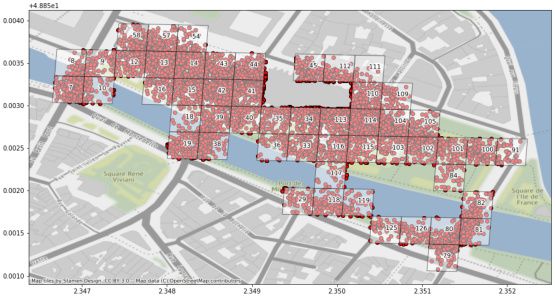
3 Durchführung
Positionen mit der x-, y- und z-Achse bestimmt werden. Um die zu exportierenden Bil-
der für das spätere Training labeln zu können, bedarf es eines geografischen Referenz-
punktes innerhalb dieses Koordinatensystems, weshalb das 3D-Modell der Notre Dame
als Mittelpunkt der Szene mit den Koordinaten x=0, y=0, z=0 festgelegt wurde. Als
Mittelpunkt des 3D-Modells wiederum wurde der Kirchturm des Mittelschiffes gewählt
und das Modell dementsprechend platziert (Abbildung 2).
(a) Markierter Punkt in Google Maps dient als (b) Referenz-Koordinate als Nullpunkt im
Referenz-Koordinate UE4 Koordinatensystem (Draufsicht)
Abbildung 2: Wahl und Positionierung des Notre Dame Mittelpunkts in UE4
Von diesem Punkt ausgehend soll schließlich die Kamera platziert werden, sodass bei
der Annotation der exportierten Bilder der jeweilige Abstand der Kamera zum Gebäude
gemessen und daraus schließlich die entsprechenden GPS-Koordinaten berechnet werden
können.
Um die Optik bei der Generierung von Fotos den realen räumlichen Verhältnissen an-
zupassen und die spätere Umrechnung der UU-Koordinaten in Längen- und Breitengrad
zu vereinfachen, sollten sowohl die reale Größe der Notre Dame als auch die Rotation
im Raum angepasst werden. Als Hilfe diente OpenStreetMap-Kartenmaterial aus einem
Umkreis von ca. 700 m um die Notre Dame herum, das über die Exportfunktion der
OpenStreetMap-Website9 beschafft wurde. Das Kartenmaterial wird im OSM -Format
zur Verfügung gestellt, das sich über das Street Map Plugin for UE4 10 in die UE4 Szene
importieren lässt. Das Plugin unterstützt derzeit Straßen und Gebäudeumrisse, sodass
die Umgebung in originaler Größe in sehr vereinfachter Form dargestellt werden kann.
9
OpenStreetMap Kartenausschnitt um die Notre Dame:
https://www.openstreetmap.org/export#map=17/48.85306/2.34998, 10.09.20
10
https://github.com/keru1264/StreetMap, 10.09.20
83 Durchführung
Dadurch ließ sich das Notre Dame 3D-Modell exakt auf die richtige Position platzie-
ren, sodass im weiteren Verlauf die Geodaten korrekt berechnet werden können (siehe
Abbildung 4).
3.1.3 Synthese-Aufbau
In diesem Abschnitt wird die Nutzung einiger Module des NDDS-Plugins beschrieben.
Hier wird allerdings nicht ins Detail gegangen und auch auf eine Beschreibung der Unreal
Engine wird verzichtet, da beides den Rahmen dieser Arbeit sprengen würde. Für weitere
Details sei hier auf die Dokumentation des NDDS-Plugins11 sowie der Unreal Engine12
verwiesen.
SceneCapturer Die Hauptkomponente des Szenen-Aufbaus stellen die SceneCaptur-
er -Actors dar. Ein SceneCapturer simuliert die verwendete Kamera und erzeugt die ge-
wünschten Fotos durch den Export von Screenshots. Durch zusätzliche Komponenten
werden mit dem SceneCapturer sowohl Bewegung als auch Blickfokus konfiguriert. Der
RandomMovement Komponente wird ein Volume - ein dreidimensionales Rechteck, in
dem sich die Kamera bewegen darf - zugewiesen und dann so konfiguriert, dass die Ka-
mera pro Frame eine zufällige neue Position innerhalb des Volumes einnimmt. Mit der
RandomLookAt Komponente wird der Blick der Kamera auf das Notre Dame Modell
fokussiert und durch einen zusätzlich an der Spitze des Modells angebrachten Dummy-
Actor die Ausrichtung etwas variiert.
Tabelle 1 zeigt einige der vorgenommenen Einstellungen:
Tabelle 1: Exemplarischer Auszug aus einer Komponenten-Konfiguration
Komponente Parameter Wert
SceneCapturer Location (x,y,z) in UU (10450,5920,180)
SceneCapturer Max Number Of Frames To Export 5000
SceneCapturer CapturedImageSize 256x256 px
RandomMovement RandomLocationVolume CameraVolume_front
RandomMovement Should Teleport True
NotreDameModel,
RandomLookAt Focal Target Actors
NotreDameTop
RamdomLookAt RotationSpeed (in degree per second) 29
11
https://github.com/NVIDIA/Dataset_Synthesizer/blob/master/Documentation/NDDS.pdf,
12.09.20
12
https://docs.unrealengine.com/en-US/GettingStarted, 12.09.20
93 Durchführung
Insgesamt wurden vier SceneCapturer (front, back, left, right) mit den dazugehörigen
Volumes auf Personenhöhe platziert, sodass die Notre Dame von jeder Seite getrennt
„fotografiert“ werden konnte (innere vier Rechtecke in Abbildung 2b). Eine zusätzliche
Einstellung im SceneCapturer verhindert, dass die Kamera mit dem 3D-Modell kollidieren
kann. Dadurch wird versucht, ein virtuelles Szenario zu erstellen, das sich an Ort und
Blickwinkel von Touristenfotos orientiert.
Distraktoren Um Objekte, die gelegentlich die direkte Sicht auf die Notre Dame ver-
sperren, sogenannte Distraktoren, in die Fotos zu integrieren, wurde ein großes das 3D-
Modell überlagerndes Volume angelegt (äußeres großes Rechteck in Abbildung 2b). Über
den DistractorManager 13 können Anzahl, Typ und Aussehen von Objekten sowie deren
Positionen und Bewegungen bestimmt werden. Hier wurden vorerst die im Plugin mit-
gelieferten Standardformen (Zylinder, Dreieck etc.) mit unterschiedlichen Farben, Po-
sitionen und Rotation genutzt, von denen aktuell 40 bis 60 Instanzen vor jeder Seite
des 3D-Modells erzeugt werden (Abbildung 3). Ziel der Distraktoren ist, mit minimalem
Aufwand Personen, Autos und weiteren Verdeckungen, die auf realen Fotos vorhanden
sein können, zu ersetzen, um das Training robuster und weniger störanfällig dagegen zu
machen.
Abbildung 3: Distraktoren verdecken die freie Sicht und werfen Schatten
13
Neben dem DistractorManager existiert auch der GroupActorManager, der für die randomisierte Er-
scheinung der zu trainierenden Objekte genutzt wird. Dieser hat hier allerdings keine Funktion, da
die Notre Dame statisch in die Szene eingebunden wurde, und wird deshalb nicht näher beschrieben.
103 Durchführung
Lichtverhältnisse Es wurden zwei randomisierte direkte Lichtquellen des Plugins ein-
gesetzt, um die Beleuchtung der Notre Dame variabel zu machen. Da dies zu einem sehr
hohen Kontrast zwischen hell und dunkel führte, wurde mit drei direkten Lichtquellen
eine Grundhelligkeit hinzugefügt.
Zufälliger Hintergrund Mit dem RandomBackgroundActor wird der Hintergrund
durch eine Vielzahl zufälliger Bilder aus dem COCO-Datensatz14 entnommen. Die Wahl
dieses Datensatzes hatte keine besonderen Gründe, hier können auch diverse andere ver-
wendet werden. Mit dem Austauschen der Hintergründe soll das neuronale Netz beim
Training gezwungen werden, sich auf den wesentlichen Inhalt des Fotos - die Notre Dame
- zu konzentrieren. Sie soll das einzige Objekt sein, das wiederkehrend auf jedem Foto zu
finden ist.
Eine Auswahl von Beispielen befindet sich im Anhang in Abbildung 11, in der exportierte
Fotos von allen Seiten gezeigt werden.
3.1.4 S2-Zellen Integration in das Koordinatensystem
Wie in der Problemanalyse bereits dargestellt, ist die Verteilung der Trainingsdaten beim
Training des neuronalen Netzes mit realen Daten eine große Herausforderung. Ein Ziel
der synthetischen Datenerzeugung soll sein, die Verteilung der generierten Fotos voll-
ständig kontrollieren zu können. Für die Weiterentwicklung der in [5] vorstellten Pipeline
bedeutet das, dass die dort als Zielklassen fungierenden S2-Zellen möglichst gleichmäßig
mit Fotos versorgt werden müssen. Wünschenswert wäre somit, die Kamerapositionen
gezielt auf die Positionen der gewünschten Zellen positionieren zu können. Damit ließe
sich eine Vielzahl diverser Datensätze für unterschiedliche Anwendungsfälle erstellen.
Eine Idee für die Umsetzung war, die vorhandenen S2-Zellen aus dem vordefinierten
Notre Dame Areal mit den jeweiligen Bounding Boxes15 als GeoJson 16 -Datei zu expor-
tieren und ein C++-Skript für den Import der Zell-Koordinaten in UE4 zu schreiben,
damit diese dann automatisiert als Volumes in die Szene integriert werden. Aufgrund des
problematischen Kosten-Nutzen-Verhältnisses dieser Vorgehensweise wurde sich schließ-
lich für eine pragmatischere visuelle Lösung entschieden:
14
Speziell für Objekterkennungsaufgaben erstellter Datensatz: https://cocodataset.org/, 12.09.20
15
In diesem Fall die Geopositionen der Kanten der S2-Zellen
16
https://geojson.org, 14.09.20
113 Durchführung
In JOSM 17 , einem in Java geschriebenen Editor für OpenStreetMap-Karten, wurden
das Notre Dame Areal als OSM-Datei und das S2-Raster als GeoJson Datei importiert,
sodass das Raster als zweite Ebene über dem Kartenmaterial angezeigt werden konnte.
Innerhalb des Editors wurde das Raster als Straßenebene definiert, in das Kartenmaterial
integriert und als OSM-Datei exportiert. Diese Datei ließ sich schließlich wieder mit dem
Street Map Plugin for UE4 importieren, sodass das S2-Raster als Mesh 18 dargestellt
werden kann. Dies eröffnete die Möglichkeit, die Kamera-Volumes optisch an die Zellen
anzuordnen und damit Fotos gezielt zu erstellen (vgl. Abbildung 4).
(a) Draufsicht mit S2-Zellen Raster des realen Daten- (b) Perspektivische Ansicht
satzes (gelbe Markierung)
Abbildung 4: Notre Dame Szene mit eingeblendeter OpenStreetMap Umgebung und S2-Zellen-
Raster in UE4.
3.2 Integration in die bestehende Pipeline
3.2.1 Koordinaten-Import
Das NDDS-Plugin exportiert die Metadaten der synthetisierten Bilder in einer JSON-
Datei pro Bild. Innerhalb der JSON-Datei werden unter anderem die Positions- und
Rotationsdaten der zu annotierenden Objekte angegeben. Da es sich hier nur um ein
Objekt von Interesse handelt, dieses jedoch im Nullpunkt19 liegt, wurden diese Informa-
tionsausgabe nicht aktiviert. Stattdessen sind hier die Positionsdaten der Kamera von
Interesse, sodass die Pipeline um einen JSON-Parser für dessen x-, y- und z-Koordinaten
17
https://josm.openstreetmap.de/, 14.09.20
18
Aus einem Satz von Polygonen bestehendes Geometrie-Objekt in UE4:
https://docs.unrealengine.com/en-US/Engine/Content/Types/StaticMeshes/index.html, 14.09.20
19
x-, y- und z-Wert Triple: (0, 0, 0)
123 Durchführung
erweitert wurde. Die importierten Koordinaten liegen im UU-Format vor und entspre-
chen daher dem Abstand der Kamera zum Mittelpunkt des Notre Dame 3D-Modells in
Zentimetern.
Die Python-Anwendung der zu erweiternden Pipeline wurde um einen Konverter der
Kameraposition erweitert. Dafür wurde der Notre Dame Nullpunkt als Referenzwert im
UTM20 Format definiert. Im UTM-Koordinatensystem wird die Erde in vertikale Zonen
eingeteilt, deren Berechnung jeweils in einem eigenen kartesischen Koordinatensystem
durchgeführt werden. Eine Koordinate wird hier mit einem Nord- und einem Ost-Wert in
Meter beschrieben. Dies ermöglicht eine einfache Addition der aus UE4 importierten UU-
Werte auf die UTM-Referenzwerte. Mit der Proj -Bibliothek21 für Python können UTM
Werte in Längen- und Breitengrade und zurück umgewandelt werden. Als Referenzwert
für die Notre Dame wurde 48.85306◦ als Breiten- und 2.349976◦ als Längengrad genutzt,
was im UTM-Format dem Ostwert 452316 m und dem Nordwert 5411325 m in der Zone
31U entspricht. Dadurch ergeben sich die beiden Formeln (1) und (2):
U T M north = 452316 + U U x /100 (1)
U T M east = 5411325 − U U y /100 (2)
Mit Proj werden diese Werte schließlich zu Längen- und Breitengrad zurückgerechnet und
zusammen mit den Dateinamen der Bilder in eine neue Metadaten-CSV-Datei geschrie-
ben, sodass sie von der Python-Anwendung gelesen werden können. Abbildung 5 zeigt
die Verteilung der Fotos nach der Generierung mit vier CameraVolumes, anschließender
Umrechnung auf Längen- und Breitengrad und Import in die Python-Anwendung. Die
Dichte der Punkte im linken Bereich des Bildes ist weniger hoch, da hier ein größeres
Volume bei gleichbleibenden Gesamtfotos genutzt wurde.
20
Universal Transverse Mercator: https://www.killetsoft.de/t_0901_d.htm, 14.09.20
21
https://proj.org, 14.09.20
133 Durchführung
Abbildung 5: Verteilung der synthetischen Fotos
3.2.2 Datenverteilung
Minimal- und Maximalwerte Im Gegensatz zu den realen Trainingsdaten, bei de-
nen eine ausgeglichenere Verteilung der Fotos auf die Zellen durch die Quad-Tree-Teilung
ermöglicht wurde, ist dies bei der Nutzung synthetischer Daten nicht mehr nötig, da die
Anzahl der Fotos pro Zelle selbst kontrolliert werden kann. Dieser Teilungs-Mechanismus
wurde somit optional gemacht und hier nicht mehr angewandt. Über eine Konfigurations-
datei wurde die Anzahl der Fotos auf minimal 50 und maximal 600 pro Zelle bestimmt
und auf beide Datensätze angewandt. Bei Unter- bzw. Überschreiten dieser Werte wer-
den die Klassen und die dazugehörigen Fotos außerhalb des definierten Bereichs aus
der Trainingsmenge entfernt. Abbildung 6a zeigt die Verteilung beider Datensätze als
Heatmap (links) und Balkendiagramm (rechts) nach der Anwendung von Minimum und
Maximum.
Datensatz-Synchronisation Als neues Feature der Python-Anwendung wurde ein
Synchronisations-Mechanismus implementiert, der es ermöglicht, die möglichen Zellen
bzw. Zielklassen des neu erstellten Datensatzes mit denen eines anderen Datensatzes ab-
zugleichen und jeweils alle Fotos der Zellen zu entfernen, die in dem anderen Datensatz
nicht vorkommen. Dieses Feature soll genutzt werden, um die Nutzbarkeit zweier Daten-
sätze unmittelbar miteinander auf Basis der gleichen Zielklassen und der Verteilung der
Fotos darin vergleichen zu können. Konkret kann damit ein neuer synthetisch erstellter
mit dem realen Datensatz aus [5] verglichen werden, indem beide die selben Zellen mit
gleichen Indizes in der Zielmenge enthalten. Ein Import des S2-Zellen Rasters aus dem
143 Durchführung
(a) Realer Datensatz
(b) Synthetischer Datensatz
Abbildung 6: Darstellung der Fotoverteilung nach Anpassung durch Minimal- und Maximalwert
Heatmap (links): Zahl in Kästen: S2-Index, Farbbalken: Anzahl der Fotos
Balkendiagramm (rechts): x-Achse: S2-Index, y-Achse: Anzahl der Fotos
realen Datensatz in UE4 (vgl. gelb markiertes Raster in Abbildung 4a) hilft, ein übermä-
ßiges Erstellen von Fotos, die nicht im Bereich der realen Daten liegen, durch das gezielte
Setzen der CameraVolumes innerhalb des Rasters zu vermeiden.
In der Python-Anwendung sieht ein Synchronisationsprozess anschließend wie folgt aus:
• Entfernen aller S2-Zellen und der dazugehörigen Fotos aus dem realen Datensatz,
die nicht im synthetischen Datensatz gefunden werden können
• Übernahme der S2-Zellen Indizes aus einer S2CellId-Index-Mapping Tabelle des
synthetischen Datensatzes
• Entfernen aller S2-Zellen und der dazugehörigen Fotos aus dem synthetischen Da-
tensatz, die nicht im realen Datensatz gefunden werden können
Abbildung 7 zeigt die nach der Synchronisation übrig gebliebenen Zellen mit den darin
geplotteten Geopositionen der Trainingsfotos.
153 Durchführung
(a) Realer Datensatz (b) Synthetischer Datensatz
Abbildung 7: Synchronisierte Datensätze mit gleichem S2-Zellen Raster
3.3 Training
Um auf der Infrastruktur der HAW lauffähig zu sein, die in einer Arbeit von Matthias
Nitsche und Stefan Halbritter [8] beschrieben wird, wurde das Projekt „dockerisiert “ und
mit der Keras API für die Parallelisierung des Training auf multiplen GPUs konfiguriert.
Die bisherige für lokale Proof-of-Concept Tests bei geringer Verfügbarkeit von Hardware
Ressourcen erstellte 3-Schicht-CNN-Modell sollte zudem durch ein State-of-the-art Mo-
dell ersetzt werden. Dafür liefern Khan et al. [6] ein umfangreiches Survey-Paper über
eine Vielzahl von CNN-Modellen. Hier wurde sich vorerst für das 48-schichtige Incep-
tionV3 -Modell [10] entschieden, das sich direkt über die Keras API einbinden lässt22 .
Da das Modell standardmäßig mit Daten aus dem ImageNet23 vortrainiert ist, wurden
die Gewichte entfernt und der Input-Layer durch die eigenen Trainingsdaten ersetzt.
Als Loss-Funktion wurde die Categorical Crossentropy 24 mit dem Stochastic Gradient
Descent (SGD)-Optimizer verwendet.
Insgesamt wurden Trainings mit verschiedenen Datensatz-Varianten und Trainings-Para-
metern durchgeführt, von denen im Ergebnisteil dieser Arbeit hauptsächlich auf die Trai-
nings der synchronisierten Datensätze eingegangen wird. Zur Vergleichbarkeit werden das
bisherige CNN-Modell (nachfolgend „Custom“-Modell genannt) und die InceptionV3 Ar-
chitektur genutzt. Jedes Training wurde über 50 Epochen mit einer Batch Size von 150
Features durchgeführt.
22
https://keras.io/api/applications/inceptionv3, 15.09.20
23
http://www.image-net.org/, 15.09.20
24
https://peltarion.com/knowledge-center/documentation/modeling-view/build-an-ai-model/loss-
functions/categorical-crossentropy, 18.09.20
163 Durchführung
3.4 Exemplarisches Testen
Eine zentrale Herausforderung des Machine Learning ist, dass die trainierten Modelle
gut mit bisher ungesehenen Daten umgehen können und nicht nur mit denen, womit sie
trainiert wurden [2]. Da die Validierungsdaten des realen und synthetischen Datensatzes
aus unterschiedlichen Domänen (jeweils den eigenen) stammen, wurde ein unabhängiger
Testdatensatz mit Screenshots aus Google Street View und eigenen Urlaubsfotos unter
der Annahme, dass dessen Ground Truth Daten ausreichend korrekt sind, erstellt. Durch
die Python-Anwendung wurden die Längen- und Breitengrade wie üblich in das S2-
Format übertragen und den verfügbaren Zellen zugewiesen (Abbildung 8).
Abbildung 8: Test-Datensatz Verteilung im synchronisierten Raster
Somit blieben 48 Fotos, die in die synchronisierten InceptionV3-Modelle des realen und
synthetischen Datensatzes (inkl. wechselnder Hintergründe) gegeben und vorhergesagt
wurden. Da mit einer geringen Trefferzahl der exakten Zellen zu rechnen war, wurde die
Distanz in Metern zwischen den geografischen Mittelpunkten der Test- und der vorherge-
sagten Klasse berechnet und in die Modellausgabe integriert. Dadurch können genauere
und flexible Grenzwerte festgelegt werden, wann eine Vorhersage als Treffer gelten darf.
Das Ergebnis folgt in Abschnitt 4.3.
174 Ergebnisdiskussion
4 Ergebnisdiskussion
In diesem Abschnitt soll das Potenzial des synthetischen Datensatzes evaluiert werden,
indem dieser mit dem realen Datensatz aus der vorausgegangenen Arbeit verglichen wird.
Dabei folgt zuerst ein Blick auf die Datenverteilung und anschließend auf die Trainings-
ergebnisse mit exemplarischem Test. Auf Basis dieser Ergebnisse wird versucht, Rück-
schlüsse auf die Datenqualität zu ziehen und sich daraus ergebene offene Fragen für
weiterführende Arbeiten zu sammeln.
4.1 Datenverteilung
In Abbildung 1 wurde zu Beginn dieser Arbeit die Verteilung der mit der Flickr API her-
untergeladenen realen Fotos der Notre Dame aus einem Umkreis von etwa 4 km gezeigt.
Wie hier deutlich zu sehen ist, findet eine Anhäufung aufgrund touristisch favorisierter
Orte besonders am Haupteingang und an der Südseite statt. Die höchste Dichte befindet
sich allerdings innerhalb der Klassen, die direkt auf dem Zielobjekt liegen, was unter
anderem auf die Innenaufnahmen zurückzuführen ist. Abbildung 6a macht dies in Form
einer Heatmap-Darstellung besonders sichtbar, die nach der Begrenzung der Fotos auf
mindestens 50 und maximal 600 pro Zelle erstellt wurde. Durch den Wegfall von Zellen
ergibt sich bei diesem Vorgehen der Nachteil, dass sich das Netz folglich nicht für alle
Klassen trainieren lässt. Geopositionen als Klassifizierungs-Problem mit diesem Detail-
grad und statischen Klassen zu betrachten, stößt hier somit an seine Grenzen.
Diese Problematik entsteht bei der synthetischen Datengenerierung jedoch nicht: Die
Generierung der Fotos erfolgt zwar zufällig, wodurch sich ebenso eine ungleiche Verteilung
ergibt (siehe Abbildungen 5 und 6b), allerdings sind die zu erstellenden Klassen und die
Gesamtzahl der Fotos frei wählbar. Der Datensatz kann schließlich so lange und beliebig
groß produziert werden, bis jede Klasse ausreichend abgedeckt ist.
Um beide Datensätze einigermaßen „fair“ insbesondere beim Training miteinander ver-
gleichen zu können, wurden deren Zielklassen - die S2-Zellen - miteinander synchronisiert
(siehe Abschnitt 3.2.2). Abbildung 7 zeigt die daraus resultierenden Verteilungen im rea-
len und synthetischen Datensatz mit gleicher Klasseneinteilung und Indizierung. Durch
die Synchronisation wurden 2.483 Fotos aus dem realen Datensatz entfernt, sodass die
Größe nur noch 11.768 Fotos entspricht, von denen zusätzlich 25% für die Validierung
verwendet werden. Intuitiv ist dies eine sehr kleine Menge für das Training.
184 Ergebnisdiskussion
Unter Berücksichtigung der beschriebenen geringen Datenqualität (siehe Abschnitt 2.1)
müssten zudem einige Trainingsdaten mit falschen Inhalten oder Labels entfernt wer-
den, weshalb hier weitreichendere Quellen zur Aufstockung der Datenmenge erforderlich
wären. Allerdings entfällt durch die Synchronisation auch ein großer Teil der unbrauchba-
ren Innenaufnahmen, da für den synthetischen Datensatz nur Außenaufnahmen erstellt
und dadurch zumindest vier Zellen, die sich direkt auf dem Gebäude befänden, nicht
abgedeckt wurden.
Der synthetische Datensatz enthält aktuell25 nach der Synchronisation 11.000 Fotos.
Auch wenn die Verteilung dadurch mit der des realen Datensatzes vergleichbar ist, kann
diese hingegen ohne großen Aufwand durch Anhebung der Gesamt-Exportmenge verän-
dert werden, was ein deutlicher Vorteil gegenüber der Nutzung von realen Daten ist.
Dieser Datensatz entstand aus einer Gesamtmenge von 20.000 Fotos, in dem die Anzahl
der Fotos in keiner Zelle den Minimalwert von 50 unterschritt.
4.2 Training
Für die Vergleichbarkeit der Datensätze wurden Trainings mit dem Custom-Modell aus
[5] sowie dem InceptionV3-Modell für die realen und synthetischen Daten nach der Syn-
chronisation durchgeführt, deren Verläufe der ersten 50 Epochen anhand der Validie-
rungsgenauigkeit in Abbildung 9 zu sehen sind.
Der synthetische Datensatz wurde mit und ohne zufällige Hintergründe trainiert („Synth
rBG“ bzw. „Synth sBG“). Die Validierungsgenauigkeit der realen Daten erreicht einen
Maximalwert von 12 % (Custom Modell) bzw. 17 % (InceptionV3). Aufgrund dieses nied-
rigen Wertes ist anzunehmen, dass die Varianz des Inhaltes der Daten so hoch ist, dass
das Netz enorme Schwierigkeiten hat, Features zu erkennen. Da das Validierungs-Set eine
zufällig gewählte Teilmenge der Gesamtdaten ist, können hier ebenso diverse irreführende
Objekte und fehlerhafte Metadaten enthalten sein, wodurch das Netz kaum Ähnlichkeiten
im Trainings-Set findet.
Bei der Verwendung des synthetischen Datensatzes hingegen kann bereits nach der 8. Epo-
che unabhängig von Trainingsmodell und Datensatz-Variation eine Validierungsgenauig-
keit von mehr als 50 % erreicht werden. Das beste Ergebnis liegt bei 89 % und wird
mit statischem Hintergrund und dem InceptionV3 Modell erreicht. Mit dem Einsatz des
25
Zum Zeitpunkt des Abschlusses dieser Arbeit finden noch weitere Versuche bezüglich der Datenqualität
und Größe des Datensatzes statt
194 Ergebnisdiskussion
Abbildung 9: Training der synchronisierten Datensätze.
Synth sBG: Synthetischer Datensatz mit statischem Hintergrund, Synth rBG: Syn-
thetischer Datensatz mit zufälligem Hintergrund, Real : Realer Datensatz
randomisierten Hintergrundes sinkt dieser Wert auf ca. 76 %. Bei Einsatz des Custom-
Modells liegen beide Werte etwa 15 % darunter. Die Vermutung liegt hier nahe, dass die
deutlich geringere Komplexität des Datensatzes für eine bessere Anpassung sorgt. Da-
durch, dass das Validierungs-Set zudem keine fehlerhaften Daten enthält und die Komple-
xität der des Training-Sets (Anzahl der Objekte, Lichtverhältnisse etc.) entspricht, wird
eine höhere Genauigkeit erreicht werden können. Da es sich hierbei allerdings um reine
synthetische Daten handelt, wird es sich vermutlich nur um eine angemessene Generali-
sierung auf die synthetische statt reale Domäne handeln - dem Problem, dem Tremblay et
al. [13] mit der Durchmischung der Daten zum Überbrücken des „Reality Gap“ begegnen.
Ferner sind hier weitreichende Tests und darauffolgende Anpassungen nötig.
Generell zeigt der Vergleich jedoch bereits, dass mit dem InceptionV3 Modell deutlich
bessere Ergebnisse erzielt werden. Dies kann vorerst weiter verwendet werden, um iterativ
eine gute Trainingsdatengrundlage schaffen zu können. Anschließend kann in Betracht
gezogen werden, das bestmögliche Modell zu finden und die Hyperparameter wie die
verwendete Loss-Funktion, Optimizer, Learning Rate etc. zu optimieren und geeignete
Metriken aufzustellen, mit denen das Modell realistisch auf entsprechende Erwartungen
geprüft werden kann.
Auch wenn hier generell noch viel Spielraum nach oben existiert, stützen diese Werte die
204 Ergebnisdiskussion
Vermutung, dass das Synthetisieren der Daten Potential bietet, ein geeignetes Trainings-
modell zu erstellen.
4.3 Tests der trainierten Modelle
Der exemplarische Test der InceptionV3-Modelle der Datensätze Synth-rBG und Real
mit dem manuell erstellten Test-Datensatz fiel erwartungsgemäß bescheiden aus: Von 48
realen getaggten Fotos konnte das synthetische Modell nur ein Foto richtig klassifizieren,
das reale immerhin zwei. Daraus könnte schlussgefolgert werden, dass es sich hierbei
um zufällige Treffer handelt. Abbildung 10a zeigt das einzige durch Synth-rBG richtig
klassifizierte Foto (Index 45 bei einer Wahrscheinlichkeit von 81,8 %). In der Auswahl
der zu dieser Klasse gehörenden Trainingsfotos (Abbildung 10b) können mit dem bloßen
Auge aber durchaus Gemeinsamkeiten erkannt werden. Das reale Modell hingegen tippt
mit 93,6 % auf Index 114 und landet damit auf einer der maximal unsauberen Klassen
inmitten des Gebäudes (siehe Abbildung 10c).
(a) Eingabe: Google Street View (b) Klasse 45 (synthetisch) (c) Klasse 114 (real)
Testfoto mit S2-Index 45
Abbildung 10: Vorhersagen von Klassen beider Modelle und Auszug aus dessen Trainingsfotos
Im Anhang befinden sich alle Ergebnisse des realen (Tabelle 3) und synthetischen Mo-
dells (Tabelle 4). Da in Abschnitt 3.4 die Distanz zwischen Test- und vorhergesagter
Klasse ausgerechnet wurde, kann anhand dieser Tabellen nun beispielsweise die Anzahl
der Vorhersagen, die unterhalb von 50 Metern von den Testklassen entfernt sind, be-
stimmt werden. Dadurch ergibt sich schließlich eine etwas optimistischere Statistik, die
in Tabelle 2 festgehalten ist.
Im Anhang sind je ein Positivbeispiel (Abbildungen 12 und 13) und Negativbeispiel (Ab-
bildungen 14 und 15) für beide Datensätze zu finden, bei denen zufällige ungelabelte
214 Ergebnisdiskussion
Tabelle 2: StreetView-Test mit synthetischem InceptionV3-Modell (synchronisiert)
Anzahl richtiger Anzahl < 50 m
Modell
Klassen Differenz
Synthetisch 1 9
Real 2 11
Bilder aus dem Internet vorhergesagt wurden. Das synthetische Modell scheint generell
bei größerer Entfernung zum Zielobjekt auf Probleme zu stoßen (z.B. Abbildung 15), was
an der zu geringen Bildauflösung der Trainingsfotos und eventuell nicht ausreichender Be-
leuchtung oder falscher Farbgebung liegen könnte. Zudem befinden sich im synthetischen
Datensatz einige Nahaufnahmen, auf denen nichts zu erkennen ist (vgl. Abbildung 11),
die eventuell negativ zur Erkennung beitragen.
Generell ist jedoch weder die Testmenge groß genug, um wissenschaftlich triftige Aussagen
treffen zu können, noch sind die Modelle im aktuellen Status ausreichend trainiert und
optimiert. Für angemessene Tests müssen also noch weitreichende Optimierungen der
Trainingsdatensätze erfolgen.
4.4 Fazit
Der Vergleich der Trainings mit unterschiedlichen Datensätzen und deren Abwandlung
zeigte bei variierender Datenqualität und -komplexität unmittelbare Auswirkungen auf
die Trainingsergebnisse. Während der reale Datensatz aufgrund der Diversität der einzel-
nen Fotos und Metadaten sowie unausgeglichener Verteilung mit den hier verwendeten
Methoden keine akzeptablen Validierungsergebnisse erzielen kann, weist der synthetische
Datensatz dort eine weitaus bessere Genauigkeit vor - im exemplarischen Test mit realen
Daten sind beide Modelle in der aktuellen Phase allerdings noch nahezu unbrauchbar.
Dieser Versuch hat aber gezeigt, dass es zum einen nicht unmöglich ist, mit rein synthe-
tischen Daten die Geoposition von Fotos bzw. der Kamera zu bestimmen. Zum anderen
wurde bewusst auf einen qualitativ simplen Datensatz gesetzt, der in viele Richtungen
verbessert werden kann. Durch diese Arbeit konnte eine weitere Variante der Datenge-
winnung für Deep Learning Aufgaben vorgestellt und damit einhergehend eine Samm-
lung von offenen Fragen, die sich in diesem Umfeld ergeben, präsentiert werden. Um
also abschließend die Frage beantworten zu können, wie eine akzeptable Nutzbarkeit des
synthetischen Modells zu realisieren ist, werden Folgearbeiten nötig sein.
224 Ergebnisdiskussion
4.5 Ausblick
Wie in der Diskussion bereits angemerkt, hinterlässt diese Arbeit weitere Aufgaben, die
zur Realisierung einer akzeptablen Nutzbarkeit der Bestimmung von Geokoordinaten
mit neuronalen Netzen angegangen werden können. Folgende Punkte könnten z.B. in
Betracht gezogen werden:
• Vergrößern der Foto-Auflösung
• Anpassung von Anzahl der (Gesamt-) Fotos und Klassen
• Anpassung der Randomisierung in Bezug auf unterschiedliche Lichtverhältnisse,
Art und Anzahl der Distraktoren etc. (Komplexität)
• Überprüfung des Notre Dame 3D-Modells und dessen Texturen auf Realismus,
Detailgrad und Farbgebung
Es ist unklar, inwiefern diese Punkte zu einer verlässlicheren Erkennung von realen Fotos
durch ein synthetisches Modell führen können und wie genau diese sein kann. Als weiterer
Schritt kann somit versucht werden, den Datensatz mit teils fotorealistischen Elementen
oder sogar realen Fotos aufzustocken, was Tremblay et al. [13] als „Fine-Tuning“ be-
zeichnen. Neben dem bereits genannten Optimieren der Hyperparameter des genutzten
CNN-Modells kann auch darüber nachgedacht werden, statt eines Klassifikators auf eine
Regressions-Lösung zu setzen. Alternativ könnte die Masterarbeit von Dustin Spallek [9]
herangezogen werden, in der er auf [13] aufbauend beweist, dass mit dem Training synthe-
tisierter Datensätze die Lage und Position von Objekten im Raum durch neuronale Netze
bestimmt werden kann. Hier böte sich ein Test an, inwiefern diese Architektur mit dem
Notre Dame 3D-Modell harmoniert und ob sich anhand der Lageschätzung der dann
ortsdynamischen Notre Dame die Kamerapositionen zurückrechnen lassen. Hier bietet
sich eine vielversprechende Chance, sowohl die Genauigkeit der Bestimmung zu steigern
als auch durch Parallelisieren mehrerer Objekte einen Mehrwert in der Nutzbarkeit zu
schaffen.
Sollte sich dieses Projekt zukünftig unabhängig von der weiteren Vorgehensweise als
zufriedenstellend funktionsfähig erweisen, kann es letztendlich dazu genutzt werden, die
unsauberen GPS-Informationen aus den Flickr-Fotos und weiteren Internetquellen zu
bereinigen. Damit wäre dann das Ursprungsproblem aus der vorangegangen Arbeit [5]
behoben.
235 Anhang
5 Anhang
(a) Vorderseite
(b) Rechte Seite
(c) Rückseite
(d) Linke Seite
Abbildung 11: Beispielbilder aus dem synthetischen Datensatz mit zufälligen Hintergrundbildern
245 Anhang
(a) Eingabe: Testfoto (b) Ausgabe: S2-Zelle mit Index 126
(c) Realer Datensatz für S2-Index 126 (Auszug)
Abbildung 12: Realistische Prediction eines Fotos mit dem synchronisierten realen Datensatz
255 Anhang
(a) Eingabe: Testfoto (b) Ausgabe: S2-Zelle mit Index 126
(c) Synthetischer Datensatz S2 Index 126 (Auszug)
Abbildung 13: Realistische Prediction eines Fotos mit dem synchronisierten synthetischen Da-
tensatz
265 Anhang
(a) Eingabe: Testfoto (b) Ausgabe: S2-Zelle mit Index 113
(c) Realer Datensatz für S2-Index 113 (Auszug)
Abbildung 14: Fehlerhafte Prediction eines Fotos mit dem synchronisierten realen Datensatz
275 Anhang
(a) Eingabe: Testfoto (b) Ausgabe: S2-Zelle mit Index 126
(c) Synthetischer Datensatz S2 Index 126 (Auszug)
Abbildung 15: Fehlerhafte Prediction eines Fotos mit dem synchronisierten synthetischen Daten-
satz
285 Anhang
Tabelle 3: StreetView-Test mit realem InceptionV3-Modell (synchronisiert)
Real Predicted Probability Distance Next 3
Filename
S2-Idx S2-Idx in % diff in m Predictions
IMG_20190623_155317.jpg 7 8 0,245 34,979 [ 14 79 126]
IMG_20190623_155527.jpg 13 14 0,982 25,669 [ 42 111 57]
IMG_20190623_155631.jpg 12 113 0,85 191,284 [ 34 111 104]
sv000003.png 44 57 0,996 83,828 [36 40 39]
sv000005.png 45 114 0,936 85,795 [111 7 54]
sv000006.png 45 45 0,433 0 [100 110 105]
sv000007.png 110 100 0,23 122,879 [117 101 110]
sv000008.png 110 113 0,473 43,872 [101 114 34]
sv000011.png 91 82 0,493 75,084 [ 14 103 104]
sv000012.png 82 104 0,663 128,691 [82 14 80]
sv000013.png 81 114 0,593 171,588 [ 80 126 125]
sv000013a.png 81 82 0,364 34,978 [ 81 79 103]
sv000015.png 125 81 0,273 77,01 [110 113 13]
sv000019.png 19 10 0,898 102,814 [ 7 9 38]
sv000020.png 39 7 0,508 132,229 [ 79 113 19]
sv000021.png 41 43 0,863 42,898 [ 54 101 34]
sv000022.png 44 43 0,749 25,67 [34 13 44]
svp0000002.png 117 35 0,617 85,794 [ 34 118 119]
svp0000003.png 117 34 0,477 73,949 [ 35 45 112]
svp0000004.png 33 45 0,364 104,937 [104 33 82]
svp0000005.png 36 57 0,387 171,59 [113 36 34]
svp0000006.png 36 104 0,865 109,251 [ 39 33 125]
svp0000007.png 40 40 0,484 0 [38 45 39]
svp0000008.png 40 14 0,858 85,795 [39 58 36]
svp0000009.png 12 57 0,88 43,872 [ 13 102 100]
svp0000010.png 58 119 0,171 290,153 [113 126 84]
svp0000011.png 9 79 0,456 388,954 [38 10 57]
svp0000015.png 91 81 0,536 108,616 [15 29 84]
svp0000018.png 105 91 0,302 83,83 [ 84 82 103]
svp0000019.png 101 84 0,731 34,979 [ 42 111 100]
svp0000020.png 101 19 0,173 231,028 [84 29 14]
svp0000021.png 100 110 0,149 122,879 [ 14 102 81]
svp0000022.png 102 113 0,458 83,829 [126 29 38]
svp0000024.png 100 126 0,366 117,903 [114 79 81]
svp0000001.png 79 114 0,41 189,429 [ 81 100 15]
svp0000002.png 126 35 0,617 187,626 [ 34 118 119]
svp0000003.png 80 34 0,477 187,627 [ 35 45 112]
svp0000004.png 80 45 0,364 243,416 [104 33 82]
svp0000005.png 125 57 0,387 315,842 [113 36 34]
svp0000006.png 118 104 0,865 117,903 [ 39 33 125]
svp0000008.png 38 14 0,858 107,443 [39 58 36]
svp0000009.png 8 57 0,88 85,325 [ 13 102 100]
svp0000010.png 7 119 0,171 289,441 [113 126 84]
svp0000011.png 10 79 0,456 368,627 [38 10 57]
svp0000014.png 112 105 0,413 102,816 [100 104 109]
svp0000015.png 57 81 0,536 369,362 [15 29 84]
svp0000016.png 12 9 0,773 25,669 [ 34 13 102]
svp0000017.png 43 57 0,499 61,439 [13 58 14] 295 Anhang
Tabelle 4: StreetView-Test mit synthetischem InceptionV3-Modell (synchronisiert)
Real Predicted Probability Distance Next 3
Filename
S2-Idx S2-Idx in % diff in m predictions
IMG_20190623_155317.jpg 7 9 99.106 43.871 [ 8 12 58]
IMG_20190623_155527.jpg 13 41 59.562 83.827 [ 8 103 9]
IMG_20190623_155631.jpg 12 102 21.647 275.021 [117 81 103]
sv000003.png 44 10 93.5 133.819 [45 7 8]
sv000005.png 45 45 81.788 0.0 [109 110 112]
sv000006.png 45 109 25.912 83.829 [ 41 110 45]
sv000007.png 110 109 80.92 25.67 [111 114 104]
sv000008.png 110 109 56.277 25.67 [ 45 104 112]
sv000011.png 91 57 94.84 335.315 [36 13 54]
sv000012.png 82 79 72.206 75.083 [81 18 8]
sv000013.png 81 8 86.694 411.879 [39 7 18]
sv000013a.png 81 8 93.297 411.879 [10 7 9]
sv000015.png 125 10 33.269 307.189 [7 9 8]
sv000019.png 19 41 64.759 87.743 [104 115 114]
sv000020.png 39 41 38.423 43.872 [109 104 110]
sv000021.png 41 114 52.683 107.691 [113 115 110]
sv000022.png 44 114 46.713 122.878 [110 115 109]
svp0000002.png 117 109 78.532 117.904 [19 9 8]
svp0000003.png 117 10 49.777 228.402 [19 8 7]
svp0000004.png 33 109 71.373 105.254 [ 8 9 110]
svp0000005.png 36 109 79.73 125.601 [114 110 104]
svp0000006.png 36 19 91.997 77.008 [ 91 109 111]
svp0000007.png 40 109 62.147 133.823 [104 110 41]
svp0000008.png 40 110 62.353 109.251 [109 41 104]
svp0000009.png 12 109 74.94 232.845 [110 116 45]
svp0000010.png 58 9 64.715 43.871 [82 10 8]
svp0000011.png 9 8 53.477 25.669 [10 7 9]
svp0000015.png 91 18 50.255 283.709 [39 58 8]
svp0000018.png 105 8 48.71 314.269 [45 10 9]
svp0000019.png 101 9 73.53 323.073 [81 8 58]
svp0000020.png 101 104 24.676 61.439 [ 9 109 8]
svp0000021.png 100 8 78.874 372.004 [58 13 9]
svp0000022.png 102 8 33.588 323.071 [58 45 9]
svp0000024.png 100 58 83.097 335.313 [13 12 9]
svp0000001.png 79 8 36.936 409.221 [102 91 7]
svp0000002.png 126 109 78.532 176.168 [19 9 8]
svp0000003.png 80 10 49.777 350.621 [19 8 7]
svp0000004.png 80 109 71.373 181.109 [ 8 9 110]
svp0000005.png 125 109 79.73 174.893 [114 110 104]
svp0000006.png 118 19 91.997 144.721 [ 91 109 111]
svp0000008.png 38 110 62.353 147.615 [109 41 104]
svp0000009.png 8 109 74.94 283.705 [110 116 45]
svp0000010.png 7 9 64.715 43.871 [82 10 8]
svp0000011.png 10 8 53.477 42.897 [10 7 9]
svp0000014.png 112 13 51.021 154.018 [12 57 58]
svp0000015.png 57 18 50.255 107.443 [39 58 8]
svp0000016.png 12 114 43.174 215.381 [110 104 58]
svp0000017.png 43 109 67.189 157.137 [104 114 110]30Literatur
Literatur
[1] Chen, X. ; Lin, X.: Big Data Deep Learning: Challenges and Perspectives. In:
IEEE Access 2 (2014), S. 514–525
[2] Goodfellow, Ian ; Bengio, Yoshua ; Courville, Aaron: Deep Learning. MIT
Press, 2016. – http://www.deeplearningbook.org
[3] Gudivada, Venkat ; Apon, Amy ; Ding, Junhua: Data quality considerations for
big data and machine learning: Going beyond data cleaning and transformations.
In: International Journal on Advances in Software 10 (2017), Nr. 1, S. 1–20
[4] Jakobi, Nick ; Husbands, Phil ; Harvey, Inman: Noise and the reality gap: The
use of simulation in evolutionary robotics. In: Morán, Federico (Hrsg.) ; Moreno,
Alvaro (Hrsg.) ; Merelo, Juan J. (Hrsg.) ; Chacón, Pablo (Hrsg.): Advances in
Artificial Life. Berlin, Heidelberg : Springer Berlin Heidelberg, 1995, S. 704–720. –
ISBN 978-3-540-49286-3
[5] Kanne-Schludde, Thomas: Aufbau einer Pipeline zur Bestimmung von
GPS-Koordinaten aus Fotos mithilfe neuronaler Netze. (2020), Feb. – URL
https://users.informatik.haw-hamburg.de/~ubicomp/projekte/
master2020-proj/kanne.pdf
[6] Khan, Asifullah ; Sohail, Anabia ; Zahoora, Umme ; Qureshi, Aqsa S.: A
survey of the recent architectures of deep convolutional neural networks. In: Arti-
ficial Intelligence Review (2020), Apr. – URL http://dx.doi.org/10.1007/
s10462-020-09825-6. – ISSN 1573-7462
[7] Liu, Li ; Ouyang, Wanli ; Wang, Xiaogang ; Fieguth, Paul ; Chen, Jie ; Liu,
Xinwang ; Pietikäinen, Matti: Deep learning for generic object detection: A survey.
In: International journal of computer vision 128 (2020), Nr. 2, S. 261–318
[8] Nitsche, Matthias ; Halbritter, Stephan: Development of an End-to-End Deep
Learning Pipeline, Hochschule für Angewandte Wissenschaften Hamburg, 2019
[9] Spallek, Dustin: Deep Learning basierte Erkennung von 3D-Objektposen auf Basis
synthetisch erzeugter Daten, Hochschule für Angewandte Wissenschaften Hamburg,
2020
[10] Szegedy, Christian ; Vanhoucke, Vincent ; Ioffe, Sergey ; Shlens, Jonathon ;
Wojna, Zbigniew: Rethinking the Inception Architecture for Computer Vision. 2015
31Sie können auch lesen

















































