Semantische Suche mit Technologien des Semantic Web
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Semantische Suche
mit Technologien
des Semantic Web
Ausarbeitung zum Seminar zur Projektgruppe „Location Based Services“
im Wintersemester 2004/2005
von
Jan Hoffmann,
Dezember 2004
Eingereicht bei
Prof. Dr. Odej Kao
und
Dipl.-Inf. Ulf Rerrer
Arbeitsgruppe Betriebsysteme und Verteilte Systeme
Institut für Informatik
Universität Paderborn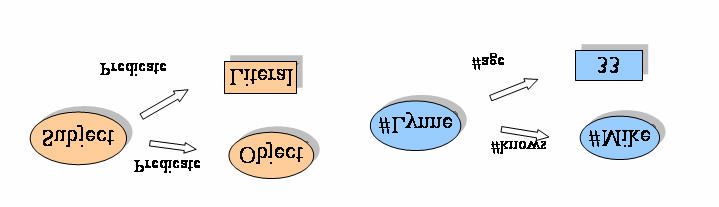
Inhaltsverzeichnis
1. Einleitung ................................................................................................................................ 3
2. Das Semantic Web – Motivation und Bedarf ......................................................................... 4
2.1. Leitvision .......................................................................................................................... 4
2.2. Bedarf für Semantik ......................................................................................................... 5
3. Ausgewählte Technologien im Semantic Web ...................................................................... 9
3.1. Einleitung und Überblick.................................................................................................. 9
3.2. Die Syntax: XML und XML Schema.............................................................................. 10
3.3. Das Resource Description Framework (RDF) .............................................................. 11
3.4. Ontologien ..................................................................................................................... 12
4. Web Services im Semantic Web.......................................................................................... 15
5. Fazit und Projektgruppenbezug ........................................................................................... 17
Quellen ..................................................................................................................................... 21
Literatur ................................................................................................................................. 21
Links & Web (Auszug).......................................................................................................... 22
Abbildungen
Abbildung 1: HTML Formular. Quelle: [Verivox] ........................................................................ 5
Abbildung 2: Semantic Web Pyramid of Languages. Nach [Ziegler04]. ................................... 9
Abbildung 3: RDF Tripel-Konzept mit Beispiel. Nach [DOS03] .............................................. 11
Abbildung 4: Bedarf für Ontologien. Quelle: http://www.informatik.hu-
berlin.de/~bien/ontologie.html........................................................................................... 13
Abbildung 5: Zusammenhang zwischen WS-Technologien. Nach [Thronicke03] . ................ 16
Abbildung 6: Einordnung Semantic Web Services. Nach [DOS03], Kap. 1, S. 7. .................. 16
Abbildung 7: Mögliche Einbettung einer Semantischen Suche............................................... 18
2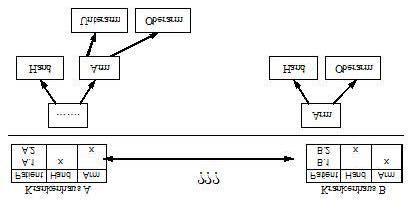
1. Einleitung
Die vorliegende Arbeit entstand im Rahmen des Seminars zur Projektgruppe „Location
Based Services“ der Arbeitsgruppe „Betriebsysteme und Verteilte Systeme“ (Prof. Dr. Odej
Kao) im Wintersemester 2004/2005 an der Universität Paderborn. Ziel war es, verschiedene
Technologien im Umfeld von Location Based Services darzustellen und somit eine Basis für
die Weiterarbeit der Gruppe zu schaffen.
Meine Arbeit beschäftigt sich dabei mit Technologien des Semantic Web. Zunächst soll also
dargestellt werden, was das Semantic Web überhaupt ist und welche Ziele damit verbunden
sind. Außerdem wird motiviert, wo Schwächen in heutigen Web-Technologien liegen und wie
semantische Verfahren helfen können, diese Schwächen zu beseitigen.
Die weiteren Kapitel stellen dann konkrete Begriffe, Technologien und Protokolle des
Semantic Web vor, wobei auch auf bereits existierende Standards eingegangen wird. Der
Zusammenhang zu Web Services soll hergestellt werden, um weitere
Nutzungsmöglichkeiten der Semantic-Web-Technologien darzustellen.
Um den Bezug zur Projektgruppe „Location Based Services“ herzustellen, wird zunächst der
Bedarf für Suchverfahren innerhalb der zu erstellenden Software ermittelt und dann geprüft,
wo und wie die vorgestellten Technologien und Konzepte sinnvoll eingesetzt werden können.
Diese Ausarbeitung folgt also im Wesentlichen der Struktur des dazugehörigen Vortrages
und versucht, das gegebene Feedback an den relevanten Stellen einzubetten, um den
Nutzen für die Projektgruppe noch stärker hervorzuheben. Nichts desto trotz sind die
verwendeten Quellen gleich.
Anmerkung: Im Verlauf der Arbeit wird der Ausdruck World Wide Web sowohl mit der
Abkürzung WWW als auch Web benannt werden. Unter Web-Technologien sollen im
Wesentlichen die Protokolle http und https sowie Markupsprachen der HTML-Familie
verstanden werden. Im weiteren Verlauf der Arbeit werden diese ergänzt, operieren aber an
den gleichen Stellen im ISO/OSI-Schichtenmodell.
32. Das Semantic Web – Motivation und Bedarf
2.1. Leitvision
Wer heutzutage über das Semantic Web spricht, assoziiert damit meistens auch die Ideen
und die Arbeit von Tim-Berners-Lee1. Diese soll also an dieser Stelle kurz dargestellt
werden.
Tim Berners-Lee ist heute Direktor des von ihm gegründeten World Wide Web Consortiums
(W3C)2. Diese Institution entwickelt und verabschiedet Standards für die Kommunikation im
World wide Web (WWW). Die bekanntesten sind sicherlich (X)HTML, CSS und andere schon
seit langem implementierte und weit verbreitete Standards. Ein weiteres großes
Betätigungsfeld, welches im Laufe der letzten Jahre stetig an Bedeutung gewonnen hat, sind
Spezifikationen im Umfeld von XML (siehe unten). Dabei wird nicht nur XML selbst definiert,
sondern auch Transformations- und Anfragesprachen (z.B. XSLT, XPath), sowie allgemeine
Implementierungskonzepte (z.B. DOM), die das Potential der zugrunde liegenden Sprache
erst ausschöpfen.
Als Forscher am CERN3 in der Schweiz hat Berners-Lee Anfang der 90er Jahre zunächst
das WWW in seiner heutigen Form erfunden. Dabei entwickelte er den ersten
funktionsfähigen Browser und Webserver, sowie die Vision einer weltweiten Verknüpfung
von Informationen und deren einfachen Austausch über das Internet. Die konzeptuelle
Einfachheit verhalf dem WWW zum heute bekannten Durchbruch. Die weitere Entwicklung
wurde, wie oben angedeutet, dann von Berners-Lee am W3C als Technologietreiber
fortgesetzt.
Im Jahre 1997 beschrieb Berners-Lee schließlich das Semantic Web als zweite große Stufe
in der Entwicklung des World Wide Web. Leitidee ist die maschinelle Lesbarkeit – und darauf
aufbauend das maschinelle Verständnis – von Informationen und Ressourcen im WWW.
Maschinen sind hier zum Beispiel intelligente Agenten, die Suchaufgaben übernehmen und
die gefunden Ergebnisse auch hinsichtlich ihrer Verwendbarkeit bewerten und auswählen
können.
1
Beispiele angeben, zb ix-artikel, ulf-buch etc.
2
Siehe auch [W3C]
3
Centre Européen pour la Recherche Nucléaire
4Weiterhin sollen Agenten eigenständig logische Schlüsse ziehen können, soweit die
definierten Zusammenhänge dies zulassen. Damit kann auch neues Wissen erzeugt werden,
welches nicht als solches schon an einer Stelle hinterlegt ist. Hier wird deutlich, dass das
Semantic Web sich auch stark in die Richtung der Künstlichen Intelligenz bewegt und
diesem Forschungsgebiet damit auch eine interessante Anwendungsmöglichkeit bietet. Für
Unternehmen ist ein Semantic Web besonders im Wissensmanagement interessant, ein
Bereich, der gerade in größeren Unternehmungen an Bedeutung gewinnt und unter
Anderem durch kürzer werdende Produktlebenszyklen strategisch kritischer wird.
2.2. Bedarf für Semantik
Mit der schon angesprochenen Verbreitung ergeben sich aber heutzutage ganz andere
Schwierigkeiten: Die schier unüberschaubare Masse an Informationen kann kaum mehr
effizient durchsucht und/oder katalogisiert werden. Dies hängt natürlich auch mit der stetigen
Dynamik des Angebots zusammen, sekündlich werden schließlich WWW-Server und Clients
dem Netz hinzugefügt oder entfernt. Doch auch vergleichsweise statische Strukturen und
Inhalte werden immer mehr undurchsuchbar, wie das folgende Beispiel zeigen soll:
Auf [Verivox] kann ein HTML-Formular zur Anfrage eines Dienstes, der günstige Call-by-Call-
Anbieter für Telefongespräche auflistet, erzeugt werden. Ein solches Formular stellt eine
typische Eingabemethode für Dienste im heutigen Web dar und ist in Abbildung 1 zu sehen.
Abbildung 1: HTML Formular. Quelle: [Verivox]
Ein solches Formular ist für einen menschlichen Benutzer intuitiv benutzbar und sollte in der
Regel zum gewünschten Ergebnis führen, nämlich der Anzeige der günstigsten Tarife für die
gewünschte Uhrzeit. In einem Szenario, in welchem diese Information maschinell gefunden
und ggf. direkt weiterverwendet werden soll (z.B. für einen Telefonanruf), stellt sich die Lage
schon komplizierter dar: Ein Agent muss genau wissen, welche Eingaben in welchem Format
5in welchem Eingabefeld gefragt sind. Die Kodierung dieses Formulars in HTML 4 enthält aber
sowohl für diese Aufgabe relevante als auch irrelevante Bestandteile:
Relevante Bestandteile des Codes können Informationen sein über:
• „Ort“ des Services: Hier in Form eine URL, angegeben im action-Attribut des form-
Tags.
• Übergabeparameter an den Service: z.B.: Werte der Felder „am“, „um“, „Dauer“. In
diesem Fall kodiert per input-Element des Forms.
• Grobe Informationen über die Art der benötigten Eingabe: Hier nur sehr beschränkt,
z.B. Länge eines Strings im size-Attribut oder Enumeration der zulässigen Werte in
der Sequenz der Select-Elemente.
Abgesehen davon, dass diese Informationen immer noch sehr wenige Anhaltspunkte liefern,
was denn der Dienst genau zur Verfügung stellt, sind die meisten Informationen der HTML-
Kodierung aus der Sicht eines intelligenten Agenten unnötig und dienen primär der
Darstellung des Formulars:
• Informationen über Schriftformatierung: Farbe, Schriftart.
• Strukturinformationen: Darstellung als Tabelle,
• Einbindung von externen Dateien: Bild als Button für menschlichen Dienstnutzer.
Weiterhin wird deutlich, dass einem Agenten die Bedeutungen der Feldbezeichnungen wie
z.B. „Duration“ explizit bekannt sein müssen, damit dieser Service auch automatisiert genutzt
werden kann. Aufgrund der hier zur Verfügung gestellten Informationen kann die Bedeutung
allerdings höchstens vermutet werden, schließlich mag ein anderer Anbieter seine
Formularfelder ganz anders benennen, erst recht dann, wenn er dies in einer anderen
Sprache tut.
Um auf das Grundproblem zurückzukommen, sei hier auf die Unterscheidung zwischen
prozeduralen und deskriptiven Markup hingewiesen5:
• Das prozedurale Markup definiert die Eigenschaften eines Dokumentes bezüglich
seines Aussehens, die Auszeichnungselemente werden auch als physische Tags
bezeichnet. Beispiele sind Kodierungen von Schriftarten von Textabschnitten.
• Das deskriptive Markup enthält dagegen Angaben über die Semantik von Teilen
eines Dokumentes, die zugehörigen Tags werden logische Tags genannt. Ein
einfaches Beispiel ist die Auszeichnung einer Textzeile als Überschrift.
4
siehe Ausgabe auf [Verivox].
5
Siehe z.B. [WBS02], s. 51f
6Diese Begriffsbestimmungen werden zwar im Allgemeinen auf Dokumente angewandt, da
aber Dokumente und Dienste im WWW mit den gleichen technischen Mitteln (hier: HTML)
kodiert werden, können die Begriffe jedoch auch auf letztere angewandt werden. Im obigen
Beispiel wurde prozedurales und deskriptives Markup stark vermischt, so dass es Agenten
schwer fällt, dies zu trennen. Ein weiteres Problem ist, dass das verwendete deskriptive
Markup nicht ausdrucksfähig genug ist, um die Besonderheiten der Anwendungsdomäne
(Telefondienste; nicht Formularverarbeitung (!)) hinreichend semantisch zu beschreiben,
worauf später eingegangen wird.
Dieser Mangel an adäquaten Informationen (bzw. deren eindeutige Definition) in der
derzeitigen Form des WWW führen zu Suchdiensten, die nur teilweise gut funktionieren:
Populäre Suchmaschinen wie Google nutzen Techniken, die auf Teilstring- und/oder Pattern-
Matching-Algorithmen beruhen und führen eine Bewertung gefundener Ergebnisse anhand
verschiedener Kriterien durch, die schließlich die Anzeigereihenfolge beim Endbenutzer
definiert. Informations- oder Service-Anbieter, die mit diesen Kriterien und genaueren Details
der verwendeten Algorithmen vertraut sind, können diese Kenntnis in einem gewissen
Umfang dazu nutzen, bewusst falsche Informationen hoch in den Trefferlisten zu platzieren.
Es ist dem Suchverfahren nämlich nicht möglich, von sich aus einen richtigen Treffer von
einem falschen zu unterscheiden, solange diese gleich heißen. Als Beispiel sei das Wort
„Bank“ genannt, welches im deutschen Kontext schon mehrdeutig ist. Unter
Berücksichtigung von englischen Ressourcen kommen noch weitere Bedeutungen hinzu,
wobei einige auch wieder zu den deutschen analog sind.
Es ist klar, dass diese Probleme zurzeit eine menschliche Selektion und Verifikation von
Suchergebnissen erfordern, bevor ein weiterer maschineller Verarbeitungsschritt einsetzt.
Dies macht in den meisten Gebieten den Einsatz von Agenten zumindest schwierig, oft
unmöglich. Diese Erkenntnis ist für die Projektgruppe „Location Based Services“ von großer
Bedeutung, da solche Suchen nach und in Diensten so automatisiert wie möglich ablaufen
sollen. Hierauf wird in einem gesonderten Kapitel genauer eingegangen. Auf die möglichst
verlustfreie Informationsgewinnung aus herkömmlichen Webquellen wird außerdem in der
Seminararbeit von Frank Brüseke eingegangen.
Soll das propagierte Semantic Web die bisherigen Probleme lösen, sind also unter anderem
folgende Herausforderungen anzugehen:
7• Hochwertigere Auszeichnung von Dokumenteninhalten: Wie im obigen Beispiel
gezeigt, reicht das heute vorhandene (bzw. dort eingesetzte) deskriptive Markup nicht
aus, um die notwendigen Informationen darzustellen. Dies beinhaltet bei Diensten
unter anderem die genaue Definition der Übergabeparameter und eine eindeutige
Beschreibung des zu erwartenden Ergebnisses (nämlich eine Telefonnummer anstatt
eines allgemeinen Strings).
• Definition von allgemeingültigen Konzepten: Um die o.g. Auszeichnung überhaupt
vornehmen zu können, müssen die dafür zu verwendenden Konzepte und Begriffe
zunächst einmal definiert werden. Neben der Definition einzelner Begriffe ist in
diesem Schritt auch zu nennen:
o Einordnung in Domänen: Bestimmte Begriffe erhalten ihre spezielle
Bedeutung (=Semantik) erst im Kontext ihrer Anwendungsdomäne, wie zum
Beispiel der Begriff „Bank“ im Umfeld der Finanzwirtschaft. Dabei muss das
branchenspezifische Wissen formalisiert werden, um die Kommunikation der
Branche durch die definierten Auszeichnungsmöglichkeiten zu unterstützen.
Ansätze dafür existieren bereits, auch wenn diese noch nicht die semantische
Stärke mancher Semantic Web-Technologien erreichen 6.
o Beziehungen zwischen Konzepten: Um die definierten Konzepte auch
maschinell verwertbar zu machen, ist es zusätzlich von Bedeutung, auch die
Beziehungen zwischen diesen formal zu spezifizieren. Erst dann können
logische Schlüsse ermöglicht werden.
o Analogien: Dinge, die für menschliche Benutzer offensichtlich gleich sind,
müssen auch formal als gleich definiert werden können. Beispiele sind Preise
in verschiedenen Währungen. Dies ermöglicht Agenten, unter verschiedenen
Diensten mit gleichem Angebot zu wählen, was zum Beispiel die
Ausfallsicherheit erhöhen kann.
• Definition von eindeutigen Namensräumen: Durch die Dynamik des Web, die ja auch
in Zukunft weiter dessen Stärke bleiben soll, wird es unvermeidlich sein, dass
unabhängig voneinander Konzepte mit gleichen Identifiern erstellt werden. Um hier
eine Eindeutigkeit sicherzustellen, müssen Namensräume deklariert und stets
referenziert werden.
• Einheitliche Syntax: Schließlich muss die Lesbarkeit durch Verwendung einer
einheitlichen und standardisierten Syntax sichergestellt werden. Durch aktuelle
Browserimplementierungen wird leider eine nicht-einheitliche Syntax toleriert.
Prinzipiell existieren hier aber bereits funktionierende Techniken (s.u.).
6
Seine z.B. [ebXML]
83. Ausgewählte Technologien im Semantic Web
3.1. Einleitung und Überblick
An dieser Stelle sollen nun verschiedene Technologien und Standards des Semantic Web
dargestellt und in Beziehung zueinander gesetzt werden. Dabei wird in der Literatur 7 oft eine
Darstellung verwendet, die diese nach deren semantischen Gehalt zu einer Pyramide
anordnet. Anhand dieses Schaubildes sollen dann im weiteren Verlauf die wichtigsten
Techniken vorgestellt werden:
Abbildung 2: Semantic Web Pyramid of Languages. Nach [Ziegler04].
Die unteren beiden Blöcke „Unicode“ und „Uniform Resource Identifier“ (URI) sind hier nur
der Vollständigkeit halber angegeben. Während Unicode nur den Zeichensatz für die
letztendliche Kodierung zur Verfügung stellt, sind URIs dafür geeignet, die schon oben
angesprochenen Namensräume bzw. deren Bezeichner zu notieren. Dass die typische
Namensraum-URI dabei einer http-URL gleicht, hat nichts mit der Rolle von http im
derzeitigen oder zukünftigen Web zu tun: Durch die Domain-Regierungsstellen wird die
Eindeutigkeit sichergestellt, die hier erforderlich ist.
7
Siehe z.B. [Ziegler04]
93.2. Die Syntax: XML und XML Schema
An dieser Stelle soll nur kurz auf die Besonderheiten von XML im Kontext des Semantic
Webs eingegangen und dargestellt werden, warum XML die Basis für die darüber liegenden
Technologien ist.
Wichtig ist, dass XML als Metasprache verstanden wird, um damit andere Sprachen zu
realisieren, die alle eine gemeinsame Syntax vereint. Die Bedeutung (Semantik) der
Sprachelemente hängt jedoch von der individuellen Definition des spezifischen Dialektes ab.
Dabei muss die Bedeutung jedoch noch explizit zugeordnet werden (s.u.), da die reine
Benennung eines Elements noch keine semantische Information transportiert 8.
Definiert werden die Metasprachen durch Definitionssprachen: Im einfachsten Fall können
Document Type Definitions verwendet werden, doch für die Verwendung von DTDs für
Syntaxdefinitionen im Kontext des Semantic Webs sind DTDs nicht geeignet, da sie die
Deklarierung von Namespaces nicht unterstützen, was jedoch notwendig ist9. Also
verbleiben im Wesentlichen die Sprachen XML Schema und Relax NG, die auch selbst in
XML kodiert werden, und somit mit den gleichen Standardtools bearbeitet und erzeugt
werden können. Dabei führen diese Sprachen komplexere Datentypmodelle ein, als dies mit
DTDs möglich wäre, innerhalb dieser kann ein Fokus auf einen eher objektorientierten
Ansatz bei XML Schema und einen eher strukturorientierten Ansatz bei Relax NG
unterschieden werden10.
In einer Sprachdefinition werden ja nun die erlaubten Elemente und deren Zusammenhänge
spezifiziert. Enthalten diese Schemata also schon Semantik im Sinne des Semantic Web?
Dies ist nicht der Fall. Auch wenn XML-Schema-Definitionen genug „interne“ Semantik
enthalten, so dass daraus Grafische Editoren, oder spezielle Parser für die definierte
Sprache generiert werden können, so gehen die Möglichkeiten nicht über eine
Strukturdefinition der beteiligten Elemente hinaus. Sie sind allerdings notwendiger
Bestandteil der Syntaxebene, um erst einmal die korrekte Verwendung dieser Syntax durch
entsprechende Validierung sicherstellen zu können. Des Weiteren werden an dieser Stelle
Namensräume eingeführt.
8
[SW.org], Abschnitt „XML & Semantics“
9
Siehe z.B. [DOS03], Kapitel 3, Seite 39.
10
Dies wird zum Beispiel in [TT04] deutlich.
103.3. Das Resource Description Framework (RDF)
Die erste wichtige Stufe semantischer Aufwertung von Ressourcen stellt im Kontext des
Semantic Web die Auszeichnung mit RDF-Technologien dar. Dies stellt im Prinzip eine
bessere Art des Labellings von Inhalten mit Meta-Tags im herkömmlichen Sinne dar, nur
dass eben diese Meta-Tags und deren Beziehungen untereinander freier definierbarer sind,
als man das von bisherigen Ansätzen kennt.
Zunächst wird zwischen dem RDF-Modell und RDF/XML unterschieden: RDF/XML ist eine
lediglich eine Serialisierung eines RDF-Modells, und zwar eine unter vielen Möglichen. Durch
die enge Verwandschaft zu Techniken der Wissensrepräsentierung in der Künstlichen
Intelligenz haben sich im Laufe der Zeit auch andere, scheinbar besser geeignete Formate
etablieren können, die sich jedoch im Umfeld des Semantic Web nicht so komfortabel
verarbeiten lassen wie die XML-basierten. Dazu zählt unter anderem die N3-Notation, die
enger an das nun vorgestellte Tripelformat des RDF Models angelehnt ist, und daher
kompakter darstellbar ist11.
In RDF werden immer Aussagen über Instanzen von Ressourcen gemacht, diese stellen,
ähnlich wie in einem Satz der deutschen Sprache, das Subjekt der Beschreibung dar. Dieses
Subjekt kann verschiedene Ausprägungen haben: Sinn macht es beispielsweise,
Binärdateien mit Metainformation anzureichern, da die darin evtl. gespeicherten
Informationen durch die Art der Codierung nicht offen und mit allgemeinen Parsern lesbar
sind. Weiterhin können natürlich auch in offenen Dateiformaten gespeicherte Informationen
angereichert werden, aber auch abstrakte Konzepte, kurz: „anything that has idendity“.
Die Subjekte stehen über Prädikate mit Objekten in Verbindung, wie die Abbildung zeigt:
Abbildung 3: RDF Tripel-Konzept mit Beispiel. Nach [DOS03] .
11
Zum Beispiel vorgestellt in [DOS03] , Kapitel 5, Seite 90.
11Prädikate sind in RDF Relationen zwischen Objekten, die so auch wieder ein eigenes
Konzept darstellen und daher auch per URI definiert sind, wie auch im Beispiel angedeutet.
Objekte sind entweder weitere Ressourcen, auf die mit Prädikaten verwiesen wird, oder
Literale wie Zahlen oder Zeichenketten. Objekte können im ersten Fall auch wieder Subjekte
weiterer RDF-Statements sein, wodurch eine Verkettung erreicht wird, die als Basis für
automatische Folgerungen dienen können (z.B. bei transitiven Relationen).
Analog zu XML / XML-Schema gibt es zu RDF auch eine Schema-Sprache, auf die hier aber
nicht näher eingegangen werden sollen. Da die RDF-Informationen (wie schon erwähnt) auf
Instanzebene wirken, können im Schema „Strukturinformationen des generischen
Konstrukts“, z.B. die dort zu verwendenden Klassen von Instanzen definiert werden. Ein
guter Überblick wird in [Roth02] gegeben.
Vorteile bei der Verwendung von RDF ergeben sich in erster Linie durch die Verwendung
von global eindeutig definierten Bezeichnern in maschinenlesbarer Syntax (entsprechende
XML-Serialisierung vorausgesetzt). Über die ebenso definierten Prädikate können dann
Beziehungen zu anderen Ressourcen automatisiert hergestellt werden. Wichtig ist also, dass
RDF nur der erste Schritt bei der Implementierung eines Semantic Web ist. Interessantere
Probleme werden auf höherer Ebene gelöst, die aber RDF dafür voraussetzen.
Trotzdem ist der Einsatz gerade im globalen Internet nicht sonderlich verbreitet: Die
RDF/XML-Formulierungen sind recht aufwendig und lang und daher kaum für die Erstellung
durch menschliche Nutzer geeignet, gerade auch durch die konsequente Verwendung von
Namensraumbezeichnern. Da der Toolsupport für RDF zurzeit noch nicht sehr hoch ist und
viele Hersteller proprietäre Metadatenformate innerhalb ihrer Tools anbieten, ist die
Motivation, aufwendige allgemeingültigere Auszeichnungen vorzunehmen, zurzeit eher
gering.
3.4. Ontologien
Ontologien sind, wie schon im Schaubild oben angedeutet, höherwertige semantische
Konzepte, die auf der Grundlage von RDF Zusammenhänge zwischen verschiedenen
Konzepten definieren. Diese können ganz unterschiedliche semantische
Ausdrucksfähigkeiten haben, wie in [DOS03]12 dargestellt wird.
12
vgl. Kapitel 7, Seite 156ff.
12Allgemein ist der Begriff der Ontologie schwer greifbar, er wird etwas mit Aussagen wie
„Formal definiertes System von Dingen“ und „Specification of a conceptualization“ recht
allgemein angegeben. Klarer wird der Zweck bei Betrachtung einiger Formen von
Ontologien:
Die (semantisch) einfachste Form einer Ontologie ist eine Taxonomie. Taxonomien ordnen
Konzepte hierarchisch in Baumform an, wobei sich benachbarte Knoten einer Ebene ein
genau einer Merkmalsausprägung unterscheiden sollen. Ein einfaches Beispiel wäre eine
Taxonomie zur Beschreibung von Kindern, die entweder Söhne oder Töchter sein können
und sich somit nur in der Eigenschaft des Geschlechts unterscheiden. Definiert werden also
SubTyp- und SuperTyp-Relationen. Dies ist zum Beispiel interessant, um ähnlich definierte
RDF-Konzepte verschiedener Anbieter ordnen zu können. Wird Rotwein als SubTyp von
Wein definiert, kann ein intelligenter Einkaufs-Agent beispielsweise aus der Kenntnis der
Relation den Schluss ziehen, dass bei einem Bedarf an Wein auch der Anbieter von Rotwein
berücksichtigt werden kann, auch wenn dieser den Begriff oder das Konzept des Weins nie
in seinen Artikelbeschreibungen verwendet hat. Im Rahmen der Projektgruppe können
Taxonomien Services (s.u.) einordnen, beispielsweise Flugvermittlung und Busvermittlung
als SubTyp von Transportdiensten.
Im angesprochenen „semantischen Spektrum“ der Ontologien ist an nächster Stelle der
Thesaurus anzusiedeln. Thesauri bieten die Möglichkeit, verschiedene Arten von Relationen
zu modellieren, die relevanteste dürfte die Definition von Synonymen sein: Angenommen,
zwei medizinische Institutionen haben eigene Taxonomien für Körperteile entwickelt, wie in
der Abbildung dargestellt:
Abbildung 4: Bedarf für Ontologien. Quelle: http://www.informatik.hu-
berlin.de/~bien/ontologie.html
13Abgesehen davon, dass die Benennungen durch unterschiedliche Zeichenketten hätten
stattfinden können (z.B. bei Verwendung von anderen Sprachen), ist die Beziehung vom
Begriff „Hand“ zum Begriff „Arm“ unterschiedlich modelliert: Im einen Fall (A) sind die
Begriffe Nachbarn im Hierarchiebaum der Taxonomie, im anderen Fall ist eine hand als Tei
des Armes dargestellt. Thesauri haben nun die Aufgabe zwischen diesen Konzepten eine
Beziehung herzustellen, so dass die Gleichartigkeit eindeutig formalisiert werden kann, auch
wenn die zugrunde liegenden Konzepte in verschiedenen Strukturen verschiedener
Namensräume eingebettet sind. Andere Anwendungsmöglichkeiten ergeben sich durch
Gleichstellung von Übersetzungen wie zum Beispiel und , oder auch im
Zusammenhang das gleiche meinende Begriffe wie hier .
Neben Synonymen können mit Thesauri aber auch Beziehungen wie „narrower than“,
„broader than“ oder noch allgemeiner „associated“ gestaltet werden 13. Für die Projektgruppe
können Thesauri dann interessant sein, wenn Dienste Ergebnisse zurückliefern, die vom Typ
gleichartig sind, aber verschieden strukturiert, um diese dann gemeinsam weiter zu
verarbeiten.
Ähnlich wie bei RDF ist die derzeitige Nutzung von Ontologien derzeit nicht sehr verbreitet,
stellen aber ein sehr aktives Forschungsthema (gerade im Zusammenhang mit Web
Services, s.u.) dar. In diesem Zusammenhang ist als Erfolg zu sehen, dass das W3C mit der
Web Ontology Language OWL in diesem Februar einen viel versprechenden Versuch
unternommen hat, eine XML-Sprache zur Beschreibung von Ontologien zu standardisieren.
Daher darf in Zukunft mit erhöhter Toolunterstützung gerechnet werden, die dann vermutlich
auch die Nutzung von RDF stärker motivieren kann, da die Verwendung dieser Metadaten
dann sehr viel mehr Nutzen bieten wird. Auf Basis von Ontologien wird es dann schließlich
möglich sein, logische Schlüsse zu ziehen und somit stärkere Semantik (vgl. auch Schaubild
Pyramide) zu ermöglichen.
13
vgl. [DOS03], Kapitel 7, Seite 160.
144. Web Services im Semantic Web
Große Teile der Literatur zum Semantic Web beschäftigen sich hauptsächlich mit der
semantischen Anreicherung von Dokumenten, also eher statischen Inhalten. Diese sind
insbesondere für unternehmensinterne Knowledge-Management-Anwendungen sinnvoll, da
hier viel statisches Material vorliegt und die Suche darin zurzeit nur ineffizient erfolgt. Wenn
man allerdings einen zweiten Blick auf die Inhalte in Intranets und erst recht im WWW des
Internets wirft, stellt man fest, dass viele Informationen primär durch Dienste zur Verfügung
gestellt werden. Dies umfasst zum einen dynamische Webseiten von Anbietern wie
Transportunternehmen oder auch das gezeigte Beispiel im zweiten Kapitel. Weiterhin sind
auch Web Services ohne konkretes User Interface verfügbar, um Daten dynamisch zur
Verfügung zu stellen (z.B. Amazons Web-Service-API) oder Dienstleistungen wie intensive
Berechnungen anzubieten.
Ein erster Bezug zum WWW im Allgemeinen ist durch die durchgängige Nutzung von Web-
Standards gegeben: SOAP-Nachrichten werden XML-kodiert über http oder https
übertragen, Dienstbeschreibungen erfolgen ebenfalls durch spezielles XML (WSDL) und
eignen sich somit zur Integration ins Semantic Web. Hierfür wurde auch schon der spezielle
Begriff „Semantic Web of Web Services“ (SWWS) geprägt14.
Applikationen, die Web Services nutzen möchten, haben die Möglichkeit diese dynamisch zu
suchen und damit die Dynamik des Internets bei der Integration von Services zu nutzen.
Dafür müssen diese aber automatisch auffindbar sein, was durch die Verwendung des
Protokolls UDDI gewährleistet werden soll: Ein Client kann darüber mit bestimmten
Verzeichnissen kommunizieren und so geeignete Dienste finden oder sich per Broker
vermitteln lassen. Da die WSDL-Beschreibungen hinterlegt sind, kann der Client dann direkt
gültige Anfragen an den ermittelten Dienst stellen. Die folgende Abbildung stellt dieses
Szenario noch einmal dar:
14
vgl. z.B. http://swws.semanticweb.org
15Abbildung 5: Zusammenhang zwischen WS-Technologien. Nach [Thronicke03] .
Soll ein Web Service also für eine möglichst große Zahl an potentiellen Clients (dies können
im Übrigen auch wieder Web Services sein) auffindbar sein, muss er sich in möglichst vielen
dieser Verzeichnisse mit seiner Dienstbeschreibung registrieren. Wünschenswert wäre
allerdings ein Suchansatz, der dies nicht voraussetzt und auch eigenständige Services z.B.
durch Webcrawling auffinden kann. In diesem Szenario ist es dann aber besonders wichtig,
dass die zur Verfügung stehenden Dienst-Informationen korrekt interpretiert werden, um eine
möglichst sachgerechte Nutzung zu ermöglichen, da keine dem Dienstanbieter bekannte
Brokerkomponente eine Steuerung (z.B. gegen Bezahlung zu seinen Gunsten) vornimmt.
Hier kommen die Auszeichnungstechnologien des Semantic Web ins Spiel: Hat der
Dienstbetreiber die Ergebnisstruktur seiner Dienste mit allgemein bekannten Metadaten
versehen, die auch Teil branchenüblicher Ontologien sind, kann der Nutzer einen echten
Mehrwert aus der Nutzung dieses Dienstes ziehen und die Ergebnisse mit einem hohen
Automatisierungsgrad weiter verarbeiten. In der folgenden Abbildung werden die
Zusammenhänge zwischen WWW, Web Services, dem Semantic Web und schließlich den
Semantic Web Services noch einmal verdeutlicht:
Abbildung 6: Einordnung Semantic Web Services. Nach [DOS03], Kap. 1, S. 7.
165. Fazit und Projektgruppenbezug
In diesem Kapitel soll abschließend der Bezug zu den Anforderungen der Projektgruppe
hergestellt werden. Dabei wird zunächst der Bedarf für semantische Suchverfahren ermittelt
und dann ein konkreter Vorschlag dargestellt und in eine mögliche Gesamtarchitektur
eingebettet.
Offenbar eignen sich die vorgestellten Technologien (insbesondere RDF) dafür,
Informationen semantisch anzureichern und die dafür verwendeten Begriffe und Konzepte zu
definieren. Ontologien können mit der Ontologie-Sprache OWL des W3C definiert werden,
um darauf aufbauend intelligente Such- und Agentendienste zu erstellen. Für eine Nutzung
dieser Suchverfahren ergeben sich meiner Meinung nach zwei grundsätzliche Szenarien:
• Suche nach Diensten (Service Discovery)
• Geografische Suchfunktionen, dies vor allem innerhalb bestimmter
Dienstrealisierungen.
Im ersten Fall ist es beispielsweise möglich, dass der Endanwender nur grob den Zweck
bzw. Nutzen eines gewünschten Dienstes angibt, also zum Beispiel „Ich möchte drucken“,
„Wo bin ich?“ oder „Ich möchte nach Frankfurt.“ In diesem Fall soll die Benutzerintention
erkannt und ein oder mehrere mögliche Dienste angeboten werden, die diesen Bedarf
decken können. Dabei könnten auch Gesamtdienste dynamisch aus Einzeldiensten
zusammengesetzt werden, so dass der Gesamtwunsch erreicht wird, auch wenn es keinen
einzelnen Service für diese Funktionalität gibt (z.B. Fahrplaninformationen von „Paderborn
Fürstenallee“ bis „London Big Ben“). Technologien wie RDF würden dazu verwendet,
Beschreibungen von Diensten auszuwerten. Haben diese beispielsweise als Rückgabe- oder
Eingabetyp ein global bekanntes Konzept wie „#bahnhof 15“ benutzt, könnte dies durch eine
geeignete Ontologie (einen Thesaurus) mit einer „#station“ gleichgesetzt werden und damit
zwei Reiserouten verschiedener Anbieter an einem solchen Punkt miteinander verknüpft
werden.
Im zweiten Fall können Auszeichnungen geografischer Objekte in Karten helfen, weitere
Information aus diesen zu generieren: Hat man beispielsweise zwei Routenplanungsdienste
nach einer bestimmten Tour angefragt, könnte ermittelt werden, ob teilweise gleiche
Strecken verwendet wurden und ob die Touren also als „echte“ Alternative zu anderen gelten
15
Diese Kurzschreibweise soll eine URI der bekannten Form andeuten.
17kann. Weiterhin sind Operationen auf geografischen Objekten denkbar, die beispielsweise
Überlappungen, Schnittpunkte oder Berührungspunkte von Regionen oder Straßen aus
verschiedenen Quellen ermitteln. Damit können Umkreissuchen intelligenter durchgeführt
werden. Im Projektgruppenzusammenhang ist es hier interessant, dass Karten mit SVG in
einem XML-Dialekt abgebildet werden können, so dass der Inhalt eines Kartenbildes
bekannt und auswertbar ist. Ebenso können auf diese Weise Kartenausschnitte (oder -
Layer) verschiedener Anbieter kombiniert ausgegeben werden, so dass die
Berührungspunkte der verschiedenen Quellen passend aneinander gefügt werden. Ideen für
weitere Einsatzfelder finden sich auch in [Corcoles03].
In vielen Diensten wird der Einsatz von Semantic Web-Techniken nicht unbedingt mehr
Nutzen bringen, als der Dienst ohnehin schon bietet. Dies wird immer dann der Fall sein,
wenn recht kleine abgeschlossene „Wissensbereiche“ betrachtet werden, wie beispielsweise
die Druckerstandorte an der Fürstenallee. Sollen allerdings externe Dienste dynamisch
eingebunden werden, ist es wünschenswert, benötigte und zurückgegebene Datentypen
nicht nur zu kennen, sondern auch wirklich zu „verstehen“, um die Weiterverarbeitung
möglicht automatisch zu gestalten.
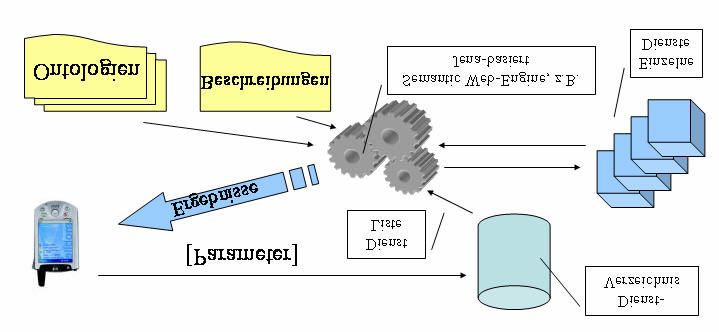
Im Vorfeld wurde überlegt, wo eine semantische Dienstsuche in einer möglichen Architektur
berücksichtigt werden kann. Die folgende Abbildung zeigt ein Schema, welches im
Anschluss kurz erläutert wird:
Abbildung 7: Mögliche Einbettung einer Semantischen Suche.
Angenommen wird eine Client-Server-Architektur, wobei erstere hier durch den PDA
dargestellt wird. Die zentrale Serverkomponente beinhaltet mindestens ein
18Dienstverzeichnis, die angedeutete Semantic-Web-Engine und die Dienste (bzw.
Schnittstellen zu diesen, falls extern). Wenn nun ein Client eine Anfrage allgemeiner Art
(s.o., vgl. „Ich möchte nach Frankfurt.“) abschickt, werden im Dienstverzeichnis noch ohne
weitere semantische Verfahren die vorhandenen Beschreibungen geprüft, welche dieser
Dienste für die Anfrage passend erscheinen. Da bei einer in Freitext formulierten Anfrage
vermutlich keine besonders genauen Treffer gefunden werden, wird eine breitere Dienstlist
(u.U. auch alle) an die SW-Engine weitergereicht, die dann feststellen kann, dass
beispielsweise „Frankfurt“ ein Ort ist und dann die Dienstbeschreibungen dahingehend
auswerten kann. Es werden also eine oder mehrere (bei Komposition von Diensten) konkrete
Dienstanfragen im speziellen Protokoll formuliert, abgeschickt und die Rückgabe an den
Client konstruiert und zurückgegeben. Dabei können natürlich weitere Transformations-
und/oder Middleware-Komponenten liegen, die beispielsweise die grafische Aufarbeitung
durchführen. Zentral abgelegte Ontologien und über das im Dienstverzeichnis gespeicherte
hinausgehende Dienst- und Typbeschreibungen werden dabei von der SW-Engine
verwendet. Die Ontologien bilden dabei Brücken zwischen verschiedenen
Beschreibungsarten und erlauben damit auch die flexiblere Einbindung externer Dienste.
Nicht berücksichtigt ist hierbei, dass gewisse Dienste auch semantische Verfahren zur
Verbesserung der Ergebnisqualität verwenden mögen, dies sollte aber meiner Meinung auch
getrennt von der o.g. Engine implementiert sein, um die Transparenz der zentralen
Middleware zu gewährleisten.
Der Gewinn liegt darin, dass nun der Raum möglicher Anfragen an das System erweitert
wird, da zum Beispiel auch die korrekte Komposition unbekannter externer Dienste
ausgenutzt wird. Voraussetzung dafür ist natürlich die Unterstützung der global bekannten
Konzepte, bzw. das Schreiben von Ontologien, um diese geeignet abzubilden.
Die Einführung von semantischen Anreicherungen, Ontologien und Software, die diese
Dinge auch nutzt ist derzeit noch recht aufwendig. Es gibt bereits Frameworks, die z.B. Java-
Klassen zur Verfügung stellen, mit denen OWL- und RDF-Fragmente verarbeitet und
interpretiert werden können, beispielsweise eine Open-Source-Implementierung der Hewlett
Packard-Labs 16. Da diese allerdings hauptsächlich in Forschungsprojekten eingesetzt
werden, sind praktische Erfahrungen zurzeit noch wenig dokumentiert. Es muss daher im
Kreis der Projektgruppe zunächst generell entschieden werden, ob eine Verwendung der
genannten Techniken einen tatsächlichen Mehrwert bringt, der den Aufwand auch
rechtfertigt. Erst die „semantisch höheren“ Ontologien bringen einen spürbaren Nutzen, für
die aber eine RDF-Auszeichnung aller zu berücksichtigenden Inhalte erforderlich ist. In den
16
Das Projekt „Jena“ ist zu finden auf [HPBristol].
19Treffen der Projektgruppe nach der Seminarphase hat sich bereits ein grobes
Architekturmodell erkennen lassen, welches darauf ausgelegt ist, zunächst einmal zu
„funktionieren“ und auch schon in der derzeitigen Form arbeitsintensiv genug für die
Projektgruppe zu sein scheint. In diesem Kontext kann die Berücksichtigung von
Semantischer Suche zurzeit nur als „Luxus“ betrachtet und zunächst nicht empfohlen
werden.
20Quellen
Literatur
[Berners-Lee97] Berners-Lee, Tim with Fischetti, Mark: Weaving the Web. Harper San
Francisco, 1997.
[Corcoles03] Cócoles, J.E.; Gonzáles, P.: Querying Spatial Resources. An Approach to the
Semantic Geospatial Web. CAiSE ’03 Workshop “Web Services, e-Business and the
Semantic Web (WES): Foundations, Models, Architecture, Engineering and Applications.”.
[DOS03] Daconta, Michael C; Orbst, Leo J.; Smith, Kevin T: The Semantic Web: A Guide to
the Future of XML, Web Services, and Knowledge Management. Wiley Canada, 2003.
[Hjelm01] Hjelm, Johan: Creating the Semantic Web with RDF. Wiley Canada, 2001.
[Roth02] Roth, Alexander: Modellierung und Anwendung von Ontologien am Beispiel
„Operations Research & Management Science“. Seminararbeit am DSOR-Lab, Universität
Paderborn, 2002.
[Thronicke03] Thronicke, Wolfgang: Web Services – Ein Überblick. Vortragsfolien des C-Lab
(Universität Paderborn und Siemens Business Services OHG), 2003.
[TT04] Tilly, Marcel; Tilkov, Stefan: Enspannung pur: Die Schema-Sprache Relax-NG. iX
special 1/2004, S.24.
[WBS02] Suhl, Leena; Kassanke, Stephan; Scholz. Michael: Grundlagen von Web Based
Systems. Vorlesungsskript zur gleichnamigen Vorlesung an der Universität Paderborn.
Paderborn, Oktober 2002.
[Ziegler04] Ziegler, Cai: Surfende Maschinen Web Ontology Language – Vokabulare fürs
Web. iX special 1/2004, S. 126.
21Links & Web (Auszug)
[ebXML] Sammlung von Spezifikationen für Geschäftskommunikation über XML:
http://www.ebxml.org
[HPBristol] Hewlett Packard Labs, Bristol, UK:
http://www.hlp.hp.com/semweb
[SW.org] The Semantic Web Community Portal:
http://www.semanticweb.org/index_old.html
[Verivox] Dienstleister im Bereich Tarifvergleiche:
http://www.verivox.de/Home/Webmaster/Fixed/Schnellabfrage.asp
[W3C] World Wide Web Consortium
http://www.w3.org
22Sie können auch lesen

















































