Maßnahmen gegen Online-Hass: Zwischen Bürgerengagement und Künstlicher Intelligenz - Prof. Thomas Mandl & Dr. Sylvia Jaki
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten

Maßnahmen gegen Online-Hass:
Zwischen Bürgerengagement und
Künstlicher Intelligenz
Prof. Thomas Mandl & Dr. Sylvia Jaki
Hate Speech im Netz
Was ist Hate Speech? • Abwertung von oder verbaler Angriff auf einzelne Personen oder Personengruppen sehr weite Definition (nicht rechtsgültig) • Der EU Code of Conduct etwas restriktiver: “the public incitement to violence or hatred directed to groups or individuals“ (öffentliche Anstiftung zu Gewalt oder Hass) • Einige der Posts, die häufig als Hate Speech betrachtet werden, sind nicht Hate Speech i.e.S., aber dennoch sehr unhöflich/beleidigend (moralisches Dilemma)

Gegen wen richtet sich Hate Speech?
•Immigrant*innen
•Angehörige bestimmter Religionen
•Menschen mit anderer Hautfarbe
•Frauen
•Übergewichtige
•Homosexuelle und Trans-Menschen
•Behinderte
•…
Gegen jede*n, der bzw. die als „anders“ empfunden wird (=
Outgroup)
Potenziell gegen jeden
Soziale Medien und Hate Speech • Verbaler Text der Posts/Kommentare • Hashtags • Emojis als nonverbale Elemente • Andere Bildelemente oder Sprach- Bild-Elemente wie Fotos oder Memes • Eingebettete Posts • Links

Einige Charakteristika
• Entmenschlichende Metaphern (Abfall,
Abschaum, Müll, Parasiten …)
• Vulgäre Ausdrücke („diese scheiß Zecke“,
„Besser tot als mit Kacke am Arsch leben“,
„Da war doch eh wieder so ein ficki ficki
Nafri“)
• Stereotypisierung („bärtige
Teppichknutscher“, „behaarte
Kanakenfotzen“, „primitives N***gesindel“,
„zwangsbekopftuchte Mädchen“)
• Umdeutung von Wörtern, z.B. bunt oder
Fachkräfte („Seit 2015 profitieren doch alle
von Merkels eloquenten Fachkräften“)
6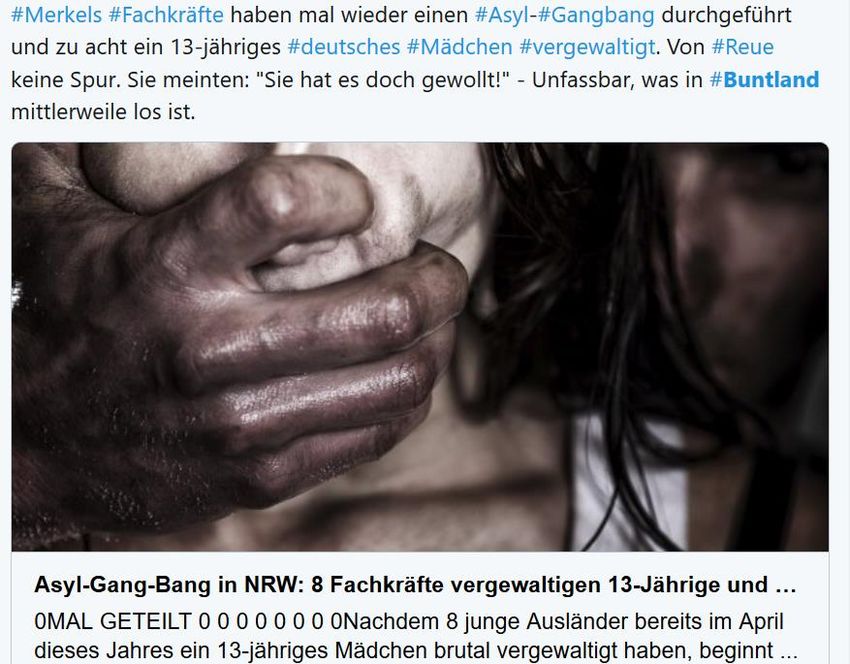
Gegenmaßnahmen

Wie kann man generell reagieren? • Ignorieren • Bei strafrechtlich relevanten Inhalten Anzeige erstatten • Melden • Automatisiert erkennen (und ggf. löschen) • Gegenrede
Erkennung durch Künstliche Intelligenz

Wie funktioniert die Erkennung durch KI?
• Moderne Verfahren halten nicht Ausschau nach einzelnen Wörtern
• Systeme benötigen Daten für das Training
• In der Forschung werden Benchmarks entwickelt
Memory: collects
output layer: next word information on the
sentence
Hidden layer(s)
Copy back
into input
input layer: current word layer
Same word, different
context -> different
outputErstellung von Trainingsdaten • Sammeln z.B. in Twitter • Bewerten in Hate und Nicht-Hate
Beispiele aus Benchmark
• Kann mein Kater aufhören mir seinen Arsch ins
Gesicht zu strecken? :((
• RT @Halbblutjurist: „Ossi“-Bashing wird die Nazis
auch nicht verschwinden lassen.
• @hanvoi Es wird Zeit, dass Plauen unter
Bundesaufsicht gestellt wird. Dann kann mit dem
braunen Pack mal aufgeräumt werden!
• @SPD_Friedenau @matzegeisthardt ihr Arschlöcher
durch euch gibt es erst niedrig Löhne.Spinner.Facebook
• “An internal meeting is held every two weeks to
review policies and update them when appropriate.
Facebook also conducts weekly audits of content
reviewers' work to make sure they are following the
guidelines consistently, Bickert says. But with millions
of posts flagged each week, critics say content
reviewers frequently have to make snap decisions on
complex questions.”
Zuckerberg
https://eu.usatoday.com/story/tech/news/2018/04/24/facebook-discloses-secret-
guidelines-policing-content-introduces-appeals/544046002/Facebook
• “Facebook executives say it's a difficult balancing act
to weigh what is acceptable expression and what is
not. ”
https://eu.usatoday.com/story/tech/news/2018/04/24/facebook-discloses-secret-
guidelines-policing-content-introduces-appeals/544046002/Annotations Prozess
• Schwierigkeiten während der HASOC Annotation
• Graphisches Material
• Zitationen erzeugen scheinbare Objektivität
• Bezüge auf andere Inhalte
• Andeutungen
(“Sind die krank?”)
Wagner & Bumann 2020
https://www.comedywildlifephoto.com/images/gallery/1/00000671_p.jpgMaschinelles Lernen: Klassifikation
Eigenschaften Klasse
0 1 2 4 A
3 5 6 8 B Extraktion
Bekannte eines
Items 0 1 2 4 A Modells
2 5 7 9 D
3 6 7 8 C
2 3 5 6 ?
Neue
Items 0 1 2 4 ? Anwendung
des Modells
3 6 7 9 ?Maschinelles Lernen: Klassifikation
Eigenschaften Klasse
Wie gewonnnen?
0 1 2 4 A Woher?
3 5 6 8 B Repräsentativ?
Bekannte
Items 0 1 2 4 A
2 5 7 9 D
3 6 7 8 C
2 3 5 6 ?
Neue
Items 0 1 2 4 ?
3 6 7 9 ?https://de.wikipedia.org/wiki/Support_Vector_Machine
Gegenrede
= Direktes Reagieren auf Hate Speech mit Gegenargumentation o.Ä.
• Nachteile von Gegenrede:
Gefahr weiterer Polarisierung
Nicht geeignet, um Hater “umzustimmen”
Ggf. mit Gefahren für die Akteur*innen verbunden
• Vorteil: positives Signal an Opfer und UnbeteiligteKombination aus automatischer Erkennung
und Gegenrede
dtct.euDetektion mit Hilfe von POW-Lexikon (Profanity and Offensive Words) • Manuell annotiertes Lexikon • Wörter, die in politischen Kontexten verwendet werden und häufig tendentiös oder vulgär bzw. beleidigend sind • Langsam auch Aufbau für Wortkombinationen • Annotation nach Intensität und Typus • Mehrsprachig: Deutsch, Englisch, Französisch, Niederländisch, Dänisch (Ungarisch, Spanisch, Russisch) • Vorteile: Erklärbarkeit der Entscheidungen (XAI), generell Kombinierbarkeit mit neuronalen Netzwerken
Anwendung • Wird in Detect then Act verwendet, um Twitter nach Hate Speech zu durchsuchen • Die als Hate Speech erkannten Tweets werden anonymisiert in einem Dashboard gesammelt, in dem Online-Aktivist*innen mit Gegenrede aktiv werden • Sprachen: Englisch, Deutsch, Niederländisch, Französisch, Ungarisch • Hauptelemente der Gegenrede hier: Memes
Vorteile & Nachteile • Automatische Erkennung wird hier als Hilfsmittel, nicht als Allheilmittel verwendet • Eine gewisse Fehlerquote ist hier weniger problematisch (Vorselektion) • Erleichtert Online-Aktivist*innen das Arbeiten • Ermöglicht es auch den Aktivist*innen, anonym zu bleiben • Gegenrede mit positiven Botschaften statt mit langen Gegenargumenten • Gewisse Arten von Hate Speech (indirekt) werden nicht erkannt
Verschiedene Sprachen • Verfahren müssen für jede Sprache neu trainiert und evaluiert werden • Zahlreiche Sprachen verfügen über sehr wenig Ressourcen • Die meiste Forschung erfolgt für das Englische
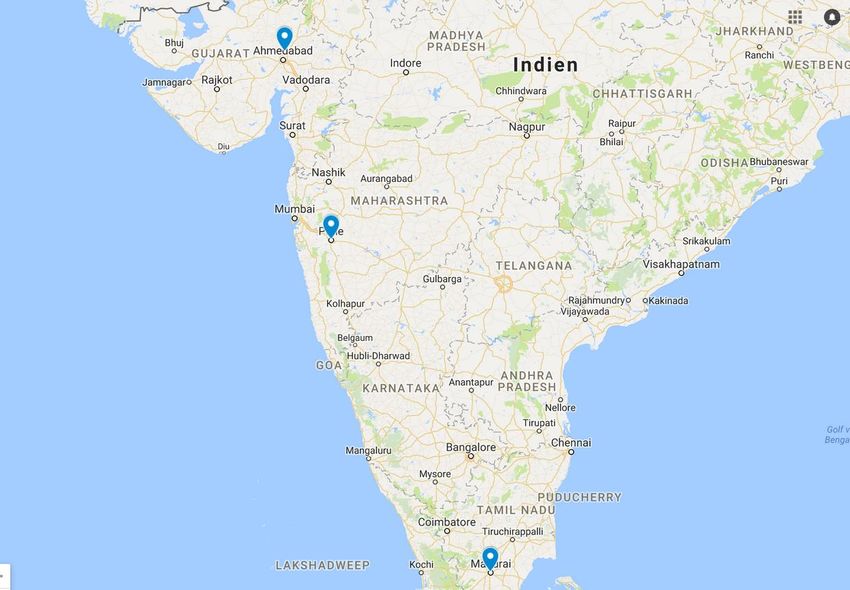
Verschiedene Sprachen • Z.B. sind zahlreiche Indische Sprachen unterrepräsentiert • Ressourcen für Hindi, Tamil und Malayalam (jeweils eigenes Schriftsystem)
Results HASOC 2020 – Hindi Task A
BiLSTM,fastTex
t
SVM, TF/idf
distilBERTThemen Analyse
Gandhinagar
DAIICT
Indien
Pune - Symbiosis
International
University
Madurai –
American CollegeGandhinagar - Dhirubhai Ambani Institute of Information and Communication Technology (DAIICT)
Gandhinagar
DAIICT
DAIICT
Veranstaltungshinweis HASeKI-Tagung 10.06.2021 KI gegen Online-Hass https://www.uni- hildesheim.de/fb3/institute/iwist/forsc hung/forschungsprojekte/aktuelle- forschungsprojekte/haseki/online- tagung-ki-gegen-online-hass/
Vielen Dank für Ihre Aufmerksamkeit!
https://www.uni-hildesheim.de/fb3/institute/iwist/forschung/forschungsprojekte/aktuelle-
forschungsprojekte/interdisziplinaere-forschungszugaenge-zu-wissenschaftskommunikation-und-
informationsverhalten-in-der-corona-pandemie-infocop/#c129213
Hinweis – Save the Date
Experten diskutieren:
• Informationskrise um die COVID-19-Pandemie
• Probleme der Wissenschaftsvermittlung
• Herausforderungen durch Misinformation und Polarisierung
Online Konferenz
InfoCoP
Interdisziplinäre Forschungszugänge zu
Wissenschaftskommunikation und Informationsverhalten
in der Corona-Pandemie
2. Juli
Kostenlose Teilnahme möglichSie können auch lesen

















































