Oracle-Statistiken im Data Warehouse effizient nutzen
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Datenanalyse
Zur performanten Ausführung von Berichten und Ad-hoc-Abfragen eines BI-Systems sind beim Oracle Optimizer
aussagekräftige und aktuelle Statistiken für die Tabellen und Indizes von essenzieller Bedeutung. Doch die Erstel-
lung der Statistiken benötigt bei großen Datenmengen oft auch sehr viel Zeit. Somit stellt sich die Frage nach einer
geeigneten Strategie für die Aktualisierung der Statistiken eines Data-Warehouse-Systems.
Oracle-Statistiken im Data Warehouse
effizient nutzen
Reinhard Mense, areto Consulting GmbH
Für die Ausführung eines SQL-State- Core und Data Marts. Die Staging Area partitioniert. Statistiken können so-
ments untersucht der Oracle Optimizer wird zur temporären Aufnahme der wohl für die einzelnen Partitionen (lo-
die möglichen Ausführungspläne und aus den Quellsystemen extrahierten kale Statistiken) als auch für die gesam-
wählt denjenigen mit den geringsten Daten und für die Speicherung von te Tabelle (globale Statistiken) erstellt
Kosten. Damit der Optimizer die Kosten Zwischenergebnissen der Transforma- werden. Das Erzeugen der lokalen Sta-
für einen Ausführungsplan ermitteln tionen im ETL-Prozess verwendet. Im tistiken kann man auf die zuletzt ge-
kann, benötigt er möglichst detaillierte Core werden dauerhaft die konsoli- änderten Partitionen beschränken, so-
Informationen über alle beteiligten Ta- dierten und homogenisierten Daten dass der Aufwand relativ gering und
bellen und Indizes. Statistiken stellen historisch gespeichert. Die Data Marts nahezu konstant bleibt.
diese Informationen zur Verfügung. stellen schließlich die Daten in für die Mit zunehmenden historischen Da-
Anhand derer versucht der Optimi- Abfragen optimierten Star- oder Snow- tenvolumen im DWH wird das Erstel-
zer unter anderem vorherzusagen, wie flake-Schemata zur Verfügung. len der globalen Statistiken jedoch im-
viele Datensätze in einem Schritt des Da die Berichte und Ad-hoc-Abfra- mer aufwändiger, da stets die gesamte
Ausführungsplans, also etwa bei einem gen insbesondere auf die dafür opti- Datenmenge betrachtet wird. Damit
Join, verarbeitet werden müssen. Diese mierten Data Marts und bei Bedarf stellt sich die Frage, ob das Erzeugen
Anzahl an Datensätzen, „Kardinalität“ auch auf die Core-Schicht ausgeführt der globalen Statistiken wirklich not-
(Cardinality) genannt, bestimmt maß- werden, sind für die Datenbank-Ob- wendig ist. Um diese Frage zu beant-
geblich die Kosten und damit die Aus- jekte dieser Schichten aktuelle Statisti- worten, muss man die Arbeitsweise
wahl eines Ausführungsplans. Das be- ken besonders wichtig. Um eine gute des Optimizers betrachten. Greift eine
deutet aber auch, dass der ausgewählte Performance der Abfragen zu erzielen, Abfrage nur auf eine Partition zu, wer-
Plan nur gut sein kann, wenn die Sta- sollten die Statistiken sowohl für alle den vom Optimizer lediglich die loka-
tistiken dem Optimizer die richtigen Tabellen und Indizes als auch für gege- len Statistiken der einzelnen Partition
Informationen liefern. Da mit jeder benenfalls zusätzlich erstellte Materia- ausgewertet. Erfolgt jedoch der Zugriff
Ausführung des ETL-Prozesses umfang- lized Views erzeugt werden. auf mehr als eine Partition, werden so-
reiche Änderungen beziehungsweise Auch wenn auf den Tabellen der wohl die lokalen als auch die globalen
neue Daten in das Data Warehouse Staging Area keine Auswertungen er- Statistiken vom Optimizer ausgewer-
(DWH) aufgenommen werden, muss folgen, ist zu bedenken, dass im Rah- tet, um die Kardinalität zu bestimmen.
großer Wert auf aktuelle Statistiken ge- men der ETL-Prozesse intensive Abfra- Abfragen, die die Daten mehrerer Par-
legt werden. gen auf die Tabellen dieser Schichten titionen auslesen, sind im DWH keine
Die folgenden Angaben und Em erfolgen. Insbesondere bei einem Tool Seltenheit, sodass neben den lokalen
pfehlungen beziehen sich auf die wie dem Oracle Warehouse Builder auch die globalen Statistiken aktuell
Oracle-Datenbank-Version 11g R2. Der (OWB) werden die ETL-Prozesse voll- zu halten sind.
Optimizer erfährt mit jeder Datenbank- ständig in der Datenbank ausgeführt, Ein Beispiel veranschaulicht die Be-
Version Veränderungen, sodass die hier sodass auch hier aktuelle Statistiken deutung aktueller globaler Statistiken:
geschilderten Verhaltensweisen bei äl- von großer Bedeutung sind, um eine Angenommen, in einer Faktentabelle
teren, aber auch bei zukünftigen Daten- gute Performance der ETL-Prozesse zu „FAKT_VERKAUF“ sind Verkaufsdaten
bankversionen zu überprüfen sind. ermöglichen. enthalten und jeden Tag wird eine Mil-
lion neuer Datensätze aufgenommen.
Welche Statistiken Lokale und globale Statistiken Die „PRODUKT_ID“ in der Fakten-Ta-
für ein Data Warehouse? Im Core und in den Data Marts wer- belle verweist auf die Produkt-Dimen-
Die typische DWH-Architektur be- den die Bewegungsdaten beziehungs- sion, bei der sämtliche Änderungen
steht aus einer Staging Area, einem weise die Fakten-Tabellen in der Regel historisiert werden (Slowly Changing
DOAG News 2-2013 | 25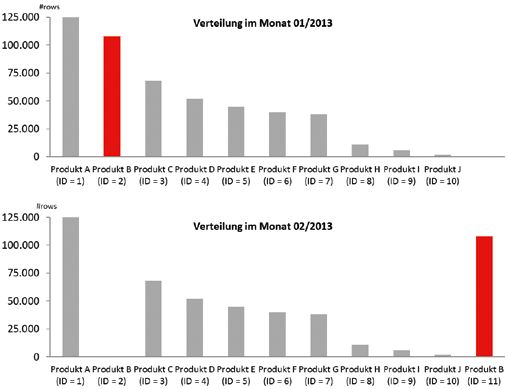
Datenanalyse
Dimension Typ 2). Die Dimension be- ken für die stets leere „MAXVALUE“- möglich ist. Verändert man die Ab-
inhaltet 100 verschiedene Produkte. Partition offensichtlich einen deut- frage so, dass der abgefragte Zeitraum
Jeden Tag ändern sich jedoch die At- lichen Einfluss auf die ermittelte auch die „MAXVALUE“-Partition um-
tribute von 50 Produkten, sodass auf- Kardinalität hat. fasst (out of range condition), weichen
grund der Historisierung täglich 50 Werden die lokalen Statistiken für die Werte für die Kardinalität ohne lo-
neue Dimensions-Einträge mit neuen die „MAXVALUE“-Partition erzeugt, kale Statistiken für die „MAXVALUE“-
„PRODUKT_IDs“ entstehen. Es wird wird für die Kardinalität vom Opti- Partition deutlich ab.
außerdem angenommen, dass jeden mizer stets 100 ermittelt. Fehlen je- Mag das Beispiel zunächst etwas
Tag alle 100 Produkte verkauft werden. doch die lokalen Statistiken für die konstruiert wirken, so wird doch deut-
Täglich nach dem Ausführen der ETL- „MAXVALUE“-Partition, nähern sich lich, dass globale Statistiken die Ge-
Prozesse wird die Menge der verkauf- die ermittelten Werte für die Kardina- nauigkeit der vom Optimizer ermittel-
ten Produkte seit dem 1. Januar 2013 lität den exakten Werten an. ten Kardinalität stark verbessern und
ermittelt. Dazu dient das in Listing 1 Man könnte jetzt auf die Idee kom- sogar zu exakten Kardinalitäts-Werten
dargestellte SQL-Statement. Dabei ist men, das als Workaround zu nutzen, führen können. Gerade für komple-
jeweils durch das Datum des um auf die Erstellung von globalen xere Abfragen kann das entscheidend
zuletzt geladenen Tages zu ersetzen. Statistiken zu verzichten. Listing 2 und für die Wahl eines guten Ausführungs-
Betrachtet man die Kardinalität Tabelle 2 zeigen jedoch, dass das nicht plans sein.
in Tabelle 1, so erkennt man schnell,
dass diese nur bei aktuellen lokalen
und globalen Statistiken der exakten select produkt_id, sum (umsatz)
from fakt_verkauf
Anzahl der tatsächlichen Datensätze
where datum between to_date (‘01.01.2013‘, ‘dd.mm.yyyy‘)
entspricht. Werden hingegen nur die and
lokalen Statistiken erzeugt, kann der group by produkt_id;
Optimizer die korrekte Kardinalität
nicht ermitteln. Interessant ist dabei,
dass die Existenz der lokalen Statisti- Listing 1: Summe der Umsätze vom 1. Januar 2013 bis zum zuletzt geladenen Tag
Kardinalität
Zuletzt geladener Tag Anzahl Ergebnis- ohne Statistiken nur lokale Statistiken nur lokale Statistiken Lokale und globale
und Datum für Datensätze (nicht für MAXVALUE- (auch für MAXVALUE- Statistiken
Partition) Partition)
01.01.2013 100 989.310 100 100 100
02.01.2013 150 1.912.425 134 100 150
03.01.2013 200 2.868.793 159 100 200
04.01.2013 250 4.220.568 179 100 250
05.01.2013 300 5.878.273 195 100 300
06.01.2013 350 5.602.747 210 100 350
07.01.2013 400 8.255.838 222 100 400
Tabelle 1: Kardinalität für die Abfrage aus Listing 1
Kardinalität
Zuletzt geladener Tag Anzahl Ergebnis- ohne Statistiken nur lokale Statistiken nur lokale Statistiken Lokale und globale
Datensätze (nicht für MAXVALUE- (auch für MAXVALUE- Statistiken
Partition) Partition)
01.01.2013 100 889.110 790.371 100 100
02.01.2013 150 2.455.191 1.673.551 100 150
03.01.2013 200 3.309.624 3.672.977 100 200
04.01.2013 250 2.838.101 3.666.418 100 250
05.01.2013 300 5.193.334 4.918.003 100 300
06.01.2013 350 6.776.543 6.988.246 100 350
07.01.2013 400 7.018.066 7.920.052 100 400
Tabelle 2: Kardinalität für die Abfrage aus Listing 2
26 | www.doag.org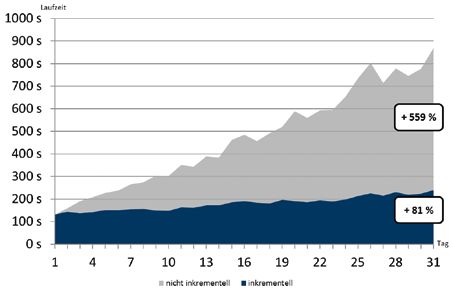
Datenanalyse
ermöglichen dem Optimizer, auch für
select produkt_id, sum (umsatz) die Spalten mit nicht gleichverteilten
from fakt_verkauf
Werten, eine genauere Vorhersage der
where datum between to_date (‘01.01.2013‘, ‘dd.mm.yyyy‘)
and to_date (‘08.01.2013‘, ‘dd.mm.yyyy‘)
zu erwartenden Datensätze.
group by produkt_id; Beim Data Warehouse ist auch zu
beachten, dass sich häufig die Vertei-
lung der Daten im historischen Verlauf
Listing 2: Summe der Umsätze vom 1. bis zum 8. Januar 2013 ändert. So kann sich zum Beispiel die
Anzahl der Verkaufs-Datensätze für ein
bestimmtes Produkt nach einer durch-
select * geführten Marketing-Kampagne deut-
from dim_produkt
lich erhöhen. Aber auch technische
where produktgruppe = ‘Obst‘
and produktkategorie = ‘Lebensmittel‘;
Gründe sind für eine Veränderung
der Verteilung möglich. So werden bei
Änderungen der „Slowly Changing Di-
Listing 3: Filterung auf korrelierende Spalten einer Produkt-Dimension mensions“ neue Datensätze mit neuen
künstlichen Schlüsseln erzeugt, sodass
sich in einer Fakten-Tabelle die Vertei-
Histogramme In der Realität liegt jedoch nicht lung der Produkt-IDs deutlich ändert
Werden die Daten beispielsweise durch immer eine Gleichverteilung vor (sie- (siehe Abbildung 3). Deshalb sollte
eine WHERE-Bedingung gefiltert, ver- he Abbildung 2), sodass der Optimi- man Histogramme ebenfalls regelmä-
sucht der Optimizer vorherzusagen, zer die falsche Anzahl an Datensätzen ßig aktualisieren.
wie viele Datensätze gefiltert werden. ermittelt und damit auch die Gefahr
Ohne Histogramme geht der Opti- besteht, einen ungünstigen Ausfüh- Große Datenmengen sind zeitintensiv
mizer von einer Gleichverteilung der rungsplan zu wählen. Im DWH wird häufig über die Attribu-
Werte aus, das heißt „Kardinalität = Für Spalten, die von der Gleichver- te der Dimensions-Tabellen gefiltert,
Gesamtzahl der Datensätze / Anzahl teilung der Daten deutlich abweichen, sodass Histogramme für diese Tabel-
unterschiedlicher Werte für die Filter- kann es deshalb sinnvoll sein, Histo- len in Betracht zu ziehen sind. Durch
spalte“ (siehe Abbildung 1). gramme zu erzeugen. Histogramme Joins der Dimensions- mit den Fakten-
Tabellen findet implizit auch eine Fil-
terung der Fakten-Tabellen statt. Des-
halb können Histogramme auch für die
Foreign-Key-Spalten der Fakten-Tabel-
len sinnvoll sein. Da die Erzeugung von
Histogrammen bei großen Datenmen-
gen jedoch sehr zeitintensiv sein kann,
sollte man Histogramme nur für Spal-
ten mit einer ungleichen Verteilung er-
zeugen.
Extended Statistics
Erfolgt eine Filterung der Daten über
Abbildung 1: Vom Optimizer angenommene Verteilung von Verkaufsdaten ohne Histogramme mehr als eine Spalte, nimmt der Op-
timizer an, dass die Werte dieser Spal-
ten unabhängig voneinander sind.
Enthält im DWH eine Produkt-Dimen-
sion beispielsweise 25.000 Produkte,
die hierarchisch in 500 Produkt-Grup-
pen und 50 Produkt-Kategorien gleich-
mäßig verteilt sind, und wird das SQL-
Statement aus Listing 3 abgesetzt, so
erwartet der Optimizer „25.000 / 500
/ 50 = 1 Datensatz“ als Ergebnis (sie-
he Abbildung 4). Da die Werte für Pro-
duktgruppen und Produktkategorien
aber aufgrund ihrer hierarchischen
Abbildung 2: Tatsächliche Verteilung von Verkaufsdaten Abhängigkeit korrelieren, werden tat-
DOAG News 2-2013 | 27Datenanalyse
sächlich „25.000 / 500 = 50 Datensät-
ze“ als Ergebnis geliefert.
Abfragen dieser Art treten im DWH
häufig auf und stellen insbesondere
bei Dimensions-Tabellen für den Op-
timizer ein Problem dar, da die Korre-
lation der Spalten nicht erkannt wird.
Extended Statistics können hier Abhil-
fe schaffen. Sie erlauben, Statistiken
für die kombinierten Werte mehrerer
Spalten zu erstellen. Diese Statistiken
ermöglichen es dann dem Optimi-
zer, die korrekte Anzahl der Datensät-
ze auch bei korrelierenden Spalten zu
ermitteln. Listing 4 erzeugt die ent-
sprechenden Statistiken für das obige
Beispiel. Anschließend wird vom Opti-
mizer die korrekte Kardinalität für das
SQL-Statement aus Listing 3 ermittelt
(siehe Abbildung 5).
Die Bedeutung der Extended Statis-
tics im DWH wird deutlich, wenn man
im obigen Beispiel zusätzlich die Fak-
ten-Tabelle mit Verkaufsdaten per Join
Abbildung 3: Veränderung der Verteilung von Verkaufsdaten durch künstliche Schlüssel hinzufügt (siehe Listing 5).
einer „Slowly Changing Dimension Typ 2“ Betrachtet man den Ausführungs-
plan für diese Abfrage, wird deutlich,
dass die Wahl der Join-Methode von
der Existenz der Extended Statistics
für die Produkt-Dimension abhängt.
Ohne Extended Statistics wird für den
Zugriff auf die Produkt-Dimension
fälschlicherweise eine zu niedrige Kar-
Abbildung 4: Kardinalität für korrelierende Spalten ohne Extended Statistiken dinalität erwartet, sodass für den Join
ein Nested Loop zum Einsatz kommt
(siehe Abbildung 6). Mit Extended Sta-
tistics hingegen wird die Kardinalität
für den Zugriff auf die Produkt-Dimen-
sion richtig ermittelt und der Optimi-
zer wählt den performanteren Hash
Join (siehe Abbildung 7).
Beim Einsatz von Standard-Berich-
ten für das Reporting werden häufig
Abbildung 5: Kardinalität für korrelierende Spalten mit Extended Statistiken Filter über korrelierende Spalten de-
finiert. So kann beispielsweise bei ei-
nem Umsatz-Bericht der Benutzer
zunächst aufgefordert werden, die
Produkt-Kategorie und anschließend
die zugehörige Produkt-Gruppe aus-
zuwählen. Ohne Extended Statistics
für die Spalten können bei solchen
aufeinanderfolgenden und voneinan-
der abhängigen Filtern schnell Perfor-
mance-Probleme für diese Standard-
Berichte auftreten.
Bei Ad-hoc-Abfragen stößt der Ein-
Abbildung 6: Ausführungsplan bei korrelierenden Spalten ohne Extended Statistiken satz der Extended Statistics jedoch an
28 | www.doag.orgDatenanalyse
belle 3). Durch Dynamic Sampling be-
declare nötigt der Optimizer zwar etwas mehr
vResult varchar2 (4000);
Zeit für das Ermitteln des Ausführungs-
begin
vResult := dbms_stats.create_extended_stats
plans, aber er kann gegebenenfalls den
(ownname => ‘MART’ deutlich besseren Plan wählen, was
, tabname => ‘DIM_PRODUKT’ insbesondere im DWH bei Abfragen
, extension => ‘(produktgruppe, produktkate auf große Datenmengen ein beträcht-
gorie)’); licher Vorteil sein kann.
Aufgrund der großen Datenmengen
dbms_stats.gather_table_stats
(ownname => ‚MART‘ im DWH ist eine möglichst effiziente
, tabname => ‘DIM_PRODUKT’ Erzeugung der Statistiken von großer
, method_opt => ‘for columns (produktgruppe, produktka Bedeutung. Die Dauer dafür hängt we-
tegorie)’); sentlich vom Umfang der für die Analy-
end;
se verwendeten Stichprobe ab. Für par-
titionierte Tabellen, wie die besonders
Listing 4: Erzeugung von Extended Statistics für eine Produktdimension großen Fakten-Tabellen, können die
globalen Statistiken seit Oracle 11g au-
ßerdem inkrementell erzeugt werden.
select sum (v.umsatz) AUTO_SAMPLE_SIZE
from dim_produkt p
Der Umfang der für die Erzeugung
, fakt_verkauf v
where p.produkt_id = v.produkt_id
der Statistiken zu analysierenden
and p.produktgruppe = ‘Obst‘ Daten kann mithilfe des „ESTIMA-
and p.produktkategorie = ‘Lebensmittel‘; TE_PERCENT“-Parameters beim Auf-
ruf der „DBMS_STAT.GATHER_TAB-
Listing 5: Filterung auf korrelierende Spalten in Verbindung mit einem Join LE_STATS“-Prozedur als Prozentsatz
(Sample Rate) angegeben werden. Ein
niedriger Prozentwert führt zu einem
geringen Umfang der Stichprobe für
die Analyse. Je geringer der Umfang
der Stichprobe, desto schneller erfolgt
die Erzeugung der Statistiken, gleich-
zeitig nimmt man aber auch eine ge-
ringere Genauigkeit der Statistiken in
Kauf.
Als Default-Wert für „ESTIMATE_
PERCENT“ ist jedoch nicht ein fes-
Abbildung 7: Ausführungsplan bei korrelierenden Spalten mit Extended Statistiken ter Prozentwert angegeben, sondern
der Wert „DBMS_STATS.AUTO_SAM-
PLE_SIZE“. Dieser bewirkt, dass die
Oracle-Datenbank selbst den geeigne-
seine Grenzen, da nicht vorhersehbar nalität zu ermitteln. Beim Dynamic ten Prozentwert für das Erzeugen der
ist, welche korrelierenden Attribute Sampling werden für das auszufüh- Statistiken ermittelt. Wird „AUTO_
die Benutzer in ihren Abfragen in wel- rende SQL-Statement zusätzliche Sta- SAMPLE_SIZE“ in der Version 11g ver-
cher Kombination verwenden. Exten- tistiken für die beteiligten Tabellen wendet, kommt dabei außerdem ein
ded Statistics für sämtliche denkbaren ermittelt. Der Datenbank-Parameter neuer, sehr effizienter Algorithmus
Kombinationen von korrelierenden „OPTIMIZER_DYNAMIC_SAMPLING“ für das Erzeugen der Statistiken zum
Attributen zu erzeugen, ist viel zu auf- gibt dabei an, in welchem Umfang Dy- Einsatz. Die von diesem Algorithmus
wändig, sodass eine andere Lösung namic Sampling zum Einsatz kommt. generierten Statistiken haben fast die
anzustreben ist. Hier kann Dynamic Wird dieser Parameter auf „Level 4“ gleiche Genauigkeit wie die Statisti-
Sampling helfen. oder höher gesetzt, werden bei Filtern ken auf Basis einer 100-Prozent-Sam-
über mehrere Spalten auch Informa- ple-Rate.
Dynamic Sampling tionen über Korrelationen der Werte Abbildung 8 zeigt die Laufzeiten ei-
Wenn keine Extended Statistics vor- dieser Spalten gesammelt. Je höher das ner 11g-Datenbank für das Erzeugen
liegen, kann der Einsatz von Dynamic Level ist, desto mehr Datenblöcke wer- der Statistiken für eine 40 Millionen
Sampling den Optimizer trotzdem in den als Stichprobe für das Sammeln Datensätze umfassende Fakten-Tabel-
die Lage versetzen, die richtige Kardi- der Informationen gelesen (siehe Ta- le mit unterschiedlichen Sample Ra-
DOAG News 2-2013 | 29Datenanalyse
tes im Vergleich zur Verwendung von
„AUTO_SAMPLE_SIZE“.
Inkrementelle Statistiken
Das Erstellen der globalen Statistiken
ist insbesondere für große Fakten-Ta-
bellen sehr aufwändig und benötigt
deshalb oft viel Zeit. Da Fakten-Tabel-
len jedoch in der Regel partitioniert
sind und sich meist nur die Daten ei-
ner oder weniger Partitionen ändern,
sollte man den Einsatz inkrementel-
ler Statistiken in Betracht ziehen (seit
Version 11g). Dazu müssen die lokalen
Statistiken der einzelnen Partitionen
aktuell sein und die inkrementellen
Statistiken für die betroffenen Tabellen
mit „DBMS_STATS.SET_TABLE_PREFS“
aktiviert werden (Preference „INCRE-
MENTAL“ auf „TRUE“ setzen). Abbildung 8: Laufzeiten für die Statistik-Erzeugung mit unterschiedlichen Sample Rates im
Durch das Aktivieren der inkremen- Vergleich zu „AUTO_SAMPLE_SIZE“
tellen Statistiken speichert die Oracle-
Datenbank für jede Partition der
Tabelle ein sogenanntes „Synopsis-Ob-
jekt“ im „SYSAUX“-Tablespace. Dieses
enthält statistische Metadaten für die
einzelnen Partitionen und Spalten in
den Partitionen. Im Vergleich zu den
vollständigen Partitionsdaten sind Sy-
nopsis-Objekte sehr klein. Wird eine
neue Partition hinzugefügt oder eine
bestehende Partition geändert, müs-
sen zunächst für diese Partition die lo-
kalen Statistiken aktualisiert werden.
Anschließend kann die Oracle-Daten-
bank anhand der Synopsis-Daten die
globalen Statistiken erzeugen, ohne
die gesamte Tabelle lesen zu müssen.
Dadurch wird die Laufzeit für die Er-
zeugung der globalen Statistiken er-
heblich reduziert. Abbildung 9 zeigt
die deutlich bessere Laufzeit inkre- Abbildung 9: Laufzeiten für inkrementell und nicht inkrementell erzeugte globale Statistiken
mentell erzeugter gegenüber nicht in- im Vergleich
krementell erzeugten Statistiken am
Beispiel einer partitionierten Fakten-
Tabelle. Betrachtet wird ein Zeitraum Level Umfang der Stichprobe
von 31 Tagen, in dem jeden Tag 10 4 64 Datenblöcke für nicht analysierte Tabellen
Millionen neue Datensätze in die Fak- 32 Datenblöcke für analysierte Tabellen
ten-Tabelle eingefügt werden. 5 64 Datenblöcke
6 128 Datenblöcke
Wann sollen Statistiken erstellt werden?
7 256 Datenblöcke
Die Oracle-Datenbank bietet die
8 1024 Datenblöcke
Möglichkeit, die Anzahl geänder-
ter Datensätze zu protokollieren 9 4096 Datenblöcke
(„MONITORING“-Klausel für Tabellen) 10 alle Datenblöcke
und mithilfe eines täglich laufenden
Jobs die Statistiken der Tabellen auto- Tabelle 3: Umfang der Stichprobe beim Dynamic Sampling
30 | www.doag.orgDatenanalyse
dass die Statistiken stets aktuell sind
und die Performance der Abfragen sich
nicht verschlechtert.
Fazit
Aktuelle Statistiken sind für das Re-
porting im DWH unverzichtbar, um
performante Berichte und Abfragen zu
garantieren. Mit den Möglichkeiten von
Oracle 11g und der richtigen Strategie ist
es möglich, auch für große Datenmen-
gen eines DWH den Aufwand für das
Erzeugen aktueller Statistiken gering zu
halten. Für eine Strategie zur Erzeugung
von Statistiken im DWH sollten folgen-
de Punkte beachtet und anhand der
konkreten Situation bewertet werden:
• Stets lokale Statistiken für geänderte
Partitionen und globale Statistiken
aktualisieren
• Globale Statistiken für partitionier-
te Fakten-Tabellen inkrementell er-
Abbildung 10: Zeitpunkte der Aktualisierung der Statistiken mit „MONITORING“ im Ver- zeugen
lauf eines Jahres • Histogramme für Spalten mit un-
gleichmäßig verteilten Daten, über
die häufig gefiltert wird, verwenden
• Extended Statistics für korrelierende
matisch zu aktualisieren. Dabei werden den ersten 10 Tagen werden die Statis- Spalten erstellen, die in Standardbe-
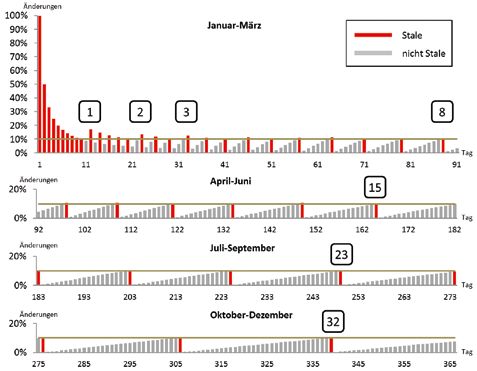
nur Tabellen aktualisiert, bei denen sich tiken jeden Tag als „Stale“ angesehen richten als Filter genutzt werden
mindestens ein festgelegter Prozentsatz und entsprechend erneuert, aber be- • Dynamic Sampling mit Level 4 oder
der Datensätze geändert hat. Die Statis- reits am 11. Tag wird die erforderliche höher einsetzen, um auch für Ad-
tiken werden dann als „Stale“ bezeich- 10-Prozent-Grenze nicht mehr erreicht hoc-Abfragen gute Laufzeiten beim
net. Per Default sind 10 Prozent einge- und das Aktualisieren der Statistiken Filtern über korrelierende Spalten
stellt. Dieses Verfahren eignet sich für somit nicht ausgeführt. Erst am 12. Tag zu erzielen
OLTP-Systeme häufig gut, da diese Sys- wird diese Grenze wieder überschritten • Statistiken in der Regel mit „AUTO_
teme in der Regel nicht umfangreiche und die Statistiken werden erneuert. SAMPLE_SIZE“ erzeugen. Nur bei
historische Daten vorhalten und somit Zu beachten ist, dass die Zeiträume, sehr großen Fakten-Tabellen gege-
eine geringe Menge geänderter Daten in denen die Statistiken nicht erneu- benenfalls gezielt kleine Werte für
ausreicht, um das Aktualisieren der Sta- ert werden, mit zunehmenden histo- „ESTIMATE_PERCENT“ angeben
tistiken auszulösen. rischen Datenvolumen immer größer • Statistiken im DWH nicht mit dem
Beim DWH hingegen ist mit zuneh- werden. Nach drei Monaten werden automatischen Statistik-Job der Da-
mender historischer Datenmenge eine bereits 8 Tage lang die Statistiken der tenbank, sondern gezielt im ETL-
immer größere Anzahl an Datensätzen Tabelle nicht aktualisiert. Am Ende des Prozess erzeugen
notwendig, um die erforderlichen 10 Jahres überschreitet der Zeitraum ohne
Prozent Änderungen zu erreichen und aktuelle Statistiken mit 32 Tagen sogar
somit das Aktualisieren der Statistiken einen ganzen Monat. Reinhard Mense
auszulösen. Im DWH kann das insbe- Insbesondere für Berichte und Ab- reinhard.mense@areto-consulting.de
sondere bei den Fakten-Tabellen dazu fragen, die auch auf die aktuellen Da-
führen, dass über einen größeren Zeit- ten des DWH zugreifen, drohen somit
raum das Aktualisieren der Statistiken aufgrund fehlender Statistiken und un-
ausbleibt. Abbildung 10 verdeutlicht passender Ausführungspläne erhöhte
das Problem anhand eines Beispiels. Laufzeiten. Für DWH-Systeme ist die-
Dabei wird davon ausgegangen, dass ses Verhalten nicht akzeptabel. Des-
in einer Tabelle (etwa einer Fakten- halb sollte das Erzeugen der Statistiken
Tabelle) jeden Tag die gleiche Anzahl regelmäßig innerhalb des ETL-Prozes-
neuer Datensätze hinzugefügt wird. In ses erfolgen. Damit wird sichergestellt,
DOAG News 2-2013 | 31Sie können auch lesen

















































