Testfallgenerierung für automotive O board-Szenarien
←
→
Transkription von Seiteninhalten
Wenn Ihr Browser die Seite nicht korrekt rendert, bitte, lesen Sie den Inhalt der Seite unten
Bachelor of Science
Fakultät Informatik
Flug- und Fahrzeuginformatik
Testfallgenerierung für automotive
Oboard-Szenarien
Vor- und Zuname: Thomas Martin Egen
Erstprüfer: Zweitprüfer:
Prof. Dr. Robert Gold Prof. Dr. Sebastian Apel
Betreuer: Dr. André Reichstaller
ausgegeben am: 03.11.2020
abgegeben am: 30.01.2021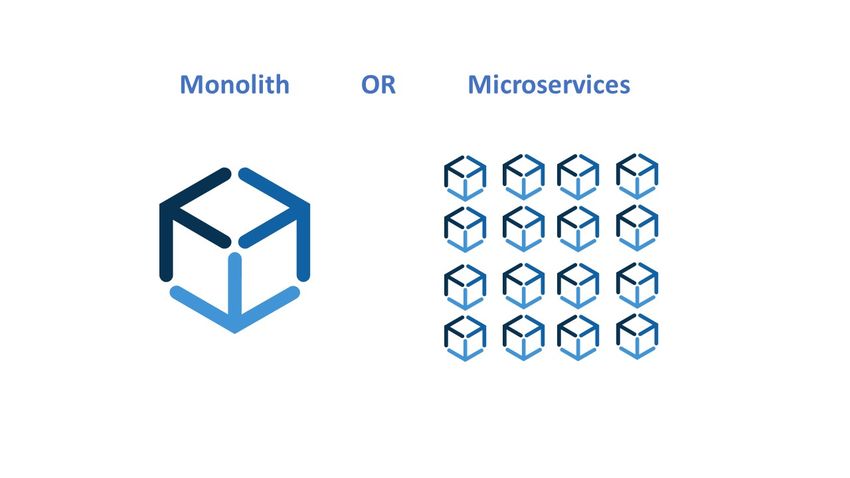
Eidesstattliche Erklärung
Erklärung nach 18 Abs. 4 Nr. 7 APO THI:
Ich erkläre hiermit, dass ich die Arbeit selbstständig verfasst, noch nicht anderweitig für Prü-
fungszwecke vorgelegt, keine anderen als die angegebenen Quellen oder Hilfsmittel benützt sowie
wörtliche und sinngemäÿe Zitate als solche gekennzeichnet habe.
Ingolstadt, 30.01.2021
Unterschrift:
Thomas Martin Egen
i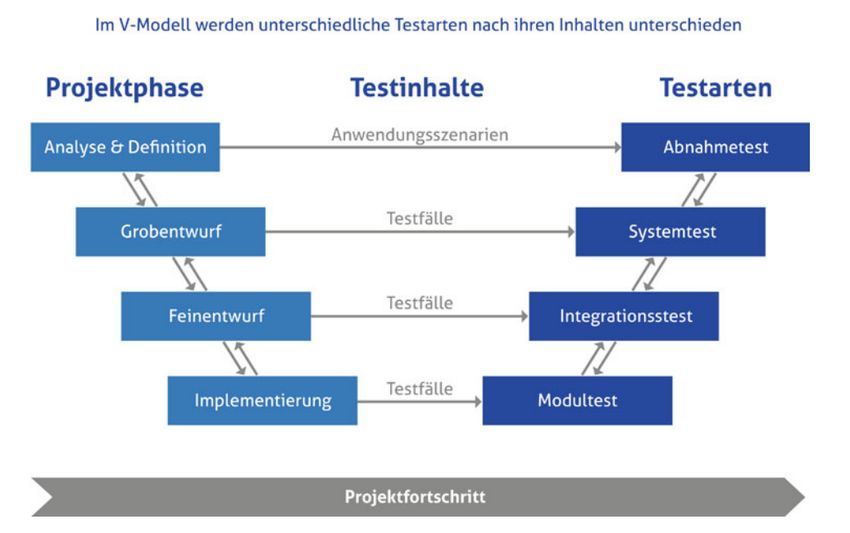
Abstract
Die automatisierte Testfallgenerierung gewinnt in der heutigen Zeit immer mehr an Be-
deutung, auch in der Automobilindustrie. Um fehlerfreie Services für den Kunden zu er-
möglichen, müssen die Systeme möglichst vollständig getestet werden.
Das Tool Plantestic generiert aus Sequenzdiagrammen ausführbare Java-Testfälle, die di-
rekt zum Testen dieser Schnittstellen verwendet werden können. Hohe Kosten, die im
Normalfall bei der Testerstellung entstehen, werden somit auf ein Minimum reduziert.
Diese Arbeit beschäftigt sich mit der Anpassung und Weiterentwicklung des Testfallgene-
rators Plantestic an die Anforderungen und Bedürfnisse in der Automobildomäne, speziell
an das Connected Drive Backend der BMW Group. Im Folgenden werden die Hindernisse
im automotiven Umfeld und die möglichen Lösungsansätze für diese Probleme angegangen.
Auÿerdem wird ein Fokus auf zukünftige Arbeiten gelegt, die Plantestic verbessern und an
ein breiteres Anwendungsszenario anpassen. Dabei werden auch mögliche Lösungsszenari-
en für diese Ideen aufgezeigt.
Schnittstellenbeschreibungen sowie implementierter Code der BMW Group sind aus Grün-
den der Geheimhaltung nicht in dieser Arbeit enthalten.
ii
Danksagung
An dieser Stelle möchte ich mich zunächst bei meinem Betreuer Dr. André Reichstaller
bedanken, der mir ein breites Angebot an Themen zur Verfügung gestellt hat und viele
Tipps bzw. Hilfestellungen in Bezug auf diese Arbeit gegeben hat.
Auÿerdem möchte ich mich bei Prof. Dr. Robert Gold für die hilfreichen Anregungen bei
den Zwischenkorrekturen und die Betreuung meiner Arbeit bedanken.
iii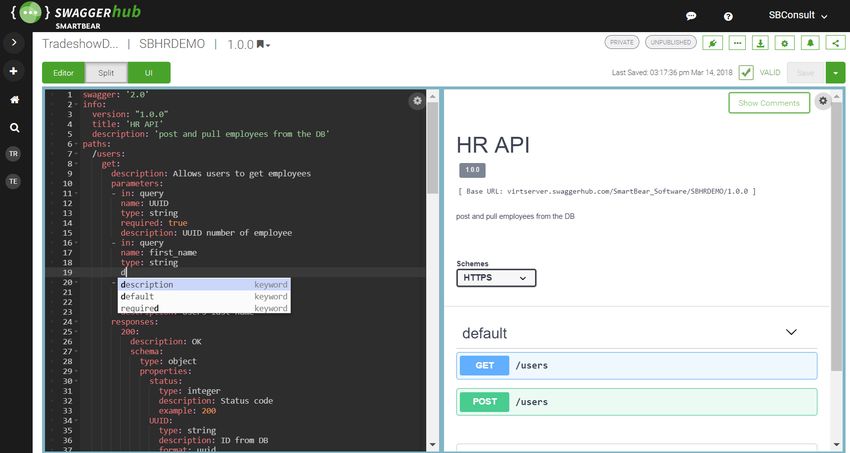
Inhaltsverzeichnis
Eidesstattliche Erklärung i
Abstract ii
Danksagung iii
Inhaltsverzeichnis iv
1 Einleitung 1
1.1 Zunehmende Bedeutung von automatisierter Testfallgenerierung . . . . . . . 1
1.2 Zielsetzung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2
1.3 Aufbau der Arbeit . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3
2 Grundlagen 4
2.1 Programmiersprache Kotlin . . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2.1.1 Eigenschaften und Unterschiede zu Java . . . . . . . . . . . . . . . . 4
2.1.2 Nützliche Funktionalitäten . . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.2.1 Scope-Funktionen . . . . . . . . . . . . . . . . . . . . . . . 6
2.1.2.2 Unterschied 'gleich' und 'identisch' . . . . . . . . . . . . . . 6
2.1.2.3 String Templates . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.2.4 Ranges . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.2.5 When-Verzweigung . . . . . . . . . . . . . . . . . . . . . . . 7
2.1.2.6 Companion Objects . . . . . . . . . . . . . . . . . . . . . . 8
2.2 Eclipse Modeling Framework . . . . . . . . . . . . . . . . . . . . . . . . . . 8
2.3 Frameworks zur Schnittstellenbeschreibung . . . . . . . . . . . . . . . . . . 9
2.3.1 Komponenten Swagger . . . . . . . . . . . . . . . . . . . . . . . . . . 10
2.3.2 API-First vs. Code-First . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.3.3 OpenAPI 2.0 vs. OpenAPI 3.0.0 . . . . . . . . . . . . . . . . . . . . 12
2.4 Testen von Software . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13
3 Stand der Technik 16
3.1 Testen in Oboard-Szenarios . . . . . . . . . . . . . . . . . . . . . . . . . . 16
3.2 Cucumber . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 17
3.3 RestAssured . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18
3.4 Verwandte Arbeiten . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.4.1 Sky
re . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
3.4.2 ParTeG . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19
4 Einsatz des Testfallgenerierungstools Plantestic 20
4.1 Funktionsweise Plantestic . . . . . . . . . . . . . . . . . . . . . . . . . . . . 20
4.2 Vergleich bestehender Versionen . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.2.1 Bestehende Features . . . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.2.1.1 Automatische Generierung von Kon
gurationsdateien . . . 22
4.2.1.2 Direkt ausführbare Test-Suite . . . . . . . . . . . . . . . . . 22
iv
4.2.1.3 Vervollständigung via Swagger . . . . . . . . . . . . . . . . 22
4.2.1.4 Gradle-Plugin . . . . . . . . . . . . . . . . . . . . . . . . . 22
4.2.1.5 Integrierte PlantUML IDE . . . . . . . . . . . . . . . . . . 23
4.2.1.6 Asynchrone Requests . . . . . . . . . . . . . . . . . . . . . 23
4.2.1.7 Integrierte GUI . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.2.2 Verwendete Version . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23
4.3 Hindernisse im automotiven Umfeld . . . . . . . . . . . . . . . . . . . . . . 25
4.4 Lösungsansätze . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26
4.4.1 Umgang mit Sicherheitsmechanismen . . . . . . . . . . . . . . . . . . 26
4.4.2 Vorverarbeitung via Swagger . . . . . . . . . . . . . . . . . . . . . . 28
4.4.3 Testen von Interaktionssequenzen . . . . . . . . . . . . . . . . . . . . 29
5 Diskussion 33
5.1 Anwendung auf ein BMW Oboard-Szenario . . . . . . . . . . . . . . . . . 33
5.1.1 Testen einer Interaktionssequenz . . . . . . . . . . . . . . . . . . . . 33
5.1.2 Testmöglichkeiten . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34
5.1.3 Angewandte Weiterentwicklungen . . . . . . . . . . . . . . . . . . . . 35
5.2 Limitierungen des Tools . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 36
5.3 Schwachstellen des Eclipse Modeling Frameworks . . . . . . . . . . . . . . . 38
6 Zusammenfassung und Ausblick 40
6.1 Zusammenfassung . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
6.2 Ausblick . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40
6.2.1 Integration von Basis-Kommunikationsmitteln des Fahrzeugs . . . . 41
6.2.2 Einbindung in den Entwicklungsprozess . . . . . . . . . . . . . . . . 41
6.2.3 Integration asynchroner Interaktionssequenzen . . . . . . . . . . . . 42
6.2.4 Erweiterung der Testfälle . . . . . . . . . . . . . . . . . . . . . . . . 43
Abbildungsverzeichnis vi
Abkürzungsverzeichnis vii
Literatur viii
v
Kapitel 1
Einleitung
1.1 Zunehmende Bedeutung von automatisierter Testfallge-
nerierung
Programmierer schreiben lieber Code als Tests und kürzen das Testschreiben manchmal
ab. (Sommerville, 2018, S.98)
Diese Feststellung traf Ian Sommerville in seinem Buch Software Engineering und sie trit
höchstwahrscheinlich auch auf den Groÿteil aller Entwickler zu. Entwickler lieben es pro-
duktiven Code zu implementieren und nicht mit vielen Zeilen von Testcode einen einzigen
Fehler zu entdecken oder im schlimmsten Fall überhaupt nie einen Fehler aufzudecken.
Aus diesem Grund soll die Testerstellung so einfach wie möglich gehalten werden und
den Entwicklern damit viel Arbeit und Zeit ersparen. Ein weiterer Grund sind die ho-
hen Kosten, die für Tests entstehen. In einem durchschnittlichen Software-Projekt werden
mittlerweile 40% der Kosten in die Testentwicklung und nur noch 60% in die tatsächliche
Implementierung des Codes gesteckt (Sommerville, 2018). Das bedeutet, je automatisierter
die Testerstellung vonstatten geht, desto mehr Geld kann gespart werden bzw. umso mehr
Zeit und Geld kann in weitere Features des Projekts investiert werden.
Testfälle können nicht auf Knopfdruck erstellt werden. Um Testfälle erstellen zu können,
werden bestimmte Eingaben benötigt. Auÿerdem muss die zugrundeliegende Architektur
genauestens gekannt werden. Es muss klar sein, wie die Testfälle aussehen und welche Tei-
le des Systems getestet werden sollten. Die vorliegende Arbeit konzentriert sich auf die
automatisierte Testfallgenerierung in der Automobildomäne, speziell dem Oboard von
Connected Drive.
Connected Drive ist ein umfangreiches System der BMW Group, bei dem der Kunde Funk-
tionen seines Fahrzeugs per Smartphone-App oder Web-API nutzen kann. Beispielhafte
Funktionen sind z.B. das Abfragen des aktuellen Tankstands oder das Önen und Schlie-
ÿen des Automobils. Aber auch Notruf-Services bei einem Unfall oder Pannenhilfen sind
Teil von Connected Drive. Die Kommunikation zum Fahrzeug erfolgt über eine eingebaute
SIM-Karte mithilfe des Protokolls joynr. Bei älteren Fahrzeugen wird das NGTP-Protokoll
verwendet. Im Backend agiert BMW über eine Microservice-Architektur, die das Verbin-
dungsglied zwischen dem Fahrzeug und der App bzw. WebAPI darstellt.
Mit einer Microservice-Architektur wird das Ziel einer Architektur verfolgt, die aus mög-
lichst kleinen, unabhängigen Services besteht. Die Kommunikation dieser Services
ndet
über leichtgewichtige Mechanismen wie beispielsweise das Protokoll HTTP statt. Anders
als beim Gegenstück Monolith können die verschiedenen Services getrennt voneinander be-
reitgestellt werden (Abbildung 1.1). Daraus ergeben sich insbesondere für groÿe Systeme
viele Vorteile, die genutzt werden können. Die Services sind unabhängig voneinander und
1
Kapitel 1. Einleitung
Abbildung 1.1: Unterschied zwischen der Architektur eines Monolith und
der eines Microservices (Abbott, 2020).
können mit verschiedenen Technologien verwirklicht werden. Dabei spielt es keine Rolle,
ob in einem Microservice Java als Programmiersprache verwendet wird und im anderen
Python. Es kann jederzeit das sinnvollste Framework oder die passendste Technologie ver-
wendet werden (Namiot, 2014). Die verschiedenen Services können auÿerdem besser auf
verschiedene Abteilungen oder Gruppen aufgeteilt werden, ohne dass jemand am Code der
anderen Gruppe implementiert (Newman, 2015). Einen groÿen Vorteil durch die Unabhän-
gigkeit der Services stellt die Skalierbarkeit dar. Microservices, die höher belastet werden,
können dadurch leicht nach oben skaliert werden, um den optimalen Rechenbedarf zu er-
füllen. Weniger belastete Services werden nach unten skaliert (Namiot, 2014).
Firmen wie BMW verwenden für die Kommunikation ihrer Microservice-Architektur REST
APIs, die auf das Protokoll HTTP zurückgreifen. Damit eine fehlerfreie Kommunikation
und somit auch verlässliche Services für den Kunden gewährleistet werden, müssen die
Schnittstellen getestet werden. Dabei werden Requests an den Server gestellt. Die Respon-
ses werden auf Vollständigkeit der benötigten Parameter und auf den richtigen Response-
Code überprüft. Durch die extrem vielen Schnittstellen und die stetigen Änderungen ist
die Erstellung der Testfälle eine sehr aufwendige Arbeit, die es zu minimieren gilt.
1.2 Zielsetzung
Da nun bekannt ist, welche Aufgaben die automatisch generierten Testfälle abdecken müs-
sen, stellt sich die Frage, woher die Informationen dieser Schnittstellen kommen. Bereits in
der De
nitionsphase der Anforderungen werden bei Firmen wie BMW Sequenzdiagramme
erstellt, die das Zusammenspiel der Microservices abbilden. Die Idee ist es, mit den Infor-
mationen der Sequenzdiagramme als Eingabe, automatisiert Testcode zu erstellen. Dabei
werden zwei Probleme auf einmal gelöst. Erstens wird gewährleistet, dass die Anforderung-
en eingehalten und nicht verschieden interpretiert werden. Zweitens wird die Erstellung des
Testcodes beschleunigt und bewirkt dadurch eine groÿe Arbeitserleichterung und Kosten-
ersparnis.
Bereits im Jahr 2019 wurde das Testfallgenerierungstool Plantestic von Studenten der
Technischen Universität München (TUM) ins Leben gerufen (Guerin, 2019). Dieses wurde
seit der Erstellung und ersten Version stetig weiterentwickelt und steht als Open-Source-
Projekt zur Verfügung. Plantestic nutzt PlantUML Sequenzdiagramme und generiert dar-
aus Java-Testfälle.
2
Kapitel 1. Einleitung
Dieses Tool wurde aber nicht für die Automobilindustrie oder speziell für das Backend von
BMW Connected Drive entwickelt. Damit wird sich die folgende Arbeit befassen. Plantestic
sollte bestmöglich an die Bedürfnisse und Anforderungen der Automobildomäne angepasst
und dahingehend weiterentwickelt werden.
1.3 Aufbau der Arbeit
In den Grundlagen dieser Arbeit wird zunächst auf die vergleichsweise neue und aufstre-
bende Programmiersprache Kotlin eingegangen. Anschlieÿend wird das Eclipse Modeling
Framework genauer durchleuchtet. Dieses verwirklicht den modellgetriebenen Ansatz in
der Entwicklung von Plantestic. Bevor einige Informationen bezüglich des Testens erläutert
werden, wird anhand des Frameworks Swagger die Beschreibung von Schnittstellen erklärt.
Im Stand der Technik wird auf das Testen in Oboard-Szenarios eingegangen. Auÿer-
dem werden die Besonderheiten der beiden Test-Frameworks Cucumber und RestAssured
herausgearbeitet. Daraus wird ersichtlich, aus welchen Gründen RestAssured für die Ent-
wicklung von Plantestic verwendet wurde.
Im Kapitel 4 wird der Fokus auf den Einsatz am Testfallgenerierungstool Plantestic gelegt.
Dort wird zuerst die Funktionsweise aufgezeigt, bevor ein Vergleich der bestehenden Ver-
sionen erfolgt. Auf die Hindernisse, die einem im automotiven Umfeld begegnen, folgt am
Ende eine Au
istung der möglichen Lösungsansätze.
Daraufhin folgt eine Anwendung an einem Szenario der BMW Oboard-Plattform. Auÿer-
dem werden die Limitierungen von Plantestic und die Schwachstellen am Eclipse Modeling
Framework hervorgehoben.
Am Schluss folgt eine Zusammenfassung der Arbeit und ein kleiner Ausblick auf mögliche
Zukunftsthemen mit Lösungsszenarien, an denen in darauolgenden Arbeiten eingegangen
werden kann.
3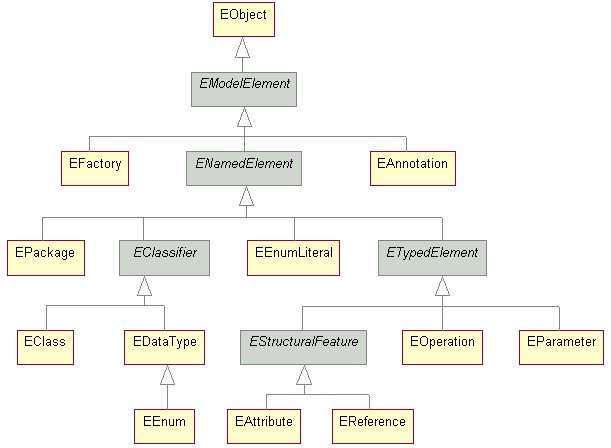
Kapitel 2
Grundlagen
2.1 Programmiersprache Kotlin
Kotlin ist eine neue Programmiersprache, deren erste stabile Version im Jahr 2016 ver-
öentlicht wurde. Bereits seit 2011 wird die Sprache von einem Team der IDE IntelliJ
gep
egt und weiterentwickelt. Deshalb besteht auch die Verbindung zu Java und Android,
da die von Google primär unterstützte IDE, Android Studio, auf IntelliJ basiert (Szwillus,
2020).
Aufgrund der einfachen Syntax und vielen weiteren Vorteilen
ndet Kotlin auch im Test-
fallgenerierungstool Plantestic Verwendung. Einige der nützlichen Funktionalitäten werden
zusätzlich im Abschnitt 2.1.2 beleuchtet.
2.1.1 Eigenschaften und Unterschiede zu Java
Java ist eine der am meist genutzten Programmiersprachen weltweit. Seit der Veröent-
lichung im Jahr 1994 hat sich eine sehr groÿe Community gebildet. Die Sprache ist sehr
gut dokumentiert. Ein sehr groÿer Erfolgsfaktor ist, dass der Code einmal geschrieben wird
und überall ausführbar ist. (Schwermer, 2018).
Listing 2.1: Java-Code
1 c l a s s Book {
2 private S t r i n g t i t l e ;
3 private Author author ;
4
5 public S t r i n g g e t T i t l e ( ) {
6 return t i t l e ;
7 }
8 public void s e t T i t l e ( S t r i n g t i t l e ){
9 this . t i t l e = t i t l e ;
10 }
11 public Author getAuthor ( ) {
12 return author ;
13 }
14 public void setAuthor ( Author author ){
15 t h i s . author = author ;
16 }
17 }
Listing 2.2: Kotlin-Code
1 data c l a s s Book ( var t i t l e : String , var aut : Author )
4Kapitel 2. Grundlagen
Diese und noch einige weitere Vorteile vereint die Programmiersprache Kotlin. Beispielswei-
se ist es kein Problem Java und Kotlin in einem Projekt zu kombinieren. D.h. ein Projekt,
das komplett in Java geschrieben ist, kann auch durch Klassen mit Kotlin-Code erweitert
werden. Zusätzlich gibt es eine Konvertierungsfunktion, mit deren Hilfe Java-Code auto-
matisch in Kotlin-Code umgewandelt wird (Szwillus, 2020).
Java is a verbose language, thus one of the main drawbacks of the language is that even
simple tasks often entail writing a signi
cant amount of code. (Flauzino, 2018, S. 1)
Da Java eine sehr wortreiche Sprache ist, war es für die Entwickler von Kotlin sehr wich-
tig, eine kürzere und damit auch wesentlich übersichtlichere Sprache zu entwickeln. Einen
groÿen Unterschied bezüglich der Länge des Codes kann in den Code Listings 2.1 und 2.2
erkannt werden (Flauzino, 2018). Dort wird eine Klasse dargestellt, die Daten eines Buchs
enthält.
Während bei Java erst alle Variablen deklariert und Getter bzw. Setter-Methoden im-
plementiert werden müssen, funktioniert dies bei Kotlin automatisch über eine data class.
Zudem werden am Ende einer Anweisung keine Semikolons mehr benötigt (Szwillus, 2020).
The best code is no code at all.
Dieser Satz aus Kotlin - Einstieg und Praxis (Szwillus, 2020, S. 25) passt sehr gut zur
Philosophie von Kotlin. Boilerplate-Code, also Standard-Code oder über
üssige Zeichen
werden auf ein Minimum reduziert. Dadurch benötigt Kotlin weniger Zeichen, um komple-
xe Zusammenhänge zu beschreiben.
Zur Reduktion werden dabei folgende Prinzipien verwendet:
Vereinfachungsregeln für zahlreiche Aufrufe und Kurzformen
Einzeilige Funktionen zur Rückgabe eines Wertes
Datenklassen, deren Quellcode auf eine Zeile reduziert werden kann
Kurzschreibweisen mit Lambdas und Standardfunktionen
Extension-Funktionen statt Helper/Utility-Klassen
Mapping-Funktionen der Collection-Klassen
Weitere Sprachfeatures wie die Null-Sicherheit und die statischen Typen reduzieren nicht
nur die Codegröÿe, sondern auch Sicherheitsrisiken. Zusätzlich verhindern die gute Test-
barkeit und die Vermeidung von Seiteneekten durch funktionale Programmstrukturen das
Entstehen von Sicherheitslücken.
Grundsätzlich kann man nicht sagen, dass Java mittlerweile eine unsichere Programmier-
sprache geworden ist. Es ist aber wahrscheinlicher, dass Sicherheitsrisiken entstehen kön-
nen, falls sich der Entwickler nicht intensiv damit befasst. Bei Java-Projekten nimmt der
Code zur Behandlung von null oder auch Fehler bei der unsauberen Prüfung von null eine
hohe Rolle ein. In Kotlin wird dem Entwickler diese Arbeit erleichtert, denn bereits der
Compiler wertet aus, ob eine Variable oder ein Objekt zum Verwendungszeitpunkt null ist
oder sein kann.
5Kapitel 2. Grundlagen
Auch bei der statischen Typisierung erkennt der Compiler welchen Typ eine Variable
zu einem bestimmten Zeitpunkt hat. Abschlieÿend kann also gesagt werden: Der Kotlin-
Compiler ist einfach cleverer als der Compiler von Java (Szwillus, 2020).
2.1.2 Nützliche Funktionalitäten
Kotlin bietet viele nützliche Funktionalitäten, die dem Entwickler leider oft verborgen
bleiben, da es sie teilweise in anderen Programmiersprachen gar nicht gibt. Diese kleine
Übersicht soll den Fokus auf ein paar dieser Funktionalitäten werfen und dadurch zur Ver-
wendung animieren.
2.1.2.1 Scope-Funktionen
Kotlin bietet eine Reihe von Hilfsmethoden (let, run, apply, also), um den Kontext oder
Scope in einem Programmblock zu verschieben (Szwillus, 2020). Als Anwendungsbeispiel
dient hier die also-Funktion. Mit dieser Funktion kann beispielsweise ein Rückgabewert
berechnet werden und gleichzeitig, bevor der Wert zurückgegeben wird, ein anderer Ne-
beneekt angewendet werden (Sree, 2020).
Listing 2.3: Scope Funktion also
1 var x = 5
2 var y = 7
3 x = y . a l s o {y=x}
4
5 p r i n t l n ( x ) //x==7
6 p r i n t l n ( y ) //y==5
Dadurch ist es möglich, die Werte zweier Variablen zu tauschen, ohne dabei eine temporäre
Variable anlegen zu müssen, in der eine Zwischenspeicherung statt
ndet (Code-Listing 2.3).
Damit der Wert einer Variable überhaupt geändert werden kann, muss sie mit 'var' dekla-
riert werden. Variablen, die mit 'val' deklariert werden, sind unveränderlich.
2.1.2.2 Unterschied 'gleich' und 'identisch'
Bei Kotlin gibt es einen Unterschied zwischen '==' und '==='. Die beiden Gleichheitszei-
chen stehen für 'gleich' und die drei Gleichheitszeichen stehen für 'identisch'.
Listing 2.4: Unterschied '==' und '==='
1 val a: Int = 128
2 val b: Int ? = a
3
4 if ( a == b ) // true
5 if ( a === b ) // f a l s e
Am Besten kann der Unterschied in Code-Listing 2.4 erkannt werden. Da die beiden Varia-
blen den gleichen Wert haben, ist die erste Bedingung true. Der Typ der beiden Variablen
ist allerdings unterschiedlich. Die Variable a ist dabei ein normaler Integer und die Variable
b ein null-sicherer Integer. Nur wenn der Wert der beiden Variablen und der Typ über-
einstimmen sind die beiden Variablen identisch und die Bedingung wäre true (Szwillus,
2020). Mit einer null-sicheren Variable sollen NullPointerExceptions verhindert werden.
Der Compiler lässt keine Aktionen zu, in denen eine NullPointerException auftreten kann.
6Kapitel 2. Grundlagen
Dazu muss immer geklärt sein, was im null-Fall passieren kann. Übergangen werden kann
diese Unterstützung über zwei Ausrufezeichen nach der Variable.
2.1.2.3 String Templates
Mithilfe der String Template Funktion können direkt in einen String die Werte anderer
Variablen eingefügt werden. Dafür muss nur ein Dollar-Zeichen vor die Variable gehängt
werden. Bei Funktionsaufrufen erfolgt der Aufruf in geschweiften Klammern nach dem
Dollar-Symbol. Wird das Dollar-Zeichen als String benötigt, dann wird vor dem Symbol
ein Backslash gesetzt.
Listing 2.5: String Templates
1 val name = "Hans"
2 val mathe = """Der junge $name lernt gerade
3 die Wurzel von 2.
4 Sie ist ${sqrt /2f)}"""
Mit dem Raw-String Format werden die Zeilenumbrüche direkt im Code untergebracht.
Dafür muss der String mit drei Anführungszeichen begonnen und mit drei Anführungs-
zeichen beendet werden. Die verschiedenen String Templates können in Code-Listing 2.5
noch einmal inspiziert werden. Dort wird der Name Hans in den String Mathe eingefügt.
Die Zeilenumbrüche werden bereits im Code durchgeführt. Das Ergebnis des Aufrufs der
sqrt-Funktion wird ebenfalls in den String eingefügt (Szwillus, 2020).
2.1.2.4 Ranges
Mithilfe einer Range können auf eine schnelle Art und Weise Listen de
niert werden.
Besonders vorteilhaft ist das in for-Schleifen. Meistens werden Ranges bei Zahlen oder
Buchstaben mit einer natürlichen Ordnung verwendet.
Listing 2.6: Ranges
1 val buchstaben = a . . Z // Buchstaben von a = z und A = Z
2 val z a h l e n = 20 u n t i l 25 // a l l e Zahlen von 20 b i s 24
3 val countdown = 5 downTo 1 // a l l e Zahlen von 5 b i s 1
4 val steps = 0..20 step 2 // 0 ,2 ,4 ,6 ,...20
Im Code-Listing 2.6 sind ein paar Operatoren dargestellt, mit denen die Erstellung noch
leichter fällt. Der Step-Operator de
niert die Schrittweite, mit 'downTo' kann die Richtung
der Erstellung umgekehrt werden und mit until wird der letzte Wert der Range ausgeschlos-
sen (Szwillus, 2020).
2.1.2.5 When-Verzweigung
Die When-Verzweigung (Code-Listing 2.7) ist im Prinzip eine Erweiterung zur Switch/case-
Verzweigung in Java. Sie wird dann eingesetzt, wenn eine Fallunterscheidung nötig ist. Bei
einer When-Verzweigung können die Bedingungen von mehreren Variablen abhängig sein.
Der Variablentyp muss dabei keinem Integer entsprechen.
7Kapitel 2. Grundlagen
Listing 2.7: when-Verzweigung
1 when {
2 e i n g a b e == 5 => p r i n t l n ( "Zahl gleich 5" )
3 e i n g a b e % 2 == 0 => p r i n t l n ( "Zahl ist gerade" )
4 }
Einen Nachteil hat die When-Verzweigung allerdings im Gegensatz zu Switch-Case. Meh-
rere positive Evaluationen können nicht mehr auf einmal durchgeführt werden. Stattdessen
ist es möglich, mehrere gleichartige Bedingungen zu kombinieren (Szwillus, 2020).
2.1.2.6 Companion Objects
Companion Objects stellen grundsätzlich Singleton-Objekte dar. Sie werden innerhalb von
Klassen de
niert. Die Funktionen und Werte können von überall aufgerufen werden, dazu
muss die Klasse nicht einmal instanziiert werden (Szwillus, 2020).
2.2 Eclipse Modeling Framework
Should I model or should I program? (Steinberg, 2009, S. 15)
Diese Frage stellen sich viele Entwickler, bevor sie an einem neuen Projekt arbeiten. Beim
Eclipse Modeling Framework gibt es deshalb die Möglichkeit beides zu tun. Es ist auf
sehr e
zientes Programmieren getrimmt und die Aufteilung zwischen Code und Modell
bleibt jedem selbst überlassen. Für Einsteiger bietet EMF eine hervorragende Möglichkeit
zu beschreiben, was eine Applikation tun soll. Dies wäre mit Code um einiges schwieriger.
Aber auch für Fortgeschrittene bringt EMF einige Möglichkeiten, um noch einfachere bzw.
e
zientere Applikationen zu entwickeln (Steinberg, 2009).
Abbildung 2.1: Aufbau Ecore-Modell (Eclipse, 2021)
8Kapitel 2. Grundlagen
In der Welt der modellgetriebenen Entwicklung ist das Eclipse Modeling Framework ein
Hauptbestandteil, auf den sehr gerne zurückgegrien wird. Er vereint drei sehr wichtige
Technologien: Java, XML und UML. Dabei können alle drei Technologien für die Modell-
erstellung verwendet werden.
Mithilfe des Frameworks werden Klassenmodelle beschrieben und Java-Code generiert, der
das Erstellen, Ändern, Speichern und Laden der Modellinstanzen gewährleistet. Der Kern
oder das Metamodell für Kernmodelle ist das Ecore-Modell. Dieses beinhaltet die verschie-
denen Modell-Elemente, die für EMF verfügbar sind.
In Abbildung 2.1 werden die Verknüpfungen zwischen den verschiedenen Elementen noch-
mals genauer dargestellt. Diese Modell-Elemente werden benötigt, um Klassen (EClass)
mit ihren Attributen (EAttribute) und ihren Beziehungen (EReference) erstellen zu kön-
nen. Die Klassen können in Packages (EPackage) gruppiert und beliebig oft verschachtelt
werden (Steinberg, 2009).
2.3 Frameworks zur Schnittstellenbeschreibung
Um Schnittstellen in einem Projekt dokumentieren zu können und die Entwicklung der
APIs zu erleichtern, werden Frameworks zur Schnittstellenbeschreibung verwendet. Bei-
spiele für ein derartiges Framework sind Swagger, API Blueprint und RAML. Jedes dieser
Frameworks hat seine eigenen Stärken. API Blueprint und RAML sind für den Menschen
z.B. sehr leicht lesbar und einfach gehalten (Kieselhorst, 2018). Swagger und RAML un-
terstützen die gängigsten Programmiersprachen.
Abbildung 2.2: Mitglieder der Open API Initiative (OpenAPI-Initiative,
2021)
Swagger ist allerdings das am meisten genutzte Framework aller Schnittstellenbeschrei-
bungen. Das hängt damit zusammen, dass Swagger viele Stärken der Mitstreiter vereint,
sowie die gröÿte und aktivste Community besitzt (Surwase, 2016). Viele groÿe Betriebe
und Konzerne setzen deshalb auf die Dienste des Open-Source Frameworks, darunter Luft-
hansa, Zalando, Ebay oder die Deutsche Bahn (Kieselhorst, 2018). Weitere Firmen sind in
9Kapitel 2. Grundlagen
Abbildung 2.2 zu sehen. Aus diesen Gründen wird in der vorliegenden Arbeit speziell auf
das Framework Swagger eingegangen.
Im Jahr 2010 wurde Swagger durch Tony Tam ins Leben gerufen und als Open-Source
Framework zur Verfügung gestellt. Zum Zeitpunkt der Er
ndung wurden Schnittstellen
häu
g in WSDL oder WADL beschrieben. Es fehlte allerdings eine Schnittstellenbeschrei-
bungssprache für REST. WSDL 2.0 war dafür zwar geeignet, aber hatte keine Ressour-
cenorientierung. WADL war zwar ressourcenorientiert, dafür war die XML-Struktur zu
umständlich. Aus diesem Grund wurde WADL auch nie standardisiert.
Der o
zielle Name von Swagger ist mittlerweile OpenAPI Speci
cation. Im Jahr 2015
wurde Swagger von der Firma SmartBear erworben. Um das Framework herstellerneutral
zu halten und einer Weiterentwicklung nicht im Weg zu stehen, wurde eine Arbeitsgruppe
mit dem Namen Open API Inititiative (OAI) gegründet. Gleichzeitig wurde der Name in
OpenAPI Speci
cation(OAS) geändert. Der Name Swagger ist allerdings gebräuchlicher,
deswegen wird er auch in dieser Arbeit verwendet (Kieselhorst, 2018).
2.3.1 Komponenten Swagger
Das Swagger Framework besteht aus 4 Hauptkomponenten. Diese heiÿen Swagger-Core,
Swagger-UI, Swagger-Codegen und Swagger-Editor. Durch die Komponente Swagger-Core
wird die Kernbibliothek von Swagger dargestellt, diese schlieÿt die anderen drei Kompo-
nenten mit ein.
Abbildung 2.3: Abbildung einer beispielhaften Swagger UI (Swagger,
2021)
10Kapitel 2. Grundlagen
Für das Editieren bzw. Beschreiben von Swagger-Schnittstellenbeschreibungen wird der
Swagger-Editor verwendet. Dieser ist entweder lokal oder online verfügbar und erleichtert
die Erstellung und Veränderung der Swagger-Dateien. Durch die Vorschaufunktion können
Fehler schnell entdeckt werden und es ist leichter, den Überblick über die Datei zu behal-
ten. Für die Datei gibt es zwei mögliche Formate, das JSON- sowie das YAML-Format.
Grundsätzlich ist die OpenAPI Speci
cation aber ein JSON-Objekt, d.h. es gibt nur zwei
unterschiedliche Darstellungsformen, von denen die bevorzugte Darstellungsart gewählt
werden kann. Oftmals ist YAML aufgrund der Übersichtlichkeit beliebter. (Kieselhorst,
2018).
Swagger-Codegen ist ein Tool, mit dem Server- bzw. Client-Code generiert wird. Diese
Komponente kann nur im lokalen Umfeld durch die Kommandozeile genutzt werden und
unterstützt über 40 Programmiersprachen. Bei Bedarf kann es auch in den Build-Prozess
eines Projekts integriert werden (Hämäläinen, 2019). Einer der Hauptgründe, warum sich
Swagger als das meistgenutzte Framework für Schnittstellenbeschreibungen durchgesetzt
hat, ist die Swagger-UI (Abbildung 2.3). Mit ihr kann die API nicht nur visualisiert, son-
dern zusätzlich Testanfragen direkt aus dem Browser abgesendet werden. Das ist eine sehr
praktische Funktionalität für Vorführungszwecke bzw. um etwas auszuprobieren. Auch für
die Swagger-UI gibt es Alternativen. Die beiden bekanntesten sind dabei Swagger2Markup
und ReDoc. Sie ermöglichen anpassbare bzw. anschaulichere Darstellungen. Der Nachteil
beider Alternativen ist allerdings die fehlende JavaScript-Funktionalität, mit der Testan-
fragen direkt aus der UI abgesendet werden können (Kieselhorst, 2018).
2.3.2 API-First vs. Code-First
Die beiden groÿen Ansätze zur Entwicklung von APIs sind Code-First und API- bzw.
Contract-First. Swagger beherrscht beide Entwicklungsansätze sehr gut. Welcher Ansatz
der Richtige ist, richtet sich immer nach dem Anwendungsfall. Beim Code-First-Ansatz
beginnt die Entwicklung der API mit dem Implementieren des Codes. Bei Java werden
dabei Annotationen verwendet, andere Programmiersprachen sind diesem Ansatz aller-
dings sehr ähnlich. Die Annotationen werden an die richtigen Stellen des Codes gesetzt,
um die wesentlichen Informationen der Schnittstelle zu suggerieren. Beispielsweise werden
Annotationen für den Pfad oder das Format eines Request bzw. einer Response angegeben.
Der Vorteil ist, dass bei Änderungen sofort die richtige Stelle im Code zu
nden ist. Ein
Problem besteht allerdings aus den vielen Annotationen, die nicht bei jedem beliebt sind.
Dafür kann z.B. mit JavaDoc eine Vereinfachung geschaen werden. Beim vorliegenden
Ansatz wird die Swagger-Beschreibung automatisiert zur Laufzeit erstellt.
Beim zweiten Ansatz
ndet die Entwicklung genau in umgekehrter Weise statt. Die Schnitt-
stellenbeschreibung wird zu Beginn der Entwicklung erstellt. Dies kann mithilfe des Swagger-
Editors erreicht werden. Anschlieÿend hat sich jeder Entwickler an die Beschreibung zu
halten und es entstehen selten Unklarheiten. Der Ansatz wird insbesondere bei Schnitt-
stellen genutzt, deren Implementierung der Server- und Client-Seite auf mehrere Abtei-
lungen oder Gruppen aufgeteilt ist. Ein weiterer Vorteil ist, dass der Code auf beiden
Seiten, Client sowie Server, automatisch generiert werden kann. Dies wird durch die Kom-
ponente Swagger-Codegen übernommen. Viele Anwender bemängeln dabei allerdings die
Unübersichtlichkeit des Codes oder äuÿern generelle Kritik an der spezi
kationsbasierten
Codegenerierung. Ihrer Meinung nach wäre das Tolerant Reader Pattern besser dafür ge-
eignet. Damit würden nur die benötigten Felder extrahiert und verarbeitet werden, was
die Test- und Wartbarkeit des Codes erhöht (Kieselhorst, 2018).
11Kapitel 2. Grundlagen
2.3.3 OpenAPI 2.0 vs. OpenAPI 3.0.0
Nachdem im Juli 2017 die OpenAPI Version 3.0.0 veröentlicht wurde, stellt sich für immer
mehr Anwender die Frage, ob sie ihre Systeme auf die neue Version umstellen sollten. Ab
der neuen Version wurde auf Semantic Versioning umgestellt, die zweite null in 3.0.0 ist
also kein Versehen. Dadurch kann noch genauer dargestellt werden, welche Veränderungen
vorgenommen wurden. Bei der dritten und letzten Zier handelt es sich nur um Bug-Fixes
und kleine Änderungen. Die zweite Zier beschreibt hinzugefügte Funktionalität, die rück-
wärtskompatibel ist. Bei der ersten Zier handelt es sich um groÿe Änderungen an der
API, die keine Kompatibilität mit vorherigen Versionen gewährleistet (Raemaekers, 2017).
Grundsätzlich lässt sich bei der neuen Version ein klarerer Aufbau erkennen, wie in Abbil-
dung 2.4 zu sehen ist. Host, BasePath und Schemes wurden zu Hosts zusammengefasst, um
die Unterstützung für mehrere Hosts anzubieten und nicht nur für einen. Dies war bislang
der Fall. Dadurch können Teilfunktionen auch auf andere Server verlagert werden. Die Fel-
der produces und consumes wurden entfernt, da es möglich sein sollte, für jede Operation
etwas anderes zurückzugeben oder abzusenden. Des Weiteren wurden die Teile de
nitions,
parameters und responses zu components zusammengefasst.
Die Zusammenfassung und Strukturierung hat nicht nur Gutes. Eine Kompatibilität der
beiden Versionen wird dadurch nicht mehr gewährleistet. Allerdings gibt es eine zuverläs-
sige automatisierte Migrationsmöglichkeit für die Konvertierung in die neue Version 3.0.0.
Abbildung 2.4: Unterschied OpenAPI 2.0 und OpenAPI 3.0.0 (Miller,
2016)
Die Prognose ist, dass die neue Version die alte ablösen wird, sobald die Toolunterstüt-
zung vollständig angepasst wurde. Ein groÿer Nachteil an der neuen Version ist, dass sie
für asynchrone Anwendungsfälle, wie MQTT oder AMQP keine Möglichkeit bietet. Dies
ist speziell in der Automobilindustrie, in der asynchron mit dem Fahrzeug kommuniziert
wird, ein groÿes Problem. Allerdings wurde aus diesem Grund basierend auf der OpenAPI
Speci
cation die AsyncAPI Speci
cation gegründet (Kieselhorst, 2018).
12Kapitel 2. Grundlagen
2.4 Testen von Software
Testing is the eort of executing programs with the intention of revealing failures. (Reich-
staller, 2018, S. 1)
Beim Testen von Software wird ein Programm mit verschiedenen Daten ausgeführt. Da-
bei sollen Fehler, Anomalien oder Informationen über die nichtfunktionalen Attribute des
Programms aufgedeckt werden (Sommerville, 2018). Das Testen verfolgt grundlegend zwei
Ziele. Erstens steht die Qualitätssicherung und Unterstützung der Entwickler im Vorder-
grund. Die Entwickler sollen schon während des Projekts aus ihren Fehlern lernen und da-
durch Verbesserungsmaÿnahmen einleiten. Bei der Qualitätssicherung ist es wichtig, dass
diese von Anfang an Bestandteil des Projektablaufs ist und sich nicht auf das Ende des
Projekts beschränkt. Der zweite Grund, warum Tests benötigt werden ist die Abnahme des
IT-Projekts. Der Auftragsnehmer zeigt dadurch, dass die entwickelte Softwarelösung die
Anforderungen des Auftraggebers erfüllt und die gewünschte Funktionalität der Software
gewährleistet. Die Abnahme ist P
icht am Ende jedes IT-Projekts (Witte, 2016).
Tests können allerdings nicht zeigen, dass eine Software fehlerfrei ist und sich immer so
verhält, wie sie sollte. Bei realen Systemen ist es unmöglich alle Eingangsdaten und Kon
-
gurationen zu testen. Ein Test kann immer vergessen werden und Tests sind auch nur dafür
ausgelegt die Anwesenheit von Fehlern zu zeigen, nicht ihre Abwesenheit (Sommerville,
2018). Testen ist kein mathematischer Beweis. (Witte, 2016, S. 11) Je höher allerdings
die Testabdeckung ist, umso geringer ist das Risiko, dass Fehler auftreten (Witte, 2016).
Die Testabdeckung kann über viele Faktoren gemessen werden, die im Folgenden erläu-
tert werden. Häu
g wird die Testabdeckung von Unit-Tests über die Statements Coverage
gemessen. Dabei wird die Anzahl der ausgeführten Statements durch Tests im Verhältnis
zur Gesamtanzahl von Statements gemessen. Ein Statement beinhaltet im Normalfall eine
Zeile Code inklusive Kommentare und Bedingungen. Eine weitere Möglichkeit bietet die
Function Coverage. Sie überprüft, ob eine Funktion aufgerufen wurde. Es ist allerdings
nicht entscheidend wie oft eine Funktion aufgerufen wurde, ob sie richtig aufgerufen wur-
de und ob sie die richtigen Werte zurückgibt. Wichtig ist, dass sie aufgerufen wurde. Die
Branch Coverage misst, ob der Wahr- und Falsch-Zweig für jede Bedingung (if, for, while)
durchlaufen wurde. Zusätzlich zu den genannten Möglichkeiten der Testabdeckung gibt es
auch noch die Decision Coverage, Condition Coverage und Path Coverage, auf die in dieser
Arbeit kein Fokus gelegt wird (Witte, 2016). Wie hoch die Testabdeckung sein sollte wird
in Abbildung 2.5 veranschaulicht. Bei einem bestimmten Grad der Abdeckung erhöht sich
die Qualität nur noch minimal, die Kosten steigen allerdings exponentiell. Deshalb sollte
der optimale Testabdeckungsgrad ermittelt werden (Witte, 2016).
Oftmals ist nicht bekannt zu welchem Zeitpunkt Tests erstellt werden sollten. Ein sehr be-
liebter Ansatz für eine zuverlässige Software ist der Test-First-Ansatz. Bei diesem Ansatz
werden bereits vor der Implementierung Tests erstellt. Die erstellten Tests werden genau
auf die Anforderungen des Systems abgestimmt und Unklarheiten dadurch bereits vor der
Implementierung ausgeräumt (Sommerville, 2018).
Der Test-First-Ansatz hat den groÿen Vorteil, dass er überschnelle Entwickler, die, ohne
groÿ zu denken, zur Tastatur greifen, dann implementieren und nach 20 Minuten wieder
alles ändern, zum Nachdenken zwingt. (Ullenboom, 2019, S. 1195)
13Kapitel 2. Grundlagen
Abbildung 2.5: Die optimale Testabdeckung (Witte, 2016, S. 208)
Groÿe Änderungen sind bei diesem Ansatz sehr selten, da die Entwickler eine gute Vorstel-
lung des Systems haben. Dadurch wird Zeit und Geld gespart (Ullenboom, 2019). Auÿer-
dem wird ein weiteres Problem der Testerstellung aus dem Weg geräumt. Entwickler testen
ihren Code häu
g selbst nach der Implementierung. Dabei sind sie geneigt, den Test so
anzupassen, damit nichts abstürzt bzw. der Test nach ihrer Einschätzung der Funktionali-
tät arbeitet. Durch die Erstellung der Tests vor der Implementierung wird dies verhindert
(Witte, 2016).
Abbildung 2.6: Testarten im V-Modell (Witte, 2016, S. 69)
Bei der Entwicklungsphase eines Projekts gibt es verschiedene Testarten, die alle ihre Be-
rechtigung haben. Abbildung 2.6 zeigt dabei den Entwicklungszyklus im V-Modell. Die
Projektphasen im V-Modell starten mit einer Analyse und De
nition des Systems und
werden mit Projektfortschritt immer weiter verfeinert. Sobald alle Anforderungen und
Verhaltensweisen des Systems bis ins Detail de
niert wurden, beginnt die Implementierung
14Kapitel 2. Grundlagen
des Projekts. In der untersten Ebene werden Modultests, häu
g als Unit-Tests bezeichnet,
erstellt. Diese Arbeit vollzieht meist der Entwickler selbst. Dabei werden die funktiona-
len Einzelteile des Programms auf korrekte Funktionalität geprüft. Algorithmen auf der
Modulebene weisen meist eine niedrige Komplexität auf und können dadurch leicht und
umfassend getestet werden.
Modultests reichen nicht aus, um die Interaktion zwischen den verschiedenen Komponen-
ten bzw. Modulen zu testen. Dazu werden Integrationstests benötigt (Witte, 2016). Diese
betrachten das Zusammenspiel komplexerer Komponenten und benutzen den Code als
Blackbox, die entweder den richtigen Zustand herstellt oder nicht (Szwillus, 2020). Mit-
tels Integrationstests können beispielsweise inkompatible Schnittstellenformate oder unter-
schiedliche Interpretationen übergebener Daten aufgedeckt werden.
Die nächste Stufe im V-Modell beinhaltet die sogenannten Systemtests. Dort wird das
gesamte System gegen die Anforderungen getestet. Wichtig ist, dass eine Testumgebung
erzeugt wird, die der Produktivumgebung des Kunden möglichst nahe kommt. Keinesfalls
dürfen diese Tests aber in der realen Umgebung statt
nden, da bei Fehlern das reale System
beschädigt werden kann. Sollten alle diese Tests die gewünschte Funktionalität vorweisen,
kann mit der letzten Testart fortgefahren werden. Abnahmetests, oft auch als Akzeptanz-
test, Verfahrenstest oder auch User Acceptance Test bekannt, sind ein Test durch den
Kunden, Endanwender oder Auftraggeber. Dabei ist das Ziel nicht mehr einen Fehler auf-
zudecken, sondern die Vertrauensgewinnung des Kunden. Die Fehler sollten bereits durch
die anderen Testarten gefunden und behoben worden sein (Witte, 2016).
15Kapitel 3
Stand der Technik
3.1 Testen in Oboard-Szenarios
Grundsätzlich gilt, je später ein Fehler in der Entwicklung auftritt, desto höher werden
die Kosten. Das liegt daran, dass die vorangegangenen Schritte der Entwicklung wieder-
holt werden müssen und es komplizierter wird ein bestehendes System zu verändern. Umso
wichtiger sind deshalb die Modultests und Integrationstests. Fehler, die damit aufgedeckt
werden, können kostengünstiger behoben werden als Fehler in den Systemtests.
Integrationstests spielen in der Oboard-Entwicklung eine groÿe Rolle. Ihre Aufgabe ist
es die Kommunikation zwischen den Microservices zu testen. Dabei werden Schnittstel-
lentests durchgeführt, die die Zusammenarbeit voneinander unabhängiger Komponenten
überprüfen. Vor dem Test muss die Umgebung komplett nachgebildet werden. Dies ist
sehr aufwändig und zeitintensiv, allerdings wird dadurch die Umgebung möglichst rea-
listisch gehalten. Alternativ können Mock-Objekte genutzt werden, die eine Komponente
simulieren (Witte, 2016). Beim Mocking geht es darum, komplexe Schnittstellen für den
Testfall zu vereinfachen und so den Code, der auf die Daten aus einer Schnittstelle ange-
wiesen ist, trotzdem testbar zu machen. (Szwillus, 2020, S. 189)
Abbildung 3.1: Hupen als Sequenzdiagramm
Bei Integrationstests gibt es verschiedene Verfahren, die genutzt werden. Diese werden an-
hand der Abbildung 3.1 beschrieben. Das Bottom-Up-Verfahren ist das meist genutzte und
bekannteste Verfahren. Dabei erfolgt die Integration in umgekehrter Richtung zur Benutzt-
Beziehung. Im Beispiel wäre dies der Test vom Backend zum Auto. Das Backend gibt dem
Auto das Signal zum Hupen und das Auto gibt die Statusmeldung nach der Ausführung
zurück. Der nächste Test ist das Signal von der App zum Backend. Dabei ist der letzte
16Kapitel 3. Stand der Technik
Test mit einbezogen. Der Nachteil dabei ist, dass die Fehler in der obersten Schicht erst
sehr spät erkannt werden.
Beim Top-Down-Verfahren erfolgt die Integration genau umgekehrt. Als Erstes wird die
komplette Kommunikation vom User zum Auto und zurück getestet. Anschlieÿend wird
die Kommunikation von der App zum Auto und zurück getestet. Solange bis die letzte
Schnittstelle erreicht wurde. Der Vorteil daran ist, dass Fehler in der obersten Schicht (lo-
gische Fehler) schnell entdeckt werden (Witte, 2016). Es gibt noch weitere Verfahren, die
allerdings in der Praxis seltener ihre Anwendung
nden.
Die Entscheidung, welche Testdaten ausgewählt werden müssen ist nicht immer trivial.
Bei den Tests von APIs ist es sehr wichtig den richtigen Response-Code zu erhalten. Der
richtige Response-Code gibt an, ob Probleme in der Kommunikation zwischen Client und
Server aufgetreten sind. Des Weiteren sind die Parameter bei Requests und Responses von
groÿer Bedeutung. Bei einem GET-Request ist es wichtig zu wissen, ob die gewünschten
Parameter auch zurück geliefert werden oder ob Parameter fehlen bzw. fehlerhaft sind. Bei
POST-Requests wird das Hauptaugenmerk auf die mitgesendeten Parameter gelegt. Dort
sollten Eingabedaten gewählt werden, die repräsentativ für den erlaubten Wertebereich
sind. Zusätzlich können aber auch Extremwerte oder spezielle Eingabewerte wie z.B. 0 und
1 gewählt werden. Häu
g reagieren Systeme sensibel auf diese Art von Werten (Balzert,
2013).
3.2 Cucumber
Cucumber is an awesome tool that allows you to develop your software using a Behavior-
Driven Approach (BDA). (Matsinopoulos, 2020, S. 199)
Durch Cucumber wird sichergestellt, dass Anforderungen eines Stakeholders verständlich
an den Entwickler weitergegeben und dadurch auch erfüllt werden (Matsinopoulos, 2020).
Die Sprache, mit der Cucumber (dt. Gurke) arbeitet, heiÿt Gherkin (dt. Essiggurke). Diese
Sprache ist sehr benutzerfreundlich und leicht zu lesen, da sie in nahezu natürlicher Spra-
che geschrieben wird. Dadurch wird die Lücke zwischen Entwicklung und Anforderungen
des Kunden geschlossen. Auch Kunden, die nicht im Bereich der Softwareentwicklung tätig
sind, können die Anforderungen lesen und an ihre Bedürfnisse anpassen. Vom Entwickler
können die Anforderungen nicht mehr missverstanden werden, da sie gleichzeitig als aus-
führbare Testfälle fungieren. Als praktische Nebensache können die Gherkin-Dateien auch
sehr gut zur Dokumentation verwendet werden. Dabei stimmen die Dokumentation und
die Tests immer überein. Ein weiterer Vorteil ist, dass die meisten IDEs ein Cucumber
Plugin besitzen, das eine Warnung ausgibt, falls es zu einem Szenario kein valides Muster
gibt. Mittlerweile unterstützt das Open-Source Framework Cucumber viele Frameworks
und Sprachen wie z.B. Ruby, Java und JavaScript (Macero, 2017).
Die Grundidee von Cucumber ist es, die Features eines Projekts in verschiedene Feature-
Dateien aufzuteilen. Zu Beginn der Datei steht eine Beschreibung der Features. Dies wird
von Cucumber ignoriert, bietet allerdings eine gute Dokumentationsmöglichkeit. Für ein
Feature gibt es dann mehrere Test-Szenarios, die wiederum in mehrere Stufen aufgeteilt
werden. Diese Stufen bestehen aus den BDD-Schlüsselwörtern 'given', 'when' und 'then'.
Zusätzlich gibt es noch die beiden Schlüsselwörter 'and' und 'but' für Erweiterungen. Mit-
tels 'given' wird eine Ausgangsposition für den Test beschrieben. Durch 'and' kann das
17Kapitel 3. Stand der Technik
Szenario mit weiteren Ausgangspositionen ergänzt werden. Mit 'when' wird anschlieÿend
eine Aktion beschrieben, durch die eine neue Situation entstehen sollte. Im 'then'-Teil
n-
det die Überprüfung statt, ob sich das Programm wie gewünscht verhalten hat.
Abbildung 3.2: Beispiel einer Cucumber Feature-Datei (Cucumber, 2021)
Ein Beispiel ist in der Abbildung 3.2 dargestellt. Darin wird zudem noch die Möglich-
keit eines Scenario Outlines aufgeführt. Bei einem Szenario Outline werden anhand eines
Szenarios mehrere Testfälle mit unterschiedlichen Werten dargestellt. Im Beispiel werden
mithilfe der Examples-Tabelle zwei verschiedene Szenarien ausgeführt. Die Zeilen werden
in die jeweiligen Parameter der Stufen eingefügt und als Testfall ausgeführt (Macero, 2017).
Für Plantestic ist Cucumber indes nicht geeignet. Es ist sehr schwer bzw. nicht möglich
Interaktionssequenzen mit Cucumber zu testen. Plantestic sollte allerdings nicht nur ein-
zelne Schnittstellen testen, sondern auch das Zusammenspiel dieser.
3.3 RestAssured
RestAssured ist ein Test-Framework, bei dem REST-Schnittstellen sehr leicht getestet wer-
den können. Es unterstützt sämtliche gängige Request-Arten wie z.B. GET, POST, PUT,
DELETE. Grundsätzlich ist ein RestAssured Test immer gleich aufgebaut. Mit given()
wird ein Szenario beschrieben. Es können z.B. Informationen wie die Authenti
zierung,
Cookies oder Parameter für einen POST-Request mitgegeben werden. Mit when() wird
die auszuführende Operation beschrieben, also die Request-Art und die URL die genutzt
werden sollte. Mit then()
ndet das eigentliche Testen statt.
Es wird überprüft, ob das Ergebnis der Annahme entspricht. Im Code-Listing 3.1 wird ein
beispielhafter RestAssured Test dargestellt. Im given-Teil wird das zu erwartende Schema
der Response angegeben. In diesem Fall wird eine JSON-Response erwartet. Auÿerdem
benötigt die abgefragte URL eine Authenti
zierung, die ebenfalls im given-Teil mit Benut-
zername und Passwort angegeben wird. Im when-Teil wird die Art des Requests und die
URL angegeben. Es handelt sich um einen GET-Request der den localhost am Port 8080
mit dem Pfad /hello anfragt. Anschlieÿend wird im then-Teil der eigentliche Test durch-
geführt. Es wird überprüft, ob der Status-Code in einem Array mit den beiden Codes 200
und 201 enthalten ist. Des Weiteren wird die Response in ein Objekt umgewandelt, mit
dem weitere Tests durchgeführt werden können.
18Kapitel 3. Stand der Technik
Listing 3.1: Java-Code
1 Response r o u n d t r i p 1 = RestAssured . g i v e n ( )
2 . contentType ( ContentType . JSON)
3 . auth ( ) . b a s i c (max . mustermann@gmail . com ,
4 passwort123 )
5 . when ( )
6 . g e t ( http : // l o c a l h o s t : 8 0 8 0 / h e l l o )
7 . then ( )
8 . assertThat ()
9 . statusCode ( I s I n . i s I n ( Arrays . a s L i s t ( 2 0 0 , 2 0 1 ) ) )
10 . and ( ) . e x t r a c t ( ) . r e s p o n s e ( ) ;
Für das Tool Plantestic bietet RestAssured eine sehr gute und einfache Möglichkeit Test-
fälle zu generieren, die Schnittstellen überprüfen. Eine Authenti
zierung kann ohne groÿen
Mehraufwand mit eingep
egt werden und auch andere gewünschte Testfälle können mü-
helos ergänzt werden. Im Gegensatz zu Cucumber können mit RestAssured auch Interak-
tionssequenzen getestet werden. Daher ist RestAssured für die Verwendung mit Plantestic
zu empfehlen.
3.4 Verwandte Arbeiten
3.4.1 Sky
re
Sky
re ist ein modell-basiertes Testgenerierungs-Tool, mit dem automatisch eektive Cu-
cumber Test-Szenarios erstellt werden. Diese können manuell erstellte Test-Szenarios erset-
zen. Das Tool liest UML-Diagramme wie z.B. Zustandsdiagramme aus und identi
ziert alle
notwendigen Elemente. Daraus werden anschlieÿend Test-Szenarios in Cucumber erstellt.
Auÿerdem ist Sky
re sehr gut im agilen Umfeld geeignet (Li, 2016).
Aus der Sicht des Benutzers ist es sehr einfach mit dem Tool zu arbeiten. Das Zustandsdia-
gramm kann sehr leicht mithilfe des UMLDesigner, der für alle gängigen Betriebssysteme
zur Verfügung steht, erstellt werden. Als Alternative kann Papyrus verwendet werden.
Das ist ein Tool, welches bereits in Eclipse integriert ist. Sky
re kann auch als Maven-
Abhängigkeit genutzt werden. Dadurch kann es auch in bestehende Projekte integriert
werden (Li, 2016). Der Nachteil an Sky
re ist, dass es keine Möglichkeit gibt, REST-
Schnittstellen zu testen. Es ist nicht vorgesehen, dass Sequenzdiagramme eingelesen wer-
den und damit APIs getestet werden können. Sky
re ist dafür gedacht, Akzeptanztests zu
generieren. Diese
nden in einem späteren Zeitpunkt der Entwicklung statt als die Inte-
grationstests. Sie sollen das Benutzerverhalten simulieren (Li, 2016).
3.4.2 ParTeG
ParTeG (Partition Test Generator) ist ein Open-Source Eclipse-Plugin, das Testfälle aus
Modellen generiert. Die Modelle können UML Zustandsdiagramme bzw. Klassendiagramme
sein. Aus diesen Diagrammen werden die Bestandteile herausge
ltert und in ausführbare
Java-Testfälle transformiert.
Ein praktischer Vorteil ist, dass die generierten Testfälle direkt in Eclipse debuggt werden
können (Sha
que, 2010). Aber auch dieses Tool ist für Integrationstests an Schnittstellen
schlechter geeignet als Plantestic und kann aus diesem Grund nicht verwendet werden.
19Kapitel 4
Einsatz des Testfallgenerierungstools
Plantestic
4.1 Funktionsweise Plantestic
Die Aufgabe dieser Arbeit ist es, das Testfallgenerierungstool Plantestic an die Bedürfnisse
und Anforderungen der Automobildomäne anzupassen. Dazu müssen zunächst die grund-
legende Funktionsweise und die zusätzlich implementierten Features des Tools verstanden
werden.
Der Fokus bei der Entwicklung von Plantestic wurde auf die automatisierte Testfallgene-
rierung aus einem Sequenzdiagramm gelegt. Mit den generierten Testfällen soll herausge-
funden werden, ob die Komponenten miteinander agieren, wie sie im Sequenzdiagramm
de
niert sind. Als minimaler Input für Plantestic wird dabei ein PlantUML Sequenzdia-
gramm benötigt. Der Ordner, in den der ausführbare Testfall generiert wird, kann optional
mit angegeben werden. Alternativ wird ein Standard-Ordner verwendet.
Abbildung 4.1: Minimales Sequenzdiagramm
In Abbildung 4.1 ist ein Beispielssequenzdiagramm zu sehen. Darin werden zuerst die
Teilnehmer A und B deklariert. Anschlieÿend werden die Interaktionen zwischen den ver-
schiedenen Teilnehmern de
niert. A sendet an B einen GET-Request mit der URL '/hello'.
Im Anschluss an diesen Request wird B aktiv und soll eine Response mit dem Status-Code
200 zurücksenden. Dieser Code steht für eine erfolgreiche Kommunikation, bei der kei-
ne Fehler aufgetreten sind. Grundsätzlich sind alle Sequenzdiagramme gleich aufgebaut.
Zwischen den Teilnehmern werden Interaktionen de
niert mit Anfragen und Antworten
(Requests und Reponses). In der Abbildung 4.1 ist allerdings ein extrem einfaches Beispiel
zu sehen, bei dem auf Parameter und Alternativen verzichtet wurde. Parameter können
zusätzlich mitgesendet werden, entweder in der URL, dem Body oder dem Header des
Requests bzw. der Response. Dadurch können weitere Informationen ausgetauscht werden.
20Kapitel 4. Einsatz des Testfallgenerierungstools Plantestic
Mit Alternativen wird ein Sequenzdiagramm in mehrere Abschnitte verzweigt, die durch
eine erfüllte Bedingung erreicht werden können. Funktionalitäten wie die Farbzuweisung
oder verschiedene Pfeilvarianten sind nur für die Darstellung des Diagramms entscheidend,
werden allerdings von Plantestic ignoriert und nicht verarbeitet.
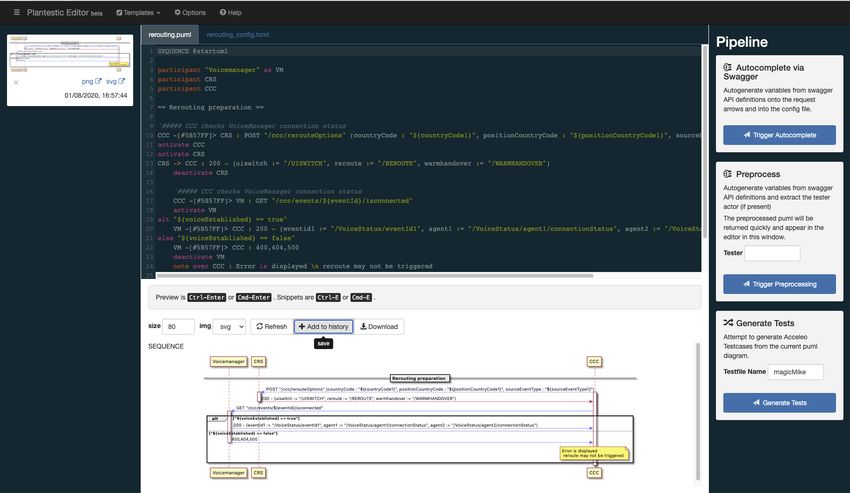
Abbildung 4.2: Plantestic Pipeline zur Testfallgenerierung
Die Transformation vom Sequenzdiagramm in einen ausführbaren Testfall wird über das
Eclipse Modeling Framework verwirklicht (Abbildung 4.2). Xtext wird dabei für die Gram-
matik von PlantUML-Sequenzdiagrammen verwendet. Aus der '.puml'-Datei werden im
ersten Schritt alle Bestandteile mithilfe dieser Grammatik interpretiert und in ein Modell
geladen. Mithilfe dieses Modells kann fortgefahren werden und eine Transformation in wei-
tere Modelle statt
nden.
Eine erste Transformation
ndet hierbei in ein Modell statt, in dem Paare aus den Requests
und Responses gebildet werden. Die Transformation wird dabei über das Tool QVTO er-
möglicht. Bei solch einer Transformation gibt es immer ein Input- und Output-Modell.
Mit QVTO wird festgelegt wie aus den verschiedenen Elementen des Input-Modells der
Output entsteht. In der vorliegenden Transformation werden z.B. alle Requests und Re-
sponses aus dem Input-Modell gezogen und zu Paaren transformiert, die Bestandteil des
Output-Modells sind. Die Bestandteile eines Modells, wie Klassen, Variablen und Attribu-
te, werden über Ecore-Dateien de
niert. Der nächste Schritt ist eine Transformation dieses
Modells in das RestAssured-Modell. Das ist der letzte Transformationsschritt, bevor eine
Generierung der Testfälle vorgenommen wird. Das Modell wird dahingehend transformiert,
sodass eine Testgenerierung mit RestAssured vereinfacht wird.
Im letzten Schritt wird dann aus dem Modell Code generiert. Acceleo bietet hierfür ei-
ne hervorragende Möglichkeit. In einer Datei werden dabei die möglichen Codeabschnitte
de
niert. Mit Bedingungen wird festgelegt, welche Abschnitte in den generierten Test-
fall übernommen werden. Die Informationen und Daten der verschiedenen Requests und
Responses werden dabei über das bestehende Modell geladen. Eine sehr praktische Eigen-
schaft von Acceleo ist es, dass Templating unterstützt wird. In den Code werden dabei
Lückenfüller eingesetzt. Damit sind Variablen gemeint, die erst später bei der Ausführung
des Testcodes geladen werden. Das ist eine extrem nützliche Funktionalität, da diverse Da-
ten nicht in den Sequenzdiagrammen zur Verfügung gestellt werden sollen. Meistens sind
diese Sequenzdiagramme nämlich einer groÿen Anzahl an Leuten zugänglich. Oft werden
sie auch für Vorführzwecke genutzt. Ein gutes Beispiel sind der Benutzername und das
Passwort bei Requests, die authenti
ziert werden müssen. Diese Daten sollten am Besten
nur der zuständige Testentwickler zur Verfügung gestellt bekommen und in den Testfall
einfügen. Ein weiterer Vorteil dieser Lückenfüller wird im Abschnitt 4.2.2 erläutert.
21Sie können auch lesen

















































